file systems implementation. 2 goals for today filesystem implementation structure for –storing...
Post on 22-Dec-2015
223 views
TRANSCRIPT

File Systems Implementation

2
Goals for Today
• Filesystem Implementation
• Structure for – Storing files– Directories– Managing free space– Shared files– Links– Consistency– Journaling– Performance
• Some Implementations– Log structured file system (LFS)– Distributed FS’s (NFS/AFS)

3
File System Implementation
• How exactly are file systems implemented?• Comes down to: how do we represent
– Volumes– Directories (link file names to file “structure”)– The list of blocks containing the data– Other information such as access control list or permissions,
owner, time of access, etc?
• And, can we be smart about layout?

4
File Control Block
• FCB has all the information about the file– Linux systems call these i-node structures

5
Implementing File Operations• Create a file:
– Find space in the file system, add directory entry.
• Open file– System call specifying name of file. – system searches directory structure to find file. – System keeps current file position pointer to the location where
next write/read occurs– System call returns file descriptor (a handle) to user process
• Writing in a file:– System call specifying file descriptor and information to be written– Writes information at location pointed by the files current pointer
• Reading a file:– System call specifying file descriptor and number of bytes to read
(and possibly where in memory to stick contents).

6
Implementing File Operations
• Repositioning within a file:– System call specifying file descriptor and new location of current
pointer – (also called a file seek even though does not interact with disk)
• Closing a file:– System call specifying file descriptor– Call removes current file position pointer and file descriptor
associated with process and file
• Deleting a file:– Search directory structure for named file, release associated file
space and erase directory entry
• Truncating a file:– Keep attributes the same, but reset file size to 0, and reclaim file
space.

7
Other file operations
• Most FS require an open() system call before using a file.• OS keeps an in-memory table of open files, so when a
reading or writing is requested, they refer to entries in this table via a file descriptor.
• On finishing with a file, a close() system call is necessary. (creating & deleting files typically works on closed files)
• What happens when multiple files can open the file at the same time?

8
Multiple users of a file
• OS typically keeps two levels of internal tables:• Per-process table
– Information about the use of the file by the user (e.g. current file position pointer)
• System wide table– Gets created by first process which opens the file– Location of file on disk– Access dates– File size– Count of how many processes have the file open (used for
deletion)

9
Files Open and Read

10
Virtual File Systems
• Virtual File Systems (VFS) provide an object-oriented way of implementing file systems.
• VFS allows the same system call interface (the API) to be used for different types of file systems.
• The API is to the VFS interface, rather than any specific type of file system.

11

12
File System Layout
• File System is stored on disks– Disk is divided into 1 or more partitions– Sector 0 of disk called Master Boot Record– End of MBR has partition table (start & end address of partitions)
• First block of each partition has boot block– Loaded by MBR and executed on boot

13
Storing Files
• Files can be allocated in different ways:• Contiguous allocation
– All bytes together, in order• Linked Structure
– Each block points to the next block• Indexed Structure
– An index block contains pointer to many other blocks• Rhetorical Questions -- which is best?
– For sequential access? Random access?– Large files? Small files? Mixed?

14
Implementing Files• Contiguous Allocation: allocate files contiguously on disk

15
Contiguous Allocation
• Pros:– Simple: state required per file is start block and size– Performance: entire file can be read with one seek
• Cons:– Fragmentation: external is bigger problem– Usability: user needs to know size of file
• Used in CDROMs, DVDs
16
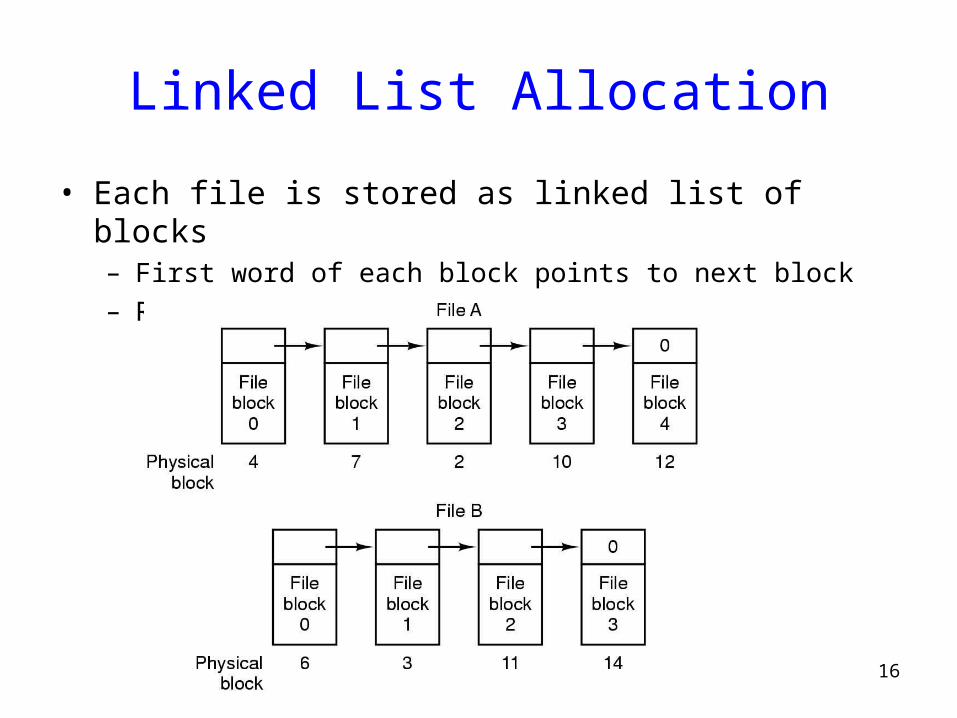
Linked List Allocation
• Each file is stored as linked list of blocks– First word of each block points to next block– Rest of disk block is file data

