template matching and object recognition. cs8690 computer vision university of missouri at columbia...
TRANSCRIPT

Template matching and object recognition

CS8690 Computer Vision University of Missouri at Columbia
Recognition by finding patterns• We have seen very
simple template matching (under filters)
• Some objects behave like quite simple templates – Frontal faces
• We have seen very simple template matching (under filters)
• Some objects behave like quite simple templates – Frontal faces
• Strategy:– Find image windows
– Correct lighting
– Pass them to a statistical test (a classifier) that accepts faces and rejects non-faces
• Strategy:– Find image windows
– Correct lighting
– Pass them to a statistical test (a classifier) that accepts faces and rejects non-faces

CS8690 Computer Vision University of Missouri at Columbia
Basic ideas in classifiers• Loss
– some errors may be more expensive than others• e.g. a fatal disease that is easily cured by a cheap medicine with no
side-effects -> false positives in diagnosis are better than false negatives
– We discuss two class classification: L(1->2) is the loss caused by calling 1 a 2
• Total risk of using classifier s
• Loss– some errors may be more expensive than others
• e.g. a fatal disease that is easily cured by a cheap medicine with no side-effects -> false positives in diagnosis are better than false negatives
– We discuss two class classification: L(1->2) is the loss caused by calling 1 a 2
• Total risk of using classifier s

CS8690 Computer Vision University of Missouri at Columbia
Basic ideas in classifiers• Generally, we should classify as 1 if the expected loss
of classifying as 1 is better than for 2• gives
• Crucial notion: Decision boundary– points where the loss is the same for either case
• Generally, we should classify as 1 if the expected loss of classifying as 1 is better than for 2
• gives
• Crucial notion: Decision boundary– points where the loss is the same for either case
1 if
2 if

CS8690 Computer Vision University of Missouri at Columbia
Some loss may be inevitable: the minimumrisk (shaded area) is called the Bayes risk

CS8690 Computer Vision University of Missouri at Columbia
Finding a decision boundary is not the same asmodelling a conditional density.

CS8690 Computer Vision University of Missouri at Columbia
• Assume normal class densities, p-dimensional measurements with common (known) covariance and different (known) means
• Class priors are• Can ignore a common factor
in posteriors - important; posteriors are then:
p x k 1
2
p2
1
2exp
1
2x
k T 1 x k
k
Example: known distributions
p k | x k 12
p2
1
2 exp 12
x k T 1 x
k

CS8690 Computer Vision University of Missouri at Columbia
• Classifier boils down to: choose class that minimizes:
x,k 2 2 log k
where
x,k x
k T 1 x k
12
because covariance is common, this simplifies to sign ofa linear expression (i.e. Voronoi diagram in 2D for =I and equal priors)
Mahalanobis distance

CS8690 Computer Vision University of Missouri at Columbia
Plug-in classifiers
• Assume that distributions have some parametric form - now estimate the parameters from the data.
• Common: – assume a normal distribution with shared covariance, different
means; use usual estimates– ditto, but different covariances; ditto
• Issue: parameter estimates that are “good” may not give optimal classifiers.

CS8690 Computer Vision University of Missouri at Columbia
Histogram based classifiers• Use a histogram to represent the class-
conditional densities– (i.e. p(x|1), p(x|2), etc)
• Advantage: estimates become quite good with enough data!
• Disadvantage: Histogram becomes big with high dimension– but maybe we can assume feature independence?
• Use a histogram to represent the class-conditional densities– (i.e. p(x|1), p(x|2), etc)
• Advantage: estimates become quite good with enough data!
• Disadvantage: Histogram becomes big with high dimension– but maybe we can assume feature independence?

CS8690 Computer Vision University of Missouri at Columbia
Finding skin• Skin has a very small range of (intensity independent)
colours, and little texture– Compute an intensity-independent colour measure, check if
colour is in this range, check if there is little texture (median filter)
– See this as a classifier - we can set up the tests by hand, or learn them.
– get class conditional densities (histograms), priors from data (counting)
• Classifier is
• Skin has a very small range of (intensity independent) colours, and little texture– Compute an intensity-independent colour measure, check if
colour is in this range, check if there is little texture (median filter)
– See this as a classifier - we can set up the tests by hand, or learn them.
– get class conditional densities (histograms), priors from data (counting)
• Classifier is

