lukaszgolab$ - university of waterloolgolab/icde2014_tutorial.pdf ·...
TRANSCRIPT

Data Stream Warehousing
Lukasz Golab [email protected] University of Waterloo
Theodore Johnson [email protected]
AT&T Labs -‐ Research

About Us
• Lukasz Golab – Assistant Professor at U. Waterloo – Previously senior member of research staff at AT&T Labs – Research interests: streaming data, data warehousing, data quality, big data for sustainability
• Ted Johnson – Lead member of research staff at AT&T Labs – AT&T Fellow – Previously Associate Professor at U. Florida – Research interests: streaming data, data warehousing, data quality

About This Tutorial
• Short version last SIGMOD 2013 • This version
– More examples – More technical details
• Slides available online – www.engineering.uwaterloo.ca/~lgolab
• CitaZons at the end

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Big Data
• Every 2 days we create as much informaZon as we did up to 2003 (Eric Schmidt)
• Becoming easier to produce/collect – Sensors, Web, cheap bandwidth
• Becoming easier/cheaper to store – Cheap hard disks, commodity hardware

Five ‘V’s of Big Data • Volume • Velocity • Variety
– Data integraZon • VerificaZon
– Data cleaning • Value
– Data mining

What is Data Stream Warehousing?
• Volume and velocity in one box • Currently handled by separate systems
– Data warehouses or Hadoop/MapReduce for big data
– Data stream management systems for fast data

But first…
• Quick review of big data management and data streaming

Typical Big Data Workflow • Wait for data to arrive • Prepare and load data
– Into HDFS – or into the data warehouse, then index
• Compute the result • Start over

Hadoop New Data
HDFS

Hadoop New Data
HDFS

Hadoop
HDFS
Analysis Job

Hadoop
HDFS
Analysis Job
Map/Reduce

TradiZonal Data Warehousing • Load a unit of data aier it
has been collected. – Many data sources
• Update all materialized views during the load process.
• Massive tables. • Lots of OLAP.
• Data in the warehouse is
consistent. • Data loading is
infrequent.
Monday Tuesday Wednesday
Base Tables
Derived Data products

TradiZonal Data Warehousing • Load a unit of data aier it
has been collected. – Many data sources
• Update all materialized views during the load process.
• Massive tables. • Lots of OLAP.
• Data in the warehouse is
consistent. • Data loading is
infrequent.
Monday Tuesday Wednesday
Base Tables
Derived Data products

TradiZonal Data Warehousing • Load a unit of data aier it
has been collected. – Many data sources
• Update all materialized views during the load process.
• Massive tables. • Lots of OLAP.
• Data in the warehouse is
consistent. • Data loading is
infrequent.
Monday Tuesday Wednesday
Base Tables
Derived Data products
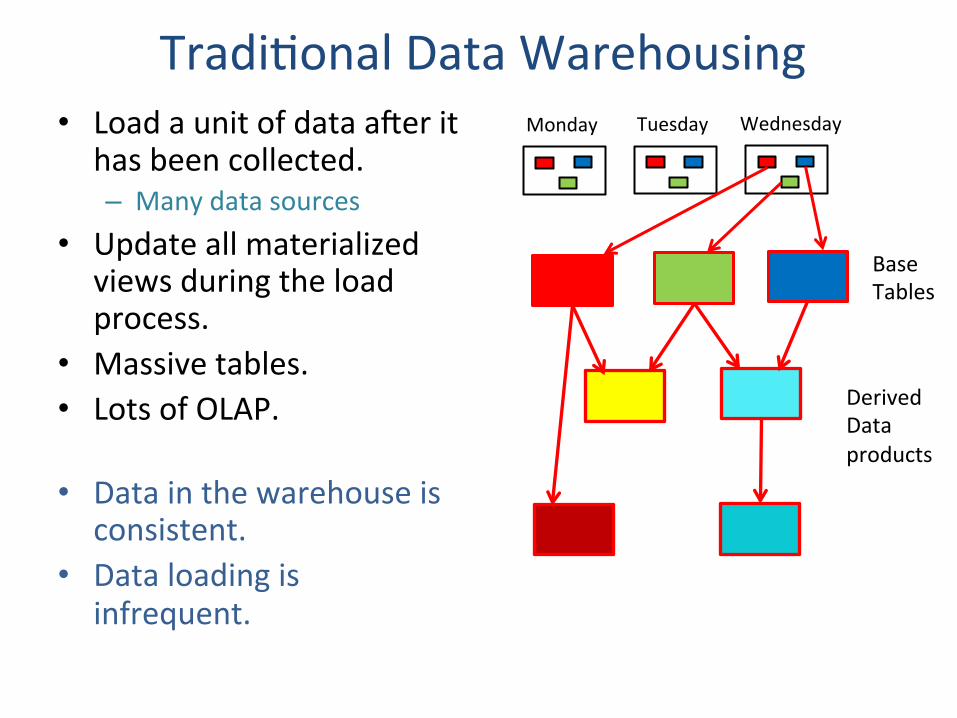
TradiZonal Data Warehousing • Load a unit of data aier it
has been collected. – Many data sources
• Update all materialized views during the load process.
• Massive tables. • Lots of OLAP.
• Data in the warehouse is
consistent. • Data loading is
infrequent.
Monday Tuesday Wednesday
Base Tables
Derived Data products

Typical Stream Data Workflow
• For each item or batch of items – Do some processing – Compute/update results
• ConZnue indefinitely

