some work on information extraction at irl ganesh ramakrishnan ibm india research lab
TRANSCRIPT

Some Work on Information Extraction at IRL
Ganesh RamakrishnanIBM India Research Lab
IBM India Research Lab

| 2
India Research Lab
Problem: Information Extraction
Extract all instances of schema <E1, E2..En> from an unstructured source S.- Company names, Designation, Person names, Date, Time
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
NAME
TITLE ORGANIZATION
Bill Gates
CEO
Microsoft
Bill Veghte
VP
Microsoft
Richard Stallman
founder
Free Soft..

| 3
India Research Lab
Rule-based Information Extraction
Statistical Rule Mining- Inductive Logic Programming and its simplifications
Rule Engines [I will mainly talk on this]- New paradigms for speedup and expressivity
Rule Consolidation- Rule ordering, RDR, SRL, etc
| 4
India Research Lab
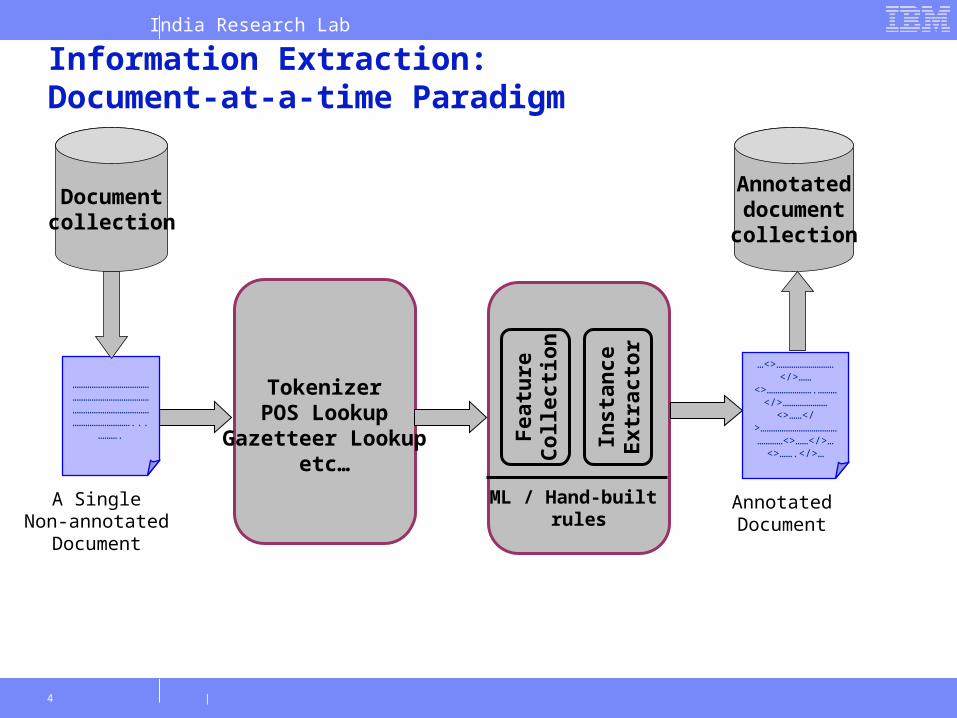
Information Extraction:Document-at-a-time Paradigm
ML / Hand-built rules
TokenizerPOS Lookup
Gazetteer Lookupetc…
Fea
ture
Co
llect
ion
Inst
ance
Ext
ract
or
AnnotatedDocument
………………………………………………………………………………………………………………………...……….
…<>………………………</>……<>………………….………</
>…………………<>……</
>…………………………………………<>……</>…<>…….</>…
A SingleNon-annotated
Document
Documentcollection
Annotateddocumentcollection

