1 lin 6932 spring 2007 lin6932: topics in computational linguistics hana filip lecture 4: part of...
TRANSCRIPT

1 LIN 6932 Spring 2007
LIN6932: Topics in Computational Linguistics
Hana FilipLecture 4:
Part of Speech Tagging (II) - Introduction to Probability
February 1, 2007

2 LIN 6932 Spring 2007
Outline
Part of speech taggingParts of speechWhat’s POS tagging good for anyhow?Tag sets
2 main types of tagging algorithmsRule-basedStatistical
Important Ideas– Training sets and test sets– Unknown words– Error analysis
Examples of taggers– Rule-based tagging (Karlsson et al 1995) EngCG– Transformation-Based tagging (Brill 1995)– HMM tagging - Stochastic (Probabilitistic) taggers

3 LIN 6932 Spring 2007
3 methods for POS tagging (recap from last lecture)
1. Rule-based taggingExample: Karlsson (1995) EngCG tagger based on the Constraint Grammar architecture and ENGTWOL lexicon– Basic Idea:
Assign all possible tags to words (morphological analyzer used) Remove wrong tags according to set of constraint rules (typically more
than 1000 hand-written constraint rules, but may be machine-learned)2. Transformation-based tagging
Example: Brill (1995) tagger - combination of rule-based and stochastic (probabilistic) tagging methodologies– Basic Idea:
Start with a tagged corpus + dictionary (with most frequent tags) Set the most probable tag for each word as a start value Change tags according to rules of type “if word-1 is a determiner and
word is a verb then change the tag to noun” in a specific order (like rule-based taggers)
machine learning is used—the rules are automatically induced from a previously tagged training corpus (like stochastic approach)
3. Stochastic (=Probabilistic) taggingExample: HMM (Hidden Markov Model) tagging - a training corpus used to compute the probability (frequency) of a given word having a given POS tag in a given context

4 LIN 6932 Spring 2007
Today
ProbabilityConditional ProbabilityIndependenceBayes RuleHMM taggingMarkov ChainsHidden Markov Models

5 LIN 6932 Spring 2007
6. Introduction to Probability
Experiment (trial)Repeatable procedure with well-defined possible outcomes
Sample Space (S)– the set of all possible outcomes – finite or infinite
Example– coin toss experiment– possible outcomes: S = {heads, tails}
Example– die toss experiment– possible outcomes: S = {1,2,3,4,5,6}
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

6 LIN 6932 Spring 2007
Introduction to Probability
Definition of sample space depends on what we are asking
Sample Space (S): the set of all possible outcomesExample– die toss experiment for whether the number is even or odd
– possible outcomes: {even,odd} – not {1,2,3,4,5,6}
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

7 LIN 6932 Spring 2007
More definitions
Eventsan event is any subset of outcomes from the sample space
Exampledie toss experiment let A represent the event such that the outcome of the die toss experiment is divisible by 3A = {3,6} A is a subset of the sample space S= {1,2,3,4,5,6}

8 LIN 6932 Spring 2007
Introduction to Probability
Some definitionsEvents– an event is a subset of sample space– simple and compound events
Example– deck of cards draw experiment – suppose sample space S = {heart,spade,club,diamond} (four
suits)– let A represent the event of drawing a heart– let B represent the event of drawing a red card– A = {heart} (simple event)– B = {heart} u {diamond} = {heart,diamond} (compound event)
a compound event can be expressed as a set union of simple events
Example– alternative sample space S = set of 52 cards– A and B would both be compound events
QuickTime™ and aTIFF (Uncompressed) decompressorare needed to see this picture.
QuickTime™ and aTIFF (Uncompressed) decompressorare needed to see this picture.

9 LIN 6932 Spring 2007
Introduction to Probability
Some definitionsCounting– suppose an operation oi can be performed in ni ways,
– a set of k operations o1o2...ok can be performed in n1 n2 ... nk ways
Example– dice toss experiment, 6 possible outcomes– two dice are thrown at the same time– number of sample points in sample space = 6 6 = 36
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.

10 LIN 6932 Spring 2007
Definition of Probability
The probability law assigns to an event a nonnegative numberCalled P(A)Also called the probability AThat encodes our knowledge or belief about the collective likelihood of all the elements of AProbability law must satisfy certain properties

11 LIN 6932 Spring 2007
Probability Axioms
NonnegativityP(A) >= 0, for every event A
Additivity If A and B are two disjoint events, then the probability of their union satisfies:P(A U B) = P(A) + P(B)
Normalization The probability of the entire sample space S is equal to 1, i.e. P(S) = 1.

