reliability and availability modeling in...
TRANSCRIPT

Reliability and Availability Modeling in Practice
Kishor S. Trivedi
Duke High Availability Assurance Lab (DHAAL)
Department of Electrical and Computer Engineering
Duke University, Durham, NC 27708-0291
Phone: (919)660-5269 E-mail: [email protected]
URL: www.ee.duke.edu/~ktrivedi
Also Researchgate.com
PRDC, Jan. 24, 2017

Duke University
Research Triangle Park (RTP)
UNC-CH
Duke
NC state
USA North Carolina
Copyright © 2017 by K.S. Trivedi

DHAAL
Dhaal means “Shield” in Hindi/Gujarati
DHAAL research is about shielding systems from various threats
Cooperating with groups in USA, Germany, Italy, Japan, China, Brazil, India, New Zealand, Norway, Spain, …

Tools Applications
Theory
HARP,
SAVE,
SHARPE,
SPNP,
SREPT
Hardware and software:
Boeing, EMC, HP, Ericsson, IBM, Sun, Zitel, Cisco, GE, 3Com, Lucent, Motorola,NEC, TCS, Huawei
Recent major achievements:
• Reliability model of CRN subsystem of Boeing 787 for certification by FAA
• Reliability model of SIP on WebSphere
Books: Blue,
Red, White, Green
Modeling paradigms & numerical solution:
Solution of large Fault trees and networks,
Solution of large & stiff Markov models,
New modeling paradigms of non-Markovian and
Fluid Petri nets
DHAAL Research Triangle
Copyright © 2017 by K.S. Trivedi

Overview of SHARPE
SHARPE: Symbolic-Hierarchical Automated Reliability and
Performance Evaluator
Stochastic Modeling tool installed at over 1000 Sites; companies and universities
Ported to most architectures and operating systems
Used for Education, Research, Engineering Practice
Users: Boeing, 3Com, EMC, AT & T, Alcatel-Lucent, IBM, NEC, Motorola, Siemens, GE, HP, Raytheon, Honda,…
http://sharpe.pratt.duke.edu/
It is the core of Boeing’s internal tool called IRAP
Copyright © 2017 by K.S. Trivedi
A Fool with a Tool is still a fool

Books Update
Probability and Statistics with Reliability, Queuing, and Computer Science Applications, 1982; Second edition, John Wiley, 2001 (Blue book) – Chinese translation, 2015; fully revised paperback, 2016
Performance and Reliability Analysis of Computer Systems: An Example-Based Approach Using the SHARPE Software Package, Kluwer, 1996 (Red book)
Queuing Networks and Markov Chains, 1998
John Wiley, second edition, 2006 (White book)
Green Book: Reliability and Availability: Modeling, Analysis, Applications, Cambridge University Press, 2017
Copyright © 2016 by K.S. Trivedi

Outline
Copyright © 2017 by K.S. Trivedi
Part I – Introduction (Chapters 1:3)
Part II - Non-state-space models (Chapters 4:8)
Part III - State-space Models with Exponential Distributions (Chapters 9:12)
Part IV - State-space Models with Non-Exponential Distributions (Chapters 13:15)
Part V - Multi-Level Models (Chapters 16:17)
Part VI - Case Studies (Chapter 18)

Outline
Copyright © 2017 by K.S. Trivedi

Outline
Introduction
Reliability and Availability Models
Model Types in Use
Illustrated through several real examples
Conclusions
Issues Raised by Prof. Iyer’s keynote
References
Copyright © 2017 by K.S. Trivedi

Health & Medicine
Communication
Avionics
Entertainment Banking
Motivation: Dependence on Technical Systems

Outline
Introduction
Reliability and Availability Models
Conclusions
Issues Raised by Prof. Iyer’s keynote
References
Copyright © 2017 by K.S. Trivedi

Model analysis approaches
Black-box (measurements + statistical inference):
the system is treated as a monolithic whole, considering its input, output and transfer characteristics without explicitly taking into account its internal structure
White-box (or grey box):
Internal structure of system explicitly considered using a Probability Model (e.g., RBD, ftree, Markov chain)
Used to analyze a system with many interacting and interdependent components
Combined approach
Use black-box approach at subsystem/component level
Use white-box approach at the system level

Model analysis approaches
White-box (or grey box):
Derive the behavior of ensembles (combinations of components to form a system or combinations of multiple systems to form a system of systems) from first principles rather than tests
Combined approach
Create validated probability models of large scale systems or networks out of individually testable subsystem models
Susan Lee and Donna Gregg, “From Art to Science: A Vision for the Future of Information Assurance,” Johns Hopkins APL Technical Digest, V. 26, No. 4, 2005, pp. 334—342.

