graph-based parallel computingwcohen/10-605/pregel-etc-2.pdfgraph-based parallel computing william...
TRANSCRIPT

Graph-Based Parallel Computing
William Cohen
1

Announcements • Next Tuesday 12/8: – Presentations for 10-805 projects. – 15 minutes per project. – Final written reports due Tues 12/15
• For exam: – Spectral clustering will not be covered – It’s ok to bring in two pages of notes – We’ll give a solution sheet for HW7 out on
Wednesday noon • but you get no credit on questions HW7 5-7 if you
turn in answers after that point
2

Outline • Motivation/where it Qits • Sample systems (c. 2010) – Pregel: and some sample programs • Bulk synchronous processing
– Signal/Collect and GraphLab • Asynchronous processing
• GraphLab descendants – PowerGraph: partitioning – GraphChi: graphs w/o parallelism – GraphX: graphs over Spark
3

Many Graph-Parallel Algorithms• Collaborative Filtering– Alternating Least Squares– Stochastic Gradient Descent– Tensor Factorization
• Structured Prediction– Loopy Belief Propagation– Max-Product Linear Programs– Gibbs Sampling
• Semi-supervised ML– Graph SSL – CoEM
• Community Detection– Triangle-Counting– K-core Decomposition– K-Truss
• Graph Analytics– PageRank– Personalized PageRank– Shortest Path– Graph Coloring
• Classification– Neural Networks
4

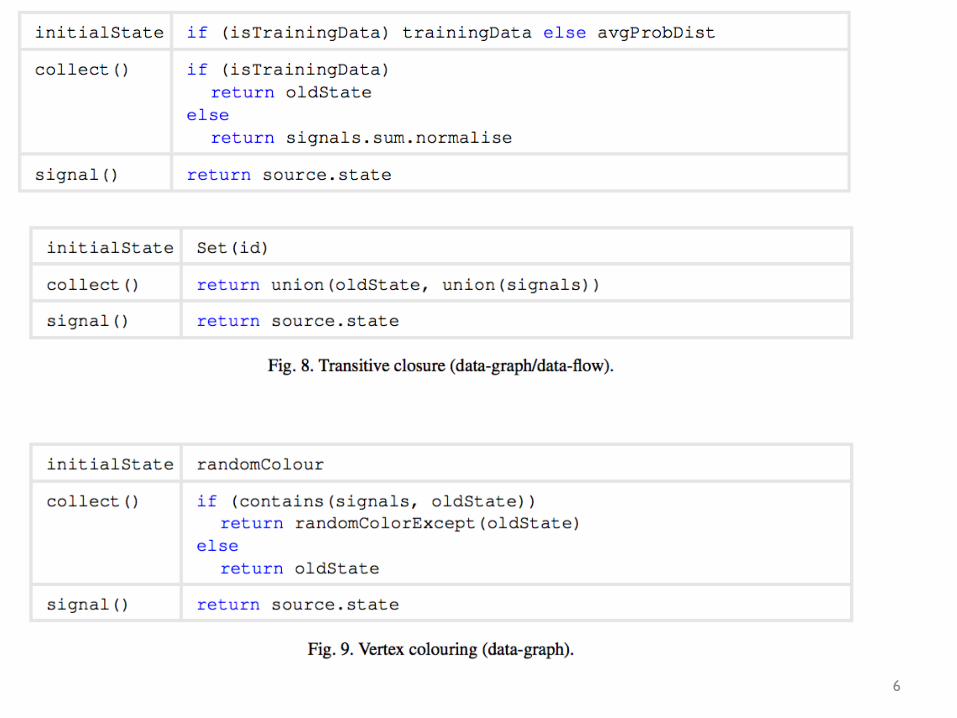
Signal/collect model
signals are made available in a list and a map
next state for a vertex is output of the collect() operation
relax “num_iterations” soon
5
6
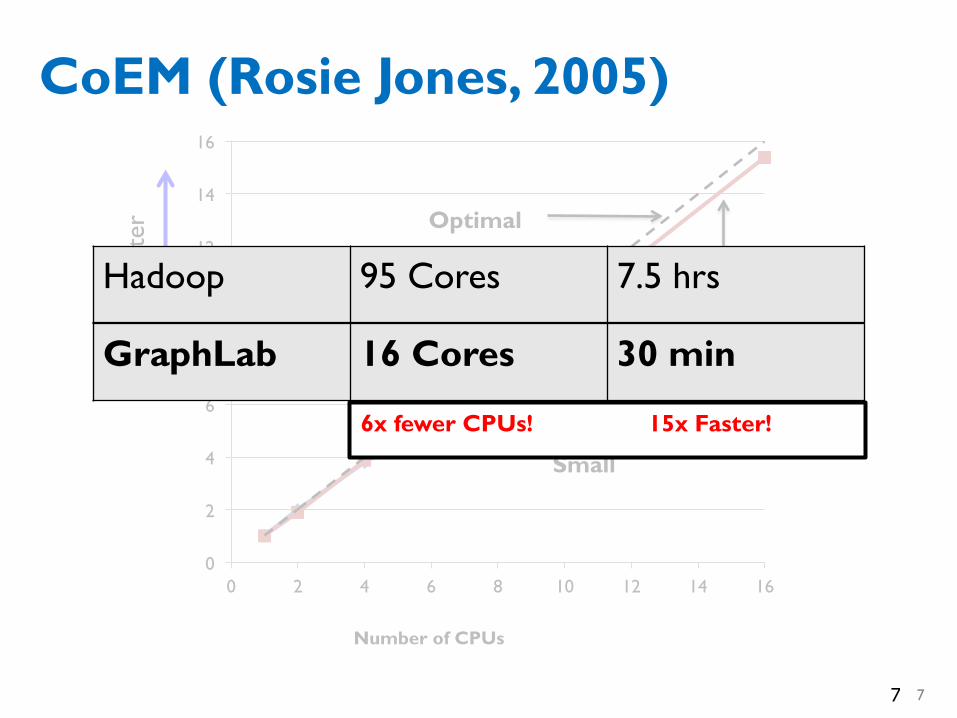
CoEM (Rosie Jones, 2005)
7 7
Optimal
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14 16
Spee
dup
Number of CPUs
Bett
er
Small
Large GraphLab 16 Cores 30 min
15x Faster! 6x fewer CPUs!
Hadoop 95 Cores 7.5 hrs

GRAPH ABSTRACTIONS: GRAPHLAB CONTINUED….
8

Outline • Motivation/where it Qits • Sample systems (c. 2010) – Pregel: and some sample programs • Bulk synchronous processing
– Signal/Collect and GraphLab • Asynchronous processing
• GraphLab descendants – PowerGraph: partitioning – GraphChi: graphs w/o parallelism – GraphX: graphs over Spark
9

GraphLab’s descendents
• PowerGraph • GraphChi • GraphX
On multicore architecture: shared memory for workers
On cluster architecture (like Pregel): different memory spaces
What are the challenges moving away from shared-memory?
10

