intro to sw eng principles for cloud computing - dnelson apr2015
TRANSCRIPT

Image: http://www.leewiseonline.com/wordpress/wp-content/uploads/2012/02/EmpireStateBuildingInClouds.jpg
Intro to
SOFTWARE ENGINEERING
PRINCIPLESfor
CLOUD COMPUTING
DARRYL NELSONApril 2015

Page 2
Except where otherwise noted, this work is licensed under the Creative
Commons Attribution-ShareAlike 4.0 International License.
To view a copy of the license, visit
http://creativecommons.org/licenses/by-sa/4.0/

BIO
o Leader & Chief Engineer
– Raytheon Big Data Analytics Group
Product Leadership (Product Engineering)
Architecture and System Design
“Technical Manager” (Google’s definition)
Thought Leadership
o Plano (Dallas), Texas, USA
o linkedin.com/in/darrylnelson

Page 4
This is an introduction.
It is not comprehensive and important concepts are left out.

Page 5
Agenda
Assumptions
Prologue
Concepts
– Dematerialization
– Shared Responsibility
– Distributed Computing
Principles
– Infrastructure
– Scalability
– Reliability
– Availability
– Vendor Lock-in
TTP’s
Q & A
Resources
http://dilbert.com/strip/2011-01-07
http://dilbert.com/strip/2011-01-07
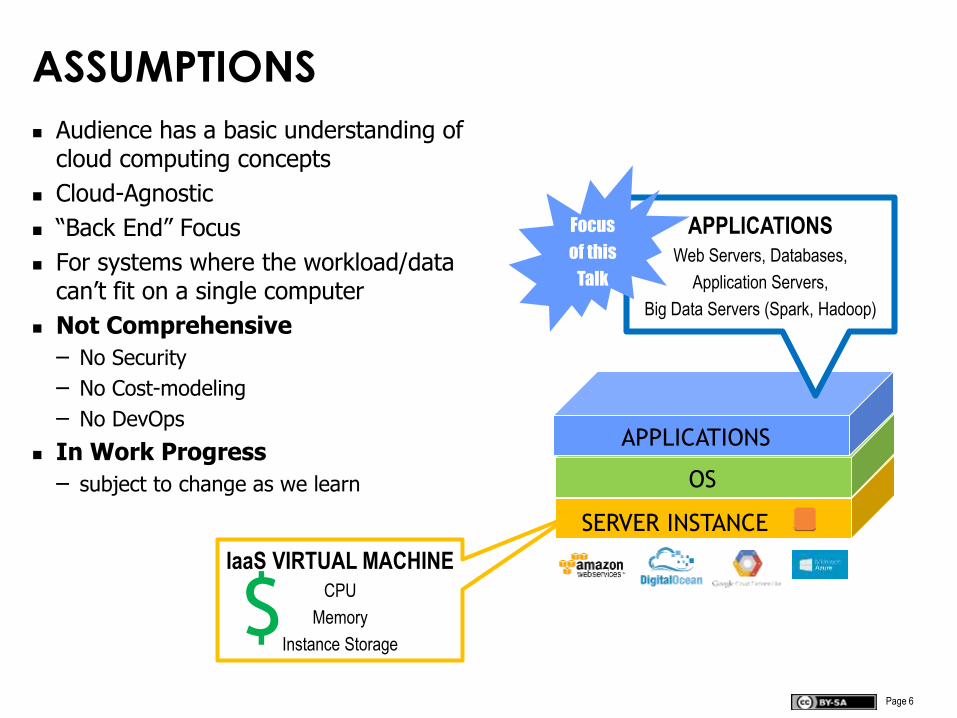
Page 6
ASSUMPTIONS
Audience has a basic understanding of cloud computing concepts
Cloud-Agnostic
“Back End” Focus
For systems where the workload/data can’t fit on a single computer
Not Comprehensive
– No Security
– No Cost-modeling
– No DevOps
In Work Progress
– subject to change as we learn
SERVER INSTANCE
OS
APPLICATIONS
IaaS VIRTUAL MACHINECPU
Memory
Instance Storage$
APPLICATIONSWeb Servers, Databases,
Application Servers,
Big Data Servers (Spark, Hadoop)
Focus
of this
Talk
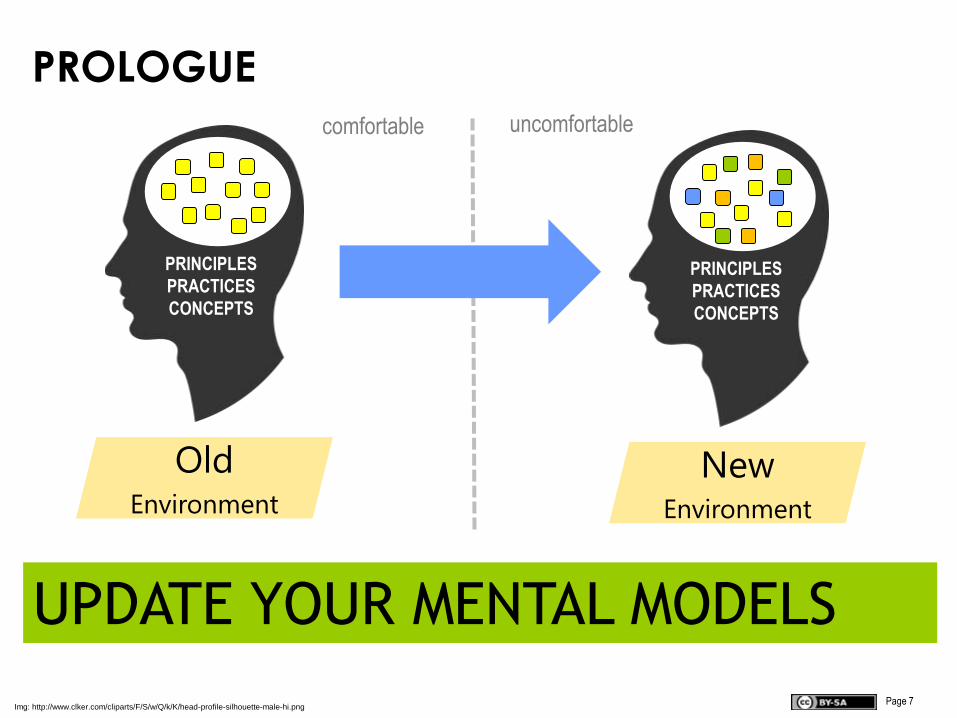
Page 7
PROLOGUE
UPDATE YOUR MENTAL MODELS
Img: http://www.clker.com/cliparts/F/S/w/Q/k/K/head-profile-silhouette-male-hi.png
PRINCIPLES
PRACTICES
CONCEPTS
PRINCIPLES
PRACTICES
CONCEPTS
OldEnvironment
NewEnvironment
comfortable uncomfortable

