model-based clustering reveals vitamin d dependent multi-centrality hubs in a network of...
TRANSCRIPT

RESEARCH ARTICLE Open Access
Model-based clustering reveals vitamin Ddependent multi-centrality hubs in a network ofvitamin-related proteinsThanh-Phuong Nguyen1, Marco Scotti1*, Melissa J Morine1 and Corrado Priami1,2
Abstract
Background: Nutritional systems biology offers the potential for comprehensive predictions that account for allmetabolic changes with the intricate biological organization and the multitudinous interactions between thecellular proteins. Protein-protein interaction (PPI) networks can be used for an integrative description of molecularprocesses. Although widely adopted in nutritional systems biology, these networks typically encompass a singlecategory of functional interaction (i.e., metabolic, regulatory or signaling) or nutrient. Incorporating multiplenutrients and functional interaction categories under an integrated framework represents an informative approachfor gaining system level insight on nutrient metabolism.
Results: We constructed a multi-level PPI network starting from the interactions of 200 vitamin-related proteins. Itsfinal size was 1,657 proteins, with 2,700 interactions. To characterize the role of the proteins we computed 6centrality indices and applied model-based clustering. We detected a subgroup of 22 proteins that were highlycentral and significantly related to vitamin D. Immune system and cancer-related processes were stronglyrepresented among these proteins. Clustering of the centralities revealed a degree of redundancy among theindices; a repeated analysis using subsets of the centralities performed well in identifying the original set of 22most central proteins.
Conclusions: Hierarchical and model-based clustering revealed multi-centrality hubs in a vitamin PPI network andredundancies among the centrality indices. Vitamin D-related proteins were strongly represented among networkhubs, highlighting the pervasive effects of this nutrient. Our integrated approach to network construction identifiedpromiscuous transcription factors, cytokines and enzymes - primarily related to immune system and cancerprocesses - representing potential gatekeepers linking vitamin intake to disease.
BackgroundNutritional systems biology is an emerging field that aimsto characterize the molecular link between diet andhealth in an integrated fashion [1]. Interactome models,in particular protein-protein interaction (PPI) networks,are fundamental to nutritional systems biology in provid-ing an abstraction of the complex relationships betweenmolecular components - ranging from nutrients andtheir derivatives to diet-sensitive transcription factors. Todate, the majority of network-based studies in nutritionalsystems biology have focused on a single interaction
paradigm - i.e., metabolic, signaling or regulatory. How-ever a systems biology-oriented approach should incor-porate multiple parallel cellular processes [2]. In the caseof nutritional systems biology, this approach entails inte-grated analysis of nutrient metabolism along with nutri-ent-mediated activation of gene expression and signalingcascades.Vitamins are an appealing dietary component to be stu-
died under such an integrated framework, as they com-prise a heterogeneous group of organic compounds thataffect a wide range of metabolic, signaling and regulatoryprocesses. For example, vitamin B12 acts as a cofactor fora number of isomerases and methyltransferases [3],whereas vitamin C and E have well-studied antioxidantfunction [4]. Vitamin D serves a hormone-like function,
* Correspondence: [email protected] Microsoft Research - University of Trento Centre for Computational andSystems Biology (COSBI), Piazza Manifattura 1, 38068 Rovereto (Trento), ItalyFull list of author information is available at the end of the article
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
© 2011 Nguyen et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative CommonsAttribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction inany medium, provided the original work is properly cited.

affecting gene transcription through activation of thevitamin D receptor [5]. The degree to which the molecu-lar effects of diverse vitamins overlap and intersect hasbeen assessed in a reductionist way in several studies onvitamin synergy [6-8] but has yet to be assessed in a hol-istic, inclusive fashion.An intriguing question in the analysis of biological net-
works is whether topological prominence of a proteinimplies biological importance. Some studies have empha-sized how well-connected hubs seem to be of high func-tional importance [9-11]. Zotenko et. al. found thatessentiality is due to the involvement of hubs in essentialcomplex biological modules, groups of densely connectedproteins with shared biological function that are enrichedin essential proteins [12]. This connection between cen-trality and functional importance is complicated by themultitudinous approaches for measuring these indices[13,14]. del Rio et al. argued that the combination of atleast two centrality measures allows to predict essentialgenes from molecular networks [15]. This perspectiveposes serious concerns on the minimum and optimal setof centralities that are needed to characterize functionalproperties of the network nodes (e.g., proteins, genes).Although redundancy among centralities has been investi-gated in social networks [16], food webs [17] and land-scape networks [18], there is a lack of insight about theircorrelations in biological networks.In this work, we obtained 200 proteins linked to vita-
mins (vitamin proteins, in short) by mining all human pro-tein data published in the Universal Protein Resource(UniProt) database [19]. These proteins span a range ofbiological functions, including metabolic enzymes, signal-ing proteins, nuclear receptors and transcription factors.Based on the initial list of vitamin proteins, we mined allfirst degree neighbors of the vitamin proteins from theInterologous Interaction Database (i2d) [20], resulting inan integrated network of metabolic, signaling and regula-tory proteins and their immediate interactions. We thenestimated 6 centralities, characterizing each protein at thelocal, intermediate and global scale, and applied model-based clustering to identify the high-centrality networkhubs. Furthermore, we assessed the centrality indices todetermine the degree of unique information provided byeach index.
MethodsNetwork constructionWe considered two databases in constructing the network:the Universal Protein Resource and the Interologous Inter-action Database. The UniProt database is the most com-prehensive, high-quality and freely accessible resource ofprotein sequence and functional information. It is com-posed of 525,997 entries - version March 2011. The i2d isan online database of known and predicted mammalian
and eukaryotic protein-protein interactions. It includes482,388 relationships (111,229 human interactions) - ver-sion 1.8. The data under investigation are human-specific.We extracted all human proteins that are related to vita-
mins; all published information was manually checked toidentify its relatedness to vitamins. In the UniProt data-base, vitamin-associated information is found in differenttypes of data such as biological function, processes, refer-ence databases and keywords. For example, proteinQ13111 (chromatin assembly factor 1 subunit A) isdescribed as functionally related to vitamin D. It isinvolved in vitamin D-coupled transcription regulation viaits association with the vitamin D receptor (VDR). Certainspecific keywords in the UniProt database consist of vita-min-related information, but they are not presented expli-citly. Protein Q13085 (AcetylCoA carboxylase 1) isclassified with the functional keyword “Biotin”, a memberof the B complex vitamins essential for fatty acid biosynth-esis and catabolism. It also acts as a growth factor formany cells and its synonyms are vitamin B7, vitamin B8,vitamin H, Coenzyme R, Biopeiderm (see more at http://www.uniprot.org/keywords/KW-0092). Note that weexcluded all proteins that are not yet reviewed by UniProtcurators. With this approach, we obtained a set of 200vitamin-associated proteins (Additional file 1). Directinteractions involving the 200 proteins were extractedfrom the i2d. This search retrieves 6,361 protein-proteininteractions. Some of these interactions are redundant asthey are obtained from different datasets, or predicted byhomologous methods. To increase the confidence in theinteraction dataset, we excluded all the interactionsinferred through homology. The resulting vitamin-relatedPPI network is composed of 1,705 proteins and 2,700interactions. The network is binary (all interactions areunweighted) and undirected. We performed our analyseson the giant component (the connected sub-network thatincludes the majority of the entire network proteins),which contained 1,657 proteins and 2,672 interactions(Additional file 2).
Network analysisTo describe the global properties of the network we mea-sured density (the ratio between the number of interac-tions and the number of possible interactions), clusteringcoefficient (the probability that the adjacent proteins of aprotein are connected), diameter (the length of the longestshortest path between two proteins) and average pathlength (the average number of steps separating all possiblepairs of proteins via shortest paths).We characterized the biological importance of proteins
using indices of topological centrality. Many studiesdemonstrate the presence of strong correlations betweenthe PPI network structure and the functional role of itsprotein constituents [9,13,21]. Since each centrality
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 2 of 12

describes a unique structural feature, reliable predictionsof the biological properties can be achieved by combina-tions of these measures, rather than relying on a singleindex [15]. In this study we analyzed centralities relatedto local (degree and eigenvector scores), intermediate(topological importance up to 1 and 4 steps) and global(betweenness and closeness) scale.Degree (D) quantifies the local topology of each protein,
by summing up the number of its adjacent proteins [22].An alternative measure of local importance is representedby eigenvector scores of network positions (EC) [23].These scores depend on a reciprocal process in which thevalue measured for a protein is proportional to the sum ofthe scores of its neighbors. While degree centrality gives asimple count of the number of interactions of a givennode, eigenvector centrality is based on how influential arethe neighbors, weighting their interactions. In general,highest scores are computed for proteins that are con-nected to many other proteins within large cliques or highdensity clusters.The topological importance (TI) considers the spread of
indirect effects at a meso-scale level [24]. It is based on therelative number of interactions linking a target protein tosurrounding proteins, in comparison to the completearrangement of interactions (direct or indirect) among thesurrounding proteins. This index is derived from the ana-lysis of two-step long, horizontal, and apparent competi-tion interactions in host-parasitoid networks [25]. Whenthe vertex i can be reached from j in m steps, the effect isdefined as rm,ij. In presence of unweighted networks, thesimplest case is with a one-step effect of j on i (m = 1),when the rm,ij effect equals the reciprocal of degree cen-trality (r1,ij = 1/Di, with Di = degree of node i). Indirecteffects are multiplicative and additive. Consider, as anexample, the case of a vertex j connected to i with a cou-ple of pathways passing through k and h. The effect of j oni through k is defined as the product of direct effects: r1,kj·r1,ik. Similarly, the effect of j on i through h is estimatedas r1,hj·r1,ih. To determine the total effect of j on i, via thetwo-step pathways, the additive principle is adopted: r2,ij =r1,kj·r1,ik + r1,hj·r1,ih. The effect generated by i over m-stepsis summarized by �m,i.
