reinforcement learning for mixed autonomy intersections
TRANSCRIPT

Reinforcement Learning for Mixed Autonomy Intersections
Zhongxia Yan1 and Cathy Wu2
Abstract—We propose a model-free reinforcement learningmethod for controlling mixed autonomy traffic in simulatedtraffic networks with through-traffic-only two-way and four-way intersections. Our method utilizes multi-agent policy de-composition which allows decentralized control based on localobservations for an arbitrary number of controlled vehicles.We demonstrate that, even without reward shaping, reinforce-ment learning learns to coordinate the vehicles to exhibittraffic signal-like behaviors, achieving near-optimal throughputwith 33-50% controlled vehicles. With the help of multi-tasklearning and transfer learning, we show that this behaviorgeneralizes across inflow rates and size of the traffic net-work. Our code, models, and videos of results are available athttps://github.com/ZhongxiaYan/mixed autonomy intersections.
Index Terms—mixed autonomy, reinforcement learning, multi-agent systems
I. INTRODUCTION
Recent adoption of autonomous vehicles (AVs) and 5G com-munication technology raise the possibility of algorithmicallycontrolling AVs for objectives such as reducing congestion,improving fuel consumption, and ensuring safety. However,in the near future, partial adoption of AVs results in mixedautonomy traffic. Several recent works have demonstratedthat optimized control of AVs in simulated mixed autonomycontexts may significantly reduce congestion in closed trafficnetworks [1] or highway scenarios [2]. We similarly viewmixed autonomy from a transportation science perspective: de-veloping better understanding of mixed autonomy has impor-tant implications for policy and business decisions concerningthe adoption of AVs.
In this study, we demonstrate near-optimal control of AVsin unsignalized mixed autonomy intersection scenarios withmodel-free multi-agent reinforcement learning (RL). Specifi-cally, we consider two-way and four-way intersection scenar-ios with no turn traffic. We quantify the effect of optimizedAVs in microscopic simulation, where controlled vehicles(hereby referred to as AVs) comprise a fraction of all vehicleswhile the remaining are simulated by a car-following model ofhuman driving. We show that our multi-agent policy gradientalgorithm learns effective policies in the mixed autonomy con-text, measured by comparisons with signal-based and priority-based baselines.
The purpose of this study is not to introduce mixed auton-omy as an alternative for traffic signal control, but rather assessas a stepping stone for RL-based analysis of joint vehicleand traffic signal control. Although there are numerous worksstudying RL in the context of traffic signal control, to the best
1Electrical Engineering and Computer Science, Massachusetts Institute ofTechnology [email protected]
2Laboratory for Information & Decision Systems, Massachusetts Instituteof Technology [email protected]
of our knowledge, RL in the context of intersection vehicularcontrol has not received adequate attention. We anticipate thatintegration of both control mechanisms may facilitate jointoptimization of throughput, safety, and fuel objectives.
Our main contributions in this study are:
1) We demonstrate that mixed autonomy traffic can achievenear-optimal throughput (as measured by outflow) inunsignalized intersection networks.
2) We characterize the performance trade-off with AVpenetration rate.
3) Without using reward shaping, we show that our policiesexhibit traffic-signal-like coordination behavior.
4) We formulate policies compatible with multiple trafficnetwork topologies and sizes, yielding good perfor-mance in larger networks unseen at training time.
Code, models, and videos of results are available on Github.
II. RELATED WORK
Traditional adaptive traffic signal control methods such asSCOOT [3] and SCATS [4] are widely deployed in the realworld and optimize the timing of traffic signals to minimizetravel time in response to traffic volume. Recently, RL-basedsignal control methods demonstrate superior performance totraditional adaptive methods [5]. These works are orthogonalto our work, as mixed autonomy control may be combinedwith traffic signal control to optimize a given objective.
On the other hand, autonomous intersection management(AIM) methods generally control all vehicles near the inter-section towards some objective [6]. Applying AIM to a mixedautonomy intersection, H-AIM [7] proposes a first-come-first-serve scheme to schedule AVs while guiding human vehicleswith a fixed-time traffic signal. Our goal is fundamentallydifferent: we would like to design a learning-based methodto flexibly maximize any given objective.
