cnn - amirkabir university of...
TRANSCRIPT

1

CNNخالصه : یادآوری
Convolutionalیاکانولوشنالعصبیشبکه• Neural NetworksیاConvNet
عمیقعصبیشبکههایازنوعی•باناظرآنیادگیریمدل•back-propagationالگوریتمباوزنهااصالح.•
ماتریسیوحجیمهایدادهبرایمناسب•
کانولوشنالعصبیشبکهچرا•عکسمانندحجیمدادگانازویژگیاستخراجمرحلهحذف•
غیرعمیقعصبیهایشبکهبامقایسه•یادگیریالگوریتمتوابع،نورونها،اجزا،:شباهت•.استتصویرورودیشودمیفرض:تفاوت•
2

شبکه عصبی کانولوشنالاجزای : یادآوری
الیههایشبکهعصبیکانولوشنال•ورودی•
گرفتنمقادیرخامازنقاطتصویر•
(CONV)کانولوشن•محاسبهضربنقطهایبینوزنهاینورونویکناحیهکوچکازحجمورودی•
(RELU)اصالحخطی•اعمالیکتابعبهعناصر•عدمتغییرابعادحجم•
•POOL(عرضوارتفاع)کاهشنمونهبرداریدرامتدادابعادمکانی•
•FCمحاسبهامتیازهرکالس•
3
ابعادنمونه
32x32x3
32x32x12(فیلتر12با )
32x32x12
16x16x12
1x1x10
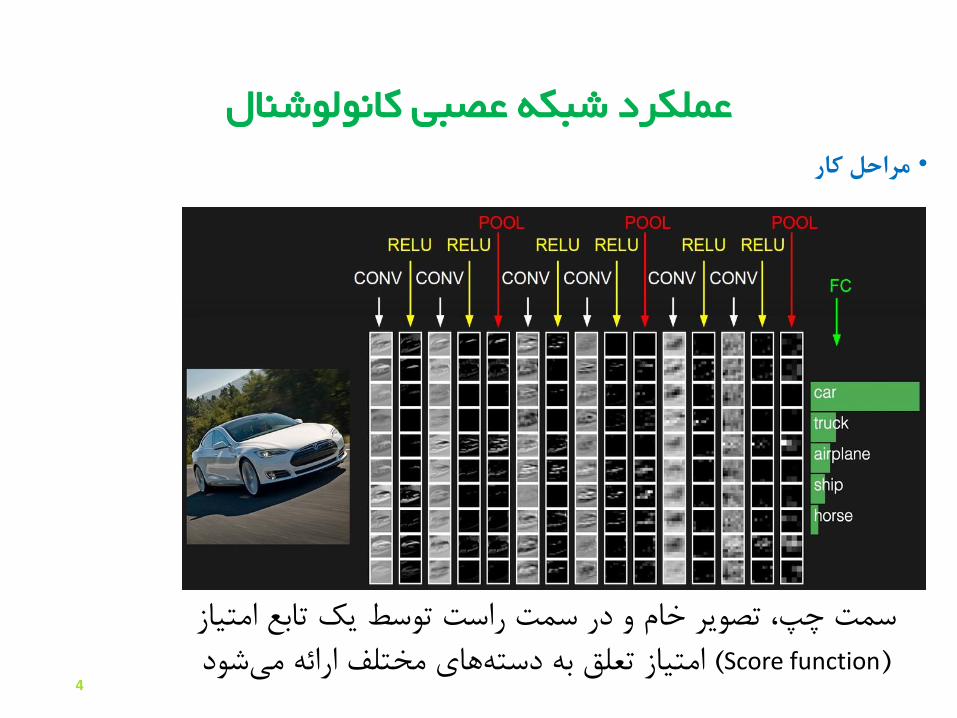
عصبی کانولوشنالعملکرد شبکه کارمراحل•
4
سمت چپ، تصویر خام و در سمت راست توسط یک تابع امتیاز (Score function )امتیاز تعلق به دسته های مختلف ارائه می شود