ϕm,i =∑
i�=j
rm,ji (1)
TImi quantifies cumulated effects of a single vertex i
on all the others in the network, up to a maximumpathway length of m steps. The sum of effects is nor-malized by the maximum number of steps considered.
TImi =
∑
q∈m
ϕq,i
m=
∑
q∈m
∑
i�=j
rm,ji
m (2)
In this study we measured topological importance fordirect interactions (TI1) and for proteins that lie 4-stepsaway from the target (TI4). We computed the topologi-cal importance up to distances of 1 and 4 steps for fill-ing the gap between local and global centralities. TI1 isa short range extension of the degree, while TI4 providesa measure of the meso-scale effects at a barycentric level(consider that the diameter of the vitamin PPI network -i.e., the longest distance separating two proteins viashortest paths - is 11)Betweenness (B) and closeness (C) are classical indices
borrowed from social network analysis. They define therole of proteins as emerging from the relative positionat the whole network level and are based on the conceptof network paths. Betweenness measures how frequentlythe shortest path connecting every pair of proteins isgoing through a given protein [26]. Closeness of a pro-tein is defined by the inverse of the average length ofthe shortest paths to access all other proteins in the net-work [22]. The larger the value, the more central is theprotein.We computed network centralities using Graph
(Graph, COSBI, The Microsoft Research - University ofTrento Centre for Computational and Systems Biology,http://www.cosbi.eu/index.php/solutions/cosbi-lab/solu-tions-graph) [27] and the igraph package [28]. Networkvisualization was realized using the software Cytoscape[29]. In Figure 1 we depicted a hypothetical network toillustrate the definition of centrality indices.
Statistical analysisSince centralities showed different ranges of variation(e.g., the maximum hypothetical degree of a target pro-tein corresponds to the total number of the other pro-teins, while eigenvector scores are automatically scaledto have a maximum value of one), we made them com-parable by setting the upper limit of each index to one.For identifying the most central proteins we groupedthe nodes through cluster analysis; the composition ofclusters is based on the centrality scores of each protein.Proteins are characterized through 6 indices of centralitywhich portray topological properties from the local levelto the global scale. We adopted a model-based cluster-ing (MBC) procedure using the R package mclust[30-32]. The optimal model and number of clusterswere inferred according to the Bayesian InformationCriterion (BIC) [33,34].We applied the Kolmogorov-Smirnov test to measure
the independence of the network structure from the cur-rent knowledge on vitamins (i.e., by comparing the num-ber of manuscripts published on vitamin proteins to theirdegree distribution), and determining whether the mostcentral proteins (extracted through cluster analysis) sig-nificantly deviate from the initial list of 200 (used as a
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 3 of 12

reference for constructing the PPI network). With thechi-squared test we investigated differences related to (fatvs. water) solubility and involvement into the regulationof transcription. Vitamin associations of proteins in dif-ferent organisms (Homo sapiens, Mus musculus, Sacchar-omyces cerevisiae and Escherichia coli) were comparedwith the Kolmogorov-Smirnov test (alternative hypoth-esis: two-sided). Individual vitamin associations andnumber of published manuscripts were extracted fromthe UniProt database.To identify which centralities provide redundant infor-
mation we compared protein rank orders, based on each
centrality index, by adopting the Goodman-Kruskal’slambda [35]. Correlation coefficients were used to con-struct a dendrogram of similarities between the differentindices. We repeated the same analysis to investigateredundant centralities in the case of null models thatwere assembled using the vitamin PPI network as areference. Finally, we tested the performance of smallersubsets of centralities (composed of 4 indices) to deter-mine whether the same proteins could be identified aswith the full set of centralities.All statistical analyses were performed with R [36].
ResultsThe giant component of the vitamin PPI network iscomposed of 1,657 proteins and 2,672 interactions. Thisnetwork is sparse (density = 0.002), with a number ofinteractions that is very far from the maximal that couldbe attained (clustering coefficient = 0.023). The majorityof the proteins tend to be isolated in many shortbranches with many weakly interacting components.Despite this highly fragmented structure, average pathlength (4.182) and diameter (11) are surprisingly short,indicating that the spread of any information wouldquickly reach all of the system proteins.We classified the proteins on the basis of 6 normal-
ized values of centrality. To this end we applied model-based clustering and, according to BIC, selected theoptimal clustering configuration (i.e., type of Gaussianmodel and number of clusters). From this, we extracteda small set of 22 most central proteins and observed adistribution of vitamin association that substantiallydeviated from that exhibited by the initial list of 200proteins. We then measured Goodman-Kruskal’s lambdato compare protein rank orders obtained with differentcentralities. This analysis highlighted how some central-ity indices provide redundant information (e.g., the rank-ing estimated with degree and betweenness wasoverlapping for more than 92% of the proteins; see therow-B, column-D in Table 1). Finally, we applied ourfindings describing the redundancy between certainindices to investigate whether the group of 22 most cen-tral proteins could be identified with a smaller subset ofcentralities. We observed that different combinations of4 centralities were sufficient to detect the 22 most cen-tral proteins, although the results did not correspondexactly with the outcomes of the original method (i.e.,the 22 proteins were classified in two clusters of largersize).
