introducciÓn a la investigaciÓn en ciencias de …histologia.ugr.es/descargas/mic-lectura.pdf ·...
TRANSCRIPT

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
INTRODUCCIÓN A LA
INVESTIGACIÓN EN CIENCIAS DE LA
SALUD: METODOLOGÍA DE
INVESTIGACIÓN

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
ÍNDICE
I.- LA CIENCIA Y EL CONOCIMIENTO CIENTÍFICO 1
II.- FASES DEL DESARROLLO DE LA INVESTIGACIÓN CUANTITATIVA 2
A.- EL PROBLEMA DE INVESTIGACIÓN 3
B.- FORMULACIÓN DE LAS HIPÓTESIS 6
C.- VALIDACIÓN DE LAS HIPÓTESIS 9
D.- INTERPRETACIÓN DE LOS RESULTADOS 22
III.- EL DISEÑO DE INVESTIGACIÓN EXPERIMENTAL 23
A.- CONCEPTO DE DISEÑO DE INVESTIGACIÓN 24
B.- OBJETIVOS DEL DISEÑO DE INVESTIGACIÓN 27
C.- CRITERIOS PARA SELECCIONAR EL DISEÑO 33
D.- CLASES DE DISENOS 36
IV. FACTORES DE VALIDEZ EN LOS DISEÑOS EXPERIMENTALES 39
A.- LA VALIDEZ INTERNA DE UN DISEÑO EXPERIMENTAL 40
B.- LA VALIDEZ EXTERNA DE UN DISEÑO EXPERIMENTAL 47
C.- CONTROL DE VARIABLES EXTRAÑAS 51
V. RESOLUCIÓN ESTADÍSTICA DEL DISEÑO EXPERIMENTAL 55
A.- EL NIVEL DE MEDICIÓN 57
B.- EL MODELO ESTADÍSTICO 60
C.- POTENCIA DE UNA PRUEBA ESTADÍSTICA 67
D.- LA POTENCIA-EFICIENCIA 78
REFERENCIAS BIBLIOGRÁFICAS 80

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
1
I.- LA CIENCIA Y EL CONOCIMIENTO CIENTÍFICO
Abordar el concepto de Ciencia resulta extremadamente complejo. Etimológicamente, el
término Ciencia proviene del vocablo latino Scientia, equivalente al Episteme griego,
cuyo significado es conocimiento, doctrina, erudición o práctica. En nuestros días, el
término se utiliza tanto para designar la actividad que realizan los científicos como para
expresar los conocimientos generados por la misma.
Respecto a su objetivo, la investigación científica se centra en hallar, formular y resolver
problemas. En este sentido, solamente el ser humano es capaz de plantear problemas
que trascienden las dificultades propias que le surgen en su interacción con el medio y,
por tanto, es el único ser capaz de hacer ciencia (García Llamas et al., 2001).
A la hora de elaborar el conocimiento humano, el científico debe preguntarse por las
características peculiares que definen al conocimiento científico y lo distinguen de otro
tipo de conocimiento. En ocasiones, cuando el ser humano elabora explicaciones a partir
de premisas que no son ciertas, se incurre en conocimiento acientífico (falacia), mientras
que en otras ocasiones, se recurre a explicar lo desconocido mediante lo desconocido
(explicatio ignoti per ignotum), generándose lo que se conoce como pseudoexplicación
debido a su carácter de circularidad. Frente a esos tipos de conocimiento no científico, la
explicación científica constituye la respuesta adecuada a la realidad de un problema
dado (López-Barajas, 2001). Este tipo de conocimiento, denominado conocimiento
científico, se caracteriza, al igual que la propia Ciencia, por su objetividad, sistematicidad,
metodicidad, verificabilidad y comunicabilidad.
Si el conocimiento científico es un conocimiento especial, diferente del conocimiento
vulgar, el método que se emplea para generarlo también es especial. El método
científico constituye un conjunto de enfoques y formas de actuar que nos permiten
contribuir al avance de la Ciencia y a la generación de conocimiento científico.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
2
Desde un punto de vista etimológico, método es el camino a seguir para alcanzar un
fin. En realidad, se trata de un medio que carece de significación por sí solo, pues
requiere de una finalidad que lo justifique y a la que ha de servir. En su acepción
semántica, el método implica el orden intencionado y una guía o ayuda intencional.
Según la Real Academia Española de la Lengua, el método es el procedimiento que se
sigue en las ciencias para hallar la verdad y enseñarla.
El objetivo fundamental del método científico o experimental es contrastar la validez o la
falsedad de las hipótesis planteadas por el investigador. Para ello, el método
experimental recurre a la utilización de un plan de investigación bien estructurado y
estandarizado que, en su conjunto, constituye lo que se conoce como diseño del estudio.
En síntesis, los objetivos del diseño experimental son, clásicamente, tres: maximizar la
varianza sistemática primaria, minimizar la varianza del error y controlar la varianza
sistemática secundaria (principio MAX-MIN-CON de Kerlinger, 1979).
II.- FASES DEL DESARROLLO DEL PROCESO DE
INVESTIGACIÓN
La investigación científica se basa en el diseño de investigación experimental, el cual
tiene varias fases o momentos que han de cumplirse necesariamente. En este punto,
estudiaremos los siguientes momentos de la investigación científica (López-Barajas,
2001): el problema de investigación, la formulación de las hipótesis de trabajo, la
validación de las hipótesis y la interpretación de los resultados.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
3
A.- EL PROBLEMA DE INVESTIGACIÓN
La formulación del problema de investigación en forma de preguntas de investigación
constituye el punto de arranque de todo proceso investigador. La importancia de este
punto es clave, pues todo el proceso irá encaminado a dar respuesta a las preguntas de
investigación inicialmente planteadas. Por ello, si las preguntas están mal planteadas o
carecen de interés, todo el proceso investigador perderá su valor o quedará inutilizado de
manera irremediable.
La investigación científica tiene como objeto principal hallar, formular y resolver
problemas. Por ello, la correcta identificación y el adecuado planteamiento de esos
problemas es fundamental para proceder a su resolución. De hecho, muchos científicos
afirman no sin fundamento que un buen planteamiento es la mitad de la solución del
problema. Por ello, antes de definir un problema hemos de tener en cuenta dos aspectos:
1. Solamente cuando un problema se plantea bien, se estará en el camino de
solucionarlo.
2. Para identificar bien un problema, es necesario especificarlo, ya que no es
una cuestión que se pretende aclarar, sino una proposición o dificultad de
solución o explicación dudosa en ese momento.
El investigador ha de conocer cómo surge un problema, cómo se manifiesta, y ha de
preguntarse qué problema merece ser investigado. La identificación de un problema
exige que éste sea específico, importante, posible y práctico.
Al plantear la metodología de la investigación, el científico ha de tomar cuando menos
tres decisiones. En primer lugar, identificar la naturaleza del problema objeto de estudio,
para seleccionar el paradigma idóneo para su resolución. En segundo lugar, decidir en
función de sus objetivos qué estrategia es la más pertinente, es decir, el nivel y el tipo de
investigación que se llevará a cabo. Por último, el investigador deberá especificar la
táctica o procedimiento a recorrer, enumerando todas y cada una de las etapas, a modo
de mapa que oriente el proceso en su totalidad.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
4
En general, sea cual sea el camino, para que la investigación permita un avance efectivo
en el conocimiento científico, deberá tener muy en cuenta el estado actual de la
cuestión que se quiere tratar. Para poder identificar los problemas de investigación, el
científico ha de estudiar con detalle los planteamientos que actualmente existen sobre el
tema y qué soluciones aportan otros investigadores. De este modo, determinando el
estado actual de la cuestión, el investigador debe identificar las posiciones teóricas más
significativas y relacionadas con el tema a tratar, así como conocer las posibilidades y
limitaciones metodológicas existentes según el problema que se trate.
Para determinar el estado actual de la cuestión, el científico deberá indagar sobre el
problema que se va a trabajar, conocer los resultados alcanzados por otros autores en
dicha cuestión, revisar desde los trabajos clásicos a los más recientes, reseñando los
más significativos en las respectivas posiciones teóricas, para estar advertido de
perspectivas y posiciones epistemológicas. Conocer el estado actual de la cuestión es un
paso importante ya que enriquece la posterior formulación de hipótesis de trabajo. Se
trata de consultar las fuentes, los orígenes del problema, y su evolución hasta el
momento presente. El reconocimiento de la propia realidad y el contexto en el que se
ubicará la investigación, es tarea imprescindible para averiguar las dificultades técnicas
que se han de plantear en cualquier estudio científico.
Las fuentes a las que se puede acudir son: La propia realidad científica, las fuentes
bibliográficas y documentales, las fuentes institucionales y los sistemas informatizados.
En el campo de la Histología y, concretamente, en el campo de la Histología Bucodental
Humana, podríamos poner multitud de ejemplos relacionados con el problema de
investigación. A modo de ejemplo, expondremos el siguiente:
Un investigador está interesado en evaluar la viabilidad celular de una población de
fibroblastos humanos mantenidos en cultivo y procedentes de la pulpa dental. Para ello,
desea plantear un proyecto de investigación que le permita determinar la viabilidad de
sus células. Lo primero que hace este científico hipotético es acudir a las fuentes de
información disponibles, incluyendo sus propios conocimientos, libros especializados en
citología y viabilidad celular, revistas especializadas y bases de datos disponibles en
internet (por ejemplo, PubMed).

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
5
Después de una completa revisión de la literatura, el científico será capaz de determinar
cuál es el estado actual de la cuestión, esto es, qué métodos son los más utilizados en la
actualidad y cuáles son los que otros autores utilizan y recomiendan para determinar la
viabilidad de las células mantenidas en cultivo (exclusión de colorantes orgánicos tipo
azul tripán, métodos enzimáticos que detectan LDH libre en el medio de cultivo,
microanálisis por energía dispersiva de rayos X, etc.). Con toda esa información, el
científico estará en condiciones de definir claramente el problema y de formular las
preguntas de investigación.
Algunos ejemplos de preguntas de investigación son los siguientes: ¿qué porcentaje de
células de la pulpa dental mantenidas en cultivo mantienen su viabilidad celular? ¿cuál es
el índice de viabilidad celular de los fibroblastos de la pulpa mantenidos en cultivo?
¿existe alguna disminución de la viabilidad celular en células correspondientes a
subcultivos más avanzados? ¿tiene algún efecto sobre la viabilidad celular la adición de
factores de crecimiento al medio de cultivo?
Problema de investigación
Los fibroblastos de la pulpa dental humana mantenidos en cultivo deben mantener elevados índices de
viabilidad celular para poder utilizarlos en la clínica humana (terapia celular e ingeniería tisular)
Preguntas de investigación
¿Qué porcentaje de células de la pulpa dental mantenidas en cultivo mantienen su viabilidad celular?
¿Cuál es el índice de viabilidad celular de los fibroblastos de la pulpa mantenidos en cultivo?

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
6
B.- FORMULACIÓN DE LAS HIPÓTESIS
La hipótesis es una proposición no demostrada, la suposición de un hecho, cuya validez y
veracidad se pretende demostrar en el curso de una investigación. Se trata, por tanto, de
una explicación tentativa a un problema de investigación. El planteamiento de las
hipótesis constituye una predicción acerca de la relación y varianza de una serie de
factores (que denominamos variables), convirtiéndose en una etapa principal y esencial
en el proyecto científico, y que sirve para orientar el curso, el proceso y la estrategia de
toda la investigación.
El confirmar o desmentir las hipótesis mediante la correspondiente recogida de
información y de datos, constituye el objeto fundamental de cualquier investigación
científica. Por ello, la elaboración correcta y pertinente de las hipótesis de trabajo es un
punto fundamental y necesario de todo proceso investigador. De esta forma, las hipótesis
deben ser bien planteadas, basadas en el estado actual de la cuestión y en las preguntas
de investigación y deben aportar una explicación razonable y plausible al tema a tratar.
Una buena hipótesis debe estar bien fundamentada y debe ser contrastable
empíricamente.
Lo más habitual es que las hipótesis se expresen en forma condicional, con la siguiente
estructura: ―Si A, entonces B‖, aunque en el ámbito de las Ciencias de la Salud podemos
encontrar hipótesis planteadas en forma afirmativa directa, o incluso en forma negativa.
Según Jiménez Fernández (2000), las propiedades y características de las hipótesis son
las siguientes:
1. Las hipótesis son proposiciones tentativas acerca de las relaciones entre
dos o más variables y se apoyan en conocimientos organizados y
sistematizados.
2. Las hipótesis contienen variables; éstas son propiedades cuya variación
puede ser medida.
3. Las hipótesis surgen normalmente del planteamiento del problema y la
revisión de la literatura (algunas veces, de teorías).

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
7
4. Las hipótesis deben referirse a una situación real. Las variables contenidas
tienen que ser precisas, concretas y poder observarse en la realidad; la
relación entre las variables debe ser clara, verosímil y medible. Asimismo, las
hipótesis deben estar vinculadas con técnicas disponibles para probarlas.
5. Las hipótesis se clasifican en: hipótesis nulas e hipótesis alternativas.
Ambos tipos de hipótesis son muy útiles cuando planteamos una investigación
en la cual existen dos o más grupos.
1. Hipótesis nula (H0)
La hipótesis nula es aquélla que nos dice que no existen diferencias significativas entre
los grupos o que las diferencias que existen se deben simplemente al azar. Esta hipótesis
enuncia que no existen diferencias entre las poblaciones de donde proceden las
muestras, por lo que las diferencias observadas son atribuibles a errores aleatorios o de
muestreo.
Por ejemplo, supongamos que un investigador cree que si los fibroblastos de la pulpa
dental humana son cultivados en presencia de ácido cítrico, aumenta la viabilidad celular.
Para llevar a cabo su investigación y demostrar o rechazar su hipótesis, toma al azar una
muestra de células de la pulpa y la distribuye en dos grupos: uno que llamaremos grupo
experimental, el cual recibirá ácido cítrico, y otro que no recibirá este ácido, al que
llamaremos grupo control. La hipótesis nula (H0) señalará que no hay diferencias en la
viabilidad celular observada entre ambos grupos, el experimental y el control.
Una hipótesis nula es importante por varias razones. La más importante de ellas es que
el hecho de contar con una hipótesis nula ayuda a determinar si existe una diferencia
entre los grupos, si esta diferencia es significativa, y si no se debió al azar. Sin embargo,
no toda investigación precisa de formular hipótesis nula. Recordemos que la hipótesis
nula es aquélla por la cual indicamos que la información a obtener es contraria a la
hipótesis de trabajo.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
8
2. Hipótesis alternativa (H1)
La hipótesis alternativa es aquélla que afirma la existencia de diferencias que no
atribuibles al azar. Al responder a un problema, es muy conveniente proponer otras
hipótesis en las que aparezcan variables independientes distintas de las primeras que
formulamos. Por tanto, para no perder tiempo en búsquedas inútiles, es necesario hallar
diferentes hipótesis alternativas como respuesta a un mismo problema y elegir entre ellas
cuáles y en qué orden vamos a tratar su comprobación.
La presencia de la hipótesis alternativa también es importante, puesto que la mayoría de
los diseños de investigación se centrarán en comprobar la veracidad o la falsedad de la
hipótesis nula. En los casos en los que la hipótesis nula demuestre ser falsa, el
investigador ha de tener una alternativa que, al ser opuesta a la hipótesis nula, será la
hipótesis verdadera y la que habremos de adoptar como cierta.
En el ejemplo que poníamos previamente, la hipótesis alternativa (H1) afirmará que sí
existen diferencias significativas en la viabilidad celular observada entre ambos grupos, el
experimental y el control.
Hipótesis nula H0
Los fibroblastos de la pulpa dental humana cultivados en medios enriquecidos con ácido cítrico presentan
índices de viabilidad celular similares a los fibroblastos cultivados en medios de cultivo sin este factor
Hipótesis alternativa H1
Los fibroblastos de la pulpa dental humana cultivados en medios enriquecidos con ácido cítrico presentan
mayor viabilidad celular que los fibroblastos cultivados en medios de cultivo sin este factor

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
9
C.- VALIDACIÓN DE LAS HIPÓTESIS
La tarea fundamental de todo investigador consiste en validar las hipótesis de trabajo.
Validar significa verificar, esto es, demostrar que las hipótesis son ciertas, o falsear, es
decir, demostrar que las hipótesis son falsas. La validación constituye una fase
eminentemente operativa dentro del proceso general de la investigación. En ella,
sometemos a prueba las hipótesis formuladas para resolver el problema y los objetivos
fijados, es decir, tratamos de constatar si existe o no base suficiente, con los datos
disponibles, para confirmar o rechazar la suposición inicial.
Para validar una hipótesis, el investigador ha de plantear un diseño de investigación
adecuado (como se verá en el siguiente apartado), el cual le permitirá analizar la realidad
para verificar o falsear sus hipótesis.
Lo primero que ha de hacer el científico es identificar y categorizar una serie de factores
que pueden tomar más de un valor y que se denominan variables. Lo segundo, será
seleccionar un conjunto de sujetos sobre los cuales llevará a cabo su estudio
experimental y que constituyen lo que se denomina muestra. A continuación, una vez
definidas las variables y seleccionada la muestra, el investigador deberá seleccionar o
elaborar los instrumentos apropiados para la recogida de datos, aplicarlos y analizar los
datos, para concluir con la decisión estadística y la constatación de los resultados de la
investigación, como veremos en distintos apartados de este documento. En estos
momentos, es interesante analizar los conceptos y tipos de variables y de muestras:
1. Definición de las variables
Una variable es una propiedad, atributo o característica, susceptible de adoptar diferentes
valores o categorías. Por ello, variable es todo aquello que puede variar o que alcanza o
puede alcanzar diferentes valores. Variable es también cada uno de los rasgos o
características de los elementos de una población y que varían de un individuo a otro (por
ejemplo, talla, edad, color, contenido intracelular de cloro, tejido de origen, etc.). Los
valores o categorías de la variable pueden variar tanto entre sujetos, como en el mismo
sujeto a lo largo del tiempo.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
10
Desde un punto de vista práctico, las variables se pueden clasificar en dependientes e
independientes (León y Montero, 1995; Vander Zanden, 1986), tal como veremos a
continuación:
a- Variable dependiente (VD). Se denomina variable dependiente a aquel factor
que resulta afectado dentro de un marco experimental, esto es, aquello que
ocurre o cambia como resultado de la manipulación de otro factor (denominado
variable independiente). Es la variable sobre la que se quieren analizar los
efectos de las variables independientes.
Si seguimos el ejemplo propuesto anteriormente, podríamos decir que la
viabilidad celular es una variable dependiente, pues se trata de un factor o
variable que el investigador quiere evaluar y sobre la cual actuarán algunos
otros factores o variables que pueden influir sobre su resultado.
b- Variable independiente (VI). La variable independiente es un factor que es
manipulado en un marco experimental, esto es, constituye un factor causal o
condición determinante de la relación que se quiere estudiar. En forma general,
la variable independiente es un factor que se considera explicación del
fenómeno que se está estudiando. Algunos investigadores la definen como una
variable cuya influencia sobre la variable dependiente se quiere estudiar. En los
estudios experimentales, la variable independiente se halla bajo el control
directo del investigador (de ahí su nombre). En los estudios observacionales, por
el contrario, los sujetos se asignan a diferentes grupos sobre la base de su
valor. En este tipo de situaciones quizá sea más apropiado denominarla
‗predictor‘, y ‗criterio‘ a la variable dependiente.
En nuestro ejemplo, una variable independiente sería la presencia de ácido
cítrico en el medio de cultivo. Esta variable tomará dos categorías en este
caso: con ácido cítrico y sin ácido cítrico. En otros experimentos, el investigador
puede llegar a considerar muchas más categorías dentro de cada variable
independiente (como varias dosis de este producto, por ejemplo).

