j. vis. commun. image r. - amirkabir university of technologyceit.aut.ac.ir/~86131045/mmn/project...
TRANSCRIPT

J. Vis. Commun. Image R. 21 (2010) 77–88
Contents lists available at ScienceDirect
J. Vis. Commun. Image R.
journal homepage: www.elsevier .com/ locate/ jvc i
Robust video multicast with joint network coding and video interleaving
Hui Wang *, C.-C. Jay KuoMing Hsieh Department of Electrical Engineering and Signal and Image Processing Institute, University of Southern California, Los Angeles, CA 90089-2564, USA
a r t i c l e i n f o
Article history:Received 2 January 2009Accepted 30 June 2009Available online 9 July 2009
Keywords:Network codingCross-layer optimizationInterleavingReal-timeH.264/SVCUnequal erasure protection (UEP)IPTVVideo conference
1047-3203/$ - see front matter � 2009 Elsevier Inc. Adoi:10.1016/j.jvcir.2009.06.008
* Corresponding author.E-mail addresses: [email protected] (H. Wang), cck
a b s t r a c t
In this work, we propose a cross-layer solution to robust video multicast in erasure networks based onrandom linear network coding (RLNC) in the network layer and video interleaving (VI) in the applicationlayer, and call it the joint RLNC-VI scheme. In the RLNC implementation, we partition one video codingunit (VCU) into several priority levels using scalable properties of H.264/SVC video. Packets from thesame priority level of several VCUs form one RLNC generation, and unequal protection is applied to dif-ferent generations. RLNC provides redundancy for video packets in the network layer and has proved tobe useful in a multicast environment. Then, we propose a new packet-level interleaving scheme, calledthe RLNC-facilitated interleaving scheme, where each received packet corresponds to a new constrainton source packets. As a result, it can facilitate the RLNC decoding at the destination node. Furthermore,we study the problem of optimal interleaving design, which selects the optimal interleaving degree andthe optimal redundancy of each generation. The tradeoff between delay and received video quality due tothe choice of different VCUs is also examined. It is shown by simulation results that the proposed RLNC-VIscheme outperforms the pure RLNC method for robust video multicast in erasure networks. This can beexplained by two reasons. First, the VI scheme distributes the impact of the loss (or erasure) of one VCUinto partial data loss over multiple neighboring VCUs. Second, the original video content can be easilyrecovered with spatial/temporal error concealment (EC) in the joint RLNC-VI scheme.
� 2009 Elsevier Inc. All rights reserved.
1. Introduction
Video multicast over the Internet faces three major challengesin meeting the quality of services (QoS) requirements: highthroughput, short delay and less packet loss (or erasure). For exam-ple, for IPTV applications, a high-definition H.264/AVC video pro-gram (1920 � 1080, 24 fps) demands a bit rate of 8 Mbps [1], andan HD video conference application may need a throughput as highas 5.1 Mbps [2]. IPTV may tolerate channel switching delay up toseconds while real-time video conferencing only allows 100–200 ms delay [2,3]. Human eyes are sensitive to packet loss in avideo bitstream. The packet loss effect in the network has to beaddressed properly to minimize its negative impact to viewers.
Network coding (NC) has emerged as a prominent method fordata multicast over networks. It has two main advantages. First,it improves the throughput of data transmission [4–7]. Particularly,it was proved in [4] that the optimal multicast capacity is the min-imum of all minimum cuts for all multicast audience, which cannotbe achieved by traditional store-and-forward networks but NC.Second, it is more resilient to packet loss by generating redundantpackets in a rateless way [8–12]. For practical implementations,
ll rights reserved.
[email protected] (C.-C.J. Kuo).
RLNC (random linear network coding) [13–15] has been proposed,since it does not demand global control of the network.
Although NC offers higher throughput and better erasure pro-tection capability, it does not guarantee one to recover transmittedsource data from received packets. This is because that some pack-ets could be lost so that the global coefficient matrix (GCM) [11]associated with RLNC may not have the full rank for inversion inthe RLNC decoding process at the destination node. One packeterasure scenario may arise due to traffic congestion in wired net-works and channel bit errors in wireless networks. Another maycome from the heterogenous nature of receivers in a multicastenvironment. When a source multicasts scalable video to heterog-enous receivers using RLNC at rate r, clients of bandwidth lowerthan r expect to receive lower layers of the video. However, ifthe minimum cut is smaller than the source video rate r, rank defi-ciency happens and even contents of lower layers cannot be de-coded properly.
Rank deficiency of GCM at the destination node could be causedby the RLNC mixing process at intermediate nodes [11]. Severalresearchers attempted to solve this problem from the viewpointof NC and error correction coding (ECC). Walsh and Weber [16]proposed a method that concatenates low-density parity-check(LDPC) with NC. The decoder can decode only if one packet in adata block is received. Source packets are arranged by priorityand coded by a method called the priority error transmission

78 H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88
(PET) [17]. Silva and Kschischang [18,19] studied a rank-metric NCmethod to guarantee erasure protection, which is measured withthe minimum-rank distance of the codes. If the number of lostpackets is smaller than the minimum distance provided by therank-metric code, it guarantees that packets can be decoded. Hallo-ush and Radha [20] proposed a multi-generation scheme.
Here, we solve the rank deficiency problem from a cross-layerviewpoint that involves NC, ECC and VI. Specifically, we proposea cross-layer solution to robust video multicast in erasure net-works based on random linear network coding (RLNC) in the net-work layer and video interleaving (VI) in the application layer,and call it the joint RLNC-VI scheme. In the RLNC implementation,we partition one video coding unit (VCU) into several priority lev-els using scalable properties of H.264/SVC video. Packets from thesame priority level of several VCUs form one RLNC generation, andunequal protection is applied to different generations. RLNC pro-vides redundancy for video packets in the network layer and hasproved to be useful in a multicast environment. Then, we proposea new packet-level interleaving scheme, called the RLNC-facilitatedinterleaving, where each received packet corresponds to a newconstraint on source packets. As a result, it can facilitate the RLNCdecoding at the destination node.
There are several parameters to be considered to improve videoquality based on the estimation (or feedback) of the end-to-endpacket loss rate. One is the interleaving length in the applicationlayer, which measures the number of VCUs in a bitstream to beinterleaved. The other is the amount of redundancy needed at eachNC generation. This cross-layer design problem will be formulated.Then, an iterative optimization procedure is proposed to solve theoptimal interleaving design problem.
One potential problem with VI is the extra delay introduced. Toalleviate this problem, we may perform interleaving among VCUsof different granualities. For example, we may choose one groupof picture (GOP) or one frame as the VCU to meet the different de-lay requirements. The GOP-based interleaving scheme has moreflexibility in video priority partition, and provides better videoquality at the cost of longer delay. In contrast, the frame-basedinterleaving scheme trades shorter delay for lower video quality.