CS8690 Computer Vision University of Missouri at Columbia
Figure from “Statistical color models with application to skin detection,” M.J. Jones and J. Rehg, Proc. Computer Vision and Pattern Recognition, 1999 copyright 1999, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Figure from “Statistical color models with application to skin detection,” M.J. Jones and J. Rehg, Proc. Computer Vision and Pattern Recognition, 1999 copyright 1999, IEEE
Receiver Operating Curve

CS8690 Computer Vision University of Missouri at Columbia
Finding faces• Faces “look like”
templates (at least when they’re frontal).
• General strategy:– search image windows at
a range of scales
– Correct for illumination
– Present corrected window to classifier
• Faces “look like” templates (at least when they’re frontal).
• General strategy:– search image windows at
a range of scales
– Correct for illumination
– Present corrected window to classifier
• Issues– How corrected?
– What features?
– What classifier?
– what about lateral views?
• Issues– How corrected?
– What features?
– What classifier?
– what about lateral views?

CS8690 Computer Vision University of Missouri at Columbia
Naive Bayes• (Important: naive not necessarily pejorative)
• Find faces by vector quantizing image patches, then computing a histogram of patch types within a face
• Histogram doesn’t work when there are too many features
– features are the patch types
– assume they’re independent and cross fingers
– reduction in degrees of freedom
– very effective for face finders
• why? probably because the examples that would present real problems aren’t frequent.
• (Important: naive not necessarily pejorative)
• Find faces by vector quantizing image patches, then computing a histogram of patch types within a face
• Histogram doesn’t work when there are too many features
– features are the patch types
– assume they’re independent and cross fingers
– reduction in degrees of freedom
– very effective for face finders
• why? probably because the examples that would present real problems aren’t frequent.
Many face finders on the face detection home pagehttp://home.t-online.de/home/Robert.Frischholz/face.htm

CS8690 Computer Vision University of Missouri at Columbia
Figure from A Statistical Method for 3D Object Detection Applied to Faces and Cars, H. Schneiderman and T. Kanade, Proc. Computer Vision and Pattern Recognition, 2000, copyright 2000, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Face Recognition• Whose face is this? (perhaps
in a mugshot)• Issue:
– What differences are important and what not?
– Reduce the dimension of the images, while maintaining the “important” differences.
• One strategy:– Principal components analysis
• Whose face is this? (perhaps in a mugshot)
• Issue:– What differences are important
and what not?
– Reduce the dimension of the images, while maintaining the “important” differences.
• One strategy:– Principal components analysis

CS8690 Computer Vision University of Missouri at Columbia
Template matching• Simple cross-correlation between images
• Best match wins
• Computationally expensive, i.e. requires presented image to be correlated with every image in the database !
• Simple cross-correlation between images
• Best match wins
• Computationally expensive, i.e. requires presented image to be correlated with every image in the database !
IImaxarg Tii
iS

CS8690 Computer Vision University of Missouri at Columbia
Eigenspace matching• Consider PCA
• Then,
• Consider PCA
• Then,
ii pI E
IpII TTT Eii
ppII TTii
ppIImaxarg TTiii
iS
Much cheaper to compute!

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia
Eigenfaces
plus a linear combination of eigenfaces

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia
Difficulties with PCA• Projection may suppress important detail
– smallest variance directions may not be unimportant
• Method does not take discriminative task into account– typically, we wish to compute features that allow
good discrimination– not the same as largest variance
• Projection may suppress important detail– smallest variance directions may not be unimportant
• Method does not take discriminative task into account– typically, we wish to compute features that allow
good discrimination– not the same as largest variance

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia
Linear Discriminant Analysis• We wish to choose linear functions of the
features that allow good discrimination.– Assume class-conditional covariances are the same– Want linear feature that maximises the spread of
class means for a fixed within-class variance
• We wish to choose linear functions of the features that allow good discrimination.– Assume class-conditional covariances are the same– Want linear feature that maximises the spread of
class means for a fixed within-class variance

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia
Neural networks• Linear decision boundaries are useful
– but often not very powerful – we seek an easy way to get more complex boundaries
• Compose linear decision boundaries– i.e. have several linear classifiers, and apply a
classifier to their output– a nuisance, because sign(ax+by+cz) etc. isn’t
differentiable.– use a smooth “squashing function” in place of sign.
• Linear decision boundaries are useful– but often not very powerful – we seek an easy way to get more complex boundaries
• Compose linear decision boundaries– i.e. have several linear classifiers, and apply a
classifier to their output– a nuisance, because sign(ax+by+cz) etc. isn’t
differentiable.– use a smooth “squashing function” in place of sign.

