properties of storage hierarchy systems with multiple page
TRANSCRIPT

Properties of Storage Hierarchy Systems with Multiple Page Sizes and Redundant Data
CHAT-YU LAM and STUART E. MADNICK Massachusetts Institute of Technology
The need for high performance, highly reliable storage for very large on-line databases, coupled with rapid advances in storage device technology, has made the study of generalized storage hierarchies an important area of research.
This paper analyzes properties of a data storage hierarchy system specifically designed for handling very large on-line databases. To attain high performance and high reliability, the data storage hierarchy makes use of multiple page sizes in different storage levels and maintains multiple copies of the same information across the storage levels. Such a storage hierarchy system is currently being designed as part of the INFOPLEX database computer project. Previous studies of storage hierarchies have primarily focused on virtual memories for program storage and hierarchies with a single page size across all storage levels and/or a single copy of infprmation in the hierarchy.
In the INFOPLEX design, extensions to the least recently used (LRU) algorithm are used to manage the storage levels. The read-through technique is used to initially load a referenced page of the appropriate size into all storage levels above the one in which the page is found. Since each storage level is viewed as an extension of the immediate higher level, an overflow page from level i is always placed in level i + 1. Important properties of these algorithms are derived. It is shown that depending on the types of algorithms used and the relative sizes of the storage levels, it is not always possible to guarantee that the contents of a given storage level i is always a superset of the contents of its immediate higher storage level i - 1. The necessary and sufficient conditions for this property to hold are identified and proved. Furthermore, it is possible that increasing the size of intermediate storage levels may actually increase the number of references to lower storage levels, resulting in reduced performance. Conditions necessary to avoid such an anomaly are also identified and proved.
Key Words and Phrases: database computer, very large databases, data storage hierarchy, storage management algorithms, inclusion properties, modeling, performance and reliability analysis CR Categories: 4.3, 4.33, 5.2, 6.22, 6.34
1. INTRODUCTION
Two- and three-level memory hierarchies have been used in practical computer systems 15, 9, 131. However, there is relatively little experience with general hierarchical storage systems. Rapid advances in storage technology coupled with the need 'for high performance, highly reliable on-line databases make the idea of
Permission to copy without fee all or part of this material is granted provided that the copies are not made or distributed for direct commercial advantage, the ACM copyright notice and the title of the publication and its date appear, and notice is given that copying is by permission of the Association for Computing Machinery. To copy otherwise, or to republish, requires a fee and/or specific permission. This material is based on work supported in part by the National Science Foundation under Grant
Authors' address: Center for Information Systems Research, Alfred P. Sloan School of Management, Massachusetts Institute of Technology, 50 Memorial Drive, Cambridge, MA 02139.
MCS77-20829.
0 1979 ACM 0362-5915/79/O900-0345 $00.75
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979, Pages 345-367

346 * C-Y. Lam and S. E. Madnick
using a generalized storage hierarchy as the repository for very large shared databases very attractive.
One major area of theoretic study of storage hierarchy systems in the past has been the optimal placement of information in a storage hierarchy system. Three approaches to this problem have been used: (1) Static placement [l, 4, 221, an approach that determines the optimal placement strategy statically at the initi- ation of the system; (2) dynamic placement [7,16], an approach that attempts to place information in the hierarchy optimally, taking into account the dynamically changing nature of access to information; and (3) information structuring [ l l , 141, an approach that manipulates the internal structure of information so that information items that are frequently used together are placed adjacent to each other.
Another major area of theoretic study of storage hierarchy systems has been the study of storage management algorithms [2,3, 8, 10, 17, 211. Here the study of storage hierarchy and the study of virtual memory systems for program storage have overlapped considerably. This is largely due to the fact that most of the studies of storage hierarchies in the past have been aimed at providing a virtual memory for program storage. These studies usually do not consider the effects of multiple page sizes across storage levels, or the problem of providing redundant data across storage levels. These considerations are of great importance for a storage hierarchy designed specifically for very large databases.
Madnick [15,18,19] proposed the design of a generalized storage hierarchy for large databases that makes use of multiple data redundancy against failure and multiple page sizes in different storage levels for high performance. Such a storage hierarchy system is to be used in the INFOPLEX database computer [12, 201.
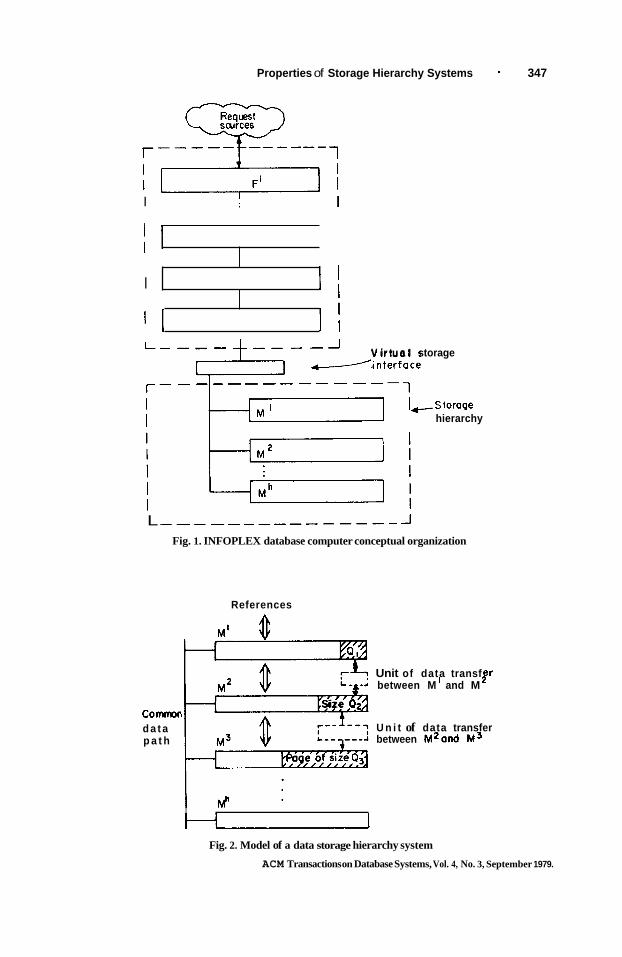
Conceptually, the INFOPLEX database computer consists of a functional hierarchy and a physical (storage) hierarchy (see Figure 1). The functional hierarchy implements all the information management functions of a database manager, such as query language interpretation, security verification, and data path accessing. In INFOPLEX, the functional hierarchy is implemented using multiple microprocessors. Both pipeline and parallel processing are exploited to realize high performance and high reliability. To support the storage requirements of the functional hierarchy, INFOPLEX makes use of a generalized data storage hierarchy system.
In this paper we extend this work by developing a model of the data storage hierarchy, proposing extensions to the least recently used (LRU) algorithm for managing the storage hierarchy, and deriving important properties of the data storage hierarchy.
2. MODEL OF A DATA STORAGE HIERARCHY
A data storage hierarchy consists of h levels of storage devices, M', M2, . . . , Mh. The page size of M i is Qi, and the size of M' is rn, pages each of size Qi. Qi is always an integral multiple of Qi-', for i = 2, 3, . . . , h. The unit of information transfer between M' and Mi+' is a page, of size Qi. Figure 2 illustrates this model of the data storage hierarchy. All references are directed to M'. The storage management algorithms auto-
matically transfer information among storage levels. As a result, the data storage ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.
Properties of Storage Hierarchy Systems - 347
I
I
I - - - - - V ir tu a I storage
It--\ - ::/.interface
I-s torage hierarchy
L _ - - _ _ _ _ _ _ - - - - - - J Fig. 1. INFOPLEX database computer conceptual organization
References
common d a t a p a t h
E-3 Size 0
Unit of data transf r between M and M t
U n i t of data transfer between M2and M3
ge o sizeQ3 r I
L Fig. 2. Model of a data storage hierarchy system
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

