software optimization: how to reclaim your...
TRANSCRIPT

Software optimization:how to reclaim your application performance
Martin Hilgeman
HPC Consultant

Dell - Internal Use - Confidential2 of 69
The key question
How are you going to make a difference?
When everybody is using the same hardware components

Dell - Internal Use - Confidential3 of 69
Differentiating through performance
• Everybody has the same microprocessors, you have to differentiate through performance
• The new reality is that Moore’s Law is not making cores faster
– We only get more cores, the clock frequency does not change
• New cores do get more powerful with new hardware instructions being added
– AVX -> AVX2, FMA3, XOP
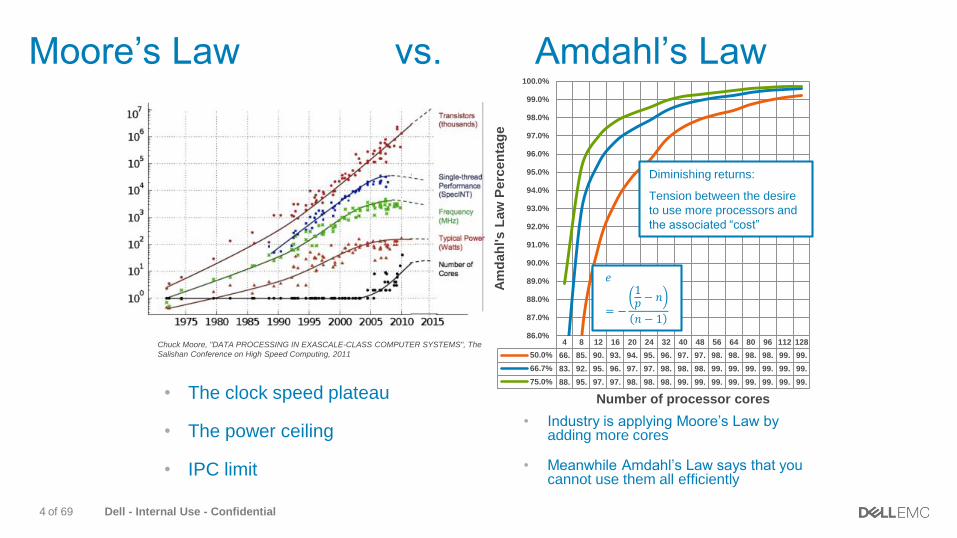
Dell - Internal Use - Confidential4 of 69
Moore’s Law vs. Amdahl’s Law
• The clock speed plateau
• The power ceiling
• IPC limit
• Industry is applying Moore’s Law by adding more cores
• Meanwhile Amdahl’s Law says that you cannot use them all efficiently
4 8 12 16 20 24 32 40 48 56 64 80 96 112 128
50.0% 66. 85. 90. 93. 94. 95. 96. 97. 97. 98. 98. 98. 98. 99. 99.
66.7% 83. 92. 95. 96. 97. 97. 98. 98. 98. 99. 99. 99. 99. 99. 99.
75.0% 88. 95. 97. 97. 98. 98. 98. 99. 99. 99. 99. 99. 99. 99. 99.
86.0%
87.0%
88.0%
89.0%
90.0%
91.0%
92.0%
93.0%
94.0%
95.0%
96.0%
97.0%
98.0%
99.0%
100.0%
Am
dah
l's L
aw
Perc
en
tag
e
Number of processor cores
Diminishing returns:
Tension between the desire
to use more processors and
the associated “cost”
𝑒
= −
1𝑝− 𝑛
𝑛 − 1
Chuck Moore, "DATA PROCESSING IN EXASCALE-CLASS COMPUTER SYSTEMS", The
Salishan Conference on High Speed Computing, 2011

Dell - Internal Use - Confidential5 of 69
Moore’s Law vs Amdahl's Law - “too Many Cooks in the Kitchen”
Meanwhile Amdahl’s Law says that
you cannot use them all efficientlyIndustry is applying Moore’s Law by
adding more cores

Dell - Internal Use - Confidential6 of 69
What levels do we have*?
• Challenge: Sustain performance trajectory without massive increases in cost, power, real
estate, and unreliability
• Solutions: No single answer, must intelligently turn “Architectural Knobs”
𝐹𝑟𝑒𝑞 ×𝑐𝑜𝑟𝑒𝑠
𝑠𝑜𝑐𝑘𝑒𝑡× #𝑠𝑜𝑐𝑘𝑒𝑡𝑠 ×
𝑖𝑛𝑠𝑡 𝑜𝑟 𝑜𝑝𝑠
𝑐𝑜𝑟𝑒 × 𝑐𝑙𝑜𝑐𝑘× 𝐸𝑓𝑓𝑖𝑐𝑖𝑒𝑛𝑐𝑦
Hardware performance What you really get
1 2 3 4 5
Software performance
*Slide previously from Robert Hormuth

Dell - Internal Use - Confidential7 of 69
Turning the knobs 1 - 4
Frequency is unlikely to change much Thermal/Power/Leakage
challenges
Moore’s Law still holds: 130 -> 14 nm. LOTS of transistors
Number of sockets per system is the easiest knob.
Challenging for power/density/cooling/networking
IPC still grows
FMA3/4, AVX, FPGA implementations for algorithms
Challenging for the user/developer
1
2
3
4

Dell - Internal Use - Confidential8 of 69
What is Intel telling us?
Intel® Core™
Microarchitecture
New
Micro-
architecture
Merom
65nm
TOCK
Penryn
New
Process
Technology
45nm
TICK
Intel® MicroarchitectureCodename Nehalem
New
Micro-
architecture
Nehalem
45nm
TOCK
Westmere
32nm
New
Process
Technology
TICK
Intel® MicroarchitectureCodename Sandy Bridge
Sandy
Bridge
32nm
New
Micro-
architecture
TOCK
Ivy
Bridge
22nm
New
Process
Technology
TICK
Intel® MicroarchitectureCodename Haswell
Haswell
22nm
New
Micro-
architecture
TOCK
Broadwell
14nm
New
Process
Technology
TICK