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
11
Variable Dependiente (VD)
Viabilidad celular de los fibroblastos pulpares mantenidos en cultivo
Variable Independiente (VI)
Presencia de ácido cítrico en el medio de cultivo: - Medio suplementado con ácido cítrico - Medio no suplementado con ácido cítrico
2. Selección de la muestra
La selección de una muestra pertinente constituye uno de los momentos clave de todo
proyecto investigador. Cuando un investigador quiere llevar a cabo un estudio, lo ideal
sería que éste pudiese acceder a todos los individuos que componen el objetivo de su
estudio o a todas las muestras que teóricamente sería posible estudiar. De este modo,
sería posible determinar el valor exacto de la variable que se pretende estudiar en la
población diana. Este valor, perteneciente a toda la población, se denomina parámetro y
suele representarse con un carácter del alfabeto griego (µ, , , etc.). Sin embargo, esta
situación ideal casi nunca es posible, por lo que el investigador ha de conformarse con
estudiar tan solo un grupo reducido de individuos o muestras y no la población general
completa. La determinación de la variable de estudio se centrará a ese grupo de
individuos, con lo que su valor puede diferir del parámetro poblacional. El valor de esta
variable en la muestra de individuos seleccionada por el investigador se denomina
estadístico, representándose con una letra del alfabeto latino (X, s, m, etc.).
En investigación, se denomina Universo al conjunto de elementos de referencia sobre el
cual van a recaer las observaciones y que son el objetivo del estudio. Por ejemplo, en
Histología Humana, Universo sería el conjunto de seres humanos que habitan la Tierra.
Por otro lado, se denomina Población al conjunto de todos los elementos que cumplen
ciertas propiedades y entre los cuales se desea estudiar un determinado fenómeno y que
son accesibles al investigador. Por ejemplo, el conjunto de seres humanos que habitan
en la misma ciudad que el investigador que lleva a cabo su experimento. Finalmente, se
denomina Muestra al subconjunto de la población que es realmente estudiado por el
investigador y a partir del cual se pretenden sacar conclusiones sobre las características
de la población. La muestra debe ser representativa, en el sentido de que las

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
12
conclusiones obtenidas deben servir para el total de la población, como veremos al hablar
de la validez externa de los diseños de investigación.
El proceso mediante el cual un investigador selecciona un grupo de sujetos que
conformarán su muestra a partir de una población, se denomina muestreo. Las técnicas
de muestreo más utilizadas son las siguientes:
- Aleatorio simple.- Proceso de selección de datos u observaciones a partir
del universo o población, de tal manera que todos hayan tenido igual
probabilidad e independencia para ser seleccionados.
- De cuotas.- Tiene por objeto el conocimiento de las características de
estratos de la población: sexo, raza, religión etc.
- Accidental.- Se utiliza cuando las muestras utilizadas son las que se ofrecen
en nuestro ámbito y no es posible por determinadas dificultades alcanzar otros
ámbitos.
- Estratificado.- Exige describir previamente la población, identificar niveles y
estratos. Se utiliza cuando es necesario establecer la proporción más
conveniente de determinados tipos de muestras (por ejemplo, un 50% de
varones y un 50% de mujeres). Las características de las submuestras
(estratos o segmentos) pueden contemplar casi cualquier tipo de variables:
edad, sexo, color, tamaño, tejido de origen, etc. Los estratos pueden así
definirse mediante un número prácticamente ilimitado de características.
- Grupo o bloque.- Es muy utilizado en las encuestas y cuando se pretende
minimizar la varianza de error. Consiste en seleccionar sucesivamente
subconjuntos, por ejemplo, provincias, colegios, clases, alumnos, etc.
Según qué técnica de muestreo se utilice, las muestras se clasifican en probabilísticas o
no probabilísticas. Una muestra probabilística es aquélla que se elige utilizando reglas
matemáticas, por lo que la probabilidad de selección de cada unidad es conocida de
antemano. Por el contrario, una muestra no probabilística no ser rige por las reglas
matemáticas de la probabilidad. De ahí que, mientras en las muestras probabilísticas es
posible calcular el tamaño del error muestral, no es factible hacerlo en el caso de las
muestras no probabilísticas. Ejemplos de éstas últimas son la muestra accesible (que

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
13
está conformada por muestras de fácil acceso para el investigador como podrían ser las
preparaciones histológicas disponibles en su laboratorio) y la muestra voluntaria (donde
los sujetos de la muestra no han sido seleccionados matemáticamente).
La modalidad más elemental de muestra probabilística es la muestra aleatoria simple, en
la que todos los componentes o unidades de la población tienen la misma oportunidad o
probabilidad de ser seleccionados. Otro procedimiento similar de muestreo aleatorio es el
llamado muestreo aleatorio sistemático en el cual se escoge uno de cada n componentes
del listado de la población. El investigador selecciona al azar un punto de partida y un
intervalo muestral. Así si el punto de partida fuera el 10 y el intervalo el 6 se elegirían el
10, 16, 22, 28, etc. hasta completar la lista de sujetos escogidos.
3. Recogida de datos
Una vez definidas las variables y seleccionada la muestra, el proceso de investigación se
centra en la recogida de datos mediante la medición de las diferentes variables del
estudio. En toda investigación, el científico dedica gran parte de su tiempo en medir las
variables contenidas en la hipótesis.
Medir es asignar numerales a los objetos, de acuerdo con ciertas reglas. Medir también
se puede definir como el proceso de vincular conceptos abstractos con indicadores
empíricos, mediante clasificación y/o cuantificación. Una buena regla debe reflejar el
grado de isomorfismo existente entre el conjunto de objetos, características o
propiedades sujetos a medición y el conjunto de los números. Operativamente, cuantificar
una propiedad de un sistema específico es proyectar el conjunto de grados de la
propiedad sobre el conjunto de los números, de tal modo que la ordenación y espaciación
de los números reflejen el orden y espaciación de los grados.
Para medir las variables del estudio, se utilizan instrumentos de medición. Un instrumento
de medición debe cubrir dos requisitos: fiabilidad y validez. Aunque no existe un
instrumento de medición perfecto, el investigador debe utilizar los instrumentos que le
permitan reducir el error de medición a límites tolerables.
Se dice que un instrumento es válido cuando mide lo que dice medir. La validez se
refiere al grado en que el instrumento de medición mide realmente la o las variables que
pretende medir. Existen varias clases de validez:

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
14
- Validez de contenido. Hace referencia a la representatividad de los
elementos de la prueba respecto de la característica o variable objeto de
medición. La validez de contenido se obtiene contrastando el universo de
ítems contra los ítems presentes en el instrumento de medición.
- Validez predictiva. Para identificar el valor predictivo de una prueba, debe
correlacionarse las puntuaciones de ésta con un criterio externo.
- Validez concurrente. Consiste operativamente en verificar si los resultados
de la prueba correlacionan con otros instrumentos que ya probaron su validez
y que medían los mismos objetos y variables.
- Validez de construcción o de constructo. Hace mención a la naturaleza
misma de lo que se mide. Identifica asimismo los valores o niveles que
construyen el objeto o variable. La validez de constructo se puede determinar
mediante el análisis de factores.
- Validez didáctica. Este tipo de validez se refiere al aspecto exterior de la
prueba. Se trata de que despierte el interés para su realización en caso de que
se presente a los individuos para su resolución. Debe cuidarse la forma de
expresión, los gráficos, etc.
La validez de una prueba se puede determinar mediante el análisis interno de la prueba o
mediante la comparación con los resultados de un criterio externo (validez de criterio).
Los factores que principalmente pueden afectar la validez son: improvisación, utilizar
instrumentos desarrollados en el extranjero y que no han sido validados a nuestro
contexto, poca o nula empatía, factores de aplicación.
Un instrumento es fiable cuando es estable, equivalente o muestra consistencia interna.
La fiabilidad indica en qué grado la repetición del procedimiento de medida, cuando no se
han modificado las condiciones, da lugar a resultados equivalentes. La fiabilidad es el
grado en que un test aporta resultados válidos. Para evaluar la fiabilidad, el test se pone
a prueba evaluando la consistencia de las puntuaciones obtenidas en dos mitades del
test, o en formas alternadas del test, o mediante su repetición tardía.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
15
Una forma especial de fiabilidad es la confiabilidad. La confiabilidad se refiere al grado en
que la aplicación repetida de un instrumento de medición al mismo sujeto u objeto,
produce iguales resultados. La confiabilidad se determina calculando un coeficiente de
confiabilidad que varía entre 0 y 1 (0 = nula confiabilidad, 1 = total confiabilidad). Los
procedimientos más comunes para calcular la confiabilidad son la medida de estabilidad,
el método de formas alternas, el método de mitades partidas, el coeficiente alfa de
Cronbach y el coeficiente KR-20.
En el ámbito de la Histología, los datos se recogen a través de un proceso de
observación. La observación es un procedimiento básico, intencionado, sistemático de
recogida de información, a través del cual el observador recoge por sí mismo, o utilizando
algún recurso tecnológico, información sobre el comportamiento de las variables de
estudio en un contexto natural o artificial.
Como muestra la Figura 1 (Gómez de Ferraris y Campos, 2004; de Juan, 1999), la
observación en Histología se fundamenta en la utilización de medios amplificantes tales
como las lupas o los microscopios ópticos, electrónicos o de resolución atómica,
utilizando para ello muestras tisulares previamente preparadas mediante fijación,
inclusión o desecación. En todo caso, los instrumentos de medida, incluyendo las
mencionadas medidas amplificantes, han de presentar elevados índices de validez y
fiabilidad. De este modo, el histólogo podrá confiar en que sus resultados son verdaderos
y reproducibles.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
16
Figura 1. Esquema general de la técnica histológica y de los instrumentos de
observación (de Gómez de Ferraris y Campos, 2004).

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
17
4. Análisis estadístico
Una vez recogidos todos los resultados del estudio, es el momento de realizar el análisis
de los mismos para decidir acerca de las hipótesis y elaborar las conclusiones. En toda
investigación científica, la decisión que se ha de tomar hace referencia a la veracidad o
falsedad de las hipótesis de trabajo, es decir, el contraste de las mismas.
El análisis estadístico constituye un conjunto de transformaciones numéricas de los datos
encaminado a lograr que éstos sean interpretables en relación a la hipótesis de
investigación. Mediante este análisis, podemos contrastar las hipótesis de trabajo para
decidir sobre las mismas basándonos en fórmulas matemáticas previamente validadas.
El análisis estadístico se puede llevar a cabo a dos niveles diferentes: el descriptivo y el
inferencial.
a- La estadística descriptiva constituye una serie de procedimientos matemáticos que
nos permiten extraer conclusiones sobre el comportamiento de una serie de variables.
Para algunos autores, la estadística descriptiva es la parte de la estadística que opera
con estadísticos usados sólo con fines descriptivos de muestras de las que derivan y no
para describir una población o universo relacionado. Uno de los propósitos es resumir y
describir de forma clara y conveniente las características de uno o más de un conjunto de
datos.
En realidad, la estadística descriptiva nos permite sintetizar y resumir los resultados del
estudio en forma de índices fáciles de reconocer y de manejar y facilitan información
sobre la serie de datos que estamos analizando. Generalmente, concluye en la
determinación de ciertos valores numéricos, denominados estadísticos, cada uno de los
cuales viene a plasmar o poner de relieve una característica del grupo estudiado. Estos
índices o estadísticos, pueden ser de distinta naturaleza, destacando especialmente las
medidas de posición y las medidas de dispersión:
Medidas de posición. Las medidas de posición nos informan acerca del
comportamiento medio de nuestras variables, generando índices que nos dan una
idea del comportamiento global de las mismas. Existen dos tipos de medidas de
posición:

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
18
a) Medidas de posición central o de tendencia central. Las medidas de
posición central informan sobre los valores medios de la serie de datos.
Las principales medidas de posición central son la media, la mediana y la
moda:
1.- Media: es el valor medio ponderado de una serie de datos.
Lo más positivo de la media es que en su cálculo se utilizan
todos los valores de la serie, por lo que no se pierde ninguna
información. Sin embargo, presenta el problema de que su
valor (tanto en el caso de la media aritmética como geométrica)
se puede ver muy influido por valores extremos, que se aparten
en exceso del resto de la serie. Estos valores anómalos
podrían condicionar en gran medida el valor de la media,
perdiendo ésta representatividad.
Se pueden calcular diversos tipos de medias, siendo las
siguientes las más utilizadas la media aritmética y la media
geométrica:
a) Media aritmética: La media aritmética es la medida
de posición central más utilizada, y se calcula
multiplicando cada valor por el número de veces que
éste se repite. La suma de todos estos productos se
divide por el total de datos de la muestra:
X = [(X1 * n1) + (X2 * n2) + (X3 * n3) + .....+ (Xn * nn)] / n
b) Media geométrica: La media geométrica se suele
utilizar en series de datos como tipos de interés
anuales, inflación, etc., donde el valor de cada año
tiene un efecto multiplicativo sobre el de los años
anteriores. Para calcularla, se eleva cada valor al
número de veces que se ha repetido. Se multiplican
todo estos resultados y al producto final se le calcula
la raíz "n" (siendo "n" el total de datos de la muestra):
X = (X1n1
* X2n2
* X3n3
* … * Xnnn
) (1/n)

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
19
2.- Mediana: La mediana es el valor de la serie de datos que
se sitúa justamente en el centro de la muestra ordenada (un
50% de valores son inferiores y otro 50% son superiores).
No presentan el problema de estar influido por los valores
extremos pero, en cambio, no utiliza en su cálculo toda la
información de la serie de datos (no pondera cada valor por el
número de veces que se ha repetido).
3.- Moda: es el valor que más se repite en la muestra.
a) Medidas de posición o de tendencia no central. Estas medidas
informan de cómo se distribuye el resto de los valores de la serie (los que
no son centrales), y permiten conocer otros puntos característicos de la
distribución que no son los valores centrales. Entre otros indicadores, se
suelen utilizar una serie de valores que dividen la muestra en tramos
iguales:
1.- Cuartiles: son 3 valores que distribuyen la serie de datos,
ordenada de forma creciente o decreciente, en cuatro tramos
iguales, en los que cada uno de ellos concentra el 25% de los
resultados.
2.- Deciles: son 9 valores que distribuyen la serie de datos,
ordenada de forma creciente o decreciente, en diez tramos
iguales, en los que cada uno de ellos concentra el 10% de los
resultados.
3.- Percentiles: son 99 valores que distribuyen la serie de
datos, ordenada de forma creciente o decreciente, en cien
tramos iguales, en los que cada uno de ellos concentra el 1%
de los resultados.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
20
Medidas de dispersión. Las medidas de dispersión son aquéllas que estudian la
distribución de los valores de la serie, analizando si éstos se encuentran más o
menos concentrados, o más o menos dispersos unos respecto a otros.
Existen diversas medidas de dispersión, entre las más utilizadas podemos
destacar las siguientes:
a) Rango: mide la amplitud de los valores de la muestra y se calcula por
diferencia entre el valor más elevado y el valor más bajo.
b) Varianza: Mide la distancia existente entre los valores de la serie y la
media. Se calcula como sumatorio de las diferencias al cuadrado entre
cada valor y la media, multiplicadas por el número de veces que se ha
repetido cada valor. El sumatorio obtenido se divide por el tamaño de la
muestra.
La varianza siempre será mayor que cero. Mientras más se aproxima a
cero, más concentrados están los valores de la serie alrededor de la
media. Por el contrario, mientras mayor sea la varianza, más dispersos
están.
c) Desviación típica: Se calcula como raíz cuadrada de la varianza.
d) Coeficiente de variación de Pearson (1916): Se calcula como cociente
entre la desviación típica y la media.
Medidas de posición
Medidas de posición central
Media aritmética
Media geométrica
Mediana
Moda
Medidas de posición no
central
Cuarteles
Deciles
Percentlies
Medidas de dispersión
Rango
Varianza
Desviación típica
Coeficiente de variación

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
21
b- La estadística inferencial constituye un conjunto de operaciones lógicas que
consisten en extraer consecuencias a partir de los datos o proposiciones iniciales. Entre
estas consecuencias, el investigador intentará utilizar los resultados obtenidos en la
muestra para confirmar o desmentir la validez de las hipótesis planteadas. De este modo,
utilizando los resultados de su estudio, podrán aplicarse una serie de modelos y fórmulas
estadísticas (que se denominan pruebas de contraste) para validar las hipótesis y poder
responder a las preguntas de investigación. La inferencia estadística hace referencia al
grado de confianza con que podemos inferir o concluir que existe covariación entre las
variables del estudio, en base a pruebas de significación estadística.
Como veremos más adelante, la confirmación (verificación) o falsación (rechazo) de las
hipótesis permitirá tomar decisiones sobre la propia muestra utilizada (validez interna del
estudio) y sobre una población más numerosa, es decir, se extrapolan a la población
general los resultados obtenidos en la muestra seleccionada (validez externa). Dado que
estas decisiones se toman en condiciones de incertidumbre, suponen el uso de
conceptos de probabilidad y están sujetas a la posibilidad de cometer errores. En el
ejemplo propuesto, la verificación de la hipótesis nula nos llevaría a afirmar que la
hipótesis nula es cierta y, por tanto, que los fibroblastos de la pulpa dental humana
cultivados en medios enriquecidos con ácido cítrico presentan índices de viabilidad
celular similares a los fibroblastos cultivados en medios de cultivo sin este factor. Por el
contrario, la falsación de la hipótesis nula nos llevaría a afirmar que la hipótesis
alternativa es correcta y que los fibroblastos de la pulpa dental humana cultivados en
medios enriquecidos con ácido cítrico presentan mayor viabilidad celular que los
fibroblastos cultivados en medios de cultivo sin este factor.
Estudiaremos este punto en detalle en el apartado correspondiente a la resolución
estadística.
Verificación de la Hipótesis Nula
Los fibroblastos de la pulpa dental humana cultivados en medios enriquecidos con ácido cítrico presentan
índices de viabilidad celular similares a los fibroblastos cultivados en medios de cultivo sin este factor
Rechazo de la Hipótesis Nula
Los fibroblastos de la pulpa dental humana cultivados en medios enriquecidos con ácido cítrico presentan
mayor viabilidad celular que los fibroblastos cultivados en medios de cultivo sin este factor

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
22
D.- INTERPRETACIÓN DE LOS RESULTADOS
La elaboración de las conclusiones constituye uno de los puntos más importantes del
trabajo de investigación. En realidad, las conclusiones son un resumen de los hallazgos
más importantes de la investigación y, sobre todo, una forma de dar respuesta a las
preguntas planteadas inicialmente y que justificaron la realización del ensayo. Después
de recoger y analizar los resultados y de tomar una decisión acerca de la validez o la
falsedad de la hipótesis nula elaborada por el investigador, es el momento de interpretar
todo el trabajo y de elaborar las conclusiones del trabajo.
Para que sean válidas, es muy importante que las conclusiones estén basadas en los
resultados obtenidos mediante el proceso de investigación. Las conclusiones derivadas
de la investigación deben recoger el resultado al que se ha llegado tras la aplicación de
las correspondientes pruebas y compararlo con la información previa. De este modo, el
investigador dará respuesta a las preguntas de investigación mediante la validación o
falsación de las hipótesis de trabajo. Así, el conocimiento generado estará basado tanto
en la información ya existente (estado actual de la cuestión) como en la nueva
información generada (los resultados de la investigación).
A la hora de redactarlas, conviene ser prudente en las conclusiones y pensar en la
provisionalidad de las mismas pues, como todo conocimiento científico, todas las
conclusiones se hacen en términos de probabilidad, no de certeza.
Por otro lado, las conclusiones no deben limitarse a ser una repetición de los resultados
ni una mera traducción de los términos estadísticos. Por el contrario, las conclusiones
han de aportar información relevante, relacionada con el problema de investigación, y
confirmar o rechazar las hipótesis generadas de una forma clara y directa. Por ello, las
conclusiones han de expresarse utilizando un lenguaje científico que sea fácil de
entender incluso por los que no son expertos en la materia de estudio.
En nuestro ejemplo, podríamos concluir que la adición de ácido cítrico favorece la
viabilidad celular de los fibroblastos pulpares mantenidos en cultivo y podríamos proponer
la adición de este factor a los cultivos de este tipo de células (Figura 2).

