distributed model shaping for scaling to decentralized pomdps with hundreds of agents prasanna...
Post on 19-Dec-2015
225 views
TRANSCRIPT

D-TREMOR - AAMAS2011 1
Distributed Model Shaping for Scaling to Decentralized POMDPs
with hundreds of agents
Prasanna Velagapudi
Pradeep Varakantham
Paul Scerri
Katia Sycara

D-TREMOR - AAMAS2011 2
Motivation
• 100s to 1000s of robots, agents, people
• Complex, collaborative tasks• Dynamic, uncertain
environment• Offline planning
Search & Rescue Military C2
Disaster Response
ConvoyPlanning

D-TREMOR - AAMAS2011 3
Motivation
• Exploit three characteristics of these domains1. Explicit Interactions
• Specific combinations of states and actions where effects depend on more than one agent
2. Sparsity of Interactions• Many potential interactions could occur between agents• Only a few will occur in any given solution
3. Distributed Computation• Each agent has access to local computation• A centralized algorithm has access to 1 unit of computation• A distributed algorithm has access to N units of computation
D-TREMOR - AAMAS2011 4
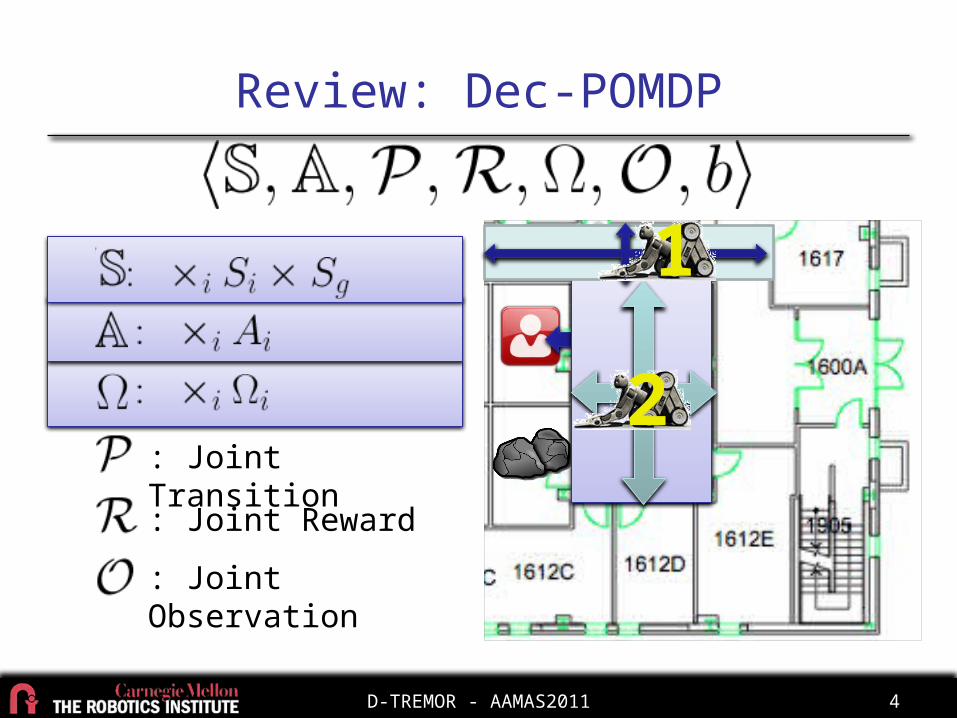
Review: Dec-POMDP
: Joint Transition
: Joint Reward
: Joint Observation
1
2

D-TREMOR - AAMAS2011 5
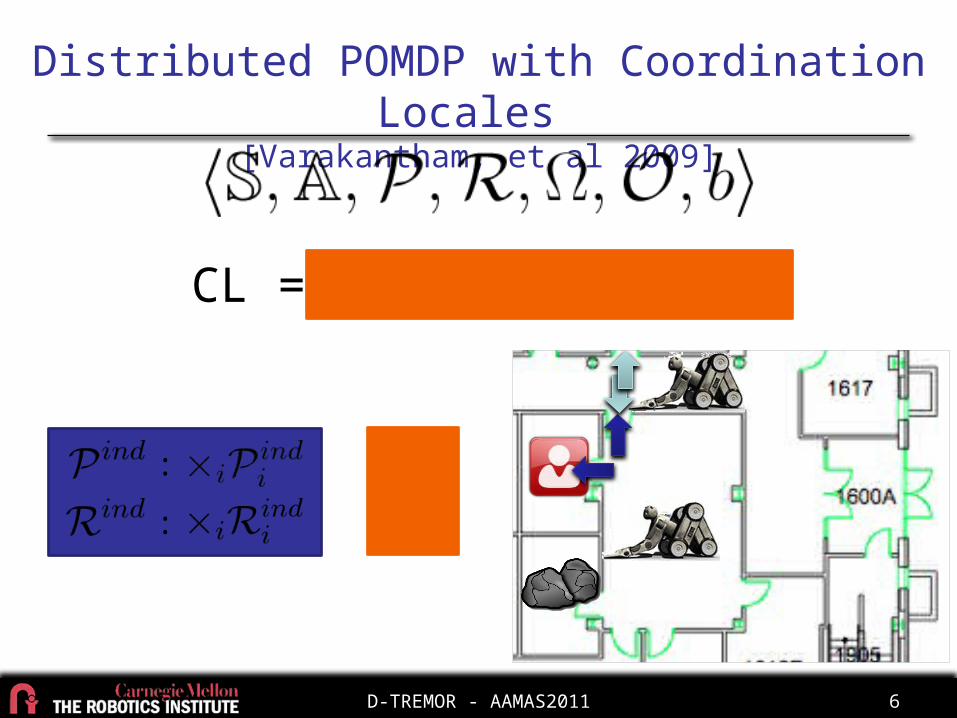
Distributed POMDP with Coordination Locales
[Varakantham, et al 2009]
CL =Nature of time constraint (e.g. affects only same-time, affects any future-
time)
Relevant region of joint state-action space
Time constraint
D-TREMOR - AAMAS2011 6
CL =
:
:
Distributed POMDP with Coordination Locales
[Varakantham, et al 2009]
D-TREMOR - AAMAS2011 7
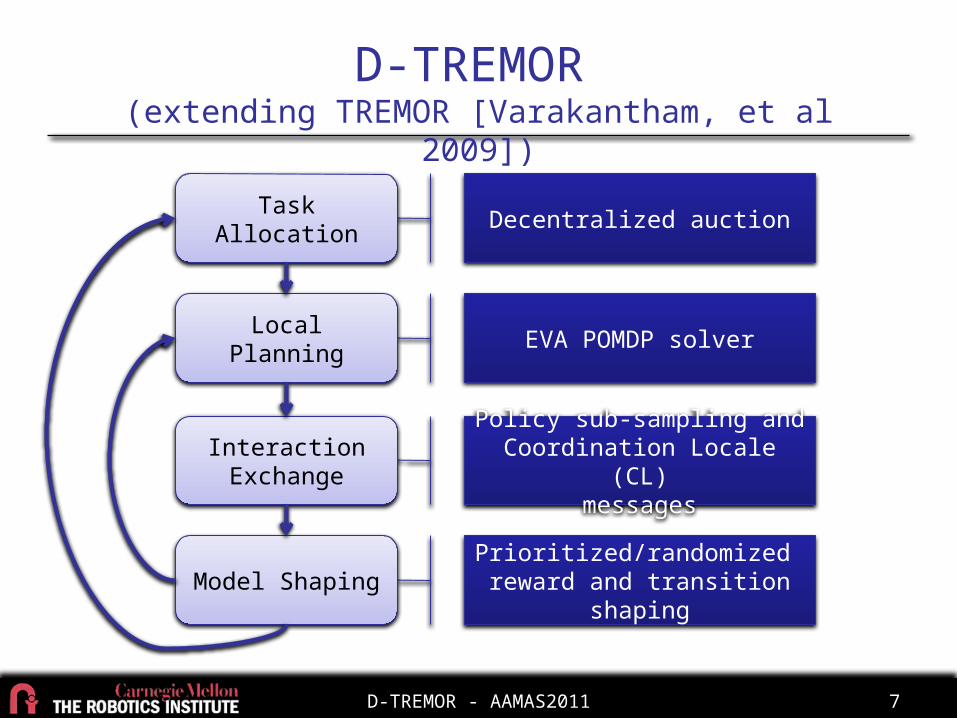
Decentralized auction
EVA POMDP solver
Policy sub-sampling and Coordination Locale (CL)
messages
Prioritized/randomized reward and transition shaping
D-TREMOR (extending TREMOR [Varakantham, et al 2009])
Task Allocation
Local Planning
Interaction Exchange
Model Shaping

D-TREMOR - AAMAS2011 8
D-TREMOR: Task Allocation
• Assign “tasks” using decentralized auction– Greedy, nearest allocation
• Create local, independent sub-problem:

D-TREMOR - AAMAS2011 9
D-TREMOR: Local Planning
• Solve using off-the-shelf algorithm (EVA)
• Result: locally-optimal policies

D-TREMOR - AAMAS2011 10
D-TREMOR: Interaction Exchange
Find PrCLi and ValCLi:
• Send CL messages to teammates:
No collision
Collision
+1
-6
ValCLi= -7
[Kearns 2002]
Entered corridor in 95 of 100 runs:
PrCLi= 0.95
D-TREMOR - AAMAS2011 11
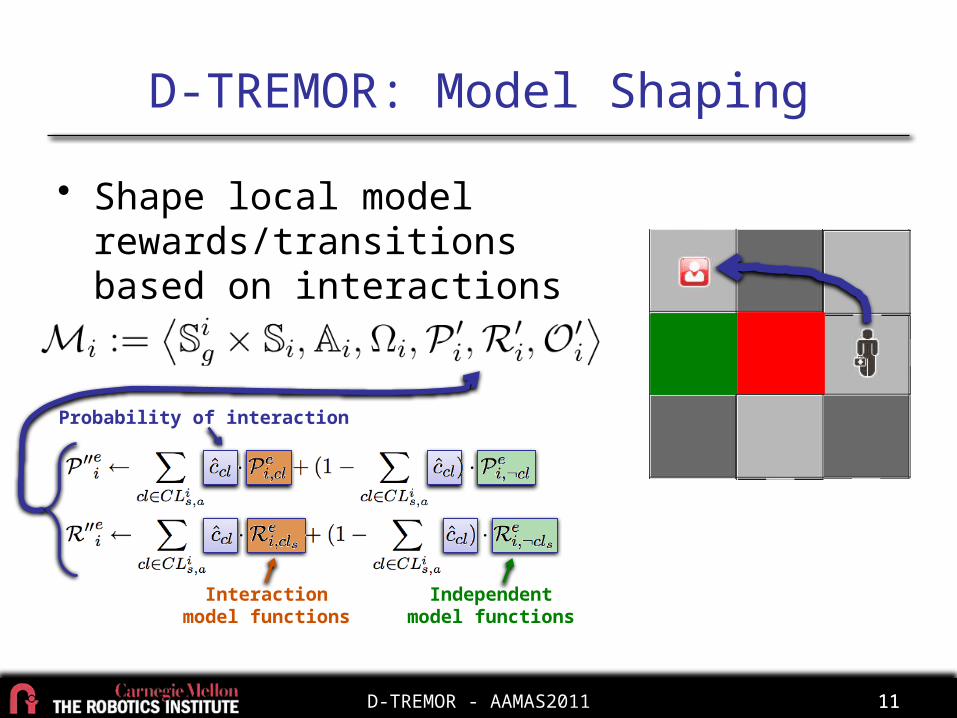
D-TREMOR: Model Shaping
• Shape local model rewards/transitions based on interactions
11
Probability of interaction
Interactionmodel functions
Independentmodel functions

D-TREMOR - AAMAS2011 12
D-TREMOR: Local Planning (again)
• Re-solve shaped local models to get new policies
• Result: new locally-optimal policies new interactions
12

