praca dyplomowa inŻynierska · data rozpoczęcia studiów: ... zastosowane technologie, metody...
TRANSCRIPT

Rok akademicki 2013/2014
Politechnika Warszawska
Wydział Elektroniki i Technik Informacyjnych
Instytut Informatyki
PRACA DYPLOMOWA INŻYNIERSKA
Jakub Sędek
Aplikacja do oceny kredytowej klientów banku
zrealizowana z wykorzystaniem środowiska
i narzędzi SAS
Opiekun pracy
dr inż. Andrzej Ciemski
Ocena: .....................................................
................................................................
Podpis Przewodniczącego
Komisji Egzaminu Dyplomowego

Kierunek: Informatyka
Specjalność: Inżynieria Systemów Informatycznych
Data urodzenia: 28 stycznia 1990 r.
Data rozpoczęcia studiów: 1 października 2009 r.
Życiorys
Nazywam się Jakub Sędek i urodziłem się 28 stycznia 1990 roku w Warszawie. Po
skończeniu szkoły podstawowej nr 124 im. Stanisława Jachowicza oraz gimnazjum
numer 104 zostałem przyjęty do XVIII LO im. Jana Zamoyskiego w Warszawie do
klasy o profilu matematyczno-fizycznym. W 2009 roku zdałem maturę i rozpocząłem
studia na Wydziale Elektroniki i Technik Informacyjnych Politechniki Warszawskiej na
kierunku Informatyka.
........................................................
Jakub Sędek
EGZAMIN DYPLOMOWY
Złożył egzamin dyplomowy w dniu ................................................................................. 20__ r
z wynikiem ...................................................................................................................................
Ogólny wynik studiów: ................................................................................................................
Dodatkowe wnioski i uwagi Komisji: .........................................................................................
......................................................................................................................................................
......................................................................................................................................................

STRESZCZENIE
Praca prezentuje projekt i implementację aplikacji umożliwiającej dokonywanie oceny
kredytowej osób starających się o kredyt w banku. Przedstawia proces budowy i oceny
modelu oceny kredytowej w oparciu o narzędzie SAS Enterprise Miner, drzewa
decyzyjne i bazę danych udzielonych kredytów klientom niemieckiego banku.
Praca opisuje także projekt aplikacji w języku UML przy użyciu diagramów
przypadków użycia, komponentów, klas i sekwencji. Definiuje wymagania
funkcjonalne i niefunkcjonalne stawiane aplikacji. Zawiera także opis implementacji
aplikacji opartej na wzorcu architektonicznym MVC i bibliotece graficznej SWING
oraz prezentuje jej działanie.
Słowa kluczowe: ocena kredytowa, MVC, SAS Enterprise Miner, SWING, drzewo
decyzyjne
The application for the credit scoring of bank customers using SAS
environment and tools
The thesis presents the design and implementation of an application that allows credit
scoring of persons applying for a loan at the bank. Shows the construction and the
evaluation process of credit scoring model based on the SAS Enterprise Miner tool,
decision trees and a database of loans granted to customers of the German bank.
The thesis also describes the application design in UML language using use case,
components, classes and sequence diagrams. Defines the functional and nonfunctional
requirements of the application. It also contains a description of the implementation
based on the MVC architectural pattern and SWING graphical library and presents its
running.
Keywords: credit scoring, MVC, SAS Enterprise Miner, SWING, decision tree

Spis treści
1. Wprowadzenie ....................................................................................................................... 1
1.1. Tematyka pracy ...................................................................................................... 1
1.2. Cel pracy ................................................................................................................ 2
1.3. Zawartość ............................................................................................................... 2
2. Zastosowane technologie, metody oraz narzędzia ............................................................. 4
2.1. Technologie ........................................................................................................... 4
2.1.1. MVC ............................................................................................................... 4
2.1.2. XML ................................................................................................................ 5
2.2. Metody ................................................................................................................... 6
2.2.1. SEMMA .......................................................................................................... 6
2.2.2. Drzewo decyzyjne ........................................................................................... 7
2.3. Narzędzia ............................................................................................................... 8
2.3.1. SAS Enterprise Miner ..................................................................................... 8
2.3.2. Eclipse IDE ..................................................................................................... 9
2.3.3. Eclipse WindowBuilder ................................................................................ 10
2.3.4. JUnit .............................................................................................................. 11
2.3.5. Javadoc .......................................................................................................... 11
3. Projekt i implementacja ..................................................................................................... 13
3.1. Model eksploracji danych .................................................................................... 13
3.1.1. Zbiór danych trenujących ............................................................................. 13
3.1.2. Partycjonowanie danych ............................................................................... 26
3.1.3. Drzewo decyzyjne ......................................................................................... 27
3.1.4. Ocena modelu ............................................................................................... 28
3.2. Analiza wymagań aplikacji .................................................................................. 30

3.2.1. Wymagania funkcjonalne ............................................................................. 30
3.2.2. Wymagania niefunkcjonalne ........................................................................ 31
3.3. Projekt aplikacji ................................................................................................... 31
3.3.1. Przypadki użycia ........................................................................................... 31
3.3.2. Diagram komponentów ................................................................................. 33
3.3.3. Diagramy klas ............................................................................................... 34
3.3.4. Diagramy sekwencji ..................................................................................... 38
3.4. Opis implementacji aplikacji ............................................................................... 40
3.4.1. Architektura i klasy pomocnicze .................................................................. 40
3.4.2. Kontroler ....................................................................................................... 42
3.4.3. Model ............................................................................................................ 45
3.4.4. Widok ............................................................................................................ 48
3.5. Testowanie aplikacji ............................................................................................ 50
3.5.1. Testy jednostkowe ........................................................................................ 50
3.5.2. Testy integracyjne ......................................................................................... 51
3.5.3. Testy systemowe ........................................................................................... 51
3.6. Przedstawienie funkcjonalności aplikacji ............................................................ 51
3.6.1. Wykonanie oceny kredytowej ...................................................................... 52
3.6.2. Konfiguracja aplikacji ................................................................................... 56
4. Podsumowanie ..................................................................................................................... 58
4.1. Weryfikacja wymagań ......................................................................................... 58
4.2. Dalsze kierunki rozwoju pracy ............................................................................ 60
Bibliografia .............................................................................................................................. 61
Spis rysunków, tabel i wydruków .......................................................................................... 63

1
1. Wprowadzenie
Cechą otaczającej nas rzeczywistości jest niepewność. Towarzyszy ona zwyczajnym
czynnościom życiowym, zawiera się w sferze marzeń, związana jest z działaniem
przedsiębiorstw, zjawiskami atmosferycznymi - ze wszystkim co nas otacza.
W związku z tym jesteśmy zmuszeni do tego, aby analizować przyczyny i możliwie
trafnie przewidywać skutki poszczególnych decyzji. Dotyczy to zarówno
przedsiębiorstw, które podejmując decyzje biznesowe, określają czy są w stanie
zachować konkurencyjność i utrzymać się na rynku, jak i poszczególnych osób
fizycznych, które podejmują określone decyzje życiowe.
1.1. Tematyka pracy
Przedmiotem niniejszej pracy jest prezentacja programu oceny ryzyka w sektorze
działalności bankowej. Jednym z rodzajów ryzyka, z jakim zmaga się ten obszar jest
udzielanie kredytów. Oferta kredytowa to istotne źródło dochodów banków oraz ich
rentowności. Pożyczkodawcy stosują różne wskaźniki opłacalności takiej działalności.
Ważna jest ocena zdolności kredytowej klienta (ang. credit scoring). Dzieli ona
klientów banku na grupę, której nie należy udzielać kredytu ze względu na zbyt duże
ryzyko oraz tych którym można zaoferować kredyt. Scoring1 kredytowy uzyskuje się na
podstawie opracowanego wcześniej modelu. Powinien być tak zbudowany, aby można
było łatwo uzyskać informacje potrzebne do jego zastosowania. Istotną jego cechą ma
być także wydajność - dla optymalizacji czasu i kosztów. Jego wyniki winny być
jednoznacznie interpretowalne i cechować się jak największą dokładnością.
Budowę takich modeli umożliwia rozwijająca się od pewnego czasu dziedzina
eksploracji danych (ang. data mining). Jest ona „(...) procesem odkrywania znaczących
nowych powiązań, wzorców i trendów przez przeszukiwanie dużych ilości danych
zgromadzonych w skarbnicach danych, przy wykorzystaniu metod rozpoznawania
wzorców, jak również metod statystycznych i matematycznych” [1].
1 Podjąłem decyzję o zastosowaniu słowa „scoring” w oparciu o jego powszechne użycie w polskiej
literaturze takiej jak artykuły SAS Institute, StatSoft i w branży bankowej (patrz słownik pojęć
kredytowych www.bik.pl dostęp 02.09.2014r.)

2
Tworzenie modeli w oparciu o eksplorację danych opiera się więc na analizie
dotychczasowych doświadczeń banku. Historia kredytowa klientów stanowi punkt
wyjścia w poszukiwaniu określonych schematów na podstawie których można określić
prawdopodobieństwo spłaty zaciągniętych zobowiązań. Algorytmy analizy danych
skupiają się więc na wyborze takich cech związanych z pożyczką jak: wielkość, czas
trwania, dane klienta. Szukanie powiązań, wzorców i trendów odbywa się poprzez
wykorzystanie różnych metod. Wśród nich można wymienić: przygotowanie danych,
graficzną wizualizację, drzewa klasyfikacyjne, regresję logistyczną, sieci neuronowe
i inne.
1.2. Cel pracy
Przy wyborze tematu pracy kierowałem się chęcią praktycznego zastosowania technik
eksploracji danych. Moje zainteresowania w dziedzinie bankowości, jak również praca
przy tworzeniu portalu dla jednego z domów maklerskich zaowocowały stworzeniem
aplikacji do oceny kredytowej. Duże korporacje korzystają z kompleksowych systemów
typu CRM (ang. Customer Relationship Management - zarządzanie relacjami
z klientami), dlatego za cel postawiłem sobie stworzenie produktu przeznaczonego dla
niewielkich przedsiębiorstw. Firmy prowadzące działalność na mniejszą skalę nie są
w stanie pozwolić sobie na zamówienie wcześniej wspomnianego systemu, który jest
kosztowny. Chciałem także, aby moja aplikacja mogła rozwijać się wraz z rozwojem
firmy, dlatego cechuje się skalowalnością i integrowalnością. Stworzony program
autorski jest przyjazny w obsłudze i umożliwia sprawną wymianę modeli.
Do zbudowania modelu oceny kredytowej wybrałem narzędzie firmy SAS Institute -
SAS Enterprise Miner, gdyż uznałem, że rozwiązania środowiska SAS są wiodącymi
w dziedzinie analizy biznesowej. Drzewo decyzyjne posłużyło za metodę modelowania.
Do stworzenia aplikacji użyłem popularnego języka programowania Java. Program
powstał przy użyciu narzędzi programistycznych opartych o platformę Eclipse i został
zbudowany w architekturze MVC.
1.3. Zawartość
Pracę zawarłem w czterech rozdziałach. Pierwszym jest niniejszy wstęp. W drugim
rozdziale przedstawiłem narzędzia, technologie i metody stosowane w pracy. Czytelnik
znajdzie w nim informacje o architekturze MVC, języku XML, metodzie SEMMA,

3
drzewach decyzyjnych, środowisku SAS, platformie Eclipse i jej wtyczkach, narzędziu
do testowania aplikacji oraz jej dokumentowania.
Rozdział trzeci opisuje projekt i jego implementację. Rozpoczyna go przedstawienie
budowy modelu oceny kredytowej w jego poszczególnych etapach. Po nim
zaprezentowałem projekt aplikacji przy użyciu języka UML. Znajdują się tam diagramy
przypadków użycia, komponentów, klas i sekwencji. Kolejną częścią jest opis
implementacji poszczególnych części programu. Po nim następuje opis testowania
aplikacji oraz przykład wybranej sesji z użytkownikiem.
Ostatni rozdział jest podsumowaniem wyników pracy. Opisałem w nim to, co udało mi
się zrealizować według oczekiwań oraz zaprezentowałem możliwe dalsze kierunki
rozwoju tej pracy. Mam nadzieję, że sporządzona przeze mnie analiza przyczyni się do
dalszego rozwoju prostych narzędzi kontroli zdolności kredytowej w sektorze średnich
i małych firm.