The most similar works to ours are mixed autonomy worksbased on the Flow framework [8], including [1] and [2].However, these works examine small scenarios with a constantnumber of control dimensions, and none address modular in-tersection networks, which are ubiquitous in real-world trafficnetworks. In contrast, we focus on mixed autonomy control ofopen intersection networks agnostic to the number of vehiclespresent at each step. Our work provide a key building blockfor scaling mixed autonomy to large traffic networks.
Our multi-agent RL method features the centralized trainingand decentralized execution paradigm, explored in multi-agentRL works such as PS-TRPO [9] and MADDPG [10]. In thisparadigm, agents are jointly optimized at training time butexecute independently afterwards.
©2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, includingreprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or
reuse of any copyrighted component of this work in other works. DOI: 10.1109/ITSC48978.2021.9565000
arX
iv:2
111.
0468
6v1
[cs
.AI]
8 N
ov 2
021

(a) Two-way 2x1 (b) Two-way 3x3 (c) Four-way 1x1
Fig. 1. Traffic Networks. For each network, every horizontal lane has inflow rate fH and every vertical lane has inflow rate fV . Red vehicles representAVs while white vehicles represent uncontrolled vehicles. Illustrations are not drawn to scale and vehicles are arbitrarily placed.
III. PRELIMINARIES
A. Policy-based Model-free Reinforcement Learning
We frame a mixed autonomy traffic scenario as a finite-horizon discounted Markov Decision Process (MDP) definedby (S,A, T, r, ρ0, γ,H) consisting of state space S, actionspace A, stochastic transition function T : S × A → ∆(S),reward function r : S × A × S → R, initial state distributionρ0 : S → ∆(S), discount factor γ ∈ [0, 1], and horizon H ∈N+, where ∆(S) is the probability simplex over S.
Policy-based model-free RL algorithms define a policyπθ : S → ∆(A) parameterized by θ, which is often aneural network. In particular, the REINFORCE policy gradientalgorithm [11] maximizes the expected discounted cumulativereward of policy πθ
maxθ
Es0∼ρ0,at∼πθ(st)st+1∼T (st,at)
[H−1∑t=0
γtr(st, at, st+1)
](1)
by sampling trajectories (s0, a0 . . . , sH−1, aH−1, sH) and per-forming the following update
θ ← θ + α
H−1∑t=0
∇θ log πθ(st)|atH−1∑t′=t
γt′−tr(st′ , at′ , st′+1)
(2)where α is the learning rate.
B. Mixed Autonomy Traffic
The mixed autonomy traffic environment in microscopicsimulation can be naturally modeled as a MDP. At each timestep t, the state st is composed of the positions, velocities, andother metadata of all vehicles in the road network. The actionat is the tuple of accelerations of all AVs in the road networkat step t; the accelerations of the rest of the vehicles is givenby a car-following model, specifically the Intelligent DriverModel (IDM) [12] with Gaussian noise. The reward functionr is typically a function of throughput, fuel consumption, orsafety in the traffic network. The stochastic transition functionT is not explicitly defined, but st+1 ∼ T (st, at) can be
sampled from the microscopic simulator, which applies theaccelerations for all vehicles for a simulation step duration δ.Like previous works in mixed autonomy, we use the SUMOmicroscopic simulator [13].
IV. PROBLEM SETUP: SIMULATED TRAFFIC SCENARIOS
We describe our method and baseline methods in the contextof traffic scenarios, each of which specifies a traffic networkand an inflow configuration.
TABLE IINFLOW CONFIGURATIONS. WE CONSIDER THE 16 INFLOW
CONFIGURATIONS MARKED WITH X. EACH HORIZONTAL (fH ) ORVERTICAL (fV ) INFLOW RATE HAS UNITS OF VEHICLE/HOUR/LANE.
fH
fV 400 550 700 850 1000
1000 X X X X850 X X X X X700 X X X550 X X400 X X
A. Traffic Networks
As shown in Fig. 1, our traffic networks are grids of single-lane two-way or four-way intersections with only through traf-fic and no turning traffic. Under a given inflow configuration,vehicles enter the traffic network via the inflow lanes at aspecified inflow rate with equal spacing and leave the trafficnetwork via outflow lanes. To populate the initial vehiclesfor s0 ∼ ρ0, we run H0 warmup steps where all AVs anduncontrolled vehicles follow the IDM.
