apuntes de quimiometria regresio lineal … analitica... · apuntes de quimiometria regresio lineal...
TRANSCRIPT

APUNTES DE QUIMIOMETRIA
REGRESIO LINEAL
Datos anómalos y levas en las rectas de calibrado. Regresión robusta
Mínima mediana de cuadrados
Recta de calibrado mediante mínimos cuadrados. Hipótesis básicas
Estimación de los coeficientes de regresión por mínimos cuadrados
La elipse: región de confianza conjunta de la pendiente y la ordenada
Validación de un método analítico en estudio con uno de referencia

Datos anómalos y levas en las rectas de calibrado. Regresión robusta.
La obtención de las rectas de calibrado requiere un estudio previo de los
datos experimentales obtenidos con el objetivo de detectar la presencia de
observaciones heterogéneas, ya que, un solo punto puede condicionar la posición de
la recta de regresión. La identificación de las observaciones heterogéneas es una
etapa clave en la obtención del calibrado de forma que, una vez que sean tratadas
convenientemente, se pueda realizar el ajuste de los datos experimentales mediante
mínimos cuadrados con garantías de precisión y exactitud.
El propósito del análisis de regresión es ajustar las variables observadas a
ecuaciones. En el modelo lineal clásico se asume una relación del tipo: yi = α + βxi
+ ei para i = 1,..., n; donde:
n es el tamaño de la muestra o número de casos; xi es la variable independiente; yi es
la variable respuesta; ei error asociado a la variable respuesta y, α y β son la
ordenada en el origen y la pendiente de la verdadera recta que relaciona ambas
variables.
Los métodos de regresión lineal permiten obtener los coeficientes de la
regresión a y b, estimadores de α y β que, operando sobre la variable independiente
resultan los valores estimados de la variable respuesta, íi = a + bxi. El residuo de
cada variable respuesta, ri, es la diferencia entre el valor de dicha variable y su valor
observado. Los distintos métodos de regresión se basan en hacer óptimo el ajuste
minimizando una función de los residuales.
A continuación se explicará e ilustrará el efecto de datos heterogéneos en el
modelo de regresión lineal. En la figura 1.a se representan cinco puntos alineados