Two Types of Uncertainty
Aleatory (irreducible)
Randomness of event occurrences in the real system captured by various distributions in the Probability Model (e.g., Markov chain or SMP)
Epistemic (reducible)
Introduced due to finite sample size in estimating parameters to be input to the Probability Model
Propagating epistemic uncertainty through a Probability Model is a topic we will cover later
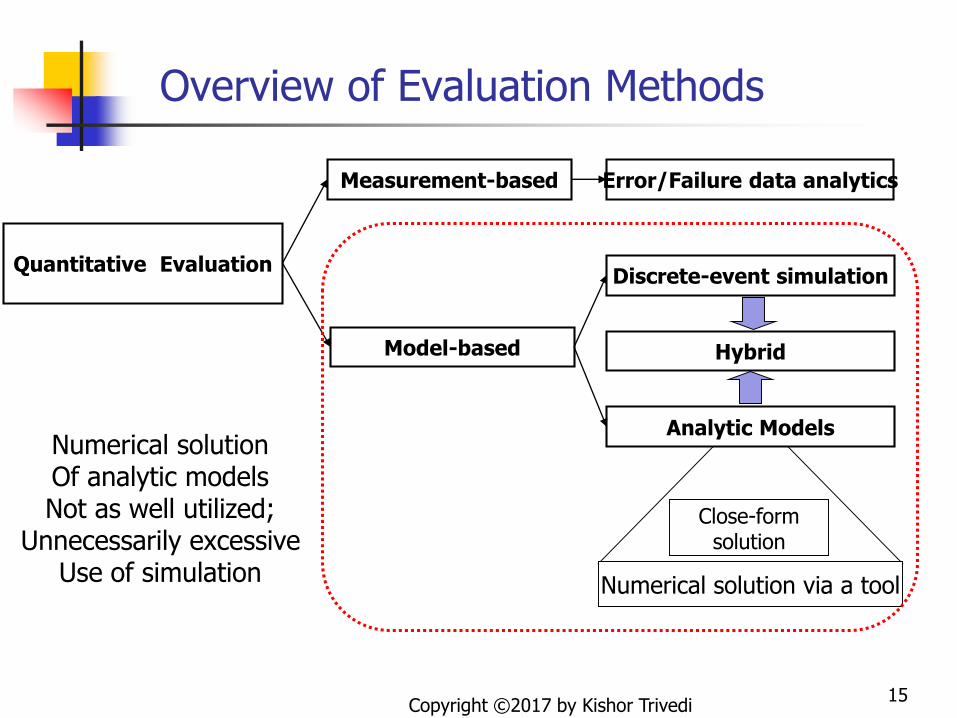
Overview of Evaluation Methods
Numerical solution via a tool
Close-formsolution
Model-based
Discrete-event simulation
Hybrid
Analytic Models
Quantitative Evaluation
Measurement-based
Numerical solutionOf analytic modelsNot as well utilized;
Unnecessarily excessiveUse of simulation
Error/Failure data analytics
15Copyright ©2017 by Kishor Trivedi
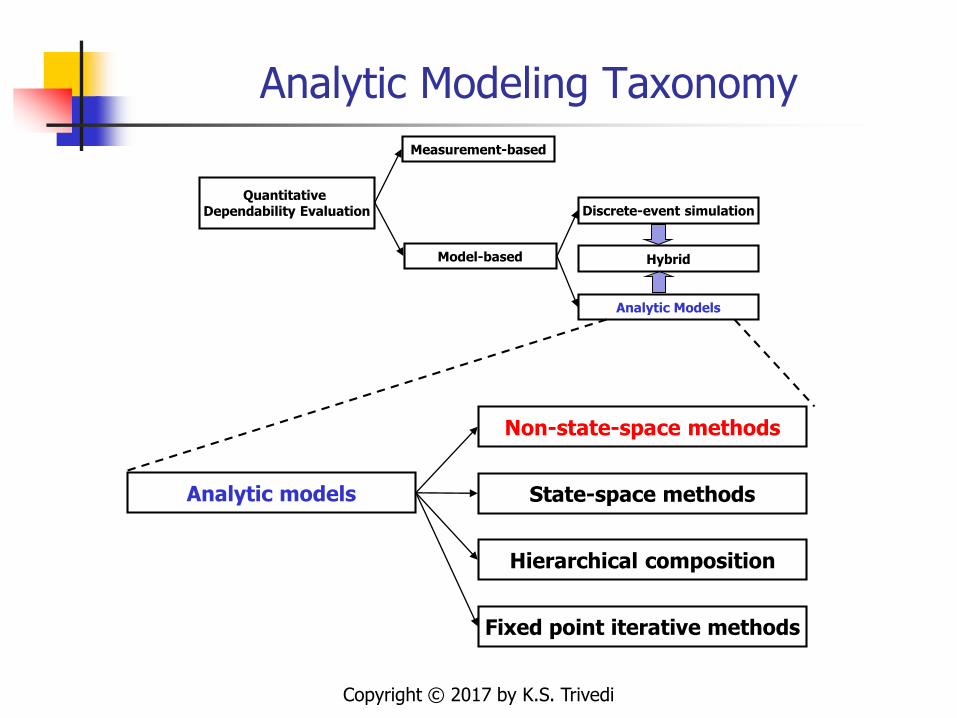
Analytic Modeling Taxonomy
Hierarchical composition
Fixed point iterative methods
Analytic models
Non-state-space methods
State-space methods
Model-based
Discrete-event simulation
Hybrid
Analytic Models
Quantitative Dependability Evaluation
Measurement-based
Copyright © 2017 by K.S. Trivedi

PURPOSE OF EVALUATION(Contd.)
Famous quotes bring out the difficulty of prediction
based on models:
“All Models are Wrong; Some Models are Useful” George Box and Albert Einstein
“Prediction is fine as long as it is not about the future”
Mark Twain

Non-State-Space Methods : taxonomy
Non-state space methods
SP reliability block diagrams (RBD)
Fault trees
Fault trees with repeated events
Non-SP reliability block diagrams (relgraph)
Extensions such as multi-state components/systems, phased-mission systems etc.
Copyright © 2017 by K.S. Trivedi

Non-state-space Methods (cont’d)
Model types such as RBDs, relgraphs and FTs are easy to use and assuming statistical independence solve for system reliability, system availability and system MTTF; can find bottlenecks
Relatively good algorithms are known for solving medium sized systems
Each component can have attached to it
A probability of failure
A failure rate
A distribution of time to failure
Steady-state or instantaneous (un)availability
Copyright © 2017 by K.S. Trivedi

Cisco & Juniper Routers
RBD of Cisco 12000 GSR
RBD of Juniper M20
K. Trivedi, “Availability Analysis of Cisco GSR 12000 and Juniper M20/M40” Cisco Internal report, 2000.
Red colored block means a sub-model.

