zastosowanie wybranych metod eksploracji … · keywords: automatic text summarization, natural...
TRANSCRIPT

Politechnika Poznanska
Wydział Informatyki i Zarzadzania
Instytut Informatyki
Praca dyplomowa magisterska
ZASTOSOWANIE WYBRANYCH METOD EKSPLORACJI DANYCH
DO TWORZENIA STRESZCZEN TEKSTÓW PRASOWYCH
DLA JEZYKA POLSKIEGO
inz. Adam Dudczak
Promotor
dr hab. inz. Jerzy Stefanowski
Poznan, 2006–2007

Tutaj przychodzi karta pracy dyplomowej;
oryginał wstawiamy do wersji dla archiwum PP, w pozostałych kopiach wstawiamy ksero.

Streszczenie
Głównym celem tej pracy było stworzenie narzedzia pozwalajacego na generowanie
dobrych jakosciowo automatycznych streszczen dla tekstów prasowych napisanych w je-
zyku polskim i tym samym zweryfikowanie skutecznosci dotychczasowych podejsc lite-
raturowych stosowanych dla tekstów angielskich.
Wszystkie zbadane metody tworza automatyczne streszczenia w oparciu o selekcje
zadanej liczby zdan. W ramach pracy zbadane zostały cztery algorytmy:
• opierajacy sie na załozeniu, ze istotnosc zdania zalezy od jego pozycji w akapicie,
• wykorzystujacy schematy tf-idf i okapi bm25 do obliczania istotnosci zdan
• oraz algorytm oparty na łancuchach leksykalnych [BE97].
Przedstawione sa równiez wyniki eksperymentu weryfikujacego jakosc otrzymanych wy-
ników na korpusie streszczen utworzonym przez wolontariuszy przy pomocy oprogra-
mowania napisanego przez autora pracy.
W ramach implementacji omawianych w pracy zagadnien powstał projekt Lakon. Za-
implementowane w Lakonie metody osiagaja srednio wyniki w zakresie od 42% do 53%
zgodnosci (w zaleznosci od algorytmu) ze zbiorem najczesciej wybieranych zdan, stwo-
rzonym przez grupe uczestników eksperymentu.
Słowa kluczowe: automatyczna sumaryzacja tekstów, przetwarzanie jezyka natural-
nego, eksploracja danych
Abstract
The main purpose of this thesis was to create a tool for generating qualitatively good
text extracts from newspapers articles written in Polish. It was also important to verify
whether existing approaches to automatic text summarization, developed for texts writ-
ten in English are suitable for language with complex inflection and syntax such as Polish.
All investigated methods create extracts by selecting given number of sentences from
original text. The research had been preceded with analysis of four algorithms:
• based on assumption that essentiality of sentence depends on its position in para-
graph,
• using tf-idf and okapi bm25 schemes to compute sentence’s weight,
• algorithm based on idea of lexical chains [BE97].
Formal evaluation has been performed, based on set of extracts created by the group of
volunteers with usage of web application written by the author of this thesis.
Implementation of thesis purposes can be found in Lakon project. Methods imple-
mented in Lakon have reached the average 42% to 53% (in dependence to analysed me-
thod) of coverage with the set of most frequently chose sentences (those numbers comes
from corpora created by volunteers).
Keywords: automatic text summarization, natural language processing, data mining,
text mining

Spis tresci
1 Wprowadzenie 1
1.1 Omówienie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Cele i załozenia pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Zarys pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Konwencje typograficzne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Przeglad istniejacych technik i algorytmów 6
2.1 Elementy przetwarzania jezyka naturalnego . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Analiza leksykalna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2 Rozpoznawanie wyrazów pospolitych . . . . . . . . . . . . . . . . . . . . 9
2.1.3 Analiza morfologiczna, lematyzacja i hasłowanie . . . . . . . . . . . . . . 9
2.1.4 Analiza składniowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Wybrane zagadanienia dotyczace wyszukiwania informacji . . . . . . . . . . . . 12
2.2.1 Budowanie indeksu dokumentów . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.2 Model wektorowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Automatyczne streszczanie dokumentów . . . . . . . . . . . . . . . . . . . . . . . 19
2.3.1 Metody statystyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3.2 Spójnosc leksykalna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3.3 Łancuchy leksykalne a streszczanie tekstów . . . . . . . . . . . . . . . . . 24
2.3.4 System Polsumm2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3 Zastosowane rozwiazania 26
3.1 Przetwarzanie jezyka naturalnego dla potrzeb sumaryzacji . . . . . . . . . . . . 26
3.1.1 Rozpoznawanie struktury tekstu . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 Sumaryzacja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.1 Metoda wykorzystujaca informacje o połozeniu zdan . . . . . . . . . . . 28
3.2.2 Metody wykorzystujace automatyczna ocene jakosci słów kluczowych . 29
3.2.3 Metody wykorzystujace łancuchy leksykalne . . . . . . . . . . . . . . . . 31
3.3 Wyszukiwanie dokumentów podobnych . . . . . . . . . . . . . . . . . . . . . . . 36
4 Implementacja 37
4.1 Lakon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.1.1 Załozenia projektowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
I

II
4.1.2 Główne składniki projektu . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.1.3 Technologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2 Tiller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2.1 Architektura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2.2 Model struktury tekstu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2.3 Przetwarzanie tekstu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.2.4 Tezaurus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2.5 Konfiguracja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3 Summarizer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3.1 Architektura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3.2 Zaimplementowane metody . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3.3 Konfiguracja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.4 GUI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.4.1 Funkcjonalnosc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.4.2 Konfiguracja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.5 Dodatkowe elementy stworzonego systemu . . . . . . . . . . . . . . . . . . . . . 55
4.5.1 Budowanie indeksu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5.2 Aplikacja do zbierania streszczen . . . . . . . . . . . . . . . . . . . . . . . 56
5 Ocena eksperymentalna 59
5.1 Opis eksperymentu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.1 Przyjete załozenia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.2 Przebieg eksperymentu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.1.3 Zebrane dane . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.2 Ocena jakosci . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.2.1 Przyjete załozenia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.2.2 Dobór minimalnych wartosci wag . . . . . . . . . . . . . . . . . . . . . . 66
5.2.3 Otrzymane wyniki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2.4 Efektywnosc implementacji . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6 Wnioski koncowe 72
6.1 Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.2 Kierunki dalszego rozwoju . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.2.1 Podziekowania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Literatura 77
Zasoby internetowe 80
Dodatki 82

Rozdział 1
Wprowadzenie
Internet zrewolucjonizował swiat oferujac kazdemu narzedzia pozwalajace na tworzenia
własnych i przetwarzanie juz istniejacych zasobów informacyjnych. W rezultacie tej rewolu-
cji ilosc danych z jaka musi sie zmierzyc uzytkownik internetu rosnie bardzo szybko. W 2003
szacowono, ze Google umozliwia wyszukiwanie w kolekcji zawierajacej 3,3 miliarda doku-
mentów [Sul03]. Po dwóch latach wartosc ta zwiekszyła sie do 8,1 miliarda [Sul05], a roz-
miar całego „przeszukiwalnego” internetu oceniano na 11,5 miliarda dokumentów [GS05].
Aby znalezc to, czego potrzebujemy, kazdy z nas musi codziennie stawic czoło ogromnej
ilosci informacji. W tym kontekscie stworzenie efektywnych narzedzi ułatwiajacych wybór
istotnych dokumentów staje sie kwestia niezmiernie wazna. Problem ten to z jednej strony
dobre jakosciowo wyniki wyszukiwania, z drugiej natomiast ułatwienie podjecia decyzji co
do adekwatnosci danego wyniku. Automatycznie generowane, sensowne streszczenia doku-
mentów moga znacznie przyspieszyc podjecie takiej decyzji.
Niniejsza praca zawiera przeglad problemów zwiazanych z automatycznym tworzeniem
streszczen dla tekstów w jezyku polskim. Przedstawione sa równiez wyniki eksperymentu
weryfikujacego jakosc otrzymanych wyników na korpusie streszczen utworzonym przez wo-
lontariuszy przy pomocy oprogramowania napisanego przez autora pracy.
1.1 Omówienie
Automatyczne streszczanie tekstów (ang. Automatic Text Summarization (TS)), zwane
zargonowo równiez sumaryzacja nie jest problemem nowym. Pierwsze prace w tej dzie-
dzinie zostały opublikowane juz pod koniec lat piecdziesiatych XX wieku [Luh58]. Ogra-
niczona moc ówczesnych komputerów nie pozwoliła na implementacje rozwiazan dokład-
nych, stworzono wiec proste metody wykorzystujace statystyczne cechy tekstu. Mimo, iz do-
stepna obecnie moc obliczeniowa wielokrotnie przewyzsza mozliwosci stosowanych wtedy
maszyn, koszt przeprowadzenia precyzyjnej komputerowej analizy jezyka naturalnego jest
wciaz relatywnie wysoki, zwłaszcza w rozwiazaniach wymagajacych przetwarzania w czasie
rzeczywistym. Proste algorytmy oparte na statystycznej analizie tekstu sa wiec wciaz popu-
larne i szeroko stosowane.
1

1.1. Omówienie 2
RYSUNEK 1.1: Ogólny schemat procesu tworzenia streszczen.
Streszczenie to „tresc czegos, ujeta krótko, zwiezle” [PWN07]. W ramach tej bardzo ogól-
nej definicji mozemy wyróznic dwa rodzaje streszczen.
Streszczenia literackie (ang. summary) – twórca wybiera z oryginalnego tekstu najwazniej-
sze informacje, a nastepnie tworzy zupełnie nowa, spójna wypowiedz.
Streszczenia automatyczne (ang. extract) – twórca (lub program) stara sie ocenic, które zda-
nia (lub akapity) niosa najistotniejsze informacje, nastepnie z tak wyselekcjonowa-
nych zdan „składa” wynikowe streszczenie. W tym przypadku nie tworzymy nowej wy-
powiedzi. W powstałym streszczeniu zwiazki logiczne miedzy zdaniami moga zostac
zaburzone – utrudnia to zrozumienie tekstu i w skrajnym przypadku moze prowadzic
do zmiany jego pierwotnego sensu.
Tworzenie streszczen literackich ciezko sobie wyobrazic bez pełnego zrozumienia tekstu,
stad tez automatyczne generowanie tego typu wypowiedzi jest problemem trudnym. Stresz-
czenia automatyczne jednak, mimo swoich wad, moga okazac sie niezbedne, gdy przetwa-
rzana jest ogromna ilosc danych. We wczesniejszych pracach pokazano, ze takie streszczenia
(składajace sie z zaledwie 20% pierwotnego tekstu) moga zawierac tyle samo wiadomosci, co
tekst oryginalny [KPC95]. Taka kompresja informacji moze znacznie skrócic czas konieczny
na podjecie decyzji o istotnosci danego dokumentu.
Według [Jon93] oraz [BE97] proces tworzenia automatycznego streszczenia mozna po-
dzielic na nastepujace etapy (zob. rys. 1.1):
1. tworzenie reprezentacji posredniej tekstu zródłowego,
2. wybór najwazniejszych informacji z reprezentacji posredniej,
3. synteza wynikowego streszczenia.
Powyzszy proces moze byc realizowany przy pomocy róznych algorytmów komputero-
wych. Stosowane metody mozna podzielic na trzy grupy:
• metody statystyczne (oparte zwykle o statystyki czestosci wystepowania słów lub cech
w oryginalnym tekscie),

1.1. Omówienie 3
• metody pogłebione (korzystajace z dodatkowej wiedzy – tezaurusa lub słowników po-
jec),
• metody korzystajace z głebokiej analizy tekstu (pełnego rozkładu składniowego).
Metody statystyczne (w tym kontekscie zwane równiez heurystykami, choc nalezy za-
znaczyc, ze jest to pojecie znacznie szersze) nie analizuja bezposrednio znaczenia słów, czy
tez zdan. O tym, czy dany fragment tekstu zawiera wazna informacje decyduje zestaw okre-
slonych czynników [Luh58, Edm69].
Czestosc wystepowania wyrazów w tekscie Słowa które wystepuja czesto moga byc potrak-
towane jako wyznacznik tresci dokumentu. W tym przypadku zdanie które zawiera
najczesciej wystepujace wyrazy uwaza sie za istotne.
Pozycja zdania w tekscie Jezeli zdanie znajduje sie na poczatku (lub koncu) tekstu (czy aka-
pitu) istnieje szansa, ze bedzie ono miało charakter podsumowujacy.
Obecnosc pewnych zwrotów Zwroty takie jak „w sumie” albo „podsumowujac” sugeruja, ze
zdanie zawiera jakiegos rodzaju podsumowanie.
Miary oceny waznosci słów Istnieja miary pozwalajace obliczac istotnosc (zawartosc infor-
macji) poszczególnych słów dla tekstu (szczegółowe omówienie niektórych z nich zo-
stanie przedstawione w dalszych rozdziałach).
Inne czynniki Inne czynniki brane pod uwage to na przykład: długosc zdania, obecnosc
w zdaniu wyrazów z tytułu lub rozpoczynajacych sie od wielkiej litery.
Mozna zauwazyc, ze dla niektórych rodzajów tekstów, przykładowo artykułów praso-
wych, jedna z najlepszych i najprostszych heurystyk jest wybór pierwszych dziesieciu zdan
z tekstu. W wielu przypadkach uzyskana w ten sposób informacja moze sie okazac wystar-
czajaca.
Rozwiazania, które opieraja sie na metodach statystycznych sa z definicji ograniczone
[Mau89]. Brak analizy znaczenia tekstu powoduje, ze sa one bezradne wobec pewnych zja-
wisk jezykowych takich jak synonimia czy homonimia. Sytuacje te wymagaja rozpatrzenia
kontekstu, w jakim dany fragment tekstu (np. słowo) wystepuje. Przeprowadzenie takiej ana-
lizy jedynie w oparciu o metody analizy wystapien jest raczej trudne (jezeli nie niemozliwe),
konieczne jest wiec dostarczenie dodatkowej wiedzy z zewnatrz. Metody pogłebione wy-
korzystuja własnie takie „zewnetrzne” zródła wiedzy w postaci tezaurusów i innych zaso-
bów leksykalnych. Dzieki temu sa one w stanie uwzglednic informacje zawarte w warstwie
semantycznej (znaczeniowej) dokumentu, zachowujac przy tym wzgledna prostote metod
heurystycznych.
Wymienione powyzej metody buduja streszczenia wybierajac gotowe zdania z pierwot-
nego dokumentu. Problem braku spójnosci takiej wypowiedzi wynika miedzy innymi z ist-
nienia w tekscie zwiazków miedzyzdaniowych. Jezeli w zdaniu wystepuje podmiot domyslny
(na przykład „. . . został on wybrany. . . ”), wybór tego zdania do streszczenia spowoduje nie

1.2. Cele i załozenia pracy 4
tylko utrate pewnej informacji (nie wiemy do kogo odnosi sie zaimek „on”), ale równiez
obnizenie czytelnosci wynikowego streszczenia. Aby rozwiazac ten problem konieczna jest
pełna analiza tekstu, uwzgledniajaca kompletny model struktury składniowej (dla jezyka an-
gielskiego znane sa równiez inne, przyblizone metody, lecz nie bedziemy sie nimi tutaj zaj-
mowali). Dysponujac taka informacja mozna przeprowadzic analize warstwy semantycz-
nej i opierajac sie na stworzonym w ten sposób modelu wygenerowac streszczenie literac-
kie [Lie98]. Wymagania obliczeniowe takich algorytmów sa zwykle dosc wysokie.
1.2 Cele i załozenia pracy
Istnieje duza liczba opracowan dotyczacych problemu automatycznej sumaryzacji dla
tekstów w jezyku angielskim, lecz niewiele w tym wzgledzie zrobiono dotychczas dla jezyka
polskiego. Głównym celem tej pracy jest stworzenie narzedzia pozwalajacego na genero-
wanie dobrych jakosciowo automatycznych streszczen dla tekstów prasowych napisanych
w jezyku polskim oraz zweryfikowanie dotychczasowych podejsc literaturowych stosowa-
nych dla jezyka angielskiego.
Ze wzgledu na duze koszty obliczeniowe zwiazane z głeboka analiza tekstu, w niniej-
szej pracy najwiekszy nacisk zostanie połozony na metody statystyczne oraz pewne aspekty
metod pogłebionych. W ramach pracy zostana zaimplementowane trzy algorytmy tworzace
automatyczne streszczania.
Aby umozliwic rzetelna analize wyników przeprowadzony został eksperyment, w cza-
sie którego grupa ochotników stworzyła referencyjny zbiór streszczen artykułów prasowych
(wybór tego rodzaju tekstów jest motywowany ich dobrze okreslona struktura). W pracy
przedstawione sa wyniki oceny jakosci streszczen otrzymanych w sposób automatyczny w po-
równaniu ze streszczeniami utworzonymi recznie.
Dodatkowym aspektem pracy, obok tworzenia streszczen tekstów prasowych, jest rów-
niez metoda pozwalajaca na wyszukiwanie tekstów podobnych. Rozwiazanie owo opiera sie
na ekstrakcji słów kluczowych z uzyciem rankingu wag. Metoda ta została stworzona z mysla
o wyborze najwazniejszych zdan, jednak z dobrymi rezultatami moze byc uzyta do pozyski-
wania tekstów o zblizonej zawartosci.
Podsumowujac, najwazniejsze cele tej pracy przedstawiono w punktach ponizej.
1. Stworzenie narzedzia pozwalajacego na segmentacje tekstów w jezyku polskim, wy-
krywanie granic zdan i akapitów.
2. Implementacja i ocena jakosci niektórych metod wyboru najwazniejszych zdan. Roz-
wazane beda nastepujace metody:
• pozycyjna – waga zdania zalezy od jego pozycji w akapicie,
• oparta o ranking wag tf-idf i okapi bm25 dla poszczególnych wyrazów,
• oparta o łancuchy leksykalne [BE97] z uzyciem tezaurusa autorstwa Marcina Mił-
kowskiego.

1.3. Zarys pracy 5
3. Zaprojektowanie i implementacja metody pozwalajacej na wyszukiwanie tekstów po-
dobnych.
4. Ocena jakosci streszczen automatycznych na podstawie danych zebranych w trakcie
eksperymentu, w którym zebrano streszczenia tych samych tekstów od uzytkowników.
1.3 Zarys pracy
Oprócz rozdziału pierwszego na niniejsza prace składa sie piec rozdziałów. W rozdziale
drugim omówione zostały podstawowe zagadnienia zwiazane z przetwarzaniem jezyka na-
turalnego (ang. Natural Language Processing) oraz wyszukiwaniem informacji (ang. Infor-
mation Retrieval). Te dwie bardzo szerokie dziedziny dostarczaja pojec i narzedzi, które leza
u podstaw automatycznej sumaryzacji tekstów. W dalszej czesci rozdziału zostana przedsta-
wione niektóre z opisywanych w literaturze algorytmów tworzenia automatycznych stresz-
czen. Rozdział drugi konczy krótkie omówienienie systemu Polsumm, który jest jak dotad
jedyna próba rozwiazania problemu automatycznej sumaryzacji dla tekstów w jezyku pol-
skim.
Szczegółowy opis zastosowanych w pracy rozwiazan znajdzie Czytelnik w rozdziale trze-
cim. Omówione zostały tam wszystkie zaimplementowane algorytmy, wraz z modyfika-
cjami, które zostały wprowadzone w stosunku do oryginalnych metod. Przedstawiono tu
równiez liczne przykłady działania zastosowanych algorytmów oraz zasygnalizowane zostały
najistotniejsze trudnosci zwiazane z realizacja postawionych w pracy celów.
Rozdział czwarty to opis projektu Lakon, który jest bezposrednia realizacja zadan posta-
wionych w ramach niniejszej pracy. Omówiona została architektura całego systemu, zało-
zenia projektowe oraz poszczególne moduły i ich zadania. Rozdział konczy opis aplikacji
internetowej uzytej do realizacji eksperymentu ewaluacyjnego.
Przedostatni rozdział to szczegółowy opis przeprowadzonego eksperymentu, informacje
na temat jego przebiegu, uczestników oraz zebranych danych. W rozdziale piatym omó-
wione zostały równiez załozenia dotyczace przeprowadzonej oceny jakosci oraz jej wyniki
dla zaimplementowanych algorytmów.
W rozdziale szóstym znajdzie Czytelnik podsumowanie pracy oraz dalsze plany rozwoju
systemu Lakon.
Do pracy dołaczona jest płyta CD, opis jej zawartosci znajduje sie w na stronie 84). Przy-
kładowe streszczenia stworzone za pomoca zaimplementowanych metod załaczono na stro-
nie 82.
1.4 Konwencje typograficzne
W niniejszej pracy zastosowano nastepujace konwencje dotyczace składu tekstu. kur-
sywa zaznaczono oryginalna terminologie angielska, przykłady, cytaty. Czcionka o stałej
szerokości ilustruje fragmenty kodu zrodłowego. Czcionka pogrubiona zaznaczono wazne
terminy wystepujace po raz pierwszy w tekscie.

Rozdział 2
Przeglad istniejacych technik
i algorytmów
W tym rozdziale omówione zostana pewne elementy przetwarzania jezyka naturalnego
(ang. Natural Language Processing) oraz wyszukiwania informacji (ang. Information Retrie-
val). Dziedziny te dostarczaja pojec i narzedzi, które leza u podstaw problemu automa-
tycznej sumaryzacji tekstów. Przedstawione równiez zostana istniejace podejscia do auto-
matycznego tworzenia streszczen. Wiekszosc z nich była z powodzeniem stosowana dla je-
zyka angielskiego, w niniejszym rozdziale zostana zasugerowane pewne zagadnienia zwia-
zane z adaptacja tych metod dla jezyka polskiego. Przedstawione tutaj informacje nie wy-
czerpuja tematu – pogłebiony opis omawianych zagadnien mozna znalezc w nastepujacych
pracach [BYRN99, DJHS, CGKS04, KPC95, BE97].
[
W pozostałej czesci rozdziału stosowana bedzie przedstawiona ponizej terminologia.
Leksem to wyraz rozumiany jako podstawowa słownikowa jednostka jezyka. Składa sie na
niego znaczenie leksykalne oraz zespół wszystkich form gramatycznych np. wyrazy
„czytac”, „czytam”, „czytali” sa formami tego samego leksemu [Wik07c].
Lemat lub forma podstawowa jest kanoniczna forma leksemu, która uzywana jest do jego
reprezentacji, np. w słowniku lub indeksie dokumentów [Wik07d].
Słowo kluczowe to sekwencja znaków pojawiajaca sie w indeksie dokumentów i charak-
terystyczna dla któregos z nich; w zasadzie moga one nie miec słownikowego sensu
(np. składac sie z symboli, lub byc zlepkami alfanumerycznymi).
Hipernim terminu tego bedziemy uzywac w stosunku do wyrazów okreslajacych dany obiekt
w sposób bardziej ogólny np. budowla jest hipernimem słowa zamek [Wik07a].
Hiponim to wyraz który odnosi sie tylko do pewnego podzbióru obiektów danego rodzaju
np. zamek to hiponim słowa budowla [Wik07b].
6

2.1. Elementy przetwarzania jezyka naturalnego 7
RYSUNEK 2.1: Schemat procesu automatycznego przetwarzania tekstów.
2.1 Elementy przetwarzania jezyka naturalnego
Przetwarzanie jezyka naturalnego to bardzo szeroka dziedzina. Jest ona fundamentalna
dla komunikacji miedzy człowiekiem a maszyna. Jezyk odwzorowuje pewne rzeczywiste za-
leznosci miedzy przedmiotami czy zjawiskami, maszyna jednak nie posiada wiedzy, która
pozwoliłaby na jednoznaczna interpretacje tych relacji. Powoduje to, ze umiejetnosci, które
kazdy z nas nabywa w pierwszych latach edukacji (czytanie ze zrozumieniem, samodzielne
budowanie zdan) sa dla komputerów wciaz ogromnym wyzwaniem. Inne problemy to dy-
namiczny charakter jezyka (neologizmy, poprawnosc jezykowa) oraz mnogosc konstrukcji
składniowych – wszystko to powoduje, ze operacje zwiazane z przetwarzaniem jezyka natu-
ralnego sa zwykle kosztowne obliczeniowo.
Automatyczne przetwarzanie tekstu mozemy podzielic na kilka etapów [BYRN99]:
1. analiza leksykalna,
2. oznaczanie wyrazów pospolitych,
3. analiza morfologiczna, lematyzacja i hasłowanie,
4. analiza syntaktyczna i semantyczna.
Cały opisany powyzej proces mozna równiez nazwac analiza lingwistyczna [CGKS04] –
szkic owej analizy przedstawia rysunek 2.1.
Celem analizy lingwistycznej jest zbudowanie modelu jezyka naturalnego łatwego w prze-
twarzaniu dla komputera. Przy tworzeniu takiej reprezentacji tracimy przewaznie pewne
informacje. Rozwazmy nastepujacy przykład:
Wlazł kotek na płotek i mruga, ładna to piosenka niedługa.
Jezeli wyraz „kotek” zostałby uzyty zupełnie niezaleznie, to nie mielibysmy problemów
z okresleniem do czego sie on odnosi. Zupełnie inaczej jest w przypadku wyrazów takich
jak : „i”, „na”, „to” - samodzielnie nie posiadaja one zadnego znaczenia. Gdy usuniemy te
wyrazy otrzymamy nastepujace wypowiedzenie.

2.1. Elementy przetwarzania jezyka naturalnego 8
Wlazł kotek płotek mruga, ładna piosenka niedługa.
Komunikat nie jest juz tak czytelny, ale mimo usuniecia czesci wyrazów wciaz wiadomo
czego powyzsza wypowiedz dotyczy. Słowa, które wystepuja w tekscie bardzo czesto i jed-
noczesnie nie niosa ze soba samodzielnego znaczenia nazywac bedziemy wyrazami pospo-
litymi (ang. stopwords). W kontekscie automatycznego przetwarzania jezyka naturalnego
wazne jest, aby móc odróznic czy dany wyraz jest pospolity, czy tez nie, oraz jaka jest jego
rola w strukturze całej wypowiedzi.
W przypadku, gdy w tekscie wystepuja rózne odmiany fleksyjne wyrazu, konieczne jest
odnalezienie ich formy podstawowej (leksemu i jego reprezentacji w formie lematu). Po-
zwoli to okreslic czy dane słowo jest tylko odmiana tego samego leksemu, czy juz zupełnie
innym pojeciem.
„Ziarnko do ziarnka, a zbierze sie miarka.”
Proste porównanie łancuchów znakowych nie wykaze, ze słowo „ziarnko” i „ziarnka”
to ten sam leksem. Dopiero, gdy okreslimy forme podstawowa kazdego z tych wyrazów
(„ziarnko”) komputer bedzie w stanie okreslic, ze jest to ten sam leksem.
Automatyczne przetwarzanie tekstu czesto jest tylko pierwszym etapem działania własci-
wego algorytmu. Realizujac proces przetwarzania tekstu musimy miec na uwadze jakie in-
formacje jezykowe sa konieczne w kontekscie stosowanej metody. Dla prostych metod cze-
stosciowych wazne jest przede wszystkim wydzielenie wspólnego mianownika dla wszyst-
kich form fleksyjnych danego wyrazu – aby móc obliczyc ile razy wystepuje on w tekscie.
W typowych zastosowaniach zwiazanych z wyszukiwaniem informacji zwykle mozna zu-
pełnie zignorowac strukture przetwarzanego tekstu. Informacja o granicach akapitów, czy
zdan jest jednak niezbedna np. w przypadku automatycznego generowania streszczen.
2.1.1 Analiza leksykalna
Analiza leksykalna to proces przekształcania ciagu znaków w ciag wyrazów lub jednostek
wyzszego rzedu: fraz, zdan, akapitów. W najprostszej postaci proces ten sprowadza sie do
rozpoznania (usuniecia nadmiarowych) przerw miedzy wyrazami. Mimo, iz implementacja
takich operacji wydaje sie trywialna, to na etapie rozpoznawania poszczególnych leksemów
pojawia sie kilka problemów [Fox92]:
• identyfikacja leksemów wielowyrazowych,
• znaki takie jak kropka i myslnik,
• liczby,
• wielkosc liter,
• elementy pozatekstowe, np. znaczniki w dokumentach HTML.

