tools and frameworks - cambridge wireless · 12. what about improving the tools, knowledge graph...
TRANSCRIPT

Tools and Frameworks
Dan Neil, BenevolentAI
3 October 2017

We are
Our mission is to invent and apply AI and
Machine Learning technology to accelerate
scientific discovery that benefits society.
Founded in 2013, $BN valuation, 80+ team of
world-class scientists and technologists

Focused on accelerating Drug Discovery as a first scientific domain

Drug Discovery is broken!
- On average it costs about $2.6bn to develop a new drug
- It requires 12-15 years of R&D from start to market
- 97% of drug programmes fail
- Less than 40% of known diseases are currently treatable
- Novel discoveries are rare and is mainly done by academic research

Eroom’s Law and Moore’s Law
5https://buildingpharmabrands.com/2013/08/16/erooms-law-of-pharma-r-d/

6
1 scientific paper is published every 30 seconds
Individual scientists access a tiny fraction of available
data in their lifetime - much less than the data
generated in 1 day
All biological databases combined are less than 5% of
available data
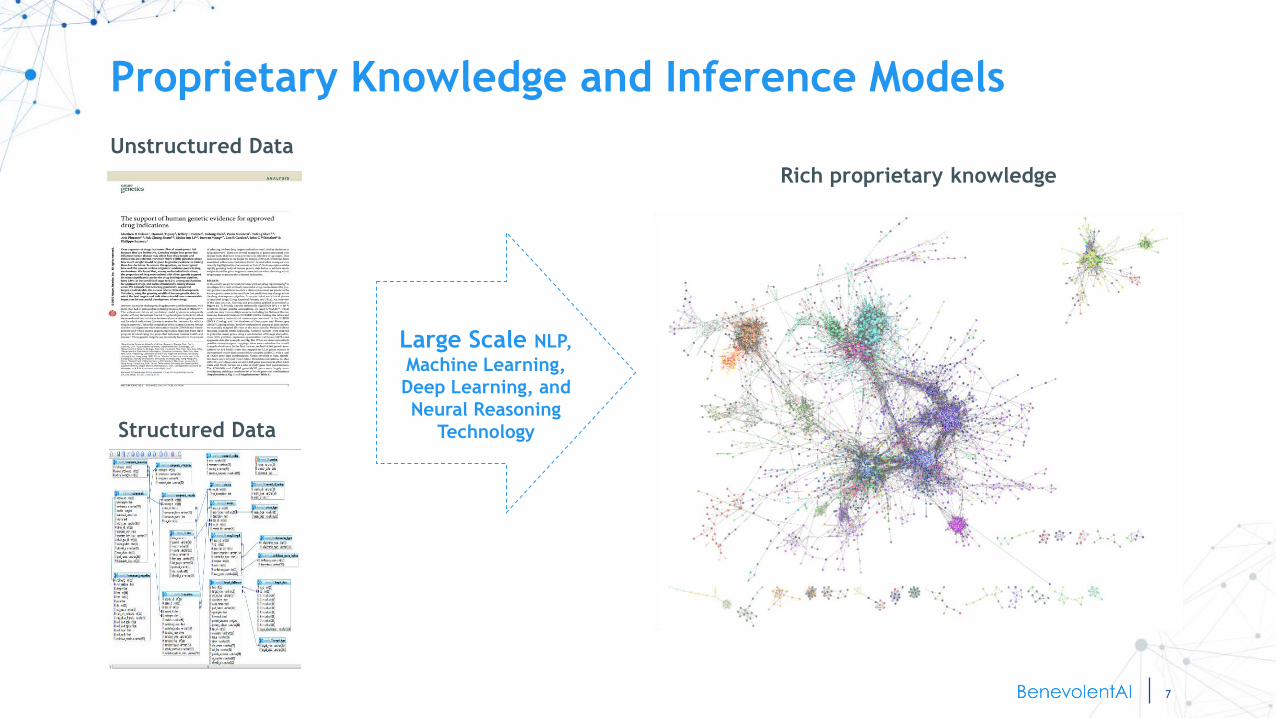
The BenevolentAI platform extracts facts and reasons
from all relevant databases and literature, structured
and unstructured
Power of the AI technology – Knowledge & Reasoning
7
Unstructured Data
Large Scale NLP,
Machine Learning,
Deep Learning, and
Neural Reasoning
TechnologyStructured Data
Rich proprietary knowledge
Proprietary Knowledge and Inference Models

BenevolentAI finds potential treatments for ALS
8

How do we put together an AI system? Can we leverage the tools out there?
9


Text Analysis, NLP, Translation, Sentiment, Voice
11https://cloud.google.com/natural-language/

Generalized Recommendation and Prediction
12https://static.bigml.com/pdf/BigML_Classification_and_Regression.pdf?ver=44e4f71

What about improving the tools, knowledge graph inference,
generative models?
13

Every Language Has a Framework
Python Tensorflow, Theano, Keras, CNTK, MXNet, Pytorch, …
Java DeepLearning4J, H2O, Weka, …
R Tensorflow, Keras, H2O, Deepnet, …
Matlab Caffe, MatConvNet, CNTK, …
C++
Javascript
MatConvNet, CNTK, Torch, …
MXNet, deeplearn.js, ConvNetJS, …

The Rising Dominance of Python – Stack Overflow
15https://stackoverflow.blog/2017/09/06/incredible-growth-python/, https://stackoverflow.blog/2017/09/14/python-growing-quickly/
0
2
4
6
8
10
12
Jan-12 Oct-12 Jul-13 Apr-14 Jan-15 Oct-15 Jul-16 Apr-17
Overall Percent of Search Queries, by Language
Python Java JavaScript c# PHP C++
0
5
10
15
20
25
30
Jan-15 May-15 Sep-15 Jan-16 May-16 Sep-16 Jan-17 May-17
Seasonal Traffic, by US and UK Universities
Java Python