Sun Microsystems
Top level RBD consists of all the subsystems joined by series, parallel and k/n blocks.Red colored block means a sub-model.
Trivedi et al., Modeling High Availability Systems, PRDC’06 Conference, Dec. 2006, Riverside, CA

Fault Trees
It is a graphical representation of the combinations of events that
can cause the occurrence of system failure.
non-state-space model type (state space is what we used when we
employed state enumeration method to solve a relgraph).
Components are represented as nodes.
Components or subsystems in series are connected together with
OR gates.
Components or subsystems in parallel are connected together with
AND gates.
Components or subsystems in “k of n” (RBD) are connected as (n-
k+1)of n gates [reason out why]

MFS=Suspension
BR=Brake Rigging
L=Liner
O=Others
S OLBR
Fault Tree Model of GE Truck- AC6000
Write down the formula for system (un)reliability

Fault Trees (Continued)
Failure of a component or subsystem causes the corresponding
input to the gate to become TRUE.
Whenever the output of the topmost gate becomes TRUE, the
system is considered failed.
Ftree is a pessimist’s model as opposed to RBD or relgraph that can
be considered optimists’ models
Extensions to Fault-trees include a variety of different gate types:
NOT, EXOR, Priority AND, cold spare gate, functional dependency
gate, sequence enforcing gate, etc. Some of these are “static” while
others are “dynamic” gates

Fault Tree Model of GE Equipment Ventilation System
Copyright © 2017 by K.S. Trivedi
Fault Tree with Repeated events; inverted triangle indicates such events

Smith, Trivedi et al, IBM Systems J. 2008
System Failure
Midplane Cooling Power
Domain 1
k/n
Base CPU Memory DISK Software
FC
Port 1
FC
Port 2Ethernet
Port 2
FC
Switch 1
FC
Switch 2Ethernet
Switch 2
Ethernet
Port 1
Ethernet
Switch 1
Base CPU Memory DISK Software
FC
Port 1
FC
Port 2Ethernet
Port 2
FC
Switch 1
FC
Switch 2Ethernet
Switch 2
Ethernet
Port 1
Ethernet
Switch 1
Blade in Power Domain 1
Fault Subtree
Blade in Power Domain 2
Fault Subtree
KEYBasic Event
Defined Sub-model
Repeated Use of Same
Sub-model Instance
Instance of Blade in Power
Domain 1 Sub-Fault tree
Instance of Blade in Power
Domain 2 Sub-Fault tree
Power
Domain 2
Copyright © 2017 by K.S. Trivedi

Fault trees
Major characteristics: Fault trees without repeated events can be solved in polynomial
time. Fault trees with repeated events -Theoretical complexity:
exponential in number of components.
Use Factoring (conditioning) [In sharpe use factor on and bdd off]
Find all minimal cut-sets & then use Sum of Disjoint products to compute reliability [In sharpe use factor off and bdd off]
Use BDD approach [In sharpe use bdd on]
In practice can solve fault trees with thousands of components
Our brand new algorithm can solve even larger fault trees [Xiaoyan
Yin’s MS Thesis]

Reliability Graph
One of the commonly used non-state-space models Many non-state-space models can be converted to
reliability graphs
Consists of a set of nodes and edges
Edges represent components that can fail
Source and target (sink) nodes
System fails when no path from source to sink
A non-series-parallel RBD
S-t connectedness or network reliability problem

Avionics
Reliability analysis of each major subsystem of a commercial airplane needs to be carried out and presented to Federal Aviation Administration (FAA) for certification
Real world example from Boeing Commercial Airplane Company
Copyright © 2017 by K.S. Trivedi

Reliability Analysis of Boeing 787
Current Return Network Modeled as a Reliability Graph
Consists of a set of nodes and edges
Edges represent components that can fail
Source and target nodes
System fails when no path from source to target
Compute probability of a path from source to target
A2
A4
A5
A1
A11
A13
A14
A7
A8
A9
A6
A10
A3
B3
B4
B6
B1
B13
B14
B15
B8
B9
B10
B7
B11
B2
B12
A12
B5
B16
C1
C3
C4
C5
C2
C6
D3
D5
D7
D1
D16
D17
D19
D9
D12
D13
D8
D14
D2
D15
D4
D18
D6
D10
D20
D11
E6
E7
E8
E5
E1
E2
E3
E4
E10
E11
E12
E9
E14
E13
target
F1
F8
F3
F2
F4
F5
F6
F9
F7
F10
source
Copyright © 2017 by K.S. Trivedi

Reliability Analysis of Boeing 787 (cont’d)
Some known solution methods for Relgraph
Find all minpaths followed by SDP (sum of disjoint products)
BDD (binary decision diagrams)-based method
Factoring or conditioning
Monte Carlo method
The first two methods have been implemented in our SHARPE software package
Boeing tried to use SHARPE for this problem but …