340 - C-Y. Lam and S. E. Madnick
hierarchy appears to the reference source as an M' storage device with the size of Mh.
As a result of the storage management algorithms (to be discussed next), multiple copies of the same information may exist in dierent storage levels.
2.1 Storage Management Algorithms
We shall focus our attention on the basic algorithms to support the read-through [18] operation. Algorithms to support other operations can be derived from these basic algorithms.
In a read-through, the highest storage level that contains the addressed information broadcasts the information to all upper storage levels, each of which simultaneously extracts the page (of the appropriate size) that contains the information from the broadcast. If the addressed information is found in the highest storage level, the read-through reduces to a simple reference to the addressed information in that level. Figure 3 illustrates the read-through opera- tion.
Note that in order to load a new page into a storage level an existing page may have to be displaced from that storage level. We refer to this phenomenon as overflow. Hence the basic reference cycle consists of two subcycles, the read- through cycle (RT) and the overflow handling cycle (OH), with RT preceding OH.
Reference to pope P,:
Pope containing pia /
rfkw from M '
Overflow from
I 9 RffERNCE C Y C L E - I I
Fig. 3. Illustration of the read-through operation
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.
M2
MI

Properties of Storage Hierarchy Systems * 349
r - I + READ-
THROUGH :- I-- A L4
r All these levek are not affected
Reference to P
1 MI I
M2 1
M" 1 MX i s the highest level where P i s found
M a + l I
M h I Fig. 4. LOCAL-LRU
For example, Figure 3 illustrates the basic reference cycle to handle a reference to the page P:a. During the read-through (RT) subcycle, the highest storage level (M") that contains P:a broadcasts the page containing Pla to all upper storage levels, each of which extracts the page of appropriate size that contains P:, from the broadcast. As result of the read-through, there may be overflow from the storage levels. These are handled in the overflow-handling (OH) subcycle.
It is necessary to consider overflow handling because it is desirable that information overflowed from a storage level be in the immediate lower storage level, which can then be viewed as an extension to the higher storage level.
One strategy of handling overflow to meet this objective is to treat overflows from M i as references to Mi+'. We refer to algorithms that incorporate this strategy as having dynamic overflow placement (DOP).
Another possible overflow handling strategy is to treat an overflow from M i as a reference to Mi" only when the overflow information is not already in Mi". If the overflow information is already in M+', no overflow handling is necessary. We refer to algorithms that incorporate this strategy as having static overflow placement (SOP).
Let us consider the algorithms at each storage level for selecting the page to be overflowed. Since the least recently used (LRU) algorithm [S, 211 serves as the basis for most current algorithms, we shall consider natural extensions to LRU for managing the storage levels in the data storage hierarchy system.
Consider the following two strategies for handling the read-through cycle. First, let every storage level above and including the level containing the addressed information be updated according to the LRU strategy. Thus, all storage levels lower than the addressed information do not know about the reference. This class of algorithms is called the LOCAL-LRU algorithm and is illustrated in Figure 4.
The other class of algorithms that we consider is called the GLOBAL-LRU algorithm. In this case all storage levels are updated according to the LRU
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

350 - C-Y. Lam and S. E. Madnick
Reference to P
I 1
READ- P I b I M 2 THROUGH A I
MX i s the highest level where P is found
These levels a r e also updated as if reference to P were made to them
M x + I I
M h I c
Fig. 5. GLOBAL-LRU
strategy whether or not that level actually participates in the read-through. This is illustrated in Figure 5.
Although the read-through operation leaves supersets of the page P:, in all levels, the future handling of each of these pages depends on the replacement algorithms used and the effects of the overflow handling. We would like to guarantee that the contents of each storage level, Mi, is always a superset of its immediately higher level, Mi-'. This property is called multilevel inclusion (MLI). Conditions to guarantee MLI are derived in a later section.
It is not difficult to demonstrate situations where handling overflows generate references which produce overflows, which generate yet more references. Hence another important question to resolve is to determine the conditions under which an overflow from M i is always found to already exist in Mi+', i.e. no reference to storage levels lower than Mi+' is generated as a result of the overflow. This property is called multilevel overflow inclusion (MLOI). Conditions to guarantee MLOI will be derived in a later section.
We shall consider these important properties in the light of four basic algorithm alternatives based on local or global LRU and static or dynamic overflow. Formal definitions for these algorithms are provided after the basic model of the data storage hierarchy system is introduced.
2.2 Basic Model of Data Storage Hierarchy
For the purposes of this paper, the basic model illustrated in Figure 6 is sufficient to model the data storage hierarchy. As far as the read-through and overflow- handling operations are concerned, this basic model is generalizable to an h-level storage hierarchy system.
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems * 351
R e f erellces
Fig. 6. Basic model of a data storage hierarchy system
M’ can be viewed as a reservoir which contains all the information. M i is the top level. It has mi pages each of size Qi. Mi ( j = i + 1) is the next level. It has mj pages each of size nQi where n is an integer greater than 1.
2.3 Formal Definitions of Storage Management Algorithms Denote a reference string by r = “rl, r2, . . . , rn,” where rt (1 5 t 5 n) is the page being referenced at the tth reference cycle. Let S,’ be the stack for M i at the beginning of the tth reference cycle, ordered according to LRU. That is, St‘ = (St i( l ) , St’(2), . . . , S t i ( K ) ) , where St’(l) is the most recently referenced page and St i (K) is the least recently referenced page. Note that K I mi (mi = capacity of M’ in terms of the number of pages). The number of pages in Sti is denoted as I Sti 1; hence I Sli I = K. By convention, S1’ = 0, I S1’ I = 0.
St‘ is an ordered set. Define M,’ as the contents of S,’ without any ordering. Similarly, we can define StJ and Mt’ for MJ.
Let us denote the pages in Mi by Pj, PzJ, . . . . Each page Py 3 in MJ consists of an equivalent of n smaller pages, each of size Qi = Q,/n. Denote this set of pages by (Py’)i; i.e. (Py’)i = {Pfl, P$, . . . , Pi}. In general, (Mt‘)1 is the set of pages, each of size Qi, obtained by “breaking down” the pages in Mt’. Formally, = UL1 (St’(k))’ where x = I StJ 1. (Py’)i is called the family from the parent page Py’. Any pair of pages Pia and Pfb from (PyJ)i are said to be family equivalent, denoted by Pfa P f b . Furthermore, a parent page PyJ and a page Piz (for 1 5 z 5 n) from its family are said to be corresponding pages, denoted by P;zoA PyJ.
Sti and St’ are said to be in corresponding order, denoted by St’ = Sl’, if Sti(rZ) A StJ(K) for K = 1,2,3, . . . , w, where w = min( I Sti I , I StJ I). Intuitively, two
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