12 LIN 6932 Spring 2007
An example
An experiment involving a single coin tossThere are two possible outcomes, H and TSample space S is {H,T}If coin is fair, should assign equal probabilities to 2 outcomesSince they have to sum to 1P({H}) = 0.5P({T}) = 0.5P({H,T}) = P({H})+P({T}) = 1.0

13 LIN 6932 Spring 2007
Another example
Experiment involving 3 coin tossesOutcome is a 3-long string of H or TS ={HHH,HHT,HTH,HTT,THH,THT,TTH,TTT}Assume each outcome is equiprobable
“Uniform distribution”What is probability of the event that exactly 2 heads occur?A = {HHT,HTH,THH} 3 events/outcomesP(A) = P({HHT})+P({HTH})+P({THH}) additivity - union of the probability of the individual events
= 1/8 + 1/8 + 1/8 total 8 events/outcomes
= 3/8

14 LIN 6932 Spring 2007
Probability definitions
In summary:
Probability of drawing a spade from 52 well-shuffled playing cards:

15 LIN 6932 Spring 2007
Moving toward language
What’s the probability of drawing a 2 from a deck of 52 cards with four 2s?
What’s the probability of a random word (from a random dictionary page) being a verb?
€
P(drawing a two) =4
52=
1
13= .077
€
P(drawing a verb) =# of ways to get a verb
all words

16 LIN 6932 Spring 2007
Probability and part of speech tags
• What’s the probability of a random word (from a random dictionary page) being a verb?
• How to compute each of these• All words = just count all the words in the
dictionary• # of ways to get a verb: # of words which are verbs!• If a dictionary has 50,000 entries, and 10,000 are
verbs…. P(V) is 10000/50000 = 1/5 = .20
€
P(drawing a verb) =# of ways to get a verb
all words

17 LIN 6932 Spring 2007
Conditional Probability
A way to reason about the outcome of an experiment based on partial information
In a word guessing game the first letter for the word is a “t”. What is the likelihood that the second letter is an “h”?How likely is it that a person has a disease given that a medical test was negative?A spot shows up on a radar screen. How likely is it that it corresponds to an aircraft?

18 LIN 6932 Spring 2007
More precisely
Given an experiment, a corresponding sample space S, and a probability lawSuppose we know that the outcome is some event BWe want to quantify the likelihood that the outcome also belongs to some other event AWe need a new probability law that gives us the conditional probability of A given BP(A|B)

19 LIN 6932 Spring 2007
An intuition
• Let’s say A is “it’s raining”.• Let’s say P(A) in dry Florida is .01• Let’s say B is “it was sunny ten minutes ago”• P(A|B) means “what is the probability of it
raining now if it was sunny 10 minutes ago”• P(A|B) is probably way less than P(A)• Perhaps P(A|B) is .0001• Intuition: The knowledge about B should change
our estimate of the probability of A.

20 LIN 6932 Spring 2007
QuickTime™ and aTIFF (Uncompressed) decompressor
are needed to see this picture.
S
Conditional Probability
let A and B be events in the sample space P(A|B) = the conditional probability of event A occurring given some fixed event B occurringdefinition: P(A|B) = P(A B) / P(B)

21 LIN 6932 Spring 2007
Conditional probability
P(A|B) = P(A B)/P(B)Or
)(
),()|(
BP
BAPBAP =
A BA,B
Note: P(A,B)=P(A|B) · P(B)Also: P(A,B) = P(B,A)

22 LIN 6932 Spring 2007
Independence
What is P(A,B) if A and B are independent?
P(A,B)=P(A) · P(B) iff A,B independent.
P(heads,tails) = P(heads) · P(tails) = .5 · .5 = .25
Note: P(A|B)=P(A) iff A,B independentAlso: P(B|A)=P(B) iff A,B independent

23 LIN 6932 Spring 2007
Bayes Theorem
)(
)()|()|(
AP
BPBAPABP =
•Idea: The probability of an A conditional on another event B is generally different from the probability of B conditional on A. There is a definite relationship between the two.