17
Linked List Allocation
• Pros:– No space lost to external fragmentation– Disk only needs to maintain first block of each file
• Cons:– Random access is costly– Overheads of pointers
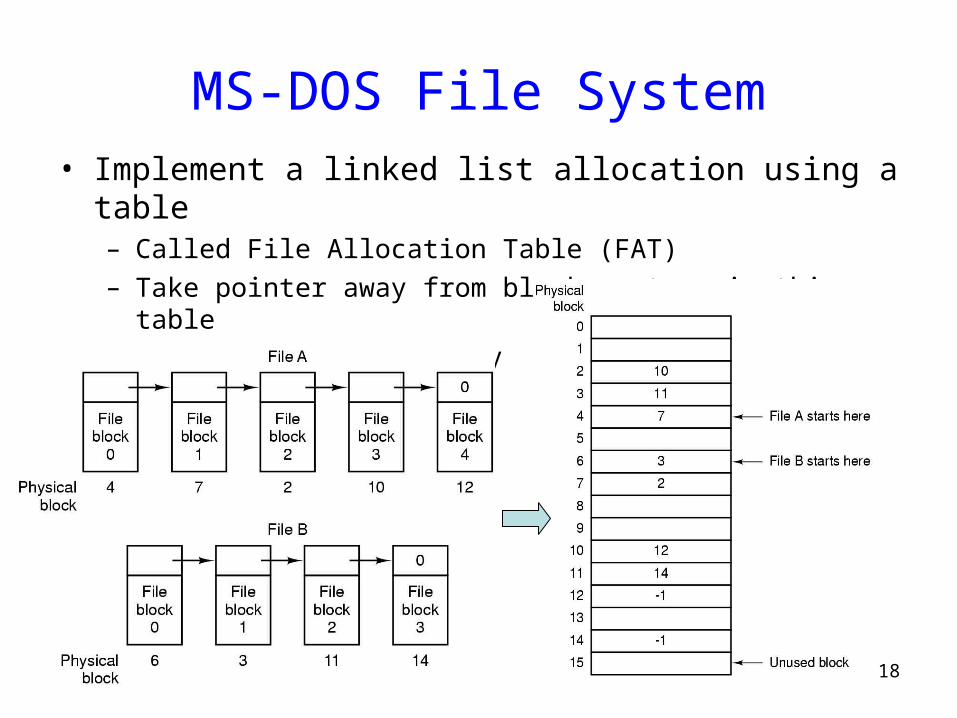
18
MS-DOS File System• Implement a linked list allocation using a table
– Called File Allocation Table (FAT)– Take pointer away from blocks, store in this table– Can cache FAT in-memory

19
FAT Discussion
• Pros:– Entire block is available for data– Random access is faster since entire FAT is in memory
• Cons:– Entire FAT should be in memory
• For 20 GB disk, 1 KB block size, FAT has 20 million entries
• If 4 bytes used per entry 80 MB of main memory required for FS

20
Indexed Allocation• Index block contains pointers to each data block• Pros?
– Space (max open files * size per I-node)
• Cons?– what if file expands beyond I-node address space?
21
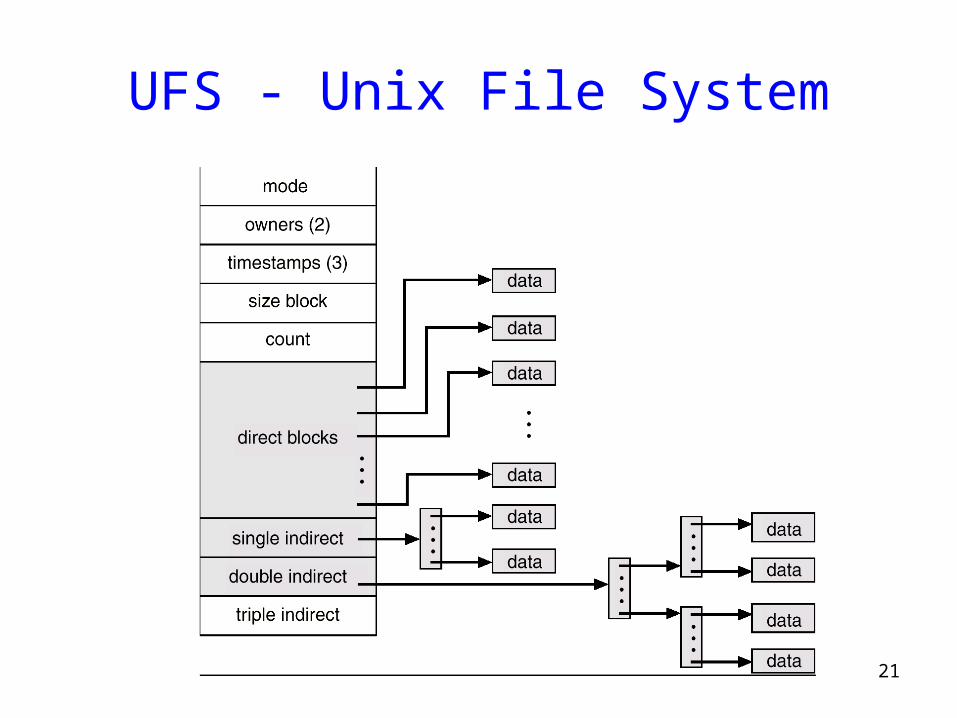
UFS - Unix File System

