the interplay of task, rating scale, and rater background...
TRANSCRIPT

55
English Teaching, Vol. 70, No. 2, Summer 2015
DOI: 10.15858/engtea.70.2.201506.55
The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL Students’ Writing
*
Soo-Kyung Park
(Korea University)
Park, Soo-Kyung. (2015). The interplay of task, rating scale, and rater
background in the assessment of Korean EFL students’ writing. English
Teaching, 70(2), 55-82.
This study examines how native English speaking (NES) and Korean non-native
English speaking (KNES) teachers assess L2 writing performance. More specifically,
this study aims to investigate whether these two groups of raters evaluate writing
samples differently when using different rating scales (holistic vs. analytic) and
different task types (narrative vs. argumentative). Four NES and four KNES raters
evaluated 78 narrative and 78 argumentative essays written by Korean EFL university
students using both holistic and analytic rating rubrics. The comparison between the
two rater groups indicated that the scores given by the two groups were statistically
significantly different for both holistic and analytic ratings regardless of the two task
types investigated. Overall, KNES teachers rated the essays more harshly than their
NES counterparts, irrespective of task type and rating scale. Multiple regression
analysis of five analytic sub-criteria revealed that the two rater groups demonstrated
similar patterns in assessing argumentative essays, while for narrative essays, the
relative influence of each analytic sub-criterion on overall writing quality differed for
the two rater groups. Implications for L2 writing assessment are included.
Key words: L2 writing assessment, rater background, task type, rating scale, holistic
scoring, analytic scoring
1. INTRODUCTION
As the importance of second language (L2) writing ability has increased, the direct
assessment of L2 writing proficiency has become a common practice. Previous studies
*
This paper is in part based on the author’s Ph.D. dissertation.

56 Soo-Kyung Park
have identified a variety of factors affecting L2 writing performance and assessment and
have also shown that these factors interact with each other in complex ways (Weigle,
2002). Of the various factors, it has been recognized that four components, i.e., the task,
the writer, the scoring procedure, and the readers (raters), play a key role in the direct
assessment of L2 writing (Hamp-Lyons, 1990).
Valid and consistent ratings of different groups of raters is a major concern in assessing
L2 writing. However, as the evaluation of L2 writing performance is often based on the
judgment of raters, rater variability has been considered a serious source of construct-
irrelevant variance and a threat to the construct validity in L2 writing assessment (Hamp-
Lyons, 2003; Knoch, 2011; Shi, 2001; Yang & Plakans, 2012).
A majority of previous studies have explored rater variability in L2 writing assessment
in relation to rating procedures, or rater background characteristics. Validity and reliability
of performance assessment may be strongly influenced by task type, scoring criteria, and
rater consistency, which can be potential problems with performance assessment
(McNamara, 1995; Miller & Legg, 1993). Yet only a few studies have looked at the
complex interaction between the task, the scoring procedure, and the rater in the
assessment of L2 writing. The present study, therefore, aims to examine the rater, the rating
scale, and the task as potential source of variability, and the interaction between these
factors, in the direct assessment of L2 writing produced by Korean EFL university students.
2. LITERATURE REVIEW
2.1. Rater Variability
The language background of the rater as a native (NS) or non-native speaker (NNS) has
been recognized as one source of rater variability in L2 writing performance assessment
(Kim & Gennaro, 2012; Lee, 2009; O’Loughlin, 1994; Santos, 1988; Shi, 2001; Tajeddin
& Alemi, 2014). However, the influence of the rater’s language background on assessing
L2 writing has been a relatively under-researched area, and moreover, the findings of these
studies are somewhat inconclusive.
In one line of study, research findings indicated that raters with different language
backgrounds showed differences in assessing overall quality of L2 writing, exhibiting a
different degree of severity in their ratings (Kim & Gennaro, 2012; Lee, 2009; O’Loughlin,
1994; Santos, 1988). Some studies demonstrated that NNS raters were harsher in their
ratings than NS counterparts (Kim & Gennaro, 2012; Santos, 1988). In a recent study, Kim
and Gennaro (2012), for instance, investigated the difference between NS and NNS raters
with a Rasch analysis. They compared eight NS and nine NNS raters in their ratings of 100

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 57
argumentative essays written by adult ESL students, and reported that NNS raters
evaluated the essays more harshly than NS raters. Another finding of this study is that the
severity of the NNS raters showed more divergence than for the NS raters. In contrast,
other studies have reported inconsistent, contradictory findings, in which NS raters
assessed the written essays more harshly than NNS raters (Lee, 2009; O’Loughlin, 1994),
or no significant differences were found in the scoring between NS and NNS rater groups
(Connor-Linton, 1995; Johnson & Lim, 2009; Shi, 2001).
Only a few studies have directly compared the ratings of NS and Korean NNS raters of
writing samples obtained from Korean EFL students. In one such study, Lee (2009)
examined the differences between five non-native EFL Korean and five native English
speaking (NES) teachers’ ratings of 420 English essays written by Korean college
freshmen. In addition to the finding that NES raters were more stringent in overall essay
ratings than Korean raters, it was also found that Korean raters exhibited lower reliability
and awarded lower scores in the areas of grammar, sentence structure, and organization,
while NES raters assigned lower scores for content area.
Another relevant line of research is concerned with the perceived gravity of specific
features of essays or scoring rubric. Although inconsistent findings have been observed, the
literature on this topic has shown that raters demonstrate significant differences in their
focus on specific features of L2 writing as well as in their views on the importance of the
various rating criteria, and display distinctive approaches to assessing L2 writing samples
(Eckes, 2008; Vaughan, 1991).
In one of these studies, O’Loughlin (1994) reported that holistic ratings of both NS and
NNS raters were most affected by the two analytic criteria of arguments and evidence and
organization. In another study, Connor-Linton (1995) found that Japanese NNS raters put
more emphasis on accuracy, whereas NS raters focused more on intersentential discourse
features when evaluating L2 writing. In a similar line, Cumming, Kantor, and Powers
(2001) compared the two groups of raters in their assessment of the TOEFL essays and
discovered that NS raters focused more on rhetoric and ideas than NNS counterparts,
while NNS raters paid more attention to language features. They also reported that NS
raters seemed to evaluate the essays with a balanced attention to both the features of
rhetoric & ideas and the features of language. Shi’s (2001) study also demonstrated that
raters reached their final decision based on somewhat different criteria. Analysis of the two
groups of raters’ self-reported comments revealed that NS raters gave more positive
comments toward content and language, while Chinese NNS raters offered more negative
comments toward organization and length of the essays.

58 Soo-Kyung Park
2.2. Rating Scale: Holistic vs. Analytic
Another important factor in L2 writing assessment is the rating scale that is employed.
As the scoring rubric used in assessing L2 writing represents the construct being measured,
the development and application of a rubric and rating scale descriptors clearly plays a key
role in the validity of the L2 writing test (McNamara, 1996; Weigle, 2002). Of the various
assessment methods, the most commonly researched and used types are holistic and
analytic scoring rubrics (Hamp-Lyons, 1991; Weigle, 2002).
Holistic scoring method assigns a single score to a composition based on the overall
impression, and has been widely used in both L1 and L2 formal writing assessment as well
as research studies for its practicality (Weigle, 2002). Previous studies have posited that it
is faster and thus more cost-effective to read a text once and award a single score than to
read it several times and give multiple scores along several aspects of the writing (Hamp-
Lyons, 1995; Weigle, 2002). Furthermore, the holistic method is claimed to simplify the
rater training process (Carr, 2000). Another advantage of holistic scoring comes from
White (1984), who argues that the holistic scoring method is more valid than the analytic
scoring method, as it reflects most closely the authentic, personal reaction of a reader to a
written text.
Several disadvantages to holistic scoring have also been documented. According to
Hamp-Lyons (1995), “the writing of second language English users is particularly likely to
show varied performance on different traits, and if we do not score for these traits and
report the scores, much information is lost” (p. 760). That is, holistic scoring is not
informative about differing levels of quality on different writing traits and thus ignores
potentially useful information about the writer’s ability in these different areas. Another
criticism of holistic scoring pertains to its correlation with relatively superficial
characteristics of L2 writing such as text length and hand writing (Markham, 1976; Sloan
& McGinnis, 1982).
In analytic scoring, scripts are rated on several components of writing or criteria such as
accuracy, cohesion, content, organization, word use, and register, rather than given a single
score (Weigle, 2002). The main advantage of analytic scoring over holistic scoring is that it
provides useful diagnostic information, and thus allows teachers, researchers, and L2
learners to identify the strengths and weaknesses of students’ L2 writing (Weigle, 2002). In
addition, analytic scoring is easier to understand and apply, as evidenced by its high
reliability (Adams, 1981, cited in Weir, 1990; Weigle, 2002). Studies have shown that
when the more detailed descriptors were used, rater reliability was substantially higher
(Knoch, 2009).
The major disadvantage associated with analytic scoring is that it is more time-
consuming, and therefore, costs more (Carr, 2000; Weigle, 2002). Another drawback to

