argus: rete + dbms = efficient persistent profile matching on large-volume data streams chun jin...
TRANSCRIPT

ARGUS: Rete + DBMS = Efficient Persistent Profile Matching on Large-Volume Data Streams
Chun Jin
Language Technologies InstituteSchool of Computer ScienceCarnegie Mellon [email protected]

Chun Jin Carnegie Mellon 2
Stream Processing Model Stream Processing becomes
demanding and prevalent.
Storage
Data Streams Output

Chun Jin Carnegie Mellon 3
Stream Databases Stream Database Applications
Network Traffic Analysis and Router Configuration
Dynamic Internet Services Sensor Data Analysis Anomaly Detection
Stream Database Projects STREAM, TelegraphCQ, Aurora NiagaraCQ, OpenCQ, WebCQ Gigascope, Tribeca Tapestry, Alert, Tukwila, etc. ARGUS

Chun Jin Carnegie Mellon 4
Stream Anomaly Monitoring Systems (SAMS)
SAMS monitors structured data streams for anomalies or potential hazards.
Matches of queries may be high urgency alerts. Prompt detections are desirable.
Satisfaction of a SAMS query is often rare (very-high-selectivity).

Chun Jin Carnegie Mellon 5
SAMS Dataflow
Analyst
Stream Anomaly Monitoring System
Stream Anomaly Monitoring System
Storage
Que
ries
Alerts
Data Streams
FedWire Money TransfersPatient Records

Chun Jin Carnegie Mellon 6
Challenges to SAMS
Persistent queries may number in thousands or tens of thousands.
Daily stream volumes may exceed millions of records.
Prompt detections are desirable.
Very-high-selectivity Query Property.

Chun Jin Carnegie Mellon 7
Proposed ARGUS Approach Basic Framework:
Incremental evaluation schemes (Adapted Rete algorithm)
Rete (Forgy 1982): Incremental Evaluation based on Materialized Intermediate Results.
Upon a traditional DBMS platform Exploiting Very-High-Selectivity Query Property:
Transitivity Inference Conditional Materialization Optimizing Join Order Computation Sharing
Related to Other Applications Stream Databases Modern DBMS Query Optimization

Chun Jin Carnegie Mellon 8
Query Example 4 Suppose for every big transaction of
type code 1000, the analyst wants to check if the money stayed in the bank or left within ten days. An additional sign of possible fraud is that transactions involve at least one intermediate bank. The query generates an alarm whenever the receiver of a large transaction (over $1,000,000) transfers at least half of the money further within ten days of this transaction using an intermediate bank.

Chun Jin Carnegie Mellon 9
SQL Query for Example 4FROM transaction r1, transaction r2, transaction r3WHERE r2.type_code = 1000 AND
r3.type_code = 1000 ANDr1.type_code = 1000 ANDr1.amount > 1000000 ANDr1.rbank_aba = r2.sbank_aba ANDr1.benef_account = r2.orig_account ANDr2.amount > 0.5 * r1.amount ANDr1.tran_date <= r2.tran_date ANDr2.tran_date <= r1.tran_date + 10 ANDr2.rbank_aba = r3.sbank_aba ANDr2.benef_account = r3.orig_account ANDr2.amount = r3.amount ANDr2.tran_date <= r3.tran_date ANDr3.tran_date <= r2.tran_date + 10;

Chun Jin Carnegie Mellon 10
ARGUS System Architecture
Rete NetworkGenerator
Query
ReteNetworks
Data Tables
Analyst
Identified Threats
IntermediateTables
Data Streams
QueryTable
StreamAnomalyMonitoring
Do_queries
Scheduler

Chun Jin Carnegie Mellon 11
ReteGenerator Architecture
SystemCatalog
TransitivityInference
SQL Queries
ReteGenerator
SharingModule
Join Order
ConditionalMaterialization
Optimizer
Common Computation Identification Predicate Indexing Extended Predicate Set Operations
Choose what and how to share Recording and Manipulating Network Topology Estimating Sharing Costs

Chun Jin Carnegie Mellon 12
Adapted Rete Algorithm (Selection)
n and m are old data sets Δn and Δm are the new much
smaller incremental data sets. Selection ơ
ơ(n+ Δn) ơ(n) ơ(Δn)= +

Chun Jin Carnegie Mellon 13
Adapted Rete Algorithm (Join) Join (n+Δn) (m+Δm)
= n m + Δn m + n Δm + Δn Δm
When Δn and Δm are very small compared to n and m, time complexity of incremental join is O(n+m)
Old ResultsNew Incremental Results

Chun Jin Carnegie Mellon 14
Incremental Evaluation in Rete Example 4
DataTable
r1, r2, r3
Type_code=1000Amount>1000000
Type_code=1000
Type_code=1000
r1.rbank_aba = r2.sbank_abar1.benef_account = r2.orig_accountr2.amount > r1.amount*0.5r1.tran_date <= r2.tran_dater2.tran_date >= r1.tran_date+10
r2.rbank_aba = r3.sbank_abar2.benef_account = r3.orig_accountr2.amount = r3.amountr2.tran_date <= r3.tran_dater3.tran_date >= r2.tran_date+10

Chun Jin Carnegie Mellon 15
Complex Queries A persistent query may contain multiple
SQL statements, and a single SQL statement may contain unions of multiple SQL terms.
Each SQL term is mapped to a sub-Rete network.
These sub-Rete networks are then connected to form the statement-level sub-networks.
And the statement-level subnetworks are further connected based on the view references to form the final query-level Rete network.