Fast Data Systems • Data Stream Management Systems (DSMS)
– Borealis, StreamBase, GS Tool, Storm – Simple queries over fast append-‐only data – Results streamed out, usually not stored
• Key-‐value stores have fast transacZonal response, but analyZcs are difficult – Put/get interfaces – Scalability via parZZoning
• AnalyZcs require correlaZon
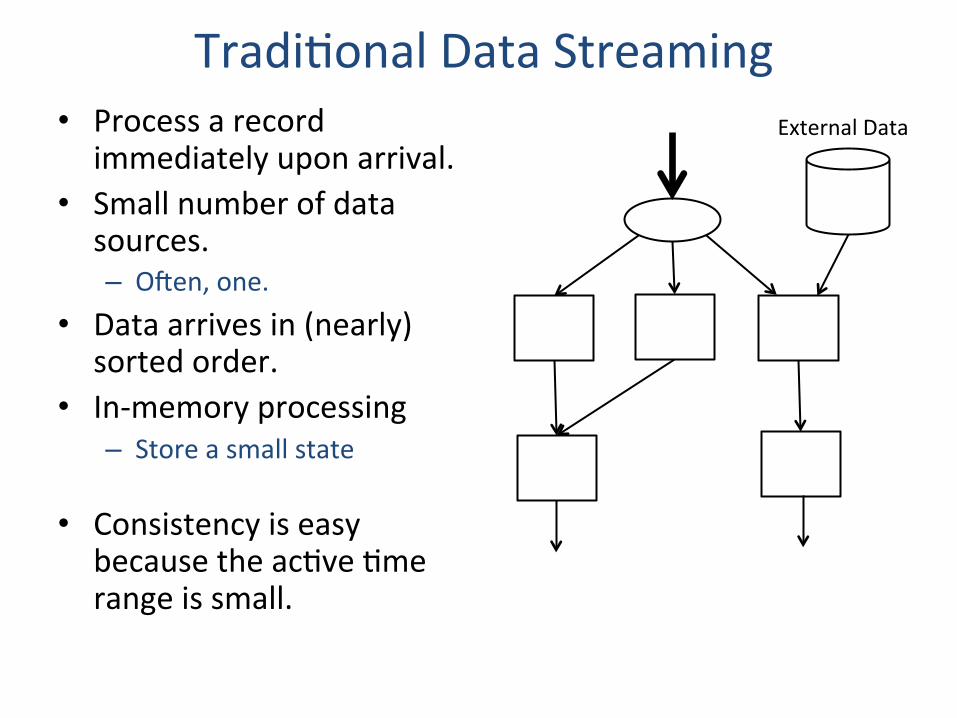
TradiZonal Data Streaming • Process a record
immediately upon arrival. • Small number of data
sources. – Oien, one.
• Data arrives in (nearly) sorted order.
• In-‐memory processing – Store a small state
• Consistency is easy because the acZve Zme range is small.
External Data

TradiZonal Data Streaming • Process a record
immediately upon arrival. • Small number of data
sources. – Oien, one.
• Data arrives in (nearly) sorted order.
• In-‐memory processing – Store a small state
• Consistency is easy because the acZve Zme range is small.
External Data

TradiZonal Data Streaming • Process a record
immediately upon arrival. • Small number of data
sources. – Oien, one.
• Data arrives in (nearly) sorted order.
• In-‐memory processing – Store a small state
• Consistency is easy because the acZve Zme range is small.
External Data

TradiZonal Data Streaming • Process a record
immediately upon arrival. • Small number of data
sources. – Oien, one.
• Data arrives in (nearly) sorted order.
• In-‐memory processing – Store a small state
• Consistency is easy because the acZve Zme range is small.
External Data

TradiZonal Data Streaming • Process a record
immediately upon arrival. • Small number of data
sources. – Oien, one.
• Data arrives in (nearly) sorted order.
• In-‐memory processing – Store a small state
• Consistency is easy because the acZve Zme range is small.
External Data

Hadoop/MapReduce Streaming • E.g., MapUpdate/Muppet
– Stream processing front end – Map stream records to “slates” for updates
• Stored in a key value store – Streaming updates to customer signatures.
Input stream
Stream Processing
Slates Key-‐Value Store

Slates Server 1
Server 2
Server 2
Joe Mary
Bill Hillary
Pete Susan

Slates Server 1
Server 2
Server 2
Joe Mary
Bill Hillary
Pete Susan

In This Tutorial • Big Data Management
– Focus on scalability and deep analyZcs, but high latency
• Fast Data Management – DSMSs have low latency, but limited capability and no persistent storage
• Can/should we do both? – Combine large scale and deep analyZcs with low-‐latency processing
– Data Stream Warehousing

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

ApplicaZons • Monitoring (IP networks, infrastructure, smart transportaZon systems and power grids, RFID, system logs, manufacturing processes)
• TransacZons (stock Zckers, credit card purchases)
• User behavior logs (Web, social media)

Example 1 : Network Monitoring
• Historical analysis – ForecasZng, planning, what-‐if analysis
• Real-‐Zme alerZng and troubleshooZng – High load, too many connecZons, …
• Alerts need historical data – High load during otherwise low-‐usage Zmes
• Alerts lead to troubleshooZng/analyZcs – Automated troubleshooZng needs (current and past) data on which alert was based plus related data

Example 2: Smart Grid
• GeneraZon, transmission & consumpZon data • Historical analysis
– Planning, forecasZng, what-‐if analysis • Real-‐Zme alerZng and troubleshooZng
– Voltage sag, outages, lights lei on • Alerts need historical data
– Typical consumpZon profiles, line temperature trends
• Alerts lead to troubleshooZng/analyZcs

Example 3: Manufacturing • E.g., semiconductor manufacturing
– www.extremetech.com/extreme/155588-‐applied-‐materials-‐designs-‐tools-‐to-‐leverage-‐big-‐data-‐and-‐build-‐beCer-‐chips
• Sensor measurements throughout the process – 141 Tbyte/year for a 14 nm process
• Historical analysis – OpZmizaZon of manufacturing processes
• Real-‐Zme alerZng and troubleshooZng – Fault detecZon

Example 4: Social Media
• Historical analysis: – Related topics
• Real-‐Zme queries: – TwiCer – related query suggesZons
• Real-‐Zme queries need up-‐to-‐date results of related topic analysis

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Requirements • Load data from a mulZtude of streaming sources
– Wide variaZon in data latencies
• Maintain base and derived data – Complex analyZcs through materialized views
• Provide transparent access to both real-‐Zme and historical data
• Gracefully handle late-‐arriving data • Schedule queries and updates in spite of highly variable workloads – Load shedding by dropping data is not an opZon

MulZtude of streaming sources • Data become most useful when you can correlate results from many sources – Hundreds to thousands of disZnct data feeds
• Network monitoring – Correlate twiCer feeds, acZve monitoring streams, and link uZlizaZons to idenZfy trouble spots
• Smart Grid – Correlate smart meter readings, line temperature measurements, and phasor measurement units to proacZvely react to overloads and avoid blackouts

0
2
4
6
8
10
12
0 100000 200000 300000 400000 500000 600000
Num
ber o
f Windo
ws
Time ( seconds)
Late-‐arriving data • Late arriving data is a common problem for streaming systems.
• DSMS : data arrive minutes late
• Stream Warehouse : data can arrive days late
• Load all data and propagate their results in spite of lateness.

