video sketch: a middle-level representation for action
TRANSCRIPT

https://doi.org/10.1007/s10489-020-01905-y
Video sketch: A middle-level representation for action recognition
Xing-Yuan Zhang1 · Ya-Ping Huang1 · YangMi2 · Yan-Ting Pei1 ·Qi Zou1 · SongWang2
© Springer Science+Business Media, LLC, part of Springer Nature 2020
AbstractDifferent modalities extracted from videos, such as RGB and optical flows, may provide complementary cues for improvingvideo action recognition. In this paper, we introduce a new modality named video sketch, which implies the human shapeinformation, as a complementary modality for video action representation. We show that video action recognition can beenhanced by using the proposed video sketch. More specifically, we first generate video sketch with class distinctive actionareas and then employ a two-stream network to combine the shape information extracted from image-based sketch andpoint-based sketch, followed by fusing the classification scores of two streams to generate shape representation for videos.Finally, we use the shape representation as the complementary one for the traditional appearance (RGB) and motion (opticalflow) representations for the final video classification. We conduct extensive experiments on four human action recognitiondatasets – KTH, HMDB51, UCF101, Something-Something and UTI. The experimental results show that the proposedmethod outperforms the existing state-of-the-art action recognition methods.
Keywords Action recognition · video sketch · attention model
1 Introduction
Action recognition [1, 2] is a popular research topic inmultimedia community and plays an important role in manymultimedia applications, such as video surveillance [3, 4],human-robot interaction [5] and video summarization [6].
� Ya-Ping [email protected]
Xing-Yuan [email protected]
Yang [email protected]
Yan-Ting [email protected]
Song [email protected]
1 Beijing Key Laboratory of Traffic Data Analysis and Mining,Beijing Jiaotong University, Beijing 100044, China
2 Department of Computer Science and Engineering, Universityof South Carolina, Columbia, SC 29208, USA
Although it has been studied for years, resulting in manyadvanced action recognition algorithms [7, 8], it is far frombeing a solved problem, due to various complexities, such aslarge feature variations for each action, view angle changes,lighting differences and occlusions.
Prior researches have revealed that the use of differentmodalities, such as RGB and optical flows, can benefitaction recognition, even if they are all extracted fromthe original RGB image [9, 10]. Other modalities, e.g.,depth map or human skeleton, can further promote actionrecognition [11, 12]. But its acquisition may requireadditional devices, such as MS Kinect sensors.
Human action always involves the body-posture variationover time. Those variations are well reflected by the spatial-temporal change of the shape of the human’s body. Videosketch, which represents body shape variations, is a set oflines and points, whose shapes and positions can be trackedbetween frames [13] and has been proved to be an importantcue for video action representation [14].
However, how video sketch can benefit video actionrecognition is still an open problem and has not been wellexplored yet. In this paper, we investigate this problemby more effectively incorporating video sketch into actionrecognition. As shown in Fig. 1, we propose to use videosketch as a new complementary modality along with thetraditional appearance (RGB) and motion (optical flow)modalities for enhancing video action recognition.
Published online: 6 November 2020
Applied Intelligence (2021) 51:2589–2608

Ac�on: HulaHoop
Combina�on
Appearance Mo�on Sketch
Image-based sketch Point-set-based sketchRGB Op�cal flow
Fig. 1 An illustration of the three components used for action recognition in the proposed method. From the sample video frames, we deriveappearance (RGB), motion (optical flow) and video sketch and combine the feature representation extracted from network for final video actionrecognition
There are two key issues that need to be solved forvideo-sketch-based action recognition. The first one is thatirrelevant information may be still preserved during theaction sketch generation process, which may hinder the lateraction recognition. Thus, how to generate the action-relatedsketch while ignoring the irrelevant background informationis a crucial step in introducing shape information for actionrecognition. The other difficulty is that video sketch consistsof highly abstract lines. Different from images containingrich texture and color information, it is a great challengeto learn distinctive and powerful features for videosketches.
To tackle the above issues, we develop a novel videosketch convolutional neural network for action recogni-tion, named Video Sketch Action Network (VSA-Net),which adaptively learns an action-related and sketch-based video representation. The architecture of theproposed VSA-Net is illustrated in Fig. 2. We first pro-pose an attention guided sketch generation method thatcan generate the action-related sketch. Secondly, we trans-form the sketch images into point-set-based data to obtaina powerful shape representation. Thirdly, we propose atwo-stream network, which combines the image-based
sketch and the point-based sketch to produce a moreeffective sketch based representation for video action.In the experiments, we combine the proposed VSA-Net network with temporal segment networks (TSN) [9]on RGB and optical flow and achieve very promisingresults.
To summarize, we make the following contributions inthis paper:
– We combine the video sketch generation andclass-discriminative localization technique to gen-erate attention-based sketch with localizationdiscriminability for representing actions.
– We propose a two-stream network for effective deeprepresentations of video sketch. Especially, we usepoint-based sketch representation to further improveaction recognition accuracy.
– We show that video sketch is an important modal-ity which is complementary to the traditional appear-ance and motion modalities, and achieve state-of-the-art performance on challenging action recognitionbenchmarks (KTH, HMDB51, UCF101, Something-Something and UTI).
2590 X.-Y. Zhang et al.

Video Sketch Shape Representa�on Network (Sec�on 4)
SGAV ModelInput Fine-tune Output
Training SGAV model (Sec�oin 3)
Sketch Recogni�on ModelInput
Clean And Jerk
Shape Predic�on
Video Ac�on Recogni�onTraining Images
Class Ac�va�onMaps
GeneratedSketches
RGB
Op�cal Flow
Shape
Training Sketches
Feature Extrac�on
Shape Classifica�on
Class Score Fusion
Video Ac�on Recogni�on
Top1: Clean And Jerk
Fig. 2 An overview of our unified VSA-Net architecture for actionrecognition (better viewed in color). Given a consecutive framesequence, we first produce original sketches from the action video(Section 3.1). Salient regions for object classes and background arefirst localized by Grad-CAM based on the above result. From the com-bination of salient regions and original sketches, the attention-guidedsketches are then used to train SGAV model to generate final sketches
(Section 3.2). The sketches are then processed in the image-basedsketch recognition blocks and point-based sketch recognition blocksto encode shape information. Subsequently, a score weighted averageof two separate networks is used to estimate the action label for shapeinformation (Section 4). Finally, the class score fusions of appearance,motion, and shape are fused for the final video action recognition
2 Related work
There exists a body of literature on human actionrecognition. Here we cover the previous works which arerelated to our method. We first outline the works involvingdifferent modality of action recognition. Then, we introducethe works of sketch generation. Finally, we cover the workrelated to sketch recognition.
2.1 Action recognition
We can summarize existing action-recognition approachesbased on different popular modalities: spatial (RGB),temporal (Optical Flow), pose and skeleton.
Feature extraction from RGB video data is a well-explored field in complex human action classification.Many existing techniques extract the most salient features,such as histogram of 3D oriented gradients (HOG3D) [15],3D scale invariant feature transforms (3D-SIFT) [16]and volume local binary pattern (volume-LBP) [17].In [18], Du et al. propose a new model named C3D foraction recognition on RGB videos and achieve promisingperformance. In [19], Wang et al. propose a two-stream3D ConvNet framework and show that RGB data issufficient to discriminate most of actions. In [20], Hu et al.explore modality-temporal mutual information and combineRGB features with other features to supply the contextualinformation. In [21], Liu et al. propose to use diversecombinations of atomic actions and their temporal relationsunder uncertainty for complex activity recognition.
Owing to the use of optical flow, action recognitionhas got a significant breakthrough, such as the two-stream-based method [9] and 3D-convolution-based method [22].Several works learn CNNs to predict optical flow and
achieve good performance in action recognition [23–25].Derived from optical flow, Su et al. [26] proposes OpticalFlow guided Feature (OFF) by computing the gradientsof representations and temporal differences, which enablesthe network to distill temporal information through a fastand robust approach. Unlike prior works, Piergiovanniet al. [27] introduce the concept of learning ‘flow of flow’only relying on RGB input to obtain powerful representationwith fewer parameters. Wang et al. [28] present a two-stream 3D ConvNet fusion framework by considering bothappearance and optical flows, which solves the issues offixed-sized and fixed-length input video.
Human pose is certainly an important cue for actionrecognition [29] in addition to appearance and motion. It hasbeen proven that pose modality is highly discriminative torecognize complex actions [30, 31]. Recently, pose-relateddeep learning methods [32, 33] have been introduced toboost recognition accuracy. Luvizon et al. [32] proposean end-to-end trainable multitask framework to perform2D and 3D human pose estimation jointly with actionrecognition.
Recently, skeleton-based human action recognition hasattracted more attention [34]. It can be mainly classifiedinto two categories: hand-crafted feature based methodsand deep-learning based methods. Traditional methodsdesign several hand-crafted features to capture the dynamicsof joint motion, including covariance matrix of jointtrajectories [35], relative positions of joints [36], graphrepresentation [37] or rotation and translation between bodyparts [38]. Deep learning feature based methods can befurther divided into the CNN-based model [7, 11, 39] andthe RNN-based model [34, 40]. These approaches mainlyemphasize the importance of modeling the joints withinparts of human bodies. Different from recurrent neural
2591Video sketch: A middle-level representation for action recognition