24 LIN 6932 Spring 2007
Deriving Bayes Rule
€
P(A | B) =P(A ∩ B)
P(B)
€
P(A | B) =P(A ∩ B)
P(B)
The probability of event A given event B is

25 LIN 6932 Spring 2007
Deriving Bayes Rule
€
P(B | A) =P(A ∩ B)
P(A)
€
P(B | A) =P(A ∩ B)
P(A)
The probability of event B given event A is

26 LIN 6932 Spring 2007
Deriving Bayes Rule
€
P(B | A) =P(A ∩ B)
P(A)
€
P(B | A) =P(A ∩ B)
P(A)
€
P(A | B) =P(A ∩ B)
P(B)
€
P(A | B) =P(A ∩ B)
P(B)
€
P(B | A)P(A) = P(A ∩ B)
€
P(B | A)P(A) = P(A ∩ B)
€
P(A | B)P(B) = P(A ∩ B)
€
P(A | B)P(B) = P(A ∩ B)

27 LIN 6932 Spring 2007
Deriving Bayes Rule
€
P(B | A) =P(A ∩ B)
P(A)
€
P(B | A) =P(A ∩ B)
P(A)
€
P(A | B) =P(A ∩ B)
P(B)
€
P(A | B) =P(A ∩ B)
P(B)
€
P(B | A)P(A) = P(A ∩ B)
€
P(B | A)P(A) = P(A ∩ B)
€
P(A | B)P(B) = P(A ∩ B)
€
P(A | B)P(B) = P(A ∩ B)
€
P(A | B)P(B) = P(B | A)P(A)
€
P(A | B)P(B) = P(B | A)P(A)
€
P(A | B) =P(B | A)P(A)
P(B)
€
P(A | B) =P(B | A)P(A)
P(B)

28 LIN 6932 Spring 2007
Deriving Bayes Rule
€
P(A | B) =P(B | A)P(A)
P(B)
€
P(A | B) =P(B | A)P(A)
P(B)
the theorem may be paraphrased as
conditional/posterior probability = (LIKELIHOOD multiplied by PRIOR) divided by NORMALIZING CONSTANT

29 LIN 6932 Spring 2007
Hidden Markov Model (HMM) Tagging
Using an HMM to do POS taggingHMM is a special case of Bayesian inference
Foundational work in computational linguisticsn-tuple features used for OCR (Optical Character Recognition)W.W. Bledsoe and I. Browning, "Pattern Recognition and Reading by Machine," Proc. Eastern Joint Computer Conf., no. 16, pp. 225-233, Dec. 1959.F. Mosteller and D. Wallace, “Inference and disputed Authorship: The Federalist,” 1964.statistical methods applied to determine the authorship of the Federalist Papers (function words, Alexander Hamilton, James Madison)
It is also related to the “noisy channel” model in ASR (Automatic Speech Recognition)

30 LIN 6932 Spring 2007
POS tagging as a sequence classification task
We are given a sentence (an “observation” or “sequence of observations”)
Secretariat is expected to race tomorrowsequence of n words w1…wn.
What is the best sequence of tags which corresponds to this sequence of observations?Probabilistic/Bayesian view:
Consider all possible sequences of tagsOut of this universe of sequences, choose the tag sequence which is most probable given the observation sequence of n words w1…wn.

31 LIN 6932 Spring 2007
Getting to HMM
Let T = t1,t2,…,tn
Let W = w1,w2,…,wn
Goal: Out of all sequences of tags t1…tn, get the the most probable sequence of POS tags T underlying the observed sequence of words w1,w2,…,wn
Hat ^ means “our estimate of the best = the most probable tag sequence”
Argmaxx f(x) means “the x such that f(x) is maximized” it maximazes our estimate of the best tag sequence

32 LIN 6932 Spring 2007
Getting to HMM
This equation is guaranteed to give us the best tag sequence
But how do we make it operational? How do we compute this value?Intuition of Bayesian classification:
Use Bayes rule to transform it into a set of other probabilities that are easier to computeThomas Bayes: British mathematician (1702-1761)

33 LIN 6932 Spring 2007
Bayes Rule
Breaks down any conditional probability P(x|y) into three other probabilities
P(x|y): The conditional probability of an event x assuming that y has occurred

34 LIN 6932 Spring 2007
Bayes Rule
We can drop the denominator: it does not change for each tag sequence; we are looking for the best tag sequence for the same observation, for the same fixed set of words

35 LIN 6932 Spring 2007
Bayes Rule

36 LIN 6932 Spring 2007
Likelihood and prior
n

37 LIN 6932 Spring 2007
Likelihood and prior Further Simplifications
n
1. the probability of a word appearing depends only on its own POS tag, i.e, independent of other words around it
2. BIGRAM assumption: the probability of a tag appearing depends only on the previous tag
3. The most probable tag sequence estimated by the bigram tagger