It is observed by simulation results that the proposed RLNC-VIscheme outperforms the pure RLNC method in erasure networksby a significant margin. This can be explained by two reasons. First,the VI scheme distributes the impact of the loss (or erasure) of oneVCU into partial data loss over multiple neighboring VCUs. Second,the VI scheme allows NC to cooperate with error concealmentmethods more effectively. It also improves the unequal protectioncapability of H.264/SVC priority layers.
The rest of the paper is organized as follows. The backgroundknowledge on H.264/SVC video, VI and RLNC is reviewed in Section2. We propose the joint RLNC-VI algorithm for robust video multi-cast in erasure networks in Section 3. The optimal interleaving de-sign problem is formulated and solved in Section 4. Simulationresults are given in Section 5 to demonstrate the superior perfor-mance of the proposed RLNC-VI scheme. Finally, concluding re-marks and possible future extensions are given in Section 6.
T0 T3 T2 T3 T1 T3 T2 T3 T0
Fig. 1. An example of the layering structure of H.264/SVC consisting of fourtemporal layers and two quality layers.
2. Background review
2.1. H.264/SVC video and error concealment
Generally speaking, a scalable video coding (SVC) technique en-codes a video stream with a number of meaningful (decodable) vi-deo layers. A scalable bit-stream of full resolution/quality can betruncated to get lower layers. Although it has been adopted insome video standards such as MPEG-2 and MPEG-4, it was notwidely used due to its poor coding gain and higher coding com-
plexity as compared with the single layer coding scheme. Theemerging H.264/SVC standard has received a lot of attention re-cently due to its improved coding gain and reduced coding com-plexity. The video bit-stream of multiple priority layers can beadaptive to bandwidth fluctuation in a network easily. By discard-ing packets of less importance (or truncating a bit-stream), a re-duced spatial-temporal-quality resolution of a full video bit-stream can be obtained with graceful quality degradation. It is anideal candidate for video transmission in scenarios such as erasurenetworks and networks with heterogeneous clients. Moreover, itcan be used in a surveillance video storage system to provide flex-ible storage by partially removing less important part of archivedvideo.
A competitive alternative to scalable video is video encoded bymultiple description codes (MDC) [17,21]. MDC encodes a videosource into several correlated descriptions, where any subset ofthese descriptions can be decoded to reconstruct the video sourcepartially. In contrast, SVC encodes a video source into a layered bit-stream consisting of a base layer and several enhancement layers.We choose the H.264/SVC coded bitstream in this research forthree reasons. First, since it provides a set of layers along the tem-poral, spatial and quality dimensions, it allows partial decoding ofthe bitstream when receiving a set of low resolution layers. Second,unequal error protection can be used in association with prioritylayers efficiently. Third, error concealment can be easily per-formed. For example, the low resolution video can be used to con-ceal high resolution video by interpolation.
Error concealment (EC) methods in H.264/SVC handle not onlyintra-layer concealment but also inter-layer concealment. Twosimple ideas to be used in this work are reviewed below.
1. Frame copy and temporal direct: Frame copy and temporal directmethods can conceal lost frames (or slices) from adjacentframes. Every pixel of the lost frame is copied from the firstframe of the reference picture list in the frame copy method.For example, if a frame in layer T3 is lost in the hierarchy Bstructure as shown in Fig. 1, it is copied from the left adjacentframe. All the motion information is lost in the frame copymethod. With the temporal direct method, motion vectors inlost slices are calculated in the same way as that used in thetemporal direct mode [22]. As compared with the frame copymethod, the temporal direct method estimates the motioninformation from reference frames, which results in betterquality than that of frame copy. However, there may exist blockartifacts which could be annoying to human eyes.
2. BLSkip: The BLSkip method proposed by Kai et al. [23] is an ECtool to conceal missing quality or spatial layers by exploitinginter-layer correlations in the H.264/SVC decoder. When thebase layer is received while the enhancement layer is lost,

H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88 79
BLSkip up-samples the motion and the residual informationfrom the base layer to reconstruct the enhancement layer. Sincecoarse quality layers are encoded similarly as spatial layers,BLSkip can also be used to reconstruct quality enhancementlayers.
For extensive surveys on EC methods, we refer to [24,25].
2.2. Video interleaving (VI)
By interleaving, we rearrange the transmission order of a datastream at the source of a network. The purpose is to break a longburst error into shorter ones, which facilitates the detection andconcealment of burst errors. The interleaving scheme can be doneat two levels; namely, the bit-level and the packet-level. The bit-le-vel interleaving is often integrated with error correction codes toreduce the damage of burst bit errors at the physical layer. Wecan also adopt VI to increase the robustness of source video againstpacket erasure, which is called the packet-level interleaving [26],at the application layer. The bit-level and the packet-level videointerleaving schemes are illustrated in Figs. 2 and 3, respectively.
Each column in Fig. 2 corresponds to one packet, which has Ksource bits and R redundant bits. Horizontally, the length of therow, g, is the interleaving depth (or the interleaving degree). Thesource data are protected by FEC vertically as represented by a col-umn in Fig. 2. Redundancy is introduced by forward error correc-tion (FEC) codes. One example of FEC code is the Reed–Solomoncode, which is a maximum distance separable (MDS) code. TheðK þ R;KÞ Reed–Solomon code can correct up to R erasure bits.However, its computational complexity is high. To reduce the com-plexity, another type of FEC, known as the LDPC codes, can be usedto generate redundancy. The Raptor code [27] is an example ofLDPC codes. It behaves like MDS codes asymptotically. Since itsgenerator matrix is sparse, it only requires linear encoding anddecoding complexity.
The interleaving scheme increases the erasure protection capa-bility because of g, which decides how a burst erasure can bespread. The larger the g value, the less redundancy is required forFEC codes. For example, to correct bit errors shown in Fig. 2, FECcodes must correct at least 2 bit erasures. However, for a larger gvalue, lost bits may not be overlapped at all vertically. Then, FECcodes only need to correct 1 bit erasure. For the ðK þ R;KÞ Reed–Solomon code, the interleaving scheme allows maximum Rerasures.
The above idea can be generalized to the packet-level interleav-ing. As shown in Fig. 3, there are g video coding units (VCU) andeach VCU consists of a certain number of packets. (Note that eachsmallest square unit in Fig. 3 denotes a packet.) Some packets are
K
g
R
Source bits Redundant bits Lost bits
Transmission order
FECencoding
order
Fig. 2. Illustration of the bit-level interleaving scheme.
dedicated to coding bits of source video while others are to errorcorrection codes. The interleaving degree, g, refer to the numberof video coding units involved in the interleaving process.