Model-based clustering and protein rankingFor each protein we computed 6 centralities (see Addi-tional file 3). By assessing centrality at local (D, EC),meso-scale (TI1, TI4) and global (B, C) level we com-piled a comprehensive picture of protein importance.
Figure 1 Centralities of a target protein in a toy model.Illustration of degree (D), eigenvector score (EC), topologicalimportance up to one step (TI1), betweenness (B) and closeness (C).The black protein has three gray neighbors: D = 1+1+1 = 3. Whenthe importance of direct connections is weighted, the black node isranked 2nd (EC = 0.925) since two gray nodes out of three arehighly connected (EC = 1.000 and EC = 0.676). We also know thewhite neighbors of its gray neighbors: TI1 = 1 + 0.25 + 0.33 = 1.58.This latter index defines the relative importance of the targetprotein (in black), in comparison to the “clouds” of (white) proteinsconnected to its direct (gray) neighbors (since it is computed up to1 step, TI1). The relative importance of the black protein at thewhole network level depends on its mediator-role in connectingevery other pair of proteins (B = 19), or is measured in terms ofaverage proximity to the others (C = 0.615). Because of itsbarycentric position, the black node ranks 1st both in terms ofbetweenness and closeness.
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 4 of 12
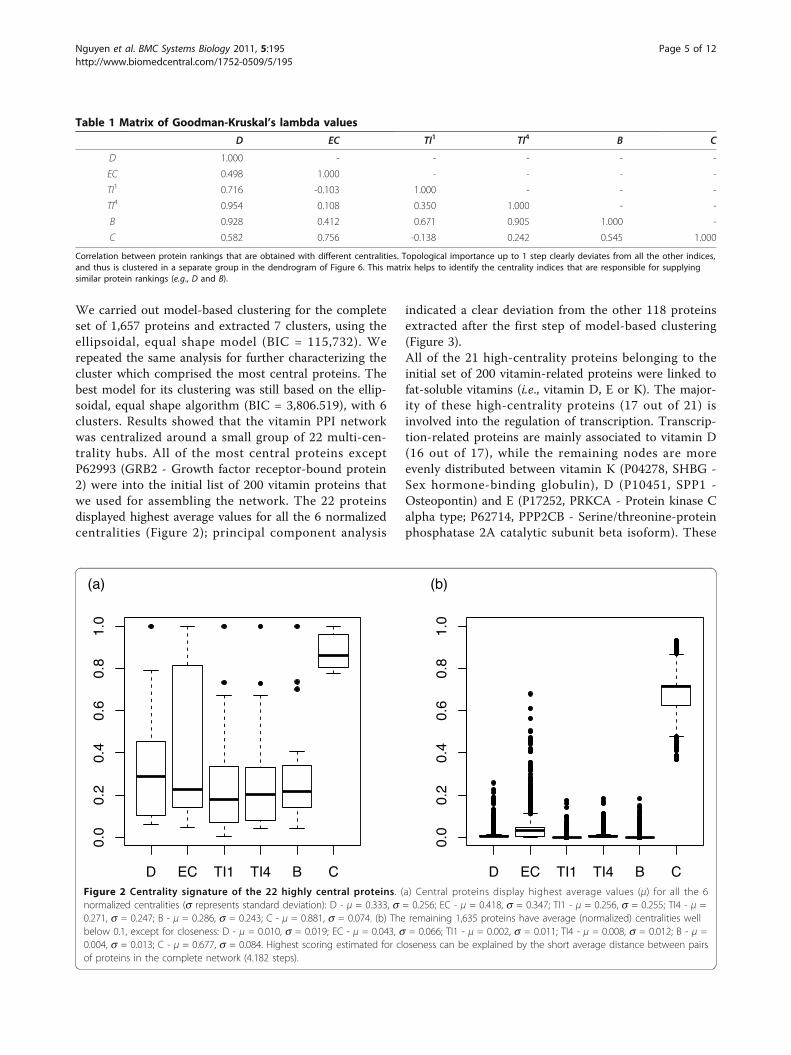
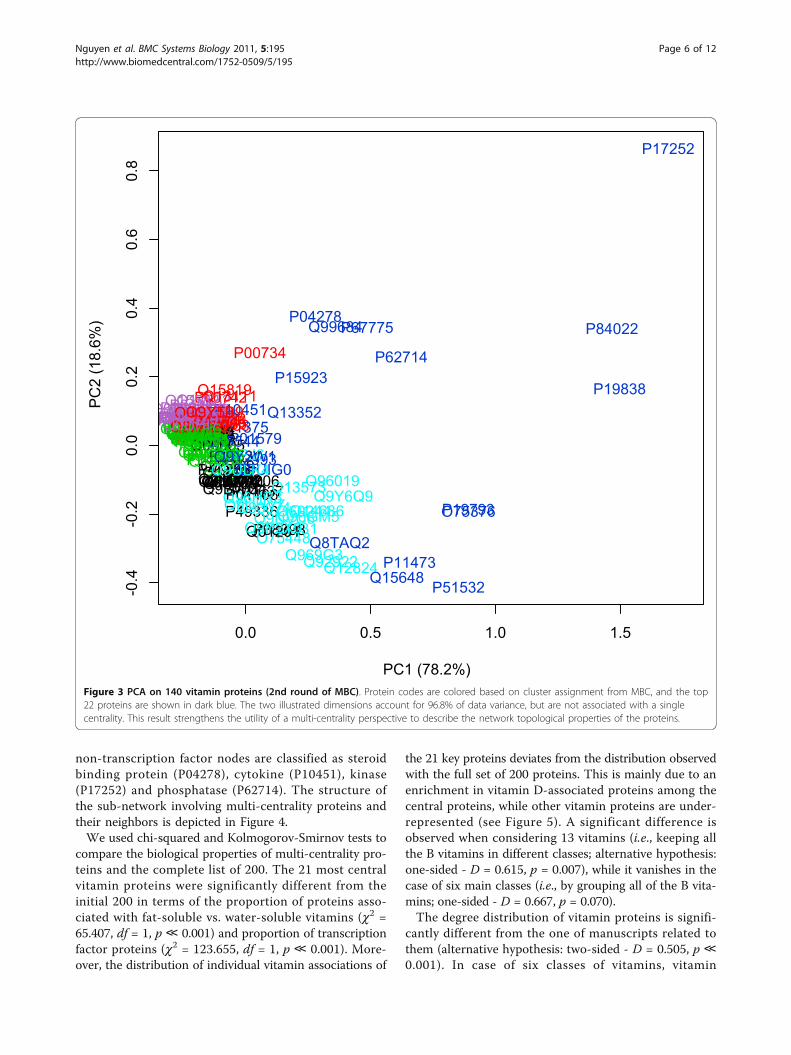
We carried out model-based clustering for the completeset of 1,657 proteins and extracted 7 clusters, using theellipsoidal, equal shape model (BIC = 115,732). Werepeated the same analysis for further characterizing thecluster which comprised the most central proteins. Thebest model for its clustering was still based on the ellip-soidal, equal shape algorithm (BIC = 3,806.519), with 6clusters. Results showed that the vitamin PPI networkwas centralized around a small group of 22 multi-cen-trality hubs. All of the most central proteins exceptP62993 (GRB2 - Growth factor receptor-bound protein2) were into the initial list of 200 vitamin proteins thatwe used for assembling the network. The 22 proteinsdisplayed highest average values for all the 6 normalizedcentralities (Figure 2); principal component analysis
indicated a clear deviation from the other 118 proteinsextracted after the first step of model-based clustering(Figure 3).All of the 21 high-centrality proteins belonging to theinitial set of 200 vitamin-related proteins were linked tofat-soluble vitamins (i.e., vitamin D, E or K). The major-ity of these high-centrality proteins (17 out of 21) isinvolved into the regulation of transcription. Transcrip-tion-related proteins are mainly associated to vitamin D(16 out of 17), while the remaining nodes are moreevenly distributed between vitamin K (P04278, SHBG -Sex hormone-binding globulin), D (P10451, SPP1 -Osteopontin) and E (P17252, PRKCA - Protein kinase Calpha type; P62714, PPP2CB - Serine/threonine-proteinphosphatase 2A catalytic subunit beta isoform). These
Table 1 Matrix of Goodman-Kruskal’s lambda values
D EC TI1 TI4 B C
D 1.000 - - - - -
EC 0.498 1.000 - - - -
TI1 0.716 -0.103 1.000 - - -
TI4 0.954 0.108 0.350 1.000 - -
B 0.928 0.412 0.671 0.905 1.000 -
C 0.582 0.756 -0.138 0.242 0.545 1.000
Correlation between protein rankings that are obtained with different centralities. Topological importance up to 1 step clearly deviates from all the other indices,and thus is clustered in a separate group in the dendrogram of Figure 6. This matrix helps to identify the centrality indices that are responsible for supplyingsimilar protein rankings (e.g., D and B).
D EC TI1 TI4 B C
0.0
0.2
0.4
0.6
0.8
1.0
(a)
D EC TI1 TI4 B C
0.0
0.2
0.4
0.6
0.8
1.0
(b)
Figure 2 Centrality signature of the 22 highly central proteins. (a) Central proteins display highest average values (μ) for all the 6normalized centralities (s represents standard deviation): D - μ = 0.333, s = 0.256; EC - μ = 0.418, s = 0.347; TI1 - μ = 0.256, s = 0.255; TI4 - μ =0.271, s = 0.247; B - μ = 0.286, s = 0.243; C - μ = 0.881, s = 0.074. (b) The remaining 1,635 proteins have average (normalized) centralities wellbelow 0.1, except for closeness: D - μ = 0.010, s = 0.019; EC - μ = 0.043, s = 0.066; TI1 - μ = 0.002, s = 0.011; TI4 - μ = 0.008, s = 0.012; B - μ =0.004, s = 0.013; C - μ = 0.677, s = 0.084. Highest scoring estimated for closeness can be explained by the short average distance between pairsof proteins in the complete network (4.182 steps).
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 5 of 12
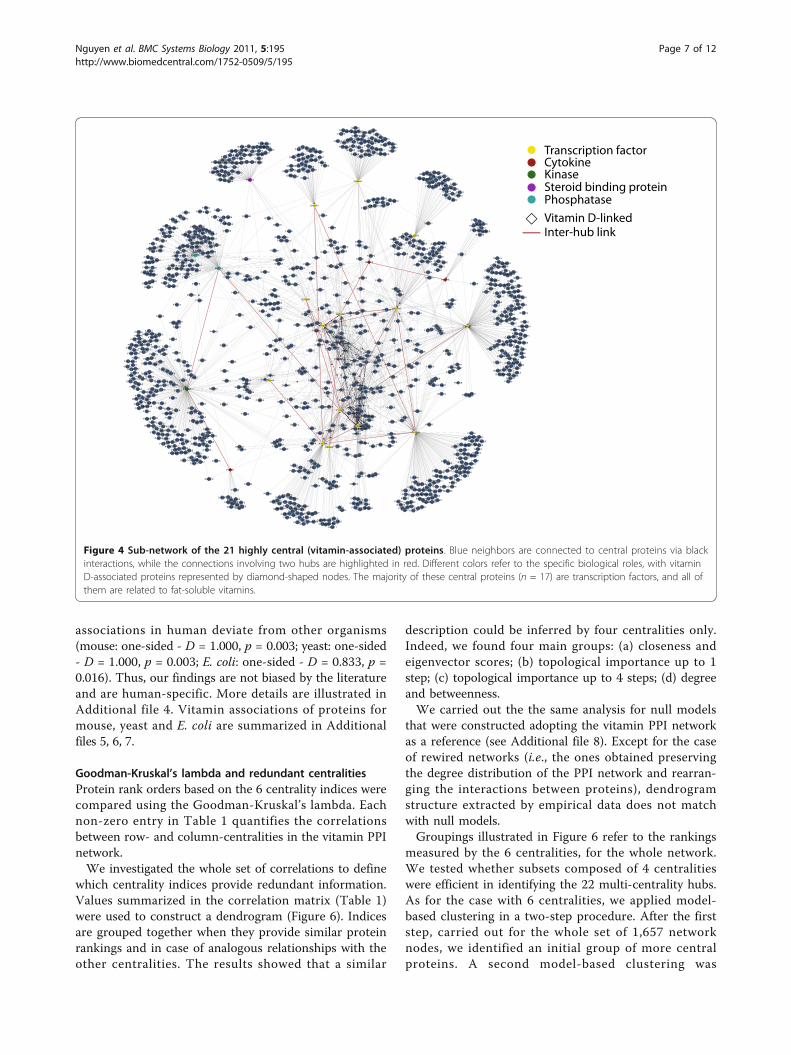
non-transcription factor nodes are classified as steroidbinding protein (P04278), cytokine (P10451), kinase(P17252) and phosphatase (P62714). The structure ofthe sub-network involving multi-centrality proteins andtheir neighbors is depicted in Figure 4.We used chi-squared and Kolmogorov-Smirnov tests to
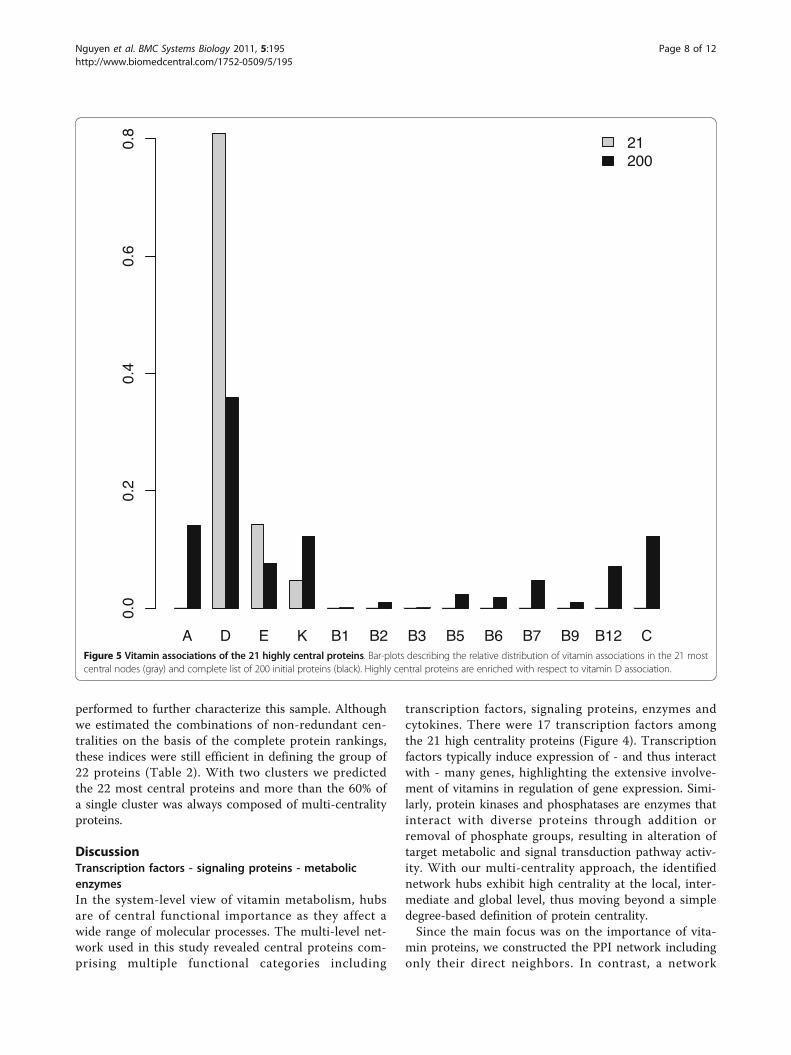
compare the biological properties of multi-centrality pro-teins and the complete list of 200. The 21 most centralvitamin proteins were significantly different from theinitial 200 in terms of the proportion of proteins asso-ciated with fat-soluble vs. water-soluble vitamins (c2 =65.407, df = 1, p ≪ 0.001) and proportion of transcriptionfactor proteins (c2 = 123.655, df = 1, p ≪ 0.001). More-over, the distribution of individual vitamin associations of
the 21 key proteins deviates from the distribution observedwith the full set of 200 proteins. This is mainly due to anenrichment in vitamin D-associated proteins among thecentral proteins, while other vitamin proteins are under-represented (see Figure 5). A significant difference isobserved when considering 13 vitamins (i.e., keeping allthe B vitamins in different classes; alternative hypothesis:one-sided - D = 0.615, p = 0.007), while it vanishes in thecase of six main classes (i.e., by grouping all of the B vita-mins; one-sided - D = 0.667, p = 0.070).The degree distribution of vitamin proteins is signifi-
cantly different from the one of manuscripts related tothem (alternative hypothesis: two-sided - D = 0.505, p ≪0.001). In case of six classes of vitamins, vitamin
0.0 0.5 1.0 1.5