Natural Graphs ! Power Law
100 102 104 106 108100
102
104
106
108
1010
degree
count
Top1%ofver+cesisadjacentto
53%oftheedges!
AltavistaWebGraph:1.4BVer+ces,6.7BEdgesGraphLab group/Aapo 11
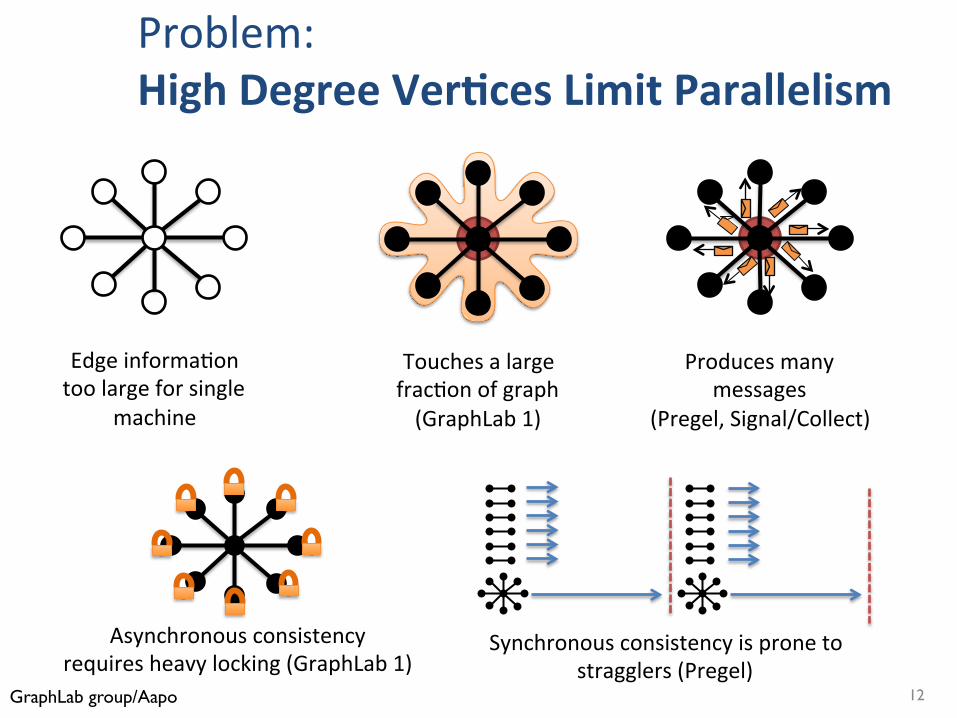
Touchesalargefrac.onofgraph(GraphLab1)
Producesmanymessages
(Pregel,Signal/Collect)
Edgeinforma.ontoolargeforsingle
machine
Asynchronousconsistencyrequiresheavylocking(GraphLab1)
Synchronousconsistencyispronetostragglers(Pregel)
Problem:HighDegreeVer+cesLimitParallelism
GraphLab group/Aapo 12

PowerGraph • Problem: GraphLab’s localities can be large – “all neighbors of a node” can be large for hubs,
high indegree nodes • Approach: – new graph partitioning algorithm • can replicate data
– gather-apply-scatter API: Qiner-grained parallelism • gather ~ combiner • apply ~ vertex UDF (for all replicates) • scatter ~ messages from vertex to edges
13
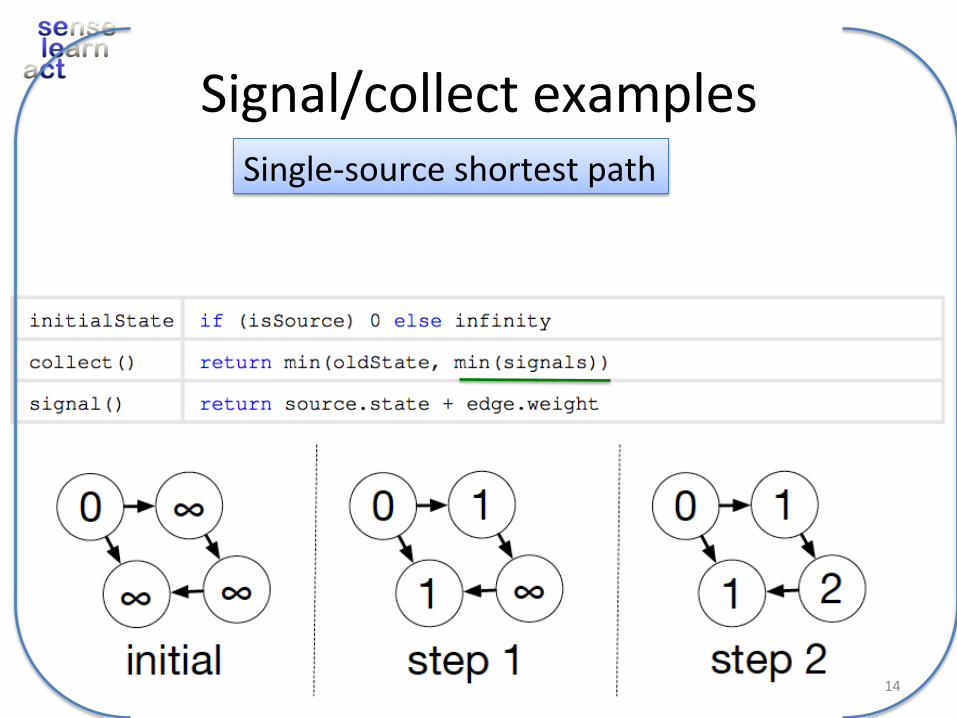
Signal/collectexamplesSingle-sourceshortestpath
14

Signal/collectexamples
PageRank
Life
15

Signal/collectexamplesCo-EM/wvRN/Harmonicfields
16

PageRankinPowerGraph
PageRankProgram(i)Gather(j à i):returnwji * R[j]sum(a,b):returna+b;Apply(i, Σ) : R[i] = β + (1 – β) * Σ Scatter( i àj ) : �
if (R[i] changes) then activate(j)
R[i] = � + (1� �)X
(j,i)2E
wjiR[j]
17
GraphLabgroup/Aapo
jedgeivertex
gather/sumlikeacollectoragroupby…reduce(withcombiner)
scaVerislikeasignal

