4/22: unexpected hanging and other sadistic pleasures of teaching today: probabilistic plan...
Post on 19-Dec-2015
215 views
TRANSCRIPT

4/22: Unexpected Hanging and other sadistic pleasures of teaching
Today: Probabilistic Plan RecognitionTomorrow: Web Service Composition (BY 510;
11AM)Thursday: Continual Planning for Printers (in-class)
Tuesday 4/29: (Interactive) Review

Oregon State University
Approaches to plan recognition
Consistency-based Hypothesize & revise Closed-world reasoning Version spaces
Probabilistic Stochastic grammars Pending sets Dynamic Bayes nets Layered hidden Markov models Policy recognition Hierarchical hidden semi-Markov models Dynamic probabilistic relational models Example application: Assisted Cognition
Can be complementary.. First pick the consistent plans, and check which of them is most likely (tricky if the agent can make errors)

Oregon State University
Agenda (as actually realized in class) Plan recognition as probabilistic (max weight)
parsing
On the connection between dynamic bayes nets and plan recognition; with a detour on the special inference tasks for DBN
Examples of plan recognition techniques based on setting up DBNs and doing MPE inference on them
Discussion of Decision Theoretic Assistance paper

Stochastic grammars
Huber, Durfee, & Wellman, "The Automated Mapping of Plans for Plan Recognition", 1994
Darnell Moore and Irfan Essa, "Recognizing Multitasked Activities from Video using Stochastic Context-Free Grammar", AAAI-02, 2002.
CF grammar w/ probabilistic rules
Chart parsing + Viterbi
Successful for highly structured tasks (e.g. playing cards)
Problems: errors, context

Probabilistic State-dependent grammars
Connection with DBNs

Time and Change in Probabilistic Reasoning

Temporal (Sequential) Process
• A temporal process is the evolution of system state over time
• Often the system state is hidden, and we need to reconstruct the state from the observations
• Relation to Planning:– When you are observing a temporal process,
you are observing the execution trace of someone else’s plan…




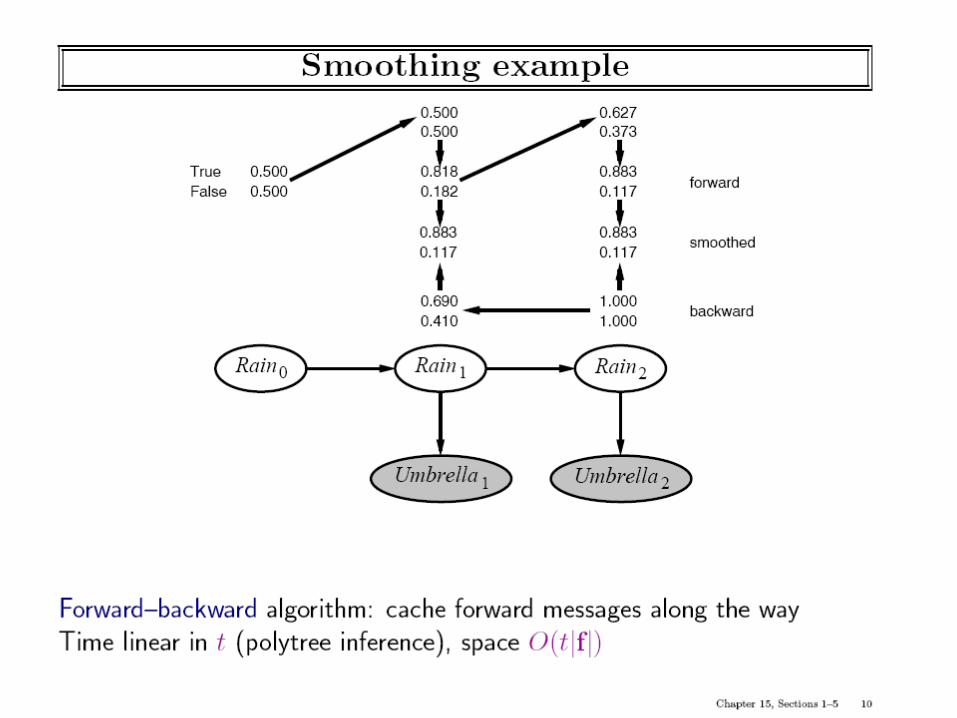
Dynamic Bayes Networks are “templates” for specifying the relation between the values of a random variable across time-slices e.g. How is Rain at time t related to Rain at time t+1? We call them templates because they need to be expanded (unfolded) to the required number of time steps to reason about the connection between variables at different time points

Normal LW takes each sample through the network one by one
Idea 1: Take them all from t to t+1 lock-step the samples are the distribution
Normal LW doesn’t do well when the evidence is downstream (the sample weight will be too small)
In DBN, none of the evidence is affecting the sampling! EVEN MORE of an issue