B. Inflow Configurations
For every traffic network, we consider 16 inflow config-urations shown in Table I, which are chosen to excludeconfigurations with trivially low inflow or infeasibly highinflow. Each inflow configuration specifies a single inflow ratefH for every horizontal lane and another inflow rate fV for
2

every vertical lane. If a vehicle is unable to inflow due tocongestion, it is dropped from the simulation.
C. Distribution of Autonomous Vehicles
We test our mixed autonomy method under multiple pen-etration rates of AVs as a percentage of all vehicles. Unlessotherwise stated, AVs are regularly-spaced on each lane of thetraffic network (e.g. under 50% AV penetration, every secondvehicle is an AV).
D. Traffic Objective
Our main objective is to maximize throughput of thenetwork, measured by outflow. In addition, to encouragesafe intersection control and because higher collision implieslower outflow, our secondary objective seeks to minimizethe collision rate. We believe that future works may easilyadapt our method to other objectives involving combinationsof throughput, fuel consumption, and safety.
V. REINFORCEMENT LEARNING FOR MIXED AUTONOMY
Our method for mixed autonomy control is rooted in policy-based model-free RL as described in Section III-A. Here wedetail modifications specific to our method.
Fig. 2. Observation Function. We illustrate the observation z(s, i) ofAV i, only showing vehicles approaching the intersection. The cyan vehiclerepresents the ego AV i, red vehicles represent other AVs, and white vehiclesrepresent uncontrolled vehicles. Let L(i) be the lane of i and I(L(i)) bethe approaching intersection. For convenience, we number the lanes from 1to 4, clockwise from lane L(i). Chains and half-chains are denoted by line-segments and half-segments, respectively; observed half-chains and chainsare colored in orange; eye symbols are placed next to observed vehicles inobserved chains. Notice that lanes 2 and 3 do not have a leading half-chain,so the observation is padded with default values.
A. Multi-agent Policy Decomposition
To tractably optimize mixed autonomy traffic, we formulatethe scenario as a decentralized partially observable MDP(Dec-POMDP) [14]. We decompose the policy πθ : S →∆(A) into per-AV policies πiθ : Oi → ∆(Ai) such that
πθ(s) =∏i π
iθ(o
i). Ai is the acceleration space for AVi ∈ {1, · · · , |A|} and Oi is the observation space for AV isuch that oi = z(s, i) ∈ Oi contains only a subset of theinformation of the state s ∈ S. We have O1 ×O2 × · · · ⊆ Sand A1 × A2 × · · · = A. We define z as the observationfunction which maps the observation oi for AV i at states. Our policy decomposition allows our policy to toleratearbitrary number of AVs and arbitrarily large traffic scenarios;without decomposition, the combinatorial nature of A posesan intractable problem to learning algorithms.
B. Observation Function
We define several helpful terminologies before definingour observation function. On any approaching lane L tointersection I(L), we split L’s vehicles into chains, each ledby an AV. We define the half-chain to include any possibleleading IDM vehicles in a lane.
As illustrated in Fig. 2, the observed vehicles for AV iinclude the head and tail of i’s own chain and, for each otherlane in clockwise order, the tail of the half-chain and the headand tail of the next chain. If the half-chain or chain doesnot exist, we pad the observation with appropriate defaultvalues. We define our observation function z(s, i) as thespeed and distance to intersection for every observed vehicle.While this definition introduces partial observability, it enablesdecentralized and local execution of the policy, as each per-vehicle policy only requires information near the approachedintersection.
C. Policy Architecture
We define the per-vehicle policy πiθ as a neural network withthree fully-connected layers. We share the policy parameter θacross all vehicles in the traffic network to share experiencesbetween AVs [9]. We use a discrete acceleration space Ai ={+caccel, 0,−cdecel}, where the maximum acceleration cacceland maximum deceleration cdecel are less than the maximumspermitted to IDM vehicles.
