presented by mohammed alharbi mohammed aleisabakri awaji causing incoherencies parallel sorting...
TRANSCRIPT

PRESENTED
BY MOHAMMED ALHARBI MOHAMMED ALEISA BAKRI AWAJI
Causing IncoherenciesParallel sorting algorithms and
study cache behaviors L1 and L2 on Multi-Core Architecture
Instructor Prof. Gita Alaghband

Outlines
Motivation Our implementation in detailsContributionsExperimentsEvaluationRelated workConclusion Challenges What did we learn ?

Motivation
Our motivation in this project is to cause incoherence by simulate three sorting algorithms(bubble sort, Quick sort, insertion sort) :
but, the big question is :Why would we want to cause incoherencies ?Coherence is needed to meet an architectural assumption
held by the software designer. The bad program design identified by this project demonstrates what happens when the coherence assumption is ignored.
As we know, when we use multi-core on processor effectively , that might cause coherence problems.
We need to learn how the Architecture reacts with the shared data when using multi-core processor.

Motivation(Important Questions)
How would we use the sorting algorithms in such details to demonstrate our project?
The sorting algorithms simply provide the necessary traces and overlapping reads and writes to cause coherence issues.
Why are we choosing sorting Algorithms instead of applications?Many applications use sorting algorithms of various kinds. A sorting algorithm can be an entire application (utility). Sorting algorithms provide a clear area of coherence issues when executed in parallel on the same data.

Motivation(Important Questions)
When presenting the sorting algorithms as sequential algorithms ? why are they related to cache and multicore architecture?
Sorting algorithms are frequently executed on multicore architectures and make heavy use of caches. The algorithms, again, are simply to provide functional traces that result in coherence issues.
Why are we choosing these sorting algorithms ?They are commonly known and applied and provide opportunities to examine incoherence.
How will we count the miss and hit ?Misses were counted as compulsory (never had the data to begin with), conflict (fighting same slot in direct-mapped architecture), and, in a way, coherence (in the form of updates that invalidate blocks). A hit can either be a read hit or a write hit.

Our Implementation in details
Simulating three sorting algorithms to study:
Causing Incoherence in L1 cache by applying coherences (Invalidate policy) with write through policy or write back policy
For measuring; read hit , write hit , coherence miss, conflict miss, compulsory miss Sorting Algorithms (bubble sort, Quick sort, insertion sort)
Input long data array for example:
7 3 2 1 5 4 6

Our Implementation in details
Simulating two different sorting algorithmsFor example (bobble sort vs. Quick sort) in
parallel on two cores with same array using (write through policy) with (invalidation policy).
L2 is sharing.Showing in figures the fighting on the same
data between both.

Our Implementation in details
Bus snooper
Core 1
L1
Core 2
L1
L2
Bubble sort
RAM
Quick sort
For example: causing incoherence (write through policy) in case of invalidation
Running two different algorithms In the same time with same array
Updating with Write through policy 7 3 7 3
searchswap

Our Implementation in details
Bus snooper
Core 1
L1
Core 2
L1
L2
Bubble sort
RAM
Quick sort
Sending
broadcast
to
update data in
other cores
Or request
to
invalid data
For example: causing incoherence (write through policy) ) in case of invalidation
Updating with Write through policy 7 33 7

Our Implementation in details
Bus snooper
Core 1
L1
Core 2
L1
L2
Bubble sort
RAM
Quick sort
Sending
broadcast
to
update data in
other cores
Or request
to
invalid data
For example: causing incoherence (write through policy) ) in case of invalidation
Updating with Write through policy 3 73 7

Our Implementation in details
Bus snooper
Core 1
L1
Core 2
L1
L2
Bubble sort
RAM
Quick sort
Sending
broadcast
to
update data in
other cores
Or request
to
invalid data
For example: causing incoherence (write through policy) in case invalidation
Running two different algorithms In the same time With the same data
Updating with Write through policy

Analysis(Scenario of Invalidation with write through )
For example: we apply bubble sort algorithm on core1 and Quick sort algorithm on core 2.
The array will be placed first in Main memory Then it sends all array that is inside two black from main memory to L2
cache and then each L1 cache has the same block. For example : In first (data access time), Quick sort on core 2 is
searching while bubble sort algorithm on core1 is swapping that means it wants to write, so core1 updates the value of all array in L2 cache and then main memory by using write through policy.
After that core1 sends request as broadcast on the bus snoopy to invalidation the same data on another core.
Hence the core 2 read miss the data , so it needs to update its data from L2.
That means cache coherence problem happens since each data access occurs. Two algorithms have fighting data on the same array that causes (duplicate data, losing data or wrong sort and flashing copies).