network (RNN) models, Zhang et al. [41] propose to fusegeometric features for skeleton-based action recognition,where they use a new smoothed score fusion technique tolearn classification from different streams. Hou et al. [42]use deep neural networks to represent the video for actionrecognition by encoding as much as possible the spatio-temporal information of a skeleton sequence into colortexture images.
Different from the above modalities, we propose toincorporate video sketch modality for action recognition.Most conceptually related to our work is [8], which usesfast edge detection for sketch generation and R-CNN forhuman detection. Then, four types of sketch pooling areapplied to get a uniform representation of human action.Actually, not all information in the surrounding environmentis useful for action analysis and the irrelevant informationoften brings a lot of noise [43–45], thus we need to paymore attention to the informative ones. Meanwhile, wethink that shape information conveyed by sketch plays animportant role for representing video actions, which willbe further demonstrated in Section 5.2. Based on the aboveconsiderations, we propose attention guided sketch andshape-based representation for video action recognition.
2.2 Sketch generation
Sketch generation is the process of producing a sketchsimilar to the one made by painters. Previous sketchgeneration algorithms can be mainly divided into two types:one is based on hand-crafted features and the other is basedon deep features.
For the generation methods based on hand-craftedfeatures, most of them employ a contour detection andobject segmentation method [46–49], which aim to producecontinuous curves that can perfectly depict constitute globalprofiles of the objects. Later, Lim et al. [50] propose anovel approach named sketch tokens, which uses mid-level features to learn and detect local contour-basedrepresentations. In contrast, Qi et al. [51] exploit perceptualgrouping principles to generate a sketch from a naturalimage conveniently.
For the approaches based on deep features, Xieand Tu [52] propose a new holistically nested edgedetection (HED) model, which uses multi-scale andmulti-level feature learning and perform image-to-imageprediction. Based on HED [52], Liu et al. [53] developan accurate richer convolution feature (RCF) model,which achieves edge detection by combining all themeaningful convolution features in a holistic manner. Zhanget al. [54] propose SG-Net to make full use of imagefeatures and combine a convolutional neural network andmathematical morphology technology to obtain a human-drawing-like sketch. Yu et al. [55] design an end-to-end
deep architecture named CASENet for category-awaresemantic edge detection. Recently, with the development ofGANs [56], a large number of works [57, 58] are developedto achieve the sketch generation by cross-domain image-to-image translations. Different from the above methods,generating sketches of actions needs to focus on informativeareas in each frame and try to ignore the irrelevant ones.
2.3 Sketch recognition
For sketch recognition, many researchers focus on improv-ing classification performance by using different classifierswith the help of hand-crafted local and global feature rep-resentations [59, 60]. Inspired by the release of the firstlarge-scale free-hand sketch dataset, TU-Berlins [59], manyworks [61, 62] explore free-hand sketch recognition byusing various hand-crafted features together with classifierssuch as K-Nearest Neighbors (KNN) and Support VectorMachines (SVM).
In recent years, CNNs have demonstrated excellentperformance in many computer vision tasks [63], includingsketch recognition [64, 65]. Yu et al. [66] consider thesparse visual signals and intra-class variance of sketches,and propose the first CNN-based framework for sketchrecognition, which outperforms previous handcrafted-feature based methods by a large margin. Sarvadevabhatlaand Babu [67] present a deep-learning based frameworkfor recognizing freehand sketches of object categoriesconsidering sparse visual details. Zhang et al. [68] developa triplet network to automatically learn latent structurefeatures from sketches.
Different from previous work recognizing sketchesderived from images, we propose to recognize actionsbased on sketches from videos. Specially, we use TSN tomodel long-range temporal structure of videos and representthe selected frame with image-based and point-basedsketches.
2.4 Multi-view learning
In order to use heterogeneous features, some researcherspropose to use multi-view learning for various learningtasks. Xiao et al. [69] utilize multi-view data sourcesfor the task of inferring disease-associated miRNAs. Sunet al. [70] presents eight PAC-Bayes bounds, which canbe applied to different tasks, e.g. density estimation [71]and reinforcement learning [72]. Wang et al. [73] propose ageneral Graph-Based System for multi-view clustering andboost the clustering performance by a large margin. Sunet al. [74] introduce multi-view semi-supervised learningbased co-training style and co-regularization style methods.Sun et al. [75] propose a multi-view maximum entropydiscriminant model for learning with different numbers of
2592 X.-Y. Zhang et al.

views and achieve a high performance for violent behaviorrecognition of still images.
Just like multi-view learning with different view con-struction, the property of data from real application usingmulti-modality can be described by different features. Liuet al. [76] propose a hypergraph learning model for dis-ease diagnosis with incomplete multi-modality data. Zhanget al. [77] design a generic sensor-agnostic multi-modalityMOT framework for multi-sensor multi-object tracking.Meanwhile, the idea is also extended to human actionrecognition. Gkalelis [78] and Iosifidis [79] extract binarysilhouettes of human body and use multi-view posture forhuman movement recognition. Ren et al. [80] design aneffective segmentation convolutional networks architecturebased on multi-modality hierarchical fusion strategy forhuman action recognition.
Inspired by the multi-view learning that exploits theredundant views of the same input data and improvethe learning performance, we propose a new modality,named sketch modality, to provide more abundant andcomplementary information. The multi-modality strategycaptures the spatial-temporal and shape information, andfinally obtains a better representation for action video.
3 Discriminative sketch generationarchitecture
Sketch is widely used to render the visual world, and wecan describe our ideas by sketching on different touch-screen devices [81]. How to effectively generate a sketchwith discriminative regions from action videos remains anopen problem. In general, the proposed architecture consistsof two learning stages. The first stage aims to generateoriginal sketches from action videos using sketch generationnetwork (Section 3.1). In the second stage, attention guidedconvolutional neural network is employed to refine originalsketches and focus on informative areas (Section 3.2). Someexamples are shown in Fig. 3.
3.1 Sketch generation network
To extract shape structure of the human bodies in actionvideos, we design an effective architecture called sketchgeneration of action video (SGAV ). The generated sketchesshould be able to depict the full profile of subject similarto human contours and some other important details.We design SGAV based on SG-Net [54], which extracts
Balance Beam
Pole Vault
Tai Chi
(a) (b) (c) (d)
Fig. 3 a Sample video frames for different action in UCF101. b Original generated sketch. We generate original sketch from the primitive image.c Class-discriminative frame regions in heatmaps, which is used as a guide to refine original sketch. d Final generated sketch
2593Video sketch: A middle-level representation for action recognition