D. Reward Definition, Centering, and Normalization
We define the unnormalized reward function
r′(st, at, st+1) = λooutflow(st, st+1)− λccollisions(st, st+1)(3)
where outflow(st, st+1) is the global outflow during step t, i.e.the number of vehicles that exited the network during step t,and collisions(st, st+1) is the global number of collisions dur-ing step t. We acknowledge that this centralized reward resultsin a difficult objective to optimize in large traffic scenariosbeyond the scope of this study, where reward decompositioninto decentralized rewards may be necessary. We do not useany reward shaping in our experiments.
To reduce variance of policy gradients [15], we apply rewardcentering and normalization to get the reward function
r(st, at, st+1) =r′(st, at, st+1)− µr′
σR′(4)
3

where µr′ is the running mean of r′ and σR′ is the runningstandard deviation of the running cumulative reward, which isupdated according to R′ ← γR′ + r′(st, at, st+1).
E. Multi-task Learning over Inflow ConfigurationsGiven a traffic network and AV composition, we employ
multi-task learning over all inflow configurations in Table I.During training, we initialize one environment per inflow con-figuration. At each training step, our policy gradient algorithmreceives trajectories from each environment and batches thegradient update due to these trajectories. Multi-task learningallows a single trained policy to generalize across multipleinflow configurations, avoiding the costs of training a separatepolicy for each inflow configuration.
F. Transfer Learning and FinetuningIn our experiments, we commonly transfer the trained policy
from a source scenario (e.g. one with 50% AVs) to initializethe policy for a target scenario (e.g. one with 15% AVs) beforefinetuning the policy in the target scenario. We find that thispractice tends to boost the policy performance on the targetscenario, but we do not further analyze transfer learning’simpact in this paper due to space constraint. We defer thefull details of the transfer scheme and any intermediate modelcheckpoints to the code that we provide.
In particular, we apply zero-shot transfer from the smaller2x1 scenario to the larger 3x3 target scenario, meaning thatwe evaluate the policy from the source scenario on the targetscenario without finetuning.
VI. EXPERIMENTAL SETUP
A. Baseline MethodsWe compare numerical performances of our mixed au-
tonomy method with signal-based or priority-based controlmethods, in which all vehicles are modeled with IDM.
Signal-based control methods offer anytime control at in-tersections, while mixed autonomy methods may only controltraffic at intersections when AVs are present at the intersec-tion. Therefore, under fixed inflow rates, we expect optimalsignal-based methods to be upper bounds for optimal mixedautonomy methods under the throughput objective. For fairercomparison with mixed autonomy control, we set the yellowand all-red time of signals to 0s. We design the followingsignal-based baseline methods:
1) Oracle: for each scenario, we utilize a simple iter-ative hill climbing algorithm to empirically find thebest horizontal and vertical signal phase length, whichare shared for all traffic signals. By construction, thismethod achieves the optimal throughput for a trafficscenario with a known, fixed, and deterministic inflowdistribution. Under other objectives or conditions, theOracle method would likely not be optimal.
2) Equal-phase: we equip all traffic signals with equalphase lengths in both the horizontal and vertical direc-tions. Given the traffic network, we empirically deter-mine the phase length τequal which maximizes averageperformance across all inflow configurations.
3) MaxPressure: we implement adaptive traffic signals con-trolled by the MaxPressure algorithm, which is proven tomaximize throughput in simplified intersections modeledby a queuing network [16]. Given the traffic network, weempirically determine the minimum phase duration τminwhich maximizes average throughput across all inflowconfigurations.
We use τequal = 25s and τmin = 4, 6, 12s for Two-way 2x1,Two-way 3x3, and Four-way 1x1 respectively.
Priority-based baseline methods resemble placing a stopsign along the direction without priority. Therefore, we expectthese baselines to serve as an illustrative lower bound in highinflow scenarios:
1) Priority (Vertical): we assign priority to vertical lanes.2) Priority (Horizontal): we assign horizontal lanes with
priority only in asymmetric scenarios.
B. Simulation Parameters
For all scenarios in this study, we define lanes to be 100mlong and vehicles to be 5m long. The speed limits are set to be13m/s; uncontrolled vehicles may accelerate at up to 2.6m/s2
and decelerate at up to 4.5m/s2 while AVs’ maximums aregiven by caccel = 1.5m/s2 and cdecel = 3.5m/s2. For simulateeach trajectory, we use a simulation step duration δ of 0.5s,H0 = 100 warmup steps, and a training horizon H = 2000.To evaluate the equilibrium performance of trained policiesor baseline methods, we execute the policy for trajectoriesof 500 + H steps then analyze only the last H steps. Allreported outflow or collision results are empirical means over10 evaluation trajectories.