0
10,000
20,000
30,000
40,000
50,000
60,000
70,000
80,000
Q2 2015 Q3 2015 Q4 2015 Q1 2016 Q2 2016 Q3 2016 Q4 2016 Q1 2017 Q2 2017 Q3 2017 Q4 2017
Stars on Github
Caffe Theano DL4J MXNet CNTK Pytorch

0
10,000
20,000
30,000
40,000
50,000
60,000
70,000
80,000
Q2 2015 Q3 2015 Q4 2015 Q1 2016 Q2 2016 Q3 2016 Q4 2016 Q1 2017 Q2 2017 Q3 2017 Q4 2017
Stars on Github
Caffe Theano DL4J MXNet Tensorflow CNTK Pytorch
Introduction of Tensorflow

Should I use one framework for everything?
18

Importance Weighting
1. Machine Learning Simplicity
− Many problems can be formulated as
model.fit(train, test), and it’s really fast
to use those. Some can’t.
2. Standard Algorithm Similarity
− ConvNets are cake. Recursive parse nets
aren’t.
3. Deployment Ease
− It runs on your data scientists’ computers.
How do you put it on a phone, or build a
web API around it with less than a second
of latency?
4. Debugging Ease
− Tensorized, delayed execution is
notoriously hard to debug.
09/10/2017 19

Three Optimization Points (that we use)Simplicity
Breadth
SupportDeploy
DebugH2O
TensorFlow
Pytorch
H2O
TensorFlow
Pytorch
Developed and supported by
H2O.ai (with enterprise support)
Simple API; supports Java and
Python
Plugs into existing Big Data
infrastructure (Hadoop, Hive, Pig)
Rapid, simple, scalable machine
learning for our simple predictions
Dedicated development, feature
rich
Cross-platform – including mobile
Performs heavy-lifting for NLP,
knowledge graph inference, and
factorization
Extremely fast for prototyping
research algorithms
Extremely flexible
Rapid prototyping for emerging
research topics: e.g., GANs,
complex seq2seq models

Fast, Simple Predictions: H2O Example (1/2)
21
import h2oh2o.init(ip="192.168.1.10", port=54321)-------------------------- ------------------------------------H2O cluster uptime: 2 minutes 1 seconds 966 milliseconds H2O cluster version: 0.1.27.1064H2O cluster name: H2O_96762H2O cluster total nodes: 4H2O cluster total memory: 38.34 GBH2O cluster total cores: 16H2O cluster allowed cores: 80H2O cluster healthy: True-------------------------- ------------------------------------path_train = ["hdfs://192.168.1.10/user/data/data_train.csv"]path_test = ["hdfs://192.168.1.10/user/data/data_test.csv"]train = h2o.import_file(path=path_train)test = h2o.import_file(path=path_test)#Parse Progress: [##################################################] 100%#Imported [hdfs://192.168.1.10/user/data/data_train.csv'] into cluster with 60000 rows and 500 cols#Parse Progress: [##################################################] 100%#Imported ['hdfs://192.168.1.10/user/data/data_test.csv'] into cluster with 10000 rows and 500 cols
http://docs.h2o.ai/h2o/latest-stable/h2o-py/docs/intro.html

Fast, Simple Predictions: H2O Example (2/2)
22
from h2o.estimators.gbm import H2OGradientBoostingEstimator
model = H2OGradientBoostingEstimator(ntrees=100, max_depth=10)
model.train(x=list(set(train.names)-{"label"}), y="label", training_frame=train, validation_frame=test)#gbm Model Build Progress: [##################################################] 100%
preds = model.predict(test)model.model_performance(test)
http://docs.h2o.ai/h2o/latest-stable/h2o-py/docs/intro.html

Debug anywhere: Pytorch
23
import torch
class MyLoss(torch.autograd.Function):def forward(self, x):return x.view(-1).sum(0)def backward(self, x):import pdbpdb.set_trace()return x
v = torch.autograd.Variable(torch.randn(5, 5), requires_grad=True)loss = MyLoss()(v)loss.backward()
https://discuss.pytorch.org/t/is-there-a-way-to-debug-the-backward-method-of-function-class/2246

For everything else, there’s Tensorflow
24
0
10,000
20,000
30,000
40,000
50,000
60,000
70,000
80,000
Q2 2015 Q3 2015 Q4 2015 Q1 2016 Q2 2016 Q3 2016 Q4 2016 Q1 2017 Q2 2017 Q3 2017 Q4 2017
Caffe Theano DL4J MXNet Tensorflow CNTK Pytorch

A Note About Deployments
1. Remember your deployment during
development
− Serializable? Cross-platform? On-device?
2. Tensorflow eases everything:
− Tensorflow Serving
− Universal protobufs
3. JVM is dead, long live Docker
− Package your code into Docker images
− Docker works across your scientists’
computers, your AWS instances, your local
compute
− Consider Kubernetes-style compute
management for heavy-AI companies with
local data requirements
25

1. Python is now the de facto language
of machine learning
− Deployment difficulties are offset by
Docker
− Runtime challenges are fixed by efficient
back ends
2. Consider the aim:
− Research: Pytorch
− Standard Big Data ML: H2O
− Long-term: Tensorflow
3. All still in flux
− Correct abstraction not yet determined
− Proper software engineering for ML under
development
Conclusion