vorlesung 10 unüberwachtes lernen i - universität ulm · m. giese: lernmethoden in computer...
TRANSCRIPT

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vorlesung 10
Unüberwachtes Lernen I
Martin Giese

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Übersicht
EinführungClusteranalyseHauptkomponentenanalyse (PCA)Hauptkurven

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
I. Einführung
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
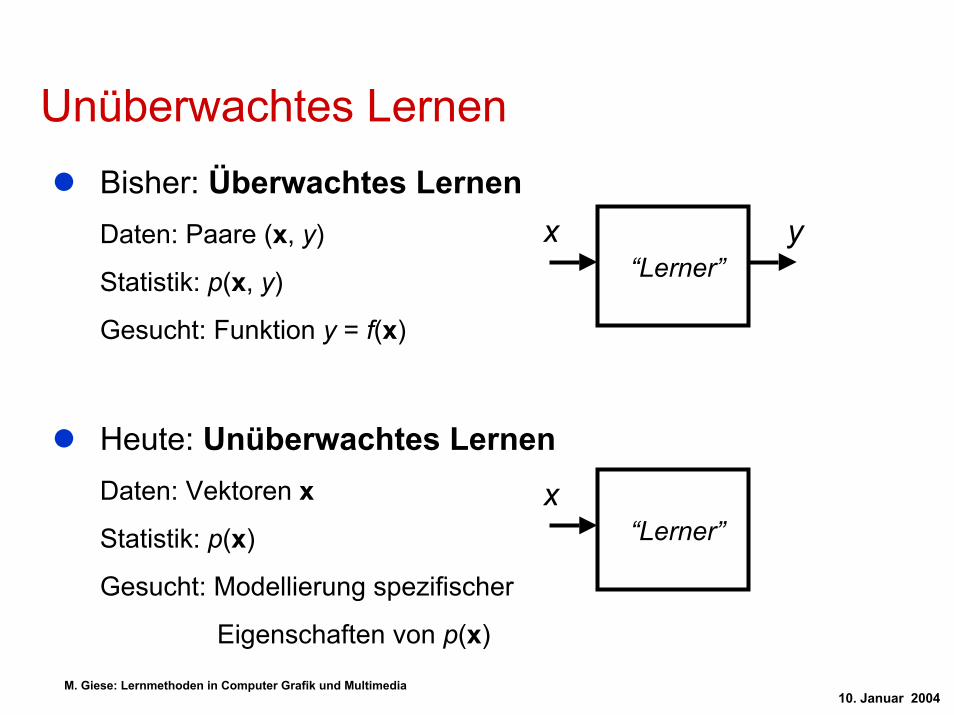
Unüberwachtes LernenBisher: Überwachtes LernenDaten: Paare (x, y)
Statistik: p(x, y)
Gesucht: Funktion y = f(x)
Heute: Unüberwachtes LernenDaten: Vektoren x
Statistik: p(x)
Gesucht: Modellierung spezifischer
Eigenschaften von p(x)
x y“Lerner”
x“Lerner”

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Unüberwachtes Lernen
Kein “Lehrersignal”
Validität von statistischen Inferenzschlüssen oft
wesentlich schwieriger zu evaluieren als bei
überwachtem Lernen

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Unüberwachtes LernenPrinzipelle Methoden
Dichteschätzung von p(x)(Schwierig für höhere Dimensionen;
Curse of Dimensionality !)
Modellierung von p(x):
– Mehrere konvexe Regionen: Clusteranalyse
– Mischung von Verteilungen (z.B. gaussian
mixture)
– Mannigfaltigkeiten: PCA, ICA, LLE
(Daten als Funktion latenter Variablen)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
II. Clusteranalyse

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Ziel der ClusteranalyseGegeben: l Datenpunkte xi mit 1 ≤ i ≤ l
Ziel: Modellierung mit Mischverteilung:
Beispiel: Gauss-Mischverteilung:
Problem: Schätzen der Cluster-Zentren: µk
Direkte Methode: Maximum-Likelihood-Schätzung ⇒
unangenehmes nichtlineares Optimierungsproblem !
∑=
− −−−K
kkk
Tkkcp
1
1 ))()(21exp(~)( µµ xKxx x1
x2
µ1
µ2
)()|()(1
kk
K
k
YpYpp ∑=
= xx Diskrete ZV