Page 8
Cloud Computing
On Demand Service
Broad Network Access
Resource Pooling
Rapid Elasticity
Maintainability
= New Challenges Mental Model Update
Img: http://www.freeimageslive.com/galleries/nature/weather/pics/sunny_clouds_8092612.jpg
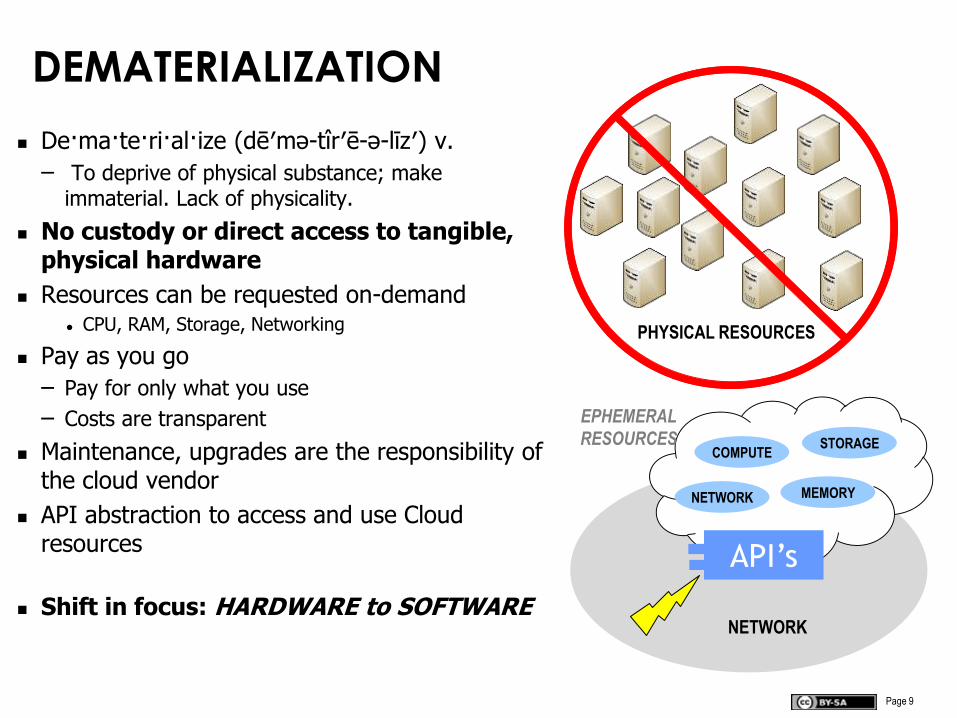
Page 9
DEMATERIALIZATION
De·ma·te·ri·al·ize (dē′mə-tîr′ē-ə-līz′) v.
– To deprive of physical substance; make immaterial. Lack of physicality.
No custody or direct access to tangible, physical hardware
Resources can be requested on-demand CPU, RAM, Storage, Networking
Pay as you go
– Pay for only what you use
– Costs are transparent
Maintenance, upgrades are the responsibility of the cloud vendor
API abstraction to access and use Cloud resources
Shift in focus: HARDWARE to SOFTWARE
PHYSICAL RESOURCES
API’s
NETWORK
COMPUTE
MEMORY
STORAGE
NETWORK
EPHEMERAL
RESOURCES
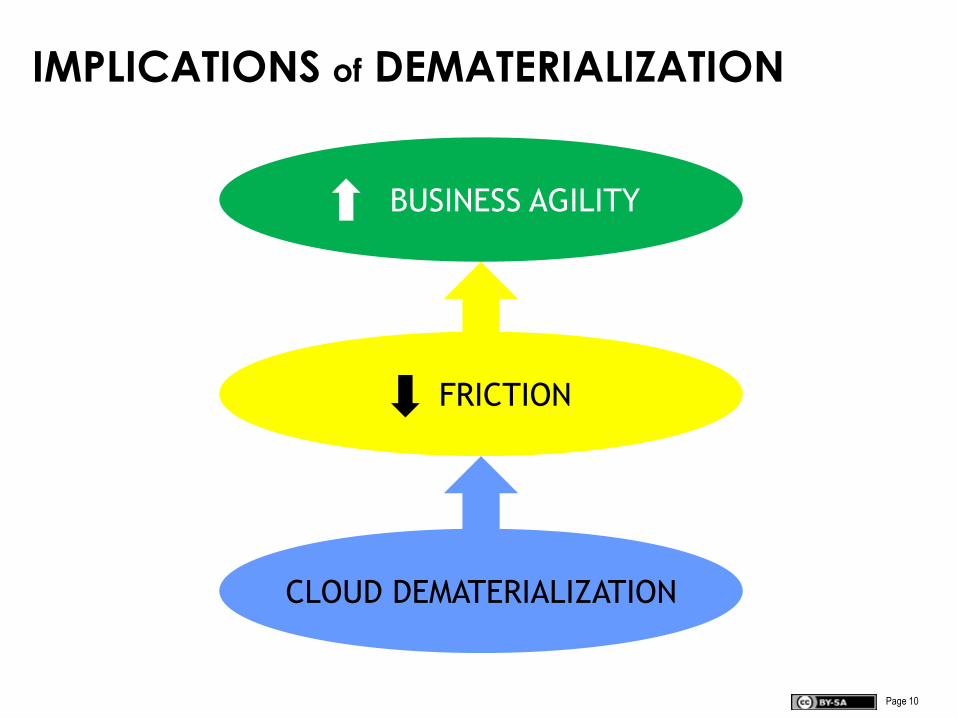
Page 10
IMPLICATIONS of DEMATERIALIZATION
CLOUD DEMATERIALIZATION
FRICTION
BUSINESS AGILITY

Page 11
Both clients and vendors share responsibility for Security, Availability, and Scalability
SHARED RESPONSIBILITY
CLOUD VENDOR
CLOUD CLIENT
SCALABILITYAVAILABILITYSECURITY

Page 12
DISTRIBUTED COMPUTING
Making a group independent, networked computers work together as one coherent system
DIVIDE & CONQUER Model
– huge problems to be broken down into many small workloads
The foundation of modern web-scale systems and a key enabler of the global digital economy
THE DATACENTER AS THE COMPUTER

Page 13
DISTRIBUTED COMPUTING cont.
Distributed computing enables scalability and availability
– Partition for scale
– Replicate for resilience
Distributed Computing is challenging
– “The network is inherently unreliable”
– “Independent things fail independently”
“Distributed Computing is the New Normal”-Francesco Cesarini & Jonas Bonér
SRC: http://www.infoq.com/presentations/reactive-concurrent-distributed-programming
DISTRIBUTED COMPUTING
SCALABILITY AVAILABILITY