Derived Data • Load raw data into base tables
• Derived tables are materialized views for complex analyZcs.
TwiCer feeds
AcZve measure
Link UZl.
Customer complaint
Service alerts
SenZment analysis
Hourly aggregate
Daily aggregate
Raw Streams
Base Tables
Derived Tables

Progress in the Stream
• Data stream warehousing just tries to make progress in the stream.
• If there is more source data, compute an update to the stream table.
Source tables
Derived data product
Update

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Why a new system? • Could have 2 separate systems, but
– Not clear where to divide the systems – Overhead of moving data from one system to the other
– Harder to develop applicaZons • Different SQL/noSQL dialects, etc.
– Historical data provides context for real-‐Zme data – Even tradiZonal analyZcs/reporZng is becoming more real-‐Zme
• Reduce Zme from ingest to insight

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Detailed Example 1: Darkstar • Darkstar project at AT&T Labs -‐ Research • MoZvaZng applicaZon for the Data Depot stream warehouse
system • Data collected:
– Passive and acZve probe measurements, route monitoring, system logs, configuraZon data, customer service Zckets and notes, ….
• For: – Networking research, data mining, alerZng, troubleshooZng, …
• The network is a large and complex system – Not just IPV4.
• Argus – He Yan, Zihui Ge
• Ptolemy – Zihui Ge, Don Caldwell, Bill BeckeC

Darkstar: Mining Vast Amounts of Data
Network
Route monitors (OSPFmon, BGPmon)
Device service monitoring (CIQ, MTANet, STREAM)
AcZve service and connecZvity monitoring
Syslog Config
SNMP Polling (router, link) Neulow
Deep Packet InspecZon (DPI)
Alarms
Tickets
AuthenZcaZon/ logging (tacacs)
Customer feedback – IVR, Zckets, MTS
IP Backhaul Enterprise IP, VPNs
Ethernet Access
IPTV
Layer one
Mobility

ARGUS: DetecZng Service Issues… • Goal: detect and isolate ac#onable anomaly events using comprehensive end-‐to-‐end performance measurements (e.g. GS tool) • SophisZcated anomaly detecZon and heurisZcs • SpaZal localizaZon • Accurately accounts for service performance that varies considerably by Zme-‐of-‐day
and locaZon • Impact: • Reduced detecZon Zme from days to approx. 15 mins for detecZng data service issues
• OperaZonal naZon-‐wide monitoring data service performance for 3G and LTE (TCP retransmission, RTT, throughput from GS Tool)

Market
Sub-‐Market Sub-‐Market …
SGSN SGSN
… RNC RNC
…
SITE SITE …
SITE
SITE
RNC
SITE
SITE
RNC
SITE
SITE RNC
SGSN
SGSN GGSN
GGSN
Collect end-‐to-‐
end Performance
Data
Approach: Mobility LocalizaZon Hierarchy

Case Example: Silent CE Overload CondiZon • ARGUS detected event: 2 Columbia 3G Ericsson SGSN’s impacZng RNC’s in West Virginia, Norfolk, and Richmond • No other indicaZon of issue • Topology highlighted CE used by only impacted SGSNs
• RCA: “6148 48 port 1gig card is limited to a shared 1 gig bus for each set
of 8 gig ports”
ARGUS alarm: clmamdorpn2 (TCP retransmissions) CE UGlizaGon flaJening

ARGUS As A General Capability… Spike in call drop rate on MSC hrndvacxca1 RTT anomalies (SGSN level)
Outage start 5:30 GMT
First Anomaly 5:40 GMT
CTS Ticket Created 08:21 GMT
Social media (TwiCer) NY outage
LA outage
Node metrics, acZve measurements (CBB, IPAG WIPM delay)…
Mobility customer Zckets (Boston market – PE isolaZon)

• 1. At-‐a-‐glance view of network topology and state
• VisualizaZon to summarize important informaZon on network health • Color-‐coded
• Complimentary to ZckeZng system – reporZng issues below “alarming” status
Page 52
hCp://ptolemy.research.aC.com/
Use network visualiza9on and convenient data explora9on to help network operators with network health monitoring and service problem troubleshoo9ng
Ptolemy
hCp://ptolemy.research.aC.com/mobility

Assess damage, idenZfy remaining capacity
Page 53
Loss of many links out of Japan. What’s lei?
Example 1: Japan Earthquake, March 11th 2011

IdenZfy traffic shiis, no congesZon
Page 54
Increase in link load as traffic re-‐routed
Link load
Example 1: Japan Earthquake, March 11th 2011

Detailed example 2: Smart grid
Credit: US Government Accountability Office, www.gao.gov/new.items/d11117.pdf

Smart grid data sources
Credit: www.sas.com/offices/NA/canada/en/news/preleases/energy-‐visual-‐analyZcs.html

Smart grid data sources
Credit: hCp://www.ambientcorp.com/prod-‐nodes/

Smart grid data analyZcs
Credit: www.thegreenitreview.com/2010/12/smart-‐grid-‐data-‐analyZcs-‐market-‐will.html

Smart meter data mining
• ConsumpZon profiles

Solar panel anomaly detecZon
Source: ecinstalls.co.uk/solar-‐panels-‐monitor-‐payback

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Outline • IntroducZon (What?) • MoZvaZon (Why?)
– ApplicaZons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance opZmizaZons – Data stream quality
• Conclusions and open problems (What’s next?)

Recap
• Need to collect and analyze data from diverse streaming sources
• Transparent access to real-‐Zme and historical data
• Could have two separate systems, but…

Data Steam Warehouse Architecture • Common elements (more on this later)
– Temporal data • storage, querying, consistency
– Update propagaZon/workflow • OpZons
– DBMS based – DSMS based – Hadoop/MapReduce

DBMS-‐based Architecture • Use the query processing and storage engine of a DBMS
• Add layers/opZmizaZons for addiZonal services – Temporal parZZoning – Update propagaZon – Refresh scheduling
• Examples: Data Depot/Daytona, Truviso/Postgres, DBStream/Postgres, DataCell/MonetDB

DSMS-‐based Architecture
• Dataflow operators + persistent storage – Enables joins of streaming data and “staZc” tables – Enables storage of streaming results
• Examples: Aurora/Borealis, MillWheel
Output stream
“StaZc” data set
ConnecZon point

Hadoop/MapReduce-‐based Architecture
• 1. Need to reduce latency – Incrementally send mapper output to reducers (Hadoop Online)
– Hashing instead of Sort-‐merge to group by key (INC-‐Hadoop)
• 2. Need to enable incremental computaZon – Save results of previous iteraZons (Spark, Muppet)
– Incremental workflows (Pig/Nova)

Discussion • DBMS-‐based
– Leverage SQL, query opZmizaZon, etc. – But not quite real-‐Zme
• DSMS-‐based – Enable real-‐Zme processing with some context – Must keep up with live data, so limited analyZcs and storage capabiliZes
• Hadoop/MapReduce-‐based – Leverage scale-‐out and fault tolerance – But not quite real-‐Zme – And analyZcs may not be as efficient as in DBMS

Outline • Introduc.on (What?) • Mo.va.on (Why?)
– Applica.ons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance op.miza.ons – Data stream quality
• Conclusions and open problems (What’s next?)