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 59
analytic scoring is that when scores for the different components are combined to form a
composite score, a large amount of the information obtained from the analytic scale is lost
(Weigle, 2002).
A substantial body of literature on rating scales for assessing L2 writing looked into
different aspects of the rating scale or scoring rubric, which include reliability and validity
of the rating scales (Knoch, 2007, 2009; Rezaei & Lovorn, 2010). Yet the effect of
different rating scales on the outcomes of L2 writing assessment has been relatively
underexplored, and thus Weigle (2002) has called for more studies in this.
2.3. Task Type
Previous research findings suggest that raters vary in their ratings when they evaluate L2
compositions written on different task types (Weigle, 1994). In a similar line, Hamp-Lyons
(1991) argues that it is important to administer the tasks that are of approximately equal
difficulty in order to make sure the writing performance is not affected or does not
fluctuate by different task types. Task difficulty is often judged by scores given to the
composition; that is, tasks that elicit lower essay scores are considered more difficult than
those that elicit higher essay scores.
One of the factors affecting task difficulty includes the mode of discourse, which falls
into the categories of narration, description, exposition, and argument (Quellmalz, Capell,
& Chou, 1982; Weigle, 2002). In an earlier study, Braddock, Lloyd-Jones and Schoer
(1963) contended that mode of discourse has been largely ignored by composition
researchers, in spite of the fact that it has more effect than variations in topic on the quality
of writing. Research on the role of discourse mode has reported that discourse mode affects
diverse features of L2 writing, which cover the quality scores awarded to L2 writing
(Carrell & Conner, 1991; Pollitt & Hutchinson, 1987), syntactic complexity (Sinclair,
1984; Yau & Belanger, 1984), lexical complexity (Park, 2013a), cohesive ties (Norment,
1984; Park, 2013b), and linguistic accuracy (Foster & Skehan, 1996; Tarone & Parrish,
1988).
A majority of the studies on the role of discourse mode have been carried out using
narrative and argumentative modes, and the findings demonstrate that narrative writing
tasks elicited higher ratings than argumentative writing tasks (Carrell & Conner, 1991;
Crowhurst, 1990; Engelhard, Gordon, & Gabrielson, 1992; Pollitt & Hutchinson, 1987).
Studies also have shown that students produced shorter essays in argumentative mode than
in narrative mode (Crowhurst, 1987; Freedman & Pringle, 1984). Researchers argue that
this discrepancy may come from the fact that the argumentative mode is considered to be
more cognitively demanding than the narrative mode (Crowhurst, 1988, 1990; Matsuhashi,
1981).

60 Soo-Kyung Park
Very few studies have investigated the relationship between the type of discourse mode
and quality rating. In one of these studies, Hake (1986) examined two different discourse
modes, i.e., narration and personal experience expository writing, and the findings
illustrated that there seems to be an interaction between raters and the type of essay they
were evaluating as evidenced by the observation that narrations were less likely to be
“objectively graded” (p. 160). In another relevant study, Bouwer, Béguin, Sanders, and van
den Bergh (2014) examined the effect of discourse mode on the generalizability of writing
scores using four different discourse types. The results revealed that across raters and tasks
of different discourse modes, only 10% of the variance in writing scores was associated
with individual writing skill. Based on the findings, they argue that when writing scores are
obtained through highly similar tasks, generalization across different discourse modes is
not straightforward.
Despite the large amount of literature referenced above, much is still unknown about
how L2 writing assessment is affected by various features of L2 writing. In addition, there
has been a limited amount of research investigating multiple sources of variability and their
interaction in L2 writing assessment. Therefore, this study compares the differences and
similarities between the two rater groups (i.e., native English speaking raters (hereafter,
NES) and Korean non-native English speaking raters (hereafter, KNES) in the direct
assessment of L2 writing produced by Korean EFL university students. More specifically,
this study aims to investigate whether these two groups of raters evaluate writing samples
differently when using different rating criteria (holistic vs. analytic) and different task types
(narrative vs. argumentative). The research questions for the study are as follows:
1. How do the two rater groups (NES & KNES) differ in their ratings of the two
different writing tasks in applying the rating scale used to measure L2 writing ability
based on holistic and analytic scoring rubrics?
2. How do the two rater groups (NES & KNES) differ in their ratings of the two
different writing tasks in the perceived gravity of specific features of an analytic
scoring rubric?
3. METHOD
3.1. Writing Samples
The writing samples were obtained from 78 Korean university EFL students including
51 males and 27 females, aged 18 to 27 years with an average age of 22.9 years. The
English proficiency level of the students was self-reported and ranged from beginner to

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 61
advanced. The participants from diverse fields of study were asked to write one narrative
and one argumentative essay during regular class time, with a 30-minute time limit. The
narrative task, adopted from the Personal Narrative Collection (Holly, n.d.), required the
participants to write about a memorable event. The argumentative task, on the other hand,
was adopted from Hinkel (2009) and asked the participants to give opinions on whether
people should choose their field of study based on personal interests or employment
possibilities. Two different discourse modes were chosen, since discourse mode was
considered to have more effect than variations in topic on the quality of writing (Braddock
et al., 1963). Of the diverse text types, narrative and argumentative tasks were selected
based on the previous research findings, which demonstrated that formal persuasive
writing is more cognitively demanding and requires more effort than personal narrative
writing (Crowhurst, 1988, 1990; Matsuhashi, 1981).
3.2. Raters
A total of eight raters participated in the study: four NES and four KNES raters. Table 1
presents the description of eight raters’ backgrounds.
TABLE 1
Description of the Raters’ Backgrounds
Rater Gender Nationality Teaching
Experience Major (Degree)
1 Male American 21 years TESOL (M.A.)2 Female American 8 years English Education (M.A.) 3 Male Canadian 4 years TESOL (M.A.)4 Male Canadian 4 years Linguistics (B.A.) 5 Female Korean 10 years English Education (Ph.D.) 6 Female Korean 11 years English Education (Ph.D.) 7 Female Korean 8 years English Education (Ph.D.) 8 Female Korean 4 years English Education (Ph.D.)
Seven raters were teaching English to students at high-school or university level in
Korea and one NES rater (Rater 1) was teaching English to Japanese university students at
the time of data collection. The mean length of teaching experience was 8.75 years.
3.3. Research Procedure
Both holistic and analytic scoring rubrics were used for assessing writing samples. For
holistic scoring, scoring rubric from the TOEFL iBT test independent writing was
employed (see Appendix A). The analytic scoring rubric was adapted from the Six Trait

