energy efficient vm placement - openstack summit vancouver may 2015
TRANSCRIPT

HUAWEI TECHNOLOGIES CO., LTD. www.huawei.com
Energy Efficient
VM Placement
Ulrich Kleber <[email protected]>
Kurt Garloff <[email protected]>
Radu Tudoran <[email protected]>
OpenStack Summit Vancouver 2015

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
The Energy Ceiling
Source: - Ian Bitterlin and Jon Summers, UoL, UK, Jul 2013
- Alexandru Iosup, Delft University, The Netherlands, Jan 2015
Over 500 YouTube videos have at least 100,000,000 viewers each
If you want to help killing the planet:https://www.youtube.com/watch?v=9bZkp7q19f0
PSY Gandnam Style consumed >300 GWh
Ø More than some countries in a year
Ø Over 35 MW of 24/7/365 diesel, 100M liters of oil
Ø 80,000 cars running for a year

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
l How much energy is wasted by idle resources?
l How much energy can be saved by re-scheduling the execution of VMs?
l What is the relation between energy consumption and load?
l How should VMs be rescheduled to save energy?
Motivating questions

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
Roadmap
Evaluate overall
cluster energy
consumption
Zoom on the node
energy consumption
Evaluate the node
performance-energy
ratio
Energy Comparison of
VM scheduling
strategies
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
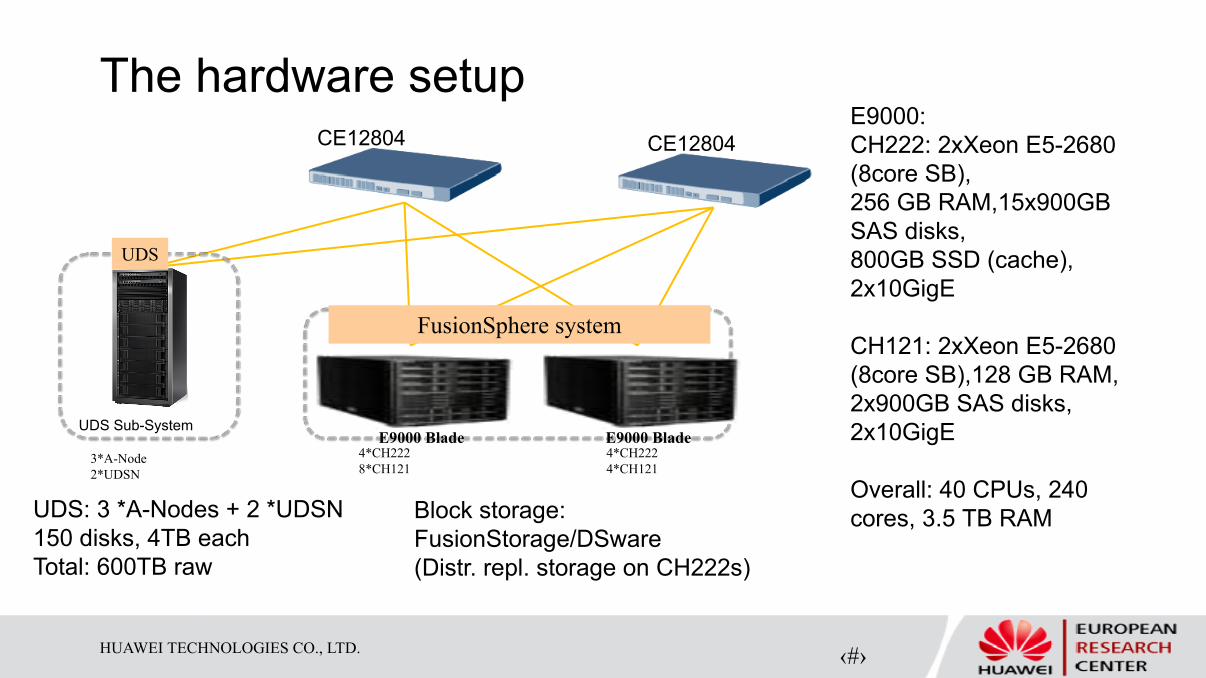
The hardware setupE9000:
CH222: 2xXeon E5-2680
(8core SB),
256 GB RAM,15x900GB
SAS disks,
800GB SSD (cache),
2x10GigE
CH121: 2xXeon E5-2680
(8core SB),128 GB RAM,
2x900GB SAS disks,
2x10GigE
Overall: 40 CPUs, 240
cores, 3.5 TB RAM
CE12804 CE12804
……
UDS Sub-SystemE9000 Blade E9000 Blade
FusionSphere system
3*A-Node
2*UDSN
4*CH222
8*CH121
4*CH222
4*CH121
UDS
UDS: 3 *A-Nodes + 2 *UDSN
150 disks, 4TB each
Total: 600TB raw
Block storage:
FusionStorage/DSware
(Distr. repl. storage on CH222s)
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
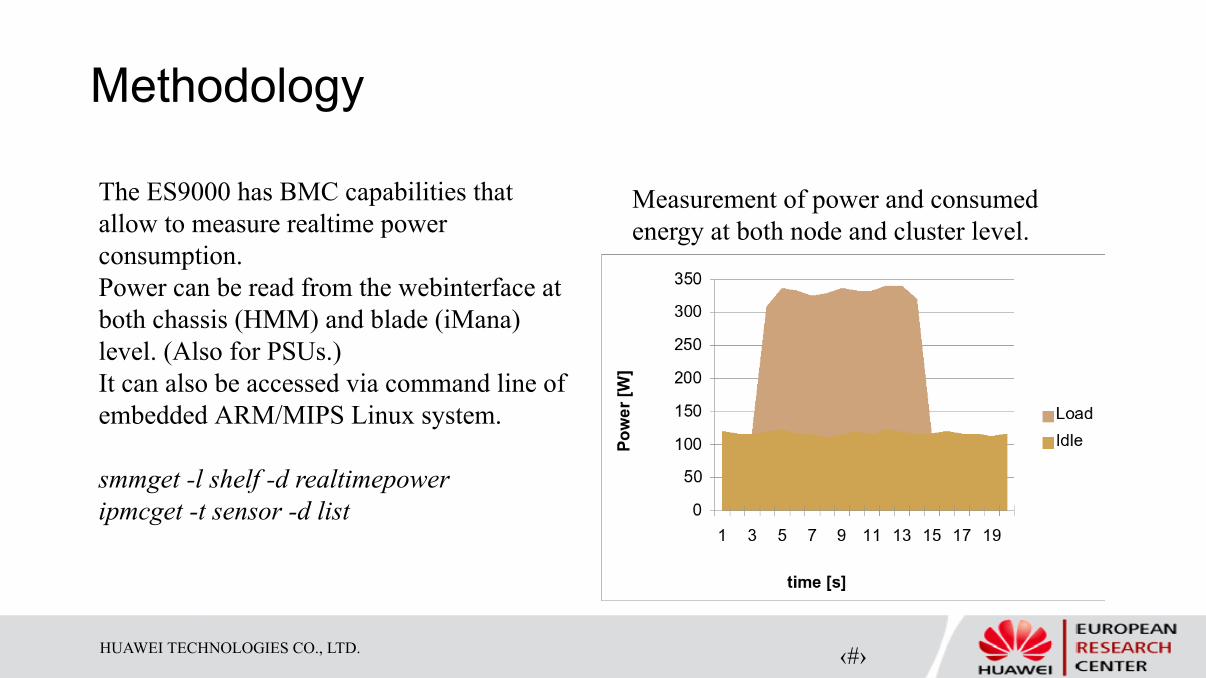
Methodology
The ES9000 has BMC capabilities that
allow to measure realtime power
consumption.
Power can be read from the webinterface at
both chassis (HMM) and blade (iMana)
level. (Also for PSUs.)
It can also be accessed via command line of
embedded ARM/MIPS Linux system.
smmget -l shelf -d realtimepower
ipmcget -t sensor -d list
Measurement of power and consumed
energy at both node and cluster level.