352 C-Y. Lam and S. E. Madnick
stacks are in corresponding order if for each element of the shorter stack, there is a corresponding page in the other stack at the same stack distance. (The stack distance for page St'(k) is defined to be k.)
Mti and M? are said to be correspondingly equivalent, denoted by Mt' A Mt' if I Mti I = I M i I and for any k = 1,2, . . . , I Mt' I there exists x, such that St'(k) = St'(x) and Sti (x) St'(y) for all y # k. Intuitively, the two memories are correspondingly equivalent when each page in one memory corresponds to exactly one page in the other memory.
The reduced stack, &', of St'is defined to be st ' (k) = St'(jk) for k = 1, . . . , I sti I where j, is the minimum j k , where j k > jh-l(jo = 0) and &'(k) 4 S t i ( j ) for j < jk . Intuitively, st' is obtained from Sti by collecting one page from each family existing in Sti, such that the page being collected from each family is the page that has the smallest stack distance within the family.
In the following, we define the storage management algorithms. In each case, assume that the page referenced at time t is Pya.
LRU(&', p;a) = Sf+, is defined as follows.
Case 1. P& E St', Pia = St'(k).
Sf+l(l) = Pia, S f + l ( X ) =
Case 2. p fa $ St'.
- l ) , l < x 5 k ,
k c x I I St' I.
s~+,(I) = Pis, If I Sti I = mi then Pi , = St'(mi) is the overflow, else
there is no overflow.
S;+~(X) = St'(x - I), 1 < x I &(mi, I St'l + 1).
LOCAL-LRU-SOP(&', St', Pf;,) = ($+I, &+I) is defined as follows.
Case 1. P$a E St'.
Si+l = LRU(Sti, P;a), S{+I = SC.
Case 2. Pf; , + St', Py' E StJ.
S$ = LRU(St', P$a),
If there is no overflow from St'
S-$ = LRU(SL', PyJ) .
then = Sf, and S{+1 = S$.
If overflow from St' is the page P L ,
then (Sf,,, S{+,) = SOP(Sfp, S$, Pi,,) defined as:
Sf+l = sf.; if Poi€ Si, then S{+, = S$,
if Po' + S{, then S{+1 = LRU(S$, Po').
Case 3. P f a $ Sti and Py' $ S). Handled as in Case 2.
LOCAL-LRU-DOP(St', St', Pia) = S{+,) is defined as follows. ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems * 353
Case 1. P f , E St'.
st+' = LRU(S,', P;,),
st. = LRU(S,', P;,),
sj,, = si'.
s{. = LRU(S~', pYJ).
Case 2. Pi, 6 S,' and PyJ E Si'.
If there is no overflow from S,' then Sf+l = Sf, and S{+, = S-$.
If the overflow from S,' is Pi, then
(Sf+l , S{+') = DOP(Sf,, Si , Pi,) which is defined as:
Sf+l = S$ and S{+l = LRU(S't,, PoJ).
Case 3. Pf, $ Sti and Pyi $ S,'. Handled as in Case 2 above.
GLOBAL-LRU-SOP($', StJ, Pi,) = (S~+I, S{+J is defined as follows.
St, = LRU(St', Pi,) and Sir = LRU(Si', PyJ).
If there is no overflow from St' then $+I = Sf, and S{+l = Sj,.
If the overflow from Sti is P!,, then ($+I, &+I) = SOP(S$, Sir, Pi,).
GLOBAL-LRU-DOP(St', St', Pf,) = (St+l, S{+,) is defined as follows.
si ,, - - LRU(S,', Pf,)
If there is no overflow from St' then St+l= S$ and Si+1 = S$.
If the overflow from S,' is Pi, then (Sf+,, S<+I) = DOP(Sf,, Sir, Pi,).
and S$ = LRU(Si', P,').
3. PROPERTIES OF DATA STORAGE HIERARCHY
One of the properties of a read-through operation is that it leaves a "shadow" of the referenced page (i.e. the corresponding pages) in all storage levels. This provides multiple redundancy for the page. Does this multiple redundancy exist at all times? That is, if a page exists in storage level Mi, wil l its corresponding pages always be in all storage levels lower than M'? We refer to this as the multilevel inclusion (MLI) property. As illustrated in Figure 7 for the LOCAL- LRU algorithms and in Figure 8 for the GLOBAL-LRU algorithms, it is not always possible to guarantee that the MLI property holds. For example, after the reference to pi l in Figure 7(a) the page pil exists in M', but its corresponding page pl' is not found in Mi. In this paper we shall derive the necessary and sufficient conditions for the MLI property to hold at all times.
Another desirable property of the data storage hierarchy is to avoid generating references due to overflows. That is, under what conditions will overflow pages from M i find their corresponding pages already existing in the storage level Mi+'? We refer to this as the multilevel overflow inclusion (MLOI) property. We shall investigate the conditions that make this property true at all times.
With reference to the basic model of a data storage hierarchy in Figure 6, for high performance it is desirable to minimize the number of references to M' (the
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979

354 - C-Y. Lam and S. E. Madnick
( a ) LOCAL - LRU -SOP
i reference t o M i plil bL1 ; P l l ! P i l P \ I I
I I I
I I
( m i = 2 )
I I I 1
1 1
I overflow from M~ 1 I I '31 I
1 j j l j l I i
I
reference to M pI I P, I 9 , p3 P A I 4 I$ I
contents of M
( m j 2 )
1 I I
reference to M' * * 4 I t 4 1 9 * * ( b ) LOCAL- LRU-DOP
Fig. 7. Examples of MLI violations for LOCAL-LRU algorithms
reservoir). If we increased the number of pages in M' or in MJ, or in both, we might expect the number of references to M' to decrease. As illustrated in Figure 9 for the LOCAL-LRU-SOP algorithm, this is not always so; i.e. for the same reference string, the number of references to the reservoir actually increased from 4 to 5 after M i is increased by 1 page in size. We refer to this phenomenon as a multilevelpaging anomaly (MLPA). One can easily find situations where MLPA occurs for the other three algorithms. Since occurrence of MLPA reduces per- formance in spite of the costs of increasing memory sizes, we would like to investigate the conditions to guarantee that MLPA does not exist. ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems - 355
i i i i rreference to M~ pII I P ~ ~ IP,, '51 '
1 ;':I I
I contents of M~
( m i = 2)
o v e r f l w from M
reference to M J p: ip; Pt [Pa
j contents of M
(m. = 2)
i
1
1
reference t o M'
( a ) GLOBAL-LRU-SOP
3.1 Summary of Properties
The MLI, MLOI, and MLPA properties of the data storage hierarchy have been derived in the form of eight theorems. These theorems are briefly explained and summarized below and formally proved in the following section.
Multilevel Inclusion ( M U ) . It is shown in Theorem 1 that if the number of pages in M i is greater than the number of pages in Mi (note that Mi pages are larger than those of Mi), then it is not possible to guarantee MLI for all reference strings at all times. It turns out that by using LOCAL-LRU-SOP or LOCAL-
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