(x1, y1),.., (x5,y5), por lo que, el método de mínimos cuadrados ofrece un ajuste muy
bueno. Supongamos que se ha cometido un error en el valor de y4 que aleja el punto
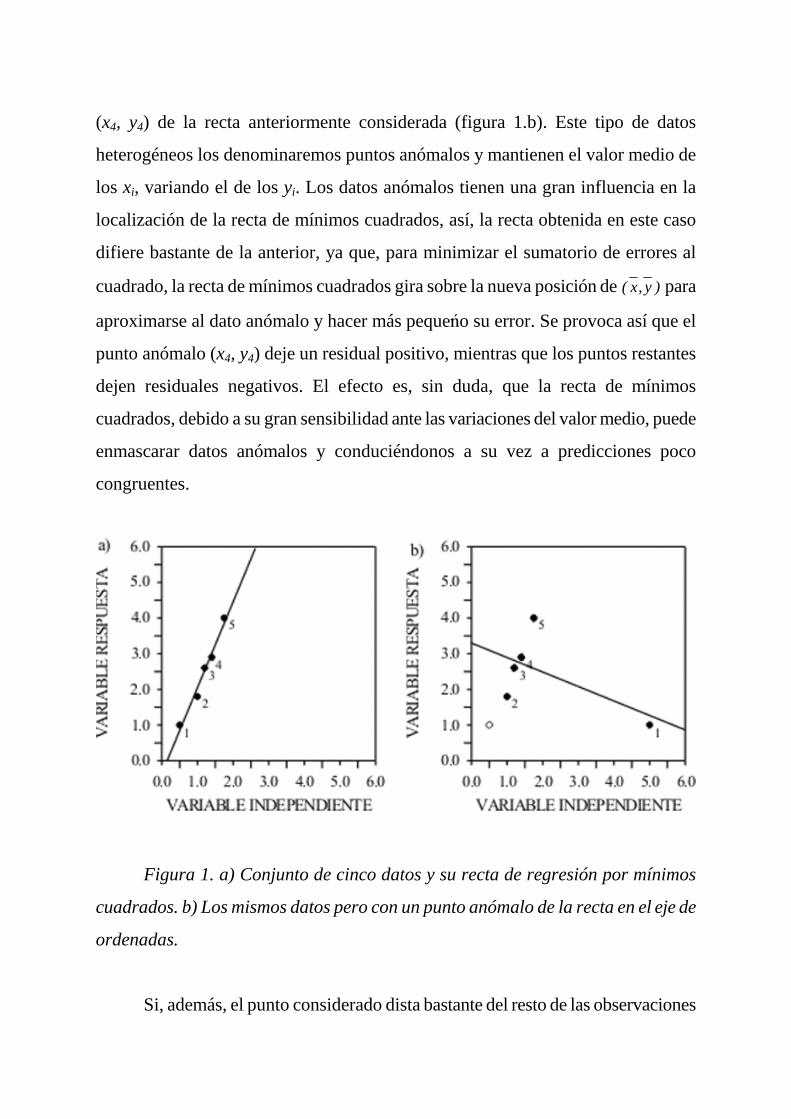
(x4, y4) de la recta anteriormente considerada (figura 1.b). Este tipo de datos
heterogéneos los denominaremos puntos anómalos y mantienen el valor medio de
los xi, variando el de los yi. Los datos anómalos tienen una gran influencia en la
localización de la recta de mínimos cuadrados, así, la recta obtenida en este caso
difiere bastante de la anterior, ya que, para minimizar el sumatorio de errores al
cuadrado, la recta de mínimos cuadrados gira sobre la nueva posición de )y,x( para
aproximarse al dato anómalo y hacer más peque½o su error. Se provoca así que el
punto anómalo (x4, y4) deje un residual positivo, mientras que los puntos restantes
dejen residuales negativos. El efecto es, sin duda, que la recta de mínimos
cuadrados, debido a su gran sensibilidad ante las variaciones del valor medio, puede
enmascarar datos anómalos y conduciéndonos a su vez a predicciones poco
congruentes.
Figura 1. a) Conjunto de cinco datos y su recta de regresión por mínimos
cuadrados. b) Los mismos datos pero con un punto anómalo de la recta en el eje de
ordenadas.
Si, además, el punto considerado dista bastante del resto de las observaciones
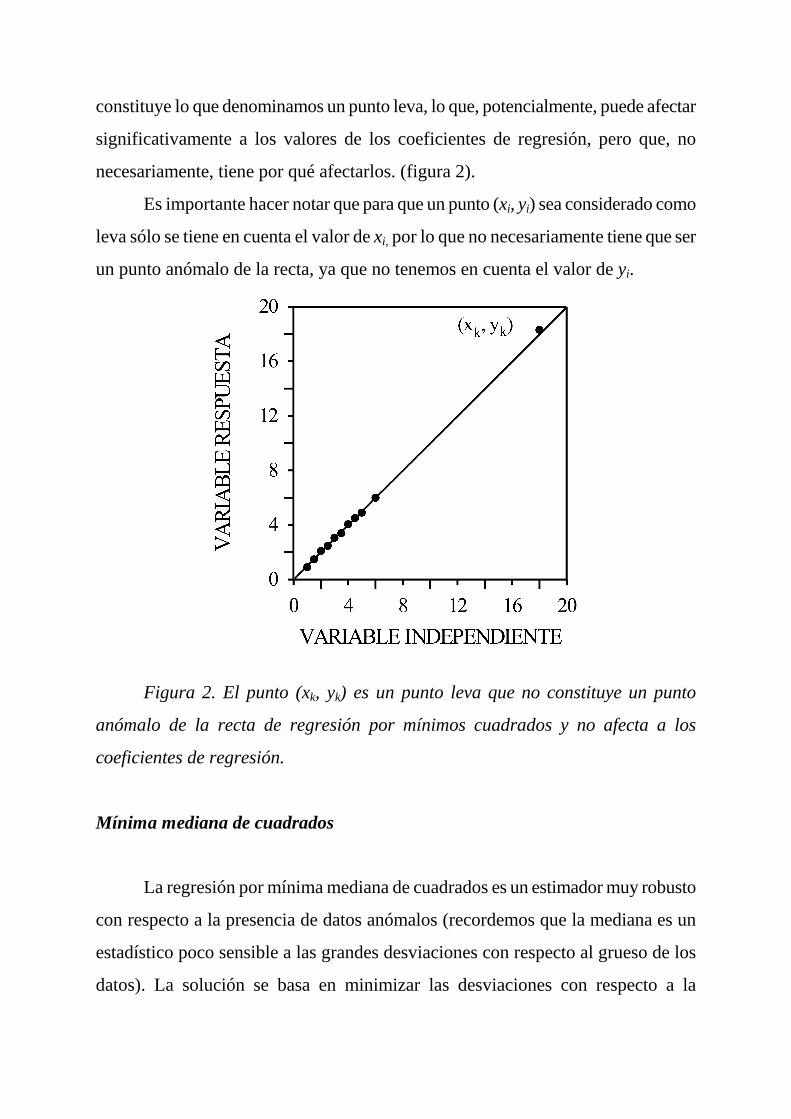
constituye lo que denominamos un punto leva, lo que, potencialmente, puede afectar
significativamente a los valores de los coeficientes de regresión, pero que, no
necesariamente, tiene por qué afectarlos. (figura 2).
Es importante hacer notar que para que un punto (xi, yi) sea considerado como
leva sólo se tiene en cuenta el valor de xi, por lo que no necesariamente tiene que ser
un punto anómalo de la recta, ya que no tenemos en cuenta el valor de yi.
Figura 2. El punto (xk, yk) es un punto leva que no constituye un punto
anómalo de la recta de regresión por mínimos cuadrados y no afecta a los
coeficientes de regresión.
Mínima mediana de cuadrados
La regresión por mínima mediana de cuadrados es un estimador muy robusto
con respecto a la presencia de datos anómalos (recordemos que la mediana es un
estadístico poco sensible a las grandes desviaciones con respecto al grueso de los
