tokyo webmining talk1
TRANSCRIPT

Deep Learning Implementationsand Frameworks(Very short version of PAKDD 2016 tutorial)
Kenta Oono [email protected] Networks Inc.25th Jun. 2016Tokyo Webmining @FreakOut
1/31

Overview
•1st session (8:30 ‒ 10:00)• Introduction (AK)• Basics of neural networks (AK)• Common design of neural network implementations (KO)
•2nd session (10:30 ‒ 12:30)• Differences of deep learning frameworks (ST)• Coding examples of frameworks (KO & ST)• Conclusion (ST)
2/31

Full contents
• Session1• Basics of neural Networks
• http://www.slideshare.net/atsu-kan/pakdd2016-tutorial-dlif-introduction-and-basics-63030841
• Common design of neural networks implementation• http://www.slideshare.net/KentaOono/common-design-of-deep-learning-
frameworks
• Session2• Differences of deep learning frameworks
• http://www.slideshare.net/beam2d/differences-of-deep-learning-frameworks
• Coding examples of frameworks• will be available soon.
3/31

Basics of Neural NetworksAtsunori Kanemura
AIST, Japan
4/31

Mathematical model for a neuron
• Compare the product of input and weights (parameters) with a threshold
• Plasticity of the neuron= The change of parameters and
……
f : nonlinear transform
bx
w
b
x1
x2y
w
xD
y = f
⇣ DX
d=1
wdxd � b
⌘= f(wT
x� b)
b5/31

Parameter update
• Gradient Descent (GD)
• Stochastic Gradient Descent (SGD)• Take several samples (say, 128) from the dataset (mini-batch),
estimate the gradient.• Theoretically motivated as the Robbins-Monro algorithm
• SGD to general gradient-based algorithms• Adam, AdaGrad, etc.• Use momentum and other techniques
w w � rrwJ(w) = w �NX
n=1
h(xn,w)xn
h(xn,w¯)def= (f(wT
xn)� yn)f(wTxn)(1� f(wT
xn))
6/31

Gradient descent• The gradient of the loss for 1-layer model is
• The update rule (r is aconstantlearningrate)
rwJ(w) =1
2
NX
n=1
rw(f(wTxn)� y⇤n)
2
=NX
n=1
(f(wTxn)� y⇤n)rwf(wT
xn)
=NX
n=1
(f(wTxn)� y⇤n)f(w
Txn)(1� f(wT
xn))xn
w w � rrwJ(w) = w �NX
n=1
h(xn,w)xn
h(xn,w)def= (f(wT
xn)� y⇤n)f(wTxn)(1� f(wT
xn))7/31

Neural networks
• Multi-layered
• Minimize the loss to learn the parameters
※ f works element-wise
y
1 = f1(W10x)
y
2 = f2(W21y
1)
y
3 = f3(W32y
2)
...
y
L = fL(W(L)(L�1)
y
L�1)
J({W }) = 1
2
NX
n=1
(yL(xn)� y⇤n)2
8/31

Backprop
• Use the chain rule to derive the gradient
• E.g. 2-layer case
• Calculate gradient recursively from top to bottom layers
• Cf. Gradient vanishing, ReLU
y
1n = f(W 10
xn), y2n = f(w21 · y1n)
@J
@W 10kl
=X
n,i
@J
@y1ni
@y1ni@W 10
kl
J(W 10,w21) =1
2
X
n
(y2n � y⇤n)2
9/31