4
2. Zastosowane technologie, metody oraz narzędzia
2.1. Technologie
2.1.1. MVC
MVC (ang. Model-View-Controller - Model-Widok-Kontroler) jest wzorcem
architektonicznym stosowanym w aplikacjach z graficznym interfejsem użytkownika.
Został zaprojektowany 1979 roku przez Trygve Reenskaug pracującego nad językiem
Smalltalk.
Zastosowanie tego wzorca ma miejsce w podziale aplikacji na trzy logiczne części.
Każda z nich spełnia wyznaczone zadania oraz komunikuje się z pozostałymi obiektami
w określony sposób. Pierwszą z nich jest widok, który odpowiedzialny jest za interakcje
z użytkownikiem - wyświetlaniem elementów interfejsu użytkownika. W zależności od
aplikacji i jej implementacji interfejs może przyjąć formę graficzną (GUI - Graphical
User Interface) lub tekstową (CLI - Command Line Interface) - widok linii komend. Do
widoku można także zaliczyć interfejs programowania aplikacji (API - Application
Programming Interface) [2].
Kolejnym elementem tej architektury jest model. W modelu implementowana jest
logika aplikacji i przechowywane są dane. Model zarządza również stanem, w jakim
znajduje się program, tzn. odpowiada na zapytania dotyczące aktualnego stanu i reaguje
na komunikaty modyfikujące go.
Ostatnim elementem MVC jest kontroler. Reaguje na zdarzenia generowane przez
użytkownika i decyduje o zmianie widoku lub modelu. Jego głównym zadaniem jest
kontrola wymiany informacji między widokiem, a modelem. Zabezpiecza on,
w wypadku równoległych zdarzeń, przed nieprzewidywalnymi zachowaniami i stanami
aplikacji.
Konsekwencją takiego podziału zadań między modelem, widokiem i kontrolerem jest
wymóg obustronnej komunikacji między kontrolerem, a widokiem. Widok musi mieć
możliwość bezpośredniego przekazywania zdarzeń kontrolerowi, a kontroler możliwość
odświeżenia i zmiany wyglądu widoku. Widok w rezultacie zna interfejs dostępu do

5
kontrolera. Kontroler zna interfejs do widoku i także do modelu, za pomocą którego
realizuje logikę przetwarzania danych. Jednak model wcale nie musi posiadać
informacji o kontrolerze. W klasycznej wersji wzorca MVC [3] mamy do czynienia
z pasywnym modelem, który nie posiada informacji o innych częściach aplikacji.
Informacje z modelu uzyskiwane są w wyniku rezultatu wywołań jego funkcji. O ile
w uzasadnionych przypadkach może zachodzić komunikacja od modelu do kontrolera,
o tyle nigdy nie może model bezpośrednio komunikować się z widokiem, ani widok
z modelem.
Efektem logicznego podziału aplikacji na trzy elementy są realne korzyści. Każda
z części realizuje paradygmat abstrakcji i hermetyzacji, a co za tym idzie, umożliwia
tworzenie słabych powiązań i ułatwia modyfikację i testowanie. Architektura umożliwia
także skalowalność poprzez fizyczne oddzielenie poszczególnych części. Przykładowo
można umieścić model na innej maszynie fizycznej lub na wielu maszynach fizycznych.
2.1.2. XML
XML (ang. Extensible Markup Language - rozszerzalny język znaczników) jest
językiem znaczników przeznaczonym do opisu dowolnego typu informacji. Został
opracowany w 1996 roku pod przewodnictwem Jona Bosaka [4]. Grupa pracująca nad
specyfikacją języka XML wyznaczyła sobie między innymi następujące cele:
programy używające dokumenty XML powinny być łatwe do napisania;
dokumenty XML powinny być czytelne dla użytkownika;
dokumenty XML powinny być łatwe w tworzeniu.
Jako metajęzyk2 umożliwia tworzenie nowych języków opisu. Definiuje reguły, według
których należy opisywać informację zawartą w dokumencie, ale sam nie proponuje,
żadnego, konkretnego języka opisu. Głównym mechanizmem języka XML są etykiety
(ang. tag) między którymi jest umieszczana przekazywana informacja. Etykiety
występują parami: etykieta otwierająca - poprzedza opisywaną informację, a etykieta
2 patrz [11] str. 8
1. <Producer> 2. <Name> SAS Enterprise Miner </Name> 3. <Version> 6.1 </Version> 4. </Producer>
Wydruk 2.1 Przykładowy fragment dokumentu XML generowany przez narzędzie SAS Enterprise Miner

6
zamykająca - następuje po tej informacji. Etykiety zawarte są w nawiasach trójkątnych -
w etykiecie zamykającej po nawiasie otwierającym następuje prawy ukośnik.
2.2. Metody
2.2.1. SEMMA
SEMMA jest akronimem używanym do opisu procesu eksploracji danych
opracowanym przez SAS Institute Inc. Pochodzi od angielskich słów Sample
(próbkowanie), Explore (eksploracja), Modify (modyfikacja), Model (modelowanie),
Assess (ocena). Choć w publikacjach uważa się SEMMA za metodę eksploracji danych,
SAS Institute definiuje ją raczej jako formę uporządkowania narzędzi analitycznych lub
część metody eksploracji danych [5]. SEMMA skupia się na zadaniu tworzenia i oceny
modelu, a nie na aspektach biznesowych (jak np. rozumienie procesów biznesowych
organizacji zlecającej przeprowadzenie takiego procesu).
SEMMA składa się z pięciu etapów [6]:
Próbkowanie - to etap, w którym importowane i wstępnie przygotowywane są
dane. Próba powinna być na tyle duża, aby zawierała wszystkie najważniejsze
cechy analizowanego zbioru i na tyle mała, aby mogła być sprawnie
analizowana. Ten etap zazwyczaj koczy się podziałem danych na zbiór uczący,
walidacyjny i testujący.
Eksploracja ma za zadanie przybliżyć analitykowi zależności, trendy i anomalie
występujące w danych przez co ma pomóc w lepszym ich zrozumieniu.
Przydatne są do tego szczególnie metody prezentacji graficznej i metody
statystyczne.
Modyfikacja, jako kolejna faza procesu SEMMA, umożliwia przygotowanie
danych do kolejnego etapu poprzez tworzenie, wybieranie i modyfikowanie
zmiennych. Zdecydowanie o sposobie radzenia sobie z brakami danych,
wartościami błędnymi, czy znaczących różnicach w zakresie wartości jest
niezbędne dla poprawnego działania niektórych modeli analitycznych i może
znacząco poprawić działanie pozostałych.
Modelowanie - to tworzenie modelu poprzez trenowanie przy użyciu
analitycznych narzędzi z zakresu statystyki i uczenia maszynowego. Do tego

7
procesu używane są takie techniki jak regresja logistyczna, drzewa decyzyjne,
sieci neuronowe i inne.
Ocena określa użyteczność i wiarygodność uzyskanych wyników. Na tym etapie
możliwe jest porównanie i wybranie skonstruowanych wcześniej modeli
i zastosowanie ich w konkretnym wdrożeniu systemowym.
SEMMA zakłada następowanie po sobie etapów w wymienionej kolejności. W celu
uzyskania zadowalających wyników, stosuje się iteracyjnie kilkakrotnie różne narzędzia
z jednego etapu, a inne etapy można pominąć. Rezultatem całego procesu powinien być
model lub ich grupa, przeznaczone do oceny nowych danych.
2.2.2. Drzewo decyzyjne
Drzewo decyzyjne jest zbiorem metod statystycznych służących do podejmowania
decyzji poprzez tworzenie acyklicznych grafów skierowanych,. W eksploracji danych
drzewa decyzyjne są popularnym narzędziem do określania prawdopodobieństwa
wystąpienia określonej wartości zmiennej celu. Do wyboru reguły podziału węzła
stosowane są różne algorytmy, a budowa drzewa może być poddana wielu parametrom.
Rysunek 2.1 Fragment drzewa decyzyjnego przewidującego zdolność kredytową klientów banku.

8
Zaletą drzew decyzyjnych jest czytelna interpretacja graficzna, prostota
w implementacji oraz wbudowane mechanizmy obsługi brakujących wartości
w zbiorach danych.
2.3. Narzędzia
2.3.1. SAS Enterprise Miner
SAS Enterprise Miner (EM) jest programem wchodzącym w skład systemu SAS
dostarczającego narzędzia z zakresu BI (ang. Business Intelligence - analityka
biznesowa), zarządzania danymi i metod analitycznych. EM wykonuje zadania
z zakresu eksploracji danych. Intuicyjny graficzny interfejs umożliwia sprawne
tworzenie modeli eksploracji danych w oparciu o metodę SEMMA. Proces tworzenia
modelu jest przedstawiany za pomocą grafu skierowanego, na którym kierunek
krawędzi obrazuje kierunek przepływu danych, a wierzchołki (nazywane dalej węzłami)
różne metody ich modyfikacji. Bogaty zestaw węzłów stwarza możliwość
rozwiązywania zadań ze wszystkich dziedzin eksploracji danych, a rozbudowany
zestaw atrybutów ułatwia precyzyjne stosowanie wybranych metod.
Rysunek 2.2 Przykładowy ekran aplikacji SAS Enterprise Miner 12.1
Aplikacja posiada także moduł reprezentacji graficznej wyników analiz. Modele
wytworzone w niej można włączyć w procesy tworzenia oprogramowania typu
CRM/ERP (ERP - ang. Enterprise Resource Planning - planowanie zasobów

9
przedsiębiorstwa) poprzez załadowanie ich do centralnego repozytorium danych
i dalsze wykorzystywanie w takich programach jak SAS Enterprise Guide, SAS Data
Integration Studio, czy SAS Model Manager. Po utworzeniu modeli dostępna jest opcja
wygenerowania kodu scoringowego w języku programowania SAS, C++ oraz Java.
2.3.2. Eclipse IDE
Eclipse jest platformą stworzoną w 2004 roku do tworzenia aplikacji typu gruby klient
(ang. rich client) napisaną w Javie. Na jej bazie powstało zintegrowane środowisko
programistyczne (IDE - Integrated Development Environment) do programowania
w Javie. Obecnie rozwijane jest przez Fundację Eclipse i udostępnione jest na zasadach
otwartego oprogramowania (ang. open source).
Platforma Eclipse została zaprojektowana i zbudowana w celu spełnienia następujących
wymagań [7]:
wspieranie budowania narzędzi do programowania;
nieograniczone wspieranie twórców oprogramowania;
wspieranie narzędzi obsługujących różne typy zawartości (np. HTML, Java, C,
XML, GIF);
ułatwienie integracji narzędzi różnych dostawców;
wspieranie środowiska z GUI (ang. Graphical User Interface - interfejs
graficzny) i bez niego;
działanie na szerokim zakresie systemów operacyjnych;
wykorzystanie popularności języka Java do pisania narzędzi.
Platforma Eclipse składa się z niewielkiego jądra (które z punktu widzenia architektury
nazywane jest Platformą Uruchomieniową - ang. Platform Runtime) i dwóch wtyczek
(ang. plug-ins), które tworzą podstawę Architektury Wtyczek (ang. Plug-in
Architecture). Na tej podstawie można budować środowiska IDE, narzędzia i aplikacje
z różnych dziedzin. Odbywa się to poprzez programowanie odpowiednich wtyczek, dla
których Platforma Eclipse jest punktem integracyjnym.
Najbardziej znanymi projektami opartymi o tą platformę są środowiska IDE.
Oprogramowanie zostało napisane dla znacznej większości języków programowania
(np. Java, PHP, C, C++, Perl). Dzięki zastosowanej Architekturze Wtyczek i licznym

10
wydanym wtyczkom3, można dowolnie konfigurować środowisko dostosowując je do
programowania w wielu językach i zarządzaniu różnymi procesami związanymi
z produkcją oprogramowania (jak np. tworzenie dokumentacji UML czy testowanie).
Rysunek 2.3 Przykładowy ekran z Eclipse Standard 4.4
W niniejszej pracy zostało użyte środowisko w wersji Eclipse Standard 4.4 (Luna
Release) dostosowane dla programistów Java. Wraz z tym środowiskiem używano
dodatkowo instalowanych wtyczek, które zostaną opisane w kolejnych podrozdziałach.
2.3.3. Eclipse WindowBuilder
Eclipse WindowBuilder jest oprogramowaniem służącym do tworzenia elementów GUI
w języku Java. Obsługuje bibliotekę SWT oraz Swing. Został wydany jako wtyczka do
Eclipse i rozwiązań bazujących na Eclipse [8].
Posiada wbudowany edytor typu WYSIWYG (ang. What You See Is What You Get -
otrzymujesz to co widzisz), pozwalający znacząco przyśpieszyć tworzenie GUI poprzez
automatyczną generację kodu z projektów tworzonych graficznie. Metoda przeciągnij
i upuść (ang. drag and drop) oraz listy dostępnych atrybutów elementów graficznych
umożliwiają intuicyjne i sprawne tworzenie skomplikowanych widoków. Niewątpliwą
zaletą aplikacji jest dynamiczne tworzenie widoku projektowania z kodu Java - zmiany
3 ponad półtora tysiąca wtyczek w oficjalnym serwisie http://marketplace.eclipse.org/ i wiele na
indywidualnych stronach projektów

11
wprowadzone w generowanym kodzie są widoczne w edytorze graficznym, a edytor
graficzny wprowadza zmiany w kodzie edytowanej klasy bez usuwania zmian
wprowadzonych bezpośrednio w kodzie. Nie są dzięki temu tworzone dodatkowe pliki
konfiguracyjne, do których programista nie ma dostępu.
Rysunek 2.4 Przykładowy widok okna projektowania Eclipse WindowBuilder
2.3.4. JUnit
JUnit jest narzędziem do tworzenia powtarzalnych testów oprogramowania pisanego
w języku Java. Został stworzony przez Ericha Gamma i Kenta Becka. Pozwala w prosty
sposób tworzyć i organizować automatyczne testy. Jego zaletą jest oddzielenie kodu
aplikacji od kodu testów.
JUnit jest narzędziem zbudowanym w architekturze xUnit, która definiuje standardy
tworzenia platform testujących oprogramowanie pisane w różnych językach.
Funkcjonalność i struktura narzędzi xUnit została zaczerpnięta z napisanej w 1998 r.
platformy testującej SUnit, napisanej dla języka Smaltalk.
W prezentowanej aplikacji JUnit został użyty jako wtyczka Elipse IDE.
2.3.5. Javadoc
Javadoc to generator dokumentacji oprogramowania napisanego w języku Java.
Stworzony przez firmę Sun Microsystems, generuje dokumenty w formacie HTML
z odpowiednio sformatowanych komentarzy umieszczonych w kodzie.

12
Javadoc pozwala generować dokumentację dla klas, interfejsów, pakietów oraz różnych
plików dołączanych do oprogramowania. Elementem charakterystycznym dla
komentarzy interpretowanych przez to narzędzie są dwie gwiazdki po ukośniku
otwierającym komentarz blokowy języka Java. Javadoc umożliwia także dodawanie
specjalnych znaczników dokumentacyjnych rozpoczynających się od symbolu małpy
umożliwiających tworzenie odniesień w generowanej dokumentacji. Używanie
narzędzia Javadoc jest standardem w tworzeniu dokumentacji kodu Java i definiowaniu
interfejsu aplikacji i klas.