Contribution
Bubble sort algorithmQuick sort AlgorithmInsertion sort AlgorithmTrace

Contribution
Bubble Sort : compares the numbers in pairs from left to right
exchanging when necessary. the first number is compared to the second and as it is larger they are exchanged.

Contribution
Bubble Sort

Contribution
Quick Sort : Given an array of n elements (e.g., integers):If array only contains one element, returnElse
pick one element to use as pivot. Partition elements into two sub-arrays:
Elements less than or equal to pivot Elements greater than pivot
Quick sort two sub-arrays Return results

Contribution
Quick Sort :

Contribution
Insertion Sort :

Our Experiments
Simulating Parallel different sorting algorithms on two cores with the same data array to study the behavior of cache.
Case 0: Bubble sort vs. Insertion sortCase 1: Bubble sort vs. Quick sort Case 2: Quick sort vs. insertion sort

Our Millstones
Cases Implementation Caches Polices
Polices of Coherences
1 Bubble sort vs. Quick sort
Write through Invalidation Done
2 Insertion sort vs. Bubble sort
Write through Invalidation Done
3 Quick vs. Insertion sort Write through Invalidation Done
4 Insertion sort vs. Bubble sort Write back Invalidation Still
5 Bubble sort vs. Quick sort
Write back Invalidation Still

Our Experiments
In our experiment we studied the higher and lower levels cache behaviors
We measured the Hits and Misses rate in the Cache.
These measurements are appeared by incoherence that occurred as a result of applying invalidation policy.

Our Experiments (Parameters)
We used the same parameters on all cases
The input data: the same array• Coherence policy: Invalidate• Cache size: 64 byte• Block size: 32 byte• Numbers of cores: 2

Our Experiments
The data type: one dimension array with size of 64 bytes.
The Trace file is generated by the code .
The Bubble Sort trace file size= 126 KB. The Insertion Sort trace file size= 62 KB. The Quick Sort trace file size= 23 KB
0x00000003 1 50x00000003 0 5

Our Experiments (result)
3- Measuring Coherence misses rate for all cases on 2 cores
Coherence Miss = Coherence Write Miss + Coherence Read Miss
CasesCoherence
miss
Bubble sort vs. Insertion sort 1574
Bubble sort vs. Quick sort 352
Quick sort vs. insertion sort 675

Our Experiments(chart)
Measuring Coherence misses rate for all cases on 2 cores
Bubble sort vs. Insertion sort Bubble sort vs. Quick sort Quick sort vs. insertion sort0
200
400
600
800
1000
1200
1400
1600
1800
Coherence misses rate for all cases
Cases
Cohe
ranc
e M
iss

Our Experiments (analysis)
This figure shows the incoherence in our simulator How ??? The incoherence happened because of the
invalidation policy. That happens because of each both algorithms fighting on the
same data As we see in the chart, the coherence misses rate is high in
the first case. Why ? The array of the bubble sort can be helpful or wasteful for
the insertion sort in the same case which increases the data accessed.
The insertion sort behaviors can increase or decrease iteration numbers of algorlthm sorting for the bubble sort because of the wrong sorting that caused by the fighting on the same data.

Our Experiments(result)
3- Measuring Read Coherence misses rate and Write Coherence misses rate for all cases on 2 cores
Read Coherence Misses Write Coherence Missescase 0 944 1352case 1 1736 5204case 2 700 1169

Our Experiments (chart)
Measuring Read Coherence misses rate and Write Coherence misses rate for all cases on 2 cores
Bubble Vs Insertion Bubble Vs Quick Quick Vs Insertion0
1000
2000
3000
4000
5000
6000
944
1736
700
1352
5204
1169
Coherence Read and WriteMisses Rate
Read Coherence Misses Write Coherence Misses
Cases
Cohe
renc
e M
isse
s R
ate

Our Experiments (analysis)
1-This figure shows the write coherence miss and read coherence miss for all cases in details for the previous coherence miss's figure
2- As we can see, write coherence miss is higher than read coherence miss. Why ?
3- Because of the incoherence that was caused by invalidation each algorithm did a lot of swapping
4- That happens because of each both algorithms fighting on the same data