62 Soo-Kyung Park
Analytic Writing Rubric1 (Coe, Hanita, Nishioka, & Smiley, 2011) and the Analytic
Scoring Rubric for CUNY Writing Sample2 (The City University of New York, 2009)
(see Appendix B).
All eight raters were trained with sample essays for about 2 hours in order to minimize
rater variability and to maximize interrater reliability. After the training session, essays
were first holistically evaluated based on the raters’ perceptions of overall essay quality on
a scale of 0 through 5. With at least a one-week interval, each essay was rated by the same
raters, using an analytical scoring rubric with each sub-category ranging between 0 and 5.
A minimum one-week interval was set to minimize memorization effects and the influence
of prior rating experience on the next stage of evaluation. That is, this was done to
minimize the effect of previous holistic scoring experience on the analytic scoring.
The scores given by NES and KNES were compared to investigate whether the two
groups of raters responded differently to students’ writing. The interrater reliabilities of the
holistic and analytic scores were assessed with Pearson correlation coefficients. Then
correlations between scores from five analytic sub-criteria, analytic total scores and holistic
scores were calculated using Polychoric and Pearson correlations to investigate the extent
to which the holistic, analytic total, and analytic sub-criteria scores given by the same rater
were similar or different. A multiple regression analysis was also conducted to determine
the predictive power of individual areas of analytic scoring for holistic scores. The
polychoric correlations were calculated using the version 2.13.1 of the R statistical
environment (The R Foundation, 2011). Other statistical analyses were conducted using
SPSS 12.0.1.
4. RESULTS
4.1. Interrater Reliability
4.1.1. Holistic scores
To investigate interrater agreement between the eight raters in two discourse modes,
1 Originally developed by the Northwest Regional Educational Laboratory (NWREL), the Six Trait
Analytic Writing Rubric identifies and evaluates written essays on the following six dimensions:
ideas & content, organization, voice, word choice, sentence fluency, and conventions. 2 The Analytic Scoring Rubric for CUNY Writing Samples includes five criteria: text and writing
task, development of writer’s ideas, structure of the response, language use I (sentences and word
choice), and language use II (grammar, usage, mechanics).
The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 63
interrater reliabilities of the holistic scores for each mode were calculated using Pearson’s
correlation coefficient.
Table 2 shows that the interrater reliability between the eight raters for holistic scores in
narrative essays (NE) was significant at p < .01. The Pearson correlation coefficient was
highest between Raters 3 and 8 (r = .830) and lowest between Raters 3 and 7 (r = .582). In
particular, Raters 5 and 7 showed relatively low correlations with four and six other raters
respectively, exhibiting a modest correlation (r < 0.7).
TABLE 2
Interrater Reliability for Holistic Scores of Narrative Essays
Rater 1 Rater 2 Rater 3 Rater 4 Rater 5 Rater 6 Rater 7 Rater 8
Rater 1 1 Rater 2 .738 1 Rater 3 .755 .745 1 Rater 4 .778 .796 .819 1 Rater 5 .698 .648 .716 .651 1 Rater 6 .703 .770 .765 .723 .827 1 Rater 7 .640 .651 .582 .601 .644 .632 1 Rater 8 .794 .783 .830 .790 .806 .814 .696 1
Note. All correlations are significant at p = .01.
TABLE 3
Interrater Reliability for Holistic Scores of Argumentative Essays
Rater 1 Rater 2 Rater 3 Rater 4 Rater 5 Rater 6 Rater 7 Rater 8
Rater 1 1 Rater 2 .735 1 Rater 3 .715 .712 1 Rater 4 .847 .689 .749 1 Rater 5 .634 .665 .652 .626 1 Rater 6 .781 .760 .799 .834 .723 1 Rater 7 .745 .676 .660 .727 .670 .822 1 Rater 8 .746 .783 .792 .772 .804 .834 .774 1
Note. All correlations are significant at p = .01.
Table 3 demonstrates that interrater reliability between the eight raters for holistic scores
in argumentative essays (AE) was also significant at the 0.01 level. The Pearson correlation
coefficients range from .626 to .847. Raters 2, 5 and 7 showed relatively low interrater
reliability, demonstrating modest correlations (r < .70) with at least three other raters.
4.1.2. Analytic scores
Interrater reliabilities for total analytic scores in both discourse modes were also
calculated using Pearson’s correlation coefficient. The total analytic score of each rater was
64 Soo-Kyung Park
based on the sum of the five sub-criteria scores. As each sub-criterion score ranges from 0
to 5 points, the total analytic score ranges from 0 to 25 points.
As seen in Table 4, the correlations between the eight raters for total analytic scores in
narrative writing are all significant at p < .01. The Pearson correlation coefficient was
highest between Raters 5 and 7 (r = .864) and lowest between Raters 1 and 5 (r = .676).
Rater 5 exhibited relatively low correlations with Raters 1 and 2 (r < .70).
Table 5 presents the interrater reliability for total analytic scores for argumentative
writing, which was also significant at the 0.01 level. The Pearson correlation coefficient
was highest between Raters 4 and 8 (r = .880) and lowest between Raters 2 and 5 (r
= .631). Raters 2, 5, and 7 showed relatively low correlations with (r < .70) with at least
three other raters.
TABLE 4
Interrater Reliability for Analytic Scores of Narrative Essays
Rater 1 Rater 2 Rater 3 Rater 4 Rater 5 Rater 6 Rater 7 Rater 8
Rater 1 1 Rater 2 .746 1 Rater 3 .809 .771 1 Rater 4 .775 .839 .745 1 Rater 5 .676 .685 .776 .715 1 Rater 6 .750 .834 .781 .795 .837 1 Rater 7 .772 .750 .796 .838 .864 .858 1 Rater 8 .795 .745 .823 .790 .793 .839 .847 1
Note. All correlations are significant at p = .01.
TABLE 5
Interrater Reliability for Analytic Scores of Argumentative Essays
Rater 1 Rater 2 Rater 3 Rater 4 Rater 5 Rater 6 Rater 7 Rater 8
Rater 1 1 Rater 2 .725 1 Rater 3 .731 .675 1 Rater 4 .845 .721 .690 1 Rater 5 .690 .631 .688 .706 1 Rater 6 .814 .723 .773 .850 .749 1 Rater 7 .822 .682 .694 .871 .688 .817 1 Rater 8 .802 .748 .745 .880 .780 .841 .852 1
Note. All correlations are significant at p = .01.
The comparison of interrater reliability between holistic and total analytic scores reveals
that the analytic scoring method produces a higher rate of interrater reliability than holistic
scoring procedure across two task types. This finding supports previous studies (Hafner &
Hafner, 2003; Hamp-Lyons, 1991; Weigle, 1998), which demonstrated that analytic
scoring yields higher reliability than holistic scoring. The researchers claimed that the

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 65
reliability difference between the two scoring methods is related to how each score is
calculated. In other words, in a holistic assessment, a single score from each rater is
calculated. On the other hand, with analytic scoring, a composite score from each rater is
calculated, adjusting for some disagreement between sub-criteria, and thus an analytic
scoring method is more likely to achieve higher reliability than holistic scoring (Weigle,
1998).
Another noteworthy finding is that KNES raters exhibited lower interrater reliability
than NES counterparts, irrespective of task type and rating scale used. This finding is in
accord with that of Lee (2009), who reported that KNES raters displayed lower reliability
than NES raters when assessing compositions written by Korean college students.
4.2. Task and Rater Effects on Holistic Scores
Table 6 presents the descriptive statistics for the holistic scores given by eight raters for
two different discourse modes. The mean score of eight raters was higher for the narrative
(M = 2.61) than the argumentative mode (M = 2.43). A comparison between the mean
scores given by the two rater groups for two different discourse modes revealed that both
NES and KNES rater groups awarded higher holistic scores for narrative essays (M = 2.90
and M = 2.31) than for argumentative essays (M = 2.62 and M = 2.25), and yet the
difference was larger for the NES group. These results are consistent with the findings of
the previous studies (Freedman & Pringle, 1984; Kegley, 1986), demonstrating that the
quality of students’ essays is affected by the type of task required in the assignments, and
that narratives tend to have a higher rating than argumentative writing tasks.
Paired t-tests were employed to compare the difference across two modes in assigning
holistic scores. As can be seen from Table 7, paired t-tests revealed significant task effects
in the NES rater group (p = .009), but no statistically significant task effects in the KNES
rater group (p = .469) or in the total rater group (p = .063). The significant task effect for
NES raters indicates that when the quality of the writing is assessed by NES raters with
holistic rating, the quality of the students’ essays is significantly affected by the type of
discourse required in the given task.
In a comparison between the scores given by two rater groups, the NES group (M = 2.90,
M = 2.62) gave higher holistic scores than did the KNES group (M = 2.31, M = 2.25).
These findings support the previous studies (e.g., Kim & Gennaro, 2012; Lee, 2009; Santos,
1988) that found NNS raters to be stricter than NS raters. These researchers explained their
findings by referring to the considerable time and energy NNS evaluators had invested in
learning a second or foreign language, which led them to attribute errors to the learners’
lack of commitment. Indeed, the findings of the present study corroborated the rater effect.
Table 8 summarizes the paired t-test between the two rater groups.