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
23
III.- EL DISEÑO DE INVESTIGACIÓN EXPERIMENTAL
El diseño de investigación constituye un aspecto fundamental y necesario de todo
proceso científico. Cuando un investigador se plantea realizar un estudio, suele tratar de
desarrollar algún tipo de comparación. El diseño de investigación supone, así, especificar
la naturaleza de las comparaciones que habrían de efectuarse, constituyendo además el
plan general del investigador para obtener respuestas a sus interrogantes o comprobar
las hipótesis de investigación. El diseño de investigación desglosa las estrategias básicas
que el investigador adopta para generar información exacta e interpretable.
La importancia de utilizar un adecuado diseño experimental en la investigación científica
ha sido señalada por numerosos investigadores. Sin embargo, estos investigadores aún
no han logrado ponerse de acuerdo a la hora de elaborar una definición adecuada del
diseño experimental.
A continuación, intentaremos aproximarnos a algunas definiciones propuestas hasta la
fecha para este concepto, así como las características fundamentales y los tipos
principales de diseños que se pueden utilizar en la investigación científica.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
24
A.- CONCEPTO DE DISEÑO DE INVESTIGACIÓN
Numerosos investigadores han propuesto diferentes definiciones para el concepto que
nos ocupa. De entre ellas, destacamos las siguientes:
Finney (1960) afirma que el diseño de un experimento esta constituido por: a) la serie de
tratamientos seleccionados para hacer comparaciones; b) la especificación de las
unidades a las cuales se aplicaran los tratamientos; c) las reglas por las cuales se
asignaran los tratamientos a las unidades experimentales, y d) la especificación de las
medidas que van a tomarse de cada unidad (variable dependiente).
Plutchnik (1968) lo define en términos de: a) las formas de disponer las condiciones
experimentales indicadas por la pregunta de investigación, y b) los métodos de control
para minimizar o reducir el error al establecer relaciones causales entre las variables
implicadas.
Para Kirk (1972) un diseño experimental es un plan de acuerdo con el cual se asigna a
los sujetos a los diferentes grupos o condiciones experimentales. Hay cinco actividades
interrelacionadas que lo caracterizan: a) la formulación de hipótesis estadísticas, b) el
establecimiento de reglas de decisión para poner a prueba dichas hipótesis, c) la
recogida de los datos de acuerdo con un plan que permita evaluar las hipótesis, d) el
análisis de los datos, y e) la toma de decisiones respecto a las hipótesis y a la
formulación de inferencias inductivas respecto de las hipótesis científicas o de
investigación.
Kerlinger (1979) define el diseño de investigación como "el plan, la estructura y la
estrategia de investigación concebidos para obtener respuestas a preguntas de
investigación y controlar la varianza". Para este autor, el plan es el esbozo general del
proyecto de investigación, e incluye todo el proceso que va desde la formulación de las
hipótesis hasta el análisis de los datos. La estructura es, para Kerlinger, más específica
que el plan, constituyendo el esquema y el paradigma de lo que se hará con las variables.
Por último, estrategia se refiere a los métodos de recogida y análisis de datos.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
25
McGuigan (1976), aparte de tratar diversos tipos de diseños experimentales, considera
aspectos como: a) el planteamiento del problema, b) la formulación de la hipótesis, c) la
manipulación de la variable independiente, d) Ia medida de la variable dependiente, e) el
procedimiento, f) tipos de análisis de los datos y g) anticipación de resultados posibles.
Castro (1980), partidario de reducir el peso de la estadística en el diseño, lo concibe
como una organización lógica de las condiciones experimentales lo suficientemente
sensible como para contestar a las preguntas de investigación.
Campbell y Stanley (1991) consideran que lo decisivo de un diseño es su capacidad para
controlar las distintas fuentes de invalidez interna y externa, e indican, junto a los factores
que controla cada diseño, el tipo de pruebas estadísticas adecuadas para el análisis de
los datos.
Doménech i Massons (1980) afirma que "bajo este nombre se designan las técnicas de
realización de experiencias que permiten estudiar la influencia de uno o varios factores o
variables".
Para Arnau (1981), "en su sentido más general, el diseño experimental incluye a los
procedimientos requeridos en una investigación experimental que van desde la
formulación de la hipótesis hasta la obtención de las conclusiones". Tales procedimientos
se refieren a la formulación de la hipótesis, selección de las variables independientes y de
las variables dependientes, control de las variables experimentales, manipulación de las
variables independientes y registro de la variable dependiente, análisis de la varianza
producida en la variable dependiente e inferencia de las relaciones entre las variables en
estudio.
En resumen, la mayor parte de los autores coinciden en afirmar que el núcleo de un
diseño consiste en la organización de las condiciones experimentales, en las reglas
para la afirmación de unidades experimentales (sujetos o grupos) a tratamientos o
viceversa, y a sus relaciones con la pregunta de investigación o hipótesis
alternativa. La mayoría considera propio del diseño experimental la especificación de la
o las variables dependientes, la manipulación de las variables independientes, el control
de las variables experimentales, el procedimiento experimental, el uso de técnicas
estadísticas y la recogida y análisis de datos, entre otros.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
26
Con independencia de la mayor o menor extensión que se dé a este concepto, todos los
autores coinciden en considerar fundamental el grado de control experimental que el
diseño ejerce sobre las variables que determinan el comportamiento de la variable
dependiente (las variables independientes y las variables intervinientes). Es decir, el
control experimental se refiere a los siguientes aspectos: a) la manipulación de la variable
independiente, b) la minimización o el mantenimiento constante del influjo de las variables
independientes no experimentales, c) la asignación al azar de los sujetos a grupos y de
éstos a tratamientos.
A partir de las definiciones de los distintos autores, Jiménez Fernández (2000) define el
diseño como un esquema o estructura lógica de acción que permite mantener
constante el influjo de las variables experimentales pertinentes y controlar así la
influencia de la o las variables independientes sobre la o las variables
dependientes.
Figura 2. Imagen de microscopía de contraste de fases correspondiente a un
cultivo primario de fibroblastos humanos procedentes de la pulpa dental.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
27
B.- OBJETIVOS DEL DISEÑO DE INVESTIGACIÓN
Los objetivos del diseño son numerosos. Para Kerlinger (1979), todos esos objetivos se
pueden resumir en dos objetivos generales: a) dar respuestas a preguntas de
investigación, y b) controlar la varianza.
Arnau Grass (1981), sin embargo, afirma que el objetivo principal del diseño es el control
de la varianza secundaria. Si la varianza secundaria no se controla adecuadamente,
corremos el peligro de experimentar un incremento notable de la varianza de error,
pudiendo llegar a contaminar la acción de los tratamientos.
1. Responder a las preguntas de investigación
El dar una respuesta adecuada a las preguntas que se plantea el investigador es el
objetivo primario y fundamental de todo diseño de investigación. Desafortunadamente,
muchos investigadores dedican mucho tiempo a la realización empírica de sus
experimentos, pero apenas ponen atención en el diseño de su estudio y en una adecuada
elaboración de las preguntas de investigación.
La evidencia empírica que proporcionan los estudios que se proyectan y realizan, debe
tener por finalidad ayudar a resolver un problema conocido que se ha especificado en
una hipótesis. A veces, determinados alumnos se entusiasman con la estadística y
comienzan a realizar trabajos cuyo objetivo suele consistir en probar la hipótesis nula
inicialmente planteada. Cuando se les pregunta: "y ahora, ¿qué?", quedan con frecuencia
desconcertados y empiezan a ver cuál es el verdadero objetivo de la investigación y el
sentido del diseño.
Es evidente que un problema de investigación admite varias hipótesis, y que algunas de
ellas pueden ponerse a prueba empíricamente con más facilidad que otras.
Teóricamente, al menos, hay tantos tipos de diseños como posibilidades de poner a
prueba una hipótesis. Es decir, los diseños se elaboran para dar respuestas válidas a los
enunciados de las hipótesis. Se puede hacer una observación e inferir a partir de ella que
existe la supuesta relación expresada en la hipótesis. También se pueden hacer múltiples
investigaciones e inferir a partir de ellas que existe la relación hipotética. El resultado
depende de cómo se hicieron las observaciones y la inferencia. De ahí la importancia del

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
28
diseño pues cuando una investigación se diseña y ejecuta con cuidado aumenta la
confianza en los resultados y se infiere con mayor solidez. Es una cuestión de calidad
tanto como de cantidad.
El diseño es en este sentido un instrumento valioso en manos del investigador que goza
además de otra característica: la flexibilidad. Si uno de sus objetivos es responder a
preguntas de investigación no existe un diseño ideal para todo problema sino un diseño
optimo para cada situación. Se han creado y se seguirán creando en función de las
necesidades del investigador. Campbell y Stanley los sitúan dentro de una concepción
evolutiva de la ciencia y ven en el diseño de experimentos no una panacea sino el único
camino hacia el progreso acumulativo. Por ello recomiendan la investigación continua y
múltiple más que los experimentos únicos y definitivos.
Kerlinger se pregunta: ¿cómo logra el diseño aumentar la confianza en los resultados y
en la inferencia? En rigor, el diseño no dice qué hay que hacer, sino que "sugiere" las
direcciones de la observación y el análisis. Según el enunciado de la hipótesis, se ve si
un diseño puede ponerla a prueba o no. Si puede probarla, sugiere si se necesita uno,
dos o mas grupos; el número de sujetos por grupo si se desea utilizar determinada
prueba estadística; el tipo de observaciones que para ella hay que obtener; si es posible
o no el obtenerlas; caso de ser posible, si debido a sus características se reducirá el
tamaño de la muestra; qué variables extrañas puede controlar y cuáles no; qué variables
son activas y cuáles atributivas y, en último término, permite esbozar posibles
conclusiones extraídas del análisis de los datos. Es decir, proporciona un marco de
referencia para poner a prueba de un modo adecuado la relación causal entre variables
que se postula en la hipótesis.
Ahora se puede comprender por que diseñar bien una investigación significa tanto huir de
la improvisación cuanto del tecnicismo estéril. Es conocer con precisión el problema y, en
función de múltiples factores científicos, técnicos y materiales, resumirlo en una hipótesis
y elegir el diseño adecuado. No es sólo diseñar experimentos sino seleccionar y hasta
inventar los diseños que mejor se adaptan a cada situación aunque no sean auténticos
experimentos. Es también abandonar la práctica de recoger cantidad de datos y
plantearse a posteriori qué hipótesis pueden probar o descubrir que no pueden poner a
prueba, al menos de la manera más concluyente posible, la hipótesis formulada.
Veamos un ejemplo: A un profesor de la asignatura del área de la Histología le preocupa
el modo de enseñar determinado núcleo temático que es al mismo tiempo árido y
fundamental. Su experiencia le dice que hay alumnos que de modo espontáneo tienden a

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
29
memorizarlo, mientras que otros se inclinan por la comprensión pero que los resultados
son desiguales. Supongamos que él está convencido de la superioridad del estudio
comprensivo y decide poner a prueba esta hipótesis, "si los alumnos aprenden el tema de
modo comprensivo, su rendimiento será superior a si estudian de memoria". Diseña un
experimento como el siguiente (diseño de dos grupos con postest solamente):
Tratamientos
x1 (memoria) x2 (comprensión)
Puntuaciones obtenidas en el examen
X1 X2
Es decir, tiene una variable independiente que varía de dos maneras y necesita, por
tanto, dos grupos o unidades experimentales. La variable dependiente será medida
mediante una prueba tipificada después de haber enseñado el tema a los dos grupos,
enfatizando la memoria y la comprensión respectivamente. De la Universidad en la que
imparte sus clases, ha elegido aleatoriamente a los alumnos y los ha asignado
aleatoriamente a los grupos y a los tratamientos experimentales para lograr el deseado
control experimental. La diferencia entre las medias X1 y X2 se analizara mediante una
prueba t o F para ver si es estadísticamente significativa. Como se ha dicho, la hipótesis
alternativa o de investigación es que X1 < X2, es decir, que en promedio obtendrá mejores
resultados en el examen el grupo al que se Ie enseña comprensivamente. La prueba
estadística indica que no existen diferencias significativas.
El profesor sigue insatisfecho a pesar del resultado y estudiando y reflexionando
considera que otras variables pueden contribuir a explicar mejor su problema y decide
manipular una nueva variable independiente, el tiempo, y formular una hipótesis de
interacción. El método comprensivo es superior al memorístico no en sus efectos
inmediatos sino a medio plazo. Si desea probar dicha hipótesis, tiene que utilizar un
diseño factorial. Elige un diseño factorial 2 x 2 como el siguiente:

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
30
MÉTODO
x1 (memoria) x2 (comprensión)
TIEMPO
y1 (un día) Puntuaciones obtenidas en el examen Y1
Y2 (un mes) Puntuaciones obtenidas en el examen Y2
X1 X2
Es fácil ver que este diseño es más potente que el anterior. Tiene dos variables
independientes, método y tiempo, divididas cada una de ellas en dos categorías. Ahora
se puede saber si la diferencia en las puntuaciones obtenidas con los dos métodos son
estadísticamente significativas, es decir, lo misino que con el primer diseño; si se obtiene
o no igual puntuación examinándose a otro día de acabar el núcleo que examinándose un
mes mas tarde y, por último, si existe interacción entre el método y el tiempo, es decir, si
ambas variables actúan en paralelo o no. Téngase en cuenta que las dos primeras
pruebas estadísticas aplicadas a las variables método y tiempo respectivamente, pueden
ser estadísticamente significativas y no serlo la tercera que analiza su interacción. Ahora,
si no hay diferencias entre tiempos y si la interacción entre métodos y tiempo tampoco las
da, se tendría una evidencia mucho más fuerte que con el diseño de dos grupos para
concluir acerca de la superioridad o no de uno de los métodos.
El diseño factorial, aunque es técnicamente más complejo, responde mejor a las
realidades complejas que constituyen la mayor parte de los problemas científicos, pues
trabajan con más de una variable independiente. Aunque el científico siempre intenta
focalizar sus estudios en aspectos puntuales y parciales de la realidad, es bien sabido
que en la mayoría de los fenómenos que más interesan al investigador, influyen múltiples
variables independientes. Más aún, en el ejemplo mostrado arriba, se hubiese podido
trabajar con más de dos niveles por variable independiente y con más de dos variables
independientes. Por ejemplo, la inteligencia hubiera podido ser una tercera variable
independiente a estudiar junto a las variables mostradas en este caso hipotético. Pero
esta facilidad de respuesta del diseño factorial lleva anejas ciertas exigencias que no
siempre pueden satisfacerse.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
31
2. El control de la varianza
EI otro gran objetivo que Kerlinger asigna al diseño es el control de la varianza. En cierto
sentido, el diseño no es sino un conjunto de instrucciones al investigador para que recoja
y analice sus datos de manera que controle la situación experimental lo más posible. El
principio estadístico en el que se basa este control lo sintetiza así: maximizar la varianza
sistemática, controlar la varianza sistemática y minimizar la varianza de error (principio
maxmincon de Kerlinger).
a- Maximizar la varianza sistemática o experimental. La varianza se refiere casi
siempre a la varianza de la variable dependiente. Al hablar de varianza
experimental quiere decirse la varianza de la variable dependiente influida por
la variable independiente de la hipótesis de investigación. En el ejemplo del
diseño factorial la varianza experimental se refiere a la varianza de las
puntuaciones, variable dependiente, debida presumiblemente a métodos, X1 y
X2, y tiempo Y1 e Y2 o variables independientes. Por eso normalmente se
persigue diferenciar bien los valores asignados a las variables independientes
para que, en caso de existir relación entre estos y la variable dependiente,
darle la oportunidad de manifestarse. Además hay que tener en cuenta que la
varianza total se debe a numerosas fuentes; si las condiciones experimentales
apenas difieren, es más difícil separar de la varianza total, la parte de la
varianza que hipotéticamente se debe a ellas. Y es que como escribe Arnau
(1981) esta varianza máxima se logra bien aumentando la diferencia de los
valores de la variable independiente, o bien seleccionando sus valores óptimos.
En el ejemplo citado es menos probable que aparezcan diferencias
estadísticamente significativas, si existen, si comparamos dos métodos de
enseñanza muy parecidos en sus características que si se comparan métodos
más extremos. El "ruido" de la investigación hace que no se perciban
diferencias pequeñas.
b- Controlar la varianza sistemática es sinónimo de control de variables
extrañas, ajenas a los objetivos del estudio y que pueden actuar como
variables independientes, es decir, ser explicaciones rivales de los resultados.
En la medida en que la posible influencia de dichas variables extrañas se
anula, aísla o minimiza, en esa misma medida controlamos la varianza
experimental. Más adelante estudiaremos diferentes formas de controlarlas.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
32
c- Y por último, este objetivo persigue minimizar la varianza de error. O lo que
es igual, la parte de la varianza que no interesa controlar en una investigación o
que no es posible controlar —puede tratarse de una investigación básica donde
lo mas importante es probar si existe o no relación o de un estudio de campo
en el que los medios no permiten aumentar el tamaño de las muestras o utilizar
un diseño mas complejo—. Esta varianza de error se debe a varios factores.
Uno de variabilidad de las medidas debida a fluctuaciones aleatorias. Estos
errores azarosos tienen como característica el que se compensan a sí mismos
en el infinito pues a veces son positivos, a veces son negativos,
compensándose al final ambas situaciones. A veces la varianza de error esta
asociada con diferencias individuales que no pueden ser identificadas o
controladas. Si pudieran serlo, la varianza que producen pasaría a ser varianza
sistemática debida a diferencias entre los sujetos. Otra fuente de varianza de
error es la asociada con los llamados errores de medida, es decir, variación de
las respuestas de una prueba a otra, estados emocionales transitorios, ligeros
lapsus de memoria, desatenciones breves, etc. Por ello al decir minimizar la
varianza de error, quiere decirse fundamentalmente la reducción de los errores
de medición mediante: a) el control de las condiciones experimentales, b)
aumento de la fidelidad de la medida de la variable dependiente.
Es por ello por lo que se insiste en cuidar las circunstancias experimentales que
condicionan la validez de un diseño. Cuanto más incontroladas sean, mas posibilidades
de actuación se dan a los determinantes de la varianza de error. Es evidente que este
control experimental es mas difícil en la investigación de campo que en la de laboratorio
pero aun en aquella puede aumentarse dando instrucciones específicas y excluyendo
factores ajenos al objeto de la investigación.
En cuanto a la fidelidad de las medidas, es obvio que la falta de precisión de un
instrumento condiciona los resultados que con el se obtienen. Si las variaciones que se
observan en los resultados son totalmente azarosas no permiten identificar y extraer
varianzas sistemáticas pues hoy nos daría puntuaciones muy buenas, mañana muy
malas, etc. Si la varianza de error es muy grande, es difícil que pueda descubrirse una
relación pequeña aunque exista.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
33
C.- CRITERIOS PARA SELECCIONAR EL DISEÑO
La selección de un adecuado diseño constituye un punto fundamental de toda
investigación. Sin embargo, seleccionar un diseño que nos permita dar una respuesta
adecuada a las preguntas de investigación no es tarea sencilla. A la hora de decidir, el
investigador debe tener en cuenta varios factores que exponemos a continuación:
1. Poner a prueba las hipótesis
Para poder poner a prueba o validar las hipótesis de investigación, el investigador debe
preguntarse acerca de la idoneidad de los distintos tipos de diseño y de si éstos son
válidos para responder a las preguntas de investigación o, en otros términos, si se puede
poner a prueba la hipótesis de modo adecuado.
Una debilidad corriente de los diseños que se proponen a veces es la falta de
congruencia entre la hipótesis y el diseño. Por ejemplo, querer probar una hipótesis que
requiere tres o más grupos utilizando un diseño de dos grupos o querer probar una
hipótesis de interacción con un diseño de dos grupos.
Otro error común que refleja falta de coherencia entre el problema y la hipótesis de
investigación por un lado, y el diseño de investigación por otro, es emparejar sujetos por
variables irrelevantes a los fines de la investigación y querer usar un diseño de dos
grupos relacionados, experimental-control, que presupone la igualdad inicial de estos. Si
las variables de emparejamiento no están estrechamente relacionadas con la variable
dependiente, el emparejamiento es irrelevante y no logra lo que se propone. Variables de
emparejamiento muy usadas, como sexo o la edad, si no correlacionan fuertemente con
la variable dependiente en una investigación concreta, no consiguen el deseado control
de variables extrañas rivales de la o las variables independientes y el diseño queda
desvirtuado.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
34
2. Control de variables independientes
Se refiere al control tanto de las variables experimentales que se miden o manipulan
como al de las variables extrañas. En cada investigación hay determinadas variables
extrañas que pueden influir en los cambios observados en la variable dependiente y que
sólo en la medida en que son controladas, dejan de ser explicaciones plausibles de los
resultados y permiten que estos sean explicados por las variables independientes
experimentales. Otra forma de ejercer el control es manipulando o midiendo el
investigador las variables experimentales, pues es precisamente esta acción sobre ellas
lo que diferencia al experimento de otros tipos de investigación.
La técnica más eficaz de control de variables extrañas es la distribución al azar. La razón
de ello es que se supone que si los grupos se han elegido así, deben ser
estadísticamente iguales antes de introducir la o las variables independientes. Por ello, se
recomienda usar la asignación al azar siempre que sea posible y aplicarla no sólo a la
selección de las muestras sino al asignar éstas a grupos, tratamientos, investigadores,
etc. En los diseños preexperimentales, es frecuente creer que se ha probado la hipótesis
y así se concluye en el informe. Estas conclusiones son engañosas pues la falta de
control de las variables extrañas impide saber si la variable independiente es la causa del
cambio observado.
3. Generalización
Este criterio es sinónimo de validez externa, como veremos mas adelante. Es responder
al interrogante, ¿en qué medida se pueden generalizar los resultados de un estudio a
otros sujetos, grupos y condiciones experimentales?
Este criterio es de gran interés en la investigación aplicada, pues se persigue generalizar
los resultados a poblaciones lo mas extensas posible. Empalma con el problema de la
representatividad de la muestra, pero los conceptos de población y muestra se aplican no
sólo a las personas, sino también a las situaciones experimentales, por ejemplo.
Con propiedad, los resultados sólo pueden generalizarse a aquellas muestras, personas,
grupos o situaciones que sean muy similares a las empleadas en la investigación y ello
siempre que se hayan ejercido los controles adecuados.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
35
En realidad, los dos últimos criterios están muy relacionados. En la medida en que
aumenta el control de variables experimentales, en esa medida aumenta la generalidad
de los resultados. Pero pueden existir experimentos que demuestren claramente
relaciones específicas entre la variable independiente y la variable dependiente, validez
interna, y sin embargo, carecer de validez externa o representatividad. Por ello, al
seleccionar el diseño hemos de preguntarnos si lo que nos interesa es sobre todo
confirmar la relación postulada en la hipótesis o si además de ello interesa generalizar
ese resultado, en cuyo caso hay que pedir al diseño validez interna y externa (como
veremos más adelante).

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
36
D.- CLASES DE DISEÑOS
Son varios los criterios que pueden emplearse en su clasificación. Los más empleados
son: la línea de investigación, el grado de control, la técnica de control empleada y el
número de variables independientes, o una combinación de los anteriores.
1. Según la línea de investigación
Según la línea de investigación que se esté utilizando, existen dos tipos de diseños:
diseños estadísticos y diseños no estadísticos (Castro, 1980; Arnau, 1981).
Los primeros, que aparecen por la década de los veinte, siguen la tradición hipotético-
deductiva y se les conoce también con el nombre de diseños de grupos, por trabajar con
grupos de sujetos. Recurren normalmente a la aleatorización como técnica de control y
emplean técnicas estadísticas en el contraste de hipótesis. Hoy se habla de ellos como
de diseños clásicos o de tradición fisheriana.
Los diseños no estadísticos son aquéllos que siguen la línea inductiva, gozando de cierta
tradición en las investigaciones clásicas de un solo sujeto de Wundt, Ebbinghauss,
Watson, Thorndike, y otros autores. Esta línea de investigación fue revitalizada por
Skinner allá por los anos treinta, siendo bastante empleada en la investigación de
laboratorio dos décadas después. Estos diseños utilizan un solo sujeto o una muestra
muy reducida y, como técnicas de control, emplean la eliminación y la constancia.
Normalmente, no recurren a pruebas de análisis estadístico.
2. Según el grado de control
Una segunda clasificación del diseño puede ser en preexperimentales,
cuasiexperimentales y experimentales propiamente dichos (Campbell y Stanley, 1991).
En ella, se atiende a la capacidad de los distintos diseños para controlar las variables
experimentales que pueden interferir con la variable independiente o tratamiento
experimental y contaminar los resultados observados en el experimento. Cuando el nivel
de control es muy alto, hablamos de diseños experimentales propiamente dichos. Cuando
es muy bajo, estamos ante un diseño preexperimental o piloto o ante un diseño
cuasiexperimental o de campo. Estos últimos diseños consisten en la observación directa

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
37
de los fenómenos en su medio ambiente natural, sin apenas influir sobre las distintas
variables del estudio. Como se verá más adelante, este tipo de estudios tienen ventajas e
inconvenientes, pero son muy poco utilizados en el campo de las Ciencias de la Salud.
Todos ellos se inscriben en la tradición estadístico-fisheriana y son, por tanto, diseños de
grupo. Utilizan técnicas de control como la aleatorización y el emparejamiento al formar
los grupos. La generalización de sus conclusiones está relacionada con el grado de
control.
3. Según la técnica de control
Este criterio de clasificación (McGuigan, 1976, Arnau, 1981) se fija en la técnica de
control específica que se utiliza en los distintos diseños. Así, cuando se emplea la
aleatorización, tenemos los diseños de grupos al azar, que pueden ser de dos o más
grupos. En ellos se emplea la selección al azar tanto al elegir los sujetos como al
asignarlos a grupos y tratamientos experimentales.
Cuando la técnica de control es la constancia de las condiciones experimentales, se
habla de diseños de grupos apareados o de diseños de bloques.
En los diseños de grupos apareados se emplea alguna medida inicial de los grupos,
denominada variable de apareamiento para lograr la equivalencia inicial de éstos antes
de introducir los tratamientos experimentales. Para la asignación de las condiciones
experimentales se recurre normalmente al azar.
En los diseños de bloques, la muestra total se divide en grupos o bloques atendiendo a
alguna característica llamada variable de bloqueo. A su vez, cada bloque se subdivide en
tantos grupos como condiciones experimentales existan, y se asignan a éstas
aleatoriamente. Tanto la variable de apareamiento como la de bloqueo deben estar
estrechamente relacionadas con la variable dependiente.
Finalmente, cuando el sujeto es su propio control, tenemos el diseño intrasujetos. En él,
cada sujeto es sometido a todos los valores de la variable independiente o condiciones
experimentales, midiéndose la variable dependiente bajo cada una de las condiciones. La
comparación de estas medidas permite determinar los efectos de los distintos valores de
la variable independiente.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
38
4. Según el número de variables independientes
De acuerdo con el número de variables independientes que intervienen se habla de
diseños univariables y diseños multivariables (McGuigan, 1976; Escotet, 1980; Arnau,
1981).
Los diseños univariables utilizan una sola variable independiente, que puede variar de
dos maneras: diseños bicondicionales o de dos grupos, o de varias, diseños
multicondicionales. En estos últimos son necesarios tantos grupos como valores tome la
variable independiente. Los diseños univariables son los más utilizados en el campo de
las Ciencias de la Salud y, concretamente, de la Histología. Presentan la ventaja de su
sencillez y el fácil control de todos los factores que afectan al experimento, aunque
adolecen de cierta artificialidad, puesto que la realidad nunca es sencilla ni simple.
Los diseños multivariables emplean dos o más variables independientes y se les conoce
con el nombre de diseños factoriales, los cuales admiten a su vez nuevas clasificaciones
si nos fijamos en la técnica de control utilizada. Estos diseños permiten obtener
información sincrónica sobre varias variables experimentales, pero tienen el problema de
su gran complejidad y la necesidad de utilizar muestras de gran tamaño.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
39
IV. FACTORES DE VALIDEZ EN LOS DISEÑOS
EXPERIMENTALES
Como acabamos de ver, el diseño en investigación experimental constituye una guía que
indica al investigador cómo debe actuar para proceder con la mayor precisión posible en
cada investigación. De este modo, los resultados que se obtengan podrán ser
interpretados de la manera más unívoca posible.
Sin embargo, uno de los problemas más importantes a los que ha de enfrentarse un
investigador es la existencia de factores incontrolados o variables extrañas que pueden
afectar al experimento. Así, numerosos factores relacionados con el experimento y que el
investigador no controla, podrían dificultar la detección de los factores que determinan un
determinado efecto, esto es, nos podrían inducir al error. En la medida en que dichos
factores incontrolados se conviertan en factores controlados, se favorece la correcta
interpretación de los resultados obtenidos. Los factores incontrolados o variables
extrañas pueden atentar tanto a la relación que se postula entre dos o mas variables
cuanto a la posibilidad de generalizarla. Veamos cuáles son estos factores.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
40
A.- LA VALIDEZ INTERNA DE UN DISEÑO EXPERIMENTAL
La validez interna de un diseño se preocupa por saber si los cambios observados en la
variable dependiente se deben a la manipulación de la o de las variables independientes.
Campbell y Stanley (1991) y Tejedor (1981) la definen como la "validez mínima
imprescindible, sin la cual es imposible interpretar el modelo". Este tipo de validez es
condición sine qua non para dar credibilidad a los resultados obtenidos y, desde luego,
para poder generalizarlos. Si no hay cierta evidencia de una relación entre variables, la
generalización carece de fundamento científico.
En realidad, la validez interna de un diseño podría responder a los siguientes
interrogantes: ¿introducían, en realidad, una diferencia los tratamientos empíricos en este
experimento concreto?; ¿qué otras variables que pudieran explicar los resultados
diferenciales han sido convenientemente controladas?
La validez interna de un diseño depende del control de múltiples factores (variables), que
los Campbell y Stanley resumen en ocho:
1. La historia.
El efecto historia se refiere a acontecimientos específicos ocurridos en el desarrollo de la
experimentación, además de la variable experimental, y que pueden afectar la actuación
de los sujetos antes o después del tratamiento experimental. Escotet (1980) afirma que
"son diferentes eventos específicos a los del tratamiento experimental que ocurren entre
la causa y el efecto o entre el pretest y el postest dándonos explicaciones alternadas de
efectos―.
Por su propia naturaleza, el experimento exige la aplicación de tratamientos diferenciados
y simultáneos en el proceso de experimentación, lo que hace difícil el control de este
efecto. Una importante fuente de sesgo puede ser el propio experimentador, pues éste no
siempre puede actuar de forma simultánea con los grupos, el mismo día de la semana,
los acontecimientos específicos, la hora del día, etc. Su control se hace más difícil en los
experimentos que requieren la aplicación individualizada de los tratamientos, pues es
más dificultoso igualar las condiciones. La forma de controlar estas fuentes de sesgo es

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
41
proceder con racionalidad y precisar al máximo condiciones, instrucciones, etc., para
evitar efectos no planeados.
En cuanto a las mediciones a tomar, normalmente pretest y postest, se evitarán los
sesgos en la medida en que se midan conjuntamente los diferentes grupos
experimentales. De este modo habrá "una historia intrasesional única que suponemos
afectará por igual a todos los sujetos experimentales" (Tejedor, 1981). Ello no siempre es
posible.
El control del efecto historia es mas difícil a medida que aumenta la duración del
experimento y el tiempo dedicado a la medición. Por ello, el control de tipo estadístico,
como la asignación al azar, no debe excluir el control racional y crítico de planificar y
operativizar en lo posible las condiciones de la experimentación.
2. La maduración.
El efecto maduración se refiere a todos aquellos procesos biológicos y/o psicológicos que
varían de modo más o menos sistemático en función del tiempo per se,
independientemente de ciertos acontecimientos externos, como puede ser el propio
experimento. El aumento en estatura o edad, así como fatiga de los sujetos a estudiar,
son ejemplos de los efectos de la maduración.
Este tipo de efecto es difícil de controlar, sobre todo si el periodo de tiempo transcurrido
en el experimento es demasiado largo, ya que los cambios ocurridos durante el mismo en
los sujetos experimentales pueden deberse a los efectos de la maduración y no a la
variable independiente. A diferencia de la variable historia, la maduración aparece desde
dentro del individuo.
Tradicionalmente se ha recurrido al diseño grupo experimental-grupo control con medidas
pretest y postest como medio de controlar la maduración. La suposición que subyace en
la utilización de este diseño es que el efecto de la maduración entre el pretest y el postest
será similar en ambos grupos (experimental y de control) y, por tanto, si existen
diferencias entre ellos en la medida postest, pueden atribuirse a los efectos del
tratamiento experimental seguido únicamente por el grupo experimental. Es decir, al
comienzo del experimento ambos grupos se suponen iguales, sobre todo si se han
formado aleatoriamente. Posteriormente ambos grupos siguen un tratamiento distinto. Al
final del experimento se vuelven a medir los grupos. Las diferencias encontradas entre
ellos en la segunda medición se deben presumiblemente a la variable independiente,

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
42
mientras que los efectos de la maduración corresponderán a los cambios observados
entre la primera y la segunda medición dentro del grupo de control.
Pero el grupo de control no resuelve el problema si el experimento dura demasiado
tiempo. A veces, el propio tratamiento experimental introduce variables que pueden
modificar las experiencias o aprendizajes de los sujetos a través del proceso normal de
maduración, como interés por ciertas actividades, cambios de actitudes, etc. Estas
modificaciones no pueden atribuirse a la influencia en si de los tratamientos
experimentales, pues invalidarían la verdadera relación entre la variable experimental y la
variable dependiente.
En los llamados diseños factoriales no existen necesariamente medidas pretests ni grupo
control en el sentido que acabamos de darle a estos conceptos, pero no por ello carecen
de control sobre los efectos de la maduración. En primer lugar, porque en todo diseño de
varios grupos, cada uno de ellos actúa como grupo control de los demás. Es decir, si se
supone que los efectos de la maduración actúan por igual en los diferentes grupos, los
cambios observados al medir la variable dependiente se deberán presumiblemente a los
diferentes tratamientos experimentales. Caso de que éstos no introduzcan diferencias, los
resultados observados en el postest serán muy similares en todos los grupos, y al
contrario. La igualdad inicial de los grupos se puede conseguir mediante la elección al
azar de los sujetos y la asignación al azar de éstos a grupos de estudio, y de los grupos a
tratamientos experimentales. En realidad, se trata de una forma de control estadístico
realizado a través del análisis de varianza.
3. La administración de tests.
Este efecto se refiere a la influencia que la administración de un test previo ejerce o
puede ejercer sobre los resultados de otro test posterior. En realidad, podríamos hablar
de los efectos reactivos de determinados instrumentos de medida y de cómo estos
efectos reactivos pueden afectar a los resultados futuros obtenidos al aplicar estos
mismos instrumentos. Una prueba es reactiva cuando produce cambio al mismo tiempo
que mide (Castro, 1980).
El efecto de administración de tests se produce en aquellos experimentos que requieren
medidas pretest o algún tipo de entrenamiento previo a la introducción de la variable
experimental. El efecto reactivo es mayor en la medida en que aumenta la novedad de la
prueba o situación, que puede servir de motivación al sujeto que se somete a ella. Como