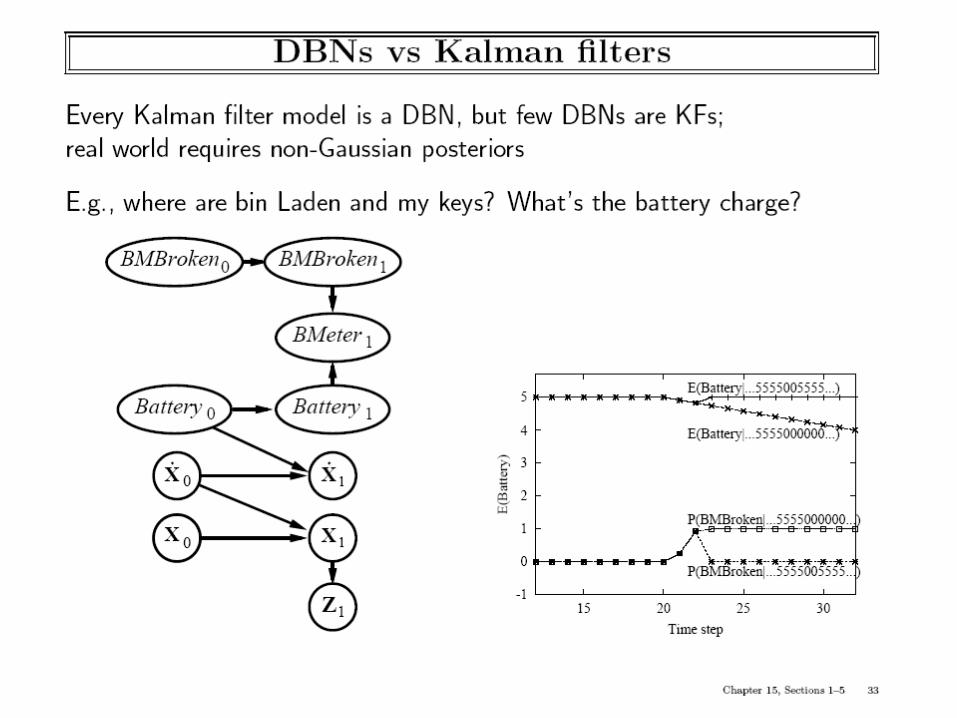
Special Cases of DBNs are well known in the literature
• Restrict number of variables per state– Markov Chain: DBN
with one variable that is fully observable
– Hidden Markov Model: DBN with only one state variable that is hidden and can be estimated through evidence variable(s)
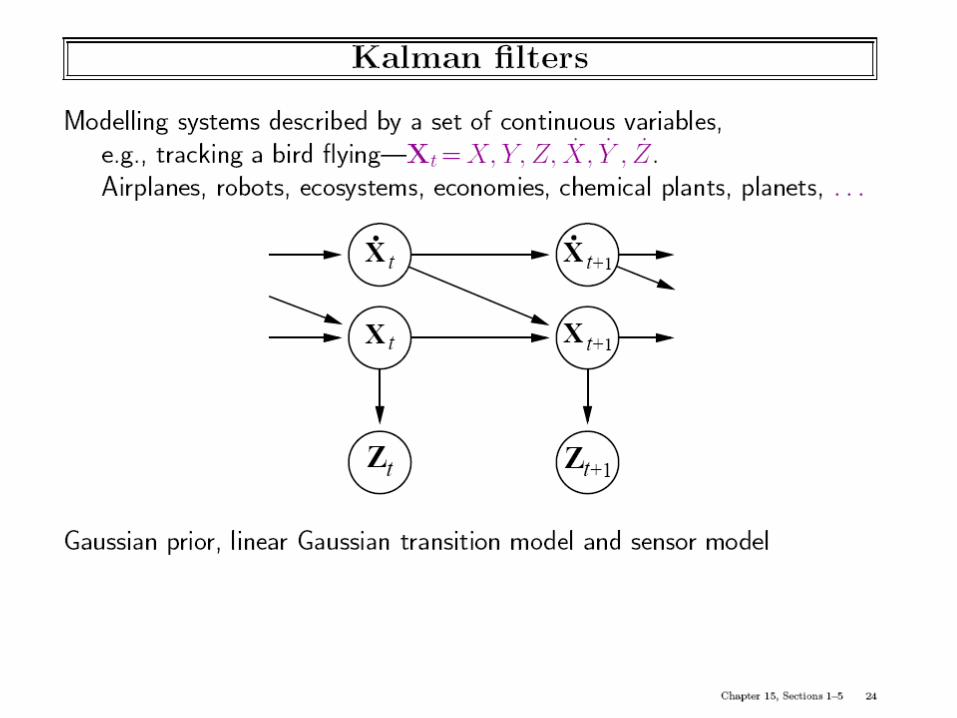
• Restrict the type of CPD– Kalman Filters: DBN
where the system transition function as well as the observation variable are linear gaussian
• The advantage of Gaussians is that the posterior distribution remains Gaussian