Page 14
INFRASTRUCTURETraditional Enterprise Cloud
Servers as PETS Servers as CATTLE
Software as PETS
“Before “the cloud” we treated our servers like pets. We named
them, cared for them, upgraded them with kit gloves, and “fixed” them
when they broke. We projected personalities onto the machines that
served files, email, firewall and other crucial enterprise IT
services. Some servers always seemed to be troublesome, and others
problem-free.
In “the cloud” we treat our servers like cattle. Numbers instead of
names. When cloud servers get sick, we “kill them” (no offense to
PETA). We don’t fix or upgrade. We bootstrap new and replace. There
is no sentimental bond between us humans and our inanimate cloud
servers. Instead we experience transference by naming and
projecting personalities onto our software components and the
clusters of cloud servers that run the software.” Greg Arnettehttp://www.gregarnette.com/blog/2012/05/cloud-servers-are-not-our-pets/
Page 15
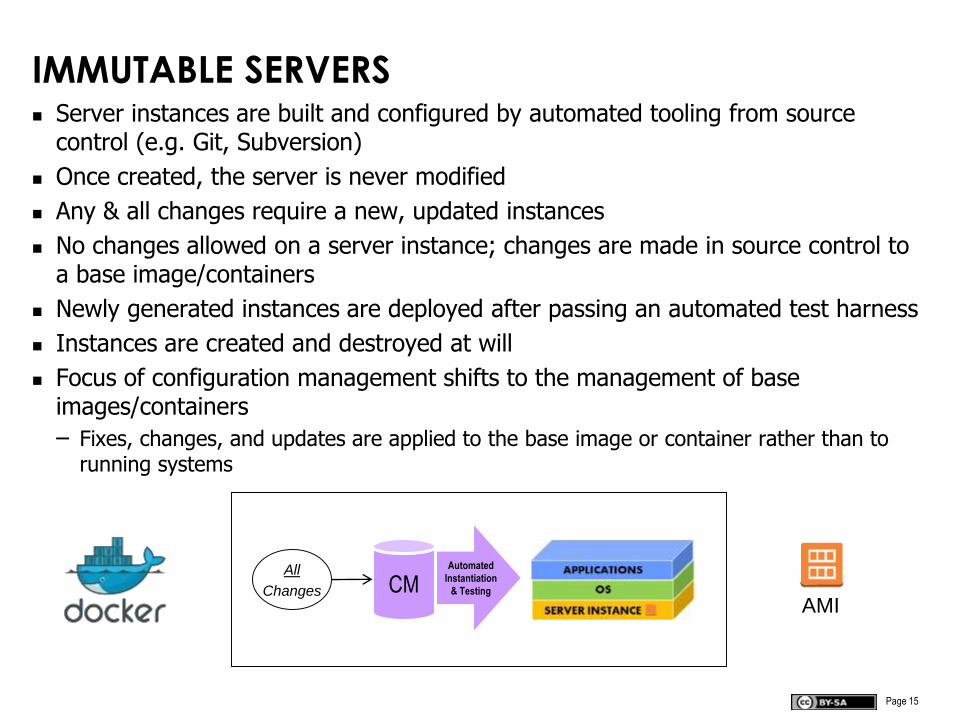
IMMUTABLE SERVERS Server instances are built and configured by automated tooling from source
control (e.g. Git, Subversion)
Once created, the server is never modified
Any & all changes require a new, updated instances
No changes allowed on a server instance; changes are made in source control to a base image/containers
Newly generated instances are deployed after passing an automated test harness
Instances are created and destroyed at will
Focus of configuration management shifts to the management of base images/containers
– Fixes, changes, and updates are applied to the base image or container rather than to running systems
AMICM
Automated
Instantiation
& Testing
All
Changes
Page 16
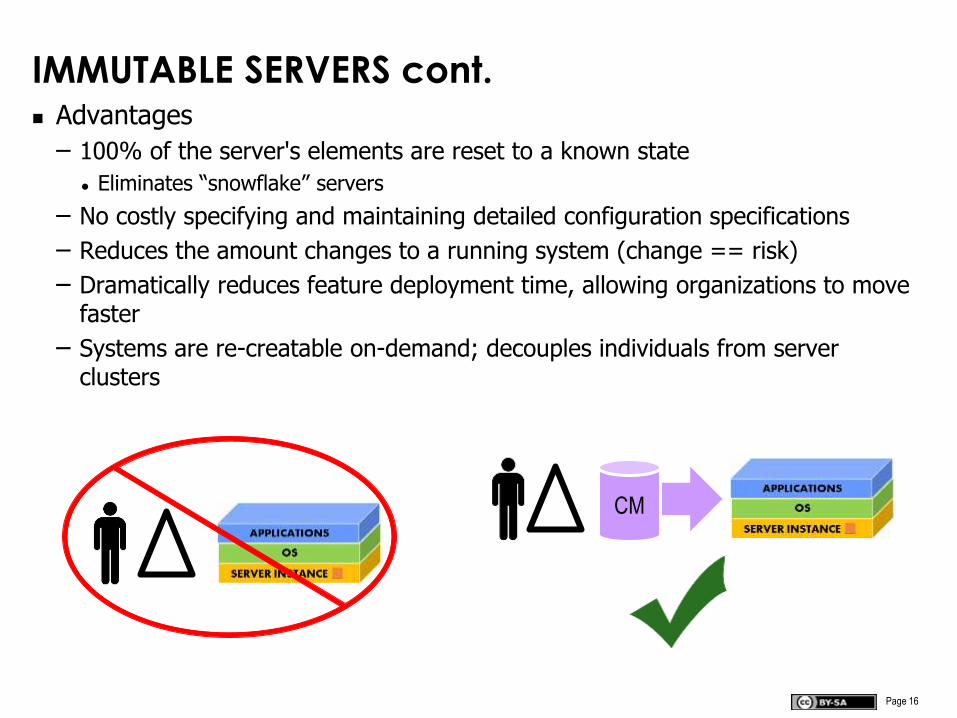
IMMUTABLE SERVERS cont. Advantages
– 100% of the server's elements are reset to a known state
Eliminates “snowflake” servers
– No costly specifying and maintaining detailed configuration specifications
– Reduces the amount changes to a running system (change == risk)
– Dramatically reduces feature deployment time, allowing organizations to move faster
– Systems are re-creatable on-demand; decouples individuals from server clusters
CM
Page 17
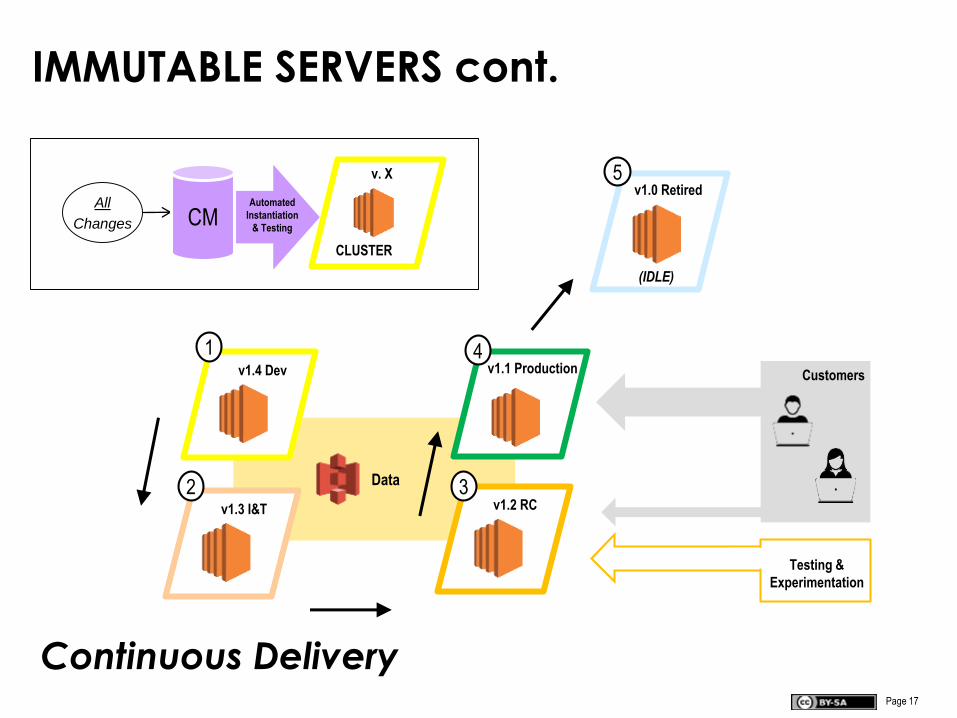
IMMUTABLE SERVERS cont.
CLUSTER
v. Xv1.0 Retired
v1.1 Production
v1.3 I&T v1.2 RC
Automated
Instantiation
& Testing
v1.4 Dev
Data
1
2 3
4
5
Customers
Testing &
Experimentation
All
Changes
(IDLE)
Continuous Delivery
CM
Page 18
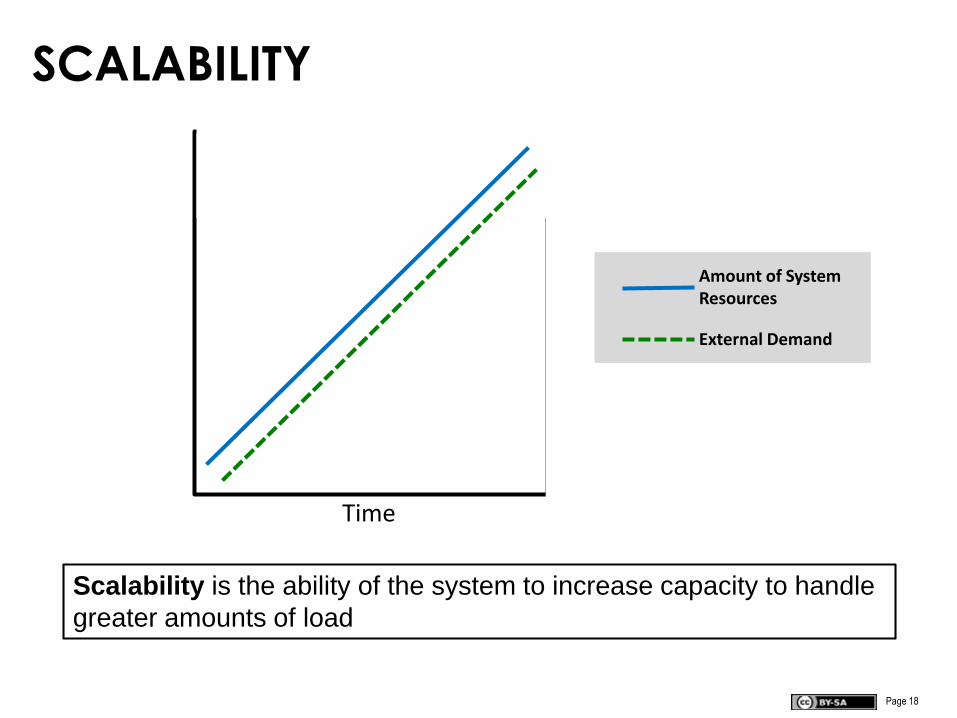
SCALABILITY
Scalability is the ability of the system to increase capacity to handle
greater amounts of load
Time
External Demand
Amount of System Resources
Page 19
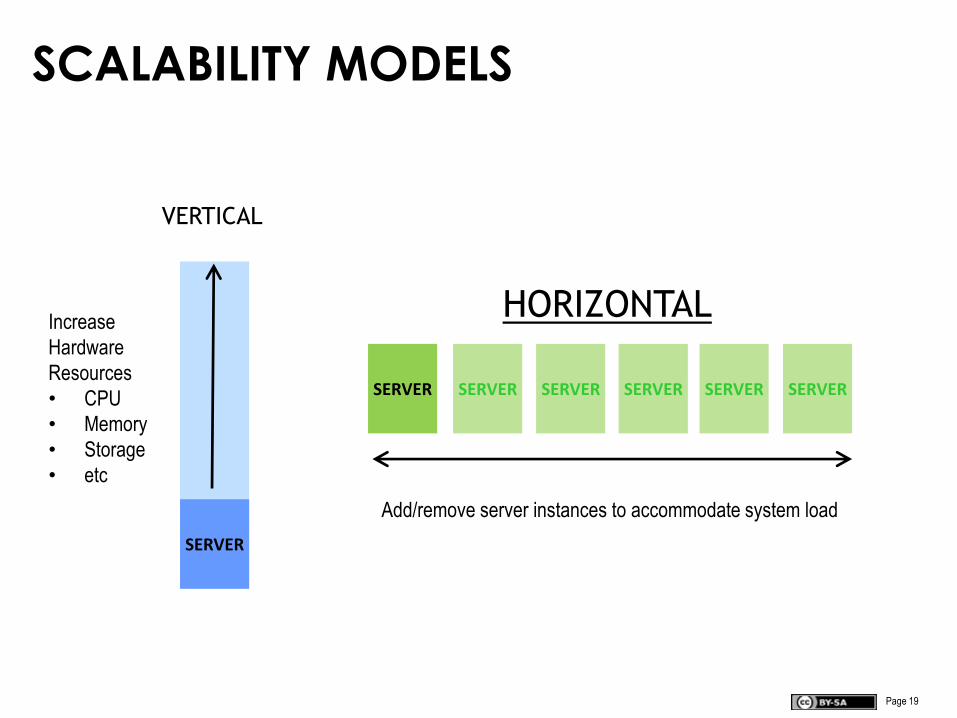
SCALABILITY MODELS
SERVER
VERTICAL
SERVER
Increase
Hardware
Resources
• CPU
• Memory
• Storage
• etc
SERVER
HORIZONTAL
SERVER SERVER SERVERSERVER
Add/remove server instances to accommodate system load