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
43
indica Fox (1981), puede ocurrir que la prueba previa se convierta en sí en una
experiencia profunda que afecte el comportamiento de los individuos durante todo el
experimento. Por ello, la mayoría de los instrumentos producen resultados algo distintos
cuando se aplican por segunda vez, resultados que suelen ser más elevados en los
campos de aprovechamiento. Estos pequeños cambios pueden tener cierto sentido,
sobre todo en los experimentos a corto plazo. Si ocurren sólo en el grupo experimental,
se pueden confundir con el efecto de la variable independiente, pues normalmente no se
esperan cambios globales demasiado grandes. Si por el contrario ocurren en el grupo de
control, pueden dar una estimación falsa de los tipos de cambio y de su evolución.
Para algunos autores, el efecto de Hawthorne constituye un tipo de efecto de
administración de tests. Este efecto se debe a que, cuando los sujetos de una
investigación se empiezan a dar cuenta de que forman parte de la misma, suelen
desencadenar una serie de conductas distintas a las que manifestarían si ignorasen que
son objeto de estudio.
En los diseños experimentales tradicionales se controla este efecto recurriendo al
establecimiento de grupos de control. En los diseños factoriales el control se ejerce bien
renunciando a medidas pretest o bien mediante la aleatorización de los grupos
experimental que compensa el término del error. Este tipo de control debe completarse
con el control lógico, racional, de utilizar siempre que se pueda pruebas mínimamente
reactivas.
4. La instrumentación.
Se refiere a los efectos que producen los cambios habidos en los instrumentos de
medición, evaluadores, entrevistadores, etc., que pasan inadvertidos al experimentador y
que pueden producir diferencias en las medidas que se obtienen. Por ejemplo, si un
proyector funcionó correctamente en una sesión experimental y no en otra, entre las dos
sesiones habrá una diferencia al medir las respuestas de los sujetos. Estas diferencias
debidas al aparato, si no se advierten, pueden llevar a inferir un efecto de la variable
independiente sobre la variable dependiente. Otras veces, si durante la realización de un
experimento que utiliza observadores, éstos cambian repentinamente, las diferencias
halladas al medir la variable dependiente pueden deberse al registro distinto utilizado por
cada observador y no a un efecto real de la variable independiente, como erróneamente
podría creerse.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
44
Este efecto perturbador es más difícil de controlar en los experimentos que utilizan
medidas pretest, en los que exigen entrenamientos laboriosos y/o medidas repetidas de
un mismo sujeto, siendo fácil de controlar en aquellos que utilizan una sesión única con
un solo experimentador y con un instrumento de medida fiable y fácil de interpretar.
La asignación al azar de los experimentadores a las distintas sesiones experimentales, el
desconocimiento por parte de los mismos de cuáles son los grupos experimentales, o, si
son pruebas a corregir, la ignorancia de cuáles pertenecen a la primera medida y cuáles
a la segunda, así como las técnicas de control estadístico, son formas de controlar esta
fuente de sesgo.
5. La regresión estadística.
La regresión ocurre cuando para un experimento se seleccionan a los grupos sobre la
base de sus puntuaciones extremas. Este problema, que intrigó a Galton a finales del
siglo XIX, esta básicamente relacionado con una baja correlación entre dos variables, en
este caso dos mediciones sucesivas. Cuanto más baja sea la correlación, más probable
es que ocurra el efecto de regresión estadística. Estos efectos operan tanto en el extremo
superior como en el inferior de la variable dependiente.
Si se selecciona un grupo de sujetos por sus puntuaciones sobresalientes en un test
previamente aplicado (valores pretest), en una prueba posterior igual o similar a ella,
estos alumnos obtendrán en promedio resultados altos, pero más bajos que los
anteriores. Por el contrario, los alumnos con bajo rendimiento en el pretest, tenderán a un
promedio más alto, más próximo a la media en una segunda aplicación de la prueba. La
"regresión" hacia la media afecta a ambos grupos extremos.
Así, parte de los cambios observados en estos grupos no pueden atribuirse al efecto de
la variable independiente, ni a los de la historia, maduración, etc., sino que simplemente
son el resultado de cierto comportamiento estadístico de los datos. Este comportamiento
obedece a la carencia de correlación perfecta entre ellos, que a su vez puede estar
ocasionada por errores de medición o por fuentes sistemáticas de varianza específica,
propia de una u otra medición.
Campbell y Stanley (1991) afirman que "los efectos de la regresión son, pues,
acompañamientos inevitables de la correlación imperfecta de test-retest para grupos
seleccionados por su ubicación extrema. No son, sin embargo, concomitantes necesarios
de puntuaciones extremas donde quiera que ellas se produzcan. Si un grupo

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
45
seleccionado por razones independientes resulta poseer una media extrema, hay una
menor expectación a priori de que la media grupal se regresione en una segunda prueba,
pues se ha permitido a las fuerzas aleatorias o externas de varianza que influyan sobre
las puntuaciones iniciales en ambas direcciones". No ocurre igual en los grupos
seleccionados a causa de su valor extremo en una sola variable.
El control estadístico de este efecto se ejerce en los diseños clásicos recurriendo a
grupos de control formados aleatoriamente, y en los diseños factoriales aplicando los
modelos estadísticos del análisis de varianza o de covarianza que exigen asimismo
técnicas de aleatorización.
6. La selección de sujetos.
El efecto de selección se produce como resultado de elegir directamente a los sujetos
que formarán los grupos de comparación. Dicha selección suele llevar consigo que los
grupos difieran a distintos niveles de significación cuando se comparan las medidas de la
variable dependiente. Estas preferencias selectivas aparecen normalmente en los
estudios que solicitan voluntarios para utilizarlos como grupo experimental (Escotet,
1980).
Para controlar esta fuente de sesgo, lo más recomendable es asignar aleatoriamente a
los sujetos a los diferentes grupos experimentales y aumentar el tamaño de los grupos.
Estos dos recursos no garantizan la equivalencia inicial de los grupos, pero es la única
forma de saber que no ha habido sesgos en el proceso de selección de los sujetos.
Campbell y Stanley (1991) se pronuncian categóricamente en contra de sustituir el
proceso de aleatorización de los sujetos por el de la equiparación entre los mismos.
Afirman que la "equiparación no constituye una ayuda real cuando se la utiliza para
solucionar diferencias iniciales entre los grupos. Ello no significa que propugnemos la
eliminación lisa y liana de este procedimiento como posible aditamento a la
aleatorización... Pero la equiparación como sustituto de la aleatorización es tabú, incluso
para los diseños cuasiexperimentales que no emplean más que dos grupos naturales
intactos, uno experimental y otro de control: aun en este endeble 'experimento' hay
medios mejores que la armonización para tratar de corregir diferencias iniciales entre las
medias de una y otra muestra".
Cuando el diseño lo permite, se puede ejercer el control estadístico aplicando las técnicas
del análisis de varianza por bloques o de covarianza recurriendo al diseño intrasujetos.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
46
7. La mortalidad experimental.
Este efecto se refiere a la perdida o deserción de participantes en los grupos de
comparación. Dicha perdida es mayor a medida que aumenta la duración del experimento
o el grado de compromiso de los tratamientos experimentales, y suele ser máxima en
aquellos en que se trabaja con personas voluntarias.
En general, se acepta que la "mortalidad" o abandono del experimento no se produce de
modo aleatorio, sino que los que permanecen en un experimento suelen tener una
motivación distinta que aquellos que lo abandonan. El abandono suele ir unido a
indiferencia, descontento, miedo, etc., hacia la experimentación, lo que no deja de ser
una diferencia sutil pero importante. En los estudios longitudinales este efecto puede
llegar a ser demoledor y sesgar los resultados.
El modo de controlarlo es evitar se produzca la mortalidad experimental o planificando la
inclusión en el experimento de sujetos de reserva asignados aleatoriamente a los
diferentes grupos y que siguen el proceso experimental normal. Las medidas obtenidas
en estos sujetos se incluirán en los análisis solo en caso de que se haya producido la no
deseada mortalidad. Las técnicas de control estadístico, como el recurrir a posteriori a
diseños no equilibrados (desigual numero de sujetos en los grupos) o a técnicas de
predicción de las puntuaciones que habrían obtenido los grupos que abandonaron el
experimento, no son del todo satisfactorias.
8. Interacción entre distintos factores.
En realidad, este efecto se refiere a que en un experimento es posible que dos o más de
los efectos que acabamos de estudiar actúen de modo conjunto, produciendo
interacciones de distinto orden. Habría que considerar por tanto, la interacción selección-
maduración, maduración-historia, selección-historia, selección-test, etc. Los efectos
producidos por esta combinación de factores podrían confundirse con el efecto producido
por la variable experimental. Recurrir a los grupos de control, es una forma de controlar
estas posibles interacciones.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
47
B.- LA VALIDEZ EXTERNA DE UN DISEÑO EXPERIMENTAL
La validez externa se refiere a la representatividad o generalización de los resultados; es
decir, plantea el siguiente interrogante: ¿a qué poblaciones, situaciones, variables de
tratamiento y variables de medición pueden generalizarse estos efectos? O, como dice
Kerlinger (1989), "después de acabado un experimento en que se ha encontrado una
relación, ¿a qué poblaciones puede ser generalizada?; ¿se puede decir que A se
relaciona con B para todos los casos similares?, ¿o sólo para la muestra con la que
hemos trabajado en nuestro estudio?".
Y es que "la validez externa no solamente se relaciona con la población a la cual el
investigador espera generalizar sus resultados, sino que también incluye la
generalización de sus datos hacia otras variables independientes interrelacionadas".
Todos estos interrogantes deben formularse y contestarse en el marco de un experimento
para generalizar con fundamento. Debe alentarnos el hecho de que la ciencia es
autocorrectiva y precede por pequeños pasos. En el campo educativo solo tras varios
estudios se establece una relación y se precede a generalizarla.
Siguiendo a Campbell y Stanley veamos qué factores amenazan la validez externa o
representatividad de un diseño.
1. El efecto reactivo o interactivo de las pruebas
Este efecto ocurre cuando la administración previa de una prueba (pretest) genera un
efecto sobre los resultados futuros que podría alterar dichos resultados. Habitualmente,
este efecto consiste en un aumento o disminución de la sensibilidad o la calidad de la
reacción del participante a la variable experimental.
Cuando esto ocurre, no es legítimo generalizar los resultados al conjunto de la población
(al cual no se administró el pretest), ya que el grupo experimental ha dejado de ser
representativo de esta población general para la variable de estudio. Es decir, el efecto
que produce la variable experimental es distinto en sujetos que han recibido pretest y en
los que no lo han recibido, por lo que no podemos extender los resultados de un grupo al
otro.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
48
El problema fundamental es que, si no tenemos en cuenta este efecto reactivo de la
prueba, podríamos pensar erróneamente que la variable independiente fue la causante
del efecto observado sobre la variable dependiente. Debido a este efecto, existe la
posibilidad de no poder generalizar los resultados experimentales a sujetos que no han
vivido la situación experimental completa.
Piénsese, por ejemplo, en un diseño que utiliza medidas pretest-postest para estudiar el
comportamiento reológico de un tejido artificial generado en laboratorio mediante
ingeniería tisular después de aplicar un tratamiento hipertónico. Antes de introducir la
variable experimental (el tratamiento hipertónico), se realiza una medición pretest de la
elasticidad y resistencia del tejido utilizando un reómetro estándar. Seguidamente, se
introduce la variable independiente (introducción del tejido en suero salino hipertónico) y
se mide de nuevo la variable dependiente aplicando el mismo reómetro que se utilizó la
primera vez. Olvidando ahora las repercusiones que el pretest pudiera tener en la validez
interna, nuestra preocupación se centra en saber si es lícito suponer que el tratamiento
hipertónico cambiará el comportamiento reológico en tejidos artificiales que no han sido
sometidos a una medición previa bajo las mismas condiciones que lo han hecho las
muestras sometidas a esta experiencia previa (el pretest). Es un problema de
representatividad y, por ende, de generalización.
El efecto pretest sobre la variable dependiente dependerá del grado en que las
situaciones de medición experimental difieran de las características del conjunto,
respecto del cual se pretende generalizar. Cuando se utilizan pruebas que tienen poco
que ver con las situaciones normales de los sujetos experimentales, es improcedente
generalizar a sujetos que no han vivido la situación experimental. Por ello se potencia la
validez externa en la medida en que el proceso de experimentación utiliza pruebas que
no provocan respuestas reactivas.
2. La interacción entre la selección y la variable experimental
Este efecto se refiere básicamente al problema de la selección de los sujetos, es decir, a
la representatividad de la muestra utilizada. Evidentemente, si la muestra que se ha
seleccionado para un experimento no representa fielmente a la población de origen, los
resultados obtenidos no podrán extrapolarse a dicha población de origen, con lo que la
validez externa del estudio será muy escasa. No hay que olvidar que las peculiaridades
de los sujetos elegidos determinan el grado de generalización de las conclusiones.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
49
A la hora de diseñar y planificar un Proyecto de Investigación, siempre debemos tender a
seleccionar correctamente a los sujetos o las muestras que incluiremos en nuestro
estudio. Sin embargo, obtener muestras representativas de las poblaciones que interesa
estudiar no es tarea fácil.
El problema de la representatividad de la muestra no tiene por qué afectar a la validez
interna del experimento, siempre que éste esté bien diseñado, pero siempre afectará a la
generalización de los resultados. La negativa de algunos sujetos a participar en algunos
tipos de investigaciones, la tendencia del experimentador a utilizar únicamente las
"muestras disponibles", el trabajar con "voluntarios", lo caro y laborioso que resulta
diseñar buenos experimentos, la imposibilidad de aplicar la selección al azar, etc., son
algunos de los factores de selección que contribuyen a minar la validez externa de un
diseño.
Si se ha experimentado una nueva técnica de tinción histológica a muestras titulares
procedentes de cerebro humano, en principio, no podemos generalizar los resultados a
todos los tejidos pertenecientes al sistema nervioso humano, ni a otros tipos de tejidos
humanos. Es muy posible que los resultados sean otros si se experimenta con biopsias
renales o hepáticas, aunque el protocolo a seguir sea el mismo. En sentido estricto, los
datos sólo permiten afirmar que aquí y ahora se ha descubierto tal tipo de relación
(validez interna). El querer generalizarla a sujetos o situaciones distintas de las
experimentales es ya otra cuestión que va más allá y que puede realizarse o no en
función de numerosos factores.
3. Efectos reactivos de los dispositivos experimentales
Como en los casos anteriores, la existencia de efectos reactivos impediría generalizar los
efectos de la variable experimental más allá de la situación experimental concreta
diseñada en nuestro estudio.
Normalmente, existe la creencia de que lo que se experimenta es mejor que lo conocido,
lo cual sólo es cierto en parte, pues si no, no se pondría a prueba. Si esta creencia se
suscita, bien porque hay filtraciones o bien por la sofisticación de la nueva situación
experimental, se producen efectos reactivos que merman la representatividad de los
sujetos. La presencia de personas o factores extraños dentro del marco experimental
desencadena con frecuencia conductas reactivas. Sin embargo, hay investigadores que
son partidarios de explicar a los sujetos experimentales la realidad de la situación en la

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
50
creencia de que ello evitará filtraciones indebidas y facilitará el desarrollo normal de los
acontecimientos. Es difícil establecer una norma. La novedad o artificialidad de un
experimento y la conciencia del sujeto de que esta participando en él (efecto Hawthorne)
son con frecuencia causa fundada de falta de representatividad y, por tanto, obstáculos
para la generalización de las conclusiones.
En términos prácticos, esto significa que se deben planificar investigaciones que sean
"naturales" a los sujetos experimentales y a la población a la que pretenden representar.
4. Interferencia de tratamientos múltiples
La interferencia se produce cuando se aplican a un mismo grupo de sujetos diferentes
tratamientos experimentales. Cuando a un grupo de muestras o de sujetos se aplica un
tipo de intervención o tratamiento y, a continuación, aplicamos un segundo tratamiento,
puede ocurrir que los efectos del primer tratamiento aún estén presentes en el grupo de
muestras o sujetos y que, por tanto, los efectos del segundo tratamiento queden
afectados por el primero. Por supuesto, todo esto se puede complicar exponencialmente
si aplicamos un tercer, un cuarto o un enésimo tratamiento a los sujetos del estudio.
Desde el punto de vista del diseño, la solución consiste en evitar los diseños de un solo
grupo para estudiar más de un tratamiento experimental. El recurso a diseños más
complejos como los factoriales, puede obviar este problema.
Según Fox (1981), existen cinco posibles fuentes de error en el desarrollo de un
experimento y que, aunque externas a éste, pueden sesgar los datos experimentales.
Estas fuentes de error son: el experimentador o sus agentes; los dispositivos de medición
utilizados; las situaciones de investigación, en especial durante la recogida de datos; la
ejecución del experimento, y la influencia del propio experimento. En realidad, estos
factores equivalen en gran medida a los factores que acabamos de analizar.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
51
C.- CONTROL DE VARIABLES EXTRAÑAS
Hasta ahora hemos visto cómo numerosos factores y variables pueden afectar a la
validez interna o externa de los estudios experimentales. Tradicionalmente, se
consideraba que la experimentación básica de laboratorio generaba investigaciones de
gran validez interna (pues las condiciones experimentales están muy controladas),
mientras que los estudios de campo tendrían sobre todo validez externa (porque
representan muy bien a la población de origen). Hoy, sin embargo, algunos autores están
reconsiderando estos planteamientos.
La capacidad de control, sobre todo de control físico, de las investigaciones de
laboratorio, desvirtúa en ocasiones los procesos observados debido a la artificialidad de
la propia situación experimental. Por otro lado, los estudios de campo renuncian, más o
menos explícitamente, al control de los factores que afectan a la validez interna al
estudiar a los sujetos en su medio y su actividad habitual.
Los estudios de campo cuasiexperimentales pueden alcanzar gran validez interna si
aplican adecuadamente diseños complejos, así como validez externa si entre la muestra
y la población existen condiciones ambientales semejantes. No hay que olvidar que los
estudios de campo cuasiexperimentales ofrecen al menos las siguientes ventajas: 1) se
realizan en un marco real, por lo que es posible evitar muchas respuestas reactivas; 2)
permiten probar hipótesis amplias con proyección practica; 3) generan nuevas hipótesis
que pueden ponerse a prueba en situaciones mas restrictivas, y 4) aumentan la
posibilidad de generalizar los resultados.
Para evitar los problemas asociados a cada tipo de situación experimental, el investigador
puede recurrir al control de las variables extrañas que influyen en éstas. De este modo,
se podrá controlar la influencia de algunas variables independientes que son extrañas a
la finalidad de la investigación, de modo que la varianza que producen se anule, minimice
o aísle. La tarea de decidir qué variables experimentales pueden ser pertinentes y cuáles
no en una investigación concreta, puede ser ardua y difícil. Precisar cuáles son y cómo se
va a proceder para evitar que influyan de modo diferencial es función del investigador.
Varias son las técnicas de control que pueden utilizarse. En este documento
expondremos las siguientes, recordando que, en los experimentos complejos, es
frecuente utilizar al mismo tiempo más de una técnica de control:

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
52
1- Eliminación. Una de las formas de controlar una variable extraña consiste en mantener
constantes los valores de dicha variable. Es decir, eliminar la variable como variable,
dando a todos los grupos experimentales una sola graduación de ella. Así, por ejemplo, si
en un cultivo celular se quiere controlar el posible efecto de los distintos subcultivos
celulares sobre la variable estudiada, el investigador puede trabajar sólo con cultivos
celulares que pertenezcan a un mismo subcultivo. O si lo que preocupa es el sexo de los
individuos de los cuales proceden ciertos tejidos, se pueden elegir los grupos de modo
que pertenezcan a todos a un solo sexo, etc.
Esta técnica, en apariencia sencilla, tiene como contrapartida que limita la generalización
de los resultados y reduce la validez externa de los mismos. ¿Se mantendrá la misma
relación en células que pertenezcan a otros subcultivos o procedentes de pacientes de
otro sexo? No se sabe. Por otro lado, muchas variables extrañas no pueden ser
eliminadas por el investigador, por lo que no hay más remedio que incluirlas en el estudio
y recurrir a otro tipo de mecanismos de control (Escotet, 1980).
2- Introducción. Otra forma de controlar la variable experimental es introducirla en el
diseño como una variable independiente para lograr que varíe de modo sistemático. Así,
en los ejemplos citados se podría trabajar en todos los grupos con muestras procedentes
de individuos de ambos sexos o células pertenecientes a más de un subcultivo. Si
interesa información sobre dicha variable extraña y la variable dependiente o sobre la
interacción entre ella y la o las variables independientes, esta técnica es adecuada. Si no
es así, ata menos al investigador que la técnica anterior, pero no deja de ser laboriosa.
3- Constancia. Una tercera forma de control es la constancia de las condiciones. Cuando
una variable extraña no puede eliminarse, se la puede controlar manteniéndola fija
durante el proceso experimental. Es decir, cualquiera que sea esa variable, a todos los
sujetos se les asignará el mismo valor. Si la variable extraña influye del mismo modo y en
el mismo grado sobre las variables experimentales, no es probable que su efecto nos
pueda enmascarar los efectos de las variables causales sobre la variable problema. Por
ejemplo, aplicar los tratamientos experimentales en el mismo lugar, utilizar un solo
experimentador para todos los grupos, recoger las medidas con el mismo instrumento o
aparato, etc. En cuanto a los sujetos o las muestras, elegirlos del mismo tipo, la misma
edad, etc. En realidad, esta técnica está íntimamente relacionada con la eliminación.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
53
4- Emparejamiento. Una cuarta técnica de control es el emparejamiento de sujetos. Si
tenemos una variable experimental que correlaciona altamente con la variable
dependiente, el emparejamiento reduce el término de error y aumenta la precisión del
experimento, pero ofrece ciertas dificultades. En primer lugar, es difícil obtener
coeficientes de correlación elevados, de 0,8, por ejemplo, y como mínimo de 0,6, entre
ambas variables. Por otra parte, es más difícil aún lograr el emparejamiento en dos o más
variables sin perder muestras o sujetos, pues en ocasiones es difícil encontrar pares de
muestras o sujetos igualados en varias variables. No obstante, cuando existe una
correlación sustancial entre la variable de apareamiento y la variable dependiente, es
recomendable utilizar el emparejamiento, si bien es necesario asignar después al azar a
los grupos experimentales a cada uno de los sujetos apareados. Este tipo de control es
ventajoso en los llamados diseños de medidas repetidas, que utilizan los mismos sujetos
con diferentes tratamientos experimentales.
5- Aleatorización. Otra forma de control es la distribución al azar. Teóricamente, este
método es la única forma de controlar todas las variables experimentales posibles, lo que
no quiere decir que necesariamente lo logre. La aleatorización, que fue introducida por
Fisher en 1928, supone una de las herramientas más poderosas con las que cuenta el
científico para controlar las variables extrañas en un marco experimental. Es decir, si se
ha utilizado en todo momento la distribución al azar, un investigador puede suponer que
sus grupos son estadísticamente iguales, aunque por azar podrían no serlo. Pero existen
mayores probabilidades de que lo sean que de que no lo sean. En efecto, cuando se lleva
a cabo una selección aleatoria de las muestras y de los casos a estudiar, es muy
probable que los sesgos se repartan de forma aleatoria en todos los grupos de estudio,
con lo que la posibilidad de llegar a una conclusión falsa por causa de un factor externo
será muy baja. Hoy en día, todo marco experimental ha de contar en mayor o menor
medida, con un proceso de aleatorización.
La aleatorización se emplea generalmente en dos situaciones: a) Cuando se sabe que
ciertas variables extrañas actúan en la situación experimental y no es posible controlarlas
por ninguna de las técnicas anteriores; b) Cuando se supone que existen algunas
variables extrañas que pueden actuar en nuestro estudio pero no es posible identificarlas
y, por tanto, no se puede recurrir a las otras técnicas.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
54
6- Control estadístico. Por último, recordar que existe el control estadístico, en el sentido
de que los métodos estadísticos sirven para aislar y cuantificar la varianza de unos datos.
La elección de la prueba estadística apropiada al diseño depende de varios criterios,
como veremos en el apartado correspondiente.
La técnica de control estadístico más utilizada es el análisis de covarianza. Se trata de
una forma de controlar la varianza que se lleva a cabo a nivel del análisis estadístico de
los datos, una vez ha concluido la recogida de información en forma de resultados. Por
ello, la potencia de este tipo de control es menor que la que se realiza en niveles previos
a la recogida de datos.
7- El diseño intrasujeto. En ocasiones, se puede recurrir a diseños experimentales
especiales, como el intrasujeto, que nos ayudan a controlar la varianza. Este tipo de
diseños, sin embargo, presentan poca utilidad en el campo de la investigación básica
experimental en ciencias de la salud.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
55
V. RESOLUCIÓN ESTADÍSTICA DEL DISEÑO EXPERIMENTAL
Según Kerlinger, la estadística es ―la teoría y el método para analizar datos cuantitativos
obtenidos de muestras de observaciones para estudiar y comparar fuentes de varianza
de fenómenos, ayudar a tomar decisiones sobre aceptar o rechazar relaciones hipotéticas
entre los fenómenos y ayudar a hacer inferencias fidedignas de observaciones
empíricas‖. Para López González, estadística es ―la ciencia que recoge, ordena y analiza
las muestras extraídas de ciertas poblaciones o conjuntos de elementos, con base en
éstas y en el cálculo de probabilidades, se encarga de hacer averiguaciones (inferencias)
acerca de las correspondientes poblaciones‖.
A la hora de decidir si una hipótesis concreta ha de ser aceptada o rechazada, el
investigador necesita contar con un criterio objetivo y universal. Después de elaborar sus
hipótesis y de llevar a cabo la fase experimental de un Proyecto de Investigación, el
científico ha de analizar sus resultados y compararlos con las hipótesis iniciales para
tomar una decisión en uno u otro sentido (en el sentido de las hipótesis planteadas o en
el contrario).
En ocasiones, los resultados son muy claros, mostrando enormes diferencias entre los
distintos criterios utilizados y confirmando las hipótesis iniciales de forma evidente. Otras
veces, las diferencias son muy sutiles o no existen en absoluto. En este abanico de
posibilidades, y para evitar interpretaciones subjetivas que restarían valor a los
resultados, es necesario utilizar criterios matemáticos previamente validados y aceptados
por la comunidad científica universal. Estos criterios son lo que hoy denominamos
estadística o, más concretamente, estadística inferencial. Las pruebas estadísticas
cumplen aquí un doble cometido. Por un lado, indican la probabilidad que tiene un
resultado determinado de ser explicado por las variaciones del azar y, por otro, al fijar
convencionalmente unos coeficientes de riesgo, proveen de un criterio objetivo para
decidir sobre la aceptación o el rechazo de las hipótesis de investigación.
Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
56
Por otro lado, algunos diseños de investigación, como hemos visto en los apartados
anteriores, pueden resultar enormemente complejos y muy difíciles de abordar si no se
cuenta con las estrategias de análisis múltiple que nos ofrece la estadística (por ejemplo,
el análisis factorial o el de covarianza).
Todo lo anterior indica que las pruebas estadísticas son un instrumento valioso en el
contraste de hipótesis. Normalmente existe más de una prueba estadística para cada tipo
de diseño, por lo que el investigador puede seleccionar una u otra. Pero esta elección no
es gratuita, sino que obedece, entre otros, a cuatro factores que estudiaremos a
continuación: el nivel de medición, el modelo estadístico, la potencia de la prueba y la
potencia-eficiencia.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
57
A.- EL NIVEL DE MEDICIÓN
Medir es asignar números a los objetos de acuerdo con ciertas reglas. Cuando un físico
mide la temperatura de fusión de ciertos metales y las compara, obtiene informaciones de
los objetos que mide. Y es que la relación entre lo que observa y los números es tan
directa, que mediante la manipulación de éstos es fácil generar nueva información.
En ocasiones tendemos a extrapolar los métodos y técnicas que utilizan las ciencias
experimentales más controladas, como pueden ser las ciencias físicas, a cualquier
modelo experimental como puede ser el de la Histología Humana. Sin embargo, cuando
tomamos la física como modelo, podemos caer en errores al intentar medir variables
humanas complejas, asignándoles numerales y realizar con éstos operaciones que
presuponen la correspondencia isomórfica entre la estructura de las observaciones y la de
los números. Y es que dentro de la teoría de la medición existen diferentes niveles de
medida que comportan distintos tipos de relaciones y, en consecuencia, distintas
operaciones de los datos. Los más conocidos son: nominal, ordinal, de intervalo y de
razón (Tabla 1):
1. En la escala nominal los números y símbolos se utilizan para distinguir entre
sí los grupos a que pertenecen varios objetos. Se clasifican los sujetos y las
clases se numeran. La relación es la de equivalencia. Esto es, los objetos o
miembros de cualquier clase deben ser equivalentes en la propiedad medida.
En el campo de la Histología, podemos encontrar numerosos ejemplos de
distribuciones de escala nominal. Un caso concreto sería el tipo de epitelios
encontrados en el organismo humano (simple, estratificado,
pseudoestratificado, etc.).
Algunas pruebas estadísticas que utilizan o pueden utilizar datos nominales son
la binomial, la 2 y la de McNemar, por ejemplo. En estas pruebas, los datos
son meras agrupaciones de frecuencias obtenidas según cierta clasificación.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
58
2. La escala ordinal se diferencia de la anterior fundamentalmente porque a la
relación de equivalencia incorpora la de mayor a menor. Es decir, en ella los
números asignados a los objetos reflejan la cuantía de los atributos que los
objetos o sujetos poseen sin que ello signifique que a diferencias iguales entre
los números correspondan diferencias iguales en la cuantía de los atributos. Por
ejemplo, si medimos la responsabilidad con que los alumnos de la asignatura
de Histología Bucodental Humana acatan la disciplina académica universitaria,
tendremos una medida ordinal. En cualquier caso, podrían arbitrarse
instrumentos que indicarán que A la acata con más responsabilidad que B, éste
con más responsabilidad que C, y así sucesivamente. Si a A, B, C, etc., le
asignamos números que reflejen de mayor a menor el grado de
responsabilidad, tenemos datos ordinales. Así, le asignaríamos el 1 a A, el 2 a
B, el 3 a C, etc. Lo que no significa que entre el 1 y el 2 exista la misma
diferencia en responsabilidad que entre el 2 y el 3.
La mayor parte de las pruebas que se denominan no paramétricas y que
describiremos más adelante, utilizan este tipo de datos. Alguna de ellas, como
la prueba de los signos, requiere que los datos tengan como base una
distribución continua, aunque se midan en categorías discretas.
3. En la escala de intervalo la unidad de medida permite que los sujetos no
sólo puedan ser ordenados, sino asignados a números reales, de tal manera
que unas diferencias iguales entre los números asignados a dichos sujetos
reflejan diferencias idénticas en la cuantía de los atributos medidos. El punto
cero de la escala es arbitrario y no indica ausencia del atributo, siendo también
arbitraria la unidad de medida. A las relaciones de equivalencia y de mayor a
menor, se añade la de proporción conocida entre dos intervalos cualesquiera.
Gran número de pruebas estadísticas de uso muy frecuente utilizan este tipo de
datos. El problema es que en ciertos tipos de experimentos es difícil lograr
medidas de intervalo, por no hablar de la posible discusión acerca de la
naturaleza exacta de algunas distribuciones que, para algunos, son
consideradas de intervalo, siendo de cuasintervalo para otros y ordinales para
otros.
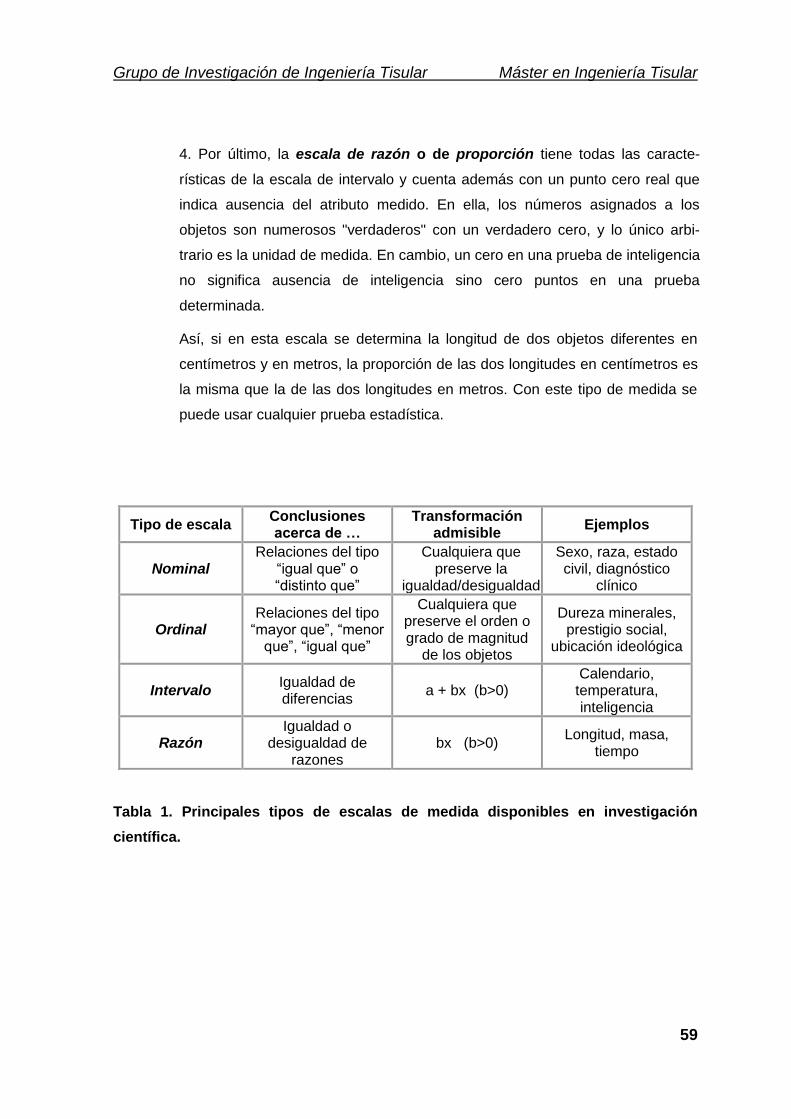
Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
59
4. Por último, la escala de razón o de proporción tiene todas las caracte-
rísticas de la escala de intervalo y cuenta además con un punto cero real que
indica ausencia del atributo medido. En ella, los números asignados a los
objetos son numerosos "verdaderos" con un verdadero cero, y lo único arbi-
trario es la unidad de medida. En cambio, un cero en una prueba de inteligencia
no significa ausencia de inteligencia sino cero puntos en una prueba
determinada.
Así, si en esta escala se determina la longitud de dos objetos diferentes en
centímetros y en metros, la proporción de las dos longitudes en centímetros es
la misma que la de las dos longitudes en metros. Con este tipo de medida se
puede usar cualquier prueba estadística.
Tipo de escala Conclusiones acerca de …
Transformación admisible
Ejemplos
Nominal Relaciones del tipo
―igual que‖ o ―distinto que‖
Cualquiera que preserve la
igualdad/desigualdad
Sexo, raza, estado civil, diagnóstico
clínico
Ordinal Relaciones del tipo
―mayor que‖, ―menor que‖, ―igual que‖
Cualquiera que preserve el orden o grado de magnitud
de los objetos
Dureza minerales, prestigio social,
ubicación ideológica
Intervalo Igualdad de diferencias
a + bx (b>0) Calendario, temperatura, inteligencia
Razón Igualdad o
desigualdad de razones
bx (b>0) Longitud, masa,
tiempo
Tabla 1. Principales tipos de escalas de medida disponibles en investigación
científica.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
60
B.- EL MODELO ESTADÍSTICO
Un modelo es una analogía en la que un conjunto de datos representa a otro conjunto por
ser isomórficos. Dos conjuntos se consideran isomórficos cuando en ellos existe
correspondencia entre todos y cada uno de los elementos de uno y otro conjunto y
cuando poseen entre sí ciertas estructuras semejantes (García Hoz, 1981). Para aclarar
este concepto, utilizaremos el siguiente ejemplo:
Supongamos una población celular correspondiente a un cultivo primario de
queratinocitos de la piel humana. Supongamos también que algunos estudios previos
sugieren que las muestras de piel sólo son capaces de generar cultivos primarios de
queratinocitos en el 40% de los casos. Para aumentar ese porcentaje de éxito, el
investigador plantea un estudio en el que utiliza factor de crecimiento epidérmico (EGF)
en la generación de cultivos primarios de queratinocitos, manteniendo las condiciones
normales de cultivo en un grupo de muestras que utiliza como controles.
En este momento, el investigador plantea la siguiente hipótesis: las muestras de piel
humana en las que se utiliza EGF generan cultivos primarios de queratinocitos con mayor
probabilidad que las muestras control. Supongamos que el investigador elige un nivel de
significación del 5 %.
A continuación, el investigador utiliza dos muestras de piel humana y las procesa en
presencia de EGF para generar cultivos primarios de queratinocitos. El resultado es
positivo en ambos casos, generándose cultivos primarios viables a partir de las dos
muestras utilizadas (éxito del 100%). Aunque se trata tan sólo de dos muestras
individuales, ante estos resultados caben plantearse las siguientes preguntas: ¿Cuál es
la probabilidad de que un porcentaje del 100 % de resultados positivos se haya producido
por azar? ¿Qué deducciones se pueden hacer acerca de la hipótesis?
Lo primero es determinar la estructura matemática de los datos. Desde el punto de vista
matemático el problema tiene las siguientes características: 1) se tienen dos opciones:
generación de cultivos primarios de queratinocitos o no; 2) por los datos anteriores
sabemos que lo habitual es que el 40 por ciento de las muestras sea capaz de generar
cultivos primarios, mientras que el 60 por ciento no los genera; 3) las dos opciones son
inclusivas, 40 por ciento más 60 por ciento dan el 100 por ciento; y 4) hay tres resultados
posibles para la muestra: ambas muestras generan cultivos primarios de queratinocitos;