D-TREMOR - AAMAS2011 13
D-TREMOR: Adv. Model Shaping
• In practice, we run into three common issues faced by concurrent optimization algorithms:– Slow convergence– Oscillation– Local optima
• We can alter our model-shaping to mitigate these by reasoning about the types of interactions we have

D-TREMOR - AAMAS2011 14
D-TREMOR: Adv. Model Shaping
• Slow convergence Prioritization– Assign priorities to agents, only model-shape collision
interactions for higher priority agents
– Can quickly resolve purely negative interactions• Negative interaction: when every agent is guaranteed to have a
lower-valued local policy if an interaction occurs

D-TREMOR - AAMAS2011 15
D-TREMOR: Adv. Model Shaping
• Oscillation Probabilistic shaping– Often caused by time dynamics between agents
• Agent 1 shapes based on Agent 2’s old policy• Agent 2 shapes based on Agent 1’s old policy
– Each agent only applies model-shaping with probability δ [Zhang 2005]
– Breaks out of cycles between agent policies
D-TREMOR - AAMAS2011 16
D-TREMOR: Adv. Model Shaping
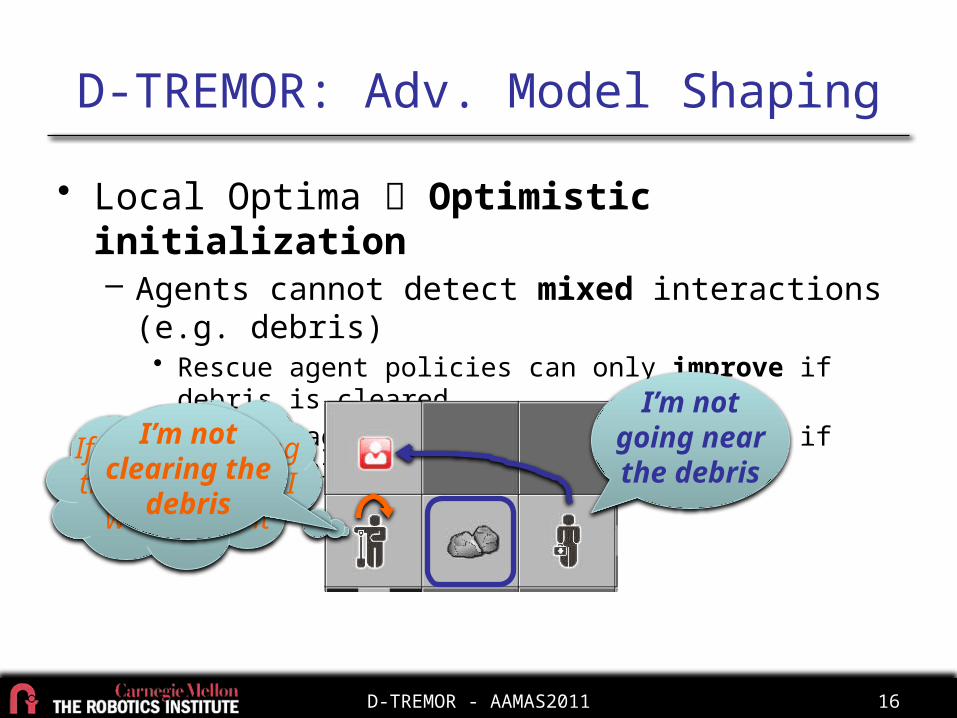
• Local Optima Optimistic initialization– Agents cannot detect mixed interactions (e.g. debris)
• Rescue agent policies can only improve if debris is cleared• Cleaner agent policies can only worsen if they clear debris
I’m not going near the
debrisIf no one is going through debris, I
won’t clear it
I’m not clearing the
debris

D-TREMOR - AAMAS2011 17
D-TREMOR: Adv. Model Shaping
• Local Optima Optimistic initialization– Agents cannot detect mixed interactions (e.g. debris)
• Rescue agent policies can only improve if debris is cleared• Cleaner agent policies can only worsen if they clear debris
– Let each agent solve an initial model that uses an optimistic assumption of interaction condition

D-TREMOR - AAMAS2011 18
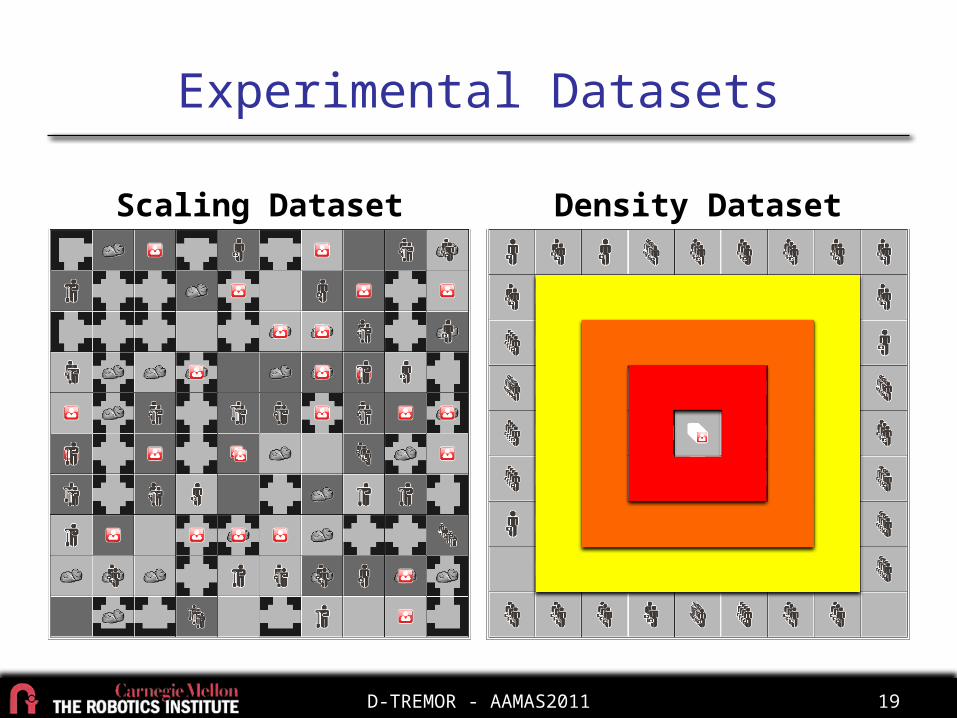
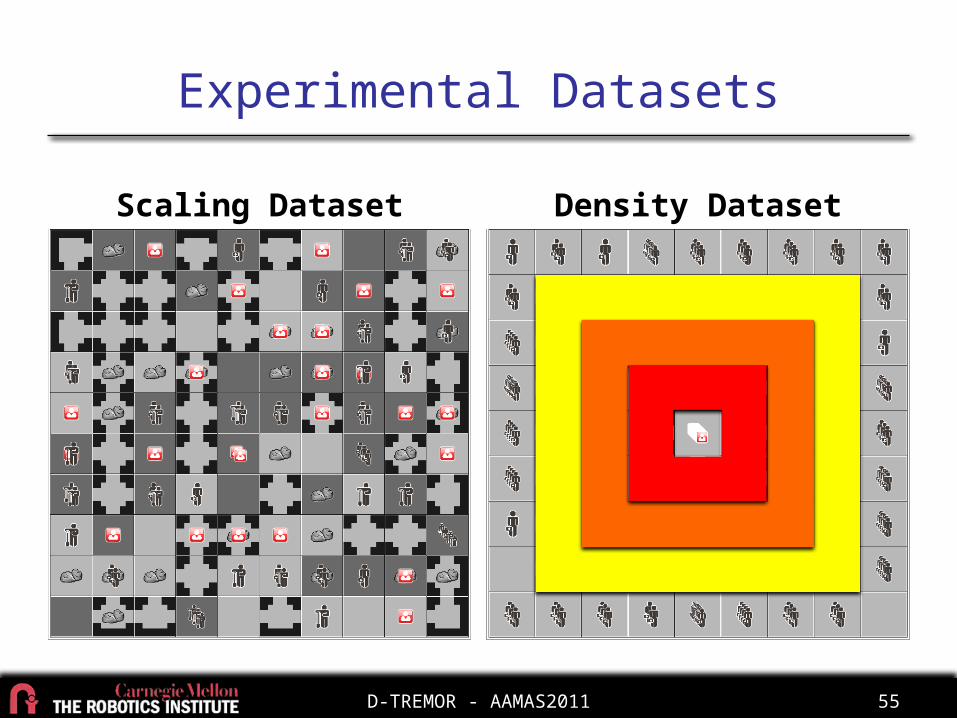
Experimental Setup
• D-TREMOR policies– Max-joint-value– Last iteration
• Comparison policies– Independent– Optimistic– Do-nothing– Random
• Scaling:– 10 to 100 agents– Random maps
• Density– 100 agents– Concentric ring maps
• 3 problems/condition• 20 planning iterations• 7 time step horizon• 1 CPU per agent
D-TREMOR produces reasonable policies for 100-agent planning problems in under 6 hrs.
(with some caveats)
D-TREMOR - AAMAS2011 19
Experimental Datasets
Scaling Dataset Density Dataset
D-TREMOR - AAMAS2011 20
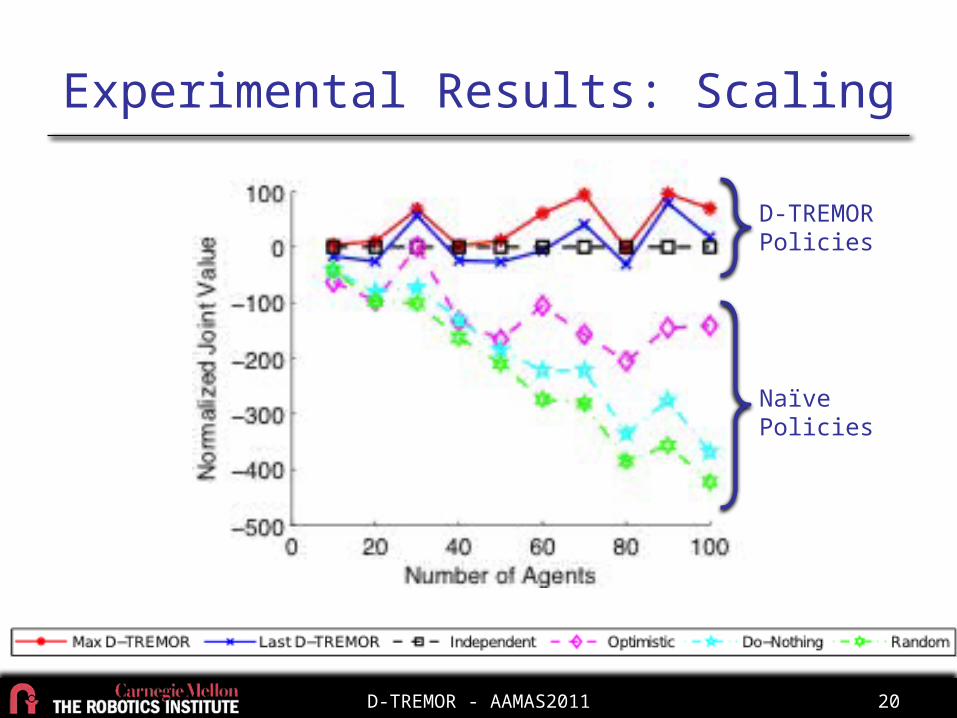
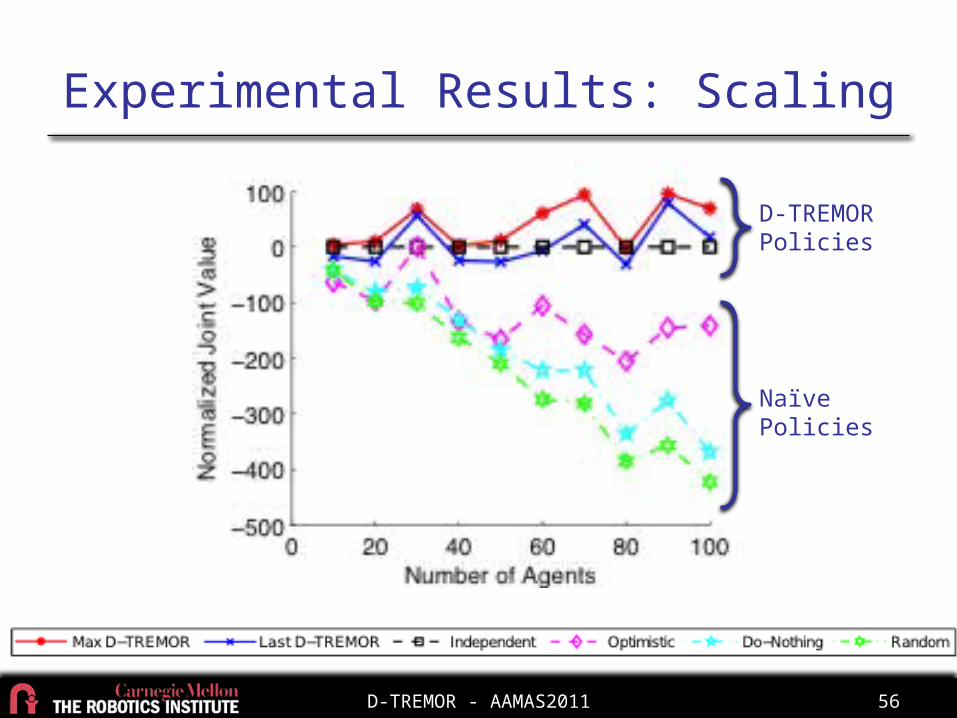
Experimental Results: Scaling
Naïve Policies
D-TREMOR Policies
D-TREMOR - AAMAS2011 21
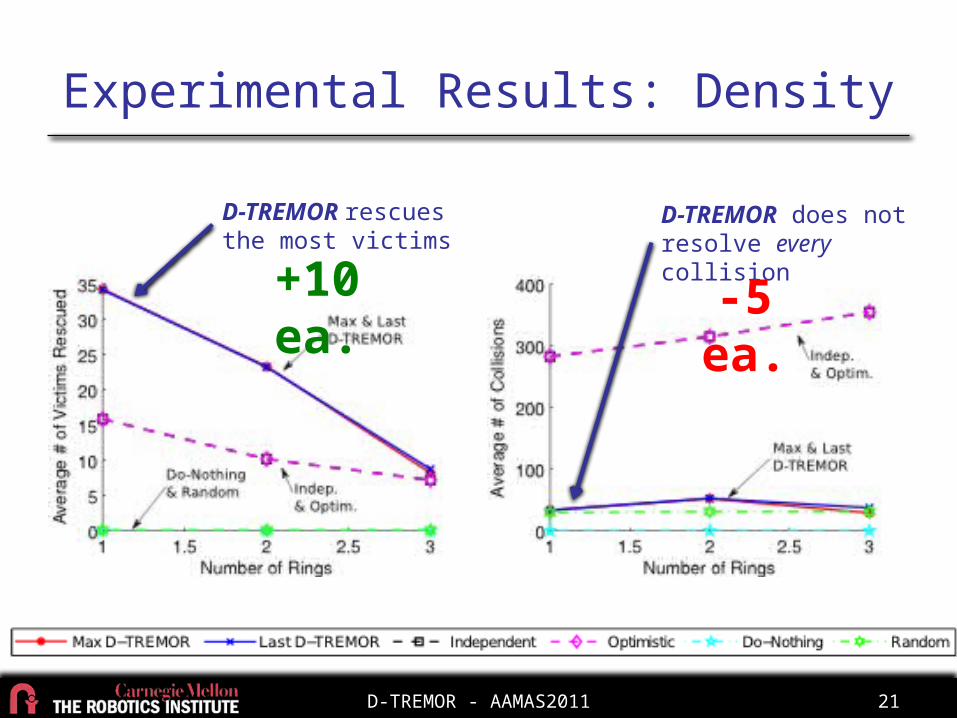
Experimental Results: Density
D-TREMOR rescues the most victims D-TREMOR does not
resolve every collision+10 ea. -5 ea.
D-TREMOR - AAMAS2011 22
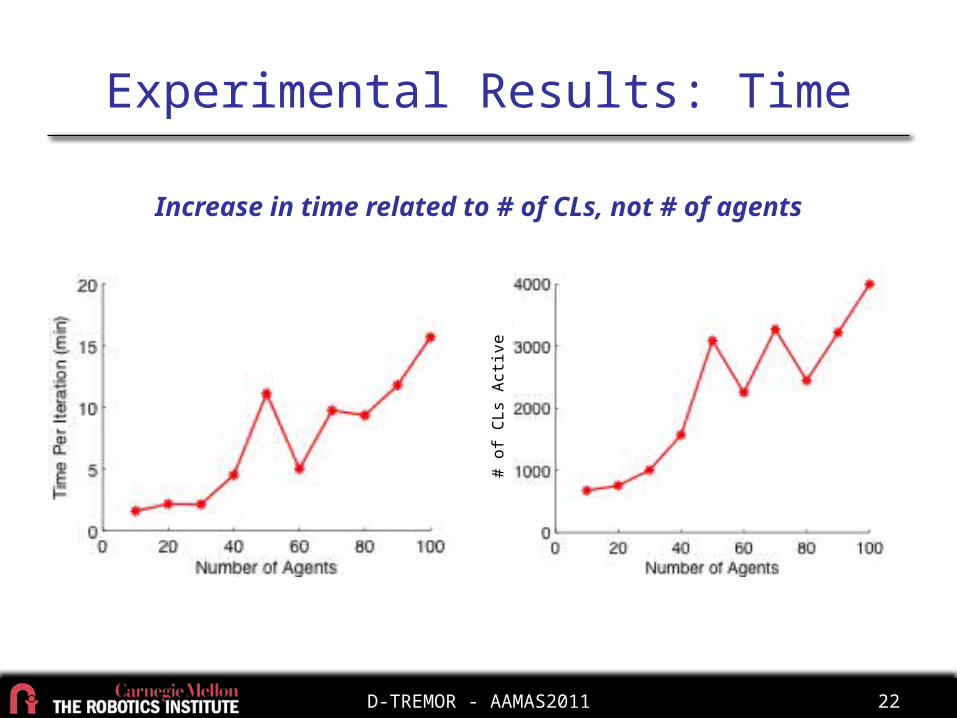
Experimental Results: Time
Increase in time related to # of CLs, not # of agents
# of
CLs
Acti
ve