-0.4
-0.2
0.0
0.2
0.4
0.6
0.8
PC1 (78.2%)
PC
2 (1
8.6%
)
A0JLT2
O00268O00622
O14497
O14669O14832
O14939O15198O43852
O60244
O60494O60568
O60885
O75376
O75448
O75469O95402 O96019
P00734
P00740P00742
P01106
P01375P01579
P02753P02768P02774P02818P04003
P04070
P04278
P04637
P04798P05107P05108P05771
P06213P07225
P08670P08684
P08709P09455P09917P10109
P10451
P11473
P12931P14625P14859
P15104P15559
P15923
P16083P16152
P17252
P18074P18084P18206P19021
P19793
P19838
P23743P29373P30101P30281
P35520P35625
P38398
P40337P41180
P41235P46531
P46934P49023
P49336P51531
P51532
P55273
P62714
P62820
P62993P63104
P63167
P67775 P84022
Q00005
Q01201
Q01968Q02809
Q04206
Q08999
Q12824
Q13085
Q13111Q13352
Q13573
Q14164
Q14686
Q14789
Q15544Q15545
Q15582
Q15648
Q15811
Q15819
Q16665
Q8TAQ2
Q92624
Q92922
Q92993
Q93074
Q969G3
Q96GM5Q96HR3
Q96KS0Q96RT1
Q99684
Q99759Q99814
Q9BTT4Q9BWU1
Q9GZT9
Q9H204
Q9H6Z9
Q9NPJ6
Q9NRL2
Q9NRR5
Q9NVC6
Q9NVH6
Q9NWA0Q9NX70
Q9UHI7
Q9UHV7
Q9UIG0Q9ULK4Q9Y230Q9Y2W1
Q9Y2X0
Q9Y5B9
Q9Y6Q9
Figure 3 PCA on 140 vitamin proteins (2nd round of MBC). Protein codes are colored based on cluster assignment from MBC, and the top22 proteins are shown in dark blue. The two illustrated dimensions account for 96.8% of data variance, but are not associated with a singlecentrality. This result strengthens the utility of a multi-centrality perspective to describe the network topological properties of the proteins.
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 6 of 12
associations in human deviate from other organisms(mouse: one-sided - D = 1.000, p = 0.003; yeast: one-sided- D = 1.000, p = 0.003; E. coli: one-sided - D = 0.833, p =0.016). Thus, our findings are not biased by the literatureand are human-specific. More details are illustrated inAdditional file 4. Vitamin associations of proteins formouse, yeast and E. coli are summarized in Additionalfiles 5, 6, 7.
Goodman-Kruskal’s lambda and redundant centralitiesProtein rank orders based on the 6 centrality indices werecompared using the Goodman-Kruskal’s lambda. Eachnon-zero entry in Table 1 quantifies the correlationsbetween row- and column-centralities in the vitamin PPInetwork.We investigated the whole set of correlations to define
which centrality indices provide redundant information.Values summarized in the correlation matrix (Table 1)were used to construct a dendrogram (Figure 6). Indicesare grouped together when they provide similar proteinrankings and in case of analogous relationships with theother centralities. The results showed that a similar
description could be inferred by four centralities only.Indeed, we found four main groups: (a) closeness andeigenvector scores; (b) topological importance up to 1step; (c) topological importance up to 4 steps; (d) degreeand betweenness.We carried out the the same analysis for null models
that were constructed adopting the vitamin PPI networkas a reference (see Additional file 8). Except for the caseof rewired networks (i.e., the ones obtained preservingthe degree distribution of the PPI network and rearran-ging the interactions between proteins), dendrogramstructure extracted by empirical data does not matchwith null models.Groupings illustrated in Figure 6 refer to the rankings
measured by the 6 centralities, for the whole network.We tested whether subsets composed of 4 centralitieswere efficient in identifying the 22 multi-centrality hubs.As for the case with 6 centralities, we applied model-based clustering in a two-step procedure. After the firststep, carried out for the whole set of 1,657 networknodes, we identified an initial group of more centralproteins. A second model-based clustering was
O76024P08559
Q9Y2X7Q6IBL2Q92665
Q8N806
P53365
Q9NWY4
P20248P17661
Q96HD1O00291
Q06323
Q13352
Q8TEY7
O15287
O75665Q9BWH2P05106
Q5UIP0P05091
Q96B36Q14181
Q13330
P18084
Q0VDD7
Q8NE71Q02878
Q9UJ04
Q8IXK0Q9Y4J8Q96PM5 Q9UGP4Q9Y219Q13077
Q14767
Q9NXR7P14373Q9P1U0 Q9HBL0Q9BRK4 O95967Q9HC77
P62760P98160
Q9UJV3
Q92832Q9NVW2
P23142Q9P0K8
P25788Q96T51
Q86YS3
Q6ZW76
Q6X4W1Q7Z406
Q86UL3O75095P07942
Q76G19
Q96SN8Q9NRW3P30626
P13640
O00571Q15772
P07339
Q96QD9 Q9BXW7
P57057
P02795
Q96G75O15523
Q75MZ6
O95295P04733
O75955
O00303
P08123
Q7Z7M0Q99435Q92905
Q9UBX5
Q12805
Q99700Q9UHF1
Q9BUH8P61978 P28799
O00468Q9P2E2Q14457
Q08117Q6NUQ1
O14964Q9NVP4 O95376
P07199
Q6PKC3
Q9BZI7Q9P2H0
Q96P50O94762Q9Y5P4
Q9GZR7
Q8TC92
Q99684O43680
P12830Q99750P15173
O60682P52945P63279
Q16559Q6GYQ0Q7RTS1
Q02535
Q86U70
Q8TE12P11912
Q02363P41970
P50553Q8N436
P55036Q9NQ33
P49137
O00233
O95273
P0C1Z6
P41134
Q99081
Q92858
Q02575Q16644
P01009
P13349O60663
Q15672P49639Q92878
P23409
Q15654
Q92561
P82094
Q05639
P46934
Q68DZ5
Q99816
P19387
Q15811
P51513Q99759
O75381
Q92997
Q9UL17P49711
P14902P05113P38484Q14765P15260O60216
P30101Q92786P18846
Q13761
Q8WXA9
Q13322P30480
P54278P23508
P49368Q5VSL9
Q5FBB7
Q16589
P50990
Q13136Q969G9
Q9NRL3
Q9P2B4
Q9Y570
P62714
P68104 Q8NEZ4
P60981P01023 P63267Q8N6Q3
P17987
Q9UIC8
O75815Q13541
P42229
P49674
P47870
P78396
P10636
Q99259
P51959
Q01955
Q5JPE7
Q96GR7
Q13275O95782
Q5D1E8
Q00796
Q86X54
Q9Y5K2P0C869
P04278
Q15155Q9H939
P41222
Q14582P54819
Q10567Q04941
P0C870
Q6UXB4
Q5HYM0
Q05086
O75352
Q8NCR6
Q9HCK3O14493
P25705
P14618
Q8WZ42
P13798
P15309
Q495Z4
P98164
P29966P28472
P16144
P08034O75112Q8WWG9
Q9UJY1P05783
P41594
P18507
Q8N556
Q15311
P34741
Q07617
Q9NSE2
P63000
P48067
O15399
P17677Q16760
P32927
P21926
P48551
P27635
P05204
Q5JVS0
P62988
P06127
P06746
P18505
Q8N4X5P06239
Q14134
Q13769
P49795
Q8WV44
P30086Q16658
P05114
P57078
Q14344P02686
P42261
P23458
P10721
Q05586
Q13574
O95622
P25098
P22681
P06730
O00161
Q06210
Q13873
P31749P14625
Q9UKL0
P24864Q09028
Q68CP9
Q96J02
P51532
O15360Q15831
Q92922
Q13351
Q12824
Q969G3
P51531
O96019
Q9Y6Q9
Q12962
Q92925P15172
P35869
P04637
P48443Q15532P60510P27708
P05556P51674
Q16539
O95644
P21675
Q15543P62136
Q8IZQ8
P09914Q16666P61296
P27361 Q8NFD5P28482Q04206
P42858
P08100
P56537
Q14315O14641
P20226
P06400
Q02880
O00268
Q15544Q15545
Q00613
P98082
P02545P11171
P11473
Q15596
O75469Q9Y4A5
Q07869
P12004P68400
O14920
P28702
P12931
O15164
Q6P1X5Q15542
Q01844Q10570
P17844
P02768Q16625
P11388
P20700
P35269
Q92804Q16514P49848
Q16594Q5VWG9
P29083
Q03060
Q9BR76Q6R327