CNNتوسعه های
CNNنمونهتوسعههاروی••AlexNet
•ZF Net
•VGG Net•GoogLeNet
•Microsoft ResNet
•R-CNN•Fast R-CNN
•Faster R-CNN
•3D-CNN
•GAN
•....
5

AlexNet
CNN(2012)شروعشبکههایعصبی•.راشروعمیدانندLeNet(1998)برخی•
ImageNet:عنوانمقاله• Classification with Deep Convolutional Networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton:نویسندگانمقاله•
*17700بیشاز:تعدادارجاعات•
• large, deep convolutional neural network
• was used to win the 2012 ILSVRC (ImageNet Large-Scale Visual Recognition Challenge)-• the annual Olympics of computer vision • for tasks such as classification, localization, detection
.میباشد96درآذرماهGoogle Scholarکلیهارجاعاتدراینارائهبرمبنایآمار*
6
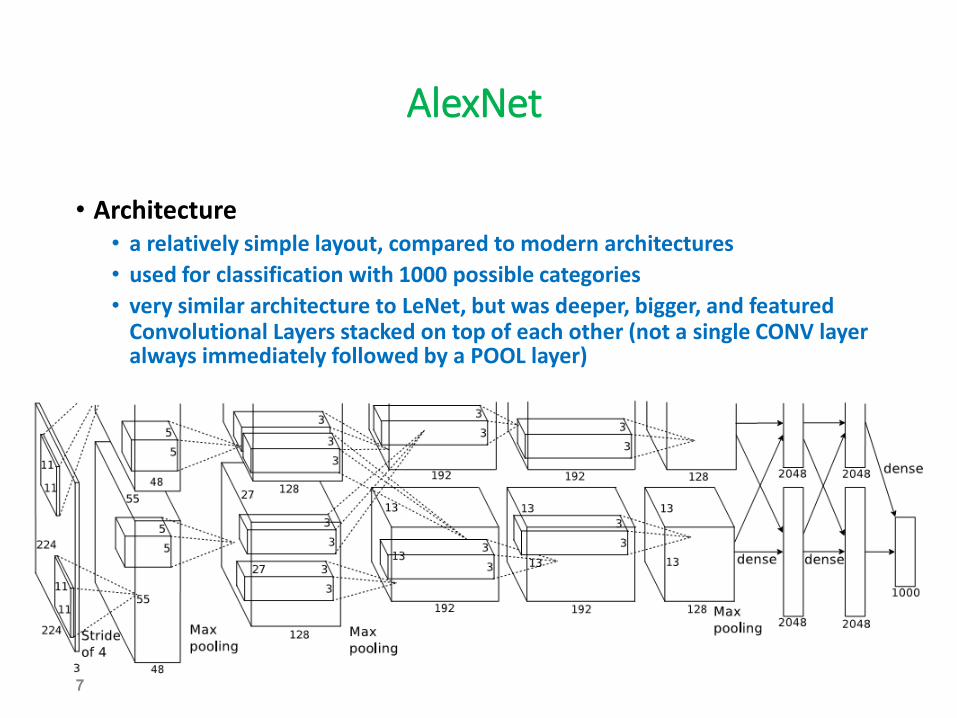
AlexNet
• Architecture • a relatively simple layout, compared to modern architectures
• used for classification with 1000 possible categories
• very similar architecture to LeNet, but was deeper, bigger, and featured Convolutional Layers stacked on top of each other (not a single CONV layer always immediately followed by a POOL layer)
7