| 5
India Research Lab
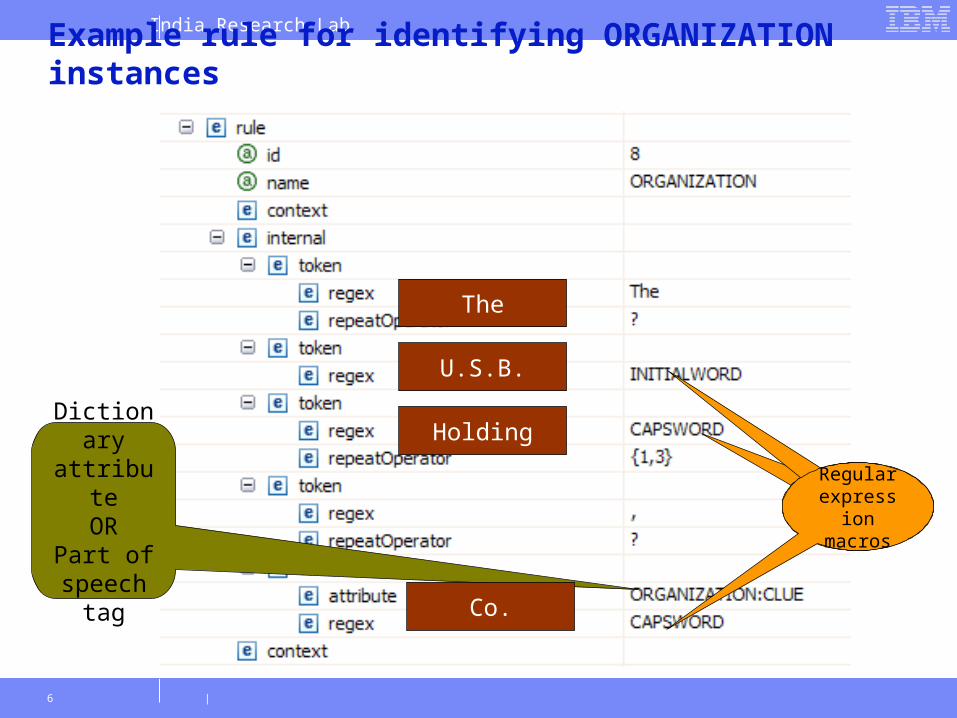
Example: Rules for identifying ORGANIZATIONs
How to identify?
B.P. Marsh PlcThe U.S.B. Holding Co.U.S.B. Holding Group
| 6
India Research Lab
Example rule for identifying ORGANIZATION instances
Regular expression macros
Dictionary attribute
ORPart of speech
tag
U.S.B.
The
Holding
Co.

| 7
India Research Lab
Problems with Existing Grammar-based Approachs on large corpora
Repeated computations for multiple occurrences of same token:- Dictionary-lookups- Regular expression matches
Large over-heads while- Re-annotating a corpus after changing dictionary entries
The user realizes that “Group” is a too generic word to be included as an ORGANIZATION:CLUE and want to remove its entry

| 8
India Research Lab
Problems with Existing Grammar-based Approachs on large corpora
Repeated computations for multiple occurrences of same token:- Dictionary-lookups- Regular expression matches
Large over-heads while- Re-annotating a corpus after changing dictionary entries
The user realizes that “Group” is a too generic word to be included as an ORGANIZATION:CLUE and want to remove its entry
- Re-annotating a corpus with slight modification in rules The user realizes that the optional “The” at the beginning introduces too many wrong
annotations and modifies the rule

| 9
India Research Lab
Problems with Existing Grammar-based Approachs on large corpora
Repeated computations for multiple occurrences of same token:- Dictionary-lookups- Regular expression matches
Large over-heads while- Re-annotating a corpus after changing dictionary entries
The user realizes that “Group” is a too generic word to be included as an ORGANIZATION:CLUE and want to remove its entry
- Re-annotating a corpus with slight modification in rules The user realizes that the optional “The” at the beginning introduces too many wrong
annotations and modifies the rule- Making incremental annotation updates by adding new rules
The user wants a new rule that identifies “C.B. Fairlie Holding & Finance Limited”

| 10
India Research Lab
Problems with Existing Grammar-based Approachs on large corpora
Repeated computations for multiple occurrences of same token:- Dictionary-lookups- Regular expression matches
Large over-heads while- Changing dictionary entries
The user realizes that “Group” is a too generic word to be included as an ORGANIZATION:CLUE and want to remove its entry
- Re-annotating a corpus with slight modification in rules The user realizes that the optional “The” at the beginning introduces too many wrong
annotations and modifies the rule
- Making incremental annotation updates by adding new rules The user wants a new rule that identifies “C.B. Fairlie Holding & Finance Limited” The user wants a new rule that identifies acquiring organizations:
“AT&T Wireless, Inc. ” (that purchased Alaska Communications System in 1995)