Machine2Machine1
Machine4Machine3
DistributedExecu.onofaPowerGraphVertex-Program
Σ1 Σ2
Σ3 Σ4
+++
YYYY
Y’
Σ
Y’Y’Y’Gather
Apply
ScaVer
18
GraphLabgroup/Aapo
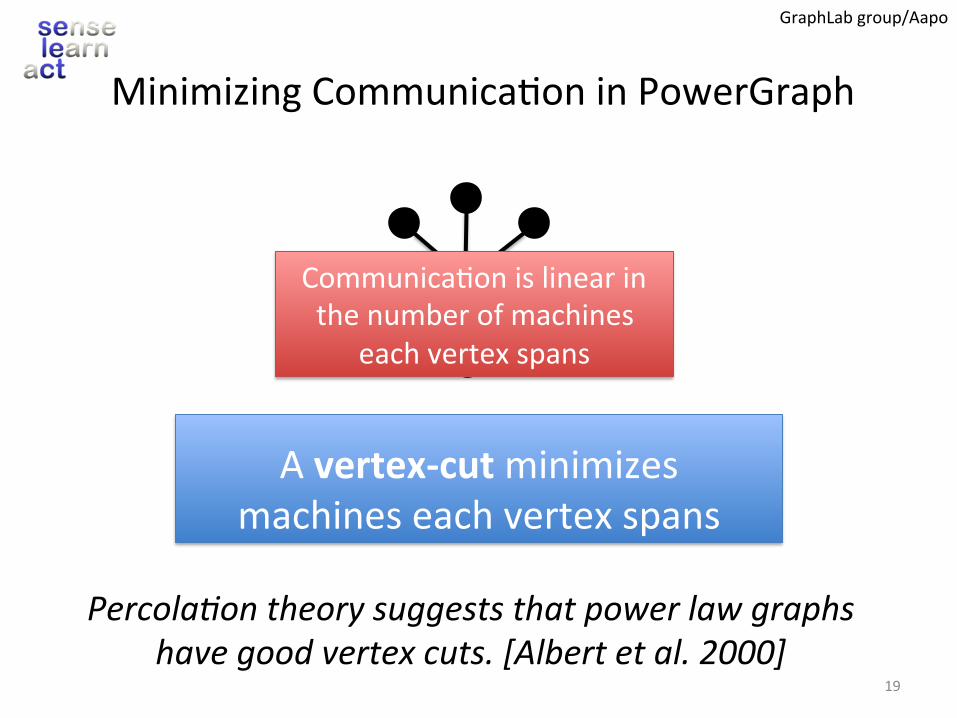
MinimizingCommunica.oninPowerGraph
YYY
Avertex-cutminimizesmachineseachvertexspans
Percola4ontheorysuggeststhatpowerlawgraphshavegoodvertexcuts.[Albertetal.2000]
Communica.onislinearinthenumberofmachines
eachvertexspans
19
GraphLabgroup/Aapo
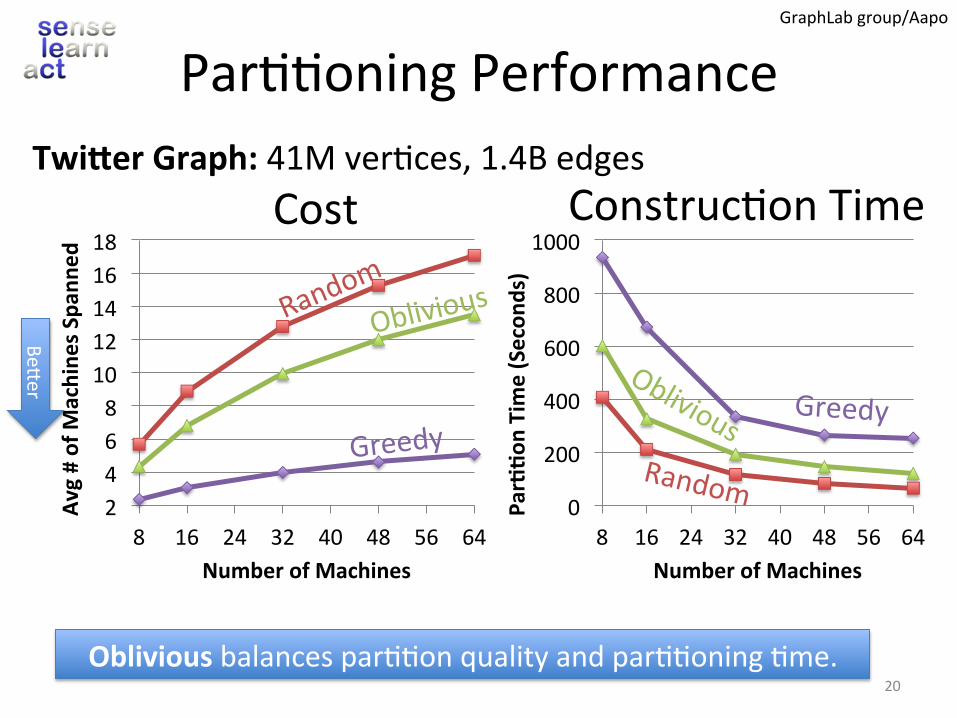
Par..oningPerformanceTwiUerGraph:41Mver.ces,1.4Bedges
Obliviousbalancespar..onqualityandpar..oning.me.
2468
1012141618
8 16 24 32 40 48 56 64
Avg#ofM
achine
sSpa
nned
NumberofMachines
0
200
400
600
800
1000
8 16 24 32 40 48 56 64Pa
r++o
nTime(Secon
ds)
NumberofMachines
Oblivious
GreedyGreedy
Random
20
Cost Construc.onTime
BeVer
GraphLabgroup/Aapo
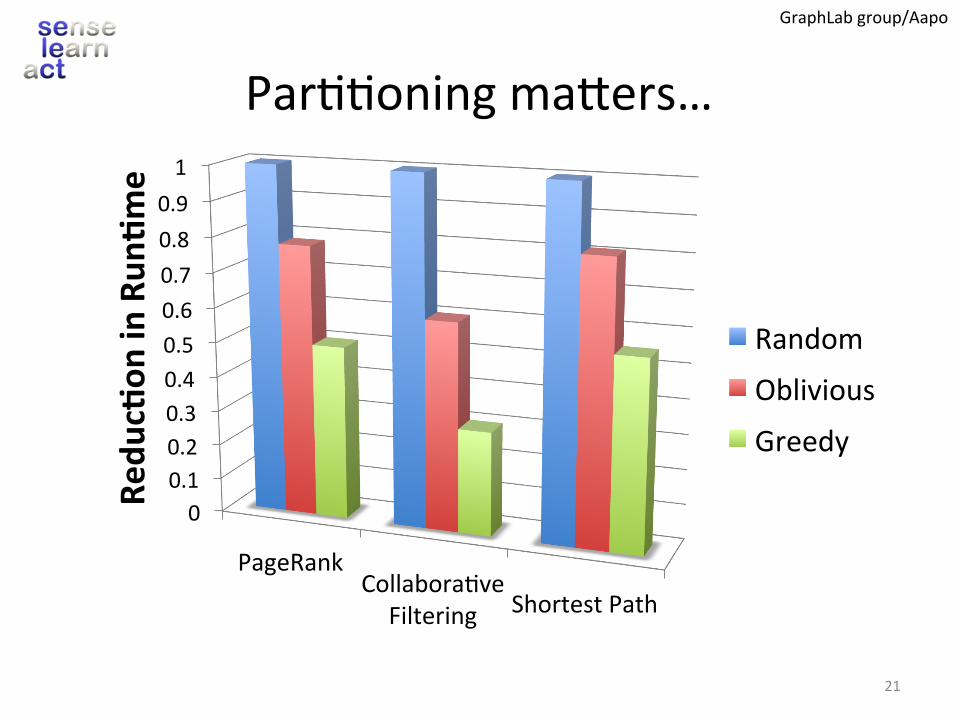
Par..oningmaVers…
00.10.20.30.40.50.60.70.80.91
PageRankCollabora.ve
Filtering ShortestPath
Redu
c+on
inRun
+me
Random
Oblivious
Greedy
GraphLabgroup/Aapo
21

Outline
• Mo.va.on/whereitfits• Samplesystems(c.2010)– Pregel:andsomesampleprograms
• Bulksynchronousprocessing– Signal/CollectandGraphLab
• Asynchronousprocessing• GraphLabdescendants– PowerGraph:par..oning– GraphChi:graphsw/oparallelism– GraphX:graphsoverSpark
22