C. Training Hyperparameters
For training, we use outflow and collision coefficientsλo = 1 and λc = 5. Our policy πθ consists of two hiddenlayers of size 64. We use discount factor γ = 0.99, learningrate α = 0.001, and the RMSprop optimizer [17]. In theparadigm of multi-task learning described in Section V-E, eachpolicy gradient update uses a batch of 640 total trajectorieswith multiple trajectories per inflow configuration. Startingfrom a random or pretrained initial policy, we perform up to200 policy gradient updates to train or finetune the policy. Wesave a policy checkpoint every 5 gradient updates and selectthe checkpoint which achieves the best mean outflow acrossthe training batch to evaluate.
VII. EXPERIMENTAL RESULTS
A. Two-way 2x1: Near-optimal Performance
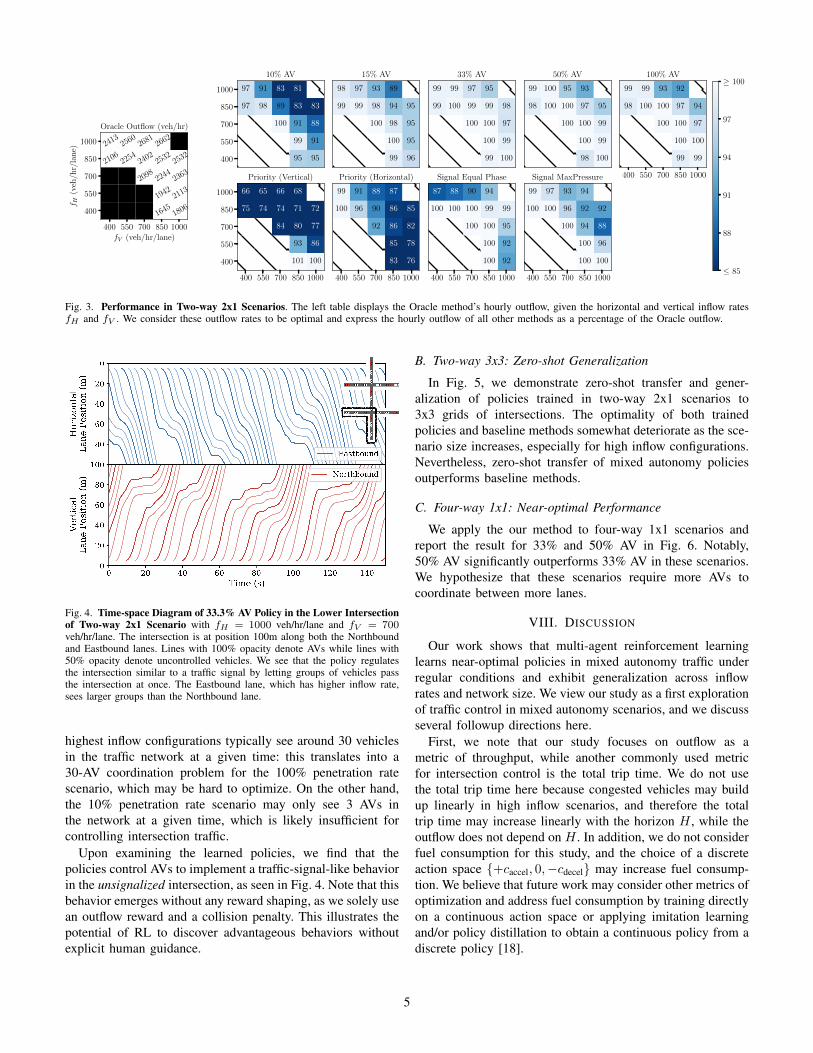
As seen in Fig. 3, our method produces near-optimal poli-cies in two-way 2x1 traffic networks across the 16 inflowconfigurations. Each policy is trained and evaluated on thesame AV penetration rate: 10%, 15%, 33.3%, 50%, or 100%.