Page 20
Software needs to be designed from the ground up to scale
The software must be “aware” it is distributed
THE SCALABILITY TESTYou have a scalable architecture when, under
pressure to scale, you need a new instance, not a
new architecture.
Page 21
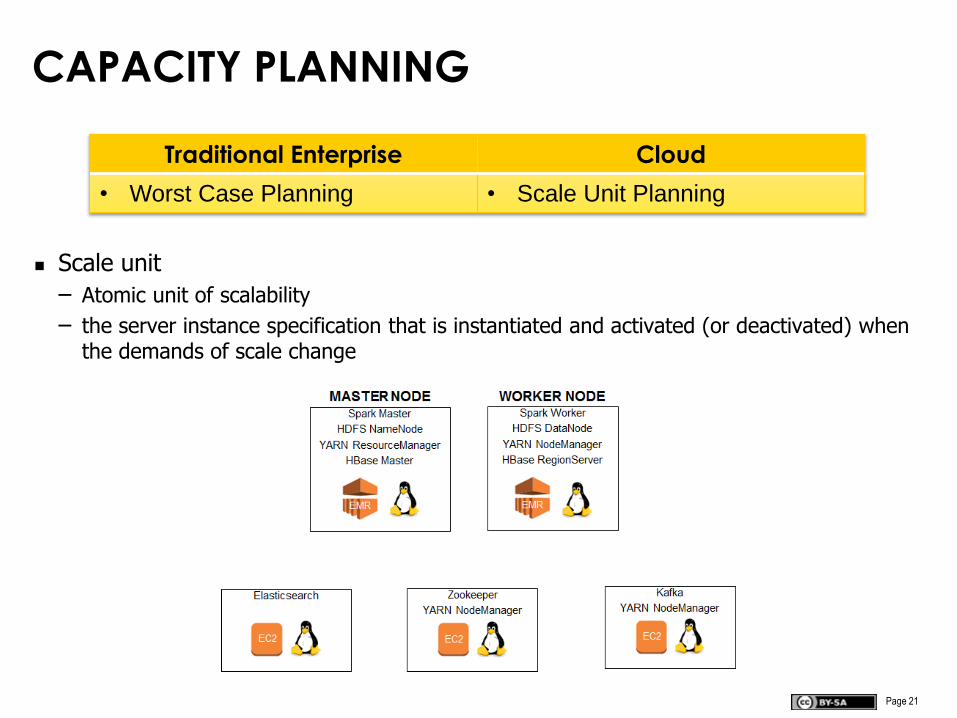
CAPACITY PLANNING
Scale unit
– Atomic unit of scalability
– the server instance specification that is instantiated and activated (or deactivated) when the demands of scale change
Traditional Enterprise Cloud
• Worst Case Planning • Scale Unit Planning

