practica nº 02
DESCRIPTION
hidrológiaTRANSCRIPT

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
PRACTICA Nº 02
HIDROLOGIA ESTADÍSTICA
Los estudios hidrológicos requieren del análisis de cuantiosa información hidrometeológica; esta información puede consistir de datos de precipitación, caudales, temperatura, evaporación, etc.Los datos recopilados, solo representan una información en bruto, pero si éstos se organizan y analizan en forma adecuada, proporcionan al hidrólogo una herramienta de gran utilidad, quele permite tomar decisiones en el diseño de estructuras hidráulicas.Para el análisis de la información, la hidrología utiliza los conceptos de probabilidades y estadística, siendo este campo, una de las primeras áreas de la ciencia e ingeniería, en usar losconceptos estadísticos, en un esfuerzo para analizar los fenómenos naturales.
Objetivos: El objetivo del estudio de la Hidrología Estadística, está orientada a ayudar a comprender los principios fundamentales de la probabilidad y la estadística, aplicada a la hidrología, así como, mostrar algunas herramientas estadísticas, que han sido aplicados con éxito, en la solución de problemas hidrológicos.Para la simplificación del análisis de la abundante información, se requiere del uso de la computadora digital, y el uso de software, que tiene la finalidad de procesar fácilmente esta información. Ella se utiliza en la solución de los ejemplos resueltos.
1. Frecuencias de una muestra 1.1 Representación tabular y gráfica de las muestras En hidrología se trabaja con informaciones hidrometeoro lógicas; estas informaciones pueden consistir de datos de precipitación, caudales, temperatura, evaporación, etc.Por lo general, se cuenta solo con una muestra de los datos de esa población, es decir, nunca se puede disponer de la totalidad de los datos. Pero cuando éstos datos se organizan en forma compacta y fácil de utilizar, los hidrólogos pueden disponer de una herramienta |de gran utilidad, para las decisiones a tomar.Existen muchas formas de clasificar los datos, una manera útil, es dividirlo en categorías similares o clases, y luego contar el número de observaciones que caen en cada categoría, lo que constituye unatabla de frecuencias o una distribución de frecuencias.Para una muestra dada, se escoge un rango R, que contenga a todos los valores de la misma. Se subdivide R en subintervalos que se llaman intervalos de clase; los puntos medios de estos intervalos se denominan marcas de clase. Se dice que los valores de la muestraen cada uno de los intervalos forma una clase.. Al número de valores en una clase se llama frecuencia de la clase; su división entre el tamaño N de la muestra es la frecuencia relativa de clase. Esta frecuencia considerada como función de las marcas de clase, se denomina función de frecuencias de la muestra, y se denota comof(x). La función de frecuencias acumuladas de la muestra, se denota como F(x), y se define como:
1.2 Procedimiento de cálculo-A continuación se indica un procedimiento práctico, para el cálculo de las frecuencias y frecuencias acumuladas, la misma que se usará más adelante para el cálculo de la distribución de probabilidades empíricas de datos agrupados en intervalos de clase:Procedimiento:1. Ordenar la muestra en forma creciente o decreciente:Para agilizar los cálculos resulta conveniente contar con una aplicación que permita el ordenamiento de

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
los datos.Por ejemplo, si se ordenan los datos en forma creciente, se tiene:
Xmin, X2, X3, ....Xmáx (1.1)
donde:
Xmin = X1 es el valor mínimo de los datos
Xmax = XN es el valor máximo de los datos
2. Calcular el rango R de la muestra:
R = Xmax - Xmin (1.2)
3. Seleccionar el número de intervalos de clase NC:NC depende del tamaño de la muestra N. En aplicaciones de hidrología el número de intervalos de clase puede estar entre 6 y 25.Yevjevich sugiere para seleccionar NC, las siguientes relaciones empíricas:(a) NC = l.33lnN+1 (1.3)(b) si N < 30 => NC < 5
si 30 < N < 75 => 8 < NC < 10si N > 75 => 10 > NC < 30
donde:N = tamaño de la muestralnN = logaritmo natural o neperiano del tamaño muestral.
4. Calcular la amplitud de cada intervalo de clase x, según la ecuación:
= (1.4)Al dividir el rango entre NC - 1, lo que en realidad se hace es incrementar el rango en x, incluyendo un intervalo más, el mismo que resulta, de agregar medio intervalo (x /2), en cada extremo de la serie ordenada, a fin de que xmax y xmin respectivamente, las marcas de clase de la primera y última clase.
5. Calcular los límites de clase de cada uno de los intervalos:Como se manifestó en el punto 4, con el artificio de dividir entre NC-1, se logra que x^fn y x^áx queden centrados y representan las marcas de clase de la primera y última clase, entonces los límites de clase inferior y superior del primer intervalo de clase, son:
LCI1 = (1.5)
LCS1 = = LCI1 + x (1.6)
Los otros límites de clase, se obtienen sumando la amplitud x, al límite de clase anterior.
6. Calcular las marcas de clase de cada uno de los intervalos:Las marcas de clase se obtienen del promedio de los límites de clase.Así 1: marca de clase del primer intervalo es:
Con el artificio realizado anteriormente la marca de clase del primer intervalo es igual al valor mínimo,