Steps for training neural networks
Prepare the training dataset
Repeat until meeting some criterionPrepare for the next (mini) batch
Compute the loss (forward prop)
Initialize the Neural Network (NN) parameters
Save the NN parameters
Define how to compute the loss of this batch
Compute the gradient (backprop)Update the NN parameters
11/31
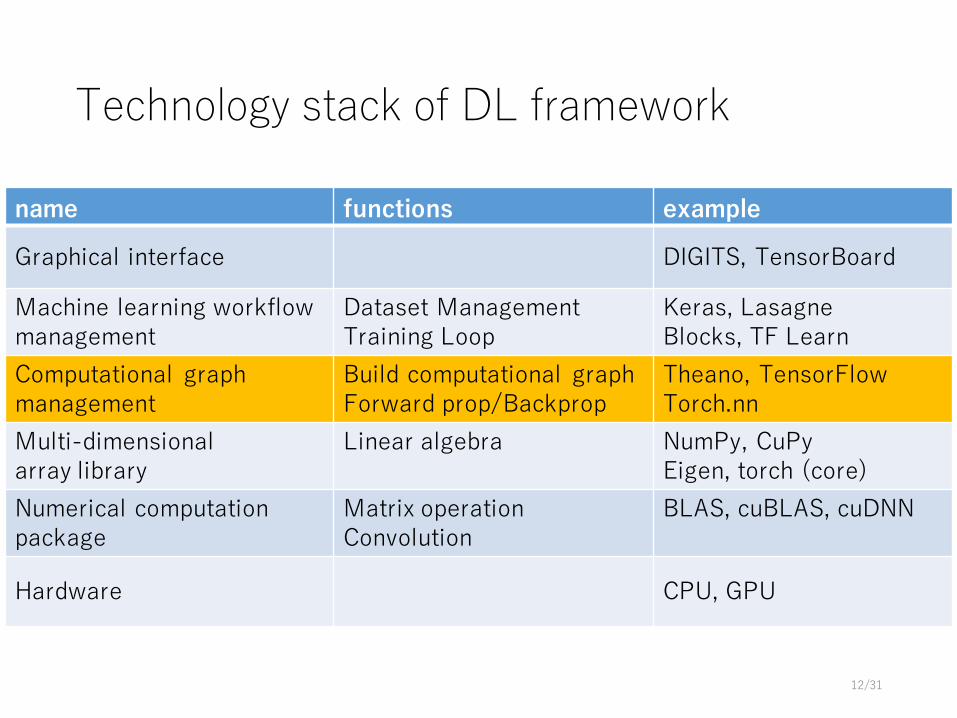
Technology stack of DL framework
name functions example
Graphical interface DIGITS, TensorBoard
Machine learning workflowmanagement
Dataset ManagementTraining Loop
Keras, LasagneBlocks, TF Learn
Computational graph management
Build computational graphForward prop/Backprop
Theano, TensorFlowTorch.nn
Multi-dimensionalarray library
Linear algebra NumPy, CuPyEigen, torch (core)
Numerical computationpackage
Matrix operationConvolution
BLAS, cuBLAS, cuDNN
Hardware CPU, GPU
12/31
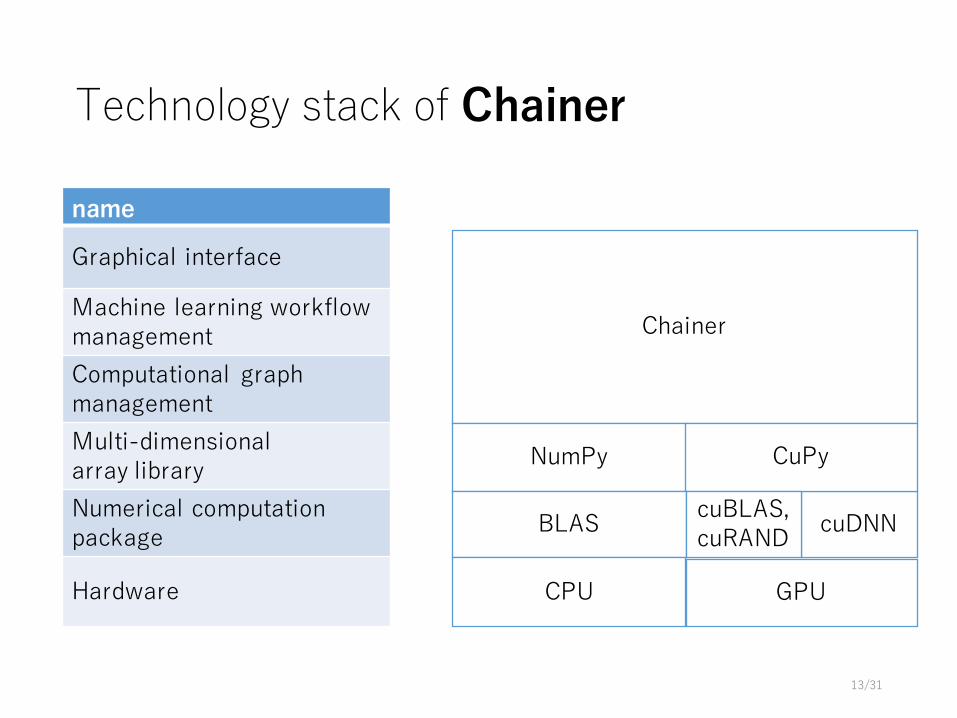
Technology stack of Chainer
cuDNN
Chainer
NumPy CuPy
BLAS cuBLAS, cuRAND
CPU GPU
name
Graphical interface
Machine learning workflowmanagementComputational graph managementMulti-dimensionalarray libraryNumerical computationpackage
Hardware
13/31