Challenges • Tension between consistency and .meliness.
– Either wait un.l all the data has arrived, or load data that isn’t (yet) consistent.
• Con.nual data loading – Mul.-‐version Concurrency Control (MVCC) – Update propaga.on algorithms which avoid the “missing update” problem.
– Consistency markers in the tables.
• All metadata is temporal – E.g., network topology such as NetDB – Can’t use sta.c snapshot tables for metadata.

Common Elements
• Temporal par..oning • Update propaga.on / workflow • Temporal dimension tables • Temporal consistency management

Temporal Par..oning
• The primary par..oning field is the record .mestamp • Stream data is mostly sorted • Most new data loads into a new par..on
– Avoid rebuilding indices • Simplified data expira.on – roll off oldest par..ons
Time
Data
Index
New data

Derived Data • Streaming analy.cs –
maintain a system of complex materialized views
• Load raw data into base tables
• Derived tables are materialized views for complex analy.cs.
• Push new data through base tables to all dependent tables – Create new par..ons – Update exis.ng
par..ons as needed
Twi\er feeds
Ac.ve measure
Link U.liza.on
Customer complaint
Service alerts
Sen.ment analysis
Hourly aggregate
Daily aggregate
Raw Data
Base Tables
Derived Tables

Update Propaga.on • Basic algorithm: recompute par..ons
– In general, most of the par..on is affected. – Non-‐SQL views : outputs of analyses
• Determine the source par..ons of a Derived par..on • Recompute if a source changes • Eventual Consistency
S
D
update

Update Propaga.on

Update Propaga.on

Update Propaga.on

Update Propaga.on

Update Propaga.on

Update Propaga.on

Temporal Dimension Tables • Most streaming data describes events
– Occurs in a point in .me, or is a measurement during a well-‐defined interval
• Some streaming data defines condi*ons – Proper.es of an en.ty that endures for a .me interval – Temporal dimension tables – .mestamp is valid .me interval.
• Pervasive use – You can’t evaluate an event without knowing about the environment
– Link speeds, cell tower loca.ons, power grid organiza.on • Snapshot tables don’t work
– Late arriving data, recomputa.on, new long-‐term analyses.

Why don’t snapshot tables work? • Temperature (ts,id, degrees)
– Event stream • Loca.on(id,X,Y,Z)
– Store as a snapshot – Update periodically
• Join Temperature and Loca.on to find server room hot spots • Problems
– A set of sensors are moved, but Loca.on isn’t refreshed un.l three hours later
– Sensors are moved, Loca.on is updated within 15 minutes, but a networking problem delays reports of sensor data for 2 hours.
– Some sensors have been repor.ng Celsius instead of Fahrenheit for the last 3 days, so the data has to be reloaded.
• Result – Incorrect diagnosis of hot spots.

Temporal Dimension Table Example SNMP_BytesTransferred
Ip_address Timestamp Bytes_xfered
4.3.2.1 1:05 1,000,000
4.3.2.1 1:10 1,200,000
4.3.2.1 1:15 2,200,000
LinkSpeed Ip_address Tlo Thi Speed
4.3.2.1 12:15 1:15 1,000,000 B/min
4.3.2.1 1:15 -‐ 2,000,000 B/min
Ip_address Timestamp U.liza.on
4.3.2.1 1:05 .2
4.3.2.1 1:10 .24
4.3.2.1 1:15 .22
LinkU.liza.on

Temporal Dimension Tables • Updates
– Snapshots of current status, deltas. • Snapshot windows in StreamInsight • Compute from the stream
– Frames – based on a condi.on of records in a stream – Interval punctua.on
• Maintain temporal dimension tables as a stream – Use par..oning to preserve the locality of updates – Merge par..ons to avoid space blowup.

Outline • Introduc.on (What?) • Mo.va.on (Why?)
– Applica.ons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance op.miza.ons – Data stream quality
• Conclusions and open problems (What’s next?)

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Mul.-‐version Concurrency Control • MVCC allows queries and updates to proceed concurrently – Read isola.on – Long analy.c queries do not block real-‐.me updates
• Single-‐updater MVCC is cheap and easy – Use a directory-‐swap algorithm
• Encourages use of cloud-‐friendly write-‐once files.

Mul.-‐version Concurrency Control
Version 1 Version 2
Directory swap

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Par..on Restructuring • As data ages, its best representa.on changes
– Most recent data : op.mize for fast ingest – Stable data : op.mize for queries – Historical data : minimize storage cost
• Restructure par..ons as the data ages – MVCC allows data maintenance to occur as a non-‐interfering background task
• Move the data as it ages – Ramdisk → SSD → fast disk storage → archival disk storage

Par..on Sizing
• New par..ons should match the update increment
• Problem : par..on explosion – 1 minute par..ons, 1440 per day, 525,600 per year
• Merge par..ons as they age
Time
Data
Index
Indexes op.onal

Data Lifecycle Management • Write-‐op.mized data
– Row-‐oriented, lightly indexed, uncompressed • Read-‐op.mized data
– Highly indexed, lightly compressed, column storage if beneficial
• Transform as a background task when the data becomes stable – Combine with par..on merging
• Aggressive compression for archival data • Implementa.ons in SAP HANA and Ver.ca

Data Lifecycle Management in SAP HANA
• L1 delta -‐> L2 delta -‐> main • L1 delta
– Raw data, row storage, no compression, completely write-‐op.mized (10k-‐100k rows)
• L2 delta – Column storage, bulk updates, dic.onary encoding to save space, but unsorted dic.onary (up to 10million rows)
• Main store – Highest compression, sorted dic.onary, completely read-‐op.mized

Data Lifecycle Management in SAP HANA
• L1 delta -‐> L2 delta is easy – Incremental merge – Can be done onen
• L2 delta -‐> main is harder – L2 delta already read-‐op.mized but larger memory footprint than main
– Incremental merge is difficult – Not done too onen

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Par..on Revisions
• Some data always arrives late • Problem : need to recompute exis.ng par..ons – Disk prefers sequen.al access – Write-‐once files : need to recompute the en.re par..on
• Solu.on: chain updates to the par..on – Value of the par..on is the sum of the primary (anchor) contents plus the updates (revisions).