66 Soo-Kyung Park
TABLE 6
Descriptive Statistics for Holistic Scores
Rater Narrative (N = 78) Argumentative (N = 78)
Min. Max. Mean SD Min. Max. Mean SD
Rater 1 1 5 2.68 0.90 1 5 2.56 1.04 Rater 2 1 5 3.03 1.43 1 5 2.44 1.37 Rater 3 1 5 2.94 1.07 1 5 2.68 0.88 Rater 4 1 5 2.97 1.15 1 5 2.80 1.17
NES Mean 1 5 2.90 1.04 1 5 2.62 1.00
Rater 5 1 5 2.41 0.83 1 5 2.45 0.89 Rater 6 1 5 2.28 1.29 1 5 2.17 1.21 Rater 7 1 4 2.10 1.11 1 4 1.86 0.98 Rater 8 1 5 2.46 1.11 1 5 2.51 1.21
KNES Mean 1 4.75 2.31 0.97 1 4.75 2.25 0.98
NES+KNES 1 4.75 2.61 0.97 1 4.75 2.43 0.96
Note. NES stands for native English-speaking raters; KNES represents Korean non-native English-speaking raters.
TABLE 7
Task Effect for Holistic Scores
Paired Differences Mean SD S.E.M. t df Sig.
NES(N) – NES(A) 0.29 0.94 0.11 2.689 77 0.009 KNES(N) – KNES(A) 0.07 0.82 0.09 0.728 77 0.469 NES+KNES (N) – NES+KNES (A) 0.18 0.83 0.09 1.886 77 0.063
Note. NES (N) = native English-speaking raters’ scores for narrative essays; NES (A) = native English-speaking raters’ scores for argumentative essays; KNES (N) = Korean non-native English-speaking raters’ scores for narrative essays; KNES (A) = Korean non-native English-speaking raters’ scores for argumentative essays
TABLE 8
Rater Effect for Holistic Scores
Paired Differences Mean SD S.E.M. T df Sig.
NES(N) – KNES(N) 0.59 0.51 0.06 10.189 77 0.000 NES(A) – KNES(A) 0.37 0.45 0.05 7.297 77 0.000 NES(N&A) – KNES(N&A) 0.48 0.38 0.04 11.313 77 0.000
The results of the paired t-test showed that the differences between two rater groups
were found to be statistically significant (p < .001) in both narrative and argumentative
modes.
4.3. Task and Rater Effects on Analytic Scores
4.3.1. Analytic mean scores
Table 9 presents the descriptive statistics for the analytic mean scores given by eight
The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 67
raters for two different discourse types. The analytic mean scores were calculated by
dividing the sum of the five sub-criteria scores by the number of sub-criteria.
The results of the task effect on analytic scores are similar to the findings of the previous
section (holistic scores). The mean analytic score of eight raters was higher for the
narrative (M = 2.61) than the argumentative mode (M = 2.53). Both NES and KNES rater
groups awarded slightly higher analytic scores for narrative essays (M = 2.82 and M =
2.41) than argumentative essays (M = 2.70 and M = 2.35), and the difference was greater
for the NES group. However, the mean differences of the two discourse modes were
smaller than for the holistic scores. Paired t-tests revealed no statistically significant
difference in task effects for NES, KNES, or total rater groups.
TABLE 9
Descriptive Statistics for Analytic Scores
Rater Narrative (N = 78) Argumentative (N = 78)
Min. Max. Mean SD Min. Max. Mean SD
Rater 1 0.8 4.8 2.54 0.87 1.0 4.8 2.54 0.95 Rater 2 0.4 4.8 2.91 1.29 0.4 4.8 2.29 1.33 Rater 3 1.4 4.8 2.96 0.73 1.6 5.0 3.12 0.65 Rater 4 1.0 5.0 2.85 0.97 1.6 4.8 2.86 0.79
NES Mean 1.25 4.75 2.82 0.88 1.35 4.7 2.70 0.83
Rater 5 1.0 4.4 2.43 0.78 1.2 4.4 2.56 0.71 Rater 6 1.0 5.0 2.67 1.17 1.2 5.0 2.80 1.14 Rater 7 0.0 5.0 2.11 1.22 0.0 3.8 1.58 1.13 Rater 8 1.0 4.8 2.44 1.04 0.8 4.8 2.47 1.14
KNES Mean 0.75 4.6 2.41 0.99 0.85 4.4 2.35 0.95
NES+KNES 1.00 4.57 2.61 0.91 1.10 4.53 2.53 0.87
TABLE 10
Rater Effect for Analytic Scores
Paired Differences Mean SD S.E.M. t df Sig.
NES(N) – KNES(N) 0.40 0.44 0.05 8.153 77 0.000 NES(A) – KNES(A) 0.35 0.38 0.04 8.119 77 0.000 NES(N&A) – KNES(N&A) 0.37 0.32 0.04 10.344 77 0.000
As with the rater group comparison of the holistic scores, a similar trend was observed
in the analytic mean scores. On average, NES raters awarded higher scores (M = 2.82, M =
2.70) than did KNES raters (M = 2.41, M = 2.35) in both discourse modes, but the
differences were smaller than for the holistic scores. Further analysis was conducted to
determine if these differences were statistically significant. The results of paired t-tests
4.3.2. Five analytic sub-criteria scores
Table 11 presents the means and standard deviations for five analytic sub-criteria scores
68 Soo-Kyung Park
given by eight raters in two discourse modes. The comparison of the mean analytic sub-
scores between the two rater groups showed that on average, NES raters gave higher scores
for four areas of sub-criteria (fluency/syntax, grammar, organization, and content/idea) in
narrative than in argumentative mode, and the same scores for the criteria of word use in
two discourse modes. However, KNES raters, on average, awarded higher scores for three
sub-criteria i.e. fluency/syntax, organization, and content/idea in narrative rather than
argumentative mode, while they assigned slightly lower scores for two sub-criteria
including word use and grammar in narrative rather than argumentative mode.
Paired t-tests were conducted to investigate whether the task effect on the five sub-
criteria scores was significantly different. Table 12 displays a significant task effect was
found in the sub-criterion of content/idea of the NES rater group (p = .005). No significant
differences were found in four other sub-criteria of the NES raters or in all five sub-scores
of the KNES raters. The significant task effect on the sub-criterion of content/idea among
the NES raters may imply that for NES raters, this criterion is sensitive to the discourse
type of the written essays. On the other hand, the non-significant discourse effects on four
other sub-criteria for NES raters and five sub-criteria for KNES suggests that these sub-
criteria for corresponding rater groups are not affected by the modes of discourse.
TABLE 11
Descriptive Statistics for Analytic Sub-Criteria Scores
Narrative Argumentative
F W G O C Total F W G O C Total
Rater 1 2.46
(1.05) 2.44
(0.92) 2.41
(0.75) 2.68
(0.96)2.72
(1.09)12.71(4.36)
2.49(0.99)
2.37(0.91)
2.50(0.75)
2.71 (1.11)
2.62 (1.47)
12.68 (4.75)
Rater 2 2.97
(1.47) 2.90
(1.25) 2.86
(1.16) 2.74
(1.57)3.06
(1.50)14.54(6.44)
2.51(1.46)
2.41(1.30)
2.27(1.12)
2.15 (1.74)
2.08 (1.67)
11.42 (6.63)
Rater 3 3.18
(0.80) 3.05
(0.79) 3.09
(0.61) 2.73
(0.98)2.76
(1.18)14.81(3.66)
3.36(0.74)
3.23(0.70)
3.38(0.69)
2.94 (1.05)
2.71 (1.06)
15.62 (3.25)
Rater 4 3.15
(1.01) 2.79
(1.00) 2.72
(0.94) 2.85
(1.24)2.73
(1.29)14.24(4.84)
3.13(0.67)
3.13(0.71)
2.83(0.57)
2.86 (1.33)
2.35 (1.44)
14.29 (3.93)
NES Mean 2.94
(1.88) 2.79
(1.66) 2.77
(1.41) 2.75
(2.10)2.82
(2.27)2.90
(2.08)2.87
(1.56)2.79
(1.45)2.75
(1.24)2.66
(2.30) 2.44
(2.51) 2.62
(2.00)
Rater 5 2.35
(0.83) 2.31
(0.83) 2.40
(0.90) 2.53
(0.99)2.56
(0.88)12.14(3.91)
2.46(0.85)
2.49(0.72)
2.74(0.81)
2.74 (0.84)
2.38 (0.89)
12.82 (3.53)
Rater 6 2.91
(1.27) 2.81
(1.13) 3.27
(1.27) 2.18
(1.36)2.21
(1.37)13.37(5.86)
3.14(1.25)
3.10(1.05)
3.29(1.31)
2.38 (1.32)
2.08 (1.25)
14.00 (5.70)
Rater 7 2.18
(1.29) 1.97
(1.17) 1.90
(1.17) 2.27
(1.35)2.22
(1.38)10.54(6.08)
1.63(1.17)
1.49(1.18)
1.40(1.17)
1.72 (1.23)
1.67 (1.29)
7.90 (5.64)
Rater 8 2.47
(1.11) 2.24
(1.02) 2.10
(1.04) 2.60
(1.23)2.78
(1.29)12.21(5.22)
2.58(1.26)
2.31(1.11)
2.27(0.98)
2.68 (1.33)
2.51 (1.44)
12.35 (5.71)
KNES Mean 2.48
(2.07) 2.33
(1.85) 2.42
(1.80) 2.39
(2.26)2.44
(2.29)2.31
(1.94)2.45
(2.03)2.35
(1.78)2.43
(1.74)2.38
(2.10) 2.16
(2.22) 2.25
(1.96)
NES+KNES 2.71
(2.69) 2.56
(2.38) 2.59
(2.15) 2.57
(2.98)2.63
(3.14)2.61
(2.75)2.66
(2.45)2.57
(2.20)2.59
(1.97)2.52
(3.03) 2.30
(3.26) 2.43
(2.73)
Note. Numbers in parentheses represent standard deviations; F = Fluency/Syntax; W = Word use; G
= Grammar; O = Organization; C = Content/Idea