Dell - Internal Use - Confidential9 of 69
New capabilities according to Intel
Intel® Core™
Microarchitecture
New
Micro-
architecture
Merom
65nm
SSE2
Penryn
New
Process
Technology
45nm
SSSE3
Intel® MicroarchitectureCodename Nehalem
New
Micro-
architecture
Nehalem
45nm
SSE4
Westmere
32nm
New
Process
Technology
SSE4
Intel® MicroarchitectureCodename Sandy Bridge
Sandy
Bridge
32nm
New
Micro-
architecture
AVX
Ivy
Bridge
22nm
New
Process
Technology
AVX
Intel® MicroarchitectureCodename Haswell
Haswell
22nm
New
Micro-
architecture
AVX2
Broadwell
14nm
New
Process
Technology
AVX2
2005 2007 2009 2011 2012 2013 2014 2015

Dell - Internal Use - Confidential10 of 69
Meanwhile the bandwidth is suffering
0
0.5
1
1.5
2
2.5
Intel XeonX5690
Intel XeonE5-2690
Intel XeonE5-2690v2
Intel XeonE5-2690v3
Intel XeonE5-2690v4
Cores Clock QPI Memory

Dell - Internal Use - Confidential11 of 69
And data is becoming sparser (think “Big Data”)
X =
Sparse Matrix “A”
• Most entries are zero
• Hard to exploit SIMD
• Hard to use caches
A x y
• This has very low arithmetic density and hence memory
bound
• Common in CFD, but also in genetic evaluation of species

Dell - Internal Use - Confidential12 of 69
What does Intel do about these trends?
Problem Westmere Sandy Bridge Ivy Bridge Haswell Broadwell
QPI
bandwidth
No problem Even better Two snoop
modes
Three snoop
modes
Four (!) snoop
modes
Memory
bandwidth
No problem Extra memory
channel
Larger cache Extra
load/store
units
Larger cache
Core
frequency
No problem • More
cores
• AVX
• Better
Turbo
• Even
more
cores
• Above
TDP
Turbo
• Still more
cores
• AVX2
• Per-core
Turbo
• Again
even
more
cores
• optimized
FMA
• Per-core
Turbo
based on
instruction
type

Dell - Internal Use - Confidential13 of 69
Gustavson’s Law: what about workload size?
• Claim is that parallel performance scales with the size of the workload (think: weak scaling)
• Network is becoming increasingly important
Node 2
Node 4 Node 5
Node 3
Node 1 Node 1
= send
= receive

Dell - Internal Use - Confidential14 of 69
System trend over the years (1)
C
C C
C
≈≈≈
~1970 - 2000
≈≈≈
2005
Multi-core: TOCK
Dell - Internal Use - Confidential15 of 69
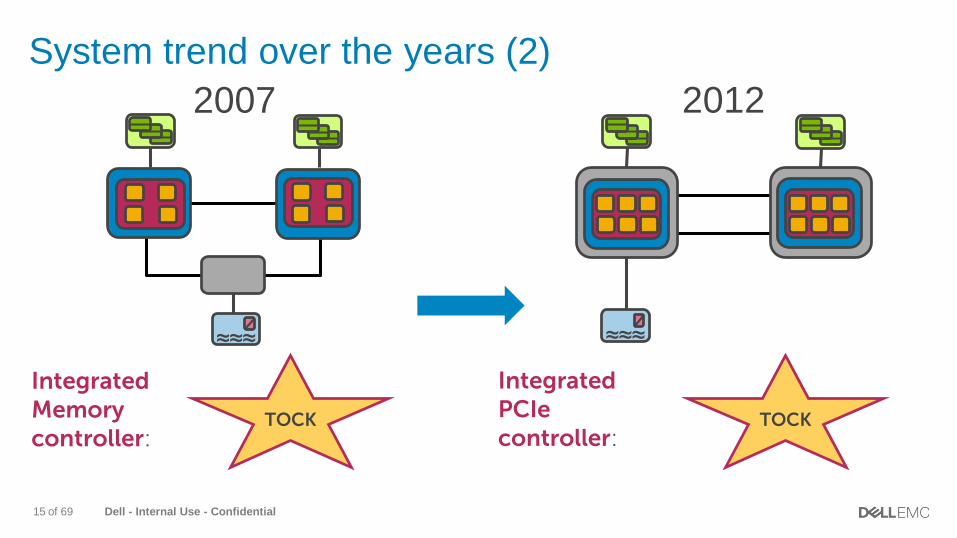
System trend over the years (2)
2007
IntegratedMemorycontroller:
TOCK
IntegratedPCIecontroller:
TOCK
2012
≈≈≈≈≈≈

Dell - Internal Use - Confidential16 of 69
Future
IntegratedNetworkFabric Adapter:
TOCK
SoC designs:
TOCK
≈≈≈ ≈≈≈ ≈≈≈ ≈≈≈

Dell - Internal Use - Confidential17 of 69
Predicting performance – the roofline model
• Bound system performance as function of peak performance, maximum bandwidth and arithmetic
intensity
Obtained from: https://crd.lbl.gov/departments/computer-science/PAR/research/roofline/

Dell - Internal Use - Confidential18 of 69
Roofline model of an E5-2697 v4 processor
1
2
4
8
16
32
64
128
256
512
1024
0.0625 0.125 0.25 0.5 1 2 4 8 16 32
GF
LO
P/s
Arithmetic intensity (FLOP/Byte)
Memory Compute
Bound
FP peak (~ 1TF)
Williams et al.: “Roofline: An Insightful Visual Performance Model“, CACM 2009
Better use of
caches
Micro
optimi
zation