Page 22
RELIABILITY
MTTR is time is takes for software to become operational after a failure event
Reliability now tied to resiliency in the cloud, not hardware
Traditional Enterprise Cloud
• MTBFMean Time Between Failure
• Hardware focus
• MTTRMean Time To Recovery
• Software focus

Page 23
AVAILABILITY
DEF: The ability of the system to have consistently high uptimes, rapid recovery, and graceful degradation
Goal
– Individual components can fail without affecting the availability of the entire system
Traditional Enterprise Cloud
• “No Failure”
• Failure is an anomaly
• Failure is a crisis
• Fault tolerance
• Failure is common
• Failure is a maintenance ticket
13
5
2 4
DATA STORE
CRASH
STATUS: AVAILABLE
CLIENTS

Page 24
Screen capture: http://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf
Jeff Dean, Google Fellow:

4 TYPES of FAILURE
1) SOFTWARE2) HARDWARE3) NETWORK4)WETWARE
Img: http://xpda.com/junkmail/junk215/f18crashc.jpg

Page 26
Deutsch’s FALLACIES of DISTRIBUTED COMPUTING
1. The network is reliable.
2. Latency is zero.
3. Bandwidth is infinite.
4. The network is secure.
5. Topology doesn't change.
6. There is one administrator.
7. Transport cost is zero.
8. The network is homogeneous.
ACCOUNT for the NETWORK

Page 27
DISTRIBUTING COMPUTING ANTIPATTERNS
1. Guaranteed Delivery
2. Synchronous RPC
3. Distributed Objects
4. Distributed Shared Mutable State
5. Serializable Distributed Transactions
SRC: http://www.infoq.com/presentations/reactive-concurrent-distributed-programming
ANTIDOTE:
SHARE NOTHING ARCHITECTURE & IMMUTABLE DATA