13
3. Projekt i implementacja
3.1. Model eksploracji danych
Każda aplikacja scoringowa, aby mogła poprawnie działać, potrzebuje modelu według
którego będzie dokonywany scoring. W dalszej części rozdziału przedstawiłem model
do oceny kredytowej klientów banku. Kolejno opisałem zbiór danych, który
odpowiednio zmodyfikowany służy do trenowania drzewa decyzyjnego. Proces
tworzenia modelu zakończyłem na przedstawieniu wyników osiągniętych przez drzewo
decyzyjne i sposobie zintegrowania go z aplikacją oceny kredytowej.
Do implementacji modelu eksploracji danych użyłem SAS Enterprise Miner 12.1
(wersja Workstation), który opisałem w rozdziale „2.3.1 SAS Enterprise Miner”.
Rysunek 3.1 Etapy budowy modelu przedstawione w programie SAS Enterprise Miner
3.1.1. Zbiór danych trenujących
Pierwszym etapem budowy modelu scoringowego jest określenie zbioru danych, który
posłuży do trenowania modelu. Do tego celu wybrałem zbiór „German Credit Data”
zwierający dane historyczne udzielonych 1000 pożyczek. Zbiór pochodzi z Niemiec
i zawiera 20 zmiennych charakteryzujących pożyczkobiorcę oraz jedną zmienną celu,
w której zawarta jest informacja o tym, czy pożyczka została spłacona, czy też nie. 700
rekordów jest oznaczonych jako pożyczka spłacona. Poniżej przeprowadzam wstępną
analizę danych ze zbioru, podejmując decyzję o odrzuceniu pewnych zmiennych.
W nawiasach zamieszczam oryginalne nazwy kolumn z bazy danych.
Wiek (AGE)
Zmienna określa wiek w latach. Wartości zmiennej zawierają się miedzy 19, a 75.
Średnia wartość to ok. 36 lat.

14
Rysunek 3.2 Wykres rozkładu zmiennej „Wiek"
Kwota kredytu (AMOUNT)
Zmienna określa kwotę, na jaką był zaciągnięty kredyt. Zbiór danych dotyczy klientów
niemieckiego banku sprzed roku 2002 (data zmiany waluty w Niemczech na euro), więc
podawana jest w markach niemieckich. Kwoty wahają się od 250 do 18424 DM,
a średnia kwota to 3271 DM. Warto zauważyć, że kwoty kredytów są niemalże unikalne
- najliczniejsza grupa jednakowych kwot ma 3 obserwacje.
Rysunek 3.3 Wykres rozkładu zmiennej „Kwota kredytu"; zakreskowana część słupka wyznacza pozytywne
obserwacje

15
Stan otwartych rachunków (CHECKING)
Zmienna określa ilość środków na otwartych rachunkach. Wartości zmiennej
przyporządkowują obserwację do jednego z wcześniej określonych przedziałów:
1 - poniżej 0DM;
2 - 0-200DM;
3 - powyżej 200DM;
4 - brak konta.
Rysunek 3.4 Wykres rozkładu zmiennej „Stan otwartych rachunków"
Wspólnik (COAPP)
Zmienna zawiera informację o tym, czy klient bierze pożyczkę wspólnie z inna osobą,
lub czy posiada żyranta. Dopuszczalne wartości:
1 - brak wspólnika;
2 - kredyt zaciągany z inną osobą;
3 - inna osoba poświadcza za kredytobiorcę.
Większość obserwacji (907 na 1000) przybiera wartość „1” - brak wspólnika.

16
Rysunek 3.5 Wykres rozkładu zmiennej „Wspólnik"
Liczba osób na utrzymaniu (DEPENDS)
Zmienna określa liczbę osób na utrzymaniu. W przedstawianym zbiorze obserwacje
przyjmują tylko dwie wartości: 1 i 2. Dominują pożyczki udzielane osobom, które same
się utrzymują - średnia wartość zmiennej to 1,155.
Rysunek 3.6 Wykres rozkładu zmiennej „Liczba osób na utrzymaniu"
Czas spłaty (DURATION)
Zmienna określa termin, w jakim ma zostać spłacona pożyczka. Wartości podane są
w miesiącach. Najkrótsza pożyczka została udzielona na czas 4 miesięcy; najdłuższa na
72 miesiące (6 lat). Średni okres trwania pożyczki to ok. 21 miesięcy. Wykres rozkładu
pokazuje, że największa liczba pożyczek została udzielona na okres roku (179

17
obserwacji) i dwóch lat (184 obserwacje). Znacząco wyższe od pozostałych są także
pożyczki udzielana na wielokrotność okresu trzech miesięcy.
Rysunek 3.7 Wykres rozkładu zmiennej „Czas spłaty"
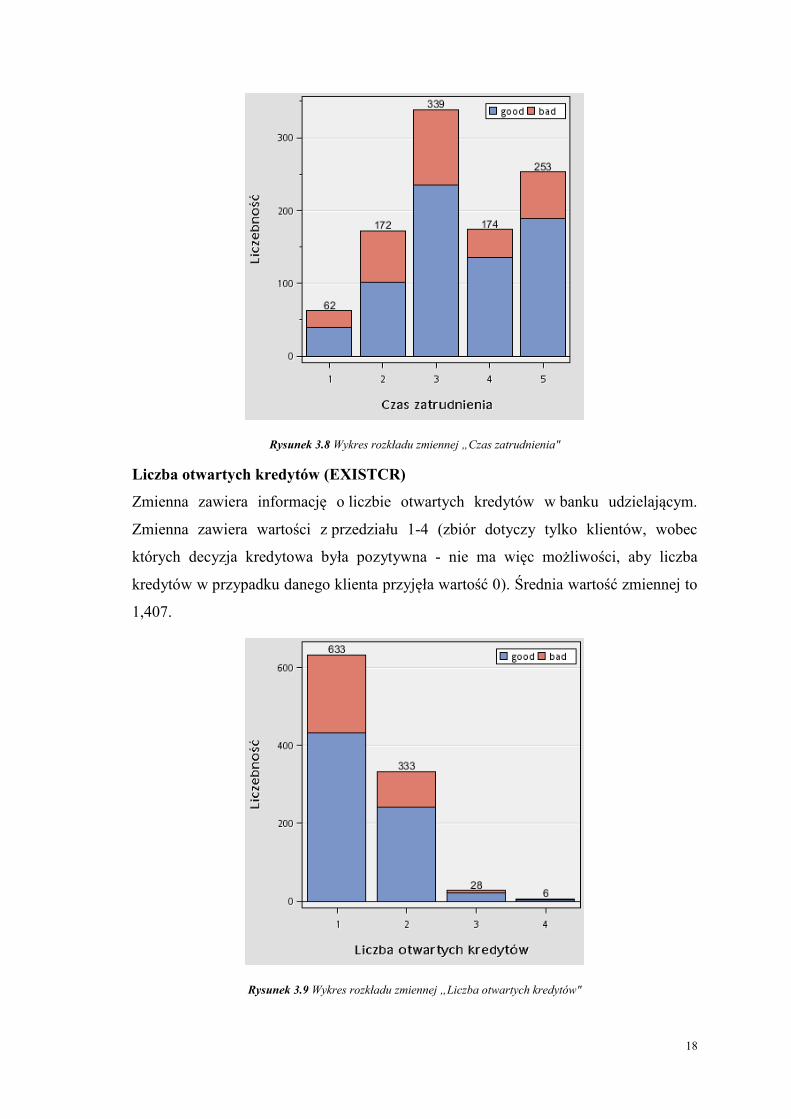
Czas zatrudnienia (EMPLOYED)
Zmienna „czas zatrudnienia” wyznacza okres w jakim klient nieprzerwanie pracuje od
momentu objęcia pracy w jednej firmie do chwili obecnej. Wartości te nie definiują
całego okresu zatrudnienia w przypadku zmiany pracy. Zmienna przyjmuje jedną
z wcześniej ustalonych wartości:
1 - klient obecnie jest bezrobotny;
2 - klient pracuje jeden rok;
3 - klient pracuje 1-4 lata;
4 - klient pracuje 4-7 lat;
5 - klient pracuje powyżej 7 lat.
18
Rysunek 3.8 Wykres rozkładu zmiennej „Czas zatrudnienia"
Liczba otwartych kredytów (EXISTCR)
Zmienna zawiera informację o liczbie otwartych kredytów w banku udzielającym.
Zmienna zawiera wartości z przedziału 1-4 (zbiór dotyczy tylko klientów, wobec
których decyzja kredytowa była pozytywna - nie ma więc możliwości, aby liczba
kredytów w przypadku danego klienta przyjęła wartość 0). Średnia wartość zmiennej to
1,407.
Rysunek 3.9 Wykres rozkładu zmiennej „Liczba otwartych kredytów"

19
Zagraniczne zatrudnienie (FOREIGN)
Jest to zmienna, której znaczenie nie jest do końca pewne. Opis dostarczony z bazą
danych brzmi - „foreign worker” - „pracownik zagraniczny”. Oznacza to
najprawdopodobniej to, że klient jest zatrudniony za granicą. Rozkład zmiennej przy
takiej interpretacji jest jednak zaskakujący - 963 osoby posiadają pozytywną wartość tej
zmiennej, w tym 62 osoby bezrobotne (według zmiennej „Czas zatrudnienia”). Ze
względu na brak jednoznacznej i wiarygodnej interpretacji, zdecydowałem nie
uwzględnić jej na dalszych etapach tworzenia modelu.
Historia kredytowa (HISTORY)
Zmienna klasyfikuje klienta do jednej z wcześniej ustalonych grup oceny historii
kredytowej. Oto one, wraz z przypisaną im liczbą porządkową w analizowanym
zbiorze:
0 - brak zaciągniętych kredytów lub wszystkie spłacone należycie;
1 - wszystkie kredyty w tym banku spłacone należycie;
2 - kredyty spłacane należycie do teraz;
3 - opóźnienia w płatnościach rat kredytów w przeszłości;
4 - krytyczny stan spłat lub istniejące kredyty w innych bankach.
Rysunek 3.10 Wykres rozkładu zmiennej „Historia kredytowa"

20
Mieszkanie (HOUSING)
Zmienna określająca rodzaj mieszkania, w którym mieszka pożyczkobiorca. Przyjmuje
jedną z następujących wartości:
0 - wynajmowane;
1 - własne;
2 - darmowe.
Rysunek 3.11 Wykres rozkładu zmiennej „Mieszkanie"
Stosunek dochodu do raty (INSTALLP)
Powyższa zmienna przedstawia, jaki procent dochodu klienta jest równy określonej
racie. Wartość jest liczona od dochodu netto. Przyjmuje wartości całkowitoliczbowe
z przedziału 1-4. Ta cecha wskazuje na duże prawdopodobieństwo pogrupowania
wartości, ale ze względu na brak opisu w dokumentacji dołączonej do zbioru danych
eliminuję zmienną z dalszej analizy.
Praca (JOB)
Zmienna określa rodzaj wykonywanej pracy. Może przyjąć jedną z określonych
wartości:
1 - niezatrudniony lub niewykwalifikowany - zamiejscowy;
2 - niewykwalifikowany - miejscowy;

21
3 - wykwalifikowany lub urzędnik;
4 - dyrektor, samozatrudniony, wysoko wykwalifikowany lub oficer.
Rysunek 3.12 Wykres rozkładu zmiennej „Praca"
Stan cywilny (MARITAL)
Zmienna określa stan cywilny klienta. Przyjmuje jedną ze zdefiniowanych wartości:
1 - mężczyzna - rozwiedziony lub w separacji;
2 - kobieta - rozwiedziona, w separacji lub żonata;
3 - kawaler;
4 - mężczyzna - żonaty lub wdowiec;
5 - panna.

22
Rysunek 3.13 Wykres rozkładu zmiennej „Stan cywilny"
Inne plany ratalne (OTHER)
Zmienna zawiera informację o innych planach ratalnych podjętych przez klienta. Jej
wartości określają gdzie zostało podjęte zobowiązanie:
1 - bank;
2 - sklep;
3 - brak innych planów ratalnych.
Rysunek 3.14 Wykres rozkładu zmiennej „Inne plany ratalne"

23
Majątek (PROPERTY)
Zmienna określa rodzaj majątku zabezpieczającego kredyt. Zmienna przyjmuje
określone wartości:
1 - nieruchomość;
2 - oszczędności w kasie mieszkaniowej lub ubezpieczenie na życie;
3 - samochód lub inny majątek;
4 - brak majątku lub brak informacji.
Rysunek 3.15 Wykres rozkładu zmiennej „Majątek"
Przeznaczenie (PURPOSE)
Zmienna określa, z jakiego powodu jest brany kredyt. Przyjmuje jedną z określonych
wartości definiujących na co zostaną przeznaczone środki z kredytu:
0 - nowy samochód;
1 - używany samochód;
2 - meble lub inne wyposażenie domu;
3 - radio lub telewizor;
4 - artykuły gospodarstwa domowego;
5 - przeprowadzenie pewnych napraw;
6 - edukacja;

24
7 - sfinansowanie wakacji;
8 - przeprowadzenie szkolenia;
9 - cel biznesowy;
X - inny cel.
Jako jedyna zmienna wejściowa jest typu znakowego. Pozostałe są typu numerycznego.
Rysunek 3.16 Wykres rozkładu zmiennej „Przeznaczenie"
Czas zamieszkania (RESIDENT)
Zmienna zawiera informację o okresie zamieszkania. Ze względu na niepełną
dokumentację rodzajów grup wartości oraz niewielki wpływ na skuteczność modelu
zmienna nie zostanie uwzględniona w dalszych etapach budowania modelu.
Oszczędności (SAVINGS)
Zmienna określa jaką kwotę oszczędności klient posiada na rachunku
oszczędnościowym lub w obligacjach. Zmienna przyjmuje jedną z określonych
wartości:
1 - do 100DM;
2 - 100-500DM;
3 - 500-1000DM;
4 - powyżej 1000DM;
5 - nieznana kwota oszczędności lub brak rachunku oszczędnościowego.