Dell - Internal Use - Confidential19 of 69
E5-2697 v4 processor data
1
2
4
8
16
32
64
128
256
512
1024
0.0625 0.125 0.25 0.5 1 2 4 8 16 32
GF
LO
P/s
Arithmetic intensity (FLOP/Byte)
No SIMD
Sparse
Solvers
(CFD)
No FMA
FP peak (~ 1TF)
STREAM
Triad
HPCG
HPL
GROMACS
OpenFOAM
CP2k
Dell - Internal Use - Confidential20 of 69
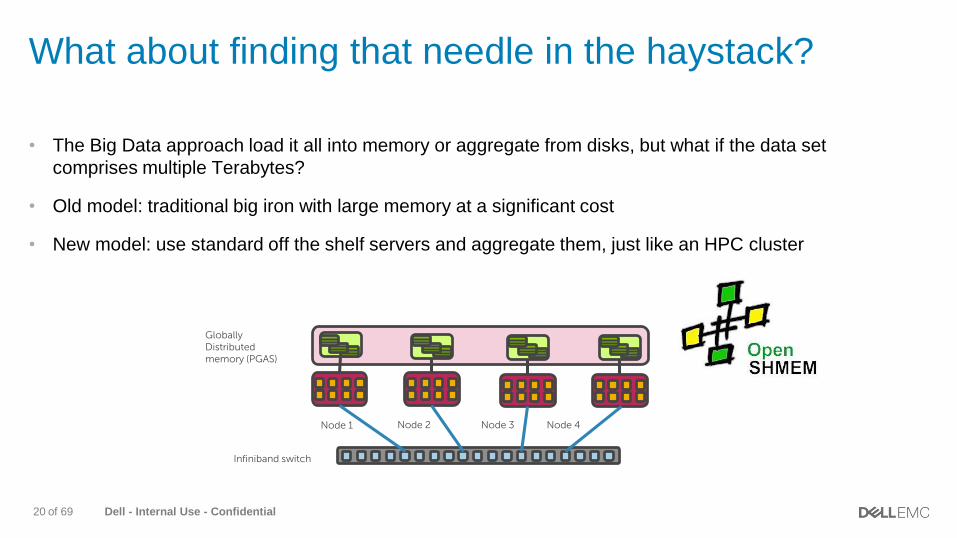
What about finding that needle in the haystack?
• The Big Data approach load it all into memory or aggregate from disks, but what if the data set
comprises multiple Terabytes?
• Old model: traditional big iron with large memory at a significant cost
• New model: use standard off the shelf servers and aggregate them, just like an HPC cluster
Node 1 Node 2 Node 3 Node 4
Infiniband switch
Globally Distributed memory (PGAS)

Dell - Internal Use - Confidential21 of 69
My data is somewhere, but how long does it take to get to me? Data movement Latency Equals to..
L1 cache reference 0.4 ns One heartbeat
L2 cache reference 5 ns Long Yawn
L3 cache reference 14 ns Getting out of bed
Main memory reference 71 ns Brushing your teeth
MPI ping pong latency 1 us A run to the grocery store
MPI Allreduce latency (1 kB
message)
30 us FedEx delivery somewhere today
SSD random read 150 us Weekend
Read 1 MB sequentially from memory 250 us Holiday weekend
Round trip within data center 0.5 ms Vacation
Read 1 MB sequentially from SSD 1 ms Two weeks
Disk seek 10 ms University semester
Read 1 MB sequentially from disk 20 ms One year
Send Packet CA->Netherlands->CA 150 ms Getting a Bachelor’s Degree

Dell - Internal Use - Confidential22 of 69
Collective MPI function latency
1
10
100
1000
10000
100000
1000000
1 16 256 4096 65536 1048576
Late
ncy (
us)
Size (bytes)
Alltoall
Allreduce
Allgather
Brushing my teeth
Going on a lunch break
Vacation
> 1 year

Optimizing without having the source code

Dell - Internal Use - Confidential24 of 69
Tuning knobs for performance
Hardware tuning knobs are limited, but there’s far more possible in the software layer
Hardware
Operating
system
Middleware
Application
BIOS
P-states
Memory profile
I/O cache tuning
Process affinity
Memory allocation
MPI (parallel) tuning
Use of performance
libs (Math, I/O, IPP)
Compiler hints
Source changes
Adding parallelism
easy
hard

Operating system tuning – setting affinity

Dell - Internal Use - Confidential26 of 69
dell_affinity.exe – automatically adjust process affinity for the architecture
Mode Time (s)
Original 6342
Platform MPI 6877
dell_affinity 4844
Memory Memory
QPI
QPI
QPIMemoryMemory
Original: 152 seconds
Memory Memory
QPI
QPI
QPIMemoryMemory
With dell_affinity: 131 seconds

Middleware tuning –dell_toolbox

Dell - Internal Use - Confidential28 of 69
MPI profiling interface – dell_toolbox• Works with every application using MPI - Plugin-and-play!
• Provides insight in computation/computation ratio
• Allows to dig deeper into MPI internals
• Generates CSV files that can be imported into Excel
Confiden2
0
100
200
300
400
500
600
700
800
900
0 32 64 96 128 160 192 224
Wall
clo
ck t
ime (
s)
MPI Rank
MPI_Allreduce
MPI_Irecv
MPI_Scatterv
MPI_Gather
MPI_Gatherv
MPI_Isend
MPI_Allgather
MPI_Alltoallv
MPI_Bcast
MPI_Wait
App
0
1E+09
2E+09
3E+09
4E+09
5E+09
6E+09
7E+09
8E+09
MP
I_B
ca
st
MP
I_G
ath
er
MP
I_Ir
ecv
MP
I_Is
end
MP
I_R
ecv
MP
I_R
educe
MP
I_S
end
MP
I_W
ait
MP
I_W
aitanyN
um
be
r o
f m
essag
es
1 node
2 nodes
4 nodes
8 nodes
16 nodes
MPI_Bcast0-512bytes
512-4096bytes
4096-16384bytes
MPI_Irecv0-512bytes
512-4096bytes
4096-16384bytes
MPI_Isend0-512bytes
512-4096bytes
4096-16384bytes
MPI_Recv0-512bytes
512-4096bytes
4096-16384bytes

