analys och prediktion av bostadsrättens pris i …690723/fulltext01.pdfanalys och prediktion av...
TRANSCRIPT

Analys och prediktion
av bostadsrättens pris i Stockholms innerstad
med hjälp av multipel regressionsanalys
Victor Reyes
Examensarbete inom teknisk fysik, grundnivå
Institutionen för Matematik, inriktning Matematisk Statistik
Kungliga Tekniska Högskolan
Handledare: Gunnar Englund
May 21, 2013

Abstract
The purpose of this study is to find out which factors have impact on residential andcommercial prices in Stockholm inner city, and to what extent, and to create a modelthat can predict the price. For these purposes multiple regression analysis is used. Themodel assumes that an absolute change in one factor gives a relative change in the price.Data on the final price, apartment’s and regions characteristics were collected and addedto the model. The model was improved by excluding of non-significant variables. Theresults are presented in tables and charts. With use of those importance of each factorcan be read off and the final price predicted. The final model is considered to be satisfyingthe study’s purpose.

Sammanfattning
Syftet med denna studie är att reda ut vilka faktorer som har verkan på bostadsrättens-priser i Stockholmsinnerstad och i vilken utsträckning, samt att skapa en modell som kanpredicera dessa pris. För dessa ändamål används multipel regressionsanalys. Modellenantar att en absolut förändring i en faktor ger en relativ förändring i priset. Data överslutpriset, lägenheters och områdens egenskaper samlades in och sattes in i modellen.Modellen förbättrades genom att icke-signifikanta variabler uteslöts. Resultatet presen-teras i form av tabeller och diagram. Med hjälp av dessa kan vikt av varje faktor kanoch slutpriset prediceras. Därmed anses den slutliga modellen uppfylla studiens syfte.

Innehåll
1 Inledning 3
2 Regressionsanalys. Teoretisk bakgrund 4
2.1 Den klassiska normala linjära regressionsmodellen (KLNR-modellen) . . . 42.1.1 Introduktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.1.2 Definition och viktig terminlogi . . . . . . . . . . . . . . . . . . . 42.1.3 Antaganden till den klassiska modellen . . . . . . . . . . . . . . . 5
2.2 Minstakvadratmetod skattningen - Ordinary Least Squares estimation . 62.3 Konsekvenser av avvikilser till KLR-modellen och dess åtgärder . . . . . 7
2.3.1 Frånvaro av relevanta kovariater och närvaro av irrelevanta kovariater 72.3.2 Icke-linjäritet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3.3 Heteroskedasticitet . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3.4 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.5 Perfekt multikollinearitet . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Tester för antaganden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.5 Hypotesprövning, F-test och BIC-kriterium . . . . . . . . . . . . . . . . . 10
2.5.1 Hypotesprövning . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.5.2 F-test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.5.3 BIC-kriterium . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.6 Indikator-kovariater . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.7 White’s kovariansskattning . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.7.1 Justering för kluster . . . . . . . . . . . . . . . . . . . . . . . . . 12
3 Metod 13
3.1 Datainsamling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.1.1 Datans trovärdighet . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Förstudie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2.1 Byggårsperiod indikators . . . . . . . . . . . . . . . . . . . . . . . 143.2.2 Områden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2.3 Uppfyllning av antaganden . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Genomförande . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16

Kapitel 0. INNEHÅLL
3.3.1 Utelämnande av icke signifikanta variabler . . . . . . . . . . . . . 163.3.2 Kovariater . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Resultat 18
4.1 Tabeller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.2 Diagram och grafer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5 Diskutioner 31
5.1 Den slutliga modellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.1.1 Predikering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.1.2 Strukturtolkning . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.2 Linjära modellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.3 Slutsatser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.4 Felkällor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
6 Referencer 34
2

Kapitel 1
Inledning
Innehavande av sin egen bostad har länge förknippats med hög status. Det är bådeprestigefull och bra investering in sin/sin familjs framtid och trygghet. I stora städer,speciellt i huvudstaden dit alla söker sig är det även en objekt till spekulationer. Me-delvärdet på priset på bostadsrätt i Stockjolms innerstad är nu 3 Mkr. Dessutom ärbostadsmarknaden inte särskilt transparent. Det är bara 8%1 som har hög förtroendepå mäklaren. Det är därför viktigt att förstå vilka faktorer som påverkar slutpriset ochi vilken utsträckning.Detta problem studerades med hjälp av multipel Regressionsanalys, vilket beskriver hurförändringen i en oberoende variabel orsakar förändringen i en beroende variabeln.
1http://www.fastighetsbyran.se/Pressrum/Pressmeddelanden/2010/Fortroende/

Kapitel 2
Regressionsanalys. Teoretisk bakgrund
2.1 Den klassiska normala linjära regressionsmodellen
(KLNR-modellen)
2.1.1 Introduktion
Regressionsanalys är en statistik metod som undersöker hur förändringen i en av obero-ende variabler orsakar förändringen i det beroende variabeln, när alla andra oberoendevariabler hålls fixa. Regressionsmodell är därefter en ekvation bäst anpassad till givendata. Att den är normal innebär att dess felterm är normalfördelade. Att den är lin-
jär betyder att det finns enlinjär samband mellan den beroende och dem oberoendevariablerna. Att den är klassisk innebär att den är giltig under vissa antaganden(2.1.3)
2.1.2 Definition och viktig terminlogi
Den klassiska normala linjära regressionsmodellen definieras som:
𝑦𝑖 =∑𝑘
𝑗=0 𝑥𝑖𝑗𝛽𝑗 + 𝜖𝑖; 𝑖 = 1, ..., 𝑛;
I ekvationen 𝑦𝑖 betecknar den observerade beroende variabeln som påverkasäv enmängd {𝑥𝑖𝑗}𝑘𝑗=0, oberoende eller förklarande variablerna. Dem oberoende variablernakommer att vidare kallas kovariater. {𝛽𝑗}𝑘𝑗=0 står för koefficienter för respektive kovariat𝑥𝑖𝑗. Dessa koefficienter och oftast även deras varians är okända och ska skattas med hjälpav regressionsanalys. 𝜖𝑖 är normalfördelad feltermen. Det är oftast bekvämare att skrivadet i matris form:
𝑌 = 𝑋𝛽𝑇 + 𝜖

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
där Y är en 1×k matris
𝑌 =
⎛⎜⎝ 𝑦1...𝑦𝑘
⎞⎟⎠;
X är en n×k matris
𝑋 =
⎛⎜⎝ 𝑥11 . . . 𝑥𝑛1.... . .
...𝑦1𝑘 . . . 𝑥𝑛𝑘
⎞⎟⎠;
𝛽 är 1× n matris,
𝛽 =
⎛⎜⎝ 𝛽0
...𝛽𝑛−1
⎞⎟⎠och 𝑒 är 1× k matris,
𝜖 =
⎛⎜⎝ 𝜖1...𝜖𝑘
⎞⎟⎠2.1.3 Antaganden till den klassiska modellen
För användning av KLR-modellen behövs att data uppfyller 5 grundantaganden:
1. Det finns ett linjärt samband mellan den beroende variabeln och dem förklarandeoberoende kovariaterna och feltermen.
Matematiskt uttryckt i matris form: 𝑌 = 𝑋𝛽𝑇 + 𝑒,
Eventuella avvikilser:
∙ Frånvaro av relevanta kovariater och närvaro av irrelevanta kovariater.
∙ Icke-linjäritet
2. Väntevärdet av feltermerna är lika med noll, d.v.s. att medelvärde av feltermernasdistribution är noll.
Matematiskt uttryckt i matris form: 𝐸[𝑒] = 0
3. Alla feltermerna har samma varians(homoskedastiska), korrelerar inte med varand-ra och är normalfördelade.
Matematiskt uttryckt i matris form: 𝐸[𝑒𝑒′] = 𝜎𝐼
Eventuella avvikilser:
5

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
∙ Heteroskedasticitet
4. Antal observationer är större än antal oberoende variabler samt det finns inte någonperfekt linjär samband emellan oberoende variabler.
Matematiskt uttryckt i matris form: 𝑟𝑎𝑛𝑔𝑋 ≤ 𝑁
Eventuella avvikilser:
∙ Perfekt multikoliniaritet
2.2 Minstakvadratmetod skattningen - Ordinary Le-
ast Squares estimation
Minsta kvadratmetod skattningen (på engelska Ordinary Least Squares - OLS) är sta-tistik metod som bäst skattar okända parametrar under KLR-modellens antaganden1(antagandendiskuteras i kapitel 2.1.3). Metoden skattar 𝛽 sa att feltermernas kvadratsumma mini-meras. Skattningen av någon parameter med hjälp av OLS-metod betecknas med hatt.Som exempel, betecknas skattningen av 𝛽 som 𝛽. Under KMR-modellens antagandenhar OLS-skattningen följande egenskaper:
∙ Minimerar feltermernas kvadratsumma. Det följer ur definitionen.
∙ Ger den högsta 𝑅2.
∙ Är väntevärdesriktig skattning.
∙ Är bäst väntevärdesriktig skattning emellan alla möjliga skattningarna.
∙ Asymptotiskt väntevärdesriktig.
1Econometrics, sida 43
6