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
de igual forma la marca de clase del último intervalo es igual al valor máximo es decir:MCl=XminMCn = Xmáx
Las otras marcas de clase, se obtienen sumando la amplitud x, a las marcas de clase anteriores.
7. Calcular la frecuencia absoluta:Esta es igual al número de observaciones, que caen dentro de cada intervalo definido por sus límites de clases respectivos, la misma que se obtiene por conteo, así se obtiene:fabi = ni ... (1.8)donde:fabi = frecuencia absoluta del intervalo ini = número de observaciones en el intervalo i
8. Calcular la frecuencia relativa fri, de cada intervalo:Esta es igual a la frecuencia absoluta del mismo, dividido entre el número total de observaciones, es decir:
...(1.9)
N Ndonde:fri = frecuencia relativa del intervalo ini = número de observaciones en el intervalo iN = número total de observaciones
9. Calcular la frecuencia relativa acumulada Fri, usando la fórmula:
(1.10)
donde:Fri = frecuencia relativa acumulada hasta el intervalo ij = 1, 2,..., i acumulación de los intervalos hasta ini =- número de observaciones en el intervalo iN = número total de observaciones
10. Calcular la función densidad empírica fp para cada intervalo:Esta función según Yevjevich, se calcula usando la fórmula:
...(2.11)
donde:fi = función densidad empírica para el intervalo ini = número de observaciones en el intervalo iN = número total de observaciones x = amplitud del intervalo de clases
11. Calcular la función de distribución acumulada empírica usando la fórmula:
...(1.12)
7=1donde:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
F¡ = función de distribución acumuladafi = función densidad empírica para el intervalo jAx = amplitud del intervalo de claseLos valores de Fri y Fi obtenidos con las ecuaciones (1.10) y (1.12) resultan similares.
EjemploDada la serie histórica de caudales medios anuales en m3/s (tabla 1.1), de la estación Salinar del Río Chicama (Perú), para el período 1911-1980, calcule las frecuencias absolutas, relativa, acumulada,función densidad, función acumulada.Solución:
1. Ordenando los datos de la tabla 1.1, se obtiene la tabla 1.2.Tabla 1.1. Serie histórica de caudales medios anuales en m3/s del río Chicama, estación Salinar (1911 - 1980)
Año Caudal m3/s
Año Caudal m3/s
Año Caudal m3/s
1911 7.91 1935 24.58 1959 22.881912 8.01 1936 28.49 1960 17.571913 13.27 1937 10.05 1961 14.601914 16.39 1938 28.01 1962 31.141915 80.83 1939 34.92 1963 18.201916 60.08 1940 31.36 1964 24.691917 21.55 1941 42.74 1965 22.991918 27.71 1942 12.94 1966 11.781919 28.63 1943 41.16 1967 32.261920 30.27 1944 35.90 1968 4.761921 33.43 1945 33.76 1969 12.701922 35.16 1946 29.28 1970 16.191923 27.21 1947 19.17 1971 30.141924 15.58 1948 29.37 1972 30.571925 64.81 1949 30.06 1973 45.381926 51.26 1950 9.67 1974 18.911927 33.48 1951 10.42 1975 34.991928 25.79 1952 23.99 1976 21.491929 25.80 1953 42.17 1977 29.261930 18.93 1954 16.00 1978 4.581931 16.15 1955 22.78 1979 12.461932 38.30 1956 32.69 1980 3.141933 54.54 1957 34.281934 59.40 1958 20.24
2. Cálculo de R:De (1.2), se tiene:R = 80.83 - 3.14R = 77.69
Tabla 1.2 Serie de caudales en m3/s, del río Chicama, ordenado ascendentemente
3.14 4.58 4.76 7.91 8.01 9.67 10.05

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
10.42 11.78 12.46 12.70 12.92 13.27 14.60 15.58 16.00 16.15 16.19 16.39 17.57 18.20 18.91 18.93 19.77 20.24 21.49 21.55 22.78 22.88 22.99 23.99 24.58 24.69 25.79 25.80 27.21 27.71 28.01 28.49 28.63 29.26 29.28 29.37 30.06 30.14 30.27 30.57 31.14 31.36 32.26 32.69 33.43 33.48 33.76 34.28 34.92 34.99 35.16 35.90 38.30 41.16 42.17 42.74 45.38 51.26 54.54 59.40 60.08 64.81 80.83
3. Cálculo de NC:
De (1.3), resulta:NC = 1.33 1n70 + lNC = 6.65
Redondeando:NC=7
4. Cálculo de x:
De (1.4) se obtiene:
Si se quisiera redondear a fin de que los límites y las marcas de clase resulten números más simples, podría ser: x=13 ó s =12.Si se escoge x = 13 los límites de clase superior e inferior, resultan un poco mayor y menor respectivamente que si se escoge x = 12.Para el ejemplo se escoge x = 12, a fin de obtener valores parecidos, al que se obtiene con el proceso computacional.
5. Cálculo de los límites de clase:
De (1.5), el límite de clase inferior del primer intervalo sería:LCI1=3.14- 12/2 == -2.86pero físicamente los caudales no pueden ser negativos, el menor valor sería 0.LCI1 =0De (1.6), se tiene:LCSI = 0+12=12Los otros límites, se calculan sumando x al límite de clase que le antecede; los resultados se muestran en la columna 1 de la tabla 1.3.Nota. Cuando el límite de clase es negativo, su valor, por condiciones físicas será cero.
6. Cálculo de las marcas de clase
De (1.7), la marca de clase del primer intervalo es:
Las marcas de clase de los otros intervalos se obtienen sumando x a la precedente; los resultados se muestran en la columna 2 de la tabla 1.3.Nota. Observar que cuando el límite de clase es inferior a cero, la marca de clase del primer intervalo,

