
Genome annotation

What we haveGATCAATGATGATAGGAATTGAAAGTGTCTTAATTACAATCCCTGTGCAATTATTAATAACTTTTTTGTT CACCTGTTCCCAGAGGAAACCTCAAGCGGATCTAAAGGAGGTATCTCCTCAAAAGCATCCTCTAATGTCA GAAGCAAGTGAGCACTGGGAAGAATACTTGAGAAAGTGGCATGCTTACGAAACTGCTAAGGTGCACCCCA GGGAGGTTGCAAAACCTGCATCTAAAGGAAAGCCCAGGCTTCCAAAGGCTTCTCCTAAGGCAACCTCCAA ACCCAAGCACAGGCATAGGAAAGCACAAATCAAGACCCCGGAGACCCTCGGGCCAAATACAAATTCCAAT AACAACATAGAAGATGATCAGGATGTCCATTCCGAACAGCACCCTTCCCAAAAGGATCTCCAGCAGCTTA AGAAAAAGCCCCGGATCGTCCTACCTTGGTGGTGTGTTTATGTTGCATGGTTTTTGGTTTTTGCTACTTC TAGCATATCCTCATTCTTCATTGTATTTTATGGACTGACTTACGGCTATGACAAGTCAATAGAATGGCTC TTTGCATCTTTTTGTTCATTCTGTCAGTCAGTTCTTCTGGTGCAGCCATCTAAAATTATACTCCTGTCAG GCTTCAGAACGAATAAACCCAAGTATTGCAAAAACCTTTCATGGTCAACCAAGTATAAATATACTGAGAT CAGGTTGGATGGAATGCGTATGCATCCAGAAGAAATGCAGAGGATACATGACCAGATCGTCCGAATCCGA GGCACGAGGATGTACCAACCCCTTACAGAAGATGAAATCAGAATATTCAAAAGAAAGAAGAGGATCAAGA GAAGAGCACTCCTGTTTCTGAGTTACATTCTAACTCACTTTATCTTTCTAGCCCTTCTGTTGATCCTTAT CGTCTTACTACGTCACACTGACTGCTTTTACTATAACCAGTTTATTCGTGATCGGTTCTCTATGGATCTT GCTACTGTGACTAAGCTGGAAGACATCTATAGATGGCTAAACAGCGTGCTGTTGCCTTTGTTACACAATG ACCTGAATCCAACATTTCTTCCTGAAAGCTCGTCTAAAATCCTTGGCCTTCCATTGATGAGGCAAGTGAG AGCAAAATCTAGTGAAAAAATGTGTCTACCTGCCGAAAAGTTTGTGCAAAACAGCATCAGAAGAGAAATT CATTGTCACCCCAAATATGGCATTGACCCAGAAGACACAAAAAACTATTCTGGCTTTTGGAATGAAGTTG ATAAGCAGGCTATAGATGAGAGTACCAATGGATTTACTTATAAGCCTCAAGGAACGCAATGGCTATATTA TTCCTATGGACTACTACACACCTATGGATCTGGAGGATATGCACTCTATTTTTTTCCAGAACAGCAGCGG TTTAATTCCACACTGAGGCTCAAAGAACTTCAAGAAAGCAATTGGCTGGATGAGAAGACATGGGCTGTGG TTTTGGAATTAACAACTTTTAATCCAGATATAAATCTGTTCTGTAGCATTTCGGTCATATTTGAAGTCTC TCAGTTAGGAGTTGTCAACACAAGCATATCTCTGCACTCTTTTTCACTTGCTGATTTTGACAGAAAAGCT TCAGCAGAAATCTACTTGTATGTGGCCATTCTCATTTTTTTCTTAGCCTACGTTGTTGATGAGGGTTGTA TCATTATGCAAGAAAGAGCCTCCTATGTGAGAAGTGTGTATAATTTGCTCAACTTTGCTTTAAAGTGCAT ATTTACTGTGTTGATTGTGCTCTTTCTCAGGAAACATTTCCTGGCCACTGGCATAATTCGGTTTTACTTG TCGAACCCAGAAGACTTCATTCCCTTTCATGCAGTTTCTCAGGTAGATCACATTATGAGGATAATTTTGG GTTTCCTGTTATTTCTGACAATTTTGAAGACCCTCAGGTATTCCAGATTCTTCTACGATGTGCGCCTGGC TCAGAGGGCCATCCAGGCTGCCCTCCCTGGCATCTGCCACATGGCATTTGTTGTGTCCGTGTATTTCTTC GTATACATGGCTTTTGGTTACCTGGTGTTTGGTCAGCATGAATGGAACTACAGTAACTTGATTCATTCCA CTCAGACAGTATTTTCCTATTGTGTCTCAGCTTTCCAGAACACTGAATTTTCCAATAACAGGATTCTGGG GGTCCTGTTCCTCTCATCTTTCATGCTGGTGATGATCTGCGTCTTGATCAACTTATTTCAGGCTGTAATT