22
Unix inodes
• If data blocks are 4K …– First 48K reachable from the inode– Next 4MB available from single-indirect– Next 4GB available from double-indirect– Next 4TB available through the triple-indirect block
• Any block can be found with at most 3 disk accesses
23
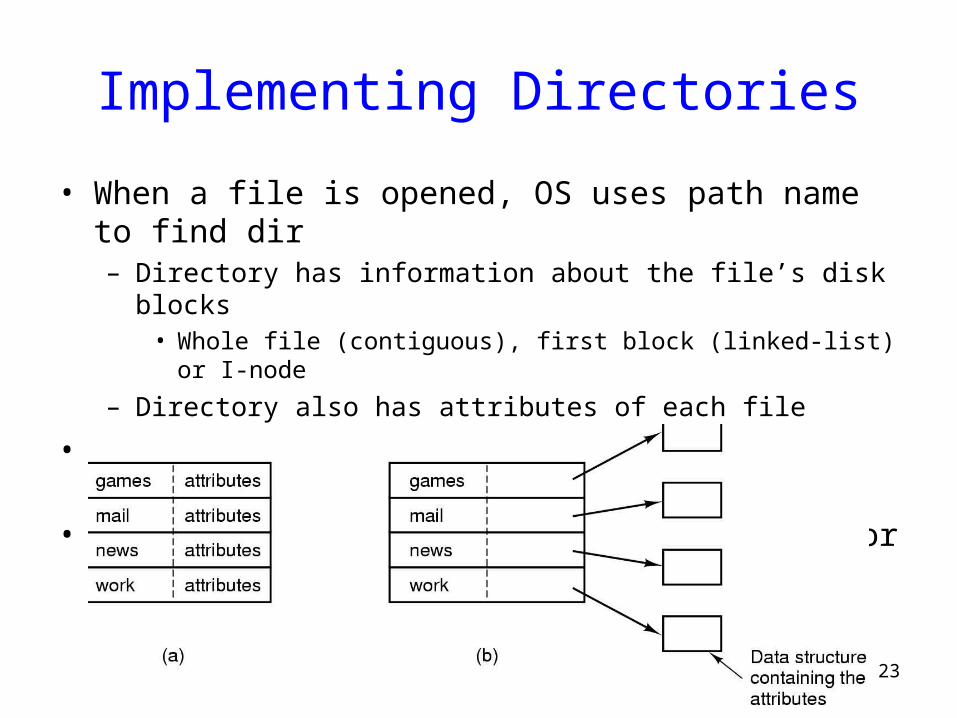
Implementing Directories
• When a file is opened, OS uses path name to find dir– Directory has information about the file’s disk blocks
• Whole file (contiguous), first block (linked-list) or I-node
– Directory also has attributes of each file
• Directory: map ASCII file name to file attributes & location• 2 options: entries have all attributes, or point to file I-node

24
Implementing Directories
• What if files have large, variable-length names?• Solution:
– Limit file name length, say 255 chars, and use previous scheme• Pros: Simple
• Cons: wastes space
– Directory entry comprises fixed and variable portion• Fixed part starts with entry size, followed by attributes
• Variable part has the file name
• Pros: saves space
• Cons: holes on removal, page fault on file read, word boundaries
– Directory entries are fixed in length, pointer to file name in heap• Pros: easy removal, no space wasted for word boundaries• Cons: manage heap, page faults on file names

25
Managing file names: Example

26
Directory Search
• Simple Linear search can be slow• Alternatives:
– Use a per-directory hash table• Could use hash of file name to store entry for file
• Pros: faster lookup
• Cons: More complex management
– Caching: cache the most recent searches• Look in cache before searching FS

