各言語の k-means 比較
TRANSCRIPT

各言語の k-means比較2015/06/30
第10回「続・わかりやすいパターン認識」読書会
自己紹介名前◦ 内山雄司
職業◦ エンジニア (プログラマ)
私的なアカウント
◦ Twitter @y__uti
◦ はてなブログ http://y-uti.hatenablog.jp
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 2

今日の発表内容各言語の k-means を比較調査してみました
◦ MATLAB
◦ R
◦ Python
いろいろと違いがありました
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 3

調査対象MATLAB◦ Statistics Toolbox の kmeans関数
R◦ stats パッケージの kmeans関数
Python◦ scikit-learn の KMeansクラス
◦ SciPyの kmeans関数
◦ SciPyの kmeans2 関数
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 4

MATLAB の k-meansStatistics Toolbox (要購入) の kmeans関数
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 5
>> load fisheriris;>> [idx, C, sumd] = kmeans(meas, 3);>> idx'ans =
1 列から 18 列
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 319 列から 36 列
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 337 列から 54 列
3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 1 2
(省略)
127 列から 144 列
2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1145 列から 150 列
1 1 2 1 1 2
>> sum(sumd)ans =
78.8514

R の k-meansstats パッケージ (標準) の kmeans関数
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 6
> km <- kmeans(iris[,1:4], 3)> km$cluster[1] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3[37] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2[73] 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1 1 1 1 2 1[109] 1 1 1 1 1 2 2 1 1 1 1 2 1 2 1 2 1 1 2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1[145] 1 1 2 1 1 2
> km$tot.withinss[1] 78.85144

Python の k-means [1/3]scikit-learn の sklearn.cluster.KMeansクラス
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 7
>>> from sklearn import *>>> iris = datasets.load_iris()>>> kmeans = cluster.KMeans(n_clusters=3)>>> kmeans.fit(iris.data)>>> kmeans.labels_array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 2,1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 1, 2, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1,2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 2], dtype=int32)
>>> km.inertia_78.940841426146164
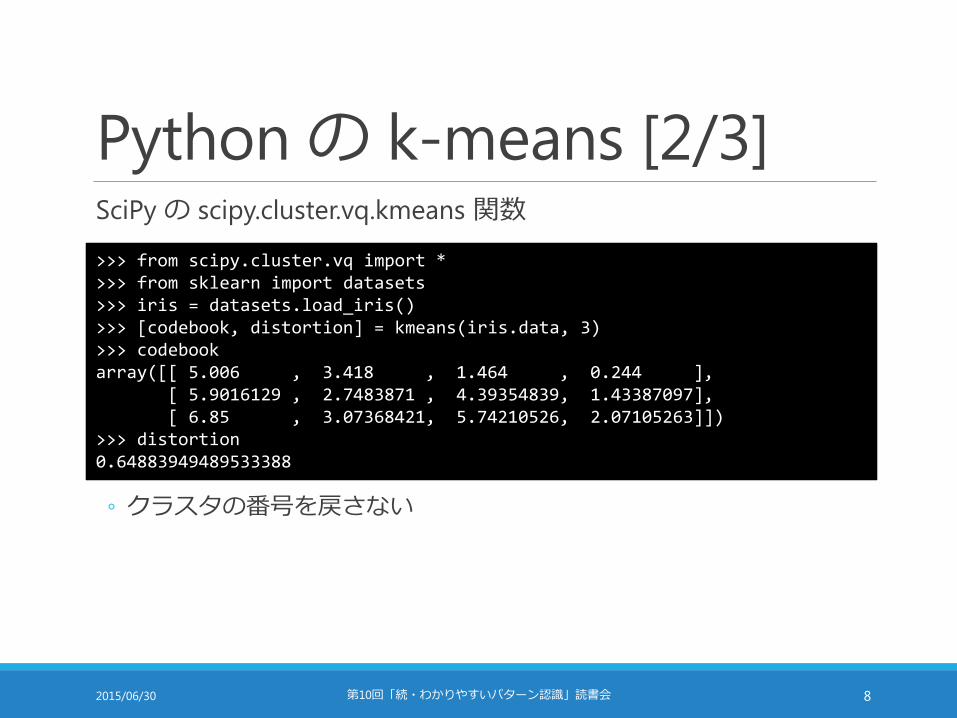
Python の k-means [2/3]SciPyの scipy.cluster.vq.kmeans関数
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 8
>>> from scipy.cluster.vq import *>>> from sklearn import datasets>>> iris = datasets.load_iris()>>> [codebook, distortion] = kmeans(iris.data, 3)>>> codebookarray([[ 5.006 , 3.418 , 1.464 , 0.244 ],
[ 5.9016129 , 2.7483871 , 4.39354839, 1.43387097],[ 6.85 , 3.07368421, 5.74210526, 2.07105263]])
>>> distortion0.64883949489533388
◦ クラスタの番号を戻さない