What we want: Annotated sequenceGATCAATGATGATAGGAATTGAAAGTGTCTTAATTACAATCCCTGTGCAATTATTAATAACTTTTTTGTT CACCTGTTCCCAGAGGAAACCTCAAGCGGATCTAAAGGAGGTATCTCCTCAAAAGCATCCTCTAATGTCA GAAGCAAGTGAGCACTGGGAAGAATACTTGAGAAAGTGGCATGCTTACGAAACTGCTAAGGTGCACCCCA GGGAGGTTGCAAAACCTGCATCTAAAGGAAAGCCCAGGCTTCCAAAGGCTTCTCCTAAGGCAACCTCCAA ACCCAAGCACAGGCATAGGAAAGCACAAATCAAGACCCCGGAGACCCTCGGGCCAAATACAAATTCCAAT AACAACATAGAAGATGATCAGGATGTCCATTCCGAACAGCACCCTTCCCAAAAGGATCTCCAGCAGCTTA AGAAAAAGCCCCGGATCGTCCTACCTTGGTGGTGTGTTTATGTTGCATGGTTTTTGGTTTTTGCTACTTC TAGCATATCCTCATTCTTCATTGTATTTTATGGACTGACTTACGGCTATGACAAGTCAATAGAATGGCTC TTTGCATCTTTTTGTTCATTCTGTCAGTCAGTTCTTCTGGTGCAGCCATCTAAAATTATACTCCTGTCAG GCTTCAGAACGAATAAACCCAAGTATTGCAAAAACCTTTCATGGTCAACCAAGTATAAATATACTGAGAT CAGGTTGGATGGAATGCGTATGCATCCAGAAGAAATGCAGAGGATACATGACCAGATCGTCCGAATCCGA GGCACGAGGATGTACCAACCCCTTACAGAAGATGAAATCAGAATATTCAAAAGAAAGAAGAGGATCAAGA GAAGAGCACTCCTGTTTCTGAGTTACATTCTAACTCACTTTATCTTTCTAGCCCTTCTGTTGATCCTTAT CGTCTTACTACGTCACACTGACTGCTTTTACTATAACCAGTTTATTCGTGATCGGTTCTCTATGGATCTT GCTACTGTGACTAAGCTGGAAGACATCTATAGATGGCTAAACAGCGTGCTGTTGCCTTTGTTACACAATG ACCTGAATCCAACATTTCTTCCTGAAAGCTCGTCTAAAATCCTTGGCCTTCCATTGATGAGGCAAGTGAG AGCAAAATCTAGTGAAAAAATGTGTCTACCTGCCGAAAAGTTTGTGCAAAACAGCATCAGAAGAGAAATT CATTGTCACCCCAAATATGGCATTGACCCAGAAGACACAAAAAACTATTCTGGCTTTTGGAATGAAGTTG ATAAGCAGGCTATAGATGAGAGTACCAATGGATTTACTTATAAGCCTCAAGGAACGCAATGGCTATATTA TTCCTATGGACTACTACACACCTATGGATCTGGAGGATATGCACTCTATTTTTTTCCAGAACAGCAGCGG TTTAATTCCACACTGAGGCTCAAAGAACTTCAAGAAAGCAATTGGCTGGATGAGAAGACATGGGCTGTGG TTTTGGAATTAACAACTTTTAATCCAGATATAAATCTGTTCTGTAGCATTTCGGTCATATTTGAAGTCTC TCAGTTAGGAGTTGTCAACACAAGCATATCTCTGCACTCTTTTTCACTTGCTGATTTTGACAGAAAAGCT TCAGCAGAAATCTACTTGTATGTGGCCATTCTCATTTTTTTCTTAGCCTACGTTGTTGATGAGGGTTGTA TCATTATGCAAGAAAGAGCCTCCTATGTGAGAAGTGTGTATAATTTGCTCAACTTTGCTTTAAAGTGCAT ATTTACTGTGTTGATTGTGCTCTTTCTCAGGAAACATTTCCTGGCCACTGGCATAATTCGGTTTTACTTG TCGAACCCAGAAGACTTCATTCCCTTTCATGCAGTTTCTCAGGTAGATCACATTATGAGGATAATTTTGG GTTTCCTGTTATTTCTGACAATTTTGAAGACCCTCAGGTATTCCAGATTCTTCTACGATGTGCGCCTGGC TCAGAGGGCCATCCAGGCTGCCCTCCCTGGCATCTGCCACATGGCATTTGTTGTGTCCGTGTATTTCTTC GTATACATGGCTTTTGGTTACCTGGTGTTTGGTCAGCATGAATGGAACTACAGTAACTTGATTCATTCCA CTCAGACAGTATTTTCCTATTGTGTCTCAGCTTTCCAGAACACTGAATTTTCCAATAACAGGATTCTGGG GGTCCTGTTCCTCTCATCTTTCATGCTGGTGATGATCTGCGTCTTGATCAACTTATTTCAGGCTGTAATT
Exon 1
Exon 2
Exon 3
Exon 4

Making sense of genomic seqs
• HMM analysis• Compare genomes to each other• Compare to other kind of supprting data
– Which kinds of data can you think of?

Other kinds of data
1. mRNA sequences (and ESTs)
2. Protein sequences

-OMEs
• Genome • Transcriptome• Proteome• Interactome• Metabolome• Phenome

-OMEs Technologies
• Genome • Transcriptome• Proteome• Interactome• Metabolome• Phenome
Sequencing
Microarray
Computer (ORFs), Mass-spec
Y2H, Mass-spec
Mass-spec
Phenotype
Biochemical
Disease