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia
Training• Choose parameters to minimize error on training set
• Stochastic gradient descent, computing gradient using trick (backpropagation, aka the chain rule)
• Stop when error is low, and hasn’t changed much
• Choose parameters to minimize error on training set
• Stochastic gradient descent, computing gradient using trick (backpropagation, aka the chain rule)
• Stop when error is low, and hasn’t changed much
Error p 12
n xe; p oe
e
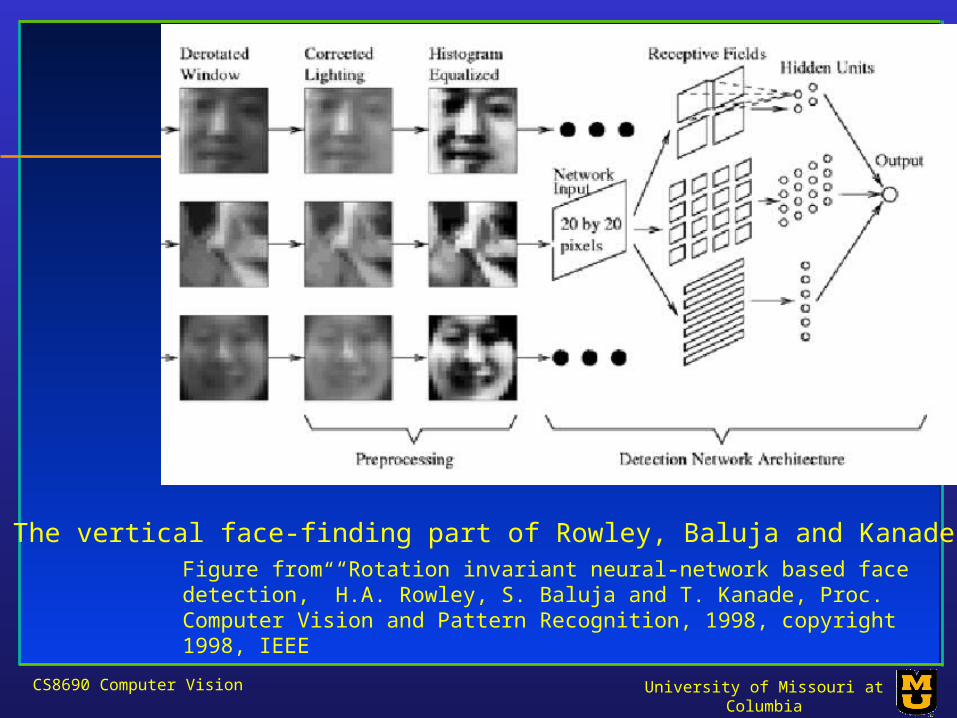
CS8690 Computer Vision University of Missouri at Columbia
The vertical face-finding part of Rowley, Baluja and Kanade’s systemFigure from “Rotation invariant neural-network based face detection,” H.A. Rowley, S. Baluja and T. Kanade, Proc. Computer Vision and Pattern Recognition, 1998, copyright 1998, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Histogram equalisation gives an approximate fix for illumination induced variability

CS8690 Computer Vision University of Missouri at Columbia
Architecture of the complete system: they use another neuralnet to estimate orientation of the face, then rectify it. They search over scales to find bigger/smaller faces.
Figure from “Rotation invariant neural-network based face detection,” H.A. Rowley, S. Baluja and T. Kanade, Proc. Computer Vision and Pattern Recognition, 1998, copyright 1998, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Figure from “Rotation invariant neural-network based face detection,” H.A. Rowley, S. Baluja and T. Kanade, Proc. Computer Vision and Pattern Recognition, 1998, copyright 1998, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Convolutional neural networks• Template matching using NN classifiers seems
to work
• Natural features are filter outputs– probably, spots and bars, as in texture– but why not learn the filter kernels, too?
• Template matching using NN classifiers seems to work
• Natural features are filter outputs– probably, spots and bars, as in texture– but why not learn the filter kernels, too?