GraphLab’sdescendents
• PowerGraph• GraphChi• GraphX
23
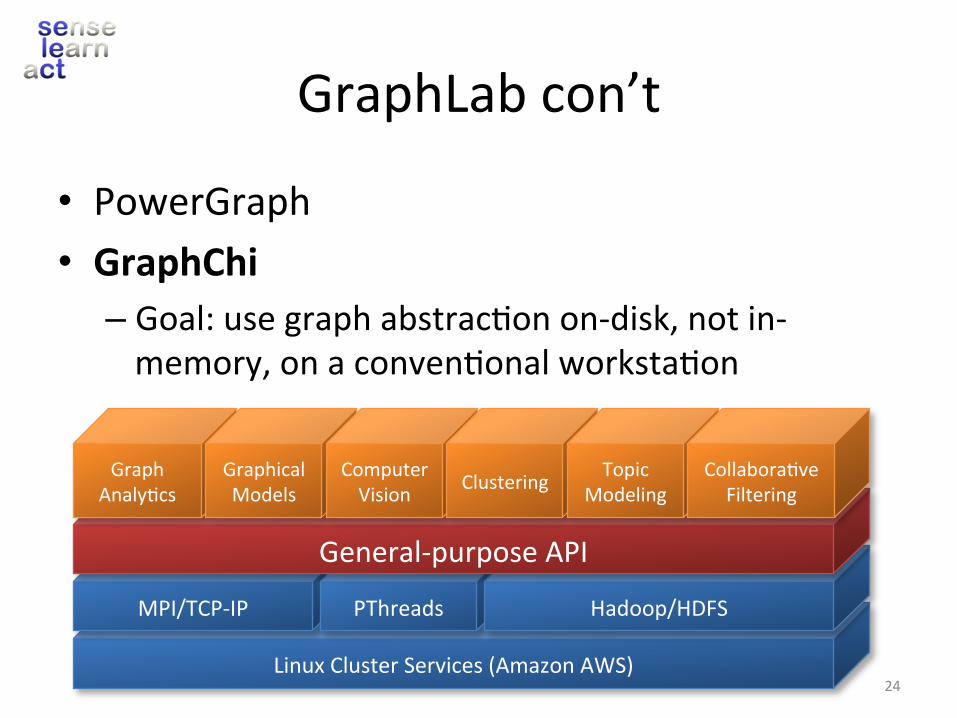
GraphLabcon’t
• PowerGraph• GraphChi– Goal:usegraphabstrac.onon-disk,notin-memory,onaconven.onalworksta.on
LinuxClusterServices(AmazonAWS)
MPI/TCP-IP PThreads Hadoop/HDFS
General-purposeAPI
GraphAnaly.cs
GraphicalModels
ComputerVision Clustering Topic
ModelingCollabora.ve
Filtering
24

GraphLabcon’t
• GraphChi– Keyinsight:
• somealgorithmsongrapharestreamable(i.e.,PageRank-Nibble)• ingeneralwecan’teasilystreamthegraphbecauseneighborswillbescaVered• butmaybewecanlimitthedegreetowhichthey’rescaVered…enoughtomakestreamingpossible?
– “almost-streaming”:keepPcursorsinafileinsteadofone
25
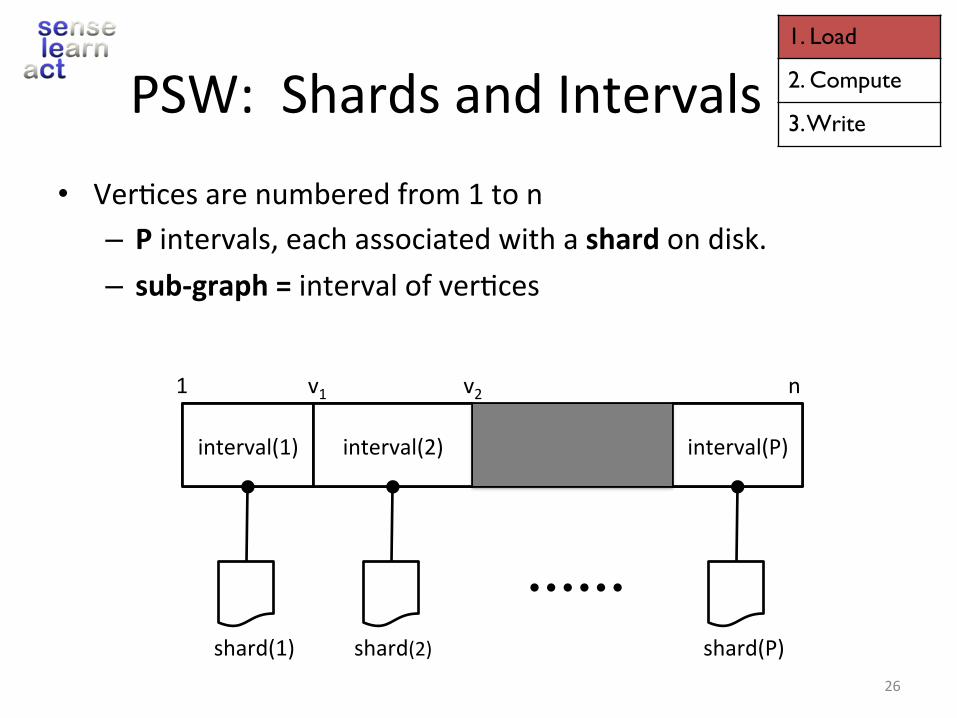
• Ver.cesarenumberedfrom1ton– Pintervals,eachassociatedwithashardondisk.– sub-graph=intervalofver.ces
PSW:ShardsandIntervals
shard(1)
interval(1) interval(2) interval(P)
shard(2) shard(P)
1 nv1 v2
26
1. Load
2. Compute
3. Write
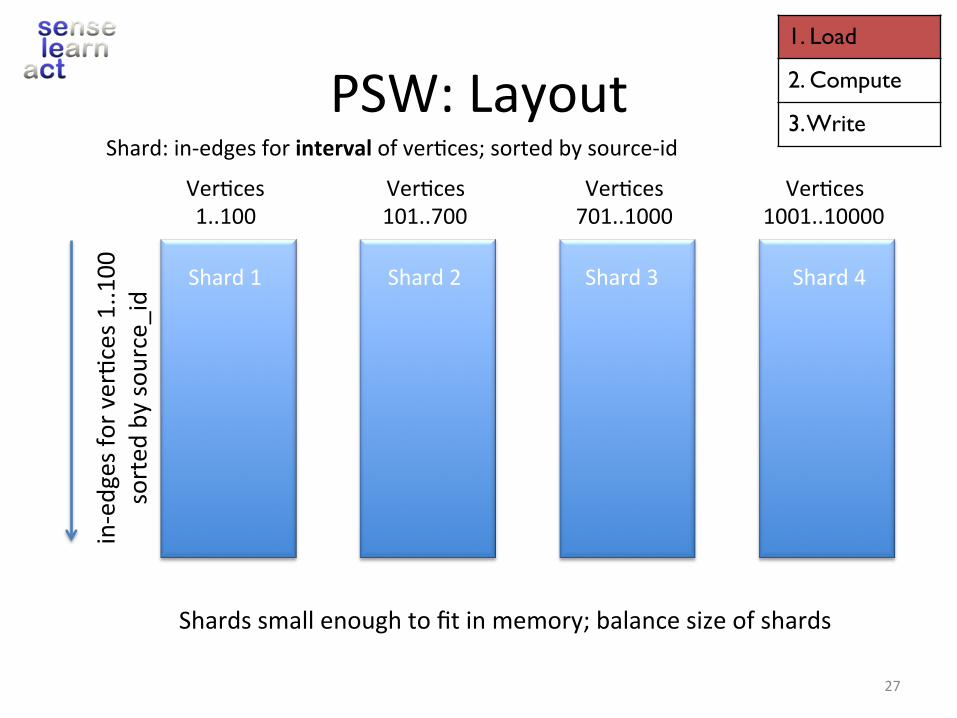
PSW:Layout
Shard1
Shardssmallenoughtofitinmemory;balancesizeofshards
Shard:in-edgesforintervalofver.ces;sortedbysource-id
in-edgesfo
rver.ces1..100
sorted
bysource_id
Ver.ces1..100
Ver.ces101..700
Ver.ces701..1000
Ver.ces1001..10000
Shard2 Shard3 Shard4Shard1
1. Load
2. Compute
3. Write
27