Our Experiment (result)
1- Measuring Miss and Hit Rate with write through for all cases using invalidation
ALL CACES ( HIT/MISS)- WRITE Through
Hit Miss
Bubble Vs Insertion 14909 3151
Bubble Vs Quick 11042 707
Quick Vs Insertion 7136 1353

Our Experiments (Chart)
Measuring Hits and Misses Rate with right through for all cases using invalidation
Bubble Vs Insertion Bubble Vs Quick Quick Vs Insertion0
2000
4000
6000
8000
10000
12000
14000
16000 14909
11042
7136
3151
7071353
Hits and Misses Rate - Write Through
Hit Miss
Cases
Hit a
nd M
iss
Rate

Our Experiments (analysis)
Measuring the Cache performance.The Hit rates in all cases are greater than the Miss
rates. The reason is: the write hit occurs more often; because of
swapping operation.
The higher rate of Hit is showed in the Bubble sort. This algorithm has more 'comparing and swapping' operations
than the other sorting algorithms, and it is not efficient algorithm.

Our Experiments (Result)
2- Measuring Hits and Misses Rate with write through on each core for each case using
invalidation (to show impact of the fighting on the same data on
higher level). Bubble Sort Vs Insertion Sort
Algorithms HITMIS
S
CORE 0 (Bubble Sort)6702 1826
CORE 1 (Insertion Sort)3048 1324
Bubble Sort Vs Quick Sort
Algorithms HIT MISS
CORE 0 (Bubble Sort)
7489 500
CORE 1 (Quick Sort) 1140 454
Quick Sort Vs Insertion Sort
algorithms HIT MISS
CORE 0 (Quick Sort) 7489 952
CORE 1 (Insertion Sort)
1140 400
Case 0 Case 1 Case 2
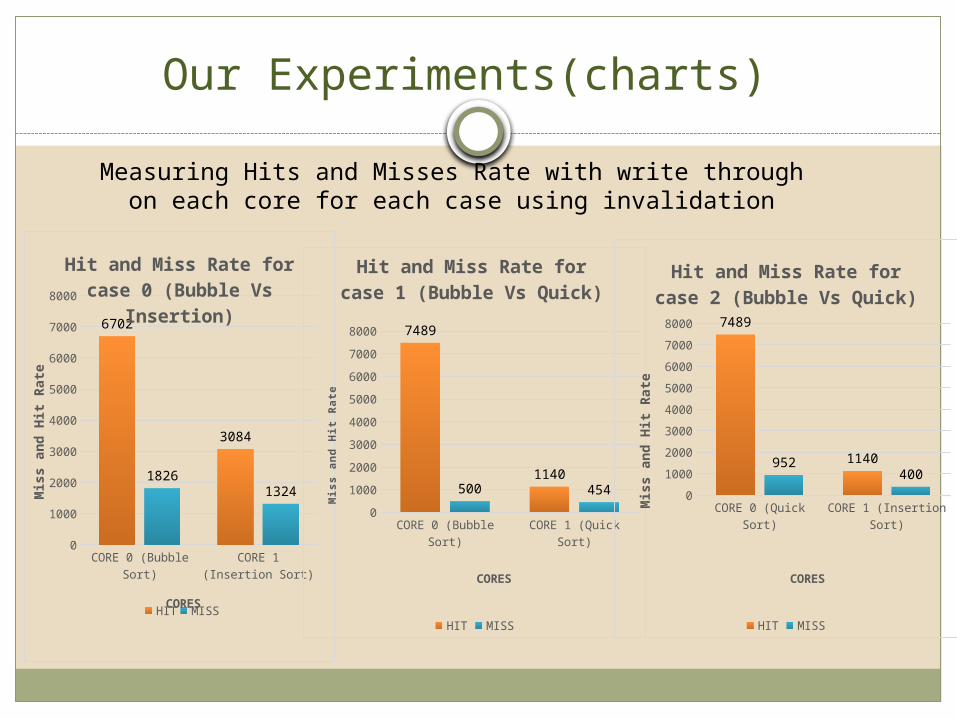
Our Experiments(charts)
Measuring Hits and Misses Rate with write through on each core for each case using invalidation
CORE 0 (Bubble Sort) CORE 1 (Insertion Sort)0
1000
2000
3000
4000
5000
6000
7000
8000
6702
3084
18261324
Hit and Miss Rate for case 0 (Bubble Vs Insertion)
HIT MISS
CORES
Miss
and
Hit
Rate
CORE 0 (Bubble Sort) CORE 1 (Quick Sort)0
1000
2000
3000
4000
5000
6000
7000
8000 7489
1140500 454
Hit and Miss Rate for case 1 (Bubble Vs Quick)
HIT MISS
CORES
Mis
s and
Hit
Rat
e
CORE 0 (Quick Sort) CORE 1 (Insertion Sort)0
1000
2000
3000
4000
5000
6000
7000
8000 7489
1140952400
Hit and Miss Rate for case 2 (Bubble Vs Quick)
HIT MISS
CORES
Miss
and
Hit
Rate