Chun Jin Carnegie Mellon 16
Transitivity Inference Exploring transitivity properties of
comparison operators To derive hidden high-selective selection
predicates High-selective selection predicates can
significantly improve performance as they may produce very small intermediate results. Subsequent join could be performed very fast on the materialized intermediate results.
Ono/Lohman VLDB90, Pirahesh/Leung/Hasan ICDE97

Chun Jin Carnegie Mellon 17
Transitivity Inference Example Given
r1.amount > 1000000 and r2.amount > r1.amount * 0.5 and r3.amount = r2.amount
r1.amount > 1000000 is very high-selective on r1
We can infer high-selective predicates: r2.amount > 500000 r3.amount > 500000
Chun Jin Carnegie Mellon 18
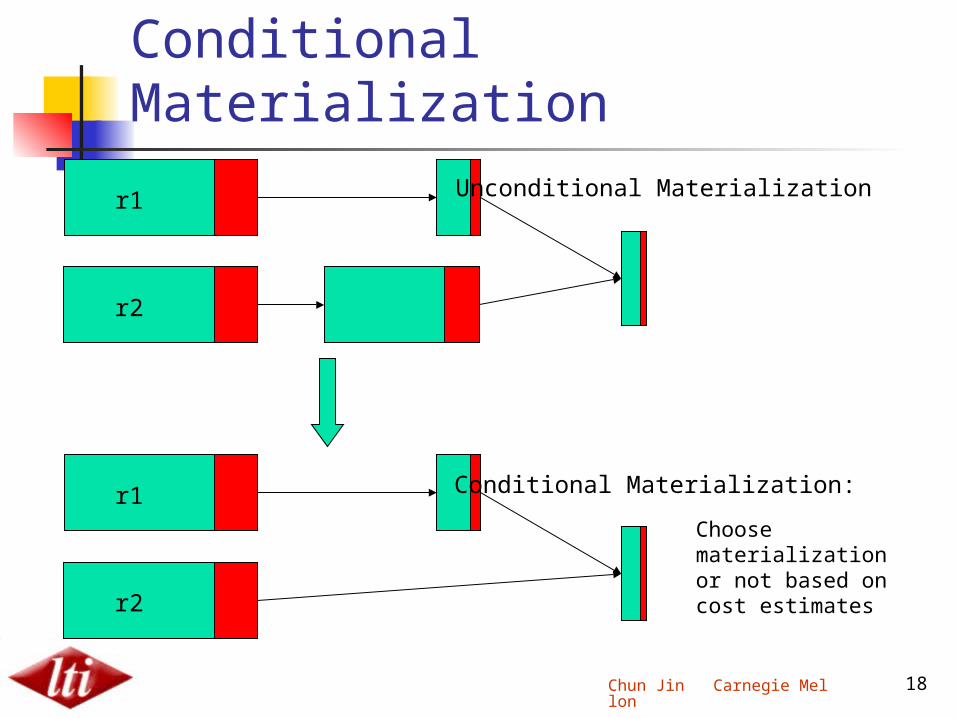
Conditional Materialization
r2
r1
r2
r1
Unconditional Materialization
Conditional Materialization:
Choose materialization or not based on cost estimates

Chun Jin Carnegie Mellon 19
Preliminary Evaluation:Queries and Data
7 queries on synthesized FedWire money transfer database. 320006 records.
Two Data Conditions: Data1: Old: first 300000 records
New: remaining 20006 recordsALERT
Data2: Old: first 300000 recordsNew: next 20000 recordsNOT alert

Chun Jin Carnegie Mellon 20
Preliminary Results
Rete with Transitivity Inference
0
10
20
30
40
50
Q1 Q2 Q3 Q4 Q5 Q6 Q7
Ex
ecu
tio
n T
ime
(s)
Rete Data1 SQL Data1 Rete Data2 SQL Data2

Chun Jin Carnegie Mellon 21
Transitivity Inference
Q2
Q4
0
5
10
15
20
25
Data1 Data2
Exe
cuti
on
Tim
e(s)
05
101520253035404550
Data1 Data2
Ex
ec
uti
on
Tim
e(s
)
Rete TI Rete Non-TI SQL Non-TI SQL TI

Chun Jin Carnegie Mellon 22
Conditional Materialization
Q4 assumes Transitivity Inference not applicable
05
101520253035404550
Data1 Data2
Ex
ecu
tio
n T
ime
(s)
Conditional
Rete
SQL

Chun Jin Carnegie Mellon 23
ARGUS Summary Adapted Rete Algorithm upon a
traditional DBMS platform Exploit the very-high-selectivity
query property for optimization: Transitivity Inference Conditional Materialization
Current and Future Work: Optimizing Join Order Computation Sharing

Chun Jin Carnegie Mellon 24
Thank you!
Questions and Comments?