2.1. Elementy przetwarzania jezyka naturalnego 9
Istotne dla dalszego procesu przetwarzania moze byc to, jak potraktujemy myslniki ła-
czace wyrazy np. niebiesko-czarni. Kazdy z tych wyrazów ma sens rozpatrywany oddzielnie,
ale gdy konstrukcja ta zostanie rozdzielona utracimy pierwotne znaczenie całego leksemu.
Znak kropki moze takze wystepowac w róznym znaczeniu – jako zakonczenie zdania, na
koncu skrótowców typu „inz.” lub w jeszcze bardziej specyficznych kontekstach jak kon-
strukcje z jezyków programowania: „x.id”. Usuniecie kropki ze strumienia znaków spowo-
duje wiec utrate informacji o podziale tekstu na zdania.
Leksemy rozpoczynajace sie od wielkiej litery moga sugerowac, ze jest to nazwa własna
lub poczatek zdania. Analogicznie jak w przypadku kropki, gdy chcemy zachowac informa-
cje dotyczace struktury tekstu konieczne jest uwzglednienie wielkosci liter przy przetwarza-
niu.
W przypadku dokumentów HTML trzeba w wiekszosci przypadków usunac znaczniki,
gdyz nie sa one nosnikiem tresci, a jedynie elementem warstwy prezentacji.1
Mozemy równiez pokusic sie o pominiecie liczb, poniewaz samodzielnie nie posiadaja
one w wiekszosci konkretnego znaczenia. Jest to istotne zwłaszcza w procesie budowania
indeksu dokumentów, gdzie wyrazy powinny miec jednoznaczna interpretacje (zob. rozdział
2.2). Takie podejscie jest natomiast niedopuszczalne z perspektywy automatycznej sumary-
zacji. Obecnosc liczb, wielkosc liter, pozycja kropki moga byc istotne w zaleznosci od uzy-
tego algorytmu streszczania. Jak widac konieczne jest rozpatrywanie tego etapu procesu
przetwarzania w kontekscie pózniejszych zastosowan otrzymanej reprezentacji posredniej.
2.1.2 Rozpoznawanie wyrazów pospolitych
W kazdej kolekcji dokumentów spotkac mozna wyrazy, które pojawiaja sie o wiele cze-
sciej, niz pozostałe. Takie słowa sa raczej nieprzydatne w kontekscie wydobywania doku-
mentu z kolekcji. Wyrazy takie okresla sie mianem wyrazów pospolitych.
Do wyobrebniania (oznaczania) słów pospolitych korzysta sie ze słowników frekwencyj-
nych2. W internecie dostepnych jest wiele list zawierajacych najczesciej wystepujace wyrazy
pospolite dla jezyka angielskiego. Dla jezyka polskiego został równiez stworzony słownik
frekwencyjny na którego podstawie mozna stworzyc taka liste [Kur90]. Niezaleznie istnieje
równiez lista publikowana i utrzymywana przez polska społecznosc Wikipedystów [Wik07e].
Zostały równiez zaproponowane metody automatyczne, pozwalajace na tworzenie list wy-
razów pospolitych na podstawie duzych korpusów tekstu. Wiecej informacji na temat tych
metod znajdzie Czytelnik w pracach [MW00, Wei01].
2.1.3 Analiza morfologiczna, lematyzacja i hasłowanie
W przypadku jezyków o bogatej fleksji wyraz moze wystepowac w wielu formach. Pro-
ces odnajdywania formy podstawowej – lematu (jednego badz kilku, w przypadku wyrazów
1Niektóre znaczniki HTML moga byc uzywane do okreslania struktury tekstu. W zaleznosci od potrzeb znacz-niki te moga równiez zostac usuniete lub zastapione odpowiednikami tekstowymi (znak spacji lub nowej linii).
2Słownik taki zawiera informacje o czestosci wystepowania wyrazów. Czestosc obliczana jest ona na podstawieanalizy duzej liczby tekstów.

2.1. Elementy przetwarzania jezyka naturalnego 10
wieloznacznych) nazywamy lematyzacja (ang. lemmatization). Dla leksemu moze istniec
wiecej niz jeden lemat, wybranie własciwej formy wymaga przeprowadzenia dezambiguacji
morfosyntaktycznej.
Dobrym przykładem moze byc słowo „zamek” – moze ono oznaczac budowle lub zamek
do drzwi. Nie dysponujac kontekstem trudno okreslic w jakim znaczeniu zostało uzyte dane
słowo i jaka jest jego forma podstawowa.
W wielu zastosowaniach wystarczy wyodrebnic wspólny rdzen wszystkich form danego
wyrazu – nie musi on odpowiadac poprawnej gramatycznie formie bazowej; wystarczy, ze
bedzie jednoznacznie identyfikował dany wyraz i jego odmiany. Proces ten nazywany jest
hasłowaniem (ang. stemming). Hasłowanie jest wykorzystywane w wyszukiwaniu doku-
mentów. Tworzenie indeksu dokumentów w oparciu o hasła (ang. stems), a nie oryginalne
formy wyrazu zwykle korzystnie wpływa na jakosc otrzymywanych wyników [TKJ97], szcze-
gólnie w przypadku jezyków o bogatej fleksji. Przeglad dostepnych programów do hasłowa-
nia dla jezyka polskiego jest zawarty np. w [HK01, Wei05].
Róznice miedzy lematyzacja, a hasłowaniem mozna pokazac przy pomocy prostego przy-
kładu. Rozwazmy trzy formy jednego wyrazu: „piosenka”, „piosenki”, „piosenka”. Forma
podstawowa dla tej grupy bedzie wyraz „piosenka”. Algorytm hasłujacy w najprostszym
przypadku wyszuka najdłuzszy wspólny ciag znaków: „piosenk”. Nie jest to poprawny wyraz,
niemniej jednak jednoznacznie identyfikuje cała grupe, wydzielajac z niej wspólny rdzen.
Algorytmy lematyzacji i hasłowania mozemy z grubsza podzielic ze wzgledu na sposób,
w jaki dokonuja wydzielenia rdzenia na regułowe, słownikowe oraz hybrydowe.
Algorytmy regułowe, jak sama nazwa wskazuje, do wyodrebniania rdzenia wykorzystuja
pewne reguły. Moga byc one tworzone przez człowieka lub wydobywane automatycznie
z duzych zbiorów danych. Przykładowa reguła moze wygladac tak:
Jezeli wyraz konczy sie na „ac” (np. pracowac) jest to forma podstawowa.
Oczywiscie w przypadku wielu wyrazów ta reguła spowoduje niepoprawna interpretacje i roz-
poznany wyraz nie zawsze bedzie bezokolicznikiem. Reguły uzywane w rzeczywistych al-
gorytmach sa bardziej skomplikowane, niemniej jednak algorytmy regułowe moga czasem
zwracac niepoprawne wyniki.
Metody słownikowe opieraja sie na wyszukiwaniu odpowiedniej formy w predefiniowa-
nym słowniku. W przypadku gdy wyraz nie znajduje sie w słowniku nie jestesmy w stanie
zwrócic poprawnej formy bazowej. Wada tych rozwiazan jest koniecznosc zarezerwowanie
odpowiednio duzej przestrzeni dyskowej na słownik. W odróznieniu jednak od rozwiazan
regułowych, zwracany wynik zawsze odpowiada lematowi wyrazu.
Dla jezyka polskiego zaprezentowano równiez rozwiazania hybrydowe, łaczace oba po-
wyzsze podejscia. W przypadku, gdy lemat dla wyrazu nie zostanie znaleziony w słowniku,
stosowany jest algorytm regułowy. Wykazano, ze zastosowanie tego podejscia wpływa po-
zytywnie na ogólna skutecznosc (poprawnosc) procesu wyodrebniania podstawowej formy
wyrazu [Wei05].
Głównym celem hasłowania i lematyzacji jest wyodrebnienie formy podstawowej (lub
hasłowej). Pojeciem bardziej ogólnym jest analiza morfologiczna. W wyniku takiej analizy

2.1. Elementy przetwarzania jezyka naturalnego 11
RYSUNEK 2.2: Drzewo rozbioru gramatycznego zdania: „Wybitny poeta pisze sercem.” obra-zuje role, jaka pełnia poszczególne leksemy w zdaniu (rysunek pochodzi z [D07]).
kazdemu wyrazowi przypisywana jest jego charakterystyka morfologiczna. Otrzymana w ten
sposób kompletna informacja jest konieczna w sytuacji, gdy chcemy przeprowadzic rozbiór
składniowy zdania. Dla jezyka polskiego istnieje kilka analizatorów morfologicznych – opis
niektórych z nich znajdzie Czytelnik w dalszych rozdziałach.
2.1.4 Analiza składniowa
Zadaniem analizy składniowej (w polskiej literaturze funkcjonuje tez nazwa analiza syn-
taktyczna) jest rozpoznanie ról, jakie pełnia poszczególne wyrazy wewnatrz zdania, a na-
stepnie stworzenie drzewa rozbioru gramatycznego (zob. rys. 2.2).
Na tym etapie istotne sa przede wszystkim:
• własnosci fleksyjne poszczególnych wyrazów,
• pozycja wyrazu w zdaniu (jest to najwazniejsze w przypadku jezyka angielskiego).
W jezyku angielskim głównym nosnikiem powiazan składniowych jest szyk wyrazów. Zu-
pełnie inaczej niz w jezyku polskim, gdzie pozycja wyrazu w zdaniu ma mniejszy wpływ na
składniowa strukture zdania. Rozwazmy nastepujace zdania w jezyku angielskim: „John hit
Paul” oraz „Paul hit John”. Podmiot wystepuje na poczatku zdania, zmiana kolejnosci po-
woduje zmiane sensu całej wypowiedzi. W jezyku polskim to, jaka funkcje w zdaniu beda
pełniły poszczególne wyrazy zalezy w duzej mierze od ich formy fleksyjnej: „Paweł uderzył
Jana”, ale „Jana uderzył Paweł”.
Innym istotnym problemem obliczeniowym sa zwiazki anaforyczne. Przez zwiazek ana-
foryczny rozumiemy relacje nie miedzy poszczególnymi wyrazami, a miedzy całymi grupami
składniowymi. Przykładowo:
„Dawno, dawno temu, w małym wiejskim domku, mieszkała pewna dziewczynka,
której prawdziwego imienia nikt nie pamieta.”
Zwiazki tego typu moga wystepowac na poziomie całych zdan, lub ich czesci składowych.
W powyzszym przykładzie zdanie podrzedne :„której prawdziwego imienia nikt nie pamieta”
odwołuje sie do podmiotu zdania nadrzednego [Sus05].

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 12
Dla jezyka polskiego zostały stworzone gramatyki formalne które umozliwiaja nie tylko
weryfikacje poprawnosci zdania, ale pełny jego rozbiór. Przykładem takiego formalizmu
moze byc składniowa gramatyka grupujaca dla jezyka polskiego (ang. Syntactic group gram-
mar for Polish language, SGGP) [CGKS04]. Inna próba implementacji gramatyki jezyka pol-
skiego w sposób efektywny jest [Mar04] – implementacja gramatyki opisanej w ksiazce Skład-
nia współczesnego jezyka polskiego [SS98].
2.2 Wybrane zagadanienia dotyczace wyszukiwania informacji
Wyszukiwanie informacji (ang. Information Retrieval) to bardzo rozległa dziedzina, która
nie sposób omówic w niniejszym rozdziale w pełni. Zagadnienia przedstawione ponizej zo-
stały uznane za istotne w kontekscie implementowanych w pracy rozwiazan. Wiecej infor-
macji na ten temat znajdzie czytelnik np. w doskonałym podreczniku [BYRN99] lub w do-
stepnej w internecie ksiazce [MRSar].
W przypadku duzych kolekcji dokumentów, okreslenie które z dokumentów zawieraja
istotne informacje staje sie sporym problemem. Zapoznanie sie z trescia kazdego tekstu
moze trwac bardzo długo. Nalezy wiec stworzyc mechanizm, który pozwoli wybrac te do-
kumenty, które zawieraja istotne informacje. Musimy równiez okreslic sposób, w jaki uzyt-
kownik bedzie specyfikował jakie dane sa dla niego istotne. W klasycznym podejsciu do tego
problemu, kazdy dokument jest opisany za pomoca zbioru słów kluczowych. Słowem klu-
czowym moze byc w najprostszym przypadku kazde słowo z danego dokumentu.
Na rozwiazanie problemu wyszukiwania składaja sie trzy zagadnienia:
• budowanie struktur pomocniczych,
• sposób specyfikacji zapytan,
• algorytm (model) wyboru dokumentów pasujacych do zapytania.
Wyszukiwanie dokument po dokumencie byłoby bardzo nie efektywne. Jezeli jednak
załozymy, ze kolekcja dokumentów zmienia sie relatywnie rzadko, to opłacalne moze byc
stworzenie pewnych struktur pomocniczych. Struktury te powinny spełniac nastepujace po-
stulaty:
• przyspieszac proces wyszukiwania,
• miec mały rozmiar (w stosunku do rozmiaru całej kolekcji),
• byc proste w utrzymaniu (w przypadku, gdy zmianie ulegna dokumenty w kolekcji).
Przykładem takiej struktury moze byc indeks odwrotny. W takim indeksie kazdemu
słowu kluczowemu przyporzadkowana jest lista dokumentów, w jakim owo słowo wystapiło.
Pozwala to znacznie przyspieszyc proces wyszukiwania, ogranicza sie ono wtedy do:
• odnalezienia słów z zapytania w indeksie,

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 13
RYSUNEK 2.3: Wyszukiwarka Ask.com dla zapytania „Jaka jest najwyzsza góra w Polsce?”zwraca poprawna odpowiedz: „najwyzsza góra w Polsce to Rysy”.
• utworzenia czesci wspólnej list dokumentów dla kazdego ze słów (zakładamy logiczna
koniunkcje miedzy słowami w zapytaniu)
• prezentacje wyników uzytkownikowi.
Istnieja równiez bardziej skomplikowane systemy, które pozwalaja na wydawanie zapy-
tan w jezyku naturalnym (np. wyszukiwarka http://ask.com działajaca dla jezyka angiel-
skiego, zob. rys. 2.3), jednak nie sa one przedmiotem niniejszej pracy.
Jednym z najszerzej stosowanych teoretycznych modeli wyszukiwania jest model wekto-
rowy. Kazdy dokument jest reprezentowany przez wektor słów kluczowych. Zapytanie jest
traktowane jako kolejny dokument w kolekcji. W procesie wyszukiwania obliczamy zwykle
miare podobienstwa miedzy wektorem zapytania a dokumentami (najczesciej cosinus kata
pomiedzy nimi) Wyniki nastepnie sortujemy malejaco tworzac ranking, na którego szczycie
znajduja sie dokumenty najlepiej pasujace do zapytania. Wazna cecha modelu wektorowego
jest to, ze dopuszcza on aby dokumenty, które tylko czesciowo spełniaja zapytanie, równiez
były umieszczane w wynikach wyszukiwania.
2.2.1 Budowanie indeksu dokumentów
Indeksy i spisy spotyka sie na kazdym kroku: w kazdej bibliotece mozemy znalezc in-
deks autorów, w wiekszosci ksiazek naukowych znajdziemy na koncu skorowidz waznych
terminów. Sa to dwa klasyczne przykłady indeksów odwrotnych. Indeks odwrotny wyko-
rzystywany w wyszukiwaniu najbardziej przypomina skorowidz, gdzie dla kazdego terminu
wypisane sa strony na których jest o nim mowa.
Proces budowania takiego indeksu mozemy podzielic na trzy najwazniejsze etapy:
• wstepne przetwarzanie dokumentu,
• wybór słów kluczowych,
• dodanie dokumentu do indeksu.

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 14
RYSUNEK 2.4: Przykład tradycyjnego indeksu odwrotnego.
Wstepne przetwarzanie dokumentu
W podrozdziale 2.1 zasygnalizowane zostały pewne zagadnienia zwiazane z przetwarza-
niem tekstów na potrzeby budowania indeksów. Nalezy podkreslic przede wszystkim moz-
liwosc :
• usuniecia interpunkcji oraz wiekszosci informacji dotyczacych struktury tekstu,
• eliminacji leksemów niejednoznacznych i wystepujacych zbyt czesto,
• hasłowania i lematyzacja.
Wymagania te wynikaja z natury procesu wyszukiwania opartego o model wektorowy, gdzie
zarówno dokumenty, jak i zapytania reprezentowane sa przez wektory słów. Bezposrednim
nastepstwem tego jest marginalizacja roli struktury tekstu oraz znaków interpunkcyjnych.
Pozostałe dwa czynniki maja wpływ na wielkosc indeksu i wzrost selektywnosci procesu wy-
szukiwania.
Przykład budowania indeksu odwrotnego
Rozwazmy nastepujacy dokument:
Wrzuciłes Grzesiu list do skrzynki, jak prosiłam?
- List, prosze cioci? List?
Wrzuciłem, ciociu miła!
- Nie kłamiesz, Grzesiu? Lepiej przyznaj sie kochanie!

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 15
Po usunieciu interpunkcji i wyrazów pospolitych, otrzymujemy:
Wrzuciłes Grzesiu list skrzynki prosiłam
List prosze cioci List
Wrzuciłem ciociu miła
kłamiesz Grzesiu Lepiej przyznaj kochanie
Nastepnie szukamy form podstawowych dla kazdego z wyrazów (Tablica 2.1). Dysponujac
taka postacia dokumentu mozemy stworzyc indeks. W ponizszym przykładzie (Tablica 2.2)
pozycje w tekscie numerowane sa od 1.
TABLICA 2.1: Formy podstawowe wyrazów wystepujacych w przykładowym tekscie.
Lemat Słowa
wrzucac Wrzuciłes, Wrzuciłemgrzesiu Grzesiu, Grzesiulist list, Listskrzynka skrzynkiprosic prosiłam, proszeciocia cioci, ciociumiła miłakłamac kłamieszlepiej lepiejprzyznawac przyznajkochanie kochanie
TABLICA 2.2: Gotowy do uzycia indeks odwrotny.
Słowo Wystapienia
wrzucac 1, 10grzesiu 2, 14list 3, 6, 9skrzynka 4prosic 5, 7ciocia 8, 11miła 12kłamac 13lepiej 14przyznawac 15kochanie 16
Poniewaz w indeksie zawsze wystepuje wiecej niz jeden dokument, konieczne jest wpro-
wadzenie infromacji o dokumencie z którego pochodzi dane słowo (ponizszy przykład wy-
korzystuje wartosci z Tabeli 2.2).

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 16
list: (Dokument 1, pozycje: 3, 6, 9)
Własnosci indeksu odwrotnego
Miejsce wystapienia danego słowa moze byc wskazywane z dokładnoscia do:
• pozycji w danym dokumencie,
• bloku,
• dokumentu.
Jezeli utworzony indeks bedzie zawierał informacje o pozycji kazdego słowa w dokumen-
cie, to bedzie mozna wyszukiwac całe frazy np. „Wrzuciłes Grzesiu”. Wyszukujemy wtedy
w indeksie wystapienia wyrazu „Wrzuciłes”, a nastepnie odnajdujemy wystapienia wyrazu
„Grzesiu”. Jezeli pozycja „Grzesia” jest o jeden wieksza – znalezlismy szukana fraze. Nie be-
dziemy w stanie przeprowadzic takiego wyszukiwania dysponujac tylko informacja o tym,
ze wyraz znajduje sie w danym dokumencie (bez jego pozycji). Nalezy jednak podkreslic,
ze indeks zawierajacy dokładne informacje o pozycji wyrazu moze zajmowac nawet dwu-
krotnie wiekszy rozmiar (na dysku) niz indeks o dokładnosci dokumentu [BYRN99]. Me-
toda posrednia jest adresowanie blokowe, w tym wypadku kazdy dokument dzielony jest na
bloki. W jednym bloku moze znajdowac sie wiecej niz jedno słowo kluczowe. W zwiazku
z tym przestrzen adresowa potrzebna, aby oznaczyc wystapienia wszystkich dokumentów
jest mniejsza, niz w przypadku, gdy posługujemy sie dokładnymi pozycjami. Rozmiaru uzy-
wanych bloków to parametr pozwalajacy okreslic czy wazniejsza jest dokładnosc wskazania
czy rozmiar indeksu.
Wielkosc indeksów odwrotnych – stosujac techniki takie adresowanie blokowe nie po-
winna przekroczyc 5% rozmiaru całej kolekcji.
Naiwna złozonosc obliczeniowa procesu wyszukiwania w oparciu o indeks odwrotny to
O(n) gdzie n jest liczba róznych słów w indeksie, a wyrazy znajduja sie na zwykłej liscie.
W przypadku gdy zbiór słów jest zamodelowany za pomoca bardziej zaawansowanych struk-
tur danych (B-drzewo) mozemy obnizyc ten koszt nawet do O(logn).
Wybór słów kluczowych
Gdy tworzymy indeks odwrotny mozemy wykorzystac wszystkie słowa zawarte w doku-
mencie lub tylko niektóre. Budowanie reprezentacji dokumentu w oparciu tylko o niektóre
słowa wymaga przeprowadzenia wstepnej selekcji. W klasycznych indeksach bibliotecznych
wyboru najwazniejszych terminów dokonywał specjalista. Jednak w przypadku duzych ko-
lekcji dokumentów klasyczne podejscie wymaga poswiecenia zbyt duzej ilosci czasu.
Stworzenie automatycznych metod, które pozwalaja wyselekcjonowac wartosciowe słowa
kluczowe wymaga okreslenia jakie cechy powinno ono posiadac.
Selektywnosc – jezeli dane słowo wystepuje tylko w nielicznych dokumentach pełnej kolek-
cji, to zwykle mozna uznac, ze dobrze identyfikuje ono te dokumenty.

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 17
Niezaleznosc znaczeniowa – w podrozdziale 2.1 zostało pokazane, ze niektóre wyrazy moga
niesc znaczenie niezaleznie od kontekstu w jakim zostały uzyte. Przykładem takich
wyrazów sa rzeczowniki.Nalezy jednak zwrócic uwage na konstrukcje łaczace przy-
miotnik z rzeczownikiem, np. „rakiety balistyczne”. Jezeli jako słowa kluczowego uzy-
jemy tylko wyrazu „rakiety” utracimy czesc pierwotnego znaczenia pełnej frazy.
TF-IDF
Jedna z najszerzej stosowanych metod pozwalajacych na obliczenie wagi danego słowa
kluczowego w modelu wektorowym jest schemat tf-idf (skrót pochodzi od angielskiej frazy
term frequency – inverse document frequency).
Dla kazdego słowa obliczana jest waga:
tf-idf = tf · log
( |D||d j ⊃ t j |
)(2.1)
gdzie przez |D| oznaczamy liczbe dokumentów w kolekcji, a przez |d j ⊃ t j | liczbe doku-
mentów (nalezacych do kolekcji) które zawieraja wystapienia termu t j .
tf = ni∑k nk
(2.2)
Przez ni rozumiemy liczbe wystapien danego termu, natomiast∑
k nk oznacza liczbe wszyst-
kich termów [Wik07f].
Dobre słowa kluczowe (wysoka wartosc wagi tf-idf) to takie, które wystepuja czesto w da-
nym dokumencie, ale jednoczesnie rzadko pojawiaja sie w innych dokumentach z rozpatry-
wanej kolekcji.
Okapi BM25
W przypadku długich dokumentów prawdopodobienstwo tego, ze dany wyraz pojawi sie
wiele razy jest wyzsza. Spowoduje to wzrost wartosci czynnika tf, w efekcie szansa na to,
ze długi dokument zostanie zwrócony w odpowiedzi na zapytanie uzytkownika jest wyz-
sza [SBM96].
BM25 to rodzina funkcji po raz pierwszy, uzyta w systemie Okapi, które mozna wyko-
rzystac do obliczenie wagi wyrazów z uwzglednieniem długosci dokumentów [RWHB+92].
Majac dokument D i wyraz t :
bm25(D, t ) = idf(t ) · f (t ,D) · (k1 +1)
f (t ,D)+k1 · (1−b +b · |D|avgdl )
, (2.3)
gdzie:
f (t ,D) – liczba wystapien wyrazu t w dokumencie D .
|D| – długosc dokumentu D
avdl – srednia długosc dokumentu w kolekcji
k1 i b – wartosci stałe (przewaznie przyjmuje sie k1 = 1,2 i b = 0,75).

2.2. Wybrane zagadanienia dotyczace wyszukiwania informacji 18
Natomiast IDF (ang. inverse document frequency), jest opisane wzorem:
IDF(qi ) = logN −n(qi )+0,5
n(qi )+0,5, (2.4)
Zakładamy, ze N to liczba wszystkich dokumentów w kolekcji, a n(t ) to liczba dokumentów
w kolekcji zawierajacych słowo t .
2.2.2 Model wektorowy
Jak zostało to juz wspomniane (por. 2.2), w modelu wektorowym zapytanie oraz kazdy
z dokumentów w kolekcji sa reprezentowane przez wektor słów kluczowych. Wektor ten dla
kazdego dokumentu składa sie z pewnej liczby słów oraz odpowiadajacych im wag. Przyj-
muje sie, ze wyrazy z indeksu, które nie wystepuja w danym dokumencie maja wage 0.
Obliczanie podobienstwa dokumentów
Rozwazmy nastepujace dane:
• dokument 1: „Ziarnko do ziarnka, a zbierze sie miarka”,
• dokument 2: „Zbierał, zbierał az uzbierał”,
• zapytanie: „ziarnko uzbierał”.
W indeksie znajduje sie 4 rózne terminy (nie liczac wyrazów pospolitych) – ponizej przed-
stawione zostały ich formy podstawowe:
zbierac, ziarnko, uzbierac, miarka
Dokumenty bedzie wiec reprezentował wektor składajacy sie z 4 liczb (wag) odpowiada-
jacych poszczególnym słowom kluczowym. Zaproponowano wiele sposobów na oblicze-
nie wartosci wag, najszerzej stosowany sposób opiera sie na wykorzystaniu schematu tf-
idf [SB87].
TABLICA 2.3: Wartosci wagi tf-idf, obliczone dla:∑
k nk = 7, |D| = 2.
zbierac ziarnko uzbierac miarka
ni 3 2 1 1tf 0,43 0,29 0,14 0,14|d j ⊃ t j | 2 1 1 1idf 0 0,3 0,3 0,3
tf-idf 0 0,09 0,04 0,04
Na podstawie przedstawionych w Tablicy 2.3 wartosci mozemy stworzyc wektory dla
wszystkich dokumentów oraz zapytania (por. Tablica 2.4). W modelu wektorowym podo-
bienstwo sim(d j , q) dokumentów jest równe cosinusowi kata miedzy reprezentujacymi je
wektorami d j i q .

2.3. Automatyczne streszczanie dokumentów 19
TABLICA 2.4: Wektory słów dla omawianego przykładu.
zbierac ziarnko uzbierac miarka
d1 0 0,09 0 0,04d2 0 0 0,04 0q 0 0,09 0,04 0
sim(d j , q) = cos(~d j 6 ~q) (2.5)
Otrzymane wyniki sortujemy malejaco wzgledem otrzymanej wartosci miary podobienstwa.
Dla powyzszego przykładu otrzymamy nastepujace wartosci:
sim(d1, q) = 0,84, sim(d2, q) = 0,4.
Widac zatem, ze zaden dokument w pełni nie pasuje do wydanego zapytania, ale w wy-
nikach znajda sie oba (czesciowo pasujace) dokumenty.
2.3 Automatyczne streszczanie dokumentów
Dysponujac odpowiednio przetworzonym tekstem, mozemy przystapic do tworzenia au-
tomatycznego streszczenia. Naszym celem jest ustalenie które informacje sa najwazniejsze,
a nastepnie dokonanie ich selekcji oraz przetworzenie do postaci przyjaznej dla czytelnika.
W wyniku tego procesu powinnismy otrzymac tekst objetosciowo mniejszy, ale zawierajacy
jak najwiecej informacji z tekstu pierwotnego. Aby tego dokonac konieczne jest ustalenie
funkcji oceny, która okresli, które z informacji zawartych w tekscie sa istotne. Mozemy
uwzglednic tylko lingwistyczne własnosci tekstu lub skorzystac z dodatkowej wiedzy.
Niniejszy rozdział prezentuje krótka charakterystyke najwazniejszych (zdaniem autora)
technik automatycznego generowania streszczen. Przeglad ten w duzej mierze został oparty
o [Zec96a] oraz [KPC95]. Wykorzystanie łancuchów leksykalnych dla potrzeb sumaryzacji
zostało szczegółowo opisane w [BE97].
2.3.1 Metody statystyczne
Ogólny schemat wykorzystywany przez wiekszosc metod statystycznych składa sie z na-
stepujacych etapów: wstepne przetwarzanie tekstu, ocena oraz wybór najwazniejszych zdan
lub akapitów. Podstawowe róznice miedzy istniejacymi rozwiazaniami dotycza przede wszyst-
kim tego, jak zbudowana jest funkcja oceny zdan.
W przypadku prezentowanych w tym podrozdziale technik uprawnione byłoby uzycie
nazwy metody czestosciowe. Obok tej grupy algorytmów, opierajacych swe działanie na
pewnych ogólnych cechach tekstu, istnieja równiez metody wykorzystujace bardziej zaawan-
sowane narzedzia statystyczne: niejawne modele Markova [CO01] (ang. Hidden Markov Mo-
del) czy analize skupien (ang. clustering).

2.3. Automatyczne streszczanie dokumentów 20
Wczesne prace
Wczesne prace dotyczace automatycznej sumaryzacji budowały funkcje oceny w oparciu
o czestosc wystepowania wyrazów w tekscie oraz ich wzajemna odległosc w zdaniu. Zakła-
dano przy tym eliminacje wyrazów pospolitych, aby uniknac potencjalnych zakłócen zwia-
zanych z ich czestym wystepowaniem [Luh58].
W latach pózniejszych stworzono bardziej zaawansowane systemy, w których czestosc
była wykorzystywane jako jeden z wielu czynników decydujacych o tym, czy zdanie zosta-
nie uwzglednione w streszczeniu lub tez jako rozwiazanie referencyjne przy ocenie jakosci
otrzymanych wyników. [Edm69] wprowadza trzy dodatkowe heurystyki:
1. Metoda sygnałowa (ang. Cue Method) – obecnosc w zdaniu pewnych słów wpływa po-
zytywnie/negatywnie na istotnosc całego zdania. Zbiór słów sygnałowych został stwo-
rzony metodami statystycznymi na podstawie streszczen tworzonych przez ludzi.
2. Metoda bazujaca na słowach z tytułu (ang. Title Method) – obecnosc w zdaniu słów
zawartych w tytule tekstu (lub w nagłówkach akapitów) zwieksza jego szanse na to, by
trafic do streszczenia.
3. Metoda wykorzystujaca informacje o połozeniu (ang. Location Method) – zakładamy,
ze zdania wystepujace na poczatku lub na koncu tekstu (lub akapitu) moga zawierac
wazniejsze tresci sa zatem istotniejsze w kontekscie zachowania informacji z oryginal-
nego tekstu.
Ocena jakosci otrzymanych streszczen pokazała, ze najlepsze wyniki daje uzycie kombinacji
trzech powyzszych heurystyk, z pominieciem czestosci słów.
Automatyczne streszczanie jako problem klasyfikacji
Kontynuacje i rozwiniecie idei [Edm69] mozna znalezc w pracy [KPC95]. Wybór zdan zo-
stał potraktowany jako problem klasyfikacji. Został stworzony klasyfikator Bayesowski, który
dla kazdego zdania s okresla prawdopodobienstwo tego, ze znajdzie sie ono w streszcze-
niu S.
P (s ∈ S|F1,F2, . . . ,Fk ) = P (F1,F2 . . . ,Fk |s ∈ S)P (s ∈ S)
P (F1, . . . ,Fk )(2.6)
Zakładajac niezaleznosc F1,F2, . . .Fk :
P (s ∈ S|F1,F2, . . . ,Fk ) =∏k
j=1 P (F j |s ∈ S)P (s ∈ S)∏kj=1 P (F j )
(2.7)
gdzie:
P (s ∈ S|F1,F2, . . .Fk ) – to prawdopodobienstwo warunkowe tego, ze zdanie s znajdzie sie
w wynikowym ekstrakcie S dla okreslonych wartosci cech F1,F2 . . . ,Fk .
P (s ∈ S) – prawdopodobienstwo tego, ze zdanie s znajdzie sie w wyniku.
P (F j |s ∈ S) – prawdopodobienstwo wystapienia danej wartosci czynnika F j w zdaniu. War-
tosc stała, obliczana na podstawie analizy zbioru uczacego.
P (F j ) – prawdopodobienstwo niezaleznego wystapienia danego czynnika F j .