| 11
India Research Lab
An alternative approach: Operating on the Inverted Index (EMNLP 2006 & ICDE 2008)
Inverted Index- A compact representation of the collection- Captures redundancies/repetition information
Many applications required annotations to be reflected in the index anyways

| 12
India Research Lab
Index Based Entity Annotation[EMNLP 2006, ICDE 2008, InfoScale 2008]
An order of magnitude speedup by converting
regex matching to operations on index
A further factor of 2-3 speedup by deriving
optimal plans
| 13
India Research Lab
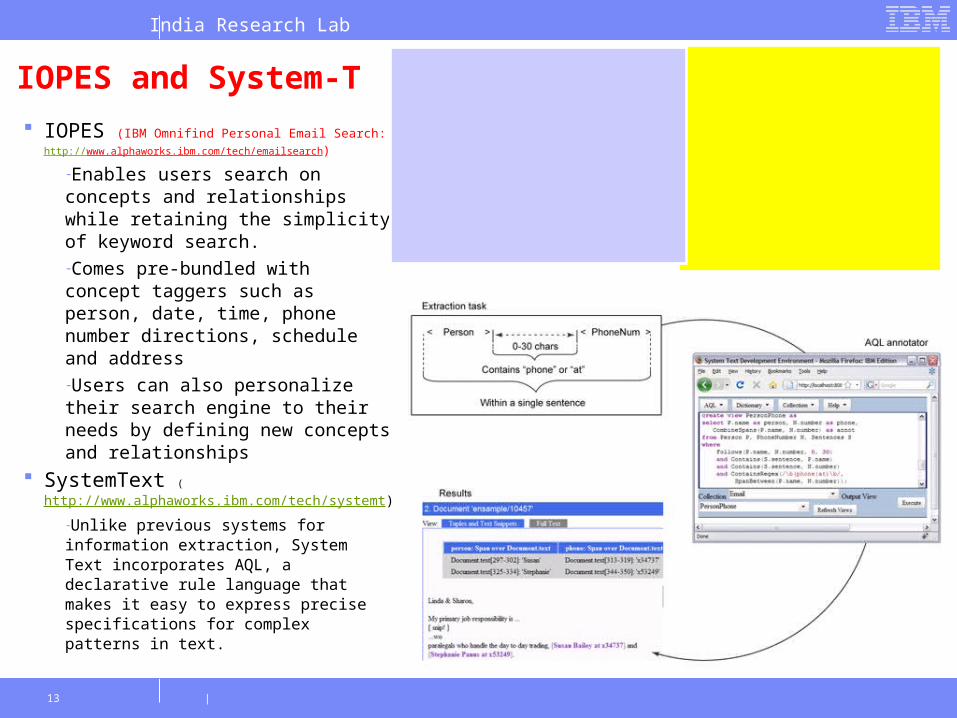
IOPES and System-T
IOPES (IBM Omnifind Personal Email Search: http://
www.alphaworks.ibm.com/tech/emailsearch)
-Enables users search on concepts and relationships while retaining the simplicity of keyword search.-Comes pre-bundled with concept taggers such as person, date, time, phone number directions, schedule and address -Users can also personalize their search engine to their needs by defining new concepts and relationships
SystemText (
http://www.alphaworks.ibm.com/tech/systemt)
-Unlike previous systems for information extraction, System Text incorporates AQL, a declarative rule language that makes it easy to express precise specifications for complex patterns in text.