38 LIN 6932 Spring 2007
Likelihood and prior Further Simplifications
n
1. the probability of a word appearing depends only on its own POS tag, i.e, independent of other words around it
thekoalaputthekeysonthetable
WORDSTAGS
NVPDET

39 LIN 6932 Spring 2007
Likelihood and prior Further Simplifications
2. BIGRAM assumption: the probability of a tag appearing depends only on the previous tag
Bigrams are groups of two written letters, two syllables, or two words; they are a special case of N-gram.
Bigrams are used as the basis for simple statistical analysis of text
The bigram assumption is related to the first-order Markov assumption

40 LIN 6932 Spring 2007
Likelihood and prior Further Simplifications
3. The most probable tag sequence estimated by the bigram tagger
n
biagram assumption
---------------------------------------------------------------------------------------------------------------

41 LIN 6932 Spring 2007
Two kinds of probabilities (1)
Tag transition probabilities p(ti|ti-1)Determiners likely to precede adjs and nouns– That/DT flight/NN– The/DT yellow/JJ hat/NN– So we expect P(NN|DT) and P(JJ|DT) to be high– But P(DT|JJ) to be:?

42 LIN 6932 Spring 2007
Two kinds of probabilities (1)
Tag transition probabilities p(ti|ti-1)Compute P(NN|DT) by counting in a labeled corpus:
# of times DT is followed by NN

43 LIN 6932 Spring 2007
Two kinds of probabilities (2)
Word likelihood probabilities p(wi|ti)P(is|VBZ) = probability of VBZ (3sg Pres verb) being “is”
Compute P(is|VBZ) by counting in a labeled corpus:
If we were expecting a third person singular verb, how likely is it that
this verb would be is?

44 LIN 6932 Spring 2007
An Example: the verb “race”
Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NRPeople/NNS continue/VB to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NNHow do we pick the right tag?

45 LIN 6932 Spring 2007
Disambiguating “race”
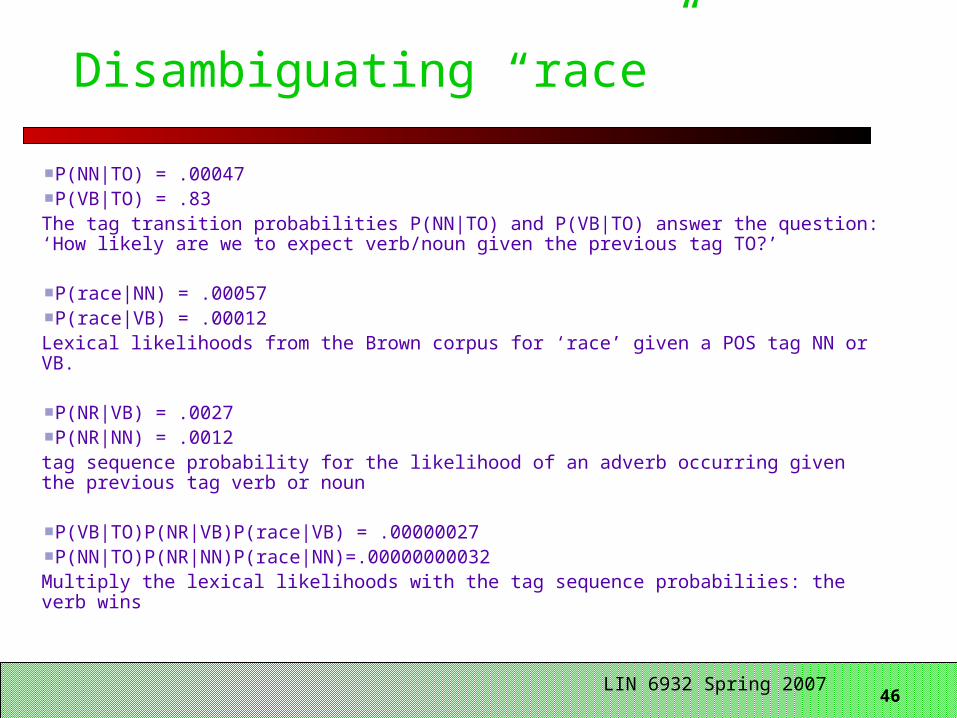
46 LIN 6932 Spring 2007
Disambiguating “race”
P(NN|TO) = .00047P(VB|TO) = .83
The tag transition probabilities P(NN|TO) and P(VB|TO) answer the question: ‘How likely are we to expect verb/noun given the previous tag TO?’
P(race|NN) = .00057P(race|VB) = .00012
Lexical likelihoods from the Brown corpus for ‘race’ given a POS tag NN or VB.
P(NR|VB) = .0027P(NR|NN) = .0012
tag sequence probability for the likelihood of an adverb occurring given the previous tag verb or noun
P(VB|TO)P(NR|VB)P(race|VB) = .00000027P(NN|TO)P(NR|NN)P(race|NN)=.00000000032
Multiply the lexical likelihoods with the tag sequence probabiliies: the verb wins