P60880
Q92888
P27987
Q9UEY8
P17302
Q15746
P07355
O60479
P05198P19429P14598
P41143
P14151
P04004
Q02952
P20020
Q05209
Q15349
P30679P18206 P61586
P51811
Q5T7P8Q9NQ66
Q12802
O95810
O75689
P29475
Q02383
Q9HCX4Q9BXL7
P06213
P17252
Q06187
O15527
P29353
Q12879
P78352P01891
P41220
O14908
Q14831
P14136
P43405
P45379
O43739
P63244
Q06124
P15311
Q92686
Q96A00
P37288
Q9Y624
O75356
P25445P47872
P15382
Q13224
P23677
P43119
P43005
P26010
P16455Q8IV61
P28329
P31431P47901
Q9H1D0
P04049P05023
Q15121
P20073
P55042
Q8NI35
P42262
Q02156 Q86VB7
Q13976Q13009
P29597Q05513 O60825
Q9ULU4P48058
P15153
P60983P00533
P24588P78543
P61764O00453
P49802P29692
Q99973
Q12772
P05108
P17947
Q13546
P12956P49715
Q96S59
P17542P12980
P62158Q13309
P17676P08047Q13526
P10275Q13573
P04150
Q05516
Q99933Q01201
P03372Q13547Q96GM5
P01106
P38398
P11831
P49336
P10827
Q92769
Q08043
P15976
Q92985P08670
Q9Y3F4
P01243
Q9NYN1
P51587Q8TEW8
Q9NQ69
O00255
Q7LFL8
Q96D21
O75593Q9UEE9Q6DJT9
P49796
Q7Z3E2
Q92963
Q9UJU2Q13484Q9H0M0
Q9NZH6Q05066Q9Y692
Q9UJ37
P54792Q9UKN5P57729
P11802P78451 Q13042
Q9Y5J3
P56915
P35573
P46108
P29590Q15797
P01100
P18075
Q96RN5Q8N2M8P01584
P02778
P51522
Q9UM63P06737P49716
Q8N2W9
Q9UK99
Q9UIS9Q9NPG8P35658
Q9NQ87
Q96RI1
Q14994
Q04771
Q00403
P60520P49913
Q9H0E9
O15111
P62195P28069
P13631
Q99743
P30281
Q15651
Q9HC29
Q9H0R8
Q8N7K6
P48552
P14859Q13569
P29375
Q6P4E1
P42224
O15516P23769A5YKK6
P17096P57727
O75528
Q14469
P07900
Q07021P09429
P11142
Q9NRR5
Q13887O60869
P10451
P24593
Q9NR12
P00734
P17936
P06756Q8WYA6
P43364Q13797
Q9NUQ8
P08648 P16070P08254
Q9NPJ4Q96F24
P35227Q9BZL6
Q5QJE6Q13164
P07711
P49454P10588O95257
P06493P43354
O76064
P61201Q15652
Q96L73
P35637Q3L8U1
Q9H9Y6Q9BV79
Q9H211
Q13112P12882
O00159Q9UIF9
Q9UBC5
Q9Y5J5
P08684
Q9BY60
O60264
P01871
P28370
O15228O43593
P09769P50613
P10589P29372
O00327Q9NZW4
Q12756
Q8TCU4P24522
Q13772 P09086Q15649Q15642
O43765P13686
P09237P19784
P10276
P37231
Q9Y618Q13133
Q92731
P24928
Q6STE5
Q15788O60244
P55055
O75448Q9NVC6
O75586
P10828P49841
Q13315
P41235
Q96G25
Q14789Q9BWU1Q9UHV7
Q93074Q9Y2X0Q13503
A0JLT2Q9H204O95402
Q9NWA0Q9BTT4
Q15466Q9UBK2
P17544
P18847Q14686
Q02556
P25963
Q00653P56524
Q9NYJ8
O15379Q9Y5X4Q03181
P14921
Q15796
Q01094
P41279Q92993
Q8NFZ5
Q99576
Q96RS0
P19838
Q9Y6K9
P42226 Q14690 P35606
Q9UQC1
Q03169
P08238
Q04864
O00629
P61086
O60658 O15226P52294
O00505
P61626
P31689
P34931
Q9BVA1
O00221Q9UBI1
Q8IU54
P16581
Q9P086P36956 P35398P43694
Q00987Q06546 P27348
Q92908
P02741P23771O43513
P01574
P17066
Q8N163
Q9GZQ3
Q9NRL2
P61218Q6P2C8
Q9Y3C7
P20749Q15653Q15650
Q13489
P62241
Q7Z4G1P80188
Q9Y297P11021
Q8N668
Q86VX2Q15306
Q13748
Q9NX08
P52926Q9UN86
O95816
P08107
Q9Y6G5P32519
Q9BYH8Q3ZCQ8
Q9UKB1
P61077
P23396
P52272
P19793
Q9UIG0P22736
Q9NPJ6
P08833P09874
Q04917
Q71SY5
Q9BUE0
Q15648Q9NX70
Q96HR3
Q15528P55345
P07437P15924 P01589
P60660P05362P12270
Q12888P38646
O15519
P12236P19320
Q9H0A8
P10145Q9UHD2
Q9P000
P04350P19105
Q96AZ6
P58546
Q6P4R8
Q8IV45
Q99731Q00610
O14625
P78556P50750
Q9UNE7
Q96T23
P52597
Q15233
P05141O60271Q9NZC4
P35580
P17612
P98170
P78545 Q15025
P12277Q8IUK7
Q8IZI9
Q6UXZ4
P23246
O14788
P04141
P78527
P13500
Q9BUF5
P10599Q86X83
P14316
P35579
Q9P2J3Q9UPQ4
P08621
Q16254
Q03112
Q9GZN2Q08174
Q14213
Q16665P36897
Q9NPF7
P36896
P15692Q86YA9
P06753
P15822Q12778Q96SV5
Q9ULV0P21980Q96DE7
Q9UBH0
Q9HDC5
P61244P98177
P78368
P05388
O14543
Q6ZNA4
Q14974
O00308Q7Z3B3
P46734
P35908
Q9UBW7Q9UMN6
P09466Q8WZ47
Q9H2X6
Q13608
Q96RT1
P11926
Q13445
Q8NDD8O43294
Q547Q3O43318
O60318
Q9Y2K7
P17535
Q9UHL9
P62070
O60315Q8TAI7
Q13485P28749
Q9HCE7
P01375
P84022
P24158
Q9UI36
Q15459Q13501
Q86UC2
Q9H7M9
Q8N6I1
O43524
Q9NRA8
Q99814Q14155Q9H0E3
Q15052
O00231O15105
P30260
Q9HAU4
Q8WXH2P30291Q9Y483
Q9UM13
Q4LDE5P13645Q15583
Q86UD4
O95405
Q15834
Q8N6Y0
O43707
Q06455
P35609
Q86U42
Q13127
P51608
P35232
P35222
P15036
P52630
Q8TAQ2
P16220
P60709
P62993
O14497
Q9UK53
Q86U86Q9H160
Q9NQC7
P19532
P41182
Q92831
Q92793
Q09472
Q15149
Q96ST3
P01579
Q15326
Q6ZRS2
P33076
Q96EP0P43243
Q96EY1
O75376
P10914
P05412
Q9Y265 Q9Y230
Q01196
Q06330
P40763
P15336
P17275P46531
P12757
Q13227
Q9BZK7
Q9UBP5
Q16342
P18615
Q6MZP7Q15393Q14995
Q9UHI6
P12755
P49759
Q15303
Q86T24
P02794
Q14511Q15406O75081P10244
O14646Q92828
P50402Q9UPN9 Q7L2E3 Q96EB6
O75446
P20393P13236O43439
P34932Q96T58Q9UKV0Q86Y13
Q13490
Q9Y6X2
P15923P06454P19876
P45452Q86UQ4
Q9UBX0O75164
P07585Q13443P21810P20333
Q12933Q8N165Q15628P78536
P19438
P09603
Q9ULZ9
Q8WUI4Q93009
Q16576Q9UQL6
Q9NNW7
P54253 O60907P52732
Q13263
P24941
P26367
P32121
O43295
Q9Y2W1
P84243
P13164
P45973
Q9NZZ3
P68431
O00287
Q9NR09
Q66LE6
Q00005
P30153
P35228
Q15287P05452
Q9BS40
O75962
Q9C0C9
P49407
O00213
Q14BN4
Q9Y4K3
Q9NRD5Q96HC4
Q96L34
P62736
Q14164Q9Y5B9
Q9NSI6
P21333O96004
Q14839
Q16548
P27694
Q13422
Q99547
P63261
P61224
P35251Q9NZW5
Q06190Q9Y2U5
Q9GZL7
Q562F6
P42574
Q8IWZ6Q9Y2T4
P01011
P49840
P49757
Q16659P28476
P15056
P24046
O14939 O15530
Q02742P30518
P35368Q03113Q13255
P05107P04279
O60674
P31751
P13639
P50570
O15212Q15464
Q08379
P40145
P25025
O15344
Q9UHV9
P82933
O75688
Q9BSF8
Q07507
O75334
Q9BTW9
Q00534
P14866
Q9Y6E0P42684
Q9H0K1
Q9Y228
Q15257P55072
Q9P289
Q9Y5Z4
Q9H7D0
Q16566
O00506
Q9H0H5Q9BUL8
O76090
Q9NPH2
O43597P49591
O75145P46695
P49023
P24071
P50991
Q13033
P10415
Q8WZ74
O00186P46013Q9UQ80
P60953
P13569P63104
O43526Q06481
Q13393
Q13813
P19397
Q05655
Q9BYN8
Q14738
Q59GV6
Q15645
P23443
P78318P48729
Q6VY07Q9Y2T1
Q9Y5P8
Q96D88
Q16537
O43815
Q9Y243
P62745
Q02241
Q9BRV8
P62495
P63151
Q15172Q9Y3A3
O00238
Q5THK1P30154
O15169
Q15173
P10301
Q99832
O14640
Q99471
Q13362
O95684
P19021
O00764
P41180
P61981
P31314
P21246
P61758
P48643
P22392
Q01105
P40227
P67775
P49815
P01241
P36404
Q86XL3
P78371
P25054
Transcription factorCytokineKinaseSteroid binding proteinPhosphatase
Inter-hub linkVitamin D-linked
Figure 4 Sub-network of the 21 highly central (vitamin-associated) proteins. Blue neighbors are connected to central proteins via blackinteractions, while the connections involving two hubs are highlighted in red. Different colors refer to the specific biological roles, with vitaminD-associated proteins represented by diamond-shaped nodes. The majority of these central proteins (n = 17) are transcription factors, and all ofthem are related to fat-soluble vitamins.