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
l 4 vCPU and 8GB memory per VM
l 2 Clusters with a FusionManager and OpenStack Havana (FS5)
l Some node reserved (idling/switched off)
l Warm data center (~35°C)
l Induce load and measure the energy consumption
– using linux stress tool
– using a synthetic benchmark
l 5-10 samples collected ~1 minute apart and averaged.
– measurements performed after cluster reaches stability from the energy
consumption point of view (~1 minute after operation is started)
Experiment 1: Methodology
OpenStack-based Hypervisor
Virtual
hardware
OS
Application
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
l Scale the cluster occupancy:
- 10 VMs scale steps ~9% of the compute capacity
l Use stress tool to induce constant load in VMs
- CPU consumption 3 threads spinning over sqrt
- Memory consumption 3 threads spinning over alloc/dealloc
l Compare with idle cluster as base-line, when:
- VMs hibernate
- VMs run but are idle
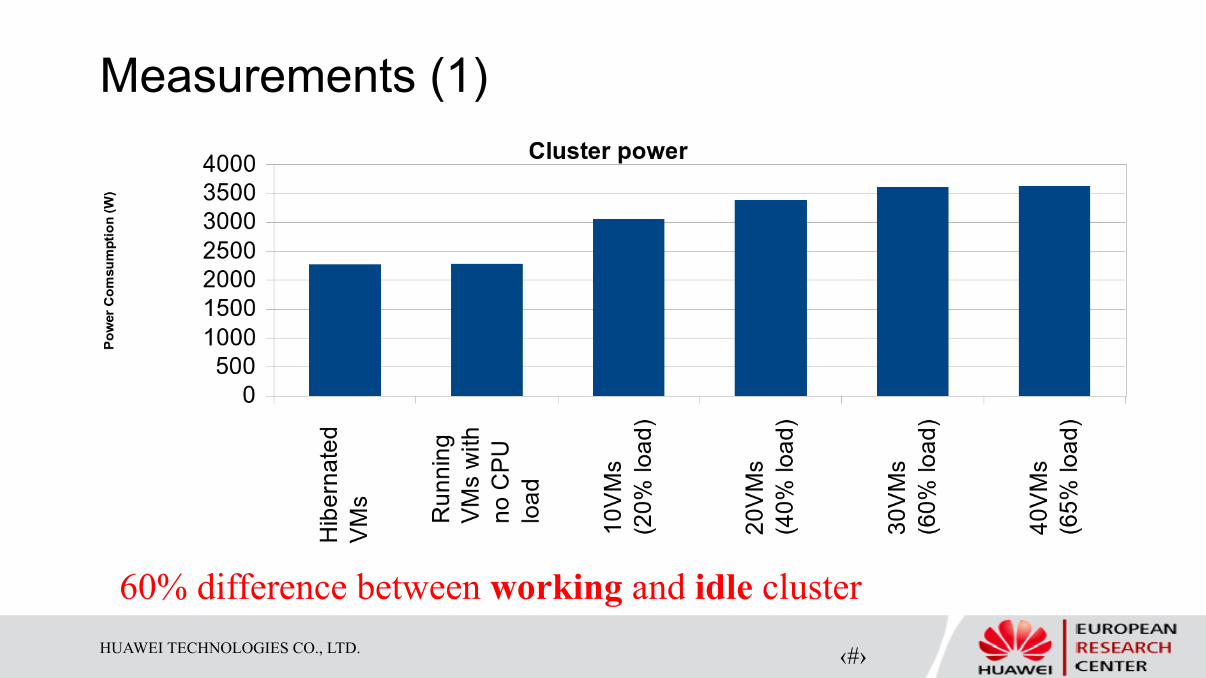
Experiment 1: Cluster energy consumption
Determine cluster energy consumption based on load
Hypervisor
Virtual hardware
OS
Virtual hardware
OS
Hypervisor
Virtual hardware
OS
Virtual hardware
OS
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
Measurements (1)
60% difference between working and idle cluster