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
K-means-Cluster-AlgorithmusEinfach, funktioniert sehr gut in der Praxis
Vorgabe der Zahl der Cluster: K
Euklidisches Abstandsmass
Algorithmus:1. Initialisierung: Wahl von K Datenpunkten als Cluster-Zentren µi
2. Zuweisung aller l Datenpunkte zum nächsten Cluster-Zentrum
3. Ersetzen von µi durch Mittelwert aller zugewiesenen
Datenpunkte
4. Iteration ab 2. bis sich die Werte von µi nicht mehr ändern
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
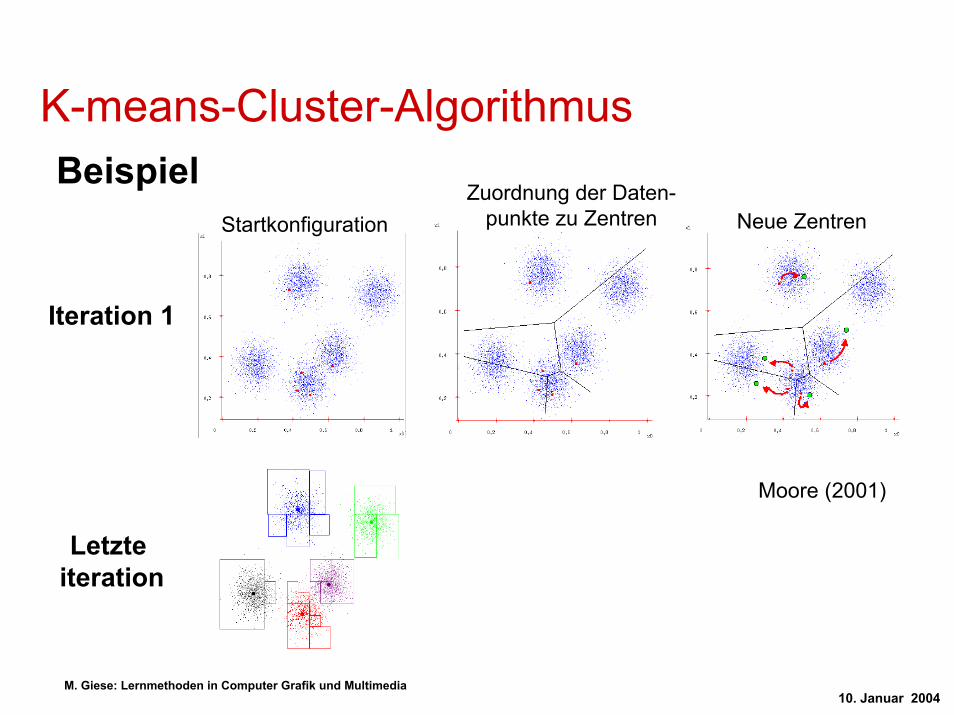
K-means-Cluster-AlgorithmusBeispiel
Zuordnung der Daten-punkte zu Zentren Neue ZentrenStartkonfiguration
Iteration 1
Moore (2001)
Letzte iteration

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
K-means-Cluster-AlgorithmusAlgorithmische Komplexität: O(lnK) (n: Dimensionalität
von xi)
Man kann beweisen, dass der Algorithmus terminiert.
Lokale Minima; daher verschiedene Startkonfigurationen
ausprobieren.
Moore (2001)
Suboptimale Lösungen