AlexNet
• Architecture • eight layers
• first five are convolutional
• the remaining three are fully-connected
• last fully-connected layer is produces 1000 class labels
8
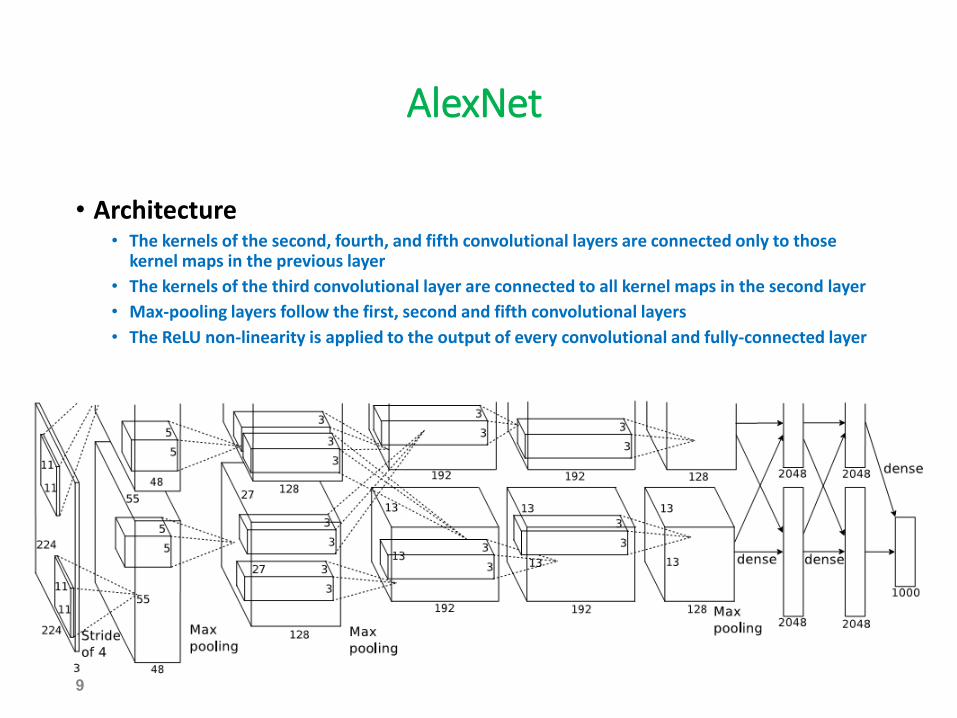
AlexNet
• Architecture • The kernels of the second, fourth, and fifth convolutional layers are connected only to those
kernel maps in the previous layer
• The kernels of the third convolutional layer are connected to all kernel maps in the second layer
• Max-pooling layers follow the first, second and fifth convolutional layers
• The ReLU non-linearity is applied to the output of every convolutional and fully-connected layer
9

AlexNet
• Architecture • The first convolutional layer filters the 224 × 224 × 3 input image with 96 kernels of size 11 × 11 × 3 with a stride
of 4 pixels .
• The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5 × 5 × 48
• The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers.
• The third convolutional layer has 384 kernels of size 3 × 3 × 256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3 × 3 × 192
• The fifth convolutional layer has 256 kernels of size 3 × 3 × 192
• The fully-connected layers have 4096 neurons each
10

AlexNet
• Main Points• Trained the network on ImageNet data, which contained over 15 million annotated images
from a total of over 22,000 categories.
• Used ReLU for the nonlinearity functions faster than the conventional tanh function.
• Used data augmentation techniques that consisted of image translations, horizontal reflections, and patch extractions.
• Implemented dropout* layers in order to combat the problem of overfitting to the training data.
• Trained the model using batch stochastic gradient descent, with specific values for momentum and weight decay.
• Trained on two GTX 580 GPUs for five to six days.
* Dropout: setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in back-propagation
11

AlexNet
• Why It’s Important• The first time a model performed so well on a historically difficult ImageNet
dataset
• Utilizing techniques that are still used today, such as data augmentation and dropout
• It illustrated the benefits of CNNs
• It breaking performance in the competition
12

ZF Net
ILSVRC 2013برنده•
Visualizing and Understanding Convolutional Neural:عنوانمقاله•Networks
Matthew Zeiler:نویسندگانمقاله• and Rob Fergus
2750بیشاز:تعدادارجاعات•• This architecture was more of a fine tuning to the previous AlexNet
structure, but still developed some very keys ideas about improving performance
• the authors spent a good amount of time explaining a lot of the intuition behind ConvNets and showing how to visualize the filters and weights correctly.
• The main contributions:• a slightly modified AlexNet model • a very interesting way of visualizing feature maps.
13