Plan Recognition Approaches based on setting up DBNs

Dynamic Bayes nets (I)
E. Horvitz, J. Breese, D. Heckerman, D. Hovel, and K. Rommelse. The Lumiere Project: Bayesian User Modeling for Inferring the Goals and Needs of Software Users. Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, July 1998.
Towards a Bayesian model for keyhole plan recognition in large domains Albrecht, Zukermann, Nicholson, Bud
Models relationship between user’s recent actions and goals (help needs)
Probabilistic goal persistence
Programming in machine language?

Excel help (partial)

Cognitive mode { normal, error }
Dynamic Bayesian Nets
GPS reading
Edge, velocity, position
Data (edge) association
Transportation mode
Trip segment
Goal
zk-1 zk
xk-1 xk
k-1 k
Time k-1 Time k
mk-1 mk
tk-1 tk
gk-1 gk
ck-1 ck
Learning and Inferring Transportation Routines Lin Liao, Dieter Fox, and Henry Kautz, Nineteenth National Conference on Artificial Intelligence, San Jose, CA, 2004.

Decision-Theoretic Assistance
Don’t just recognize!
Jump in and help..
Allows us to also talk about POMDPs

Oregon State University
Intelligent Assistants
Many examples of AI techniques being applied to assistive technologies
Intelligent Desktop Assistants Calendar Apprentice (CAP) (Mitchell et al. 1994) Travel Assistant (Ambite et al. 2002) CALO Project Tasktracer Electric Elves (Hans Chalupsky et al. 2001)
Assistive Technologies for the Disabled COACH System (Boger et al. 2005)

Oregon State University
Not So Intelligent Most previous work uses problem-specific, hand-crafted
solutions Lack ability to offer assistance in ways not planned for by designer
Our goal: provide a general, formal framework for intelligent-assistant design
Desirable properties: Explicitly reason about models of the world and user to provide
flexible assistance Handle uncertainty about the world and user Handle variable costs of user and assistive actions
We describe a model-based decision-theoretic framework that captures these properties

Oregon State University
An Episodic Interaction ModelAn Episodic Interaction Model
User Assistant
W6 W7 W8 W9
Goal Achieved
W2
User Action
W4 W5W3
Assistant Actions
W1
Goal
Initial State
Each user and assistant action has a cost
Action set UAction set A
Objective: minimize expected cost of episodes

Oregon State University
Example: Grid World DomainExample: Grid World Domain
World states:
(x,y) location and door status
Possible goals:
Get wood, gold, or food
User actions:
Up, Down, Left, Right, noop
Open a door in current room
(all actions have cost = 1)
Assistant actions:
Open a door, noop
(all actions have cost = 0)

Oregon State University
World and User ModelsWorld and User Models
Ut
Wt
At
Wt+1
G P(G)
P(Ut | G, Wt)
W1 W2 W3 W4
U1
A1
U2
?
• Model world dynamics as a Markov decision process (MDP)
• Model user as a stochastic policy
P(Wt+1 | Wt, Ut, At)
Goal Distribution
Action distribution conditioned on goal and world state
Transition Model
Given: model,action sequence
Output: assistant action