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
K-means-Cluster-Algorithmus
Auswahl der optimalen Zahl der Cluster schwierig
Möglich durch Vergleich der Varianzen innerhalb /
zwischen Clustern
Komplexitätskriterien (z.B. Schwartz-Kriterium)
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
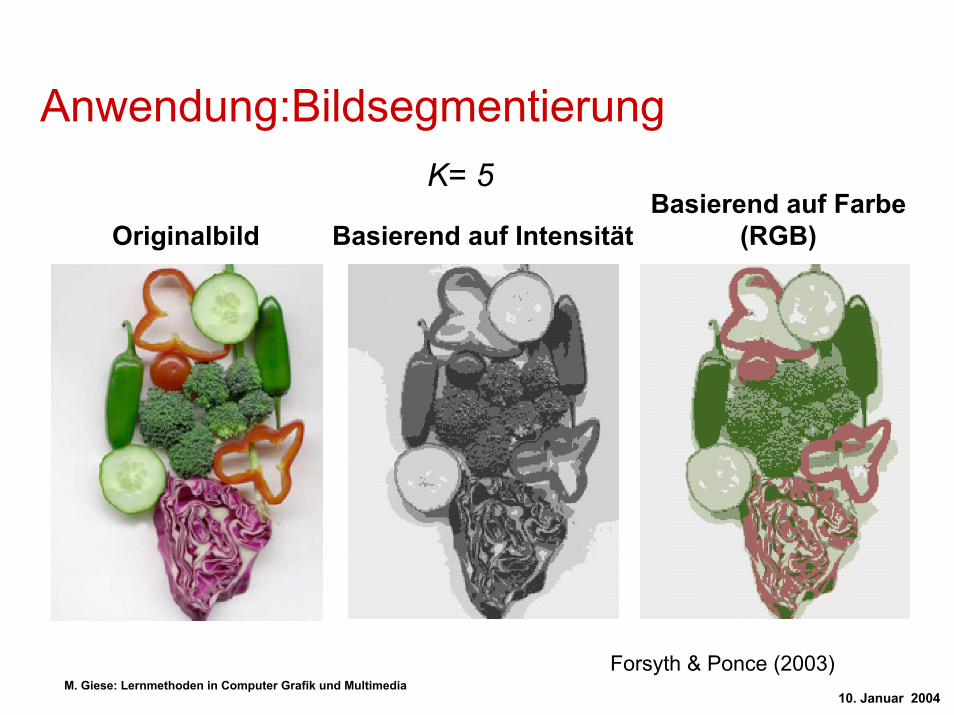
Anwendung:BildsegmentierungK= 5
Basierend auf Farbe (RGB)Originalbild Basierend auf Intensität
Forsyth & Ponce (2003)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
VektorquantisierungMethode zur DatenkompressionDatenpunkte xi mit 1 ≤ i ≤ l ersetzt durch jeweils nächstes Cluster-Zentrum µk mit 1 ≤ k ≤ KNur Clusterindex k übertragen (Datenkompression!)Typischerweise K << lClusterzentren definieren ein “Codebuch”
Encodierung Kanal Decodierer
)(ˆ
xfµx
== k
Kod
e-Sy
mbo
le
Kod
e-Sy
mbo
le
Rek
onst
ruie
rtes
Sign
al
Sign
al
xk k

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: Theorie
Daten: xi ∈ IRn ; endliches Codebuch: C = {µ1,…, µK},
µk ∈ IRn
Jedem Element µk ist Region Rk ⊂ IRn zugeordnet.
Regionen Rk , 1 ≤ k ≤ K, sind disjunkt und überdecken
ganzen Eingangsraum.
Vektorquantisierer entspricht der Funktion:
∑=
∈=K
kkk RIf
1
)()( xµx
Indikatorfunktion
I x(
∉∈
=∈k
kk R
RR
xx falls 0
falls 1)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: Theorie
Folgende Kostenfunktion misst die “Störung” des
rekonstruierten Signals:
Minimierung dieser Risikofunktion liefert notwendige
Bedingungen für optimalen Vektorquantifizierer
(Loyd-Max-Bedingungen)
V ∫ −= xxxx dpf )(|)(| 2

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: Theorie
Lloyd-Max-Bedingungen IFeste Regionen Rk, Optimierung der µk
Minimierung von
liefert (ableiten nach µk )
Optimaler Decoder:
∈−= ∑=
2
11 )(),...,(
K
kkkK RIEV xµxµµ
≤≤=
∈−∈ ∑=
KlRIRIEK
kkkl 10)()(
1
xµxx
{ } KlRIE ll ≤≤∈= 1mit )(|* xxµ
⇒