Neural Network as a Computational Graph
• In simplest form, NN is represented as a computational graph (CG) that is a stack of bipartite DAGs (Directed Acyclic Graph) consisting of data nodes and operator nodes.
y = x1 * x2z = y - x3
x1 mul suby
x3
z
x2
data node
operator node14/31
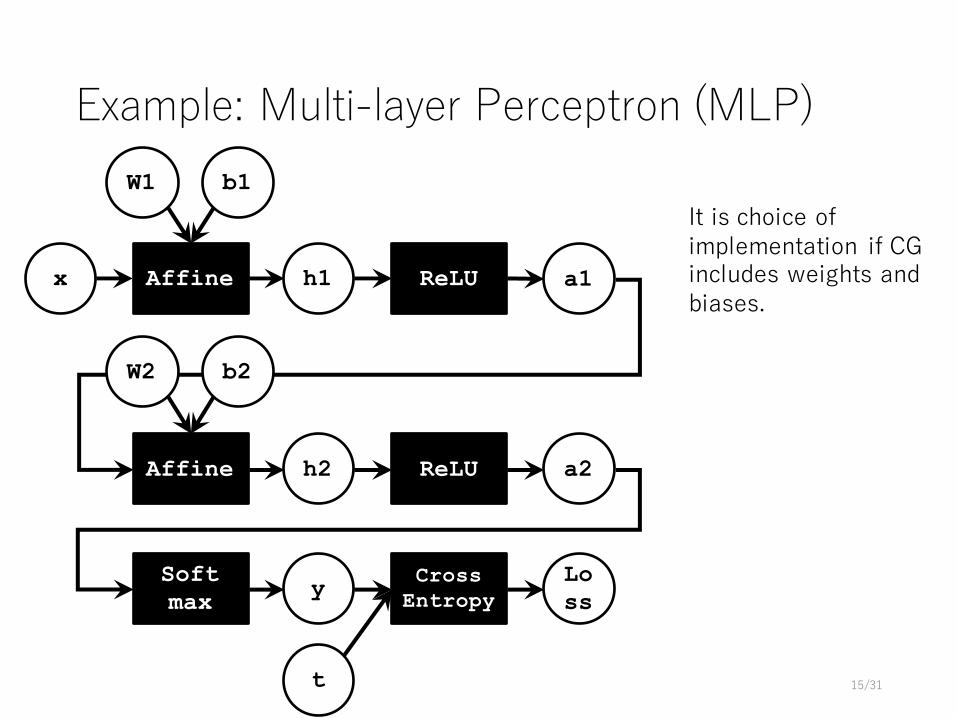
Example: Multi-layer Perceptron (MLP)
x Affine
W1 b1
h1 ReLU a1
Affine
W2 b2
h2 ReLU a2
Softmax y Cross
EntropyLoss
t
It is choice of implementation if CG includes weights and biases.
15/31

