why so continuous
TRANSCRIPT

Continuous IntegrationKuberDock, 10 Jun 2016

Agenda- Why so continuous?- Some huge examples
- OpenStack- Spotify- World of Tanks- Ancestry
- KuberDock CI today- Automated Dev/QA env- Integration Testing API & Tests- Jobs, Triggers
- KuberDock CI in future- Parallelization -> scaling- CI as a Service- Quality Authority, sticking into the business processes- Continuous Delivery

Why so continuous?Continuous integration (CI) is the practice, in software engineering, of merging all developer working copies to a shared mainline several times a day © Wikipedia
Benefits:- Detect failure as earlier as possible- Repeatable, Stable & Incrementally improving - Catchall CI == Low mistake fear & Lower project entry barrier- Constant flow of changes to benefit users, no break & fix turnarounds- Fast regression == Fast release cycle
Cons:- Expensive to Implement & Maintain

Yes, catchall CI is expensive, but
Source: Bug fix cost over SW lifecycle

OpenStack CIOpenStack - Open source cloud platform
~ 20M Lines of code~ 800 subprojects (different repos)~ 2,5K Active contributors~ 80K Gerrit reviews per cycle (6 months)
OpenStack CI:
Source: Zuul

OpenStack CI: the workflow

OpenStack CI, points of interestTheir CI is fully declarative, lives under git
- project:
name: cinder
github-org: openstack
node: bare-precise
tarball-site: tarballs.openstack.org
doc-publisher-site: docs.openstack.org
jobs:
- python-jobs
- python-grizzly-bitrot-jobs
- python-havana-bitrot-jobs
- openstack-publish-jobs
- gate-{name}-pylint
- translation-jobs
- job: name: example-docs node: node-label
triggers: - zuul
builders: - git-prep - docs
publishers: - scp: site: 'scp-server' files: - target: 'dir/ectory' source: 'build/html/foo' keep-hierarchy: true - console-log

OpenStack CI, points of interestElastic Recheck
With elastic-recheck now in place, contributors can:1. Identify a pattern in the failure logs and visualize it in Kibana at http://logstash.openstack.org/
to search through a few weeks of logs to determine frequency.2. Create a bug in our bug tracker for the error, add a comment to the bug with the exact query
identified via Kibana, and a link to the logstash url for that query search.3. Submit a simple YAML-based change to the elastic-recheck repository’s queries/ directory,
which contains the list of bugs to track: https://git.openstack.org/cgit/openstack-infra/elastic-recheck/tree/queries.
4. Re-run tests only on the affected reviews / projects

OpenStack CI, points of interestHardware vendors CI plugins
TL;DR if you are hardware vendor writing your driver for an OpenStack component, you build your own CI server with that particular hardware, and link it to a common OpenStack gate.
Gerrit has an event stream which can be subscribed to. Using this event stream, it is possible to test commits against testing systems beyond those supplied by OpenStack’s Jenkins setup. It is also possible for these systems to feed information back into Gerrit and they can also leave non-gating votes on Gerrit review requests.
There are several examples of systems that read the Gerrit event stream and run their own tests on the commits on this page. For each patch set the third party system tests, the system adds a comment in Gerrit with a summary of the test result and links to the test artifacts.

Let’s talk about ~ 100M active users~ 12K servers~ Once a month desktop client releases - seamless~ Clients on all mainstream mobiles and desktops & web.~ All under CI/CD based on own container orchestration: Helios
How Spotify does Continuous Delivery with Docker and Helios (video)
Managing Machines at Spotify (tech blog)