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 7 of 12
performed to further characterize this sample. Althoughwe estimated the combinations of non-redundant cen-tralities on the basis of the complete protein rankings,these indices were still efficient in defining the group of22 proteins (Table 2). With two clusters we predictedthe 22 most central proteins and more than the 60% ofa single cluster was always composed of multi-centralityproteins.
DiscussionTranscription factors - signaling proteins - metabolicenzymesIn the system-level view of vitamin metabolism, hubsare of central functional importance as they affect awide range of molecular processes. The multi-level net-work used in this study revealed central proteins com-prising multiple functional categories including
transcription factors, signaling proteins, enzymes andcytokines. There were 17 transcription factors amongthe 21 high centrality proteins (Figure 4). Transcriptionfactors typically induce expression of - and thus interactwith - many genes, highlighting the extensive involve-ment of vitamins in regulation of gene expression. Simi-larly, protein kinases and phosphatases are enzymes thatinteract with diverse proteins through addition orremoval of phosphate groups, resulting in alteration oftarget metabolic and signal transduction pathway activ-ity. With our multi-centrality approach, the identifiednetwork hubs exhibit high centrality at the local, inter-mediate and global level, thus moving beyond a simpledegree-based definition of protein centrality.Since the main focus was on the importance of vita-
min proteins, we constructed the PPI network includingonly their direct neighbors. In contrast, a network
A D E K B1 B2 B3 B5 B6 B7 B9 B12 C
21200
0.0
0.2
0.4
0.6
0.8
Figure 5 Vitamin associations of the 21 highly central proteins. Bar-plots describing the relative distribution of vitamin associations in the 21 mostcentral nodes (gray) and complete list of 200 initial proteins (black). Highly central proteins are enriched with respect to vitamin D association.
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 8 of 12
obtained with neighbors of neighbors would be less vita-min-specific and applying model-based clustering on itscentrality scores would deviate from the target (i.e.,characterizing the multi-functional backbone formed byvitamin-proteins). We adopted a pseudo ego-networkperspective that well fits with the study of centralities,while networks composed by larger portions of i2dwould require a more systemic view (i.e., the compari-son between structural clusters - based on networktopology - and biological clusters - that depend on thespecific function of proteins; e.g., the proteins involvedinto the folate biosynthesis should be grouped together).
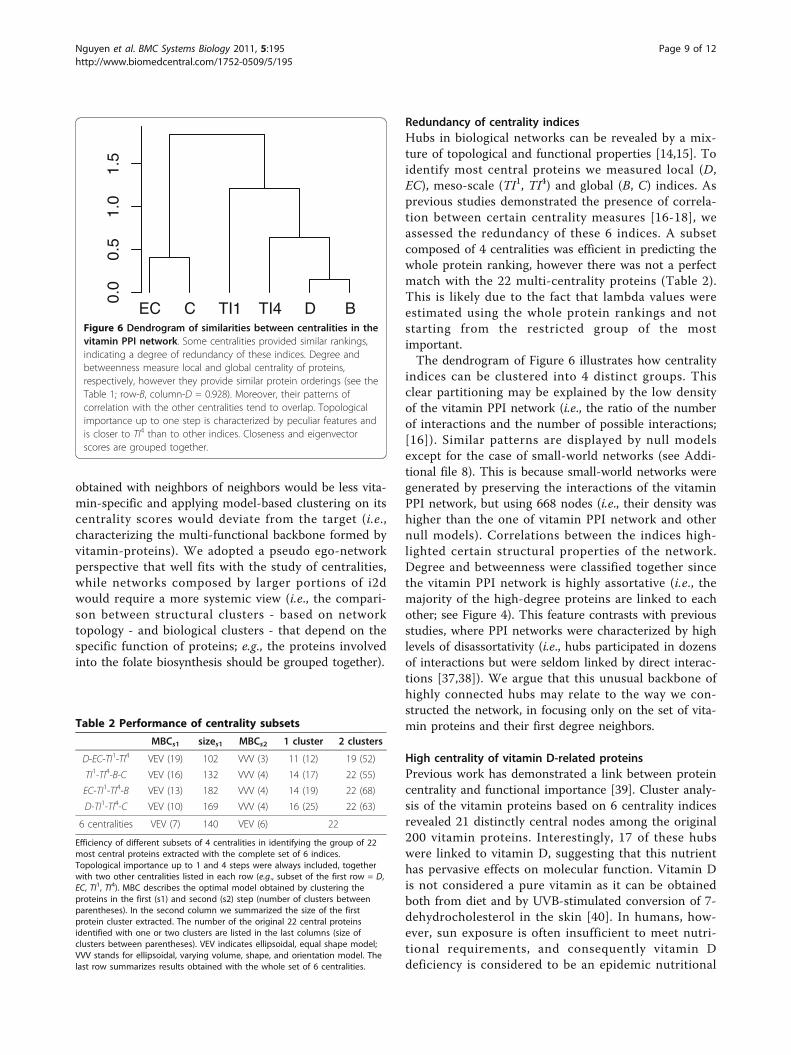
Redundancy of centrality indicesHubs in biological networks can be revealed by a mix-ture of topological and functional properties [14,15]. Toidentify most central proteins we measured local (D,EC), meso-scale (TI1, TI4) and global (B, C) indices. Asprevious studies demonstrated the presence of correla-tion between certain centrality measures [16-18], weassessed the redundancy of these 6 indices. A subsetcomposed of 4 centralities was efficient in predicting thewhole protein ranking, however there was not a perfectmatch with the 22 multi-centrality proteins (Table 2).This is likely due to the fact that lambda values wereestimated using the whole protein rankings and notstarting from the restricted group of the mostimportant.The dendrogram of Figure 6 illustrates how centrality
indices can be clustered into 4 distinct groups. Thisclear partitioning may be explained by the low densityof the vitamin PPI network (i.e., the ratio of the numberof interactions and the number of possible interactions;[16]). Similar patterns are displayed by null modelsexcept for the case of small-world networks (see Addi-tional file 8). This is because small-world networks weregenerated by preserving the interactions of the vitaminPPI network, but using 668 nodes (i.e., their density washigher than the one of vitamin PPI network and othernull models). Correlations between the indices high-lighted certain structural properties of the network.Degree and betweenness were classified together sincethe vitamin PPI network is highly assortative (i.e., themajority of the high-degree proteins are linked to eachother; see Figure 4). This feature contrasts with previousstudies, where PPI networks were characterized by highlevels of disassortativity (i.e., hubs participated in dozensof interactions but were seldom linked by direct interac-tions [37,38]). We argue that this unusual backbone ofhighly connected hubs may relate to the way we con-structed the network, in focusing only on the set of vita-min proteins and their first degree neighbors.
High centrality of vitamin D-related proteinsPrevious work has demonstrated a link between proteincentrality and functional importance [39]. Cluster analy-sis of the vitamin proteins based on 6 centrality indicesrevealed 21 distinctly central nodes among the original200 vitamin proteins. Interestingly, 17 of these hubswere linked to vitamin D, suggesting that this nutrienthas pervasive effects on molecular function. Vitamin Dis not considered a pure vitamin as it can be obtainedboth from diet and by UVB-stimulated conversion of 7-dehydrocholesterol in the skin [40]. In humans, how-ever, sun exposure is often insufficient to meet nutri-tional requirements, and consequently vitamin Ddeficiency is considered to be an epidemic nutritional
Table 2 Performance of centrality subsets
MBCs1 sizes1 MBCs2 1 cluster 2 clusters
D-EC-TI1-TI4 VEV (19) 102 VVV (3) 11 (12) 19 (52)
TI1-TI4-B-C VEV (16) 132 VVV (4) 14 (17) 22 (55)
EC-TI1-TI4-B VEV (13) 182 VVV (4) 14 (19) 22 (68)
D-TI1-TI4-C VEV (10) 169 VVV (4) 16 (25) 22 (63)
6 centralities VEV (7) 140 VEV (6) 22
Efficiency of different subsets of 4 centralities in identifying the group of 22most central proteins extracted with the complete set of 6 indices.Topological importance up to 1 and 4 steps were always included, togetherwith two other centralities listed in each row (e.g., subset of the first row = D,EC, TI1, TI4). MBC describes the optimal model obtained by clustering theproteins in the first (s1) and second (s2) step (number of clusters betweenparentheses). In the second column we summarized the size of the firstprotein cluster extracted. The number of the original 22 central proteinsidentified with one or two clusters are listed in the last columns (size ofclusters between parentheses). VEV indicates ellipsoidal, equal shape model;VVV stands for ellipsoidal, varying volume, shape, and orientation model. Thelast row summarizes results obtained with the whole set of 6 centralities.