Automatic Differentiation
• Computes gradient of some specified data nodes (e.g. loss) with respect to each data node.
• Each operator node must have backward operation to calculate gradients w.r.t. its inputs from gradients w.r.t. its outputs (realization of chain rule).
• e.g. Function class of Chainer has backwardmethod.• e.g. Each layer classes of Caffe has Backward_cpu and Backward_gpumethods
• e.g. Autograd has a thin wrapper that adds gradient methods as a closure to most of NumPy methods.
16/31
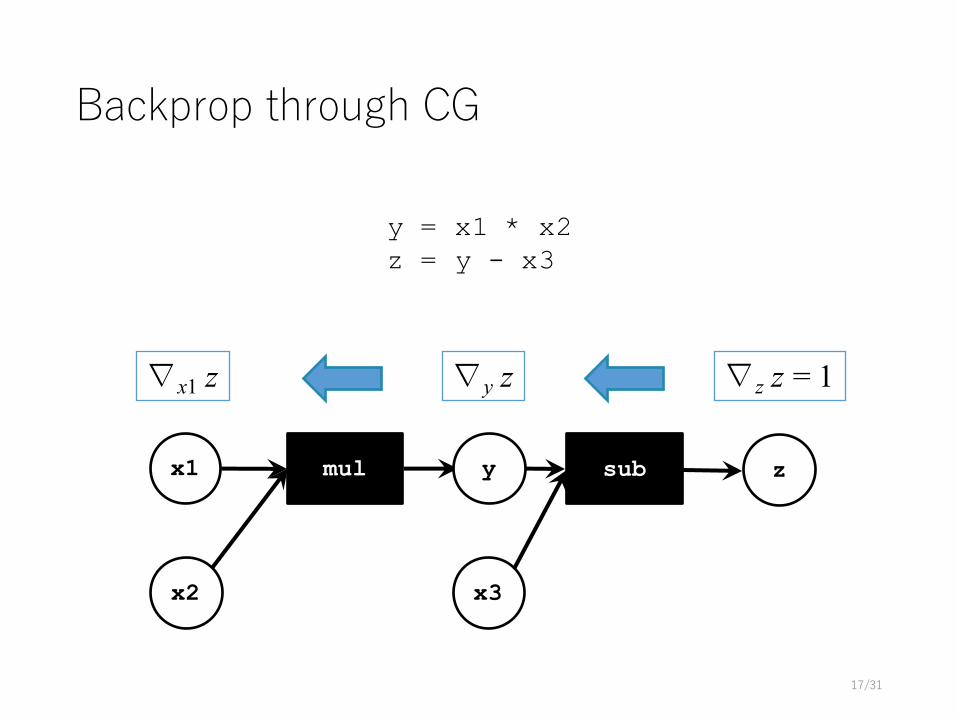
Backprop through CG
∇y z∇x1 z ∇z z = 1
y = x1 * x2z = y - x3
x1 mul suby
x3
z
x2
17/31
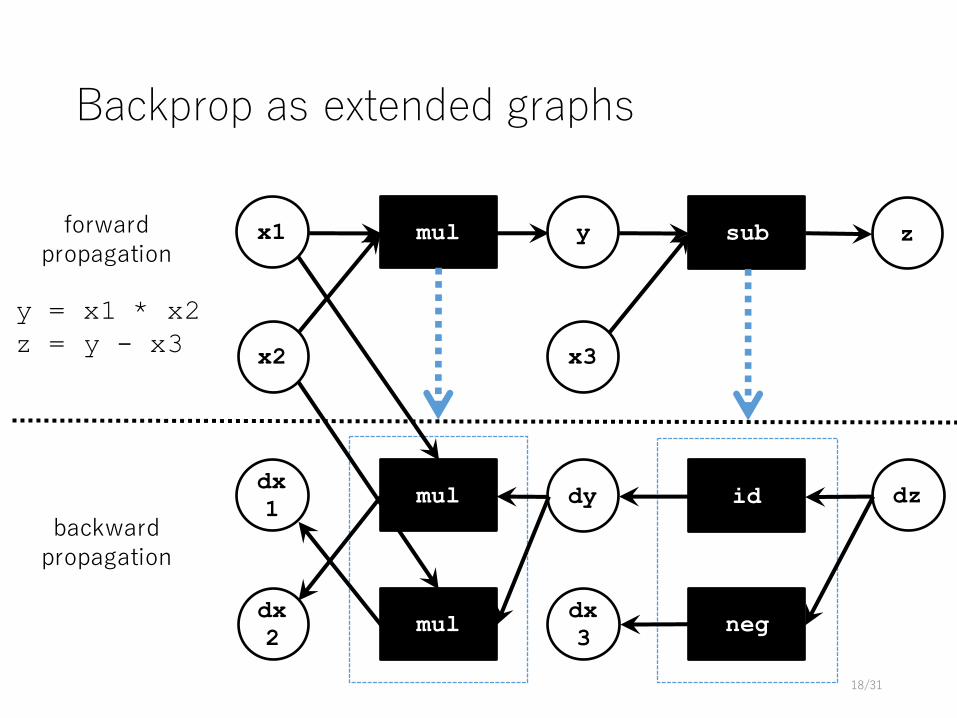
Backprop as extended graphs
x1 mul suby
x3
z
x2
dzid
neg
mul
mul
dy
dx3
dx1
dx2
forwardpropagation
backwardpropagation
y = x1 * x2z = y - x3
18/31