Dell - Internal Use - Confidential29 of 69
STAR CCM+ MPI tuning for F1 team
0
500
1000
1500
2000
2500
3000
0 32 64 96 128 160 192 224 0 32 64 96 128 160 192 224
Wa
ll c
loc
k t
ime
(s)
MPI rank
R022, lemans_trim_105m, 256 cores, PPN=16MPI_Waitany
MPI_Waitall
MPI_Wait
MPI_Sendrecv
MPI_Send
MPI_Scatterv
MPI_Scatter
MPI_Recv
MPI_Isend
MPI_Irecv
MPI_Gatherv
MPI_Gather
MPI_Bcast
MPI_Barrier
MPI_Alltoall
MPI_Allreduce
MPI_Allgatherv
AS-IS: 2812 seconds Tuned MPI: 2458 seconds
12.6 % speedup

Dell - Internal Use - Confidential30 of 69
0
200
400
600
800
1000
1200
1400
1600
0 40 80 120 160 200 240 280 0 40 80 120 160 200 240 280 0 40 80 120 160 200 240 280
Wa
ll c
loc
k t
ime
(s)
MPI Rank
Neon benchmark16x M620, E5-2680v2, Intel MPI
MPI_Waitany
MPI_Wait
MPI_Send
MPI_Reduce
MPI_Recv
MPI_Isend
MPI_Irecv
MPI_Gather
MPI_Bcast
App
14.4 % faster
1507 seconds 1417 seconds 1287 seconds
STAR CCM+ MPI tuning for F1 team
As-is Tuning knob #1 Tuning knob #2

Code modernization

Dell - Internal Use - Confidential32 of 69
The state of ISV software
Segment Applications Vectorization support
CFD Fluent, LS-DYNA, STAR
CCM+
Limited SSE2 support
CSM CFX, RADIOSS, Abaqus Limited SSE2 support
Weather WRF, UM, NEMO, CAM Yes
Oil and Gas Seismic processing Not applicable
Reservoir Simulation Yes
Chemistry Gaussian, GAMESS, Molpro Not applicable
Molecular dynamics NAMD, GROMACS,
Amber,…
PME kernels support SSE2
Biology BLAST, Smith-Waterman Not applicable
Molecular mechanics CPMD, VASP, CP2k,
CASTEP
Yes
Bottom line: ISV support for new instructions is poor. Less of an issue
for in-house developed codes, but programming is hard

Dell - Internal Use - Confidential33 of 69
#define N 2000for (i = 0; i < N; i+=4) { do a branch
c[i] = a[i] + b[i]; 2 loadsc[i+1] = a[i+1] + b[i+1];c[i+2] = a[i+2] + b[i+2];c[i+3] = a[i+3] + b[i+3]; 1 store
} 4 instructions fused into asingle instructionincrement the index
Optimizing applications still pays off!
Dell
Consider this vector addition
#define N 2000for (i = 0; i < N; i++) { do a branch
c[i] = a[i] + b[i]; 2 loads1 store1 instruction
} increment the index

Dell - Internal Use - Confidential34 of 69
But you have to make your hands dirty…
#include <xmmintrin.h>#define N 2000
double *restrict a, b, c;
a = __mmalloc(N * sizeof(double), 32);b = __mmalloc(N * sizeof(double), 32);c = __mmalloc(N * sizeof(double), 32);
#pragma vector alwaysfor (i = 0; i < N; i++) {
c[i] = a[i] + b[i]; /* 1 instruction */}
__mm_free(a};__mm_free(b);__mm_free(c);

Dell - Internal Use - Confidential35 of 69
Or even dirtier…
#include <immintrin.h>#define N 2000#define VECTOR_SIZE 4
typedef double v4df __attribute__((vector_size(8 * VECTOR_SIZE)));double *restrict a, b, c;
a = __mmalloc(N * sizeof(double), 32);b = __mmalloc(N * sizeof(double), 32);c = __mmalloc(N * sizeof(double), 32);
for (i = 0; i < N; i+=4) {v4df ta = __builtin_ia32_loadupd256(a+i);v4df tb = __builtin_ia32_loadupd256(b+1);v4df tc = __builtin_ia32_addpd256(ta, tb);
__builtin_ia32_storeupd256(c+i, tc);}
__mm_free(a};__mm_free(b);__mm_free(c);

Dell - Internal Use - Confidential36 of 69
Distinguish between inside and outside a server
Inside a server, memory is shared
I/O hubMemory Memory
QPI
I/O hub

Dell - Internal Use - Confidential37 of 69
The same vector addition OpenMP style
#include <omp.h>#define N 2000
#pragma omp parallel for default (none) private (i) shared (a, b, c, N) schedule (static)for (i = 0; i < N; i++) {
c[i] = a[i] + b[i];}
6 7
9 a
8
b
0 1
3 4
2
5

Dell - Internal Use - Confidential38 of 69
Outside a server memory is distributed
Node 1 Node 2 Node 3 Node 4
Network switch

Dell - Internal Use - Confidential39 of 69
The same vector addition MPI style
#include <mpi.h>#define N 2000
MPI_Init(argc, argv);MPI_Comm_rank(MPI_COMM_WORLD, &me);MPI_Comm_size(MPI_COMM_WORLD, &num_ranks);
if (me == 0) c_buf = malloc(N * sizeof(c));
MPI_Bcast(a, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);MPI_Bcast(b, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
count = N / num_ranks;
for (i = me * count; i < me * count + count; i++) {c[i] = a[i] + b[i];
}
MPI_Barrier(MPI_COMM_WORLD);MPI_Reduce(c, c_buf, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
MPI_Finalize();

Dell - Internal Use - Confidential40 of 69
OpenMP is simple, MPI is hard
• Best is to combine the two, MPI between the nodes and OpenMP inside each node
• That is called hybrid parallelism
• It also sets the foundation for many core architectures (Xeon Phi, NVIDIA CUDA, AMD FirePro)
• 100,000s of cores become unmanageable once we get to Exascale performance!