Oregon State University
Optimal Solution: Assistant POMDPOptimal Solution: Assistant POMDP
Ut
Wt
At
Wt+1
G P(G)
P(Ut | G, Wt)
P(Wt+1 | Wt, Ut, At)
Goal Distribution
Action distribution conditioned on goal and world state
Transition Model
Can view as a POMDP called the assistant POMDP Hidden State: user goal Observations: user actions and world states
Optimal policy gives mapping from observation sequences to assistant actions Represents optimal assistant
Typically intractable to solve exactly
Oregon State University
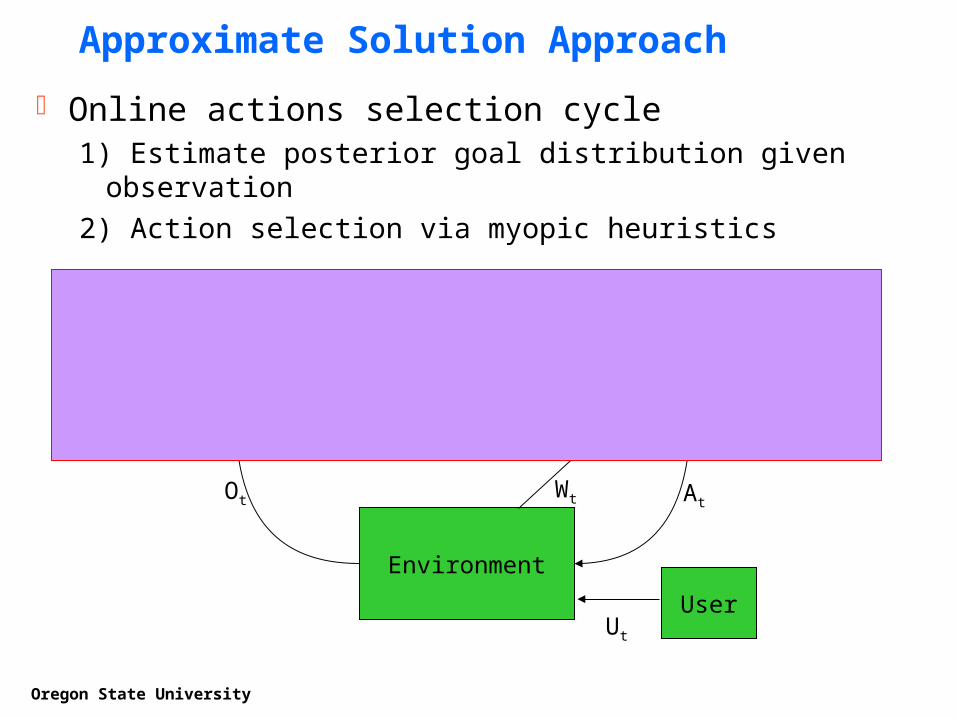
Approximate Solution Approach
Goal Recognizer Action Selection
Environment
UserUt
AtOt
P(G)
Assistant
Wt
Online actions selection cycle1) Estimate posterior goal distribution given observation
2) Action selection via myopic heuristics

Oregon State University
Approximate Solution Approach
Goal Recognizer Action Selection
Environment
UserUt
AtOt
P(G)
Assistant
Wt
Online actions selection cycle1) Estimate posterior goal distribution given observation
2) Action selection via myopic heuristics

Oregon State University
Goal EstimationGoal Estimation
Wt
Current State
P(G | Ot)
Goal posterior given observations up to time t
Wt+1
Ut
P(G | Ot+1)
Updated goal posterior
new observation
Given P(G | Ot) : goal posterior at time t
initally equal to prior P(G) P(Ut | G, Wt) : stochastic user policy Ot+1 : new observation of user action and world state
it is straightforward to update goal posterior at time t+1
must learn user policy
),|()|()|( 11 tttt WGUPOGPOGP

Oregon State University
Learning User PolicyLearning User Policy
Use Bayesian updates to update user policy P(U|G, W) after each episode Problem: can converge slowing, leading to poor goal estimation Solution: use strong prior on user policy derived via planning
Assume that user behaves “nearly rational” Take prior distribution on P(U|G, W) to be bias toward optimal user actions
Let Q(U,W,G) be value of user taking action U in state W given goal G Can compute via MDP planning Use prior P(U | G, W) α exp(Q(U,W,G))