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
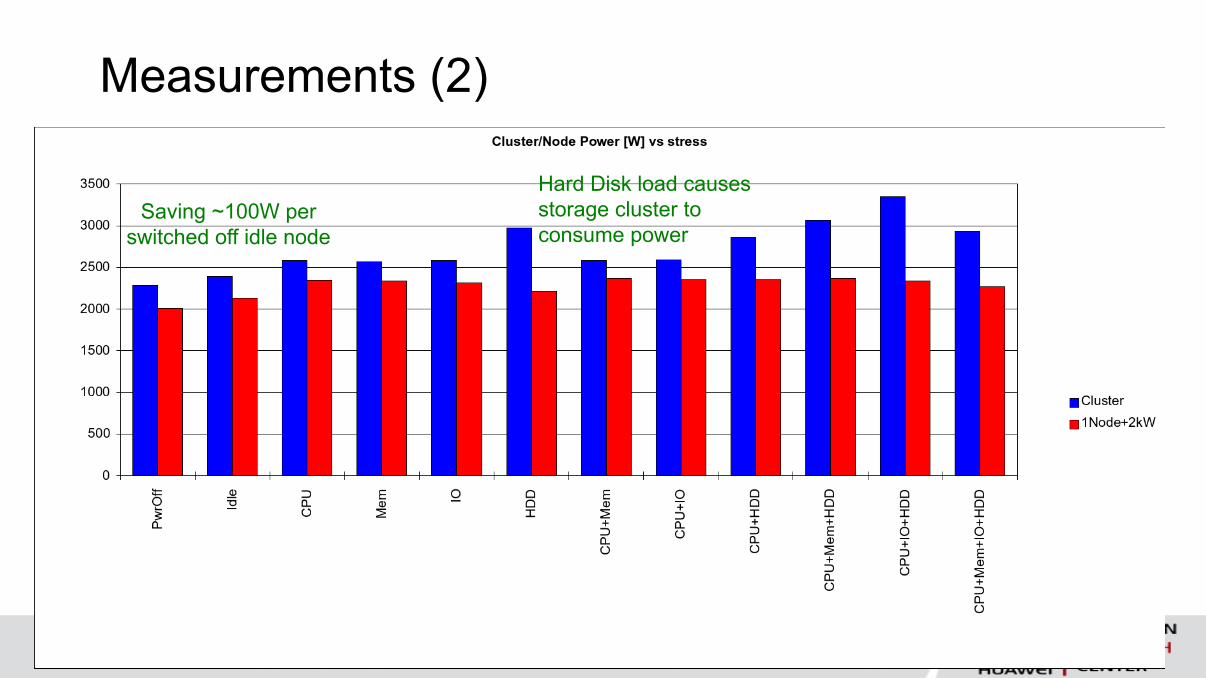
Experiment 2: Node energy consumption
Determine the node energy consumption based on load
l Fully occupy a node : 8 VMs to occupy the 32 CPU threads
l Fully use the VM compute power: 6 threads per VM (4vCPUs)
l Use stress tool to induce different loads in VMs
- CPU load - spinning over sqrt
- Memory load - spinning over alloc/dealloc
- IO load - spinning over sync
- HDD load - spinning over write/unlink
l Compare with the idle node and the powered off node
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
Measurements (2)
Saving ~100W per
switched off idle node
Hard Disk load causes
storage cluster to
consume power

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
l CPU + Memory intensive patterns seem to be the most energy consuming per node
l External storage increases total energy consumption
l Significant energy difference per node between powered off and idle states
Ø Significant energy savings for mostly idle clusters (50+%)
Ø Reschedule VMs to empty some nodes?
q But how does the energy relates to performance?
q Does lower average power consumption mean lower energy for a fixed workload ?
Preliminary conclusions
Reschedule in order to empty nodes or to
distribute the load?