Transcript databases
• RefSeq contains full length sequences of mRNAs, carefully reviewed– Currently 20.000 human sequences
• dbEST contains 5’ and 3’ reads of random cDNAs– Currently 3.7 mio. human seqs
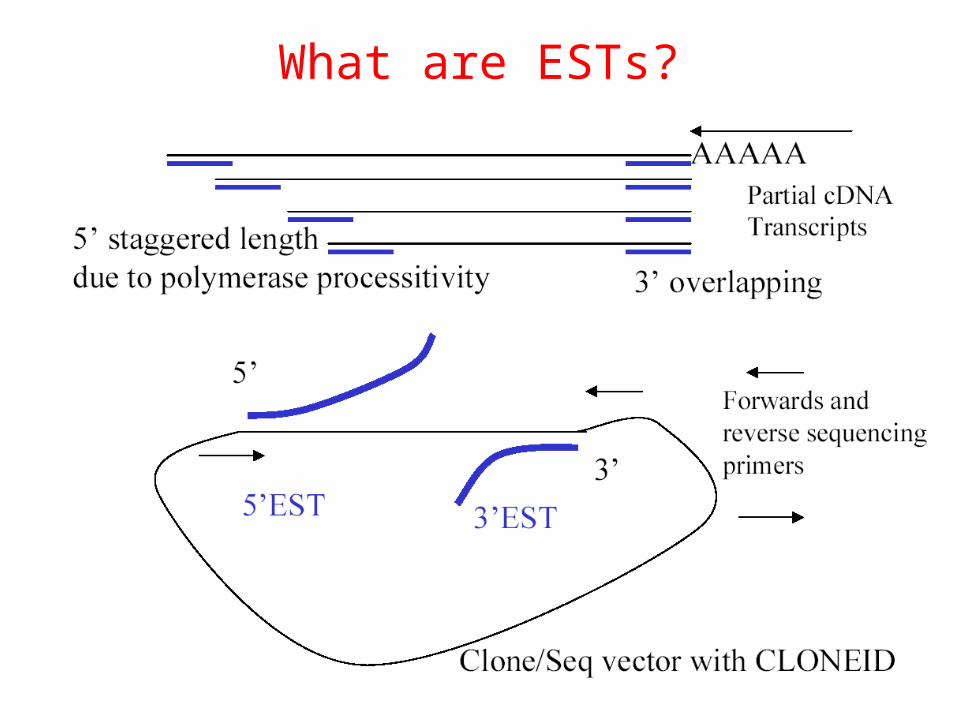
What are ESTs?

UniGene
• UniGene: Merge (cluster) any two ESTs when >100 bp are identical
• 4 mio -> 104.214 clusters

ESTs
UniGene: total # clusters 104.214
Cluster size Number of clusters 1 (singletons) 37503 2 14605 3-4 15912 5-8 10798 9-16 5978 17-32 4143 33-64 3658 65-128 4117 129-256 4109 257-512 2317 513-1024 743 1025-2048 227 2049-4096 68 4097-8192 29 8193-16384 6 16385-32768 1

Transcripts: what can we learn?
• Comparing genome sequences to transcripts allows: – Confirmation of gene predictions
– Experimental identification of Exons/Introns, 5’ UTRs, 3’ UTRs
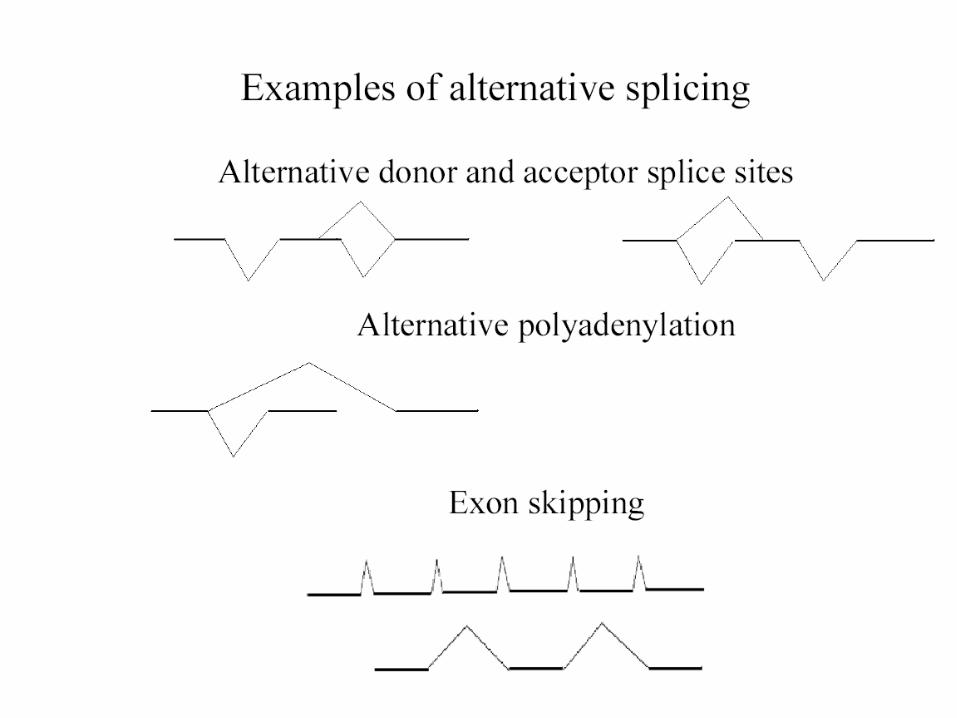
– Alternative splicing
• Asses the relative abundance of transcripts: Digital differential display.