| 14
India Research Lab
Capture the voice-of-customer by extracting important (and unimportant) repetitive discourse patterns from (noisy) call center conversations
Approach1. Assumption: Conversations proceed in the form
of questions and answers.2. Named entities such as CAR-TYPE,
DISCOUNT-TYPE, RENTAL-AGENCY, LOCATION, DATE, TIME, etc., abstracted away to types for increasing feature density.
3. Canonical “question” and “answer” types determined by clustering questions and answers, using non-consecutive sequences over entities and tokens as features. A canonical type is assigned to each cluster
4. Learn a discourse model as patterns of non-consecutive sequence of canonical “question” and “answer” types.
Identification of Conversational Discourse Patterns[Anup, Venkat, Sumit, Ganesh, CIKM 2008, TextLink 2006]
PATTERN RECOGNIZED: #CAR-QUESTION…#CAR-TYPE… #AMOUNT… #NEGATION…
#better rate#
Customer: < CAR-QUESTION> ok. do you have a midsize</CAR-QUESTION>.Agent: ya. sure for a <CAR-Type>midsize car</CAR-Type> you are paying just <AMOUNT>309.49$</AMOUNT> alright.Customer: I am <NEGATION>not interested</NEGATION> I think I can get much better rate from the web so I think go with that.
Mining “horizontal”
patterns
Mining “vertical” patterns
Greeting segment and the conversation relating to the agent asking for the pick up and car details are repetitive
More interesting patterns: discourse relating to the agent presenting the rate and the customer raising an objection to it would not be present in all the calls
Also interesting to capture how the agent overcomes the objection to make the sale

| 15
India Research Lab
BACKUP

| 16
India Research Lab
Structure of Index
Example:The company said that it will acquire the other company
the
company
said
that
it
will
acquire
other
sid first last
Posting List
sid: a sentence identifierfirst: beginning position of an occurrencelast: end position of the same occurrence
Basic Entities Orthographic properties
E.g.: CANYWORD, INITIALWORD , etc.
Dictionary Features E.g.: ORGANIZATION:CLUE, ORGANIZATION:CONJ, etc.
| 17
India Research Lab
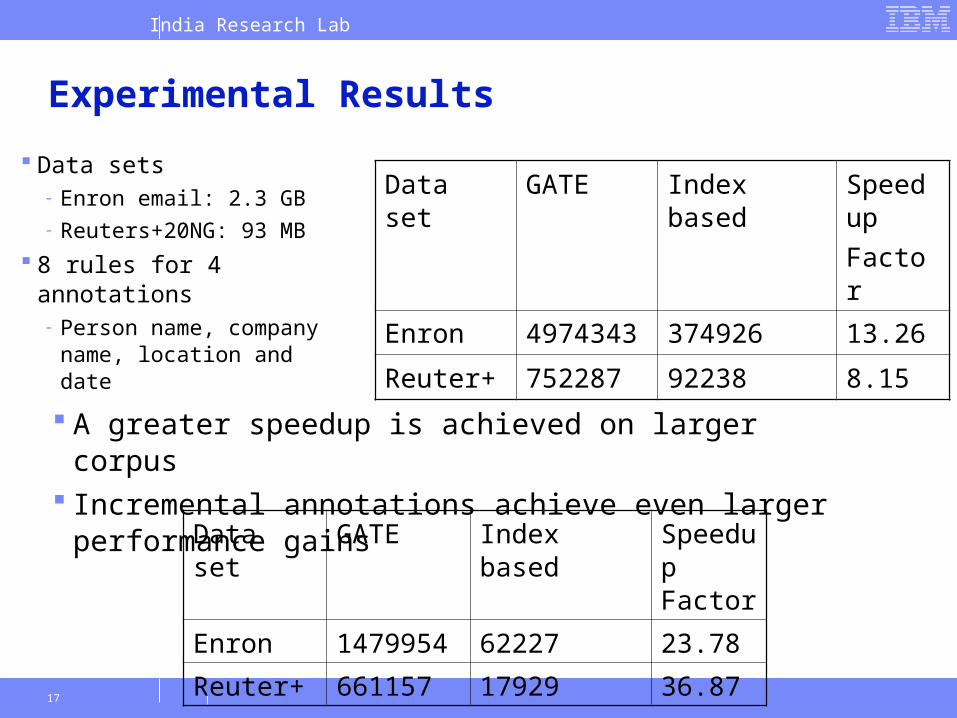
Experimental Results
Data sets- Enron email: 2.3 GB- Reuters+20NG: 93 MB
8 rules for 4 annotations- Person name, company
name, location and date
Data set GATE Index based Speedup
Factor
Enron 4974343 374926 13.26
Reuter+ 752287 92238 8.15
A greater speedup is achieved on larger corpus Incremental annotations achieve even larger performance gains
Data set GATE Index based Speedup Factor
Enron 1479954 62227 23.78
Reuter+ 661157 17929 36.87