Par..on Revisions
• Problem: Don’t change old par..ons, but what if data arrives out-‐of-‐order?
• Solu.on: Overflow chains (Truviso)
Time
anchor
revisions
Packet_Stream
Packets

When can we use overflow chains? • Whenever there is a simple and fast way to
– Compute a delta – Add the delta to the main result.
• Examples: – Select/project
• Select/project on the source delta, Union to integrate with the anchor par..on.
– Aggrega.on queries (commuta.ve aggregates) • Subaggrega.on / superaggrega.on
– Outer join on a foreign key • Collect replacement values

• Works with “raw” and derived/aggregated data
• E.g., packet counts:
Data Layout
A: 1000 B: 1500 C: 1750
A:1090 B:1200 C:2000
A:1150 B:2975 C:1450
A:1400 B:1150 C:1925
Time
25
Packet_Stream
Packets
Packet_counts
B:25

Propagate Incremental Updates
Packets
Anchor
Revision 1
Revision 2
Revision 3
Packet_counts
Anchor
Revision 1
Revision 3

Using Revisions • On access, load the anchor and update using the delta par..ons – Select/project : scan all par..ons
– Aggrega.on: load hash table with delta, add to matching anchor records
• Merge anchor and revisions as a par..on restructuring task.
Anchor
Revision 1
Revision 3
Scan
Load subaggregates Hash Table
Merged Records

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Temporal Consistency Management
• Tradi.onal no.on of consistency : a snapshot of the system.
• Doesn’t apply in a stream warehouse – Late-‐arriving data is common – Different data sources have different .me lags and different likelihoods of late data
• Instead, label data by its degree of completeness

0
2
4
6
8
10
12
0 100000 200000 300000 400000 500000 600000
Num
ber o
f Windo
ws
Time ( seconds)
Number of windows per package

Query Stability • How do I know when the data is stable enough to query?
• What is stable enough? – Data will never change – Data won’t change much. – I’ll take whatever is there.

Consistency Levels • Punctua.ons on par..ons that indicate completeness.
• Example (simple) collec.on of consistency levels – Open : The par..on should have some data in it. – Closed : The par..on will not change. – Complete : the par..on will not change, and all data has been received.
• Closed is a guess – WeaklyClosed, StronglyClosed
• Infer at base tables, propagate inferences to materialized views.

Example • Troubleshoo.ng
– Compass_BPS correlates • Compass_BPS_Base : SNMP measurements of bytes-‐per-‐second over a router interface
• NetDB_SPEED : Link speed of an interface
– to provide link u.liza.ons. – Compass_BPS_RAW : Mostly_Closed
Open
Mostly_Closed
Closed
Compass_BPS_Base NetDB_Speed
Compass_BPS
OK for troubleshoo.ng

Examples
• Update Propaga.on – Roll up Compass_BPS into daily aggregates. – All source Compass_BPS data should be Closed to avoid expensive recomputa.ons.

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Workflow Scheduling • Need to limit resource use to avoid thrashing.
– Hundreds of tables to update, limited (CPU, memory, cache, network) resources.
– Exclusive resources: non-‐preemp.ve scheduling. • Ensure that high-‐priority jobs can execute
– Real-‐.me scheduling • Measures of lateness:
– Staleness : difference between current .me and most recent data.
– Tardiness : the difference between a task deadline and task comple.on.
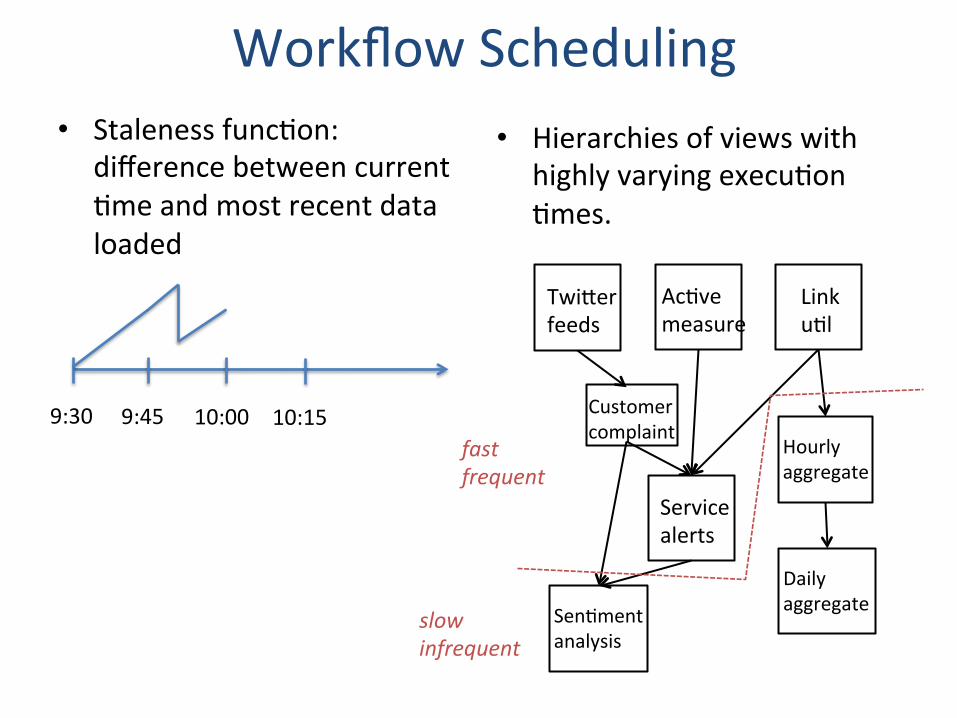
Workflow Scheduling • Staleness func.on:
difference between current .me and most recent data loaded
• Hierarchies of views with highly varying execu.on .mes.
9:30 9:45 10:00 10:15
Twi\er feeds
Ac.ve measure
Link u.l
Customer complaint
Service alerts
Sen.ment analysis
Hourly aggregate
Daily aggregate
fast frequent
slow infrequent

Bounded Tardiness Scheduling • Bound on the maximum tardiness of any task in a task set.
• If update jobs are scheduled regularly, bounded tardiness => bounded staleness
• Most real-‐.me scheduling algorithms have bounded tardiness – EDF, minimum slack, etc. – There can be differences in the tardiness bounds
• Pick a heuris.c that works well – E.g. pick the task that provides the largest marginal reduc.on in staleness.