Python の k-means [3/3]SciPyの scipy.cluster.vq.kmeans2 関数
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 9
>>> from scipy.cluster.vq import *>>> from sklearn import datasets>>> iris = datasets.load_iris()>>> [centroid, label] = kmeans2(iris.data, 3)>>> centroidarray([[ 5.885 , 2.74 , 4.37666667, 1.41833333],
[ 5.006 , 3.418 , 1.464 , 0.244 ],[ 6.8275 , 3.07 , 5.7 , 2.0625 ]])
>>> labelarray([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 2, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 0, 2,2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2,0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0])

比較結果基本的な引数
戻り値
オプション◦ 終了条件・実行回数
◦ セントロイドの初期配置
◦ 反復アルゴリズム
◦ 距離関数
◦ 空クラスタ発生時の挙動
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 10

基本的な引数MATLAB R sklearn SciPy-1 SciPy-2
データ ● ● ● ● ●
クラスタ数 ● ● ○ (8) ● ●
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 11
◦ 記号の意味 (この後のスライドで使う記号を含む)
◦ ● 必須
◦ ◎ 既定の項目
◦ ○ 任意 (かっこ内の値は既定値)
◦ - 該当する設定項目なし

戻り値 [1/2]MATLAB R sklearn SciPy-1 SciPy-2
クラスタラベル ○ ○ ○ - ○
セントロイド ○ ○ ○ ○ ○
距離行列 ○ - - - -
クラスタ内の合計距離 ○ ○ - - -
の全クラスタ総和 - ○ ○ △ (注) -
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 12
◦ 距離行列について◦ SciPy-1 各点からセントロイドへのユークリッド距離の平均を返す
◦ その他 二乗ユークリッド距離を用いる (平方根をとらない)

戻り値 [2/2] (R のみ)R others
各データから全データの重心への距離の総和 (totss) ○ -
セントロイドから全データの重心への距離の重み付け総和 (betweenss)
○ -
各クラスタのデータ数 (size) ○ -
実行された反復回数 (iter) ○ -
エラーコード (ifault) ○ -
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 13

終了条件・実行回数MATLAB R sklearn SciPy-1 SciPy-2
最大反復回数 ○ (100) ○ (10) ○ (300) - ○ (10)
閾値 - - ○ (1e-4) ○ (1e-5) -
k-means 実行回数 ○ (1) ○ (1) ○ (10) ○ (20) -
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 14
◦ 閾値◦ sklearn セントロイドの移動距離の二乗和が閾値未満になれば終了
◦ SciPy-1 セントロイドからの距離の平均減少幅が閾値未満になれば終了

セントロイドの初期配置MATLAB R sklearn SciPy-1 SciPy-2
k-means++ ◎ - ◎ - -
データ点からランダム ○ ◎ ○ ◎ ○
データ範囲から生成 ○ - - - ◎
予備クラスタリング ○ - - - -
ユーザ指定 ○ ○ ○ ○ ○
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 15
◦ データ範囲から生成◦ MATLAB データが存在する範囲の一様分布から
◦ SciPy-2 データの平均と共分散をパラメータとする正規分布から
◦ 予備クラスタリング◦ データの 10% 標本で k-means を実行して決定 (その初期配置はデータ点からランダム)

k-means++セントロイドの初期配置の方法◦ データ点から k 個を選択する
◦ ただし「ランダムに k 個」選ぶのではない
選び方◦ 最初の一つ
◦ データ点の中から等確率で選ぶ
◦ 二番目以降◦ 「最も近いセントロイドとの距離の二乗」に応じた確率で選ぶ
このように選ぶと◦ クラスタ内距離の総和 𝜙 = 𝑥∈𝑋min𝑐∈𝐶 𝑥 − 𝑐 2 について
◦ 期待値が E 𝜙 ≤ 8 log 𝑘 + 2 𝜙opt で押さえられる …らしい
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 16