2.3. Random linear network coding (RLNC)
Since the pioneering work of Ahlswede et al. [4] on NC, proper-ties and applications of NC have been extensively studied byresearchers. For example, NC can reduce the power consumptionby broadcasting NC packets in wireless networks [28–30] and thedata gathering time in sensor networks. It can also enhance net-work’s capability in error correction [8–10], security [31], storage[32,33], etc.
Ahlswede et al. [4] proved an important result. That is, the max-imum multicast information rate from a source to a set of receiverscan be achieved only by allowing coding at intermediate nodes.Theoretically, this optimal rate can be achieved by a generic linearnetwork coding scheme [5–7], where packets are generated by alinear combination of source packets with coefficients selectedfrom a finite field. By selecting these coefficients carefully, a newlygenerated packet is linearly independent of all other packets on allnodes in the network. The computational complexity of the algo-rithm is polynomial. However, it is a centralized method that re-quires the knowledge of network topology and a huge field sizeto guarantee a successful decoding operation. Ho and Medard[13,14] proposed a RLNC scheme, which selects coefficients overthe Galois finite field randomly and independently. RLNC is a dis-tributed scheme that does not demand the knowledge of networktopology, and its computational complexity is significantly low. Be-sides, it demands a small field size to achieve a reasonably highsuccessful decoding probability.
Data packets are grouped into blocks of different generations atthe source node. Packets of the same generation that arrive at anintermediate node are linearly combined to generate new packetsfor outgoing links. This process can be described mathematically asfollows. Let node i be an intermediate node that has lðiÞin incominglinks and lðiÞout outgoing links. It generates a packet for each outgo-ing link by randomly and independently selecting linear NC coeffi-cients cnm from the Galois Field (GF) and performing a linearcombination as
Yn ¼X
m
cnmPm; ð1Þ
where m and n are, respectively, indices for the incoming and theoutgoing links, Pm is the packet received from incoming linkm; Yn is the generated packet for outgoing link n, and cnm is anRLNC coefficient. We call Eq. (1) a mixing process of packets, whichcan be well described by a mixing matrix. To decode Pm from Yn, weneed coefficients cnm of the mixing matrix, which are often ap-pended to the tail of the outgoing packet. This mixing processmay go through multiple RLNC stages before a packet arriving atthe destination node. The coefficients of the mixing process canbe updated to reflect the cumulative effect of multiple RLNC stagesto reduce the transmission overhead.
For each end-to-end source–destination pair, we can relate thesource packets and the received packets by a global coefficient ma-trix (GCM) in form of
R ¼ G� S; ð2Þ
where S ¼ ½P1; . . . ; Pk�T is a vector of source packets, R ¼ ½Y1; . . . ;Yj�T
is a vector of received packets, and G is the GCM of dimension j� k.When a new packet arrives at the destination node, which is inde-pendent of all of previously received packets, we call it an innova-tive packet since we can add one more equation to the system in(2) so that the row of G increases by 1.

Transmission order
VCU0 VCU1
g
K
R
VCUg-1 FECencoding
orderSource packets Redundant packets Lost packets
Fig. 3. Illustration of the packet-level interleaving scheme, where VCU denotes the video coding unit.
80 H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88
Once G reaches the rank of k, which is equal to the dimension ofthe input vector space, we are able to decode source packets in Sfrom received packets in R by Gaussian Elimination as illustratedin Fig. 4. Sometimes, due to random coefficient selection, somepackets may be linearly dependent with each other. Then, the des-tination node has to wait for more packets to arrive so that GCMcan reach the full rank of k. It was proved in [13] that the probabil-ity for a received packet to be linearly dependent on other packetsis very small if the finite field size is sufficiently large.
3. Proposed RLNC-VI scheme for video multicast
In this section, we propose a video multicast system based onthe joint application of RLNC and VI, and call it the RLNC-VIscheme. The system overview is examined in Section 3.1. Videopartitioning and unequal protection are studied in Section 3.2.The RLNC-facilitated interleaving scheme is described in Section3.3.
3.1. System overview
The joint RLNC-VI video multicast system in an erasure networkis shown in Fig. 5. The system consists of three main modules asdetailed below.
� Processing at the source node: First, the video input is coded by anH.264/SVC encoder. The coded H.264/SVC video bitstream is
NC Enabled Network
Fig. 4. The global coefficient matrix (GCM) of an end-to-end delivery system usingRLNC.
then partitioned into priority layers and packetized into packetsof equal length at the source node. A cross-layer optimizer gath-ers the bitstream information and computes parameters such asthe interleaving degree and redundancy required by each RLNCgeneration. The parameter optimization process will be dis-cussed in detail in Section 4.
� RLNC encoding at intermediate nodes: Each intermediate node inthe network selects RLNC coefficients and generates RLNC-encoded packets and packet headers independently. The head-ers consist of several fields such as cumulative RLNC coefficients,the bitstream layer information, etc. These packets travel in anerasure network, where packets may be lost or delayed due tobit errors, traffic congestion or buffer overflow of intermediatenodes.
� Processing at the destination node: At the destination node,received packets are buffered until the GCM becomes a full rankmatrix. Then, Gaussian elimination is used for RLNC decoding,which is followed by video de-interleaving. Afterwards, videodata are decoded with an H.264/SVC decoder equipped withthe error concealment capability.
Finally, video data are played back at each destination node, andwe can evaluate the system performance by comparing the qualityof the source video bitstream with that of the decoded bitstream.
3.2. Video partitioning and unequal protection
When VI is applied to prioritized video layers, unequal erasureprotection can improve the visual performance of reconstructed vi-deo. Here, we discuss methods to partition a VCU into priority lay-ers, and then present ways to perform unequal protection in theinterleaving scheme.
We examine four partition methods based on error resilientcoding tools of H.264/AVC and H.264/SVC, and discuss whetherthey are suitable for RLNC-VI.
1. Partition a VCU into three groups that contain only I, P or B frames,respectively: This was considered in some early work on unequalerror protection [34]. It is a simple and effective idea, where thetemporal correlation is exploited for EC. Moreover, the impor-tance of I, P and B groups is obvious. Similarly, the H.264/SVCbitstream can be organized into T0; T1; . . . ; Tt groups based onthe hierarchy B structure as shown in Fig. 1. The importanceof those groups is measured by delta PSNR. We adopt thismethod to generate the input H.264/SVC bitstream in computersimulation. Each partition of a VCU contains one or several tem-poral layers.

EvaluationPSNR
SVC encodingwith prioritized
layers
Packetization
NC-orientedInterleaving
SVC decoding
Buffering
Source Destination
RLNC Encoding with PacketErasure and Delay
Optimizer(Add
redundancy)
ErrorConcealment
RLNCDecoding
De-interleaving
Timer
Fig. 5. Video transmission with the proposed RLNC-VI scheme in an erasure network.