D-TREMOR - AAMAS2011 23
Conclusions
• D-TREMOR: Decentralized planning for sparse Dec-POMDPs with many agents
• Demonstrated complete distributability, fast heuristic interaction detection, and local message exchange to achieve high scalability
• Empirical results in simulated search and rescue domain

D-TREMOR - AAMAS2011 24
Future Work
• Generalized framework for distributed planning under uncertainty through iterative message exchange
• Optimality/convergence bounds
• Reduce necessary communication• Better search over task allocations• Scaling to larger team sizes

D-TREMOR - AAMAS2011 25
Questions?

D-TREMOR - AAMAS2011 26

D-TREMOR - AAMAS2011 27
Motivation
• Scaling planning to large teams is hard– Need to plan (with uncertainty) for each agent in team– Agents must consider the actions of a growing number of
teammates– Full, joint problem has NEXP complexity [Bernstein 2002]
• Optimality is going to be infeasible• Find and exploit structure in the problem• Make good plans in reasonable amount of time

D-TREMOR - AAMAS2011 28
Motivation
• Exploit three characteristics of these domains1. Explicit Interactions
• Specific combinations of states and actions where effects depend on more than one agent
2. Sparsity of Interactions• Many potential interactions could occur between agents• Only a few will occur in any given solution
3. Distributed Computation• Each agent has access to local computation• A centralized algorithm has access to 1 unit of computation• A distributed algorithm has access to N units of computation