27
Shared Files
• If B wants to share a file owned by C– One Solution: copy disk addresses in B’s directory entry– Problem: modification by one not reflected in other user’s view
28
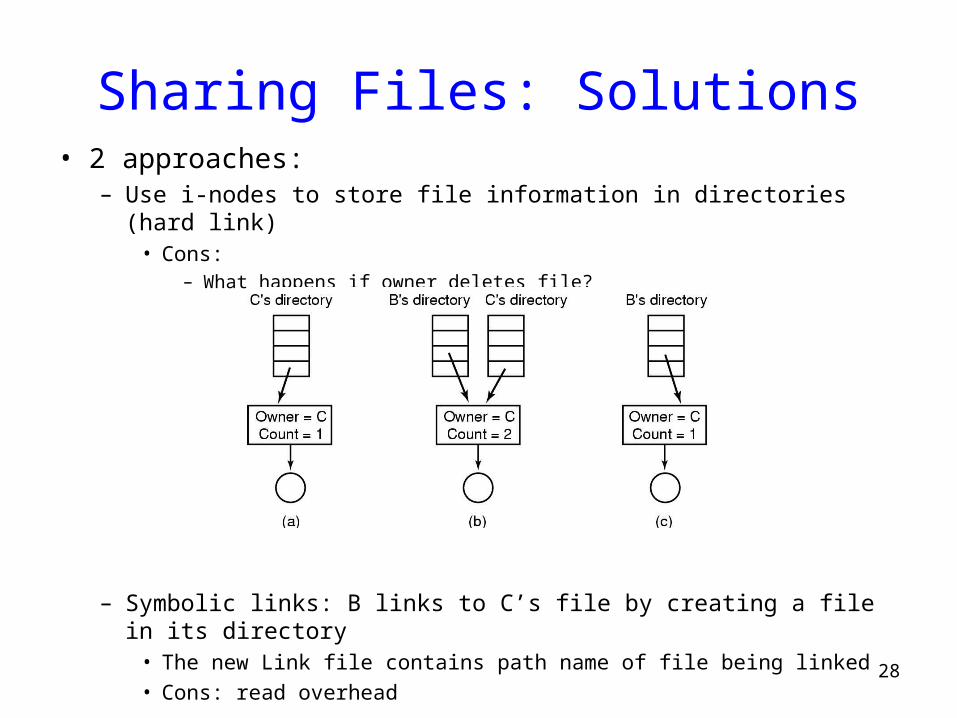
Sharing Files: Solutions• 2 approaches:
– Use i-nodes to store file information in directories (hard link)• Cons:
– What happens if owner deletes file?
– Symbolic links: B links to C’s file by creating a file in its directory• The new Link file contains path name of file being linked
• Cons: read overhead

29
Hard vs Soft Links
File name Inode# Inode
Foo.txt 2433
Hard.lnk 2433
Inode #2433

30
Hard vs Soft Links
Foo.txt 2433
Soft.lnk 43234
Inode #2433
Inode #43234
/path/to/Foo.txt
..and then redirects to Inode #2433 at open() time..

31
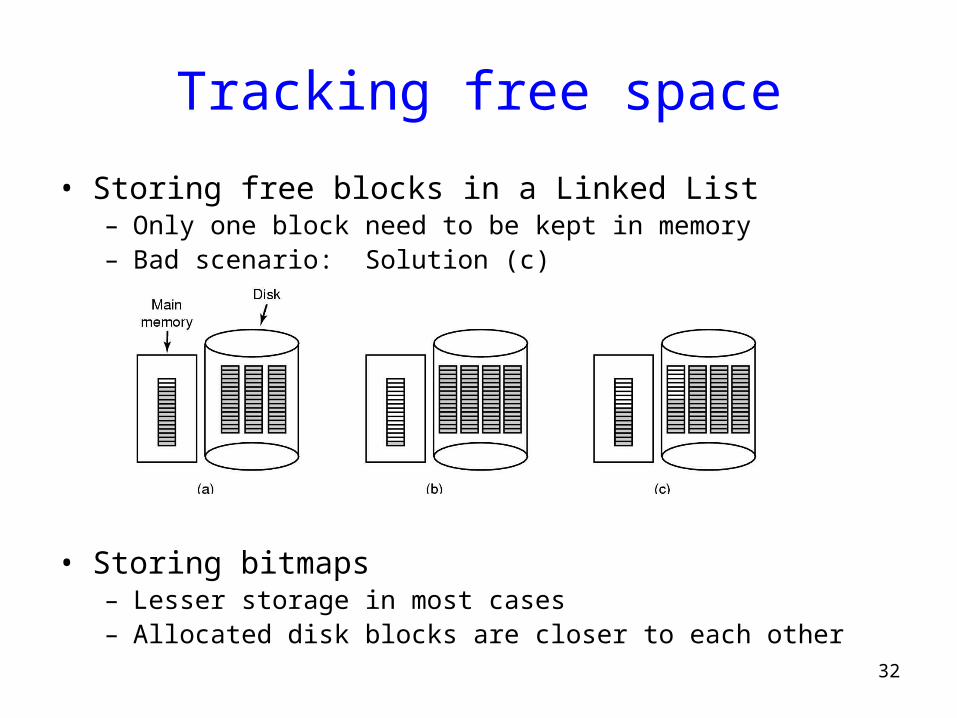
Managing Free Disk Space
• 2 approaches to keep track of free disk blocks– Linked list and bitmap approach
32
Tracking free space
• Storing free blocks in a Linked List– Only one block need to be kept in memory– Bad scenario: Solution (c)
• Storing bitmaps– Lesser storage in most cases– Allocated disk blocks are closer to each other
33
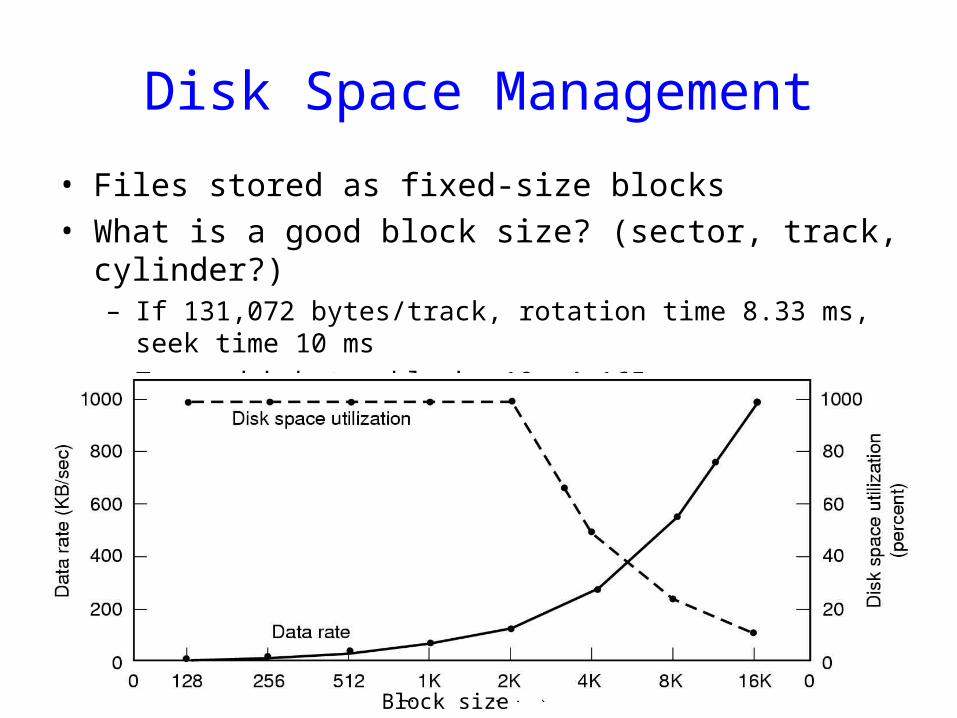
Disk Space Management
• Files stored as fixed-size blocks• What is a good block size? (sector, track, cylinder?)
– If 131,072 bytes/track, rotation time 8.33 ms, seek time 10 ms– To read k bytes block: 10+ 4.165 + (k/131072)*8.33 ms– Median file size: 2 KB
Block size