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
Tabell 2.1: OLS definitioner
Matematiskt uttryckt Förklaring
𝑌 = 𝑋𝛽𝑇 + 𝜖 KLR-modellen
𝛽 = (𝑋𝑇𝑋)−1𝑋𝑇𝑌 OLS-skattningen av 𝛽
𝜖 = 𝑌 −𝑋𝛽 OLS-skattningen av feltermen
𝑋𝑇 𝜖 = 0 minimeras feltermernas kvadratsumma
𝐶𝑜𝑣(𝛽|𝑋) = (𝑋𝑇𝑋)−1|𝜖|2(𝑛−𝑘−1) OLS-skattningen av varians-kovariansmatris
𝐸(𝛽|𝑋) = 𝛽OLS-skattningen av 𝛽 är väntevärdesriktig skatt-ning
2.3 Konsekvenser av avvikilser till KLR-modellen och
dess åtgärder
Avvikelser från KLR-modellen kan försämra OLS-estimering avsevärt. I detta avsnitt skakonsekvenser av avvikelser och åtgärder som kan minimera dem negativa konsekvensernadiskuteras.
2.3.1 Frånvaro av relevanta kovariater och närvaro av irrelevanta
kovariater
Konsekvenser av dem relevanta kovariaternas frånvaro:
∙ OLS-metoden ger icke-väntevärdesriktig skattningen av koefficienter till kovariatersom är korrelerade till den frånvarande relevanta kovariaten. Om den frånvaranderelevanta kovariaten är ej-korrelerad med kovariater som används i modellen fåsicke-väntevärdesriktig skattning endast av intercept termen.
∙ Skattning av varians-kovanrians matris blir icke-väntevärdesriktig och snedvridenuppåt.
Konsekvenser av dem irrelevanta kovariaternas närvaro:
∙ Skattningen av varians-kovanrians matris blir större i magnituden, dock förblirskattningen väntevärdesriktig.
Åtgärder:
∙ En bra strategi är att inkludera alla kovariater som kan tänkas kunna påverka denförklarande kovariaten. Det är bättre att få flera irrelevanta kovariater först än attmissa en relevant. Irrelevanta kovariater kan sedan identifieras med hjälp av F-testoch BIC-kriterium (se mer i kapitel 2.5)
7

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
2.3.2 Icke-linjäritet
Linjäritet innebär att enabsolut förändring i 𝑋𝑛 ger en absolut förändring i Y. ∆𝑋 →𝛽∆𝑌 Icke-linjäritet innebär att det inte finns något linjärt samband mellan den förkla-rande kovariaten och en eller flera kovariater. Ett exempel är hur människans längd berorpå ålder. Det kan modelleras med en exponentiell funktion 𝑙��𝑛𝑔𝑑 = 𝑒−𝛽��𝑙𝑑𝑒𝑟
, d.v.s. att människa växer snabbt tills 18 år och efter ett tag minskar tillväxten tills såsmåningom avstannar helt.Konsekvenser:
∙ OLS-metoden ger icke-väntevärdesriktig skattningen av koefficienter.
Åtgärder:
∙ Transformering av variabler
Sammanfattningen av tre populära transformationer:
1. Log-log trasformation. Om den sanna sambandet är på form 𝑌 = 𝛽0𝑋𝛽1
1 𝑋𝛽2𝜖, kandet transformeras till 𝑙𝑛𝑌 = 𝑙𝑛𝛽0 + 𝛽1𝑙𝑛𝑋1 + 𝛽2𝑙𝑛𝑋2 + 𝑙𝑛𝜖. Det senare är enlinjär ekvation, där 𝛽1 och 𝛽2 koefficienter kallas för elasticitet. Detta ekvationenkan tolkas som att relativt(i procent) förändring i 𝑋𝑛 ger relativ förändring i Y.%∆𝑋 →≈ %∆𝑌
2. Semilog transformation. Transformerar den urspungliga 𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + 𝜖
till
(a) 𝑌 = 𝑙𝑛𝛽0 + 𝛽1𝑙𝑛𝑋1 + 𝛽2𝑙𝑛𝑋2 + 𝑙𝑛𝜖. Denna ekvation kan tolkas som att enrelativ förändring i 𝑋𝑛 ger en absolut förändring i Y. %∆𝑋 →≈ ∆𝑌
(b) eller till 𝑙𝑛𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + 𝜖. Denna ekvation kan tolkas som att enabsolut förändring i 𝑋𝑛 ger en relativ förändring i Y .∆𝑋 →≈ %∆𝑌
3. Polynomiell transformation. Det icke-linjära sambandet mellan den beroende vari-abeln och en kovariat approximeras med dess Taylors utveckling. Oftast ändvändsendast kvadrat- och kubiktermer. 𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛽2𝑋2 + 𝜖 transformeras till𝑌 = 𝛽0 + 𝛽1𝑋1 + 𝛾1𝑋
21 + 𝛽2𝑋2 + 𝛾2𝑋
32 + 𝜖
2.3.3 Heteroskedasticitet
Heteroskedasticitet innebär att variansen av alla feltermer 𝜖𝑖 är inte detsamma.Konsekvenser:
∙ På grund av heteroskedasticitet är skattningen 𝑐𝑜𝑣(𝛽) inte längre väntevärdesriktig,vilket gör intervalsskattning och hypotesprövning omöjligt. Skattningen av 𝛽 förblirväntevärdesriktig.
8

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
Åtgärder:
∙ Användning av heteroskedasticitetskonsistenta kovariansskattningarna. I denna stu-die används White’s heteroskedasticitetskonsistenta kovariansskattning (Se kapitel2.7)
∙ Tranformering av variabler kan i vissa fall eliminera heteroskedasticitet. Om viantar att feltermens standardavvikelse är proportionell till väntavärdet av den för-klarande kovariaten, dvs vår modell 𝑦 = 𝑥𝛽 + 𝑒 kan skrivas som 𝑦 = 𝑥𝛽(1 + 𝑣)
där v är oberoende av x. Om man nu logaritmerar vår ekvation fås att 𝑙𝑛(𝑦) =
𝑙𝑛(𝑥𝛽) + 𝑙𝑛(1 + 𝑣), där variansen av den andra termen i högerled är oberoendeav x. Denna ekvation blir därmed homoskedastisk, d.v.s. att alla ferltermerna hardetsamma varians.
Som den andra åtgärden visar att kan heteroskedasticitet vara tecken för modellensmisspecifikation, d.v.s. att om man upptäcker heteroskedasticitet, ska man i första handse till att modellens specifikation är rätt innan användning av White’s heteroskedastici-tetskonsistenta kovariansskattning.
2.3.4 Clustering
Kluster innebär att datan innehåller delmängder grupperade efter en viss egenskap. Dettainnebär att om flera observationer hör till en viss grupp, är deras feltermer i en viss delkorrelerade. Om flera observationer hör till olika grupp är deras feltermer okorrelerade.Konsekvenser:
∙ Kovariansskattningen blir icke-väntevärdesriktig.
Åtgärder:
∙ Justering avWhite’s heteroskedasticitetskonsistenta kovariansskattning. (Se kapitel2.7.1)
2.3.5 Perfekt multikollinearitet
Multikollinearitet innebär att det finns en linjärt (perfekt multikollinearitet) eller nästanlinjärt (imperfekt multikollinearitet) samband mellan 2 eller flera kovariater, d.v.s. 𝑥1 =
𝛼𝑥2 + 𝛾𝑥3. Perfekt multikollinearitet uppstår ofta vid felaktig användning av indikator-kovariat (se kapitel 2.6)Konsekvenser:
∙ Perfekt multikollinearitet gör skattningen av 𝛽 koefficienter omöjligt.Betrakta ett exempel, där 𝑦 = 𝛽1𝑥1 + 𝛽2𝑥2 + 𝛽3𝑥3 och 𝑥1 = 𝑥2 + 𝑥3. Om man nusubtraherar ett konstant 𝑎 från 𝛽1 och adderar den till 𝛽2 och 𝛽3 får man att
9

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
𝑦 = (𝛽1 + 𝑎)𝑥1 + (𝛽2 − 𝑎)𝑥2 + (𝛽3 − 𝑎)𝑥3 = 𝛽1𝑥1 + 𝛽2𝑥2 + 𝛽3𝑥3 + 𝑎(𝑥1 − 𝑥2 − 𝑥3) =
𝛽1𝑥1 + 𝛽2𝑥2 + 𝛽3𝑥3’, d.v.s. säga att man får samma ekvation trots utbytte av koefficienter.
∙ Imperfekt multikollinearitet försämrar inte predicering styrka, men skattningen avvarians ökar, vilket i sin tur försämrar hypotesprövning.
Åtgärder:
∙ Om perfekt multikollinearitet uppstår pga. fel användning indikator-kovariat ge-nom utelämnande av en av kollinjära variabler. Den utelämnade kovariat sätts tillreferenskategori.
2.4 Tester för antaganden
I detta stycke nämns vissa tester för antaganden. Bakomliggande teori presenteras inte,utan den intresserade hänvisas till referenslistan i kapitel 6.
∙ Test för linjäritet:Efter regression plottas residualerna och/eller dem predicerade priset mot varjekovariat. Om sambandet inte ser linjär ut är det ett tecken på linjäritet.
∙ Test för heteroskedastisitet:White’s heteroskedasticitets test.
∙ Test för icke-normal fördelning av residualer:Residualerna plottas tillsammans med normalfördelningens täthetsfunktion. De skainte skilja sig mycket åt.
2.5 Hypotesprövning, F-test och BIC-kriterium
2.5.1 Hypotesprövning
Hypotesprövning innebär att man ställer upp en hypotes angående hur fördelningenav någon stokastiska variabel Z ser ut och prövar om den stämmer. Denna hypotesbrukar kallas nollhypotesen och betecknas𝐻0. För att pröva en hypotes, hittas en lämpligtestvariabel 𝛾* som är en observation av 𝛾(𝑍). Nollhypotesen ska då väljas så att om𝛾* ∈ 𝐶, där C är något område, förkastas 𝐻0. Området C väljs så att sannolikhet att𝛾(𝑍) ∈ 𝐶 är lika med 𝛼. 𝛼 bestäms av testaren och kallas signifikantnivå(anges oftast
10