VCU1 VCU2 VCU3 VCU4 VCU5
H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88 81
2. Partition a frame spatially with Flexible Macroblock Ordering(FMO) in H.264/AVC: The slices that correspond to the same loca-tion of different frames are put into one generation. The spatialcorrelation is utilized for EC. It provides the flexibility to definethe area of slices, and regions of interest (ROI) and the impor-tance of each slice can be obtained accordingly.
3. Partition a packet at the fine-grain level: Packet classificationusing the Relative Loss Index (RLI) was proposed by Kim et al.[35] for the Quality of Service (QoS) mapping to the DiffServnetwork. The underlining idea of RLI is to evaluate the lossimpact of every packet at the macroblock level by consideringfactors such as the magnitude and the direction of the motionvector, encoding types, initial error, etc. Then, packets are cate-gorized based on the RLI value. Since the computation of theloss impact considers both spatial and temporal correlation, itis suitable for the interleaving scheme.
4. H.264/AVC data partition: The coded information of each slice inH.264/AVC has three partitions.� Type A partition – including the slice header information
such as MB types, quantization parameters and motionvectors.
� Type B partition – including intra coded block patterns andintra coefficients.
� Type C partition – including inter coded block patterns andinter coefficients.
The above partition generates an embedded bitstream. If parti-tion A is lost, the whole slice cannot be decoded and the bandwidthused for the transmission of partitions B and C is wasted. Thus, thismethod is not suitable for RLNC-VI.
(c) Unequal redundant assignment
(b) Interleaved blocks for network coding
(a) Original video bitstream
Data with highest priority Data with lowest priority Redundant data
Fig. 6. Illustration of the RLNC-facilitated VI scheme, where each VCU contains Qpriority levels and g VCUs are involved in the RLNC coding process (with Q ¼ 5 andg ¼ 5 in this example).
3.3. RLNC-facilitated interleaving
With the video partitioning and unequal protection techniquespresented in Section 3.2, we can use the bit- and packet-levelinterleaving schemes as reviewed in Section 2.2 to protect the vi-deo contents. In the context of RLNC, there is another importantpurpose of interleaving; namely, to protect against the insufficientrank of GCM so that RLNC decoding can be performed at the desti-nation node. In this subsection, we propose a VI scheme to facili-tate RLNC decoding. The idea is illustrated in Fig. 6.
As shown in Fig. 6(a), each VCU at the source node consists of Qpriority layers. If the interleaving length is g, we group partitions of
the same priority from g VCUs into a data block, which is called ageneration, as shown in Fig. 6(b). Consequently, the number ofgenerations is Q. Finally, we add a redundant data block to eachgeneration as shown in Fig. 6(c). The size of the redundant datablock depends on the importance of the priority layer. The higherpriority, the longer the redundant data block. Then, the parametersof the VI scheme include: g;Q and the ratio of redundant packetsover the total number of packets of each generation, called theredundant ratio (or redundancy) and denoted by ai; i ¼ 1; . . . ;Q .
When the rank of GCM is smaller than the number of packets,received packets are useless to the video decoder. Besides, EC can-not be applied to the pure RLNC method since identifying the spa-tial location of lost packets is ambiguous. In this case, EC is noteffective. In contrast, the interleaving scheme allows effective ECby spreading the longer burst erasure pattern into shorter isolatedones. It increases the spatial and the temporal correlation betweenlost and received packets.
Most importantly, it helps the GCM of each generation to reachits rank as fast as possible. This idea is illustrated in Fig. 7, where ki
is the number of source packets and ri is the number of redundantpackets in generation i. The GCM associated with generation 1 hasthe highest priority and should be protected by the largest amountof redundancy. With the RLNC-facilitated interleaving, each gener-ation forms an interleaving group which is protected by redundantpackets. If some packets are erased during the transmission, the

r1
k1
GCM sub-matrix to generate Redundancy
GCM1
rn
kn
GCMn
rQ
kQ
GCMQ
GCM sub-matrix to generate source data
Fig. 7. GCM protected by redundant packets for different generations.
82 H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88
redundant packet can provide extra rows for the GCM so that GCMcan reach its full rank faster.
The above statement can be analyzed quantitatively below.With unequal erasure protection, the probability of rank deficiencyfor generation i is
Pi ¼Xki�1
j¼1
ki þ ri
j
� �ð1� pÞjpkiþri�j; ð3Þ
where p is the probability of packet loss rate. In Eq. (3), a large valueof ri results in small Pi. Therefore, as long as the generation of higherpriority is assigned more redundancy, the probability of rank defi-ciency is reduced.
3.4. Comparison of GOP-based and frame-based interleaving
The selection of the VCU size for interleaving is a design choice.If we choose the VCU to be one GOP and the interleaving length tobe 4 or 8, the interleaving scheme introduces 2 or 4 s (under theassumption that one GOP corresponds to 0.5 s), which could betoo long for some applications. To reduce the delay, we can choosethe VCU to be a frame. However, the video quality of the frame-based interleaving scheme is worse than the GOP-based interleav-ing scheme. The longer delay can be used to trade for better videoquality.
The higher quality degradation of the frame-based interleavingscheme is resulted from two reasons. First, the partition in frame-based interleaving is limited to the intra frame, which containsonly spatial or quality partitions. In contrast, the GOP-based inter-leaving allows more flexible partitions, including spatial, qualityand temporal partitions. Second, when the packet loss rate is small,the larger interleaving length introduces the higher probability ofreceiving packets. We will compare the frame- and GOP-basedinterleaving schemes using the same video partition method;namely, in Section 5.
The temporal partition of the H.264/SVC bitstream provides agood way to provide UEP (unequal erasure protection) for key pic-tures since the temporal correlation can be exploited for error con-cealment. A possible way to improve the performance of frame-based interleaving is the 2-D video erasure protection. For exam-ple, for H.264/SVC video with coarse-grain scalability (CGS), wemay first perform erasure protection by assigning redundancy todifferent generations according to the priority of quality layers.Then, we can assign redundancy to those generations (not all gen-erations) containing key frames.
4. Design of optimal interleaving scheme
4.1. Problem formulation
Given Q priority partitions (RLNC generations), we consider theoptimization of the RLNC-facilitated interleaving scheme by choos-ing the following parameters:
1. interleaving length g (i.e., the number of VCUs involved in aninterleaving operation);
2. the optimal number of redundant packets in each generationdenoted by vector r ¼ ðr1; . . . ; rQ ÞT .
The optimal interleaving length g should not be too large since lar-ger g demands longer encoding/decoding delay and a larger buffersize. Besides, a large g value demands a large field size for RLNCcoefficients in the packet header.
We use G to denote the upper bound on g. Then, the optimiza-tion problem can be formulated as follows.