25
Rysunek 3.17 Wykres rozkładu zmiennej „Oszczędności"
Telefon (TELEPHON)
Zmienna binarna określająca, czy klient posiada zarejestrowany na siebie numer
telefonu. Przyjmuje wartości:
1 - brak numeru telefonu;
2 - telefon zarejestrowany na nazwisko klienta.
Rysunek 3.18 Wykres rozkładu zmiennej „Telefon"

26
3.1.2. Partycjonowanie danych
Podział danych na odpowiednie podzbiory jest kolejnym etapem przygotowania
danych. W eksploracji danych stosuje się podział na trzy partycje: dane uczące,
walidacyjne i testujące. Zbiór uczący jest wykorzystywany do trenowania modelu -
w wypadku tego projektu do zbudowania drzewa decyzyjnego. Zgodnie z zależnościami
zawartymi w tym zbiorze podejmowane są decyzje o wyborze reguły podziału
kolejnych węzłów drzewa. Zbiór walidacyjny służy do przeprowadzenia oceny modelu.
W niektórych przypadkach dane walidacyjne są wykorzystywane do dopracowania
modelu - w drzewie decyzyjnym algorytm stwarza najlepsze poddrzewo. Celem
tworzenia danych testujących jest ostateczna ocena i porównanie wytrenowanych
modeli.
Zastosowałem podział na zbiór uczący i walidacyjny w proporcji 7 do 3. Pominąłem
zbiór danych testujących ze względu na posiadaną niewielką próbkę danych
wejściowych i niewielkie zastosowanie w projekcie danych testujących. Dzięki temu
uzyskałem duży zbiór danych uczących, który lepiej posłużył do trenowania modelu.
Dane zostały podzielone przy pomocy algorytmu partycjonowania warstwowego.
Algorytm dzieli dane wejściowe na warstwy ze względu na zmienną celu - według
pożyczek spłaconych i niespłaconych. Dane wewnątrz każdej warstwy mają równe
prawdopodobieństwo trafienia do każdego ze zbiorów danych. Algorytm zapewnia
odwzorowanie proporcji warstw w podzielonych zbiorach, co może zwiększyć trafność
modelu. Wynik działania algorytmu został przedstawiony w tabeli poniżej.
Zbiór Wartość zmiennej
celu
Liczba wystąpień Procent danego
zbioru
Dane wejściowe
zła 300 30
dobra 700 70
Dane testujące
zła 209 29,8999
dobra 490 70,1001
Dane walidacyjne
zła 91 30,2326
dobra 210 69,7674
Tabela 3.1 Podział danych wejściowych na zbiory według algorytmu podziału warstwowego

27
3.1.3. Drzewo decyzyjne
Tak przygotowane dane użyłem do zbudowania drzewa decyzyjnego. W drzewie
zastosowałem domyślne algorytmy podziału węzła. Wykorzystałem drzewo binarne,
o maksymalnej głębokości ograniczonej do sześciu poziomów. Algorytm wybrał cztery
zmienne, według których dokonywał podziałów: Stan otwartych rachunków
(CHECKING), Czas spłaty (DURATION), Oszczędności (SAVINGS), oraz Historia
kredytowa (HISTORY). Poniżej zaprezentowałem wykres wytrenowanego drzewa.
Rysunek 3.19 Drzewo decyzyjne od poziomu 0 do poziomu 2

28
Rysunek 3.20 Drzewo decyzyjne od poziomu 2 do poziomu 4 (prawe odgałęzienie)
Rysunek 3.21 Drzewo decyzyjne od poziomu 2 do poziomu 3 (lewe odgałęzienie)
3.1.4. Ocena modelu
Ostatnim etapem tworzenia modelu jest jego ocena i wygenerowanie odpowiedniego
kodu do integracji z aplikacją. Częstą metodą oceny modelu jest przedstawienie
wykresu przyrostu skumulowanego (ang. cumulative lift). Pokazuje on ile razy częściej
względem losowej próby w wybranym podzbiorze wystąpią pozytywne przypadki (w

29
wypadku oceny kredytowej - ile razy więcej klientów spłaci kredyt). Przyrost
skumulowany na poziomie 1 odpowiada losowemu wybieraniu przypadków z danego
zbioru danych. W prezentowanym przypadku lift na poziomie 10/7 (ok. 1,43) daje
pewność, że dane obserwacje będą pozytywne (70% pozytywnych obserwacji w zbiorze
wyjściowym pomnożone przez 10/7 daje 100%). Trenowane drzewo decyzyjne
osiągnęło przyrost dla pierwszego decyla danych walidacyjnych równy ok. 1,27.
Oznacza to, że ze zbioru 10% klientów wytypowanych przez model kredyt spłaci ok.
89%.
Rysunek 3.22 Wykres przyrostu skumulowanego dla danych trenujących i walidacyjnych
Ważnym wskaźnikiem użyteczności modelu jest także przebieg krzywej. W pierwszych
decylach krzywa powinna być relatywnie wysoko i gładko maleć wraz ze wzrostem
liczby uwzględnionych obserwacji. Wszelkie załamania krzywej przejawiające się np.
wzrostem przyrostu w środkowych decylach wskazują na nieużyteczność modelu4.
Krzywa dla przedstawionego modelu ma przebieg zgodny z oczekiwaniami i posiada
wysokie wartości dla pierwszej połowy zbioru, stopniowo malejąc dla pozostałych
obserwacji.
Po ocenie modelu i stwierdzeniu jego użyteczności pozostaje zapisanie go w formacie
odpowiednim do dalszego wykorzystania. SAS Enterprise Miner posiada możliwość
umieszczenia modelu w pakiecie i zarejestrowanie go na serwerze metadanych. Dzięki
takiemu rozwiązaniu możliwe jest przetwarzanie go innymi narzędziami środowiska
SAS i włączenie go w proces produkcyjny systemu typu CRM/ERP. Ja skorzystałem
z innej możliwości - wygenerowałem zbiór plików do skompilowania z programem
napisanym w języku Java. Pliki generowane przez SAS Enterprise Miner to:
4 [14] str. 28

30
JScore.xml - plik zawierający metadane funkcji scoringowej, takie jak dane
wejściowe i zwracane przez funkcję;
JscoreUserFormats.java - plik zawierający formaty zdefiniowane przez
użytkownika. Klasa JscoreUserFormats zawarta w pliku zawiera istotne
informacje w przypadku stosowania własnych algorytmów w procesie
budowania modelu;
metadata.xml - plik zawierający metadane plików - nazwy i typy wszystkich
generowanych plików;
Score.java - plik zawierającą klasę z interfejsem do klasy DS.class;
DS.class - plik zawierający skompilowaną klasę implementującą kod
scoringowy.
Pliki te zostały włączone w projekt i implementację aplikacji do oceny kredytowej
klientów banku, którą opisałem w pracy.
3.2. Analiza wymagań aplikacji
Początkiem pracy nad aplikacją jest zdefiniowanie zadań, jakie ma spełniać. Wyraża się
to przez zdefiniowanie wymagań funkcjonalnych i niefunkcjonalnych.
3.2.1. Wymagania funkcjonalne
Wymagania funkcjonalne opisują funkcje wykonywane przez projektowane
oprogramowanie. Poniżej znajdują się wymagania, które powinna realizować aplikacja
oceny kredytowej klientów banku.
1. Program powinien umożliwiać wykonanie oceny kredytowej klienta.
1.1. Program powinien zawierać interfejs pozwalający wprowadzić wybrane dane
klienta.
1.2. Program powinien określić prawdopodobieństwo zwrotu kredytu na podstawie
wprowadzonych danych.
2. Program powinien mieć możliwość konfiguracji poziomów ryzyka kredytowego.
2.1. Program powinien mieć możliwość zdefiniowania trzech grup ryzyka: wysokie
ryzyko, średnie ryzyko, niskie ryzyko.
3. Program powinien informować o błędach konfiguracji i wprowadzonych danych.

31
3.2.2. Wymagania niefunkcjonalne
Wymagania niefunkcjonalne określają jakość i granice wykonywania funkcji
określonych w wymaganiach funkcjonalnych.
1. Program powinien mieć możliwość wymiany modelu scoringowego bez potrzeby
wprowadzania znaczących zmian w kodzie programu.
2. Program powinien być skalowalny - posiadać pakiety możliwe do wykorzystania
w wypadku integracji z systemem CRM.
3. Program powinien posiadać intuicyjny interfejs w języku polskim.
4. Program powinien mieć możliwość uruchamiania na komputerach klasy PC
posiadających systemy operacyjne rodziny Windows, UNIX i Linux.
3.3. Projekt aplikacji
Projekt aplikacji opisałem przy użyciu języka UML. Przy wyborze tego narzędzia
kierowałem się jego powszechnym użyciem i tym, że zawiera bogaty i intuicyjny
zestaw narzędzi do opisu projektu.
Przedstawione diagramy zawierają finalny opis aplikacji - pominąłem etapy, na których
były dokonywane zmiany, gdyż nie są one istotne z punktu widzenia tej analizy.
3.3.1. Przypadki użycia
Diagramy przypadków użycia dokumentują wymagania dotyczące systemu z pozycji
użytkownika. Przedstawiają możliwe wykorzystanie programu. Niniejsza dokumentacja
zawiera dwa przypadki użycia uwzględniające odpowiednio wymagania funkcjonalne
numer 1 i 2. Wymaganie funkcjonalne numer 3, dotyczące informowania o błędach, nie
jest opisywane jako samodzielny przypadek użycia, ale zostało włączone w pozostałe.
Wykonanie oceny kredytowej
Ocena zdolności kredytowej wykonywana jest przez analityka kredytowego
w odpowiedzi na prośbę o przyznanie kredytu. Kredytobiorca zobowiązany jest
dostarczyć komplet danych przedstawionych za pośrednictwem analityka kredytowego
za pomocą programu.

32
Rysunek 3.23 Diagram przypadku użycia „Wykonanie oceny kredytowej"
Scenariusz główny:
1. Analityk kredytowy pobiera zestaw wymaganych danych przedstawionych przez
program od klienta.
2. Analityk kredytowy wprowadza dane otrzymane od klienta do programu.
3. Program dokonuje oceny kredytowej.
4. Program wyświetla prawdopodobieństwo zwrotu kredytu oraz grupę ryzyka do
której został zaliczony klient.
Scenariusz alternatywny - niekompletne dane:
1. Jak w scenariuszu głównym.
2. Analityk kredytowy wprowadza niekompletne dane do programu.
3. Program dokonuje oceny kredytowej jeśli jest to możliwe.
4. Program wyświetla wynik oceny kredytowej lub komunikat błędu.
Określenie przedziałów ryzyka kredytowego
Określanie przedziałów ryzyka kredytowego jest wykonywane przez analityka grup
ryzyka i umożliwia określenie, do jakiej grupy ryzyka kredytowego należy zaliczyć
danego klienta. W skład grup ryzyka kredytowego wchodzą: wysokie ryzyko, średnie
ryzyko, niskie ryzyko. Definiowanie grup ryzyka odbywa się poprzez określenie
wartości granicznych prawdopodobieństwa spłaty kredytu.
Rysunek 3.24 Diagram przypadku użycia „Określenie przedziałów ryzyka kredytowego"
Scenariusz główny:
1. Analityk grup ryzyka kredytowego wprowadza wartości graniczne
prawdopodobieństwa dla grup ryzyka kredytowego w pliku konfiguracyjnym.

33
2. Program, po ponownym uruchomieniu, dokonuje oceny kredytowej
z wprowadzonymi parametrami.
W przypadku wprowadzenia nieprawidłowych wartości, program po uruchomieniu
wyświetla odpowiedni komunikat błędu.
3.3.2. Diagram komponentów
Diagram komponentów przedstawia architekturę aplikacji na poziomie elementów,
które mogą być wymieniane niezależnie od siebie. Tak długo, jak interfejsy pozostają
niezmienione, zostaje zachowana funkcjonalność aplikacji.
Aplikacja składa się z trzech komponentów: widok, kontroler i model. Ich zadania
zostały opisane w rozdziale poświęconym architekturze MVC.
Rysunek 3.25 Diagram komponentów aplikacji
Kontroler i widok komunikują się ze sobą przy pomocy interfejsów o takich samych
nazwach. Kontroler komunikuje się z widokiem w celu przekazania mu niezbędnych
danych do wyświetlenia (metody „setPolaFormularza()” oraz „pokaz()”), w celu
przekazania komunikatu błędu (metody „wyswietlOstrzezenie()”

34
i „wyswietlBladKrytyczny()”) oraz w celu przekazania wyniku scoringu
(„wyswietlWynikScoringu()”). Widok komunikuje się z kontrolerem w odpowiedzi na
żądanie wykonania scoringu wygenerowane przez użytkownika. Użyta architektura
MVC z biernym modelem zakłada, że model nie komunikuje się z innymi częściami
systemu samoczynnie, lecz zwraca wartości wywołanych funkcji. Jego metody służą do
zdefiniowania zestawu pól wprowadzania danych („getMozliweArgumentyScoringu()”)
i wyliczenia scoringu („wyliczPrawdopodobienstwo()”).
3.3.3. Diagramy klas
Diagramy klas opisują strukturę klas i ich wzajemne powiązania. W przedstawianym
projekcie pokażę projekt budowy każdego z komponentów oraz klasy za pomocą
których realizowany jest przepływ danych między komponentami.
Kontroler
Komponent kontrolera pośredniczy między widokiem a modelem. Jego funkcją jest
również zainicjowanie całej aplikacji (metoda „start()”). Realizacja przypadku użycia
„Określenie przedziałów ryzyka kredytowego” wymaga użycia pliku konfiguracyjnego,
którego umiejscowienie w systemie określa pole prywatne głównej klasy kontrolera.
Rysunek 3.26 Diagram klas komponentu „kontroler”
Model
Model, zawierający logikę aplikacji, ma do spełnienia kilka zadań. Jak już
wspomniałem w rozdziale „3.1 Model eksploracji danych”, funkcja scoringowa jest

35
opisana plikiem metadanych zapisanym w formacie XML. W celu poznania zmiennych
wejściowych do tej funkcji należy odczytać je z tego pliku. Dodatkowo nazwy
zmiennych należy zamienić na takie, które będą czytelne i zrozumiałe dla użytkownika
- w tym celu do modelu dołączyłem słownik wszystkich danych wejściowych dla zbioru
danych opisanych w rozdziale „3.1.1 Zbiór danych trenujących”. Wreszcie model
odpowiedzialnych jest za scoring wprowadzonych danych. Wykonuje to poprzez
odwołanie się do wygenerowanej wcześniej klasy implementującej stworzony model.
Rysunek 3.27 Diagram klas dla komponentu „model"
Na przedstawionym diagramie klasa „ModelDoSkompilowanegoModelu” jest główną
klasą komponentu implementującą jego interfejs. Klasa „ParserJScoreXML” odczytuje
plik metadanych, a klasa „ParserSlownikaBazyDanych” przypisuje zmiennym
wejściowym funkcji scoringowej nazwy i opisy czytelne dla użytkownika.