CS8690 Computer Vision University of Missouri at Columbia
Figure from “Gradient-Based Learning Applied to Document Recognition”, Y. Lecun et al Proc. IEEE, 1998 copyright 1998, IEEE
A convolutional neural network, LeNet; the layers filter, subsample, filter,subsample, and finally classify based on outputs of this process.

CS8690 Computer Vision University of Missouri at Columbia
LeNet is used to classify handwritten digits. Notice that the test error rate is not the same as the training error rate, becausethe test set consists of items not in the training set. Not all classification schemes necessarily have small test error when theyhave small training error.
Figure from “Gradient-Based Learning Applied to Document Recognition”, Y. Lecun et al Proc. IEEE, 1998 copyright 1998, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Support Vector Machines• Neural nets try to build a model of the posterior,
p(k|x)
• Instead, try to obtain the decision boundary directly– potentially easier, because we need to encode only
the geometry of the boundary, not any irrelevant wiggles in the posterior.
– Not all points affect the decision boundary
• Neural nets try to build a model of the posterior, p(k|x)
• Instead, try to obtain the decision boundary directly– potentially easier, because we need to encode only
the geometry of the boundary, not any irrelevant wiggles in the posterior.
– Not all points affect the decision boundary

CS8690 Computer Vision University of Missouri at Columbia
Support Vector Machines• Neural nets try to build a model of the posterior,
p(k|x)
• Instead, try to obtain the decision boundary directly– potentially easier, because we need to encode only
the geometry of the boundary, not any irrelevant wiggles in the posterior.
– Not all points affect the decision boundary
• Neural nets try to build a model of the posterior, p(k|x)
• Instead, try to obtain the decision boundary directly– potentially easier, because we need to encode only
the geometry of the boundary, not any irrelevant wiggles in the posterior.
– Not all points affect the decision boundary

CS8690 Computer Vision University of Missouri at Columbia

CS8690 Computer Vision University of Missouri at Columbia
Support Vector Machines• Linearly separable data
means
• Choice of hyperplane means
• Hence distance
• Linearly separable data means
• Choice of hyperplane means
• Hence distance

CS8690 Computer Vision University of Missouri at Columbia
Support Vector Machines
Actually, we construct a dual optimization problem.
By being clever about what x means, I can have muchmore interesting boundaries.

CS8690 Computer Vision University of Missouri at Columbia
Space in which decisionboundary is linear - aconic in the original spacehas the form
x, y x2 , xy, y2, x, y u0 ,u1,u2 ,u3 ,u4
au0 bu1 cu2 du3 eu4 f 0

CS8690 Computer Vision University of Missouri at Columbia
Support Vector Machines• Set S of points xiRn, each xi belongs to one of two classes yi {-
1,1}• The goals is to find a hyperplane that divides S in these two classes
• Set S of points xiRn, each xi belongs to one of two classes yi {-1,1}
• The goals is to find a hyperplane that divides S in these two classes
S is separable if w Rn,b R
1x.w by ii
Separating hyperplanes
0x.w b wdy ii
1
w
bd i
i
x.wdi
Closest point
wdy ii
1
ww

CS8690 Computer Vision University of Missouri at Columbia
Problem 1:
Support Vector Machines• Optimal separating hyperplane maximizes• Optimal separating hyperplane maximizes
Optimal separating hyperplane (OSH)
w
1
w.w21
Niby ii ,...,2,1,1x.w Minimize
Subject to
w2
support vectors

CS8690 Computer Vision University of Missouri at Columbia
Solve using Lagrange multipliers• Lagrangian
– at solution
– therefore
• Lagrangian
– at solution
– therefore
1x.ww.wα,w,1
21
bybL ii
N
ii
01
N
iiiy
b
L
0xww 1
ii
N
ii y
L
jijij
N
jii
N
ii yyL x.x
1,1 2
1
0

CS8690 Computer Vision University of Missouri at Columbia
Problem 2:
Dual problem
N
iiD
12
1 τ
01
N
iiiy
0
jijiij yyD x.x
Minimize
Subject to
where
Kühn-Tucker condition: 01x.w by iii
jjyb x.w
ii
N
ii y xw
1
(for xj a support vector)
(i>0 only for support vectors)