D-TREMOR - AAMAS2011 29
Experimental Results: Density
Do-nothing does the best?
Ignoring interactions = poor performance
D-TREMOR - AAMAS2011 30
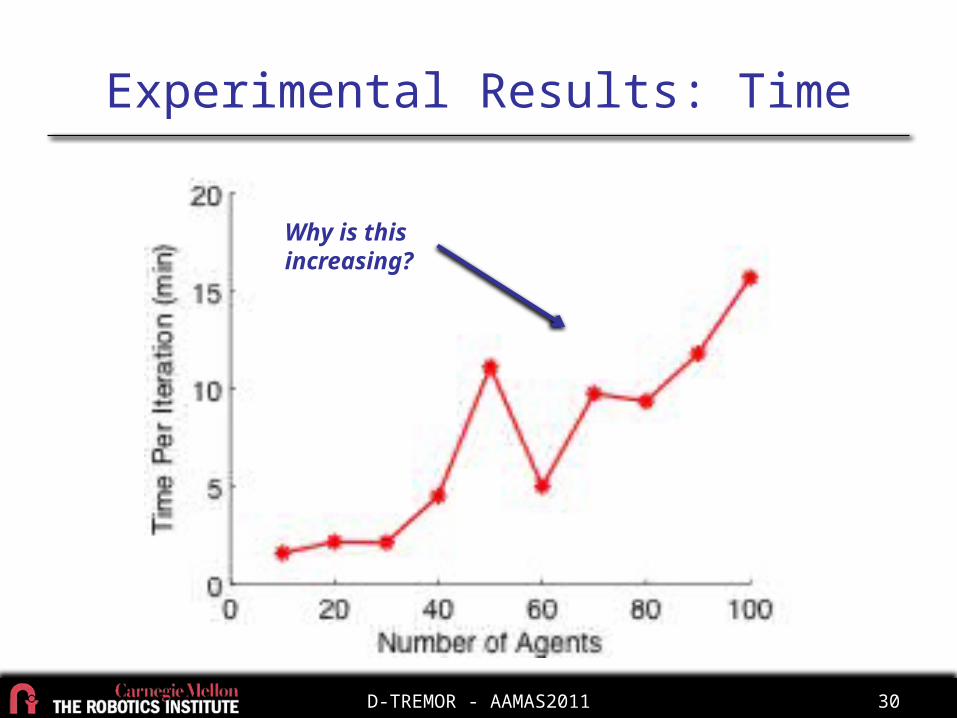
Experimental Results: Time
Why is this increasing?
D-TREMOR - AAMAS2011 31
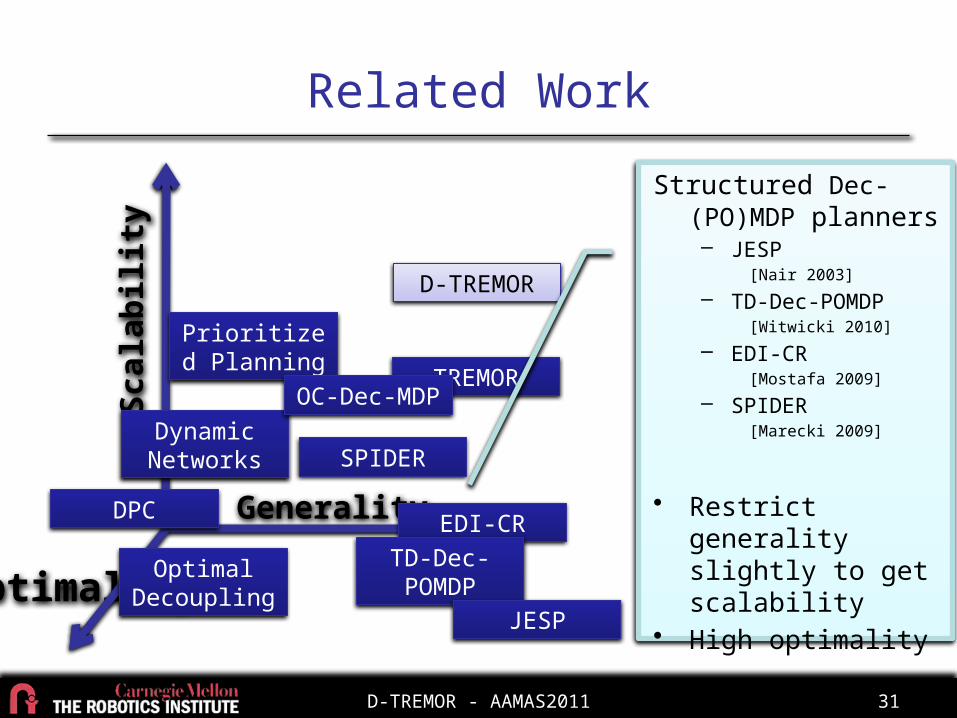
Related WorkSc
alab
ility
Opti
mal
ity Generality EDI-CRTD-Dec-POMDP
TREMOR
Dynamic Networks
JESP
Prioritized Planning
D-TREMOR
DPC
OC-Dec-MDP
SPIDER
Structured Dec-(PO)MDP planners– JESP
[Nair 2003]
– TD-Dec-POMDP[Witwicki 2010]
– EDI-CR[Mostafa 2009]
– SPIDER[Marecki 2009]
• Restrict generality slightly to get scalability
• High optimalityOptimal Decoupling
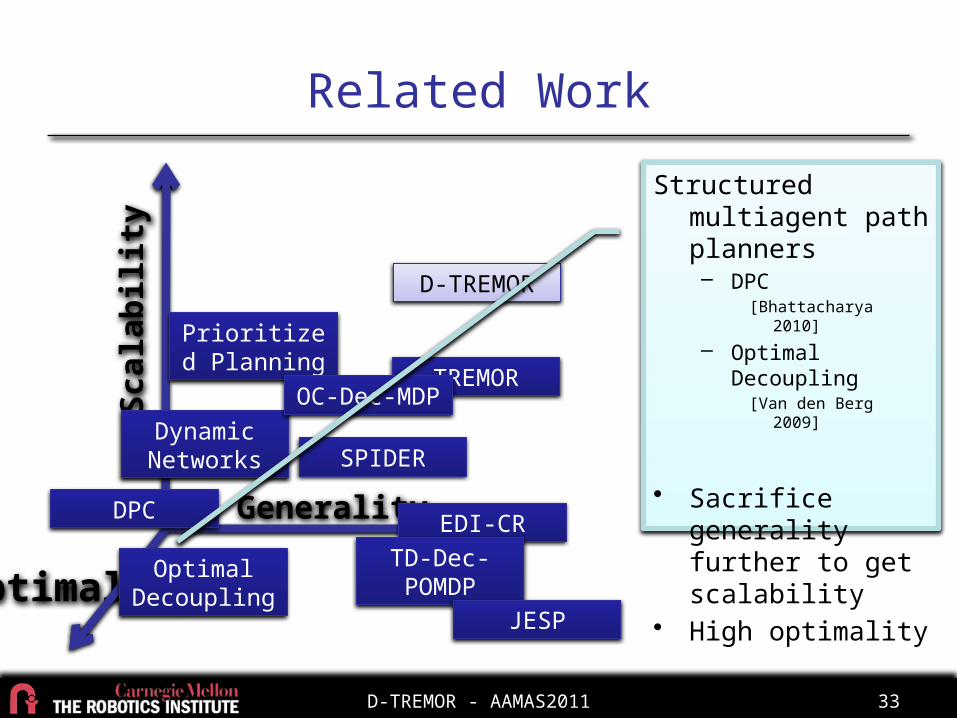
D-TREMOR - AAMAS2011 32
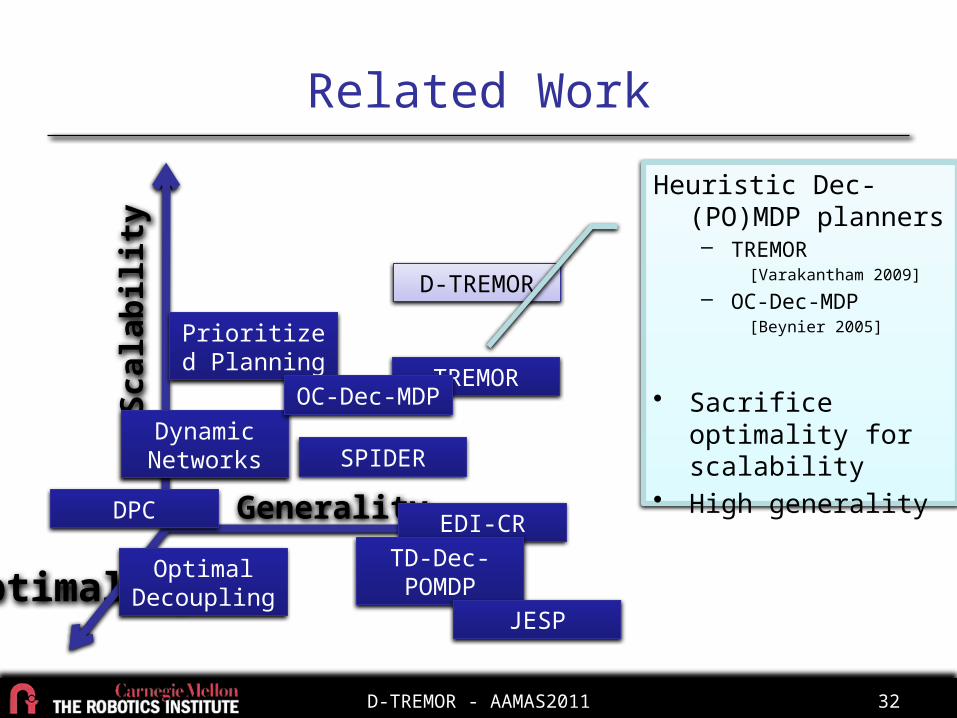
Related WorkSc
alab
ility
Opti
mal
ity Generality EDI-CRTD-Dec-POMDP
TREMOR
Dynamic Networks
JESP
Prioritized Planning
D-TREMOR
DPC
OC-Dec-MDP
SPIDER
Heuristic Dec-(PO)MDP planners– TREMOR
[Varakantham 2009]
– OC-Dec-MDP[Beynier 2005]
• Sacrifice optimality for scalability
• High generality
Optimal Decoupling
D-TREMOR - AAMAS2011 33
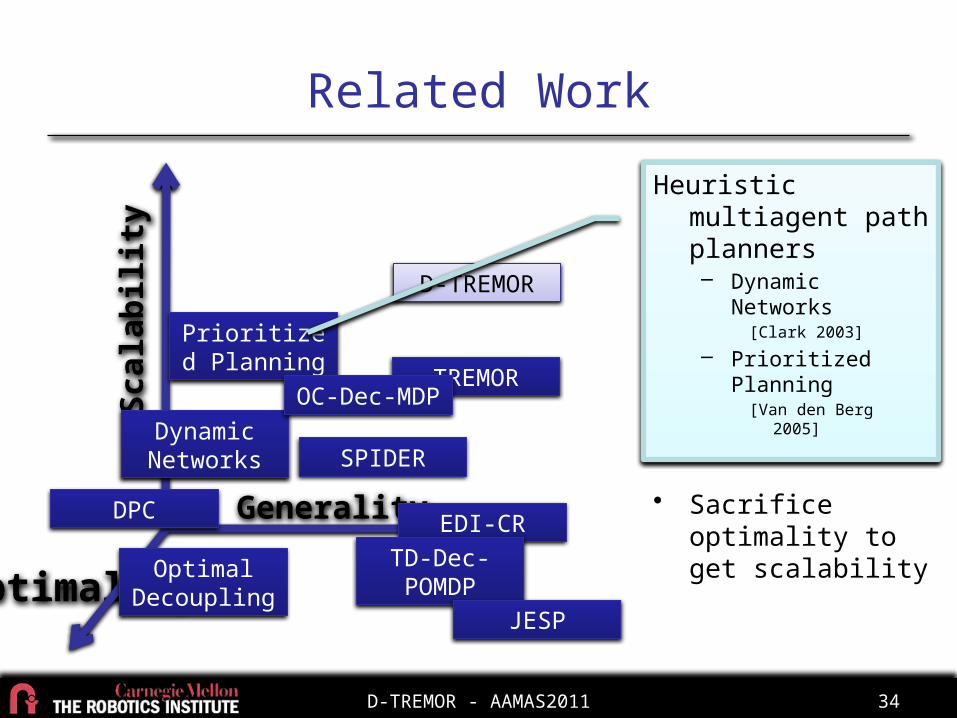
Related WorkSc
alab
ility
Opti
mal
ity Generality EDI-CRTD-Dec-POMDP
TREMOR
Dynamic Networks
JESP
Prioritized Planning
D-TREMOR
DPC
OC-Dec-MDP
SPIDER
Optimal Decoupling
Structured multiagent path planners– DPC
[Bhattacharya 2010]
– Optimal Decoupling[Van den Berg 2009]
• Sacrifice generality further to get scalability
• High optimality
D-TREMOR - AAMAS2011 34
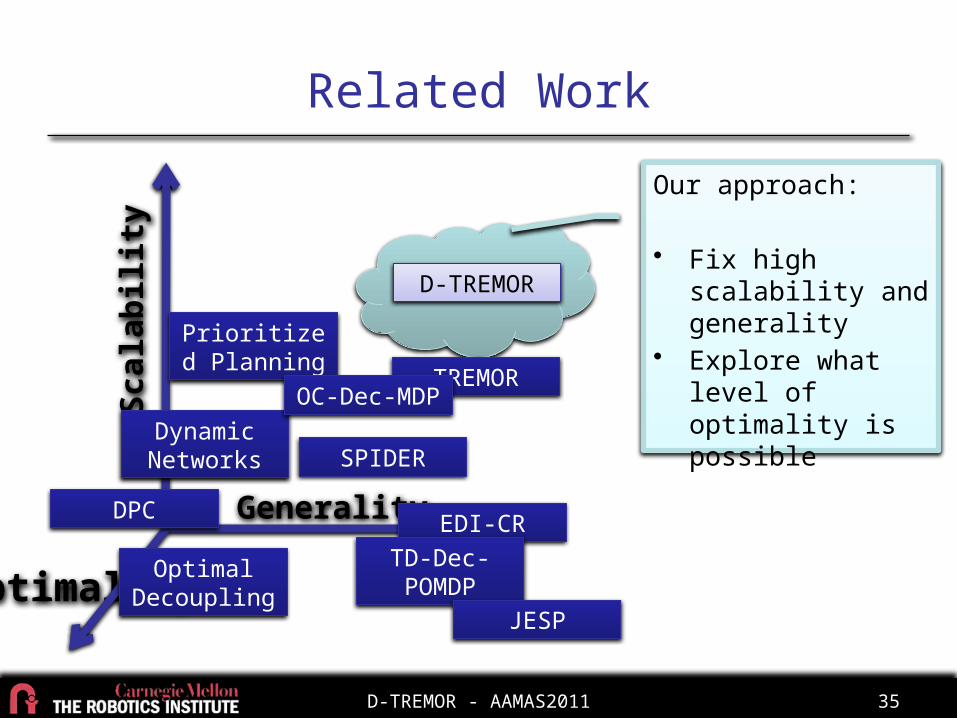
Related WorkSc
alab
ility
Opti
mal
ity Generality EDI-CRTD-Dec-POMDP
TREMOR
Dynamic Networks
JESP
Prioritized Planning
D-TREMOR
DPC
OC-Dec-MDP
SPIDER
Optimal Decoupling
Heuristic multiagent path planners– Dynamic Networks
[Clark 2003]
– Prioritized Planning[Van den Berg 2005]
• Sacrifice optimality to get scalability
D-TREMOR - AAMAS2011 35
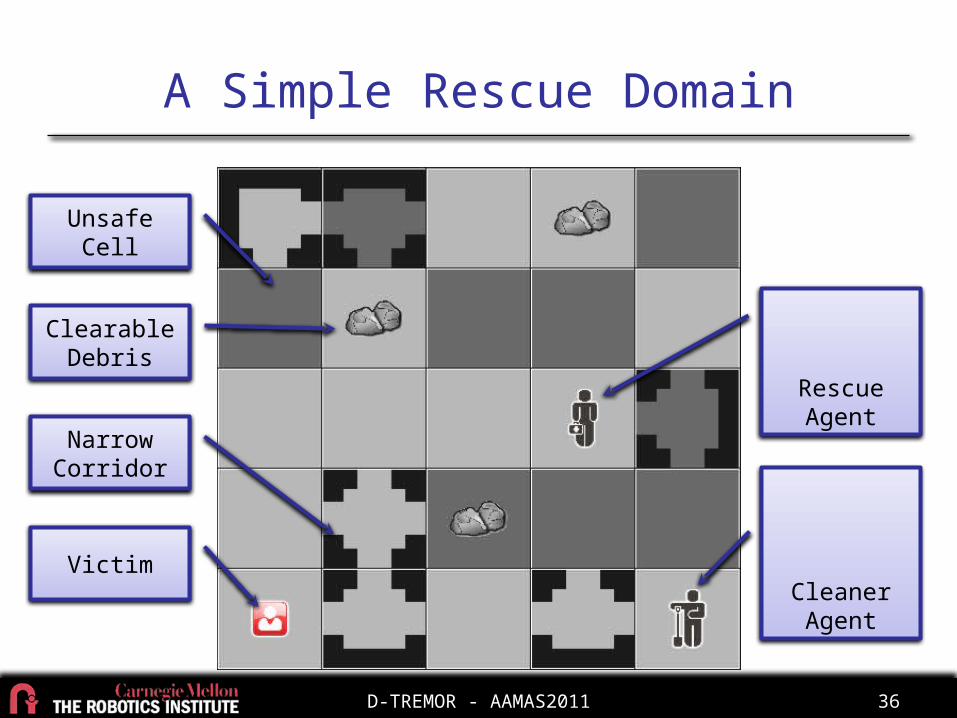
Scal
abili
ty
Opti
mal
ity Generality
Related Work
EDI-CRTD-Dec-POMDP
TREMOR
Dynamic Networks
JESP
Our approach:
• Fix high scalability and generality
• Explore what level of optimality is possible
Prioritized Planning
D-TREMOR
DPC
OC-Dec-MDP
SPIDER
Optimal Decoupling
D-TREMOR - AAMAS2011 36
A Simple Rescue Domain
Rescue Agent
Cleaner Agent
Narrow Corridor
Victim
Unsafe Cell
Clearable Debris