multi-scale and multi-level information from different CNNlayers for sketch generation. The baseline method [54]is based on VGG-Net [63], in which the network onlycombines the last convolutional feature maps of four stagesfor sketch generation. Meanwhile, it only generates asketch for clean background in an image. However, actionvideos usually involve objects with complex background.To address this issue, we propose to combine all theconvolutional features maps in four stages for final actionsketch generation. This way, more levels of informationcan be utilized [82] and we can obtain lots of usefulinformation. The modification is shown in Fig. 4. Comparedwith SG-Net, each convolution layer at four stages inSGAV is connected to a 1 × 1 convolution layer andthe number of channel is half of the previous layer. Theresulting feature maps in each stage are accumulated toformulate hybrid features. When training the network,similar to [54], our loss function can be formulated asfollows:
L (W) =|I |∑
i=1
(K∑
k=1
l(X
(k)i ; W
)+ l
(Xf use
i ; W))
, (1)
where X(k)i denotes the activation value from stage k.
W denotes all the parameters that will be learned in ourarchitecture. X
f usei denotes the result from the fusion layer.
|I | is the number of pixels in image I , and K is the number
of stages (equals to 4 here). l(X
(k)i ; W
)is defined using
class-balanced cross-entropy loss function as follows:
l (X; W) = −β∑
j∈Y+log Pr
(yj = 1|X, W
)
−γ∑
j∈Y−log Pr
(yj = 0|X, W
), (2)
where β = |Y−|/ (|Y+| + |Y−|) and γ =|Y+|/ (|Y+| + |Y−|) · |Y+| and |Y−| denote the sketchand non-sketch ground truth label sets, respectively.Pr(·) = ϑ
(a(K)
) ∈ [0, 1] is computed using sigmoidfunction ϑ (·) on the activation value at pixel j . a(K) areactivation maps of the side-output of layer K .
3.2 Attention guided sketch refinement
Previous works [43, 83] have already demonstrated that ineach action sequence, there exists a subset of informative
Stage4
Input image
3×3-64 Conv
3×3-64 Conv
2×2 Pooling
3×3-128 Conv
3×3-128 Conv
2×2 Pooling
3×3-256 Conv
3×3-256 Conv
3×3-256 Conv
2×2 Pooling
3×3-512 Conv
3×3-512 Conv
3×3-512 Conv
1×1-32 Conv
1×1-32 Conv
1×1-64 Conv
1×1-64 Conv
1×1-128 Conv
1×1-128 Conv
1×1-128 Conv
1×1-256 Conv
1×1-256 Conv
1×1-256 Conv
Upsampling
Upsampling
Upsampling
Loss/sigmoid
Loss/sigmoid
Loss/sigmoid
Loss/sigmoid
1×1-1 Conv
1×1-1 Conv
1×1-1 Conv
1×1-1 Conv
Concact1×1-1 ConvLoss/sigmoid
Loss/sigmoid
UpsamplingLoss/sigmoid
Loss/sigmoid
Loss/sigmoid
Upsampling
Upsampling
Concact Loss/sigmoid
SG-Net SGAV
Stage1
Stage2
Stage3
SG-Net SGAV VGG16
Fig. 4 Illustration of two networks. The left with red solid line is SG-Net. The right with purple dotted line is SGAV. The cross area denotesimproved VGG-Net and two networks share it
2594 X.-Y. Zhang et al.
areas of human body which are important, while theothers can be irrelevant (or even noisy) for actionrecognition. Thus, we need to identify more informativeareas, meanwhile trying to ignore the features of theirrelevant areas.
Following Selvaraju et al. [84], we use the concept of“visual sentinel” as a reference to determine which sketchregion need to be focused for accurate action recognition.To achieve this, we fine-tune SGAV on sketches thatare extracted from the training videos in video actiondatasets [85–87], which aims to get video-sketch basedmodel for attention map generation. Then, we use the abovemodel and get the gradients of class scores with respectto pixel intensities, which can visualize important sketchregions as a class activation mapping Y c and is calculatedas follows:
Y c =∑
k
wck · 1
Z
∑
i
∑
j
Akij , (3)
where 1Z
∑i
∑j
Akij is the output of global average pooling
(GAP) on feature map Akij . Z is the pixel number of feature
map. i and j denote the pixel position. wck is the weight
connecting the kth feature map with the cth classes.Finally, we can get discriminative area and the redundant
information will be filtered out by (4). The calculationprocess is repeated for all pixel values.
F(X) = α ∗ Xij . (4)
If the discriminative area is activated in the attention map,we set α to 1, otherwise 0. Xij is original sketches withdifferent gray values in (i, j).
4 Action sketch network
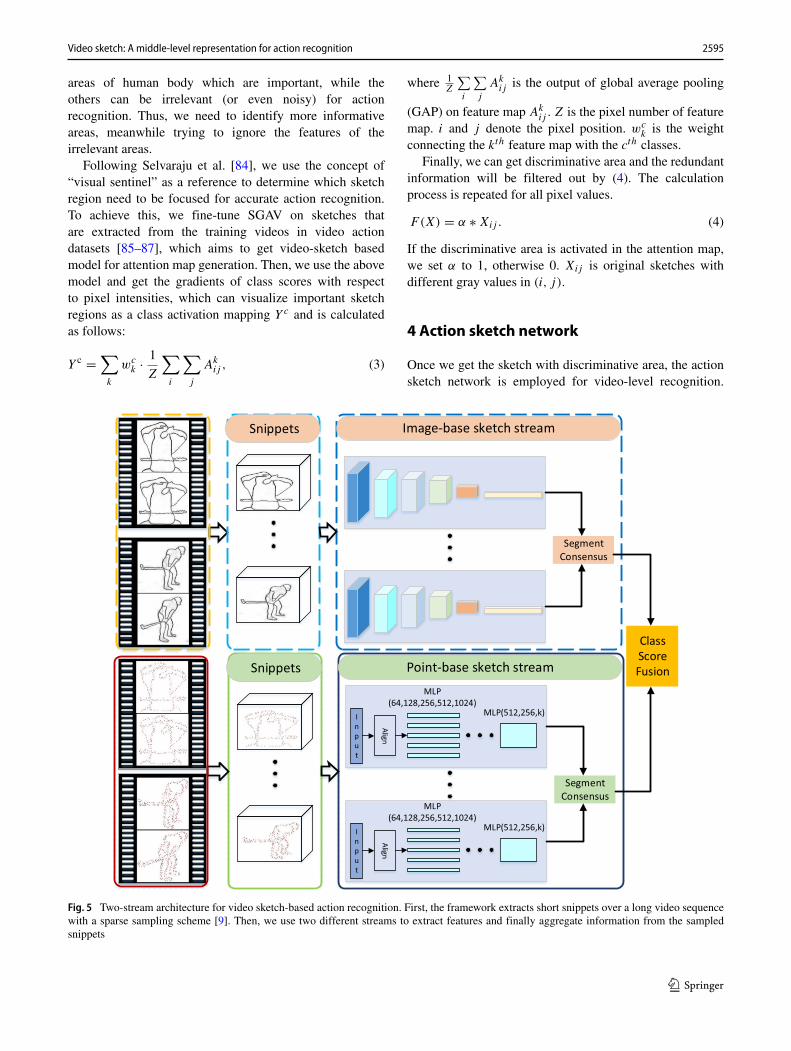
Once we get the sketch with discriminative area, the actionsketch network is employed for video-level recognition.
SegmentConsensus
Image-base sketch streamSnippets
SegmentConsensus
Point-base sketch streamSnippets
ClassScoreFusion
Input
Align
MLP(64,128,256,512,1024)
MLP(512,256,k)
Input
Align
MLP(64,128,256,512,1024)
MLP(512,256,k)
Fig. 5 Two-stream architecture for video sketch-based action recognition. First, the framework extracts short snippets over a long video sequencewith a sparse sampling scheme [9]. Then, we use two different streams to extract features and finally aggregate information from the sampledsnippets
2595Video sketch: A middle-level representation for action recognition

Fig. 6 The input alignment isachieved by 2 × 2 affinetransformation matrix. Specially,the input of point-sets is a512 × 2 matrix. We use a 2 × 2transform matrix generated fromthe neural network to multiplythe input, and the return valuewill be a 512 × 2 matrix
S×
2
Featu
re
Ex
pan
sion
fc1
S×
64
fc2
fc3
Matrix Product
MLP(64,128,256,512,1024)
Input Output
S×
2
Alignment Matrix Learning
The network can be decomposed into two streams: image-based sketch stream and point-based sketch stream. Theimage-based part, in form of original sketch, extracts textureinformation from a video. The point-based part, in the formof point-set-based sketch, conveys shape information fromthe video. Generally speaking, the shape descriptor is robustfor high flexibility of sketch, which is complementary toimage-based representation [88]. Therefore, we use TSNto model long-range temporal structure and achieve video-sketch-based action recognition by fusing two differentstreams. The architecture is shown in Fig. 5.
4.1 Image-based sketch stream
We follow TSN to construct this stream and choose BatchNormalization (BN-Inception) [89] as the building block.Different from original TSN [9], the image-based sketchstream operates on video sketch. Meanwhile, we use largerfilters (11 × 11) for the first convolution layer. The mainreason is that the filters in the first convolutional layercontain the most sensitive parameter [90], as all subsequentprocessing depends on the first layer output. What’s more,sketches are highly iconic and abstract, and lack textureand color information. Therefore, larger filters are moreappropriate for sketch modeling and can capture morestructured context information [66].
4.2 Point-based sketch stream
The representation dedicated to image-based sketch streamtreats the action sketch as original RGB. The idea may leadto ambiguous feature representations due to more variationsof sketches, which can be addressed by learning point-basedstructural representations [65]. Inspired by shape matching
Table 1 Ablation comparisons of action recognition accuracy only usesketches on the KTH, HMDB51 (split1) and UCF101 (split1) datasets.Baseline denotes that the network is trained on original sketches anduses image-based sketch feature for action recognition
Method KTH HMDB51 UCF101
baseline 77.17% 50.46% 77.86%
baseline, w/ AS 84.72% 56.93% 81.46%
baseline, w/ AS+PSF 85.67% 57.92% 82.53%
in 2D shape [91] and sketch recognition by landmark-based structural representation [65], we think that point-based sketch can be helpful to recognize and understandthe physical structures of human bodies and the objectsinteracted with the bodies in video action recognition [92–94]. To achieve this, we first transform a video sketch intoa set of points. Then, we extract the point-based featuresfor the shape representation. When representing humanaction by point-based sketch, there are two difficulties to beaddressed:
– Point-based shape invariance. We consider that thefeatures learned from sampling points should beinvariant for certain transformations of human bodiesand objects in action videos, such as rotation andtranslation [95].
– Invariance under different point sampling order. Pointssampling is usually required when extracting a fairlylarge number of points from a video sketch. However,points sampling from different starting position maylead to various degrees of point perturbations even forthe same action sketch [96].
Here, we propose a unified architecture, named SketchPoint Network (SPN). To insure the first invariance, we usea small alignment network to predict a matrix and align thepoints to the same space. To insure the second invariance,we use pooling strategy to achieve invariant representation.Next, we will first introduce the algorithm of point samplingin details. Then, we describe the network architecture ofSPN.
Table 2 Action recognition accuracy of sketches based on componentsanalysis of the proposed method on the HMDB51 and UCF101datasets (split2 and split3). From top to bottom we add the componentone by one
Method HMDB51 UCF101
split2 baseline 50.90% 77.42%
baseline, w/ AS 56.89% 81.24%
baseline, w/ AS+PSF 57.73% 82.15%
split3 baseline 51.02% 77.65%
baseline, w/ AS 57.12% 81.20%
baseline, w/ AS+PSF 58.12% 82.31%
2596 X.-Y. Zhang et al.