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
i procenter). Det är den högsta tillåtna av testaren sannolikheten att nollhypotesenförkastas om den är sann. I samband med signifikants nivå införs ofta begrepp p-värde. P-värde är sannolikhet att nollhypotesen förkastas om den är sann. Några av de populärastetesterna är t-test, F-test och 𝜒2-test.
2.5.2 F-test
F-test kan användas för prövning såväl en enkel som multipel hypotes. F-testvariabel förhypotesprövning av J linjära restrektioner med K parameter inkluderat intercept termoch N observationer ser ut på följande sätt:
𝐹 = [|𝜖𝑟𝑒𝑠𝑡𝑟𝑖𝑐𝑡𝑒𝑑|2−|𝜖𝑓𝑢𝑙𝑙|2]/𝐽|𝜖𝑟𝑒𝑠𝑡𝑟𝑖𝑐𝑡𝑒𝑑|2/𝑁−𝐾
F kovariat har F(J, N-K) distribution med J och (N-K) är frihetsgrader under nollhypo-tesen. Om F kovariat är ”för stor” förkastar man nollhypotes. F-test är exakt signifikantunder antagande att feltermerna är normalfördelade. Även om feltermerna inte är nor-malfördelade, är F-test asymptotiskt signifikant.
2.5.3 BIC-kriterium
BIC (eng. Bayesian information criterion) kriterium används främst för att identifieringav irrelevanta kovariater i modellen. BIC är en funktion som minimerar feltermernaskvadratsumma och antalet variabler. Om feltermerna är normalfördelade har formelenför BIC följande utseende:
𝐵𝐼𝐶 = 𝑙𝑛( |𝜖|2
𝑁) + 𝐾𝑙𝑛(𝑁)/𝑁
, där N och K är antal observationer respektive kovariater. BIC-kriterium har en viktigegenskap att den väljer den sanna modellen bland alla modeller, om den sanna modellenfinns bland modeller att välja.
2.6 Indikator-kovariater
En indikator-kovariat eller bara indikator är kovariat som används för att visa om obser-vationer har vissa egenskarer eller inte. En indikator kan anta antingen 1 eller 0, där 1står för sant och 0 för falskt. Man interpreterar indikators koefficient som en förflyttningupp eller ner av intercept term. Som exempel, kan indikatorer användas för att betecknavilken område observation hör till och detta område kan ge förflyttning upp eller nerav intercept term jämfört med referensnivån. Om man multiplicerar två indikatorer sombetecknar olika egenskarper skapas det en ny indikator som betecknar innehav av bådeegenskaperna. Som exempel, om man multiplicerar indikator för område med indikator
11

Kapitel 2. Regressionsanalys. Teoretisk bakgrund
för byggperiod får man en indikator som säger att huset ligger i ett visst område ochbyggdes under en viss period. Indikatorer kan även multipliceras med kvantitativa ko-variater. Då är tolkning av den nya kovariaten är olika lutning. Som exempel, om manmultiplicerar indikator för område med yta, fås en ny kovariat som kan tolkas att ytager högre eller lägre pris ett område jämfört med ett annat.
2.7 White’s kovariansskattning
White’s heteroskedasticitetskonsistenta kovariansskattning:
𝐶𝑜𝑣(𝛽) = (𝑋𝑇𝑋)−1(∑𝑛
𝑖=1(𝑒𝑖𝑥𝑖)𝑇 (𝑒𝑖𝑥𝑖)(𝑋
𝑇𝑋)−1
är en väntevärdesriktig skattning och ska alltid användas ifall man upptäcker heteroske-dasticitet.
2.7.1 Justering för kluster
Om datan är klusterade, ska man använda den justerade White’s heteroskedasticitets-konsistenta kovariansskattning som ser ut på följande sätt:
𝐶𝑜𝑣(𝛽) = (𝑋𝑇𝑋)−1(∑𝑛𝑘𝑙
𝑖=1(𝑢𝑇𝑗 𝑢𝑗)(𝑋
𝑇𝑋)−1
där
𝑢𝑗 =∑
𝑗𝑘𝑙𝑒𝑖𝑥𝑖
𝑛𝑘𝑙 är det totala antalet av kluster.
12

Kapitel 3
Metod
3.1 Datainsamling
Data samlades in i första hand från slupris.se och begränsades med en tidsperiod på 6månader (från den 15 oktober till den 15 april) över Stockholms innerstad. Sidan innehöllföljande parametrar för varje lägenhet: antalet rum, boyta, månadsavgiften, våningen,byggår, närvaro av hiss, balkong, öppet spis, huruvida lägenheten är etage samt visnings-månad. Andra relevanta uppgifter som adresser av idrotsplatser, parklekar, fritidsgårdaroch grundskolorr togs från Stockholm stads websida, ränta togs från Statistiska Central-byrås (SCB) websida och geografiska koordinater för vattens gränser inom Stockholmområde togs från Google Maps.
3.1.1 Datans trovärdighet
Datan från slutpris.se är inte alltid korrekt eftersom slutpris.se samlar in datan frånmäklarnas webbsidor. Det är antagligen sista budet som slutpris.se registrerar, vilketkan skilja sig ibland från det aktuella slutpriset. Här är citat från slutpris.se:
Uppgifter om lägenheter på slutpris.se bygger på den information som mäkla-re tillhandahåller och publicerar i lägenhetsprospekt. slutpris.se kan därmedinte garantera att uppgifterna för varje enskilt objekt är korrekta. I undan-tagsfall kan t ex en lägenhet av misstag publiceras som såld på slutpris.se,eller visa ett pris som avviker från den slutliga köpeskillingen. Slutpris.seansvarar inte för några följder av sådana eventuella fel eller avvikelser.1
Härav behövde datan inspekterades. Detta ledde till att alla lägenheter som saknade dataom byggår (sammanlagd 453 lägenheter) togs bort. Även 8 lägenheter med orimliga pristogs bort. Efter borttagning kvarstod datan om 1913 lägenheter. Av kvarvarande datankorrigerades informationen om 21 lägenhet till: hissavsaknande ändrades till närvaro av
1http://slutpris.se/about/