D-TREMOR - AAMAS2011 37
A Simple (Large) Rescue Domain

D-TREMOR - AAMAS2011 38
Distributed POMDP with Coordination Locales (DPCL)
• Often, interactions between agents are sparse
Only fits one agent Passable if
cleaned
[Varakantham, et al 2009]

D-TREMOR - AAMAS2011 39
Distributed, Iterative Planning
• Inspiration:– TREMOR
[Varankantham 2009]
– JESP[Nair 2003]
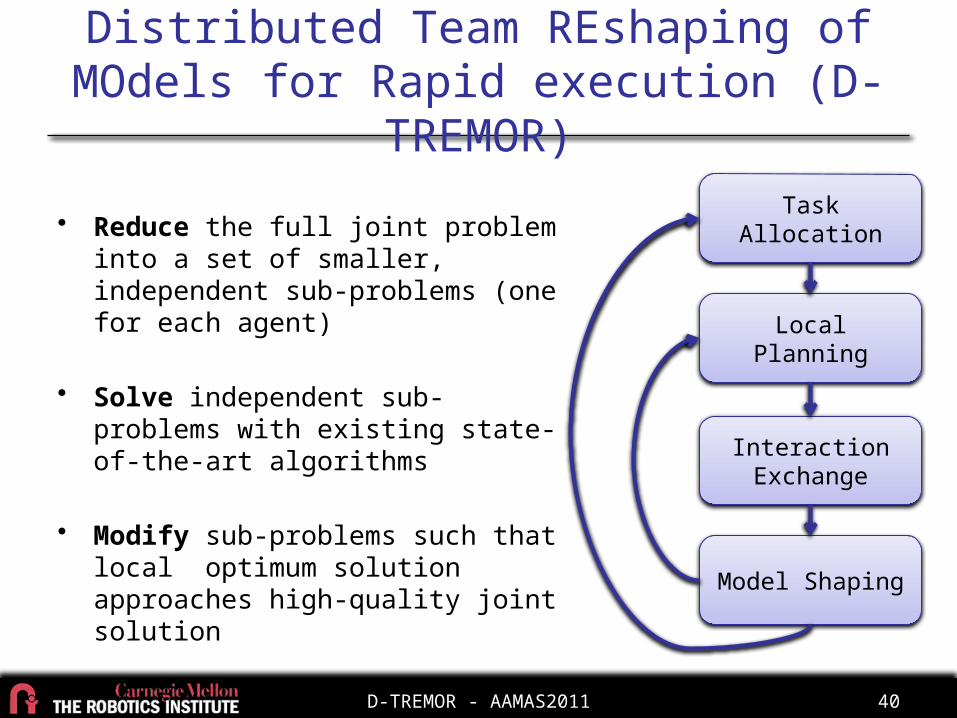
• Reduce the full joint problem into a set of smaller, independent sub-problems
• Solve independent sub-problems with local algorithm
• Modify sub-problems to push locally optimal solutions towards high-quality joint solution
D-TREMOR - AAMAS2011 40
Distributed Team REshaping of MOdels for Rapid execution (D-
TREMOR)
• Reduce the full joint problem into a set of smaller, independent sub-problems (one for each agent)
• Solve independent sub-problems with existing state-of-the-art algorithms
• Modify sub-problems such that local optimum solution approaches high-quality joint solution
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
D-TREMOR - AAMAS2011 41
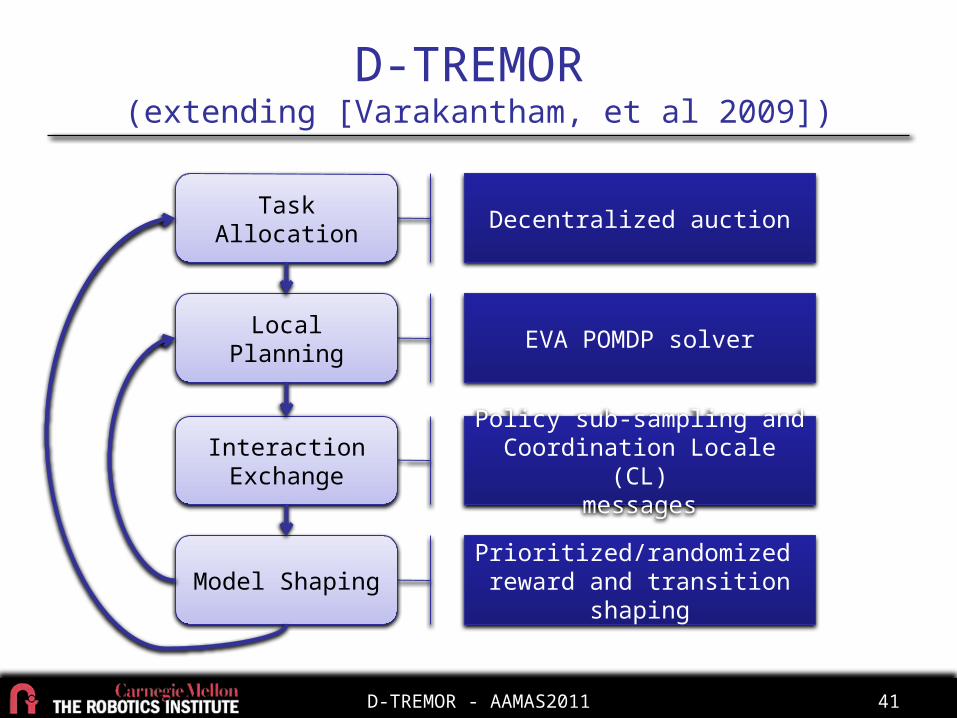
Decentralized auction
EVA POMDP solver
Policy sub-sampling and Coordination Locale (CL)
messages
Prioritized/randomized reward and transition shaping
D-TREMOR (extending [Varakantham, et al 2009])
Task Allocation
Local Planning
Interaction Exchange
Model Shaping

D-TREMOR - AAMAS2011 42
D-TREMOR: Task Allocation
• Assign “tasks” using decentralized auction– Greedy, nearest allocation
• Create local, independent sub-problem:

D-TREMOR - AAMAS2011 43
D-TREMOR: Local Planning
• Solve using off-the-shelf algorithm (EVA)
• Result: locally-optimal policies

D-TREMOR - AAMAS2011 44
D-TREMOR: Interaction Exchange
Finding PrCLi
• Evaluate local policy
• Compute frequency of associated si, ai
[Kearns 2002]:
Entered corridor in 95 of 100 runs:
PrCLi= 0.95

D-TREMOR - AAMAS2011 45
D-TREMOR: Interaction Exchange
Finding ValCLi
• Sample local policy value with/without interactions– Test interactions independently
• Compute change in value if interaction occurred
No collision
Collision
+1
-6
ValCLi= -7
[Kearns 2002]:

D-TREMOR - AAMAS2011 46
D-TREMOR: Interaction Exchange
• Send CL messages to teammates:
• Sparsity Relatively small # of messages
D-TREMOR - AAMAS2011 47
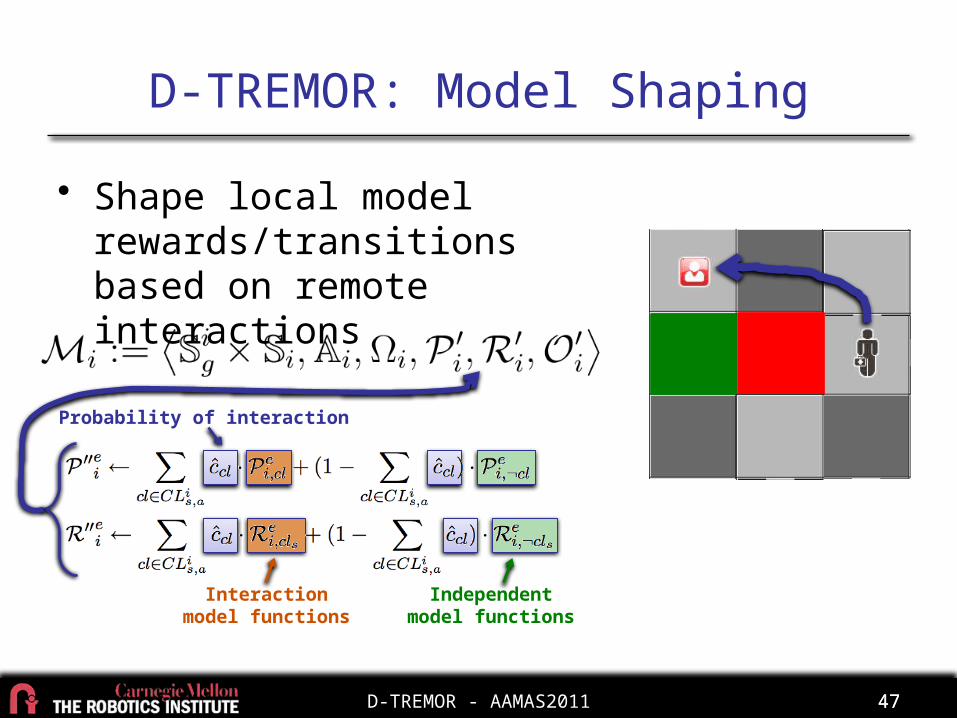
D-TREMOR: Model Shaping
• Shape local model rewards/transitions based on remote interactions
47
Probability of interaction
Interactionmodel functions
Independentmodel functions

D-TREMOR - AAMAS2011 48
D-TREMOR: Local Planning (again)
• Re-solve shaped local models to get new policies
• Result: new locally-optimal policies new interactions
48