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 69
As shown in Table 11, the NES rater group assigned higher scores than did the KNES
raters for five analytic sub-criteria scores across two discourse modes. Paired t-tests were
conducted to examine whether the five analytic sub-scores of two rater groups differed
significantly from each other in the two discourse modes.
TABLE 12
Task Effect for Five Analytic Sub-Criteria Scores
Rater Group Analytic Sub-criteria
Mean Difference
t df Sig.
NES Fluency/Syntax (N–A) 0.28 0.867 77 0.389 Word use (N–A) 0.04 0.111 77 0.912 Grammar (N–A) 0.09 0.323 77 0.748 Organization (N–A) 0.35 0.744 77 0.459 Content/Idea (N–A) 1.53 2.871 77 0.005
KNES Fluency/Syntax (N–A) 0.10 0.271 77 0.787 Word use (N–A) -0.05 -0.149 77 0.882 Grammar (N–A) -0.04 -0.105 77 0.916 Organization (N–A) 0.05 0.110 77 0.913 Content/Idea (N–A) 1.13 2.476 77 0.015
TABLE 13
Rater Effect for Five Analytic Sub-Criteria Scores (NES-KNES)
Discourse Mode Analytic sub-criteria
MeanDifference
t df Sig.
Narrative Fluency/Syntax 1.86 7.890 77 0.000 Word use 1.85 7.827 77 0.000 Grammar 1.41 5.706 77 0.000 Organization 1.42 5.493 77 0.000 Content/Idea 1.50 6.504 77 0.000
Argumentative Fluency/Syntax 1.68 6.987 77 0.000 Word use 1.76 8.158 77 0.000 Grammar 1.28 4.861 77 0.000 Organization 1.13 4.808 77 0.000 Content/Idea 1.10 4.484 77 0.000
As seen in Table 13, the differences in all five analytic sub-scores between the two rater
groups were statistically significant in both discourse modes. This finding is similar to the
rater effect on holistic scores in both discourse modes. In narrative mode, the mean
difference between the two rater groups was highest for the sub-score of fluency/syntax
(Mean Difference = 1.86), followed by word use (Mean Difference = 1.85), and lowest for
the sub-criterion of grammar (Mean Difference = 1.41). For the argumentative mode, the
mean difference was highest for the sub-criterion of word use (Mean Difference = 1.76),
followed by fluency/syntax (Mean Difference = 1.68), and lowest for content/idea (Mean
Difference = 1.10).

70 Soo-Kyung Park
4.4. Holistic vs. Analytic Scores
4.4.1. Correlation between holistic and analytic scores
Correlations were calculated between the ratings for the five sub-criteria of analytic
scoring, analytic totals, and the holistic scores. Correlations between each rater’s scores
were calculated using Polychoric3 correlation, since the holistic and analytic scores given
by each rater were ordinal (i.e., 0, 1, 2, 3, 4, or 5). Correlations between each rater group
and the total group were calculated with Pearson’s correlation because the mean scores of
each rater group and all eight raters were not ordinal but continuous.
TABLE 14
Correlation of Analytic Sub-Criteria, Analytic Total, and Holistic Rating (NE)
Fluency/ Syntax
Word Use
Grammar OrganizationContent/
IdeaAnalytic
Total
Rater 1 0.950 0.937 0.934 0.953 0.959 0.897 Rater 2 0.970 0.917 0.942 0.943 0.941 0.970 Rater 3 0.735 0.626 0.485 0.905 0.881 0.862 Rater 4 0.840 0.759 0.746 0.862 0.955 0.914
NES Meana 0.939 0.900 0.878 0.953 0.959 0.974
Rater 5 0.956 0.928 0.816 0.935 0.943 0.903 Rater 6 0.907 0.914 0.730 0.962 0.955 0.922 Rater 7 0.822 0.843 0.813 0.856 0.837 0.859 Rater 8 0.977 0.954 0.798 0.958 0.980 0.946
KNES Meana 0.965 0.950 0.843 0.954 0.955 0.971
NES+KNES Meana 0.979 0.951 0.888 0.970 0.972 0.983
Note. Correlations between each rater’s scores were calculated with Polychoric correlations; aMean correlations were calculated with Pearson’s correlations.
An examination of the correlation coefficients in Tables 14 and 15 indicates that the
mean holistic scores of eight raters correlate substantially with the total analytic scores for
both narrative (r = 0.983) and argumentative modes (r = 0.983). The correlation between
holistic ratings and five analytic areas seems to indicate that, on average, both NES and
KNES raters are well-balanced in taking into account all five sub-criteria when deciding
the overall holistic rating for the two different discourse modes (r > .70). The strongest
correlation for rating components between NES raters was found for content/idea in both
narrative (r = .959) and argumentative (r = .950) writing. On the other hand, for KNES
raters, the highest correlation was found for fluency/syntax (r = .965) in narrative, and for
3 The Polychoric correlation coefficient introduced by Pearson is an alternative to the Pearson r, and
estimates the linear relationship between two unobserved continuous variables, given only
observed ordinal data (Rigdon & Ferguson, 1991).

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 71
content/idea (r = .961) in argumentative mode. For the two rater groups, the correlation
coefficient was lowest for the sub-criterion of grammar in the two modes (r = .888, r
= .861). This may suggest that all eight raters gave relatively less weight to the
grammatical errors when they decided the overall quality of the writing using the holistic
scoring method, regardless of the type of discourse mode.
TABLE 15
Correlation of Analytic Sub-Criteria, Analytic Total, and Holistic Rating (AE)
Fluency/ Syntax
Word Use
Grammar OrganizationContent/
IdeaAnalytic
Total
Rater 1 0.960 0.903 0.835 0.982 0.962 0.937 Rater 2 0.953 0.930 0.851 0.864 0.930 0.959 Rater 3 0.549 0.449 0.442 0.729 0.788 0.777 Rater 4 0.674 0.697 0.447 0.922 0.946 0.898
NES Meana 0.886 0.868 0.793 0.938 0.950 0.965
Rater 5 0.972 0.919 0.763 0.900 0.858 0.903 Rater 6 0.894 0.861 0.788 0.939 0.928 0.916 Rater 7 0.984 0.921 0.917 0.971 0.972 0.952 Rater 8 0.984 0.973 0.875 0.929 0.969 0.946
KNES Meana 0.960 0.945 0.857 0.954 0.961 0.975
NES+KNES Meana 0.954 0.937 0.861 0.965 0.975 0.983
Note. Correlations between each rater’s scores were calculated with Polychoric correlations; aMean correlations were calculated with Pearson’s correlations.
A close look at each rater’s correlation indicates that in narrative essay rating, Rater 3
showed a moderate correlation between holistic scores and analytic sub-criteria for
grammar (r = 0.485) and word use (r = 0.626). This means that Rater 3 demonstrated a
clear tendency to give less weight to grammar and word use features in narrative mode. On
the other hand, for argumentative essay scoring, Raters 3 and 4 exhibited a moderate
correlation between holistic scores and analytic sub-criteria for grammar (r = 0.442, r =
0.447), word use (r = 0.449, r = 0.697), and fluency/syntax (r = 0.549, r = 0.674); but
overall, Rater 3 showed relatively weaker correlations than did Rater 4. These results
indicate that in argumentative mode, while the other six raters were relatively well-
balanced in considering all five analytic sub-criteria when assigning holistic scores, Raters
3 and 4 seemed to give less weight to the sub-criteria of grammar, word use, and
fluency/syntax. This may suggest that two NES raters with relatively short teaching
experience (4 years) considered two aspects (organization and content/idea) as more
important criteria when assessing essays with the holistic scoring method.
4.4.2. Multiple regression analysis
In order to obtain a clearer picture of the relative contribution and predictive power of
72 Soo-Kyung Park
individual areas of analytic scoring, multiple regression analysis was conducted. Table 16
presents the degree to which perceptions of overall writing quality (i.e., holistic scores)
could be predicted from the score on each of subareas of analytic scores. The sub-criteria
are ordered by rank on the basis of their importance or contribution to this prediction. The
R-squared coefficients (in parentheses) indicate the amount of variance accounted for in
the overall quality after a variable and all its preceding variables have been entered. These
coefficients were arrived at using the forward selection procedure in multiple regression
analysis. The final R-squared coefficients, when converted to percentages, indicate the total
amount of variance accounted for when all five sub- scores enter the regression equation.
TABLE 16
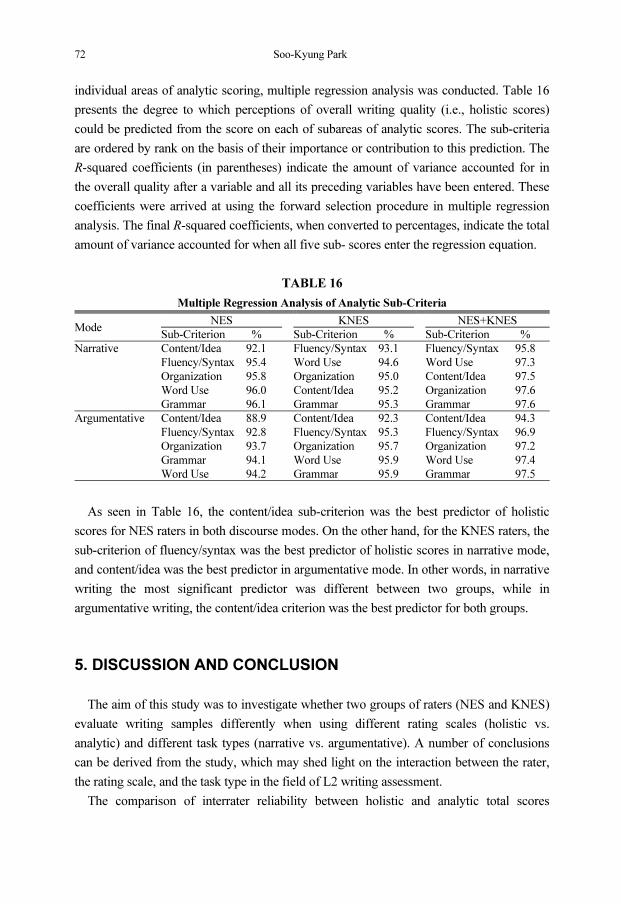
Multiple Regression Analysis of Analytic Sub-Criteria
Mode NES KNES NES+KNES
Sub-Criterion % Sub-Criterion % Sub-Criterion %
Narrative Content/Idea 92.1 Fluency/Syntax 93.1 Fluency/Syntax 95.8
Fluency/Syntax 95.4 Word Use 94.6 Word Use 97.3
Organization 95.8 Organization 95.0 Content/Idea 97.5
Word Use 96.0 Content/Idea 95.2 Organization 97.6
Grammar 96.1 Grammar 95.3 Grammar 97.6
Argumentative Content/Idea 88.9 Content/Idea 92.3 Content/Idea 94.3
Fluency/Syntax 92.8 Fluency/Syntax 95.3 Fluency/Syntax 96.9
Organization 93.7 Organization 95.7 Organization 97.2
Grammar 94.1 Word Use 95.9 Word Use 97.4
Word Use 94.2 Grammar 95.9 Grammar 97.5
As seen in Table 16, the content/idea sub-criterion was the best predictor of holistic
scores for NES raters in both discourse modes. On the other hand, for the KNES raters, the
sub-criterion of fluency/syntax was the best predictor of holistic scores in narrative mode,
and content/idea was the best predictor in argumentative mode. In other words, in narrative
writing the most significant predictor was different between two groups, while in
argumentative writing, the content/idea criterion was the best predictor for both groups.
5. DISCUSSION AND CONCLUSION
The aim of this study was to investigate whether two groups of raters (NES and KNES)
evaluate writing samples differently when using different rating scales (holistic vs.
analytic) and different task types (narrative vs. argumentative). A number of conclusions
can be derived from the study, which may shed light on the interaction between the rater,
the rating scale, and the task type in the field of L2 writing assessment.
The comparison of interrater reliability between holistic and analytic total scores

