waop 2014 presentation
TRANSCRIPT

eduworks-network.eufacebook.com/eduworksnetwork
@EduworksNetwork
Discovering Emerging Research
Topic and Trends in W&O
Psychology by Text Mining
Scientific Articles
Vladimer Kobayashi, Stefan T Mol, Ph.D., GáborKismihók, Ph.D.

Contents
• Background – Why this study? Hasn’t this been done before?
• Objectives – What are we really trying to do here?
• Materials – The ingredients
• Methods – The tools
• Results – Show me the outcome!
• Conclusion and Future Work – What has been achieved? How to proceed
Kobayashi, Mol, & Kismihók - University of Amsterdam 2

Kobayashi, Mol, & Kismihók - University of Amsterdam 3

Background
• The psychological literature is huge (PsychINFO abstracts 3.7 million documents and PubPsych has 900,000 searchable records)
• Text Mining applications• Mining biomedical literature• Web textual data• Opinion and Sentiment mining from product reviews, microblogging, users’ posts and
comments.
• Text Mining opportunities for gaining insight into trends in the scientific literature
• Key term extraction to support efficient document search and retrieval• Identifying topics to group document with similar themes
• So far little text mining effort has been made in the W&O psychology Literature
Kobayashi, Mol, & Kismihók - University of Amsterdam 4

Kobayashi, Mol, & Kismihók - University of Amsterdam 5

Objectives
• Apply text mining, specifically, topic modeling techniques to the W&O literature
• Pair topics and publication dates to reveal topical trends in this field
Contributions• Efficient search and retrieval of W&O psychology literature
• Supporting systematic literature review and automatic knowledge discovery
• Identifying topics (or themes) and topic trendsKobayashi, Mol, & Kismihók - University of Amsterdam 6

Kobayashi, Mol, & Kismihók - University of Amsterdam 7

Terminology
• Document – a file that contains sequence of characters or text
• Corpus – collection of documents
• Term – smallest unit in a document (e.g. word, phrase, sentence, or even a single character)
• Vocabulary or lexicon – set of all unique terms
Kobayashi, Mol, & Kismihók - University of Amsterdam 8

Kobayashi, Mol, & Kismihók - University of Amsterdam 9

SOURCE• Abstracts from 4 journals
1975-20141096 abstracts
2008-201489 abstracts
1977-20141115 abstracts
1991-2014602 abstracts
Total number of abstracts: 2902
Kobayashi, Mol, & Kismihók - University of Amsterdam 10

For this study…
• DOCUMENT• A single abstract
• CORPUS• Collection of abstracts
• TERMS• Words
• VOCABULARY• Set of all unique words (after preprocessing) in the corpus
Kobayashi, Mol, & Kismihók - University of Amsterdam 11

Why Abstracts only?
• The abstract contains the gist of the whole article
• Commonly, articles are indexed based on titles, keywords and abstracts.
Kobayashi, Mol, & Kismihók - University of Amsterdam 12

Kobayashi, Mol, & Kismihók - University of Amsterdam 13

Techniques
• String Processing
• Natural Language Processing
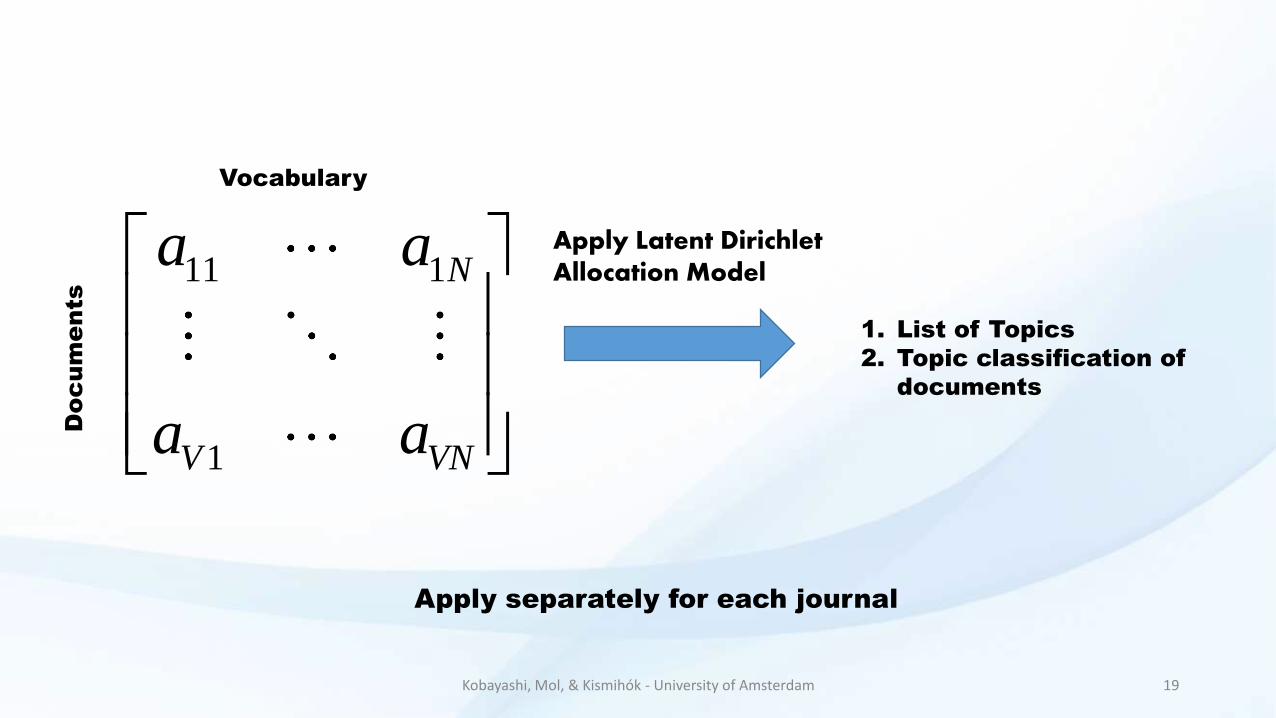
• Topic Modeling• Latent Dirichlet Allocation Model
• Assumes that each document is a mixture of topics
• Each word is generated from a specific topic
• An algorithm for topic discovery
• Topical Trend Analysis
Kobayashi, Mol, & Kismihók - University of Amsterdam 14

