variant discovery different approaches: with or without a reference? with a reference – limiting...
Post on 19-Dec-2015
217 views
TRANSCRIPT

Variant discovery
• Different approaches: With or without a reference?• With a reference – Limiting factors are CPU time and memory required– Crossbow – a cluster-based cloud computing approach
• Without a reference– CPU time and RAM requirements are still limiting– Now error rate and distribution become limiting also– Statistical methods for estimating probability that a
putative SNP is a true SNP are still developing– Some analytical methods require experimental designs
specifically for the variant discovery objective
BIT 815: Analysis of Deep Sequencing Data

Structural variants in 7 flavors
Figure from Alkan et al, Nature Reviews Genetics 2011 doi:10.1038/nrg2958

Different technologies have different resolutions
Figure from Alkan et al, Nature Reviews Genetics 2011 doi:10.1038/nrg2958
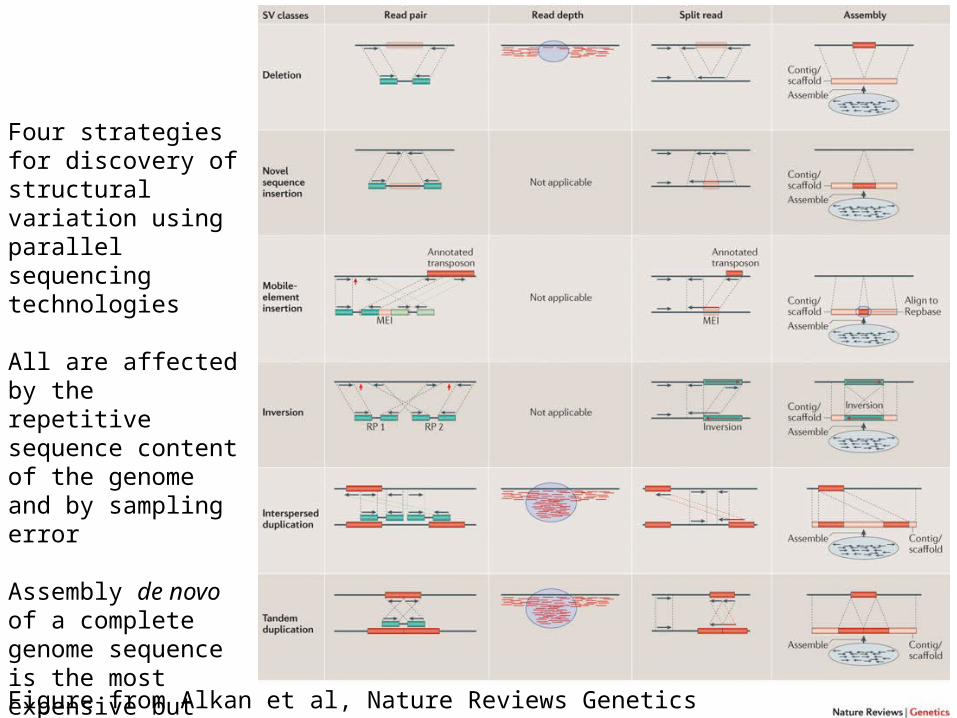
Figure from Alkan et al, Nature Reviews Genetics 2011 doi:10.1038/nrg2958
Four strategies for discovery of structural variation using parallel sequencing technologies
All are affected by the repetitive sequence content of the genome and by sampling error
Assembly de novo of a complete genome sequence is the most expensive but most complete approach
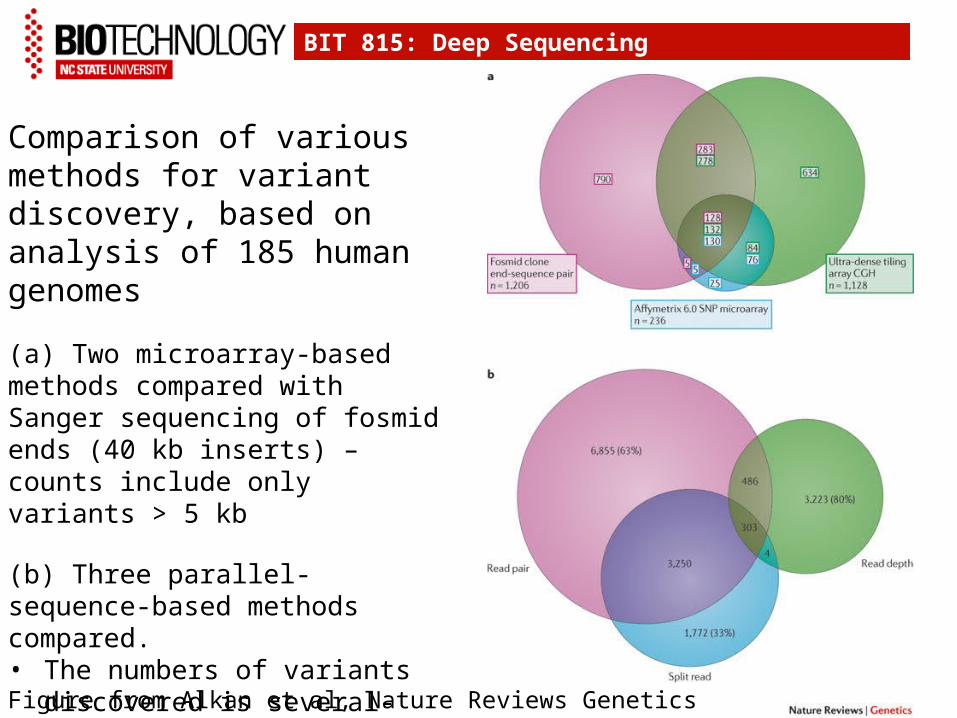
BIT 815: Deep Sequencing
Figure from Alkan et al, Nature Reviews Genetics 2011 doi:10.1038/nrg2958
Comparison of various methods for variant discovery, based on analysis of 185 human genomes
(a) Two microarray-based methods compared with Sanger sequencing of fosmid ends (40 kb inserts) – counts include only variants > 5 kb
(b) Three parallel-sequence-based methods compared. • The numbers of variants discovered
is several-fold higher than in part (a)• There is relatively little overlap
among the variants discovered using different methods