Jðg�; r�Þ ¼ minXQ
i¼1
DiPi
!; ð4Þ
where Pi is the probability of losing generation i and Di is the qualitydegradation due to the loss of the ith partition, subject to the fol-lowing three constraints:
ð1Þ 0 6 g 6 G; ð5Þ
ð2ÞXQ
i¼1
ri 6 R; ð6Þ
ð3Þ r1
k1P
r2
k2P � � �P rQ
kQð7Þ
where ki is the number of source video packets in generation i.Parameter R in constraint (6) is the total number of redundant pack-ets. Constraint (7) implies that we need more protection for data ofhigher priority (with a smaller value in subscript i). We define theredundancy at generation i as
ai ¼ri
ki:
and the total redundancy as
a ¼PQ
i¼1riPQi¼1ki
:
We examine the expressions for Pi and Di below. Suppose thatthe end-to-end packet loss rate is p. Since we are able to performRLNC decoding if the destination node receives ki packets for gen-eration i, it is straightforward to derive
Pi ¼Xki�1
j¼1
ni
j
� �ð1� pÞjpni�j
where ni ¼ ki þ ri. For the value of Di, we adopt the off-line calcula-tion in our simulation. That is, the PSNR degradation due to the dropof the ith partition is calculated individually. For on-line qualitydegradation using the relative loss index (RLI), we refer to [35].
4.2. Iterative optimization
We propose a low-complexity iterative algorithm to solve theoptimization problem in (4). The input parameters of the iterativeoptimization algorithm include:
� the number of packets ki in the ith partition (or generation);� the quality degradation Di caused by the loss of the ith genera-
tion video data;� the total redundancy a.
where 1 6 i 6 Q . The output parameters are the optimal interleav-ing length g� and the optimal redundancy denoted by vector r�.
The idea of the iterative optimization process is illustrated inFig. 8. Initially, every generation is treated equally so that weset all ai values the same, i.e., ai ¼ a=Q . After that, redundancy as-

(c) Optimized redundant assignment
(b) intermediate redundant assignment
(a) Initial redundant assignment
Fig. 8. Iterative adjustment of redundancy among generations.
H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88 83
signed to the generation of lower priority is moved to that of high-er priority (which may be the closest neighbor generation or a gen-eration in the far left) as long as the new assignment r satisfiesCondition (7) and the cost function J ¼
PQi¼1DiPi is lowered. Redun-
dancy adjustment is iterated until no further improvement can bereached. The detailed implementation of the iterative optimizationalgorithm is given in Table 1 for clarity.
The number of packets to be relocated at each round of the loopin Table 1 defines the granularity. The computational complexity ofthe optimization algorithm is higher if the granularity is finer. Thesmallest granularity is to adjust one packet at each iteration, whichdemands the highest complexity. If the granularity is larger, thecomplexity is lower. However, it may result in a sub-optimalsolution.
To validate the solution of the iterative optimization algorithm,we consider a small scale problem with two priority levels, andcompare results of optimal parameters obtained from the exhaus-tive search and the proposed iterative search algorithm. Both algo-rithms give the same answer while the iterative search algorithm issignificantly faster.
5. Simulation results
5.1. Simulation setup
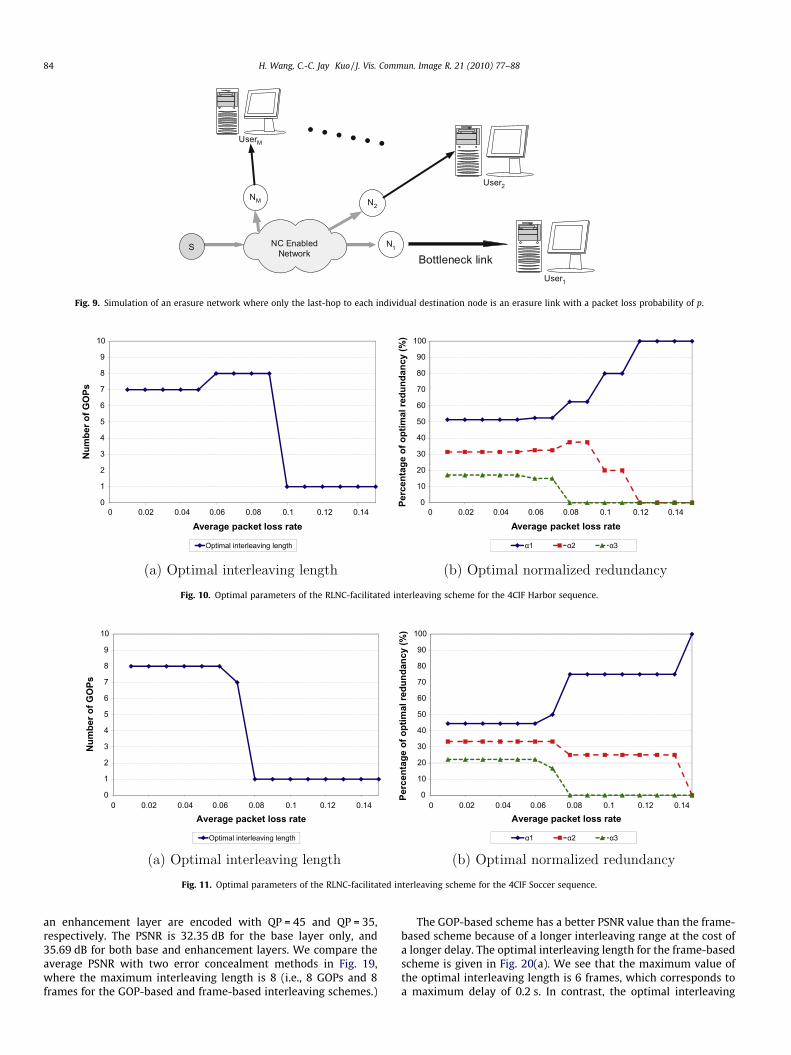
To evaluate the performance of the proposed RLNC-VI scheme,we consider a simulated network environment as shown inFig. 9, where node S multicasts its video to node Ni; 1 6 i 6 M. It
Table 1Iterative algorithm for optimal interleaving design.
J� ¼ 0g� ¼ 0; r�½i� ¼ 0 for all i 2 1 . . . Qqactive ¼ 0; qnext ¼ 0for g ¼ 1 to G do
Calculate ki for layer i in g VCUs for all i 2 1 . . . Qr½i� ¼ k½i� � a for all i 2 1 . . . Qqactive ¼ 0; qnext ¼ 0while r½i�P 0 for all i 2 2 . . . Q do
if Jðg; r1; r2; . . . ; rQ Þ > J� theng� ¼ g; r�½i� ¼ r½i� for all i 2 1 . . . Q ; J� ¼ J
end ifrepeat
if qactive P 2 thenr½qactive � 1� þ þ; r½qactive� � �
end ifif r½qnext � ¼¼ 0 then
qnext ��end if
until r½i�1�k½i�1� >
r½i�k½i� for all i 2 1 . . . Q
end whileend for
is assumed that there are a sufficient number of RLNC packets(including both source video packets and redundant packets)transmitted in the network before the last hop to each individualdestination node. To model the erasure property of the network,we assume that only the last hop to each destination node is anerasure link with a pack loss probability of p.