Kapitel 3. Metod
hiss för 7 lägenheter, våningsändring genomfördes för 14 lägenheter till. Efter genomfördaändringar togs ett stickprov på 30 lägenheter och jämfördes med informationen frånmäklarnas websidor. Bara en lägenhet hittades, vars pris skilde sig, dock mindre än 2%.Därmed ansågs datan taget från slutpris.se vara tillräckligt trovärdig.
3.2 Förstudie
I förstudie analyseras data med hjälp av tabeller, grafer. I tabeller ser man enskilda ko-variaters medelvärde, standardavvikelse samt min- och maxvärde.( se tabell 4.6) I graferplottades priset mot en enskild kovariater i taget. Även en enkel regression genomfördes,där den enda kovariat förutom intercept term var yta. Regressionen visade att enbartyta förklarar nästan 84% av priset.
3.2.1 Byggårsperiod indikators
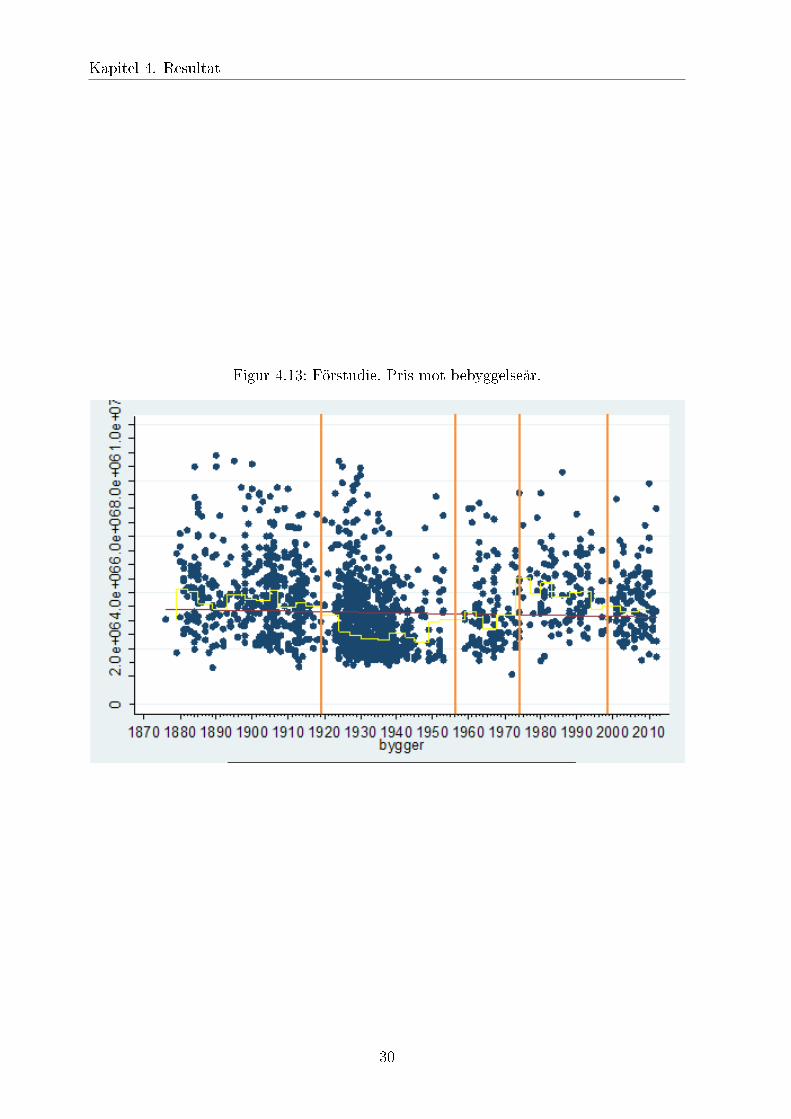
När priset plottades mot byggåret insågs att 5 tydliga bebyggelseperioder fanns (se figur4.13). Därmed skapades 5 indikatorer:
Tabell 3.1: Bebyggelse period
Kovariat Kort sammanfattning
Bygg till1919 Alla hus som byggdes till och med 1919
Bygg 1920-53 Alla hus som byggdes från och med 1920 till och med 1953
Bygg 1959-72 Alla hus som byggdes från och med 1959 till och med 1972
Bygg 1973-99 Alla hus som byggdes från och med 1973 till och med 1999
Bygg 2000-13 Alla hus som byggdes från och med 2000 till och med 2013
Perioden 2000-2013 användes som referenskategori.
3.2.2 Områden
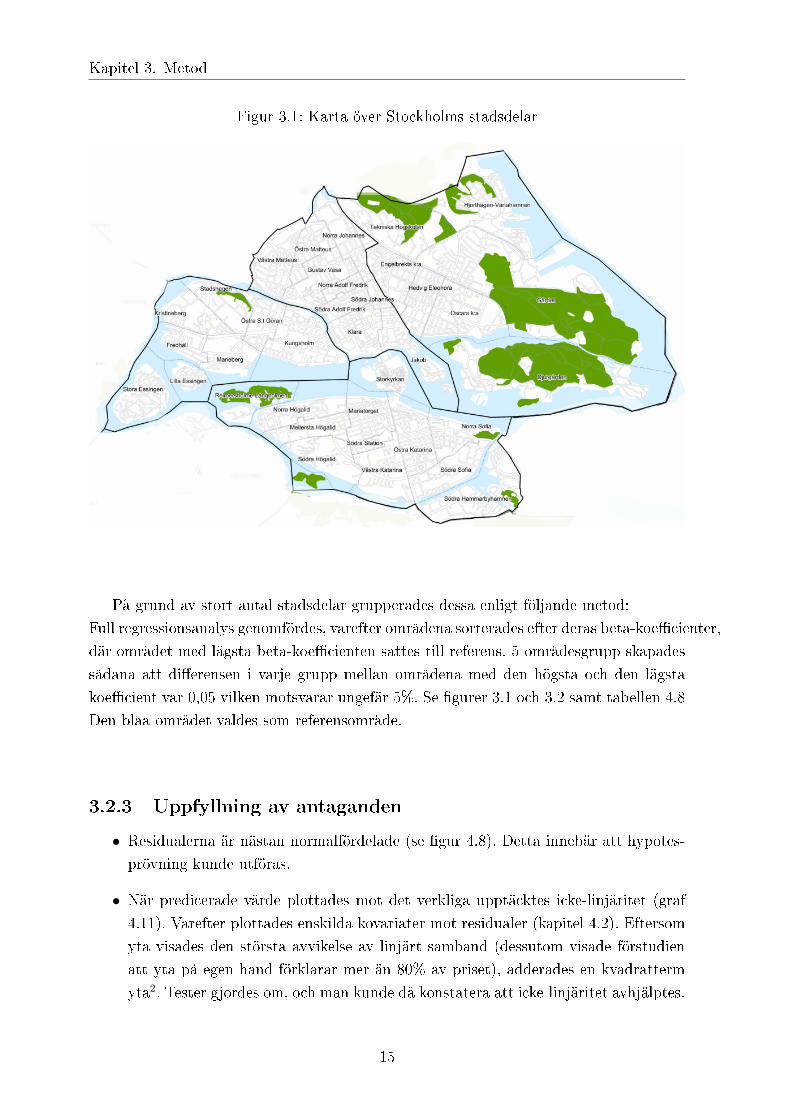
Stockholms innerstad består av 37 stadsdelar:Storkyrkan, Klara, Jakob, Södra Johannes, Norra Johannes, Södra Adolf Fredrik, Nor-ra Adolf Fredrik, Gustav Vasa, Östra Matteus, Västra Matteus, Engelbrekts k:a, Tek-niska Högskolan, Universitetet, Hjorthagen-Värtahamnen, Hedvig Eleonora, Oscars k:a,Djurgården, Gärdet, Kungsholm, Östra S:t Göran, Marieberg, Stadshagen, Kristineberg,Fredhäll, Lilla Essingen, Stora Essingen, Mariatorget, Södra Station, Norra Högalid,Mellersta Högalid, Södra Högalid, Reimersholme-Långholmen, Västra Katarina, ÖstraKatarina, Norra Sofia, Södra Sofia och Södra Hammarbyhamnen.Därmed skapades det 36 indikatorer, en för varje stadsdel förutom Djurgården, eftersomdet inte fanns några sålda lägenheter i Djurgården över valda perioden. Se figur 3.1
14
Kapitel 3. Metod
Figur 3.1: Karta över Stockholms stadsdelar
På grund av stort antal stadsdelar grupperades dessa enligt följande metod:Full regressionsanalys genomfördes, varefter områdena sorterades efter deras beta-koefficienter,där området med lägsta beta-koefficienten sattes till referens. 5 områdesgrupp skapadessådana att differensen i varje grupp mellan områdena med den högsta och den lägstakoefficient var 0,05 vilken motsvarar ungefär 5%. Se figurer 3.1 och 3.2 samt tabellen 4.8Den blåa området valdes som referensområde.
3.2.3 Uppfyllning av antaganden
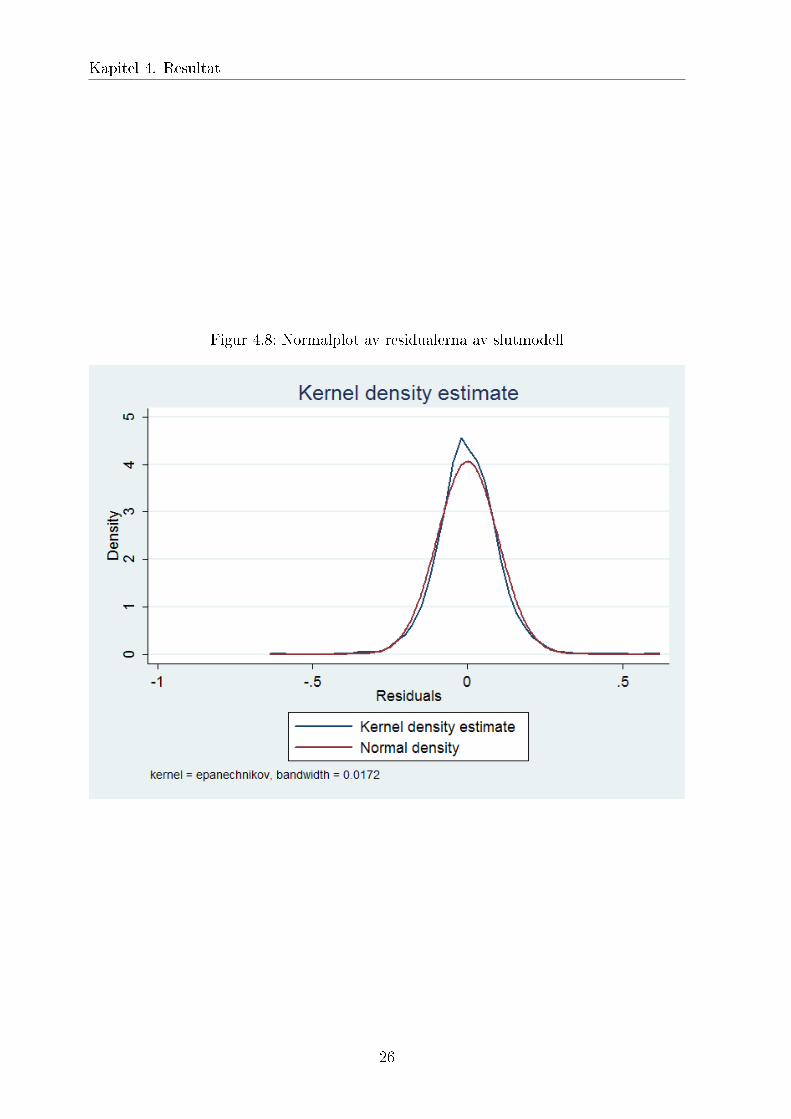
∙ Residualerna är nästan normalfördelade (se figur 4.8). Detta innebär att hypotes-prövning kunde utföras.
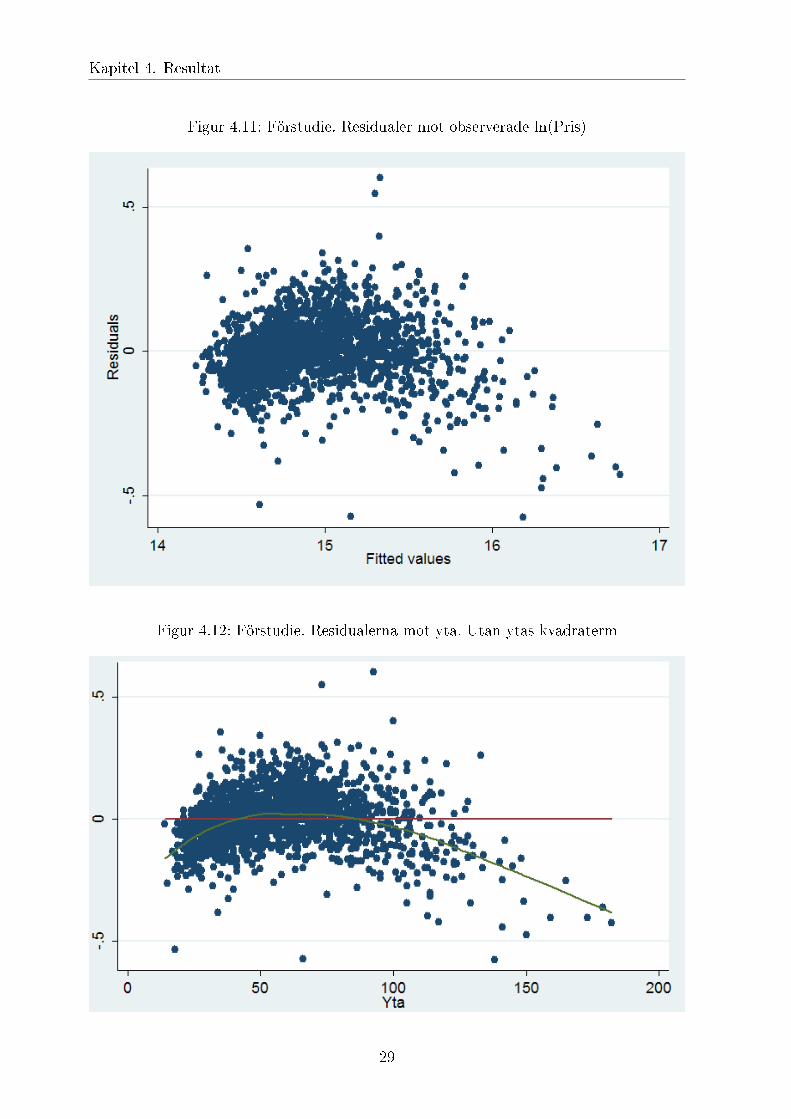
∙ När predicerade värde plottades mot det verkliga upptäcktes icke-linjäritet (graf4.11). Varefter plottades enskilda kovariater mot residualer (kapitel 4.2). Eftersomyta visades den största avvikelse av linjärt samband (dessutom visade förstudienatt yta på egen hand förklarar mer än 80% av priset), adderades en kvadrattermyta2. Tester gjordes om, och man kunde då konstatera att icke-linjäritet avhjälptes.
15