D-TREMOR - AAMAS2011 49
D-TREMOR: Adv. Model Shaping
• In practice, we run into three common issues faced by concurrent optimization algorithms:– Slow convergence– Oscillation– Local optima
• We can alter our model-shaping to mitigate these by reasoning about the types of interactions we have

D-TREMOR - AAMAS2011 50
D-TREMOR: Adv. Model Shaping
• Slow convergence Prioritization– Majority of interactions are collisions
– Assign priorities to agents, only model-shape collision interactions for higher priority agents
– From DPP: prioritization can quickly resolve collision interactions
– Similar properties for any purely negative interaction• Negative interaction: when every agent is guaranteed to have a
lower-valued local policy if an interaction occurs

D-TREMOR - AAMAS2011 51
D-TREMOR: Adv. Model Shaping
• Oscillation Probabilistic shaping– Often caused by time dynamics between agents
• Agent 1 shapes based on Agent 2’s old policy• Agent 2 shapes based on Agent 1’s old policy
– Each agent only applies model-shaping with probability δ [Zhang 2005]
– Breaks out of cycles between agent policies
D-TREMOR - AAMAS2011 52
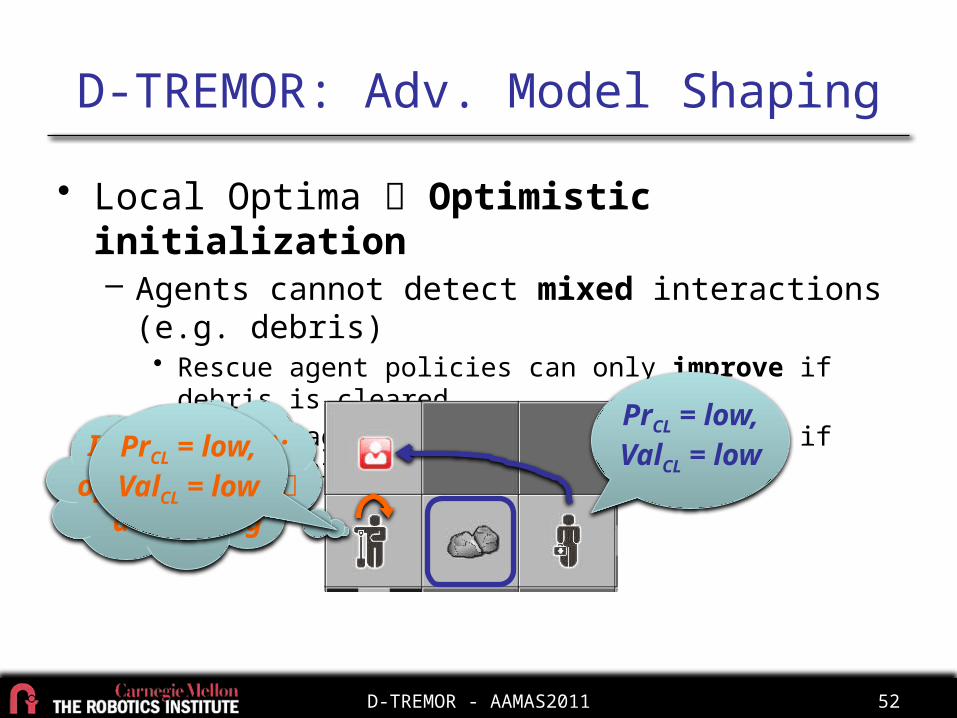
D-TREMOR: Adv. Model Shaping
• Local Optima Optimistic initialization– Agents cannot detect mixed interactions (e.g. debris)
• Rescue agent policies can only improve if debris is cleared• Cleaner agent policies can only worsen if they clear debris
PrCL = low, ValCL = lowIf (ValCL = low):
optimal policy do nothing
PrCL = low, ValCL = low

D-TREMOR - AAMAS2011 53
D-TREMOR: Adv. Model Shaping
• Local Optima Optimistic initialization– Agents cannot detect mixed interactions (e.g. debris)
• Rescue agent policies can only improve if debris is cleared• Cleaner agent policies can only worsen if they clear debris
– Let each agent solve an initial model that uses an optimistic assumption of interaction condition

D-TREMOR - AAMAS2011 54
Experimental Setup
• D-TREMOR policies– Max-joint-value– Last iteration
• Comparison policies– Independent– Optimistic– Do-nothing– Random
• Scaling:– 10 to 100 agents– Random maps
• Density– 100 agents– Concentric ring maps
• 3 problems/condition• 20 planning iterations• 7 time step horizon• 1 CPU per agent
D-TREMOR produces reasonable policies for 100-agent planning problems in under 6 hrs.
(with some caveats)
D-TREMOR - AAMAS2011 55
Experimental Datasets
Scaling Dataset Density Dataset
D-TREMOR - AAMAS2011 56
Experimental Results: Scaling
Naïve Policies
D-TREMOR Policies
D-TREMOR - AAMAS2011 57
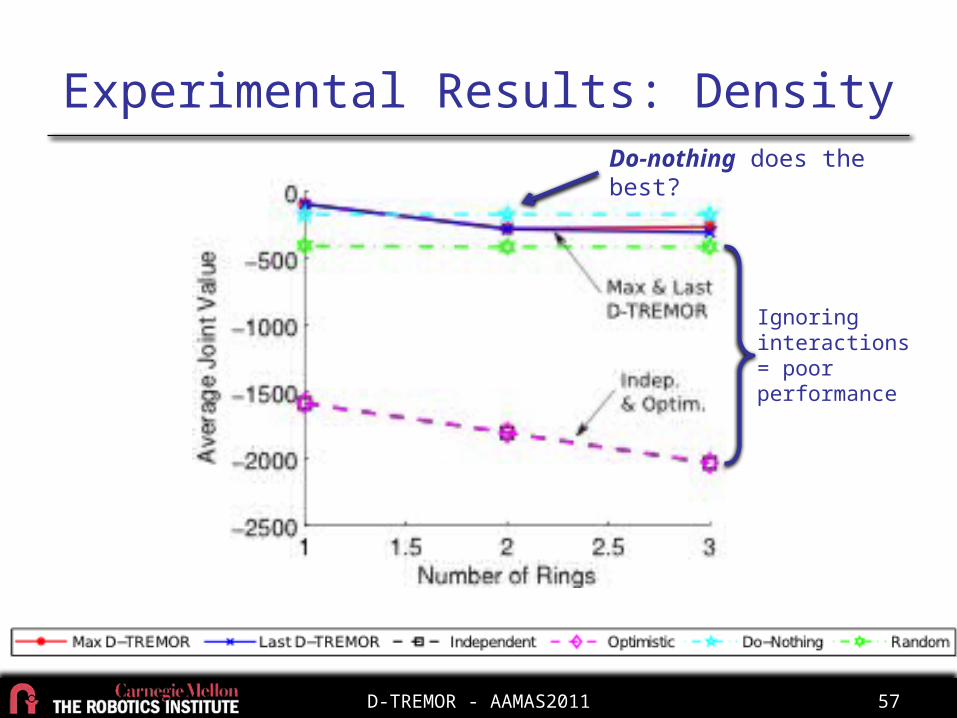
Experimental Results: Density
Do-nothing does the best?
Ignoring interactions = poor performance

D-TREMOR - AAMAS2011 58
Experimental Results: Density
D-TREMOR rescues the most victims D-TREMOR does not
resolve every collision+10 ea. -5 ea.
D-TREMOR - AAMAS2011 59
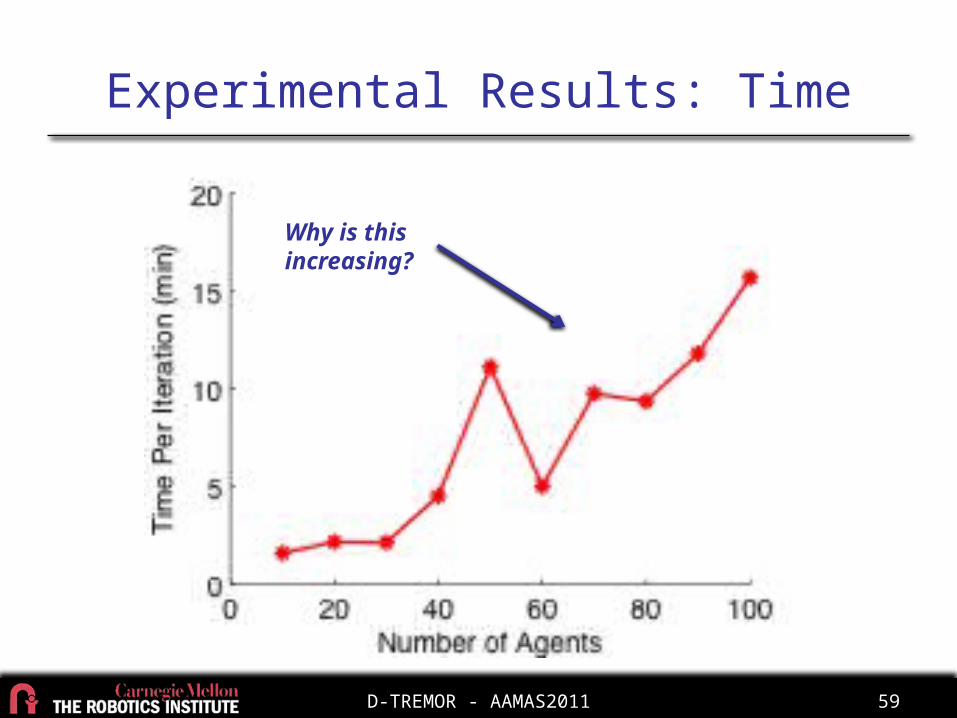
Experimental Results: Time
Why is this increasing?
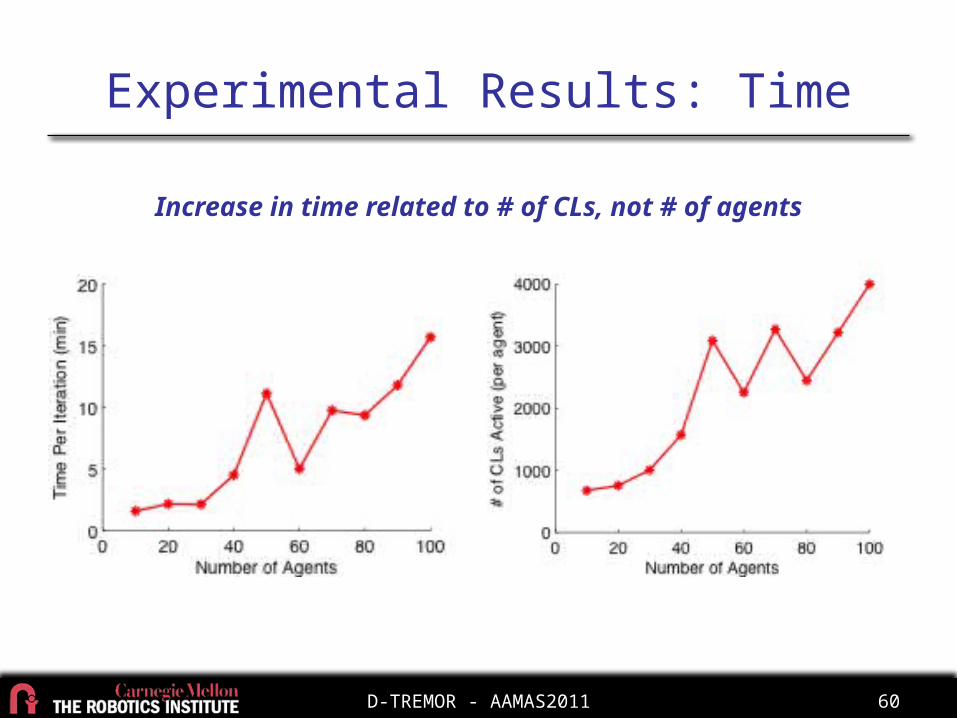
D-TREMOR - AAMAS2011 60
Experimental Results: Time
Increase in time related to # of CLs, not # of agents