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 73
revealed that analytic scoring method produced a higher rate of interrater reliability than
holistic scoring procedure across two task types. This finding is compatible with previous
research (Hafner & Hafner, 2003; Hamp-Lyons, 1991; Weigle, 1998), which demonstrated
that analytic scoring yields higher reliability than holistic scoring. The comparison between
two rater groups indicated that the scores given by two groups were statistically
significantly different for both holistic and analytic ratings regardless of the task types
investigated. In addition, the KNES teachers rated the essays more harshly overall than the
NES teachers, and the KNES raters also exhibited lower interrater reliability than the NES
counterparts, irrespective of task type and rating scale used. A multiple regression analysis
of the five analytic sub-criteria revealed that the two rater groups demonstrated similar
patterns in assessing argumentative essays, in that the content/idea sub-criterion was the
best predictor, followed by fluency/syntax, and organization. On the other hand, for
narrative essays, the relative influence of each analytic sub-criterion on overall writing
quality (i.e., holistic scores) was different for the two rater groups.
Based on the findings of the present study, several implications can be drawn. First,
despite the fact that the number of years each rater had been teaching English in an EFL
context differed (4 to 21 years), raters with the same language background showed similar
patterns in their assessment of L2 writing. These findings highlight the need for rater
training and more efficient scoring rubrics for rating procedures which include raters with
different language backgrounds. As documented in previous studies, reliability of
performance assessment can be improved by intensive rater training and clearly described
scoring criteria (Dunbar, Koretz, & Hoover, 1991; Jang, 2011; Norris, Brown, Hudson, &
Yoshioka, 1998; Stiggins, 1988).
Another implication is that the specific task type (or types) employed in L2 writing
assessment needs to be chosen carefully, as different task types elicit different types of
rating behavior. This finding underscores the value of using multiple tasks, which already
has been widely acclaimed by researchers of L2 writing assessment, since the use of
multiple tasks is said to minimize threats to the validity of performance assessment
(Messick, 1994; Miller & Legg, 1993; Norris et al., 1998).
Although the present study provides valuable implications for L2 writing assessment,
there are limitations inherent in the study. A major limitation involves the number of raters;
the small number of raters in the study restricts the generalizability of the results. In
particular, to some extent, the interpretation of the results may be limited by the unequal
distribution of gender and ethnicity across raters. Although previous research on rater
characteristics revealed mixed results with respect to the impact of rater’s gender on the
rating process (O’Loughlin, 2002; Reed & Cohen, 2001), the fact that the majority of the
raters were female may affect the validity of the study. In addition, the limited ethnicity of
the raters in the present study may challenge the representativeness of the rater pool as

74 Soo-Kyung Park
ethnicity of raters, both native and non-native English speaking raters, may influence rater
behavior. Therefore, future studies with a large number of raters and with a more balanced
gender and ethnicity distribution are necessary to confirm the findings of the present study
and to properly investigate the issue of rater background.
Another potential limitation relates to the number of tasks employed. In the present
study, the effect of different task types was analyzed based on only two different tasks. As
such, further study with more diverse task types is needed to clarify the role of different
task type in L2 writing assessment. Moreover, as Weigle (2002) pointed out, it would be
also useful to identify the source of differences between different task types in order to
decide whether the differences in the scores given to different task types are related to
observable differences in grammatical, lexical, or rhetorical features of written texts, or
whether these differences are mainly associated with raters’ use of different criteria in
assigning scores to different task types.
REFERENCES
Bouwer, R., Béguin, A., Sanders, T., & van den Bergh, H. (2014). Effect of genre on the
generalizability of writing scores. Language Testing, 32(1), 83-100.
Braddock, R., Lloyd-Jones, R., & Schoer, L. (1963). Research in written composition.
Champaign, IL: National Council of Teachers of English.
Carr, N. T. (2000). A comparison of the effects of analytic and holistic rating scale types in
the context of composition tests. Issues in Applied Linguistics, 11(2), 207-241.
Carrell, P. L., & Connor, U. (1991). Reading and writing descriptive and persuasive texts.
The Modern Language Journal, 75(3), 314-324.
Coe, M., Hanita, M., Nishioka, V., & Smiley, R. (2011). An investigation of the impact of
the 6+1 trait writing model on grade 5 student writing achievement final report.
U.S. Department of Education (NCEE 2012-4010). Retrieved on December 16,
2011, from the World Wide Web: http://ies.ed.gov/ncee/edlabs/regions/northwest/
pdf/REL_20124010.pdf.
Connor-Linton, J. (1995). Crosscultural comparison of writing standards: American ESL
and Japanese EFL. World Englishes, 14(1), 99-115.
Crowhurst, M. (1987). Cohesion in argument and narration at three grade levels. Research
in the Teaching of English, 21(2), 185-201.
Crowhurst, M. (1988). Research review: Patterns of development in writing persuasive
/argumentative discourse. (ERIC Document Reproduction Service No. ED 299
596).
Crowhurst, M. (1990). Teaching and learning the writing of persuasive/argumentative