Page 28
EXPLICITLY REASON ABOUT & DESIGN HOW YOUR SYSTEM BEHAVES UNDER FAILURE
1. Define what is requirede.g. no loss of acknowledge writes to the data store
no loss of availability of data
2. Research and choose a technologye.g. Apache Cassandra
3. Define the safety properties the technology depends one.g. P2P architecture, gossip protocols, replication
4. Document a proof outline of why #2 achieves #1 because of #3
5. Verify and test under simulated operational conditions
Page 29
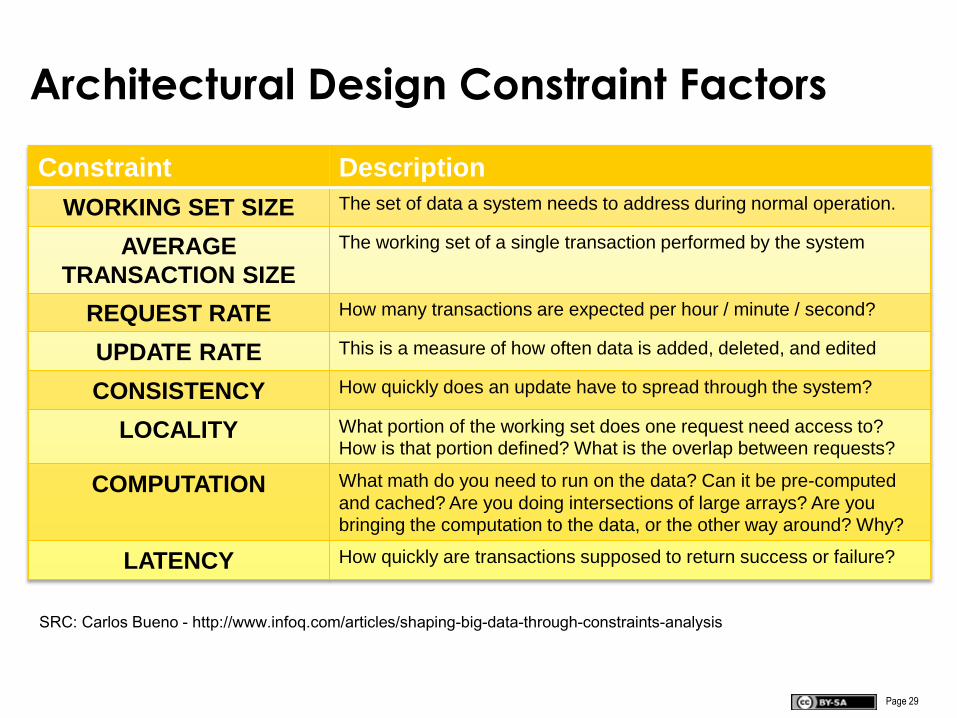
Architectural Design Constraint Factors
Constraint Description
WORKING SET SIZE The set of data a system needs to address during normal operation.
AVERAGE
TRANSACTION SIZE
The working set of a single transaction performed by the system
REQUEST RATE How many transactions are expected per hour / minute / second?
UPDATE RATE This is a measure of how often data is added, deleted, and edited
CONSISTENCY How quickly does an update have to spread through the system?
LOCALITY What portion of the working set does one request need access to? How is that portion defined? What is the overlap between requests?
COMPUTATION What math do you need to run on the data? Can it be pre-computed
and cached? Are you doing intersections of large arrays? Are you bringing the computation to the data, or the other way around? Why?
LATENCY How quickly are transactions supposed to return success or failure?
SRC: Carlos Bueno - http://www.infoq.com/articles/shaping-big-data-through-constraints-analysis
Page 30
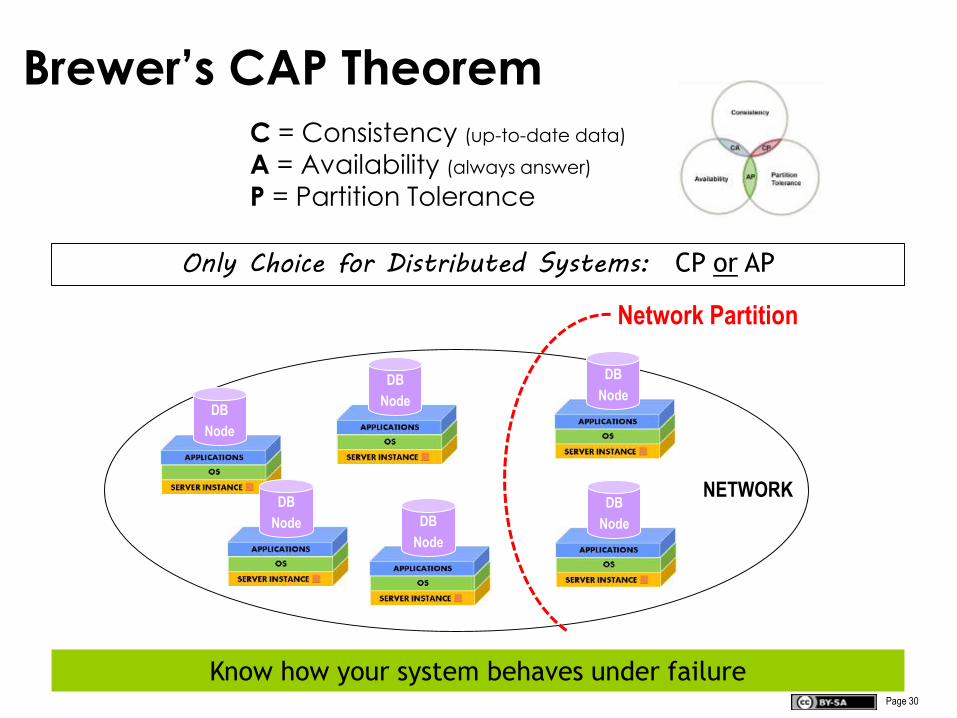
Brewer’s CAP TheoremC = Consistency (up-to-date data)
A = Availability (always answer)
P = Partition Tolerance
Only Choice for Distributed Systems: CP or AP
Network Partition
DB
Node
DB
Node
DB
Node
DB
Node
DB
Node
DB
Node
NETWORK
Know how your system behaves under failure

Sendyour
SOFTWAREto
BOOTCAMP beforeit goesinto
COMBAT(production)
IMG: https://www.flickr.com/photos/marine_corps/8002881829

Page 32
“Chaos” Harness as a Deliverable Gather a package of tools to comprehensively test the
software system Performance
Throughput
Reliability
Fault tolerance
Rich reporting
Automated
Scriptable
Example: Netflix’s Simian Army for AWS
– Chaos Monkey
randomly disables production servers
– Chaos Gorilla
simulates an outage of an entire Amazon availability zone.
– Latency Monkey
Simulates service degradation by inducing and artificial delays in client-server communications
– Conformity Monkey
finds instances that don’t adhere to best-practices and shuts them down
– Doctor Monkey
detects unhealthy servers and removes from service
– Janitor Monkey
searches for unused resources and disposes of them
– Security Monkey
finds security violations or vulnerabilities and terminates the offending instances
Page 33http://comcsoft.com/content/images/agile_process.png
Test Harness
+
“Chaos Engineers”
Chaos Engineering

Page 34
http://techblog.netflix.com/2011/07/netflix-simian-army.html
“…just designing a fault tolerant
architecture is not enough. We have to
constantly test our ability to actually
survive these ‘once in a blue moon’
failures.”

Page 35
“Fault-tolerant software is inevitable”-Jeff Dean, Google Fellow
src: http://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf
Page 36
VENDOR LOCKIN
SimpleDB
Redshift
Elasticache
ElasticMapReduce
Dynamo
Data Pipeline
Kinesis
Machine Learning
Big Query
BigData
App engine
VS.