Ver.ces1..100
Ver.ces101..700
Ver.ces701..1000
Ver.ces1001..10000
Loadallin-edgesinmemory
Loadsubgraphforver+ces1..100
Whataboutout-edges?Arrangedinsequenceinothershards
Shard2 Shard3 Shard4
PSW:LoadingSub-graph
Shard1
in-edgesfo
rver.ces1..100
sorted
bysource_id
1. Load
2. Compute
3. Write
28
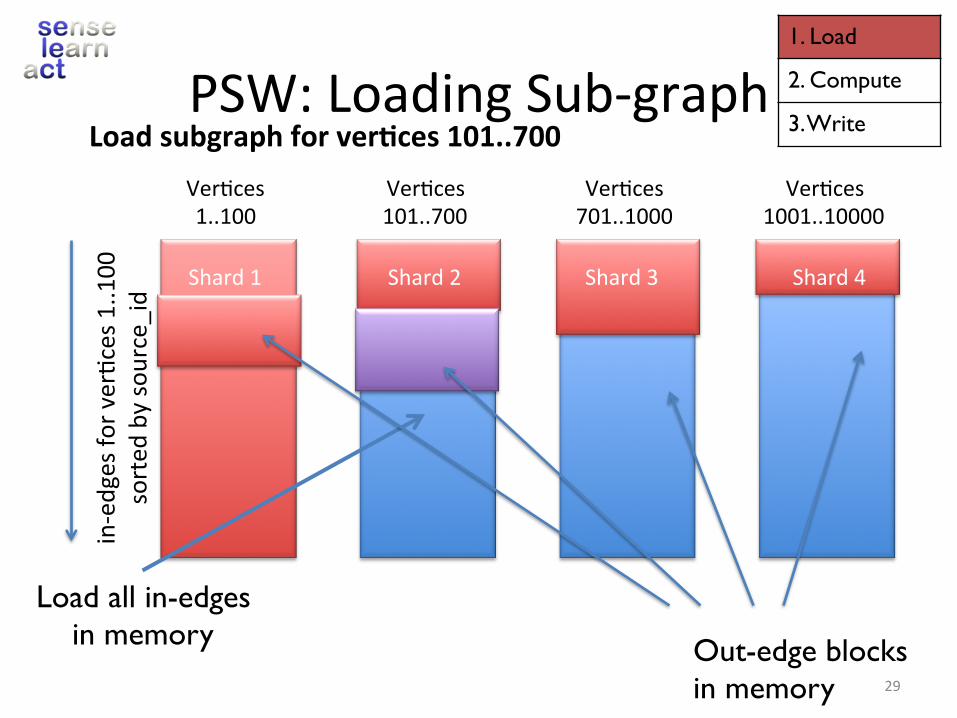
Shard1
Load all in-edges in memory
Loadsubgraphforver+ces101..700
Shard2 Shard3 Shard4
PSW:LoadingSub-graphVer.ces1..100
Ver.ces101..700
Ver.ces701..1000
Ver.ces1001..10000
Out-edge blocks in memory
in-edgesfo
rver.ces1..100
sorted
bysource_id
1. Load
2. Compute
3. Write
29
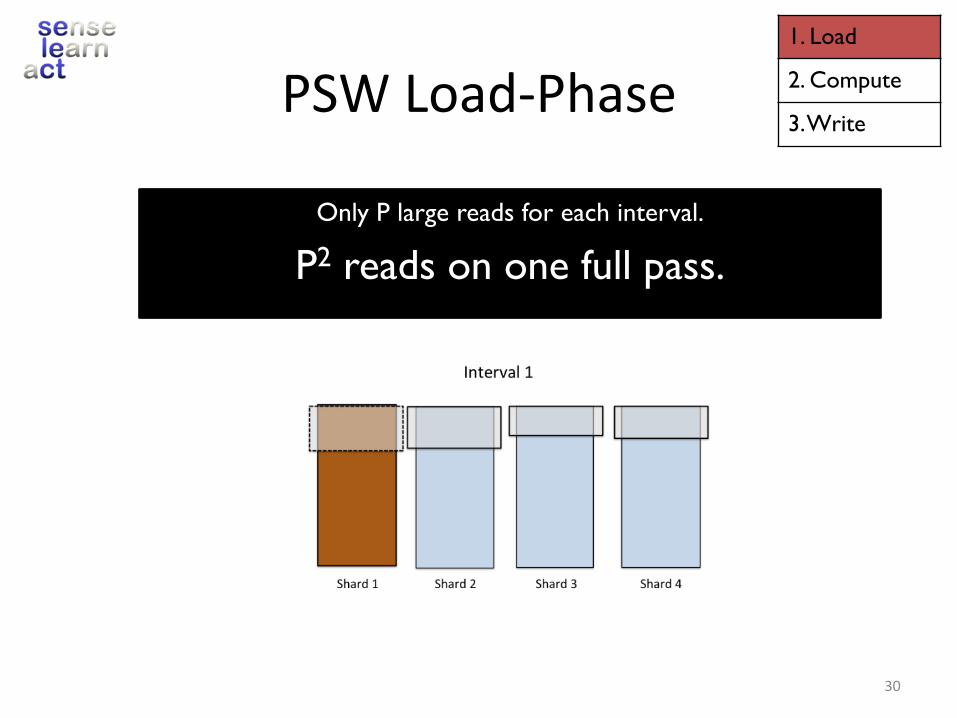
PSWLoad-Phase
Only P large reads for each interval.
P2 reads on one full pass.
30
1. Load
2. Compute
3. Write
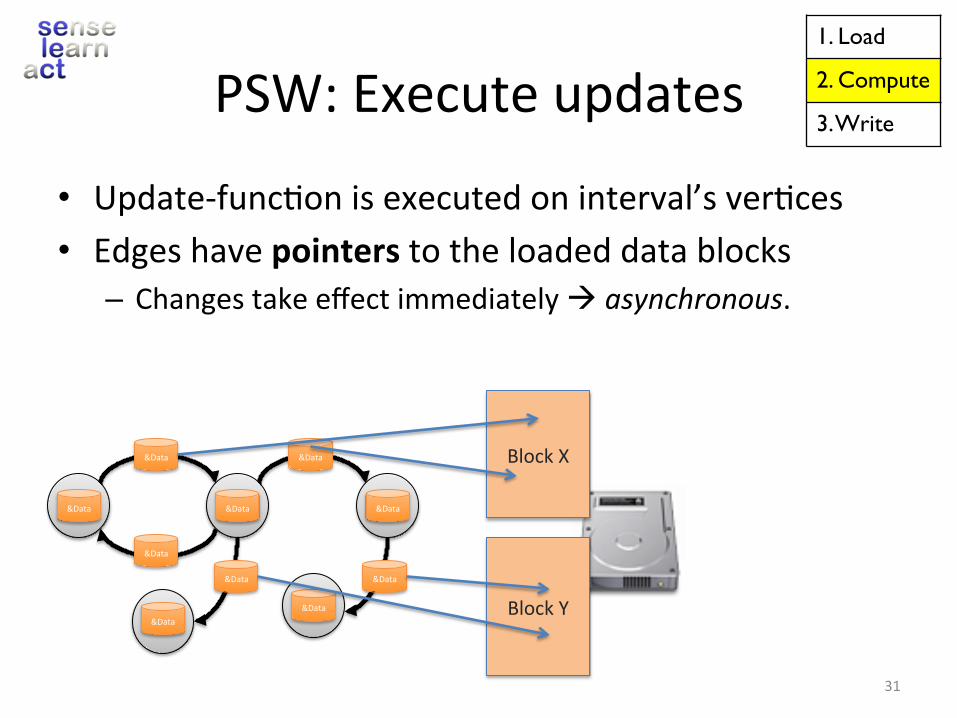
PSW:Executeupdates
• Update-func.onisexecutedoninterval’sver.ces• Edgeshavepointerstotheloadeddatablocks– Changestakeeffectimmediatelyàasynchronous.
&Data
&Data &Data
&Data
&Data&Data&Data
&Data&Data
&Data
BlockX
BlockY
31
1. Load
2. Compute
3. Write
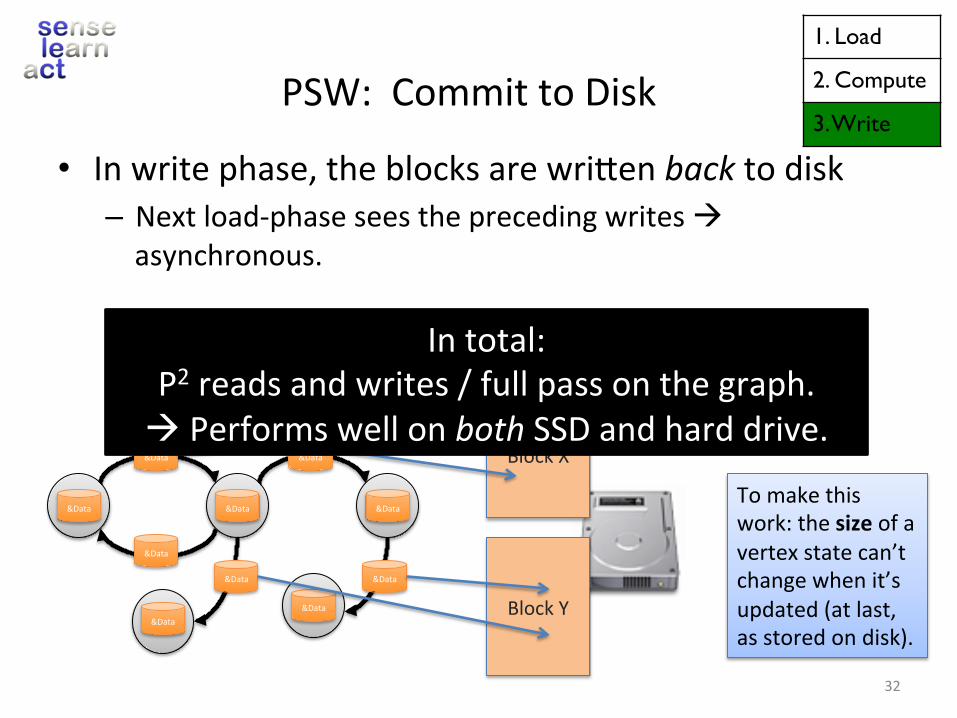
PSW:CommittoDisk
• Inwritephase,theblocksarewriVenbacktodisk– Nextload-phaseseestheprecedingwritesàasynchronous.
32
1. Load
2. Compute
3. Write
&Data
&Data &Data
&Data
&Data&Data&Data
&Data&Data
&Data
BlockX
BlockY