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: Theorie
Lloyd-Max-Bedingungen II
Feste Eingangssignale xi, Optimierung der Regionen Rk
Annahme: beliebiges x ∈ IRn, Regionen Rk gegeben
Sei x ∈ Rk, aber |x– µk| > |x– µl|.
Beitrag zur Kostenfunktion V: |x– µk|2
Dann kann die Kostenfunktion
verringert werden indem x zu Rl hinzugenommen wird.
∈−= ∑=
2
11 )(),...,(
K
kkkK RIEV xµxµµ
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: Theorie
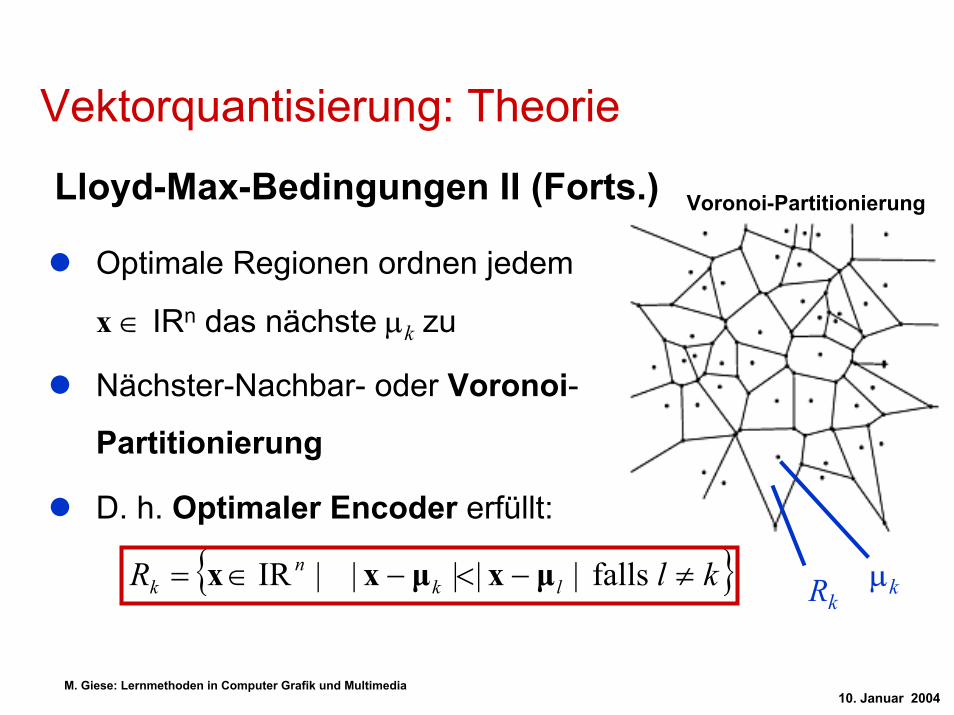
Lloyd-Max-Bedingungen II (Forts.) Voronoi-Partitionierung
Optimale Regionen ordnen jedem
x ∈ IRn das nächste µk zu
Nächster-Nachbar- oder Voronoi-
Partitionierung
D. h. Optimaler Encoder erfüllt:
{ }klR lkn
k ≠−<−∈= falls |||||IR µxµxx µkRk

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: AnwendungOriginalbild: 1024 x 1024 Pixel, 8 Bit,
Grauwertinformation
Aufteilen in Pixelblöcke der Grösse 2 x 2
Grauwerte der Blöcke aufgefasst als Vektor in IR4
K-Means-Methode angewendet auf diesen 4D-Raum
Kompression von 8 Bit / Pixel auf 1.9 bzw. 0.5 Bit / Pixel
Nur geringe Zahl von verschiedenen Viererblocks treten
in natürlichen Bildern auf.

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Vektorquantisierung: AnwendungOriginal 200 Kodevektoren 4 Kodevektoren
Hastie et al. (2001)
8 Bit / Pixel
1.9 Bit / Pixel
0.5 Bit / Pixel

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
III. Hauptkomponentenanalyse (PCA)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
DimensionalitätsreduktionAnnahme: Datenpunkte xi bedecken nur einen Teil des
hochdimensionalen Raumes IRn
Ziel: Modellieren des “erzeugenden Prozesses” ,
wobei für z geeignete Verteilungs-
annahmen gemacht werden
Typischerweise z ∈ IRm mit m << n
: Schätzer für z
Gute Lösung sollte Risiko der Form minimieren:
)(zfx =
∫= xxxzfx d)()))(ˆ(,( pVR
)(ˆ xz
z xf(z)
( )zxz ≈)(ˆ d.h.