Kapitel 3. Metod
Figur 3.2: Grupperade stadsdelar
∙ White’s heteroskedasticitets test pekar att heteroskedasticitet förekommer, varförWhite’s heteroskedasticitetskonsistenta kovariansskattning användes.
∙ Att residualerna är icke-korrelerade ifrågasattes. Det finns orsaker att tro att resi-dualerna korrelerar efter område, d.v.s. att om en lägenhet som ligger inom GustafVasa stadsdel har en positiv residual, tenderar andra lägenheter som också lig-ger i denna stadsdel att ha en positiv residual. Härav genomfördes justeringar avWhite’s heteroskedasticitetskonsistenta kovariansskattning för rumslig klustering.
3.3 Genomförande
Semilog modellen valdes, där den beroende variabeln(priset) logaritmedes. Denna mo-dell antar att en absolut förändring i kovariater ger en relativ förändring i den förklarandekovariaten. Alla kovariater som fanns i tabellen sattes in, varefter regression genomfördes.Modellen testades sedan för KNLR-modellens antaganden(se kapitel 2.1.3). Om modelleninte uppfyllde antaganden tillämpades åtgärder som är beskrivna i section 2.3.
3.3.1 Utelämnande av icke signifikanta variabler
I denna studie sattes signifikansnivån till 5%. Efter regressionen kovariat med högsta p-värde som är över 5% togs bort. Det gjordes om och om igen tills en modell med endast
16
Kapitel 3. Metod
signifikanta kovariter var kvar.
3.3.2 Kovariater
Tabell 3.2: Kovariater
.
Kovariat Enhet Kort sammanfattning
Yta 𝑚2 Lägenhetens yta
Yta2 𝑚4 Kvadrattermen av lägenhetens yta
Rum Tal Antalet rum i lägenheten
Våning Tal Våning lägenheten ligger på
Månadsavgift SEK Månadsavgiften för lägenheten
Bygg1919 Indikator Alla hus som byggdes till och med 1919
Bygg1920-53 Indikator Alla hus som byggdes från och med 1920 till och med 1953
Bygg1959-72 Indikator Alla hus som byggdes från och med 1959 till och med 1972
Bygg1973-99 Indikator Alla hus som byggdes från och med 1973 till och med 1999
Bygg2000-13 Referens. Alla hus som byggdes från och med 2000 till och med 2013
Bolåneränta N år % Medel bolåneränta i procenter vid den månad lägenheten såldes
Avståndet till . . .
. . . vatten km Minsta avståndet till vattnet
. . . grundskola km Avståndet till närmaste grundskolan
. . . fritidsgård km Avståndet till närmaste fritidsgården
. . . idrotsplats km Avståndet till närmaste idrotsplatsen
. . . parklek km Avståndet till närmaste parkleken
Hiss Indikator Tillgänglighet av hiss
Balkong Indikator Tillgänglighet av balkong
Öppenspis Indikator Tillgänglighet av öppen spis
Etage Indikator Lägenhetens typ (etage eller ej)
Grå IndikatorStadsdelar: Stora Essingen, Hjorthagen-Värtahamnen, Södra Hammarby-hamnen, Lilla Essingen
Röd IndikatorStadsdelar: Södra Högalid, Kristineberg, Fredhäll, Stadshagen, TekniskaHögskolan, Marieberg.
Blå IndikatorStadsdelar: Mellersta Högalid, Södra Sofia, Västra Katarina, Östra Kata-rina, Norra Högalid, Östra S:t Göran, Maratorget, Södra Station
Grön IndikatorStadsdelar: Norra Johannes, Södra Adolf Fredrik, Norra Sofia,Reimersholme-Långholmen, Gärdet, Kungsholm, Östra Matteus, GustavVasa, Klara, Jakob, Storkyrkan, Västra Matteus, Norra Adolf Fredrik
Gul Indikator Stadsdelar: Engelbrekts k:a, Oskars k:a, Hedvig Eleonora
Stora Essingen Referens
17