Our Experiments (analysis)
These figures show the high rate of hits and misses in cache for each case.
That happens because of each both algorithms fighting on the same data on the higher level.
The hits rate and misses rate occurred by incoherence that was caused by invalidation.
The array of the first algorithm can be helpful or wasteful for the second algorithm in the same case. It can reduce or increase the data accesses .
The first algorithm behaviors can increase or decrease iteration numbers of sorting for the second algorithm because of the wrong sorting that caused by the fighting on the same data.

Evaluation
In our evaluation we studied the impact of varying parameters on cache optimization :
Different block size with constant cache size To measure the coherence misses. To measure the hits and misses rate in both levels of
cache.
Different cache size with constant block size To measure the conflict misses in both levels of cache .

Evaluation (block size)
Bubble sort
vs. In
serti
on sort
Bubble sort
vs. Q
uick so
rt
Quick so
rt vs.
inse
rtion so
rt0
200
400
600
800
1000
1200
1400
1600
1800
1574
352
675
Cases
Cohe
renc
e M
iss
Coherence misses rate for all cases
Block Size= 32 Cache Size= 64
Bubble Vs Insertion Bubble Vs Quick Quick Vs Insertion0
500
1000
1500
2000
2500
3000
3500
2935
695
911
Cases
Cohe
renc
e M
isse
s Ra
te
Coherence misses rate for all cases
Block Size= 64 Cache Size= 64

Evaluation(analysis)
We increased the parameter value for block size and we constant the cache size with write through for all cases. Why ? to study the impact of causing incoherence
These two figures show the increase of coherence misses since we increased the block size .Why ?
Because we put the same data that means the invalidation applied many times which showed the fighting of data
The block size vector parameter plays the role of impacting on cache.

Evaluation (Block size)
Bubble Vs Insertion Bubble Vs Quick Quick Vs Insertion0
2000
4000
6000
8000
10000
12000
14000
1600014909
11042
7136
3151
7071353
Hits and Misses Rate - Write ThroughBlock Size= 32 Cache Size= 64
Hit Miss
Cases
Hit a
nd M
iss R
ate
Bubble Vs Insertion Bubble Vs Quick Quick Vs Insertion0
2000
4000
6000
8000
10000
12000
14000
1600014909
11042
7136
5872
13921824
Hits and Misses Rate - Write ThroughBlock Size= 64 Cache Size= 64
Hit Miss
Axis Title
Hit a
nd M
iss R
ate

Evaluation(analysis)
We increased the parameters values for block size with constant cache size with write through for all cases. Why ? to study the impact of this change on the cache optimization.
These two figures show the same hits rate and increase the misses since we increased the block size.
Because increasing of the invalidation message

Evaluation (Block size)
CORE 0 (Bubble Sort) CORE 1 (Quick Sort)0
1000
2000
3000
4000
5000
6000
7000
80007489
1140
500 454
Hit and Miss Rate for case 1 (Bubble Sort Vs Quick Sort)
Block Size=32 byte L1 Cache Size= 64 byte
HIT MISS
CORES
Miss
and
Hit
Rate
Bubble Quick0
1000
2000
3000
4000
5000
6000
7000
80007347
940537
854
Hit and Miss Rate for case 1 (Bubble Sort Vs Quick Sort)
Block Size= 64 byte L1 Cache Size= 64 byte
Hit Miss
Cores
Mis
s an
d H
it ra
te

Evaluation (analysis)
We increased the parameters values for block size and we constant the cache size with write through for specific cases. Why ? to study the impact of this change on the higher level optimization.
These two figures show the different of hits and increased misses since we increased the block size .
Here we studied each algorithms behavior as we see hits of the bubble is high because has much more cycles than another which clearly seen in its trace file
The block size vector parameter plays the role of impacting on L1 cache .