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponentenanalyse (Principal Components Analysis, PCA)
Annahme: Datenpunkte xi , mit 1 ≤ i ≤ l, liegen in linearem
Unterraum
Modellierung der Daten durch Linearkombination von
festen Basisvektoren zk, mit Offset z0.
Annahme: Basisvektoren orthonormal, d.h. o
oo
o
x1
x2∑
=
+==K
kk
iki w
10)(ˆ zzzfx
Krkkr
k
rTk
≤≤=≠=
,11|| falls 0
zzz
Gewichte der BV zur Approximation von xi

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponentenanalyse (Principal Components Analysis, PCA)
L2-Kostenfunktion mit Z = [z1, …, zK], :
Minimierung nach z0:
Minimierung nach wi: mit der
Zusatzbedingung
Mit und folgt:
∑∑ ∑== =
−−=−−=l
i
ii
l
i
K
kk
iki l
wl
R1
2
01
2
100emp
11),( ZwzxzzxZz
∑=
=l
iil 1
01ˆ xz
( ) ˆˆ 0zxZw −= iTi
( )0ˆ~ zxx −= ii ]~,...,~[ 1 lxxX =
∑=
−=l
ii
Til
R1
2
0emp~~1),ˆ( xZZxZz
TiK
ii ww ],...,[ 1=w
.ˆ1
0w =∑=
l
ii
(Mittelwert der Daten)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponentenanalyse (Principal Components Analysis, PCA)
Die Matrix P = ZZT ist eine Projektionsmatrix auf einen
Unterraum mit der Dimensionalität ≤ K
Die ideale Wahl für diesen Projektor selektiert die
Dimensionen im Raum IRn, die am meisten Varianz von X
erklären. (In diesem Falle minimal für
gegebenes K.)
),ˆ( 0emp ZzR

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Singulärwertzerlegung(Singular value decomposition, SVD)
Sei A eine n x m Matrix mit Rang r.
Dann kann A immer zerlegt werden in der Form
A = UΣVT mit
U = UT: n x n Orthogonalmatrix
V = VT: m x m Orthogonalmatrix
Σ: n x m Matrix mit
≤=≥
=Σsonst 0
und falls 0 rijiiij
σ
Singulärwerte

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Singulärwertzerlegung (Forts.)(Singular value decomposition, SVD)
Beachte:
– Spalten von U sind Eigenvektoren von AAT
– Spalten von V sind Eigenvektoren von ATA
– Die σi2 sind die Eigenwerte von AAT und ATA
Wenn die Singulärwerte geordnet sind, so dass
σi ≥ σi+1 ≥ 0, gilt mit den Spaltenvektoren ui und vj
∑=
==r
k
Tkkk
T
1
vuVUΣA σRang von A

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Singulärwertzerlegung (Forts.)(Singular value decomposition, SVD)
Def.: Die Matrixnorm ||.||2 ist definiert als
Satz (Approximationseigenschaft):
ist die Matrix vom Rang s, die Matrix A am besten im
Sinne der Matrixnorm ||.||2 approximiert, d.h.
rss
k
Tkkks ≤=∑
=
mit 1
vuA σ
||||sup|||| 2 x
AxA0x≠
=
Die Matrix
12s)rang(2 ||||min|||| +≤=−=− ss σQAAA
Q

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Singulärwertzerlegung (Forts.)(Singular value decomposition, SVD)
Beachte: mit
d.h. nur die ersten s Singulärwerte werden berücksichtigt;
oder mit
Tss VUΣA =
≤=≥
=Σsonst 0
und falls 0,
sijiiijs
σ
Tss VΣUA = ],...,,,...,[ 1 00uuU ss =

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponenten
Wenn n mit |n|=1 ein Normalenvektor ist, dann definiert
y = nTx ein skalares Merkmal.
y = XT n ist die Projektion der Daten auf dieses Merkmal.
Die Richtung n mit maximaler Varianz ergibt sich aus:
22
2
1||
1||1||
||||1-
1||1-
1max
)(Varmax)(Varmax
XnX
nXy
n
nn
llT
T
=
==
=
==

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponenten
Die Matrixnorm von X bestimmt also die Varianz entlang
der Merkmalsrichtung mit maximaler Varianz.
Wird X mit einer Q Matrix mit Rang s approximiert, so ist
yu = (X-Q)Tn der Teil der Variation entlang der Merkmals-
dimension, die nicht durch die Approximation erklärt wird.
Der nichterklärte Anteil der Variation ist somit:
221||u1||
||||1-
1))((Varmax)(Varmax QXnQXynn
−=−=== l
T