2.3. Automatyczne streszczanie dokumentów 21
Zdania o najwyzszej wartosci prawdopodobienstwa trafiaja do tekstu wynikowego.
Opierajac sie na wczesniejszych pracach [Edm69, Luh58] wziete zostało pod uwage piec
cech zdania:
• pozycja w akapicie (ang. paragraph feature),
• wystepowanie ustalonych słów lub fraz (ang. fixed-phrase feature),
• wystepowanie słów z tytułu lub nagłówków (ang. thematic word feature),
• długosc zdania (ang. sentence length cut-off feature)
• wystepowanie wyrazów rozpoczynajacych sie od wielkiej litery (ang. uppercase word
feature).
Wagi przyporzadkowane poszczególnym cechom zostały obliczone na podstawie analizy
zbioru 188 par dokument-streszczenie. Ze wzgledu na mały rozmiar wykorzystywanego kor-
pusu niemozliwe było wydzielenie osobnego korpusu uczacego i testowego, zastosowano
weryfikacje naprzemienna (ang. cross-validation). Aby zweryfikowac jakosc otrzymanych
automatycznych streszczen były one porównywane ze streszczeniami literackimi stworzo-
nymi przez ekspertów. Na podstawie porównania identyfikowano odpowiadajace sobie zda-
nia z obu rodzajów streszczen.
Najlepsze wyniki otrzymano wykorzystujac 3:
• informacje o pozycji zdania w akapicie,
• obecnosci ustalonego słowa/frazy,
• pomijanie zdania o długosci mniejszej niz pewna ustalona wartosc.
Najgorsze wyniki natomiast dało uzycie czynników (posrednio) opartych o czestosc wyste-
powania słów czyli: słowa z tytułu oraz wyrazy rozpoczynajace sie od wielkiej litery. Potwier-
dza to poczynione przez [Edm69] spostrzezenie o niskiej jakosci streszczen generowanych
przy pomocy metod opartych na czestosci słów [Zec96a, KPC95].
Wykorzystanie schematu tf-ifd
Z uwagi na słaba jakosc streszczen otrzymanych przy uzyciu czestosci wyrazów, pewna
alternatywa moze byc uzycie schematu tf-idf. Takie rozwiazanie zostało zastosowane w sys-
temie ANES (ang. Automatic News Extraction System) [BMR95], jego głównym zadaniem
było tworzenie automatycznych streszczen wiadomosci prasowych. Proces tworzenia stresz-
czenia składał sie z nastepujacych etapów.
1. Wykorzystywanie referencyjnego korpusu dokumentów – dla kazdego wyrazu w tek-
scie obliczamy wartosc wagi tf-idf.
3Wiecej na informacji dotyczacych technik ewaluacji jakosci automatycznych streszczen znajdzie Czytelnikw rozdziale 5.

2.3. Automatyczne streszczanie dokumentów 22
2. Wybór słów znaczacych (ang. signature words), do zbioru wchodza:
• słowa kluczowe o najwyzszej wadze,
• wyrazy z tytułu.
3. Obliczanie wagi zdan (ang. sentence weighting) odbywa sie poprzez dodanie wag słów
znaczacych znajdujacych sie w danym zdaniu. Uwzgledniane sa równiez dodatkowe
czynniki takie jak pozycja wyrazu w zdaniu.
4. Wybór zdan – do streszczenia wybierane sa zdania z najwyzszymi wagami.
Zostało pokazane, ze ilosc informacji w automatycznych streszczeniach generowanych
przy uzyciu metod opartych na schemacie tf-idf jest wieksza niz dla metod prostych (np. wzie-
cie pierwszych n zdan) [Zec96b].
Problemy zwiazane z metodami statystycznymi
Opisane wyzej podejscie – selekcja zdan na podstawie pewnych statystycznych cech tek-
stu, posiada liczne wady. Nie jestesmy w stanie uniknac sytuacji, w której zostana zakłó-
cone zwiazki logiczne miedzy zdaniami w tekscie wynikowym (głównie za sprawa zwiazków
anaforycznych). Pewnym rozwiazaniem tego problemu moze byc wybór całych akapitów –
pozwoli to na stworzenie bardziej spójnego streszczenia, choc niestety nie zawsze da sie to
rozwiazanie zastosowac.
Zadna metoda oparta w całosci na prostych statystykach słów nie jest równiez w stanie
uwzglednic warstwy znaczeniowej dokumentu. Zasygnalizowane wczesniej problemy z sy-
nonimami, homonimami, czy metaforami wymagaja semantycznej analizy tekstu [Mau89].
Rozwazmy nastepujacy przykład:
„Wiele wytrzymał zamek w Kamiencu Podolskim za panowania króla Michała
Korybuta, kiedy to w 1672 turecka nawałnica zagroziła pokojowi Rzeczypospoli-
tej.”
„Pokój w którym przebywał król Michał Korybut był wyposazony w mosiezny za-
mek. Sforsowac go nie dałaby rady nawet turecka nawałnica z 1672.”
Pierwszy tekst traktuje o roli zamku w Kamiencu Podolskim w czasie najazdu tureckiego
w roku 1672. Drugi – mimo iz zbudowany jest w duzej mierze z tych samych wyrazów, mówi
o pokoju (miejscu), w którym schronił sie król Michał Korybut. Zwrócmy uwage, ze słowa
„zamek” i „pokój” wystepuja w obu zdaniach, jednak ich znaczenie jest zupełnie inne. In-
formacje przenosza wiec nie tylko słowa, ale i ich wzajemne zwiazki. Aby poprawic jakosc
streszczen opracowano metody uwzgledniajace takze syntaktyczna i semantyczna strukture
tekstu.

2.3. Automatyczne streszczanie dokumentów 23
2.3.2 Spójnosc leksykalna
Dobrze zredagowany tekst jest postrzegany przez odbiorce jako całosc. Spójnosc ta znaj-
duje odzwierciedlenie w warstwie leksykalnej: w doborze odpowiednich wyrazów, w czesto-
sci ich wystepowania. [BE97] opisuje dwa podstawowe rodzaje spójnosci leksykalnej:
reiteracja – wystepuje miedzy tymi samymi wyrazami (powtórzenia), synonimami, hiponi-
mami.
kolokacja – wystepuje miedzy słowami, które czesto pojawiaja sie razem w pewnych kon-
tekstach np. „Ona pracuje jako nauczyciel w szkole”. Wyrazy „nauczyciel” i „szkoła”
wystepuja razem w konkretnym kontekscie znaczeniowym.
Spójnosc leksykalna zachodzi nie tylko miedzy dwoma wyrazami, ale równiez miedzy
sekwencjami wyrazów – tworzy wtedy łancuchy leksykalne (ang. lexical chains).
Budowanie łancuchów leksykalnych
Istnieje kilka algorytmów pozwalajacych na tworzenie łancuchów leksykalnych. Ogólna
procedura przebiega nastepujaco:
1. wybór słów, które beda brane pod uwage przy tworzeniu łancuchów,
2. dla kazdego z wybranych słów znajdowany jest odpowiadajacy mu łancuch leksykalny,
3. jezeli odpowiedni łancuch nie istnieje – tworzony jest nowy,
4. słowo jest umieszczane w odpowiednim łancuchu.
Analizujac powyzszy proces nalezy zwrócic uwage na kilka czynników, które moga wpłynac
na jakosc stworzonych łancuchów leksykalnych.
Poniewaz nie wszystkie wyrazy sa dobrymi „nosnikami” znaczenia, przy budowie łancu-
chów mozemy ograniczyc sie tylko do rzeczowników. Zmniejsza to liczbe mozliwosci, które
trzeba sprawdzic, dzieki czemu czas konieczny do zbudowania łancucha jest znacznie krót-
szy.
Istotnym problemem przy konstrukcji łancuchów jest dezambiguacja poszczególnych
wyrazów. Niektóre z istniejacych algorytmów nie przeprowadzaja jej w ogóle (wybierajac
dla wszystkich wystapien pierwsze mozliwe znaczenie danego wyrazu). Poniewaz dokładna
dezambiguacja jest kosztownym obliczeniowo procesem, zaproponowano pewne heurystyki
pozwalajace obnizyc ten koszt przy zachowaniu wysokiej trafnosci [BE97].
Miara jakosci dla łancuchów leksykalnych
Aby efektywnie wykorzystac reprezentacje jaka sa łancuchy leksykalne nalezy zdefinio-
wac dla nich miare jakosci (siły) . [BE97] zaproponowali nastepujaca funkcje oceny:
Ocena(Łancuch) = l ·h, (2.8)

2.3. Automatyczne streszczanie dokumentów 24
gdzie: l – długosc (ang. length) to liczba wystapien elementów składowych łancucha w tek-
scie, natomiast h – jednorodnosc (ang. homogenity) jest równe (przez d oznaczamy liczbe
elementów w łancuchu):
h = 1−(
d
l
). (2.9)
2.3.3 Łancuchy leksykalne a streszczanie tekstów
Łancuchy leksykalne maja wiele cech w oparciu o które mozemy stworzyc algorytm wy-
bierajacy zdania do streszczenia. W najprostszym przypadku do streszczenia wybierane
beda zdania, w których po raz pierwszy wystapił leksem zawarty w najsilniejszych łancu-
chach (łancuchy sa posortowane malejaco wzgledem miary jakosci). Rozwazmy nastepujacy
przykład:
„Zamek króla Korybuta był ogromny. O twierdzy tej słyszała cała Europa. Mury
zamku siegały prawie do nieba.”
Dla którego stworzono nastepujacy łancuch leksykalny:
zamek (2 wystapienia), twierdza (1 wystapienie).
Załózmy, ze mamy stworzyc streszczenie składajace sie z jednego zdania. Wybieramy wtedy
pierwszy leksem z najsilniejszego łancucha – w tym przypadku jest to leksem „zamek”. Do
streszczenia trafia wiec pierwsze zdanie w którym pojawia sie forma tego leksemu.
W [BE97] zaproponowano równiez inne algorytmy. Autorzy zauwazyli, ze pierwszy wy-
raz w łancuchu nie musi byc jego najlepszym reprezentantem. Autorzy wprowadzaja po-
jecie wyrazów reprezentatywnych (ang. representative words) – sa to wyrazy, których cze-
stosc wystepowania (w tekscie) jest wieksza niz srednia czestosc w danym łancuchu. Do
wyboru zdan uzywane sa tylko wyrazy reprezentatywne. W powyzszym przykładzie srednia
jest równa 1,5, słowem reprezentatywnym bedzie wiec równiez wyraz „zamek”.
Zastosowanie łancuchów leksykalnych rozwiazuje tylko czesc z problemów wspomnia-
nych w sekcji 2.3.1. Problemy zwiazane z wystepowaniem w tekscie anafor pozostaja nieroz-
wiazane. Niemniej jednak uzycie łancuchów leksykalnych jako reprezentacji posredniej jest
ciekawa metoda pozwalajaca obejsc niektóre ograniczenia rozwiazan statystycznych. Cze-
sto zdarza sie, ze to co mozna nazwac „tematem” jest okreslane w tekscie za pomoca kilku
wyrazów o podobnym znaczeniu. Rozkład czestosci tych wyrazów moze byc podobny, ale
nie musza byc one wcale najczesciej wystepujacymi słowami. Dzieki uzyciu łancuchów lek-
sykalnych mozemy wykryc, ze kilka wyrazów reprezentuje to samo pojecie i uwzglednic ich
sumaryczna czestosc.
2.3.4 System Polsumm2
Problem automatycznej sumaryzacji tekstów dla jezyka polskiego został opisany w pra-
cach dotyczacych systemu Polsumm2 4 [CGKS04]. Opisane tam rozwiazanie wykorzystuje
4Polsumm2 nie jest niestety dostepny online.

2.3. Automatyczne streszczanie dokumentów 25
głeboka analize tekstu z uzyciem gramatyki jezyka polskiego SGGP (ang. syntactic group
grammar for Polish language, SGGP). System Polsumm2 jest kompletnym rozwiazaniem po-
zwalajacym na tworzenie streszczen z uwzglednieniem znaczenia wyrazów i zwiazków mie-
dzyzdaniowych.
RYSUNEK 2.5: Schemat systemu Polsum2, schemat pochodzi z [CGKS04].
Polsum2 potrafi wygenerowac dobrej jakosci streszczenia nie ograniczajac sie przy tym
tylko do wyboru najwazniejszych zdan w niezmienionej formie. Proces tworzenia streszczen
obejmuje [CGKS04]:
1. analize lingwistyczna tekstu (morfologia, składnia, semantyka),
2. rozwiazywanie niektórych zaleznosci anaforycznych.
3. podział zdan złozonych na proste,
4. wybór najwazniejszych zdan,
5. generowanie wynikowego streszczenia – linearyzacja.
Polsum2 korzysta z utworzonego w Instytucie Informatyki Politechniki Slaskiej serwera
analizy lingwistycznej LAS (ang. Linguistic Analysis Server)5. LAS realizuje wszystkie trzy
etapy analizy lingwistycznej: identyfikacje morfologiczna wyrazów, tworzenie grup składnio-
wych, rozbiór gramatyczny zdania w oparciu o SGGP oraz analize semantyczna [Sus05].
Opisywany system implementuje bardzo ciekawa w kontekscie sumaryzacji funkcjonal-
nosc: rozwiazywanie zaleznosci anaforycznych. Polsum2 jest w stanie zidentyfikowac i za-
stapic niektóre anafory terminem do którego sie ona odnosi. Dzieki temu wygenerowane
streszczenie jest zwykle czytelniejsze.
5Serwer LAS dostepny jest pod adresem: http://thetos.zo.iinf.polsl.gliwice.pl/las2/.

Rozdział 3
Zastosowane rozwiazania
Zastosowane w niniejszej pracy rozwiazania w duzej mierze opieraja sie na pracach opi-
sanych w rozdziale 2. W tej czesci pracy zostanie omówiona wiekszosc modyfikacji, jakie zo-
stały wprowadzone w stosunku do oryginalnych metod. Rozwiniecie informacji zawartych
tutaj znajdzie Czytelnik w rozdziale 4, który w całosci opisuje szczegóły zwiazane z imple-
mentacja zaprezentowanych ponizej algorytmów.
3.1 Przetwarzanie jezyka naturalnego dla potrzeb sumaryzacji
Model jezyka uzywany na potrzeby automatycznej sumaryzacji musi spełniac okreslone
wymagania. Poziom komplikacji takiego modelu zalezy od ilosci informacji, jaka musi byc
w nim zawarta, a to wynika bezposrednio z potrzeb uzywanej metody.
Najwazniejsze w kontekscie sumaryzacji sa nastepujace postulaty.
• Zachowanie pierwotnej struktury tekstu: podział na zdania i akapity, wyodrebnione
nagłówki i tytuł tekstu.
• Pozyskanie informacji o cechach morfologicznych poszczególnych wyrazów i ich for-
mie podstawowej.
• Rozpoznanie wyrazów pospolitych.
3.1.1 Rozpoznawanie struktury tekstu
Podstawowa jednostka składniowa wykorzystywana przez metody implementowane w ra-
mach tej pracy jest zdanie. Czesto zdarza sie, ze tekst jest podzielony na jednostki wyzszego
rzedu (akapity, sekcje), z których kazda poprzedzona jest tytułem. Omawiane metody wy-
korzystuja tylko niektóre z informacji o strukturze wyzszego rzedu. Zastosowana heurystyka
rozpoznaje granice akapitów, potrafi równiez rozróznic, czy dany fragment tekstu to tytuł,
czy nowy akapit.
26

3.1. Przetwarzanie jezyka naturalnego dla potrzeb sumaryzacji 27
Granice akapitów
Program dzieli najpierw tekst na fragmenty – potencjalne akapity – nastepnie sa one
przegladane w kolejnosci wystapienia. Fragment tekstu jest akapitem gdy:
• jest dłuzszy niz zadana minimalna długosc akapitu,
• jezeli jest ostatnim wydzielonym fragmentem w tekscie.
Fragment tekstu jest traktowany jako tytuł nastepujacego po nim akapitu, jezeli jest krót-
szy niz zadana minimalna długosc akapitu oraz:
• znajduje sie na poczatku tekstu,
• wystepujacy bezposrednio przed nim akapit nie jest tytułem (jest dłuzszy niz mini-
malna długosc akapitu).
Rozpatrzmy nastepujacy przykład, zakładajac, ze minimalna długosc akapitu to 6 wyra-
zów:
Dobre regulacje
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest
spółek notowanych na giełdzie.
Zakonczenie
To jednak tylko kwestia czasu.
W pierwszym etapie działania algorytm podzieli tekst na cztery czesci.
• „Dobre regulacje” – uznajemy za tytuł poniewaz jest krótszy niz zadana minimalna dłu-
gosc akapitu, znajduje sie na poczatku tekstu.
• „Rynek kapitałowy w Polsce. . . ” – fragment jest dłuzszy niz minimalna długosc, uzna-
jemy go za akapit. Algorytm zapamietuje równiez, ze poprzednie zdanie jest tytułem
tego akapitu.
• „Zakonczenie” – tekst jest krótszy niz zadany próg, a poniewaz nie znajduje sie na
koncu tekstu, uznajemy, ze to tytuł akapitu.
• „To jednak tylko kwestia czasu.” – Zdanie to jest krótsze niz zadany próg, ale znajduje
sie na koncu tekstu; uznajemy je wiec za akapit opatrzony tytułem „Zakonczenie”.
Jako minimalna długosc akapitu przyjeto liczbe 10, wartosc ta została wyznaczona na
podstawie recznej analizy korpusu „Rzeczpospolitej” [Rze] i innych dostepnych tekstów pra-
sowych.

3.2. Sumaryzacja 28
Rozpoznawanie zdan
W jezyku polskim istnieja dwa rodzaje wypowiedzen: zdania i równowazniki zdan. Wy-
powiedzenie moze byc zakonczone znakiem kropki, wielokropkiem, znakiem zapytania lub
wykrzyknikiem. Bedziemy je traktowac na równi jako podstawowe elementy budujace auto-
matyczne streszczenie.
Kropka w jezyku polskim jest uzywana równiez do oznaczania skrótów. Jezeli skrót kon-
czy sie na litere inna niz oryginalny wyraz nalezy umiescic na koncu kropke. W tekstach
prasowych czesto wystepuja jednoliterowe skróty nazwisk np. „Adam D.”. Znak kropki uzy-
wany jest równiez dla liczebników porzadkowych takich jak „16. Dywizji”, aby podkreslic ze
chodzi o szesnasta, a nie o szesnascie dywizji.
Zastosowany algorytm przeglada tekst słowo po słowie. Gdy po danym wyrazie wyste-
puje kropka program sprawdza czy dany ciag znaków jest skrótem lub liczebnikiem porzad-
kowym. Jezeli przetwarzane słowo nie jest skrótem, algorytm zakłada ze odnalazł koniec
zdania. W przypadku pozostałych znaków konca zdania algorytm nie musi sprawdzac czy
przetwarzany wyraz to skrót. Ciag znaków jest oznaczany jako skrót, jezeli:
• znajduje sie na liscie najpopularniejszych skrótów,
• jest to pojedyncza litera lub liczba zakonczona kropka.
Wspomniana lista zawiera tylko skróty które zawsze koncza sie kropka. Skróty takie jak kg
czy zł – które oznaczaja jednostki fizyczne, pisane sa bez kropki. Jezeli w poprawnie zreda-
gowanym tekscie po takim wyrazie pojawi sie kropka jednoznacznie wskazuje to na koniec
wypowiedzenia.
Taka heurystyka działa bardzo dobrze, dla poprawnie zredagowanych tekstów praso-
wych. Zawodzi ona jednak w przypadku gdy na koncu zdania rozpoznany zostanie skrót,
który powinien konczyc sie kropka. W tej sytuacji nie stawia sie oczywiscie dodatkowej
kropki.
„Sztuka zostanie wystawiona 15 dnia bm. Andrzej Grabowski zagra w niej główna
role.”
Poniewaz po „bm.” nie ma przecinka zakładamy, ze przedstawiony tekst składa sie z
dwóch zdan. Algorytm uzna jednak, ze kropka po „bm.” nalezy do skrótu i w tej sytuacji
uzna cały przykładowy tekst za jedno zdanie.
3.2 Sumaryzacja
3.2.1 Metoda wykorzystujaca informacje o połozeniu zdan
Pisaniem artykułów prasowych (badz naukowych) rzadza pewne dosc scisłe zasady. Kazdy
taki tekst posiada wstep, w którym krótko okreslona jest jego zawartosc. Nastepnie, w kolej-
nych akapitach (sekcjach), omawiane sa szczegółowo zagadnienia wprowadzone we wste-
pie. Artykuł konczy sie podsumowaniem – czesto własnie w tej czesci pojawiaja sie wnioski,

3.2. Sumaryzacja 29
które moga byc najbardziej istotne dla czytelnika. Wiedze o zasadach redakcji tekstów mo-
zemy wykorzystac dla potrzeb automatycznego generowania streszczen.
Stworzona heurystyka wykorzystuje informacje o połozeniu poszczególnych zdan w tek-
scie. W pierwszej kolejnosci do streszczenia wybierane sa zdania znajdujace sie na poczatku
akapitu. Z tak wybranych zdan budowane jest streszczenie, które jest nastepnie uzupełniane
zdaniami znajdujacymi sie na dalszych pozycjach.
Dobre regulacje
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest
spółek notowanych na giełdzie. Polski rynek prezentuje sie dobrze, jest własciwie
przygotowany pod wzgledem organizacyjnym i prawnym.
Zdaniem prezesa giełdy warunki handlu na rynku giełdowym i pozagiełdowym
beda inne, nie bedzie wiec miedzy nimi konkurencji. Giełda jest przygotowana
do rozwoju drugiego parkietu i stworzenia trzeciego.
Działanie tego algorytmu najlepiej zobrazuje ponizszy przykład. Tekst składa sie czterech
zdan i 2 akapitów w zaleznosci od zadanej długosci w streszczeniu znajda sie nastepujace
zdania:
1. „Rynek kapitałowy w Polsce...” – wybieramy pierwsze zdanie z pierwszego akapitu.
Poniewaz osiagnieta została zadana długosc streszczenia algorytm konczy działanie.
2. „Rynek kapitałowy w Polsce...”, „Zdaniem prezesa...”
• wybieramy pierwsze zdanie z pierwszego akapitu,
• sprawdzamy czy osiagnieta została zadana długosc,
• poniewaz istnieje drugi akapit, wybieramy z niego pierwsze zdanie,
• osiagnieta została zadana długosc, algorytm konczy działanie.
3. „Rynek kapitałowy w Polsce...”, „Polski rynek prezentuje”, „Zdaniem prezesa...”
• pierwsze dwa kroki przebiegaja identycznie jak w poprzednim przykładzie,
• poniewaz nie została osiagnieta zadana długosc i nie ma trzeciego akapitu algo-
rytm wraca do pierwszego. Wybiera z niego drugie zdanie i konczy działanie.
3.2.2 Metody wykorzystujace automatyczna ocene jakosci słów kluczowych
W rozdziale 2.2.1 na stronie 13 omówione zostały zagadnienia zwiazane z technikami
automatycznego wyboru słów kluczowych. Przedstawione zostały dwa schematy (tf-idf oraz
bm25) umozliwiajace automatyczne okreslanie waznosci poszczególnych słów i od wielu lat
z powodzeniem stosowane w wyszukiwaniu informacji. Metody automatycznego wazenia
słów mozna w intuicyjny sposób wykorzystac do okreslania istotnosci poszczególnych zdan.
Dysponujac taka informacja mozemy stworzyc automatyczne streszczenie.
Zastosowany algorytm w duzej mierze przypomina ten zastosowany w systemie ANES
(por. rozdział 2.3.1 na stronie 21). Składaja sie na niego nastepujace fazy:

3.2. Sumaryzacja 30
1. tworzenie zbioru słów znaczacych,
a) wybór słów,
b) tworzenie rankingu słów,
2. obliczanie wag zdan – polega na sumowaniu wag słów znaczacych wchodzacych w skład
danego zdania,
3. Wybór zdan – do streszczenia wybierane sa zdania z najwyzszymi wagami.
Przeprowadzenie opisanego powyzej postepowania wymaga zdefiniowania wartosci kilku
parametrów.
• Czy wagi sa obliczane dla wszystkich słów, czy tylko dla rzeczowników?
• Wartosc progowa – jezeli wartosc wagi dla danego wyrazu jest mniejsza, niz zadany
próg wyraz jest ignorowany.
• Liczba słów wchodzacych do zbioru znaczacego – jezeli wartosc jest okreslona, w zbio-
rze znajdzie sie tylko n wyrazów o najwyzszych wagach.
Tworzenie zbioru słów znaczacych odbywa sie w dwóch etapach. W przypadku gdy algo-
rytm operuje tylko na rzeczownikach, w pierwszym kroku sa one oddzielane od pozostałych
wyrazów. Dalej, dla przetwarzanego zbioru słów obliczamy wartosci wag. Nastepnie wyli-
czane sa wagi dla poszczególnych zdan, wybierana jest odpowiednia liczba zdan ocenionych
najwyzej. W koncowej fazie działania algorytmu, wybrane zdania sa ustawiane w kolejnosci
w jakiej wystepowały w tekscie zródłowym.
Oba uzyte sposoby obliczania wag wymagaja dostepu do referencyjnego zbioru doku-
mentów. Uzyty do tego celu został korpus stworzony na podstawie kopii bazy danych pol-
skiej Wikipedii1. Zawiera on ponad 300 tys. artykułów w jezyku polskim. W przypadku funk-
cji bm25 konieczne jest równiez okreslenie sredniej długosci dokumentu w referencyjnej ko-
lekcji. Wartosc ta dla opisanego korpusu to około 80 słów.
Rozpatrzmy fragment znanego nam juz tekstu:
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest
spółek, notowanych na giełdzie. Polski rynek prezentuje sie dobrze, jest własciwie
przygotowany pod wzgledem organizacyjnym i prawnym.
Załózmy, ze wielkosc zbioru znaczacego jest równa 3, dla obliczenia wag uzyjemy za-
równo tf-idf jak i bm25 biorac pod uwage tylko rzeczowniki. Otrzymane słowa kluczowe
i wartosci ich wag przedstawiono w tabeli 3.1 na nastepnej stronie. W obu przypadkach wy-
brane zostanie zdanie „Rynek kapitałowy w Polsce. . . ”. Zawiera ono wszystkie trzy najlepiej
ocenione słowa kluczowe w efekcie czego jego ocena jest najwyzsza.
1Szczegóły dotyczace sposobu pozyskania tych danych znajdzie czytelnik w rozdziale 4

3.2. Sumaryzacja 31
TABLICA 3.1: Otrzymane słowa kluczowe wraz z wartosciami wag w obu schematach.
tf-idf bm25
rynek 0,331 1,061giełdzie 0,237 0,801spółek 0,2 0,677
3.2.3 Metody wykorzystujace łancuchy leksykalne
Zastosowany algorytm w ogólnosci nie rózni sie zbytnio od tego przedstawionego w roz-
dziale 2.3.2. Zostały jednak wprowadzone pewne uproszczenia wynikajace ze złozonej obli-
czeniowo natury tego algorytmu.
Tezaurus
Konstrukcja łancuchów leksykalnych wymaga dostarczenia informacji o powiazaniach
miedzy słowami. Dla jezyka polskiego dostepny jest darmowy tezaurus http://synonimy.
ux.pl redagowany przez Marcina Miłkowskiego. Jest on dystrybuowany w kilku formatach:
• prosty plik tekstowy,
• format słownikowy wykorzystywany w pakiecie OpenOffice,
• format słownikowy programu KOffice.
Na potrzeby konstrukcji łancuchów leksykalnych potrzebna jest nie tylko informacja o sy-
nonimach, ale równiez dane o pojeciach nad- i podrzednych. Opisywany tezaurus nie za-
wiera tych informacji w prostej wersji tekstowej, konieczne było stworzenie własnego par-
sera dla formatu słownika pakietu OpenOffice. Tezaurus w tym formacie zbudowany jest
z dwóch plików: indeksu i własciwego pliku tekstowego, zawierajacego powiazania miedzy
wyrazami. Przykładowy wpis w takim pliku tekstowym ma postac:
gruzy|2
-|gruzowisko|resztki|ruina|rumowisko|zgliszcza
|nieczystości (pojęcie nadrzędne)|odpady (pojęcie nadrzędne)
-|kamienie polne|piarg|żwir
Wyraz „gruzy” znajduje sie w dwóch zbiorach znaczeniowych (ang. synsets). Elementami
takiego zbioru moga byc oznaczone jedna badz kilkoma etykietami, np. „pojecie nadrzedne”,
„pojecie podrzedne”, „przestarz.”, „pot.”, „ksiazk.”, „specjalist.”. W omawianym przypadku
istotna jest dla nas informacja o pojeciach nad- (hipernimach) i podrzednych (hiponimach),
pozostałe etykiety moga zostac zignorowane, a wyrazy potraktowane jako synonimy.
Ponadto kazdemu zbiorowi znaczeniowemu przyporzadkowany został unikalny liczbowy
identyfikator.