Annotation example

Annotation example
18 exons623 AA


Regulation of Gene Expression
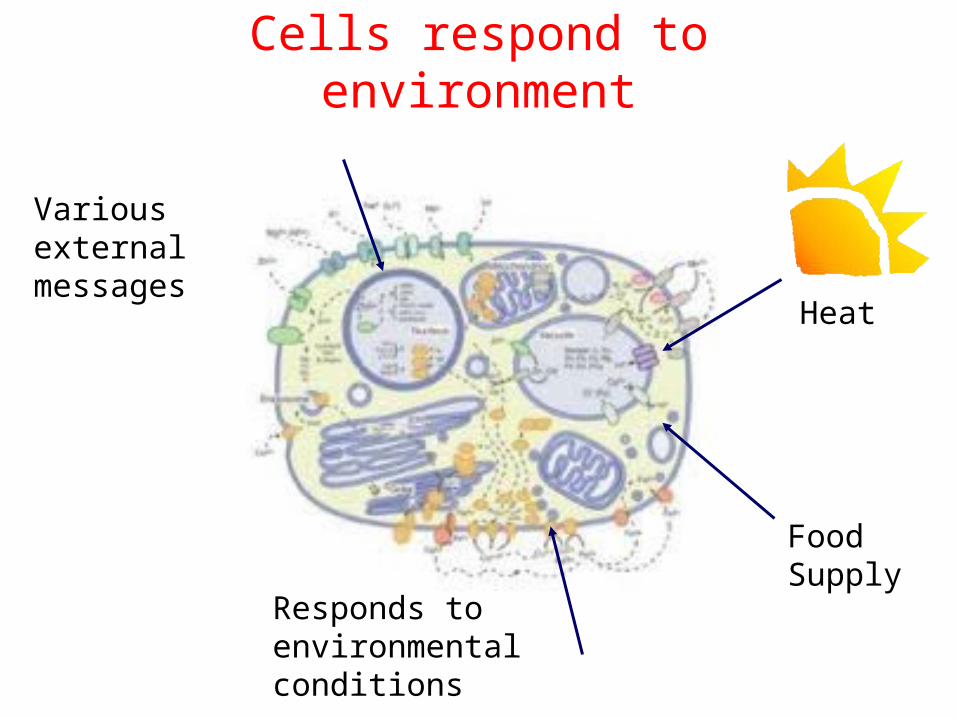
Cells respond to environment
Heat
FoodSupply
Responds toenvironmentalconditions
Various external messages
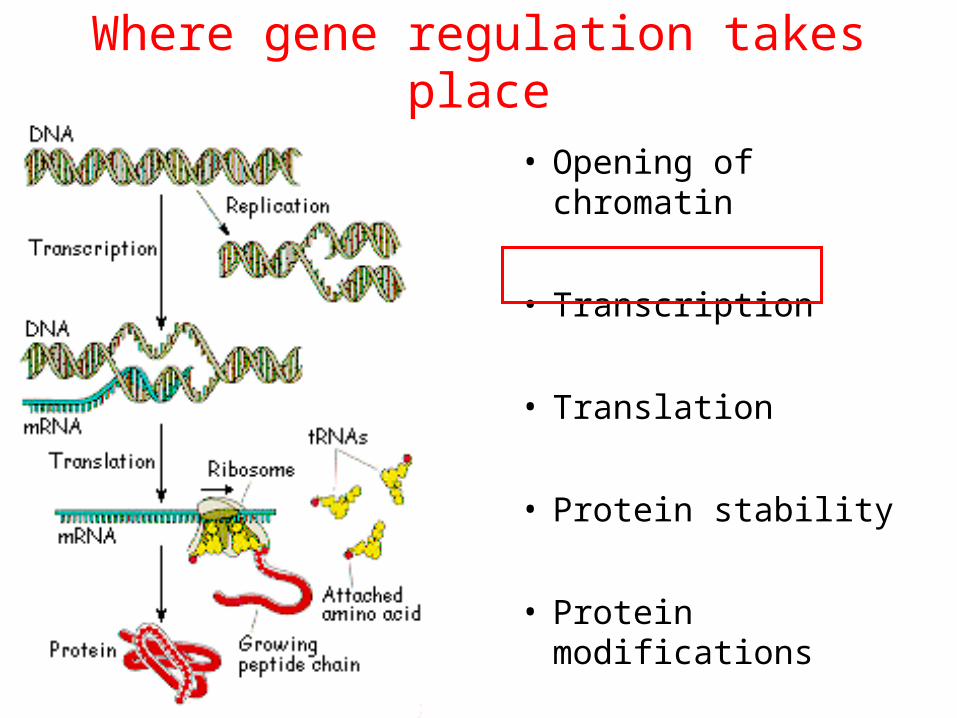
Where gene regulation takes place
• Opening of chromatin
• Transcription
• Translation
• Protein stability
• Protein modifications