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
61
ninguna muestra genera dichos cultivos o una muestra genera cultivos primarios y la otra
no.
Determinada la estructura matemática, se procede en segundo lugar a buscar una
función matemática que le sirva de modelo. Una función que sirve para problemas de
este tipo es el desarrollo del binomio (X + Y)n, que tiene asimismo cuatro características:
1) hay dos términos o resultados X e Y; 2) cada término tiene una probabilidad de
ocurrencia determinada; 3) X e Y cumplen la propiedad de la inclusión, ya que la suma de
sus respectivas probabilidades es igual a 1; y 4) el universo de X e Y se muestra n veces.
En nuestro ejemplo, n = 2; luego si desarrollamos (X + Y)2, tenemos: X2 + 2XY + Y2.
Si se aplica este modelo a los datos del ejemplo, tenemos que X representa a las
muestras que son capaces de generar cultivos primarios de queratinocitos e Y a las que
no son capaces de ello. De este modo, el modelo es análogo con respecto a los datos.
Asi, X2 representa una muestra formada por dos biopsias de piel que sí son capaces de
generar cultivos primarios; el segundo término, 2XY, representa a una biopsia que será
cultivada con éxito y a otra que no, y el tercer término Y2, representa a dos biopsias de
piel que no generarán cultivos primarios. Como los datos se ajustan a las características
del modelo, podemos utilizarlo para conocer la probabilidad de ocurrencia de unos
resultados como los del ejemplo, es decir, un 100 por cien de cultivos con éxito. A esto se
le llama contrastar la hipótesis.
Con los resultados de la población formemos la distribución de probabilidad
correspondiente al desarrollo del binomio:
Conclusión de la investigación Término en el modelo Probabilidad (P) P %
Dos cultivos primarios (++) X2 0,42 0,16 16
Un cultivo primario (+-) 2XY 2 (0,4) (0,6) 0,48 48
Ningún cultivo primario (--) Y2 0,62 0,36 36
Total 1,00 100

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
62
Con esta distribución de probabilidad a la vista, el investigador puede saber ahora que su
100 por cien de éxitos en los cultivos primarios no es significativamente distinto a la
probabilidad original de 0,40. Es decir, aunque la probabilidad de cultivar los
queratinocitos con éxito siguiera siendo de 0,40, habría un 16 por ciento de probabilidad
de encontrar dos alumnos que aspirasen a ello. Como esta probabilidad es muy superior
al nivel de significación elegido, 5 por ciento, tiene que rechazar su hipótesis de que las
condiciones de cultivo especiales han producido cambios.
Este ejemplo nos indica varias cosas. En primer lugar, que es posible construir una tabla
de probabilidades binominales para todas las combinaciones posibles de X e Y (es decir,
X = 0,01 e Y = 0,99; X = 0,02 e Y = 0,98, etc.) y para distintos tamaños de muestra (n
puede valer 2, 3, 4, etc.). Por supuesto, esta tabla (denominada tabla de probabilidades
binomiales) y la de otros modelos matemáticos, ya han sido elaboradas por diferentes
investigadores que han dedicado su tiempo al campo de la estadística durante los últimos
años. En segundo lugar, nuestro ejemplo indica que con una muestra de dos biopsias de
piel y un nivel de significación del 5 por ciento, nunca se podría probar la hipótesis de
investigación, ya que para ello, este modelo exige una muestra de mayor tamaño. La
consulta a la tabla de probabilidades binomiales se lo hubiera advertido, lo que significa
que los modelos tienen también sus exigencias. Por último, indica que los modelos
matemáticos son construcciones lógicas que guardan estrecha relación con los datos a
los que se aplican.
En resumen, la elección del modelo requiere determinar las características de los datos y
conocer los modelos disponibles y los supuestos subyacentes a cada modelo. Como
veremos a continuación, en el campo de las Ciencias Experimentales, se han
desarrollado dos tipos de modelos: los parámetricos, llamados así porque especifican
ciertas condiciones acerca de los parámetros de la población de la que se ha obtenido la
muestra, y los no parámetricos, que no parten de ningún supuesto relativo a los
parámetros de la población o en todo caso, son supuestos menores.
1. Pruebas paramétricas
Estas pruebas son las más poderosas, siempre que se cumplan los supuestos de los que
parte el modelo. Los tres supuestos más corrientes son: 1) que las características que se
estudian existan en la población; 2) que en ella están distribuidas normalmente, y 3) que
el estadístico muestral da una estimación del parámetro.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
63
Si se está estudiando el contenido intracelular de calcio en un grupo de células, por
ejemplo, se podría utilizar una prueba paramétrica siempre que pueda suponerse que la
concentración de calcio existe en la población celular, que esta concentración se
distribuye entre las células siguiendo el modelo de la curva normal y, por último, que la
media de la muestra de células escogidas es una estimación del parámetro (valor medio
de calcio en la población general de células). El segundo supuesto incluye un cuarto: la
necesidad de contar con medidas de intervalo. De ahí que "los métodos paramétricos
están limitados al contraste de hipótesis en las que intervienen estadísticos del sistema
de momentos, como medias, varianzas y correlaciones producto-momento" (Jiménez
Fernández, 2000).
Las pruebas paramétricas más conocidas por la mayoría de los investigadores son las
denominadas pruebas t y F. Ambas son consideradas pruebas muy potentes, pero parten
de los supuestos anteriores, lo cual restringe su uso. La prueba t de Student es quizás la
prueba estadística más utilizada en el campo de las ciencias básicas, pues puede
aplicarse a datos experimentales, siempre que éstos reúnan los requisitos de:
- Independencia. Lo que significa que al elegir la muestra, la elección de un
caso cualquiera de la población no afecta a la elección de ningún otro caso y que
la puntuación asignada a un sujeto no influye en la puntuación asignada a
ningún otro. Este requisito afecta también a los modelos no paramétricos.
Naturalmente, en los grupos relacionados no se pide este requisito como es el
caso de los diseños de medidas repetidas en el que los mismos sujetos se
miden dos o más veces.
- Normalidad. Las observaciones registradas en el experimento deben proceder
de poblaciones distribuidas normalmente, esto es, que sigan una distribución
similar a una campana de Gauss. En la mayor parte de los experimentos, el
investigador no se preocupa en verificar este supuesto, sino que se asume que
los datos de las variables observadas obedecen a una distribución normal.
- Homoscedasticidad. Lo que quiere decir que los grupos en estudio proceden
de una misma población o de poblaciones con igual varianza. Es, quizá, el único
requisito que suele probarse antes de llevar a cabo el análisis estadístico
mediante la t de Student, porque su violación puede ser grave en determinadas
condiciones.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
64
- Medida de intervalo. La variable dependiente o variable de análisis debe
haber sido medida, como mínimo, en una escala de intervalo para poder aplicar
las operaciones aritméticas a los datos (como veremos al final de este capítulo
dedicado al análisis estadístico).
- Linealidad. Las medidas de estas poblaciones normales y homoscedásticas
deben ser combinaciones lineales de los efectos atribuidos a las columnas y a
las filas o a ambos. Es decir, que la relación atribuida a tales efectos debe ser
aditiva y no multiplicativa. Este quinto requisito sólo es necesario cuando se
utiliza la prueba F (análisis de varianza).
Cuando se puede suponer razonablemente que los datos a analizar cumplen estas
condiciones, la elección de una de estas pruebas es excelente, porque la prueba
paramétrica será más poderosa que la no paramétrica a la hora de rechazar H0 cuando
ésta realmente deba ser rechazada. Es decir, "cuando los datos de la investigación
pueden ser analizados adecuadamente por una prueba paramétrica, será el medio más
poderoso para rechazar una hipótesis falsa" (Siegel y Castellán, 1995).
Pero cuando estas condiciones no son satisfechas (debido, por ejemplo, a que la
población no se distribuye normalmente, a que la medida no es tan fuerte como la escala
de intervalo o a que las poblaciones tienen distinta varianza), hay que acudir a las
pruebas no paramétricas.
Algunos autores como Arnau (1981), Welkowitz et al. (1981), Glass y Stanley (1980),
entre otros, sostienen que una ligera violación de estos supuestos no afecta radicalmente
la probabilidad obtenida en las pruebas paramétricas. Sin embargo, Siegel argumenta en
contra diciendo que "no hay hasta ahora acuerdo general en cuanto a lo que se entiende
por 'una ligera' desviación" y que, en cambio, cuando ésta ocurre "es difícil, si no
imposible, medir la potencia de la prueba. Incluso es difícil estimar el significado de una
aseveración de probabilidad acerca de la hipótesis en cuestión cuando la aseveración
proviene de aplicaciones inaceptables de una prueba" (Siegel y Castellán, 1995). En todo
caso, cuando existen poderosas razones para dudar del cumplimiento de los supuestos
el investigador no tiene otra alternativa que el recurso de las pruebas estadísticas no
paramétricas.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
65
2. Pruebas no paramétricas
Las pruebas no paramétricas son aquéllas cuyo modelo estadístico no parte de
supuestos acerca de la población o éstos son muy débiles. Asimismo, estas pruebas
pueden operar incluso con datos ordinales y hasta nominales. Los dos supuestos
asociados a la mayoría de estas pruebas son la independencia de las observaciones y la
continuidad básica de la variable, supuestos mucho menos restrictivos que los estudiados
en el punto anterior.
Como indicamos anteriormente, las pruebas no paramétricas deben aplicarse siempre
que: a) los datos estén recogidos en escala nominal u ordinal, y b) cuando los datos,
aunque estén medidos en escala de intervalo, no permiten hacer suposiciones acerca de
la forma de la distribución de la población ni de la homoscedasticidad de las poblaciones.
Las ventajas de este tipo de pruebas son:
- Permiten hacer afirmaciones exactas de probabilidad. Independientemente de
la forma de la distribución de donde se obtuvo la muestra, las probabilidades
obtenidas con la mayoría de estas pruebas son probabilidades exactas, con un
determinado nivel de significación. En consecuencia, se pueden hacer a partir
de ellas inferencias probabilísticas conociendo los riesgos de error.
- Permiten trabajar con muestras de pequeño tamaño. Si se trabaja con
muestras muy pequeñas, como n = 4, 5 ó 6, por ejemplo, no pueden aplicarse
pruebas paramétricas, salvo que se conozca exactamente la naturaleza de la
distribución poblacional.
- Con observaciones obtenidas de poblaciones diferentes, la única alternativa
válida son las pruebas no paramétricas.
- Estas pruebas son aplicables tanto para datos inherentes a los rangos como
para datos cuyas puntuaciones aparentemente numéricas tienen fuerza de
rangos.
- Si los datos de un estudio son simplemente clasifícatenos, esto es, están
medidos en una escala nominal, sólo pueden aplicarse pruebas no
paramétricas.
- Son más fáciles y rápidas de aplicar que las pruebas paramétricas.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
66
Sin embargo, los inconvenientes de este tipo de pruebas son los siguientes (Jiménez
Fernández, 2000):
- El despilfarro de datos o sujetos que con ellas se cometen si se aplican a
datos que reúnen los requisitos exigidos por las pruebas paramétricas. El grado
de despilfarro se expresa por la potencia-eficacia de la prueba no paramétrica,
esto es, dicha prueba precisaría un mayor número de sujetos que la
paramétrica para ser tan potente como ésta.
- Otro inconveniente que se cita es que las pruebas y sus tablas de
probabilidades se hallan dispersas en distintas publicaciones. Actualmente
puede considerarse superado al contar con algunas obras que las recopilan,
como la de Siegel y Castellán (1995) o algunos libros de estadística aplicada.
En resumen, la elección de una prueba estadística adecuada a los datos concretos de
una investigación se rige, entre otros, por los siguientes principios:
1) Si el nivel de medida logrado es nominal u ordinal, se ha de elegir
necesariamente una prueba no paramétrica.
2) Como suelen existir varios tipos de pruebas no paramétricas, siempre que
los datos lo permitan, se elegirá aquella que utilice el nivel de medida más alto
ya que es más potente al utilizar más información.
3) Si se ha logrado una medida de intervalo, se elegirá una prueba
paramétrica siempre que los datos cumplan con los requisitos asociados a
ella.
4) Habrá casos en que a pesar de contar con datos medidos en intervalos, se
usará una prueba no paramétrica debido al tipo de hipótesis en estudio.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
67
C.- POTENCIA DE UNA PRUEBA ESTADÍSTICA
Potencia estadística es la probabilidad de que el efecto que se pretende encontrar sea
detectado por el investigador, suponiendo que este efecto esté presente. La potencia de
un análisis estadístico es en parte una función de la prueba estadística empleada. La
potencia de una prueba se define como la probabilidad que existe de rechazar H0 cuando
ésta es realmente falsa. Matemáticamente, la potencia se representa como la
complementaria del error tipo II o error β (1 – β), siendo β la probabilidad de aceptar H0
cuando ésta es falsa (y, por tanto, H1 es cierta).
En situaciones comparables, las pruebas paramétricas son más potentes que las no
paramétricas. Esto se comprende fácilmente si consideramos que las pruebas
paramétricas necesitan datos medidos al menos en escala de intervalos. Estos datos
pueden reducirse a una escala inferior, de orden, y emplear así una prueba no
paramétrica. Pero observamos en seguida que se produce una pérdida de información,
pues la escala ordinal considera sólo el orden de las observaciones, y no la cuantía de su
separación.
Veamos un ejemplo sencillo. Supongamos que hemos determinado el número de
mitocondrias que existe en un determinado compartimiento celular en cuatro células
endoteliales humanas. Los resultados que hemos obtenido son los siguientes, medidos a
nivel de intervalo: 4, 6, 7 y 9. Una prueba paramétrica considera el orden y la cuantía de
separación que existe entre ellas. Así el 9 está por encima del 7, pero separado de éste
exactamente 2 unidades; el 7 ocupa un orden superior al 6, del que le separan 1 unidad,
etc. De este modo la prueba paramétrica recoge toda la información que contienen los
datos. Para su equivalente no paramétrica, el alumno que obtuvo 9 puntos ocupa también
el primer lugar; el que obtuvo 7, el segundo; el de 6, el tercero, etc., pero no considera
que entre estos órdenes existe una distancia distinta. Así, ignora que entre el primer y el
segundo alumno la distancia es de 2 puntos; de sólo 1 entre el segundo y el tercero, etc.
Al utilizar menos información son menos potentes para datos comparables, lo que en
términos prácticos significa que, aunque para la mayoría de los datos los dos tipos de
pruebas llevarán a la misma conclusión, habrá ciertos datos para los que la prueba no
paramétrica llevaría a aceptar H0 mientras que la correspondiente paramétrica llevaría a
rechazarla.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
68
Habitualmente, la mayoría de los investigadores desean rechazar las hipótesis de nulidad
que plantearon al inicio de su proyecto. Por ello, lo que más les interesa es utilizar una
prueba estadística con una potencia más bien alta. Sin embargo, se le ha prestado poca
atención a este punto y con frecuencia se realizan experimentos en lo que existen
muchas probabilidades de cometer errores de tipo II, sin saberlo el investigador, y se
abandonan líneas de investigación que pueden ser prometedoras. El análisis de la
potencia de la prueba aclararía este error.
Para Welkowitz (1981), la potencia de una prueba depende de tres factores
fundamentales: α, n y . Como veremos a continuación, el nivel de significación α está
fijado convencionalmente en 0,05 ó 0,01 para la mayoría de los casos, aunque el
investigador puede cambiarla, mientras que el tamaño de muestra n suele ser fijado de
antemano por el investigador. Desafortunadamente, suele quedar casi siempre fuera del
control del investigador. La falta de control sobre suele ser el verdadero problema para
el cálculo de la potencia de una prueba estadística.
Tabla 2. Tabla resumen de los principales conceptos relacionados con la potencia
y los errores estadísticos.
Error tipo I Consiste en llegar a la conclusión de que existe una relación entre las
variables cuando ésta no existe. La probabilidad de cometerlo es α
Nivel de confianza
Indica la probabilidad de acertar cuando no se rechaza una hipótesis nula que es, efectivamente cierta (complementaria de α)
Error de tipo II Cuando no se detecta una relación entre variables que en realidad sí
existe en la población. Probabilidad se llama β
Potencia Capacidad de una prueba estadística para detectar una relación entre
variables. Probabilidad 1 – β (complementaria de β)

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
69
1. El nivel de significación α
El nivel de significación α de una prueba estadística representa la probabilidad de
rechazar la hipótesis nula H0 cuando ésta es verdadera, es decir, la probabilidad de que
las diferencias halladas en nuestros resultados se deban puramente al azar. Por
supuesto, cuanto más baja sea esa probabilidad de error (denominado error tipo I o error
α), más fiables serán los resultados y el investigador podrá confiar en mayor medida en
que las diferencias observadas sean diferencias reales y no diferencias debidas al azar.
De hecho, y si los demás factores se mantienen constantes, cuanto más alto sea el nivel
de significación, más difícil será rechazar H0 cuando ésta es verdadera.
Sin embargo, todo aumento del nivel de significación se asocia a una disminución de la
potencia del test estadístico utilizado y, por tanto, a un aumento de la probabilidad de
error β. Por ejemplo, si el investigador decide utilizar un nivel de significación α de 0,05
en lugar de un nivel α de 0,01, la potencia aumenta. El problema es que la manipulación
de α no suele ser una técnica eficaz porque, para unos datos determinados, dicha
manipulación suele tener efectos opuestos en los dos tipos de errores α y β. Por ese
motivo, la mayoría de los investigadores utilizan niveles de significación estándar fijados
en 0,05 (o lo que es lo mismo, 5%) o en 0,01 (1%). Estos conceptos se muestran de
forma sintética en la Tabla 2.
Un ejemplo de este efecto de α sobre β y de β sobre α se muestra en la Figura 3. En
dicha figura, se ilustra la interacción que se produce entre α y β, al analizar los datos de
un diseño pretest-postest de grupo único. Supongamos que se está investigando un
nuevo procedimiento pedagógico para la enseñanza universitaria de la Histología
Bucodental Humana. La media del grupo en el pretest (antes de utilizar el nuevo
procedimiento) es de 5 puntos y el contraste es de tipo unilateral derecho, ya que el
investigador afirma en su hipótesis que la media del postest (tras el nuevo procedimiento)
será superior a 5. En el primer par de figuras, la curva bajo la hipótesis de nulidad indica
el valor de µ = 5 y el valor crítico de 7,06 para α = 5 %. La zona rayada de las curvas
alternativas indica la probabilidad de un error de tipo II, β, cuando la hipótesis alternativa
especifica que el valor de la media es de 6,5 puntos.
En el ejemplo B de la Figura 3, el nivel de significación se ha elevado. Del 5 % se ha
pasado al 1 %, con lo que el valor crítico se ha elevado también. Ahora ha disminuido la
probabilidad de un error de tipo I pero ha aumentado la de un error de tipo II. Las dos
últimas figuras ilustran la situación típica de querer reducir el riesgo de error de tipo II
bajando el nivel de significación. En este caso se ha fijado en 0,08 pero al descender el