3.2. Sumaryzacja 32
Budowanie łancuchów leksykalnych
Zastosowany w niniejszej pracy algorytm automatycznego tworzenia streszczen został
oparty na heurystyce uwzgledniajacej wieloznacznosc elementów łancucha leksykalnego za-
proponowanej w [BE97]. W pierwszej fazie działania algorytm tworzy łancuchy leksykalne,
nastepnie dokonywany jest wybór najwazniejszych zdan i synteza wynikowego streszczenia.
Budowanie łancuchów składa sie z opisanych ponizej kroków:
1. wybór wyrazów,
2. dla kazdego wyrazu:
• pobranie z tezaurusa grup znaczeniowych,
• dodanie wyrazu do zbioru mozliwych interpretacji,
3. gdy algorytm dotrze do konca zdania usuwane sa najmniej obiecujace interpretacje,
4. gdy osiagnieta zostanie granica akapitu:
• z zebranych interpretacji tworzone sa łancuchy leksykalne,
• nowe łancuchy sa łaczone z łancuchami z poprzednich akapitów,
• ze zbioru połaczonych łancuchów wybierane sa te najmocniejsze,
5. po przetworzeniu wszystkich akapitów łancuchy sa sortowane malejaco wzgledem miary
ich jakosci.
Do budowy łancuchów moga zostac wykorzystane tylko rzeczowniki, badz wszystkie wy-
razy – w obu przypadkach wyrazy pospolite zostana zignorowane.
Dla kazdego wyrazu (leksemu) pobierana jest z tezaurusa informacja o grupach znacze-
niowych do których on nalezy. Na podstawie otrzymanych grup znaczeniowych tworzone sa
interpretacje. Gdy algorytm rozpoczyna swoje działanie lista interpretacji jest pusta.
Przez interpretacje bedziemy rozumiec obiekt o nastepujacych cechach:
• do jednej interpretacji moze nalezec wiele róznych leksemów,
• leksem jest opisywany przez liste wystapien oraz identyfikator zbioru znaczeniowego,
Jezeli wyraz posiada dwa rózne znaczenia (znajduje sie w dwóch róznych zbiorach znacze-
niowych), nalezy stworzyc dwie oddzielne interpretacje. Dodanie do interpretacji wyrazu (w
konkretnym znaczeniu), który juz sie w niej znajduje spowoduje dodanie kolejnej pozycji na
liscie jego wystapien.
Poniewaz liczba elementów na liscie interpretacji rosnie bardzo szybko, gdy osiagniety
zostanie koniec zdania program sprawdza, czy liczba interpretacji nie przekroczyła zadanej
wartosci maksymalnej. Jezeli warunek ten zostanie spełniony, ze stworzonych dotychczas
interpretacji wybierane sa najsilniejsze. To, czy dana interpretacja jest lepsza od innej za-
lezy od tego, ile sposród jej elementów jest ze soba powiazanych (im wiecej powiazan tym

3.2. Sumaryzacja 33
lepiej). Powiazanie wystepuje miedzy dwoma leksemami, które posiadaja ten sam identyfi-
kator zbioru znaczeniowego – oznacza to, ze według rozpatrywanej interpretacji zostały one
uzyte w tym samym znaczeniu.
Łancuchy sa tworzone w momencie, gdy osiagnieta zostanie granica akapitu. Dla kaz-
dej interpretacji wybierane sa wszystkie jej elementy. Nastepnie program sprawdza, które
z elementów sa ze soba powiazane. [BE97] proponuje trzy rodzaje relacji miedzy wyrazami:
• bardzo silna (ang. extra-strong) – miedzy wyrazem, a jego powtórzeniem,
• silna (ang. strong) – pomiedzy słowami połaczonymi relacja wynikajaca z tezaurusa
(synonimia, hypernimia),
• srednia (ang. medium-strong) – jezeli sciezka łaczaca dwa wyrazy (wynikajaca z tezau-
rusa) jest dłuzsza niz 1.
W zastosowanym rozwiazaniu rozpatrywane sa jedynie pierwsze dwa typy relacji. Elemen-
tami tego samego łancucha leksykalnego moga wiec byc tylko powtórzenia danego wyrazu
lub słowa nalezace do tego samego zbioru znaczeniowego.
Stworzone w ten sposób łancuchy sa łaczone z łancuchami utworzonymi dla poprzed-
nich akapitów. Dwa łancuchy moga zostac ze soba połaczone, jezeli leksemy które je two-
rza znajduja sie w tym samym zbiorze znaczeniowym. Informacja o znaczeniu w jakim zo-
stał uzyty wyraz wynika z interpretacji na podstawie której został wygenerowany dany łan-
cuch. Wewnatrz łancucha kazde słowo jest równiez reprezentowane za pomoca identyfika-
tora zbioru znaczeniowego i liste wystapien. W tabeli 3.2 zaprezentowany został przykład
łaczenia dwóch łancuchów leksykalnych, których elementy naleza do tego samego zbioru
znaczeniowego.
TABLICA 3.2: Łaczenie łancuchów leksykalnych.
słowo wystapienia
łancuch 1 zamek 1, 1, 2, 3twierdza 0, 10
łancuch 2 twierdza 4, 5cytadela 6, 7
wynik zamek 1, 1, 2, 3cytadela 6, 7twierdza 0, 6, 7, 10
Po połaczeniu, sposród zebranych z dotychczas przetworzonego tekstu łancuchów lek-
sykalnych wybierane sa silne łancuchy. W rozdziale 2.3.2 przedstawiona została miara siły
jakosci łancuchów zaproponowana przez [BE97]. Nalezy jednak zwrócic uwage na fakt, ze
tak sformułowana funkcja oceny, posiada zasadnicza wade. Rozwazmy nastepujace dwa łan-
cuchy leksykalne (w nawiasach znaczenie, liczba wystapien):

3.2. Sumaryzacja 34
• zamek (budowla, 1), cytadela (budowla, 1), twierdza (budowla, 1),
• zamek (zasuwa, 1)
Zgodnie z zaproponowana przez [BE97] miara jakosci oba te łancuchy maja taka sama
siłe. Oba łancuchy powstały ze słowa „zamek”. W przypadku pierwszego, znaczenie wyrazu
„zamek” zostało „potwierdzone” poprzez odnalezienie w tekscie jego synonimów. W tekscie
natomiast nie wystapiły wyrazy powiazane ze słowem zamek w znaczeniu „zasuwa”. Wi-
dzimy, wiec, ze długosc łancucha jest istotna w kontekscie poprawnej dezambiguacji wy-
razu. Wykorzystujac miare jakosci zaproponowana przez [BE97], istnieje mozliwosc utraty
dłuzszego łancucha na etapie wyboru silnych łancuchów. W zastosowanej metodzie wpro-
wadzono do funkcji oceny dodatkowy składnik:
Ocena(Łancuch) = l ·h +d (3.1)
Gdzie d to liczba leksemów z których dany łancuch sie składa.
Łancuch leksykalny bedziemy nazywali silnym, jezeli jego ocena jest wieksza lub równa
sredniej ocenie łancuchów z rozpatrywanego zbioru.
Gdy algorytm dociera do konca tekstu, łancuchy leksykalne sa sortowane malejaco wzgle-
dem funkcji oceny.
Wybór zdan
Na podstawie otrzymanych łancuchów leksykalnych i ich oceny algorytm dokonuje wy-
boru najwazniejszych zdan. Kazdy łancuch leksykalny składa sie z wyrazów i ich listy wysta-
pien. Lista wystapien to po prostu lista zdan, w których dany wyraz wystepuje. Waga danego
zdania jest równa sumie ocen łancuchów, których elementy znajduja sie w danym zdaniu.
Rozpatrzmy nastepujacy przykład:
„Zamek króla Korybuta był ogromny, o władcy i jego twierdzy słyszała cała Eu-
ropa.”
oraz łancuchy leksykalne (w nawiasach liczba wystapien, numer zdania):
1. zamek (1,1) i twierdza (1,1)
2. król(1,1) i władca(1,1)
Siła tych łancuchów jest równa 2. Poniewaz zdanie to zawiera dwa wyrazy z pierwszego
łancucha oraz dwa wyrazy z drugiego łancucha jego łaczna waga to: 2 ·2+2 ·2 = 8. Zdania
których wyrazy nie naleza do zadnego z łancuchów otrzymuja wage 0.
Synteza streszczenia polega wiec na wyborze n zdan o najwyzszych wagach.

3.2. Sumaryzacja 35
Przykład
Rozwazmy prosty przykład:
„Zamek króla Korybuta był ogromny, o twierdzy tej słyszała cała Europa.”
Przy budowie łancucha uwzglednione beda tylko rzeczowniki. Po wstepnym przetwo-
rzeniu otrzymamy nastepujaca liste wyrazów:
zamek, król,korybut, twierdza, europa
Budowe łancucha rozpoczynamy od wyrazu „zamek”. Zgodnie z tezaurusem ma on trzy
znaczenia: twierdza(1), zamkniecie(2), zamek błyskawiczny(3). Istnieja wiec trzy mozliwe, wy-
kluczajace sie interpretacje.
Kolejny wyraz: „król” ma równiez (wg. tezaurusa) trzy znaczenia: monarcha(1), figura
szachowa(2), samiec królika(3). Zadna z interpretacji nie jest powiazana ze słowem zamek
(nie jest synonimem, ani hypernimem) musimy wiec rozwazyc wszystkie mozliwe interpre-
tacje – ich liczba wzrasta do 9 (patrz rysunek 3.1).
RYSUNEK 3.1: Drzewo mozliwych interpretacji tworzone w podczas budowania łancuchówleksykalnych.
Słowo „korybut” nie wystepuje w tezaurusie, przechodzimy wiec do nastepnego wyrazu.
Dla terminu „twierdza” otrzymujemy równiez trzy grupy synonimów: cytadela(1), gród(2),
zamek(3). Liczba mozliwosci wzrosnie wiec do 27!
Dodanie słowa „Europa” nic juz nie zmieni, wystepuje ono tylko w jednym znaczeniu
jako stary kontynent(1). Liczba mozliwych interpretacji pozostanie wiec taka sama. Po za-
konczeniu przetwarzania zdania usuwane sa najsłabsze interpretacje. Po zakonczeniu prze-
twarzania fragmentu tekstu, tworzone sa łancuchy leksykalne. Najdłuzszy łancuch (jedyny
dwuelementowy) w powyzszym przykładzie to: zamek-twierdza, poza nim otrzymamy rów-
niez nizej punktowane łancuchy jednoelementowe składajace sie tylko ze słowa „zamek”.

3.3. Wyszukiwanie dokumentów podobnych 36
Liczba mozliwych interpretacji rosnie bardzo szybko, nawet w tak prostym przypadku
konieczne było rozpatrzenie 27 róznych interpretacji.
3.3 Wyszukiwanie dokumentów podobnych
Algorytm wyszukiwania tekstów podobnych na wejsciu przyjmuje tekst, a w wyniku zwraca
dokumenty (z zadanej kolekcji) o najbardziej zblizonej zawartosci. Jest to de facto prosta re-
alizacja załozen modelu wektorowego (por. 2.2.2).
Proces wyszukiwania dokumentów podobnych przebiega w nastepujacych etapach:
1. z tekstu wejsciowego utwórz reprezentujace go zapytanie (wektor słów kluczowych),
a) oblicz wagi wszystkich słów w tekscie wejsciowym,
b) wybierz n najlepiej ocenionych słów,
c) stwórz z najlepszych słów zapytanie,
d) przypisz elementom zapytania odpowiednie wagi,
2. dla kazdego dokumentu w kolekcji stwórz wektor słów,
3. znajdz dokumenty, dla których podobienstwo miedzy zapytaniem, a wektorem słów
kluczowych jest najwyzsze.
W zastosowanym rozwiazaniu uzyty został schemat tf-idf, a do obliczenia wartosci wagi
wykorzystujemy zadana kolekcje dokumentów. Dysponujac wartosciami wag dla wszyst-
kich słów w tekscie wejsciowym, wybieramy n słów o najwyzszych wartosciach, gdzie n jest
mniejsze lub równe liczbie róznych słów w tekscie. Z tych słów tworzone jest zapytanie
(wektor słów), którego poszczególnym elementom przypisane sa obliczone wczesniej wagi.
Nastepnie sposród dokumentów w zadanej kolekcji wybierane sa te, których wektory słów
kluczowych sa najbardziej podobne do zapytania. Tworzenie wektorów słów dla poszcze-
gólnych tekstów odbywa sie na podobnej zasadzie jak w przypadku tekstu wejsciowego. Po-
dobienstwo jest mierzone za pomoca standardowej miary zdefiniowanej dla modelu wek-
torowego (por. rozdział 2.2.2). Wynikowe dokumenty sa posortowane malejaco wzgledem
wartosci miary podobienstwa.

Rozdział 4
Implementacja
Problemem automatycznego generowania streszczen zajmowano sie juz wielokrotnie,
a wypracowane rozwiazania czesto nadaja sie aby wdrozyc je w srodowisku produkcyjnym.
Brakuje jednak ogólnodostepnej implementacji. Projekt taki mógłby byc równiez srodowi-
skiem umozliwiajacym porównywanie i udoskonalanie dotychczas istniejacych metod oraz
implementacje nowych.
W niniejszym rozdziale zostana opisane tylko najwazniejsze koncepcje zwiazane z im-
plementacja algorytmów przedstawionych wczesniej. Szczegółowa dokumentacja techniczna
znajduje sie na płycie dołaczonej do pracy.
4.1 Lakon
W ramach implementacji omawianych w pracy zagadanien powstał program Lakon, któ-
rego nazwa wzieła sie od zwrotu „mówic lakonicznie” czyli krótko, zwiezle i na temat. Wa-
runkiem koniecznym dla dalszego rozwoju stworzonego rozwiazania jest jego ogólna do-
stepnosc – w najblizszej przyszłosci Lakon zostanie udostepniony jako Wolne Oprogramo-
wanie (ang. open-source).
Stworzone narzedzia oferuja mozliwosc testowania nowych metod i porównanie ich z juz
istniejacymi. Przy projektowaniu uwzgledniono mozliwosc rozszerzenia funkcjonalnosci o ob-
sługe jezyków innych niz polski.
4.1.1 Załozenia projektowe
Główne załozenia projektowe to:
Modularnosc Podział wymagan funkcjonalnych na mozliwie niezalezne czesci składowe i ich
implementacja w formie autonomicznych podprojektów.
Przenosnosc Stworzony program powinien przy mozliwie małym nakładzie pracy nadawac
sie do uruchomienia w ramach wielu platform.
37

4.1. Lakon 38
Mozliwosc dalszej rozbudowy Zastosowanie zasad projektowania obiektowego z uwzgled-
nienim wzorców projektowych gwarantuje, ze stworzone rozwiazanie da sie bez wiek-
szych problemów rozszerzyc o nowa funkcjonalnosc.
„Test driven development” (TDD) Wsród wielu praktyk proponowanych przez współcze-
sna inzynierie oprogramowania TDD jest chyba jedna z najwazniejszych. Paradygmat
ten zakłada, ze automatyczny test jednostkowy jest rodzajem kontraktu, który two-
rzony kod programu musi spełnic. Tworzenie nowej funkcjonalnosci rozpoczynamy
od stworzenia automatycznego testu, który weryfikuje wszystkie wymagania ujete w spe-
cyfikacji. Dopiero dysponujac gotowym testem przystepujemy do tworzenia kodu re-
alizujacego dana funkcjonalnosc [Bec02].
4.1.2 Główne składniki projektu
Projektujac wewnetrzna strukture projektu wzieto pod uwage, iz niektóre elementy moga
byc uzywane niezaleznie. Lakon składa sie wiec z czterech podprojektów, z których kazdy
obejmuje swoim zakresem tylko pewien wycinek funkcjonalnosci.
RYSUNEK 4.1: Główne składniki Lakona i ich wzajemne zaleznosci.
Tiller Moduł odpowiedzialny za wstepne przetwarzanie tekstu, jest on bezposrednia reali-
zacja omówionego w rozdziale 3.1 schematu procesu przetwarzania jezyka natural-
nego na potrzeby sumaryzacji.
Summarizer W tym podprojekcie znajduje sie implementacja wszystkich opisywanych w
pracy metod automatycznej sumaryzacji. Ponadto projekt dostarcza srodków umozli-
wiajacych ocene jakosci generowanych streszczen.

4.1. Lakon 39
GUI Graficzny interfejs uzytkownika, umozliwia nie tylko tworzenie streszczen, ale rów-
niez eksperymentowanie z parametrami poszczególnych metod. Z poziomu GUI do-
stepne sa równiez pewne czynnosci nie zwiazane bezposrednio z samym tworzeniem
streszczen np. wyszukiwanie dokumentów podobnych czy wyszukiwanie synonimów
w oparciu o tezaurus.
Aplikacja do zbierania streszczen – jest to aplikacja internetowa, której głównym zadaniem
było udostepnienie grupie ochotników srodków potrzebnych do tworzenia streszczen.
Zebrane w ten sposób dane posłuzyły do oceny jakosci wyników otrzymanych z metod
automatycznych.
Niezaleznie od Lakona stworzone zostało narzedzie nazwane Wiki i umozliwiajace bu-
dowanie indeksu z kolekcji dokumentów. Wiki zostało uzyte do stworzenia indeksu odwrot-
nego w oparciu o kopie zapasowa bazy danych polskiej wersji Wikipedii. Indeks ten jest
wykorzystywany przez niektóre metody automatycznego tworzenia streszczen.
4.1.3 Technologia
Lakon został w całosci napisany w jezyku Java. Java to nowoczesny, obiektowy jezyk pro-
gramowania o jego sile najlepiej swiadczy ogromna liczba projektów ze swobodnie dostep-
nych kodem zródłowym napisanych własnie w Javie. Sposród wielu zalet tego jezyka jedna
z najwazniejszych jest niezaleznosc od srodowiska w jakim aplikacja jest uruchamiana. La-
kon przy stosunkowo niewielkim nakładzie pracy moze byc uruchamiany pod teoretycznie
dowolnym systemem operacyjnym.
W stworzonej implementacji uzyte zostały nastepujace biblioteki:
Lucene Jest to bardzo wydajne i elastyczne narzedzie słuzace do wyszukiwania pełnoteksto-
wego. Biblioteka ta jest wykorzystywana przy wyszukiwaniu dokumentów podobnych
oraz budowaniu indeksu z kolekcji dokumentów. Wiecej informacji o mozliwosciach
tego narzedzia mozna znalezc na stronach projektu: http://lucene.apache.org.
Morfeusz To stworzony przez Marcina Wolinskiego komputerowy słownik morfologiczny
dla jezyka polskiego, wykorzystujacy dane i gramatyke formalna zaproponowana w
[SS98]. Morfeusz nie jest biblioteka Javowa, dostepny jest w formie biblioteki łaczonej
dynamicznie (ang. Dynamic link library, DLL). Dostepny jest jednak moduł umozli-
wiajacy korzystanie z Morfeusza z poziomu programów napisanych w Javie. Morfeusz
do oznaczania czesci mowy wykorzystuje system znaczników morfosyntaktycznych
korpusu IPI PAN [Wol04].
Stempelator To hybrydowy lematyzator dla jezyka polskiego. Składa sie on własciwie z
dwóch czesci: Lametyzator (lematyzator słownikowy), oraz Stempel (lematyzator heu-
rystyczny). W przypadku gdy własciwa forma nie zostanie odnaleziona w słowniku,
uruchamiany jest lematyzator heurystyczny. Wiecej informacji na temat Stempelatora
znajdzie Czytelnik w [Wei05].

4.2. Tiller 40
Ponadto w projekcie uzyty został Apache Maven – jest to narzedzie słuzace do zarzadza-
nia konfiguracja i automatyzacji podstawowych czynnosci zwiazanych z tworzeniem opro-
gramowania. Maven wprowadza obiektowy model projektu (ang. Project Object Model), który
okresla nie tylko strukture wewnetrzna projektu, ale równiez wiekszosc czynnosci zwiaza-
nych z poszczególnymi fazami wytwarzania oprogramowania [MvZ07].
Realizacja postulatów TDD była mozliwa dzieki uzyciu systemu JUnit (w wersji 3.8)1.
W ramach całego projektu powstało około stu testów jednostkowych, obejmujacych swoim
zakresem wiekszosc zaimplementowanej funkcjonalnosci.
Oprócz wymienionych narzedzii w implementacji aplikacji do zbierania streszczen uzyto
dodatkowych bibliotek, najwazniejsze z nich to:
Spring Jest to jedna z najbardziej znanych bibliotek szkieletowych (ang. framework) przy-
spieszajacych tworzenie aplikacji internetowych. Spring jest rodzajem „kleju”, który
ułatwia integracje wielu bibliotek Javowych w tworzonej aplikacji.
Hibernate To narzedzie pozwalajace w łatwy sposób stworzyc odwzorowanie miedzy sche-
matem relacyjnej bazy danych, a modelem obiektowym. Poniewaz sama Java jest je-
zykiem obiektowym, operowanie na obiektach jest o wiele łatwiejsze. Hibernate roz-
wiazuje równiez wiele standardowych problemów zwiazanych z wykorzystaniem bazy
danych np. obsługa puli połaczen, czy obsługa pamieci podrecznej wyników zapytan.
Velocity – biblioteka składa sie z dwóch najwazniejszych elementów: jezyka (ang. Velocity
Template Language, VTL) oraz silnika obsługi szablonów stron HTML.
HSQLDB – prosta baza danych, przechowujaca dane w plikach tekstowych.
JQuery – implementacja wszystkich skyptów w jezyku Javascript została oparta o biblioteke
JQuery. Jest to bardzo proste narzedzie ułatwiajace realizacje złozonych operacji na
strukturze DOM strony HTML oraz elastyczna obsługe zdarzen (np. klikniecie w dany
odsyłacz, załadowanie strony).
4.2 Tiller
Tiller to moduł odpowiedzialny za wstepne przetwarzanie jezyka naturalnego, realizuje
on wszystkie postulaty sformułowane w podrodziale 3.1. Głównym zadaniem projektu jest
przygotowanie na podstawie tekstu wejsciowego modelu, którym beda sie mogły posługiwac
pozostałe składowe systemu.
4.2.1 Architektura
Moduł ten składa sie z nastepujacych pakietów:
1Wiecej informacji na temat omawianych tutaj narzedzi znajdzie Czytelnik w internecie, lista wszystkich od-nosników została zebrana w sekcji 6.2.1.

4.2. Tiller 41
org.grejpfrut.tiller.entities oraz jego podpakiet impl – interfejsy i klasy zawarte
w tych pakietach reprezentuja wewnetrzna strukture tekstu. Definiuja równiez pod-
stawowy zbiór operacji dostepnych dla poszczególnych jednostek strukturalnych tek-
stu (np. akapitów, zdan).
org.grejpfrut.tiller.builders – budowanie modelu okreslonego przez klasy z pakie-
tów entities. Tutaj odbywa sie własciwe przetwarzanie tekstu wejsciowego oraz wy-
dzielanie poszczególnych jednostek strukturalnych.
org.grejpfrut.tiller.analysis – klasy odpowiadajace za analize leksykalna, morfolo-
giczna oraz rozpoznawanie wyrazów pospolitych.
org.grejpfrut.tiller.utils.thesaurus – tezaurus uzywany w programie OpenOffice
zawiera sporo nadmiarowych danych. Aby zwiekszyc jego uzytecznosc dla potrzeb
projektu stworzony został parser, który przygotowuje wersje pozbawiona powtórzen.
Poniewaz tworzenie takiej reprezentacji zajmuje dłuzsza chwile, stworzono narzedzia
umozliwiajace zapis i odczyt z dysku tezaurusa w formacie juz przetworzonym.
org.grejpfrut.tiller.utils – zawiera klasy pomocnicze.
W głównym pakiecie org.grejpfrut.tiller znajduja sie przykładowe programy wy-
korzystujace interfejs programistyczny zdefiniowany w tym module.
4.2.2 Model struktury tekstu
Model struktury tekstu wykorzystywany przez Lakona zbudowany jest z czterech pozio-
mów.
Poziom artykułu – obejmuje on cały tekst. Kazdy artykuł posiada liste akapitów, z których
sie składa, moze tez posiadac tytuł (nie jest to wymagane).
Poziom akapitu – kazdy akapit zbudowany jest z pewnej liczby zdan, ponadto moze posia-
dac nagłówek.
Poziom zdania – składa sie z pojedynczych wyrazów, znaków interpunkcyjnych oraz znaku
konca zdania.
Poziom wyrazu – w stworzonym modelu wyraz posiada dwie formy: oryginalna (taka jak
w tekscie wejsciowym), oraz mozliwe formy podstawowe. Dla form podstawowych
przechowywana jest równiez informacja o ich charakterystyce morfologicznej. Po-
nadto kazdy wyraz moze zostac oznaczony jako pospolity.
Dla kazdego z wymienionych poziomów strukturalnych został zdefiniowany pewien zbiór
operacji. Obejmuje on odwołania do atrybutów dostepnych na danym poziomie (np. tytułu
dla artykułu, czy form podstawowych na poziomie wyrazu). Dla jednostek powyzej poziomu
zdania dostepne sa równiez odwołania do własnosci jednostek podrzednych np. dla akapitu

4.2. Tiller 42
RYSUNEK 4.2: Wszystkie operacje dostepne dla poszczególnych jednostek strukturalnych
mamy mozliwosc pobrania wszystkich nalezacych do niego wyrazów. Wszystkie dostepne
operacje zostały przedstawione na diagramie (rysunek 4.2).
Dodatkowego komentarza wymagaja:
• getText() – zwraca oryginalny, nieprzetworzony tekst.
• getStemmedText() – zwraca ona tekst oczyszczony ze znaków interpunkcyjnych, gdzie
zamiast oryginalnych wyrazów uzyte zostały ich formy podstawowe (w przypadku gdy
dany wyraz posiada kilka form, brana pod uwage jest tylko pierwsza).
• getNumberOfOccur(Token token) – zwraca liczbe wystapien danego wyrazu w bie-
zacej jednostce tekstu.
• interfejs Token:

4.2. Tiller 43
– enumeracja PartOfSpeech – zaden z zaimplementowanych algorytmów nie wy-
magał dokładnego rozpoznawania cech morfologicznych wyrazu. W wiekszosci
przypadków wystarczyła informacja o tym, czy dany wyraz jest rzeczownikiem.
Rozpoznawane sa wiec tylko trzy kategorie wyrazów: rzeczowniki (ang. nouns),
przymiotniki (ang. adjectives) i czasowniki (ang. verbs), pozostałym przyporzad-
kowywana jest etykieta „nieznany” (ang. unknown).
– getInfo() oraz getFirstInfo() – pierwsza zwraca informacje o kategorii mor-
fologicznej do jakiej naleza formy podstawowe wyrazu.
– getBaseForm() – zwraca pierwsza forme podstawowa wyrazu.
– getTerm() interfejsu Token – w Lucene odpowiednikiem interfejsu Token jest
klasa org.apache.lucene.index.Term. Metoda umozliwia konwersje do obiektu
wykorzystywanego w Lucene.
• interfejs Article
– getDocument() – zwraca ona instancje klasy org.apache.lucene.document-
.Document, która jest wykorzystywana przez biblioteke Lucene do budowania
indeksu dokumentów. Stworzony dokument składa sie z trzech pól:
* title – gdzie znajduje sie tytuł artykułu (jezeli został zdefiniowany),
* text – oryginalny tekst,
* stems – wynik działania metody getStemmedText().
4.2.3 Przetwarzanie tekstu
Proces rozpoznawanie struktury tekstu został omówiony szczegółowo w podrozdziale
3.1. Realizacja przedstawionych tam algorytmów zajmuja sie klasy z pakietu org.grejp-
frut.tiller.builders. Na rysunku 4.3 przedstawiony został diagram klas, nalezacych do
omawianego pakietu.
ArticleBuilder – tworzy instancje klasy implementujacej interfejs Article.
ParagraphBuilder – odpowiada za wyodrebnienie akapitów z tekstu wejsciowego, jest to
dokładna implementacja algorytmu opisanego w podrozdziale 3.1.1.
SentenceBuilder – zadaniem tej klasy jest wykrycie w zadanym tekscie granic zdan (por.
3.1.1).
TokenBuilder – tworzy instancje klasy Token, która reprezentuje pojedynczy wyraz. Klasa
ta realizuje nastepujace czynnosci:
• wykrycie, czy dany wyraz jest wyrazem pospolitym,
• w przypadku, gdy dostepny jest odpowiedni analizator, odnalezienie formy pod-
stawowej (badz formy hasłowej),

4.2. Tiller 44
RYSUNEK 4.3: Diagram klas dla pakietu org.grejpfrut.tiller.builders.
• w przypadku, gdy dostepny jest analizator morfologiczny, przydzielenie odnale-
zionym formom podstawowym odpowiednich etykiet morfologicznych.
Kazda z powyzszych klas moze byc uzywana samodzielnie np. dla zadanego tekstu po-
bierane sa wyłacznie zdania, pomijamy tworzenie akapitów.
Przetwarzaniem na poziomie pojedynczych wyrazów zajmuja sie klasy z pakietu
org.grejpfrut.tiller.analysis (por. rysunek 4.4).
StopWordsTokenizer – klasa jest odpowiedzialna za:
• usuniecie wszystkich znaków interpunkcyjnych „przyklejonych” do wyrazu,
• ustalenie, czy dany wyraz znajduje sie na liscie wyrazów pospolitych.
Tworzy ona instancje klasy implementujacej interfejs Token, obiekt ten jako forme
podstawowa wyrazu przyjmuje oczyszczony z interpunkcji wyraz oryginalny.
StempelatorTokenizer – realizuje te same czynnosci co StopWordsTokenizer, potrafi
jednak odnalezc forme hasłowa wyrazu, wykorzystuje do tego Stempelator.
MorpheusTokenizer – rozszerza funkcjonalnosc StopWordsTokenizer o wszystkie formy
podstawowe wyrazu, wraz z ich charakterystyka morfologiczna (przy uzyciu słownika
morfologicznego zaimplementowanego w Morfeuszu).
Wszystkie trzy omówione klasy implementuja interfejs TillerTokenizer, który defi-
niuje metode: getToken(String word) zwracajaca instancje klasy implementujacej inter-
fejs Token.