Transcriptional Regulation
• Strongest regulation happens during transcription
• Best place to regulate: No energy wasted making intermediate products
• However, slow response timeAfter a receptor notices a change:
1. Cascade message to nucleus
2. Open chromatin & bind transcription factors
3. Recruit RNA polymerase and transcribe
4. Splice mRNA and send to cytoplasm
5. Translate into protein
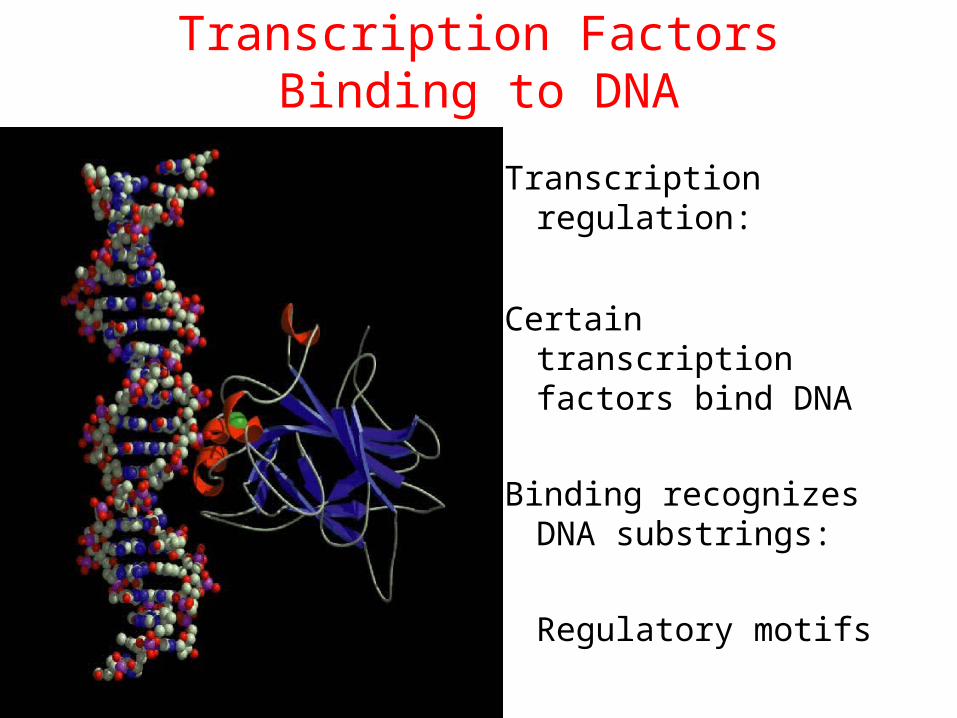
Transcription Factors Binding to DNA
Transcription regulation:
Certain transcription factors bind DNA
Binding recognizes DNA substrings:
Regulatory motifs
RNA Polymerase
TBP
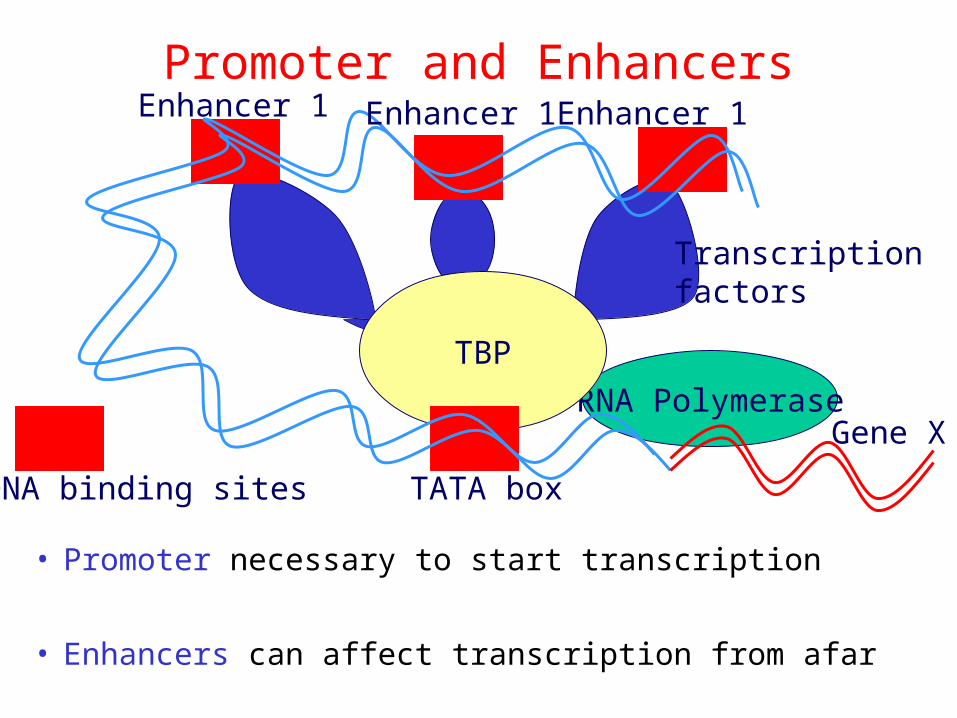
Promoter and Enhancers
• Promoter necessary to start transcription