ZF Net
• architecture
14

ZF Net
• Main Points• Very similar architecture to AlexNet, except for a few minor modifications.
• AlexNet trained on 15 million images, while ZF Net trained on only 1.3 million images.
• Instead of using 11x11 sized filters in the first layer (same as AlexNet), ZF Net used filters of size 7x7 and a decreased stride value to keep a lot of original pixel information in the input volume.
• As the network grows, we also see a rise in the number of filters used.
• Used ReLUs for their activation functions, cross-entropy loss for the error function, and trained using batch stochastic gradient descent.
• Trained on a GTX 580 GPU for twelve days.
• Developed a visualization technique named Deconvolutional Network (DeConvNet), which helps to examine different feature activations and their relation to the input space. Called “deconvnet” because it maps features to pixels.
15

ZF Net
• DeConvNet• At every layer of the trained CNN, you attach a “deconvnet” which has a
path back to the image pixels.
• forward pass: An input image is fed into the CNN and activations are computed at each level
• This deconvnet has the same filters as the original CNN
• Steps:• store the activations of this one feature map, but set all of the other activations in the
layer to 0
• pass this feature map as the input into the deconvnet
• This input then goes through a series of unpool (reverse maxpooling), rectify, and filter operations for each preceding layer until the input space is reached
16

ZF Net
17
• DeConvNet

ZF Net
18
• DeConvNet• The first layer of your
ConvNet is always a low level feature detector that will detect simple edges or colors in this particular case. We can see that with the second layer, we have more circular features that are being detected. Let’s look at layers 3, 4, and 5.

ZF Net
• Why It’s Important• ZF Net was not only the winner of the competition in 2013, but also
provided great intuition as to the workings on CNNs and illustrated more ways to improve performance.
• The visualization approach described helps not only to explain the inner workings of CNNs, but also provides insight for improvements to network architectures.
• The fascinating deconv visualization approach and occlusion experiments make this one of my personal favorite papers.
19

VGG Net
2014:سالانتشار•
Very Deep Convolutional Networks for Large-Scale Image:عنوانمقاله•Recognition
Karen Simonyan:نویسندگان• and Andrew Zisserman•Visual Geometry Group
7650بیشاز:تعدادارجاعات•
• Simplicity and depth.• a 19 layer CNN
• strictly used 3x3 filters with stride and pad of 1• along with 2x2 maxpooling layers with stride 2
20
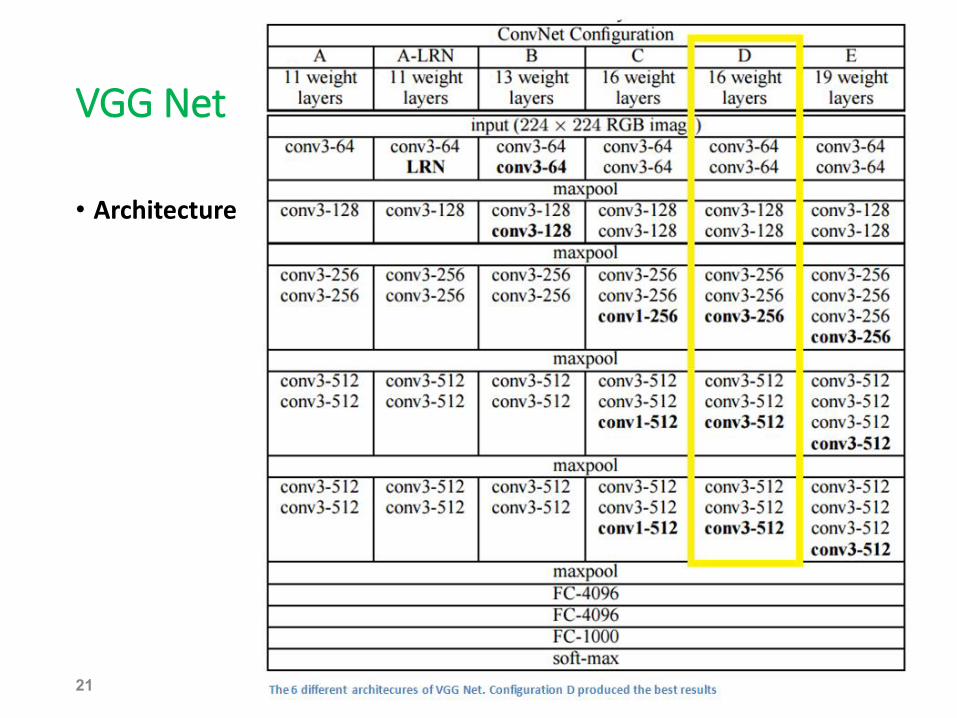
VGG Net
• Architecture
21