4.2. Tiller 45
RYSUNEK 4.4: Hierarchia klas w pakiecie org.grejpfrut.tiller.analysis.
4.2.4 Tezaurus
SynSet – klasa implementujaca ten interfejs reprezentuje zbiór znaczeniowy, posiada on
nastepujace cechy:
• liste wyrazów o tym samym znaczeniu (synonimów),
• liste pojec nadrzednych (hipernimów),
• liste pojec podrzednych (hiponimów),
• identyfikator danego zbioru znaczeniowego.
ThesaurusParser – przetwarza plik tekstowy z tezaurusem w formacie programu OpenOf-
fice, rozpoznaje elementy oznaczone jako „pojecie nadrzedne” i „pojecie podrzedne”.
Przygotowuje równiez indeks, który umozliwia szybkie odnalezienie identyfikatora zbioru
znaczeniowego, do którego nalezy szukany wyraz.
ThesaurusFactory – klasa odpowiedzialna za:

4.2. Tiller 46
• stworzenie instancji klasy Thesaurus na podstawie wyników działania
ThesaurusParser,
• serializacje i deserializacje instancji Thesaurus,
• pełni równiez funkcje pamieci podrecznej, poniewaz deserializacja danych z dysku
zajmuje dłuzsza chwile, klasa ta zapamietuje raz wczytany tezaurus i przy kaz-
dym kolejnym zadaniu zwraca te sama instancje.
Thesaurus – klasa reprezentujaca tezaurus, udostepnia ona dwie metody:
• getSynSets(String term) – zwraca liste elementów typu SynSet, w których
znajduje sie szukany wyraz,
• getById(int id) – zwraca obiekt reprezentujacy zbiór znaczeniowy od danym
identyfikatorze.
4.2.5 Konfiguracja
W rozdziałach poswieconych automatycznej analizie jezyka naturalnego zostało zasy-
gnalizowane, ze niektóre etapy tego procesu moga byc w zaleznosci od zastosowania po-
mijane. Takimi opcjonalnymi czynnosciami sa miedzy innymi:
• analiza morfologiczna
• lematyzacja,
• rozpoznawanie struktury wewnetrznej tekstu,
• oznaczanie wyrazów pospolitych
• odróznianie nagłówków od akapitów.
To, które etapy maja byc realizowane i w jakim zakresie okreslane jest w konfiguracji. Do-
myslne ustawienia zawarte sa w pliku tiller-conf.xml (plik ten znajduje sie w katalogu:
lakon/tiller/src/main/resources). Kazda z klas wykorzystywanych do przetwarzania
tekstu (pakiety builders i analysis) przyjmuje w konstruktorze instancje
TillerConfiguration. Udostepnia ona domyslna konfiguracje, która mozna zmodyfiko-
wac według potrzeb.
Zostały zdefiniowane nastepujace parametry konfiguracyjne:
• tokenizer.class.name – w zaleznosci od potrzeb mozemy wyspecyfikowac która
z klas pakietu analysis ma zostac uzyta przy tworzeniu obiektów reprezentujacych
wyrazy,
• min.paragraph.length – minimalna długosc akapitu, jezeli nie chcemy, aby Tiller
rozpoznawał nagłówki akapitów, nalezy ustawic tu 0.
• path.to.thesaurus – sciezka do pliku tekstowego, w którym znajduje sie tezaurus
w formacie programu OpenOffice,

4.3. Summarizer 47
• stop.words – lista wyrazów pospolitych,
• abbr.list – lista najczesciej wystepujacych skrótowców.
4.3 Summarizer
Druga składowa systemu jest Summarizer. W module tym znajduja sie implementacje
wszystkich omówionych dotychczas metod. Krótki opis zagadnien zwiazanych z implemen-
tacja tych algorytmów znajdzie czytelnik w rozdziale 4.3.1. Moduł ten zawiera równiez na-
rzedzia słuzace do oceny jakosci generowanych streszczen.
4.3.1 Architektura
W skład omawianego modułu wchodza nastepujace pakiety:
org.grejpfrut.lakon.summarizer.methods wraz podpakietami weights i lc – zawie-
raja implementacje metod automatycznego generowania streszczen.
org.grejpfrut.lakon.summarizer.settings – to klasy odpowiedzialne za zarzadzajace
parametrami konfiguracyjnymi poszczególnych metod.
org.grejpfrut.lakon.summarizer.evaluation – głównym zadaniem klas w tym pakie-
cie jest przeprowadzenie analizy wyników działania automatycznych metod w oparciu
o wyniki eksperymentu ewaluacyjnego (por. rozdział 5).
org.grejpfrut.lakon.summarizer.utils – klasy pomocnicze.
W głównym pakiecie org.grejpfrut.lakon.summarizer znajduja sie przykładowe pro-
gramy wykorzystujace interfejs programistyczny zdefiniowany w tym module.
4.3.2 Zaimplementowane metody
Dla celów porównawczych zaimplementowane zostały równiez dwie dodatkowe metody:
• losowy wybór zdan,
• wybór pierwszych n zdan.
Summarizer udostepnia w sumie szesc metod automatycznego generowania streszczen.
Wszystkie implementacje rozszerzaja klase SummarizerBase, która z kolei implementuje in-
terfejs Summarizer, zaleznosci te zostały zaprezentowane na rysunku 4.5 na nastepnej stro-
nie.
RandomSummarizer – klasa ta w sposób losowy wybiera n zdan z przekazanego na wejsciu
tekstu.
LocationBasedSummarizer – działa ona w dwóch trybach:
• FIRST – jako streszczenie zwracane jest pierwsze n zdan z tekstu,

4.3. Summarizer 48
RYSUNEK 4.5: Hierarchia klas w pakiecie org.grejpfrut.tiller.summarizer.
• FIRST_IN_PARAGRAPH – streszczenie jest tworzone zgodnie z algorytmem omó-
wionym w rozdziale 3.2.1.
WeightsBasedSummarizer – jest to dokładna implementacja algorytmu omówionego w roz-
dziale dotyczacym metod opartych na technikach automatycznego wyboru najwaz-
niejszych wyrazów (por. rozdział 3.2.2). Obok parametrów takich jak długosc stresz-
czenia, czy rodzaj branych pod uwage słów, nalezy okreslic jaki schemat obliczania
wag ma byc uzyty. Dostepne sa dwa (odpowiednie klasy znajduja sie w pakiecie
...summarizer.methods.weights):
• tf-idf (klasa TFIDFWeight),
• Okapi bm25 (klasa BM25Weight).
LexicalChainsSummarizer – obszerne omówienie zastosowanego tu algorytmu znajdzie
czytelnik w rozdziale 3.2.3. Omawiana metoda posiada nastepujace parametry konfi-
guracyjne:
• maksymalna liczba interpretacji,
• jakie czesci mowy sa brane pod uwage przy konstrukcji łancuchów leksykalnych,
• czy przy tworzeniu streszczenia uwzgledniac tylko wyrazy reprezentatywne.
4.3.3 Konfiguracja
Za konfiguracje poszczególnych metod odpowiedzialna jest klasa Settings wraz z pod-
klasami. Głównym zadaniem klas konfigurujacych jest wczytanie wartosci domyslnych z pli-
ków i uzupełnienie ich wartosciami uzytkownika. Zdefiniowane sa tutaj wszystkie enume-

4.3. Summarizer 49
racje okreslajace dopuszczalne wartosci parametrów oraz nazwy wszystkich kluczy które
identyfikuja wartosci poszczególnych parametrów. Wartosci domyslne znajduja sie w pliku
summarizer-conf.properties w (katalog summarizer/src/main/resource). Ponizej przed-
stawione zostały najwazniejsze parametry konfiguracyjne.
Metody wykorzystujace wagi tf-idf i bm25.
• ref.index.dir – sciezka do katalogu w którym znajduje sie indeks stworzony na
podstawie referencyjnej kolekcji dokumentów jest on uzywany: przy obliczaniu war-
tosci wag, oraz wyszukiwaniu tekstów podobnych.
• ave.doc.length – jest to srednia długosc dokumentu znajdujacego sie w indeksie
referencyjnym. Wartosc ta jest oczywiscie rózna w zaleznosci od tego, jaka kolekcja
dokumentów została wykorzystana do stworzenia indeksu. Lakon dostarcza narze-
dzi umozliwiajacych obliczenie sredniej długosci dokumentu w zadanym indeksie, ich
działanie zostanie omówione w nastepnym podrozdziale.
• min.tfidf i min.bm25 – minimalna wartosci dla wag tf-idf i bm25. Słowa o charakte-
ryzujace sie nizsza wartoscia wagi nie beda uwzgledniane przy: obliczaniu istotnosci
zdan, wyszukiwaniu dokumentów podobnych.
• weight.type – jaka waga zostanie uzyta aby obliczac siłe poszczególnych zdan, moz-
liwe wartosci to: TFIDF, BM_25.
• signature.words.type – jakiego typu słowa sa brane pod uwage przy tworzeniu
zbioru słów znaczacych mozliwe wartosci to:
– ALL – wszystkie słowa,
– NOUNS – tylko rzeczowniki.
• no.of.keywords – ile słów ma byc wzietych pod uwage przy tworzeniu zbioru słów
znaczacych (por. rozdział 3.2.2). Jezeli przy tworzeniu maja byc wykorzystane wszyst-
kie słowa, których waga przekroczyła wartosc progowa, nalezy przypisac temu para-
metrowi wartosc -1.
Sumaryzacja z wykorzystaniem łancuchów leksykalnych.
• only.nouns – czy przy tworzeniu łancuchów leksykalnych maja byc brane pod uwage
tylko rzeczowniki (wartosc true) czy wszystkie wyrazy (wartosc false).
• max.interpretation – maksymalna liczba interpretacji, które sa rozpatrywane w trak-
cie tworzenia łancuchów.
• representative.mode – do tworzenia streszczenia wykorzystywane sa tylko wyrazy
reprezentatywne.

4.4. GUI 50
4.4 GUI
Głównym zadaniem tego modułu jest:
• prezentacja wyników działania zaimplementowanych algorytmów,
• eksperymenty z wartosciami parametrów konfiguracyjnych,
Ponizej zostanie krótko opisana aplikacja okienkowa realizujaca wymienione powyzej
cele. Została ona stworzona z wykorzystaniem biblioteki Swing, która jest czescia biblioteki
klas dostarczanych z jezykiem Java. Poza nia wykorzystane zostały:
• fragmenty kodu zródłowego projektu C ar r ot 2 (http://www.carrot2.org),
• biblioteki JGoodies Forms oraz JGoodies Looks (http://jgoodies.com).
4.4.1 Funkcjonalnosc
Funkcjonalnosc aplikacji mozemy podzielic na dwie czesci:
1. demonstracje działania algorytmów:
a) wykrywanie struktury wewnetrznej tekstu,
b) informacje o strukturze wewnetrznej tekstu – długosc tekstu, liczba zdan i akapi-
tów,
c) demonstracja działania tezaurusa,
d) wyszukiwanie dokumentów podobnych,
e) konstrukcja łancuchów leksykalnych,
f) automatyczna sumaryzacja tekstu:
• losowy wybór zdan,
• wybór pierwszych n zdan,
• metoda wykorzystujaca informacje o połozeniu zdania w tekscie,
• metoda wykorzystujaca schematy wag tf-idf oraz bm25,
• w oparciu o łancuchy leksykalne.
2. czynnosci dodatkowe:
a) tworzenie „lakonicznej” reprezentacji tezaurusa w oparciu o plik tekstowy w for-
macie programu OpenOffice,
b) obliczanie sredniej długosci dokumentu w indeksie zbudowanym na podstawie
referencyjnej kolekcji dokumentów,

4.4. GUI 51
RYSUNEK 4.6: Główne okno aplikacji oraz najwazniejsze jego elementy.
Główne okno aplikacji
Rysunek 4.6 przedstawia najwazniejsze elementy głównego okna aplikacji.
1. Główne okno aplikacji.
2. Przycisk powodujacy ukrycie panelu z parametrami konfiguracyjnymi (na rysunku pa-
nel oznaczony został numerem 6).
3. Pierwszy przycisk (ikonka rakiety) uruchamia aktualnie wybrana metode, natomiast
drugi otwiera okienko dialogowe z wyborem pliku, na którym bedziemy operowac.
Plik musi byc prostym plikiem tekstowym kodowanym zgodnie z UTF-8.
4. Znajduje sie tu lista dostepnych metod (demonstracji).
5. Obszar w którym mozemy wpisywac tekst recznie lub wczytac plik za pomoca opisa-
nego powyzej przycisku.
6. Panel z ustawieniami dostepny jest dla wiekszosci zaimplementowanych metod. Kazda
zmiana wartosci zostanie natychmiast uwzgledniona w czesci prezentujacej wyniki.
7. Ta czesc prezentuje wyniki działania poszczególnych metod. W przypadku algoryt-
mów generujacych streszczenia wyniki moga byc wyswietlane w dwóch trybach: wy-
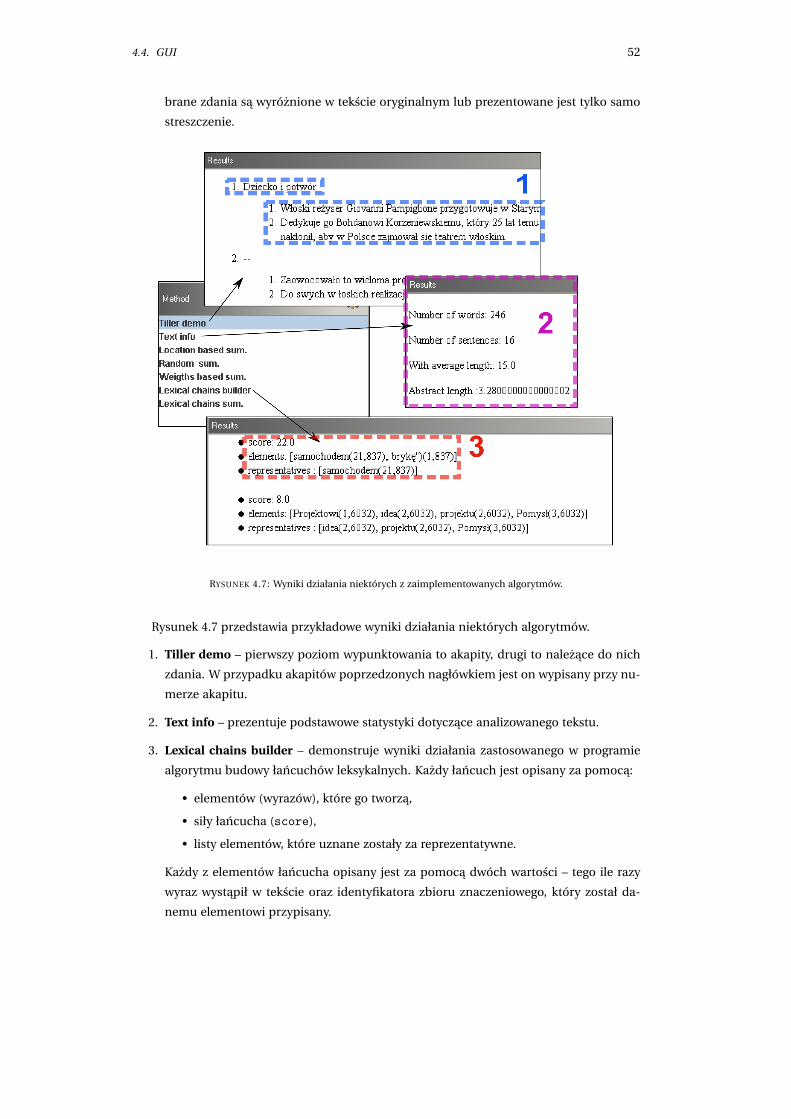
4.4. GUI 52
brane zdania sa wyróznione w tekscie oryginalnym lub prezentowane jest tylko samo
streszczenie.
RYSUNEK 4.7: Wyniki działania niektórych z zaimplementowanych algorytmów.
Rysunek 4.7 przedstawia przykładowe wyniki działania niektórych algorytmów.
1. Tiller demo – pierwszy poziom wypunktowania to akapity, drugi to nalezace do nich
zdania. W przypadku akapitów poprzedzonych nagłówkiem jest on wypisany przy nu-
merze akapitu.
2. Text info – prezentuje podstawowe statystyki dotyczace analizowanego tekstu.
3. Lexical chains builder – demonstruje wyniki działania zastosowanego w programie
algorytmu budowy łancuchów leksykalnych. Kazdy łancuch jest opisany za pomoca:
• elementów (wyrazów), które go tworza,
• siły łancucha (score),
• listy elementów, które uznane zostały za reprezentatywne.
Kazdy z elementów łancucha opisany jest za pomoca dwóch wartosci – tego ile razy
wyraz wystapił w tekscie oraz identyfikatora zbioru znaczeniowego, który został da-
nemu elementowi przypisany.

4.4. GUI 53
Narzedzia dodatkowe
Czesc z utworzonych narzedzi została udostepniona z poziomu głównego menu. Na ry-
sunku 4.8 na nastepnej stronie pokazane zostało okienko dialogowe (na rysunku oznaczone
jako „1”) słuzace do konwersji tezaurusa z formatu programu OpenOffice do reprezentacji
uzywanej w projekcie. Numer „2” to okienko dialogowe pozwalajace na wyszukiwanie syno-
nimów podanego wyrazu. Szukane słowo wpisujemy w pole tekstowe u góry okienka, a w
głównej jego czesci zostana wyswietlone wszystkie zbiory znaczeniowe, w których dany wy-
raz wystepuje. Wyswietlany jest cały zbiór znaczeniowy: identyfikator, nalezace do niego
synonimy, hiponimy i hipernimy.
Wybranie opcji oznaczonej na rysunku numerem „3” spowoduje wyswietlenie okienka
dialogowego. Nalezy wskazac sciezke pod która znajduje sie indeks dla którego ma zostac
policzona srednia długosc dokumentu.
Ostatnia z dostepnych opcji jest uruchomienie aplikacji wyszukujacej dokumenty po-
dobne. Widok głównego okna tej aplikacji został przedstawiony na rysunku 4.9 na nastepnej
stronie.
1. W pasku narzedziowym („1” na rysunku) dostepne sa nastepujace opcje (od lewej):
• uruchomienie wyszukiwania,
• wczytanie zawartosci prostego pliku tekstowego (kodowanie UTF-8),
• nowa zakładka w polu edycji tekstu,
• ukrycie panelu konfiguracyjnego.
2. W polu edycyjnym („2”) moze znajdowac sie wiele otwartych plików, kazda z zakładek
moze byc w kazdej chwili zamknieta.
3. Na podstawie tekstu umieszczonego w aktywnej zakładce tworzony jest ranking („3”)
najbardziej wartosciowych słów (w oparciu o schemat tf-idf).
4. Lista („4”) zawiera tytuły artykułów, które zostały uznane za najbardziej podobne do
tekstu znajdujacego sie w aktywnej zakładce edycyjnej.
5. Panel konfiguracyjny („5”) działa analogicznie jak w przypadku aplikacji demonstru-
jacej działanie algorytmów automatycznej generacji streszczen.
4.4.2 Konfiguracja
Cała konfiguracja znajduje sie w pliku gui-conf.xml, aby uruchomic aplikacje konieczne
jest podanie trzech parametrów:
ref.index.dir – sciezka do indeksu zawierajace dane o referencyjnym zbiorze dokumen-
tów.
path.to.thesaurus – sciezka do katalogu w którym znajduje sie tezaurus w wewnetrznej
reprezentacji.
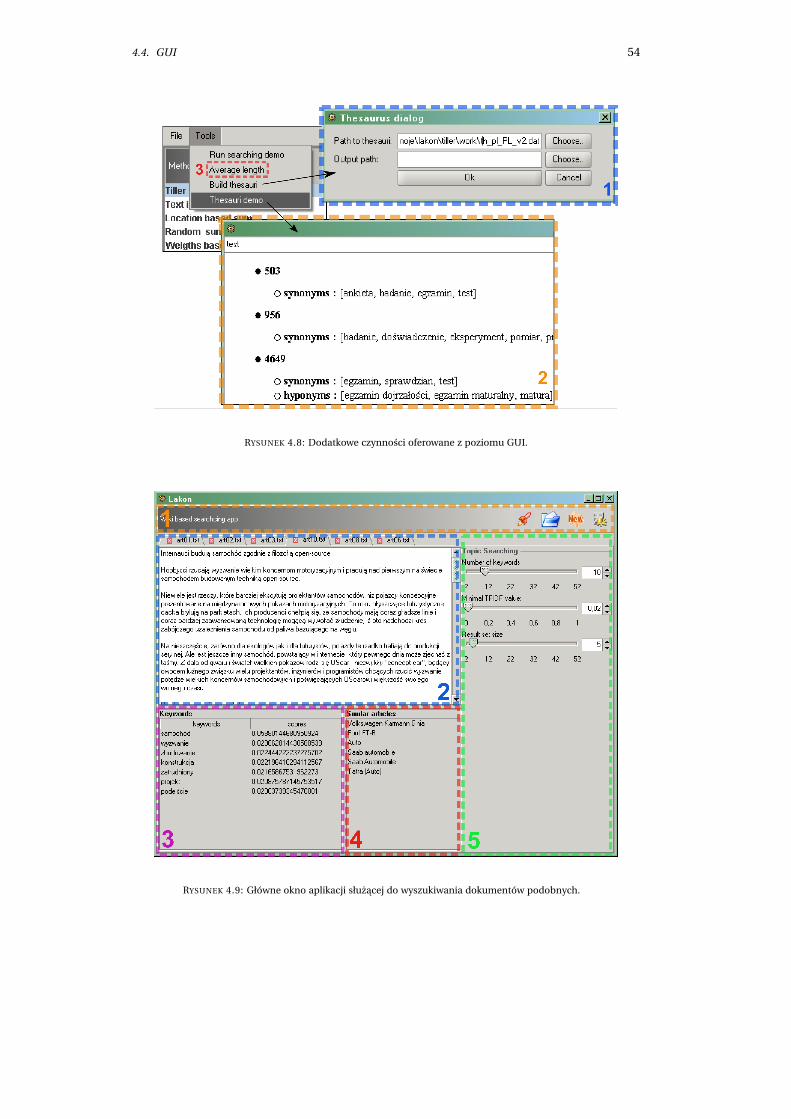
4.4. GUI 54
RYSUNEK 4.8: Dodatkowe czynnosci oferowane z poziomu GUI.
RYSUNEK 4.9: Główne okno aplikacji słuzacej do wyszukiwania dokumentów podobnych.

4.5. Dodatkowe elementy stworzonego systemu 55
preload.thesauri – poniewaz wczytywanie pliku tezaurusa z dysku, zajmuje dłuzsza chwile.
Istnieje mozliwosc skonfigurowania aplikacji tak, aby na starcie zawczasu wczytywały
plik z tezaurusa do pózniejszego wykorzystania.
4.5 Dodatkowe elementy stworzonego systemu
Oprócz głównych składowych projektu wykorzystywanych bezposrednio do tworzenia
streszczen powstały równiez inne moduły.
4.5.1 Budowanie indeksu
Wikipedia udostepnia kopie zapasowe zawierajace wszystkie artykuły oraz materiały do-
datkowe2. Kopie te dostepne sa w dwóch formatach:
• statycznych stron HTML,
• pliku XML.
Dane te sa dostepne dla wszystkich wersji jezykowych Wikipedii. Do stworzenia referen-
cyjnej kolekcji dokumentów wykorzystana została kopia polskiej wikipedii w formacie XML.
Kopia zapasowa w tym formacie składa sie z kilku plików, zawierajacych miedzy innymi in-
formacje o historii modyfikacji stron, grupach uzytkowników, tytułach artykułów i ich tresci.
Plik zawierajacy kopie artykułów (pages-articles.xml.bz2) w wersji spakowanej zajmuje
około 260MB, po rozpakowaniu jest kilkakrotnie wiekszy.
Stworzone narzedzie przetwarza opisany powyzej plik i na podstawie uzyskanych w ten
sposób informacji buduje indeks odwrotny umozliwiajacy wyszukiwanie (tutaj równiez wy-
korzystana została biblioteka Lucene).
Do redakcji Wikipedii wykorzystywany jest specjalny zbiór znaczników (ang. Wiki mar-
kup)3. Poniewaz tworzony indeks jest wykorzystywany głównie jako zródło pewnych staty-
stycznych informacji zwiazanych z wystepowaniem róznych wyrazów (obliczanie wag tf-idf
oraz bm25), informacja o znacznikach wystepujacych w tekscie jest zbedna.
Najbardziej interesujace z naszego punktu widzenia sa strony zawierajace artykuły z opi-
sem poszczególnych haseł, oprócz nich Wikipedia zawiera wiele informacji technicznych,
takich jak odnosniki do grafik, szablony stron, czasem równiez fragmenty kodu w jezyku
PHP. Strony zawierajace takie informacje nie sa uwzgledniane w procesie budowania in-
deksu.
Po usunieciu stron specjalnych w utworzonym indeksie znalazło sie ponad 300 tysiecy
artykułów. Stworzony na tej podstawie indeks odwrotny zajmuje 305MB. Program potrafi
utworzyc indeks na bazie dowolnego pliku XML, którego struktura zgodna jest z przedsta-
wiona ponizej:
2Wiecej informacji dostepnych jest na stronie http://download.wikimedia.org/backup-index.html.3Dokładny ich opis znajdzie czytelnik pod adresem: http://en.wikipedia.org/wiki/Wikipedia:How_to_
edit_a_page

4.5. Dodatkowe elementy stworzonego systemu 56
...
<page>
<title>...</title>
<text>....</text>
</page>
...
Konfiguracja i uruchamianie
Kazde z omówionych zagadnien zostało sparametryzowane, konfiguracji podlegaja na-
stepujace elementy:
• usuwanie znaczników specjalnych (Wiki markup),
• tytuły stron specjalnych, które sa pomijane przy tworzeniu indeksu,
• wykorzystywana stop lista,
• lista zawierajace znaki (lub łancuchy znaków) które sa pomijane.
Domyslna konfiguracja zakłada równiez, ze w indeksie umieszczane beda formy podsta-
wowe wyrazów; uzyty w tym celu moze zostac Morfeusz lub Stempelator.
Na dołaczonej płycie znajduje sie gotowa do uzycia wersja dystrybucyjna, samo narze-
dzie słuzace do budowania indeksu mozna uruchomic z linii polecen:
java -jar wiki-1.0.jar -p -dd ... -cp .. -o ...
Po przełaczniku
• dd – podajemy sciezke do pliku zawierajacego XML zgodny z opisana wczesniej (por. strona
56) struktura.
• cp – sciezka do pliku zawierajacego dodatkowa konfiguracje (ten przełacznik jest opcjo-
nalny),
• so – sciezka gdzie ma zostac zapisany wynikowy działania programu.
4.5.2 Aplikacja do zbierania streszczen
Na potrzeby eksperymentu (którego dokładny opis znajdzie czytelnik w nastepnym roz-
dziale) stworzona została aplikacja internetowa.
Aby korzystac z wiekszosci zasobów konieczne jest posiadanie konta uzytkownika, mozna
je uzyskac wypełniajac prosty formularz rejestracyjny. Zostały zdefiniowane trzy poziomy
uprawnien:
1. uzytkownik nie zalogowany – strona główna, strona z informacjami o projekcie,
2. zwykły uzytkownik – dodatkowo mozliwosc tworzenia streszczen,
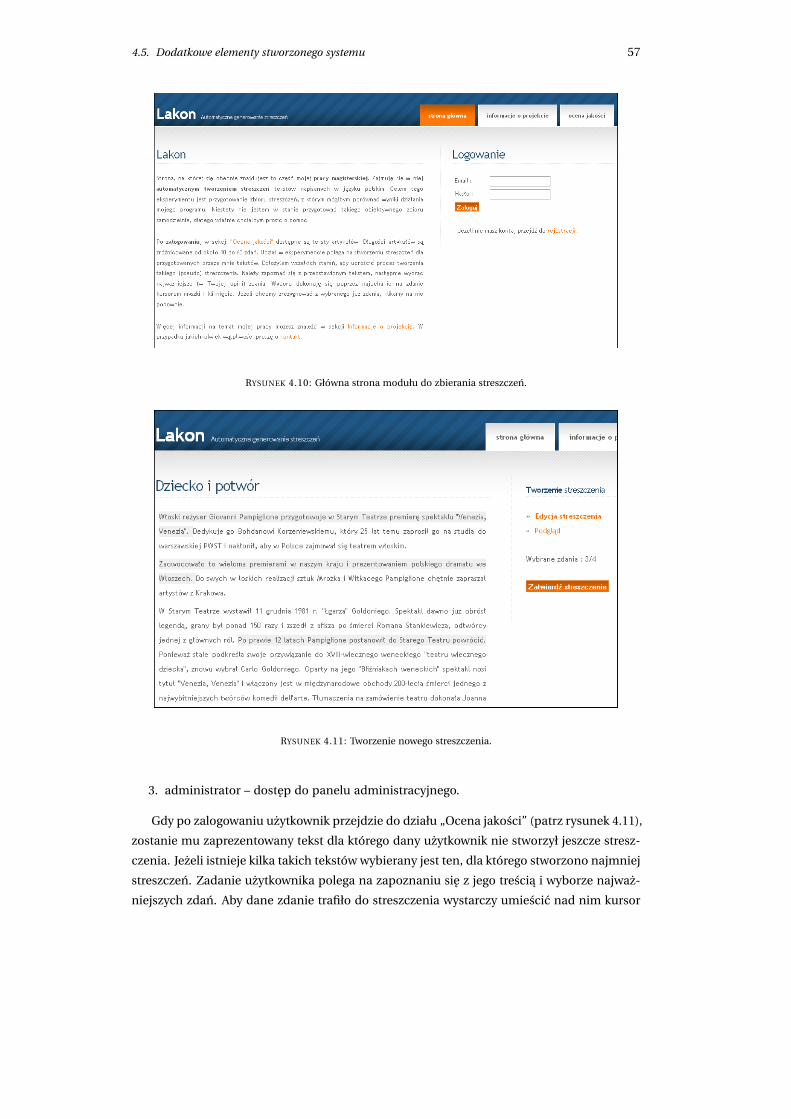
4.5. Dodatkowe elementy stworzonego systemu 57
RYSUNEK 4.10: Główna strona modułu do zbierania streszczen.
RYSUNEK 4.11: Tworzenie nowego streszczenia.
3. administrator – dostep do panelu administracyjnego.
Gdy po zalogowaniu uzytkownik przejdzie do działu „Ocena jakosci” (patrz rysunek 4.11),
zostanie mu zaprezentowany tekst dla którego dany uzytkownik nie stworzył jeszcze stresz-
czenia. Jezeli istnieje kilka takich tekstów wybierany jest ten, dla którego stworzono najmniej
streszczen. Zadanie uzytkownika polega na zapoznaniu sie z jego trescia i wyborze najwaz-
niejszych zdan. Aby dane zdanie trafiło do streszczenia wystarczy umiescic nad nim kursor

4.5. Dodatkowe elementy stworzonego systemu 58
myszki i kliknac (zaznaczone zdania sa widoczne na rysunku 4.11 jako tekst z szarym tłem).
Ponowne klikniecie powoduje odznaczenie zdania. Opcja „Podglad” powoduje wyswietlenie
tylko tych zdan, które zostały juz wybrane do streszczenia. Gdy uzytkownik wybierze juz
odpowiednia liczbe zdan moze zatwierdzic swoje streszczenie. Sposób w jaki okreslana jest
liczba zdan wchodzacych do streszczenia (dla danego tekstu) zostanie dokładnie objasniony
w kolejnym rozdziale.
RYSUNEK 4.12: Opcje dostepne z poziomu panelu administracyjnego.
Uzytkownicy z uprawnieniami administratorów maja równiez dostep do panelu admi-
nistracyjnego (rysunek 4.12). Na głównej stronie nie ma bezposredniego odnosnika do tej
czesci aplikacji; aby przejsc do niej nalezy wpisac w przegladarce adres bezposredni np.
../evaluations.html, ../users.html. Panel oferuje nastepujaca funkcjonalnosc:
• przegladanie listy wszystkich stworzonych streszczen,
• eksport stworzonych streszczen w formacie XML,
• lista zarejestrowanych uzytkowników,
• dodawanie, usuwanie i modyfikacja danych uzytkowników,
• lista artykułów znajdujacych sie w systemie,
• dodawanie, usuwanie i modyfikacja artykułów.