Oregon State University
Q(U,W,G) for Grid WorldQ(U,W,G) for Grid World
Oregon State University
Approximate Solution Approach
Goal Recognizer Action Selection
Environment
UserUt
AtOt
P(G)
Assistant
Wt
Online actions selection cycle1) Estimate posterior goal distribution given observation
2) Action selection via myopic heuristics
Oregon State University
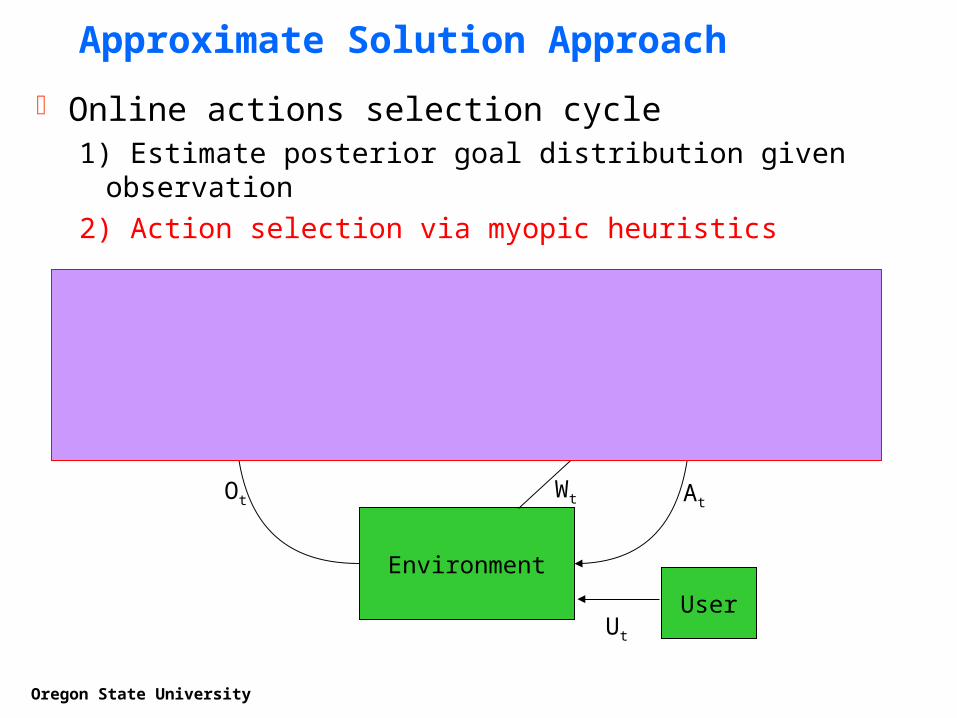
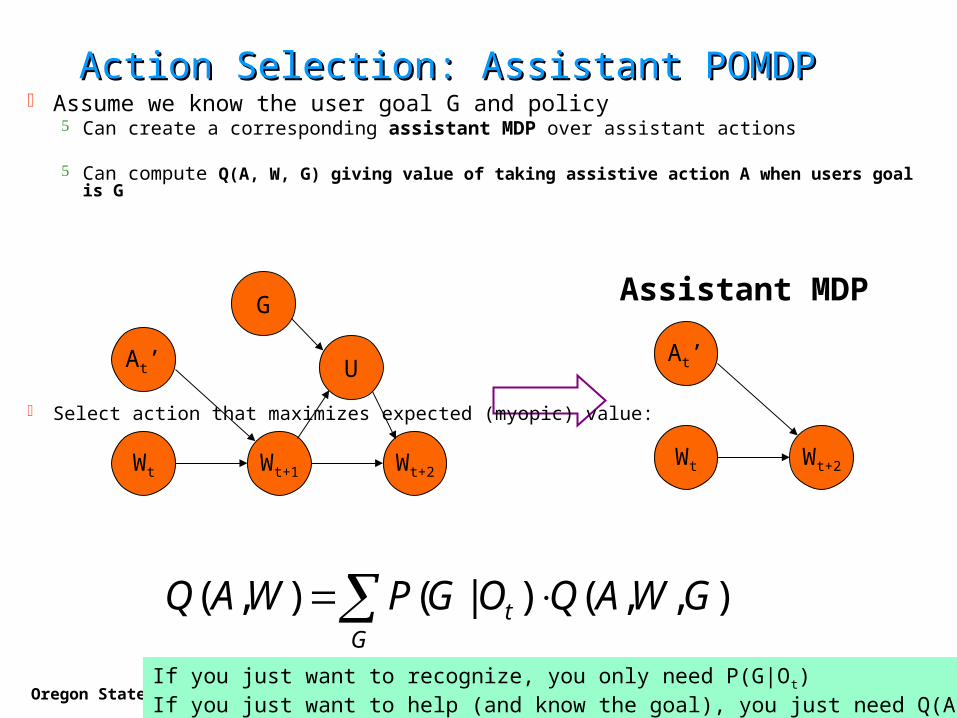
Action Selection: Assistant POMDPAction Selection: Assistant POMDP
At’
Wt Wt+1 Wt+2
U
G
At’
Wt Wt+2
Assistant MDP
Assume we know the user goal G and policy Can create a corresponding assistant MDP over assistant actions
Can compute Q(A, W, G) giving value of taking assistive action A when users goal is G
Select action that maximizes expected (myopic) value:
G
t GWAQOGPWAQ ),,()|(),(
If you just want to recognize, you only need P(G|Ot)If you just want to help (and know the goal), you just need Q(A,W,G)