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 75
discourse. Canadian Journal of Education, 15(4), 348-359.
Cumming, A., Kantor, R., & Powers, D. E. (2001). Scoring TOEFL essays and TOEFL
2000 prototype written tasks: An investigation into raters’ decision making and
development of a preliminary analytic framework. (TOEFL Monograph Series No.
22). Princeton, NJ: Educational Testing Service.
Dunbar, S. B., Koretz, D. M., & Hoover, H. D. (1991). Quality control in the development
and use of performance assessments. Applied Measurement in Education, 4(4),
289-303.
Eckes, T. (2008). Rater types in writing performance assessments: A classification
approach to rater variability. Language Testing, 25(2), 155-185.
Engelhard, Jr. G., Gordon, B., & Gabrielson, S. (1992). The influences of mode of
discourse, experiential demand, and gender on the quality of student writing.
Research in the Teaching of English, 26(3), 315-335.
Foster, P., & Skehan, P. (1996). The influence of planning and task type on second
language performance. Studies in Second Language Acquisition, 18(3), 299-323.
Freedman, A., & Pringle, I. (1984). Writing in the college years: Some indices of growth.
College Composition and Communication, 31(3), 311-324.
Hafner, J. C., & Hafner, P. M. (2003). Quantitative analysis of the rubric as an assessment
tool: An empirical study of student peer-group rating, International Journal of
Science Education, 25(12), 1509-1528.
Hake, R. (1986). How do we judge what they write? In K. L. Greenberg, H. S. Weiner, &
R. A. Donovan (Eds.), Writing assessment: Issues and strategies (pp. 153-167).
New York: Longman.
Hamp-Lyons, L. (1990). Second language writing: Assessment issues. In B. Kroll (Ed.),
Second language writing: Research insights for the classroom (pp. 69-87).
Cambridge: Cambridge University Press.
Hamp-Lyons, L. (1991). Pre-text: Task-related influences on the writer. In L. Hamp-Lyons
(Ed.), Assessing second language writing in academic contexts (pp. 87-107).
Norwood, NJ: Albex.
Hamp-Lyons, L. (1995). Rating nonnative writing: The trouble with holistic scoring.
TESOL Quarterly, 29(4), 759-762.
Hamp-Lyons, L. (2003). Writing teachers as assessors of writing. In B. Kroll (Ed.),
Exploring the dynamics of second language writing (pp. 162-189). Cambridge:
Cambridge University Press.
Hinkel, E. (2009). The effects of essay topics on modal verb uses in L1 and L2 academic
writing. Journal of Pragmatics. 41(4), 667-683.
Holly, J. (n.d.). Personal narrative collection. Retrieved on December 1, 2011, from the
World Wide Web: http://home.earthlink.net /~jhholly/pnarrative.html.

76 Soo-Kyung Park
Jang, S. Y. (2011). The development of a standardized rater training program on essay
scoring: A case study. English Teaching, 66(3), 201-231.
Johnson, S. J., & Lim, S. G. (2009). The influence of rater language background on writing
performance assessment. Language Testing, 26(4), 485-505.
Kegley, P. H. (1986). The effect of mode of discourse on student writing performance:
Implications for policy. Educational Evaluation and Policy Analysis, 8(2), 147-
154.
Kim, A. Y., & Gennaro, D. K. (2012). Scoring behavior of native vs. non-native speaker
raters of writing exams. Language Research, 48(2), 319-342.
Knoch, U. (2007). Little coherence, considerable strain for reader: A comparison between
two rating scales for the assessment of coherence. Assessing Writing, 12(2), 108-
128.
Knoch, U. (2009). Diagnostic assessment of writing: A comparison of two rating scales.
Language Testing, 26(2), 275-304.
Knoch, U. (2011). Investigating the effectiveness of individualized feedback to rating
behavior—a longitudinal study. Language Testing, 28(2), 179-200.
Lee, H. K. (2009). Native and nonnative rater behavior in grading Korean students’
English essays. Asia Pacific Education Review, 10(3), 387-397.
Markham, L. R. (1976). Influences of handwriting quality on teacher evaluation of written
work. American Educational Research Journal, 13(4), 277-283.
Matsuhashi, A. (1981). Pausing and planning: The tempo of written discourse production.
Research in the Teaching of English, 15(2), 113-134.
McNamara, T. F. (1995). Modelling performance: Opening Pandora’s box. Applied
Linguistics, 16(2), 159-179.
McNamara, T. F. (1996). Measuring second language performance. New York: Addison
Wesley Longman.
Messick, S. (1994). The interplay of evidence and consequences in the validation of
performance assessments. Educational Researcher, 23(2), 13-23.
Miller, M. D., & Legg, S. M. (1993). Alternative assessment in a high-stakes environment.
Educational Measurement: Issues and Practice, 12(2), 9-15.
Norment, M. (1984). Contrastive analyses of organizational structures and cohesive
elements in native and ESL Chinese, English, and Spanish writing. Unpublished
doctoral dissertation, Fordham University, New York.
Norris, J. M., Brown, J. D., Hudson, T. D., & Yoshioka, J. (1998). Designing second
language performance assessments. Honolulu, HI: University of Hawaii Press.
O’Loughlin, K. (1994). The assessment of writing by English and ESL teachers. Australian
Review of Applied Linguistics, 17(1), 23-44.
O’Loughlin, K. (2002). The impact of gender in oral proficiency testing. Language Testing,

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 77
19(2), 169-192.
Park, S. K. (2013a). Lexical analysis of Korean university students’ narrative and
argumentative essays. English Teaching, 68(3), 131-157.
Park, S. K. (2013b). Korean EFL learners’ use of cohesive devices in narrative and
argumentative essays. Studies in English Education, 18(2), 51-81.
Pollitt, A., & Hutchinson, C. (1987). Calibrating graded assessments: Rasch partial credit
analysis of performance in writing. Language Testing, 4(1), 72-92.
Quellmalz, E. S., Capell, F. J., & Chou, C. P. (1982). Effects of discourse and response
mode on the measurement of writing competence. Journal of Educational
Measurement, 19(4), 241-258.
Reed, D., & Cohen, A. (2001). Revising raters and ratings in oral language assessment. In
C. Elder, A. Brown, E. Grove, K. Hill, N. Iwashita, T. Lumley, T. McNamara, & K.
O’Loughlin (Eds.), Experimenting with uncertainty: Language testing in honour of
Alan Davies (Vol. 11, pp. 82-96). Cambridge: Cambridge University Press.
Rezaei, A. R., & Lovorn, M. (2010). Reliability and validity of rubrics for assessment
through writing. Assessing Writing, 15(1), 18-39.
Rigdon, E., & Ferguson, C. E. (1991). The performance of the polychoric correlation
coefficient and selected fitting functions in confirmatory factor analysis with
ordinal data. Journal of Marketing Research, 28(4), 491-497.
Santos, T. (1988). Professors’ reactions to the academic writing of nonnative-speaking
students. TESOL Quarterly, 22(1), 69-90.
Shi, L. (2001). Native- and nonnative-speaking EFL teachers’ evaluation of Chinese
students’ English writing. Language Testing, 18(3), 303-325.
Sinclair, V. E. (1984). The effect of mode variation on syntactic complexity in adult ESL
composition writing. Unpublished doctoral dissertation, University of British
Columbia, Vancouver, Canada.
Sloan, C., & McGinnis, I. (1982). The effect of handwriting on teachers’ grading of high
school essays. Journal of Association for the Study of Perception, 17(2), 15-21.
Stiggins, R. J. (1988). Revitalizing classroom assessment: The highest instructional priority.
Phi Delta Kappan, 69(5), 363-368.
Tajeddin, Z., & Alemi, M. (2014). Pragmatic rater training: Does it affect non-native L2
teachers’ rating accuracy and bias? Iranian Journal of Language Testing, 4(1), 66-
83.
Tarone, E., & Parrish, B. (1988). Task‐related variation in interlanguage: The case of
articles. Language Learning, 38(1), 21-44.
The City University of New York. (2009). Report of the task force on writing assessment.
Retrieved on December 16, 2011, from the World Wide Web: http://owl.cuny.edu:
7778/portal/page/portal/oira/OIRA_HOME/Writing%20Task%20Force%20Final%

78 Soo-Kyung Park
20Report.pdf.
The R Foundation. (2011). The R statistical environment. The R project for statistical
computing. Retrieved on April 8, 2012, from the World Wide Web: http://www.r-
project.org.
Vaughan, C (1991). Holistic assessment: What goes on in the rater’s mind? In L. Hamp-
Lyons (Ed.), Assessing second language writing in academic contexts (pp. 111-
125). Norwood, NJ: Ablex.
Weigle, S. C. (1994). Effects of training on raters of ESL compositions: Quantitative and
qualitative approaches. Unpublished doctoral dissertation, University of California,
Los Angeles.
Weigle, S. C. (1998). Using FACETS to model rater training effects. Language Testing,
5(2), 263-287.
Weigle, S. C. (2002). Assessing writing. Cambridge: Cambridge University Press.
Weir, C. J. (1990). Communicative language testing. New York: Prentice Hall.
White, E. M. (1984). Holisticism. College Composition and Communication, 35(4), 400-
409.
Yang, H. C., & Plakans, L. (2012). Second language writers’ strategy use and performance
in an integrated reading‐listening‐writing task. TESOL Quarterly, 46(1), 80-103.
Yau, M., & Belanger, J. (1984). The influence of mode on the syntactic complexity of EFL
students at three grade levels. TESL Canada Journal, 2(1), 65-76.