Kapitel 4
Resultat
4.1 Tabeller
Tabell 4.1: Den slutliga modellen
Kovariater Koeff. Std. avvikelse. F-värde p-värde Justerade koeff.
Yta 0.0214311 0.0005585 38.37 0 1.359211
Yta2 -0.0000551 0.00000335 -16.43 0 -0.5017286
Måndasavgift -0.0000491 0.00000401 -12.26 0 -0.1460377
Rum 0.054345 0.006915 7.86 0 0.1263004
Område Grå -0.1617838 0.0120403 -13.44 0 -0.104521
Område Gul 0.1601122 0.0102579 15.61 0 0.1037971
Byggperiod 3 och 4 -0.1025633 0.0141514 -7.25 0 -0.0853745
Område Röd -0.1047101 0.0079617 -13.15 0 -0.0809169
Våning 0.0136594 0.0011853 11.52 0 0.0745238
Område Grön 0.04823 0.0052528 9.18 0 0.0601128
Balkong 0.0390493 0.004575 8.54 0 0.0484279
Byggperiod 2 -0.0374974 0.0122123 -3.07 0.002 -0.0471777
Ränta -0.0944915 0.0153752 -6.15 0 -0.0360726
Byggperiod 1 0.0268 0.0131325 2.04 0.041 0.0297834
Öppen spis 0.0270569 0.0084507 3.2 0.001 0.024136
Intercept 14.19364 0.0504093 281.57 0
Kapitel 4. Resultat
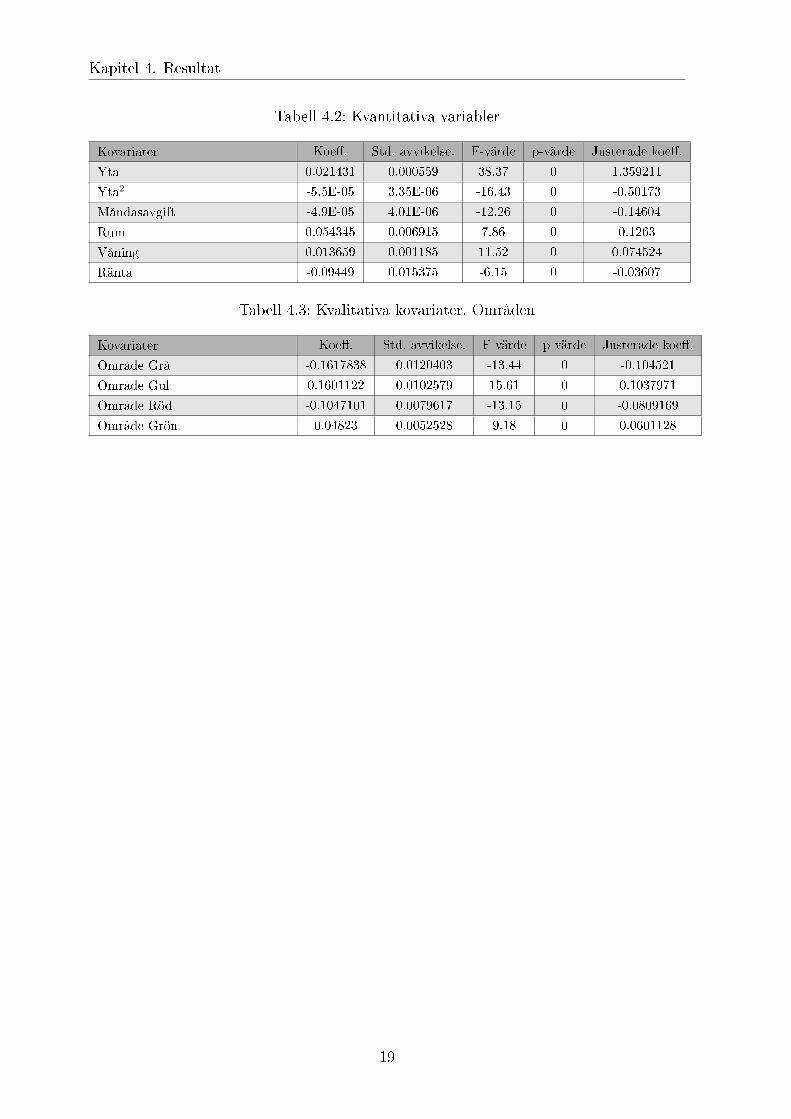
Tabell 4.2: Kvantitativa variabler
Kovariater Koeff. Std. avvikelse. F-värde p-värde Justerade koeff.
Yta 0.021431 0.000559 38.37 0 1.359211
Yta2 -5.5E-05 3.35E-06 -16.43 0 -0.50173
Måndasavgift -4.9E-05 4.01E-06 -12.26 0 -0.14604
Rum 0.054345 0.006915 7.86 0 0.1263
Våning 0.013659 0.001185 11.52 0 0.074524
Ränta -0.09449 0.015375 -6.15 0 -0.03607
Tabell 4.3: Kvalitativa kovariater. Områden
Kovariater Koeff. Std. avvikelse. F-värde p-värde Justerade koeff.
Område Grå -0.1617838 0.0120403 -13.44 0 -0.104521
Område Gul 0.1601122 0.0102579 15.61 0 0.1037971
Område Röd -0.1047101 0.0079617 -13.15 0 -0.0809169
Område Grön 0.04823 0.0052528 9.18 0 0.0601128
19
Kapitel 4. Resultat
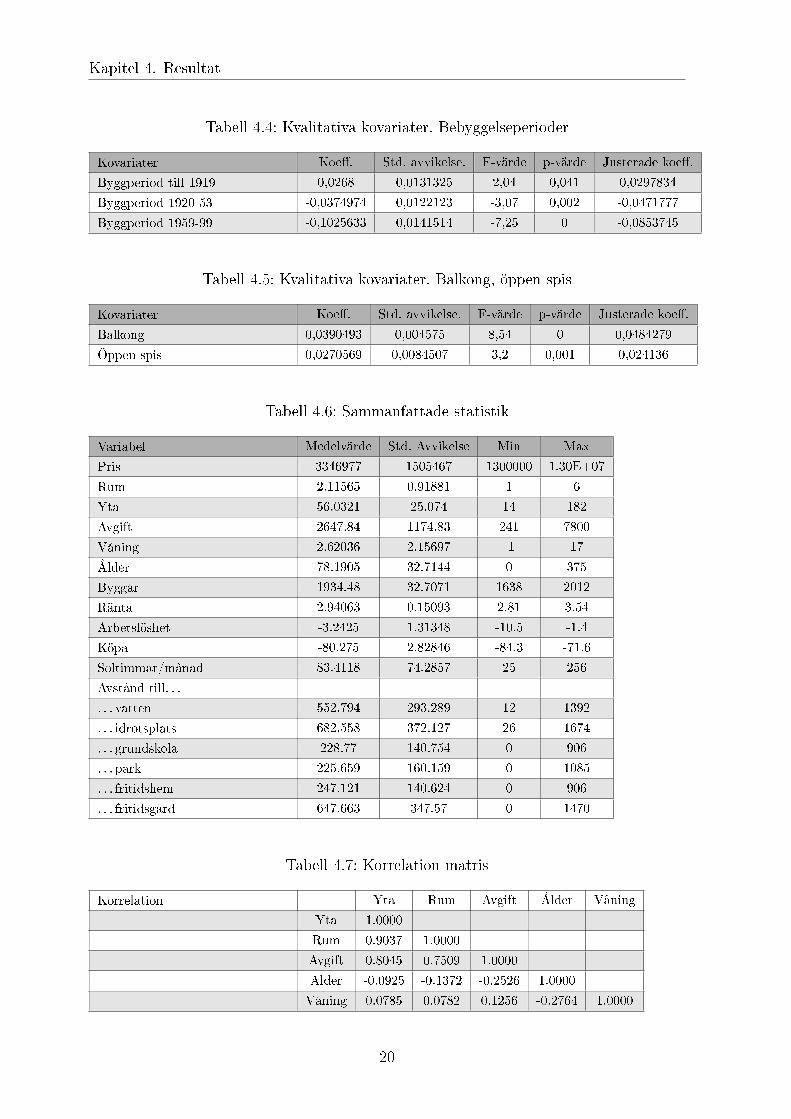
Tabell 4.4: Kvalitativa kovariater. Bebyggelseperioder
Kovariater Koeff. Std. avvikelse. F-värde p-värde Justerade koeff.
Byggperiod till 1919 0,0268 0,0131325 2,04 0,041 0,0297834
Byggperiod 1920-53 -0,0374974 0,0122123 -3,07 0,002 -0,0471777
Byggperiod 1959-99 -0,1025633 0,0141514 -7,25 0 -0,0853745
Tabell 4.5: Kvalitativa kovariater. Balkong, öppen spis
Kovariater Koeff. Std. avvikelse. F-värde p-värde Justerade koeff.
Balkong 0,0390493 0,004575 8,54 0 0,0484279
Öppen spis 0,0270569 0,0084507 3,2 0,001 0,024136
Tabell 4.6: Sammanfattade statistik
Variabel Medelvärde Std. Avvikelse Min Max
Pris 3346977 1505467 1300000 1.30E+07
Rum 2.11565 0.91881 1 6
Yta 56.0321 25.074 14 182
Avgift 2647.84 1174.83 241 7800
Våning 2.62036 2.15697 -1 17
Ålder 78.1905 32.7144 0 375
Byggår 1934.48 32.7071 1638 2012
Ränta 2.94063 0.15093 2.81 3.54
Arbetslöshet -3.2425 1.31348 -10.5 -1.4
Köpa -80.275 2.82846 -84.3 -71.6
Soltimmar/månad 83.4118 74.2857 25 256
Avstånd till. . .
. . . vatten 552.794 293.289 12 1392
. . . idrotsplats 682.558 372.127 26 1674
. . . grundskola 228.77 140.754 0 906
. . . park 225.659 160.159 0 1085
. . . fritidshem 247.121 140.624 0 906
. . . fritidsgård 647.663 347.57 0 1470
Tabell 4.7: Korrelation matris
Korrelation Yta Rum Avgift Ålder Våning
Yta 1.0000
Rum 0.9037 1.0000
Avgift 0.8045 0.7509 1.0000
Ålder -0.0925 -0.1372 -0.2526 1.0000
Våning 0.0785 0.0782 0.1256 -0.2764 1.0000
20
Kapitel 4. Resultat
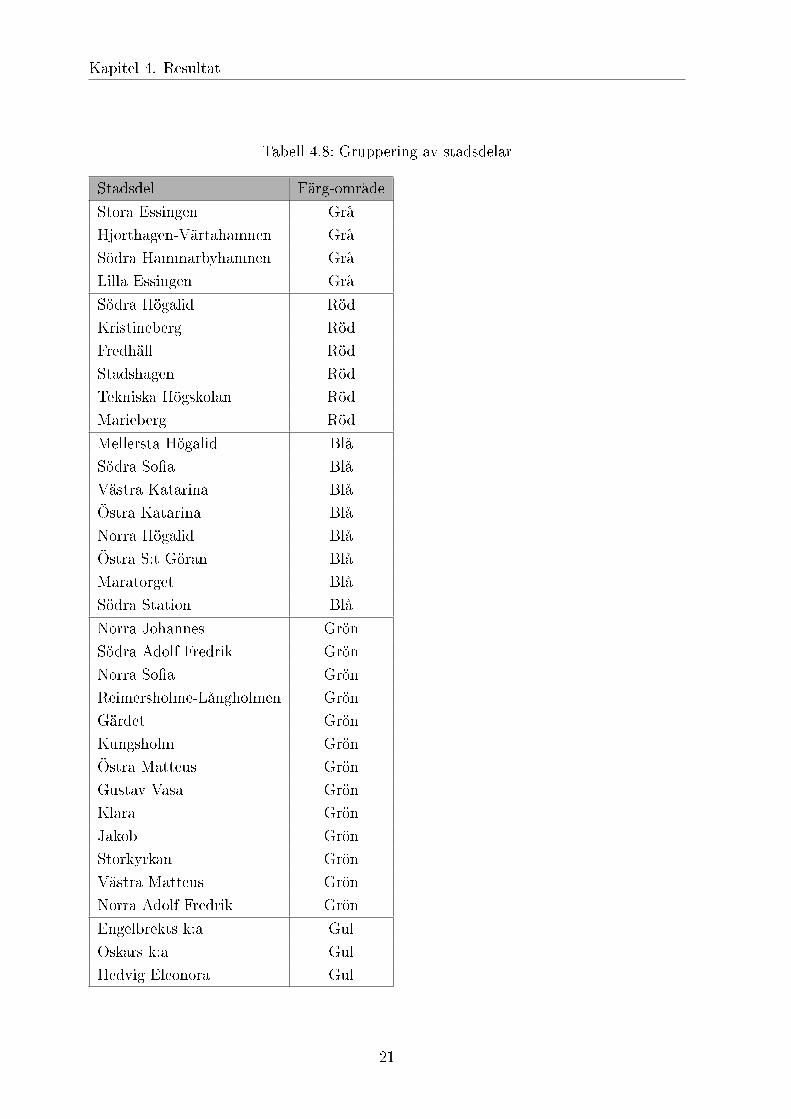
Tabell 4.8: Gruppering av stadsdelar
Stadsdel Färg-område
Stora Essingen GråHjorthagen-Värtahamnen GråSödra Hammarbyhamnen GråLilla Essingen Grå
Södra Högalid RödKristineberg RödFredhäll RödStadshagen RödTekniska Högskolan RödMarieberg Röd
Mellersta Högalid BlåSödra Sofia BlåVästra Katarina BlåÖstra Katarina BlåNorra Högalid BlåÖstra S:t Göran BlåMaratorget BlåSödra Station Blå
Norra Johannes GrönSödra Adolf Fredrik GrönNorra Sofia GrönReimersholme-Långholmen GrönGärdet GrönKungsholm GrönÖstra Matteus GrönGustav Vasa GrönKlara GrönJakob GrönStorkyrkan GrönVästra Matteus GrönNorra Adolf Fredrik Grön
Engelbrekts k:a GulOskars k:a GulHedvig Eleonora Gul
21