36
Rysunek 3.28 Diagram klas dla komponentu „widok"
Widok
Widok spełnia dwa główne zadania. Umożliwia użytkownikowi wprowadzanie danych
oraz wyświetla wynik oceny kredytowej. Dodatkowo zapewnia wyświetlanie błędów -
tych które uniemożliwiają dalsze działanie aplikacji oraz tych, które informują
o niepoprawnym wprowadzeniu danych.

37
Klasa „OknoAplikacji” jest główną klasą tego komponentu implementującą jego
interfejs. Klasy „PanelWyswietlaniaWynikow” i „PanelWprowadzaniaDanych”
odpowiadają odpowiednio za wyświetlanie wyników i wprowadzanie danych. Są one
zaprojektowane specjalnie do wyświetlania w klasie „OknoAplikacji” i nie mogą istnieć
w oderwaniu od tej klasy. Klasa „WykresSlupkowy” zapewnia możliwość graficznego
przedstawienia wyniku oceny kredytowej. Klasa „OdczytywanieDanychFormularza”
jest implementacją klasy obsługi zdarzeń typowej dla użytej biblioteki SWING.
Dane
W projekcie zastosowałem dwie klasy do realizacji przepływu danych. Jedna
przekazuje informację o ocenie kredytowej z modelu do widoku („WynikScoringu”).
Rysunek 3.29 Diagram klas dla wyniku scoringu
Druga przechowuje dane dotyczące zmiennej wejściowej funkcji scoringowej
(„ArgumentFunkcjiScoringowej”). Klasa ta przechowuje takie informacje jak typ
zmiennej (realizowane przy pomocy dziedziczenia), jej wartość, nazwa, nazwa czytelna
dla użytkownika i opis. Zbiór obiektów tej klasy generowany jest w modelu i tam jest
uzupełniany o informacje opisowe. Następnie poprzez kontroler wędruje do widoku,
w którym uzupełniane są pola wartości argumentu. Na koniec zbiór jest przekazywany
z powrotem do modelu, gdzie jest używany do stworzenia oceny kredytowej.

38
Rysunek 3.30 Diagram klas dla argumentu funkcji scoringowej
3.3.4. Diagramy sekwencji
Diagramy sekwencji przedstawiają interakcje poszczególnych części systemu. Na
poniższych diagramach prezentuję sekwencje komunikatów dla przypadku użycia
„Wykonanie oceny kredytowej”.
Rysunek 3.31 ukazuje interakcje wewnątrz komponentu „widok”. Sekwencje wyzwala
aktor „Analityk kredytowy” wprowadzając dane do systemu. Zdarzenie rejestruje obiekt
klasy „PanelWprowadzaniaDanych” i zdarzenie przekazuje obiektowi
„OdczytywanieDanychFormularza”. Po pobraniu od obiektu „OknoAplikacji”
aktualnego wskazania na obiekt „PanelWprowadzaniaDanych”,
„OdczytywanieDanychFormularza” pobiera wskazania na pola wprowadzania danych.
Pobiera z nich wartości i tworzy z nich listę argumentów funkcji scoringowej.
Przekazuje ją obiektowi „OknoAplikacji”, który przesyła ją do komponentu
„Kontroler”. Obiekt „Kontroler” przesyła listę argumentów do modelu, gdzie dokonuje
się ocena kredytowa i wynik zwraca przez interfejs „Widok” do klasy „OknoAplikacji”
(rysunek Rysunek 3.32). „OknoAplikacji” wynik scoringu przekazuje do obiektu
„PanelWyswietlaniaWynikow”, który po narysowaniu wykresu słupkowego
przedstawia wynik aktorowi „Analityk kredytowy”.

39
Rysunek 3.31 Diagram sekwencji komponentu widok dla przypadku użycia „Wykonanie oceny kredytowej”
Rysunek 3.32 Diagram sekwencji komponentów dla przypadku użycia „Wykonanie oceny kredytowej”

40
3.4. Opis implementacji aplikacji
W niniejszym podrozdziale opisałem najważniejsze elementy implementacji aplikacji,
uzasadniając podjęcie konkretnych decyzji implementacyjnych. Całość implementacji
jest zgodna z projektem przedstawionym w poprzedniej części tego rozdziału oraz
uzupełniona o elementy niezbędne do prawidłowego i wydajnego funkcjonowania.
3.4.1. Architektura i klasy pomocnicze
Zgodnie z projektem architektura aplikacji jest zgodna z wzorcem MVC. Każdy
z komponentów, zgodnie z konwencją tworzenia oprogramowania w języku Java,
umieszczony jest w oddzielnym pakiecie. Oprócz pakietów „model”, „kontroler” oraz
„widok” na aplikację składa się pakiet „pomocnicze” i jedna klasa będąca w pakiecie
nadrzędnym.
Pakiety wzorca MVC zostaną omówione w kolejnych podrozdziałach. Pakiet
„pomocnicze” zawiera klasy używane w pozostałych pakietach - są to klasy do
realizacji przepływu danych między komponentami oraz pewnych operacji
pomocniczych do przekształcania danych. Wspomniane operacje nie są specyficzne dla
pojedynczego komponentu i dostęp do nich jest możliwy z każdego innego pakietu.
Takie rozwiązanie pozwala nie tworzyć silnych powiązań między poszczególnymi
pakietami wzorca.
Jedną z klas pakietu pomocnicze jest klasa „WynikScoringu”. Jest to prosta klasa
używana do przekazania wyniku oceny kredytowej z modelu do widoku. Zawiera dwa
pola: „prawdopodobieństwo” - określające prawdopodobieństwo spłaty kredytu
zawierające się w przedziale <0, 1> i „grupaRyzyka” będące typu wyliczeniowego
o nazwie „GrupaRyzyka”. Typ wyliczeniowy zaimplementowałem wewnątrz klasy
„WynikScoringu” ze względu na prostotę i czytelność kodu. „GrupaRyzyka” zawiera
trzy wartości zgodnie z przedstawionym projektem.
Pozostałymi klasami pakietu „pomocnicze” są: klasa abstrakcyjna
„ArgumentFunkcjiScoringowej”, a także dwie klasy pochodne od niej -
„ArgumentFunkcjiScoringowejNapis” i „ArgumentFunkcjiScoringowejNumeryczny”.
Klasy te przechowują dane dotyczące argumentów funkcji scoringowej i przemieszczają
się między komponentami w dwie strony - od modelu do widoku przenoszą informację

41
o nazwie i opisie argumentów i od widoku do modelu przenoszą informacje
o wartościach argumentów.
„ArgumentFunkcjiScoringowej” jest klasą abstrakcyjną, ponieważ każdy argument
funkcji scoringowej jest określonego typu i część logiki dla wszystkich argumentów jest
wspólna (co determinuje wybranie mechanizmu abstrakcji, a nie interfejsu). Wszystkie
argumenty zawierają opis i odpowiednią nazwę do wyświetlenia. Wszystkie zawierają
także nazwę zmiennej z bazy danych, która umożliwia funkcji scoringowej określić,
z którym obiektem mamy do czynienia. Różne są natomiast typy wartości argumentów.
Generowany kod modelów przyjmuje jeden z dwóch typów - numeryczny (typ
„double”) lub znakowy (typ „String”). Zastosowany mechanizm dziedziczenia pozwala
rozszerzyć dopuszczalne typy - wystarczy zaimplementować kolejną klasę
z odpowiednimi polami i metodami. Kod jest dzięki temu czytelniejszy, hermetyczny
i rozszerzalny.
Przykładem logiki stosowanej we wszystkich klasach argumentów funkcji scoringowej
jest kod odpowiedzialny za pobranie nazwy przez komponent widoku. Model ładuje do
argumentów odpowiednie nazwy do wyświetlenia, jednak może się zdarzyć, że dla
pewnego modelu nie będzie mógł zlokalizować słownika, lub słownik będzie niepełny.
Logiczne jest, że widok nie jest odpowiedzialny za znalezienie odpowiedniej nazwy
argumentu, ale klasa, która te argumenty opakowuje. Omawianą logikę implementuje,
metoda „getNazwaArgumentuDoWyswietlenia()”, która w razie braku załadowanej
nazwy poda identyfikator z bazy danych. Jest ona częścią klasy
„ArgumentFunkcjiScoringowej”.
Przykładem logiki abstrakcyjnej dla klasy „ArgumentFunkcjiScoringowej” jest podanie
wartości argumentu. Klasa abstrakcyjna wie, że jej implementacja musi posiadać
wartość, ale nie jest w stanie dostać się do pola, które tą wartość będzie przechowywało.
Dlatego wszystkie klasy pochodne muszą zaimplementować metodę „getWartosc()”.
Metoda abstrakcyjna „getWartosc()” zwraca obiekt typu „Object”, składając
odpowiedzialność na odpowiednie zrzutowanie wartości na logikę, które jej używa. Nie
jest to jednak istotne, bo metoda ta jest używana tylko do konwertowania obiektów
klasy „ArgumentFunkcjiScoringowej” na format danych przyjmowany przez funkcję
scoringową, która przyjmuje wskazania wartości typu „Object”.

42
„ArgumentFunkcjiScoringowej” zawiera również metody statyczne używane do
konwertowania zbiorników obiektów tej klasy. Wynika to z różnic między używanymi
kontenerami obiektów między komponentami i między modelem a funkcją scoringową.
Komponenty przekazują sobie informacje o argumentach za pomocą list z obiektami
typu „ArgumentFunkcjiScoringowej”. Jednak funkcja scoringowa oczekuje na wejściu
mapy, w której kluczem jest nazwa argumentu z bazy danych, a wartością jest
wskazanie typu „Object” na odpowiednią wartość argumentu (typ „double” lub
„String”). Umiejscowienie logiki konwersji w tej klasie ułatwia utrzymanie kodu
związanego z obsługą typów danych.
Poza pakietem „pomocnicze” oraz komponentami wzorca MVC w aplikacji znajduje się
jeszcze jedna klasa. Jest to „KlasaStartowa” zawierająca metodę statyczną „main()” od
której zaczyna się działanie programu. Jej zadaniem jest powołanie do życia
komponentów, podanie im odpowiednich wskazań do siebie i zasygnalizowanie
kontrolerowi, że może przeprowadzić odpowiednie czynności konfiguracyjne.
3.4.2. Kontroler
Kontroler jest częścią aplikacji, która odpowiada nie tylko za zarządzanie przepływem
danych między widokiem a modelem. Jako jedyny komponent posiadający wskazania
na pozostałe komponenty jest odpowiedzialny za zarządzanie pracą całej aplikacji. Do
jego zadań należy także odpowiednia inicjacja pozostałych komponentów.
Ze względu na niewielkie rozmiary kodu (mniej niż 200 linii łącznie z odstępami
i komentarzami) zdecydowałem się umieścić całą logikę komponentu w jednej klasie -
„KontrolerAplikacji”. W rezultacie w pakiecie „kontroler” znajduje się jeszcze tylko
jeden obiekt - interfejs „Kontroler”, który jest oczywiście implementowany przez
jedyną dostępną klasę.
Najciekawszą częścią klasy „KontrolerAplikacji” jest logika odpowiedzialna za
inicjowanie pozostałych komponentów. Składa się ona z trzech etapów:
1. ładowanie konfiguracji;
2. pobranie z modelu listy argumentów funkcji scoringowej;
3. zainicjowanie widoku.