D-TREMOR - AAMAS2011 61
Conclusions
• D-TREMOR: Decentralized planning for sparse Dec-POMDPs with many agents
• Demonstrated complete distributability, fast heuristic interaction detection, and local message exchange to achieve high scalability
• Empirical results in simulated search and rescue domain

D-TREMOR - AAMAS2011 62
Conclusions
D-TREMOR produces reasonable policies for 100-agent planning problems in under 6 hrs.– Partially-observable, uncertain world– Multiple types of interactions & agents
• Improves over independent planning• Resolved interactions in large problems• Still some convergence/efficiency issues

D-TREMOR - AAMAS2011 63
DPCL vs. other models
• EDI/EDI-CR– Adds complex transition functions
• TD-Dec-MDP– Allows simultaneous interaction (within epoch)
• Factored MDP/POMDP– Adds interactions that span epochs

D-TREMOR - AAMAS2011 64
D-TREMOR

D-TREMOR - AAMAS2011 65
D-TREMOR

D-TREMOR - AAMAS2011 66
D-TREMOR: Reward functions
• Probability that a debris will not allow a robot to enter the cell: – P_Debris = 0.9;
• Probability of action failure– P_ActionFailure = 0.2;
• Probability that success is observed if the action succeeded.– P_ObsSuccessOnSuccess = 0.8;
• Probability that success is observed if the action failed– P_ObsSuccessOnFailure = 0.2;
• Probability that a robot will return to the same cell after collision– P_ReboundAfterCollision = 0.5;
• Reward of saving a victim– R_Victim = 10.0;
• Reward of cleaning debris– R_Cleaning = 0.25;
• Reward of moving– R_Move = -0.5;
• Reward of observing– R_Observe = -0.25;
• Reward for a collision– R_Collision = -5.0;
• Reward for landing in an unsafe cell– R_Unsafe = -1;
D-TREMOR - AAMAS2011 67
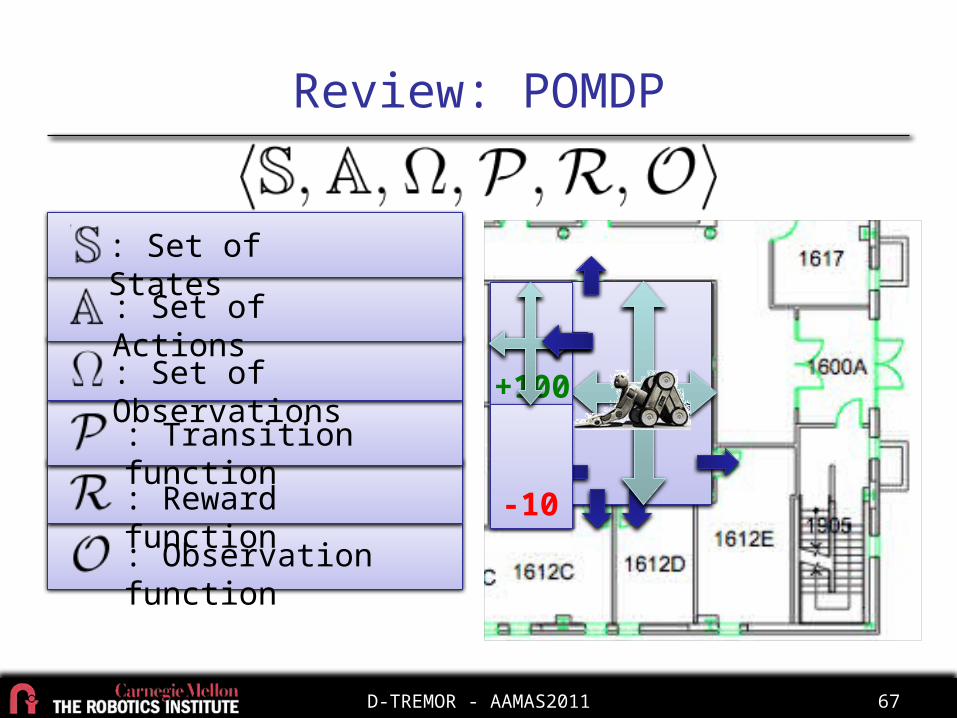
Review: POMDP
+100
-10
: Set of States
: Set of Actions
: Set of Observations
: Transition function
: Reward function
: Observation function