Too many minpaths
Idea: Compute bounds instead of exact reliability Lower bound by taking a subset of minpaths Upper bound by taking a subset of mincuts
A2
A4
A5
A1
A11
A13
A14
A7
A8
A9
A6
A10
A3
B3
B4
B6
B1
B13
B14
B15
B8
B9
B10
B7
B11
B2
B12
A12
B5
B16
C1
C3
C4
C5
C2
C6
D3
D5
D7
D1
D16
D17
D19
D9
D12
D13
D8
D14
D2
D15
D4
D18
D6
D10
D20
D11
E6
E7
E8
E5
E1
E2
E3
E4
E10
E11
E12
E9
E14
E13
target
F1
F8
F3
F2
F4
F5
F6
F9
F7
F10
source
Number of paths from source to target
Reliability Analysis of Boeing 787 (cont’d)
Copyright © 2017 by K.S. Trivedi

Our Approach : Developed a new efficient algorithm for (un)reliability bounds computation and incorporated in SHARPE
• 2011 patent for the algorithm jointly with Boeing/Duke • A paper appeared in EJOR, 2014• Satisfying FAA that SHARPE development used DO-178 B
software standard was the hardest part
SHARPE: Symbolic Hierarchical Automated Reliability and Performance EvaluatorDeveloped by my group at Dukehttp://sharpe.pratt.duke.edu/
Reliability Analysis of Boeing 787 (cont’d)

Non-state-space Methods (cont’d)
Non-state-space methods provide relatively fast algorithms forsystem reliability, system availability, system MTTF & to findbottlenecks assuming stochastic independence between systemcomponents Series-parallel composition algorithm. Factoring (conditioning) algorithms. All minpaths followed by Sum of Disjoint Products (SDP) algorithm. Binary Decision Diagrams (BDD) based algorithms. Bounding algorithm for relgraphs
All of the above implemented in SHARPE
Solving a fault tree of a whole plane (B787) is still a challenge
Failure/Repair Dependencies are often present; RBDs, relgraphs,FTREEs cannot easily handle these (e.g., shared repair,warm/cold spares, imperfect coverage, non-zero switching time,travel time of repair person, reliability with repair).
Copyright © 2017 by K.S. Trivedi

State-space models : Markov chains
To model complex interactions between components, use
models like Markov chains or more generally state space models.
Markov reliability models will have one or more absorbing states;
Markov availability models will have no absorbing states
Many examples of dependencies among system components
have been observed in practice and captured by continuous-time
Markov chains (CTMCs)
Extension to Markov reward models makes computation of
measures of interest relatively easy.
Copyright © 2017 by K.S. Trivedi

Analytic Modeling Taxonomy
Analytic models
Non-state-space methods
State-space methods

Availability model of SIP on IBM WebSphere
Availability model of the Linux OS
UP DN DWlOS
mOS
RPasp
bOSbOS
(1-bOS)bOSDT
dOS
Detection delay, imperfect coverage, two-levels of recovery modeled

Markov Availability model of WebSphere AP Server
Application server and proxy server (with escalated levels of recovery)
• Delay and imperfect coverage in each step of recovery modeled
UA UR UB(1-r)rm
rrm
qra
(1-q)ra
bbm
RE(1-b)bm
m
UOUPg ed2
1D
ed2dd1
(1-e)d2
UN
dm
1N
(1-d)d1
(1-e)d2
2N(1-d)d1
(1-e)d2
ed2 dd1
Failure detection
By WLM
By Node Agent
Manual detection
Recovery
Node Agent Auto process
restart
Manual recovery Process restart
Node reboot
Repair
Copyright © 2017 by K.S. Trivedi

Avaya Swift System Availability Model
Availability model with hardware & software redundancy
(warm replication) of application server
Performance and Reliability Evaluation of Passive Replication Schemes in Application Level Fault-Tolerance
S. Garg, Y. Huang, C. Kintala, K. Trivedi and S. Yagnik
Proc. of Intl. Symp. On Fault-Tolerant Computing, FTCS, June 1999.
Assumptions
A web server software, that fails at the rate gp running on a machine that fails at the rate gm
Mean time to detect server process failure d-1
p and the mean time to detect machine failure d-1
m
The mean restart time of a server -1
p
The mean restart time of a machine -1
m

Markov model of Kidney Disease
Reliability Models Of Chronic Kidney Disease, Fricks et al, RAMS 2016

State-Space model taxonomy
Can relax the assumption of exponential distributions
(discrete) State space models
Markovian models
non-Markovian models
discrete-time Markov chains (DTMC)
continuous-time Markov chains (CTMC)
Markov reward models (MRM)
Semi-Markov process (SMP)
Markov regenerative process
Non-Homogeneous Markov
Copyright © 2017 by K.S. Trivedi
Phase-Type Expansion

Should I Use Markov Models?
+ Model Fault-Tolerance and Recovery/Repair
+ Model Dependencies
+ Model Contention for Resources and concurrency
+ Generalize to Markov Reward Models for Degradable systems
+ Can relax exponential assumption – SMP, MRGP, NHCTMC, PH
+ Performance, Availability and Performability Modeling Possible
- Large State Space
Copyright © 2017 by K.S. Trivedi

Problems with Markov (or State Space) Models and their solutions
State space explosion or the largeness problem
Stochastic Petri nets and related formalisms for ease of specification and automated generation/solution of underlying Markov model --- Largeness Tolerance
Copyright © 2017 by K.S. Trivedi