EC C TI1 TI4 D B
0.0
0.5
1.0
1.5
Figure 6 Dendrogram of similarities between centralities in thevitamin PPI network. Some centralities provided similar rankings,indicating a degree of redundancy of these indices. Degree andbetweenness measure local and global centrality of proteins,respectively, however they provide similar protein orderings (see theTable 1; row-B, column-D = 0.928). Moreover, their patterns ofcorrelation with the other centralities tend to overlap. Topologicalimportance up to one step is characterized by peculiar features andis closer to TI4 than to other indices. Closeness and eigenvectorscores are grouped together.
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 9 of 12

problem [41]. The vitamin D receptor (VDR) is highlyspecific to the vitamin D ligand, and is expressed innearly all human cells and tissues [40]. VDR is amongthe most central nodes in the vitamin PPI, and also dis-plays the property of assortativity through a large num-ber of connections to other multi-centrality hubs in thenetwork. This would be expected to multiply the influ-ence of this protein on activity in the network. Accord-ingly, vitamin D deficiency and/or impairment of thevitamin D receptor is linked to abnormalities in bonedevelopment, hair growth, cell cycle, immune systemfunction, glucose homeostasis and cardiovascular health[40].In addition to pervasive involvement in molecular pro-
cesses, vitamin D is proposed to have ancient origins, withvitamin D usage and VDR being conserved across diversespecies of plants and animals. A common explanation forthis relates to the central function of vitamin D in calciumhomeostasis, an essential function in species ranging fromphytoplankton to higher mammals [42]. The strong con-servation of vitamin D usage and VDR may also explainthe centrality of vitamin D-related proteins, as highly cen-tral proteins show a tendency for stronger evolutionaryconservation than peripheral proteins [43,44].
Functional roles of central proteinsTaken together, 17 of the 21 central proteins in the vita-min PPI formed a connected module of interactors, sug-gesting partially overlapping functional roles of theseproteins. A number of key immune system regulatorswere present in this module, including the cytokinesTNFa and IFNg, the kinase KPCA and the transcriptionfactors SMAD3, MED1, TFE2, NFKB1, RXR and VDR.The majority of these proteins are linked to vitamin D,reflecting the demonstrated molecular evidence of vitaminD intake on immune system function and widespread linkbetween vitamin D deficiency and immune disorders [45].The active form of vitamin D - 1,25-(OH)2D - stimulatesproduction of TNFa in bone marrow cells through bind-ing of a VDR-RXR complex to a response element in theTNFa promoter region [46]. This same complex inhibitsIFNg production through binding to a negative responseelement and interaction with an upstream enhancer ele-ment [47]. In addition to the VDR-RXR complex, uncom-plexed VDR interferes with immune system regulatorsincluding NFKB1, NFAT and AP1 [48-51]. Vitamin D reg-ulation of these critical immune system factors is expectedto have widespread downstream consequences given thehigh centrality of these proteins in the vitamin PPInetwork.In addition to immune system function, a number of
the vitamin PPI network hubs play a role in cell cyclecontrol and cancer progression (NFKB1, KPCA,SMAD3, RXR, VDR, SMCA4, TNFa, TFE2), reflecting
previous findings that cancer-related proteins are morehighly connected than non-cancer-related proteins [52].Epidemiological studies have reported an inverse corre-lation between serum 25(OH)D (the 1,25-(OH)2D pre-cursor metabolite) and colon, breast and ovarian cancer[53]. On a molecular level, vitamin D plays a role incancer progression through inhibition of cell prolifera-tion, angiogenesis and metastasis [54-56]. Among thevitamin PPI network hubs, the RXR transcription factorcontrols cell proliferation through dimerization withVDR and subsequent transcriptional regulation of cell-cycle related genes such as c-myc, c-fos, p21, p27 andhoxa10 [57]. Coordinated activity of these proteins istherefore critical in prevention of cancer onset and pro-gression. Accordingly, a number of studies have demon-strated links between VDR polymorphisms and risk of avariety of cancers including skin, breast, colorectal andprostate cancer [58].
ConclusionThe 22 proteins are multi-centrality hubs that lie inmore densely connected parts of the network (e.g., theyare characterized by highest closeness, a measure whichquantifies the propensity to transmit informationthrough direct or short paths). Moreover, they tend tointeract with each other (i.e., high overlap betweendegree and betweenness; see Table 1 and Figure 6),showing many analogies with the essential proteinsdescribed by Zotenko et al. [12]. By using a multi-cen-trality approach to identifying network hubs, we havedetected vitamin-related proteins that are stronglyembedded in the vitamin PPI network. Given thedemonstrated link between network centrality and func-tional importance, these proteins are expected to havepervasive effects on a range of downstream molecularprocesses, and thus represent potential gatekeepers inthe link between vitamin intake and disease.
Additional material
Additional file 1: This table includes details about the initial list of200 vitamin-related proteins. These proteins were used as a referencefor constructing the vitamin PPI network and are listed in alphabeticalorder. The first two columns indicate UniProtKB accession numbers andUniProtKB/Swiss-Prot entry names, while the third column describesvitamin associations, as extracted from UniProtKB. Number ofpublications related to each protein are shown in the last column(source: UniProt). The 21 most central proteins that pertain to this list arehighlighted in yellow.
Additional file 2: Edgelist summarizing the 2,672 undirectedinteractions between the 1,657 proteins of the giant component.Each line of the edgelist describes an interaction between the proteinsidentified by the column labels protein1 and protein2.
Additional file 3: This table provides the centrality values computedfor the 1,657 proteins of the giant component. Proteins are inalphabetical order and the 22 most central proteins are highlighted inyellow. Centrality indices included are: D = degree; EC = eigenvector
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 10 of 12

score; TI1 = topological importance up to 1 step; TI4 = topologicalimportance up to 4 steps; B = betweenness; C = closeness.
Additional file 4: For the 200 vitamin-related proteins we testedwhether the number of interactions is determined by the numberof publications associated with a given vitamin. We found that thestructure of the PPI network is independent from the literature. We alsoanalyzed patterns of vitamin associations in four organisms, observinghow human differs from mouse, yeast and E. coli.
Additional file 5: Vitamin associations of proteins in mouse (Musmusculus).
Additional file 6: Vitamin associations of proteins in yeast(Saccharomyces cerevisiae).
Additional file 7: Vitamin associations of proteins in Escherichia coli.
Additional file 8: Correlation matrices describing the Goodman-Kruskal’s lambda values for null models of network connectivity.These correlations between the rankings are used to constructdendrograms for each type of null model. Dendrograms illustrate thesimilarities between centralities (i.e., when protein orderings measuredwith two indices are similar, and their relationships with other centralitiesdo not differ, these two indices are grouped into the same cluster).
AcknowledgementsFerenc Jordán, James Kaput and Carolyn Wise are kindly acknowledged forhelpful comments. We are also grateful to Bianca Baldacci for the graphicdesign contribution.
Author details1The Microsoft Research - University of Trento Centre for Computational andSystems Biology (COSBI), Piazza Manifattura 1, 38068 Rovereto (Trento), Italy.2Department of Information Engineering and Computer Science, Universityof Trento, Via Sommarive 14, 38123 Povo (Trento), Italy.
Authors’ contributionsTPN, MS, MM and CP conceived and designed the research. TPN, MS andMM collected and processed the data. TPN, MS, MM and CP wrote thepaper. All authors read and approved the final manuscript.
Received: 4 September 2011 Accepted: 2 December 2011Published: 2 December 2011
References1. van Ommen B, Cavalieri D, Roche HM, Klein UI, Daniel H: The challenges
for molecular nutrition research 4: the “nutritional systems biologylevel”. Genes and Nutrition 2008, 3:107-113.
2. Lee JM, Gianchandani EP, Eddy JA, Papin JA: Dynamic analysis ofintegrated signaling, metabolic, and regulatory networks. PLoSComputational Biology 2008, 4:e1000086.
3. Banerjee R, Ragsdale SW: The many faces of vitamin B12: catalysis bycobalamin-dependent enzymes. Annual Review of Biochemistry 2003,72:209-247.
4. Kojo S, Tanaka K, Tokumaru S: Oxidative stress and vitamins. NipponRinsho 1999, 57:2325-2331.
5. Haussler MR, Haussler CA, Jurutka PW, Thompson PD, Hsieh JC, Remus LS,Selznick SH, Whitfield GK: The vitamin D hormone and its nuclearreceptor: molecular actions and disease states. The Journal ofEndocrinology 1997, 154:S57-S73.
6. Chan SSK, Chen JH, Hwang SM, Wang IJ, Li HJ, Lee RT, Hsieh PCH:Salvianolic acid B-vitamin C synergy in cardiac differentiation fromembryonic stem cells. Biochemical and Biophysical ResearchCommunications 2009, 387:723-728.
7. Chepda T, Cadau M, Lassabliere F, Reynaud E, Perier C, Frey J, Chamson A:Synergy between ascorbate and alpha-tocopherol on fibroblasts inculture. Life Sciences 2001, 69(14):1587-1596.
8. Bolton-Smith C, McMurdo MET, Paterson CR, Mole PA, Harvey JM,Fenton ST, Prynne CJ, Mishra GD, Shearer MJ: Two-year randomizedcontrolled trial of vitamin K1 (phylloquinone) and vitamin D3 plus
calcium on the bone health of older women. Journal of Bone and MineralResearch 2007, 22:509-519.
9. Jeong H, Mason SP, Barabási AL, Oltvai ZN: Lethality and centrality inprotein networks. Nature 2001, 411:41-42.
10. Yu H, Greenbaum D, Xin LH, X Z, Gerstein M: Genomic analysis ofessentiality within protein networks. Trends in Genetics 2004, 20:227-231.