datos). La solución se basa en minimizar las desviaciones con respecto a la

mediana, es decir:
Geométricamente, corresponde a encontrar la banda más estrecha, medida en el eje
de ordenadas, que contiene la mitad de las observaciones. La recta se sitúa justo en
medio de dicha banda, por tanto, la robustez de este método es tal que puede
discernir la recta buscada con una contaminación de los datos incluso del 50%.
El principio básico de la mínima mediana de cuadrados es ajustar los datos y,
posteriormente, identificar los datos anómalos como aquellos que distan bastante
del ajuste robusto, es decir, aquellos que producen grandes residuos “RS” positivos
o negativos.
Los puntos leva se determinan calculando la resistencia al diagnóstico “RD”
teniendo en cuenta la lejanía de la observación
El 50% de las RDi valdrán menos que la unidad. Un punto i será leva si RDi >
2.5. En cualquier caso, una observación que tenga RDi grande necesariamente no es
un punto anómalo de la recta en el sentido de producir un gran residuo.
Recta de calibrado mediante mínimos cuadrados. Hipótesis básicas
El método de mínimos cuadrados admite que los factores que pueden influir
en la variable respuesta (se½al analítica) pueden dividirse en dos grupos: el primero
contiene a la variable independiente (concentración), que se supone no aleatoria y
conocida al registrar la se½al analítica; el segundo incluye un conjunto de muchos
factores, cada uno de los cuales influye en la respuesta sólo en peque½a magnitud, y
que, se engloban en la perturbación o error aleatorio. El modelo de regresión es por
tanto: yi = α + βxi + ei, donde yi y ei son variables aleatorias, xi es una variable
predeterminada con valores conocidos y α y β son parámetros desconocidos. Las
hipótesis que se establecen para el error aleatorio son:
))xb+(a-y( med Minimizar 2iiiba,

a) El error aleatorio tiene esperanza nula, es decir su media se hace cero:
b) La varianza del error es siempre constante, y no depende de la
concentración, es decir, el error aleatorio es homocedástico:
c) El error está distribuido según una distribución Gaussinana para cualquier
yi.
d) Los errores aleatorios son independientes entre sí.