反復アルゴリズムMATLAB R sklearn SciPy-1 SciPy-2
Lloyd (Forgy) ◎ ○ ◎ ◎ ◎
MacQueen - ○ - - -
Hartigan-Wong - ◎ - - -
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 17
各アルゴリズムの特徴 (一部の論文 + R の実装より)
◦ Lloyd (Forgy)
◦ 各データをクラスタに割り当て。全データの割り当て後にセントロイドを更新
◦ MacQueen
◦ 一つのデータをクラスタに割り当てるたびにセントロイドを更新
◦ Hartigan-Wong
◦ 次のスライドで説明

Hartigan-Wong の方法以下の反復をクラスタ割り当てが変化しなくなるまで繰り返す
For each 𝑥𝑖 ∈ 𝑋◦ 点 𝑥𝑖 を現在のクラスタから外す
◦ クラスタが 𝑥𝑖 ただ一点を含む場合は 𝑥𝑖 の処理をスキップする
◦ 次式を最小にするクラスタ 𝐶𝑘に 𝑥𝑖を割り当てる
Δ 𝑥𝑖 , 𝐶𝑘 =𝑥 ∈ 𝐶𝑘
𝑥 ∈ 𝐶𝑘 + 1∙ 𝑥𝑖 − 𝑐𝑘
2
このように計算すると◦ Hartigan-Wong の局所解は Lloyd の局所解の真部分集合 …らしい
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 18

距離関数 (MATLAB のみ)MATLAB others
二乗ユークリッド距離 ◎ -
マンハッタン距離 ○ -
1 -コサイン類似度 ○ -
1 -標本相関 ○ -
ハミング距離 ÷次元数 ○ -
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 19
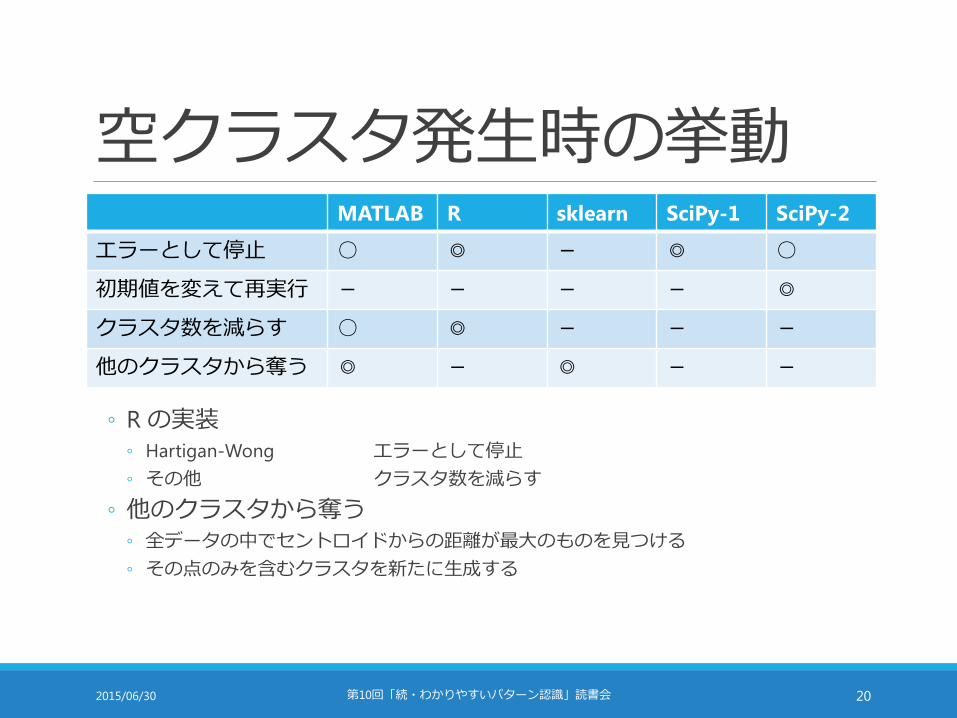
空クラスタ発生時の挙動MATLAB R sklearn SciPy-1 SciPy-2
エラーとして停止 ○ ◎ - ◎ ○
初期値を変えて再実行 - - - - ◎
クラスタ数を減らす ○ ◎ - - -
他のクラスタから奪う ◎ - ◎ - -
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 20
◦ R の実装◦ Hartigan-Wong エラーとして停止
◦ その他 クラスタ数を減らす
◦ 他のクラスタから奪う◦ 全データの中でセントロイドからの距離が最大のものを見つける
◦ その点のみを含むクラスタを新たに生成する