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
no es igual al valor mínimo.
7. Cálculo de la frecuencia absoluta
A partir de los datos ordenados de la tabla 1.2, es fácil determinar el número de valores comprendidos en cada intervalo, así en el primer intervalo entre 0-12, hay 9 valores y así sucesivamente, los resultados se muestran en la columna 3 de la tabla 1.3.
8. Cálculo de la frecuencia relativa
Usando (1.9), se obtienen los valores que se muestran en la columna 4 de la tabla 1.3.
9. Cálculo de la función densidad empírica y la función de distribución acumulada.usando (1.11) y (1.12), se obtienen los valores que se muestran en las columnas 5 y 6 de la tabla 1.3.
Tabla 1.3. Cálculo de la frecuencia relativa, absoluta, función densidad y acumulada del río Chicama, proceso manual.
Intervalo de clase
Marca de Frecuencia Frecuencia Función Función
Clase aabsoluta relativa densidad acumulada
(1) (2) (3) (4) (5) (6) 0 0 0
0 12 6 9 0.1286 0.0107 0.1286
12 24 18 22 0.3143 0.0262 0.4429
24 36 30 28 0.4000 0.0333 0.8429
36 48 42 5 0.0714 0.0060 0.9143
48 60 54 3 0.0429 0.0036 0.9571
60 72 66 2 0.0286 0.0024 0.9857
72 84 78 1 0.0143 0.0012 1.0000
Total 70
1.3 Representación gráfica
Existen varias formas de representar las muestras en forma gráfica, dentro de las cuales se pueden mencionar:
Histograma
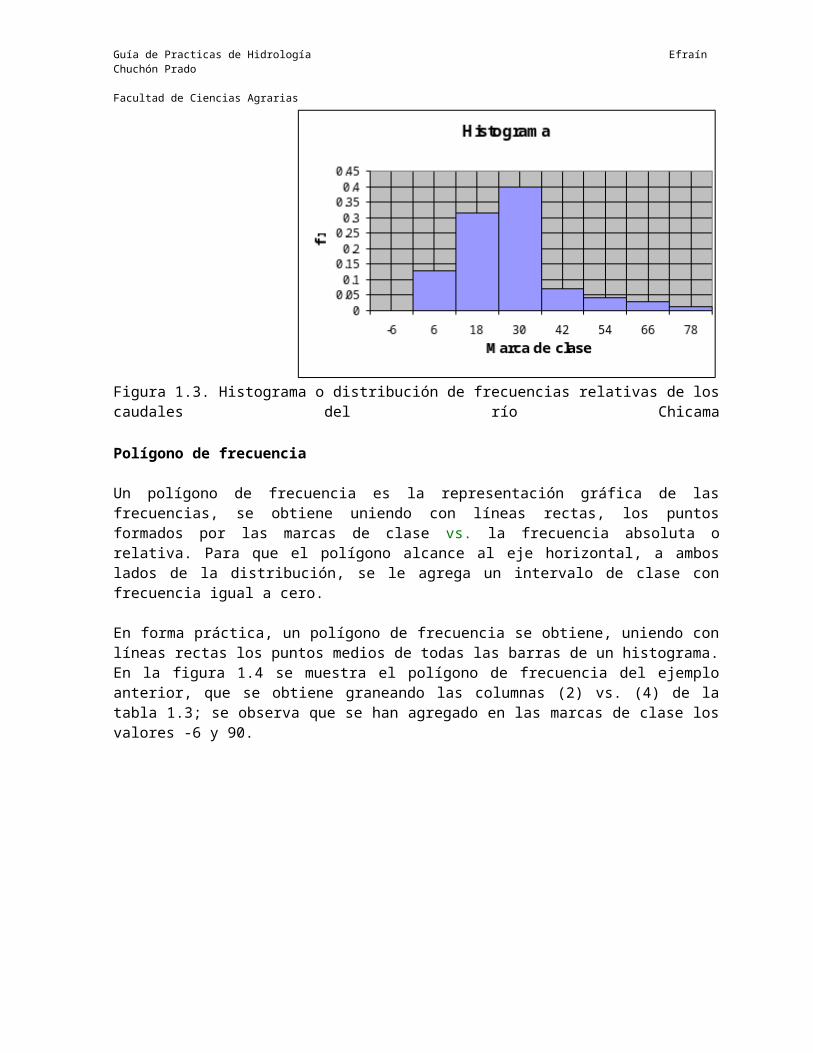
Un histograma es la representación gráfica de las frecuencias, en forma de rectángulos, siendo la base de cada rectángulo el intervalo de clase y la altura la frecuencia absoluta, fab i ó la frecuencia relativa fri.En la figura 1.3, se muestra el histograma del ejemplo anterior, que se obtiene grafícando las columnas (1) y (4) de la tabla 1.3.