Differences ofDeep Learning FrameworksSeiya TokuiPreferred Networks, Inc.
19/31
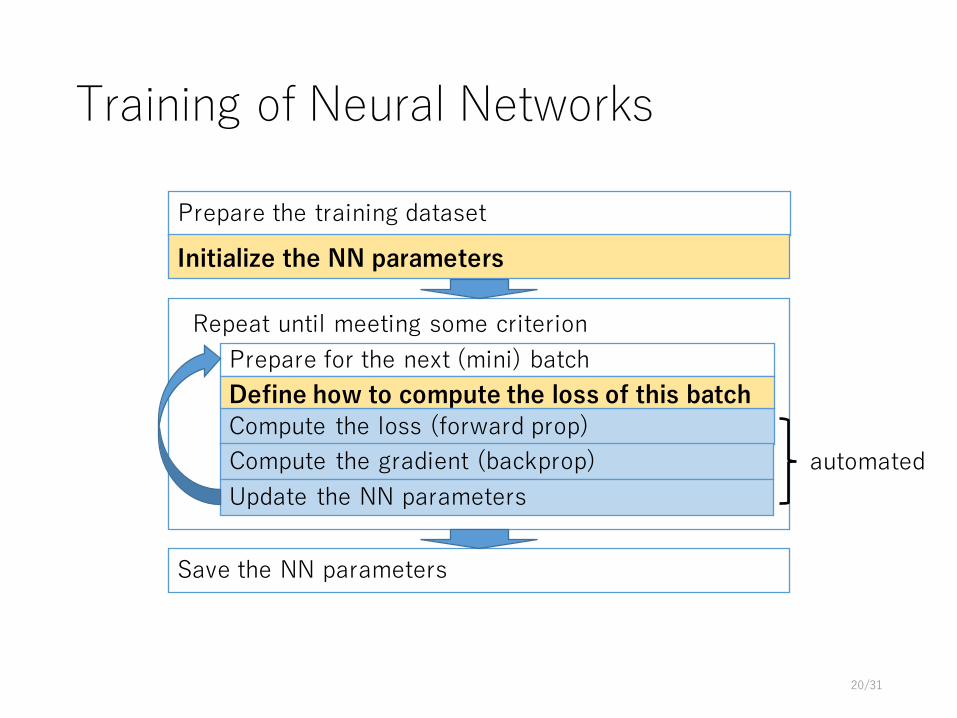
Training of Neural Networks
Prepare the training dataset
Repeat until meeting some criterionPrepare for the next (mini) batch
Compute the loss (forward prop)
Initialize the NN parameters
Save the NN parameters
Define how to compute the loss of this batch
Compute the gradient (backprop)Update the NN parameters
automated
20/31

Framework Design Choices
• The most crucial part of NN frameworks is• How to define the parameters• How to define the loss function of the parameters
(= how to write computational graphs)• These also influence on APIs for forward prop, backprop, and
parameter updates (i.e., numerical optimization)• And all of these are determined by how to implement
computational graphs
• Other parts are also important, but are mostly common to implementations of other types of machine learning methods
21/31