Small indels create problemsfor SNP-calling programs
Figure from http://samtools.sourceforge.net/mpileup.shtml
Correctly aligned
Artifactual SNP calls
Incorrectly aligned
Incorrectly aligned

Base Alignment Quality (BAQ)is one approach to dealing with the problem
Figure from http://samtools.sourceforge.net/mpileup.shtml

Small indels create problemsfor SNP-calling programs
Figure from http://samtools.sourceforge.net/mpileup.shtml
Correctly aligned
BAQ downgrades quality scores of thesebases so they are not considered reliable by SNP-calling programs
Incorrectly aligned
Incorrectly aligned

Short Read Multiple Aligner (SRMA)is another approach – actually re-aligns reads
Figure from Homer and Nelson, Genome Biology 2010, 11:R99

Short Read Multiple Aligner (SRMA)The downside is computational intensity
From Homer and Nelson Genome Biology 2010, 11:R99

What about rare alleles?Efficient screening in pooled samples
• Druley TE, et al. (2009) Quantification of rare allelic variants from pooled genomic DNA. Nat Methods 6(4):263-5.
• Vallania FL, et al. (2010) High-throughput discovery of rare insertions and deletions in large cohorts. Genome Res 20(12):1711-8.
• Bansal V, et al (2010) Accurate detection and genotyping of SNPs utilizing population sequencing data.Genome Res 20(4):537-45.
• Bansal V. (2010) A statistical method for the detection of variants from next-generation resequencing of DNA pools. Bioinformatics 26(12):i318-24.
• Bansal V, et al. (2011) Efficient and cost effective population resequencing by pooling and in-solution hybridization. PLoS One 6(3):e18353.
• Altmann A, et al (2011) vipR: variant identification in pooled DNA using R. Bioinformatics 27(13):i77-84.

What about rare alleles?Comparing across pools adds to power
(a) Five alternate base calls in one of four pooled samples is unlikely to arise by chance sequencing errors alone – the p-value from the contingency table is 0.002
(b) Five of nine alternate base calls in one pool, with one call in each of the other three, is a pattern that cannot be distinguished from that expected of sequencing errors – the contingency table p-value is 0.24