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
Figura 1.3. Histograma o distribución de frecuencias relativas de los caudales del río Chicama
Polígono de frecuencia
Un polígono de frecuencia es la representación gráfica de las frecuencias, se obtiene uniendo con líneas rectas, los puntos formados por las marcas de clase vs. la frecuencia absoluta orelativa. Para que el polígono alcance al eje horizontal, a ambos lados de la distribución, se le agrega un intervalo de clase con frecuencia igual a cero.
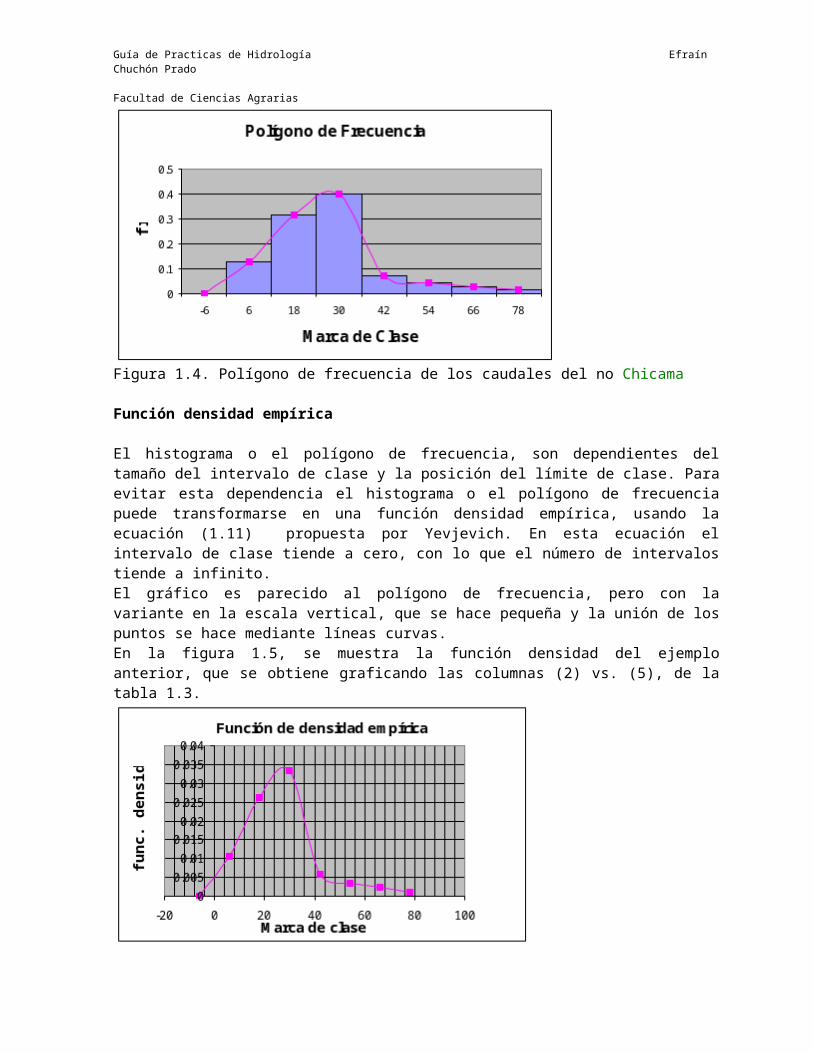
En forma práctica, un polígono de frecuencia se obtiene, uniendo con líneas rectas los puntos medios de todas las barras de un histograma.En la figura 1.4 se muestra el polígono de frecuencia del ejemplo anterior, que se obtiene graneando las columnas (2) vs. (4) de la tabla 1.3; se observa que se han agregado en las marcas de clase losvalores -6 y 90.
Figura 1.4. Polígono de frecuencia de los caudales del no Chicama
Función densidad empírica
El histograma o el polígono de frecuencia, son dependientes del tamaño del intervalo de clase y la

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
posición del límite de clase. Para evitar esta dependencia el histograma o el polígono de frecuenciapuede transformarse en una función densidad empírica, usando la ecuación (1.11) propuesta por Yevjevich. En esta ecuación el intervalo de clase tiende a cero, con lo que el número de intervalos tiende a infinito.El gráfico es parecido al polígono de frecuencia, pero con la variante en la escala vertical, que se hace pequeña y la unión de los puntos se hace mediante líneas curvas.En la figura 1.5, se muestra la función densidad del ejemplo anterior, que se obtiene graficando las columnas (2) vs. (5), de la tabla 1.3.
Figura 1.5. Función densidad empírica de los caudales del río Chicama
Este gráfico de la función densidad, es muy útil para comparar los resultados empíricos, con la función densidad de probabilidad de distribuciones conocidas, como la normal, log-normal y otras.
Función de distribución acumulada o empírica
Permite ver el porcentaje de las observaciones que quedan por encima o por debajo de ciertos valores, con respecto al total. El gráfico se obtiene uniendo los puntos obtenidos por las marcas declase vs. la función acumulada.En la Figura 2.6, se muestra la función acumulada del ejemplo anterior, que se obtiene graneando las columnas (2) vs. (6) de la tabla 2.3.
Figura 1.6. Función de distribución acumulada de los caudales del no Chicama
Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
En la tabla 1.4 se muestran los resultados, para los mismos datos, usando el proceso computacional. En esta tabla 1.4, la frecuencia relativa y la función de densidad acumulada se expresan en %.
Tabla 1.4. Función densidad empírica y función acumulada, proceso computacional
Intervalo de clase Frecuencia absoluta
Frecuencia relativa (%)
Función densidad
(%)
Función acumulad
(%)LCI MCL LCS 0.00 6.00 12.00 9.00 12.857 1.072 12.857 12.00 17.99 23.99 22.00 31.429 2.620 44.286 23.99 29.99 35.99 28.00 40.000 3.335 84.286 35.99 41.99 47.98 5.00 7.143 0.595 91.429 47.98 53.98 59.98 3.00 4.286 0.357 95.714 59.98 65.98 71.97 2.00 2.857 0.238 98.571 71.97 77.97 83.97 1.00 1.429 0.119 100.000
1.4 Problemas propuestos
1. Dada la serie histórica de caudales medios anuales en m^/s del río Santa que se muestran en la tabla 1.5.Tabla 1.5 Serie histórica de caudales medios anuales del río Santa
239.07 101.76 100.18 107.43 183.11 154.80 197.58 153.64 169.18 124.31 107.62 108.75 144.22 134.10 156.80 119.52 105.21 116.69 169.64 158.48 164.35 163.88 105.81 110.77 212.48 123.22 177.00 193.78 162.29 133.97 184.98 146.08 128.15 101.66 123.00 127.82 98.13 106.40 145.79 207.78 217.52 208.18 182.53 183.49 95.05 132.49 114.31 136.22 266.54 256.62
Realizar el gráfico de: Histograma de distribución de frecuencias relativas Polígono de frecuencias Función densidad empírica Función acumulada
2. Dada la serie histórica de caudales medios anuales en m3/s de la estación 76-20-01 del río Corobicí , que se muestra en la tabla 2,6, realizar el gráfico de:
Histograma de distribución de frecuencias relativas Polígono de frecuencias Función densidad empírica Función acumulada
Tabla 2.6 Caudales medios anuales del río Corobicí
Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
Año hidrológico
Caudal (m3/s)
Año hidrológico
Caudal (m3/s)
54-55 13.35 70-71 15.0655-56 21.90 71-72 10.2056-57 11.13 72-73 4.8557-58 5.22 73-74 11.7758-59 4.40 74-75 8.4159-60 6.70 75-76 8.5760-61 8.55 76-77 6.1061-62 8.12 77-78 5.3362-63 7.86 78-79 6.6863-64 5.35 79-80 45.9264-65 7.51 80-81 56.9265-66 5.82 81-82 52.6466-67 10.05 82-83 42.5667-68 9.66 83-84 44.1968-69 7.61 84-85 41.9469-70 10.54 85-86 44.73
2. Parámetros estadísticos