34
Managing Disk Quotas
• Sys admin gives each user max space– Open file table has entry to Quota table– Soft limit violations result in warnings– Hard limit violations result in errors– Check limits on login

35
Efficiency and Performance
• Efficiency dependent on:– disk allocation and directory algorithms– types of data kept in file’s directory entry
• Performance– disk cache – separate section of main memory for frequently
used blocks– free-behind and read-ahead – techniques to optimize sequential
access– improve PC performance by dedicating section of memory as
virtual disk, or RAM disk

36
File System Consistency
• System crash before modified files written back– Leads to inconsistency in FS– fsck (UNIX) & scandisk (Windows) check FS consistency
• Algorithm:– Build 2 tables, each containing counter for all blocks (init to 0)
• 1st table checks how many times a block is in a file
• 2nd table records how often block is present in the free list
– >1 not possible if using a bitmap
– Read all i-nodes, and modify table 1– Read free-list and modify table 2– Consistent state if block is either in table 1 or 2, but not both

37
A changing problem
• Consistency used to be very hard– Problem was that driver implemented C-SCAN and this could
reorder operations– For example
• Delete file X in inode Y containing blocks A, B, C• Now create file Z re-using inode Y and block C
– Problem is that if I/O is out of order and a crash occurs we could see a scramble
• E.g. C in both X and Z… or directory entry for X is still there but points to inode now in use for file Z

38
Inconsistent FS examples
(a) Consistent
(b) missing block 2: add it to free list
(c) Duplicate block 4 in free list: rebuild free list
(d) Duplicate block 5 in data list: copy block and add it to one file

39
Check Directory System
• Use a per-file table instead of per-block• Parse entire directory structure, starting at the root
– Increment the counter for each file you encounter– This value can be >1 due to hard links– Symbolic links are ignored
• Compare counts in table with link counts in the i-node– If i-node count > our directory count (wastes space)– If i-node count < our directory count (catastrophic)

40
Log Structured File Systems
• Log structured (or journaling) file systems record each update to the file system as a transaction
• All transactions are written to a log– A transaction is considered committed once it is written
to the log– However, the file system may not yet be updated

41
Log Structured File Systems• The transactions synchronously written to the log are
subsequently asynchronously written to the file system– When the file system is modified, the transaction is removed from
the log
• If the file system crashes, all remaining transactions in the log must still be performed
• E.g. ReiserFS, XFS, NTFS, etc..

42
FS Performance
• Access to disk is much slower than access to memory– Optimizations needed to get best performance
• 3 possible approaches: caching, prefetching, disk layout• Block or buffer cache:
– Read/write from and to the cache.