CS8690 Computer Vision University of Missouri at Columbia
Linearly non-separable cases
• Find trade-off between maximum separation and misclassifications • Find trade-off between maximum separation and misclassifications
iii by 1x.w
wi1
Problem 3:
iC w.w21
Niiii by ,...,2,1,1x.w Minimize
Subject to
0

CS8690 Computer Vision University of Missouri at Columbia
Dual problem for non-separable cases
Problem 4:
N
iiD
12
1 τ
01
N
iiiy
Ci 0
jijiij yyD x.x
Minimize
Subject to
where
Kühn-Tucker condition:
0
01x.w
ii
iiii
C
by
Support vectors: 0 ii C
0
10
1
i
i
i
i C
misclassified
margin vectors
too close OSHerrors

CS8690 Computer Vision University of Missouri at Columbia
Decision function• Once w and b have been computed
the classification decision for input x is given by
• Note that the globally optimal solution can always be obtained (convex problem)
• Once w and b have been computed the classification decision for input x is given by
• Note that the globally optimal solution can always be obtained (convex problem)

CS8690 Computer Vision University of Missouri at Columbia
Non-linear SVMs• Non-linear separation surfaces can be obtained by non-linearly
mapping the data to a high dimensional space and then applying the linear SVM technique
• Note that data only appears through vector product
• Need for vector product in high-dimension can be avoided by using Mercer kernels:
• Non-linear separation surfaces can be obtained by non-linearly mapping the data to a high dimensional space and then applying the linear SVM technique
• Note that data only appears through vector product
• Need for vector product in high-dimension can be avoided by using Mercer kernels: iiiiK xxx,x
pK y.xyx, (Polynomial kernel)
2
2yx
expyx,
K (Radial Basis Function)
y.xtanhyx,K (Sigmoïdal function)
22
222121
21
21
2y.xyx, yxyyxxyxK
2221
21 ,,x xxxx
e.g.

CS8690 Computer Vision University of Missouri at Columbia
Space in which decisionboundary is linear - aconic in the original space has the form
x, y x2 , xy, y2, x, y u0 ,u1,u2 ,u3 ,u4
au0 bu1 cu2 du3 eu4 f 0

CS8690 Computer Vision University of Missouri at Columbia
SVMs for 3D object recognition- Consider images as vectors
- Compute pairwise OSH using linear SVM
- Support vectors are representative views of the considered object (relative to other)
- Tournament like classification
- Competing classes are grouped in pairs
- Not selected classes are discarded
- Until only one class is left
- Complexity linear in number of classes
- No pose estimation
- Consider images as vectors
- Compute pairwise OSH using linear SVM
- Support vectors are representative views of the considered object (relative to other)
- Tournament like classification
- Competing classes are grouped in pairs
- Not selected classes are discarded
- Until only one class is left
- Complexity linear in number of classes
- No pose estimation
(Pontil & Verri PAMI’98)

CS8690 Computer Vision University of Missouri at Columbia
Vision applications• Reliable, simple classifier,
– use it wherever you need a classifier
• Commonly used for face finding
• Reliable, simple classifier, – use it wherever you need a
classifier
• Commonly used for face finding
• Pedestrian finding– many pedestrians look like
lollipops (hands at sides, torso wider than legs) most of the time
– classify image regions, searching over scales
– But what are the features?– Compute wavelet coefficients
for pedestrian windows, average over pedestrians. If the average is different from zero, probably strongly associated with pedestrian
• Pedestrian finding– many pedestrians look like
lollipops (hands at sides, torso wider than legs) most of the time
– classify image regions, searching over scales
– But what are the features?– Compute wavelet coefficients
for pedestrian windows, average over pedestrians. If the average is different from zero, probably strongly associated with pedestrian

CS8690 Computer Vision University of Missouri at Columbia
Figure from, “A general framework for object detection,” by C. Papageorgiou, M. Oren and T. Poggio, Proc. Int. Conf. Computer Vision, 1998, copyright 1998, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Figure from, “A general framework for object detection,” by C. Papageorgiou, M. Oren and T. Poggio, Proc. Int. Conf. Computer Vision, 1998, copyright 1998, IEEE

CS8690 Computer Vision University of Missouri at Columbia
Figure from, “A general framework for object detection,” by C. Papageorgiou, M. Oren and T. Poggio, Proc. Int. Conf. Computer Vision, 1998, copyright 1998, IEEE