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
El hidrólogo generalmente tendrá disponible un registro de datos hidrometeorológico (precipitación, caudales, evapotranspiración, temperaturas, etc.), a través de su conocimiento del problema físico, escogerá un modelo probabilístico a usar, que represente en forma satisfactoria el comportamiento de la variable.Para utilizar estos modelos probabilísticos, se deben calcular sus parámetros estadísticos y realizar la prueba de bondad de ajuste. Dentro de estos parámetros estadísticos calculados por los momentos ordinarios, se tiene:
media rango desviación estándar varianza coeficiente de variación coeficiente de sesgo coeficiente de curtosis
también estos parámetros estadísticos se pueden calcular utilizando los momentos lineales (L-moments)
2.1 MediaMedia muestral o poblacional datos no agrupados:
donde: µ = media muestral o poblacional xi = valor i-ésimo de la muestra n = número total de datosMedia muestral o poblacional datos agrupados:
donde: µ = media xi = valor de la i-ésima marca de clase fi = valor de la i-ésima frecuencia absoluta, es decir, número de datos en el intervalo i k = número de intervalos de clase n = número total de datos
2.2 RangoEs una medida de distancia y representa la diferencia entre el mayor y el menor de los valores observados, es decir:
R = Xmáx - Xmín donde: R = rango Xmáx = valor máximo de los datos Xmín = valor mínimo de los datos El rango o la amplitud es una manera conveniente de describir la dispersión, sin embargo, no da medida alguna de la dispersión entre los datos con respecto al valor central.