Framework Comparison: Basic information*Viewpoint Torch.nn** Theano*** Caffe
autograd(NumPy, Torch)
Chainer MXNet Tensor-Flow
GitHub stars 4,719 3,457 9,590 N: 654
T: 554 1,295 3,316 20,981
Started from 2002 2008 2013 2015 2015 2015 2015
Open issues/PRs 97/26 525/105 407/204 N: 9/0
T: 3/1 95/25 271/18 330/33
Main developers
Facebook, Twitter,
Google, etc.Université
de MontréalBVLC
(U.C. Berkeley)
N: HIPS (Harvard Univ.)T: Twitter
PreferredNetworks DMLC Google
Core languages C/Lua C/Python C++ Python/Lua Python C++ C++/Python
Supported languages Lua Python C++/Python
MATLAB Python/Lua PythonC++/PythonR/Julia/Go
etc.C++/Python
* Data was taken on Apr. 12, 2016** Includes statistics of Torch7*** There are many frameworks on top of Theano, though we omit them due to the space constraints
22/31

List of Important Design Choices
Programming paradigms1. How to write NNs in text format2. How to build computational graphs3. How to compute backprop4. How to represent parameters5. How to update parametersPerformance improvements6. How to achieve the computational performance7. How to scale the computations
23/31

Framework Comparison: Design ChoicesDesignChoice Torch.nn Theano-
based Caffeautograd(NumPy, Torch)
Chainer MXNet Tensor-Flow
1.NN definition
Script (Lua)
Script* (Python)
Data(protobuf)
Script (Python,
Lua)Script
(Python)Script (many)
Script (Python)
2. Graph construction Prebuild Prebuild Prebuild Dynamic Dynamic Prebuild** Prebuild
3. Backprop
Through graph
Extendedgraph
Through graph
Extended graph
Through graph
Throughgraph
Extended graph
4. Parameters
Hidden in operators
Separate nodes
Hidden in operators
Separate nodes
Separate nodes
Separate nodes
Separate nodes
5. Update formula
Outside of graphs
Part of graphs
Outside of graphs
Outside of graphs
Outside of graphs
Outside of graphs**
Part of graphs
6. Optimization - Advanced
optimization - - - - Simple optimization
57 Parallel computation Multi GPU Multi GPU
(libgpuarray) Multi GPU Multi GPU (Torch) Multi GPU Multi node
Multi GPUMulti nodeMulti GPU
* Some of Theano-based frameworks use data (e.g. yaml)** Dynamic dependency analysis and optimization is supported (no autodiff support)24/31

How to write NNs in text format
Write NNs in declarative configuration filesFramework builds layers of NNs as written in the files (e.g. prototxt, YAML).
E.g.: Caffe (prototxt), Pylearn2 (YAML)
Write NNs by procedural scriptingFramework provides APIs of scripting languages to build NNs.
E.g.: most other frameworks
25/31

2. How to build computational graphs
Prepare the training dataset
Repeat until meeting some criterionPrepare for the next (mini) batchCompute the loss (forward prop)
Initialize the NN parameters
Save the NN parameters
Compute the gradient (backprop)Update the NN parameters
Define how to compute the loss
Prepare the training dataset
Repeat until meeting some criterionPrepare for the next (mini) batch
Compute the loss (forward prop)
Initialize the NN parameters
Save the NN parameters
Define how to compute the loss
Compute the gradient (backprop)Update the NN parameters
Build once, run several times Build one at every iteration
26/31