Dell - Internal Use - Confidential41 of 69
The next buzzword is PGAS
PGAS stands for Partitioned Global Address Space
• Think of MPI, but then lighter weight and memory is “shared” across nodes
Node 1 Node 2 Node 3 Node 4
Network switch

Dell - Internal Use - Confidential42 of 69
Example
/** Read the input data into symmetric memory*/if (me == 0) {
for (i = 0; i < npes; i++) {ptr = shmem_ptr(&image[g_image_start[i]], i);ret = read(fpd, ptr, sizeof(unsigned char) * image_block[i]);
}close(fpd) ;
}for(z = tw2; z < dimz-tw2+1; z += 4) {
for(y = tw2; y < dimy-tw2+1; y += 4) {for(x = tw2; x < dimx-tw2+1; x += 4) {
istart = (z + gstart[me]) * dimx * dimy + (y + -tw2) * dimx;/** Find the PE of the remote data object*/pe = istart / g_image_block;shmem_getmem(buf, &image[istart], len * sizeof(unsigned char), pe);label_texture(buf, tw, tw, giblock[me], val_min, val_max,nl, nb, bodies, matrix_a, matrix_b, matrix_c,
matrix_d) ;}
}}
shmem_barrier_all();shfree(image);

Optimization examples

Case study 1: 3D anti-leakage FFT

Dell - Internal Use - Confidential45 of 69
Seismic reflection and processing
Oil companies use reflection seismology to estimate the properties of the Earth’s surface by
analyzing the reflection of seismic waves
Image obtained from: https://en.wikipedia.org/wiki/Reflection_seismology#/media/File:Seismic_Reflection_Principal.png

Dell - Internal Use - Confidential46 of 69
Seismic data processing
Data processing is being used to reconstruct the reflected seismic waves into a picture
(deconvolution)
These events can be relocated into space or time to the exact location by discrete Fourier
Transformations
Image obtained from: http://groups.csail.mit.edu/netmit/wordpress/wp-content/themes/netmit/images/sFFT.png
F 𝜔 = −∞∞f 𝑡 𝑒−𝑖𝜔𝑡𝑑𝑡

Dell - Internal Use - Confidential47 of 69
Anti leakage Fourier Transformations
• In order to perform a correct Fourier Transformation, the input data needs to be uniformly
distributed. Two problems can occur in the case of seismic processing:
– The data may be undersampled (aliasing)
– The data may be irregularly sampled, leading to “spectral leakage”, where energy of one Fourier coefficient
leaks into another
• Anti leakage Fourier Transformations use a multiple phase FFT
1. Solve the most energetic Fourier coefficient
2. Subtract this component from the original grid and solve the next
3. Repeat until all coefficients are estimated

Dell - Internal Use - Confidential48 of 69
Benchmarking and profiling
• A single record was used to limit the job turnaround time
• All cores (including logical processors) are used
• Profiling was done using Intel® Advisor XE
– Shows application hotspots with most time consuming loops
– Shows data dependencies
– Shows potential performance gains (only with 2016 compilers)
– Makes compiler output easier to read (only with 2016 compilers)
Image obtained from: https://software.intel.com/en-us/intel-advisor-xe

Dell - Internal Use - Confidential49 of 69
As-is profile from a single record with 12.1 compilers
• 76.5% scalar code
• 23.5% vectorized
• Two routines make up for the
majority of the wall clock time

Dell - Internal Use - Confidential50 of 69
Data alignment and loop simplificationfloat *amp_tmp = mSub.amp_panel;int m = 0;int m1 = (np - ifq) * ny * nx;
for (int n1 = 0; n1 < ny; n1++) {for (int n2 = 0; n2 < nx; n2++) {
float a = four_data[m1].r + four_out[m1].r;float b = four_data[m1].i + four_out[m1].i;amp_tmp[m] = (a * a + b * b);m1 ++;m ++;
}}
mSub.amp_panel = (float *) _mm_malloc(mySize * sizeof(float), 32);float *amp_tmp = mSub.amp_panel;int m1 = (np - ifq) * ny * nx;
for (int n1 = 0; n1 < ny * nx; n1++) {__assume_aligned(amp_tmp, 32);__assume_aligned(four_data, 32);__assume_aligned(four_out, 32);amp_tmp[n1] = ((four_data[m1 + n1].r + four_out[m1 + n1].r) *
(four_data[m1 + n1].r + four_out[m1 + n1].r)) + ((four_data[m1 + n1].i + four_out[m1 + n1].i) *(four_data[m1 + n1].i + four_out[m1 + n1].i));
}
AS-IS
OPT