VGG Net
• Main Points• The use of only 3x3 sized filters is quite different from AlexNet’s and ZF
Net’s filters. (combination of two 3x3 conv layers has an effective receptive field of 5x5)
• 3 conv layers back to back have an effective receptive field of 7x7.
• As the spatial size of the input volumes at each layer decrease (result of the conv and pool layers), the depth of the volumes increase due to the increased number of filters as you go down the network.
• The number of filters doubles after each maxpool layer. This reinforces the idea of shrinking spatial dimensions, but growing depth.
22

VGG Net
• Main Points• Worked well on both image classification and localization tasks.
• Built model with the Caffe toolbox.
• Used scale jittering* as one data augmentation technique during training.
• Used ReLU layers after each conv layer and trained with batch gradient descent.
• Trained on 4 Nvidia Titan Black GPUs for two to three weeks.
* a single model is trained to recognize objects over a wide range of scales
23

VGG Net
• Why It’s Important• VGG Net is one of the most influential papers because it reinforced the
notion that convolutional neural networks have to have a deep network of layers in order for this hierarchical representation of visual data to work.
• Keep it deep.
• Keep it simple.
24

GoogLeNet
ILSVRC 2014برنده•
Going Deeper with Convolutions:عنوانمقاله•
Christian Szegedy, Wei Liu, Yangqingنویسندگان• Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke,
Andrew Rabinovich
2015انتشارمقالهسال•5400بیشاز:تعدادارجاعات•
ویژگیاصلی•عمقزیادشبکه•Inception moduleمعرفی•
25

GoogLeNet
تحقیقانگیزه•
یااماآ.راحتترینراهبهبودنتایجشبکههایعمیقافزایشاندازهوعمقآنهاست•اینبهترینراهاست؟
.استپیچیدگیمحاسباتی(بامرتبهچندجملهای)مهمترینمشکلاینراهحلافزایشچندبرابری•
تیکراهدیگربرآوردتوزیعاحتماالتیدادگانتوسطشبکهعمیقخلوتوساخ•.لاستتوپولوژیبهینهشبکهباتحلیلالیهبهالیههمبستگیآمارههایالیهقب
neurons that fire together, wire together:برمبنایقانونهب•
26

GoogLeNet
Inceptionمعماری•زبررسیآناستکهچگونهمیتوانیکساختارخلوتبهینهاInceptionایدهاصلیمعماری•
.شبکههایدیداریکانولوشنالیبرآوردکرد
27

GoogLeNet
Inceptionمعماری•.دومآناستکهکاهشبعدحتماضروریاستهرچندبارمحاسباتیداشتهباشدایده•
.ادغاموتولیدماتریسهایبابعدکمهمحاویاطالعاتبسیارزیادیازتکهتصویراست•
28

GoogLeNet
برایکاهشبعد1*1افزودنکانولوشن•باشد100×100×60مثالاگرحجمورودی•
،حجمخروجیخواهدشد1×1فیلتر20با20×100×100
29