11. Barabási AL, Oltvai ZN: Network biology: understanding the cell’sfunctional organization. Nature Reviews Genetics 2004, 5:101-113.
12. Zotenko E, Mestre J, O’Leary DP, Przytycka TM: Why Do Hubs in the YeastProtein Interaction Network Tend To Be Essential: Reexamining theConnection between the Network Topology and Essentiality. PLoSComputational Biology 2008, 4:e1000140.
13. Lin Wh, Liu Wc, Hwang Mj: Topological and organizational properties ofthe products of house-keeping and tissue-specific genes in protein-protein interaction networks. BMC Systems Biology 2009, 3:32.
14. Vallabhajosyula RR, Chakravarti D, Lutfeali S, Ray A, Raval A: Identifyinghubs in protein interaction networks. PLoS ONE 2009, 4:e5344.
15. del Rio G, Koschützki D, Coello G: How to identify essential genes frommolecular networks? BMC Systems Biology 2009, 3:102.
16. Valente TW, Coronges K, Lakon C, Costenbader E: How Correlated AreNetwork Centrality Measures? Connections 2008, 28:16-26.
17. Bauer B, Jordán F, Podani J: Node centrality indices in food webs: Rankorders versus distributions. Ecological Complexity 2010, 7:471-477.
18. Baranyi G, Saura S, Podani J, Jordán F: Contribution of habitat patches tonetwork connectivity: Redundancy and uniqueness of topologicalindices. Ecological Indicators 2011, 11:1301-1310.
19. Bairoch A, Apweiler R, Wu CH, Barker WC, Boeckmann B, Ferro S,Gasteiger E, Huang H, Lopez R, Magrane M, Martin MJ, Natale DA,O’Donovan C, Redaschi N, Yeh LS: The universal protein resource(UniProt). Nucleic Acids Research 2005, 33:D154-D159.
20. Brown KR, Jurisica I: Online Predicted Human Interaction Database.Bioinformatics 2005, 21:2076-2082.
21. Yook SH, Oltvai ZN, Barabási AL: Functional and topologicalcharacterization of protein interaction networks. Proteomics 2004,4:928-942.
22. Wasserman S, Faust K: Social Network Analysis Cambridge, UK: CambridgeUniversity Press; 1994.
23. Bonacich P: Power and Centrality: A Family of Measures. American Journalof Sociology 1987, 92:1170-1182.
24. Jordán F, Liu WC, Davis A: Topological keystone species: measures ofpositional importance in food webs. Oikos 2006, 112:535-546.
25. Müller CB, Adriaanse ICT, Belshaw R, Godfray HCJ: The structure of anaphid-parasitoid community. Journal of Animal Ecology 1999, 68:346-370.
26. Freeman LC: Centrality in Social Networks: Conceptual Clarification. SocialNetworks 1979, 1:215-239.
27. Valentini R, Jordán F: CoSBiLab Graph: the network analysis module ofCoSBiLab. Environmental Modelling and Software 2010, 25:886-888.
28. Csardi G, Nepusz T: The igraph software package for complex networkresearch. InterJournal 2006 [http://igraph.sf.net], Complex Systems:1695.
29. Shannon P, Markiel A, Ozier O, Baliga NS, Wang JT, Ramage D, Amin N, B S,Ideker T: Cytoscape: A Software Environment for Integrated Models ofBiomolecular Interaction Networks. Genome Research 2003, 13:2498-2504.
30. Fraley C, Raftery AE: MCLUST: Software for Model-based Cluster Analysis.Journal of Classification 1999, 16:297-306.
31. Fraley C, Raftery AE: Enhanced Software for Model-based Clustering,Density Estimation, and Discriminant Analysis: MCLUST. Journal ofClassification 2003, 20:263-286.
32. Fraley C, Raftery AE: Model-based Microarray Image Analysis. R News 2006,6:60-63.
33. Fraley C, Raftery AE: Model-based clustering, discriminant analysis, anddensity estimation. Journal of the American Statistical Association 2002,97:611-631.
34. Fraley C, Raftery AE: Bayesian regularization for normal mixtureestimation and model-based clustering. Journal of Classification 2007,24:155-181.
35. Goodman LA, Kruskal WH: Measures of association for crossclassifications. Journal of the American Statistical Association 1954,49:732-764.
36. R Development Core Team: R: A language and environment for statisticalcomputing. R Foundation for Statistical Computing, Vienna, Austria. 2005[http://www.r-project.org].
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 11 of 12

37. Maslov S, Sneppen K: Specificity and stability in topology of proteinnetworks. Science 2002, 296:910-913.
38. Lin C, Cho YR, Hwang WC, Pei P, Zhang A: Clustering Methods In Protein-Protein Interaction Network. In Knowledge Discovery in Bioinformatics:Techniques, Methods and Application. Edited by: Hu X, Pan Y. John Wiley2006:1-35.
39. He X, Zhang J: Why Do Hubs Tend to Be Essential in Protein Networks?PLoS Genetics 2006, 2:e88.
40. Bouillon R, Carmeliet G, Verlinden L, van Etten E, Verstuyf A, Luderer HF,Lieben L, Mathieu C, Demay M: Vitamin D and human health: lessonsfrom vitamin D receptor null mice. Endocrine Reviews 2008, 29:726-776.
41. MacFarlane GD, Sackrison JL Jr, Body JJ, Ersfeld DL, Fenske JS, Miller AB:Hypovitaminosis D in a normal, apparently healthy urban Europeanpopulation. Journal of Steroid Biochemistry and Molecular Biology 2004, , 89-90: 621-2.
42. Bikle DD: Vitamin D: an ancient hormone. Experimental Dermatology 2011,20:7-13.
43. Kim PM, Korbel JO, Gerstein MB: Positive selection at the protein networkperiphery: evaluation in terms of structural constraints and cellularcontext. Proceedings of the National Academy of Sciences of the UnitedStates of America 2007, 104:20274-20279.
44. Wuchty S: Evolution and topology in the yeast protein interactionnetwork. Genome Research 2004, 14:1310-1314.
45. Bartley J: Vitamin D: emerging roles in infection and immunity. ExpertReview of Anti-infective Therapy 2010, 8:1359-1369.
46. Hakim I, Bar-Shavit Z: Modulation of TNF-alpha expression in bonemarrow macrophages: involvement of vitamin D response element.Journal of Cellular Biochemistry 2003, 88:986-998.
47. Cippitelli M, Santoni A: Vitamin D3: a transcriptional modulator of theinterferon-gamma gene. European Journal of Immunology 1998,28:3017-3030.
48. Towers TL, Staeva TP, Freedman LP: A two-hit mechanism for vitamin D3-mediated transcriptional repression of the granulocyte-macrophagecolony-stimulating factor gene: vitamin D receptor competes for DNAbinding with NFAT1 and stabilizes c-Jun. Molecular and Cellular Biology1999, 19:4191-4199.
49. Komine M, Watabe Y, Shimaoka S, Sato F, Kake K, Nishina H, Ohtsuki M,Nakagawa H, Tamaki K: The action of a novel vitamin D3 analogue, OCT,on immunomodulatory function of keratinocytes and lymphocytes.Archives of Dermatological Research 1999, 291:500-506.
50. Yu XP, Bellido T, Manolagas SC: Down-regulation of NF-kB protein levelsin activated human lymphocytes by 1,25-dihydroxyvitamin D3.Proceedings of the National Academy of Sciences of the United States ofAmerica 1995, 92:10990-10994.
51. Boonstra A, Barrat FJ, Crain C, Heath VL, Savelkoul HF, O’Garra A: 1α,25-Dihydroxyvitamin D3 has a direct effect on naive CD4(+) T cells toenhance the development of Th2 cells. Journal of Immunology 2001,167:4974-4980.
52. Jonsson PF, Bates PA: Global topological features of cancer proteins inthe human interactome. Bioinformatics 2006, 22:2291-2297.
53. Garland CF, Garland FC, Gorham ED, Lipkin M, Newmark H, Mohr SB,Holick MF: The role of vitamin D in cancer prevention. American Journalof Public Health 2006, 96:252-261.
54. Jensen SS, Madsen MW, Lukas J, Binderup L, Bartek J: Inhibitory effects of1α, 25-dihydroxyvitamin D3 on the G1-S phase-controlling machinery.Molecular Endocrinology 2001, 15:1370-1380.
55. Majewski S, Skopinska M, Marczak M, Szmurlo A, Bollag W, Jablonska S:Vitamin D3 is a potent inhibitor of tumor cell-induced angiogenesis.Journal of Investigative Dermatology Symposium Proceedings 1996, 1:97-101.
56. Nakagawa K, Sasaki Y, Kato S, Kubodera N, Okano T: 1α, 25-dihydroxyvitamin D3 inhibits metastasis and angiogenesis in lungcancer. Carcinogenesis 2005, 26:1044-1054.
57. Freedman LP: Transcriptional targets of the vitamin D3 receptor-mediated cell cycle arrest and differentiation. Journal of Nutrition 1999,129:581S-586S.
58. Raimondi S, Johansson H, Maisonneuve P, Gandini S: Review and meta-analysis on vitamin D receptor polymorphisms and cancer risk.Carcinogenesis 2009, 30:1170-1180.
doi:10.1186/1752-0509-5-195Cite this article as: Nguyen et al.: Model-based clustering revealsvitamin D dependent multi-centrality hubs in a network of vitamin-related proteins. BMC Systems Biology 2011 5:195.
Submit your next manuscript to BioMed Centraland take full advantage of:
• Convenient online submission
• Thorough peer review
• No space constraints or color figure charges
• Immediate publication on acceptance
• Inclusion in PubMed, CAS, Scopus and Google Scholar
• Research which is freely available for redistribution
Submit your manuscript at www.biomedcentral.com/submit
Nguyen et al. BMC Systems Biology 2011, 5:195http://www.biomedcentral.com/1752-0509/5/195
Page 12 of 12