• Enhancers can affect transcription from afar
Enhancer 1 Enhancer 1 Enhancer 1
TATA box
Gene X
DNA binding sites
Transcription factors
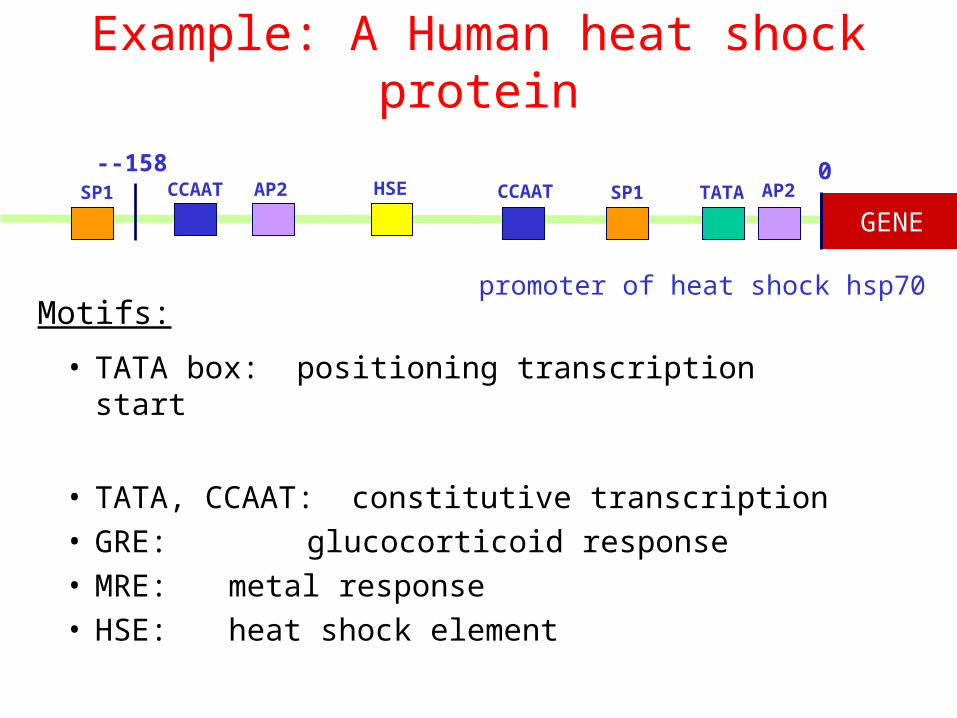
Example: A Human heat shock protein
• TATA box: positioning transcription start
• TATA, CCAAT: constitutive transcription• GRE: glucocorticoid response• MRE: metal response• HSE: heat shock element
TATASP1CCAAT AP2HSEAP2CCAATSP1
promoter of heat shock hsp70
0--158
GENE
Motifs:
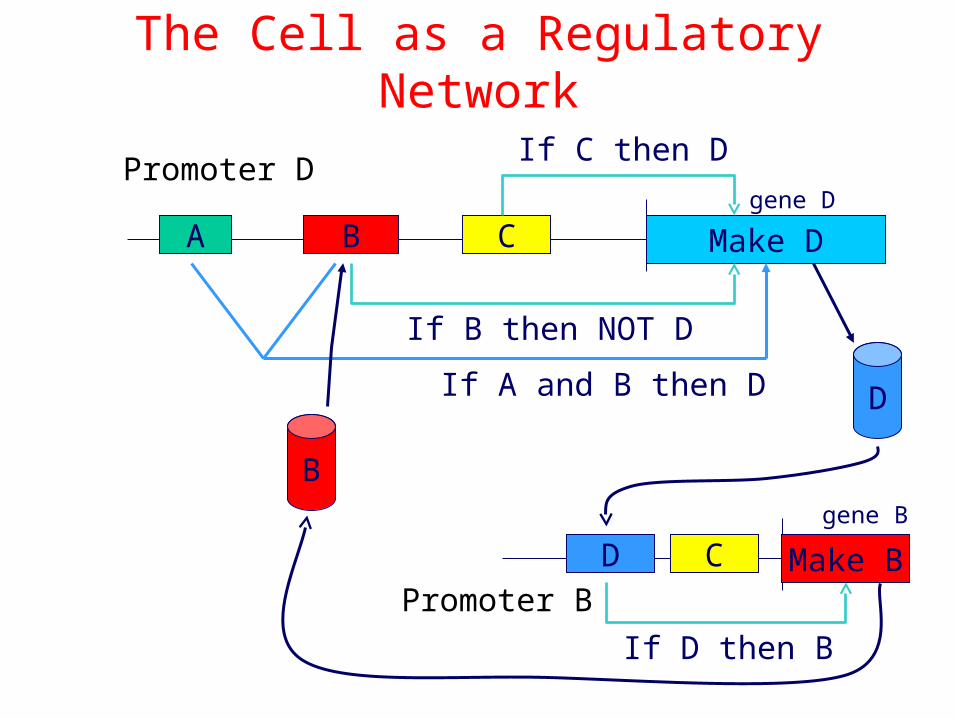
The Cell as a Regulatory Network
A B Make DC
If C then D
If B then NOT D
If A and B then D D
Make BD
If D then B
C
gene D
gene B
B
Promoter D
Promoter B
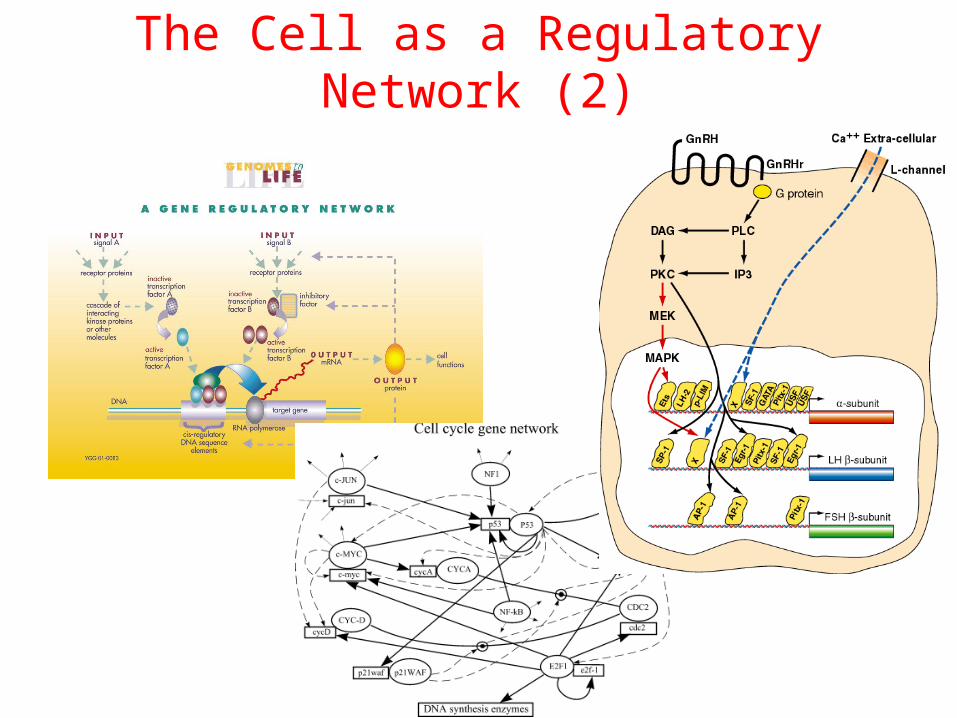
The Cell as a Regulatory Network (2)