D-TREMOR - AAMAS2011 68
Distributed POMDP with Coordination Locales
[Varakantham, et al 2009]• Extension of Dec-POMDP which modifies ,• Coordination locales (CLs) represent interactions:
Explicit time
Explicit time constraint
Implicitly construct interaction functions
CL =
D-TREMOR - AAMAS2011 69
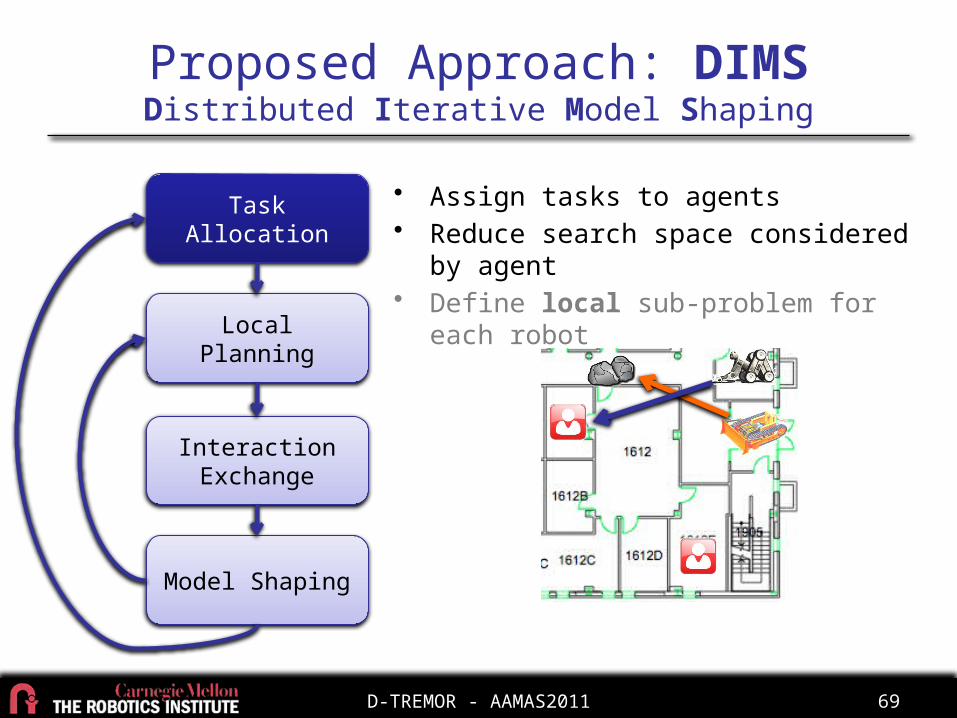
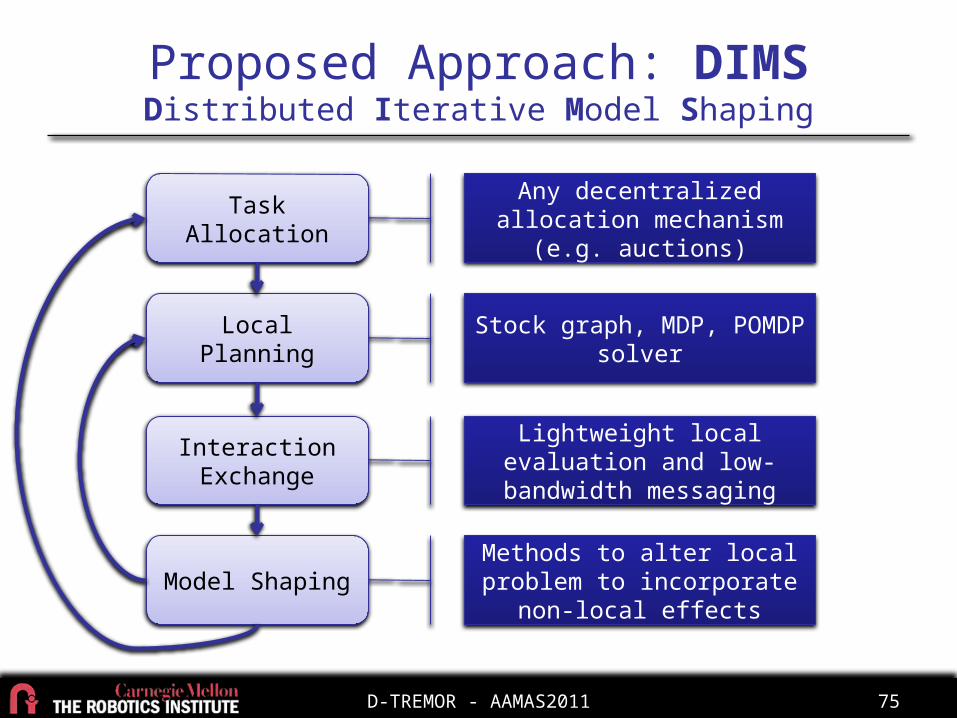
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
• Assign tasks to agents• Reduce search space considered by agent• Define local sub-problem for each robot
D-TREMOR - AAMAS2011 70
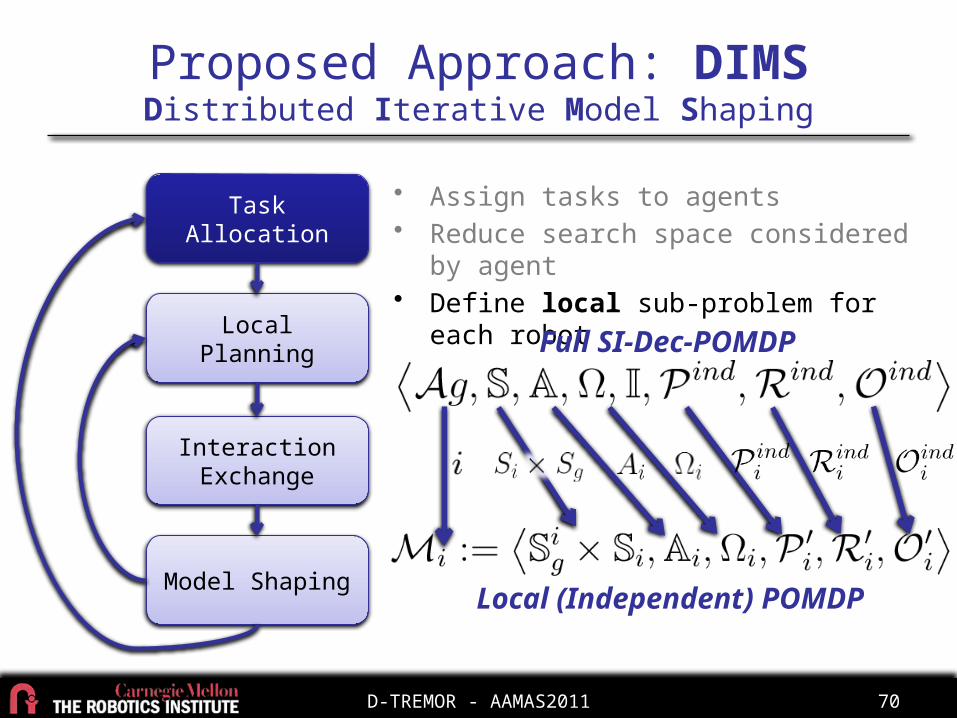
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
• Assign tasks to agents• Reduce search space considered by agent• Define local sub-problem for each robot
Full SI-Dec-POMDP
Local (Independent) POMDP
D-TREMOR - AAMAS2011 71
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
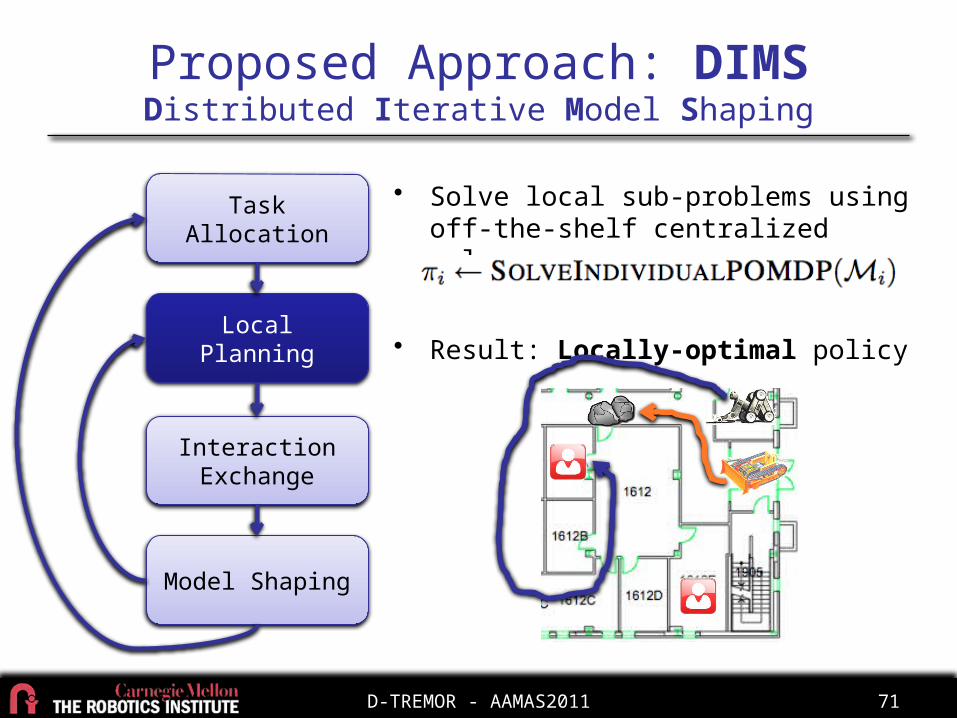
• Solve local sub-problems using off-the-shelf centralized solver
• Result: Locally-optimal policy
D-TREMOR - AAMAS2011 72
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
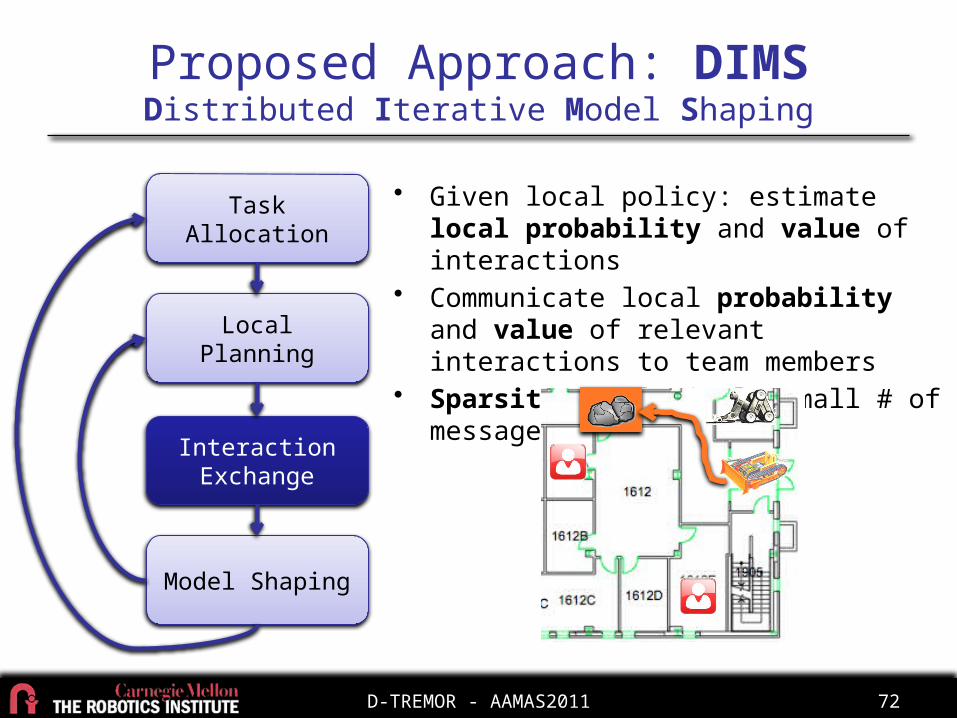
• Given local policy: estimate local probability and value of interactions
• Communicate local probability and value of relevant interactions to team members
• Sparsity Relatively small # of messages
D-TREMOR - AAMAS2011 73
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
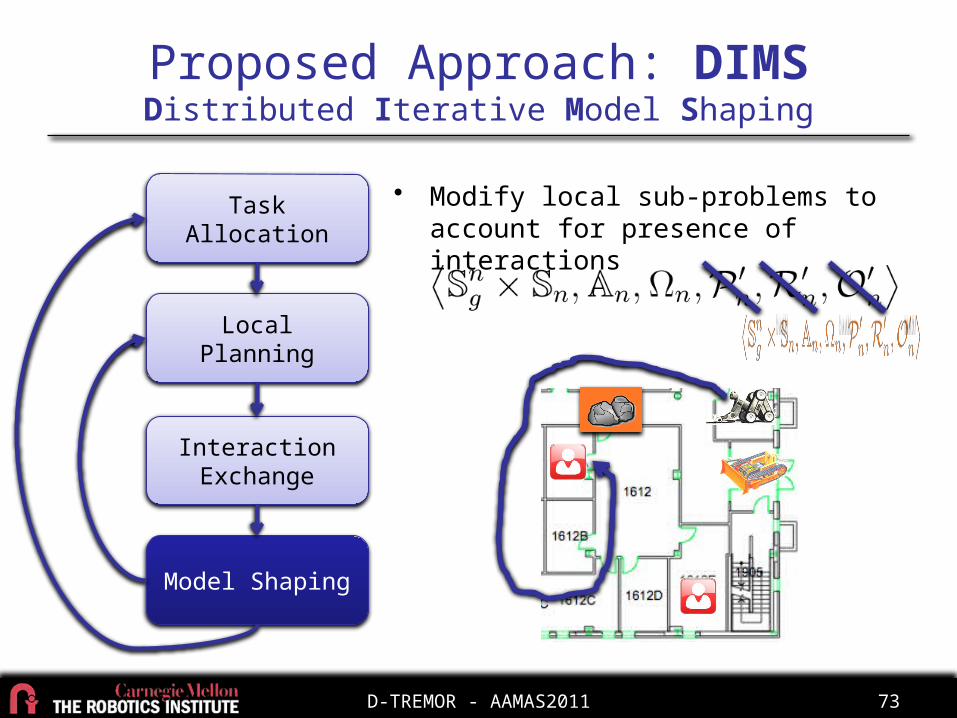
• Modify local sub-problems to account for presence of interactions
D-TREMOR - AAMAS2011 74
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping
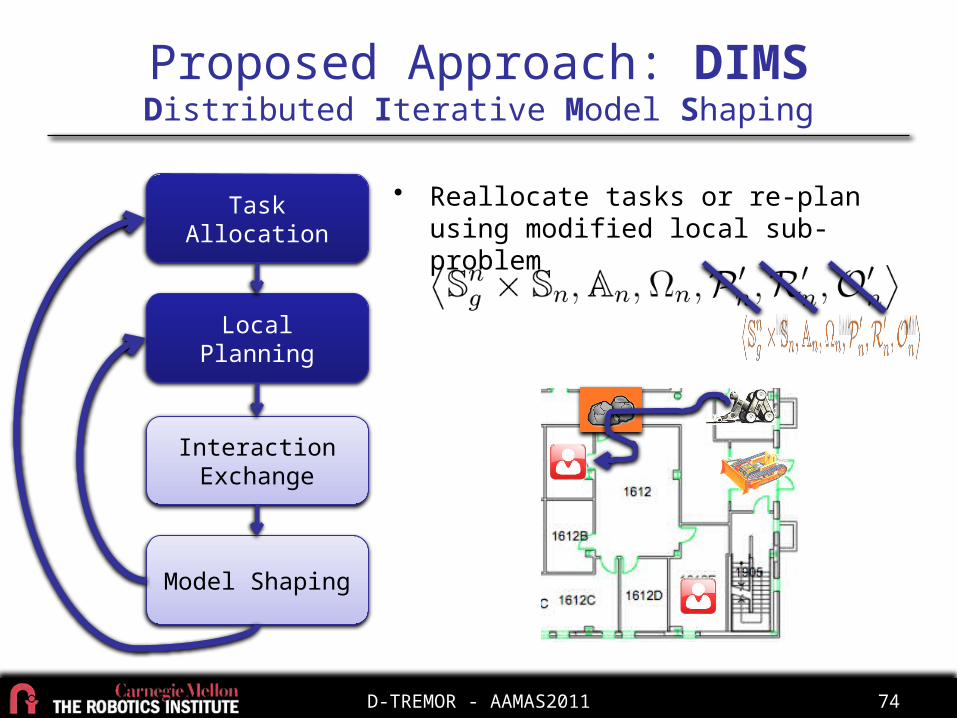
• Reallocate tasks or re-plan using modified local sub-problem
D-TREMOR - AAMAS2011 75
Any decentralized allocation mechanism (e.g. auctions)
Stock graph, MDP, POMDP solver
Lightweight local evaluation and low-bandwidth messaging
Methods to alter local problem to incorporate non-local effects
Proposed Approach: DIMSDistributed Iterative Model Shaping
Task Allocation
Local Planning
Interaction Exchange
Model Shaping

D-TREMOR - AAMAS2011 76
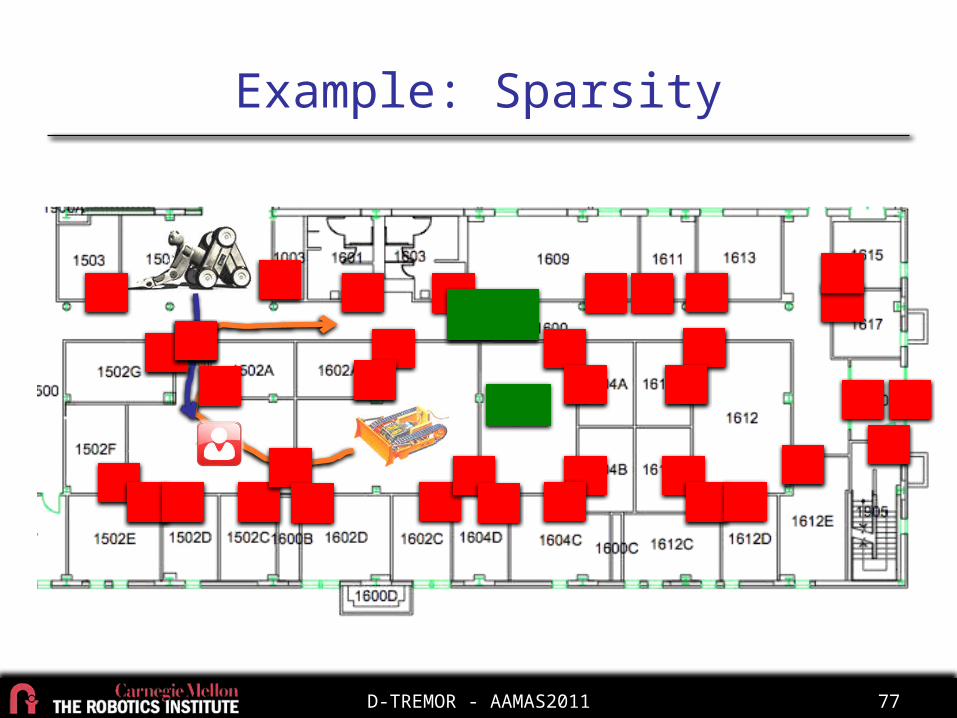
Example: Interactions
Rescue robot
Cleaner robot
Debris
Victim
D-TREMOR - AAMAS2011 77
Example: Sparsity