GoogLeNet
یکشبکهازماژولهاییازانواعباالستکهپشتسرهمInceptionیکشبکه•نصفکردنگریدبرای2انباشتهشدهوگاهگاهیالیههایادغامبیشینهباگام
.استفادهشدهاست
•GoogLeNetنامیکمعماریInceptionخاصاستکهبرایمسابقاتISSVRC .انتخابشدهاست2014
پهنترهمارائهشدهکهنتایجبهتریInceptionنویسندگاننسخهعمیقتروبا•.بدستآوردهاست
.براساسمشاهداتمقادیردقیقپارامترهایمعماریتاثیرچندانینداشتهاست•
•...:
30
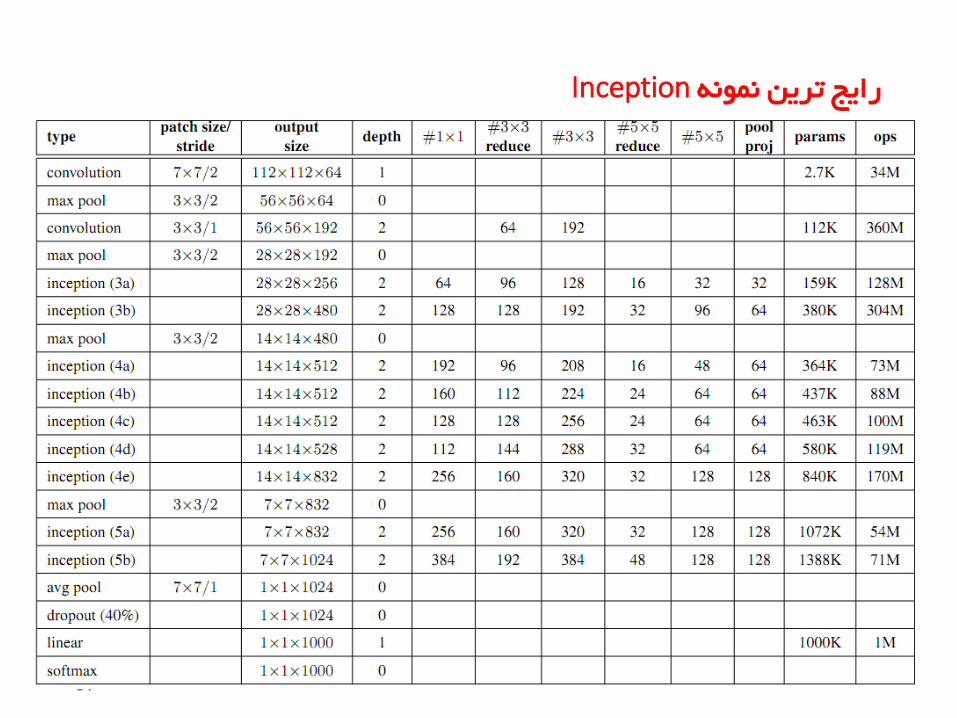
Inceptionرایج ترین نمونه
31
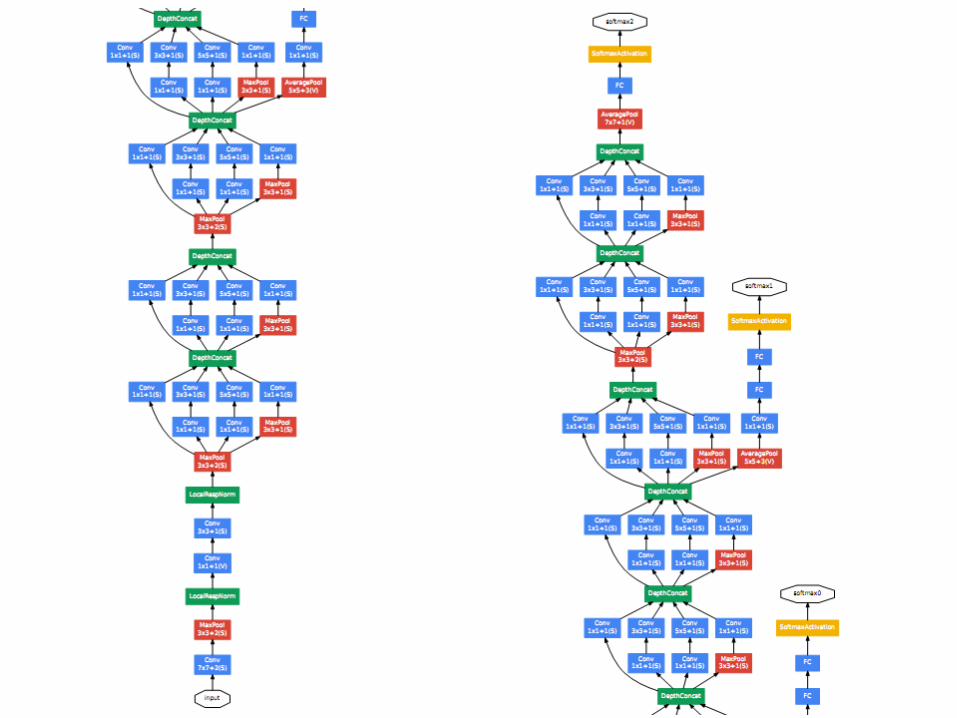
32