[Scalable] Model for IaaS Cloud Availability
and Downtime[paper in IEEE Trans. On Cloud Computing 2014]

Three Pools of Physical Machines (PMs)
To reduce power usage costs, physical machines
are divided into three pools [IBM Research
Cloud]
Hot pool (high performance & high power usage)
Warm pool (medium performance & power usage)
Cold pool (lowest performance & power usage)
Similar grouping of PMs is recommended by Intel*
*Source: http://www.intel.com/content/dam/www/public/us/en/documents/guides/lenovo-think-server-smart-grid-technology-cloud-builders-guide.pdf

System Operation Details
Failure/Repair (Availability):
PMs may fail and get repaired.
A minimum number of operational hot PMs are
required for the system to function.
PMs in other pools may be temporarily assigned to the
hot pool to maintain system operation (migration).

Analytic model
Markov model (CTMC) is too large to construct by hand.
We use a high level formalism of stochastic Petri net (the
flavor known as stochastic reward net (SRN)).
SRN models can be automatically converted into
underlying Markov (reward) model and solved for the
measures of interest such as DT (downtime), steady-state
(instantaneous, interval) availability, reliability, derivatives
of this measures --- all numerically by solving underlying
equations
Analytic-numeric as opposed to simulation

Monolithic Stochastic Reward Net Model

Other High Level Formalisms
Many other High level formalism (like SRN) are
available and corresponding software packages
exist (SAN, SPA, ….)
Can generate/store/solve moderate size Markov
models
Have been extended to non-Markov and fluid
(continuous state) models

Monolithic ModelMonolithic SRN model is automatically translated into CTMC or
Markov Reward Model
However the model not scalable as state-space size of this model is
extremely large
#PMs per pool #states #non-zero matrix entries
3 10, 272 59, 560
4 67,075 453, 970
5 334,948 2, 526, 920
6 1,371,436 11, 220, 964
7 4,816,252 41, 980, 324
8 Memory overflow Memory overflow
10 - -

Problems with Markov (or State Space) Models and their solutions
State space explosion or the largeness problem
Stochastic Petri nets and related formalisms for easy specification and automated generation/solution of underlying Markov model --- Largeness Tolerance
Use hierarchical (Multilevel) model composition
Largeness Avoidance
e.g. Upper level : FT or RBD, lower level: Markov chains
Many practical examples of the use of hierarchical models exist
Copyright © 2017 by K.S. Trivedi

Analytic Modeling Taxonomy
Hierarchical compositionTo avoid largeness
Analytic models
Non-state-space methodsEfficiency, simplicity
State-space methodsDependency capture
Copyright © 2017 by K.S. Trivedi

State Space Explosion– Largeness Avoidance
State space explosion can be avoided by using hierarchical model composition.
Use state-space methods for those parts of a system that require them, and use non-state-space methods for the more “well-behaved” parts of the system.

Availability model of SIP on IBM WebSphere
Real problem from IBM SIP: Session Initiation Protocol Hardware platform: IBM BladeCenter Software platform: IBM WebSphere
Subsystems modeled using Markov chains to capture dependence within the subsystem
Fault tree used at higher levels as independence across subsystems can be assumed
This is an example of hierarchical composition A single monolithic model is not constructed/stored/solved Each submodel is built and solved separately and results are
propagated up to the higher level model SHARPE facilitates such hierarchical model composition
Copyright © 2017 by K.S. Trivedi

Architecture of SIP on IBM WebSphere
Blade 4
IP Sprayer-IBM Load
Balancer
-
SIP
IBM PC
Replication
Group 3
Blade 2
Blade 3
Blade 4
Blade 2
AS 1
AS 2
AS 3
AS 4
AS 5
AS 1
AS 4
AS 2
AS 5
AS 6
AS 3
AS 6
Blade 3
Replication Domain 1
Replication Domain 2
Replication Domain 3
SIP
Proxy 1
SIP
Proxy 1
Blade 1
Blade 1
Replication Domain 4
Replication Domain 5
Replication Domain 6
Blade Chassis 1
Blade Chassis 2
Blade 4
Test Driver
Test Driver
Test drivers
DM
AS1 thru AS6 are
Application Server
Proxy1's are Stateless
Proxy Server
Replication domain
Nodes
1 A, D
2 A, E
3 B, F
4 B, D
5 C, E
6 C, F
AS: WebSphere Appl. Server(WAS)
Copyright © 2017 by K.S. Trivedi

Availability model of SIP on IBM WebSphere (cont’d)
failures
Physical faults Software failures
Power faults
OS
Memory faults
NIC faults
Cooling faults
Blade faults
midplane faults
Network faults
CPU faults
base faults
Application
I/O (RAID) faults
WAS Proxy
Failures modes incorporated in Models
Mandelbugs
Copyright © 2017 by K.S. Trivedi

Availability model of SIP on IBM WebSphere (cont’d)
SIP Application Server top level of the availability model
AS6
6C BSC CM1
AS5
5C BSC CM1
AS4
4B BSB CM1
AS3
3B BSB CM1
AS2
2A BSA CM1
AS1
1A BSA CM1
AS12
6F BSF CM2
AS11
3F BSF CM2
AS10
5E BSE CM2
AS9
2E BSE CM2
AS8
4D BSD CM2
AS7
1D BSD CM2
App
servers
System Failure
PX1
P1 BSG CM1
PX2
P2 BSH CM2
proxy
system
k of 12
iX: ith appserver on node X
Pi: ith proxy server
BSX: node X hardware
CMi: chassis i hardware
Copyright © 2017 by K.S. Trivedi