Three 4CIF sequences (i.e., Harbor, Soccer and Crew) are used inthe simulation. The frame rate is 30 frames per second (fps), the QPparameter is 35, the GOP size is 8, and the intra period is 8. The fi-nite field size is chosen to be 28 ¼ 256. We use H.264/SVC refer-ence software JSVM7.9 to generate the video bitstream with onequality layer and four temporal layers. We partition each video bit-stream into three priority levels, where each one defines a genera-tion of RLNC packets. Specifically, the first generation consists oftemporal layers T0, the second generation consists of temporallayer T1 and the third generation consists of temporal layer T2
and T3.
5.2. Results of optimal interleaving parameters
In this example, we use a GOP as one VCU. We plot the optimalinterleaving length g� and the optimal normalized redundancy as afunction of the average packet loss rate p obtained by the designprocedure as described in Section 4. By normalization, the totalredundancy is set to 100% so that we focus on only the distributionof redundancy among different generations (rather than theirabsolute values). The results of Harbor, Soccer and Crew are shownin Figs. 10–12, respectively.
For subfigure (a), we see that g� may take a larger value for avery small value of p. However, when p is larger than a threshold,g� drops quickly to 1. In other words, interleaving only occursamong three priority levels within one GOP. For subfigure (b),when p is small, normalized redundancy ai; i ¼ 1;2;3, is roughlyproportional to the number of packets of each generation sincethe need to differentiate the importance of different generationsis lower. However, when p is higher, more redundancy is assignedto more important layers. When p is sufficiently large, all redun-dant packets are assigned to the most important generation (i.e.,the first generation).
5.3. Comparison of RLNC-VI and pure RLNC
We show the quality degradation as a function of the packetloss rate, p, for the three test video sequences in Figs. 13(a),14(a), and 15(a). When p is small, the quality degradation is almostzero, which means that effective protection is achieved by the pro-posed RLNC-VI scheme. We also compare the average PSNR valuesof the proposed RLNC-VI scheme and the pure RLNC scheme (with-out VI) as a function of the packet loss rate, p, when the totalredundancy is equal to a ¼ 10%. We see that the RLNC-VI schemeoutperforms the pure RLNC scheme for a larger p value. The perfor-mance gap can be as large as 3–5 dB.
For visual quality comparison, we show reconstructed framesusing RLNC-VI and pure RLNC in Figs. 16–18. Frames sent by pureRLNC have obvious visual artifacts, which are signicantly worsethan that obtained by RLNC-VI. For example, there is a ghost shadein Fig. 17(b). In contrast, key frames are received with higher prob-ability, and EC works effectively because of high temporal correla-tions of lost and received frames in the proposed RLNC-VI scheme.As a result, decoded video has much better quality.
5.4. Comparison of GOP- and frame-based interleaving schemes
To compare the GOP- and frame-based interleaving schemes,we generate a H.264/SVC CGS bitstream with the following setting.Every GOP has 8 frames, and the intra period is 8. A base layer and
S NC EnabledNetwork
N1
User1
Bottleneck link
User2
UserM
N2NM
Fig. 9. Simulation of an erasure network where only the last-hop to each individual destination node is an erasure link with a packet loss probability of p.
0
1
2
3
4
5
6
7
8
9
10
Num
ber o
f GO
Ps
Average packet loss rate
Optimal interleaving length
0
10
20
30
40
50
60
70
80
90
100
0 0.02 0.04 0.06 0.08 0.1 0.12 0.140 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Perc
enta
ge o
f opt
imal
redu
ndan
cy (%
)
Average packet loss rate
α1 α2 α3
Fig. 10. Optimal parameters of the RLNC-facilitated interleaving scheme for the 4CIF Harbor sequence.
0
1
2
3
4
5
6
7
8
9
10
Num
ber o
f GO
Ps
Average packet loss rate
Optimal interleaving length
0
10
20
30
40
50
60
70
80
90
100
Perc
enta
ge o
f opt
imal
redu
ndan
cy (%
)
Average packet loss rate
α1 α2 α3
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Fig. 11. Optimal parameters of the RLNC-facilitated interleaving scheme for the 4CIF Soccer sequence.
84 H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88
an enhancement layer are encoded with QP = 45 and QP = 35,respectively. The PSNR is 32.35 dB for the base layer only, and35.69 dB for both base and enhancement layers. We compare theaverage PSNR with two error concealment methods in Fig. 19,where the maximum interleaving length is 8 (i.e., 8 GOPs and 8frames for the GOP-based and frame-based interleaving schemes.)
The GOP-based scheme has a better PSNR value than the frame-based scheme because of a longer interleaving range at the cost ofa longer delay. The optimal interleaving length for the frame-basedscheme is given in Fig. 20(a). We see that the maximum value ofthe optimal interleaving length is 6 frames, which corresponds toa maximum delay of 0.2 s. In contrast, the optimal interleaving

0
1
2
3
4
5
6
7
8
9
10N
umbe
r of G
OPs
Average packet loss rate
Optimal interleaving length
0
10
20
30
40
50
60
70
80
90
100
Perc
enta
ge o
f opt
imal
redu
ndan
cy (%
)
Average packet loss rate
α1 α2 α3
0 0.02 0.04 0.06 0.08 0.1 0.12 0.140 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Fig. 12. Optimal parameters of the RLNC-facilitated interleaving scheme for the 4CIF Crew sequence.
0
20
40
60
80
100
120
140
160
180
200
Qua
lity
degr
adat
ion
(dB
)
Average packet loss rateRLNC-VI Pure RLNC
15
20
25
30
35
40Av
erag
e PS
NR
(dB
)
Average packet loss rateRLNC-VI Pure RLNC
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Fig. 13. Quality degradation and the average PSNR for the 4CIF Harbor sequence.
0
20
40
60
80
100
120
140
Qua
lity
degr
adat
ion
(dB
)
Average packet loss rate
RLNC-VI Pure RLNC
15
20
25
30
35
40
Aver
age
PSN
R (d
B)
Average packet loss rateRLNC-VI Pure RLNC
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Fig. 14. Quality degradation and the average PSNR for the 4CIF Soccer sequence.
H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88 85

0
20
40
60
80
100
120
140
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Qua
lity
degr
adat
ion
(dB
)
Average packet loss rate
RLNC-VI Pure RLNC
15
20
25
30
35
40
Aver
age
PSN
R (d
B)
Average packet loss rateRLNC-VI Pure RLNC
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Fig. 15. Quality degradation and the average PSNR for the 4CIF Crew sequence.