356 * C-Y. Lam and S. E. Madnick
i i reference to M i I ' 1 1 j i ':I !';I! j '41
I I 1 I 1 I I
number of references to M' = 5 I Fig. 9. MLPA for LOCAL-LRU-SOP
LRU-DOP, no matter how many pages are in MJ or Mi, one can always find a reference string that violates the MLI property (Theorem 2). Using the GLOBAL- LRU algorithms, however, conditions to guarantee MLI exist. For the GLOBAL- LRU-SOP algorithm, a necessary and sufficient condition to guarantee that MLI holds at all times for any reference string is that the number of pages in Mi be greater than the number of pages in Mi (Theorem 3). For the GLOBAL-LRU- DOP algorithm, a necessary and sufficient condition to guarantee MLI is that the ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems - 357
number of pages in M' be greater than or equal to twice the number of pages in M i (Theorem 4).
Multilevel Overflow Inclusion (MLOI). I t is obvious that if MLI cannot be guaranteed, then MLOI cannot be guaranteed. Thus the LOCAL-LRU algorithms cannot guarantee MLOI. For the GLOBAL-LRU-SOP algorithm, a necessary and sufficient condition to guarantee MLOI is the same condition as that to guarantee MLI (Theorem 5). For the GLOBAL-LRU-DOP algorithm, a necessary and sufficient condition to guarantee MLOI is that the number of pages in M' is strictly greater than twice the number of pages in M i (Theorem 6). Thus for the GLOBAL-LRU-DOP algorithm, guaranteeing that MLOI holds will also guar- antee that MLI will hold, but not vice versa.
Multilevel Paging Anomaly (MLPA). We have identified and proved suffi- ciency conditions to avoid MLPA for the GLOBAL-LRU algorithms. For the GLOBAL-LRU-SOP algorithm, this condition is that the number of pages in MJ must be greater than the number of pages in M i before and after any increase in the sizes of the levels (Theorem 7). For the GLOBAL-LRU-DOP algorithm, this condition is that the number of pages in MJ must be greater than twice the number of pages in M i before and after any increase in the sizes of the levels (Theorem 8).
In summary, we have shown that for the LOCAL-LRU algorithms, no choice of sizes for the storage levels can guarantee that a lower storage level always contains all the information in the higher storage levels. For the GLOBAL-LRU algorithms, by choosing appropriate sizes for the storage levels, we can (1) ensure that the above inclusion property holds at all times for al l reference strings, (2) guarantee that no extra page references to lower storage levels are generated as a result of handling overflows, and (3) guarantee that increasing the sizes of the storage levels does not increase the number of references to lower storage levels. These results are formally stated as the following eight theorems. Formal proofs of these theorems are presented in the following section.
THEOREM 1. Under LOCAL-LR U-SOP, or LOCAL-LRU-DOP, or GLOBAL- LRU-SOP, or GLOBAL-LRU-DOP, for any mi 2 2, m, 5 mi implies 3r, t, ( M i )i a Mti .
THEOREM 2. Under LOCAL-LRU-SOP or LOCAL-LRU-DOP, for any mi 2 2 and any m,, 3, t, ( M t J ) i 2 Mti.
THEOREM 3. Under GLOBAL-LRU-SOP, for any mi 2 2, Vr, t , 2 Mt' i f f mj > mi.
THEOREM 4. Under GLOBAL-LRU-DOP, for any mi 2 2, Vr, t, (MtJ) i 2 Mt' i f f m, 2 2mi.
THEOREM 5. Under GLOBAL-LRU-SOP, for any mi 2 2, Vr, t, an overflow from M i finds its corresponding page in Mi i f f mj > mi.
THEOREM 6. Under GLOBAL-LRU-DOP, for any mi 2 2, Vr, t, an overflow from Mi finds its corresponding page in MJ iff mj > 2mi.
THEOREM 7. Let Mi (with mi pages), MJ (with mjpages), and M be system A. Let M" (with mi pages), M'J (with mj pages), and M' be system B. Let mi 2 mi and mj 2 mi. Under GLOBAL-LRU-SOP, for any mi 2 2, no MLPA can exist if mj > mi and mj > mi.
THEOREM 8. Let system A and system B be defined as in Theorem 7. Let ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

358 C-Y. Lam and S. E. Madnick
mi 2 mi and mj 2: m,. Under GLOBAL-LRU-DOP, for any mi L 2, no MLPA can exist i f mj > 2mi and m$ > 2ml.
3 .2 Derivation of Properties
THEOREM 1. Under LOCAL-LR U-SOP, or LOCAL-LRU-DOP, or GLOBAL- LRU-SOP, or GLOBAL-LRU-DOP, for any mi ? 2, mj 5 mi implies 3r, t, ( M i ) i 2 M t i .
PROOF Case 1. mj < mi. Consider the reference string r = "Pis, Pi,, ... , Ptm,+l),”.
Using any one of the algorithms, the following stacks are obtained at t = mj + 2:
St’ = (Pfmj+l)a, pija, . . ., P6a, Pla), Sr‘ (Pjmj+l), PLj, - - 9 P3J9 P2J).
Thus, Pila E Mti , but Pia !Z (Mt;)i; i.e. (Mt’)i 2 Mi. Case 2. m, = mi = w. Consider the reference string r = “Pta, Pha,
. . ., Pfw+l)a”. Using any one of the above algorithms, the following stacks are obtained at t = w + 2:
Sti = (Pfw+l)a, Pta, . . ., FL, Pia), StJ = (PI39 P{w+1), Pw’, * * a , PdJ, ~ ‘ 3 ’ ) .
Thus, Pia E M t i , but Pia 62 Q.E.D. THEOREM 2. Under LOCAL-LRU-SOP or LOCAL-LRU-DOP, for any
mi 2 2 and any m,, 3r, t, ( M t J ) i 2 Mti. PROOF (For LOCAL-LRU-SOP). For m, I: mi the result follows directly
from Theorem 1. For m, > mi, using the reference string r = “Pi zap P i la , P i za , P$a, . . ., Pfa, Pkja”, the following stacks will be produced at t = 2m; + 1:
i.e. (Mt’)’ 2 Mti.
st’ = (PLja, Pfa, Pfmj-l)a, ., p imj -mi+2 )a ) , S / = ( P i j , PLj,_,, - - - 9 PZJ,
Thus Pia E Mti, but P f , !Z (A&’)’, i.e. ( M J ) i 2 Mti.
Theorem 1. For m, > mi, using the reference string
Q.E.D. PROOF (For LOCAL-LRU-DOP). For m, I mi the result follows directly from
r = “ ~ 6 , , Pi, , Pia, Pba, . . ., Pfa, PLj2’,
the following stacks will be produced at t = 2mj + 1:
Sti = ( P L , ~ , pia, . . ., Pfmj-mi+2)a), S/ = (a1, a2, . . ., amj)
where for 1 I i I m,, ai E {Pi,,, Pk,-,, I . ., PB’, Pz’, P I ’ } , since P,’ is the only overflow from Mi. Thus, P & E Mli, but P f a fZ (Ml’)i; i.e. (Ml’) i 2 M I L . . Q.E.D.
THEOREM 3. Under GLOBAL-LRU-SOP, for any mi 2 2, Vr, t, ( M i ) i 2 Mt’ iff m, > mi.
PROOF. This proof has two parts: part (a) to prove Vr, t , 2 Mti * mj > mi, or equivalently, m, 5 mi * 3r, t, ( M i ) i 2 Mti; part (b) to prove mj > mi Vr, t, 2 kfti.
Part (a) of the Proof mj I mi * 3r, t, (Mt’ ) i 2 Mt’.
This follows directly from Theorem 1. For part (b) of the Proof we need the following results.
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.
Q.E.D.