Estos postulados se representan gráficamente en la figura 3.
Figura 3. Hipótesis del modelo de regresión para la recta de calibrado.
Estas hipótesis deberán comprobarse una vez construida la recta de calibrado.
0=en
1=e i
n
1=i∑
σ 2i =)eVar(

Sin duda, la hipótesis principal del modelo es aquella que plantea que la media de
las distribuciones de y, para cada valor de x, varía linealmente al aumentar el valor
de x. Esta hipótesis condiciona toda la construcción del modelo, por tanto, en la
aproximación lineal se ha de tener presente el intervalo de concentraciones dentro
del cual se van a hacer estimaciones y el peligro de extrapolar.
La suposición de que los errores tengan media nula no será cierta cuando
existan observaciones tomadas en distintas condiciones con respecto al resto. Este
hecho puede detectarse mediante un análisis de residuos del modelo y es muy
importante, ya que, una sola observación anómala puede tener una gran influencia
en el modelo. La hipótesis de homocedasticidad no se cumplirá si la variabilidad de
cada distribución depende de la media de dicha distribución. Así, a bajos niveles de
concentración, se puede tener una variabilidad más limitada en la se½al analítica,
mientras que a mayores niveles de concentración, las desviaciones de la ley de
Lambert Beer o factores de filtro interno cobran más importancia, existiendo más
variabilidad entre las muestras.
Estimación de los coeficientes de regresión por mínimos cuadrados
En el método de mínimos cuadrados la función objetivo a minimizar, a partir
de la cual se obtienen los coeficientes de la regresión, es el sumatorio de los
residuales al cuadrado, es decir:
Igualando a cero las derivadas parciales de la función objetivo respecto a ambos
coeficientes, ordenada en el origen y pendiente, se obtienen las ecuaciones normales
de la regresión:
))xb+(a-y( Minimizar 2ii
n
=1iba, ∑
xb+xa=xy 2iiii ∑∑∑
xb+na=y ii ∑∑

Dividiendo por n la primera resulta: ,xb+a=y lo que indica que la recta de
regresión siempre contiene el punto ).y,x( Dividiendo también por n la segunda
resulta: xb+xa=x-y 2 , que al restarse a la primera ecuación normal resulta la
expresión que permite calcular la pendiente:
el término de la izquierda es la covarianza entre ambas variables y el que multiplica
a la pendiente es la varianza muestral de x, sx2, por tanto, la pendiente estimada es
proporcional a la covarianza entre ambas variables, expresándose como:
La ordenada en el origen se obtiene inmediatamente si tenemos en cuenta que
la recta de calibrado pasa por el punto medio, la obtención de la ordenada en el
origen es inmediata, ya que: .xb-y=a
Las ecuaciones normales de la regresión pueden escribirse como:
que nos indican que los n residuos no son independientes y al existir dos ecuaciones
de restricción entre los residuos hay n-2 grados de libertad. Por tanto, la varianza de
la estimación es:
El coeficiente de la determinación del modelo es la medida más adecuada de
la bondad del ajuste, que se define como la proporción de variabilidad explicada, es
decir:
) x-nxb(=yx-
nxy 2
2iii ∑∑
s
y)Cov(x,=b
2x
0=r i
n
=1i∑
0=xr ii
n
=1i∑
2-nr=s
2i2
yx
∑
)y-y(
)y-y(=
talVarianzaTo
plicadaVarianzaEx=r 2
i
2i2
∑
∑^

a) si la regresión entre x e y es exacta existe, por tanto, una total dependencia entre
ambas variables entonces íi = yi y r2 = 1.
b) si no existe relación lineal entre ambas variables íi será próximo ay-,y r2 será
peque½o e incluso nulo.