Dell - Internal Use - Confidential51 of 69
Compiler diagnostic outputLOOP BEGIN at test3d_subs.cpp(701,4)
remark #15389: vectorization support: reference four_data has unaligned access [ test3d_subs.cpp(702,40) ]remark #15389: vectorization support: reference four_out has unaligned access [ test3d_subs.cpp(702,40) ]remark #15389: vectorization support: reference amp_panel has unaligned access [ test3d_subs.cpp(704,7) ]remark #15381: vectorization support: unaligned access used inside loop bodyremark #15305: vectorization support: vector length 16remark #15309: vectorization support: normalized vectorization overhead 0.393remark #15300: LOOP WAS VECTORIZEDremark #15442: entire loop may be executed in remainderremark #15450: unmasked unaligned unit stride loads: 2 remark #15451: unmasked unaligned unit stride stores: 1 remark #15460: masked strided loads: 4 remark #15475: --- begin vector loop cost summary ---remark #15476: scalar loop cost: 29 remark #15477: vector loop cost: 3.500 remark #15478: estimated potential speedup: 6.310 remark #15488: --- end vector loop cost summary ---
LOOP END
LOOP BEGIN at test3d_subs.cpp(692,8)remark #15388: vectorization support: reference amp_panel has aligned access [ test3d_subs.cpp(696,4) ]remark #15389: vectorization support: reference four_data has unaligned access [ test3d_subs.cpp(696,4) ]remark #15389: vectorization support: reference four_out has unaligned access [ test3d_subs.cpp(696,4) ]remark #15381: vectorization support: unaligned access used inside loop bodyremark #15305: vectorization support: vector length 16remark #15309: vectorization support: normalized vectorization overhead 0.120remark #15300: LOOP WAS VECTORIZEDremark #15449: unmasked aligned unit stride stores: 1 remark #15450: unmasked unaligned unit stride loads: 2 remark #15460: masked strided loads: 8 remark #15475: --- begin vector loop cost summary ---remark #15476: scalar loop cost: 43 remark #15477: vector loop cost: 3.120 remark #15478: estimated potential speedup: 9.070 remark #15488: --- end vector loop cost summary ---
LOOP END
AS-IS
OPT

Dell - Internal Use - Confidential52 of 69
Expensive type conversionsfor (int i = 0; i < nx; i++){
int ii = i - nxh;float fii = (float) ii*scale + (float) (nxh) ;
if (fii >= 0.0) {ii = (int) fii;ip = ii+1;if(ip < nx && ii >= 0) {
t = (fjj - (float) jj);u = (fii - (float) ii);int n1 = jj*nx + ii;int n2 = jp*nx + ii;int n3 = jp*nx + ip;int n4 = jj*nx + ip;amp[m] += ((1.0-t)*(1.0-u)*amp_tmp[n1]+t*(1.0-u)*amp_tmp[n2]+t*u*amp_tmp[n3]+(1.0-t)*u*amp_tmp[n4]);
}}m ++;
}
remark #15417: vectorization support: number of FP up converts: single precision to double precision 8 [ test3d_subs.cpp(784,26) ]remark #15418: vectorization support: number of FP down converts: double precision to single precision 1 [ test3d_subs.cpp(784,26) ]remark #15300: LOOP WAS VECTORIZEDremark #15475: --- begin vector loop cost summary ---remark #15476: scalar loop cost: 48 remark #15477: vector loop cost: 25.870 remark #15478: estimated potential speedup: 1.780 remark #15487: type converts: 12
AS-IS

Dell - Internal Use - Confidential53 of 69
Expensive type conversions - solutionunion convert_var_type { int i; float f; };union convert_var_type convert_fii_1, convert_fii_2;
for (ii = -nxh; ii < nx - nxh; ii++) {convert_fii_1.f = ii * scale + nxh;fii = convert_fii_1.f;if (fii >= 0.0f) {
convert_fii_2.i = fii;iii = convert_fii_2.i;if(iii < nx - 1 && iii >= 0) {
convert_iii.f = iii;t = fjj - jjf;u = fii - convert_iii.f;n1 = jjj * nx + iii;n2 = (jjj + 1) * nx + iii;amp[m] += ((1.0f-t)*(1.0f-u)*amp_tmp[n1]+t*(1.0f-u)*amp_tmp[n2]
+t*u*amp_tmp[n2+1]+(1.0f-t)*u*amp_tmp[n1+1]);}
}m ++;
}
remark #15300: LOOP WAS VECTORIZEDremark #15475: --- begin vector loop cost summary ---remark #15476: scalar loop cost: 42 remark #15477: vector loop cost: 20.370 remark #15478: estimated potential speedup: 1.960remark #15487: type converts: 3
OPT

Dell - Internal Use - Confidential54 of 69
What about parallelization?
Window processing is embarrassingly parallel
#pragma omp parallel for schedule(dynamic, 1)for (int iwin = 0; iwin < NumberOfWindows; iwin++) {
/* thread number handling the window */int tn = omp_get_thread_num();
<< Do computation >>}
Memory allocation is not
for (int i = 0; i < numThreads; i++) {mySize = maxntr_win;if(!(mem_sub[i].trcid_win = new int[mySize])) ierr = 1;memset(mem_sub[i].trcid_win, 0, sizeof(int) * mySize);mb += sizeof(int) * mySize;
}
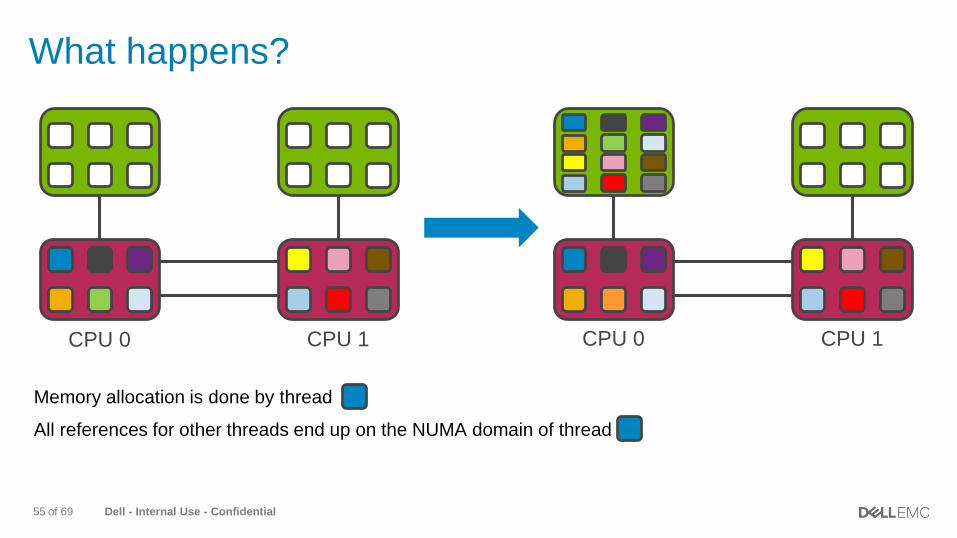
Dell - Internal Use - Confidential55 of 69
What happens?
Memory allocation is done by thread
CPU 0 CPU 1 CPU 0 CPU 1
All references for other threads end up on the NUMA domain of thread

