steam learn: introduction to rdbms indexes
TRANSCRIPT

4th of December 2014
Introduction to RDBMS IndexesWith PostgreSQL
by Clément Prévost

4th of December 2014
Introduction
● You DO need indexes
● This is how a basic index works
● Indexes are used in those cases
● Different indexes types for different problems

4th of December 2014
You DO need Indexes
● Disk access is AWFULLY slow
● RAM is limited
1000px by 12500px

4th of December 2014
From query to data
SQL Query DataParse Rewrite Plan
Metadata, Rules,...
Statistics,Indexes,...
Execute
4th of December 2014
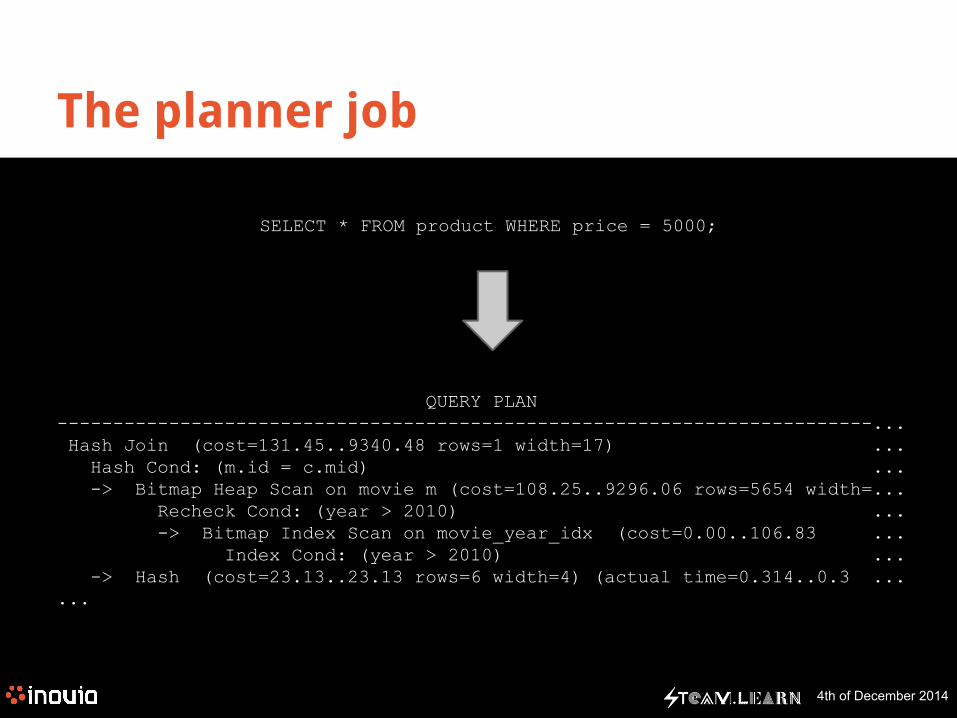
The planner job
SELECT * FROM product WHERE price = 5000;
QUERY PLAN-------------------------------------------------------------------------... Hash Join (cost=131.45..9340.48 rows=1 width=17) ... Hash Cond: (m.id = c.mid) ... -> Bitmap Heap Scan on movie m (cost=108.25..9296.06 rows=5654 width=... Recheck Cond: (year > 2010) ... -> Bitmap Index Scan on movie_year_idx (cost=0.00..106.83 ... Index Cond: (year > 2010) ... -> Hash (cost=23.13..23.13 rows=6 width=4) (actual time=0.314..0.3 ... ...

4th of December 2014
The planner job
● Create an optimal execution plan that minimize disk access
○ Input: declarative description of the query, Output: imperative way to retrieve the data.○ Fetch this page then this page, then lookup this table using these ids, then call function f, then …○ If the underlying table changes in volume, another plan may be optimal, the planner must adapt
● Doesn’t execute the final query○ Brute-forcing every possible plan would be sub-optimal○ Use statistics to access informations such as the table size, estimated row count, most found column
values, ...
● Cost based planners○ Most used type of planner○ Each function call, disk access, sort operation is associated to a cost○ Compute a cost estimation for each plan and keep better performing plan○ Allow the DBA to fine tune costs based on the database hardware (PostgreSQL)
4th of December 2014
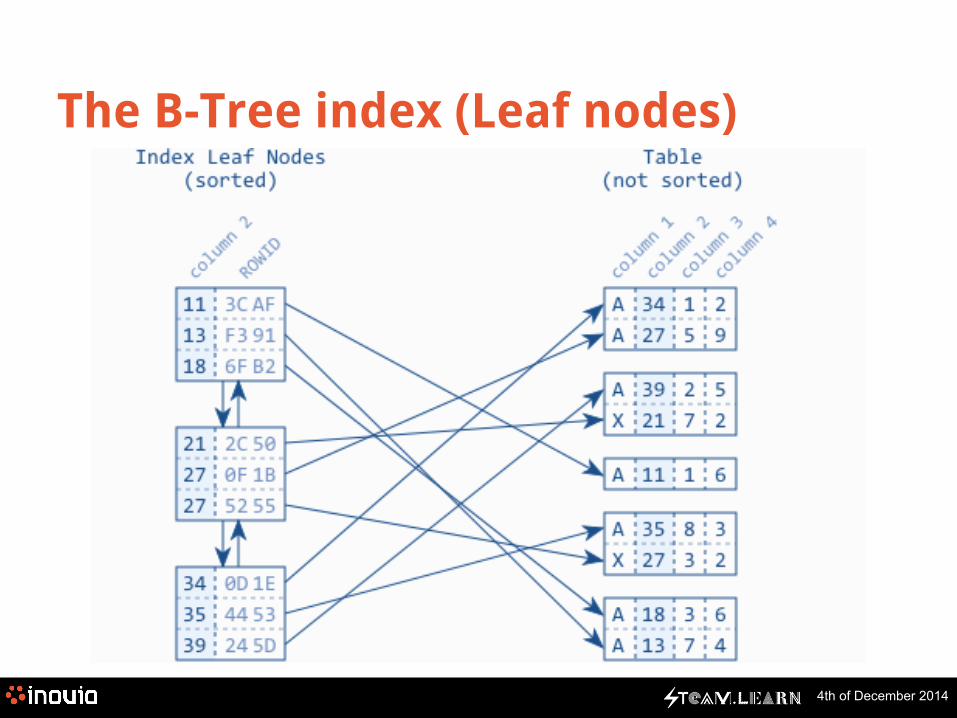
The B-Tree index (Leaf nodes)