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
2.3 Desviación estándarDesviación estándar poblacional datos no agrupados:
Desviación estándar muestral datos no agrupados:
donde: S = desviación estándar muestral = desviación estándar poblacional xi = valor i-ésimo de la muestra = µ = media muestral o poblacional n = número total de datos
Desviación estándar poblacional datos agrupados:
Desviación estándar muestral datos agrupados:
donde: S = desviación estándar muestral = desviación estándar poblacional xi = valor de la i-ésima marca de clase = µ = media fi = valor de la i-ésima frecuencia absoluta, es decir, número de datos en el intervalo i k = número de intervalos de clase n = número total de datos
2.4 VarianzaVarianza poblacional datos no agrupados:
Varianza muestral datos no agrupados:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
donde: S² = varianza muestral ² = varianza poblacional xi = valor i-ésimo de la muestra = µ = media muestral o poblacional n = número total de datos
Varianza poblacional datos agrupados:
Varianza muestral datos agrupados:
donde: S² = varianza muestral ² = varianza poblacional xi = valor de la i-ésima marca de clase = µ = media fi = valor de la i-ésima frecuencia absoluta, es decir, número de datos en el intervalo i k = número de intervalos de clase n = número total de datos
2.5 Coeficiente de variaciónEs una medida relativa de dispersión, que relaciona la desviación estándar y la media, es decir:
Es una medida adimensional de la variabilidad alrededor de la media, generalmente en Hidrología se suele trabajar con datos muestrales.
2.6 Coeficiente de sesgoEl sesgo es el estadístico que mide la simetría y asimetría.Sesgo poblacional datos no agrupados:
donde:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
Sesgo muestral datos no agrupados:
donde:
Sesgo poblacional datos agrupados:
Sesgo muestral datos agrupados:
2.7 Coeficiente de curtosisEl grado de achatamiento se mide con el estadístico denominado coeficiente de curtosis.
Curtosis poblacional datos no agrupados:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
donde:
Curtosis muestral datos no agrupados:
donde:
Curtosis poblacional datos agrupados:
donde:
Curtosis muestral datos agrupados:
donde:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
Momentos lineales (L-Moments)Los momentos lineales (L–moments), constituyen una metodología moderna que permite estimar los parámetros estadísticos de una población o de una muestra. Son otra manera de expresar las propiedades estadísticas de datos hidrológicos, son similares a los momentos ordinarios pues proporcionan las medidas de localización, dispersión, asimetría, curtosis, pero se calculan de las combinaciones lineales de los datos (de aquí el nombre de momento lineal). Los parámetros estadísticos estimados con esta metodología, son menos sensibles a los valores extremos, por lo que permite determinar la distribución teórica de probabilidad que mejor ajusta a los datos analizados.Por el método de momentos lineales la dispersión no se calcula con respecto a un valor central, sino que se calculan las diferencias de todos los datos entre sí, considerando todas las posibles combinaciones. Además, las diferencias nunca se elevan a ninguna potencia, se mantienen lineales, por lo cual los parámetros estimados por este método son menos sensibles a los valores extremos.Las ecuaciones simplificadas de los momentos lineales, son:
donde:Xi (para i = 1,2 , 3, ..., n) = son los valores de la muestra ordenados ascendentemente
= combinaciones de n elementos en grupos de k en k
para k<nSi k = n Si k > n El primer momento lineal 1 representa la media aritmética de la muestra, es una medida de localización y su valor es el mismo que el calculado por el método tradicional. El segundo momento lineal 2 es equivalente a la desviación estándar pero calculada mediante las diferencias de todos los datos entre sí, no con respecto a un valor central; es un parámetro de escala o dispersión de la variable aleatoria X. Dividiendo el segundo momento lineal entre el primer momento lineal (desviación estándar entre la media), se obtiene el coeficiente lineal de variación (CLV), es decir:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
Dividiendo el momento lineal de orden r, entre la medida de dispersión, se obtiene la relación de momentos, es decir:
El t3 es una medida de asimetría y t4 es una medida de curtosis, éstas son respectivamente el coeficiente lineal de asimetría o sesgo (CLS) y el coeficiente lineal de curtosis (CLK), es decir:
Los cálculos de los momentos lineales 1, 2, 3, 4, con el uso de calculadoras e incluso con la computadora, resulta bastante complejo. Con el fin de simplificar éstos cálculos, se presenta el código fuente en Basic, de la subrutina que calcula estos momentos, también se incluyen los cálculos de los parámetros estadísticos lineales. En el código: L1= 1, L2=2, L3=3, L4=4 y xxord(j) es la serie ordenada en forma ascendente.' Cálculo de los parámetros lineales' xxord(j) es la serie ordenada en forma ascendente que se tiene disponible L1 = 0L2 = 0L3 = 0L4 = 0For j = 1 To nCL1 = j - 1CL2 = CL1 * (j - 1 - 1) / 2CL3 = CL2 * (j - 1 - 2) / 3CR1 = n - jCR2 = CR1 * (n - j - 1) / 2CR3 = CR2 * (n - j - 2) / 3L1 = L1 + xxord(j)L2 = L2 + (CL1 - CR1) * xxord(j)L3 = L3 + (CL2 - 2 * CL1 * CR1 + CR2) * xxord(j) L4 = L4 + (CL3 - 3 * CL2 * CR1 + 3 * CL1 * CR2 - CR3) * xxord(j)Next jC1 = nC2 = C1 * (n - 1) / 2c3 = C2 * (n - 2) / 3C4 = c3 * (n - 3) / 4L1 = L1 / C1L2 = L2 / C2 / 2L3 = L3 / c3 / 3L4 = L4 / C4 / 4'Cálculo de los parámetros con momentos linealesCIMedia = L1

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
CIDesEstandar = L2CIVarianza = L2 ^ 2CIVariacion = L2 / L1CISesgo = L3 / L2CIKurtosis = L4 / L2
Los cálculos de los estadísticos de una serie de datos son por sí laboriosos. Para la simplificación de los cálculos, donde se requieren la determinación de la media, varianza, desviación estándar, elcoeficiente de variación, coeficiente de sesgo y coeficiente de curtosis, tanto para datos poblacionales o muéstrales y para datos agrupados o no agrupados, es mejor contar con una aplicación que realice estos cálculos.
En la práctica se va realizat utilizando computacionalmente el Microsft Excel y el HIDROESTA para éstos cálculos.
Ejemplo 2:Dado los datos de precipitación anual, en mm de la estación El Coyol, para el período 1974-1986, los mismos que se muestran en la tabla 2.1. Calcular su media, varianza, desviación estándar, coeficiente de variación, coeficiente de sesgo y el coeficiente de curtosis.
Tabla 2.1 Precipitación anual de la estación El Coyol
Año Precipitación (mm)
Año Precipitación (mm)
1974 1418.60 1981 1441.501975 1527.30 1982 1133.201976 1108.60 1983 891.001977 1084.20 1984 1429.801978 1509.10 1985 1141.501979 1394.90 1986 1312.601980 1334.40
Solución:
Utilizando la aplicación de Microsoft Excel y haciendo uso de la opción de datos no agrupados, los resultados que se obtienen, son los que se muestran:
Poblacionales MuéstralesMedia 1286.67 1286.67Varianza 35214.73 38149.29Desviación Estándar 187.66 195.32Coeficiente Variación 0.15 0.15Coeficiente Sesgo Coeficiente Curtosis
-0.55 2.20
-0.63 3.12
Nota. Para calcular estos parámetros estadísticos solo hay que hacer uso de las fórmulas indicadas. Como práctica se sugiere que se realicen estos cálculos, tiene de antemano los resultados que debeencontrar.
2.2 Problemas propuestos