43
Ładowanie konfiguracji
Konfiguracja aplikacji odbywa się przy pomocy pliku konfiguracyjnego. Powinien być
umieszczony w tym samym folderze co pliki wykonywalne programu i nosić nazwę
„plikKonfiguracyjny.txt”. W jego wnętrzu znajdują się rekordy w formacie „właściwość
= wartość” po jednym w linii. Poniżej znajduje się przykładowy wydruk pliku
konfiguracyjnego.
Parametry konfigurowane w tym pliku przedstawione są w tabeli poniżej.
Nazwa parametru Rodzaj Opis
JScoreXML napis Określa położenie pliku „JScore.xml”
wygenerowanego razem z modelem
scoringowym i zawierającym argumenty
funkcji scoringowej.
SlownikBazyDanych napis Określa położenie pliku słownika bazy danych.
Parametr opcjonalny.
OdciecieNiskiejGrupyRyzyka liczba Określa granicę wartości prawdopodobieństwa
między niską i średnią grupą ryzyka
kredytowego.
OdciecieSredniejGrupyRyzyka liczba Określa granicę wartości prawdopodobieństwa
między średnią i wysoką grupą ryzyka
kredytowego.
Tabela 3.2 Parametry pliku konfiguracyjnego aplikacji
Kontroler odczytuje rekordy pliku konfiguracyjnego sprawdzając ich poprawność.
W przypadku braku któregoś z koniecznych parametrów lub niemożności ich
odpowiedniej konwersji wyświetla za pomocą specjalnej funkcji widoku komunikat
błędu. Przy poprawnym odczytaniu wszystkich parametrów zapisuje je w odpowiednich
polach prywatnych klasy. Parametry „JScoreXML” i „SlownikBazyDanych” są
potrzebne przy pobraniu listy argumentów z modelu. Parametry odcięć podawane są
Wydruk 3.1 Przykładowa zawartość pliku konfiguracyjnego
1. JScoreXML = JScore.xml 2. ObciecieNiskiejGrupyRyzyka = 0.85 3. ObciecieSredniejGrupyRyzyka = 0.6 4. SlownikBazyDanych = slownikDMAGECR.txt

44
wraz z listą argumentów funkcji scoringowej do modelu w celu wygenerowania wyniku
scoringu.
Pobranie listy argumentów
Kolejnym etapem inicjowania aplikacji jest odwołanie się do modelu. Poprzez metodę
o nazwie „getMozliweArgumentyScoringu” przekazywane są do modelu dwa
parametry: „JScoreXML” i „SlownikBazyDanych”. Kontrakt tej metody zobowiązuje ją
do zwrotu listy argumentów funkcji scoringowej. Argument określający ścieżkę
położenia słownika jest opcjonalny - w przypadku błędnej ścieżki lub jej braku metoda
nie generuje wyjątku. Zwraca listę argumentów bez uzupełnionych informacji opisu
i bez specjalnej nazwy do wyświetlenia.
Argument „JScoreXML” jest podstawą do odczytania listy potrzebnych argumentów.
Ścieżka pliku musi być w nim poprawna, a plik musi mieć właściwą budowę.
W przypadku błędu metoda rzuca odpowiedni wyjątek. Z punktu widzenia kontrolera
nie jest istotne jaki to jest wyjątek - przechwytuje je wszystkie i wyświetla ogólny
komunikat o błędzie przetwarzania pliku argumentów funkcji scoringowej.
Zainicjowanie widoku
Po odczytaniu listy argumentów funkcji scoringowej można przystąpić do ostatniego
etapu inicjowania aplikacji. Jest nim uruchomienie widoku. Widok przekazany
w konstruktorze klasy nie jest w pełni gotowy - należy przekazać mu listę argumentów,
aby mógł odpowiednio wyświetlić formularz wprowadzania danych. Dodatkowo należy
wywołać metodę widoku - „pokaz()”, która sprawdza czy wszystkie wymagania
potrzebne do poprawnego wyświetlania zostały spełnione i rysuje okno aplikacji
w odpowiedni sposób. Metoda „pokaz()” może zwrócić wyjątek w przypadku braku
gotowości do wyświetlenia - kontroler wtedy przekazuje komunikat błędu
użytkownikowi i kończy działanie aplikacji.
Pozostała logika klasy
Realizacja kontroli przepływu danych między widokiem, a modelem jest w tym
projekcie trywialna. Nie występuje w aplikacji współbieżna komunikacja między
widokiem, a modelem, kontroler więc spełnia rolę prostego pośrednictwa z obsługą
wyjątków.

45
3.4.3. Model
Kolejnym komponentem aplikacji jest model. Zgodnie z przyjętym wzorcem
architektonicznym model jest pasywny, tzn. nie posiada referencji do pozostałych
komponentów aplikacji. Przez to komunikacja z pozostałą częścią programu zachodzi
tylko za pomocą zwracania wartości funkcji oraz poprzez rzucanie wyjątków.
Model spełnia dwie istotne zadania. Pierwszym z nich jest przygotowanie argumentów
funkcji scoringowej, drugim - wykonanie scoringu.
Argumenty funkcji scoringowej
Stworzenie listy argumentów funkcji scoringowej odbywa się dwuetapowo. Pierwszym
z nich jest pobranie informacji o tym, które argumenty przyjmuje funkcja scoringowa.
Ta informacja zawarta jest w pliku generowanym przez program SAS Enterprise Miner
razem z innymi plikami modelu. Plik domyślnie nazywa się „JScore.xml” i zawiera
informacje w formacie XML. Zawiera kilka sekcji z informacjami o:
wersji programu generującego kod modelu;
klasie, nazwie pakietu i deklaracji metody funkcji scoringowej;
argumentach funkcji scoringowej;
wyniku zwracanym przez funkcję scoringową.
Wydruk 3.2 Fragment pliku „JScore.xml" zawierający argumenty funkcji scoringowej
1. <Input count="4"> 2. <Variable index="0"> 3. <Name> CHECKING </Name> 4. <Type> double </Type> 5. </Variable> 6. <Variable index="1"> 7. <Name> DURATION </Name> 8. <Type> double </Type> 9. </Variable> 10. <Variable index="2"> 11. <Name> HISTORY </Name> 12. <Type> double </Type> 13. </Variable> 14. <Variable index="3"> 15. <Name> SAVINGS </Name> 16. <Type> double </Type> 17. </Variable> 18. </Input>

46
Celowo zaznaczam, że plik metadanych zawiera informację o argumentach i wyniku,
ponieważ jako argument funkcja scoringowa przyjmuje mapę i mapę zwraca w wyniku
działania. Może się w niej znaleźć dowolna liczba obiektów, jednak tylko niektóre będą
użyte.
Interesującym z punktu widzenia działania programu jest tylko fragment zawierający
argumenty funkcji scoringowej. Pozostałe części pliku metadanych są stałe.
Za analizę składniową pliku metadanych odpowiedzialana jest klasa
„ParserJScoreXML”. Do analizy składniowej wykorzystuje klasę „DOMParser”
z rodziny analizatorów składniowych „Apache Xerces”. Sprawdza zgodność pliku ze
standardem i spójność logiczną (np. czy jest tylko jedna sekcja „input”). Po odczytaniu
nazw i typów argumentów zwraca listę argumentów funkcji scorngowej.
Drugim etapem tworzenia listy argumentów jest uzupełnienie jej o informację ze
słownika. W słowniku znajdują się informację dotyczące tekstów wyświetlanych
w widoku. Dla każdego z argumentów funkcji scoringowej w słowniku są dwa rekordy
- rekord z czytelną nazwą oraz rekord z opisem. Rekordy słownika zapisane są
w formacie „nazwaArgumentu = nazwa do wyświetlenia” oraz „nazwaArgumentuopis =
opis argumentu w formacie HTML”. Poniżej zamieszczam fragment wydruku słownika
dla zmiennych bazy danych stosowanej w projekcie.
1. AGE = Wiek 2. AGEopis = <html><b>Wiek w latach</b></html> 3. AMOUNT = Kwota 4. AMOUNTopis = <html><b>Kwota kredytu</b></html> 5. CHECKING = Rachunek 6. CHECKINGopis = <html><b>Stan otwartych rachunków</b><br />1:
0<DM;<br /> 2: 0-200DM;<br /> 3: >200DM;<br /> 4: brak konta</html>
7. COAPP = Wspólnik 8. COAPPopis = <html>1: brak <br />2: współpożyczkobiorca<br />3:
żyrant</html> 9. DEPENDS = Utrzymanie
10. DEPENDSopis = <html><b>Liczba osób na utrzymaniu</b></html> 11. DURATION = Czas 12. DURATIONopis = <html><b>Czas trwania w miesiącach</b></html> 13. EMPLOYED = Zatrudnienie 14. EMPLOYEDopis = <html><b>Okres obecnego zatrudnienia</b><br
/>1: bezrobotny <br />2: <1 rok<br />3: 1-4 lata<br />4: 4-7 lat<br />5: >7 lat</html>
Wydruk 3.3 Fragment pliku słownika bazy danych

47
Słownik należy stworzyć w oparciu o opis stosowanej bazy danych. Za analizę
składniową i odpowiednie uzupełnienie listy argumentów funkcji scoringowej
odpowiada klasa „ParserSlownikaBazyDanych”.
Ocena kredytowa
Przeprowadzenie oceny kredytowej przez model dokonuje się na żądanie komponentu
„widok”, który przekazuje kontrolerowi wartości wprowadzone przez analityka
kredytowego. Kontroler wywołuje funkcję o nazwie „wyliczPrawdopodobieństwo”
z trzema argumentami: listą wartości i dwoma argumentami definiującymi przedziały
grup ryzyka kredytowego.
Pierwszym etapem wykonywania oceny kredytowej jest wywołanie funkcji
scoringowej. W tym celu należy przeprowadzić konwersję listy argumentów do mapy
zawierającej pary wartości: nazwa argumentu - wartość. Funkcja scoringowa
przeprowadza weryfikację poprawności wprowadzonych danych i scoring. Niestety
można zanalizować tylko logikę odpowiedzialną za poprawność wprowadzanych
danych - reszta logiki dostarczana jest w formie skompilowanej. Funkcja scoringowa
dostarcza mapę w rezultacie działania, w której interesujące z punktu widzenia aplikacji
są dwa rekordy. Jeden z nich to „EM_EVENTPROBABILITY” zawierający
prawdopodobieństwo spłaty kredytu podawane jako liczba rzeczywista z przedziału <0,
1>. Ten rekord będzie dalej przetwarzany w programie.
Drugim interesującym rekordem z mapy wynikowej funkcji scoringowej jest
„_WARN_”. Zawierają się w nim ostrzeżenia wygenerowane w czasie dokonywania
oceny. Niestety dostawca oprogramowania generującego funkcję scoringową nie podaje
dokumentacji dotyczącej rodzajów komunikatów ostrzeżeń. Ich format nie umożliwia
zorientowania się czego dotyczą (są to komunikaty znakowe, np. „U”, albo „M”).
Badając różne modele zorientowałem się, że komunikaty są generowane w przypadku
braku wystarczającej ilości danych lub ich niepoprawnych zakresach. W przypadku
modelu opartego na drzewie decyzyjnym komunikaty nie są generowane ze względu na
to, że drzewa decyzyjne posiadają wbudowane mechanizmy obsługi braków danych.
Ich ocena kredytowa jest sensowna dla niepełnego zestawu danych, choć oczywiście nie
tak wiarygodna jak dla pełnego zestawu danych.
Istnienie wartości dla klucza „_WARN_” w mapie wyniku funkcji scoringowej jest
ostrzeżeniem przed tym, że wynik działania może być niewiarygodny. Metoda

48
„wyliczPrawdopodobieństwo()” w takim przypadku generuje wyjątek informujący
użytkownika o potrzebie poprawienia danych wejściowych.
Pierwszy rekord, zawierający prawdopodobieństwo spłaty kredytu, służy do stworzenia
wyniku scoringu. W nowo utworzonym obiekcie klasy „WynikScoringu” umieszczane
jest prawdopodobieństwo oraz grupa ryzyka wyznaczona na podstawie podanych
wcześniej przedziałów.
3.4.4. Widok
Ostatnim omawianym komponentem aplikacji jest widok. Umożliwia wprowadzenie
danych, wyświetlenie wyników oceny kredytowej i wyświetlanie komunikatów błędów.
Widok zbudowany jest w oparciu o bibliotekę graficzną SWING. Główna klasa
komponentu - „OknoAplikacji” jest więc klasą pochodną od klasy „JFrame”. „JFrame”
definiuje podstawowe cechy wyświetlanego okna, jak kontrolowanie jego wymiarów
oraz reakcja na komunikat zamknięcia okna. Zawartość jest wyświetlana zgodnie
z polityką zarządcy układu (ang. layout manager) typu „BorderLayout”. Dzieli ekran na
pięć sektorów: północny, wschodni, południowy, zachodni i centralny. Sektory
północny i południowy mają stałą wysokość i zajmują pas przestrzeni na górze i dole
okna. Analogiczne sektory wschodni i zachodni mają stałą szerokość i zajmują pasy
przestrzeni z lewej i prawej strony okna.
W przedstawianej aplikacji użyłem tylko sektora zachodniego i centralnego. W sektorze
zachodnim umieściłem panel wprowadzania danych, a w sektorze centralnym panel
wyświetlania wyników. Dzięki temu formularz wprowadzania danych posiada stałą
szerokość zapewniającą poprawne wyświetlanie pól wprowadzania danych i ich
opisów. Przestrzeń sektora centralnego zajmuje panel wyświetlania wyników.
Wprowadzanie danych
Wprowadzanie danych realizowane jest przez obiekt klasy
„PanelWprowadzaniaDanych”. Po jego utworzeniu należy dla każdego dopuszczalnego
argumentu wywołać funkcję „dodajPoleFormularza()”, która dodaje odpowiednie pole
w formularzu. Biblioteka SWING posiada specjalne pola wprowadzania danych
umożliwiające w łatwy sposób zapewnić kontrolę poprawności danych. Klasa
„JFormattedTextField” umożliwia wprowadzanie wartości tylko w zdefiniowanym
formacie. Dzięki temu mam pewność, że użytkownik do pola numerycznego nie

49
wprowadzi wartości nie numerycznych. Odpowiedzialność dokładniejszego
sprawdzenia poprawności wprowadzonych danych spoczywa na modelu.
Metoda „dodajPoleFormularza()”, oprócz narysowania pól wprowadzania danych i ich
opisów, zachowuje odwołania do nich w odpowiednim formacie. Jest to niezbędne do
odczytywania danych z pól - do identyfikacji zmiennych musi przechowywać ich
nazwy z bazy danych.
Analityk kredytowy, po wprowadzeniu danych do odpowiednich pól formularza, wciska
przycisk „Oceń”. Sterowanie jest wtedy przekazywane do obiektu
„OdczytywanieDanychFormularza”. Obiekt pobiera od obiektu klasy
„PanelWprowadzaniaDanych” reprezentację pól wprowadzania danych w postaci
i mapy i konwertuje ją na listę argumentów funkcji scoringowej, odczytując ze
wszystkich pól ich wartości. Gotową listę przekazuje obiektowi klasy „OknoAplikacji”,
która dalej kieruje ją do kontrolera.
Wyświetlanie wyników
Wyświetlanie wyników realizuje klasa „PanelWyswietlaniaWynikow”. Wyświetla
prawdopodobieństwo spłaty kredytu w postaci tekstowej razem z grupą ryzyka
kredytowego.
Dodatkowo wynik oceny kredytowej jest przedstawiany w postaci graficznej. Klasa
„WykresSlupkowy” realizuje rysowanie wykresu słupkowego i ustalenie jego koloru
w zależności od grupy ryzyka kredytowego. Dla grupy wysokiego ryzyka jest to kolor
czerwony, dla grupy średniego ryzyka kolor żółty, dla grupy niskiego ryzyka kolor
zielony.
Okno błędów
Wymagana dla widoku jest implementacja mechanizmu wyświetlania błędów. Część
błędów jest wyświetlana jeszcze przed zainicjowaniem widoku (jak błąd pliku
konfiguracyjnego), więc musi on zapewniać specjalny mechanizm ich wyświetlania.
Idealnym do tego jest mechanizm okien dialogowych. W prosty sposób biblioteka
SWING umożliwia wyświetlenie jednego z zestawu zdefiniowanych okien z podaniem
odpowiednich parametrów. Dzięki temu inne okno jest wyświetlanie dla komunikatu
błędu krytycznego po którym następuje zamknięcie aplikacji i inne do wyświetlenia
ostrzeżenia. Widok okna błędu krytycznego przedstawiłem w rozdziale „3.6.2
Konfiguracja aplikacji”.