Rozdział 5
Ocena eksperymentalna
Aby ocenic jakosc otrzymywanych wyników przeprowadzony został eksperyment. W cza-
sie jego trwania zadaniem grupy ochotników było tworzenie streszczen artykułów praso-
wych. Dzieki zbudowanemu w ten sposób korpusowi mozliwe było okreslenie jak skuteczne
sa zaimplementowane metody automatycznej selekcji zdan.
5.1 Opis eksperymentu
Głównym celem przeprowadzonego eksperymentu było skompilowanie referencyjnego
zbioru streszczen. Wszystkie zaimplementowane metody rozwiazuja problem tworzenia au-
tomatycznych streszczen poprzez wybór pewnej liczby zdan. Uznano za zasadne postawic
przed podobnym problemem ochotników bioracych udział w eksperymencie.
5.1.1 Przyjete załozenia
[KPC95] do oceny jakosci wykorzystali tworzone przez ekspertów streszczenia literackie.
Rozwiazanie to zostało odrzucone z nastepujacych powodów:
1. Proste porównywanie – zarówno streszczenia automatyczne jak i te stworzone w ra-
mach eksperymentu składaja sie z tych samych zdan. Łatwo jest wiec porównac wy-
niki otrzymane z obu zródeł. W rozwiazaniu opisanym przez [KPC95] okreslone zo-
stały rózne rodzaje dopasowan czesciowych. Zaproponowanie dokładnego algorytmu
obliczania takich dopasowan moze sie okazac dosc trudne. Wystarczy bowiem wy-
obrazic sobie sytuacje, gdy do reprezentacji tego samego pojecia uzyty zostanie inny
wyraz.
2. Minimalny koszt stworzenia streszczenia – tworzenie streszczen literackich na pewno
wymagałoby od ochotników wiekszego zaangazowania niz w przypadku prostego wy-
boru zdan. Ponadto załozono, ze wiekszosc uczestników eksperymentu nie bedzie po-
siadała profesjonalnego przygotowania w zakresie przygotowywania streszczen. Aby
zapewnic reprezentatywnosc zebranych danych istotne było równiez uzyskanie od-
powiednio duzej liczby streszczen dla kazdego z artykułów. Dzieki skróceniu czasu
59

5.1. Opis eksperymentu 60
koniecznego do utworzenia streszczenia szansa na uzyskanie odpowiedniej ich liczby
znacznie wzrosła.
Aby w jak najwiekszym stopniu ułatwic zadanie uczestnikom do realizacji eksperymentu
uzyto aplikacji internetowej (dokładniejszy jej opis znajduje sie w rozdziale 4.5.2).
Dla celów eksperymentu pozyskano 10 artykułów prasowych o zróznicowanej długo-
sci i charakterze. Zostały one zaczerpniete z korpusu „Rzeczpospolitej” [Rze] (3 artykuły)
oraz z zebranego na potrzeby tej pracy zbioru tekstów z „Gazety Wyborczej” (7 artykułów).
W uzytym do oceny zbiorze tekstów znalazły sie zarówno teksty krótkie (typowe „newsy”)
oraz dłuzsze artykuły o bardziej rozbudowanej strukturze. Dołozono równiez wszelkich sta-
ran, aby tematyka wybranych artykułów była mozliwie zróznicowana. Podstawowe statystyki
liczbowe dla uzytych artykułów przedstawiono w tabeli 5.1, a ich tytuły i pochodzenie w ta-
beli 5.2. Wszystkie uzyte artykuły znajduja sie na płycie dołaczonej do pracy.
TABLICA 5.1: Informacje dotyczace artykułów wykorzystanych w eksperymencie.
numer 1 2 3 4 5 6 7 8 9 10
liczba słów 419 246 236 397 632 467 732 276 859 1061liczba zdan 22 16 16 20 44 29 49 14 54 56
sr. długosc zdania 19 15 14 19 14 16 14 19 15 18
TABLICA 5.2: Tytuły artykułów uzytych w eksperymencie.
numer zródło tytuł
1 Rz Dobre regulacje, mało spółek2 Rz Dziecko i potwór3 Rz Zjazd „S” rolników indywidualnych w Zgierzu4 GW Rzad Ukrainy bez Pomaranczowych5 GW Ségolene Royal kandydatem socjalistów w wyborach prezydenckich6 GW Były dyktator Urugwaju Juan Maria Bordaberry poszedł za kraty7 GW Albo młodosc, albo rak8 GW Włoska telewizja wykryła narkotyki u deputowanych9 GW Zapomniany ojciec kina
10 GW Internauci buduja samochód zgodnie z filozofia open-source
Dla kazdego artykułu zostało okreslone z ilu zdan musi składac sie jego streszczenie. We-
dług [KPC95], streszczenie składajace sie z zaledwie 20% oryginalnego tekstu moze zawierac
tyle samo informacji co jego pierwotna wersja. Przyjete zostało wiec, ze długosc streszczenia
odpowiada liczbie zdan zawartych w około 20% oryginalnego tekstu (por. tabela 5.3).

5.1. Opis eksperymentu 61
TABLICA 5.3: Wyznaczone długosci streszczen dla poszczególnych artykułów.
numer 1 2 3 4 5 6 7 8 9 10
liczba zdan 22 16 16 20 44 29 49 14 54 56długosc streszczenia 5 4 4 5 10 7 11 3 11 12
5.1.2 Przebieg eksperymentu
Eksperyment trwał około miesiaca – od 13.05.2007 do 14.06.2007. Aktywny udział wzieło
60 ochotników, stworzyli oni w sumie 285 streszczen. Poszczególne artykuły posiadaja od 27
do 30 streszczen (por. Tablica 5.4).
TABLICA 5.4: Informacje dotyczace liczby zebranych streszczen.
numer 1 2 3 4 5 6 7 8 9 10
zebrano streszczen 27 28 28 28 29 29 27 29 30 30
W eksperymencie wzieli udział głównie studenci oraz absolwenci studiów magisterskich.
Osoby te w wiekszosci sa (lub były) zwiazane z uczelniami poznanskimi. Uczestników eks-
perymentu mozna podzielic na cztery grupy (wzgledem reprezentowanych specjalnosci):
• nauki scisłe: informatyka, ekonomia,
• nauki przyrodniczo-medyczne: fizjoterapia, farmacja, psychologia,
• nauki humanistyczne: prawo, filologia polska, kulturoznawstwo, socjologia, filozofia,
filologia angielska, sinologia, filologia klasyczna, bibliotekoznawstwo,
• inne w przypadku gdy nie udało sie zdobyc informacji o uczestnikach.
W tabeli 5.5 przedstawiono udział poszczególnych specjalnosci wsród uczestników. Tak
duza róznorodnosc wsród uczestników eksperymentu powinna pozwolic na wyciagniecie
obiektywnych, ogólnych wniosków.
TABLICA 5.5: Udział specjalnosci zawodowych wsród bioracych udział w eksperymencie.
scisłe medyczne humanistyczne inne
liczba uczestników 34 3 21 2
W tabeli 5.6 przedstawiono rozkład liczby streszczen stworzonych przez pojedynczego
uczestnika eksperymentu. Nie jest zaskoczeniem, ze uczestnicy przewaznie poprzestawali
na 1 do 3 streszczen. Ciekawe jest jednak, ze liczba osób które stworzyły streszczenia dla
wszystkich 10 tekstów jest tak duza w porównaniu z przedziałem 7–9.
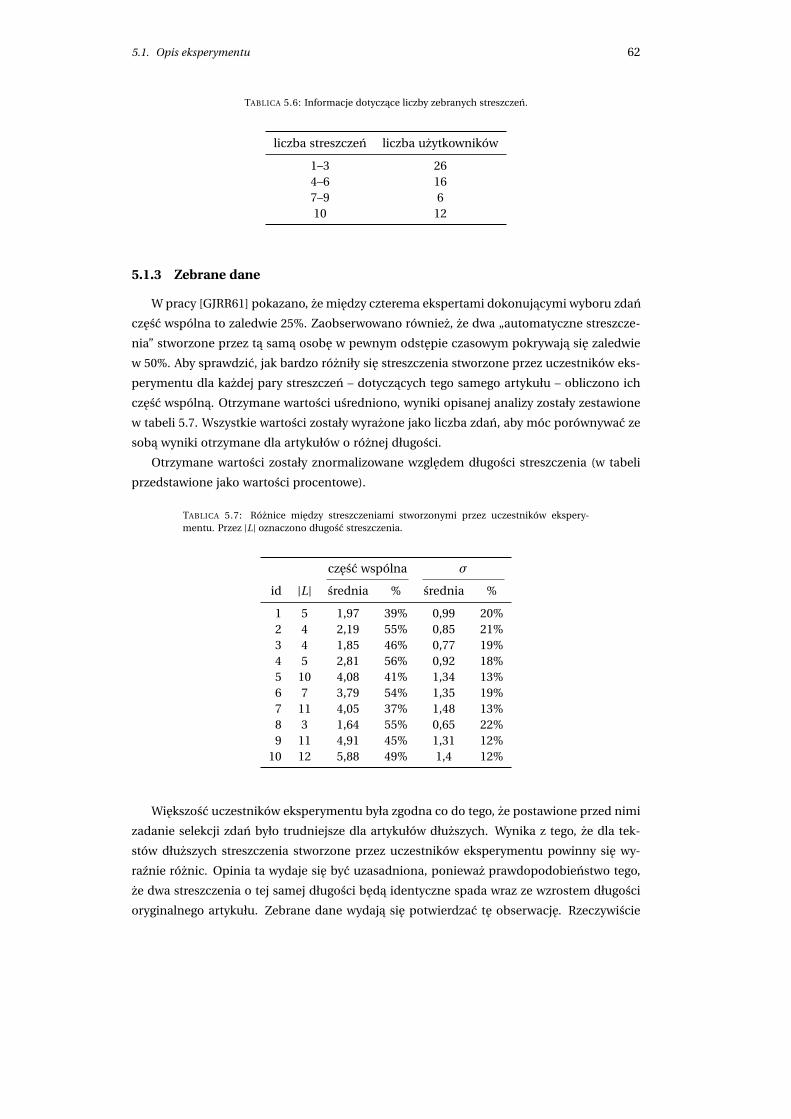
5.1. Opis eksperymentu 62
TABLICA 5.6: Informacje dotyczace liczby zebranych streszczen.
liczba streszczen liczba uzytkowników
1–3 264–6 167–9 610 12
5.1.3 Zebrane dane
W pracy [GJRR61] pokazano, ze miedzy czterema ekspertami dokonujacymi wyboru zdan
czesc wspólna to zaledwie 25%. Zaobserwowano równiez, ze dwa „automatyczne streszcze-
nia” stworzone przez ta sama osobe w pewnym odstepie czasowym pokrywaja sie zaledwie
w 50%. Aby sprawdzic, jak bardzo rózniły sie streszczenia stworzone przez uczestników eks-
perymentu dla kazdej pary streszczen – dotyczacych tego samego artykułu – obliczono ich
czesc wspólna. Otrzymane wartosci usredniono, wyniki opisanej analizy zostały zestawione
w tabeli 5.7. Wszystkie wartosci zostały wyrazone jako liczba zdan, aby móc porównywac ze
soba wyniki otrzymane dla artykułów o róznej długosci.
Otrzymane wartosci zostały znormalizowane wzgledem długosci streszczenia (w tabeli
przedstawione jako wartosci procentowe).
TABLICA 5.7: Róznice miedzy streszczeniami stworzonymi przez uczestników ekspery-mentu. Przez |L| oznaczono długosc streszczenia.
czesc wspólna σ
id |L| srednia % srednia %
1 5 1,97 39% 0,99 20%2 4 2,19 55% 0,85 21%3 4 1,85 46% 0,77 19%4 5 2,81 56% 0,92 18%5 10 4,08 41% 1,34 13%6 7 3,79 54% 1,35 19%7 11 4,05 37% 1,48 13%8 3 1,64 55% 0,65 22%9 11 4,91 45% 1,31 12%
10 12 5,88 49% 1,4 12%
Wiekszosc uczestników eksperymentu była zgodna co do tego, ze postawione przed nimi
zadanie selekcji zdan było trudniejsze dla artykułów dłuzszych. Wynika z tego, ze dla tek-
stów dłuzszych streszczenia stworzone przez uczestników eksperymentu powinny sie wy-
raznie róznic. Opinia ta wydaje sie byc uzasadniona, poniewaz prawdopodobienstwo tego,
ze dwa streszczenia o tej samej długosci beda identyczne spada wraz ze wzrostem długosci
oryginalnego artykułu. Zebrane dane wydaja sie potwierdzac te obserwacje. Rzeczywiscie
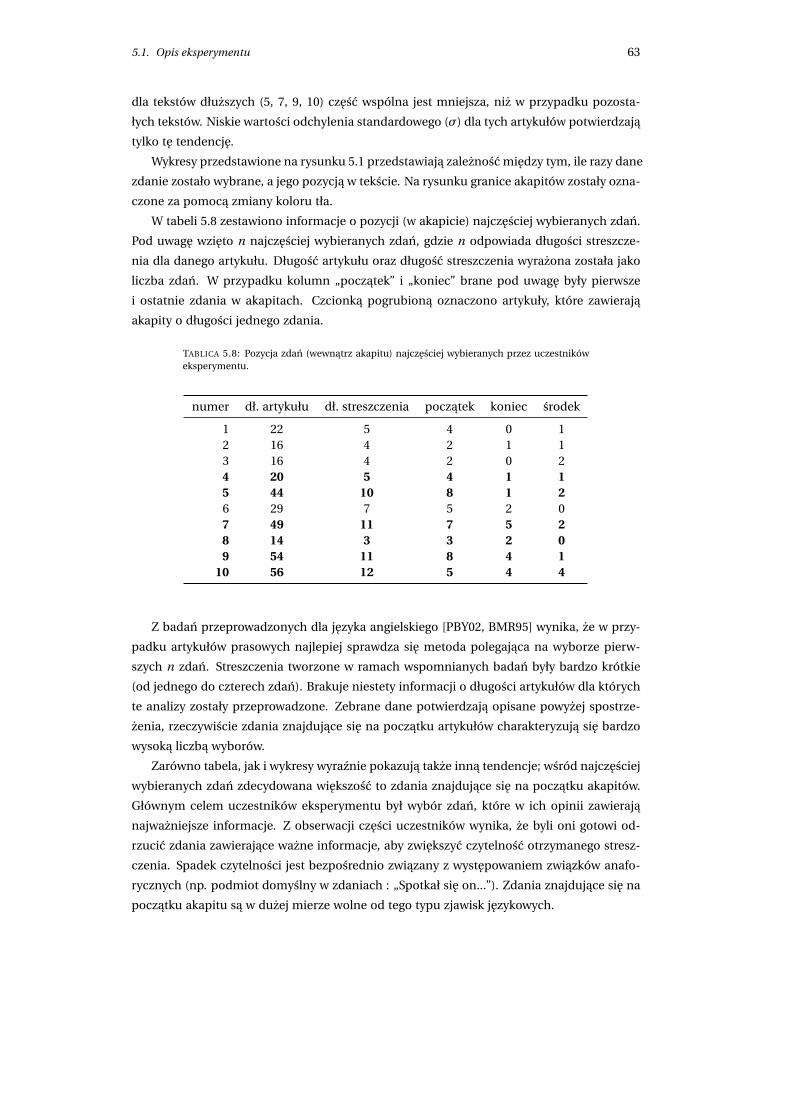
5.1. Opis eksperymentu 63
dla tekstów dłuzszych (5, 7, 9, 10) czesc wspólna jest mniejsza, niz w przypadku pozosta-
łych tekstów. Niskie wartosci odchylenia standardowego (σ) dla tych artykułów potwierdzaja
tylko te tendencje.
Wykresy przedstawione na rysunku 5.1 przedstawiaja zaleznosc miedzy tym, ile razy dane
zdanie zostało wybrane, a jego pozycja w tekscie. Na rysunku granice akapitów zostały ozna-
czone za pomoca zmiany koloru tła.
W tabeli 5.8 zestawiono informacje o pozycji (w akapicie) najczesciej wybieranych zdan.
Pod uwage wzieto n najczesciej wybieranych zdan, gdzie n odpowiada długosci streszcze-
nia dla danego artykułu. Długosc artykułu oraz długosc streszczenia wyrazona została jako
liczba zdan. W przypadku kolumn „poczatek” i „koniec” brane pod uwage były pierwsze
i ostatnie zdania w akapitach. Czcionka pogrubiona oznaczono artykuły, które zawieraja
akapity o długosci jednego zdania.
TABLICA 5.8: Pozycja zdan (wewnatrz akapitu) najczesciej wybieranych przez uczestnikóweksperymentu.
numer dł. artykułu dł. streszczenia poczatek koniec srodek
1 22 5 4 0 12 16 4 2 1 13 16 4 2 0 24 20 5 4 1 15 44 10 8 1 26 29 7 5 2 07 49 11 7 5 28 14 3 3 2 09 54 11 8 4 1
10 56 12 5 4 4
Z badan przeprowadzonych dla jezyka angielskiego [PBY02, BMR95] wynika, ze w przy-
padku artykułów prasowych najlepiej sprawdza sie metoda polegajaca na wyborze pierw-
szych n zdan. Streszczenia tworzone w ramach wspomnianych badan były bardzo krótkie
(od jednego do czterech zdan). Brakuje niestety informacji o długosci artykułów dla których
te analizy zostały przeprowadzone. Zebrane dane potwierdzaja opisane powyzej spostrze-
zenia, rzeczywiscie zdania znajdujace sie na poczatku artykułów charakteryzuja sie bardzo
wysoka liczba wyborów.
Zarówno tabela, jak i wykresy wyraznie pokazuja takze inna tendencje; wsród najczesciej
wybieranych zdan zdecydowana wiekszosc to zdania znajdujace sie na poczatku akapitów.
Głównym celem uczestników eksperymentu był wybór zdan, które w ich opinii zawieraja
najwazniejsze informacje. Z obserwacji czesci uczestników wynika, ze byli oni gotowi od-
rzucic zdania zawierajace wazne informacje, aby zwiekszyc czytelnosc otrzymanego stresz-
czenia. Spadek czytelnosci jest bezposrednio zwiazany z wystepowaniem zwiazków anafo-
rycznych (np. podmiot domyslny w zdaniach : „Spotkał sie on...”). Zdania znajdujace sie na
poczatku akapitu sa w duzej mierze wolne od tego typu zjawisk jezykowych.
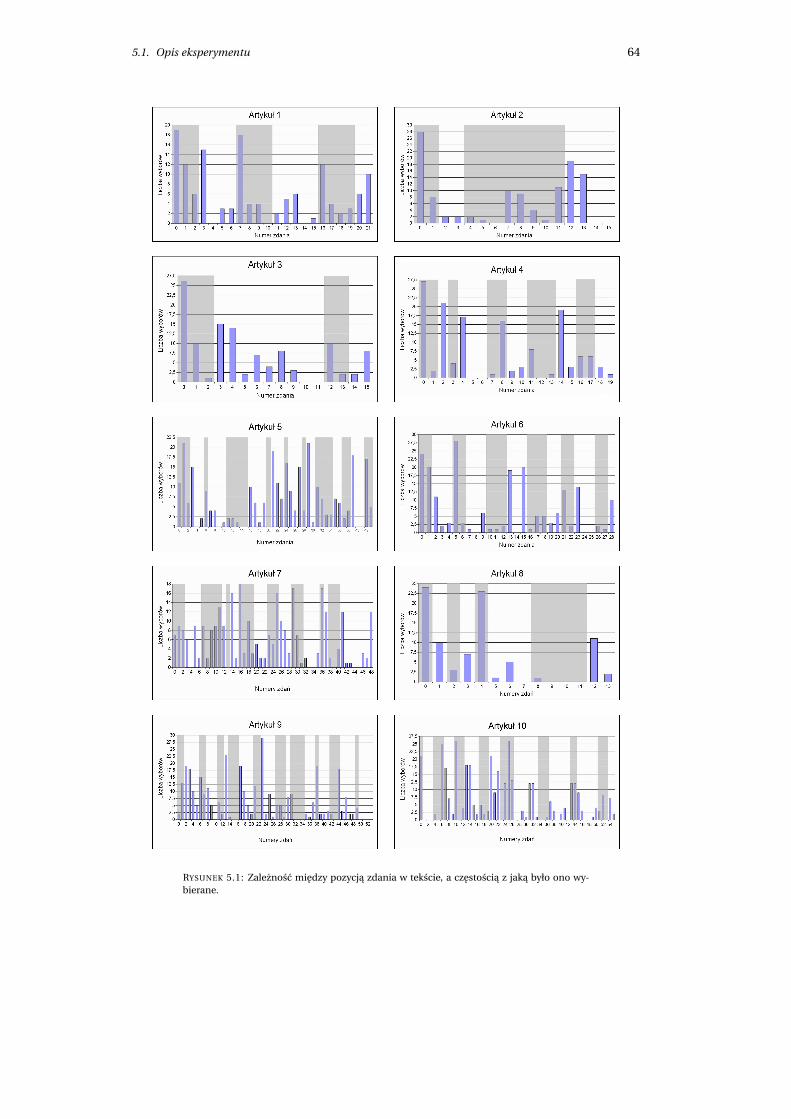
5.1. Opis eksperymentu 64
RYSUNEK 5.1: Zaleznosc miedzy pozycja zdania w tekscie, a czestoscia z jaka było ono wy-bierane.