Intotal:P2readsandwrites/fullpassonthegraph.àPerformswellonbothSSDandharddrive.
Tomakethiswork:thesizeofavertexstatecan’tchangewhenit’supdated(atlast,asstoredondisk).
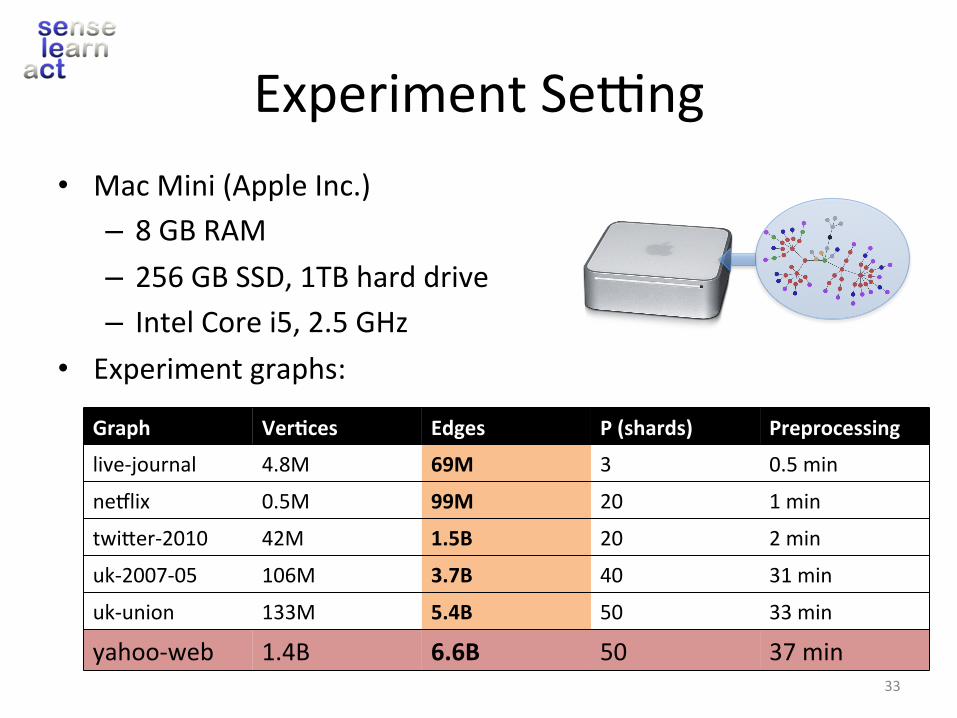
ExperimentSerng• MacMini(AppleInc.)– 8GBRAM– 256GBSSD,1TBharddrive– IntelCorei5,2.5GHz
• Experimentgraphs:
Graph Ver+ces Edges P(shards) Preprocessing
live-journal 4.8M 69M 3 0.5min
neslix 0.5M 99M 20 1min
twiVer-2010 42M 1.5B 20 2min
uk-2007-05 106M 3.7B 40 31min
uk-union 133M 5.4B 50 33min
yahoo-web 1.4B 6.6B 50 37min33
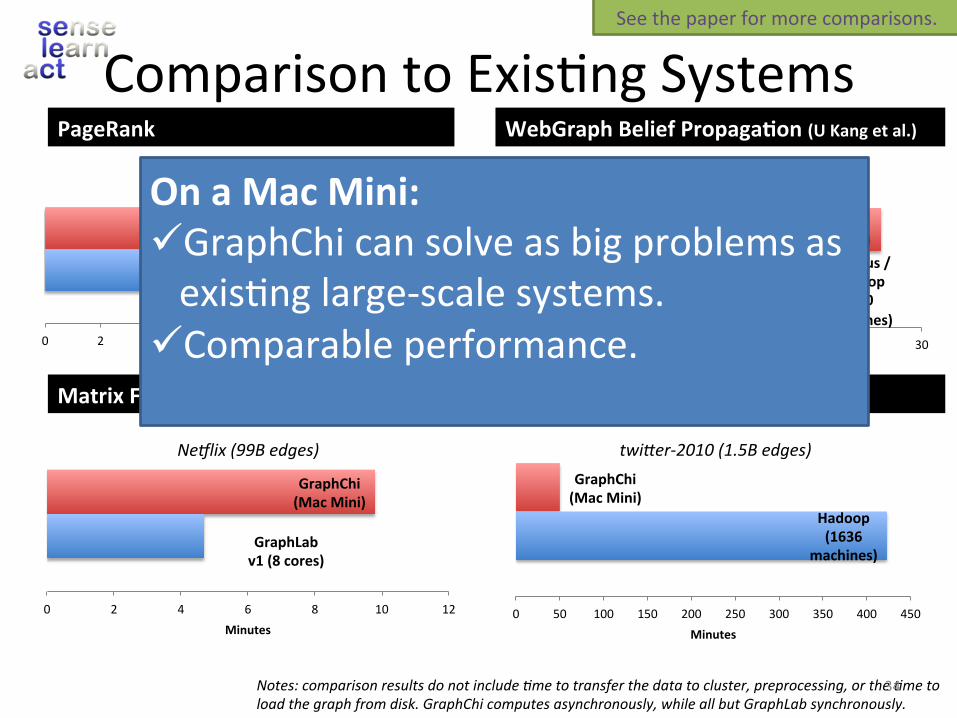
ComparisontoExis.ngSystems
Notes:comparisonresultsdonotinclude4metotransferthedatatocluster,preprocessing,orthe4metoloadthegraphfromdisk.GraphChicomputesasynchronously,whileallbutGraphLabsynchronously.
PageRank
Seethepaperformorecomparisons.
WebGraphBeliefPropaga+on(UKangetal.)
MatrixFactoriza+on(Alt.LeastSqr.) TriangleCoun+ng
GraphLabv1(8cores)
GraphChi(MacMini)
0 2 4 6 8 10 12Minutes
NeHlix(99Bedges)
Spark(50machines)
GraphChi(MacMini)
0 2 4 6 8 10 12 14Minutes
TwiNer-2010(1.5Bedges)
Pegasus/Hadoop(100
machines)
GraphChi(MacMini)
0 5 10 15 20 25 30Minutes
Yahoo-web(6.7Bedges)
Hadoop(1636
machines)
GraphChi(MacMini)
0 50 100 150 200 250 300 350 400 450Minutes
twiNer-2010(1.5Bedges)
OnaMacMini:ü GraphChicansolveasbigproblemsasexis.nglarge-scalesystems.
ü Comparableperformance.
34