CM
MP Cool Pwr
CM Failure
Chassis failure
BS
Base CPU Mem RAID OSeth
eth1 eth2
nic1 nic2esw1 esw2
BS Failure
Blade server failure
A circle as a leaf node is a basic eventAn inverted triangle is a shared eventA square indicates a submodel
Availability model of SIP on IBM WebSphere (cont’d)
Availability models of a Blade Server and Common BladeCenter
Hardware

Availability model of SIP on IBM WebSphere (cont’d)
Markov Availability models of subsystems
UP U1
DN
RP
cmp×lmp
(1-cmp)×lmp
asp
mmp
asp
midplane model Cooling subsystem model
UP U1 RP
DN
DW2lc
lc
asp
mc
lc
m2c
asp

Availability model of SIP on IBM WebSphere (cont’d)
Availability models of subsystems (cont.)
UP U1
DN
RP DW2cps×lps asp
mps
lps
m2ps
2(1-cps)×lpsasp
lps
UP D1 RP2lcpu asp
mcpu
UP D1 RP4lmem asp
mmem
Power domain model
CPU model memory model
Base, Switch and NIC
UP DN RPl asp
m

RAID model
OS model
Availability model of SIP on IBM WebSphere (cont’d)
Availability models for subsystems (cont.)
UP DN DWlOS
mOS
RPasp
bOSbOS
(1-bOS)bOSDT
dOS
m2hd
UP U1 RP CP
DN
RBkp
m_ bkp
mhd
lhd
lsp2*lhd mhd lhd_ src
lhd_ dst
DNsrc
m2hd
UP U1 RP CP
DN
RBkp
m_ bkp
mhd
lhd
lsp2*lhd mhd lhd_ src
lhd_ dst
DNsrc
m2hd
UP U1 RP CP
DN
RBkp
m_ bkp
mhd
lhd
lsp2*lhd mhd lhd_ src
lhd_ dst
DNsrc
m2hd
UP U1 RP CP
DN
RBkp
m_ bkp
mhd
lhd
lsp2*lhd mhd lhd_ src
lhd_ dst
DNsrc
m2hd
UP U1 RP CP
DN
RBkp
m_ bkp
mhd
lhd
lsp2*lhd mhd lhd_ src
lhd_ dst
DNsrc
m2hd
UP U1 RP CP
DN
RBkp
m_ bkp
mhd
lhd
lsp2*lhd mhd lhd_ src
lhd_ dst
DNsrc
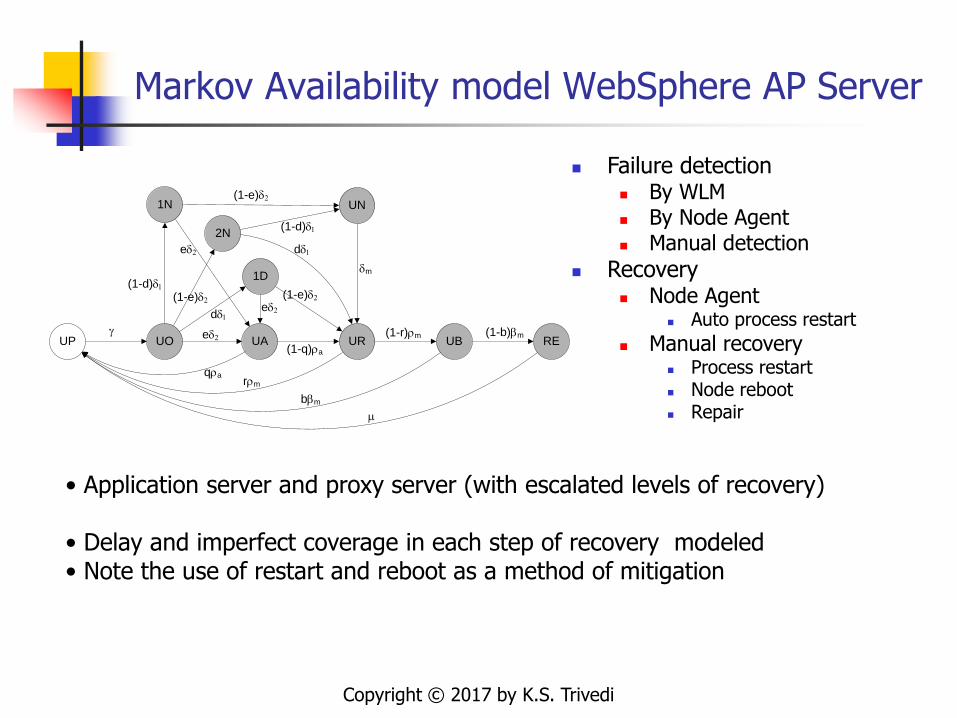
Markov Availability model WebSphere AP Server
UA UR UB(1-r)rm
rrm
qra
(1-q)ra
bbm
RE(1-b)bm
m
UOUPg ed2
1D
ed2dd1
(1-e)d2
UN
dm
1N
(1-d)d1
(1-e)d2
2N(1-d)d1
(1-e)d2
ed2 dd1
Failure detection By WLM By Node Agent Manual detection
Recovery Node Agent
Auto process restart
Manual recovery Process restart Node reboot Repair
• Application server and proxy server (with escalated levels of recovery)
• Delay and imperfect coverage in each step of recovery modeled• Note the use of restart and reboot as a method of mitigation
Copyright © 2017 by K.S. Trivedi