Oregon State University
Experiments: Grid World Domain Experiments: Grid World Domain
Oregon State University
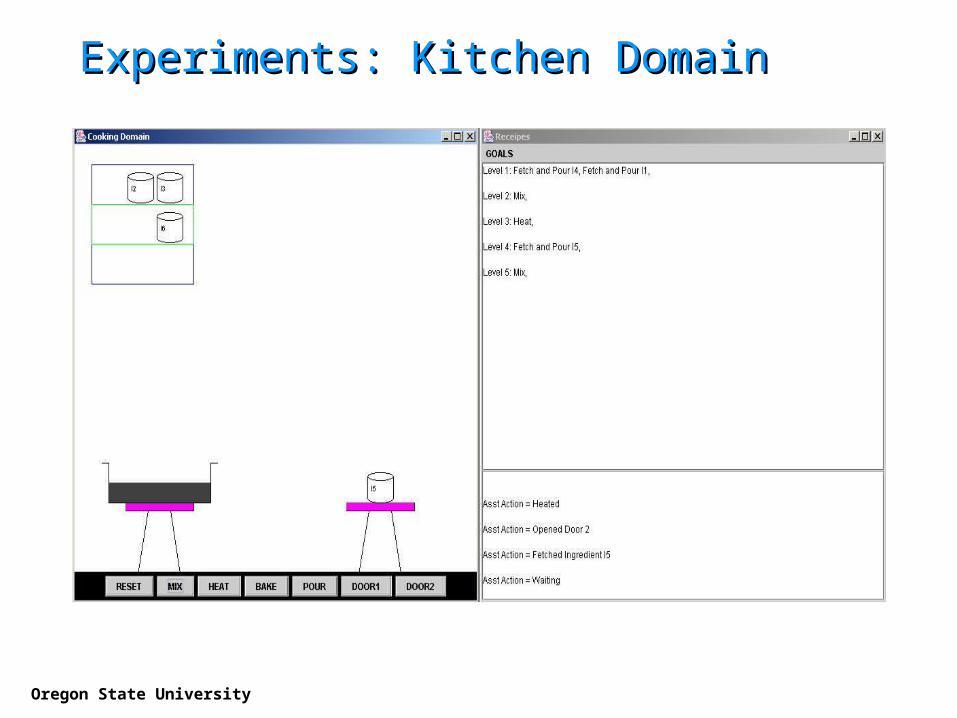
Experiments: Kitchen DomainExperiments: Kitchen Domain

Oregon State University
Experimental ResultsExperimental Results
Experiment: 12 human subjects, two domains
Subjects were asked to achieve a sequence of goals
Compared average cost of performing tasks with assistant to optimal cost without assistant
Assistant reduced cost by over 50%

Oregon State University
Summary of AssumptionsSummary of Assumptions
Model Assumptions: World can be approximately modeled as MDP User and assistant interleave actions (no parallel activity) User can be modeled as a stationary, stochastic policy Finite set of known goals
Assumptions Made by Solution Approach Access to practical algorithm for solving the world MDP User does no reason about the existence of the assistance Goal set is relatively small and known to assistant User is close to “rational”

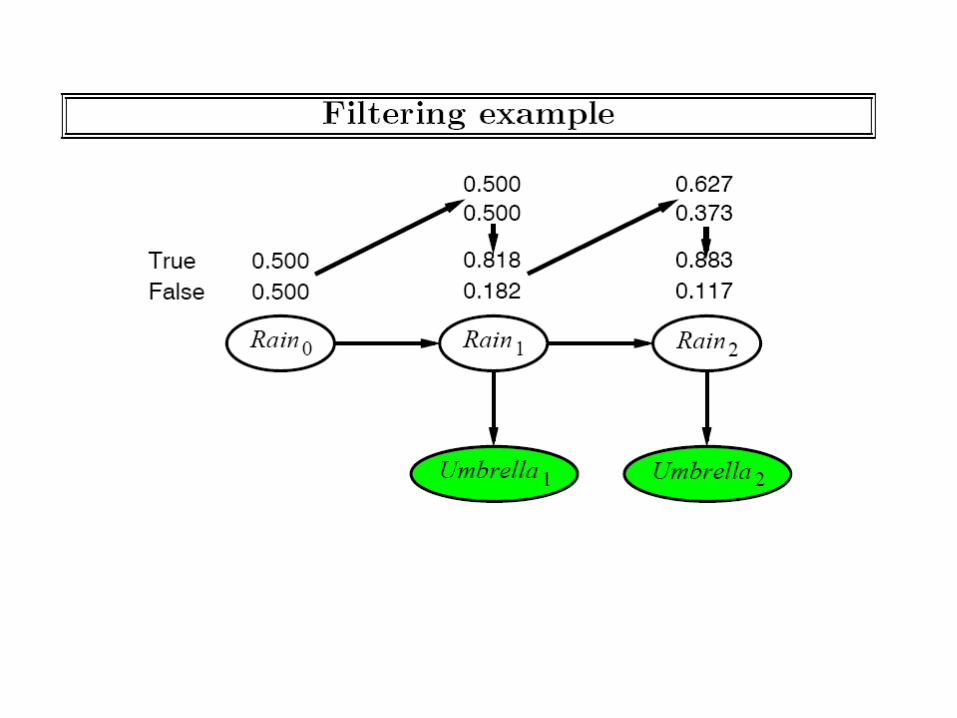
While DBNs are special cases of B.N.’s there are a certain inference tasks that are particularly frequently useful for them (Notice that all of them involve estimating posterior probability distributions—as is done in any B.N. inference)