Dell - Internal Use - Confidential56 of 69
Correct way of “first touch” memory allocation
Do the memory allocation and population in parallel so that each thread initializes its own memory
for (int i = 0; i < numThreads; i++) {mySize = maxntr_win;if(!(mem_sub[i].trcid_win = new int[mySize])) ierr = 1;
}
#pragma omp parallel{
int i = omp_get_thread_num();memset(mem_sub[i].trcid_win, 0, sizeof(int) * mySize);mb += sizeof(int) * mySize;
}
CPU 0 CPU 1

Dell - Internal Use - Confidential57 of 69
Hardly any thread overhead to be seen

Dell - Internal Use - Confidential58 of 69
Confiden
Final result of optimized code
5
• 76.5% vectorized
• 23.5% scalar code

Dell - Internal Use - Confidential59 of 69
Final results
Node Original version Optimized version
E5-2670 @ 2.6 GHz, 32 threads 192 seconds 145 seconds (+24.4%)
E5-2680 v3 @ 2.5 GHz, 48 threads 156 seconds 112 seconds (+28.2%)
Node With AVX With FMA + AVX2
E5-2680 v3 @ 2.5 GHz, 48 threads 86 seconds 68 seconds (+20.9%)
• Even better with 16.1 compilers, optimized version:
• 24.4% speedup obtained on SNB, 28.2% on HSW

Case study 2: Elan application

Dell - Internal Use - Confidential61 of 69
The Elan application
• The ELAN application is used to post-process recorded Controlled Source Electromagnetic data
(CSEM)
• Written in C++, with the compute intensive parts in Fortran 90
• Uses FFTW and Intel MKL linear algebra functions
• Application is memory bound, customer statement was “There’s nothing to improve”

Dell - Internal Use - Confidential62 of 69
Performance analysis
1. Workload is highly memory bandwidth dependent
– Amount of cache misses is high due to use of array sections
– Non unit stride array access inhibit software pipelining
2. 3D stencil operations use a lot of array references
– High register pressure
– Unbalanced use of execution ports of on the CPU
3. Unnecessary calculations
– IF (0 * <some value> == 0) THEN is still zero!

Dell - Internal Use - Confidential63 of 69
Calculation of Green’s functionsINTEGER, INTENT(IN) :: x1,x2,y1,y2,z1,z2,nfCOMPLEX(wp), INTENT(INOUT) :: FD(nf,x1:x2+1,y1:y2+1,z1:z2+1)INTEGER, INTENT(IN) :: k0x,klx,k0y,kly,k0z,klzREAL(wp), INTENT(IN) :: F(k0x:klx,k0y:kly,k0z:klz)COMPLEX(wp), INTENT(IN) :: corr(nf)
INTEGER :: iz, iy, ix
DO iz=z1,z2+1DO iy=y1,y2+1DO ix=x1,x2+1FD(:,ix,iy,iz) = FD(:,ix,iy,iz) + F(ix,iy,iz) &
* corr(:)END DO
END DOEND DO
INTEGER, INTENT(IN) :: x1,x2,y1,y2,z1,z2,nfCOMPLEX(wp), INTENT(INOUT) :: FD(nf,x1:x2+1,y1:y2+1,z1:z2+1)INTEGER, INTENT(IN) :: k0x,klx,k0y,kly,k0z,klzREAL(wp), INTENT(IN) :: F(k0x:klx,k0y:kly,k0z:klz)COMPLEX(wp), INTENT(IN) :: corr(nf)COMPLEX(wp) :: corr_tmpINTEGER :: iz, iy, ix
DO if1 = 1, nfcorr_tmp = corr(if1)DO iz=z1,z2+1DO iy=y1,y2+1DO ix=x1,x2+1FD(ix,iy,iz,if1) = FD(ix,iy,iz,if1) + F(ix,iy,iz) &
* corr_tmpEND DOEND DO
END DOEND DO
149 seconds 52 seconds
Caxpy type multiply with real – complex addition:
Re.FD = Re.FD + ((Re.F * Re.corr) – (0 * Im.corr)) 2 loads, 2 additionsIm.FD = Im.FD + ((0 * Re.corr) + (Re.F * Im.corr)) 2 summations, 1 store