Analysis done separately for each journal
Kobayashi, Mol, & Kismihók - University of Amsterdam 15

Original abstract
Preprocessed abstract
Lower case transformation Stopwords removal Delete punctuations Stemming
Kobayashi, Mol, & Kismihók - University of Amsterdam 16

11 1
1
N
V VN
a a
a a
Abstracts
Do
cu
me
nts
VocabularyThe document-by-term matrix
The entries (the a’s) are the tf-idf
weight of the terms in each
document
Kobayashi, Mol, & Kismihók - University of Amsterdam 17

tf-idf
• There are many ways to assign weights to terms in the documents
• The most popular is the tf-idf, computed by
, ,tf-idf tf idft d t d t
frequency of term t in document d inverse document frequency of term tidf log
number of documents in the corpus where occurst
N
t
Kobayashi, Mol, & Kismihók - University of Amsterdam 18
11 1
1
N
V VN
a a
a a
Do
cu
me
nts
Vocabulary
Apply Latent DirichletAllocation Model
1. List of Topics
2. Topic classification of
documents
Apply separately for each journal
Kobayashi, Mol, & Kismihók - University of Amsterdam 19

Topical Trends
• Topic for each document
• Publication dates of documents
• Create a chart depicting the evolution of topics from the publication dates and topics of the documents
Kobayashi, Mol, & Kismihók - University of Amsterdam 20

Document Topic Publication Date
Document 1 Topic 3 1990
Document 2 Topic 5 1993
… … …
Document N Topic 12 1998
Publication Date Topic 1 Topic T
1975 Number of publications
… Number of publications
1976 Number of publications
… Number of publications
… … … …
2014 Number of publications
… Number of publications
Kobayashi, Mol, & Kismihók - University of Amsterdam 21

Kobayashi, Mol, & Kismihók - University of Amsterdam 22

Kobayashi, Mol, & Kismihók - University of Amsterdam 23

Kobayashi, Mol, & Kismihók - University of Amsterdam 24

Kobayashi, Mol, & Kismihók - University of Amsterdam 25

Kobayashi, Mol, & Kismihók - University of Amsterdam 26

Conclusion
Demonstrated the use of text mining to this type of application
Idea of what is keeping the researchers of W&O psychology busy
Offers a view of how W&O Psychology topics evolve and gain attention (which might reflect the development and maturation of the field)
Can be alternative to traditional content analysis
Facilitate peer review process by suggesting to researchers the outlet that will most likely accept their work.
Kobayashi, Mol, & Kismihók - University of Amsterdam 27

Future Work
• Aside from extracting topics one can also extract concepts, techniques, and key issues
• Create a hierarchy of topics
• Consider other parts of the document and not just the abstract.
Kobayashi, Mol, & Kismihók - University of Amsterdam 28

MAIN REFERENCES
• Learning Topic Models by Arora, Ge, and Moitra (2012)
• Text Mining Infrastructure in R by Feinerer, Hornik, and Meyer (2008)
• Understanding Evolution of Research Themes by Wang, Zhai, and Roth (2013)
Kobayashi, Mol, & Kismihók - University of Amsterdam 29

ACKNOWLEDGEMENT
• We would like to thank our colleague Ms Sofija Pajic for helping us out in interpreting the topics.
Kobayashi, Mol, & Kismihók - University of Amsterdam 30