Fig. 16. Comparison of a decoded frame (the 44th frame of the Harbor sequence of resolution 704� 576) using RLNC-VI and pure RLNC with 10% redundancy and the packetloss rate p ¼ 8%.
Fig. 17. Comparison of a decoded frame (the 26th frame of the Soccer sequence of resolution 704� 576) using RLNC-VI and pure RLNC with 10% redundancy and the packetloss rate p ¼ 8%.
86 H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88
length of the GOP-based scheme can be as high as 8 so that themaximum decoding delay can be around 2.13 s (or 64 frames).The maximum delay in the GOP-based interleaving scheme canbe as high as ten times of that in the frame-based interleavingscheme.
The average PSNR of decoded video sequences depends on ECmethods. We show results of the BLSkip error concealment method
and the frame copy method in Fig. 19(a) and (b), respectively. TheBLSkip method compensates the lost enhancement layer by pre-dicting from the base layer. The UEP allows the base layers to bereceived with a higher probability. Therefore, the BLSkip methodcooperates well with CGS-partitioned and the interleaving schemeand outperforms the frame copy method by a significant marginwhen the packet loss rate is higher.
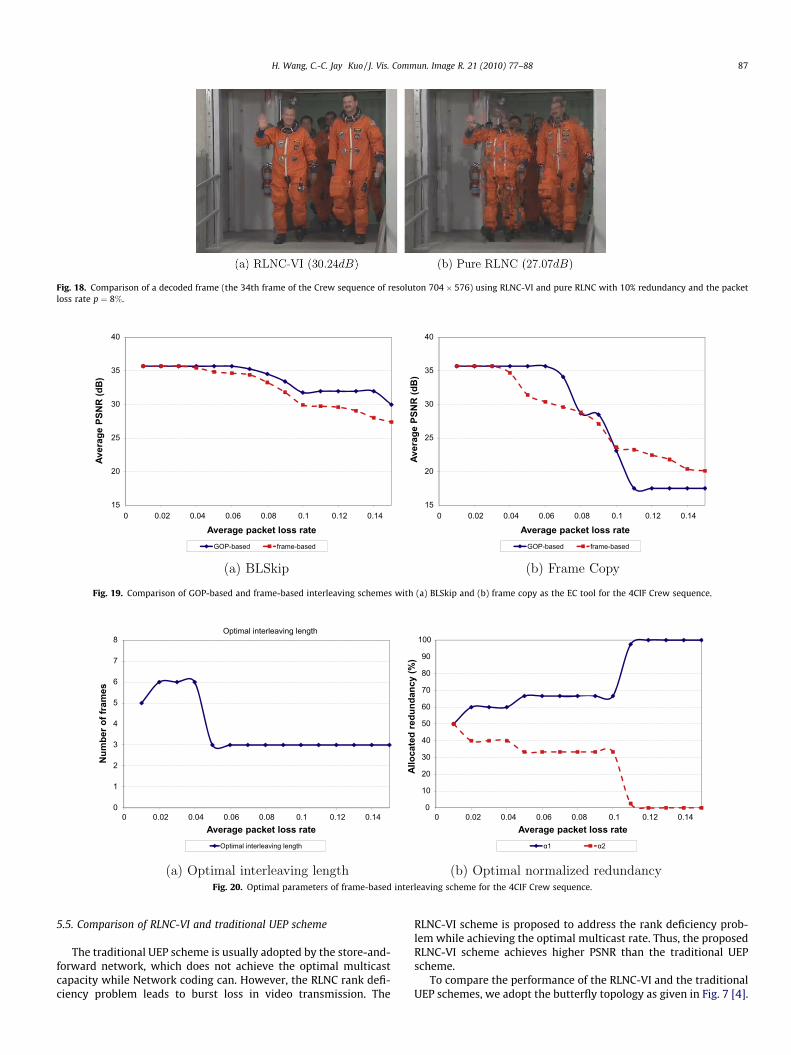
Fig. 18. Comparison of a decoded frame (the 34th frame of the Crew sequence of resoluton 704� 576) using RLNC-VI and pure RLNC with 10% redundancy and the packetloss rate p ¼ 8%.
15
20
25
30
35
40
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Aver
age
PSN
R (d
B)
Average packet loss rateGOP-based frame-based
15
20
25
30
35
40
Aver
age
PSN
R (d
B)
Average packet loss rateGOP-based frame-based
Fig. 19. Comparison of GOP-based and frame-based interleaving schemes with (a) BLSkip and (b) frame copy as the EC tool for the 4CIF Crew sequence.
0
1
2
3
4
5
6
7
8
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Num
ber o
f fra
mes
Average packet loss rate
Optimal interleaving length
Optimal interleaving length
0
10
20
30
40
50
60
70
80
90
100
Allo
cate
d re
dund
ancy
(%)
Average packet loss rateα1 α2
Fig. 20. Optimal parameters of frame-based interleaving scheme for the 4CIF Crew sequence.
H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88 87
5.5. Comparison of RLNC-VI and traditional UEP scheme
The traditional UEP scheme is usually adopted by the store-and-forward network, which does not achieve the optimal multicastcapacity while Network coding can. However, the RLNC rank defi-ciency problem leads to burst loss in video transmission. The
RLNC-VI scheme is proposed to address the rank deficiency prob-lem while achieving the optimal multicast rate. Thus, the proposedRLNC-VI scheme achieves higher PSNR than the traditional UEPscheme.
To compare the performance of the RLNC-VI and the traditionalUEP schemes, we adopt the butterfly topology as given in Fig. 7 [4].

15
20
25
30
35
40
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14
Aver
age
PSN
R (d
B)
Average packet loss rateRLNC-VI Pure RLNC
Fig. 21. Comparison of the RLNC-VI and the traditional UEP schemes for the Crewsequence.
88 H. Wang, C.-C. Jay Kuo / J. Vis. Commun. Image R. 21 (2010) 77–88
The optimal multicast capacity is set to the video bitrate. With NC,both users can achieve the optimal multicast capacity. With thestore-and-forward network, one achieves the optimal capacitywhile the other only achieves half of the capacity. For simplicity,packet loss is only simulated in the last hop. The average PSNR val-ues of the received video are shown in Fig. 21. Since the optimalmulticast rate cannot be achieved in the store-and-forward net-work, one user only receives a partial video bitstream. Thus, theaverage PSNR is smaller even when the packet loss rate is small.The RLNC-VI scheme achieves a higher PSNR value due to higherNC throughput and provision of an efficient solution to rankdeficiency.