50
3.5. Testowanie aplikacji
Istotnym elementem procesu wytarzania aplikacji jest przeprowadzenie testów. Ich
celem jest wykrycie błędów, wskazanie miejsc wymagających poprawek, sprawdzenie
stabilności oprogramowania oraz zgodności z wymaganiami.
Dobrą praktyką stosowaną przy tworzeniu oprogramowania jest tworzenie testów
równolegle z implementowaniem programu. Do powstającego kodu aplikacji dołącza
się automatyczne testy od razu po napisaniu jego części5. Przynosi to dwojakie
korzyści. Po pierwsze pozwala sprawdzić, czy dany fragment kodu działa zgodnie
z oczekiwaniami. Po drugie pozwala na bieżąco sprawdzać, czy zmiany wprowadzane
w kodzie nie generują błędów w innych miejscach.
W przedstawianym projekcie rozplanowałem testy na trzy etapy. Pierwszym było
tworzenie testów jednostkowych wraz z implementowaniem funkcjonalności. Drugim
były testy integracyjne sprawdzające współdziałanie komponentów. Trzecim - testy
systemowe weryfikujące działanie całej aplikacji, pod kątem spełnienia postawionych
wymagań. Do automatycznego testowania użyłem narzędzia JUnit, w postaci wtyczki
do platformy Eclipse. Wykorzystałem także bibliotekę „EasyMock” do izolowania
części testowanej funkcjonalności oraz symulowania części aplikacji trudnych do
testowania. W poniższych podrozdziałach opisałem poszczególne etapy testowania,
wraz z uzasadnieniem podjętych wyborów, co do tego, co było sprawdzane.
3.5.1. Testy jednostkowe
Testy jednostkowe mają za zadanie sprawdzić działanie izolowanych fragmentów kodu
takich jak funkcje czy klasy. Zdecydowałem się stworzyć automatyczne testy do metod
realizujących nietrywialną logikę. Na tej podstawy wraz z implementowaniem kodu
powstały automatyczne testy do wszystkich klas komponentu „model” oraz do metod
przekształcania danych zawartych w pakiecie „pomocnicze”. Sprawdziłem prawidłowe
wykonanie i przypadki brzegowe dla metod klas: „ModelDoSkompilowanegoKodu”,
„ParserJScoreXML”, „ParserSlownikaBazyDanych” i „ArgumentFunkcjiScoringowej”.
Łącznie, dla wymienionych klas, stworzyłem 20 automatycznych testów
jednostkowych.
5 Niektóre metody programowania zalecają tworzenie testów przed implementowaniem funkcjonalności,
co ma skłonić programistę do implementowania tylko tego co niezbędne i, w rezultacie, zwiększyć jego
efektywność (patrz Extreme Programming - [16]).

51
3.5.2. Testy integracyjne
Testy integracyjne sprawdzają współdziałanie określonych części aplikacji.
Funkcjonalność komponentu „kontroler” koncentruje się wokół integrowania działania
modelu i widoku, dlatego uznałem, że testy integracyjne najskuteczniej sprawdzą jego
działanie. Ułożyłem trzy automatyczne testy sprawdzające ładowanie konfiguracji,
inicjowanie widoku, informowanie o błędach i wykonywanie oceny kredytowej. Ze
względu na zbyt dużą komplikację testowania graficznych elementów interfejsu
użytkownika, zdecydowałem się podmienić w tych testach komponent „widok” na
obiekt symulowany. Sprawdzanie widoku odłożyłem do testów systemowych.
3.5.3. Testy systemowe
Testy systemowe były ostatnim etapem sprawdzania poprawności działania aplikacji.
Plan testowania wyznaczyłem według projektu diagramów przypadków użycia -
najpierw przetestowałem funkcjonalność wykonywania oceny kredytowej, a następnie
konfiguracji grup ryzyka. Testy systemowe wykonywałem ręcznie, wprowadzając
przygotowany zbiór danych.
Testy systemowe wykazały poprawne funkcjonowanie programu i spełnienie wymagań
funkcjonalnych. W czasie testowania ujawnił się jednak pewien defekt działania dla
wykonywania oceny kredytowej. Aplikacja nie informowała o wprowadzeniu danych
spoza dopuszczalnego zakresu. Analiza implementacji wykazała, że odpowiedzialna
jest za to generowana automatycznie funkcja scoringowa. Zastosowany model oparty na
drzewie decyzyjnym posiada wbudowane mechanizmy obsługi wartości spoza zakresu
i nie informuje w tych przypadkach o błędach. Uznałem, że ze względu na brak
możliwości edycji kodu funkcji scoringowej dostarczanego w postaci skompilowanej,
pozostawię program w niezmienionej postaci. Funkcja scoringowa przedstawiała
wiarygodną ocenę kredytową, co minimalizowało koszty związane z nieprzewidzianym
działaniem aplikacji.
3.6. Przedstawienie funkcjonalności aplikacji
W ostatniej części tego rozdziału przedstawiłem przykładowe scenariusze
z użytkowania aplikacji. W pierwszej części opisałem dwa scenariusze zgodne
z przypadkiem użycia „Wykonanie oceny kredytowej”. W drugiej części pokazałem
działanie aplikacji przy różnych wartościach konfiguracji, co odpowiada przypadkowi

52
użycia „Określenie przedziałów ryzyka kredytowego” jak również wymaganiu
funkcjonalnemu numer 3 („Program powinien informować o błędach konfiguracji
i wprowadzonych danych.”).
Rysunek 3.33 Okno aplikacji przed wprowadzeniem danych
3.6.1. Wykonanie oceny kredytowej
Po uruchomieniu programu analityk kredytowy widzi gotowe okno do oceny
kredytowej. Z lewej strony okna znajduje się formularz wprowadzania danych wraz
z kompletnymi opisami do wprowadzania danych i przyciskiem „Oceń”. W prawej
części jest natomiast panel do prezentacji wyników: miejsce na wartość
prawdopodobieństwa spłacenia kredytu, miejsce na grupę ryzyka do której zostanie
zakwalifikowany klient oraz graficzną reprezentację wyniku w postaci wykresu
słupkowego. Przed wprowadzeniem danych wyniki jeszcze nie są pokazane - miejsca

53
na wartość prawdopodobieństwa i grupę ryzyka są puste, a wykres reprezentacji wyniku
nie jest narysowany (pokazuje wartość „0.0%”).
Dla zbudowanego modelu w części formularza znajdują się cztery pola do
wprowadzenia danych. Są to: stan otwartych rachunków, czas trwania kredytu, historia
kredytowa klienta, oszczędności klienta na koncie lub w obligacjach.
Do przedstawienia funkcjonalności wybrałem dwa przypadki ze zbioru wejściowego.
Pierwszym kredytobiorcą jest mężczyzna w wieku 25 lat starający się o kredyt
w kwocie 5152 DM na dwa lata na radio lub telewizor. Dane historyczne zawierają
informacje, że kredyt został przez niego spłacony. Drugą osobą zaciągającą kredyt jest
kobieta w wieku 24 lat starająca się o kredyt w kwocie 626 DM na rok również na radio
lub telewizor. Jednak w jej przypadku kredyt nie został spłacony. Obydwie obserwacje
zbioru wejściowego zaprezentowałem w tabeli poniżej.
Numer rekordu bazy
danych
478 549
Wiek (AGE) 25 (lat) 24 (lata)
Kwota kredytu (AMOUNT) 5152 (DM) 626 (DM)
Stan otwartych rachunków
(CHECKING)
3 (powyżej 200 DM) 1 (poniżej 0 DM)
Wspólnik (COAPP) 1 (kredyt brany samodzielnie) 1 (kredyt brany samodzielnie)
Liczba osób na utrzymaniu
(DEPENDS)
1 1
Czas spłaty (DURATION) 24 (miesiące) 12 (miesięcy)
Czas zatrudnienia
(EMPLOYED)
4 (4-7 lat) 3 (1-4 lat)
Liczba otwartych kredytów
(EXISTCR)
1 1
Historia kredytowa
(HISTORY)
2 (kredyty spłacane należycie
do teraz)
1 (brak zaciągniętych
kredytów lub wszystkie
spłacone należycie)
Mieszkanie (HOUSING) 2 (własne) 2 (własne)

54
Praca (JOB) 3 (pracownik
wykwalifikowany lub
urzędnik)
2 (pracownik miejscowy -
niewykwalifikowany)
Stan cywilny (MARITAL) 3 (kawaler) 2 (kobieta - rozwiedziona,
w separacji lub żonata)
Inne plany ratalne
(OTHER)
1 (bank) 1 (bank)
Majątek (PROPERTY) 3 (samochód lub inny
majątek)
1 (nieruchomość)
Przeznaczenie (PURPOSE) 3 (radio lub telewizor) 3 (radio lub telewizor)
Oszczędności (SAVINGS) 1 (do 100DM) 1 (do 100DM)
Telefon (TELEPHON) 1 (brak) 1 (brak)
Czy kredyt został spłacony
(GOOD_BAD)
tak nie
Tabela 3.3 Wybrane rekordy do prezentacji działania aplikacji
Z prezentowanego zbioru interesują nas tylko wspomniane wartości pobierane przez
aplikację. Dla obserwowanego mężczyzny analityk kredytowy wprowadza do programu
następujące wartości: rachunek - 3, czas - 24, historia - 2 i oszczędności - 1. Ocena
kredytowa klienta jest pozytywna - szansa na spłatę kredytu wynosi 86,76%, co
kwalifikuje go do niskiej grupy ryzyka. Ocena kredytowa jest wiarygodna, ponieważ
klient rzeczywiście spłacił kredyt.

55
Rysunek 3.34 Okno aplikacji dla oceny kredytowej klienta z 478 rekordu bazy danych
Dla drugiej wybranej obserwacji ze zbioru danych (kobieta - 24 lata) analityk
kredytowy wprowadza do programu następujące wartości: : rachunek - 1, czas - 12,
historia - 1 i oszczędności - 1. Ocena kredytowa jest negatywna - szansa na spłatę
kredytu wynosi zaledwie 29,41%. Program zaklasyfikował klienta do wysokiej grupy
ryzyka, co skłania analityka kredytowego do odmowy przyznania kredytu. Wynik
podany przez model zgadza się z informacjami znajdującymi się w bazie danych -
wiadomo, że klient nie spłacił kredytu.

56
Rysunek 3.35 Okno aplikacji dla oceny kredytowej klienta 549 rekordu bazy danych
3.6.2. Konfiguracja aplikacji
Ustawienie konfiguracji odbywa poprzez zmianę w edytorze tekstowym pliku
konfiguracyjnego. Za ustawienia wartości granicznych grup ryzyka kredytowego
odpowiadają właściwości „OdciecieNiskiejGrupyRyzyka”, która domyślnie ustawiona
jest na wartość „0.85” (85%) i właściwość „OdciecieSredniejGrupyRyzyka” domyślnie
ustawionej na „0.6” (60%). Po zmianie tych właściwości, uruchomieniu programu
i wprowadzeniu danych możemy zauważyć zmianę zakwalifikowania klienta o tych
samych cechach do grup ryzyka kredytowego.