Outline
• Mo.va.on/whereitfits• Samplesystems(c.2010)– Pregel:andsomesampleprograms
• Bulksynchronousprocessing– Signal/CollectandGraphLab
• Asynchronousprocessing• GraphLab“descendants”– PowerGraph:par..oning– GraphChi:graphsw/oparallelism– GraphX:graphsoverSpark(Gonzalez)
35

GraphLab’sdescendents
• PowerGraph• GraphChi• GraphX– implementa.onofGraphLabsAPIontopofSpark– Mo.va.ons:
• avoidtransfersbetweensubsystems• leveragelargercommunityforcommoninfrastructure
– What’sdifferent:• Graphsarenowimmutableandopera.onstransformonegraphintoanother(RDDèRDG,resiliantdistributedgraph)
36
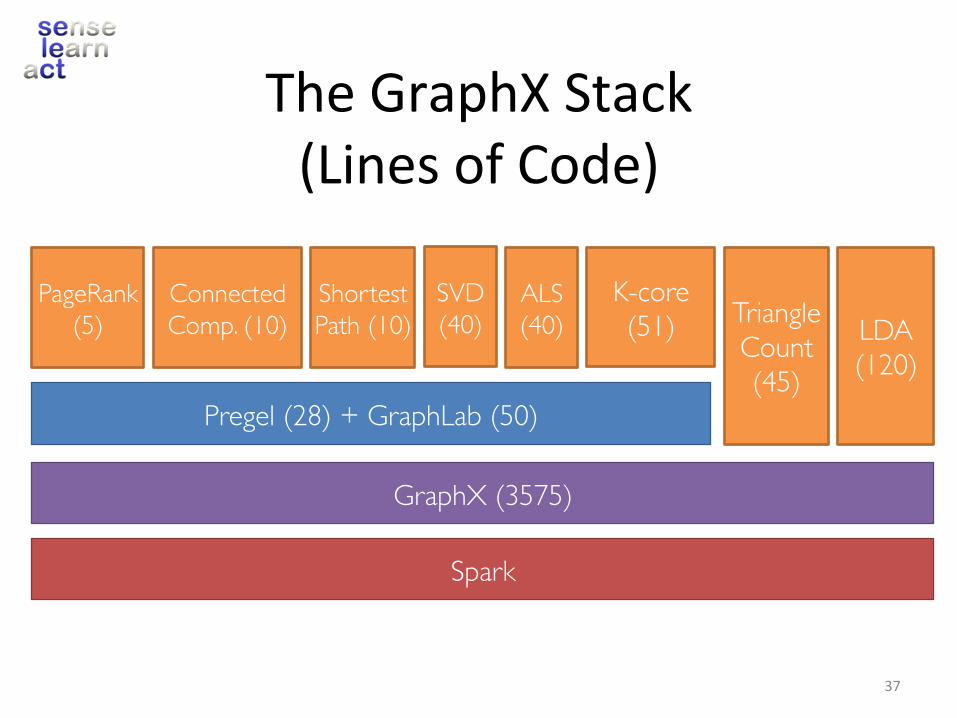
TheGraphXStack(LinesofCode)
GraphX (3575)
Spark
Pregel (28) + GraphLab (50)
PageRank (5)
Connected Comp. (10)
Shortest Path (10)
ALS(40) LDA
(120)
K-core(51) Triangle
Count(45)
SVD(40)
37