Table 3 Exploration of fusion with RGB and optical flow modalityfor action recognition accuracy on the HMDB51 and UCF101 datasets(split1). “TSN-RGB” refers to the setting where the temporal segmentnetwork framework [9] is applied on top of the best performingBN-Inception architecture
Method HMDB51 UCF101
TSN-RGB 59.54% 83.74%
TSN-Flow 71.42% 89.23%
TSN-TwoStream 75.42% 94.32%
VSA-Net+TSN-RGB 67.14% 87.90%
VSA-Net+TSN-Flow 76.18% 93.94%
VSA-Net+TSN-TwoStream 78.82% 97.27%
4.2.1 Point sampling
The points in action sketches are denoted as X ={x1, x2, ..., xn}, which can be sampled randomly. However,the points may be heavily concentrated in some posi-tions [97] and it results in poor shape representation ofsketch. Therefore, we sample point sets from the sketch byiterative farthest point sampling (FPS) [98] and get equidis-tantly spaced points. The main advantage of this strategyis that the final points have better coverage, which guaran-tees the object shape have a good representation. We sample512 points for each frame in the action sketch, which repre-sent the horizontal and vertical positions of the points in theframe.
4.2.2 Architecture of SPN
SPN consists of two processing stages. First, we aligndifferent point-sets to the same space before featureextraction. Second, the points are processed sequently by
MLP, pooling and fully connected layers and finally weobtain high-level point-based sketch representation.
Alignment The spatial representation should be relativelyinsensitive to certain transformation in the video. To solvethe alignment problem, we propose a neural network, whichcan predict a 2 × 2 affine transformation matrix. Actually,the affine transformation is shown to be effective forrepresenting human action transformation in videos [99,100]. The point-based video sketch can be aligned to theinput space by multiplying the prediction matrix. As shownin Figure 6, the alignment network consists of MLP andmultiple fully connected layers. Then, the following layersare composed of a max pooling and three fully connectedlayers with output size 1024, 512 and 101.
MLP The structure of MLP [101] is composed of threelayers, including one input layer, more than one hiddenlayer, and one output layer. The five hidden layers of MLPhave the size of 64, 128, 256, 512 and 1024, respectively.
Pooling As described in [102], point orderless is a keyissue when we extract the shape feature. In order toachieve invariant representation of point-based sketch,we follow [103] to use max pooling and aggregate theinformation extracted from previous layers. Here, n vectorsare used as the input of max pooling, which is calculated bythe MLP module.
Fully connected layers The output of max pooling is fedto the fully connected layers, which can transform theextracted vectors into a new space and make the final outputeasier to classify.
Fig. 7 The Confusion Matrix on KTH Dataset. The left figure uses RGB and optical flow modality and the right is by using RGB, optical flowand the new proposed sketch modality
2597Video sketch: A middle-level representation for action recognition

Finally, we train the network with standard categoricalcross-entropy loss. Specifically, given training videos V
with action class C and the groundtruth yi concerning classi, the loss function is defined as follows:
L = −C∑
i=1
yi
⎛
⎝Pi − logC∑
j=1
expPj
⎞
⎠, (5)
where Pi = F(WX1 + b, WX2 + b, ..., WXN + b) denotesvideo-level score of the same class on all the snippets.F (·) is the function representing point-based sketch streamwith parameters W which operates on the short snippet{X1, X2, ..., XN }. b denotes the bias term.
5 Experiments
We conduct extensive experiments on action recognitionfor different strategies. In section 5.1, we introduce fivedatasets and some protocols in details. Section 5.2 performsanalysis for the architecture design. Section 5.3 makes moreanalysis for different modules, followed by the comparisonwith state-of-the-arts by combining video sketch modalityand RGB/optical flow modality in section 5.4.
5.1 Experimental setup
Datasets. KTH [85]. The KTH dataset contains a totalof 2,391 grayscale videos and six types of action class:walking, jogging, running, boxing, hand waving, and handclapping. Meanwhile, there are four different environmentsin the video sequences: outdoors, indoors, scale variation indifferent scenes and cloth variation of different people.
HMDB51 [86]. This dataset contains 6,849 videos fromvarious sources and 51 action classes, which provides threecross-validation folds and each with 3570 training and 1530test videos. The dataset provides two versions: the originaland the one with motion stabilization. We choose to use theformer version, which contains more complex scenes andthus it is more challenging.
UCF101 [87]. This dataset is composed of 13,320 RGBvideo clips and 101 action classes, which also providesthree cross-validation folds for evaluation. UCF101 isparticularly interesting, because this dataset is composedof several aspects of action, e.g., various types of indoorand outdoor activities, camera motion at different speed andcapturing picture at different angles, cluttered background
Table 4 Experimental results on UCF101 dataset using differentkernel size in action recognition task
Kernel Size 7 × 7 11 × 11 15 × 15
Accuracy 97.3% 97.6% 97.8%
Table 5 Comparison of adding alignment module or not in thearchitecture design for SPN
Method
Dataset
UCF101 HMDB51
VSA-Net+TT w/o alignment 97.4% 79.5%
VSA-Net+TT 97.8% 80.0%
and various objects. Following other recent works on end-to-end learning such as [104] and [105], we report averagedaction recognition accuracy on all the splits.
Something-V1 [106] This dataset consists of 110k videosof 174 different low-level actions. Each video lasts between2 to 6 seconds. There are some challenging videos withambiguous activity, such as ‘Turn something upside down’versus ‘Pretending to turn something upside down’. Thecharacter of the above video is the temporal relations andtransformations rather than the appearance of the objects.
UT-Interaction [107] The UT-Interaction dataset (UTI) isa popular action recognition dataset for the interaction oftwo different people, which includes six kinds of behaviourswith 16 people in real scenes, namely, shaking hands,pointing, hugging, pushing, kicking and punching. UTIcontains two sub-data sets (UTI-1 and UTI-2) and eachcontains 10 videos. Each video consists of 180 frames withthe frame rate set at 30 frame/s. UTI-1 is collected onthe parking lot and UTI-2 is collected on a lawn. Whenmeasuring the recognition accuracy, we use 10-fold leave-one-out cross validation for each set.
Training details We perform our evaluation on fourdatasets, using the training split for training and thetesting split for testing. And, we use ImageNet [108] and
0
10
20
30
40
50
60
70
80
90
100
Rec
og
nit
ion
Acc
ura
cy (
%)
Baseline Baseline+AS Baseline+AS+PSF
Fig. 8 Per class recognition accuracy of our proposed method on theHMDB51 dataset (split1). The meaning of “AS” and “PSF” is the sameas Table 1
2598 X.-Y. Zhang et al.

Fig. 9 Visualization of the proposed video sketch modality on theHMDB51 dataset. The first and fourth column denote different framesof action video. The second and fifth column denote the generated
video sketch. The third and sixth column denote feature map extractedfrom the convolution layer of inception 3a 1x1 out for sketch.
Kinetics [22] as the primary benchmarks, as they are largeenough to enable training of deep models from scratch. Forthe SGVA network, the hyper-parameters we set include:learning rate (1e-6), momentum (0.8), and the number oftraining iterations (60,000; divide learning rate by 100after 10,000). During the training process, video frames areall scaled to 224 × 224. For the attention-guided sketchrefinement, the input size is set to 224×224. Meanwhile, weuse stochastic gradient descent with 0.9 momentum and fixlearning rate schedule (decreasing the learning rate by 8%every 5 epochs) for BNIception network [89]. For the SPN,we sample 512 points. We use dropout with keeping ratio of0.7 on the last three fully connected layers. The decay ratefor batch normalization starts from 0.4, which is graduallyincreased to 0.99. We adopt adam optimizer with a learningrate of 0.001, and a batch size of 128. The learning rate isdivided by 4 every 6 epochs.
For Something-V1 dataset, we finetune the network for25 epochs. For KTH, HMDB51 and UCF101, we finetunefor 20k iterations. The whole training process on UCF101and HMDB51 takes around 1.5 days on two Titan Xp GPUfor the VSA-Net architecture.
Testing details We perform frame-wise evaluation asTSN [9]. Specifically, following the testing scheme of TSN,we sample 25 snippets of different modalities. For thesampled snippets, we crop 4 corners and 1 center, and their
horizontal flipping. Meanwhile, to aggregate the predictionsof different crops and snippets, we adopt average pooling.For the fusion of predictions from multiple modalities, wetake a weighted average of them, where the fusion weightsare determined empirically.
5.2 Architecture design analysis
In this section, we perform the ablation study on threedatasets to evaluate the significance of each component inour proposed VSA-Net. In the first and second experiments,the baseline model uses original sketches that is generatedfrom SGAV, and only extracts image-based sketch featuresfor human action recognition. To prove the effectivenessof representation information, we establish the followingsettings: AS refers to combine attention guided sketch inaction recognition, while PSF represents that the actionrecognition is combined with point-based sketch feature. TTrepresent TSN-TwoStream.
Comparison of attention guided sketch refinement We firstevaluate the impact of attention guided sketch for VSA-Net. The improvement is striking (shown in Table 1and Table 2): sketches without attention mechanism lagfar behind ours and fine-tuning with the above datasetscan increase accuracy by 5% to baseline model. Theresult suggests that attention-guided sketches can remove
Fig. 10 Illustration of twodifferent modalities. The picturefrom left to right: originalimage, sketch generated by ourmethods and edge-detectionmap generated from gPb
Sketch gPb edge-detec�on
map
2599Video sketch: A middle-level representation for action recognition