Track Scheduling • Complica.on: Large differences in task execu.on .me – Update a base table with 1 minute of data vs. compute a daily aggregate.
• Tardiness bounds depend on the largest task execu.on .mes. – Long tasks block short cri.cal tasks.
• Track Scheduling : – par..on tasks by execu.on .me. – Restrict the number of long tasks that can execute concurrently
– Reserve resources for short cri.cal tasks

Transient Overload • Common source of overload : catch-‐up processing. – A feed breaks for a day, then is restored. – The source schema changes, requiring a pause in processing to change update procedures.
– New tables load a long history • Update Chopping
– Break a (temporally) long update into short segments. • Update period adjustment
– Decrease the period of backlogged tables to use up (but not oversubscribe) available resources.

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

DB-‐toaster • Maintain complex
aggregate views over streaming data.
• In-‐memory architecture : all storage is via hash table. – 1TB main memory servers are
inexpensive • Uses novel recursive-‐delta
technique to accelerate maintenance – Collec.on of support views
that can significantly reduce update .me.
Join(R,S,T))
Join(S,T)) Join(R,T)) Join(R,S))
T) S) R)

R-‐Store • Maintain data cubes from OLTP streams using Hbase and MapReduce – Base table stored in Hbase – MapReduce used to periodically materialize a data cube – Use mul.-‐versioning feature of Hbase
• Query is assigned a .mestamp of its entry .me. • Use to find records in Hbase which arrived since last data cube materializa.on but before query arrivel
• Compute incremental update to data cube • Data cube materializa.on allows Hbase compac.on (discard old records).
– Use MapReduce to compute query result from incrementally updated data cube
• Tuesday 10:30 – 12:00 session.

Op.miza.ons
• Mul.-‐version Concurrency Control • Data Layout Op.miza.ons
– Data Aging – Par..on Restructuring
• Par..on Revisions • Temporal Consistency Management • Workflow Scheduling • Real-‐.me View Maintenance • Distributed Data Placement

Distributed Stream Warehousing
• Distribute (and replicate) data and queries across mul.ple servers – Fault tolerance – Parallel processing – But: the data you need may be on different servers
• à data communica.on/shuffling penalty

Data Placement
• OLTP: distribute data such that (most) transac.ons don’t have touch more than one server – i.e., can make local commit decisions
• Minimize the number of distributed transac.ons -‐-‐> hypergraph par..oning to minimize the number of cut hyperedges

Hypergraph Par..oning
• 4 queries/transac.ons – Each is a hyperedge
• 6 tuples, T1 through T6 – Each is a node
• E.g., if T1 and T2 are placed on different servers, Q3 hyperedge is cut à Q3 is a distributed transac.on
T1
T5
Q1
T2 T6
Q2
T4
Q3 T3
Q4

Stream Warehouse Sewng
• Don’t have transac.ons/mul.ple writers • Instead, standing queries/views/workflows over data feeds – Whenever a new batch of data arrives, same workload runs
• Which are onen very data-‐intensive – Have to collect data from mul.ple servers before doing any computa.on

Stream Warehouse Sewng
• Turns out that – Minimize data transfers à (regular) graph par..oning to minimize the weight of the cut edges
– (For a carefully constructed bipar.te graph)

Bipar.te Graph Par..oning
• Queries on the len • Tables on the right Q1
Q2
Q3
Q4
T1
T2
T3
T4
T5
T6

Outline • Introduc.on (What?) • Mo.va.on (Why?)
– Applica.ons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance op.miza.ons – Data stream quality
• Conclusions and open problems (What’s next?)

Data Stream Quality
• New data quality problems – Systema.c errors in machine-‐generated streams – Correlated glitches
• Missing values followed by very large value
– Missing/delayed/future/imprecise/duplicate data • CPU u.liza.on = -‐1 • Counter looparound • Link u.liza.on = 5000% • Failing smart meters -‐> undercount

Integrity Constraints for Data Quality
• Func.onal Dependencies – Postcode -‐> City
• Condi.onal Func.onal Dependencies – Country,Postcode -‐> City but only for Country=Canada
• Inclusion Dependencies • CHECK Constraints

New Integrity Constraints for Streaming Data
• New seman.cs – Order – Data arrival frequency – Conserva.on laws among related streams

62
Examples
● Sequential Dependencies ● Golab, Karloff, Korn, Saha, Srivastava, VLDB
2009
● Conservation Dependencies ● Golab, Karloff, Korn, Saha, Srivastava, ICDE
2012 and TKDE (to appear)

63
Sequen.al Dependencies
● Given an interval g, X àg Y asserts that the distance between two consecu.ve Y values, when sorted on X, is within g
● X à(0,∞) Y means that Y is strictly increasing with X ● e.g., .me à(0,∞) sequence_number ● Viola.ons indicate out-‐of-‐order arrivals ● shipping_date à(0,∞) delivery_date

64
Sequen.al Dependencies
● More complex examples: ● sequence_number à[4,5] .me
● i.e., .me "gaps" between consecu.ve records (sequence numbers) are between 4 and 5
● Can measure QoS of a data feed expected to arrive with some frequency

65
Example 1: IP Network Monitoring
● Network operators collect stats from routers, e.g., number of packets
● Routers store cumula.ve counters that can be queried
● Counters periodically loop around ● and reset aner reboot
● Spurious mesurements ● queried the wrong router?