Let’s talk about

Let’s talk about
source

KuberDock CI today- Automated Dev/QA environment. About 20 minutes build time.
TASK [debug] *******************************************************************ok: [kd_master] => { "msg": "http://XXX.XXX.XXX.XXX:5000 [user:XXX, password:XXX]"}
TASK [debug] *******************************************************************skipping: [kd_master]
PLAY RECAP *********************************************************************kd_master : ok=69 changed=32 unreachable=0 failed=0kd_node1 : ok=34 changed=9 unreachable=0 failed=0
- Based on Vagrant and Ansible- Hosted in CL OpenNebula OR locally (VirtualBox)- Engineer can multiple environments at time- Customizable - skip_by_tag, hooks, dotfiles, etc.- Developer friendly - code runs from source, multiple hacks are built-in.
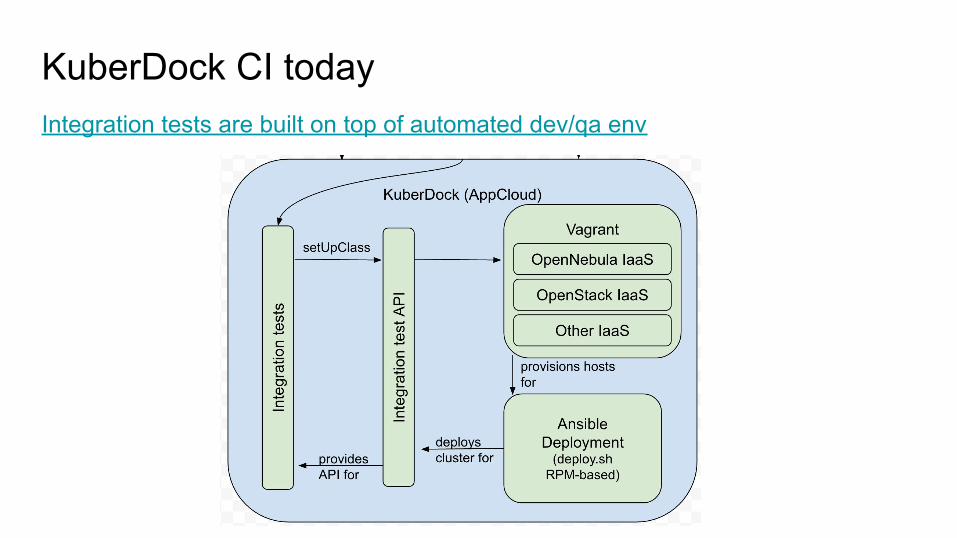
KuberDock CI todayIntegration tests are built on top of automated dev/qa env
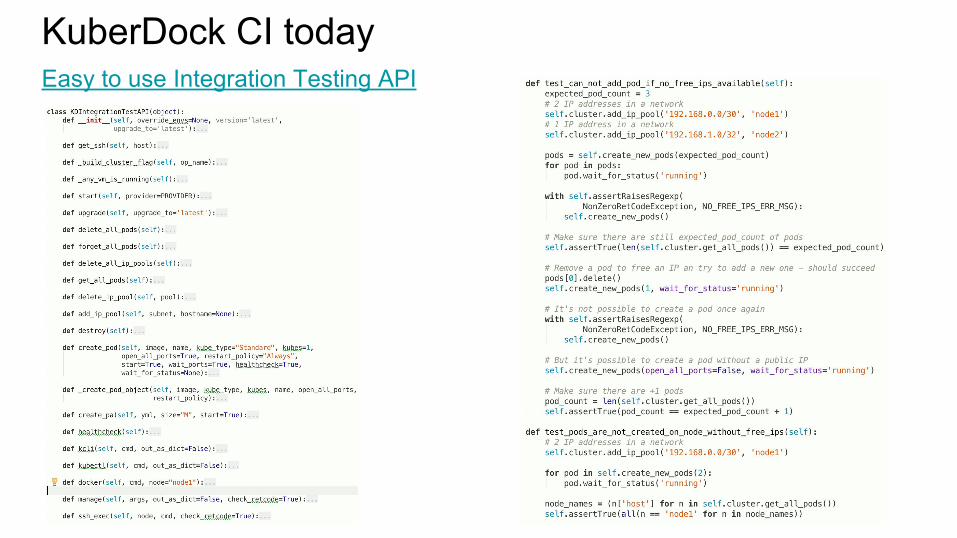
KuberDock CI todayEasy to use Integration Testing API

KuberDock CI today
Integration tests triggers:- “integration” comment posted to review.
- “dev-cluster” comment posted to review.- Night builds of both variants
Unit tests triggers:- Run for each review- Run before merge (Workflow +1): 1-threaded rebase -> test -> merge

KuberDock CI in nearest futureKuberDock Upgrades testing:
- Allow to run the same test for clean cluster & upgraded cluster.- @clean_cluster()- @upgraded_cluster(from=’release’, to=’latest’)
- Dedicated test to check if cluster workload survives after the upgrade- self.cluster.start(version=’release’)- pod = self.cluster.create_pod(healthcheck=True)- self.cluster.upgrade(version=’latest’)- pod.healthcheck()

KuberDock CI in nearest future
Parallelization and test pipelines:- Tests are grouped in test pipelines- Pipelines are run in parallel to each other (they are differently-configured clusters)- Pipeline itself is divided to threads (one or more - different clusters, similar config)- Parallelized declaratively, constant arrangement, via pipeline name and thread
number:- @pipeline(“clean”, thread=1)- @pipeline(“upgrade”, thread=1)- @pipeline(“non_floating_ips_clean”, thread=1)- @pipeline(“non_floating_ips_upgrade”, thread=1)
- New tests are creating new pipelines or go to the new threads in existing ones- Integration test suite grows horizontally (more servers involved).- Full integration run time is kept around 40 minutes

KuberDock CI in future future- CI as a Service : everything is done through CI
- Automated regression- Clusters for QAs for manual regression- Stable master cluster every hour- Release Candidate clusters
- Release process tied to CI- Failure conditions (HA) testing (dropping nodes by one etc.)- Backup & restore testing (deploy -> check -> backup -> kill -> restore -> check)- Deployment configurations testing- Deployment performance testing- Cluster performance testing

Q & A

Links● Understanding OpenStack CI ● OpenStack Gerrit-based workflow● Elastic Recheck● A CI/CD Alternative to Push and Pray for OpenStack● How Spotify does Continuous Delivery with Docker and Helios● Ancestry
● KuberDock automated DEV/QA env● KuberDock integration tests