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponenten
Wegen der Approximationseigenschaft ist somit Xs die
Matrix mit Rang s, die die maximale Varianz der Daten X
erklärt.
Wegen impliziert dies mit Vorhersage
⇒ Z = Us (Spalten orthonormal !)
Tss VΣUX =
[ ] [ ]llss
s
k
Tkkk
s
k
Tkkk
Tss
ZwZwwUwU
vuvuVΣUX
,...,,...,
)()(
1111
==
=== ∑∑==
σσ
ii Zwx =~̂

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkomponenten
Die Korrelationsmatrix von X ist Cx = XXT = UΣ2UT
Σ2 ist die diagonalisierte Kovarianzmatrix
Es gilt X = UΣVT und Xs = UsΣVT
Die Spalten von UΣ heissen Hauptkomponenten.
Die Spalten von V bestimmen die Gewichte, mit denen
die Hauptkomponenten zum i-ten Datenpunkt beitragen.

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Eigengesichter (eigen faces)
(Sirovitch & Kirby, 1987; Turk & Pentland, 1991)
Heute Standardmethode; sehr populär
In Signalverabeitung auch bekannt als Karhunen-Loewe-
Transformation
Grauwertvektoren von Bildern als Daten xi
Bei meisten Bildern starker Abfall der Singulärwerte für grosse s;
daher relativ niedrigdimensionale Approximation möglich
Für (normalisierte !) Gesichter s ≈ 40 erforderlich für gute
Approximation.
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Eigengesichter (eigen faces)
(Sirovitch & Kirby, 1987; Turk & Pentland, 1991)
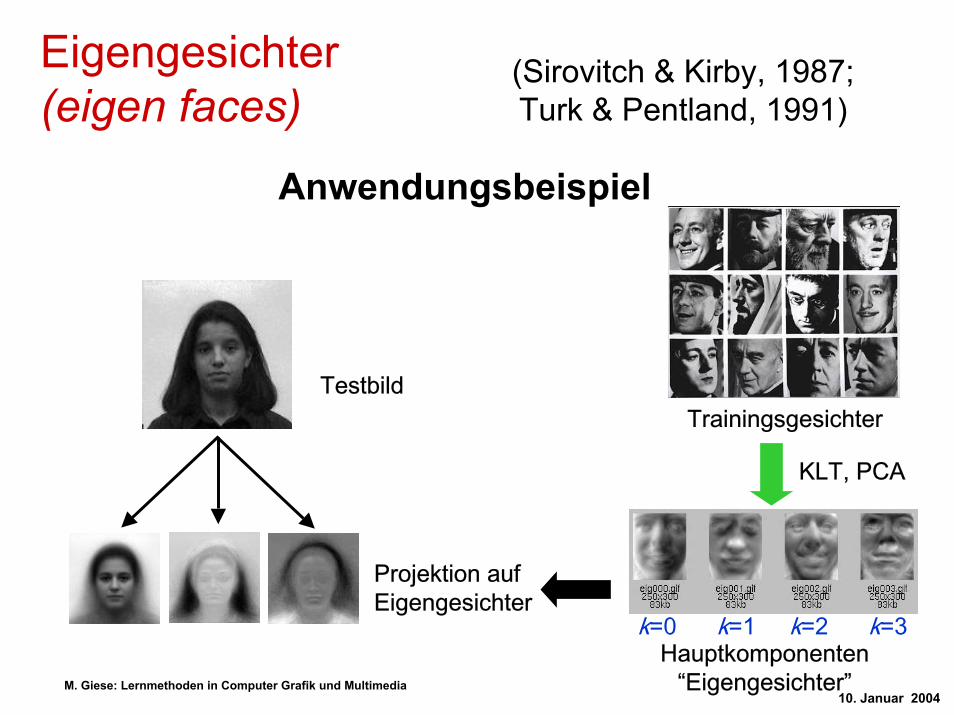
Anwendungsbeispiel
TestbildTrainingsgesichter
KLT, PCA
Hauptkomponenten“Eigengesichter”
k=0 k=1 k=2 k=3
Projektion aufEigengesichter

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Eigengesichter (eigen faces)
(Sirovitch & Kirby, 1987; Turk & Pentland, 1991)
AnwendungsbeispielOriginalbild Rekonstruktion
Approximationsgüte stark abhängig von Zahl der
Hauptkomponenten

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Eigengesichter (eigen faces)
Anwendung für Klassifikation (Turk & Pentland, 1991):
– Klassifikation (nearest neighbour)
im Gewichtsraum der Eigengesichter
– Gesicht vs. Nicht-Gesicht bei zu
grossem Abstand von linearem
Gesichtsraum
– Gesichteridentifikation durch Vergleich mit
Mittelwertsgewichtsvektoren von Personen
aus Trainingsdatensatz.