47 LIN 6932 Spring 2007
Hidden Markov Models
What we’ve described with these two kinds of probabilities is a Hidden Markov Model (HMM)Let’s just spend a bit of time tying this into the modelIn order to define HMM, we will first introduce the Markov Chain, or observable Markov Model.

48 LIN 6932 Spring 2007
Definitions
A weighted finite-state automaton adds probabilities to the arcs
The sum of the probabilities leaving any arc must sum to one
A Markov chain is a special case of a WFST in which the input sequence uniquely determines which states the automaton will go throughMarkov chains can’t represent inherently ambiguous problems
Useful for assigning probabilities to unambiguous sequences

49 LIN 6932 Spring 2007
Markov chain = “First-order observed Markov Model”
a set of states Q = q1, q2…qN; the state at time t is qt
a set of transition probabilities: a set of probabilities A = a01a02…an1…ann.
Each aij represents the probability of transitioning from state i to state jThe set of these is the transition probability matrix A
Distinguished start and end states
Special initial probability vector
i the probability that the MM will start in state i, each i
expresses the probability p(qi|START)
€
aij = P(qt = j | qt−1 = i) 1≤ i, j ≤ N
€
aij =1; 1≤ i ≤ Nj=1
N
∑

50 LIN 6932 Spring 2007
Markov chain = “First-order observed Markov Model”Markov Chain for weather: Example 1three types of weather: sunny, rainy, foggywe want to find the following conditional probabilities:P(qn|qn-1, qn-2, …, q1)
- I.e., the probability of the unknown weather on day n, depending on the (known) weather of the preceding days- We could infer this probability from the relative frequency (the
statistics) of past observations of weather sequencesProblem: the larger n is, the more observations we must collect.
Suppose that n=6, then we have to collect statistics for 3(6-1) =
243 past histories

51 LIN 6932 Spring 2007
Markov chain = “First-order observed Markov Model”Therefore, we make a simplifying assumption, called the (first-order) Markov assumption
for a sequence of observations q1, … qn,
current state only depends on previous state
the joint probability of certain past and current observations

52 LIN 6932 Spring 2007
Markov chain = “First-order observable Markov Model”

53 LIN 6932 Spring 2007
Markov chain = “First-order observed Markov Model”
Given that today the weather is sunny, what's the probability that tomorrow is sunny and the day after is rainy?
Using the Markov assumption and the probabilities in table 1, this translates into:

54 LIN 6932 Spring 2007
The weather figure: specific example
Markov Chain for weather: Example 2

55 LIN 6932 Spring 2007
Markov chain for weather
What is the probability of 4 consecutive rainy days?Sequence is rainy-rainy-rainy-rainyI.e., state sequence is 3-3-3-3P(3,3,3,3) =
1a11a11a11a11 = 0.2 x (0.6)3 = 0.0432

56 LIN 6932 Spring 2007
Hidden Markov Model
For Markov chains, the output symbols are the same as the states.
See sunny weather: we’re in state sunny
But in part-of-speech tagging (and other things)
The output symbols are wordsBut the hidden states are part-of-speech tags
So we need an extension!A Hidden Markov Model is an extension of a Markov chain in which the output symbols are not the same as the states.This means we don’t know which state we are in.