Table 6 Performance under different modalities. The first columnrepresents that the action recognition is performed using TSN-TwoStream under RGB and optical flow modality. The second andthird column represents that the action recognition is performedusing TSN-TwoStream+VSA-Net under RGB, optical flow and newmodality on HMDB51 split2
Base Base+edge map Base+sketch map
76.13% 76.18% 79.12%
non-relevant information and leverage action recognitionperformance.
Comparison of point-based sketch representation Asshown in Table 1 – 2, we can observe that the perfor-mance can be improved by incorporating the point-basedsketch representation. The reason is that point-based sketchconveys more shape information and combining bothimage-based and point-based sketch can lead to a bettershape description.
To further investigate the effect of the shape modality, afusion analysis with RGB and optical flow in term of therecognition accuracy are also presented in Table 3. We cansee that VSA-Net is able to boost the performance of RGBand optical flow. This demonstrates that modeling videosketch modality is crucial for better understanding action invideos. We also find that the new video sketch modality isonly a complementary for RGB and optical flow and it cannot be used as a replacement of them.
In order to clearly clarity the sketch modality, we alsoprovide the visualized confusion matrix on KTH datasetby combining three modalities. As shown in Fig. 7, theperformance is improved significantly for action classes -“handwaving” and “clappiing”.
Study of kernel size and alignment We present the studyby conducting the following experiments: the effect ofkernel size in the architecture design of image-based sketchrepresentation (referred in Section 4.1) and the ablationstudy of alignment in the architecture design of SPN(referred in Section 4.2.2).
Table 4 analyzes the action recognition accuracy of theimproved TSN network and the native TSN network fordifferent kernel sizes. We observe that the small kernel sizeresults in dramatic performance reduction. We contributethe reason to two aspects: one is that the size of filters inthe first convolutional layer possesses the most sensitiveparameter and all subsequent operations depend on thefirst layer output, and the other is that sketch is composedof lines and lacks color and contextual information whenwe perform feature extraction and action recognition.Larger filters can contribute to the network capturing morestructured context rather than textured information.
Table 5 shows the positive effects of alignment module.It’s interesting to see that using input alignment givesa 0.4% and 0.3% performance boost on UCF101 andHMDB51 datasets, respectively. Thus, the affine matrixlearned by alignment module is necessary for the videoaction transformation to work. By combining it to the input,we achieve the best performance.
5.3 Further analysis
In this section, we show the quantitative and qualitativeresults for further analysis.
Action recognition results We randomly select 19 cate-gories from the HMDB51 dataset to validate the effect ofeach module of VSA-Net and the results are shown in Fig.8. From the results, we can observe that the average gain is
Fig. 11 Accuracy on HMDB51and UCF101 dataset whenleveraging different numbers ofsegments in action recognition
0 10 20 30 40 50 60 70 8075
80
85
90
95
100
Number of Segment
Accu
racy
(%)
HMDB51UCF101
2600 X.-Y. Zhang et al.

Table 7 Comparison of different network combination selection on Something-V1 dataset
Architecture Accuracy(%) Parameters(Millions)
TSN-TwoStream 32.63 13
I3D 41.57 25
VSA-Net+TSN-TwoStream 34.75 23.5
VSA-Net+I3D 42.87 35.5
5%. Especially, the performance on the action “pour” and“swing baseball” is improved by 7% and 11% respectively.We believe that our proposed model is able to capture theinteraction by coupling deep feature and shape informa-tion between human-body and environmental objects. Wealso notice that the performances of “kiss” and “pullup” arejust little better than baseline models. This is because theRGB and optical flow already provide enough cues for theseactions, and coupling video sketch can not bring more extrabenefits.
Visualization results We further perform the qualitativeevaluation. Firstly, we visualize sketch generation module(in Section 3) of our VSA-Net in Fig. 9. The results shown inthe 2nd and 5th columns demonstrate that sketch-attentionmechanism can take temporal evolutions of video action asa dynamic cue to effectively capture discriminative regions.Moreover, we show some feature maps from the videosketch. As shown in Fig. 9 (the 3rd and 6th column),the feature map visualization of sketch is extracted fromthe convolution layer of inception 3a 1x1 out. We canconclude that models with fine-tuning are more capableof representing visual concepts. With the knowledgetransferred from a fine-tuning process with attention guidedsketches, we can capture more meaningful visual structure.
Different modality comparison To further demonstrate theeffectiveness of sketch modality, we try another similarmodality using edge-detection map (shown in Fig. 10).As shown in Table 6, we combine the edge map toTSN-TwoStream, and there is almost no performanceimprovement on HMDB51 split2. While we achieve morethan 3% performance gain by proposing to use two differentsketch features: video sketch-based feature by adaptingan existing architecture and point-set-based sketch featureby designing a new architecture, which shows that real
sketch features can help action recognition while classicaledge maps can not. The main reason is that edge mapscontain many redundant lines and seriously affect theaction-recognition performance.
Effect of number selection of segments To validate theeffects of parameters involved in VSA-Net towardsreognition performance, we conduct experiments with threemodalities fusion on HMDB51 and UCF101 datasets.
In previous inference experiments, we follow thestandard setting [109] and the number of frame is set to25 for fair comparisons. Furthermore, during the inferencephrase, we extract different numbers of frames per videoto validate the effect towards recognition accuracy. Fig. 11illustrates the performance of action recognition whenleveraging different numbers of segments. It is clear to seethat the performance generally improves with an increase innumber of segments. When the number exceeds a point of50, the accuracy becomes smooth gradually. This result isalso expected as only a few segments may not be sufficientto present the entire video such as 5 in this case, whereas acertain number of segments (25 in this paper) could alreadyprovide a good coverage.
Effect of larger dataset and parameters In the evaluation ofSection 5.2, we observe that the proposed modality showsthe promising performance on small benchmarks. To see theeffectiveness on larger dataset and how many parameters arerequired, we conduct another experiments on Something-V1 dataset. The result is shown in Table 7, and we canhave the following observations: the combination of VSA-Net+TSN-TwoStream and VSA-Net+I3D achieves higherperformance than any single network, and they require moreparameters. It is possibly due to that VSA-Net can providemore shape information and a better description of shapepattern. Thus, the final combination of RGB, optical flow
Table 8 Run time analysis on UCF101 dataset. “OF” denotes the optical flow modality
Method Usage TSN-RGB+OF TSN-OF+VSA-Net-Sketch TSN-RGB+VSA-Net-Sketch
RunTime (hours) 49.3 49.3 3.7
FPS 14 14 186
Accuracy 94.2% 93.8% 88.4%
2601Video sketch: A middle-level representation for action recognition

Fig. 12 Action recognitionaccuracy by Inception-resnet-v2with iDT [110], TSN and ourmodel on the UT-Interactiondataset
Punching Kicking Pushing Hugging PointingShaking
handsAverage
Inception-Resnet-v2 95 100 95 95 98 95 96.3
TSN 96 100 96 98 98 96 97.3
Ours 98 100 98 100 99 99 99
80
82
84
86
88
90
92
94
96
98
100
Inception-Resnet-v2 TSN Ours
and sketch can contribute to more discriminative power foraction recognition.
Analysis of time and efficiency For the process of sketchgeneration, VSA-Net takes about 0.012s per frame and thusit needs additional 8.2 hours to generate video sketch forUCF101. Furthermore, to analysis the running time whenevaluating the video-level representation, we compute theruntime of TSN and VSA-Net on the UCF101 dataset. Theresult is shown in Table 8, and we can obtain the followingconclusions: (i) the extraction of optical flow is very time-consuming. (ii) when the input is RGB or sketch modality,the runtime of feature extraction is much faster.
Multi-person dataset In the above evaluation, we can seethat the model performs well on single-player sports. To
Table 9 Action recognition accuracy of our method compared withstate-of-the-art methods on the UT-Interaction dataset
Method UTI-1 UTI-2 Avg.
RSTF [111] 83.5% 72.5% 78.0%
HSTF [112] 88.3% 80.0% 84.1%
BSTF [113] 90.0% 83.9% 86.9%
SAFARRIs [114] 89.2% 87.7% 88.5%
LTRC [115] 85.0% - -
MS-LSTM [116] 90.0% - -
MMAPM [117] 95.0% 86.0% 90.5%
Poselet key-framing [118] 93.3% - -
SCM [119] 93.3% 91.7% 92.5%
PA-DRL [120] 96.7% 91.7% 94.2%
Prediction-CGAN [121] 99.8% 94.6% 97.2%
LSTM-IRN [122] 98.3% 96.7% 97.5%
Ours 99.2% 98.5% 98.8%
further validate the model, we conduct the experimenton multi-person dataset of UT-interaction. Fig. 12 depictsthe action recognition accuracy and Table 9 presents thecomparison with state-of-the-art methods. From the results,we can conclude that: (1) Our method achieves superiorresult over the existing spatial-temporal method by a largemargin for both UTI-1 and UTI-2 in Table 9; (2) Fig. 12suggests that the proposed method performs better thanTSN.
5.4 Comparison with the state-of-the-art
To further evaluate the performance of the proposed method,we compare it with both traditional and deep learningmethods. We train the standard TSN model on Kinetics withRGB and optical flow. The performance comparisons onUCF101 and HMDB51 are shown in Table 10. From theresult, we have the following explanations:
– Overall, there is a performance gap between deeplearning based methods and hand-crafted feature-basedmodel.
– The final result constantly indicates that adding VSA-Net to the TSN-TwoStream model outperforms othersand exhibits an absolute improvement over TSN-TwoStream by 2%, except for I3D and the resultachieves equivalent performance with R(2+1)D onUCF101. In the former situation, ImageNet is usedin addition to Kinetics for pretraining, but we onlytrain the model using Kinetics. We believe that we canboost the performance by training on larger trainingdataset. For the latter situation, R(2+1)D takes themodel trained on 10 clips evenly spaced in the videoand select 8 frames for each video clip as input duringthe training process, and we only choose 3 segmentsfor each video and 6 frames per segment. Training on
2602 X.-Y. Zhang et al.