No obstante, el criterio principal para juzgar un modelo es estudiar si las
hipótesis que se han realizado al construirlo son ciertas. En este sentido, es de gran
utilidad, una vez realizada la regresión, el análisis de los residuos (figura 4), ya que
con él comprobaremos:
a) Si su distribución es aproximadamente normal (por supuesto se requiere un
elevado número de observaciones).
b) Si su variabilidad es constante, y no depende de x o de otra causa asignable.
c) Si presentan evidencia de una relación no lineal entre variables.
d) Si existen observaciones anómalas.
La observación de los residuos, tanto de su forma como de la proximidad
entre el número de residuos positivos y negativos, pone de manifiesto si la regresión
es homocedástica o heterocedástica. En cuanto a la estimación y su error, es preciso
que las bandas de dispersión de la recta y de la estimación sean lo más estrechas
posible (figura 5).

Figura 4. Distribución de residuos a la recta de mínimos cuadrados.
Figura 5. Bandas de dispersión de la recta de regresión y de la estimación.
La elipse: región de confianza conjunta de la pendiente y la ordenada

Los intervalos de α y β para un nivel de confianza del 95%, establecidos
anteriormente, se han calculado de forma independiente, pero no se puede asegurar
con el mismo nivel de confianza que α y β se sitúen, simultáneamente, en los
extremos de los intervalos calculados en su estimación. Las estimaciones a y b son
dependientes entre sí. Errores por exceso en la pendiente producirán errores por
defecto en la ordenada, y viceversa. Esta dependencia disminuirá con el valor dexy
con los factores que contribuyen a estimar la pendiente con más precisión. De esta
forma, al representar los valores de a frente a b para repetidas muestras aleatorias,
se obtiene una elipse (Figura 6) en torno al centro verdadero (α, β), y a la inversa,
en el que los extremos del intervalo conjunto para un nivel de confianza del 95%
son ligeramente superiores que los de los intervalos independientes (el estadístico
t(0.05,n-2) a dos lados, se debe reemplazar porF2 2)-n(0.05,2, de un lado).