5.2. Ocena jakosci 65
5.2 Ocena jakosci
Ocenie jakosci podlegały cztery metody automatycznego tworzenia streszczen (w nawia-
sach podano skrótowe odpowiedniki pełnych nazw):
• metoda wykorzystujaca informacje o połozeniu zdan (Pos),
• metody wykorzystujace automatyczna ocene jakosci słów kluczowych
– oparte o schemat tf-idf (TFIDF),
– oparte o schemat okapi bm25 (BM25),
• metoda wykorzystujaca łancuchy leksykalne (LC).
Ponadto, głównie dla celów porównawczych, wszystkie analizy zostały równiez przeprowa-
dzone dla losowego wyboru zdan (Rand) oraz wyboru pierwszych n zdan z tekstu (FIRST).
W przypadku metody opartej na losowym wyborze zdan wszystkie przedstawione wyniki to
wartosc srednia obliczona na podstawie 30 pomiarów. Metody TFIDF, BM25 oraz LC operuja
tylko na rzeczownikach.
5.2.1 Przyjete załozenia
Dla kazdego artykułu z zebranych danych wydzielono zbiór n najczesciej wybieranych
zdan („idealne streszczenie”), gdzie n to długosc streszczenia załozona dla tego artykułu. W
przypadku gdy zdanie n i n +1 było przez uczestników eksperymentu wybierane tak samo
czesto, do „idealnego streszczenia” wybierane było to zdanie, które wystapiło wczesniej w
tekscie 1.
Zarówno zebrane dane (por. tablica 5.7 na stronie 62), jak i wczesniejsze badania [KPC95]
wskazuja na mozliwosc wystepowania duzych róznic miedzy streszczeniami okreslanymi
przez człowieka jako „dobre”. Trafne spostrzezenie czyni zreszta [Edm69]: „There is no sin-
gle correct summary.”
W tabeli 5.9 przedstawiono wyniki podstawowej analizy czestosci z jaka zdania w da-
nym tekscie były wybierane przez uczestników eksperymentu. Aby poszerzyc spektrum „do-
brych” streszczen zdecydowano sie zbudowac zbiór zdan istotnych (ang. relevant sentence
set). Gdyby za zdania istotne uznac wszystkie, które uzytkownicy wybrali chociaz raz (w ta-
beli 5.9 kolumna „wybrane”), stanowiłyby one (w zaleznosci od artykułu) od 70% do 86%
całkowitej liczby zdan. Przy budowaniu takiego zbioru konieczne wiec było ograniczenie
liczby branych pod uwage zdan tylko do tych wybieranych najczesciej. To ile razy uczestnicy
eksperymentu wybrali najczesciej wybierane zdanie zestawiono dla poszczególnych tekstów
w kolumnie „Maksymalna liczba wyborów” (tabela 5.9). Na podstawie tego ile razy poszcze-
gólne zdania (dla danego tekstu) były wybierane przez uzytkowników obliczono srednia cze-
stosc wyborów. Zdecydowano, ze do zbioru zdan istotnych wchodza tylko te, które ochot-
nicy wybierali czesciej niz srednia czestosc wyborów. Z analizy danych przedstawionych
1Miało to miejsce w przypadku 3 badanych tekstów.
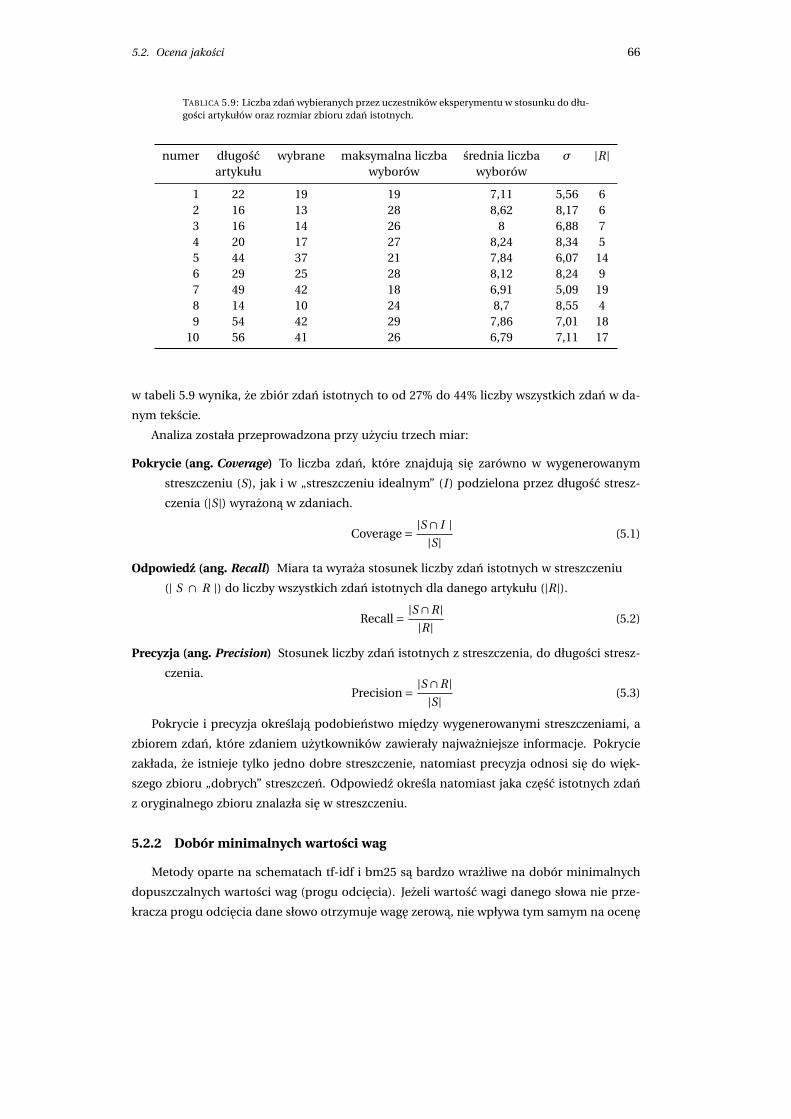
5.2. Ocena jakosci 66
TABLICA 5.9: Liczba zdan wybieranych przez uczestników eksperymentu w stosunku do dłu-gosci artykułów oraz rozmiar zbioru zdan istotnych.
numer długosc wybrane maksymalna liczba srednia liczba σ |R|artykułu wyborów wyborów
1 22 19 19 7,11 5,56 62 16 13 28 8,62 8,17 63 16 14 26 8 6,88 74 20 17 27 8,24 8,34 55 44 37 21 7,84 6,07 146 29 25 28 8,12 8,24 97 49 42 18 6,91 5,09 198 14 10 24 8,7 8,55 49 54 42 29 7,86 7,01 18
10 56 41 26 6,79 7,11 17
w tabeli 5.9 wynika, ze zbiór zdan istotnych to od 27% do 44% liczby wszystkich zdan w da-
nym tekscie.
Analiza została przeprowadzona przy uzyciu trzech miar:
Pokrycie (ang. Coverage) To liczba zdan, które znajduja sie zarówno w wygenerowanym
streszczeniu (S), jak i w „streszczeniu idealnym” (I ) podzielona przez długosc stresz-
czenia (|S|) wyrazona w zdaniach.
Coverage = |S ∩ I ||S| (5.1)
Odpowiedz (ang. Recall) Miara ta wyraza stosunek liczby zdan istotnych w streszczeniu
(| S ∩ R |) do liczby wszystkich zdan istotnych dla danego artykułu (|R|).
Recall = |S ∩R||R| (5.2)
Precyzja (ang. Precision) Stosunek liczby zdan istotnych z streszczenia, do długosci stresz-
czenia.
Precision = |S ∩R||S| (5.3)
Pokrycie i precyzja okreslaja podobienstwo miedzy wygenerowanymi streszczeniami, a
zbiorem zdan, które zdaniem uzytkowników zawierały najwazniejsze informacje. Pokrycie
zakłada, ze istnieje tylko jedno dobre streszczenie, natomiast precyzja odnosi sie do wiek-
szego zbioru „dobrych” streszczen. Odpowiedz okresla natomiast jaka czesc istotnych zdan
z oryginalnego zbioru znalazła sie w streszczeniu.
5.2.2 Dobór minimalnych wartosci wag
Metody oparte na schematach tf-idf i bm25 sa bardzo wrazliwe na dobór minimalnych
dopuszczalnych wartosci wag (progu odciecia). Jezeli wartosc wagi danego słowa nie prze-
kracza progu odciecia dane słowo otrzymuje wage zerowa, nie wpływa tym samym na ocene
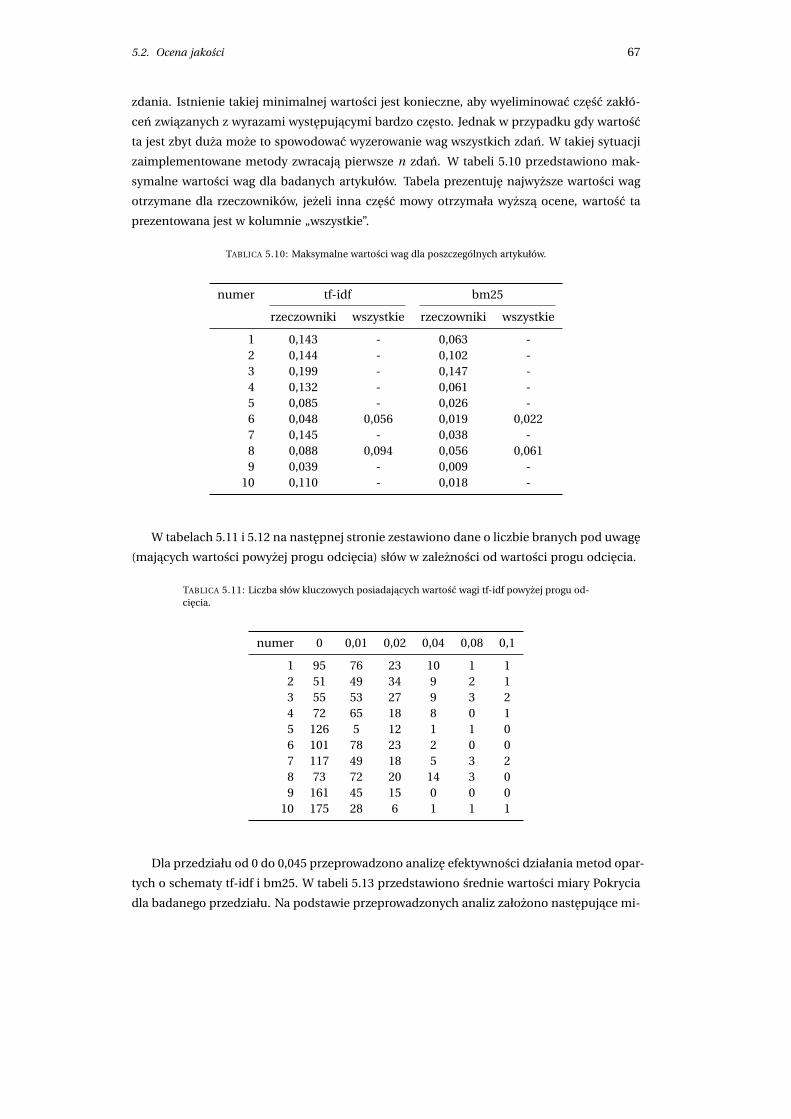
5.2. Ocena jakosci 67
zdania. Istnienie takiej minimalnej wartosci jest konieczne, aby wyeliminowac czesc zakłó-
cen zwiazanych z wyrazami wystepujacymi bardzo czesto. Jednak w przypadku gdy wartosc
ta jest zbyt duza moze to spowodowac wyzerowanie wag wszystkich zdan. W takiej sytuacji
zaimplementowane metody zwracaja pierwsze n zdan. W tabeli 5.10 przedstawiono mak-
symalne wartosci wag dla badanych artykułów. Tabela prezentuje najwyzsze wartosci wag
otrzymane dla rzeczowników, jezeli inna czesc mowy otrzymała wyzsza ocene, wartosc ta
prezentowana jest w kolumnie „wszystkie”.
TABLICA 5.10: Maksymalne wartosci wag dla poszczególnych artykułów.
numer tf-idf bm25
rzeczowniki wszystkie rzeczowniki wszystkie
1 0,143 - 0,063 -2 0,144 - 0,102 -3 0,199 - 0,147 -4 0,132 - 0,061 -5 0,085 - 0,026 -6 0,048 0,056 0,019 0,0227 0,145 - 0,038 -8 0,088 0,094 0,056 0,0619 0,039 - 0,009 -
10 0,110 - 0,018 -
W tabelach 5.11 i 5.12 na nastepnej stronie zestawiono dane o liczbie branych pod uwage
(majacych wartosci powyzej progu odciecia) słów w zaleznosci od wartosci progu odciecia.
TABLICA 5.11: Liczba słów kluczowych posiadajacych wartosc wagi tf-idf powyzej progu od-ciecia.
numer 0 0,01 0,02 0,04 0,08 0,1
1 95 76 23 10 1 12 51 49 34 9 2 13 55 53 27 9 3 24 72 65 18 8 0 15 126 5 12 1 1 06 101 78 23 2 0 07 117 49 18 5 3 28 73 72 20 14 3 09 161 45 15 0 0 0
10 175 28 6 1 1 1
Dla przedziału od 0 do 0,045 przeprowadzono analize efektywnosci działania metod opar-
tych o schematy tf-idf i bm25. W tabeli 5.13 przedstawiono srednie wartosci miary Pokrycia
dla badanego przedziału. Na podstawie przeprowadzonych analiz załozono nastepujace mi-
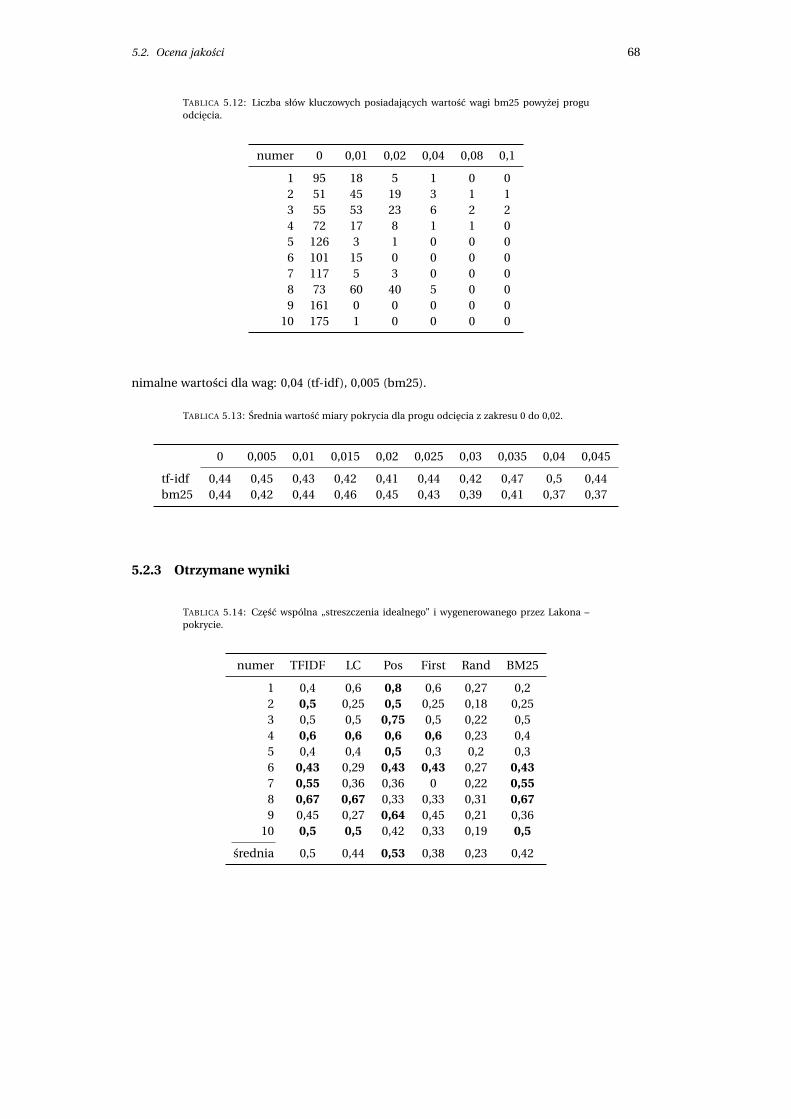
5.2. Ocena jakosci 68
TABLICA 5.12: Liczba słów kluczowych posiadajacych wartosc wagi bm25 powyzej proguodciecia.
numer 0 0,01 0,02 0,04 0,08 0,1
1 95 18 5 1 0 02 51 45 19 3 1 13 55 53 23 6 2 24 72 17 8 1 1 05 126 3 1 0 0 06 101 15 0 0 0 07 117 5 3 0 0 08 73 60 40 5 0 09 161 0 0 0 0 0
10 175 1 0 0 0 0
nimalne wartosci dla wag: 0,04 (tf-idf), 0,005 (bm25).
TABLICA 5.13: Srednia wartosc miary pokrycia dla progu odciecia z zakresu 0 do 0,02.
0 0,005 0,01 0,015 0,02 0,025 0,03 0,035 0,04 0,045
tf-idf 0,44 0,45 0,43 0,42 0,41 0,44 0,42 0,47 0,5 0,44bm25 0,44 0,42 0,44 0,46 0,45 0,43 0,39 0,41 0,37 0,37
5.2.3 Otrzymane wyniki
TABLICA 5.14: Czesc wspólna „streszczenia idealnego” i wygenerowanego przez Lakona –pokrycie.
numer TFIDF LC Pos First Rand BM25
1 0,4 0,6 0,8 0,6 0,27 0,22 0,5 0,25 0,5 0,25 0,18 0,253 0,5 0,5 0,75 0,5 0,22 0,54 0,6 0,6 0,6 0,6 0,23 0,45 0,4 0,4 0,5 0,3 0,2 0,36 0,43 0,29 0,43 0,43 0,27 0,437 0,55 0,36 0,36 0 0,22 0,558 0,67 0,67 0,33 0,33 0,31 0,679 0,45 0,27 0,64 0,45 0,21 0,36
10 0,5 0,5 0,42 0,33 0,19 0,5
srednia 0,5 0,44 0,53 0,38 0,23 0,42
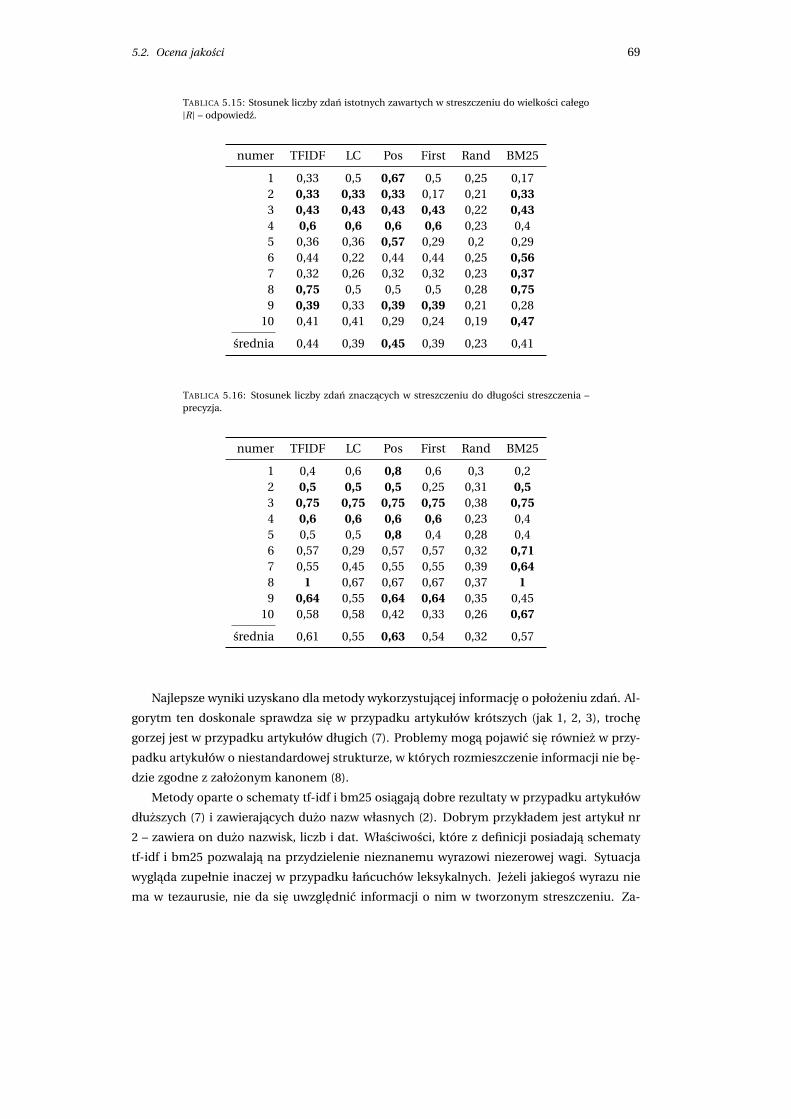
5.2. Ocena jakosci 69
TABLICA 5.15: Stosunek liczby zdan istotnych zawartych w streszczeniu do wielkosci całego|R| – odpowiedz.
numer TFIDF LC Pos First Rand BM25
1 0,33 0,5 0,67 0,5 0,25 0,172 0,33 0,33 0,33 0,17 0,21 0,333 0,43 0,43 0,43 0,43 0,22 0,434 0,6 0,6 0,6 0,6 0,23 0,45 0,36 0,36 0,57 0,29 0,2 0,296 0,44 0,22 0,44 0,44 0,25 0,567 0,32 0,26 0,32 0,32 0,23 0,378 0,75 0,5 0,5 0,5 0,28 0,759 0,39 0,33 0,39 0,39 0,21 0,28
10 0,41 0,41 0,29 0,24 0,19 0,47
srednia 0,44 0,39 0,45 0,39 0,23 0,41
TABLICA 5.16: Stosunek liczby zdan znaczacych w streszczeniu do długosci streszczenia –precyzja.
numer TFIDF LC Pos First Rand BM25
1 0,4 0,6 0,8 0,6 0,3 0,22 0,5 0,5 0,5 0,25 0,31 0,53 0,75 0,75 0,75 0,75 0,38 0,754 0,6 0,6 0,6 0,6 0,23 0,45 0,5 0,5 0,8 0,4 0,28 0,46 0,57 0,29 0,57 0,57 0,32 0,717 0,55 0,45 0,55 0,55 0,39 0,648 1 0,67 0,67 0,67 0,37 19 0,64 0,55 0,64 0,64 0,35 0,45
10 0,58 0,58 0,42 0,33 0,26 0,67
srednia 0,61 0,55 0,63 0,54 0,32 0,57
Najlepsze wyniki uzyskano dla metody wykorzystujacej informacje o połozeniu zdan. Al-
gorytm ten doskonale sprawdza sie w przypadku artykułów krótszych (jak 1, 2, 3), troche
gorzej jest w przypadku artykułów długich (7). Problemy moga pojawic sie równiez w przy-
padku artykułów o niestandardowej strukturze, w których rozmieszczenie informacji nie be-
dzie zgodne z załozonym kanonem (8).
Metody oparte o schematy tf-idf i bm25 osiagaja dobre rezultaty w przypadku artykułów
dłuzszych (7) i zawierajacych duzo nazw własnych (2). Dobrym przykładem jest artykuł nr
2 – zawiera on duzo nazwisk, liczb i dat. Własciwosci, które z definicji posiadaja schematy
tf-idf i bm25 pozwalaja na przydzielenie nieznanemu wyrazowi niezerowej wagi. Sytuacja
wyglada zupełnie inaczej w przypadku łancuchów leksykalnych. Jezeli jakiegos wyrazu nie
ma w tezaurusie, nie da sie uwzglednic informacji o nim w tworzonym streszczeniu. Za-
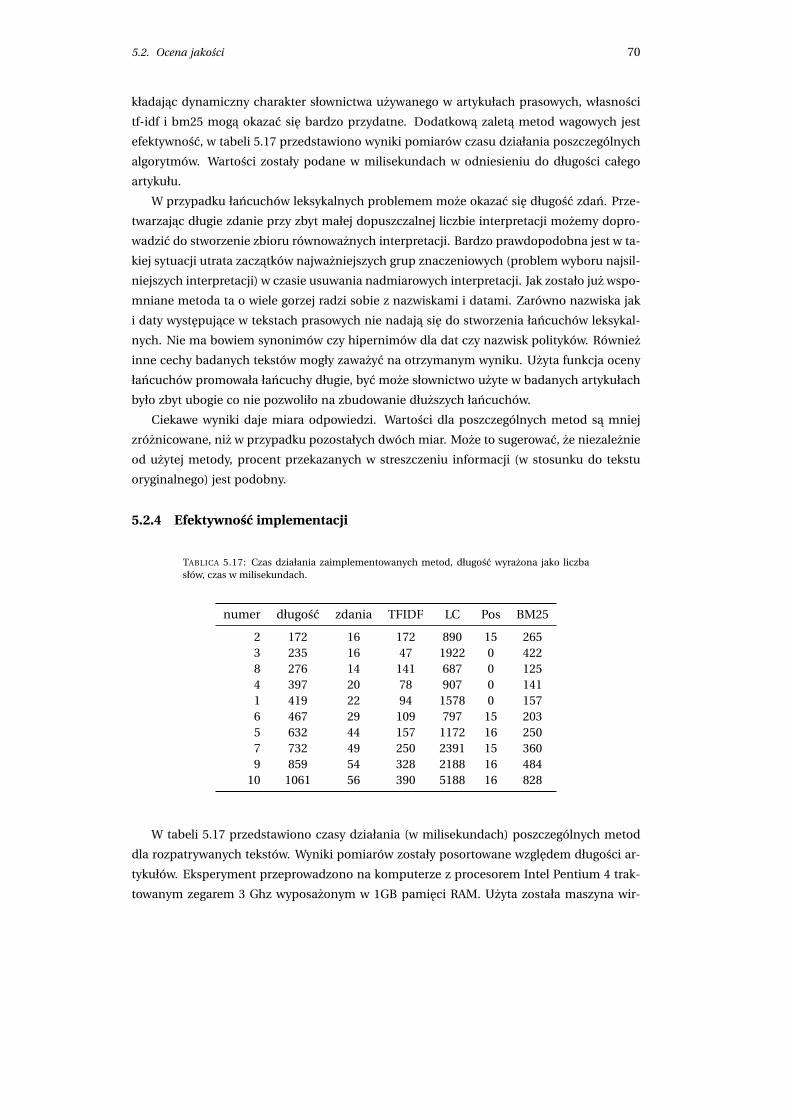
5.2. Ocena jakosci 70
kładajac dynamiczny charakter słownictwa uzywanego w artykułach prasowych, własnosci
tf-idf i bm25 moga okazac sie bardzo przydatne. Dodatkowa zaleta metod wagowych jest
efektywnosc, w tabeli 5.17 przedstawiono wyniki pomiarów czasu działania poszczególnych
algorytmów. Wartosci zostały podane w milisekundach w odniesieniu do długosci całego
artykułu.
W przypadku łancuchów leksykalnych problemem moze okazac sie długosc zdan. Prze-
twarzajac długie zdanie przy zbyt małej dopuszczalnej liczbie interpretacji mozemy dopro-
wadzic do stworzenie zbioru równowaznych interpretacji. Bardzo prawdopodobna jest w ta-
kiej sytuacji utrata zaczatków najwazniejszych grup znaczeniowych (problem wyboru najsil-
niejszych interpretacji) w czasie usuwania nadmiarowych interpretacji. Jak zostało juz wspo-
mniane metoda ta o wiele gorzej radzi sobie z nazwiskami i datami. Zarówno nazwiska jak
i daty wystepujace w tekstach prasowych nie nadaja sie do stworzenia łancuchów leksykal-
nych. Nie ma bowiem synonimów czy hipernimów dla dat czy nazwisk polityków. Równiez
inne cechy badanych tekstów mogły zawazyc na otrzymanym wyniku. Uzyta funkcja oceny
łancuchów promowała łancuchy długie, byc moze słownictwo uzyte w badanych artykułach
było zbyt ubogie co nie pozwoliło na zbudowanie dłuzszych łancuchów.
Ciekawe wyniki daje miara odpowiedzi. Wartosci dla poszczególnych metod sa mniej
zróznicowane, niz w przypadku pozostałych dwóch miar. Moze to sugerowac, ze niezaleznie
od uzytej metody, procent przekazanych w streszczeniu informacji (w stosunku do tekstu
oryginalnego) jest podobny.
5.2.4 Efektywnosc implementacji
TABLICA 5.17: Czas działania zaimplementowanych metod, długosc wyrazona jako liczbasłów, czas w milisekundach.
numer długosc zdania TFIDF LC Pos BM25
2 172 16 172 890 15 2653 235 16 47 1922 0 4228 276 14 141 687 0 1254 397 20 78 907 0 1411 419 22 94 1578 0 1576 467 29 109 797 15 2035 632 44 157 1172 16 2507 732 49 250 2391 15 3609 859 54 328 2188 16 484
10 1061 56 390 5188 16 828
W tabeli 5.17 przedstawiono czasy działania (w milisekundach) poszczególnych metod
dla rozpatrywanych tekstów. Wyniki pomiarów zostały posortowane wzgledem długosci ar-
tykułów. Eksperyment przeprowadzono na komputerze z procesorem Intel Pentium 4 trak-
towanym zegarem 3 Ghz wyposazonym w 1GB pamieci RAM. Uzyta została maszyna wir-

5.2. Ocena jakosci 71
tualna Javy firmy Sun Microsystems w wersji 1.5.0_11 działajaca w trybie interpretowanym.
Maszyna wirtualna operowała na pamieci o wielkosci 512MB.
Przedstawione wyniki wskazuja, ze czas działania algorytmu nie zalezy tylko od długosci
artykułu. Widac to najwyrazniej w przypadku metody opartej o łancuchy leksykalne, gdzie
bardzo wazne jest równiez to jakie wyrazy algorytm bedzie przetwarzał. Jezeli słowo po-
siada kilka róznych znaczen wówczas tworzone sa wszystkie mozliwe interpretacje, rosnie
nie tylko zuzycie pamieci, ale równiez czas działania algorytmu. Własnie ze wzgledu na
liczbe rozpatrywanych kombinacji metoda oparta o łancuchy leksykalne ma najdłuzszy czas
wykonania. Nie sa to jednak czasy które dyskwalifikowałyby ten algorytm w przypadku za-
stosowan produkcyjnych wymagajacych tworzenia streszczen „w locie”.
W literaturze brak informacji na temat efektywnosci pierwotnej implementacji omawia-
nych metod stad tez niemozliwe jest przeprowadzenie porównania.

Rozdział 6
Wnioski koncowe
6.1 Podsumowanie
Napisany w ramach niniejszej pracy system jest nie tylko kompletna realizacja postawio-
nych celów, ale równiez fundamentem pozwalajacym na dalsze rozwijanie opisanych tech-
nik.
Jednym z najwazniejszych celów pracy było sprawdzenie, czy opisywane w literaturze
angielskiej metody tworzenia automatycznych streszczen sa uzyteczne w przypadku tekstów
w jezyku polskim. [KPC95] podaja, ze opracowane przez nich narzedzie do generowania
automatycznych streszczen tekstów angielskich osiagało srednio 35% zgodnosci ze stresz-
czeniami tworzonymi przez ekspertów. Opisywana przez [KPC95] ewaluacja oparta została
o zbiór 188 par tekst-streszczenie; były to głównie teksty naukowe o sredniej długosci 86
zdan. Zaimplementowane w Lakonie metody osiagaja srednio wyniki w zakresie od 42% do
53% zgodnosci (w zaleznosci od algorytmu) ze „streszczeniem idealnym” stworzonym przez
grupe uczestników eksperymentu.
Warto nadmienic, ze losowy wybór zdan dla badanych tekstów dał srednio 23% zgod-
nosci, a metoda polegajaca na wyborze pierwszych n zdan 38%. Do oceny jakosci tworzo-
nych przez Lakona streszczen uzyto 10 tekstów prasowych o sredniej długosci 32 zdan. Ze
wzgledu na ograniczenia czasowe oraz trudnosci z zebraniem odpowiednio licznej grupy
eksperckiej nie udało sie stworzyc wiekszego zbioru referencyjnego.
Mimo oczywistych róznic eksperyment opisany w [KPC95] jest dobrym punktem od-
niesienia, a otrzymane wyniki potwierdzaja, ze ogólnie znane metody moga byc stosowane
równiez dla jezyka polskiego.
Dane zebrane w ramach eksperymentu pozwalaja wysnuc nastepujace wnioski:
• Uczestnicy eksperymentu byli zgodni co do tego, ze o wiele trudniej stworzyc stresz-
czenie dla tekstów dłuzszych, znajduje to równiez potwierdzenie w przeprowadzonych
analizach (por. rozdział 5.1.3).
• Zebrane w ramach przeprowadzonego eksperymentu dane zdaja sie potwierdzac, ze
w przypadku tekstów prasowych najwazniejsze informacje znajduja sie przewaznie na
72

6.1. Podsumowanie 73
poczatkach akapitów. Znajduje to odzwierciedlenie w bardzo dobrych wynikach me-
tody opartej na pozycji zdania w tekscie.
• Uczestnicy eksperymentu preferowali zdania nie zawierajace odwołan do wypowie-
dzen wystepujacych wczesniej w tekscie (bez tzw. zwiazków anaforycznych). Wyste-
pujace w tekscie zwiazki miedzyzdaniowe moga utrudnic stworzenie czytelnego, in-
formatywnego streszczenia.
Badania prowadzone na tekstach angielskich potwierdzaja, ze w przypadku tekstów pra-
sowych najwazniejsze informacje znajduja sie na poczatku akapitów. Sa to zdania z re-
guły wolne od odwołan do innych jednostek składniowych, wydaje sie wiec, ze dla tak krót-
kich streszczen problem zwiazków anaforycznych jest kwestia drugorzedna. Jednak zebrane
w czasie trwania eksperymentu dane moga byc z powodzeniem wykorzystywane do dal-
szych badan nad tym zagadanieniem.
W ramach planów na przyszłosc mozliwe jest przeprowadzenie dokładniejszych analiz
zwiazanych z wystepowaniem zwiazków anaforycznych. Wykrywanie istnienia zwiazków
anaforycznych jest mozliwe dysponujac bogatsza informacja lingwistyczna. [Sus05] podaje,
ze 80% anafor zamyka sie w obrebie 1–2 zdan. Dysponujac informacja o tym, ze dane zdanie
zawiera odwołanie do innej jednostki składniowej istnieja trzy mozliwosci:
• zastapienie odwołania adresatem anafory np. [CGKS04]
Ja jestem w rzedzie. On jest daleko. Mój przyjaciel idzie do niego.
po zastapieniu otrzymujemy:
Ja jestem w rzedzie. Rzad jest daleko. Mój przyjaciel idzie do rzedu.
• właczenie do streszczenia zdania wystepujacego bezposrednio przed zdaniem w któ-
rym wykryto anafore,
• eliminacja zdania z wynikowego streszczenia.
Mozliwosc pierwsza jest zdecydowanie najtrudniejszym rozwiazaniem i ze wzgledu na
mozliwe komplikacje istniejace rozwiazania radza sobie tylko z niektórymi rodzajami anafor.
Rozwiazanie drugie i trzecie nie wymagaja stworzenia rozbudowanego algorytmu, byc moze
uda sie tego typu heurystyke właczyc do metod zaimplementowanych w Lakonie.
Przedstawione w niniejszej pracy analizy jakosci sa integralna czescia zaimplementowa-
nego systemu, dzieki temu Lakon jest nie tylko narzedziem słuzacym do tworzenia stresz-
czen, ale równiez platforma pozwalajaca na rozwijanie i testowanie nowych metod. Dzieki
przyjetym załozeniom projektowym niektóre moduły moga byc uzywane zupełnie niezalez-
nie, czego najlepszym przykładem jest Tiller; oferuje on duza dowolnosc w definiowaniu
zakresu poszczególnych faz procesu przetwarzania jezyka naturalnego. Dzieki temu moze
byc on z powodzeniem uzywany w zastosowaniach innych niz sumaryzacja tekstów.