Evaluation (Conflict VS. Cache Size)
Bubble sort vs. Inser-tion sort
Bubble sort vs. Quick sort
Quick sort vs. insertion sort
0
200
400
600
800
1000
1200
1400
1600
1800
1572
350
673
Conflict Misses Rate for All caseBlock Size= 32 Cache Size= 64
Cases
Confl
ict M
isses
Rat
e
Bubble sort
vs. In
serti
on sort
Bubble sort
vs. Q
uick so
rt
Quick so
rt vs.
inse
rtion so
rt0
500
1000
1500
2000
2500
1982
710
1260
Conflict Misses Rate for All caseBlock Size= 32 Cache Size= 32
Cases
Confl
ict M
isses
Rat
e

Evaluation (analysis)
These two figures distinguish that when the cache size increased, the conflict miss rate will be decreased. Why ?
In the figure 1, the block size is 32 bytes and when the level 1 cache size is equal to block size , the conflict miss rate will be increased since the cache size fits to only one block
In the figure 2, In this case, the block size is 32 bytes and when the level 1 cache size is twice the block size , the conflict miss rate will be decreased since the cache size fits with number of blocks.

Related Work
the effect of false sharing on parallel algorithm performance occurs depending on many factors such as block size, access pattern and coherence polices[9]
The impact of false sharing to be main vector in performance among the optimal policy that uses traditional coherence policies with the new merge facility[9]

Conclusion
Coherence is needed to meet an architectural assumption held by the software designer.
flashing data extra time prevents data losing and duplicate data and fixes performance of cache.
Invalidation message increases when we changes block size with static cache size.

Future Work
Using Update coherence policy with write through and write back.
Executing algorithms parallel on more cores and counting the false sharing
Using the large data size.

Challenges
Clarifying the project idea to the class. First time to simulate the caches in software.We had a large effort for implementation with
short time.The write bake and the Quick sort algorithm
were too complicated. We read a lot of papers to find a related work
to our project; because of our big area.

What did we learn ?
Reacting of Architecture with software How to pick up small feature to make it big
research. How to make a big project from a specific
feature. The comprehensive questions from labs
assignment, we have learned how to analyze our simulation performance.

References
[1] Prabhu, Gurpur M. "COMPUTER ARCHITECTURETUTORIAL." Computer Architecture Tutorial. 2 Feb. 2003. pubesher. 05 Apr. 2014 http://www.cs.iastate.edu/~prabhu/Tutorial/title.html.[2-12]
[2] Gita Alaghband (2014) CSC 5593 Graduate Computer Architecture Lecture 2[2-12].
[3] Shaaban, Muhammed A. "EECC 550 Winter 2010 Home Page." EECC 550 Winter 2010 Home Page. 27 Nov. 2010. RIT. 07 Apr. 2014.[10-25]. <http://people.rit.edu/meseec/eecc550-winter2010/>.[2-17]
[4] Guanjun Jiang; Du Chen; Binbin Wu; Yi Zhao; Tianzhou Chen; Jingwei Liu, "CMP Thread Assignment Based on Group Sharing L2 Cache," Scalable Computing and Communications; Eighth International Conference on Embedded Computing, 2009. SCALCOM-EMBEDDEDCOM'09. International Conference on, vol., no., pp.298, 303, 25-27 Sept. 2009[13-17]
[5] Kruse and Ryba (2001). Mergesort and Quicksort [42-72]. Retrieved from www.cs.bu.edu/fac/gkollios/cs113/Slides/quicksort.ppt[16-17]
[6] Wei Zhang (2010). Multicore Architecture [ 73-81]. Retrieved from https://www.pdffiller.com/en/project/16525498.htm?form_id=11909329.[2-12]
[7] J. Hennessy, D. Patterson. Computer Architecture: A Quantitative Approach (4th ed.). Morgan Kaufmann, 2011.[2-12]
[8] D. Patterson, J. Hennessy. Computer Organization and Design (5th ed.). Morgan Kaufmann, 2011.[2-12}
[9] W. Bolosky and M. Scott. False sharing and its effect on shared memory performance. In Proceedings of the USENIX Symposium on Experiences with Distributed and Multiprocessor Systems (SEDMS IV), San Diego, CA, September 1993.