Table 10 Comparison of action recognition accuracy with the state-of-the-arts on the UCF101 and HMDB51 dataset
method pretraining dataset UCF101 HMDB51
DT+MVSV [123] ImageNet 83.5% 55.9%
iDT+FV [110] ImageNet 85.9% 57.2%
iDT+HSV [124] ImageNet 87.9% 61.1%
MoFAP [125] ImageNet 88.3% 61.7%
Two-Stream [10] ImageNet 88.0% 59.4%
Action Transf [126] ImageNet 92.4% 62.0%
Conv Pooling [127] Sports1M 88.6% –
FST CN [128] ImageNet 88.1% 59.1%
Two-Stream Fusion [129] ImageNet 92.5% 65.4%
Asymmetric 3D-CNN [130] ImageNet 92.6% 65.4%
Spatiotemp. ResNet [131] ImageNet 93.4% 66.4%
STAN [132] ImageNet 93.6% -
TBN [133] ImageNet 93.6% 69.4%
TSN [9] ImageNet 94.2% 69.4%
Action Sketch [8] ImageNet 95.1% –
TEA [134] ImageNet 96.9% 73.3%
R(2+1)D-RGB [135] Kinetics 96.8% 74.5%
R(2+1)D-Flow [135] Kinetics 95.6% 76.4%
R(2+1)D-TwoStream [22] Kinetics 97.3% 78.7%
I3D-RGB [136] ImageNet+Kinetics 95.6% 74.8%
I3D-Flow [136] ImageNet+Kinetics 96.7% 77.1%
I3D [136] ImageNet+Kinetics 97.9% 80.2%
TSN [9] Kinetics 95.7% 76.2%
VSA-Net+TSN Kinetics 97.8% 80.0%
VSA-Net+R(2+1)D Kinetics 98.0% 80.5%
VSA-Net+I3D ImageNet+Kinetics 98.7% 81.0%
longer clips yields better clip-level models, as the filterscan learn long-term temporal patterns. We believe thatthe performance can be further improved by the samesampling strategy.
– We investigate whether the proposed sketch featurerepresentation also works well when combining withother backbone. Given a video, R(2+1)D and I3D isutilized as the backbone to extract rgb and optical flowfeatures, which are sequentially concatenated into thesketch feature. From Table 10, we can find that theperformance of different combinations is improved onthe UCF101 and HMDB51 dataset, which consistentlyindicates that VSA-Net exhibits better performanceof modeling shape information. Meanwhile, the newmodality can be fused with other models and boost therecognition accuracy.
All of the above comparisons show that sketch-basedmodel can provide complementary information to RGB andoptical flow models. We believe that the effectiveness of ourmethod relies on three strategies: First, the attention-guided
sketch can focus on discriminative regions and eliminateirrelevant information during video action recognition.Second, thanks to our fully differentiable architecture,we can fine-tune the model from a large benchmark topredict actions, which brings a significant gain in accuracy.And third, the proposed approach also benefits fromcomplementary image-based sketch and point-based sketchrepresentation, which leads to better classification accuracyonce aggregated.
To validate the above conclusion and demonstrate theadvantages of our model, we give additional examples ofaction recognition. We visualize some difficult actions andreport the result in Fig. 13. From the figure, we can seethat our method achieves better performance than TSN forthese difficult actions. Moreover, our method behaves wellfor the single person pattern and human interaction patternon the HMDB51 dataset. The main reason is that the learnedfeature representations contain abundant shape informationand are complementary to RGB and optical flow, whichis not considered in TSN. In addition, the attention-guidedsketch can capture the fine-grained action for building the
2603Video sketch: A middle-level representation for action recognition

Fig. 13 The top-5 actionrecognition results using TSNand our method on HMDB51dataset. The red bars stand forthe ground truth. The green barsstand for different methods. Thegolden bars stand for correctpredictions. The blue bars standfor incorrect predictions. Thelength of bars stands forprediction confidences
Chew
TSN
Chew
Eat
Drink
Laugh
Run
Ours
Chew
Eat
Drink
Sit
Laugh
Clap
TSN
Handstand
Clap
Wave
Somersault
Throw
Ours
Clap
Handstand
Wave
Hit
Somersault
Draw Sword
TSN
Wave
Draw Sword
Clap
Sword_exercise
Pour
Ours
Draw Sword
Wave
Sword
Sword_exercise
Punch
sketch-level representation, which leads to high accuracy forthese difficult actions.
6 Conclusions
In this paper, we proposed to incorporate the use ofvideo sketch modality for sketch recognition jointly withvideo action recognition. Our model first predicts thesketch with discriminative areas from the raw RGB frames.These distinctive sketches are then used for video actionusing a two-stream network by combining the image-basedsketch and the point-based sketch. Finally, we fused threedifferent modalities: appearance, motion, and sketch forfinal action recognition. In the experiments, we showedthat the proposed method achieves the state-of-the-artperformance on four public video action datasets.
Acknowledgements This work is supported by Fundamental ResearchFunds for the Central Universities (2018YJS045, 2019JBZ104).
References
1. Shi Y, Tian Y, Wang Y, Huang T (2017) Sequential deeptrajectory descriptor for action recognition with three-streamcnn. IEEE TMM
2. Zhang P, Lan C, Xing J, Zeng W, Xue J, Zheng N (2019) Viewadaptive neural networks for high performance skeleton-basedhuman action recognition. PAMI
3. Liu Y, Pados DA (2016) Compressed-sensed-domain l 1-pcavideo surveillance. IEEE TMM
4. Perez-Hernandez F, Tabik S, Lamas AC, Olmos R, Fujita H,Herrera F (2020) Object detection binary classifiers methodologybased on deep learning to identify small objects handledsimilarly: Application in video surveillance. Knowledge BasedSystems, pp 105590
5. Yang X, Shyu M-L, Yu H-Q, Sun S-M, Yin N-S, Chen W(2018) Integrating image and textual information in human–robot
interactions for children with autism spectrum disorder. IEEETMM
6. Kuanar SK, Ranga KB, Chowdhury AS (2015) Multi-view videosummarization using bipartite matching constrained optimum-path forest clustering. IEEE TMM
7. Liu M, Liu H, Chen C (2017) Enhanced skeleton visualizationfor view invariant human action recognition. PR
8. Zheng Y, Yao H, Sun X, Zhao S, Porikli F (2018) Dis-tinctive action sketch for human action recognition. SignalProcessing
9. Wang L, Xiong Y, Wang Z, Qiao Y, Lin D, Tang X, Van Gool L(2016) Temporal segment networks: Towards good practices fordeep action recognition. In: ECCV
10. Simonyan K, Zisserman A (2014) Two-stream convolutionalnetworks for action recognition in videos. In: NIPS
11. Tang Y, Yi T, Lu J, Li P, Zhou J (2018) Deep progressivereinforcement learning for skeleton-based action recognition. In:CVPR
12. Yan S, Xiong Y, Lin D (2018) Spatial temporal graphconvolutional networks for skeleton-based action recognition. In:AAAI
13. Han Z, Xu Z, Zhu S-C (2015) Video primal sketch: A unifiedmiddle-level representation for video. JMIV
14. Yilmaz A, Shah M (2015) Actions sketch: a novel actionrepresentation. In: CVPR
15. Klaser A, Marszałek M, Schmid C (2008) A spatio-temporaldescriptor based on 3d-gradients. In: BMVC
16. Scovanner P, Ali S, Shah M (2007) A 3-dimensional siftdescriptor and its application to action recognition. In: ACM MM
17. Ojala T, Pietikainen M, Maenpaa T (2002) Multiresolutiongray-scale and rotation invariant texture classification with localbinary patterns. PAMI
18. Tran D, Bourdev L, Fergus R, Torresani L, Paluri M(2015) Learning spatiotemporal features with 3d convolutionalnetworks. In: ICCV
19. Wang X, Gao L, Wang P, Sun X, Liu X (2017) Two-stream 3-d convnet fusion for action recognition in videos with arbitrarysize and length. IEEE TMM
20. Hu J-F, Zheng W-S, Pan J, Lai J, Zhang J (2018) Deep bilinearlearning for rgb-d action recognition. In: ECCV
21. Li L, Wang S, Hu B, Qiong Q, Wen J, Rosenblum DS(2018) Learning structures of interval-based bayesian networksin probabilistic generative model for human complex activityrecognition. Pattern Recognition 81:545–561
2604 X.-Y. Zhang et al.