The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 79
APPENDIX A
Holistic Scoring Rubric
Score Task Description
5
An essay at this level largely accomplishes all of the following:▪ effectively addresses the topic and task. ▪ is well organized and well developed, using clearly appropriate explanations,
exemplifications, and/or details ▪ displays unity, progression and coherence ▪ displays consistent facility in the use of language, demonstrating syntactic
variety, appropriate word choice, and idiomaticity, though it may have minor lexical or grammatical errors
4
▪ addresses the topic and task well, though some points may not be fully elaborated
▪ is generally well organized and well developed, using appropriate and sufficient explanations, exemplifications, and/or details
▪ displays unity, progression, and coherence, though it may contain occasional redundancy, digression, or unclear connections
▪ displays facility in the use of language, demonstrating syntactic variety and range of vocabulary, though it will probably have occasional noticeable minor errors in structure, word form, or use of idiomatic language that do not interfere with meaning
3
▪ addresses the topic and task using somewhat developed explanations, exemplifications, and/or details
▪ displays unity, progression, and coherence, though connection of ideas may be occasionally obscured
▪ may demonstrate inconsistent facility in sentence formation and word choice that may result in lack of clarity and occasionally obscure meaning
▪ may display accurate but limited range of syntactic structures and vocabulary.
2
▪ limited development in response to the topic and task▪ inadequate organization or connection of ideas ▪ inappropriate or insufficient exemplifications, explanations, or details to
support or illustrate generalizations in response to the task ▪ a noticeable inappropriate choice of words or word forms ▪ an accumulation of errors in sentence structure and/or usage
1
▪ serious disorganization or underdevelopment▪ little or no detail, or irrelevant specifics, or questionable responsiveness to the task ▪ serious and frequent errors in sentence structure or usage
0 An essay at this level merely copies words from the topic, rejects the topic, or is otherwise not connected to the topic; is written in a foreign language, consists of key stroke characters, or is blank.

80 Soo-Kyung Park
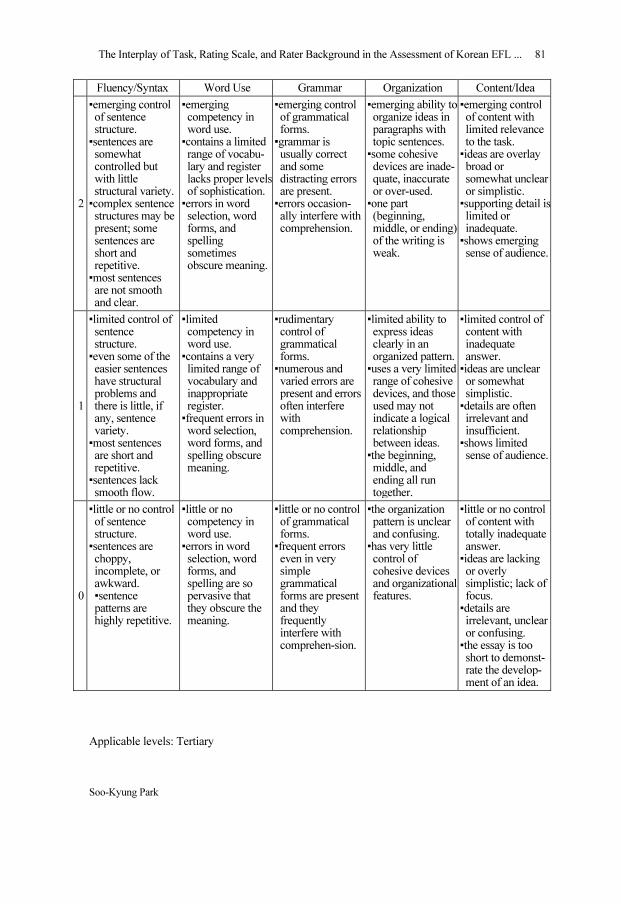
APPENDIX B
Analytic Scoring Rubric
Fluency/Syntax Word Use Grammar Organization Content/Idea
5
▪strong control of sentence structure.
▪sentences are well controlled with effective variety in structure.
▪shows a natural, smooth flow.
▪strong control of word use.
▪word choice is specific, precise, and supports clarity.
▪contains a broad range of vocabul-ary and appropriate register.
▪consistent accuracy in idiomatic expression, word selection, word forms, and spelling.
▪strong control of grammatical forms.
▪a few errors are present, but they do not interfere with comprehen-sion and the meaning is clear throughout the response.
▪strong control of organization.
▪uses a variety of cohesive devices effectively.
▪exhibits a smooth progression of ideas.
▪strong control of content with highly relevant and adequate answer to the task.
▪ideas are excep- tionally clear, focused and captivating.
▪supporting details are relevant, tho-rough and credible.
▪a developed, interesting piece of writing that engages the reader.
4
▪consistent control of sentence structure.
▪sentences are usually well controlled and their structure is somewhat varied.
▪much of the writing shows a smooth flow but has some rough spots.
▪consistent control of word use.
▪word choice is clear and supports clarity.
▪contains a relatively broad range of vocabu-lary and appro-priate register.
▪general accuracy in the use of idiomatic expre-ssions, word selection, word forms, and spelling.
▪consistent control of grammatical forms.
▪a few distracting errors are present, but generally meaning is clear.
▪a recognizable organizational pattern.
▪uses a range of cohesive devices appropriately although there may be some under-/over-use.
▪well organized with a clear beginning, middle, and ending.
▪consistent control of content with relevant and adequate answer to the task.
▪ideas are clear, focused and hold the reader’s attention throughout.
▪supporting details are relevant and support the main idea well.
▪awareness of audience and purpose is evident.
3
▪moderate control of sentence structure.
▪sentences are adequately controlled and there is a little structural variety.
▪some sentences are choppy or awkward, but most are smooth and clear.
▪moderate competency in word use.
▪contains accurate but limited range of vocabulary.
▪moderate control of idiomatic expression and register.
▪errors in word selection, word forms, and spelling are distracting and may obscure meaning.
▪moderate control of grammatical forms.
▪grammar is mostly correct and some distracting errors are present, but meaning is clear.
▪may occasionally interfere with comprehension.
▪a discernible organization.
▪though often simple and obvious, cohesive devices are usually used to convey relationships among ideas.
▪well organized with beginning, middle, and ending, but one of those parts needs to be strengthened.
▪moderate control of content with some gaps or redundant information.
▪ideas are clear, focused and easily understandable.
▪supporting details are relevant, but may be overly general or limited.
▪shows some sense of audience.
The Interplay of Task, Rating Scale, and Rater Background in the Assessment of Korean EFL ... 81
Fluency/Syntax Word Use Grammar Organization Content/Idea
2
▪emerging control of sentence structure.
▪sentences are somewhat controlled but with little structural variety.
▪complex sentence structures may be present; some sentences are short and repetitive.
▪most sentences are not smooth and clear.
▪emerging competency in word use.
▪contains a limited range of vocabu-lary and register lacks proper levels of sophistication.
▪errors in word selection, word forms, and spelling sometimes obscure meaning.
▪emerging control of grammatical forms.
▪grammar is usually correct and some distracting errors are present.
▪errors occasion-ally interfere with comprehension.
▪emerging ability to organize ideas in paragraphs with topic sentences.
▪some cohesive devices are inade-quate, inaccurate or over-used.
▪one part (beginning, middle, or ending) of the writing is weak.
▪emerging control of content with limited relevance to the task.
▪ideas are overlay broad or somewhat unclear or simplistic.
▪supporting detail is limited or inadequate.
▪shows emerging sense of audience.
1
▪limited control of sentence structure.
▪even some of the easier sentences have structural problems and there is little, if any, sentence variety.
▪most sentences are short and repetitive.
▪sentences lack smooth flow.
▪limited competency in word use.
▪contains a very limited range of vocabulary and inappropriate register.
▪frequent errors in word selection, word forms, and spelling obscure meaning.
▪rudimentary control of grammatical forms.
▪numerous and varied errors are present and errors often interfere with comprehension.
▪limited ability to express ideas clearly in an organized pattern.
▪uses a very limited range of cohesive devices, and those used may not indicate a logical relationship between ideas.
▪the beginning, middle, and ending all run together.
▪limited control of content with inadequate answer.
▪ideas are unclear or somewhat simplistic.
▪details are often irrelevant and insufficient.
▪shows limited sense of audience.
0
▪little or no control of sentence structure.
▪sentences are choppy, incomplete, or awkward. ▪sentence patterns are highly repetitive.
▪little or no competency in word use.
▪errors in word selection, word forms, and spelling are so pervasive that they obscure the meaning.
▪little or no control of grammatical forms.
▪frequent errors even in very simple grammatical forms are present and they frequently interfere with comprehen-sion.
▪the organization pattern is unclear and confusing.
▪has very little control of cohesive devices and organizational features.
▪little or no control of content with totally inadequate answer.
▪ideas are lacking or overly simplistic; lack of focus.
▪details are irrelevant, unclear or confusing.
▪the essay is too short to demonst-rate the develop-ment of an idea.
Applicable levels: Tertiary
Soo-Kyung Park

82 Soo-Kyung Park
Department of English Education
College of Education, Korea University
145 Anam-ro, Seongbuk-gu
Seoul 136-701, Korea
Phone: 02-3290-2350
Email: [email protected]
Received in March 1, 2015
Reviewed in April 15, 2015
Revised version received in May 15, 2015