その他細かなオプションはいろいろ・・・◦ オンライン更新 (MATLAB)
◦ 並列計算に関するオプション (MATLAB, scikit-learn)
◦ 計算中の詳細情報の表示 (各言語)
細かいので省略
終わり
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 21

参考 [1/6]MATLAB ドキュメンテーション - Statistics Toolbox
◦ k 平均クラスタリング
◦ http://jp.mathworks.com/help/stats/kmeans.html
◦ 標本データセット
◦ http://jp.mathworks.com/help/stats/_bq9uxn4.html
The R Reference Index (PDF)
◦ http://cran.r-project.org/doc/manuals/r-release/fullrefman.pdf
◦ 0624 ページ "Edgar Anderson's Iris Data"
◦ 1362 ページ "K-Means Clustering"
◦ いずれも Version 3.2.1 (2015-06-18)での情報
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 22

参考 [2/6]scikit-learn
◦ KMeans
◦ http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
◦ The Iris Dataset
◦ http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
SciPy
◦ kmeans
◦ http://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.vq.kmeans.html
◦ kmeans2
◦ http://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.vq.kmeans2.html
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 23

参考 [3/6]Lloyd◦ Lloyd, S. Least squares quantization in PCM. IEEE Transactions on Information Theory 28(2), 129–137, Mar
1982.[https://dx.doi.org/10.1109/TIT.1982.1056489] (有料)
Forgy◦ E.W. Forgy. Cluster analysis of multivariate data: efficiency versus interpretability of classifications.
Biometrics 21: 768–769. 1965. (URL 不明)
MacQueen◦ MacQueen, J. Some methods for classification and analysis of multivariate observations. Proceedings of
the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, 281–297, University of California Press, Berkeley, Calif., 1967. [http://projecteuclid.org/download/pdf_1/euclid.bsmsp/1200512992]
Hartigan-Wong◦ J. A. Hartigan and M. A. Wong. Algorithm AS 136: A K-Means Clustering Algorithm. Journal of the Royal
Statistical Society. Series C (Applied Statistics), Vol. 28, No. 1 (1979), pp. 100-108. [http://www.jstor.org/stable/2346830] (有料)
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 24
参考 [4/6]Hartigan-Wong の方法を説明している論文◦ Noam Slonim, Ehud Aharoni, Koby Crammer. Hartigan’s K-Means Versus Lloyd’s K-Means - Is It Time for a
Change? IJCAI 2013.[http://ijcai.org/papers13/Papers/IJCAI13-249.pdf]
◦ Matus Telgarsky, Andrea Vattani. Hartigan’s Method: k-means Clustering without Voronoi. AISTATS 2010.[http://jmlr.csail.mit.edu/proceedings/papers/v9/telgarsky10a/telgarsky10a.pdf]
k-means++◦ David Arthur and Sergei Vassilvitskii. 2007. k-means++: the advantages of careful seeding. In Proceedings
of the eighteenth annual ACM-SIAM symposium on Discrete algorithms (SODA ‘07). Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 1027-1035.[http://dl.acm.org/citation.cfm?id=1283494] (有料)[http://ilpubs.stanford.edu:8090/778/] (同じタイトルのテクニカルレポート)
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 25

参考 [5/6]特に参考になったウェブ上の情報
◦ k-means return value in R
◦ http://stackoverflow.com/questions/8637460/k-means-return-value-in-r
◦ kmeans関数の 'singleton' オプション
◦ http://d.hatena.ne.jp/nthrn/20081025/1224901102
◦ what’s the implementation of SciKit-Learn K-Means for empty clusters?
◦ http://stats.stackexchange.com/questions/152333/whats-the-implementation-of-scikit-learn-k-means-for-empty-clusters
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 26

参考 [6/6]R のソースコード
◦ http://cran.rstudio.com/src/base/R-3/R-3.2.1.tar.gz
k-means の実装◦ R の関数
◦ R-3.2.1/src/library/stats/R/kmeans.R
◦ アルゴリズムごとに C または FORTRAN の関数が呼ばれる (26-63 行目の switch 文)
2015/06/30 第10回「続・わかりやすいパターン認識」読書会 27
アルゴリズム ファイル 行番号・関数名
Lloyd-Forgy R-3.2.1/src/library/stats/src/kmeans.c 25~ 73 行目 kmeans_Lloyd
MacQueen R-3.2.1/src/library/stats/src/kmeans.c 75~146 行目 kmeans_MacQueen
Hartigan-Wong R-3.2.1/src/library/stats/src/kmns.f (全体)