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
70
valor crítico, el riesgo de error de tipo I ha aumentado considerablemente bajo la
hipótesis alternativa.
Estas figuras ilustran que el descenso o aumento del nivel de significación no puede
expresarse en una regla matemática que indique que a un aumento o descenso
determinado del mismo corresponde un descenso o aumento concreto en el riesgo de
error de tipo II. Lo único que se puede afirmar es, pues, que ambos tipos de errores se
relacionan inversamente. Por ello es más interesante manipular el tamaño de la muestra.
Figura 3. Ilustración del poder del contraste de H0: µ= 5 comparado con H1: µ.= 6,5
para distintos valores de α.
A
B
C
A
B
C

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
71
2. El tamaño de la muestra n
Cuando todos los demás factores se mantienen constantes, el investigador puede
aumentar el poder del contraste de H0 aumentando el tamaño de muestra n. El motivo
de ello es que la exactitud de la mayoría de los valores estadísticos depende del tamaño
de n, pues casi todos estos valores tienen alguna función de n en el denominador. Al
aumentar n disminuye el error y se incrementa la potencia del test. Por ello, en principio,
cuanto mayor sea el tamaño de muestra escogido, mayor será la potencia del test
estadístico y menor la probabilidad de error.
Este fenómeno se puede apreciar esquemáticamente en la Figura 4, que muestra cómo
aumenta la potencia del test al aumentar el tamaño de la muestra. Estas muestras se
tomaron de poblaciones normales con varianza σ2.
Figura 4. Curvas de potencia de una prueba de dos colas con α= 0,05 y distintos
valores de n.
n=100 n=50

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
72
3. El grado de discrepancia entre H0 Y H1
Otro factor del cual depende la potencia de un test estadístico es la proximidad o lejanía
de los valores postulados por la hipótesis nula y la hipótesis alternativa. En realidad,
cuando se dice que una hipótesis nula es falsa, esta hipótesis puede ser falsa en mayor
o menor grado, aumentando su grado de falsedad en la medida en que supone un valor
más extremo del parámetro. Para valores fijos de α y n, el poder del contraste aumenta
a medida que el parámetro se aparta del valor supuesto para él en H0.
En estadística, es una medida general del grado de falsedad de la hipótesis nula o de
la magnitud del "efecto" en la población estudiada. Por ejemplo, dado n = 200 y α =
0,05, el poder de contraste de H0: ρ = 0 es mayor para ρ1 = 0,20 que para ρ1 = 0,10.
Por ello, en el contraste de hipótesis, puede considerarse como un valor especifico
que constituye una alternativa para H0.
Para Glass y Stanley (1980), la probabilidad de rechazar H0 a un determinado nivel de
significación aumenta a medida que aumentan los valores específicos de H1. El poder
del contraste tiende a 1 a medida que ρ difiere de cero.
4. Determinación de la potencia
Las hipótesis alternativas específicas son las que hacen posible el análisis de la
potencia de una prueba. Generalmente, la hipótesis de nulidad es simple, esto es,
especifica y concreta un valor del parámetro. Por el contrario, la hipótesis alternativa
suele ser compuesta y contiene dos o más elementos o estados del conjunto de
parámetros.
Ejemplos de hipótesis simples son: µ = 120; ρ = 0,3; σ = 12. Ejemplos de hipótesis
compuestas son: µ ≠ 120; ρ ≠ 0,3; σ ≠ 12.
La hipótesis compuesta está constituida por todas las hipótesis simples compatibles con
ella. Cuando H1 es compuesta, la potencia de la prueba dependerá de los valores
asignados al parámetro bajo la hipótesis alternativa. Además, H1 puede ser direccional o
no direccional, pudiendo existir diversas hipótesis alternativas para una hipótesis de
nulidad simple.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
73
La potencia de una prueba es fácil de calcular, ya que existen tablas que recogen las
probabilidades de 1 - β para distintos niveles de significación.
Por ejemplo: Supongamos que un investigador quiere probar que el nivel de expresión
del gen KSR1 en células de endotelio corneal difiere 3 puntos del nivel de expresión en
la población general de células humanas, que se ha estimado en 100 copias de ARNm
por célula. Dicho investigador toma una muestra aleatoria de 64 células endoteliales
corneales y fija un nivel de significación α de 0,05. Supongamos que conoce la varianza
de la población de células del organismo humano para este gen, que es de 100 y que
los datos obedecen a una distribución normal. Tenemos lo siguiente:
H0 : µ0 = 100
α =0,05
σ2 = 100
H1 : µ1 = 103 ó 97
n = 64
La media X es el estimador muestral. Bajo H0 se tiene una distribución muestral de
medias como la representada en la parte superior de la Figura 5. Si H1 : µ1 = 103 es la
verdadera, la distribución muestral de medias es como la representada en la parte
central de la figura. Las dos distribuciones muestrales difieren sólo en el valor de µ y
tienen el mismo error típico. Utilizando la curva normal se aceptará H0 siendo falsa si se
observa una media muestral (valor crítico) inferior a 1,96 expresada en puntuaciones
típicas z (z0,975 = 1,96). Se conoce por tipificación al proceso de restar la media y dividir
por su desviación típica a una variable X. De este modo se obtiene una nueva variable z
= (x – X)/s de media y desviación típica Sz = 1, que denominamos variable
tipificada.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
74
Figura 5. Poder del contraste H0 : µ0 = 100 y H1 : µ1 = 103 ó 97 (n = 64 y α = 0,05).
Para calcular la potencia del ejemplo propuesto, procederemos del siguiente modo:
1. Calculamos el error típico de la media: σ/√n = 10/√64 = 1,25
2. Calculamos la media "crítica", es decir, el valor de la media que divide la
curva normal en dos partes, la de aceptación y rechazo de H0: Xc = 1,96 ×
1,25 + 100 = 102,45
3. Determinamos la puntuación típica que corresponde a este valor de 102,45
bajo H1, es decir, cuando H1, es verdadera: z1 = (102,45 – 103)/1,25 = -0,44
4. Utilizando cualquier tabla estadística de áreas de la curva normal, hallamos
el porcentaje del área de la curva normal que se encuentra a la derecha de z1
= -0,44. Su valor es de 67 por cien (50% + 17%). Esta es la potencia de la
prueba ó 1 - β y el valor de β es de 33%, esto es, el riesgo de un error de tipo
II es de 0,33. Lo que esto significa es que cuando H1 es verdadera (µ = 103),
el 67% de las medias muestrales que se pueden obtener serían significativas
por ser mayores que 102,45. Así, la probabilidad de rechazar H0 cuando µ =
103 es de 0,67 y ésta es la potencia de la prueba.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
75
En el caso de que µ fuera igual a 97, el mismo contraste de hipótesis correría el mismo
riesgo de un error de tipo II y tendría el mismo poder (0,67), puesto que la prueba es
bilateral y el análisis simétrico. Bajo estas condiciones, puede concluirse que si µ = 97 ó
103 la probabilidad de rechazar H0 es de 0,67.
Si la hipótesis alternativa especificara un valor menos distante de H0, como por ejemplo,
H1 : µ1 = 101, el poder del contraste disminuye. De igual modo, el poder de contraste
también disminuye si se baja a 0,01 ó 0,001 el nivel de significación, y sería igual a la
unidad si H0 es tan errónea que virtualmente no existe probabilidad de un error de tipo II.
Ello no significa que el experimento sea necesariamente bueno, pues se puede estar
comprobando algo tan evidente que resultara inútil. Por ejemplo, que el nivel medio de
expresión de KSR1 en células corneales es de 10000 (valor demasiado alto para ser
mínimamente probable).
Cuando se trabaja con hipótesis unilaterales, el procedimiento es el mismo, sólo que en
tales casos varía el valor de las puntuaciones típicas correspondientes a los distintos
niveles de significación.
Una vez que hemos visto el concepto y las peculiaridades del análisis de la potencia,
veamos cómo puede calcularse esta potencia recurriendo a una tabla de probabilidades.
Al mismo tiempo, veremos cómo se puede determinar el tamaño de la muestra. Por ello,
a continuación se va a determinar la potencia y el tamaño de n para la media de una
población cualquiera (Doménech i Massons, 1980):
Para la determinación de la potencia, hemos de calcular la probabilidad de obtener un
resultado significativo y de rechazar H0 a partir de los datos de nuestra distribución
muestral. Para ello, los pasos a seguir son los siguientes:
1. Calcular el valor de . Dicho valor debe expresarse en términos de z.
2. Calcular el valor de δ. El valor δ corresponde a veces n, y se puede
calcular como δ = f(n)
3. Consultar una tabla estadística de potencias en función de δ y de . Estas
tablas nos darán la probabilidad de rechazar H0 para distintos valores de µ.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
76
Para la determinación del tamaño de la muestra hay que decidir previamente qué
potencia se desea. Cada investigador puede fijar el valor más oportuno para su estudio,
pero si se quiere un valor convencional, Welkowitz recomienda el de 0,80, que fija en
0,20 la probabilidad de un error de tipo II. El sugerir una probabilidad mayor para los
errores de tipo II que para los de tipo I se debe a que en la mayoría de los problemas que
se investigan resultan menos perjudiciales los falsos negativos (aceptar H0 cuando es
falsa o error de tipo II) que los falsos positivos (rechazar H0 cuando es verdadera o error
de tipo I). Por otra parte, si se fija convencionalmente una potencia de 0,95 ó 0,99 la
muestra resultante no estará al alcance de muchos investigadores (Jiménez Fernández,
2000).
Para finalizar lo relativo al análisis de la potencia, sólo nos queda insistir en los puntos
siguientes:
1. Dicho análisis requiere que se formulen hipótesis alternativas específicas,
es decir, que concreten un valor numérico para la población.
2. El análisis de la potencia se relaciona totalmente con valores de la
población y no con los resultados observados o por observar en las muestras.
3. Puede hacerse antes de realizar el experimento para determinar cuál será
la potencia con los valores de , n y especificados, o después de realizado
para determinar la potencia que tenía la prueba, dados , n y . Si se realiza
después y la potencia resulta ser muy baja, los resultados obtenidos, si no son
estadísticamente significativos, no pueden tomarse como concluyentes.
4. Normalmente, el problema radica en formular valores específicos para la
hipótesis alternativa que sean suposiciones razonables del parámetro y sin los
cuales es imposible calcular la potencia. Cuando esto ocurre, Welcowitz
recomienda especificar valores convencionales para y que si bien son
arbitrarios, sean tan razonables como lo es la regla de decisión del 0,05 ó
0,01. Para cada prueba recomienda tres valores, según que se sospeche que
la magnitud del efecto en la población, esto es, y, sea pequeño, mediano o
grande. Los valores que recomienda son los siguientes:

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
77
a) Para la prueba de la media de una población y para la prueba de la
diferencia entre dos medias independientes, y puede fijarse en 0,2; 0,5 y 0,8
respectivamente.
b) Para la prueba de la proporción de una población y para la de un
coeficiente de correlación de Pearson los valores recomendados son de 0,10,
0,30 y 0,50, según que se postulen efectos pequeños, medianos o grandes
respectivamente.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
78
D.- LA POTENCIA-EFICIENCIA
Hasta el momento, hemos estudiado tres criterios que conviene considerar en la
resolución estadística de los diseños. En primer lugar, hemos hablado de los niveles de
medición de las variables. A continuación, hemos estudiado el modelo estadístico, que
nos indica que existen dos tipos de pruebas, las paramétricas y las no paramétricas,
analizando las exigencias de ambas. En tercer lugar, hemos tratado el concepto de
potencia, que indica que, en igualdad de condiciones, las pruebas paramétricas son más
potentes. Analicemos ahora un cuarto criterio: el de la potencia-eficiencia.
Este concepto hace referencia al incremento de n necesario para hacer que la prueba
estadística B sea tan poderosa como la A. Dada una potencia, compara el tamaño de la
muestra necesario para una prueba, B, con el tamaño requerido por una segunda, A, que
actúa como término de comparación. Ambas pruebas se aplicarían bajo las mismas
condiciones. Así, dadas una hipótesis de nulidad, una hipótesis alternativa, la potencia, el
nivel de significación y el tipo de contraste, la potencia-eficiencia del estadístico de
contraste B con respecto a otro A es A/B o como escribe Siegel (1995):
Donde na es el número de sujetos de la prueba A para una potencia dada y nb es el
tamaño de la muestra de la prueba B necesario para tener la misma potencia que A. Sea
na = 20 y nb = 25. La prueba B tiene una potencia-eficiencia de: 20/25 × 100 = 80%
Lo que significa que son necesarios 100 casos de B por cada 80 casos de A, siempre que
se cumplan todos los supuestos que subyacen a la aplicación de ambas pruebas y
cuando la prueba A es más poderosa.
Potencia-eficiencia de la prueba B = na/nb por ciento

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
79
Ya se ha dicho que a medida que son menores o más débiles los supuestos de un
modelo particular, más generales son las conclusiones obtenidas tras la aplicación de la
prueba estadística asociada con el modelo, pero menos poderosa es aquella para
rechazar la hipótesis de nulidad. La forma de conjugar potencia y generalidad es elegir
una prueba estadística de amplia generalidad e incrementar su potencia hasta un nivel
dado, aumentando el tamaño de la muestra. Por ejemplo, si tenemos un diseño de dos
grupos relacionados en el que podemos elegir entre la prueba t (paramétrica) y la prueba
de McNemar para la significación de los cambios (no paramétrica), si nos inclinamos por
la segunda, es necesario aumentar el tamaño de n para que ésta tenga la misma potencia
que aquélla. Es decir, la prueba t es más potente pero requiere datos que cumplan con
los requisitos de independencia, normalidad, homoscedasticidad y medida de intervalo,
mientras que la segunda posee mayor generalidad, pues sólo le afecta el primer requisito.
Su potencia puede aumentar hasta la que tendría la prueba t incrementando el tamaño de
la muestra. Respecto a ésta, su eficacia relativa oscila entre el 63 y el 95 por cien,
dependiendo de la distribución y tamaño de los datos a analizar.
En resumen, cuando se cumplen los requisitos de las pruebas paramétricas éstas tienen
más eficiencia relativa que las no paramétricas, pero pueden equipararse siempre que en
las segundas se incremente el tamaño de n hasta donde lo requiere la potencia de sus
equivalentes paramétricas. Este dato puede ser de interés práctico ya que con frecuencia
es difícil calcular la eficiencia relativa de dos pruebas, ya sean éstas paramétrica o no
paramétricas, ya sean ambas no paramétricas.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
80
REFERENCIAS BIBLIOGRÁFICAS

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
81
Arnau Grass J. 1981. Diseños experimentales en psicología y educación. Trillas, México,
vol. 3, p. 10.
Bochenski IM. 1981.Los métodos actuales del pensamiento. Ed. Rialp. Madrid.
Bunge M. 1973.La Ciencia, su método y su filosofía. Ed. Ariel. Barcelona.
Bunge M. 1981.La investigación científica. Ed. Ariel. Barcelona.
Campbell DT, Stanley JC. 1991. Diseños experimentales y cuasi-experimentales en la
investigación social. Amorrortu. Buenos Aires
Castro L. 1980. Diseño experimental sin estadística. Trillas. México
Cook TD, Reichardt CS. 1986. Métodos cualitativos y cuantitativos en investigación
evaluativa. Ed. Morata. Madrid.
De Juan Herrero J. 1999. ¿De qué están hechos los organismos? El nacimiento de la
mirada histológica. Publicaciones de la Universidad de Alicante. Alicante.
De la Orden A. 1989. Investigación cuantitativa y medida en educación. Bordón, vol. 41:
217-236.
De Miguel Díaz M. 1988. Paradigmas de la investigación educativa española. En:
Dendaluce I. Aspectos metodológicos de la investigación educativa. Narcea. Madrid.
Dendaluce Y. 1988. Aspectos metodológicos de la investigación educativa. Narcea.
Madrid.
Dendaluce Y. 1988. Investigación Educativa. Alfar. Sevilla.
Doménech i Massons JM. 1980. Bioestadística. Métodos estadísticos para
investigadores. Herder, Barcelona.
Escotet MA. 1980. Diseño multivariado en psicología y educación. CEAC, Barcelona.
Finney DJ. 1960. Experimental design and its statistical basis. The University of Chicago
Press, Chicago.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
82
Fisher RA. 1928. The general sampling distribution of the multiple correlation coefficient.
Proc. R. Soc. Sci. A. 121: 654-673.
Fox DJ. 1981. El proceso de investigación en educación. Eunsa. Pamplona.
García Hoz V. 1981. Principios de Pedagogía Sistemática. 10ª edición. Rialp. Madrid.
García Llamas JL, González Galán MA, Ballesteros Velázquez B. 2001. Introducción a la
investigación en educación. Unidades Didácticas de la UNED. 1ª ed. UNED ediciones.
Madrid.
Glass GV, Stanley JC. 1980. Métodos estadísticos aplicados a las Ciencias Sociales.
Prentice/Hall. Madrid.
Gómez de Ferraris ME, Campos A. 2004. Histología y embriología bucodental. 2ª edición.
Panamericana. Madrid.
Hernández Pina F. 1993. Concepciones en el estudio del aprendizaje de los estudiantes
universitarios. Revista de Investigación Educativa, 22: 117-150.
Jiménez Fernández C, López-Barajas Zayas E, Pérez Juste R. 2000. Pedagogía
experimental II. Unidades Didácticas de la UNED. 4ª ed. UNED ediciones. Madrid.
Kerlinger FN. 1979. La investigación del comportamiento. Interamericana. México.
Kerlinger FN. 1989. Investigación del comportamiento. Técnicas y metodología. 3ª Ed.
Interamericana. México.
Kirk RG. 1972. Statistical issues: a reader for the behavioral sciences. Wadsworth
Publishing Co.
León O, Montero I. 1995. Diseño de investigaciones, Introducción a la lógica de la
investigación en psicología y educación. McGraw Hill. Madrid.
López-Barajas Zayas E. 2001. Fundamentos de metodología científica. Unidades
Didácticas de la UNED. 1ª ed. UNED ediciones. Madrid.

Grupo de Investigación de Ingeniería Tisular Máster en Ingeniería Tisular
83
McGuigan FJ. 1976. Psicología experimental. Trillas, México.
Pearson K. 1916. Mathematical contributions to the theory of evolution.
Pelegrina M, Salvador F. 1999. La investigación experimental en psicología: fundamentos
científicos y técnicas. Aljibe. Málaga.
Plutchnik K. 1968. Foundations of experimental research. Harper & Row, Publishers.
Popper KR. 1982. Conocimiento objetivo. Tecnos. Madrid.
Popper KR. 1985. La lógica de la investigación científica. Tecnos. Madrid.
Siegel S, Castellán NJ. 1995. Estadística no Paramétrica aplicada a las ciencias de la
conducta. Trillas. México.
Tejedor FM. 1981. Validez interna y externa en los diseños experimentales. Rev.
Española de Pedagogía. 15: 15-39.
Vander Zanden J. 1986. Manual de Psicología Social. Paidós. Barcelona.
Welkowitz J, Ewen RB, Cohen J. 1981. Estadística aplicada a las Ciencias de la
Educación. Santillana. Madrid.