66
.me à(0,∞) packet_count
time
● [1,10], [11,15] and [17,20] sa.sfy the SD exactly
● [1,11] and [11,20] sa.sfy the SD approximately with one excep.on each

67
.me à(0,∞) packet_count
● Discovered intervals summarize data seman.cs and help iden.fy problems ● Disrup.ons in ordering
● Many short intervals -‐> premature counter rollover?
● Note: may not need 100% confidence ● Helps avoid overfiwng

68
Example 2: IP Network Monitoring
● Audi.ng the polling frequency
● Suppose data collec.ng mechanism configured to probe every 10 sec ● Too onen -‐> unnecessary overhead
● Not onen enough -‐> not enough info for troubleshoo.ng

69
poll_number à[9,11] .me
● [10,90] and [180,240] iden.fy intervals that sa.sfy the SD (almost exactly)
● Can also try, say, poll_number à(20,∞) .me to find periods with long gaps ● [30,60] and [120,200] ● Easier to analyze than a long list of individual viola.ons

70
Examples
● Sequential Dependencies ● Golab, Karloff, Korn, Saha, Srivastava, VLDB
2009
● Conservation Dependencies ● Golab, Karloff, Korn, Saha, Srivastava, ICDE
2012 and TKDE (to appear)

71
Conserva.on Dependencies
● Onen there exist conserva.on laws between related quan..es ● Kirchhoff's law of conserva.on of electricity ● Also holds in road networks (interesec.ons), telecom networks (routers), smart grid, bulidings, etc.
● Viola.ons of conserva.on laws ● Temporary viola.ons due to delays ● Permanent viola.ons due to missing or incorrect measurements

72
Assump.on
● Don‘t have exact correspondence between „incoming“ and „outgoing“ events – Just periodic incoming and outgoing counts
● E.g., SNMP counters, highway sensors, door sensors, transac.ons, etc.
– Otherwise easy to track viola.ons/delays ● E.g., order shipment .mes & delivery .mes

73
Conserva.on Dependencies
50 in, 70 out
65 in, 70 out
65 in, 25 out
50 in, 65 out

74
Example

75
Example
● Persistent viola.on: unmonitored side exit
● Also smaller viola.ons ● Correspond to mee.ngs in the building
● Plus, viola.ons around lunch.me
● Other examples: unmonitored links in IP network monitoring data streams

Outline • Introduc.on (What?) • Mo.va.on (Why?)
– Applica.ons – Requirements – Why yet another data management system? – Detailed examples
• Technical discussion (How?) – System architectures – Common elements – Performance op.miza.ons – Data stream quality
• Conclusions and open problems (What’s next?)

Tidalrace • Tidalrace is a next-‐genera.on stream warehousing system incorpora.ng – Micro-‐batch updates
• Patented update propaga.on algorithm – Deep levels of derived data products – Mul.-‐version concurrency control – Streaming updates to temporal metadata tables
• Patent applica.on pending – Temporal consistency support
• Patent applica.on pending – Anchor/revision op.miza.ons for in-‐the-‐past updates.
• Patent applica.on pending – Data layout op.miza.ons (row vs. column store, …) – Cloud-‐friendly write-‐once files

Tidalrace Architecture
Tidalrace metadata system
MySQL
File system (local, D3FS, HDFS) Data par..ons and indices
Data loading and update propaga.on
Queries Maintenance
Storage Manager (D3SM)

Tidalrace Status • The Tidalrace server is implemented on top of MySQL.
– Backing store database can be replaced. • Base table loading and update propaga.on algorithms. • SQL par.ally implemented.
– Select, project, aggrega.on. – Aggregates speed: 500,000 records/sec per thread.
• Update propaga.on to materialized views defined using the Tidarace SQL.
• Streaming updates to temporal metadata tables. • Materialized views defined by outer join to a temporal metadata
table. • Supports local storage (mul.ple hosts), D3FS, HDFS versions 1 and
2.
• More under development.

Open Problems • Hybrid system architectures and cross-‐system op.miza.ons
• Big and fast analy.cs as a cloud service • Big/fast data mining • Data stream quality/profiling • Complexity management and administra.on of a big/fast data management system

Bibliography

Bibliography: Applica.ons • Networking
– L. Golab, T. Johnson, S. Sen, J. Yates: A Sequence-‐Oriented Stream Warehouse Paradigm for Network Monitoring Applica.ons. PAM 2012: 53-‐63
– C. Kalmanek et al., Darkstar: Using Exploratory Data Mining to Raise the Bar on Network Reliability and Performance, DRCN 2009
– H. Yan, A. Flavel, Z. Ge, A. Gerber, D. Massey, C. Papadopoulos, H. Shah, J. Yates: Argus: End-‐to-‐end service anomaly detec.on and localiza.on from an ISP's point of view. INFOCOM 2012:2756-‐2760
• Smart Grid – S. Ramchurn et al.: Puwng the 'smarts' into the smart grid: a grand challenge for
ar.ficial intelligence. Commun. ACM 55(4): 86-‐97 (2012) • Semiconductor Manufacturing
– www.appliedmaterials.com/technologies/library/techedge-‐prizm – www.extremetech.com/extreme/155588-‐applied-‐materials-‐designs-‐tools-‐to-‐
leverage-‐big-‐data-‐and-‐build-‐be\er-‐chips • Social media
– G. Mishne, et al.: Fast data in the era of big data: Twi\er’s real-‐.me related query sugges.on architecture. SIGMOD 2013: 1147–1158

Bibliography: DBMS-‐based Systems • DataCell: E. Liarou, R. Goncalves, S. Idreos: Exploi.ng the
power of rela.onal databases for efficient stream processing. EDBT 2009: 323-‐334
• Data Depot: L. Golab, T. Johnson, J. S. Seidel, V. Shkapenyuk: Stream warehousing with DataDepot. SIGMOD Conference 2009: 847-‐854
• DBStream: A. Baer et al.: DBStream: an Online Aggrega.on, Filtering and Processing System for Network Traffic Monitoring. TRAC workshop at IWCMC 2014, to appear
• Truviso : S. Krishnamurthy, M. J. Franklin, J. Davis, D. Farina, P. Golovko, A. Li, N. Thombre: Con.nuous analy.cs over discon.nuous streams. SIGMOD 2010:1081-‐1092

Bibliography: DSMS-‐based Systems • D. J. Abadi, D. Carney, U. Çe.ntemel, M. Cherniack, C. Convey, S. Lee, M. Stonebraker, N. Tatbul, S. B. Zdonik: Aurora: a new model and architecture for data stream management. VLDB J. 12(2): 120-‐139 (2003)
• T. Akidau, A. Balikov, et al. MillWheel: Fault-‐tolerant stream processing at internet scale. VLDB 2013: 734–746
• M. Balazinska, Y. C. Kwon, N. Kuchta, D. Lee: Moirae: History-‐Enhanced Monitoring. CIDR 2007: 375-‐386