Hierarchical Composition
CM
MP Cool Pwr
CM Failure
BS
Base CPU Mem RAID OSeth
eth1 eth2
nic1 nic2esw1 esw2
BS Failure
UA UR UB(1-r)rm
rrm
qra
(1-q)ra
bbm
RE(1-b)bm
m
UOUPg ed2
1D
ed2dd1
(1-e)d2
UN
dm
1N
(1-d)d1
(1-e)d2
2N(1-d)d1
(1-e)d2
ed2 dd1
UP U1
DN
RP DW2cps×lps asp
mps
lps
m2ps
2(1-cps)×lpsasp
lps
AS6
6C BS C CM 1
AS 5
5C BS C CM 1
AS 4
4B BS B CM 1
AS 3
3B BS B CM 1
AS2
2A BS A CM 1
AS1
1A BS A CM 1
AS 12
6F BS F CM 2
AS 11
3F BS F CM 2
AS 10
5E BS E CM 2
AS9
2E BS E CM 2
AS 8
4D BS D CM 2
AS7
1D BS D CM 2
App
servers
System Failure
PX1
P1 BS G CM 1
PX 2
P2 BS H CM 2
proxy
system
k of 12 AS1
1A BSA CM1
A single monolithic Markov model will have too many statesCopyright © 2017 by K.S. Trivedi

Availability model of SIP on IBM WebSphere (contributions)
Developed a very comprehensive availability model
Hardware and software failures Hardware and Software failure-detection delays Software Failover delay Escalated levels of recovery
Automated and manual restart, reboot, repair Imperfect coverage (detection, failover, restart, reboot)
Many of the parameters collected from experiments, some obtained from tables; few of them assumed
Detailed sensitivity analysis to find bottlenecks and give feedback to designers
Developed a new method for calculating DPM (defects per million) Taking into account interaction between call flow and failure/recovery Retry of messages (this model will be published in the future)
This model was responsible for the sale of the system by IBMCopyright © 2017 by K.S. Trivedi

Hierarchical Composition
Matrix-Level vs. Model-Level vs. System-Level Decomposition
Structural decomposition vs. Behavioral decomposition
Model decomposition vs. model composition
Formalism for the expression of hierarchy; meta-modeling language?
What kinds of quantities to pass between models?
Exact vs. approximate solution
Export-import graph or simply Import graph
Acyclic
Cyclic Fixed-point iterationCopyright © 2017 by K.S. Trivedi

Analytic Modeling Taxonomy
Hierarchical modelsLargeness avoidance
Analytic models
Combinatorial modelsEfficiency, simplicity
State-space modelsDependency capture
Fixed point iterationNearly independent

Scalable Model for IaaS Cloud Availability
and Downtime[paper in IEEE Trans. On Cloud Computing 2014]

Monolithic SRN Model

Monolithic ModelMonolithic SRN model is automatically translated into CTMC or
Markov Reward Model
However the model not scalable as state-space size of this model is
extremely large
#PMs per pool #states #non-zero matrix entries
3 10, 272 59, 560
4 67,075 453, 970
5 334,948 2, 526, 920
6 1,371,436 11, 220, 964
7 4,816,252 41, 980, 324
8 Memory overflow Memory overflow
10 - -

Decompose into Interacting Sub-models
SRN sub-model for hot pool
SRN sub-model for warm poolSRN sub-model for cold pool

Import graph and model outputs
Model outputs:
mean number of PMs in each pool (E[#Ph], E[#Pw], and E[#Pc])
Downtime in minutes per year

Many questions
Existence of Fixed Point (easy): IEEE TCC 2014 (In a more general setting: Mainkar & Trivedi paper in IEEE-TSE, 1996)
Uniqueness (some cases)
Rate of convergence
Accuracy
Scalability

Monolithic vs. interacting sub-models
#states, #non-zero entries

Analytic-Numeric vs. simulative solutions
Downtime [minutes per year]

Analytic-Numeric vs. simulative solution
Solution times [seconds]

Analytic model
Markov model (CTMC) is too large to construct by hand.
We use a high level formalism of stochastic Petri net (the flavor
known as stochastic reward net (SRN)).
SRN models can be automatically converted into underlying
Markov (reward) model and solved for the measures of interest
such as DT (downtime)
To improve scalability we used decomposition and fixed point
iteration
For very large number of PMs even decomposed models are not
enough; we resort to discrete-even simulation; same SRN model
can be simulated via our software package (SPNP)

Steps for system availability modeling
List all possible component level failures (hardware, software)
List of all failure detectors & match with failure types
List all recovery mechanisms & match with failure types
Allocation of software modules to hardware units
Formulate the model
Face validation and verification of the model
Parameterization of the model (tables, websites, experiments)
Solve the model (using SHARPE, SPNP or similar software packages) to detect bottlenecks, sensitivity analysis, suggest parameters to be monitored
What-if analysis to suggest improvements
Validate the model
Copyright © 2017 by K.S. Trivedi

Outline
Introduction
Reliability and Availability Models
Conclusions
Issues Raised by Prof. Iyer’s keynote
References
Copyright © 2017 by K.S. Trivedi