Can do much better if we exploit the repetitive structure
Both Exact and Approximate B.N. Inference methods can be made to take the temporal structure into account. Specialized variable-elimination method Unfold t+1th level, and roll-up tth level by variable elimination
Specialized Likelihood-weighting methods that take evidence into account Particle Filtering Techniques
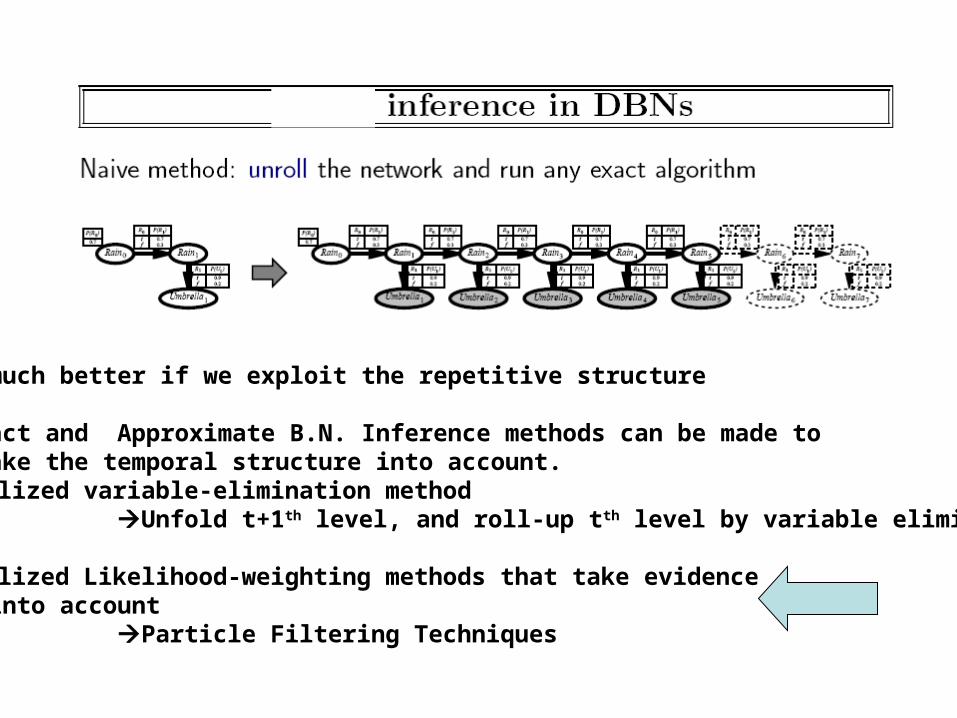
Can do much better if we exploit the repetitive structure
Both Exact and Approximate B.N. Inference methods can be made to take the temporal structure into account. Specialized variable-elimination method Unfold t+1th level, and roll-up tth level by variable elimination
Specialized Likelihood-weighting methods that take evidence into account Particle Filtering Techniques