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
1. Dado los caudales medios del mes de Mayo, de un río, en m3/s:Año Q m3/s Año Q m3/s1971 3.99 1981 4.521972 2.96 1982 3.091973 1.79 1983 5.001974 1.55 1984 6.031975 2.48 1985 2.731976 2.61 1986 3.131977 2.27 1987 4.181978 1.86 1988 3.261979 2.07 1989 4.031980 2.70
Calcular la media, varianza, coeficiente de variación, coeficiente de asimetría o sesgo y coeficiente de curtosis.
2. Si los datos del problema 1, se agrupan en los siguientes intervalos de clase:
Intervalos de clase Marca de clase1 -2 1.52-3 2.53-4 3.54-5 4.55-6 5.56-7 6.5
Calcular la media, varianza, coeficiente de variación, coeficiente de asimetría o sesgo y coeficiente de curtosis.3. Se tiene una cuenca en la que se han instalado 8 pluviómetros. Las precipitaciones promedios
anuales registradas, en mm, para el período 1970 - 1991, y las áreas de influencia, en Km2, de esas estaciones, se muestran en la siguiente tabla:
Estación Área (Km2) Precipitación (mm)1 150 29152 300 25633 187 32414 600 40175 550 53216 145 46217 278 50028 110 4932
Determinar la precipitación promedio.
4. En la tabla 2.2, se muestran los caudales picos, en m3/s, medidos en cada año, del periodo 1975-2000, de una estación.Calcular:• La media de los caudales picos• La desviación estándar• El coeficiente de variación
Tabla 2.2 Caudales picos para el periodo 1975-2000
Año Q (m3/s) Año Q (m3/s)1975 880 1988 10701976 1360 1989 10601977 885 1990 7181978 1180 1991 9651979 1100 1992 3701980 1390 1993 549

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
1981 2230 1994 22401982 1480 1995 3191983 400 1996 7721984 866 1997 8821985 6130 1998 10101986 1910 1999 11301987 1310 2000 1260
3.- Correlación y regresión3.1 Ecuaciones de regresiónEl análisis de regresión, es una técnica determinística, que permite determinar la naturaleza de la relación funcional entre dos o más variables, permite predecir los valores de y = f(x), ecuaciones de regresión, con un cierto grado de aproximación. Algunas ecuaciones de regresión más utilizadas en hidrología, son:
Ecuación de regresión lineal simple Ecuación de regresión no lineal simple Ecuación de regresión lineal múltiple Ecuación de regresión no lineal múltiple Ecuación de regresión polinomial
3.2 Regresión lineal simpleEn hidrología el modelo más simple y común, está basado en la suposición de que dos variables se relacionan en forma lineal.Como ejemplo se puede mencionar:
Caudales y precipitación de una misma cuenca Precipitación de una estación, con precipitación de otra estación Caudal de una estación con caudal de otra estación Precipitación con la altitud de una cuenca
Este hecho, permite correlacionar estas variables para completar datos o extender un registro.Ecuación de regresión
En hidrología el modelo más simple y común, está basado en la suposición de que dos variables se relacionan en forma lineal.Como ejemplo se puede mencionar:• Caudales y precipitación de una misma cuenca• Precipitación de una estación, con precipitación de otra estación• Caudal de una estación con caudal de otra estación• Precipitación con la altitud de una cuenca
Este hecho, permite correlacionar estas variables para completar datos o extender un registro.
La ecuación general de la ecuación de regresión lineal es:y = a + bx donde:x = variable independiente, variable conociday = variable dependiente, variable que se trata de predecira = intercepto, punto donde la línea de regresión cruza el eje y, es decir valor de y cuando x = 0b = pendiente de la línea o coeficiente de regresión, es decir, es la cantidad de cambio de y asociada a un cambio unitario de x.

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
Los valores de los parámetros a y b, se calculan utilizando el método de mínimos cuadrados.
Pasos para el análisis de regresión1. Selección de una función de relación correlativa, simple o múltiple, lineal o no lineal. Y = f(x)y = a + bxy = abx
y = axb
etc2. Estimación de los parámetros que miden el grado de asociación correlativa
rr2
3. Prueba de significación de los estadísticos que miden la asociación correlativa, para lo cual se aplica la prueba t.
Proceso:3.1. Se plantea la hipótesis
Ho : = 0 ( es el coeficiente de correlación poblacional y su valor varía entre -1 y 1)Ha : p 03.2. Cálculo deU calculado (te)Se utiliza la ecuación
donde:r = coeficiente de correlaciónn = número de pares de valores
3.3. Cálculo del t tabular (tt)El tt se obtiene de las tablas preparadas para este efecto, con un nivel de significación o una probabilidad (1- ), y con grado de libertad ( = n - 2), donde n es el número de pares de valores.Por ejemplo las tablas de t, permite calcular tt, si se elige una probabilidad del 95%, el valor que se
debe tomar de la tabla corresponde = 0.025
Así:para n = 15 -> =15-2 =13