GoogLeNet
• Architecture• A 22 layer CNN
• Sequential or Parallel • Inception module
33

GoogLeNet
• Architecture
34

GoogLeNet
• Main Points• Used 9 Inception modules in the whole architecture, with over 100 layers in
total!
• No use of fully connected layers! They use an average pool instead, to go from a 7x7x1024 volume to a 1x1x1024 volume. This saves a huge number of parameters.
• Uses 12x fewer parameters than AlexNet.
• There are updated versions to the Inception module (Versions 6 and 7).
• Trained on GPU within a week”.
35

Microsoft ResNet
Deep Residual Learning for Image Recognition:عنوانمقاله•
Kaiming:نویسندگان• He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
2015:سالانتشار•5100بیشاز:تعدادارجاع•
ویژگیاصلی•بسیارعمیقترازآنچهتاکنوندیدهاید•residual blockمعرفی•
36

Microsoft ResNet
:سوال•آیایادگیریبهترشبکهبهسادگیباافزودنپشتسرهمالیههابدستمیآید؟•
پیشمیآیدdegradationباافزودنعمقشبکهمشکل•یکنداینخطابعلتبیشبرازشنیستبلکهباافزودنالیههابهشبکهایکهخوبکارم•
.خطایآموزشافزایشمییابد
:راهحل•.هستند(identity)الیههایاضافهشدهنگاشتهمانی•
.سایرالیهها،کپیمدلکوتاهترآموزشدیدهاند•
وجوداینراهحلنشانمیدهدکهیکمدلعمیقترنشاندهندهآناستیکمدلعمیق•.ترنبایدخطاییبیشترازمشابهکوتاهترداشتهباشد
37
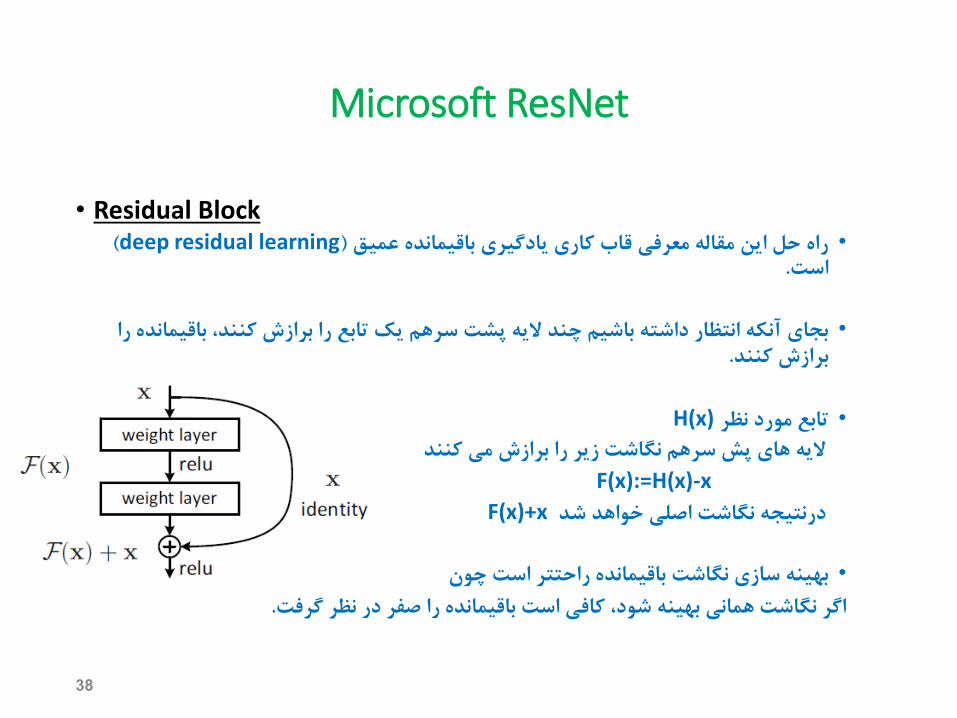
Microsoft ResNet
• Residual Block(deep residual learning)راهحلاینمقالهمعرفیقابکارییادگیریباقیماندهعمیق•
.است
ماندهرابجایآنکهانتظارداشتهباشیمچندالیهپشتسرهمیکتابعرابرازشکنند،باقی•.برازشکنند
H(x)تابعموردنظر•
الیههایپشسرهمنگاشتزیررابرازشمیکنندF(x):=H(x)-x
F(x)+xدرنتیجهنگاشتاصلیخواهدشد
بهینهسازینگاشتباقیماندهراحتتراستچون•.اگرنگاشتهمانیبهینهشود،کافیاستباقیماندهراصفردرنظرگرفت
38
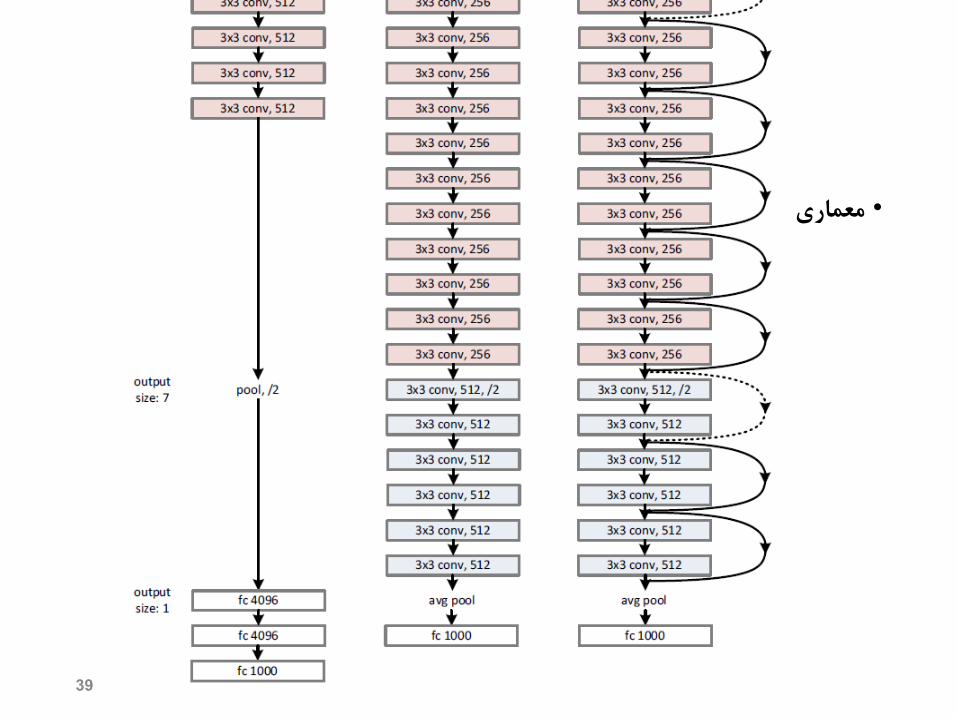
معماری•
39

Microsoft ResNet
• Main Points• “Ultra-deep, up to 152 layers.
• Authors claim that a naïve increase of layers in plain nets result in higher training and test error
• Trained on an 8 GPU machine for two to three weeks.
40

؟
41