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
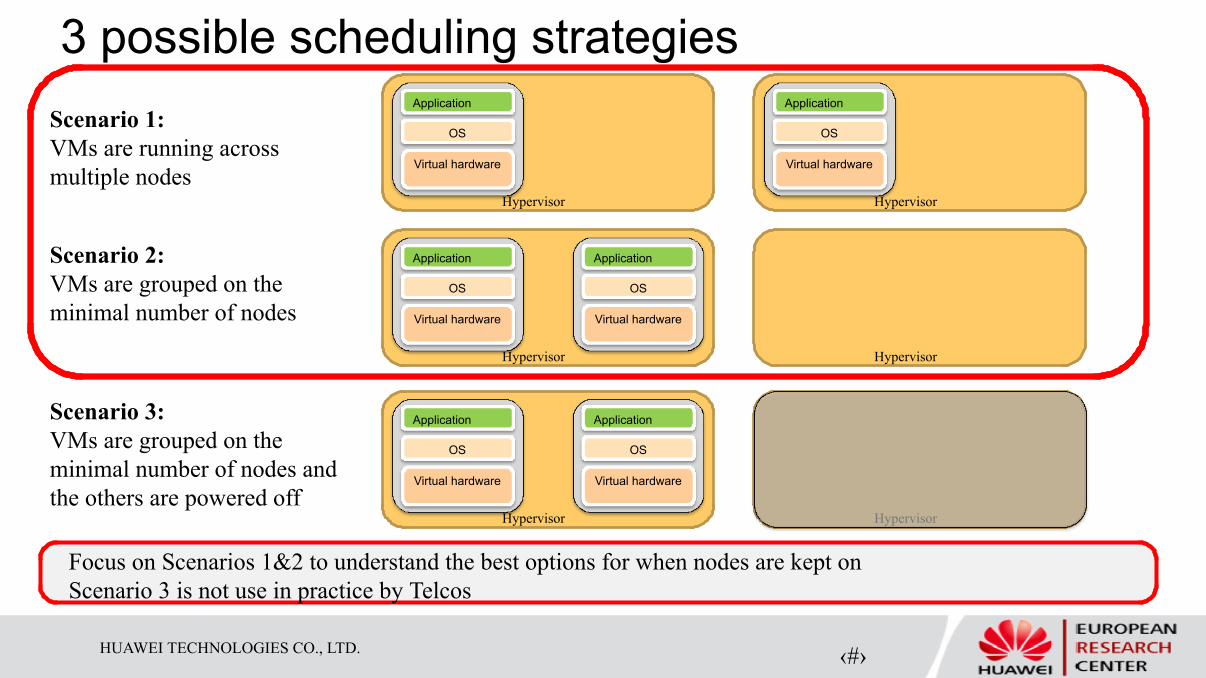
3 possible scheduling strategies
Hypervisor
Virtual hardware
OS
Hypervisor
Virtual hardware
OS
Application Application
Hypervisor
Virtual hardware
OS
Virtual hardware
OS
Hypervisor
Application Application
Hypervisor
Virtual hardware
OS
Virtual hardware
OS
Hypervisor
Application Application
Scenario 1:
VMs are running across
multiple nodes
Scenario 2:
VMs are grouped on the
minimal number of nodes
Scenario 3:
VMs are grouped on the
minimal number of nodes and
the others are powered off
Focus on Scenarios 1&2 to understand the best options for when nodes are kept on
Scenario 3 is not use in practice by Telcos

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
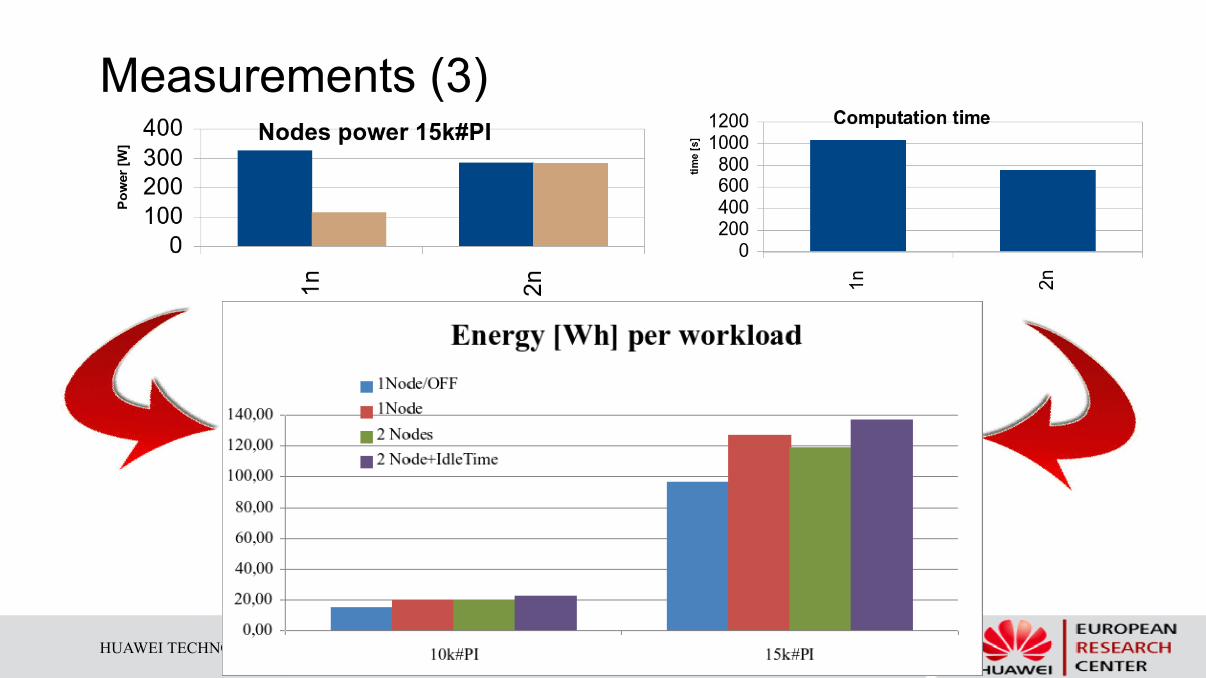
Experiment 3: Workload energy consumption
Determine the energy-performance relation
l Fully occupy 1 node : 8 VMs
l Balance the load between 2 nodes: 4 VMs per node
l Use a synthetic benchmark with a fixed computation workload
Ø Compute the first N digits of PI in each VM
echo "scale=15000; 4*a(1)" | time bc -l
l Compare the energy consumption of the 2 placement strategies
and the performance (timespan) to execute the workload
HUAWEI TECHNOLOGIES CO., LTD. ‹#›
Measurements (3)

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
Discussion
l Measurements are hard to get right
p Good sensors and well-controlled environment necessary
p Constant load vs workload -- how to account for idle machines? Can they be
assumed to do something useful?
l If switching off hosts is an option, cluster VMs and do it!