We observe that a 33.3% penetration rate achieves the bestthroughput and that smaller (10%, 15%) and larger (50%,100%) penetration rates of AVs see reduced performance; webelieve that the former is due to underactuation and that thelatter is due to increased optimization difficulty. Indeed, the
4
1000
850
700
550
400
97 91 83 81
97 98 89 83 83
100 91 88
99 91
95 95
10% AV
98 97 93 89
99 99 98 94 95
100 98 95
100 95
99 96
15% AV
99 99 97 95
99 100 99 99 98
100 100 97
100 99
99 100
33% AV
99 100 95 93
98 100 100 97 95
100 100 99
100 99
98 100
50% AV
400 550 700 850 1000
99 99 93 92
98 100 100 97 94
100 100 97
100 100
99 99
100% AV
400 550 700 850 1000
1000
850
700
550
400
66 65 66 68
75 74 74 71 72
84 80 77
93 86
101 100
Priority (Vertical)
400 550 700 850 1000
99 91 88 87
100 96 90 86 85
92 86 82
85 78
83 76
Priority (Horizontal)
400 550 700 850 1000
87 88 90 94
100 100 100 99 99
100 100 95
100 92
100 92
Signal Equal Phase
400 550 700 850 1000
99 97 93 94
100 100 96 92 92
100 94 88
100 96
100 100
Signal MaxPressure
≤ 85
88
91
94
97
≥ 100
400 550 700 850 1000fV (veh/hr/lane)
1000
850
700
550
400
f H(v
eh/h
r/la
ne)
24132560
26812662
21062254
24022532
2532
20982244
2363
19422113
16451806
Oracle Outflow (veh/hr)
Fig. 3. Performance in Two-way 2x1 Scenarios. The left table displays the Oracle method’s hourly outflow, given the horizontal and vertical inflow ratesfH and fV . We consider these outflow rates to be optimal and express the hourly outflow of all other methods as a percentage of the Oracle outflow.
Fig. 4. Time-space Diagram of 33.3% AV Policy in the Lower Intersectionof Two-way 2x1 Scenario with fH = 1000 veh/hr/lane and fV = 700veh/hr/lane. The intersection is at position 100m along both the Northboundand Eastbound lanes. Lines with 100% opacity denote AVs while lines with50% opacity denote uncontrolled vehicles. We see that the policy regulatesthe intersection similar to a traffic signal by letting groups of vehicles passthe intersection at once. The Eastbound lane, which has higher inflow rate,sees larger groups than the Northbound lane.
highest inflow configurations typically see around 30 vehiclesin the traffic network at a given time: this translates into a30-AV coordination problem for the 100% penetration ratescenario, which may be hard to optimize. On the other hand,the 10% penetration rate scenario may only see 3 AVs inthe network at a given time, which is likely insufficient forcontrolling intersection traffic.
Upon examining the learned policies, we find that thepolicies control AVs to implement a traffic-signal-like behaviorin the unsignalized intersection, as seen in Fig. 4. Note that thisbehavior emerges without any reward shaping, as we solely usean outflow reward and a collision penalty. This illustrates thepotential of RL to discover advantageous behaviors withoutexplicit human guidance.
B. Two-way 3x3: Zero-shot Generalization
In Fig. 5, we demonstrate zero-shot transfer and gener-alization of policies trained in two-way 2x1 scenarios to3x3 grids of intersections. The optimality of both trainedpolicies and baseline methods somewhat deteriorate as the sce-nario size increases, especially for high inflow configurations.Nevertheless, zero-shot transfer of mixed autonomy policiesoutperforms baseline methods.
C. Four-way 1x1: Near-optimal Performance
We apply the our method to four-way 1x1 scenarios andreport the result for 33% and 50% AV in Fig. 6. Notably,50% AV significantly outperforms 33% AV in these scenarios.We hypothesize that these scenarios require more AVs tocoordinate between more lanes.
VIII. DISCUSSION
Our work shows that multi-agent reinforcement learninglearns near-optimal policies in mixed autonomy traffic underregular conditions and exhibit generalization across inflowrates and network size. We view our study as a first explorationof traffic control in mixed autonomy scenarios, and we discussseveral followup directions here.