Kapitel 4. Resultat
4.2 Diagram och grafer
Figur 4.1: Ln(Pris) mot ln(predicerad pris)
22
Kapitel 4. Resultat
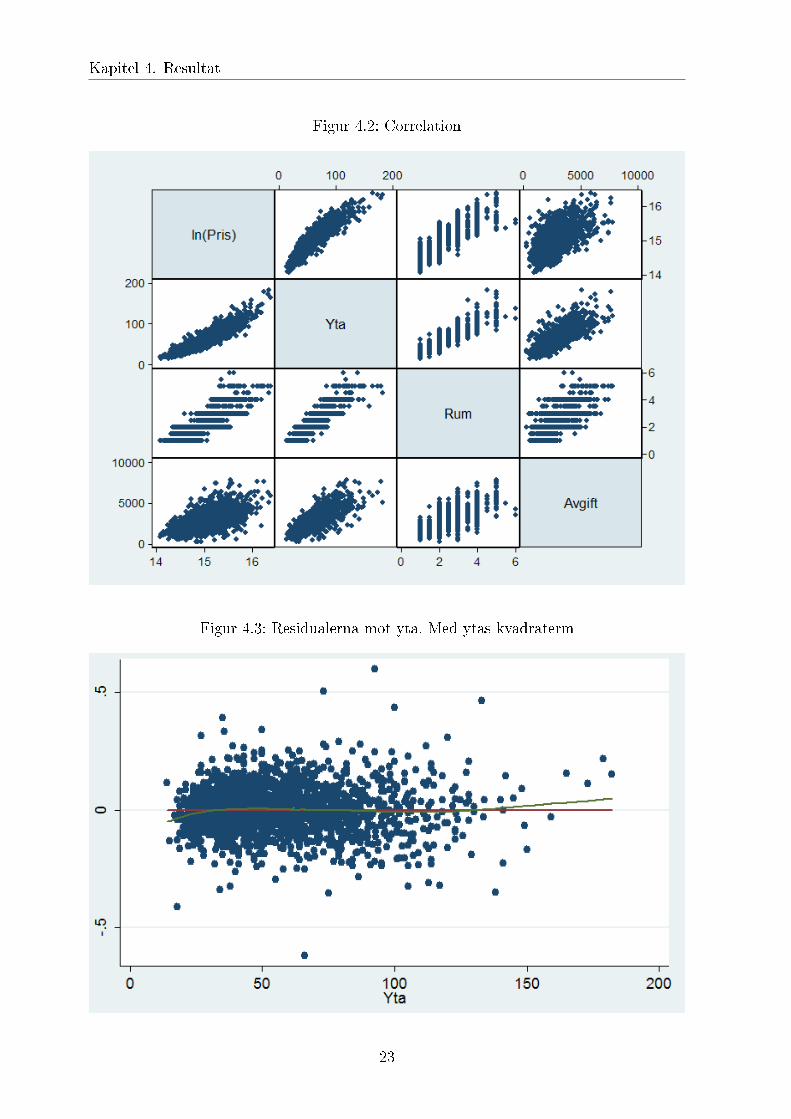
Figur 4.2: Correlation
Figur 4.3: Residualerna mot yta. Med ytas kvadraterm
23
Kapitel 4. Resultat
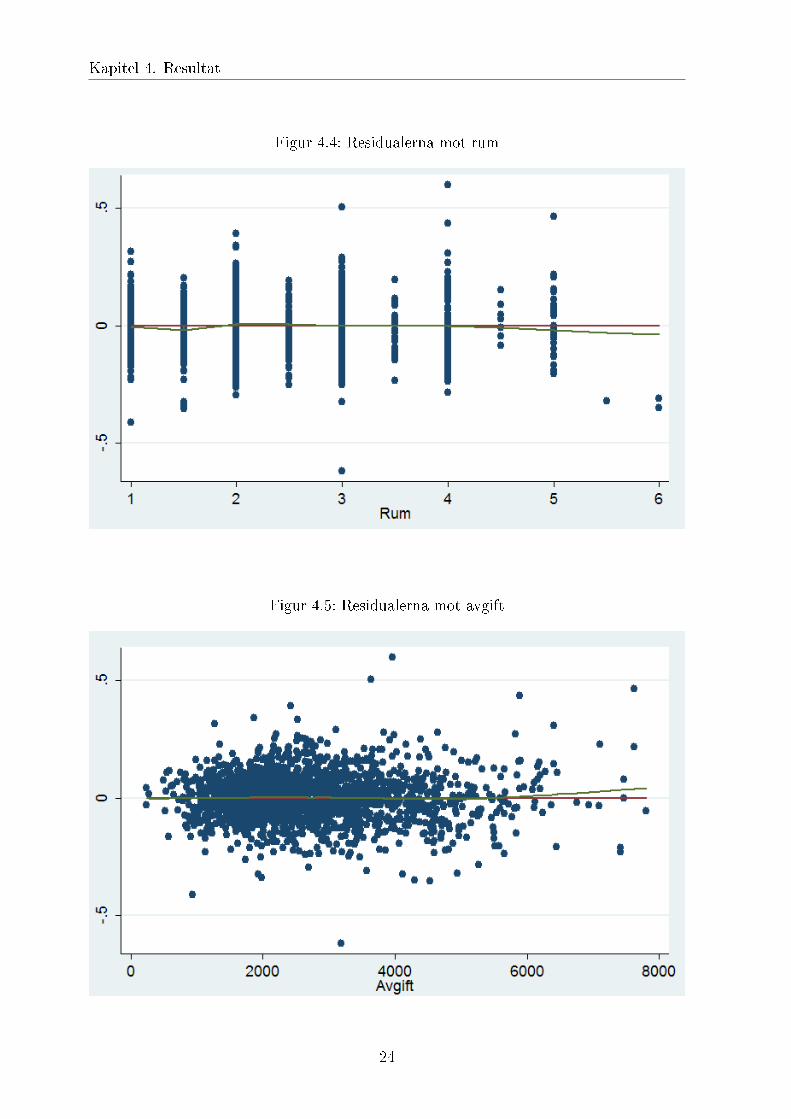
Figur 4.4: Residualerna mot rum
Figur 4.5: Residualerna mot avgift
24
Kapitel 4. Resultat
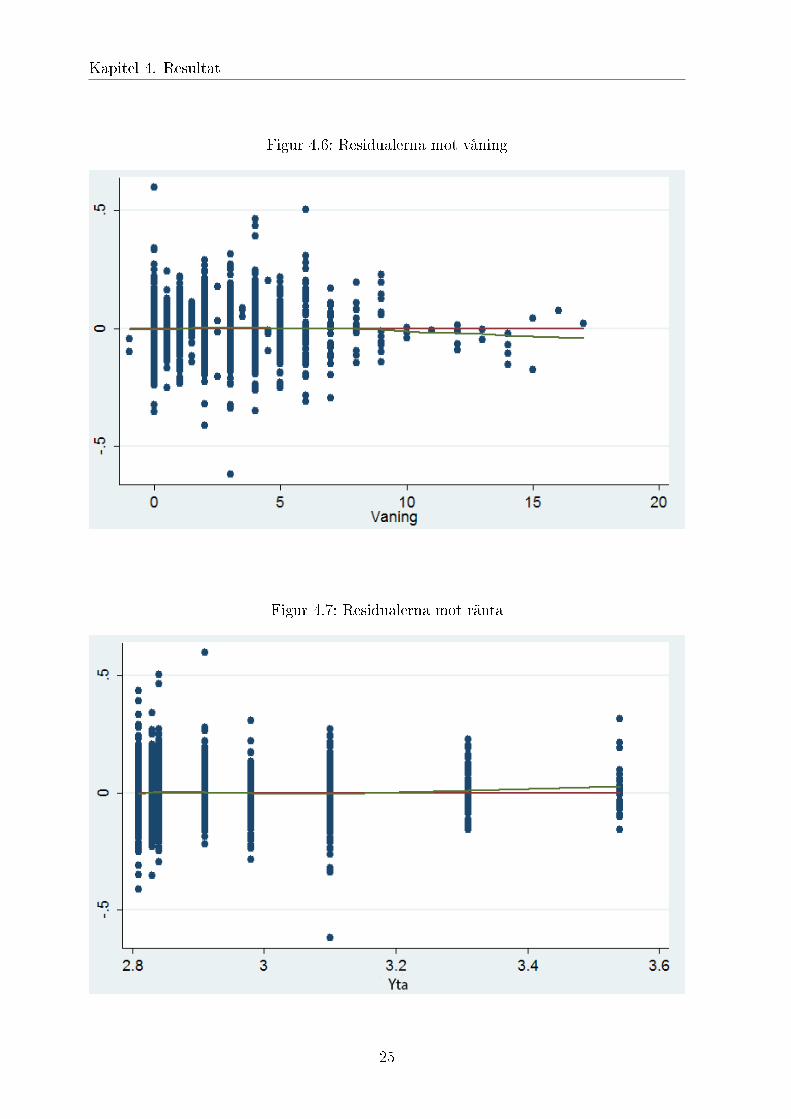
Figur 4.6: Residualerna mot våning
Figur 4.7: Residualerna mot ränta
25
Kapitel 4. Resultat
Figur 4.8: Normalplot av residualerna av slutmodell
26