Idea:GraphasTables
Id
RxinJegonzalFranklinIstoica
SrcId DstId
rxin jegonzalfranklin rxinistoica franklinfranklin jegonzal
Property (E)
FriendAdvisor
CoworkerPI
Property (V)
(Stu., Berk.)(PstDoc, Berk.)
(Prof., Berk)(Prof., Berk)
R
J
F
I
Property GraphVertex Property Table
Edge Property Table
Underthehoodthingscanbesplitevenmorefinely:egavertexmaptable+vertexdatatable.Operatorsmaximizestructuresharingandminimizecommunica.on.(Notshown:par..onid’s,carefullyassigned….)
38
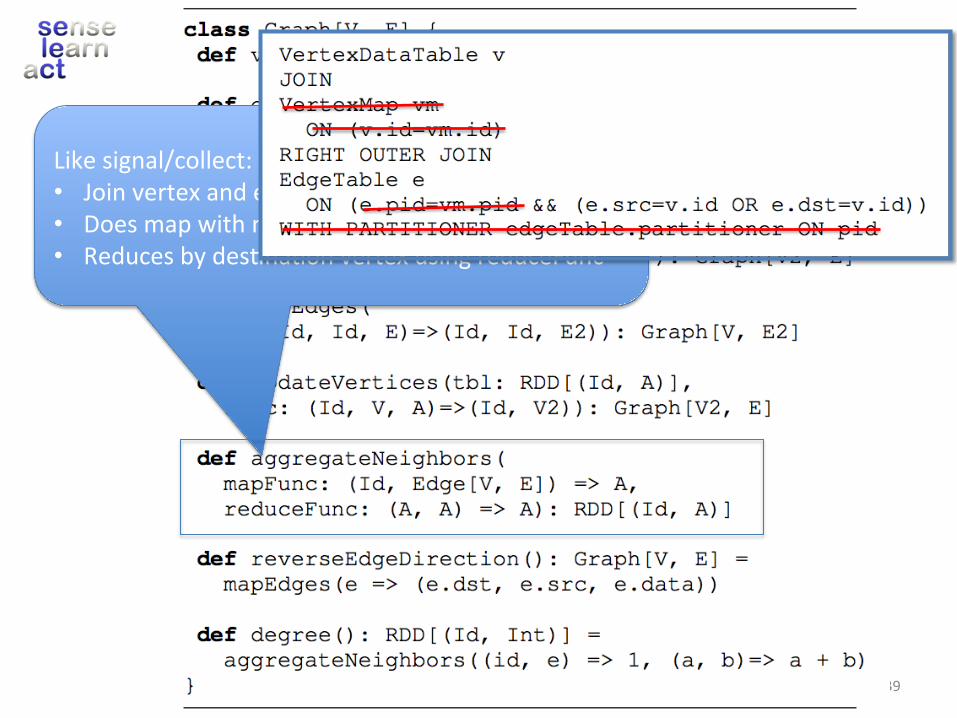
“VertexState”
“Signal”
39
Likesignal/collect:• Joinvertexandedgetables• DoesmapwithmapFuncontheedges• Reducesbydes.na.onvertexusingreduceFunc
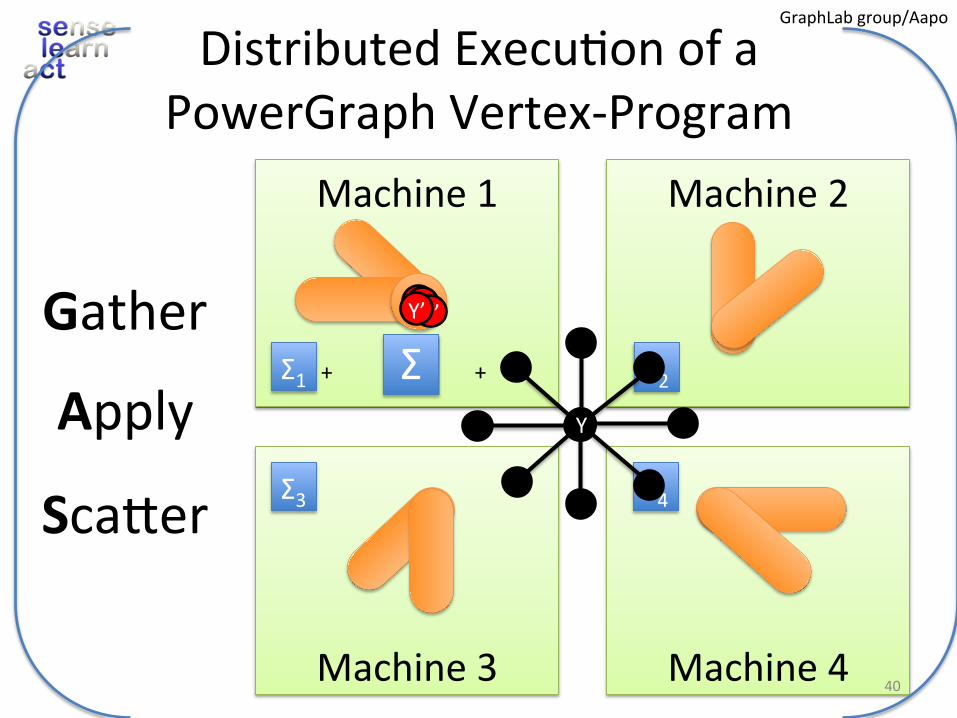
Machine2Machine1
Machine4Machine3
DistributedExecu.onofaPowerGraphVertex-Program
Σ1 Σ2
Σ3 Σ4
+++
YYYY
Y’
Σ
Y’Y’Y’Gather
Apply
ScaVer
40
GraphLabgroup/Aapo

41

42
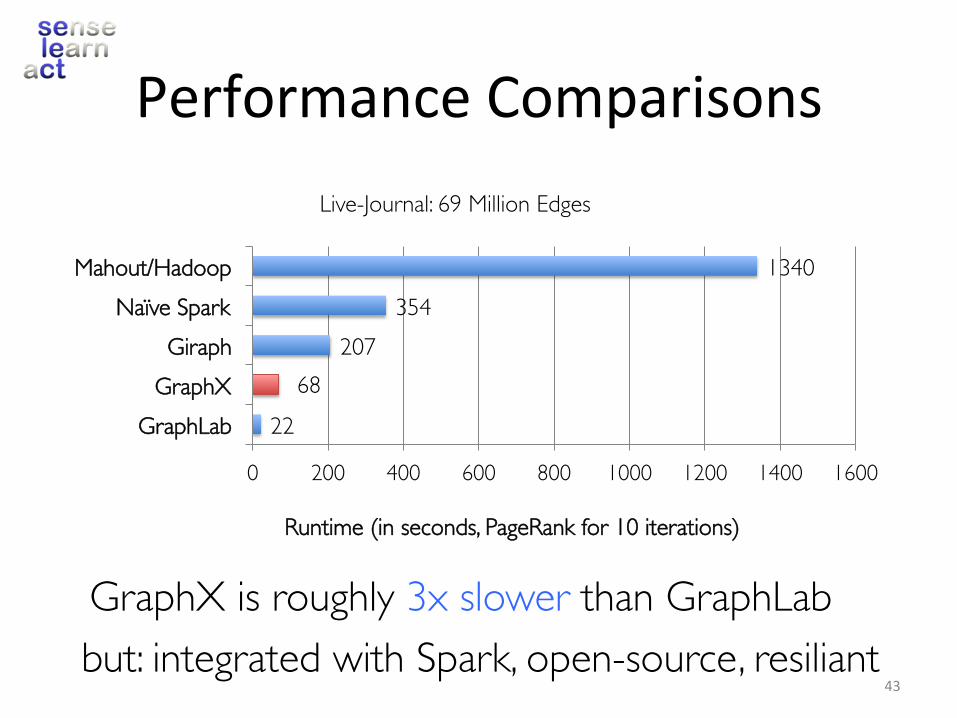
PerformanceComparisons
2268
207354
1340
0 200 400 600 800 1000 1200 1400 1600
GraphLabGraphXGiraph
Naïve SparkMahout/Hadoop
Runtime (in seconds, PageRank for 10 iterations)
GraphX is roughly 3x slower than GraphLab
Live-Journal: 69 Million Edges
43but: integrated with Spark, open-source, resiliant

Summary• Largeimmutabledatastructureson(distributed)disk,processingbysweepingthroughthenandcrea.ngnewdatastructures:– stream-and-sort,Hadoop,PIG,Hive,…
• Largeimmutabledatastructuresindistributedmemory:– Spark–distributedtables
• Largemutabledatastructuresindistributedmemory:– parameterserver:structureisahashtable– Pregel,GraphLab,GraphChi,GraphX:structureisagraph44

Summary• APIsforthevarioussystemsvaryindetailbuthaveasimilarflavor– Typicalalgorithmsitera.velyupdatevertexstate– Changesinstatearecommunicatedwithmessageswhichneedtobeaggregatedfromneighbors
• Biggestwinsare– onproblemswheregraphisfixedineachitera.on,butvertexdatachanges
– ongraphssmallenoughtofitin(distributed)memory
45

Somethingstotakeaway• Plasormsforitera.veopera.onsongraphs– GraphX:ifyouwanttointegratewithSpark– GraphChi:ifyoudon’thaveacluster– GraphLab/Dato:ifyoudon’tneedfreesowwareandperformanceiscrucial
– Pregel:ifyouworkatGoogle– Giraph,Signal/collect,…??
• Importantdifferences– Intendedarchitecture:shared-memoryandthreads,distributedclustermemory,graphondisk
– Howgraphsarepar..onedforclusters– Ifprocessingissynchronousorasynchronous
46