6.2. Kierunki dalszego rozwoju 74
Celem pracy było zaimplementowanie czterech metod automatycznego generowania stresz-
czen. Przeprowadzone analizy w oparciu o teksty prasowe wskazuja, ze skutecznosc dzia-
łania tych metod zalezy od cech takich jak obecnosc nazw własnych i dat, długosc zdan,
długosc tekstu oraz rozłozenie tekstu w akapitach.
Najlepsze wyniki osiagnieto przy zastosowaniu metod wykorzystujacych schematy tf-idf
oraz bm25 Okapi. Specyfika tych algorytmów powoduje, ze lepiej radza sobie one z tekstami
zawierajacymi nazwy własne, o nieregularnym rozłozeniem tekstu pomiedzy akapitami jak
równiez w przypadku tekstów dłuzszych.
Skutecznosc metody wykorzystujacej łancuchy leksykalne zalezy w duzej mierze od wiel-
kosci uzytego tezaurusa. Zasady redakcji uzytego w implementacji tezaurusa
synonimy.ux.pl zabraniaja właczania do niego nazw własnych, imion i nazwisk [syn07].
Obecnosc nazwisk i dat jest jedna z cech charakterystycznych tekstów prasowych, metody
wykorzystujace łancuchy leksykalne nie sa wiec najlepszym rozwiazaniem w tym przypadku.
Łancuchy leksykalne sprawdzaja sie w przypadku tekstów o rozbudowanym słownictwie,
gdzie temat artykułu reprezentuje czesto kilka róznych słów o podobnym znaczeniu.
Metode wykorzystujaca informacje o pozycji zdania najlepiej stosowac dla dokumentów
o równomiernym rozłozeniu tekstu w akapitach. Gdzie pierwsze zdania w akapitach ko-
munikuja sens akapitu, a dalsze sa rozwinieciem wprowadzonej mysli. Poniewaz taka dys-
trybucje informacji ciezko utrzymac w przypadku tekstów dłuzszych, metoda ta nadaje sie
idealnie do streszczania typowych „newsów”.
Stworzony za posrednictwem modułu Wiki indeks wyszukiwawczy to bardzo bogaty zbiór
statystycznych informacji na temat jezyka. Korpus polskiej Wikipedii składajacy sie z około
300 tys. artykułów jest bardzo uzytecznym narzedziem, pozwalajacym efektywnie wykorzy-
stywac własnosci schematów takich jak tf-idf oraz bm25 Okapi do automatycznego oblicza-
nia wag słów kluczowych. Sam indeks moze byc z powodzeniem wykorzystywany do dal-
szych badan. Moduł Wiki jest w stanie stworzyc podobny indeks dla kazdego zbioru tekstów
spełniajacego pewne podstawowe wymagania (zob. rozdział4.5.1).
W oparciu o wygenerowany indeks zaimplementowano narzedzie pozwalajace na wy-
szukiwanie dokumentów podobnych. Nie przeprowadzono zadnej formalnej analizy jakosci
wyników działania stworzonego mechanizmu. Byc moze tego typu analizy zostana prze-
prowadzone w przyszłosci. Poza demonstracja działania implementacji modelu wektoro-
wego narzedzie to posłuzyło do sprawdzenia poprawnosci stworzonego na bazie Wikipedii
indeksu wyszukiwawczego. Moze byc ono z powodzeniem stosowane z kazdym indeksem
stworzonym za pomoca modułu Wiki.
6.2 Kierunki dalszego rozwoju
Ponizej przedstawiono najciekawsze pomysły zwiazane z dalszym rozwojem stworzo-
nego w ramach niniejszej pracy projektu Lakon. Czesc z przedstawionych ponizej pomysłów
nie została zrealizowana w ramach pracy z uwagi na ograniczenia czasowe, pozostałe zas sa
bezposrednim wynikiem przeprowadzonych analiz. Na koncu rozdziału przedstawiono po-

6.2. Kierunki dalszego rozwoju 75
tencjalne mozliwosci zastosowania opisywanych rozwiazan.
Zwiazki anaforyczne Stworzenie mechanizmów pozwalajacych na rozpoznawanie zdan za-
wierajacych odwołania do innych jednostek składniowych. Nastepnie aplikacja heury-
styk pozwalajacych na zwiekszenie czytelnosci tworzonych streszczen. Rozpatrywane
beda dwie z trzech omówionych strategii: dołaczanie zdania wystepujacego przed
zdaniem z odwołaniem, badz eliminacja tego zdania z wynikowego streszczenia.
Wielomodowa funkcja oceny zdan Dane charakteryzujace najczesciej wybierane zdania ze-
brane podczas eksperymentu sugeruja, ze połaczenie róznych funkcji oceny zdan w jedna
mogłoby spowodowac wzrost jakosci otrzymywanych streszczen. W zaleznosci od cech
rozpatrywanego tekstu odpowiednie rozłozenie wag miedzy funkcjami składowymi po-
zwoliłoby lepiej odwzorowac rzeczywiste preferencje odbiorców. Podobne podejscie
prezentowano juz wczesniej [Edm69, KPC95] dla tekstów w jezyku angielskim. Wzo-
rujac sie na [KPC95] do optymalizacji parametrów takiej wielomodowej funkcji mozna
by uzyc klasyfikatora, wykorzystujac jako zbiór uczacy dane zebrane podczas ekspery-
mentu. W pierwszej kolejnosci wymagałoby to jednak zgromadzenia streszczen dla
wiekszej liczby tekstów.
Udostepnienie projektu Lakon W najblizszej przyszłosci projekt Lakon zostanie udostep-
niony na zasadach open-source (licencja Apache Software License). Po uzyskaniu zgody
autorów tekstów uzytych w eksperymencie, udostepniony zostanie równiez stworzony
w czasie trwania eksperymentu referencyjny zbiór streszczen wraz z pełnymi tekstami
artykułów.
Wsparcie dla jezyka angielskiego Jak dotad wszystkie przeprowadzone eksperymenty do-
tyczyły jezyka polskiego. Wsparcie dla jezyka angielskiego znacznie zwiekszyłoby uzy-
tecznosc stworzonego systemu.
Mniejszy korpus referencyjny Referencyjny zbiór dokumentów uzyty w pracy to ponad 300
tysiecy artykułów. Stworzony na podstawie tej kolekcji indeks wyszukiwawczy zaj-
muje ponad 300MB. Tak duzy rozmiar znacznie obniza uzytecznosc całego narzedzia.
[BMR95] w systemie ANES uzyli kolekcji dokumentów liczacej 20849 dokumentów.
Istnieja zatem przesłanki sugerujace, ze rozmiar referencyjnego zbioru dokumentów
mógłby byc mniejszy.
Eksperymenty z tekstami o innym charakterze Poczynione dotychczas obserwacje sa wła-
sciwe dla tekstów prasowych, aby móc stosowac omawiane metody w praktyce nalezy
sprawdzic jakie daja wyniki dla tekstów o innym charakterze np. artykułów nauko-
wych.
Potencjalne zastosowania
Automatyczne generowanie streszczen moze znacznie obnizyc koszt dostepu do wiedzy,
poprzez skrócenie czasu potrzebnego na odrzucenie tekstów nie adekwatnych wobec po-

6.2. Kierunki dalszego rozwoju 76
trzeb. Ostateczna weryfikacja przeprowadzonych tu analiz bedzie wdrozenie projektu Lakon
w praktyce. Autor widzi nastepujace mozliwosci wykorzystania stworzonych rozwiazan:
Agregacja wiadomosci prasowych Automatyczne generowanie skrótów artykułów prasowych
na potrzeby agregacji wiadomosci np. generowanie kanałów RSS.
Wyniki wyszukiwania Zamiast standardowej próbki tekstu zawierajacej wyszukiwana fraze,
mozna by wyswietlac krótkie streszczenie (składajace sie z 1-2 zdan). Takie streszcze-
nie przypuszczalnie lepiej oddawałoby własciwy charakter odnalezionego dokumentu.
Wymagałoby to oczywiscie dostepu do oryginalnej tresci dokumentu prezentowanego
w danym wyniku. Uwzglednienie w procesie generowania automatycznego streszcze-
nia zapytania wpisanego przez uzytkownika mogłoby poprawic adekwatnosc wygene-
rowanego streszczenia.
Katalogowanie Tworzenie w sposób automatyczny katalogów dokumentów w oparciu o ich
krótkie streszczenia.
6.2.1 Podziekowania
Przede wszystkim chciałbym serdecznie podziekowac panu Jerzemu Stefanowskiemu oraz
panu Dawidowi Weissowi za wszelkie krytyczne uwagi, pomysły oraz za poswiecony mi czas.
Osobne podziekowania naleza sie kazdemu sposród grupy 60 ochotników bioracych udział
w eksperymencie, bez Panstwa pomocy ukonczenie tej pracy byłoby niemozliwe.

Literatura
[BE97] Regina Barzilay and Michael Elhadad. Using lexical chains for text summarization.
Inteligent Scalable Text Summarization Workshop (ISTS’97), pages 10–17, 1997.
[Bec02] Kent Beck. Test Driven Development: By Example. Addison-Wesley Longman Publishing
Co., Inc., 2002.
[BMR95] Ronald Brandow, Karl Mitze, and Lisa F. Rau. Automatic condensation of electronic
publications by sentence selection. Inf. Process. Manage., 31(5):675–685, 1995.
[BYRN99] Ricardo A. Baeza-Yates and Berthier Ribeiro-Neto. Modern Information Retrieval.
Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1999.
[CGKS04] Marcin Ciura, Damian Grund, Slawomir Kulików, and Nina Suszczanska. A system to
adapt techniques of text summarizing to polish. pages 117–120, 2004.
[CO01] John M. Conroy and Dianne P. O’Leary. Text summarization via hidden markov models.
In Research and Development in Information Retrieval, pages 406–407, 2001.
[DJHS] Heikki Mannila David J. Hand and Padhraic Smyth. Principles of Data Mining (Adaptive
Computation and Machine Learning). MIT Press), year = 2001.
[Edm69] H. P. Edmundson. New methods in automatic extracting. J. ACM, 16(2):264–285, 1969.
[Fox92] Christopher J. Fox. Lexical analysis and stoplists. In Information Retrieval: Data
Structures and Algorithms, pages 102–130. 1992.
[GJRR61] A. Resnick G. J. Rath and T. R.Savage. The formation of abstracts by the selection of
sentences. American Documentation, 2(12):139–143, 1961.
[GS05] Antonio Gulli and Alessio Signorini. The indexable web is more than 11.5 billion pages.
[on-line] http://www.cs.uiowa.edu/~asignori/web-size/, 2005.
[HK01] Elzbieta Hajnicz and Anna Kupsc. Przeglad analizatorow morfologicznych dla jezyka
polskiego. Technical Report 937, IPI PAN, 2001.
[Jon93] Karen Sparck Jones. What might be in a summary? In Knorz, Krause, and
Womser-Hacker, editors, Information Retrieval 93: Von der Modellierung zur
Anwendung, pages 9–26, Konstanz, DE, 1993. Universitätsverlag Konstanz.
[KPC95] J. Kupiec, J. Pederson, and F. Chen. A trainable document summarizer. In Proceedings of
the 18th ACM-SIGIR Conference, pages 68–73, 1995.
77
78
[Kur90] Kurcz I., Lewicki A., Sambor J., Szafran K. and Woronczak J. Słownik frekwencyjny
polszczyzny współczesnej, volume t.1-2. Instytut Jezyka Polskiego PAN, Kraków, Poland,
1990.
[Lie98] D.H. Lie. Sumatra: A system for automatic summary generation. [on-line]
http://www.carp-technologies.nl/download/papers/SumatraTWLT14paper/
SumatraTWLT14.html, 1998.
[Luh58] H. P. Luhn. The automatic creation of literature abstracts. IBM Journal of Reasearch and
Development, pages 159–165, 1958.
[Mar04] Marcin Wolinski. Komputerowa weryfikacja gramatyki Swidzinskiego. PhD thesis,
Instytut Podstaw Informatyki PAN, Warszawa, 2004.
[Mau89] Michael L. Mauldin. Information retrieval by text skimming. Technical Report
CMU-CS-89-193, Carnegie Mellon University, 1989.
[MRSar] Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schuetze. Introduction to
Information Retrieval. Cambridge University Press, 2008 (to appear).
[MvZ07] Vincent Massol and Jason van Zyl. Better Builds with Maven. DevZuz, 2007.
[MW00] Irmina Masłowska and Dawid Weiss. Juicer – a data mining approach to information
extraction from the www. Foundations of Computing and Decision Sciences, 2(25):67–87,
2000.
[PBY02] Luis Perez-Breva and Osamu Yoshimi. Model selection in summary evaluation, 2002.
[PWN07] PWN. Uniwersalnego słownika jezyka polskiego pwn. [on-line]
http://usjp.pwn.pl/lista.php?co=streszczenie, 2007.
[RWHB+92] Stephen E. Robertson, Steve Walker, Micheline Hancock-Beaulieu, Aarron Gull, and
Marianna Lau. Okapi at TREC. In Text REtrieval Conference, pages 21–30, 1992.
[Rze] Korpus rzeczpospolitej. [on-line]
http://www.cs.put.poznan.pl/dweiss/rzeczpospolita.
[SB87] Gerard Salton and Chris Buckley. Term weighting approaches in automatic text retrieval.
Technical report, Ithaca, NY, USA, 1987.
[SBM96] Amit Singhal, Chris Buckley, and Mandar Mitra. Pivoted document length normalization.
In Research and Development in Information Retrieval, pages 21–29, 1996.
[SS98] Zygmunt Saloni and Marek Swidzinski. Składnia współczesnego jezyka polskiego.
Wydawnictwo Naukowe PWN, 1998.
[Sul03] Danny Sullivan. Search engine size wars and google’s supplemental results. [on-line]
http://searchenginewatch.com/showPage.html?page=3071371, 2003.
[Sul05] Danny Sullivan. New estimate puts web size at 11.5 billion pages and compares search
engine coverage. [on-line]
http://blog.searchenginewatch.com/blog/050517-075657, 2005.
[Sus05] Nina Suszczanska. Zastosowanie gs-modelu jezyka polskiego w kompleksowej analizie
tekstów. [on-line] http://nlp.ipipan.waw.pl/NLP-SEMINAR/050307.ppt, 2005.

79
[syn07] Redakcja synonimy.ux.pl. Jakie sa reguły korekty i dodawania haseł? [on-line]
http://synonimy.ux.pl/faq.php#korr,(dostep online: 01.09.2007, 2007.
[TKJ97] Evelyne Tzoukermann, Judith Klavans, and Christian Jacquemin. Effective use of natural
language processing techniques for automatic conflation of multi-word terms: The role
of derivational morphology, part of speech tagging, and shallow parsing. In Research
and Development in Information Retrieval, pages 148–155, 1997.
[Wei01] Dawid Weiss. A Clustering Interface for Web Search Results in Polish and English.
Master thesis. Poznan University of Technology., 2001.
[Wei05] Dawid Weiss. Stempelator: A Hybrid Stemmer for the Polish Language. Technical Report
RA-002/05, Institute of Computing Science, Poznan University of Technology, Poland,
2005.
[Wik07a] Wikipedia. Hypernym. [on-line] http://en.wikipedia.org/wiki/Hypernym, (dostep
online: 01.09.2007), 2007.
[Wik07b] Wikipedia. Hyponym. [on-line] http://en.wikipedia.org/wiki/Hyponym, (dostep
online: 01.09.2007), 2007.
[Wik07c] Wikipedia. Leksem. [on-line] http://pl.wikipedia.org/wiki/Leksem, (dostep
online: 22.05.2007), 2007.
[Wik07d] Wikipedia. Lemma. [on-line] http://pl.wikipedia.org/wiki/Lemma, (dostep online:
22.05.2007), 2007.
[Wik07e] Wikipedia. Stop words list. [on-line]
http://pl.wikipedia.org/wiki/Wikipedia:Stopwords, (dostep online:
22.05.2007), 2007.
[Wik07f] Wikipedia. Tf-idf. [on-line] http://en.wikipedia.org/wiki/Tf-idf, (dostep online:
22.05.2007), 2007.
[Wol04] Marcin Wolinski. System znaczników morfosyntaktycznych w korpusie ipi pan.
Polonika, pages 39–54, 2004.
[Zec96a] K. Zechner. A literature survey on information extraction and text summarization, 1996.
[Zec96b] Klaus Zechner. Fast generation of abstracts from general domain text corpora by
extracting relevant sentences. In Proceedings of the 16th conference on Computational
linguistics, pages 986–989, Morristown, NJ, USA, 1996. Association for Computational
Linguistics.

Zasoby sieci
[A] WordNet – a lexical database for the English language.
http://wordnet.princeton.edu/
[B] Regina Barzilay’s homepage
http://people.csail.mit.edu/regina/
[C] Tezaurus autorstwa Marcina Miłkowskiego
http://synonimy.ux.pl/
[D] Przemysław Kobylanski – kurs jezyka Prolog
http://www.im.pwr.wroc.pl/~przemko/prolog/m4s4.html
[E] LAS 2.0 – Zaawansowany serwer usług lingwistycznych
http://thetos.zo.iinf.polsl.gliwice.pl/las2/
[F] Korpus „Rzeczpospolitej”
http://www.cs.put.poznan.pl/dweiss/rzeczpospolita/
[G] Spring framework
http://www.springframework.org/
[H] Lucene search engine
http://lucene.apache.org/
[I] Hibernate
http://http://www.hibernate.org/
[J] Apache Velocity Engine
http://velocity.apache.org//
[K] Apache Maven
http://maven.apache.org//
[L] Analizator morfologiczny Morfeusz SIAT
http://nlp.ipipan.waw.pl/~wolinski/morfeusz/morfeusz.html
[M] Lametyzator
http://www.cs.put.poznan.pl/dweiss/xml/projects/lametyzator/index.xml
[N] Stempel
http://getopt.org/stempel/index.html
[O] C ar r ot 2
http://carrot2.org
[P] JGoodies – Java user interface design
http://jgoodies.com
80

81
[Q] HSQL DB
http://hsqldb.org
[R] Junit – Java unit testing framework
http://junit.org
[S] JQuery
http://jquery.com

Przykładowe streszczenia
Ponizej zamieszczone zostały wyniki działania zaimplementowanych algorytmów dla tek-
stu „Dobre regulacje, mało spółek” autorstwa p. Ady Kostrz-Kosteckiej, tekst pochodzi z kor-
pusu „Rzeczposlitej”, znajduje sie w pliku o nazwie: 199306050038.html.
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest spółek, notowanych na giełdzie. W
porównaniu ze standartami obowiazujacymi w krajach o rozwinietych rynkach kapitałowych, a takze innymi kra-
jami naszego regionu, polski rynek prezentuje sie dobrze, jest własciwie przygotowany pod wzgledem organiza-
cyjnym i prawnym. W niedalekiej przyszłosci powinien spełniac własciwa mu role, to znaczy, mobilizacji kapitału,
jego alokacji i wyceny przedsiebiorstw.
Do takich wniosków doszli uczestnicy posiedzenia Komisji Papierów Wartosciowych 4 biezacego miesiaca. Po-
siedzenie miało uroczysty charakter ze wzgledu na druga rocznice istnienia Komisji. Brali w nim udział, oprócz
członków Komisji, takze prezes NBP Hanna Gronkiewicz–Waltz, minister finansów Jerzy Osiatynski, minister prze-
kształcen własnosciowych Janusz Lewandowski. Podstawa do dyskusji był raport, przygotowany przez Roberta
Strachote, prawnika z Amerykanskiej Komisji Papierów Wartosciowych.
Podczas konferecji prasowej prezes Gronkiewicz-Waltz powiedziała, ze banki, ubezpieczenia i rynek kapitałowy sa
tymi segmentami rynku finansowego, na których nie mozna zrezygnowac z regulacji, zwłaszcza w okresie trans-
formacji systemowej. Giełda i Komisja Papierów Wartosciwych zdołały uzyskac w krótkim czasie dobra reputacje i
nie mozna tego stracic. Obnizenie stóp procentowych w marcu wpłyneło prawidłowo na zmiane systemu oszcze-
dzania, spowodowało przeniesienie pieniedzy na giełde. Prezes stwierdziła równoczesnie, ze jest za ostudzeniem
nastrojów, które nastapiło na giełdzie.
Odpowiadajac na pytanie o przepisy dotyczace przekazywania za granice zysków z papierów wartosciowych po-
wiedziała, ze nie ma ograniczen dla zysków z akcji i obligacji trzyletnich. Prowadzone sa rozmowy z ministrem
finansow, dotyczace zgody na transfer zysków z obligacji jednorocznych i bonów skarbowych. Pani prezes obawia
sie jednak, ze róznica stóp procentowych Polski i innych krajów moze grozic „wypłukaniem” rezerw, przy wywo-
zie tych zysków. Skala kredytów udzielanych pod zastaw akcji nie jest znana NBP, prezes Gronkiewicz ocenia, ze
obecnie nie jest ich duzo. Prawo bankowe zabrania natomiast brania kredytów na zakup akcji prywatyzowanych
banków.
Przewodniczacy Komisji Papierów Wartosciwych Lesław Paga powiedział, ze giełda jest tylko jednym ze sposobów
pozyskiwania kapitału dla spółek, jezeli maja one dobry standing finansowy moga starac sie o kredyt z banku,
co jest prostsze. Coraz wiecej prywatnych spółek jest obecnie zainteresowanych wejsciem na giełde. W Komisji
przygotowywane sa takze w stepne rozwiazania dotyczace rynku pozagiełdowego, który moze byc konkurencyjny
dla giełdy.
Zdaniem prezesa giełdy Wiesława Rozłuckiego warunki handlu na rynku giełdowym i pozagiełdowym beda inne,
nie bedzie wiec miedzy nimi konkurencji. Giełda jest przygotowana do rozwoju drugiego parkietu i stworzenia
trzeciego. O d 1995 r notowania akcji maja sie odbywac w systemie ciagłym, do tego niezbedna jest jednak zmiana
oprogramowania systemu komputerowego, potrzebny byłby takze lepszy stan telekomunikacji, zeby chociaz w
wiekszych miastach mozna było składac zlecenia w trakcie sesji giełdowej.
Ponizej zaprezentowane zostały 4 najczesciej wybierane przez uzytkowników zdania dla
cytowanego tekstu.
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest spółek, notowanych na giełdzie. W
porównaniu ze standartami obowiazujacymi w krajach o rozwinietych rynkach kapitałowych, a takze innymi kra-
jami naszego regionu, polski rynek prezentuje sie dobrze, jest własciwie przygotowany pod wzgledem organizacyj-
nym i prawnym. Do takich wniosków doszli uczestnicy posiedzenia Komisji Papierów Wartosciowych 4 biezacego
82

83
miesiaca. Podczas konferecji prasowej prezes Gronkiwicz-Waltz powiedziała, ze banki, ubezpieczenia i rynek kapi-
tałowy sa tymi segmentami rynku finansowego, na których nie mozna zrezygnowac z regulacji, zwłaszcza w okresie
transformacji systemowej.
Streszczenia otrzymane dla poszczególnych metod.
FIRST
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest spółek, notowanych na gieł-
dzie. W porównaniu ze standartami obowiazujacymi w krajach o rozwinietych rynkach kapitałowych, a
takze innymi krajami naszego regionu, polski rynek prezentuje sie dobrze, jest własciwie przygotowany pod
wzgledem organizacyjnym i prawnym. W niedalekiej przyszłosci powinien spełniac własciwa mu role, to
znaczy, mobilizacji kapitału, jego alokacji i wyceny przedsiebiorstw. Do takich wniosków doszli uczestnicy
posiedzenia Komisji Papierów Wartosciowych 4 biezacego miesiaca.
Loc
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest spółek, notowanych na gieł-
dzie. Do takich wniosków doszli uczestnicy posiedzenia Komisji Papierów Wartosciowych 4 biezacego mie-
siaca. Podczas konferecji prasowej prezes Gronkiwicz-Waltz powiedziała, ze banki, ubezpieczenia i rynek
kapitałowy sa tymi segmentami rynku finansowego, na których nie mozna zrezygnowac z regulacji, zwłasz-
cza w okresie transformacji systemowej. Odpowiadajac na pytanie o przepisy dotyczace przekazywania za
granice zysków z papierów wartosciowych powiedziała, ze nie ma ograniczen dla zysków z akcji i obligacji
trzyletnich.
TFIDF
Giełda i Komisja Papierów Wartosciwych zdołały uzyskac w krótkim czasie dobra reputacje i nie mozna tego
stracic. Odpowiadajac na pytanie o przepisy dotyczace przekazywania za granice zysków z papierów war-
tosciowych powiedziała, ze nie ma ograniczen dla zysków z akcji i obligacji trzyletnich. Przewodniczacy
Komisji Papierów Wartosciwych Lesław Paga powiedział, ze giełda jest tylko jednym ze sposobów pozyski-
wania kapitału dla spółek, jezeli maja one dobry standing finansowy moga starac sie o kredyt z banku, co
jest prostsze. W Komisji przygotowywane sa takze w stepne rozwiazania dotyczace rynku pozagiełdowego,
który moze byc konkurencyjny dla giełdy.
BM25
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest spółek, notowanych na gieł-
dzie. Giełda i Komisja Papierów Wartosciwych zdołały uzyskac w krótkim czasie dobra reputacje i nie mozna
tego stracic. Obnizenie stóp procentowych w marcu wpłyneło prawidłowo na zmiane systemu oszczedzania,
spowodowało przeniesienie pieniedzy na giełde. Prezes stwierdziła równoczesnie, ze jest za ostudzeniem
nastrojów, które nastapiło na giełdzie.
Lex
Rynek kapitałowy w Polsce nie jest przeregulowany, natomiast zbyt mało jest spółek, notowanych na gieł-
dzie. W porównaniu ze standartami obowiazujacymi w krajach o rozwinietych rynkach kapitałowych, a
takze innymi krajami naszego regionu, polski rynek prezentuje sie dobrze, jest własciwie przygotowany pod
wzgledem organizacyjnym i prawnym. Podczas konferecji prasowej prezes Gronkiwicz-Waltz powiedziała,
ze banki, ubezpieczenia i rynek kapitałowy sa tymi segmentami rynku finansowego, na których nie mozna
zrezygnowac z regulacji, zwłaszcza w okresie transformacji systemowej. Zdaniem prezesa giełdy Wiesława
Rozłuckiego warunki handlu na rynku giełdowym i pozagiełdowym beda inne, nie bedzie wiec miedzy nimi
konkurencji.

Zawartosc płyty CD
Dołaczona do pracy płyta CD zawiera nastepujace materiały.
code Kod zródłowy projektów Lakon i Wiki. W katalogach projektów znajduja sie pliki readme.txt
zawierajace podstawowa dokumentacje techniczna konieczna do pracy z projektem.
texts Teksty artykułów uzytych w eksperymencie wraz z przykładowymi streszczeniami.
demo Gotowa do uruchomienia w srodowisku win32 werjsa Lakon-GUI.
maven-repository Gotowe do uzycia repozytorium Maven, zawierajace wszystkie zaleznosci
(biblioteki) konieczne do pracy z projektem. W przypadku problemów z dostepno-
scia zaleznosci w publicznych repozytoriach, mozna skopiowac znajdujace sie w tym
katalogu zasoby do lokalnego repozytorium Maven.
seminars Prezentacje dotyczace pracy przedstawiane na seminarium dyplomowym specjali-
zacji Technologie Wytwarzania Oprogramowania.
thesis Elektroniczna wersja niniejszej pracy.
thesis-resources Wiekszosc materiałów na podstawie których stworzona została niniejsza
praca.
wiki-index Stworzony na podstawie kopii bazy danych polskiej Wikipedii indeks (zgodny z
formatem uzywanym przez Lucene) artykułów.
84