State of the Art of Reliability/Availability Models
Techniques & software packages are available for the construction & solution of reliability and availability models of real systems
System decomposition followed by hierarchical model composition is the typical approach
Modeling has been used
To compare alternative designs/architectures (Cisco)
find bottlenecks, answer what if questions, design optimization and conduct trade-off studies
At certification time (Boeing)
At design verification/ testing time (IBM)
Configuration selection phase (DEC)
Operational phase for system tuning/on-line control

Summary: System Availability Models
Model Types in Use Non-state-Space : Reliability Block Diagram, Fault tree, Reliability
graph State-space : Markov models & stochastic Petri nets, Semi-Markov,
Markov regenerative and non-homogeneous Markov models Hierarchical composition
Top level is usually an RBD or a fault tree Bottom level models are usually Markov chains
Fixed-point iterative Solution types
Analytic closed-form Analytic numerical (using a software package) Simulative
Software packages SHARPE or similar tools are used to construct and solve such
models Structural as well as parametric assumptions means that numbers
produced should be taken with a grain of saltCopyright © 2017 by K.S. Trivedi

Challenges in Dependability Models
Model Largeness (in spite of: hierarchy, fixed-point iteration, approximations)
Dealing with non-exponential distributions (in spite of SMP, MRGP, NHCTMC, PH)
Service (or user)-oriented measures as opposed to system-oriented measures
Combining performance and failure/repair Model Parameterization Model Validation and Verification Parametric uncertainty propagation

Challenges in Reliability/Availability Models
Model Verification and Validation Verification
checked by someone else,
check logical flows,
cross-check using alternative solutions (e.g. alternative analytic/simulation)
Validation
Face validation,
Input-Output validation,
Validation of model assumptions
Copyright © 2017 by K.S. Trivedi

Model Parameterization
Hardware/Software Configuration parameters
Hardware component MTTFs
Software component MTTFs
OS, IBM Application, customer software, third party
Hardware/Software Failover times
Restart/Reboot times
Coverage (Success) probabilities
Detection, location, restart, reconfiguration, repair
Repair time
Hot swap, multiple component at once, DOA (dead on arrival), shared/not shared, field service travel time, preventive vs. corrective
Uncertainty propagation: Dealing with not only Aleatory (built into the system models) but also epistemic (parametric) uncertainty
Copyright © 2017 by K.S. Trivedi

Message to Young Researchers
Pick a real problem rather than one from literature whenever possible
There should be plenty of real problems in Industry
Keep an open mind
Listen carefully
It is possible to write scholarly articles based on work done on real problems
Use software packages [e.g., SHARPE, SPNP] whenever applicable [as opposed writing your own code]

Outline
Introduction
Reliability and Availability Models
Conclusions
Issues Raised by Prof. Iyer’s keynote
References
Copyright © 2017 by K.S. Trivedi

Preliminary work on Issues
Failure of failover:
Imperfect coverage (Carter et al)
Including the effect of near-coincident faults (HARP)
Performance during recovery – survivability
Differing time constants
Solution techniques of stiff Markov models (BT method, stiff uniformization, implicit methods)
Application level reliability
Completion time in face of failure (Nicola, Kulkarni et al)
Dazhi PhD thesis
Prediction-based Proactive recovery
Software rejuvenation (many prediction methods have been tried including SVM, Machine learning, ARMA…)

Outline
Introduction
Reliability and Availability Models
Conclusions
Issues Raised by Prof. Iyer’s keynote
References
Copyright © 2017 by K.S. Trivedi

Selected References K. Trivedi, Probability and Statistics with Reliability, Queuing, and Computer
Science Applications. John Wiley, 2nd edition, 2001. L. Tomek & K. Trivedi, Fixed-Point Iteration in Availability Modeling, Informatik-
Fachberichte, Vol. 283; M.Dal Cin (ed.), Springer-Verlag, Berlin, 1991. V. Mainkar & K. Trivedi, Sufficient Conditions for Existence of a Fixed Point in
Stochastic Reward Net-Based Iterative Models, IEEE TSE, 1996 K. Trivedi, R. Vasireddy, D. Trindade, S. Nathan, R. Castro, “Modeling High
Availability Systems,” Proc. of PRDC 2006. M. Grottke, K. Trivedi, Fighting Bugs: Remove, Retry, Replicate, and Rejuvenate.
IEEE Computer Magazine, Feb. 2007 K. Trivedi, D. Wang, D. Hunt, A. Rindos, W. E. Smith, B. Vashaw, “Availability
Modeling of SIP Protocol on IBM WebSphere,” Proc. PRDC 2008. W. E. Smith, K. Trivedi, L. Tomek, J. Ackaret, Availability analysis of blade server
systems, IBM Systems J., 2008. K. Trivedi & R. Sahner, SHARPE at the Age of Twenty two, ACM SIGMETRICS,
Performance Evaluation Review, 2008 K. Trivedi, D. Wang & J. Hunt. Computing the number of calls dropped due to
failures, Proc. Int. Symp. on Software Reliability Engineering, 2010. K. Mishra, K. Trivedi & R. Some. "Uncertainty Analysis of the Remote
Exploration and Experimentation System", Journal of Spacecraft and Rockets,2012 R. Ghosh, F. Longo, F. Frattini, S. Russo & K. Trivedi, “Scalable Analytics for IaaS
Cloud Availability”, IEEE Trans. On Cloud Computing, Mar 2014.Copyright © 2017 by K.S. Trivedi

SHARPE portal ,
Copyright © 2017 by K.S. Trivedi
https://sharpe.pratt.duke.edu

Thank you!
Copyright © 2017 by K.S. Trivedi