22. Carreira J, Zisserman A (2017) Quo vadis, action recognition? anew model and the kinetics dataset. In: CVPR
23. Gao R, Bo X, Grauman K (2018) Im2flow: Motion hallucinationfrom static images for action recognition. In: CVPR
24. Ng JY-H, Choi J, Neumann J, Davis LS (2018) Actionflownet:Learning motion representation for action recognition. In:WACV
25. Zhang B, Wang L, Wang Z, Qiao Y, Wang H (2016) Real-timeaction recognition with enhanced motion vector cnns. In: CVPR
26. Sun S, Kuang Z, Sheng L, Ouyang W, Zhang W (2018) Opticalflow guided feature: a fast and robust motion representation forvideo action recognition. In: CVPR
27. Piergiovanni AJ, Ryoo MS (2019) Representation flow for actionrecognition. In: CVPR
28. Wang X, Gao L, Wang P, Sun X, Liu X (2018) Two-stream 3-d convnet fusion for action recognition in videos with arbitrarysize and length. IEEE Transactions on Multimedia 20:634–644
29. Zolfaghari M, Oliveira GL, Sedaghat N, Brox T (2017) Chainedmulti-stream networks exploiting pose, motion, and appearancefor action classification and detection. In: ICCV
30. Wang C, Wang Y, Yuille AL (2013) An approach to pose-basedaction recognition. In: CVPR
31. Nie BX, Xiong C, Zhu S-C (2015) Joint action recognition andpose estimation from video. In: CVPR
32. Luvizon DC, Picard D, Tabia H (2018) 2d/3d pose estimation andaction recognition using multitask deep learning. In: CVPR
33. Weng J, Liu M, Jiang X, Yuan J (2018) Deformable pose traversalconvolution for 3d action and gesture recognition. In: ECCV
34. Song S, Lan C, Xing J, Zeng W, Liu J (2017) An end-to-endspatio-temporal attention model for human action recognitionfrom skeleton data. In: AAAI
35. Hussein ME, Torki M, Gowayyed MA, El-Saban M (2013)Human action recognition using a temporal hierarchy ofcovariance descriptors on 3d joint locations. In: IJCAI
36. Wang J, Liu Z, Wu Y, Yuan J (2012) Mining actionlet ensemblefor action recognition with depth cameras. In: CVPR
37. Wang P, Yuan C, Hu W, Li B, Zhang Y (2016) Graph basedskeleton motion representation and similarity measurement foraction recognition. In: ECCV
38. Vemulapalli R, Arrate F, Chellappa R (2014) Human actionrecognition by representing 3d skeletons as points in a lie group.In: CVPR
39. Ke Q, Bennamoun M, An S, Sohel F, Boussaid F (2017) A newrepresentation of skeleton sequences for 3d action recognition.In: CVPR
40. Jain A, Zamir AR, Savarese S, Saxena A (2016) Structural-rnn:Deep learning on spatio-temporal graphs. In: CVPR
41. Zhang S, Yang Y, Xiao J, Liu X, Yang Y, Xie D, ZhuangY (2018) Fusing geometric features for skeleton-based actionrecognition using multilayer lstm networks. IEEE TMM
42. Hou Y, Li Z, Wang P, Li W (2018) Skeleton opticalspectra-based action recognition using convolutional neuralnetworks. IEEE Transactions on Circuits and Systems for VideoTechnology 28:807–811
43. Liu J, Wang G, Hu P, Duan L-Y, Kot AC (2017) Global context-aware attention lstm networks for 3d action recognition. In:CVPR
44. Li D, Yao T, Duan L-Y, Mei T, Rui Y (2018) Unified spatio-temporal attention networks for action recognition in videos.IEEE TMM
45. Du W., Wang Y, Qiao Y (2017) Rpan An end-to-end recurrentpose-attention network for action recognition in videos. In: ICCV
46. Zhu Q, Song G, Shi J (2007) Untangling cycles for contourgrouping
47. Wang S, Kubota T, Siskind JM, Wang J (2005) Salient closedboundary extraction with ratio contour. PAMI
48. Arbelaez P, Maire M, Fowlkes C, Malik J (2010) Contourdetection and hierarchical image segmentation. PAMI
49. Marvaniya S, Bhattacharjee S, Manickavasagam V, Mittal A(2012) Drawing an automatic sketch of deformable objects usingonly a few images. In: ECCV. Springer
50. Lim JJ, Zitnick LC, Dollar P (2013) Sketch tokens: A learnedmid-level representation for contour and object detection. In:CVPR
51. Qi Y, Song Y-Z, Xiang T, Zhang H, Hospedales T, Li Y, Guo J(2015) Making better use of edges via perceptual grouping. In:CVPR
52. Xie S, Tu Z (2015) Holistically-nested edge detection. In: ICCV53. Liu Y, Cheng M-M, Hu X, Wang K, Bai X (2017) Richer
convolutional features for edge detection. In: CVPR54. Zhang X, Huang Y, Qi Z, Guan Q, Liu J (2018) Making better
use of edges for sketch generation. JEI55. Yu Z, Feng C, Liu M-Y, Ramalingam S (2017) Casenet: Deep
category-aware semantic edge detection. In: CVPR56. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley
D, Ozair S, Courville A, Bengio Y (2014) Generative adversarialnets. In: NIPS
57. Isola P, Zhu J-Y, Zhou T, Efros AA (2017) Image-to-imagetranslation with conditional adversarial networks. In: CVPR
58. Zhang X, Li X, Li X, Shen M (2018) Better freehand sketchsynthesis for sketch-based image retrieval: Beyond image edges.Neurocomputing
59. Eitz M, Hays J, Alexa M (2012) How do humans sketch objects?ACM TOG
60. Eitz M, Hildebrand K, Boubekeur T, Alexa M (2010)Sketch-based image retrieval: Benchmark and bag-of-featuresdescriptors. TVCG
61. Schneider RG, Tuytelaars T (2014) Sketch classification andclassification-driven analysis using fisher vectors. ACM TOG
62. Li Y, Hospedales TM, Song Y-Z, Gong S (2015) Free-handsketch recognition by multi-kernel feature learning. CVIU
63. Simonyan K, Zisserman A (2014) Very deep convolutionalnetworks for large-scale image recognition. arXiv:1409.1556
64. Sert M, Boyacı E (2019) Sketch recognition using transferlearning. Multimedia Tools and Applications
65. Zhang H, She P, Liu Y, Gan J, Cao X, Foroosh H(2019) Learning structural representations via dynamic objectlandmarks discovery for sketch recognition and retrieval. IEEETIP
66. Yu Q., Yang Y, Liu F, Song Y-Z, Xiang T, Hospedales TM(2017) Sketch-a-net: A deep neural network that beats humans.IJCV
67. Sarvadevabhatla RK, Babu RV (2015) Freehand sketch recogni-tion using deep features. arXiv
68. Zhang H, Si L, Zhang C, Ren W, Wang R, Cao X (2016)Sketchnet: Sketch classification with web images. In: CVPR
69. Xiao Q, Dai J, Luo J, Fujita H (2019) Multi-view manifoldregularized learning-based method for prioritizing candidatedisease mirnas. Knowl Based Syst 175:118–129
70. Sun S, Shawe-Taylor J, Mao L (2017) Pac-bayes analysis ofmulti-view learning. Inf Fusion 35:117–131
71. Higgs M, Shawe-Taylor J (2010) A pac-bayes bound for tailoreddensity estimation. In: ALT
72. Seldin Y, Laviolette F, Cesa-Bianchi N, Shawe-Taylor J, Auer P(2012) Pac-bayesian inequalities for martingales. IEEE Trans InfTheory 58:7086–7093
73. Wang H, Yang Y, Liu B, Fujita H (2019) A study of graph-basedsystem for multi-view clustering. Knowl Based Syst 163:1009–1019
2605Video sketch: A middle-level representation for action recognition