Page 37
TPP’s – TACTICS, TECHNIQUES, & PROCEDURES
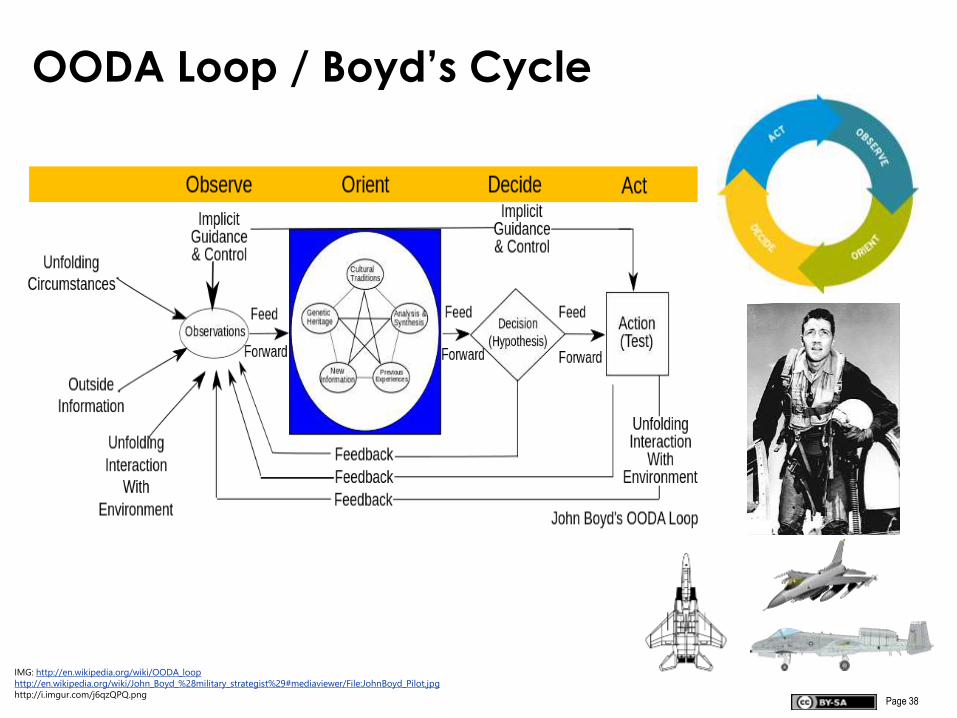
Page 38
OODA Loop / Boyd’s Cycle
IMG: http://en.wikipedia.org/wiki/OODA_loop
http://en.wikipedia.org/wiki/John_Boyd_%28military_strategist%29#mediaviewer/File:JohnBoyd_Pilot.jpg
http://i.imgur.com/j6qzQPQ.png
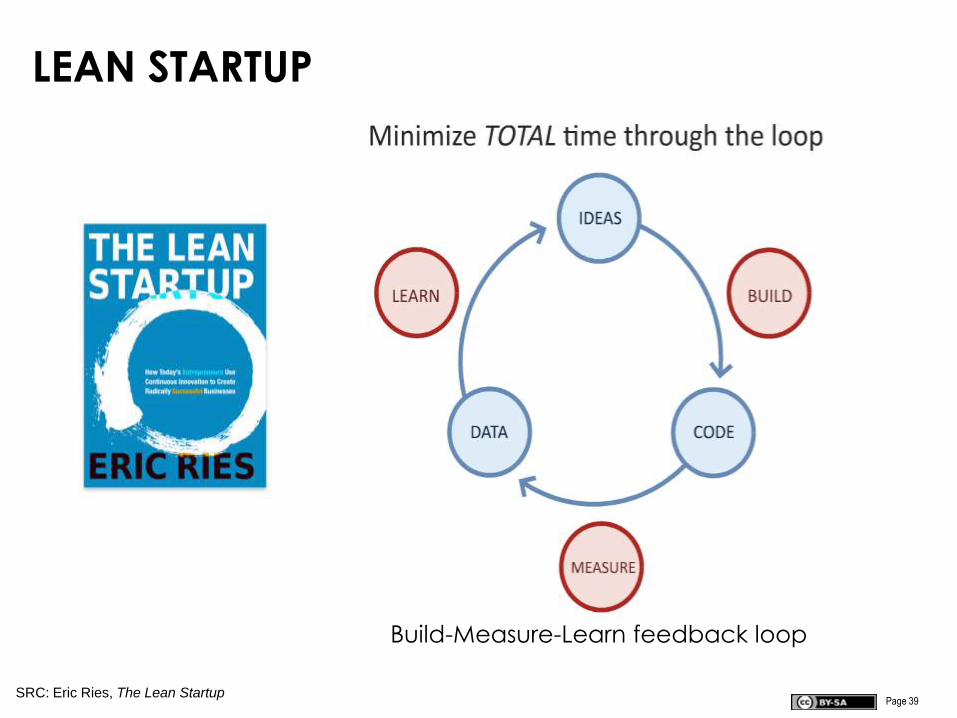
Page 39
LEAN STARTUP
SRC: Eric Ries, The Lean Startup
Build-Measure-Learn feedback loop
Page 40
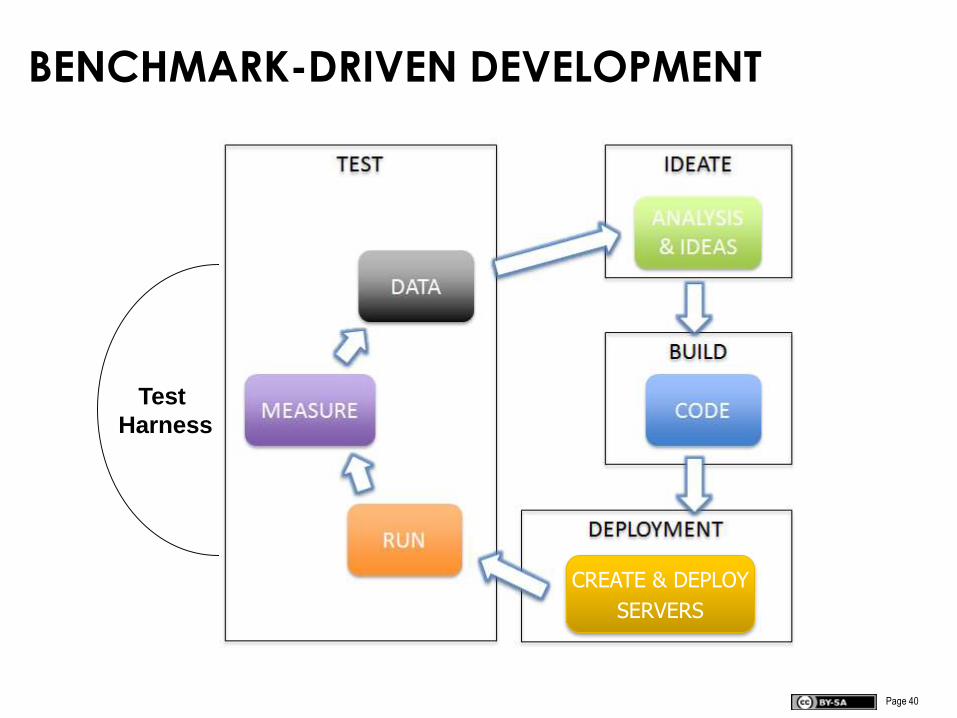
BENCHMARK-DRIVEN DEVELOPMENT
CREATE & DEPLOY
SERVERS
Test
Harness
Page 41
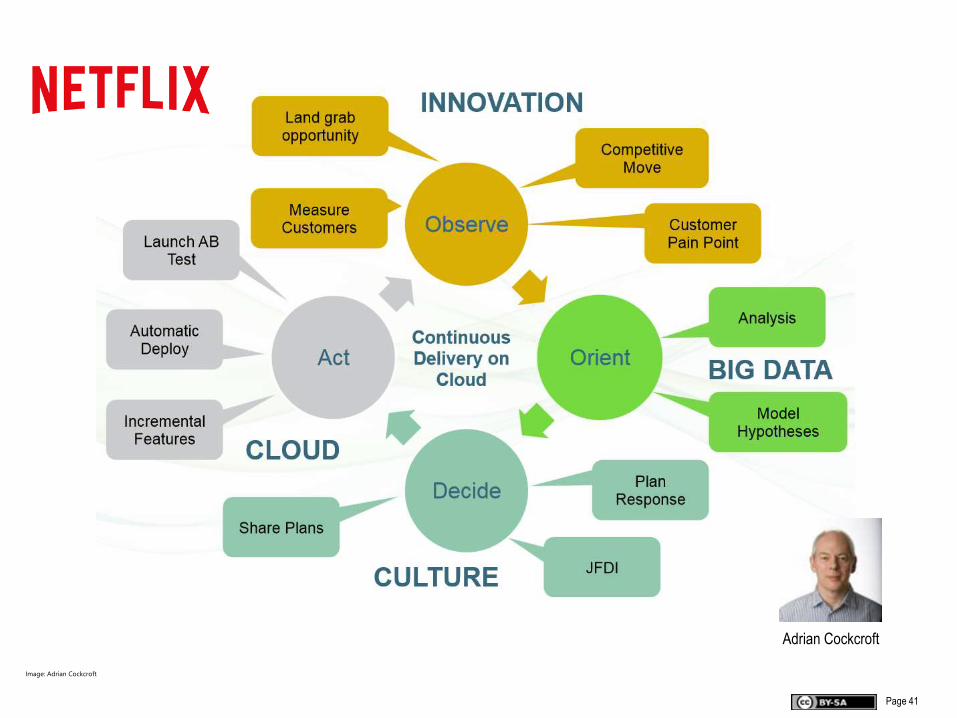
Image: Adrian Cockcroft
Adrian Cockcroft