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Eigengesichter (eigen faces)
Resultate:
– Ideale Orientierung der Gesichter: 96 % korrekt
– Variation der Orientierung: 85 % korrekt
– Skalieren der Bilder: 64 % korrekt
Echtzeitfähigkeit
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
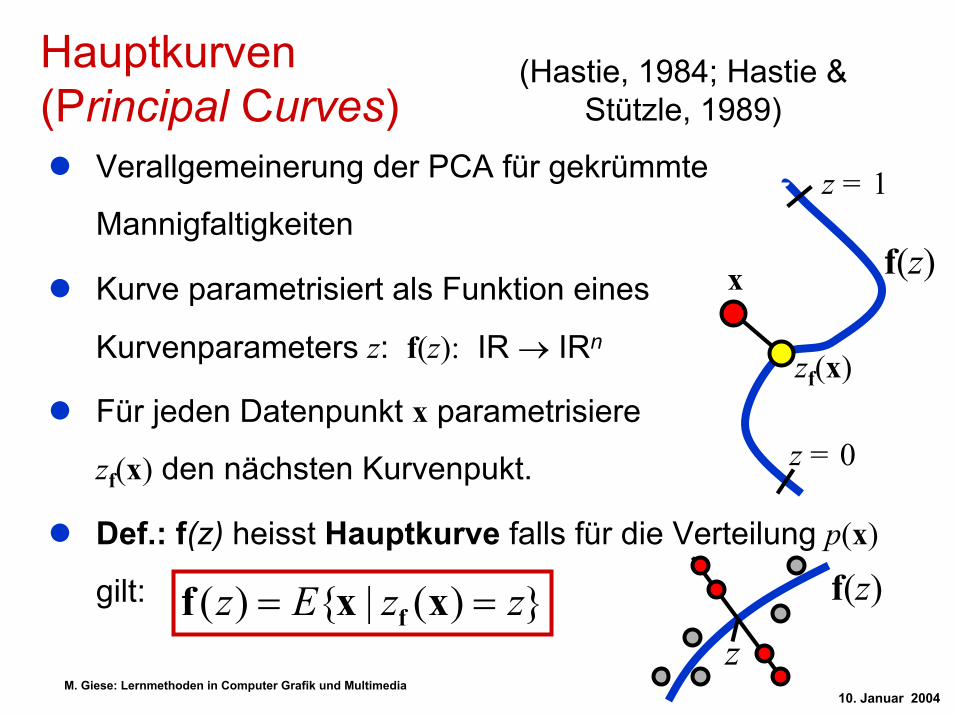
Hauptkurven (Principal Curves)
Verallgemeinerung der PCA für gekrümmte
Mannigfaltigkeiten
Kurve parametrisiert als Funktion eines
Kurvenparameters z: f(z): IR → IRn
Für jeden Datenpunkt x parametrisiere
zf(x) den nächsten Kurvenpukt.
Def.: f(z) heisst Hauptkurve falls für die Verteilung p(x)
gilt:
(Hastie, 1984; Hastie & Stützle, 1989)
})(|{)( zzEz == xxf f
zf(x)
z = 1
z = 0
x f(z)
z
f(z)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptkurven (Principal Curves)
Algorithmus ähnlich k-means
Zwei Schritte alternieren:
– Schätzen der nächsten Punkte auf Kurve zf(xi)
– Schätzen der Funktion f(z) unter Nutzung von
(Hastie, 1984; Hastie & Stützle, 1989)
})(|{)( zzEz == xxf f
o o
oo
x2(x)o o
x1(x)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptgraphen (Principal Graphs) (Kegl & Krzyzak, 2002)
Form charakterisiert durch Skelettkurve
Ziel: Robustere Erkennung, kompaktere Repräsentation
Algorithmus: Principal Curves, mit Graphen statt Kurven:
– Binäre Ausgangsbilder
– Stückweise lineare Approximation
– Partitionierung des x-Raumes in Regionen, für die Graphenknoten vi oder Punkte sj auf Zweigen nächste Punkte sind
Anwendungsbeispiel: Skelettberechnung (Skeletonization, medial axis transform, thinning)