DNA Microarrays
Measuring gene transcription in a high-throughput fashion
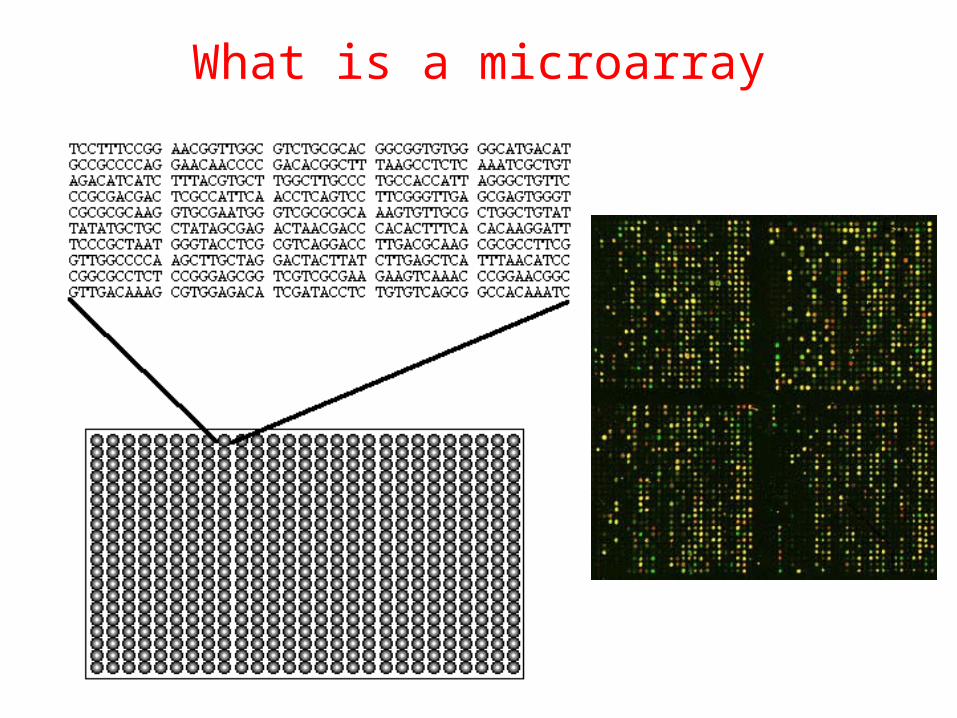
What is a microarray