First, we note that our study focuses on outflow as ametric of throughput, while another commonly used metricfor intersection control is the total trip time. We do not usethe total trip time here because congested vehicles may buildup linearly in high inflow scenarios, and therefore the totaltrip time may increase linearly with the horizon H , while theoutflow does not depend on H . In addition, we do not considerfuel consumption for this study, and the choice of a discreteaction space {+caccel, 0,−cdecel} may increase fuel consump-tion. We believe that future work may consider other metrics ofoptimization and address fuel consumption by training directlyon a continuous action space or applying imitation learningand/or policy distillation to obtain a continuous policy from adiscrete policy [18].
5

400 550 700 850 1000
1000
850
700
550
400
99 99 91 87
98 99 99 91 87
99 99 91
99 99
98 99
33% AV (Transfer)
400 550 700 850 1000
99 99 88 80
98 100 99 85 80
100 99 88
100 99
98 99
50% AV (Transfer)
400 550 700 850 1000
70 71 73 79
79 79 79 79 82
88 86 82
94 88
100 100
Priority (Vertical)
400 550 700 850 1000
90 91 93 99
99 100 100 99 99
100 100 93
100 91
99 90
Signal Equal Phase
400 550 700 850 1000
99 94 87 88
100 100 94 87 88
100 94 87
100 94
100 99
Signal MaxPressure
≤ 85
88
91
94
97
≥ 100
400 550 700 850 1000fV (veh/hr/lane)
1000
850
700
550
400
f H(v
eh/h
r/la
ne)
42054652
50095030
37584194
46435028
5030
41964643
5009
41944652
37584205
Oracle Outflow (veh/hr)
Fig. 5. Zero-shot Transfer Performance of Mixed autonomy Policies from Fig. 3 to Two-way 3x3 Scenarios.
400 550 700 850 1000
1000
850
700
550
400
95 91 89 89
97 95 93 88 89
96 93 89
95 91
97 95
33% AV
400 550 700 850 1000
99 98 95 95
100 100 99 96 95
100 99 95
100 98
100 99
50% AV
400 550 700 850 1000
64 71 47 49
71 79 50 56 67
55 51 55
73 60
69 65
Priority (Vertical)
400 550 700 850 1000
90 91 94 99
100 100 100 99 99
100 100 94
100 91
100 90
Signal Equal Phase
400 550 700 850 1000
100 97 91 90
100 100 98 90 90
100 98 91
100 97
100 100
Signal MaxPressure
≤ 85
88
91
94
97
≥ 100
400 550 700 850 1000fV (veh/hr/lane)
1000
850
700
550
400
f H(v
eh/h
r/la
ne)
28023108
33113334
24942801
30973343
3334
27963097
3311
28013108
24942802
Oracle Outflow (veh/hr)
Fig. 6. Performance in Four-way 1x1 Scenarios. We train and evaluate a 50% AV policy in four-way 1x1 scenarios.
Second, we acknowledge that our method would likelyinduce a distribution shift in human driver behavior if deployedin the real world. This is a fundamental issue in mixedautonomy and other adaptive control methods, though wespeculate that the distribution shifts induced by AVs maybe larger as humans drivers may be unaccustomed to beingshepherded by AVs, especially in unsignalized intersections.
Finally, we reiterate that our work in mixed autonomycontrol of intersections is an important stepping stone to-wards adaptive integration of mixed autonomy and trafficsignal control mechanisms. Such integration may facilitatejoint optimization of throughput, fuel consumption, and safetyobjectives beyond the capabilities of either mixed autonomyor traffic signals alone, while traffic signal control may helpalleviate distribution shift due to mixed autonomy control.
ACKNOWLEDGMENTThe authors acknowledge MIT SuperCloud and Lincoln
Laboratory Supercomputing Center for providing computa-tional resources that have contributed to the research re-sults in this paper. Zhongxia Yan was partially supported bythe Department of Transportation Dwight David EisenhowerTransportation Fellowship Program (DDETFP).
REFERENCES
[1] C. Wu, A. Kreidieh, E. Vinitsky, and A. M. Bayen, “Emergent behaviorsin mixed-autonomy traffic,” in Conference on Robot Learning. PMLR,2017, pp. 398–407.