p nova support, orchestrator?
l Distributing VMs can reduce the energy consumption per workload!
p Good for performance as well -- avoids resource sharing and Turbo-DEboost
p This can be understood by non-linear power curve of CPUs (P ~ U²)
l If there's nothing useful to be done afterwards, grouping VMs is good for
energy consumption due to high idle power (but better on newer CPUs).
l Related VMs may want to be un/grouped (anti-/affinity)

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
Towards energy aware scheduling
l A simple model would help (3 params to describe quadratic curve) a lot
p Ideally use sensors if available
p Ideally understands hardware details (e.g. AVX downclock on Haswell-EP/EX)
p Ideally understands workloads (communication b/w instances -> affinity)
l Enables various policies to be implemented
p Minimal energy consumption vs balanced vs maximum performance
p Thermal management -- avoid hot spots
l Advanced ideas (thanks, Adam! http://blog.adamspiers.org/2015/05/17/cloud-rearrangement/)
p Do (live) migrations to achieve better cloud state?
p Advanced optimizations for e.g. page sharing (KSM)
p Scalability: Hierarchical scheduler?

HUAWEI TECHNOLOGIES CO., LTD. ‹#›
• Observations:
Ø Significant room for improvement for the cluster energy management
Ø Resource and compute pattern awareness are key milestones to decrease
energy consumption
We're looking for help:
• Discussions with scheduler community
• Huawei looks for cloud engineers in Europe (Munich) and elsewhere
• Looking for other companies to work on this with us
Conclusions and Future