43
Block Cache Replacement
• Which cache block to replace?– Could use any page replacement algorithm– Possible to implement perfect LRU
• Since much lesser frequency of cache access
• Move block to front of queue
– Perfect LRU is undesirable. We should also answer:• Is the block essential to consistency of system?
• Will this block be needed again soon?
• When to write back other blocks?– Update daemon in UNIX calls sync system call every 30 s– MS-DOS uses write-through caches

44
Other Approaches
• Pre-fetching or Block Read Ahead– Get a block in cache before it is needed (e.g. next file block)– Need to keep track if access is sequential or random
• Reducing disk arm motion– Put blocks likely to be accessed together in same cylinder
• Easy with bitmap, possible with over-provisioning in free lists– Modify i-node placements

Other File Systems:LFS, NFS, and AFS

46
Announcements
• Homework due today
• Pick up prelim from homework center
• Prelim II will be Thursday, November 20th

48
Log-Structured File Systems
• The trend: CPUs are faster, RAM & caches are bigger– So, a lot of reads do not require disk access– Most disk accesses are writes pre-fetching not very useful– Worse, most writes are small 10 ms overhead for 50 µs write– Example: to create a new file:
• i-node of directory needs to be written
• Directory block needs to be written
• i-node for the file has to be written
• Need to write the file
– Delaying these writes could hamper consistency
• Solution: LFS to utilize full disk bandwidth

49
LFS Basic Idea• Structure the disk a log
– Periodically, all pending writes buffered in memory are collected in a single segment
– The entire segment is written contiguously at end of the log
• Segment may contain i-nodes, directory entries, data– Start of each segment has a summary– If segment around 1 MB, then full disk bandwidth can be utilized
• Note, i-nodes are now scattered on disk– Maintain i-node map (entry i points to i-node i on disk)– Part of it is cached, reducing the delay in accessing i-node
• This description works great for disks of infinite size
50
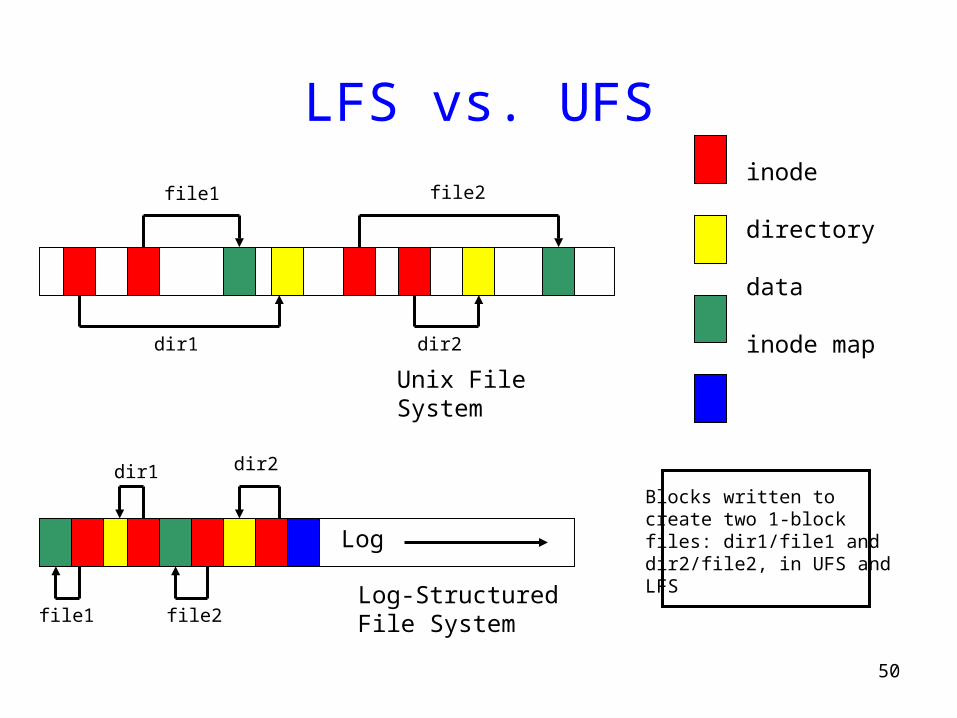
LFS vs. UFS
file1 file2
dir1 dir2
Unix FileSystem
file1 file2
dir1 dir2
Log-StructuredFile System
Log
inode
directory
data
inode map
Blocks written tocreate two 1-blockfiles: dir1/file1 anddir2/file2, in UFS andLFS

51
LFS Cleaning
• Finite disk space implies that the disk is eventually full– Fortunately, some segments have stale information– A file overwrite causes i-node to point to new blocks
• Old ones still occupy space
• Solution: LFS Cleaner thread compacts the log– Read segment summary, and see if contents are current
• File blocks, i-nodes, etc.
– If not, the segment is marked free, and cleaner moves forward– Else, cleaner writes content into new segment at end of the log– The segment is marked as free!
• Disk is a circular buffer, writer adds contents to the front, cleaner cleans content from the back