Dell - Internal Use - Confidential64 of 69
Readouts of the field recordsDO it=1,noprec
DO itSub=1,subNoprecix = ir(1,it,itSub)iy = ir(2,it,itSub)iz = ir(3,it,itSub)idx = idr(1,it,itSub)idy = idr(2,it,itSub)idz = idr(3,it,itSub)sum = 0.0testx = 0.0testy = 0.0testz = 0.0
DO ilz=-lsz,lszirez = iz + ilzIF (irez.ge.k0z.and.irez.le.klz) THEN
DO ily=-lsy,lsyirey = iy + ilyIF (irey.ge.k0y.and.irey.le.kly) THEN
DO ilx=-lsx,lsxirex = ix + ilxIF (irex.ge.k0x.and.irex.le.klx) THEN
sum = sum + field(irex,irey,irez)& * diracsx(ilx,idx) &* diracsy(ily,idy) &* diracsz(ilz,idz) * (dx*dy*dz)
testx = testx + diracsx(ilx,idx)testy = testy + diracsy(ily,idy)testz = testz + diracsz(ilz,idz)
END IFEND DO
END IFEND DO
END IFEND DOrec(it,itSub) = sum
END DOEND DO
DO itSub=1,subNoprecDO it=1, noprec
ix = ir(1,it,itSub)iy = ir(2,it,itSub)iz = ir(3,it,itSub)idx = idr(1,it,itSub)idy = idr(2,it,itSub)idz = idr(3,it,itSub)sum = 0.0startz = MAX(iz-lsz,k0z)starty = MAX(iy-lsy,k0y)startx = MAX(ix-lsx,k0x)stopz = MIN(iz+lsz,klz)stopy = MIN(iy+lsy,kly)stopx = MIN(ix+lsx,klx)
DO irez = startz, stopzilz = irez - izIF (diracsz(ilz,idz) .EQ. 0.d0 ) THEN
CYCLEEND IFdirac_tmp1 = diracsz(ilz,idz)*(dx*dy*dz)DO irey = starty, stopy
ily = irey - iydirac_tmp2 = diracsy(ily,idy) * dirac_tmp1DO irex = startx, stopx
ilx = irex - ixsum = sum + field(irex,irey,irez) &
* diracsx(ilx,idx) &* dirac_tmp2
END DOEND DO
END DOrec(it,itSub)=sum
END DOEND DO92 seconds 17 seconds

Dell - Internal Use - Confidential65 of 69
Profile result

Dell - Internal Use - Confidential66 of 69
Hardware profile resultCore (SKT) | EXEC | IPC | FREQ | AFREQ | L3MISS | L2MISS | L3HIT | L2HIT | L3CLK | L2CLK | READ | WRITE | TEMP
0 0 0.00 0.28 0.00 1.36 3216 K 3411 K 0.06 0.09 1.14 0.01 N/A N/A 511 0 0.00 0.66 0.00 1.36 488 K 532 K 0.08 0.22 0.90 0.02 N/A N/A 512 0 0.00 0.32 0.00 1.36 317 K 344 K 0.08 0.06 1.38 0.02 N/A N/A 553 0 0.00 0.31 0.00 1.36 320 K 345 K 0.07 0.05 1.44 0.02 N/A N/A 554 0 0.00 0.31 0.00 1.36 319 K 342 K 0.07 0.05 1.43 0.02 N/A N/A 525 0 0.00 0.32 0.00 1.36 323 K 349 K 0.07 0.06 1.42 0.02 N/A N/A 576 0 0.00 0.31 0.00 1.36 344 K 365 K 0.06 0.05 1.48 0.02 N/A N/A 497 0 2.15 1.57 1.36 1.36 3280 M 4210 M 0.22 0.30 0.70 0.04 N/A N/A 498 1 0.00 0.36 0.00 1.06 122 K 246 K 0.51 0.13 0.39 0.08 N/A N/A 569 1 0.00 0.48 0.00 1.27 1537 K 1961 K 0.22 0.20 1.55 0.08 N/A N/A 58a 1 0.00 0.38 0.00 1.06 233 K 412 K 0.43 0.15 0.37 0.05 N/A N/A 59b 1 0.00 0.50 0.00 1.25 115 K 259 K 0.55 0.20 0.35 0.09 N/A N/A 56c 1 0.00 0.46 0.00 1.10 59 K 142 K 0.58 0.12 0.40 0.11 N/A N/A 57d 1 0.00 0.17 0.01 1.34 581 K 920 K 0.37 0.13 0.02 0.00 N/A N/A 62e 1 0.00 0.48 0.00 1.09 56 K 141 K 0.60 0.12 0.38 0.11 N/A N/A 58f 1 0.00 0.48 0.00 1.20 101 K 219 K 0.54 0.17 0.38 0.09 N/A N/A 64
-------------------------------------------------------------------------------------------------------------------SKT 0 0.27 1.57 0.17 1.36 3285 M 4216 M 0.22 0.30 0.70 0.04 1896.56 664.44 49SKT 1 0.00 0.20 0.00 1.32 2808 K 4304 K 0.35 0.17 0.10 0.01 1.78 1.75 56
-------------------------------------------------------------------------------------------------------------------TOTAL * 0.13 1.56 0.09 1.36 3288 M 4220 M 0.22 0.30 0.70 0.04 1898.35 666.19 N/A
> 1 means
turbo mode
on
Large amount
of cache
misses
1,9 TB data read + 0.65 TB data write = 2.56 TB of total memory traffic
This equals to (2.56 * 10^3)/300s = 8.53 GB/s bandwidth used

Dell - Internal Use - Confidential67 of 69
Time line of an optimization effortSu Mo Tue We Th Fr Sa
26 27 28 29 30 START 31 1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
579 421
368 363
343 302
278
2x speedup achieved!
Customer visit

Dell - Internal Use - Confidential68 of 69
Summary of Code changes
1. Reduced memory pressure by adding scalars instead of memory references
2. Removed conditionals in inner loops and used dynamic index calculation for integrals
3. Transposed data layout of important arrays
4. Fixed data alignment of important arrays on 32-byte boundaries (for AVX)
5. Inserted conditionals in outer loops to check for ZEROs
– 0 * <some value> == 0 (unnecessary calculation!)
6. Implemented cache blocking to reduce memory pressure
7. Used Intel MKL FFT wrappers instead of FFTW
8. Tuned compiler flags for some routines