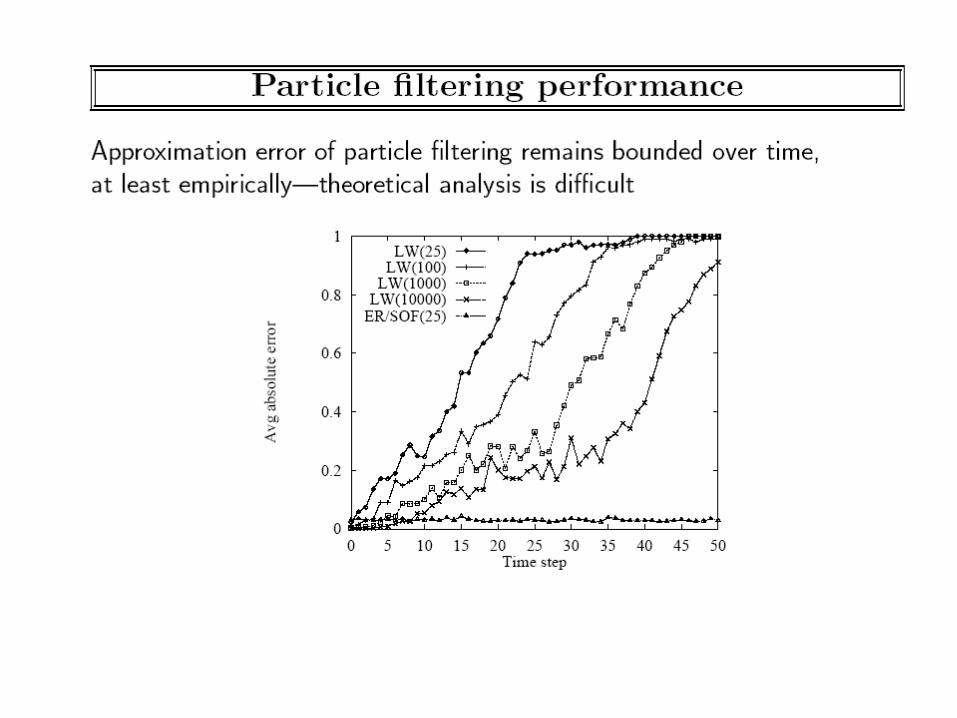



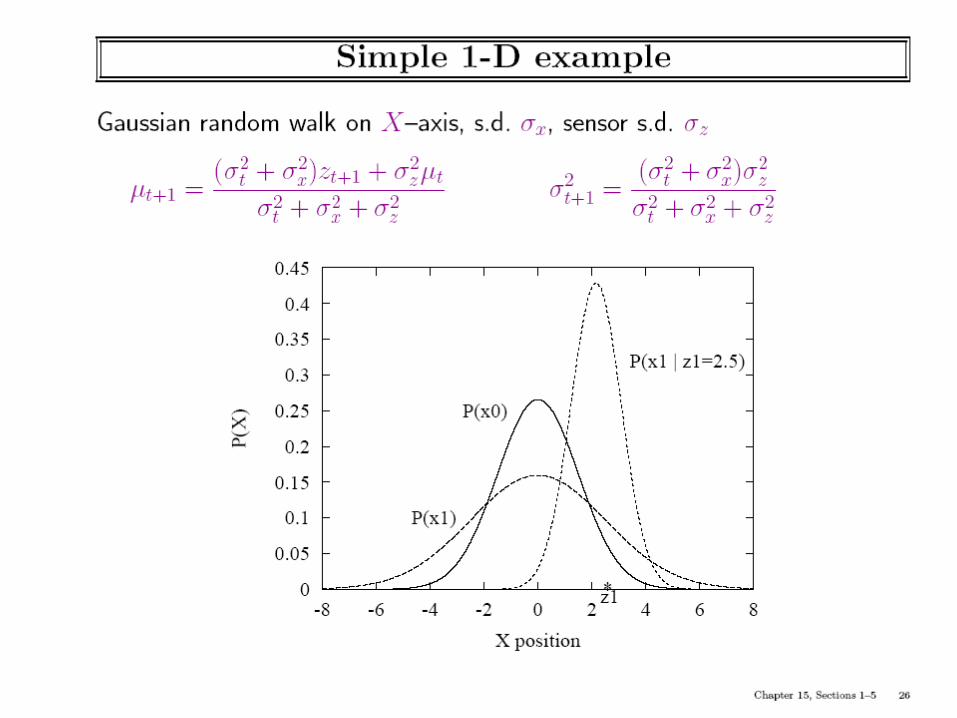


Class Ended here..Slides beyond this not discussed

Belief States• If we have k state variables,
2k states• A “belief state” is a probability
distribution over states– Non-deterministic
• We just know the states for which the probability is non-zero
• 22^k belief states– Stochastic
• We know the probability distribution over the states
• Infinite number of probability distributions
– A complete state is a special case of belief state where the distribution is “dirac-delta”
• i.e., non-zero only for one state
In blocks world, Suppose we have blocks A and B and they can be “clear”, “on-table” “On” each other
-A state: A is on table, B is on table, both are clear, hand is empty
-A belief state : A is either on B or on Table B is on table. Hand is empty
2 states in the belief state

Actions and Belief States
• Two types of actions– Standard actions: Modify the
distribution of belief states• Doing “C on A” action in the
belief state gives us a new belief state (with C on A on B OR C on A; B clear)
• Doing “Shake-the-Table” action converts the previous belief state to (A on table; B on Table; A clear; B clear)
– Notice that actions reduce the uncertainty!
• Sensing actions– Sensing actions observe some
aspect of the belief state– The observations modify the
belief state distribution• In the belief state above, if we
observed that two blocks are clear, then the belief state changes to {A on table; B on table; both clear}
• If the observation above is noisy (i.e, we are not completely certain), then the probability distribution just changes so more probability mass is centered on the {A on table; B on Table} state.
A belief state : A is either on B or on Table B is on table. Hand is empty

Actions and Belief States
• Two types of actions– Standard actions: Modify the
distribution of belief states• Doing “C on A” action in the
belief state gives us a new belief state (with C on A on B OR C on A; B clear)
• Doing “Shake-the-Table” action converts the previous belief state to (A on table; B on Table; A clear; B clear)
– Notice that actions reduce the uncertainty!
• Sensing actions– Sensing actions observe some
aspect of the belief state– The observations modify the
belief state distribution• In the belief state above, if we
observed that two blocks are clear, then the belief state changes to {A on table; B on table; both clear}
• If the observation above is noisy (i.e, we are not completely certain), then the probability distribution just changes so more probability mass is centered on the {A on table; B on Table} state.
A belief state : A is either on B or on Table B is on table. Hand is empty