6. Conclusion and future work
We proposed a joint network coding and video interleavingscheme, called RLNC-VI, for robust video multicast in erasure net-works in this work. The proposed RLNC-VI scheme enables NC tocooperate with EC effectively. We also studied the optimal inter-leaving design by optimizing the interleaving length and redun-dancy assigned to different priority layers. It was shown bysimulation results that the proposed RLNC-VI scheme yields bettervideo quality than the pure RLNC method. Our future work in-cludes the design of a more effective RLNC scheme that involvesa special mixing process in intermediate nodes and the integrationof interleaving with the special type of RLNC to yield even betterperformance in an erasure network.
Acknowledgements
This work was supported by the Okawa Foundation ResearchGrant.
References
[1] Apple, Available from: <http://www.apple.com/quicktime>.[2] Cisco, Telepresence network, Available from: <http://www.cisco.com>.[3] L.L. Peterson, B.S. Davie, Computer Networks – A System Approach, Morgan
Kaufmann, San Francisco, CA, 2003.[4] R. Ahlswede, N. Cai, S.Y.R. Li, R.W. Yeung, Network information flow, IEEE
Transactions on Information Theory 46 (2000) 1204–1216.[5] S. Li, Y.R.R.W. Yeung, N. Cai, Linear network coding, IEEE Transactions on
Information Theory 49 (2003) 371–381.
[6] R. Koetter, M. Medard, An algebraic approach to network coding, IEEE/ACMTransactions on Networking (2003) 782–795.
[7] S. Jaggi, P. Sanders, P. Chou, M. Effros, S. Egner, K. Jain, L. Tolhuizen, Polynomialtime algorithms for multicast network code construction, IEEE Transactions onInformation Theory 51 (6) (2005) 1973–1982.
[8] Z. Zhang, Linear network error correction codes in packet networks, IEEETransactions on Information Theory 54 (1) (2008) 209–218.
[9] R.W. Yeung, N. Cai, Network error correction, part I: basic concepts and upperbounds, Communications in Information and Systems 6 (1) (2006) 19–35.
[10] N. Cai, R.W. Yeung, Network error correction, part II: lower bounds,Communications in Information and Systems 6 (1) (2006) 37–54.
[11] R. Koetter, F.R. Kschischang, Coding for errors and erasures in random networkcoding, CoRR abs/cs/0703061.
[12] D. Lun, M. Mdard, M. Effros, On coding for reliable communication over packetnetworks, in: Proc. of the 42nd Annual Allerton Conference onCommunication, Control, and Computing.
[13] T. Ho, M. Medard, J. Shi, M. Effros, D. Karger, On randomized network coding,in: Proceedings of the 41st Annual Allerton Conference on Communication,Control, and Computing, Oct. 2003.
[14] T. Ho, M. Medard, R. Koetter, D. Karger, M. Effros, J. Shi, B. Leong, A randomlinear network coding approach to multicast, IEEE Transactions on InformationTheory 52 (10) (2006) 4413–4430.
[15] P. Chou, Y. Wu, K. Jain, Practical network coding, in: Proc. of the 51st AllertonConference on Communication, Control and Computing, Oct. 2003.
[16] J.M. Walsh, S. Weber, A concatenated network coding scheme for multimediatransmission, in: Proc. of the 4th Workshop on Network Coding, Theory, andApplications, Netcod 2008.
[17] V.N. Padmanabhan, H.J. Wang, P.A. Chou, Resilient peer-to-peer streaming, in:ICNP ’03: Proc. of the 11th IEEE International Conference on NetworkProtocols, 2003, p. 16.
[18] D. Silva, F.R. Kschischang, A rank-metric approach to error control in randomnetwork coding, in: Proc. of the IEEE Canadian Workshop on InformationTheory, 2007.
[19] D. Silva, F. Kschischang, Rank-metric codes for priority encoding transmissionwith network coding, in: Proc. of the 10th Canadian Workshop on InformationTheory, 2007, pp. 81–84.
[20] M. Halloush, H. Radha, Network coding with multi-generation mixing:analysis and applications for video communication, in: ICC ’08: IEEEInternational Conference on Communications, 2008.
[21] V.K. Goyal, Multiple description coding: compression meets the network, IEEESignal Processing Magazine 18 (5) (2001) 74–93.
[22] A. Tourapis, F. Wu, S. Li, Direct mode coding for bipredictive slices in the H.264standard, IEEE Transactions on Circuits and Systems for Video Technology 15(1) (2005) 119–126.
[23] X. Kai, Z. Feng, P. Purvin, B. Jill, Frame loss error concealment for SVC, Journal ofZhejiang University Science A 7 (5) (2006), doi:10.1631/jzus.2006.A0677.
[24] Y. Wang, Q. fan Zhu, Error control and concealment for video communication:a review, in: Proc. of the IEEE, 1998, pp. 974–997.
[25] B.W. Wah, X. Su, D. Lin, A survey of error-concealment schemes for real-timeaudio and video transmissions over the internet, in: Proc. of the Int’lSymposium on Multimedia Software Engineering, IEEE, 2000, pp. 17–24.
[26] Y.J. Liang, J.G. Apostolopoulos, B. Girod, Model-based delay-distortionoptimization for video streaming using packet interleaving, in: Proc. of the36th Asilomar Conference on Signals, Systems and Computers, vol. 2, 2002, pp.1315-1319.
[27] A. Shokrollahi, Raptor codes, IEEE Transactions on Information Theory 52(2006) 2551–2567.
[28] Y. Wu, P.A. Chou, S.-Y. Kung, Minimum-energy multicast in mobile ad hocnetworks using network coding, IEEE Transactions on Communications 53 (11)(2005) 1906–1918.
[29] Y. Wu, P.A. Chou, Q. Zhang, K. Jain, W. Zhu, S.-Y. Kung, Network planning inwireless ad hoc networks: a cross-layer approach, IEEE Journal on SelectedAreas in Communications, special issue on wireless ad hoc networks 23 (1)(2005) 136–150.
[30] Y. Wu, P.A. Chou, Network coding for the internet and wireless networks, IEEESignal Processing Magazine 24 (5) (2007) 77–85.
[31] L. Lima, M. Mdard, J. Barros, Random linear network coding: a free cipher?, in:IEEE International Symposium on Information Theory.
[32] S. Acedanski, S. Deb, M. Medard, R. Koetter, How good is random linear codingbased distributed networked storage? NetCod, 2005.
[33] S. Deb, C. Choutte, M. Mdard, R. Koetter, Data harvesting: a random codingapproach to rapid dissemination andf efficient storage of data, in: Proc. of theIEEE INFOCOM 2005.
[34] A. Albanese, J. Blmer, J. Edmonds, M. Luby, M. Sudan, Priority encodingtransmission, IEEE Transactions on Information Theory 42 (1994) 1737–1744.
[35] J.-G. Kim, J. Kim, C.-C.J. Kuo, Coordinated packet level protection employingsource and channel redundancy for robust video transmission, in: Proc. of theConference on Visual Communications and Image Processing (VCIP), Part ofthe Symposium on Electronic Imaging, 2001.