Properties of Storage Hierarchy Systems - 359
LEMMA 3.1. Vr, t such that I MtJI 5 mi, if m, = mi + 1, then ( a ) ;1 ML’ and (b) sti 2= St’.
PROOF OF LEMMA 3.1. For t = 2 (i.e. after the first reference), (a) and (b) are true. Suppose (a) and (b) are true for t, such that I M i I I mi. Consider the next reference:
Case 1. It is a reference to Mi. There is no overflow from M or M’, so (a) is still true. Since GLOBAL-LRU is used, (b) is still true.
Case 2. It is a reference to M’. There is no overflow from M’. If there is no overflow from M’, the same argument as Case 1 applies. If there is overflow from Mi, the overflow page finds its corresponding page in MJ. Since SOP is used, this overflow can be treated as a “no-op.” Thus (a) and (b) are preserved.
Case 3. It is a reference to M‘. There is no overflow from M’ since W{+I I 5 mi. Thus the same reasoning as in Case 2 applies. Q.E.D.
LEMMA 3.2. Vr , t, such that 1 Mt’I = m,, if m; = mi + 1 then ( a ) 3 Mt’, ( b ) Sti StJ, and ( c ) (St’(m,))i n S,’ = 0. Let us denote the conditions (a ) , ( b ) , and ( c ) jointly as Z ( t ) .
PROOF OF LEMMA 3.2. Suppose that the first time St’(mj) is filled it is by the t * th reference. That is, St’( m,) = 0 for all t 5 t * and St’( m;) # 0 for all t > t *. From Lemma 3.1 we know that (a) and (b) are true for all t 5 t*. Let t , = t* + 1, t z = t * + 2, . . . , etc. We shall show by induction on t, starting at t l , that Z( t) is true. First we show that Z( t l ) is true as follows:
Case 1. M$ .& ~ f * .
sf. 2 S{. and M{. Mf. S{.(m, - 1) f Sf.(m,) .
As a result of the reference at t* (to M “ ) , S{~+~(rn;) = S$(m; - 1) andsf. (mi) overflows from Mi. This overflow page finds its corresponding page in Mi because there is no overflow from Mi and (a). Since SOP is used, the overflow from Mi can be treated as a “no-op.” Furthermore, since GLOBAL-LRU is used, (b) is true after the t*th reference. (b) and I > 1 S$+l I * (a) and (c). Thus Z(t1) is true.
Case 2. (Mi*)’ 3 Mi* and Mi. 4 Mi*.
(M’,.)’ 3 Mi* and M{. 4 Mi. - 3S$(k ) such that (S:*(K))’ n Mi. = 0.
S;. P S/,* and (S {* (k ) ) ’ n Mi. = 0 * K > 1s;. I and (S/,*(x))’ r l Mi* = 0
for all x, where mJ-l 2 3c L k. Thus (S{*(mJ-l))’ n S:. = 0 (i.e. the last page of S/,* is not in St*). Sf*(m,) overflows from M‘. There is no overflow from M’. Thus the overflow page from M‘ finds its corresponding page in M’. For the same reasons as in Case 1, (b) is still preserved. (b) and I S++I I > I Si*+l I =$ (a) and (c) are true. Thus Z(t1) is true.
Assume that Z ( t k ) is true; to show that Z ( t k + l ) is true, we consider the next reference, at time tk+l .
Imagine that the last page of S{, does not exist, i.e. S{, (m,) = 0. If the reference at tk+l is to a page in M:, or Mi,, then (a) and (b) still hold because GLOBAL- LRU is used and because overflow from M’ finds its corresponding page in M’ (see the proof of Lemma 3.1). If the reference at &+I is to a page not inM:, , then
ACM Transactions on Database Systems, Vol. 4, No 3, September 1979.