57 LIN 6932 Spring 2007
Markov chain for weather
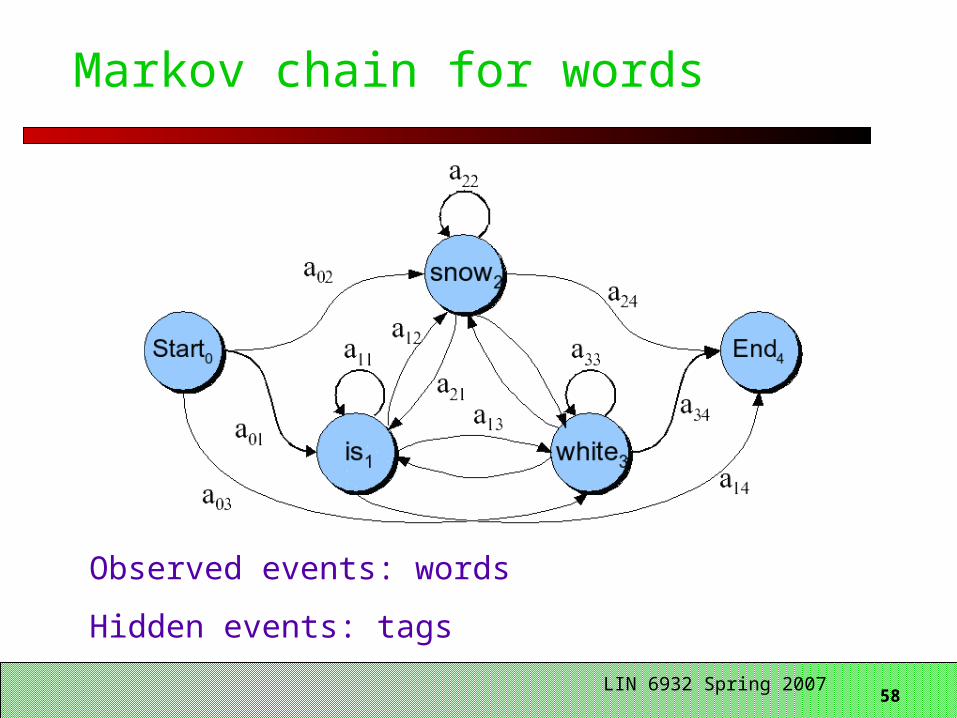
58 LIN 6932 Spring 2007
Markov chain for words
Observed events: words
Hidden events: tags

59 LIN 6932 Spring 2007
States Q = q1, q2…qN; Observations O = o1, o2…oN;
Each observation is a symbol from a vocabulary V = {v1,v2,…vV}
Transition probabilities (prior)
Transition probability matrix A = {aij}
Observation likelihoods (likelihood)
Output probability matrix B={bi(ot)}a set of observation likelihoods, each expressing the probability of an observation ot being generated from a state i, emission probabilities
Special initial probability vector
i the probability that the HMM will start in state i, each i expresses the probability
p(qi|START)
Hidden Markov Models

60 LIN 6932 Spring 2007
Assumptions
Markov assumption: the probability of a particular state depends only on the previous state
Output-independence assumption: the probability of an output observation depends only on the state that produced that observation
€
P(qi | q1...qi−1) = P(qi | qi−1)

61 LIN 6932 Spring 2007
HMM for Ice Cream
You are a climatologist in the year 2799Studying global warmingYou can’t find any records of the weather in Boston, MA for summer of 2007But you find Jason Eisner’s diaryWhich lists how many ice-creams Jason ate every date that summerOur job: figure out how hot it was

62 LIN 6932 Spring 2007
Noam task
GivenIce Cream Observation Sequence: 1,2,3,2,2,2,3…
(cp. with output symbols)
Produce:Weather Sequence: C,C,H,C,C,C,H …
(cp. with hidden states, causing states)

63 LIN 6932 Spring 2007
HMM for ice cream

64 LIN 6932 Spring 2007
Different types of HMM structure
Bakis = left-to-right Ergodic = fully-connected

65 LIN 6932 Spring 2007
HMM Taggers
Two kinds of probabilitiesA transition probabilities (PRIOR) (slide 36)B observation likelihoods (LIKELIHOOD) (slide 36)
HMM Taggers choose the tag sequence which maximizes the product of word likelihood and tag sequence probability

66 LIN 6932 Spring 2007
Weighted FSM corresponding to hidden states of HMM, showing A probs

67 LIN 6932 Spring 2007
B observation likelihoods for POS HMM

68 LIN 6932 Spring 2007
HMM Taggers
The probabilities are trained on hand-labeled training corpora (training set)Combine different N-gram levels Evaluated by comparing their output from a test set to human labels for that test set (Gold Standard)

69 LIN 6932 Spring 2007
Next Time
Minimum Edit DistanceA “dynamic programming” algorithmA probabilistic version of this called “Viterbi” is a key part of the Hidden Markov Model!