52
Distributed File Systems
• Goal: view a distributed system as a file system– Storage is distributed– Web tries to make world a collection of hyperlinked documents
• Issues not common to usual file systems– Naming transparency– Load balancing– Scalability– Location and network transparency– Fault tolerance
• We will look at some of these today
53
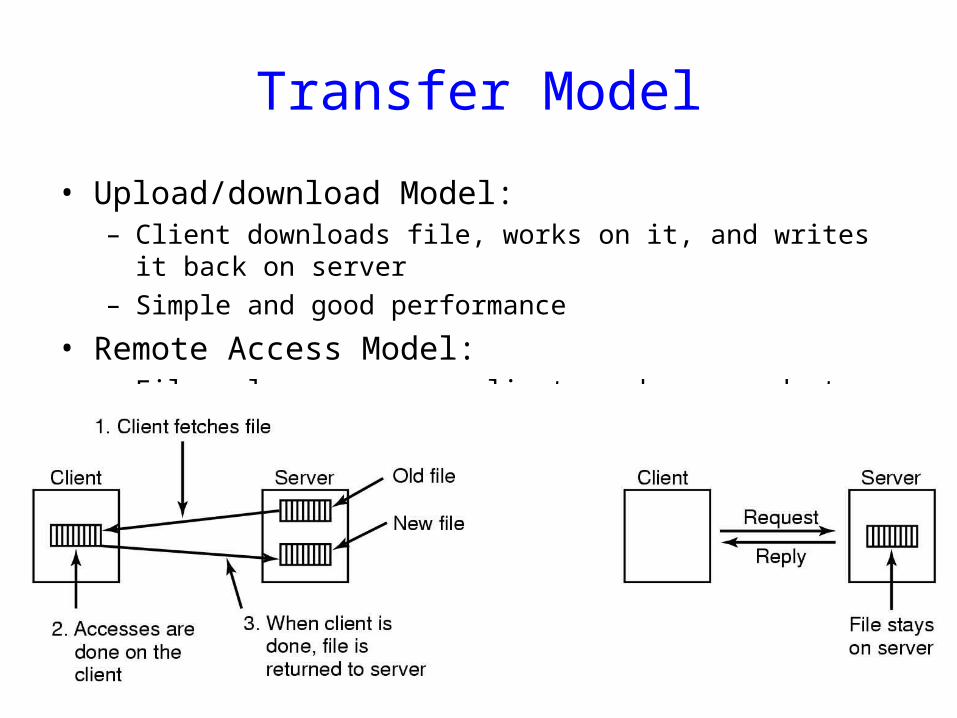
Transfer Model
• Upload/download Model:– Client downloads file, works on it, and writes it back on server– Simple and good performance
• Remote Access Model: – File only on server; client sends commands to get work done

54
Naming transparency
• Naming is a mapping from logical to physical objects• Ideally client interface should be transparent
– Not distinguish between remote and local files– /machine/path or mounting remote FS in local hierarchy are not
transparent
• A transparent DFS hides the location of files in system• 2 forms of transparency:
– Location transparency: path gives no hint of file location• /server1/dir1/dir2/x tells x is on server1, but not where server1 is
– Location independence: move files without changing names• Separate naming hierarchy from storage devices hierarchy

55
File Sharing Semantics• Sequential consistency: reads see previous writes
– Ordering on all system calls seen by all processors– Maintained in single processor systems– Can be achieved in DFS with one file server and no caching

56
Caching
• Keep repeatedly accessed blocks in cache– Improves performance of further accesses
• How it works:– If needed block not in cache, it is fetched and cached– Accesses performed on local copy– One master file copy on server, other copies distributed in DFS– Cache consistency problem: how to keep cached copy
consistent with master file copy
• Where to cache?– Disk: Pros: more reliable, data present locally on recovery– Memory: Pros: diskless workstations, quicker data access, – Servers maintain cache in memory

57
File Sharing Semantics
• Other approaches:– Write through caches:
• immediately propagate changes in cache files to server
• Reliable but poor performance
– Delayed write:• Writes are not propagated immediately, probably on file close
• Session semantics (AFS): write file back on close
• Alternative (NFS): scan cache periodically and flush modified blocks
• Better performance but poor reliability
– File Locking:• The upload/download model locks a downloaded file
• Other processes wait for file lock to be released

58
Network File System (NFS)
• Developed by Sun Microsystems in 1984– Used to join FSes on multiple computers as one logical whole
• Used commonly today with UNIX systems• Assumptions
– Allows arbitrary collection of users to share a file system– Clients and servers might be on different LANs– Machines can be clients and servers at the same time
• Architecture:– A server exports one or more of its directories to remote clients– Clients access exported directories by mounting them
• The contents are then accessed as if they were local

59
Example

60
NFS Mount Protocol
• Client sends path name to server with request to mount– Not required to specify where to mount
• If path is legal and exported, server returns file handle– Contains FS type, disk, i-node number of directory, security info– Subsequent accesses from client use file handle
• Mount can be either at boot or automount– Using automount, directories are not mounted during boot– OS sends a message to servers on first remote file access– Automount is helpful since remote dir might not be used at all
• Mount only affects the client view!

61
NFS Protocol
• Supports directory and file access via remote procedure calls (RPCs)
• All UNIX system calls supported other than open & close• Open and close are intentionally not supported
– For a read, client sends lookup message to server– Server looks up file and returns handle– Unlike open, lookup does not copy info in internal system tables– Subsequently, read contains file handle, offset and num bytes– Each message is self-contained
• Pros: server is stateless, i.e. no state about open files• Cons: Locking is difficult, no concurrency control