360 * C-Y. Lam and S. E. Madnick
we can apply the argument used in considering the reference at time tl above to show that Z(tk+l) is still true. Q.E.D.
LEMMA 3.3. Vr, t, if m; = mi + 1, then (a) (Mt’)l 2 Mti and (b ) (St’(mj))i n Sti = 0. PROOF OF LEMMA 3.3. For t such that IMlI 5 mi (a) follows directly from
Lemma 3.1 and (b) is true because Sc(m;) = 0. For t such that I MtJ I = m; (a) and (b) follow directly from Lemma 3.2. Q.E.D.
LEMMA 3.4. Vr, t, z f mj > mi, then (a) 2 Mt’ and (b ) (St’(mj))i fl St’ = 0.
PROOF OF LEMMA 3.4. Let m; = mi + k . We shall prove this lemma by induction on h. For h = 1 (a) and (b) are true from Lemma 3.3. Suppose that (a) and (b) are true for K. Consider m; = mi + ( k + 1). That is, consider the effects of increasing M’ by 1 page in size. Since M i is unchanged, MJ (with mi + k + 1 pages) sees the same reference string as MJ (with mi + k pages). Applying the stack inclusion property [ 2 1 ] , we have Mi (with mi + K + 1 pages) 1 M’ (with mi + k pages). Thus (a) is still true. Suppose (&’(mi + K + 1))’ f l St’ # 0, then there is a page in M i that corresponds to this page. But Si(mi + k + 1 ) is not in MJ (with mi + k pages). This contradicts the property that (Aft;)’ 2 Mj. This shows that (b) is still true. Q.E.D.
m; > mi * Vr, t, ( ~ 2 ) ~ 2 Mti. Part ( b ) of the Proof
This follows directly from Lemma 3.4.
iff m, 2 2mi.
Part (a): m; < 2mi * 3r, t, a Mi. Part (b): m; 2 2mi * Vr, t, ( M i ) i 2 Mi.
Q.E.D. THEOREM 4. Under GLOBAL-LRU-DOP, for any mi 2 2 , Vr, t, (MtJ)’ 2 Mti
PROOF. This proof has two parts.
Part ( a ) of the Proof
m; < 2mi * 3r, t, ( Mt’)i 2 Mti.
For m; 5 mi the result follows from Theorem 1. Consider the case for 2mi > m; > mi. The reference string r = “Pi,, Pia , P&, . . ., PfZm,)a’’ will produce the following stacks:
Sti = (Pf2mi)a, PtPm,-l)o, . . - 9 Pirn,+l)a), S/ = (al , ~ 2 , ~ 3 , . . ., antj)
where ai‘s are picked from L1 and LS alternatively, starting from L1. L1 = (PLi , P<rn,-I), - , PI’) and Lz = (P&, P{2mi-1), . . . ,%,.+I). If m; is even, then ( a l , u3, . . . , am,-l) corresponds to the frrst m;/2 elements of L1 and (az, a4, . . . , urn,) corresponds to the first m;/2 elements in L2. We see thatPf,,+l), is in St‘, but its corresponding page is not in StJ ( P<,,,,+l) is not in StJ since m;/2 < mi). If mj is odd, then ( a l , a3, . . . , a,) corresponds to the first (m; + l ) / 2 elements in LI and (a2, a4, . . . a,+) corresponds to the first (m; - 1 ) / 2 elements in L2. We see that the page Pim,+l)a is in Sti , but its corresponding page is not in St’ because max((m; - 1 ) / 2 ) = mi - 1; thus, u ( ~ , - ~ ) is at most the (mi - 1)th element of Lz, P4m,-crn,-1)+1 = P’,,2. In both cases, 2 Mi. Q.E.D. ACM.Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems - 361
+Stock distance X + M ’ I
+Stack distance 2 X -q
For Part (b) of the proof we need the following preliminary results. LEMMA 4.1. Under GLOBAL-LRU-DOP, for mi 2 2, m, 2 2mi, a page found
at stack distance k in M,’ implies that its corresponding page can be found within stack distance 2k in Mt’.
PROOF OF LEMMA 4.1. We prove by induction on t. At t = 1, the statement is trivially true. At t = 2 (i.e. after the first reference) St’( l ) and its corresponding page are both at the beginning of the stack hence the induction statement is still true. Suppose the induction statement is true at time t, i.e. Pf, = S i ( k ) * P,’ can be found within stack distance 2k within St’. Suppose the next reference is to PLa. There are three cases:
Case 1. P i , E Mti ( P i a = St i (x ) ) . From the induction statement, P,’ is found within stack distance 2k in St’, as illustrated in Figure 10. Consider the page movements in the two stacks as a result of handling the reference to Pa,: (1) PLa and P,J are both moved to the top of their stack; the induction
statement still holds for these pages. ( 2 ) Each page in A increases its stack distance by 1, but its corresponding page
is in A’, each page of which can at most increase its stack distance by 1. Thus the induction statement holds for all pages in A. None of the pages in B are moved. None of the pages in B’ are moved (see previous diagram). If a page in B has its corresponding page in B’, the induction statement is not violated. Suppose a page in B, PSa = St’(k) (k > x), has its corresponding page, PbJ = St’(w) in A‘. Then Pb’ can at most increase its stack distance by 1. But w I 2x because PbJ E A’. Since 2k > 2x, the induction statement is not violated.
Mt’, P,’ E MtJ, Each page in M increases its stack distance by 1. Each corresponding page in Mi can at most increase its stack distance by 2, one due to the reference and one due to an overflow from Mi. Hence if Pi, = S t i ( k ) , k < mi, then Pf, = Sf+l (k + l), and P,’can be found within stack distance 2(k + 1) in Mi at time t + 1.
Case 3. P i , (Z M t i , P,’ MtJ . As a result of the read-through from M’. each page in M i is increased by a stack distance of 1. That is, for k < mi,
(3)
Case 2. P i a
Pta = Sti(k) * Pfa = Sf+l (k + 1). ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

362 - C-Y. Lam and S. E. Madnick
Each page in MJ can at most increase its stack distance by 2, one due to loading the referenced page and one due to an overflow from Mi. Hence, the page P,' is found within stack distance of 212 + 2 in M'. Since max(2K + 2 ) = 2mi I m;, PzJ is still in MJ. Q.E.D.
m, > 2mi * ~ r , t, (St'(m,))' n Sl = 0. PROOF OF COROLLARY. For any Pi, in S,', its corresponding page can be found
within stack distance 2mi in St', and since pages in St' are unique, the information in the last page of Si is not found in SA i.e. (S{(m;))' n S,' = 0.
COROLLARY TO LEMMA 4.1
Part (b) of the Proof m; I 2mi * Vr, t, (MtJ)i 2 M:.
This follows directly from Lemma 4.1.
from M i finds its corresponding page in Mi iff m; > mi.
from M i finds its corresponding page in Mi i f f Vr, t, (Mi ) i 2 M,'.
Q.E.D. THEOREM 5. Under GLOBAL-LRU-SOP, for any mi 2 2, V r , t, an overflow
COROLLARY. Under GLOBAL-LRU-SOP, for any mi I 2, Vr, t, an overflow
PROOF. This proof has two parts as shown below. Part (a ) of the Proof. m; > mi * Vr , t, an overflow from M i finds its
corresponding page in M'. From Lemma 3.4 m; > mi * Vr, t, (Mt')' 2 M i and (St'(m;))i fl S,' = 0. Suppose
the overflow from Mi, Ps, is caused by a reference to MJ. Then just before Pb, is overflowed, P,' exists in Mi. After the overflow, Pka finds its corresponding page still existing in MJ. Suppose the overflow Pi, is caused by a reference to M . Then just before the overflow from Mi, P,' exists in Mi and (Si(mj))' n Sf = 0 i.e. the information in the last page of M' is not in Mi. This means that the last page of Mi is not P j ; thus, the overflow page Pi, finds its corresponding page still in MJ after an overflow from Mi occurs.
Part (b) of the Proof. m, 5 mi * 3r, t, such that an overflow from M i does not find its corresponding page in M'.
From Theorem 1, m; 5 mi * 3r, t, (Mi) ' 2 M:; then there exists P f , E M l and P,' 6Z MtJ. We can find a reference string such that a t the time of the overflow of Pi, from Mi, P,' is still not in MJ. A string of references to M' will produce this condition. Then at the time of overflow of PL,, it will not find its corresponding page in M' . Q.E.D.
THEOREM 6. Under GLOBAL-LRU-DOP, for mi 2, Vr, t, an overflow from M i finds its corresponding page in MJ iff mj > 2mi.
COROLLARY. Under GLOBAL-LRU-DOP, for mi 2 2, Vr, t, an overflow from M i finds its corresponding page in MJ implies that Vr , t,
PROOF. This proof has two parts as shown below. Part (a ) of the Proof. m; > 2mi * V r , t, an overflow from M i finds its
corresponding page in M'. Theorem 4 ensures that m; > 2mi + Vr, t, ( M i ) i 2 M,' and Lemma 4.1 ensures
that (StJ(m;))i n S,' = 0 we then use the same argument as in part (a) of the proof of Theorem 5.
Part (b) of the Proof. mj 5 2mi * 3r, t, such that an overflow from M i does not find its corresponding page in MJ.
2 M t .
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems * 363
Case 1. m; < 2mi. m; < 2mi - 3r, t, (Mt’)’ 2 M j (from part (a) of the proof of Theorem 4). We then use the same argument as in part (b) of the proof of Theorem 5.
Case 2. m; = 2mi. The reference string r = “Pfa, Pin, . . . , Pf2m,)a, Pfzmi+l)a” will produce the following stacks (at t = 2mi + 1):
St‘ = (Pf2mi)a, Pf2m,-l)a, *
st’ = (P i i , Pimi, Pi ,+ P&-1, . . . , P i , PiI+l).
Ptm;+l)a),
In handling the next reference to page Pfzmi+l)a, the pages Ptm,+ l )a and PA,+, overflow at the same time; hence the overflow page P f m i + l ) a from M i does not find its corresponding page in M’. Q.E.D.
THEOREM 7. Let M i (with mipages), M’ (with m’pages), and M be system A. Let M f i (with mI pages), M’J (with mj pages), and M‘ be system B. Let m: 2 mi and mj 2 mi. Under GLOBAL-LRU-SOP, for any mi I 2, no MLPA can exist if m; > mi and mj > mi.
( M i i U (Mt”)i ) . This wil l ensure that no MLPA can exist. Since mI P mi and LRU is used in M i and M’ i, we can apply the LRU stack inclusion property to obtain M i c M i L . From Theorem 5 we know that overflows from M i or from M” always find their corresponding pages in MJ and M’J, respectively. Since SOP is used, these overflows can be treated as “no-ops.” Thus MJ and M” see the same reference string, and we can apply the LRU stack inclusion property to obtain Mt’ C Mt‘J (since mj z mj and LRU is used).
M,‘ 5 Mt‘i and Mt’ - C ML’* ( M i U (Mi ) ’ ) _C (ML’ U Q.E.D. THEOREM 8. Let system A and system B be defined as in Theorem 7. Let mi
2 mi and mj I m;. Under GLOBAL-LRU-DOP, for any mi z 2, no MLPA can exist i f m, > 2mi and mj > 2mI.
PROOF. We shall show that Qr, t, (Mj U ( M ) ) i )
PROOF. We need the following preliminary results for this proof. LEMMA 8.1. Let S,‘ bepartitioned i d o two disjoint stacks, Wt and Vt defined
as follows: W t ( k ) = S i ( j ~ ) for k = 1, . . . , I W, I where jo = 0, and jk is the minimum j , > j k - 1 such that 3 Pf, E St‘ and P f , Sic jk). Vt(k) = SIJ( j , ) for k = 1, . . . , I Vt 1 where jo = 0, andjk is the minimum jk >jk-l such thatQP:, E Sl, P4, StJ( jk). (Intuitively, W, is the stack obtained from StJ by collecting those pages that have their corresponding pages in M j such that the order of these pages in St‘ &preserved. Vt is what is left of StJ after Wl is formed.) Then Vr, t, (a ) Wl f st‘ and (b) Vt 0, where 0, is the set ofpages corresponding to all the pages that ever overflowed from M i , up to time t.
PROOF OF LEMMA 8.1. From Theorem 4, m; > 2m, * Vr, t, (Mi’)i 2 Mt’. Thus for each page in Mt‘, its corresponding page is in Mi‘. This set of pages in Mi‘ is exactly Wt, and Wt f St‘ by definition. Since the conditions for Vt and Wt are mutually exclusive and collectively exhaustive, the other pages in M i that are not in Wt are by definition in Vt. Since a page in Vt does not have a corresponding page in Mt’, its corresponding page must have once been in M i because of read- through, and later overflowed from M‘. Thus a page in V, is a page in 0,.
Q.E.D.
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.
LEMMA 8.2. Any overflow page from M,’ is a page in V,.