En una recta de calibrado, la construcción de la elipse es interesante en el
estudio de los intervalos de confianza de la pendiente y ordenada teniendo en cuenta
la covarianza existente entre éstas. Pero, es de especial relevancia en la comparación
de métodos analíticos, ya que, esta herramienta pone de manifiesto la existencia de
diferencias significativas en la capacidad de estimación a diferentes niveles de
concentración.

Figura 6. Región de confianza conjunta para la pendiente y ordenada.
Validación de un método analítico en estudio con uno de referencia
Cuando se quieren comparar la concentración estimada por dos métodos
analíticos a diferentes niveles de concentración, se prepara un conjunto de muestras
en las que la concentración de analito varía en el intervalo de valores más frecuentes
que van a encontrarse en la práctica, y se analizan con los dos métodos que se
pretenden comparar. Los errores más comunes que pueden obtenerse cuando el
conjunto de muestras se analiza por dos métodos, pueden ponerse de manifiesto
mediante técnicas de regresión. La ausencia de todo error en los datos se
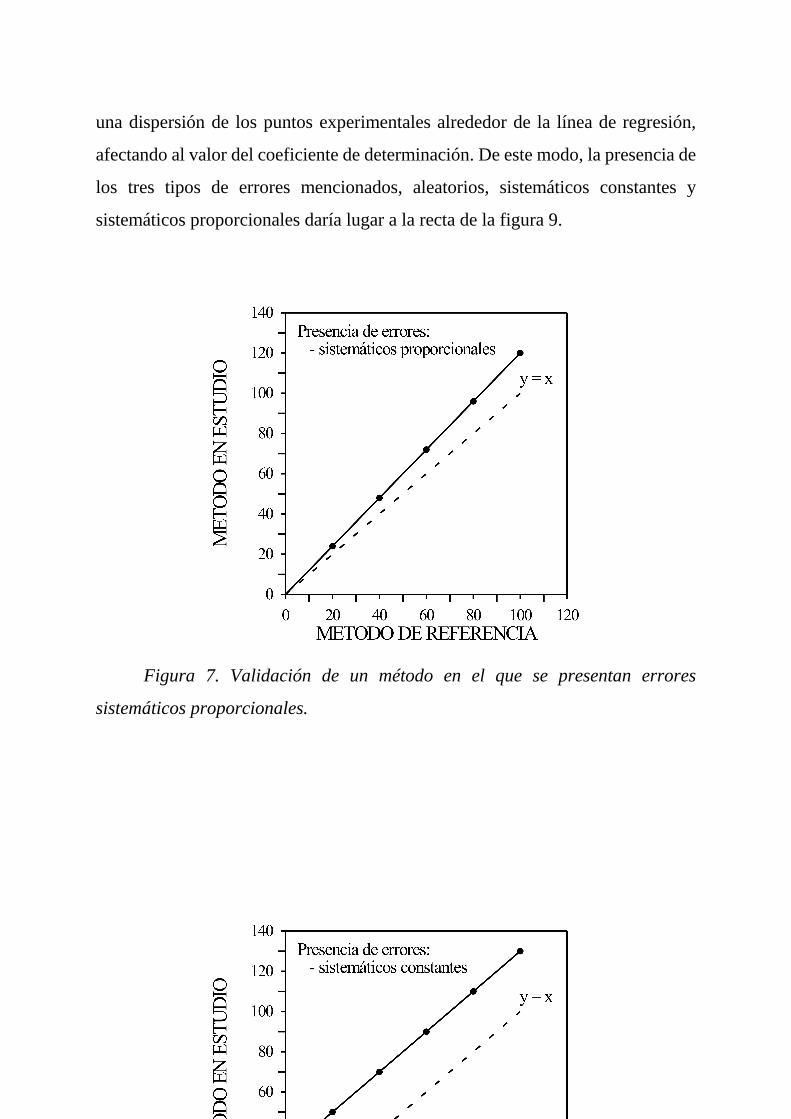
manifestaría mediante la obtención de una línea recta de pendiente unidad y
ordenada en el origen cero, tal como muestra la línea discontinua de las figuras7, 8
y 9. La presencia de un error sistemático proporcional llevaría a la obtención de una
recta, representada en la figura 7, con pendiente distinta a la unidad pero ordenada
nula, mientras que la presencia de errores sistemáticos constantes conduciría a la
obtención de una recta con una ordenada en el origen distinta de cero (figura 8). Los
errores aleatorios, que acompañan siempre a todo tipo de resultados, darían lugar a
una dispersión de los puntos experimentales alrededor de la línea de regresión,
afectando al valor del coeficiente de determinación. De este modo, la presencia de
los tres tipos de errores mencionados, aleatorios, sistemáticos constantes y
sistemáticos proporcionales daría lugar a la recta de la figura 9.
Figura 7. Validación de un método en el que se presentan errores
sistemáticos proporcionales.