Kapitel 4. Resultat
Figur 4.9: Residualerna mot predicerade ln(Pris*)
27
Kapitel 4. Resultat
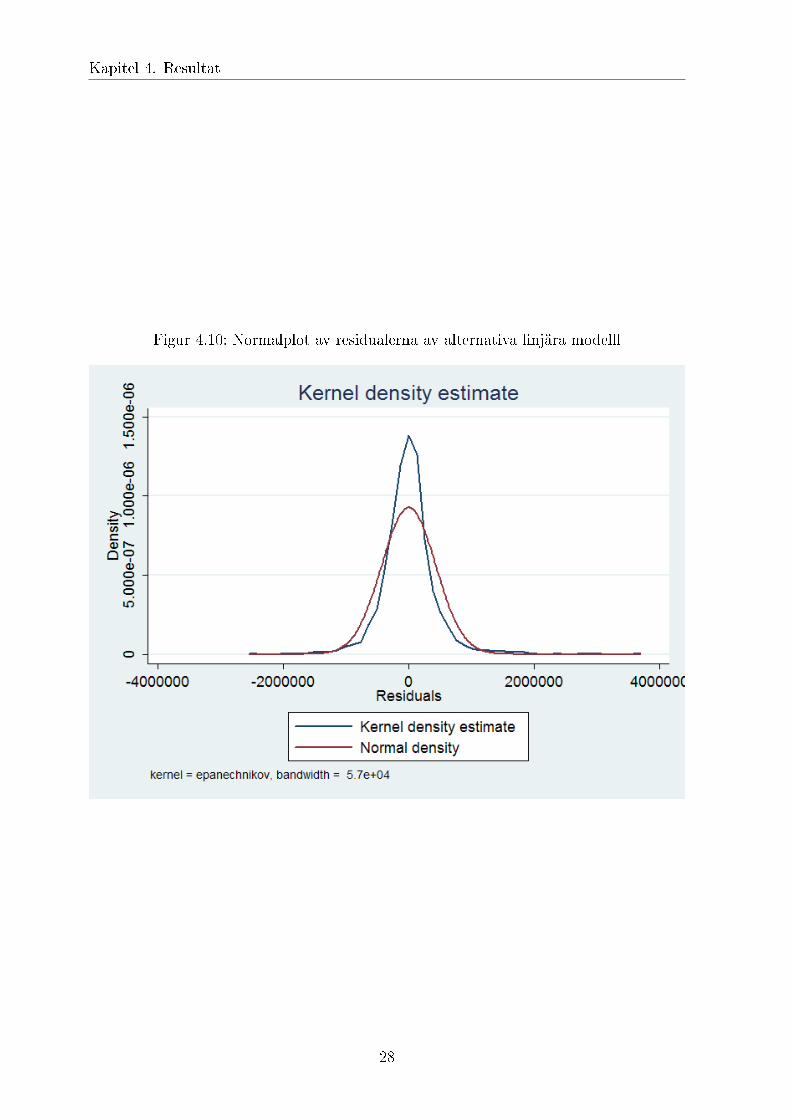
Figur 4.10: Normalplot av residualerna av alternativa linjära modelll
28
Kapitel 4. Resultat
Figur 4.11: Förstudie. Residualer mot observerade ln(Pris)
Figur 4.12: Förstudie. Residualerna mot yta. Utan ytas kvadraterm
29
Kapitel 4. Resultat
Figur 4.13: Förstudie. Pris mot bebyggelseår.
30

Kapitel 5
Diskutioner
5.1 Den slutliga modellen
5.1.1 Predicering
Den slutliga modellen (tabellen 4.1.) har en förklaringsgrad på 93% procenter och relativafel på ungefär 10%. Från figur 4.1 ser man att den predicerar slutpris ganska bra för allalägenheter förutom dem vars värde överstiger 9Mkr. Detta kan förklaras med att demdyraste lägenheterna kännetecknas med parametrar som är svårt att skatta såsom lyx,exklusivitet etc., d.v.s. att de dyra lägenheterna är på något sätt unika.
5.1.2 Strukturtolkning
För att kunna jämföra koefficienternas vikt skapades så kallade standardiserades beta-koefficienter. Koefficienterna sorterades efter sin ”vikt”. Kvantitativa och kvalitativa ko-variater diskuteras separat. Kovariaternas påverkan anges i procenter [(𝑒𝑏𝑒𝑡𝑎−1]*100%).
Signifikanta kovariater
Signifikanta variabler delades i två grupp:
∙ Kvantitativa kovariater (tabel 4.2):
– Boyta är en kovariat med största vikten. En extra kvadratterm pekar på attju större boyta är desto mindre relativ ändring ger varje extra meter.
– Varje 1000 kr i månadsavgiften minskar priset med ca 5% (motsvarar ca 150Tkr minskning räknad för en lägenhet på 3Mkr, vilket är prisets medelvärde).Det tycks vara lagom mycket, då detta belopp(150 Tkr) räcker att betala extrahyran i cirka 12 år.

Kapitel 5. Diskutioner
– Ett extra rum ökar däremot priset med ca 5.5% (170 Tkr). Detta ska tas meden nypa salt och kan tolkas som att det i allmänhet föredras flerrumslägen-heterna.
– Varje extra våning räknad från bottenvåningen ökar priset med ca 1,4% (40Tkr). Detta kan förklaras delvis med en finare utsikt från högre våningar,delvis mindre väsen från gatan.
– Varje extra procentdecimal i ränta ökar priset med ca 1% (30 Tkr); dennakovariat var ganska stabil över hela perioden, men skulle kunna få en störrebetydelse vid finanskriser etc. (då en procentändring i ränta skulle öka prisetmed ca 10%).
∙ Kvalitativa kovariater:
1. Område (tabel 4.3 och 4.8)Det blåa området (större delar av Södermalm) sattes som referens och andraområden jämfördes med den. Det gulla området (Östermalm) ökar priset medca 17% och den gröna (Norrmalm) med ca 5%. Det gråa området (avlägs-na innerstadens områden) minskar priset med ca 15% och den röda (vänst-ra Kungsholmen) med ca 10%. Därmed har man rangordnat Stockholms in-nerstads områden efter populäritet/prestige. Detta anses vara ett intressantämne för vidare studier.
2. Bebyggelse perioder (tabel 4.4)Det blev totalt 4 bebyggelse perioder: år 1638 - 1919, 1920 - 1953, en samman-fogad period år 1959-1999. Årsperioden 2000 - 2013 valdes som referensperiod,d.v.s. att prisskillnaden jämfördes med denna period. Perioden 1638-1919 ökarpriset med ca 3%. Denna period karakteriseras med jugendstil i arkitektur,höga tak och stora fönster. Period 1920-1953 minskar priset med ca 4%. Dennaperiod karakteriseras med funktionalismen i arkitektur, stora fönster. Perio-den 1959 - 1999 bestod ursprungligen av 2 områden som visade sig ha ungefärsamma inverkan på priset som nämligen är en minskning på ca 10%. Dennaperiod karakteriseras med trångboddhet.
3. Balkong ökar priset med ca 4% och öppen spis med ca 3%. (Tabel 4.5).
Icke-signifikanta kovariater
Följande varibaler visades sig vara icke-signifikanta:
∙ Hiss. Att hiss inte är signifikant, är ganska förvånande. Detta kan förklaras att av1913 lägenheter saknar 443 hiss. Alla lägenheter som ligger på minst 5 våning harhiss. Av dem 443 lägenheter som saknar hiss ligger 126 på 3:e eller 4:e våningar.
32

Kapitel 5. Diskutioner
Ännu 109 ligger på 2:a våningen. Det vill säga att de flesta lägenheter antingen hartillgång till hiss eller inte ligger på höga våningar.
∙ Etagelägenhet. Detta tyder på att etagelägenheter inte verkar vara populära. Denkan kankse tyckas vara jobbig att vara tvungen gå ner och upp på trapporna, sär-skilt för äldre människor. Avståndet till närmaste idrotsplatsen, parkleken, fritids-gårder och grundskolas samt avståndet till vattnet. Det är också ganska förvånande,då många mäklarannonser betonade att lägenheten är nära till grönaområden, sko-lor, vattnet och så vidare. Icke-signifikans kan förklaras delvis med att avståndeträknades som flygväg, vilken kan bidra till fel, och delvis att den finns en stormängd av grundskolor, parklekar med mera i Stockholms innerstad.
5.2 Linjära modellen
Även linjära modellen testades, denna hade dock icke-normalfördelade residualerna (figur4.10) samt heteroskedasticitet var något högre. Även antagande att en absolut förändringi en kovariat ger en absolut förändring i priset. Att exempelvis balkong ger samma ökningför en etta på 30 meter som för en sexa på 130 meter är inte särskilt trovärdig.
5.3 Slutsatser
Syfte med denna studie var att reda ut hur priset formas samt kunna predicera slutpriset.En loglinjär regressionsmodell användes för uppfyllningar av dessa mål. Modellen antaratt absolut förändring i en kovariat ger en relativ ändring i den beroende variabeln.Modellen inkluderade kovariater från tabellen 3.2. Värdena på skattade parametrarnaanses vara rimliga ger en bra tolkning kovariaters vikt och skulle kunna användas vidköp av en lägenhet.
5.4 Felkällor
Jag misstänker att några viktiga kovariater är utelämnade i min modell. Dessa är främstrenoveringsår samt husets totala antal våningar.En noggrannare områdesindelning kunde ge bättre prestanda, men avsågs kompliceramodellen alldeles för mycket; det var 36 olika stadsdelen
33

Kapitel 6
Referencer
∙ Kennedy, K. A Guide to Econometrics 6 edition, 2008.
∙ Lang, H. Topics on Applied Mathematical Statistics version 0.93, 2012.
∙ Blom, G. Enger, J. Englund, G. Grandel, G. Holst, L. Sannolikhetsteori och sta-tistikteori med tillämpningar 5 upplaga, 2005.
∙ White, H. A heteroskedasticity-consistent covariance matrix estimator and a directtest for heteroskedasticity. Econometrica 48: 817–830, 1980.
∙ Rogers, W. H. Regression standard errors in clustered samples. Stata TechnicalBulletin 13: 19–23, 1993.
∙ Mäklarstatistik. http://www.maklarstatistik.se/.
∙ Blocket. [http://www.blocket.se/.
∙ Fredric Beroire. Stockholms byggnader, arkitektur och statsbild, 2012.
∙ Andersson, K. Bengtsson, B. Bladh, M. Cars, G. Feldmann, B. Jacobsson, E. Fa-miljebostäder. Flera kapitel i svensk bostadspolitik, 2006.
∙ Statistiska centralbyrån. http://www.scb.se/.
∙ Konjunkturinstitutet http://www.konj.se/.
∙ Google Maps. https://maps.google.se/.
∙ Stockholms stad http://www.stockholm.se.