364 - C-Y. Lam and S. E. Madnick
PROOF OF LEMMA 8.2. From Theorem 4, m, > 2m, * Vr, t, (Mi)' 2 M i . From Theorem 6, m, > 2m, Vr, t , an overflow from M' always finds its corresponding page in MJ. An overflow from M i is caused by a reference to M . An overflow from M l also implies that there is an overflow from Mr'. Suppose the overflow page from Mi is Pd. Also suppose P,' E W t , i.e. Pd s f Vt. We s h d show that this leads to a contradiction. The overflow page from Mr' is eitherpi, OrP;, (r # 0). If Pi, P,' is overflowed from Mi, Theorem 6 is violated since Pf, and P,' overflow at the same time, so Pi, will not find its corresponding page in MJ. If P;a 4 Pd is overflowed from M,", Theorem 4 is violated since after the overflow handling, there exists a page Ph, P,' in M' (since P,/ E Wt); but P,' is no longer in MJ. Q.E.D.
LEMMA 8.3. If there is no overflow from either MJ or M" then Vr, t, Vt, and V; have the same reverse ordering.
Two stacks S and SJ are in the same reverse ordering, S' g S', if rS'(k) = rSJ(k) for 1 5 k 5 min( 1 S' I , I SJ I ), where rS denotes the stack obtained from S by reversing its ordering. By convention, S g SJ i f S' = 0 or SJ = 0.
PROOF OF LEMMA 8.3 To facilitate the proof, we introduce the following definitions. (1) The orderedparent stuck (S ' ) , of the stack S' is the stack of parent pages
corresponding to, and in the same ordering as, the pages in the reduced stack s' of S'. Formally, (S') , a s' and (S ' ) lS S'.
(2) Define a new binary operator, concatenation (II), between two stacks, S' and S2, to produce a new stack S as follows:
S'(k) for k = 1,2, . . . , IS' I ,
S2(k) f o r k = I S ' ) + l , ...,{I S')+IS21}. S = S' I( S2, where S ( k ) =
(3) Define a new binary operator, ordered difference (L), between a stack S' and a set T to produce a new stack S as follows:
S = S' 2 T, where S(k) = S'( j k )
such that j o = 0, j k is the minimum j k > such that s ' ( j k ) fl T = 0. Intuitively, S is obtained from S' by taking away those elements of S' which are also in T.
f o r k = 1 , 2 ,..., ( ~ S ' ~ - ~ S ' ~ T ~ ) ,
Figure 11 illustrates the LRU ordering of all level i pages ever referenced up to time t . Since there is no overflow from either Mi or Mf', the length of this LRU stack is less than or equal to min(mj: y). By the definition of V;, VI = ( Yt)' 0 (SF)'. But (S?)' = (S:)' 11 ((Xt)' 2 (St ) ); hence,
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems * 365
vt = ((XN 0 (Sty) 11 ((( YI)’ 2 (X,)’) 2 (s:)J) = ((XI)’ 2 (St‘)’) 11 ( ( YOJ 0 ((Sty u (Xt)’)) = ((XI)’ 2 (F3,i)J) 11 v;.
Thus the two stacks are in the same reverse ordering. Q.E.D. LEMMA 8.4. Vr, t , (a) Mi’ 2 Mi, and (b ) Vt and V; are either in the same
reverse ordering or the last element of V: is not an element of Vt. PROOF OF LEMMA 8.4. (a) and (b) are true for any time before there is any
overflow from either Mj or M’j. (a) is true because any page ever referenced is in level j; so a page found in Mi is also found in MI’. (b) is true because of the result from Lemma 8.3.
Assume that (a) and (b) are true for t. Consider the next reference at t + 1. Suppose this reference does not produce any overflow from either Mi or M’J; then (a) still holds because Mij 2 M i and M;‘ 2 M: (see Theorem 7). (b) still holds because overflows from Mi and M’J are taken from the end of stacks Vt and K, respectively, and since there is no overflow from level j , (b)’s validity is not disturbed. Suppose this reference does produce overflow(s) from level j .
Case 1. Overflow from M’j; no overflow from MJ: This cannot happen since overflow from M‘J implies reference to M which in turn implies overflow from MJ also.
Case 2. Overflow from M’; no overflow from M‘J: 1. Suppose the last element in V; is not an element of Vt. Then starting from
the end of Vi, if we eliminate those elements not in Vt, the two stacks will be in the same reverse ordering. This follows from Lemma 8.3 and is illustrated in Figure 12. Thus we see that overflow from M’, i.e. overflowing the last page of Vt, will not violate (a) since this page is still in V;. (b) is still preserved since the last page in V ; is still not in Vt.
2. Suppose Vi and Vt are in the same reverse ordering. Then overflowing the
S; 21 Most --
I Least recently referenced =$ x t y t
r ecen tI y r e fere nced
S’;
Fig. 11
Fig. 12
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