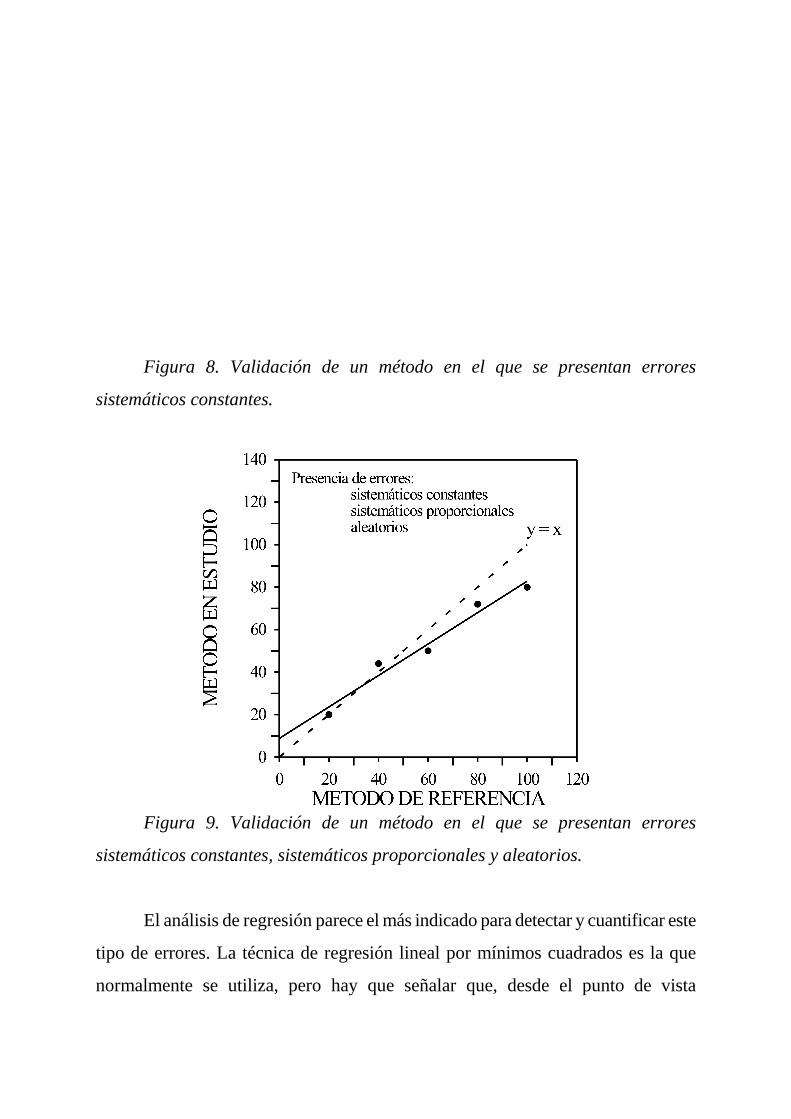
Figura 8. Validación de un método en el que se presentan errores
sistemáticos constantes.
Figura 9. Validación de un método en el que se presentan errores
sistemáticos constantes, sistemáticos proporcionales y aleatorios.
El análisis de regresión parece el más indicado para detectar y cuantificar este
tipo de errores. La técnica de regresión lineal por mínimos cuadrados es la que
normalmente se utiliza, pero hay que señalar que, desde el punto de vista

estadístico, existe una diferencia notable cuando dicha técnica se aplica a la
calibración o cuando se utiliza, como en esta ocasión, para comparar dos conjuntos
de resultados obtenidos experimentalmente. Este hecho es debido a que, en este
último, caso ninguno de los dos conjuntos de datos está libre de error, por lo que se
tendrían que aplicar técnicas de regresión que contemplen la presencia de errores en
ambos ejes de coordenadas x e y.
Como lógicamente nunca estamos en el caso ideal de que la pendiente sea
exactamente igual a uno y la ordenada en el origen dé un valor exacto de cero al
estar siempre presentes los errores aleatorios, es preciso dilucidar si los valores
obtenidos no son significativamente distintos de uno y de cero, respectivamente.
Esto se hace mediante la construcción de la región conjunta de confianza para la
pendiente y la ordenada en el origen que, como es sabido, da como resultado una
elipse (figura 6). Si el punto de pendiente unidad y ordenada en el origen nula está
contenido dentro de la región delimitada por la elipse significa que no existen
diferencias estadísticamente significativas entre ambos métodos para un nivel de
confianza elegido, es decir, pueden considerarse iguales las concentraciones
estimadas por ambos métodos. Si por el contrario el punto (1,0) está situado fuera
de la elipse se concluye que, para ese nivel de confianza, existen diferencias
significativas entre las concentraciones obtenidas por cada uno de los métodos.