Bibliography: Distributed Systems • P. Bhato.a, A. Wieder, R. Rodrigues, U. A. Acar, R. Pasquin: Incoop:
MapReduce for incremental computa.ons. SoCC 2011: 7 • T. Condie, N. Conway, P. Alvaro, J. M. Hellerstein, K. Elmeleegy, R.
Sears: MapReduce Online. NSDI 2010: 313-‐328 • W. Lam, L. Liu, S. T. S. Prasad, A. Rajaraman, Z. Vacheri, A. H.i Doan:
Muppet: MapReduce-‐Style Processing of Fast Data. PVLDB 5(12): 1814-‐1825 (2012)
• B. Li, E. Mazur, Y. Diao, A. McGregor, P. J. Shenoy: SCALLA: A Pla�orm for Scalable One-‐Pass Analy.cs Using MapReduce. ACM Trans. Database Syst. 37(4): 27 (2012)
• C. Olston et al.: Nova: con.nuous Pig/Hadoop workflows. SIGMOD Conference 2011: 1081-‐1090
• M. Zaharia et al.: Discre.zed streams: fault-‐tolerant streaming computa.on at scale. SOSP 2013: 423–438

Bibliography
• Late Arriving Data – S. Krishnamurthy et al., Con.nuous analy.cs over discon.nuous
streams, SIGMOD 2010, 1081-‐1092 – J. Li. K.Tune, V. Shkapenyuk, V. Papadimos, T. Johnson, D. Maier, Out-‐
of-‐order processing: a new architecture for high-‐performance stream systems, PVLDB 1(1): 274-‐288 (2008).
– Lukasz Golab, Theodore Johnson: Consistency in a Stream Warehouse. CIDR 2011: 114-‐122

Bibliography • Update Propaga.on / Workflow
– T. Johnson, V. Shkapenyuk: Update Propaga.on in a Streaming Warehouse. SSDBM 2011: 129-‐149
– C. Olston et al. Nova: con.nuous Pig/Hadoop workflows. SIGMOD Conference 2011: 1081-‐1090
• Temporal Dimension Tables – Interval Event Stream Processing, M. Li, M. Mani, E. A. Rundensteiner., D. Wang, T Lin, DEBS 2008
– David Maier, Michael Grossniklaus, Sharmadha Moorthy, Kris.n Tune: Capturing episodes: may the frame be with you. DEBS 2012:1-‐11
– Snapshot windows: h\p://msdn.microson.com/en-‐us/library/ff518550.aspx

Bibliography • MVCC
– D. Quass, J. Widom: On-‐Line Warehouse View Maintenance. SIGMOD Conference 1997: 393-‐404
– V. Sikka, F. Färber, W. Lehner, S. K. Cha, T. Peh, Christof B.: Efficient transac.on processing in SAP HANA database: the end of a column store myth. SIGMOD Conference 2012: 731-‐742
• Data Par..on Transforma.ons – V. Sikka, F. Färber, W. Lehner, S. K. Cha, T. Peh, B. Christof: Efficient transac.on processing in SAP HANA database: the end of a column store myth. SIGMOD Conference 2012: 731-‐742
– A. Lamb, M. Fuller, R. Varadarajan, N. Tran, B. Vandier, L. Doshi, C. Bear: The Ver.ca Analy.c Database: C-‐Store 7 Years Later . PVLDB 5(12): 1790-‐1801 (2012)

Bibliography • DB Toaster
– DBToaster: Higher-‐order Delta Processing for Dynamic, Frequently Fresh Views, Y. Ahmad O. Kennedy, C. Koch, . M. Nikolic, Proc VLDB 2012
– R-‐Store: A Scalable Distributed System for Suppor.ng Real-‐.me Analy.cs, F. Li, T. Oszu, G. Chen, B. C. Ooi, Proc. ICDE 2014.
• Par..on Revisions – S. Krishnamurthy, M. J. Franklin, J. Davis, D. Farina, P. Golovko, A. Li, N.
Thombre: Con.nuous analy.cs over discon.nuous streams. SIGMOD 2010:1081-‐1092
• Temporal Consistency Management – Lukasz Golab, Theodore Johnson: Consistency in a Stream Warehouse.
CIDR 2011:114-‐122 • Bounded Tardiness Scheduling
– H. Leontyev, J. H. Anderson: Generalized tardiness bounds for global mul.processor scheduling. Real-‐Time Systems 44(1-‐3): 26-‐71 (2010)

Bibliography • Stream Warehouse Scheduling
– Lukasz Golab, Theodore Johnson, Vladislav Shkapenyuk: Scalable Scheduling of Updates in Streaming Data Warehouses. IEEE Trans. Knowl. Data Eng. 24(6): 1092-‐1105 (2012)
– S. Guirguis, M. A. Sharaf, P. K. Chrysanthis, A. Labrinidis, K. Pruhs, Adap.ve Scheduling of Web Transac.ons. Proc. 2009 Intl. Conf. on Data Engineering

Bibliography • Distributed Stream Warehousing
– C. Curino, E. Jones, Y. Zhang, S. Madden. Schism: a workload-‐driven approach to database replica.on and par..oning. PVLDB, 3(1-‐2):48-‐57, 2010.
– L. Golab, M. Hadjielenheriou, H. Karloff, B. Saha, Distributed data placement to minimize communica.on costs via graph par..oning, CoRR abs/1312.0285

Bibliography • Data stream quality
– Lukasz Golab, Howard J. Karloff, Flip Korn, Avishek Saha, Divesh Srivastava: Sequen.al Dependencies. PVLDB 2(1): 574-‐585 (2009)
– Lukasz Golab, Howard J. Karloff, Flip Korn, Barna Saha, Divesh Srivastava: Discovering Conserva.on Rules. ICDE 2012: 738-‐749
– Tamraparni Dasu, Ji Meng Loh: Sta.s.cal Distor.on: Consequences of Data Cleaning. PVLDB 5(11): 1674-‐1683 (2012)
– Lukasz Golab, Data Warehouse Quality: Summary and Outlook, In: S. Sadiq (ed.), Handbook of Data Quality -‐ Research and Prac.ce, Springer-‐Verlag Berlin Heidelberg 2013