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
para 95% de probabilidad —> = 0.025, entonces, de la tabla —> tt = 2.160
3.4 Criterios de decisión:• Si | tc | < tt, se acepta la hipótesis nula, por lo que = 0, y por lo tanto no hay correlación
significativa.• Si | tc | > tt , se rechaza la hipótesis nula, por lo que 0, indicándose que es significativo y por lo
tanto existe correlación entre las variables.4. Estimación de los parámetros de la ecuación o función de regresión
Por ejemplo para la ecuación de regresión lineal:y = a + bx
Los parámetros a y b, utilizando mínimos cuadrados son:
5. Determinar la significación de los parámetros de la ecuación deregresión, encontrando los límites de confianza de su variación (se usa el análisis de varianza).
Ejemplo 3:En una cuenca, como se muestra en la figura 7.1 se tienen dos estaciones de aforo A y B, en las que se midieron los caudales medios mensuales, en m}/s para el año 1995, los que se muestran enla tabla 3.1. Considerando que los caudales de la estación A, son las variables independientes (x) y que los caudales de la estación B, son las variables dependientes (y):1. Probar si los datos de ambas estaciones se correlacionan linealmente.2. Calcular el caudal en la estación 5, para un caudal de 800 m3/s en la estación A.
Fig. 3.1. Estaciones de aforo A y B de una cuenca
Solución:
Tabla 3.1 Caudales promedios mensuales de las estaciones A y B
Mes Estación A (m3/s) Estación Bm3/s)
E 321 175F 222 75M 155 45A 274 77M 431 131J 446 136J 456 171A 1270 475S 2089 8970 1618 710N 431 268D 509 224

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
1. Sea la ecuación que correlaciona a las variablesy=a+bx ...(3.1)
donde:x = caudales de la estación Ay = caudales de la estación B
2. De acuerdo a los datos se tiene n = 12 (número de pares de datos); los cálculos de sus sumatorias, se muestran en la tabla 3.2.
Tabla 3.2. Productos, cuadrados y sumatorias de las variables x, y
x y xy x2 y2
321 175 56175 103041 30625222 75 16650 49284 5625155 45 6975 24025 2025274 77 21098 75076 5929431 131 56461 185761 17161446 136 60656 198916 18496456 171 77976 207936 292411270 475 603250 1612900 2256252089 897 1873833 4363921 8046091618 710 1148780 2617924 504100431 268 115508 185761 71824509 224 114016 259081 501768222 3384 4151378 9883626 1765436
3. Cálculo de r:De la ecuación, se tiene:
Sustituyendo valores, resulta:
r = 0.9871r2 = 0.97434. Prueba de significación4.1 Hipótesis:Ho: r = 0Ha: r 04.2 Calculo de tc:
tc = 19.47134.3 Cálculo del tt:De la tabla, para:

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
= n-2 = 12-2 =10
y una probabilidad del 95% ó = = 0.025
se tiene: tt = 2.228
4.4 Criterio de decisión:Como: | tc | = 19.4713 > tt = 2.228 se rechaza la hipótesis nula, siendo r 0existe correlación entre las variables x e y.
5. Cálculo de los parámetros a y b:De la ecuación, Sustituyendo valores, resulta:
a = -13.4590
b = 0.4312
6. Ecuación de regresión:Sustituyendo valores en la ecuación , se tiene:Y= -13.4590+0.4312 x
7. Cálculo del caudal en la estación A, para un caudal de 800 m3/s en la estación B.Sustituyendo valores en la ecuación, resulta:
y=-13.4590+ 0.4312x800y= 331.5010 rn3/s
Regresión no lineal simpleExisten varias relaciones no lineales, que con un artificio adecuado pueden reducirse a relaciones lineales, dentro de las cuales se pueden mencionar:
(inversa)
(exponencial)

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
(potencial)Para el uso de estas ecuaciones, en todos los casos, el proceso es como sigue:
1. Realizar la transformación de variables a fin de obtener una regresión lineal. 2. En la ecuación lineal obtenida, aplicar el método de mínimos cuadrados para estimar
los nuevos parámetros a1 y b1. 3. Restituir los cambios de variables, a fin de obtener los parámetros iniciales a y b. 4. Utilizar la ecuación siempre y cuando exista correlación adecuada entre las variables
3.3 Ecuación de regresión lineal múltipleEsta técnica de análisis, se utiliza cuando la variable dependiente y, es función de dos o más variables independientes x1, x2, x3, . . ., xm, siendo el modelo lineal:
y = ao + a1 x1 + a2 x2 + a3 x3 + . . . + amx m donde: n = número de variables independientesao, a1, a2, . . . , am = parámetros a estimarp = m + 1 = número de parámetrosEcuaciones normales
.
.
La solución del sistema proporcionan los valores ao, a1, a2, . . . , am
Error estándar del estimado para regresión múltiple (Se) Es la medida de dispersión que se calcula con la siguiente ecuación:
donde:Se= error estándar del estimadoy = valores muestrales (experimentales) de la variable dependienten = número de grupos de la muestrap = m+1 = número de parámetros a estimar a partir de la muestra n - p = grados de libertadCoeficiente de determinación múltipleRepresenta la proporción de la variación total de y que es explicada por las variables involucradas en la ecuación de regresión múltiple, se puede calcular a partir de la ecuación:
donde:R2 = coeficiente de determinación

Guía de Practicas de Hidrología Efraín Chuchón Prado Facultad de Ciencias Agrarias
y = valores muestrales (experimentales) de la variable dependienten = número de grupos de la muestra
= media de la variable dependiente
Coeficiente de correlación múltiple
3.4 Ecuación de regresión no lineal múltipleLa forma general de una ecuación de regresión no lineal múltiple es:
...
la misma que es posible transformar con un adecuado artificio, en una ecuación de regresión lineal múltiple, de la siguiente forma:
1. Tomando ln a ambos miembros de la ecuación, se tiene: +...
2. Haciendo: ln y = z
lnx1 = w1
lnx2= w2
lnx3 = w3
.
.
La ecuación obtenida es una ecuación de regresión lineal múltiple.
3.5 Ecuación de regresión polinomialLa ecuación polinomial de grado m es:
Para el ajuste de los pares de valores, se puede utilizar la metodología descrita para el caso de una ecuación de regresión lineal múltiple, siendo las ecuaciones normales:
.
.