[2] E. Vinitsky, K. Parvate, A. Kreidieh, C. Wu, and A. Bayen, “Lagrangiancontrol through deep-rl: Applications to bottleneck decongestion,” in2018 21st International Conference on Intelligent Transportation Sys-tems (ITSC). IEEE, 2018, pp. 759–765.
[3] P. Hunt, D. Robertson, R. Bretherton, R. Winton, Transport, and R. R.Laboratory, SCOOT: A Traffic Responsive Method of CoordinatingSignals, ser. TRRL Laboratory report. TRRL Urban NetworksDivision, 1981. [Online]. Available: https://books.google.com/books?id=jUH6zAEACAAJ
[4] P. Lowrie, Roads, and T. A. of New South Wales. TrafficControl Section, SCATS, Sydney Co-Ordinated Adaptive Traffic System:A Traffic Responsive Method of Controlling Urban Traffic. Roadsand Traffic Authority NSW, Traffic Control Section, 1990. [Online].Available: https://books.google.com/books?id=V4PTtgAACAAJ
[5] H. Wei, N. Xu, H. Zhang, G. Zheng, X. Zang, C. Chen, W. Zhang,Y. Zhu, K. Xu, and Z. Li, “Colight: Learning network-level cooperationfor traffic signal control,” in Proceedings of the 28th ACM InternationalConference on Information and Knowledge Management, 2019, pp.1913–1922.
[6] D. Miculescu and S. Karaman, “Polling-systems-based autonomousvehicle coordination in traffic intersections with no traffic signals,” IEEETransactions on Automatic Control, vol. 65, no. 2, pp. 680–694, 2019.
[7] G. Sharon and P. Stone, “A protocol for mixed autonomous andhuman-operated vehicles at intersections,” in International Conferenceon Autonomous Agents and Multiagent Systems. Springer, 2017, pp.151–167.
[8] C. Wu, K. Parvate, N. Kheterpal, L. Dickstein, A. Mehta, E. Vinitsky,and A. M. Bayen, “Framework for control and deep reinforcementlearning in traffic,” in 2017 IEEE 20th International Conference onIntelligent Transportation Systems (ITSC). IEEE, 2017, pp. 1–8.
[9] J. K. Gupta, M. Egorov, and M. Kochenderfer, “Cooperative multi-agentcontrol using deep reinforcement learning,” in International Conferenceon Autonomous Agents and Multiagent Systems. Springer, 2017, pp.66–83.
[10] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” inNeural Information Processing Systems, 2017.
[11] R. J. Williams, “Simple statistical gradient-following algorithms forconnectionist reinforcement learning,” Machine learning, vol. 8, no. 3-4,pp. 229–256, 1992.
[12] M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states inempirical observations and microscopic simulations,” Physical review E,vol. 62, no. 2, p. 1805, 2000.
[13] P. A. Lopez, M. Behrisch, L. Bieker-Walz, J. Erdmann, Y.-P. Flotterod,R. Hilbrich, L. Lucken, J. Rummel, P. Wagner, and E. Wießner,“Microscopic traffic simulation using sumo,” in 2018 21st InternationalConference on Intelligent Transportation Systems (ITSC). IEEE, 2018,pp. 2575–2582.
[14] C. Boutilier, “Planning, learning and coordination in multiagent decisionprocesses,” in TARK, vol. 96. Citeseer, 1996, pp. 195–210.
[15] L. Engstrom, A. Ilyas, S. Santurkar, D. Tsipras, F. Janoos, L. Rudolph,and A. Madry, “Implementation matters in deep rl: A case study on
6

ppo and trpo,” in International conference on learning representations,2019.
[16] P. Varaiya, “Max pressure control of a network of signalized intersec-tions,” Transportation Research Part C: Emerging Technologies, vol. 36,pp. 177–195, 2013.
[17] G. Hinton, N. Srivastava, and K. Swersky, “Neural networks for machinelearning lecture 6a overview of mini-batch gradient descent,” 2012.
[18] A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirk-patrick, R. Pascanu, V. Mnih, K. Kavukcuoglu, and R. Hadsell, “Policydistillation,” in ICLR (Poster), 2016.
7