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptgraphen (Principal Graphs)
(Kegl & Krzyzak, 2002)
Algorithmus (Forts.):
– Minimiertes Fehlermass: E = Distanz[Datenpunkte / Graph] +
Regularisierungsterm[Glattheit des Graphen]
– Spezielle Behandlung von Graphen-verzweigungen in Glattheitsfunktion
– Initialisierung mit einfachem Skelettie-rungsalgorithmus (Suzuki & Abe)
– Zusätzlich heuristische Nach-optimierung (Löschen kurzer Zweige, usw.)
Initialer Graph:
M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Hauptgraphen (Principal Graphs)
(Kegl & Krzyzak, 2002)
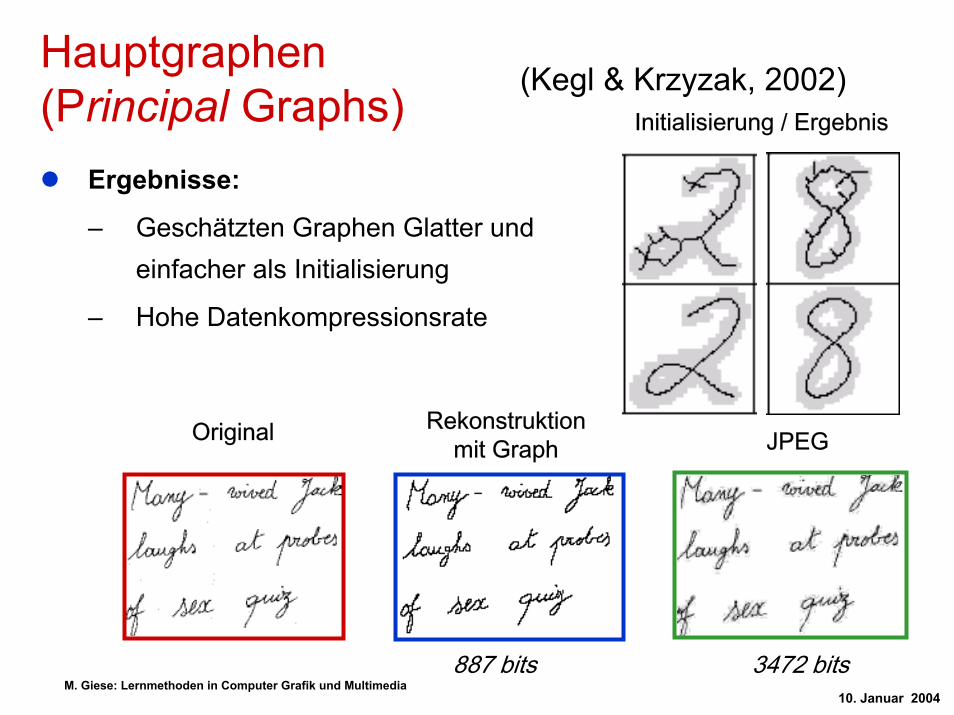
Ergebnisse:
– Geschätzten Graphen Glatter und einfacher als Initialisierung
– Hohe Datenkompressionsrate
Initialisierung / Ergebnis
Original Rekonstruktion mit Graph JPEG
887 bits 3472 bits

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Wichtige Punkte
Definition / Probleme: Unüberwachtes LernenK-means-ClusteringVektorquantisierungPCA / EigengesichterSVDHauptpkurven

M. Giese: Lernmethoden in Computer Grafik und Multimedia10. Januar 2004
Literatur
Cherkassky, V., Mulier, F. (1998). Learning From Data. John-Wiley & Sons Inc, New York.
Duda, R.O., Hart, P.E., Stork, D.G. (2001). Pattern Classification. John-Wiley & Sons Inc, New York.
Forsyth, D.A. & Ponce, J. (2003). Computer Vision: A Modern Approach. Prentice-Hall. Upper Saddle River, NJ.
Hastie, T., Tibshirani, R., Friedman, J. (2001). The Elements of Statistical Learning Theory. Springer, Berlin.
Kégl, B. Krzyzak, A. (2002). Piecewise linear skeletonization using principal curves. IEEE Transactions on Pattern Analysis and Machine Intelligence 24 (1), 59-74.