366 - C-Y. Lam and S. E. Madnick
last page of Vt does not violate (a) and results in the last page of V{ not in Vt. Case 3. Overflow from MI and overflow from M I :
1. Suppose the last element in VI is not in Vc. Referring to the diagram in Case 2, we see that the result of overflowing the last elementof V; and the last element of V, does not violate (a) and still preserves the condition that the last element of V: is not in Vt.
2. Suppose K and Vt are in the same reverse ordering. Then overflowing the last elements of VI and Vt leaves K and Vc still in the same reverse ordering. (a) is not violated since the same page is overflowed from M" and MJ. Q.E.D.
PROOF OF THEOREM 8. M" 1 M' for the same reasons as those used in Theorem 7. From Lemma 8.4 M f J 2 MJ. Hence
(Mi u ( M i ) ' ) (MI' u (MY)'). Q.E.D.
4. CONCLUSIONS
We have developed a model of a data storage hierarchy system specifically designed for very large databases. This data storage hierarchy makes use of different page sizes across storage levels and maintains multiple copies of the same information in the hierarchy.
Four algorithms obtained from natural extensions to the LRU algorithm are studied in detail, and key properties of these algorithms that affect performance and reliability of the data storage hierarchy are derived.
It is found that for the LOCAL-LRU algorithms, no choice of sizes for the storage levels can guarantee that a lower storage level always contains all the information in the higher storage levels. For the GLOBAL-LRU algorithms, by choosing appropriate sizes for the storage levels, we can (1) ensure the above inclusion property to hold at all times, (2) guarantee that no extra page references to lower storage levels are generated as a result of handling overflows, and (3) guarantee that no multilevel paging anomaly can exist.
Several areas of further study emerge from this investigation. These include the study of store-behind algorithms [la] and the study of extensions to other known storage management algorithms. We hope that this study motivates further work in the area of generalized data storage hierarchy systems for very large databases.
ACKNOWLEDGMENT
The authors would like to thank Mike Abraham, Sid Huff, and Ken Yip for reviewing an earlier version of this paper, and the referees for their editorial comments.
REFERENCES 1. ARORA, S.R., AND CALLO, A. Optimal sizing, loading and re-loading in a multi-level memory
hierarchy system. Proc. AFIPS 1971 SJCC, Vol. 38, AFIPS Press, Montvale, N.J., pp. 337-344. 2. BELADY, L.A. A study of replacement algorithms for a virtual-storage computer. IBM Syst. J. 5,
3. BELADY, L.A., NELSON, R.A., AND SHEDLER, C.S. An anomaly in space-time characteristics of
4. CHEN, P.P.S. Optimal file allocation in multi-level storage systems. Proc. AFIPS 1973 NCC, Vol.
2 (1966), 78-101.
certain programs running in a paging machine. Cornrn. ACM 12,6 (June 1969), 349-353.
42, AFIPS Press, Montvale, N.J., pp. 277-282. ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.

Properties of Storage Hierarchy Systems 367
5. CONTI, C.J. Concepts for buffer storage. IEEE Computer Group News, March 1969,6-13. 6. DENNING, P.J. Virtual memory. Computg. Surveys 2.3 (Sept. 1970). 153-189. 7. FRANASZEK, P.A., AND BENNETT, B.T. Adaptive variation of the transfer unit in a storage
8. FRANKLIN, M.A., GRAHAM, G.S., AND GUPTA, R.K. Anomalies with variable partition paging
9. GREENBERG, B.S., AND WEBBER, S.H. MULTICS multilevel paging hierarchy. LEEE INTER-
10. HATFIELD, D.J. Experiments on page size, program access patterns, and virtual memory. ZBM J.
11. HATFIELD, D.J., AND GERALD, J. Program restructuring for virtual memory. ZBM Syst. J. 20, 3
12. HSIAO, D.K., AND MADNICK, S.E. Data base machine architecture in the context of information technology evolution. Proc. Very Large Data Base Conf., Tokyo, Japan, Oct. 1977, pp. 63-84.
13. JOHNSON, C. IBM 3850-Mass storage system. IEEE INTERCON, Session 20/2, New York, April 8-10,1975.
14. JOHNSON, J. Progam restructuring for virtual memory systems. M.I.T. Project MAC TR-148, M.I.T., Cambridge, Mass., Mar. 1975.
15. LAM, C.Y., AND MADNICK, S.E. INFOPLEX data base computer architecture-concepts and directions. Working Paper Sloan School of Management, No. 1046-79, M.I.T., Cambridge, Mass., 1979.
16. LUM, V.Y., SENKO, M.E., WANG, C.P., AND LING, H. A cost oriented algorithm for data set allocation in storage hierarchies. Comrn. ACM 28,6 (June 1975), 318-322.
17. MADNICK, S.E. Storage hierarchy systems. M.I.T. Project MAC TR-105, M.I.T., Cambridge, Mass., 1973.
18. MADNICK, S.E. INFOPLEX-hierarchical decomposition of a large information management system using a microprocessor complex. Proc. AFIPS 1975 NCC, Vol. 44, AFIPS Press, Montvale,
19. MADNICK, S.E. Design of a general hierarchical storage system. IEEE INTERCON, Session 20/
20. MADNICK, S.E. The INFOPLEX database computer: Concepts and directions. Proc. IEEE
21. MATTSON, R.L., GECSEI, J., SLUTZ, D.R., AND TRAIGER, I.L. Evalulation techniques for storage
22. RAMAMOORTHY, C.V., AND CHANDY, K.M. Optimization of memory hierarchies in multipro-
hierarchy. IBM J. Res. and Deuelop. 22,4 (March 1978), 405-412.
algorithms. Comm. ACM 22,3 (March 1978), 232-236.
CON, Session 20/3, New York, April 8-10, 1975.
Res. and Deuelop. 16, 1 (Jan. 1972), 58-66.
(1971), 168-192.
N.J., DP, 581-586.
1, New York, April 6-10, 1975.
Comptr. Conf., Feb. 26,1979, pp. 168-176.
hierarchies. ZBMSyst. J. 9, 2 (1970), 78-117.
grammed systems. J. ACM 17,3 (July 1970), 426-445.
Received December 1978; revised April 1979
ACM Transactions on Database Systems, Vol. 4, No. 3, September 1979.