62
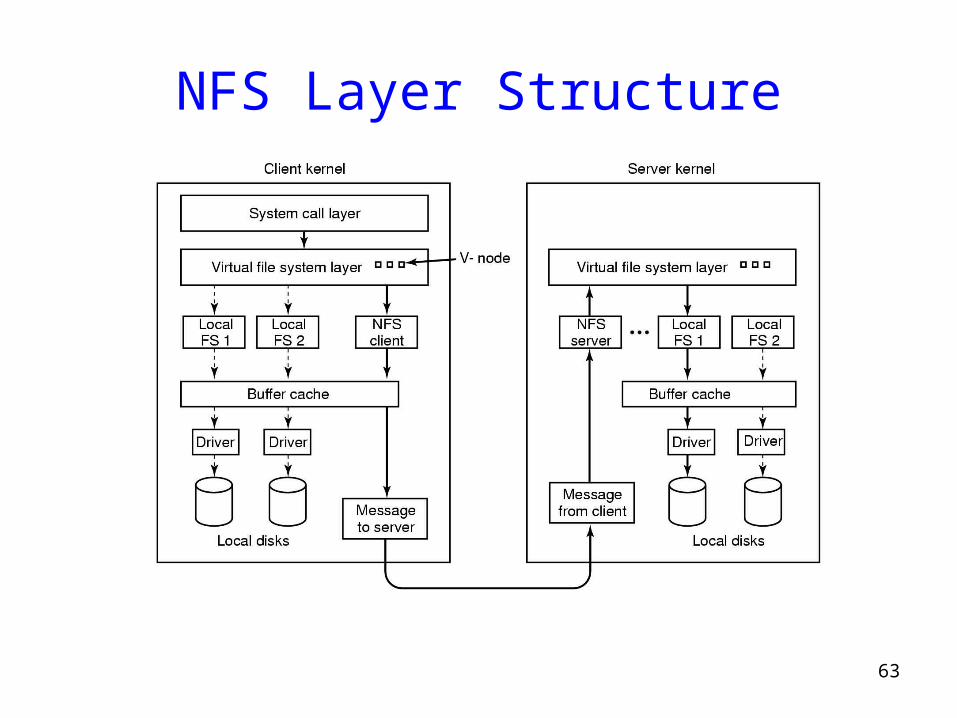
NFS Implementation
• Three main layers:• System call layer:
– Handles calls like open, read and close
• Virtual File System Layer: – Maintains table with one entry (v-node) for each open file– v-nodes indicate if file is local or remote
• If remote it has enough info to access them
• For local files, FS and i-node are recorded
• NFS Service Layer: – This lowest layer implements the NFS protocol
63
NFS Layer Structure

64
How NFS works?
• Mount:– Sys ad calls mount program with remote dir, local dir– Mount program parses for name of NFS server– Contacts server asking for file handle for remote dir– If directory exists for remote mounting, server returns handle– Client kernel constructs v-node for remote dir – Asks NFS client code to construct r-node for file handle
• Open:– Kernel realizes that file is on remotely mounted directory– Finds r-node in v-node for the directory– NFS client code then opens file, enters r-node for file in VFS,
and returns file descriptor for remote node

65
Cache coherency
• Clients cache file attributes and data– If two clients cache the same data, cache coherency is lost
• Solutions:– Each cache block has a timer (3 sec for data, 30 sec for dir)
• Entry is discarded when timer expires
– On open of cached file, its last modify time on server is checked• If cached copy is old, it is discarded
– Every 30 sec, cache time expires• All dirty blocks are written back to the server

66
Andrew File System (AFS)
• Named after Andrew Carnegie and Andrew Mellon– Transarc Corp. and then IBM took development of AFS– In 2000 IBM made OpenAFS available as open source
• Features:– Uniform name space– Location independent file sharing– Client side caching with cache consistency– Secure authentication via Kerberos– Server-side caching in form of replicas– High availability through automatic switchover of replicas– Scalability to span 5000 workstations

67
AFS Overview
• Based on the upload/download model– Clients download and cache files– Server keeps track of clients that cache the file– Clients upload files at end of session
• Whole file caching is central idea behind AFS– Later amended to block operations– Simple, effective
• AFS servers are stateful– Keep track of clients that have cached files– Recall files that have been modified

68
AFS Details
• Has dedicated server machines• Clients have partitioned name space:
– Local name space and shared name space– Cluster of dedicated servers (Vice) present shared name space– Clients run Virtue protocol to communicate with Vice
• Clients and servers are grouped into clusters– Clusters connected through the WAN
• Other issues:– Scalability, client mobility, security, protection, heterogeneity

69
AFS: Shared Name Space
• AFS’s storage is arranged in volumes– Usually associated with files of a particular client
• AFS dir entry maps vice files/dirs to a 96-bit fid– Volume number– Vnode number: index into i-node array of a volume– Uniquifier: allows reuse of vnode numbers
• Fids are location transparent– File movements do not invalidate fids
• Location information kept in volume-location database– Volumes migrated to balance available disk space, utilization– Volume movement is atomic; operation aborted on server crash

70
AFS: Operations and Consistency
• AFS caches entire files from servers– Client interacts with servers only during open and close
• OS on client intercepts calls, and passes it to Venus– Venus is a client process that caches files from servers– Venus contacts Vice only on open and close
• Does not contact if file is already in the cache, and not invalidated
– Reads and writes bypass Venus
• Works due to callback:– Server updates state to record caching– Server notifies client before allowing another client to modify– Clients lose their callback when someone writes the file
• Venus caches dirs and symbolic links for path translation

71
AFS Implementation
• Client cache is a local directory on UNIX FS– Venus and server processes access file directly by UNIX i-node
• Venus has 2 caches, one for status & one for data– Uses LRU to keep them bounded in size

72
Summary
• LFS:– Local file system– Optimize writes
• NFS: – Simple distributed file system protocol. No open/close– Stateless server
• Has problems with cache consistency, locking protocol
• AFS:– More complicated distributed file system protocol– Stateful server
• session semantics: consistency on close