Page 42
RESOURCES
Netflix (Cloud Native Architecture)
– Open Source Software Center - http://netflix.github.io/#repo
– Tech Blog - http:// techblog.netflix.com
Going Reactive: New and Old Ideas for Your 21st Century Architectures
– by Jonas Bonér, Francesco Cesarini
– http://www.infoq.com/presentations/reactive-concurrent-distributed-programming
Adrian Cockcroft
– Slides - http://www.slideshare.net/adrianco
– Blog - http://perfcap.blogspot.com/
– Twitter - https://twitter.com/adrianco
Peter Deutsch’s 8 Fallacies of Distributed Computing
– http://en.wikipedia.org/wiki/Fallacies_of_distributed_computing
Network Reliability - https://queue.acm.org/detail.cfm?id=2655736
Immutable Servers - http://martinfowler.com/bliki/ImmutableServer.html
Continuous Delivery - http://martinfowler.com/bliki/ContinuousDelivery.html
The Reactive Manifesto - http://www.reactivemanifesto.org/
Cloud Patterns

Q & A
TANKS!

Page 44
BACKUP

Page 45
Data Immutability
“Magic fairy dust of distributed computing” – Adrian Cockcroft
No updates or deletes of data, only add more/append
Provides Fault Tolerance & Simplicity– No data can be lost. If bad data is written, earlier (good) data units still exist.
Fixing the data system is just a matter of deleting the bad data units and
recomputing the views built off the master dataset.
With a mutable data model, a mistake can cause data to be lost because
values are actually overridden in the database.”
– No complex logic to handle updates in a distributed system
No data indexes required
The Dataset is queryable at any time in its history due to
timestamps and immutability

Page 46
Distributed Computing is Challenging
Omnipresent, Pervasive Failure- Network, Software, Hardware, and Wetware failures
- Processes may fail at any time for any reason
- No good way to tell that they have done so
- System and subsystem failure is omnipresent at all levels
Everything changes at scale– The entire technology stack from cache coherence across cores, multi-
level network topologies, disk IO, etc. can impact the system in unexpected ways
– Tiny behaviors in small systems are exponentially compounded in large cluster computing

Page 47
Laws of Engineering
1. Law of Specification
The human cannot correctly specify (abstract design) at
once all levels of a system at the outset of its development.
2. Law of Feedback
Rapid and successive feedback promotes the refinement of
a system specification (abstract design).
3. Law of Automation
Automated tools are required to provide rapid feedback and
handle tasks which the human is adept.

Page 48
REACTIVE MANIFESTO About technological recognition of ever increasing market expectations
– millisecond response times, 100% uptime, access to petabyte volumes of data
Not new but a re-introduction of principles lost (though never abandoned in the financial and telecom industries)
Describes software principles to deliver highly interactive UX’s with a real-time feel using a scalable using resilient application stack, able to deploy on multicore and cloud computing architectures
4 design properties that apply across the entire technology stack (all tiers and layers)
1. Interactive, responsive – React to Users
2. Event-driven – React to Events
3. Scalable – React to Load
4. Resilient – React to Failure

Page 49
REACTIVE MANIFESTO – cont. Scalable – React to Load
– An application is scalable if it is able to be expanded according to its usage
– An application is scalable if, when demands increase, you need a new instance, not a new architecture
– Elasticity – add or remove nodes as necessary
– Location Transparency – when scaling up, there is no difference between by using multiple cores or more nodes in a cluster. The SW can do either by design.
– Embraces the Network in the programming model through asynchronous message passing. Recognizes that communication in distributed computing is chronically unreliable
Resilient – React to Failure
– Downtime is highly destructive to businesses
– Make failure a First-class Construct
– Reactive applications react to and manage failure by healing and repairing themselves automatically at runtime
– Failure management: 1) isolate it 2) observe it
– Bulkheading – prevent cascading failures
– Separate business and failure logic. Failure is not handled by business logic but by a separate failure component.

Page 50
REACTIVE MANIFESTO – cont.
Interactive, responsive – React to Usersdelivered by #2-4
– Empowers end users when they can interact with data in real-time
– Interactive apps are “real-time, engaging, rich, and collaborative”. E.g Google Docs
– Increases efficiency, sense of being connected and ability to accomplish things
– Minimizes interruptions to an end user’s workflow
– People can communicate more often and effectively with tightened feedback loops
– Increases Feedback Granularity
Event-driven – React to EventsEvent data = things that ‘happen’ rather than things that ‘are’
– Asynchronous & Non-blocking
– Asynchronous - highly concurrent by design – leverage multicore hardware without changes
– Non-blocking – inactive components are suspended and their resources released
– Must be applied to entire stack to eliminate Amdahl’s Law (system as fast as its slowest link)
– E.g. SOFEA “single page” web app + websockets transporting event streams with the server-side

Page 51
REACTIVE BUILDING BLOCKS
Observable Models
– Enables other components to receive events when state changes
– Facilitates a real-time connection between end users and systems
Event Streams
– Events streams are the real-time connection between end users and systems
– Allow asynchronous & non-blocking transformations
Stateful Clients
– Execute logic and store state on the client-side
– Observable models do real-time updates to the UI as the data changes

Page 52
REACTIVE RESOURCES
Reactive Manifesto
– http://www.reactivemanifesto.org/
Reactive Design Patterns
– http://www.manning.com/kuhn/
– http://www.manning.com/kuhn/RDP_meap_CH01.pdf
Reactive Libraries and Tools
– https://github.com/Netflix/RxJava
– https://github.com/reactor/reactor
– http://lmax-exchange.github.io/disruptor/
– http://www.paralleluniverse.co/quasar/
– http://akka.io/
8/9/2015