57
Rysunek 3.36 Okna aplikacji dla różnej konfiguracji miejsc odcięcia grupy niskiego ryzyka
Niewłaściwa konfiguracja pliku, jego złe umiejscowienie lub nazwa powoduje
wyświetlenie błędu i uniemożliwia uruchomienie programu.
Rysunek 3.37 Okno błędu niewłaściwych ustawień pliku konfiguracyjnego

58
4. Podsumowanie
W ostatnim rozdziale niniejszej pracy zweryfikowałem zgodność poczynionych założeń
z osiągniętymi wynikami, opisałem zalety oraz wady przyjętych przeze mnie
rozwiązań, wskazałem przykładowe zastosowanie i przedstawiłem kierunki rozwoju
zaprezentowanej aplikacji.
4.1. Weryfikacja wymagań
W czasie analizy wymagań funkcjonalnych udało mi się wypracować trzy wymogi
stawiane tworzonej aplikacji. Pierwszy dotyczy wykonywania oceny kredytowej
klientów banku. Aplikacja zawiera następujące funkcjonalności: posiada intuicyjny
i konfigurowalny interfejs oraz prezentuje wyniki w sposób czytelny i jednoznaczny.
Dodatkowo zastosowany model pozwala dokonać oceny na podstawie niewielkiego
zestawu informacji pobieranej od klienta, co ułatwia i przyśpiesza proces podejmowania
decyzji kredytowej. Niestety, wadą zaprezentowanego modelu jest wiek danych
wybranych do jego trenowania. Wspomniany brak jest skutkiem niskiej dostępności do
takich danych - instytucje nie są skłonne udostępniać danych zgromadzonych w swoich
bazach danych. W ciągu kilkunastu lat, które minęły od zebrania zastosowanych
danych, wzorce zachowań kredytobiorców mogły ulec zmianie i model, wytrenowany
na tej bazie danych, może być mniej wiarygodny niż wykazała to analiza.
Drugie wymaganie funkcjonalne dotyczy określania przedziałów ryzyka kredytowego
przez „Analityka grup ryzyka”. Zostało ono całkowicie spełnione dzięki zastosowaniu
pliku konfiguracyjnego. Zewnętrzny plik jest łatwo edytowalny oraz umożliwia
sprawną zmianę konfiguracji w wielu instancjach programu. Takie rozwiązanie wspiera
proces opracowywania nowej polityki kredytowej banku.
Wyświetlanie odpowiednich błędów jest przedmiotem trzeciego wymagania
funkcjonalnego. Aplikacja posiada odpowiednie mechanizmy informowania o błędach
krytycznych i ostrzeżeniach. Informuje użytkownika o błędach konfiguracji
i uruchamiania aplikacji. Komponent widoku posiada zaimplementowany mechanizm
kontroli wprowadzania odpowiedniego typu danych. Komponent modelu sprawdza ich
poprawność logiczną i określa czy można na ich podstawie dokonać oceny kredytowej.

59
Co więcej, posiada mechanizmy wspierające obsługę danych niepoprawnych lub
niepełnych. Wadą złożenia odpowiedzialności za sprawdzanie poprawności
wprowadzonych danych na kod aplikacji wygenerowany przez oprogramowanie
zewnętrznego dostawcy jest niepełny zestaw komunikatów błędów takich jak
wprowadzenie wartości spoza dostępnego zakresu. W przypadku, gdy model stosuje
mechanizmy wspierające wykonywanie oceny kredytowej w oparciu o niepoprawne lub
niepełne dane, nie informuje o tym użytkownika, nawet gdy ten mógł wprowadzić takie
dane nie przez brak pełnej informacji o kliencie, ale poprzez nieuwagę.
Wymagania niefunkcjonalne postawione projektowanej aplikacji zostały spełnione.
Aplikacja umożliwia sprawną wymianę modeli oceny kredytowej bez potrzeby
wprowadzania zmian w kodzie. Wystarczy wymienić odpowiednie pliki i rekompilować
program. Rekompensuje to wady związane z koniecznością zastosowania danych
trenujących sprzed 2002 roku. Bank stosujący aplikację może z łatwością wymienić
zastosowany model na wytrenowany w oparciu o dane zebrane w ciągu swojej
działalności, znacząco podnosząc jego skuteczność.
Aplikacja jest skalowalna i integrowalna w systemami typu CRM dzięki
zastosowanemu wzorcowi architektonicznemu MVC. Ocena wykonywana przez nią
odbywa się w czasie rzeczywistym. Dzięki umieszczeniu modelu scoringowego razem
z programem jego wydajność zależy od parametrów maszyny na której jest
uruchamiany. Pozawala to uniknąć problemów związanych z nadmiernym obciążeniem
serwerów i ich utrzymaniem. Dzięki zastosowaniu technologii Java program może być
uruchomiony na prawie każdej maszynie klasy PC - około 97% komputerów
w przedsiębiorstwach korzysta z tej technologii [9].
Zaprezentowana praca i jej wynik - aplikacja do oceny kredytowej, ma pomóc małym
i średnim przedsiębiorstwom z sektora bankowego. Niewielkie koszty stworzenia
aplikacji według przedstawionego schematu i łatwość jej użycia dają możliwość
wykonywania profesjonalnej oceny kredytowej firmom, których nie stać na kosztowne
rozwiązania stosowane w tej branży jak kompleksowe systemy CRM. Jej cechy
umożliwiają także skuteczne rozwijanie programu wraz z rozbudową firmy poprzez
integrację z zamawianymi kompleksowymi systemami obsługi działalności firmy.

60
4.2. Dalsze kierunki rozwoju pracy
Niniejsza praca nie wyczerpuje wszystkich aspektów związanych z tą dziedziną
informatyki i bankowości. Przedstawione rozwiązanie może być dalej dopracowywane
i rozwijane. W trakcie pracy nad przedstawionym programem zauważyłem wiele
potencjalnych kierunków jej rozwoju.
Jednym z nich jest rozwój oprogramowania poprzez przeniesienie części
odpowiedzialnej za wykonywanie obliczeń na zewnętrzny serwer. Może to umożliwić
stosowanie bardziej skomplikowanych modeli scoringowych wymagających znacznych
mocy obliczeniowych. Dalszym etapem rozwoju może być zrealizowanie systemu
zarządzania modelami. Pomocne w tym mogą być narzędzia środowiska SAS do oceny
i integracji opracowanych modeli. Innym kierunkiem rozwoju pracy może być
opracowanie aplikacji dla urządzeń mobilnych, które dałyby możliwość oceny
kredytowej przeprowadzanej przez analityków działających poza placówkami banku.

61
Bibliografia
1. Daniel T. Larose, Odkrywanie wiedzy z danych. Wprowadzenie do eksploracji
danych, PWN, Warszawa 2006.
2. John Deacon, Model-View-Controller (MVC) Architecture. 2009.
http://www.jdl.co.uk/briefings/index.html#mvc (dostęp: 28.08.2014).
3. Steve Burbeck, Applications Programming in Smalltalk-80: How to use Model-
View-Controller (MVC), 1992, http://www.dgp.toronto.edu/~dwigdor/teaching/
csc2524/2012_F/papers/mvc.pdf (dostęp: 21.08.2014).
4. Tim Bray, Extensible Markup Language (XML), http://www.w3.org/TR/2006/REC-
xml11-20060816 (dostęp: 21.08.2014).
5. SAS Institute Inc, SEMMA, http://www.sas.com/technologies/analytics/datamining/
miner/semma.html (dostęp: 28.05.2006).
6. SAS Institute Inc, Getting Started with SAS Enterprise Miner 12.1, SAS Institute
Inc., 2012.
7. International Business Machines Corp, Eclipse Platform Technical Overview,
2006, https://www.eclipse.org/articles/Whitepaper-Platform-3.1/eclipse-platform-
whitepaper.pdf (dostęp: 25.08.2014).
8. The Eclipse Foundation, Eclipse WindowBuilder, 2014 , http://www.eclipse.org/
windowbuilder/ (dostęp: 25.08.2014).
9. Oracle, Dowiedz się więcej o technologii Java, https://www.java.com/pl/about/
(dostęp: 06.09.2014).
10. Wikipedia, MVC, http://pl.wikipedia.org/wiki/Model-View-Controller (dostęp:
22.08.2014).
11. Michael Morrison, HTML i XML, RM, Warszawa 2003.
12. Celina Olszak, Kamila Bartuś, Analiza i ocena wybranych modeli eksploracji
danych, http://ptzp.org.pl/files/konferencje/kzz/artyk_pdf_2009/092_Olszak_Bartus.pdf
(dostęp: 23.08.2014).

62
13. The Eclipse Foundation, Eclipsopedia, http://wiki.eclipse.org/Main_Page (dostęp:
25.08.2014).
14. SAS Institute Inc, Data Mining Using SAS® Enterprise Miner™: A Case Study
Approach, Third Edition, 2013.
15. Krzysztof Sacha, Inżynieria oprogramowani, PWN, Warszawa 2010.
16. Ronald E. Jeffries, XProgramming, 2014, http://xprogramming.com/index (dostęp:
08.09.2014).
17. Grzegorz Ignaciuk, Zastosowanie metod scoringowych w działalności bankowej,
statsoft.pl/czytelnia.html (dostęp: 25.08.2014).
18. Michael Berry, Gordon Linoff, Data mining techniques : for marketing, sales, and
customer relationship managment, Wiley Publishing Inc, Indiana 2004.
19. Grzegorz Migut, Janusz Wątroba, Scoring kredytowy, a modele data mining,
www.statsoft.pl/Portals/0/Downloads/scoring.pdf (dostęp: 25.08.2014).

63
Spis rysunków, tabel i wydruków
Rysunek 2.1 Fragment drzewa decyzyjnego przewidującego zdolność kredytową
klientów banku. ........................................................................................... 7
Rysunek 2.2 Przykładowy ekran aplikacji SAS Enterprise Miner 12.1 ........................... 8
Rysunek 2.3 Przykładowy ekran z Eclipse Standard 4.4 ................................................ 10
Rysunek 2.4 Przykładowy widok okna projektowania Eclipse WindowBuilder ........... 11
Rysunek 3.1 Etapy budowy modelu przedstawione w programie SAS Enterprise Miner
................................................................................................................... 13
Rysunek 3.2 Wykres rozkładu zmiennej „Wiek" ........................................................... 14
Rysunek 3.3 Wykres rozkładu zmiennej „Kwota kredytu"; zakreskowana część słupka
wyznacza pozytywne obserwacje .............................................................. 14
Rysunek 3.4 Wykres rozkładu zmiennej „Stan otwartych rachunków" ......................... 15
Rysunek 3.5 Wykres rozkładu zmiennej „Wspólnik" .................................................... 16
Rysunek 3.6 Wykres rozkładu zmiennej „Liczba osób na utrzymaniu" ........................ 16
Rysunek 3.7 Wykres rozkładu zmiennej „Czas spłaty" .................................................. 17
Rysunek 3.8 Wykres rozkładu zmiennej „Czas zatrudnienia" ....................................... 18
Rysunek 3.9 Wykres rozkładu zmiennej „Liczba otwartych kredytów" ........................ 18
Rysunek 3.10 Wykres rozkładu zmiennej „Historia kredytowa" ................................... 19
Rysunek 3.11 Wykres rozkładu zmiennej „Mieszkanie"................................................ 20
Rysunek 3.12 Wykres rozkładu zmiennej „Praca" ......................................................... 21
Rysunek 3.13 Wykres rozkładu zmiennej „Stan cywilny" ............................................. 22
Rysunek 3.14 Wykres rozkładu zmiennej „Inne plany ratalne" ..................................... 22
Rysunek 3.15 Wykres rozkładu zmiennej „Majątek" ..................................................... 23
Rysunek 3.16 Wykres rozkładu zmiennej „Przeznaczenie" ........................................... 24
Rysunek 3.17 Wykres rozkładu zmiennej „Oszczędności" ............................................ 25
Rysunek 3.18 Wykres rozkładu zmiennej „Telefon"...................................................... 25
Rysunek 3.19 Drzewo decyzyjne od poziomu 0 do poziomu 2 ...................................... 27
Rysunek 3.20 Drzewo decyzyjne od poziomu 2 do poziomu 4 (prawe odgałęzienie) ... 28
Rysunek 3.21 Drzewo decyzyjne od poziomu 2 do poziomu 3 (lewe odgałęzienie) ..... 28
Rysunek 3.22 Wykres przyrostu skumulowanego dla danych trenujących
i walidacyjnych .......................................................................................... 29

64
Rysunek 3.23 Diagram przypadku użycia „Wykonanie oceny kredytowej" .................. 32
Rysunek 3.24 Diagram przypadku użycia „Określenie przedziałów ryzyka
kredytowego" ............................................................................................. 32
Rysunek 3.25 Diagram komponentów aplikacji ............................................................. 33
Rysunek 3.26 Diagram klas komponentu „kontroler” .................................................... 34
Rysunek 3.27 Diagram klas dla komponentu „model" ................................................... 35
Rysunek 3.28 Diagram klas dla komponentu „widok" ................................................... 36
Rysunek 3.29 Diagram klas dla wyniku scoringu .......................................................... 37
Rysunek 3.30 Diagram klas dla argumentu funkcji scoringowej ................................... 38
Rysunek 3.31 Diagram sekwencji komponentu widok dla przypadku użycia
„Wykonanie oceny kredytowej” ................................................................ 39
Rysunek 3.32 Diagram sekwencji komponentów dla przypadku użycia „Wykonanie
oceny kredytowej” ..................................................................................... 39
Rysunek 3.33 Okno aplikacji przed wprowadzeniem danych ........................................ 52
Rysunek 3.34 Okno aplikacji dla oceny kredytowej klienta z 478 rekordu bazy danych
................................................................................................................... 55
Rysunek 3.35 Okno aplikacji dla oceny kredytowej klienta 549 rekordu bazy danych . 56
Rysunek 3.36 Okna aplikacji dla różnej konfiguracji miejsc odcięcia grupy niskiego
ryzyka ........................................................................................................ 57
Rysunek 3.37 Okno błędu niewłaściwych ustawień pliku konfiguracyjnego ................ 57
Tabela 3.1 Podział danych wejściowych na zbiory według algorytmu podziału
warstwowego ............................................................................................. 26
Tabela 3.2 Parametry pliku konfiguracyjnego aplikacji ................................................. 43
Tabela 3.3 Wybrane rekordy do prezentacji działania aplikacji ..................................... 54
Wydruk 2.1 Przykładowy fragment dokumentu XML generowany przez narzędzie SAS
Enterprise Miner .......................................................................................... 5
Wydruk 3.1 Przykładowa zawartość pliku konfiguracyjnego ........................................ 43
Wydruk 3.2 Fragment pliku „JScore.xml" zawierający argumenty funkcji scoringowej
................................................................................................................... 45
Wydruk 3.3 Fragment pliku słownika bazy danych ....................................................... 46