3. How to compute backprop
Backprop through graphsFramework only builds graphs of forward prop, and do backprop by backtracking the graphs.E.g.: Torch.nn, Caffe, MXNet, Chainer
Backprop as extended graphsFramework builds graphs for backprop as well as those for forward prop.
E.g.: Theano, TensorFlow
a mul suby
c
z
b
a mul suby
c
z
b
dzid
neg
mul
mul
dy
dc
da
db
∇y z∇x1 z ∇z z = 1
27/31
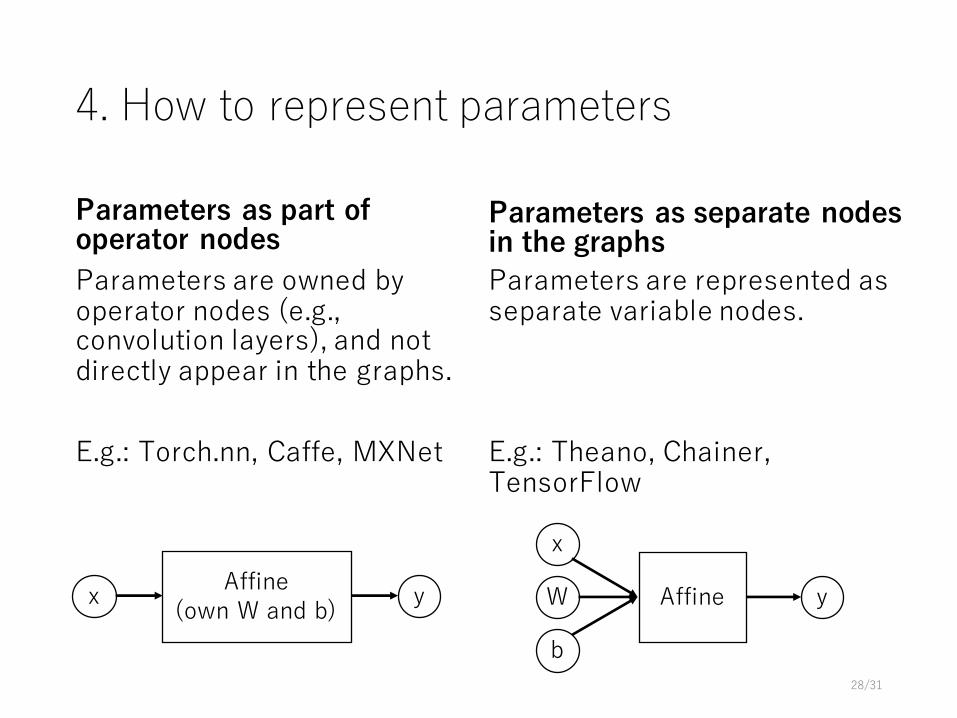
4. How to represent parameters
Parameters as part of operator nodesParameters are owned by operator nodes (e.g., convolution layers), and not directly appear in the graphs.
E.g.: Torch.nn, Caffe, MXNet
Parameters as separate nodes in the graphsParameters are represented as separate variable nodes.
E.g.: Theano, Chainer, TensorFlow
x Affine(own W and b) y
x
Affine yW
b28/31

5. How to update parameters
Update parameters by own routines outside of the graphsUpdate formulae are implemented directly using the backend array libraries.
E.g.: Torch.nn, Caffe, MXNet, Chainer
Represent update formulae as a part of the graphs
Update formulae are built as a part of computational graphs.
E.g.: Theano, TensorFlow
29/31

6. How to achieve the computational performanceTransform the graphs to optimize the computationsThere are many ways to optimize the computations.
Theano supports varioutoptimizations.TensorFlow does simple ones.
Provide easy ways to write custom operator nodesUsers can write their own operator nodes optimized to their purposes.
Torch, MXNet, and Chainerprovide ways to write one code that runs both on CPU and GPU.Chainer also provides ways to write custom CUDA kernels without manual compilation steps.
30/31

7. How to scale the computations
Multi-GPU parallelizations
Nowadays, most popular frameworks start supporting multi-GPU computations.
Multi-GPU (one machine) is enough for most use cases today.
Distributed computations (i.e., multi-node parallelizations)Some frameworks also support distributed computations to further scale the learning.
MXNet uses a simple distributed key-value store.TensorFlow uses gRPC. It will also support easy-to-use cloud environments.CNTK uses simple MPI.
31/31

Conclusion
• We introduced the basics of NNs, typical designs of their implementations, and pros/cons of various design choices.
• Deep learning is an emerging field with increasing speed of development, so quick try-and-error is crutial for the research/development in this field
• In that mean, using frameworks as highly reusable parts of NNs is important
• There are growing number of frameworks in this world, though most of them have different aspects, so it is also important to choose one appropriate for your purpose
32/31