74. Sun S, Mao L, Dong Z, Wu L (2019) Multiview machinelearning. In: Springer, Singapore
75. Sun S, Liu Y, Mao L (2019) Multi-view learning for visualviolence recognition with maximum entropy discrimination anddeep features. Inf Fusion 50:43–53
76. Liu M, Zhang J, Yap P-T, Shen D (2017) View-alignedhypergraph learning for alzheimer’s disease diagnosis withincomplete multi-modality data. Med Image Anal 36:123–134
77. Zhang W, Zhou H, Sun S, Wang Z, Shi J, Loy CC (2019) Robustmulti-modality multi-object tracking. In: 2019 IEEE/CVFInternational Conference on Computer Vision (ICCV), pp 2365–2374
78. Gkalelis N, Nikolaidis N, Pitas I (2009) View indepedenthuman movement recognition from multi-view video exploitinga circular invariant posture representation. In: 2009 IEEEInternational Conference on Multimedia and Expo. IEEE,pp 394–397
79. Iosifidis A, Tefas A, Pitas I (2013) View-independent humanaction recognition based on multi-view action images anddiscriminant learning. In: IVMSP 2013. IEEE, pp 1–4
80. Ren Z, Zhang Q, Gao X, Hao P, Cheng J (2020) Multi-modalitylearning for human action recognition. Multimedia Tools andApplications 1–19
81. Wang T, Brown H-F Drawing aid system for multi-touch devices,October 14 2014. US Patent 8,860,675
82. Zhao H, Tian M, Sun S, Shao J, Yan J, Yi S, Wang X,Tang X (2017) Spindle net: Person re-identification with humanbody region guided feature decomposition and fusion. In:Proceedings of the IEEE conference on computer vision andpattern recognition, pp 1077–1085
83. Chen H, Wang G, Xue J-H, He L (2016) A novel hierarchicalframework for human action recognition. PR
84. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, BatraD (2017) Grad-cam: Visual explanations from deep networks viagradient-based localization. In: ICCV
85. Laptev I, Caputo B, et al. (2004) Recognizing human actions: alocal svm approach. In: Null
86. Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T (2011) Hmdb:a large video database for human motion recognition. In: ICCV
87. Soomro K, Zamir AR, Shah M (2012) Ucf101: A dataset of101 human actions classes from videos in the wild. arXiv:1212.0402
88. Qi J, Yu M, Fan X, Li H (2017) Sequential dual deep learningwith shape and texture features for sketch recognition
89. Ioffe S, Szegedy C (2015) Batch normalization: Acceleratingdeep network training by reducing internal covariate shift.arXiv:1502.03167
90. Liu Z, Gao J, Yang G, Zhang H, He Y (2016) Localization andclassification of paddy field pests using a saliency map and deepconvolutional neural network. Scientific reports
91. Belongie S, Malik J, Puzicha J (2002) Shape matching and objectrecognition using shape contexts. PAMI
92. Carlsson S, Sullivan J (2001) Action recognition by shapematching to key frames. In: Workshop on models versusexemplars in computer vision, volume 1
93. Li W, Zhang Z, Liu Z (2010) Action recognition based on a bagof 3d points. In: CVPR Workshops. IEEE
94. Li W, Zhang Z, Liu Z (2008) Expandable data-driven graphicalmodeling of human actions based on salient postures. IEEEtransactions on Circuits and Systems for Video Technology
95. Devanne M, Wannous H, Berretti S, Pala P, Daoudi M, DelBimbo A (2014) 3-d human action recognition by shape analysisof motion trajectories on riemannian manifold. IEEE transactionson cybernetics
96. Ha VHS, Moura JMF (2005) Affine-permutation invariance of2-d shapes. IEEE TIP
97. Eldar Y, Lindenbaum M, Porat M, Zeevi YY (1997) The farthestpoint strategy for progressive image sampling. IEEE TIP
98. Moenning C, Dodgson NA (2003) Fast marching farthest pointsampling. Technical report, University of Cambridge, ComputerLaboratory
99. Parameswaran V, Chellappa R (2006) View invariance for humanaction recognition. IJCV
100. Ahmad M, Lee S-W (2008) Human action recognition usingshape and clg-motion flow from multi-view image sequences. PR
101. Christopher M, et al. (1995) Bishop Neural networks for patternrecognition. Oxford University Press
102. Vinyals O, Bengio S, Kudlur M (2015) Order matters: Sequenceto sequence for sets. Computer Science
103. Qi CR, Su H., Mo K, Guibas LJ (2017) Pointnet: Deep learningon point sets for 3d classification and segmentation. In: CVPR
104. Donahue J, Hendricks LA, Guadarrama S, Rohrbach M,Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrentconvolutional networks for visual recognition and description. In:CVPR
105. Li Z, Gavrilyuk K, Gavves E, Jain M, Snoek CGM (2018)Videolstm convolves, attends and flows for action recognition.CVIU
106. Goyal R, Kahou SE, Michalski V, Materzynska J, Westphal S,Kim H, Haenel V, Fruend I, Yianilos P, Mueller-Freitag M, et al.(2017) The “something something” video database for learningand evaluating visual common sense. In: ICCV
107. Ryoo MS, Aggarwal JK (2010) Ut-interaction dataset, icprcontest on semantic description of human activities (sdha).In: IEEE International Conference on Pattern RecognitionWorkshops, vol 2, p 4
108. Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S,Huang Z, Karpathy A, Khosla A, Bernstein M, et al. (2015)Imagenet large scale visual recognition challenge. IJCV
109. Qiu Z, Yao T, Mei T (2017) Deep quantization: Encodingconvolutional activations with deep generative model. In: CVPR
110. Wang H, Schmid C (2013) Action recognition with improvedtrajectories. In: Proceedings of the IEEE international conferenceon computer vision, pp 3551–3558
111. Mahmood M, Jalal A, Sidduqi MA (2018) Robust spatio-temporal features for human interaction recognition via artificialneural network. 2018 International Conference on Frontiers ofInformation Technology (FIT), pp 218–223
112. Jalal A, Mahmood M (2019) Students’ behavior mining in e-learning environment using cognitive processes with informationtechnologies. Educ Inf Technol, pp 1–25
113. Nour el Houda Slimani K, Benezeth Y, Souami F (2020)Learning bag of spatio-temporal features for human interactionrecognition. In: International Conference on Machine Vision
114. Chattopadhyay C, Das S (2016) Supervised framework forautomatic recognition and retrieval of interaction: a frameworkfor classification and retrieving videos with similar humaninteractions. IET Comput Vis 10:220–227
115. Donahue J, Hendricks LA, Rohrbach M, Venugopalan S, Guadar-rama S, Saenko K, Darrell T (2017) Long-term recurrentconvolutional networks for visual recognition and descrip-tion. IEEE Transactions on Pattern Analysis and MachineIntelligence
116. Akbarian MSA, Saleh F, Salzmann M, Fernando B, Petersson L,Andersson L (2017) Encouraging lstms to anticipate actions veryearly. 2017 IEEE International Conference on Computer Vision(ICCV), pp 280–289
117. Kong Y, Fu Y (2016) Max-margin action prediction machine.IEEE Trans Pattern Anal Mach Intell 38:1844–1858
118. Raptis M, Sigal L (2013) Poselet key-framing: A model forhuman activity recognition. 2013 IEEE Conference on ComputerVision and Pattern Recognition, pp 2650–2657
2606 X.-Y. Zhang et al.

119. Ke Q, Bennamoun M, An S, Sohel F, Boussaid F (2018) Lever-aging structural context models and ranking score fusion forhuman interaction prediction. IEEE Transactions on Multimedia20:1712–1723
120. Chen L, Lu J, Song Z, Zhou J (2018) Part-activated deepreinforcement learning for action prediction. In: Proceedingsof the European Conference on Computer Vision (ECCV),pp 421–436
121. Xu W, Yu J, Miao Z, Wan L, Ji Q (2019) Prediction-cgan: Human action prediction with conditional generativeadversarial networks. Proceedings of the 27th ACM InternationalConference on Multimedia
122. Perez M, Liu J, Kot AC (2019) Interaction relational network formutual action recognition. arXiv:1910.04963
123. Cai Z, Wang L, Peng X, Qiao Yu (2014) Multi-view super vectorfor action recognition. In: CVPR
124. Peng X., Wang L, Xingxing W., Yu Q (2016) Bag of visual wordsand fusion methods for action recognition: Comprehensive studyand good practice. CVIU
125. Wang L, Yu Q, Tang X (2016) Mofap: A multi-levelrepresentation for action recognition. IJCV
126. Wang X, Farhadi A, Gupta A (2016) Actions transformations. In:CVPR
127. Ng JY-H, Hausknecht M, Vijayanarasimhan S, Vinyals O,Monga R, Toderici G (2015) Beyond short snippets: Deepnetworks for video classification. In: CVPR
128. Sun L, Jia K, Yeung D-Y, Shi BE (2015) Human action recogni-tion using factorized spatio-temporal convolutional networks. In:ICCV
129. Feichtenhofer C, Pinz A, Zisserman A (2016) Convolutionaltwo-stream network fusion for video action recognition. In:CVPR
130. Yang HT, Yuan C, Li B, Du Y, Xing J, Hu W, Maybank SJ(2019) Asymmetric 3d convolutional neural networks for actionrecognition. Pattern Recognit 85:1–12
131. Feichtenhofer C, Pinz A, Wildes R (2016) Spatiotemporalresidual networks for video action recognition. In: NIPS
132. Li D, Yao T, Duan Ly, Mei T, Rui Y (2019) Unified spatio-temporal attention networks for action recognition in videos.IEEE Trans Multimed 21:416–428
133. Li Y, Song S, Li Y, Liu J (2019) Temporal bilinear networksfor video action recognition. In: Proceedings of the AAAIConference on Artificial Intelligence, vol 33, pp 8674–8681
134. Li Y, Ji B, Shi X, Zhang J, Kang B, Wang L (2020) Tea:Temporal excitation and aggregation for action recognition. In:Proceedings of the IEEE/CVF Conference on Computer Visionand Pattern Recognition, pp 909–918
135. Du T, Wang H, Torresani L, Ray J, LeCun Y, Paluri M (2018) Acloser look at spatiotemporal convolutions for action recognition.In: CVPR
136. Carreira J, Zisserman A (2017) Quo vadis, action recogni-tion? a new model and the kinetics dataset. 2017 IEEE Con-ference on Computer Vision and Patter Recognition (CVPR)pp 4724–4733
Publisher’s note Springer Nature remains neutral with regard tojurisdictional claims in published maps and institutional affiliations.
Xing-Yuan Zhang receivedthe B.S. degree in computerscience and technology fromTangshan University in 2013.He is currently pursuing thePh.D. degree with the Schoolof Computer and Informa-tion Technology, Beijing Jiao-tong University, China. In2019, he was a Visiting Ph.D.Student with the Universityof South Carolina, Columbia,SC, USA. His research inter-ests include deep learning,computer vision, and digitalimage processing.
Ya-Ping Huang received herBS, MS, and PhD degreesfrom Beijing Jiaotong Uni-versity, China, in 1995, 1998,and 2004, respectively. Cur-rently, she is a professorat Beijing Jiaotong Univer-sity. Her research interestsinclude pattern recognition,computer vision, computervision, image processing,and biological inspired objectrecognition.
Yang Mi received the B.S.degree in information engi-neering from the Beijing Insti-tute of Technology, China, in2009, and the M.S. degree incomputer science and engi-neering from the Universityof South Carolina in 2018,where he is currently pursu-ing the Ph.D. degree in com-puter science and engineering.His research interests includecomputer vision and machinelearning.
2607Video sketch: A middle-level representation for action recognition

Yan-Ting Pei is currentlypursuing the Ph.D. degreewith the School of Computerand Information Technology,Beijing Jiaotong University,China. In 2018, she was aVisiting Ph.D. Student withthe University of South Car-olina, Columbia, SC, USA.Her research interests includecomputer vision, image pro-cessing, machine learning,and deep learning.
Qi Zou received her BS, andPhD degrees from BeijingJiaotong University, China, in2001 and 2006, respectively.Currently, she is a professorat Beijing Jiaotong University.Her research interests includepattern recognition, computervision, computer vision, andtarget tracking.
Song Wang (Senior Member,IEEE) received the Ph.D.degree in electrical andcomputer engineering fromthe University of Illinois atUrbana-Champaign (UIUC)in 2002. From 1998 to 2002,he also worked as a ResearchAssistant with Image Forma-tion and Processing Group,Beckman Institute, UIUC. In2002, he joined the Depart-ment of Computer Scienceand Engineering, Universityof South Carolina, where heis currently a Professor. His
research interests include computer vision, medical image processing,and machine learning. He is a Senior Member of the IEEE ComputerSociety. He is currently serving as an Associate Editor of the IEEETransactions on Pattern Analysis and Machine Intelligence, PatternRecognition Letters, and Electronics Letters.
2608 X.-Y. Zhang et al.