What is a microarray (2)
• A 2D array of DNA sequences from thousands of genes
• Each spot has many copies of same gene
• Allow mRNAs from a sample to hybridize
• Measure number of hybridizations per spot

How to make a microarray
• Method 1: Printed Slides (Stanford)– Use PCR to amplify a 1 kb portion of each gene / EST
– Apply each sample on glass slide
• Method 2: DNA Chips (Affymetrix)– Grow oligonucleotides (20bp) on glass
– Several words per gene (choose unique words)
If we know the gene sequences,
Can sample all genes in one experiment!
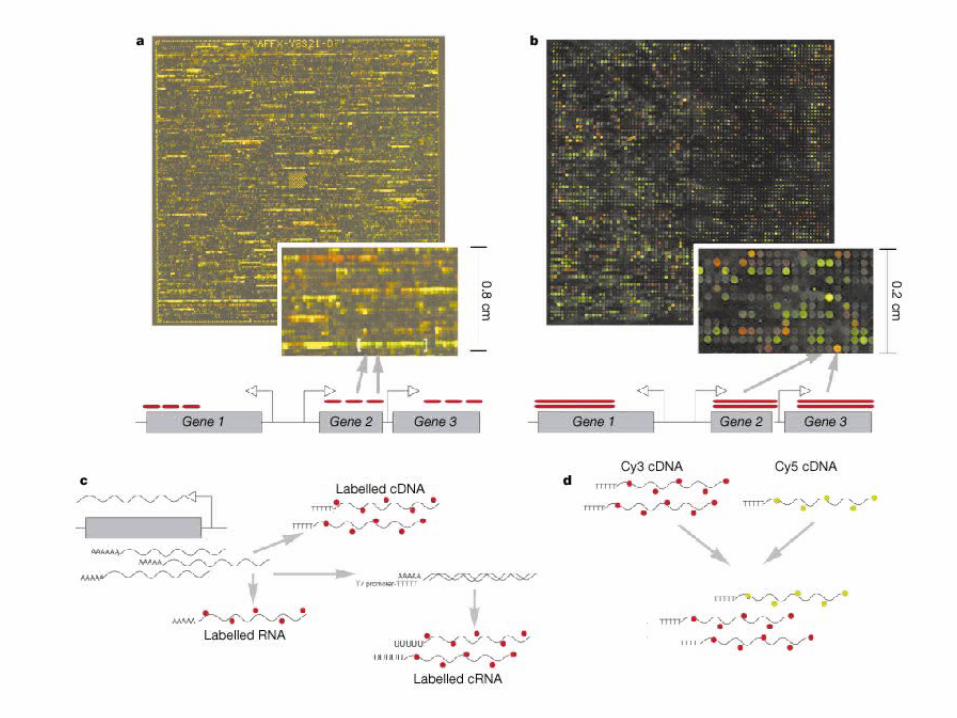
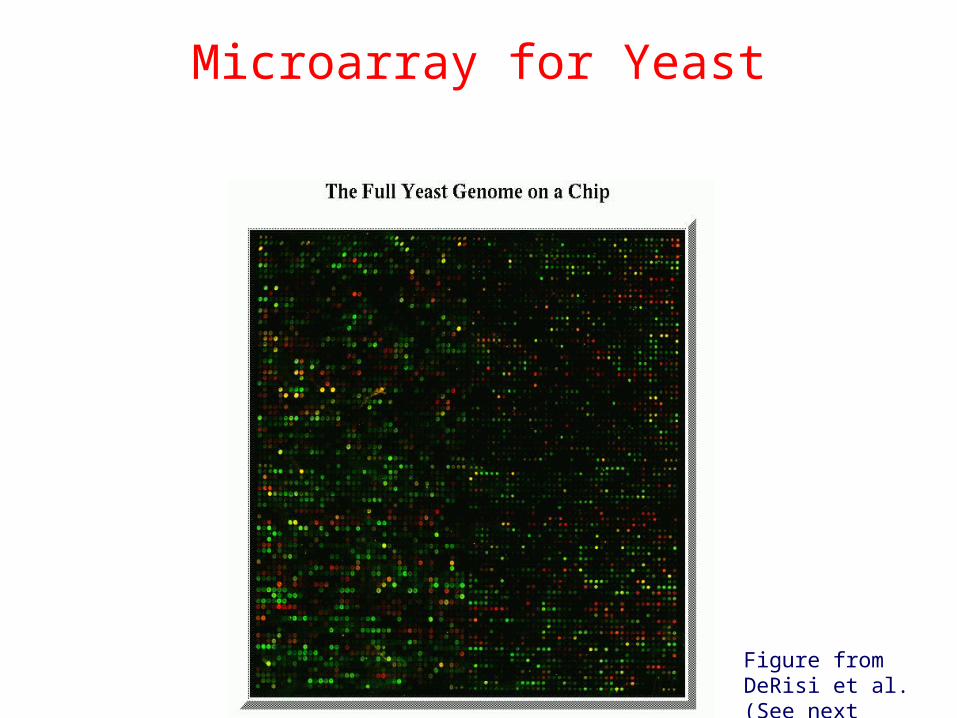
Microarray for Yeast
Figure from DeRisi et al. (See next slide).

cDNA Microarrays• Use robot to spot glass slides at precise points with
complete gene/EST sequences • Gene expression levels measured by fluorescence
hybridisation
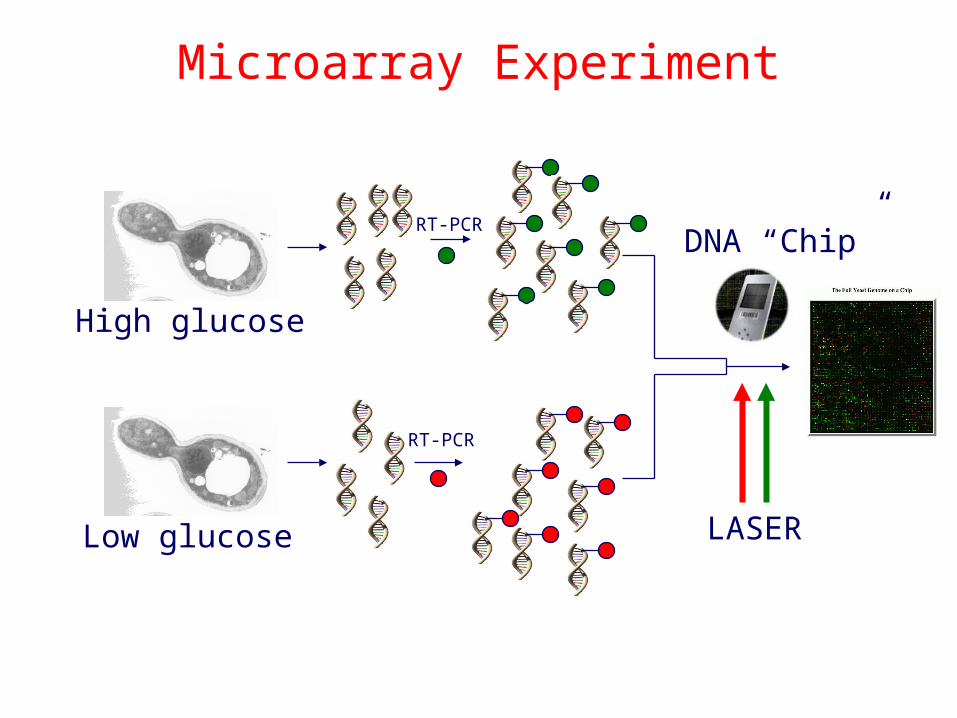
Microarray Experiment
RT-PCR
RT-PCR
LASER
DNA “Chip”
High glucose
Low glucose

Raw data – images
• Red (Cy5) dot – overexpressed or up-regulated
• Green (Cy3) dot – underexpressed or down-regulated
• Yellow dot– equally expressed
• Intensity - “absolute” level
cDNA plotted microarray

Bioinformatics in microarray data
• Array design• Data extraction (Pixel to matrix)• Background correction• Data normalization• Data analysis