4th of December 2014
The B-Tree index (Structure)

4th of December 2014
Index features (planner PoV)
● Index access by ID○ Fetch a single data row using the index structure○ Efficient computationally and from a disk access point of view as soon as the table is big enough○ Equality operator (=, IN, ...)
● Index range scan○ Fetch a list of data pages based on an index○ Use the index tree structure to find the first element, then follow the double linked list until the condition is
fulfilled○ May be less efficient than a sequential scan !! Keep your stats up to date !○ Range operators (<, >, <=, >=, BETWEEN, LIKE under certain ciscomstances, ...)
● Index only scan○ Don’t fetch the data pages if not needed○ The index contains the column data, fetching the table row may be irrelevant○ Supported by most RDBMSs

4th of December 2014
Index features (developper PoV)
● Speed up where clauses● Speed up joins● May speed up order by + limit● May speed up group by

4th of December 2014
Beware
● The filter expression must match the index content○ The planner won’t be able to use an index if the content of the index does not match the query○ Ex an index on column A may not be used in a query containing WHERE upper(A) = ‘B’. The planner
have to call upper many times to use the index, which may not be the most efficient plan○ Use indexes on expressions if you can’t change the query to match the index content
● An index contains all the distinct values of your column○ Index size matter ! The index is stored on data pages as well as the indexed data. If the cost of index
retrieval is enormous, the index may not be used at all○ You can have access to index statistics to drop unused index that vampirize your disk space
● On insert and update, the RDBMS have to update your index
○ The index have to be up to date at the end of every query, this is the “consistency” part of the RDBMS job○ Using a transaction to wrap multiple updates/inserts allow the RDBMS to update the index only once at
the end of the transaction

4th of December 2014
Concatenated index

4th of December 2014
Concatenated index
● Efficient on specific queries only○ Queries with multiple wheres or joins referencing all index columns○ Individual column ordering is important
● Rule of thumb: if the first column is not used, so is the index
○ Access on the second column is only made through the first column and so on○ Consider switching the index column order
● A concatenated index is often bigger than the sum of 2 normal B-Tree indexes
○ Values from the second column are duplicated○ Be sure to check index usage often to drop unused concatenated indexes

4th of December 2014
Common types of indexes
● B-Tree○ Default on most RDBMS○ Match the most use cases
● GIN○ General inverted index○ Allow indexing when the values are not atomic○ It is an index structure storing a set of (key, posting list) pairs
● Hash○ Ultra-fast on equality operator○ Only support equality operator
● GiST○ Generalized Search Tree○ This is not an index, this is a framework to create index-like data structures○ Extensible to new data types○ http://www.postgresql.org/docs/9.3/static/gist-intro.html
● And many more○ Any data structure that allow the RDBMS to avoid page fetch is considered an index○ An index type can be specific to a RDBMS, a table structure, a column type, a business constraint, ...

4th of December 2014
Key things to remember
● Disk accesses are evil (even on SSD)
● The main goal is to find the most efficient plan
● Thinking like a query planner is the key to a well indexed table

4th of December 2014
Thanks !
I would be pleased to answer any questions !
PS: This is how awesome use-the-index-luke.com is:

4th of December 2014
Questions ?For online questions, please leave a comment on the article.

4th of December 2014
Join the community !(in Paris)
Social networks :● Follow us on Twitter : https://twitter.com/steamlearn● Like us on Facebook : https://www.facebook.com/steamlearn
SteamLearn is an Inovia initiative : inovia.fr
You wish to be in the audience ? Join the meetup group! http://www.meetup.com/Steam-Learn/

4th of December 2014
References
● http://www.postgresql.org/docs/9.3/static/internals.html● http://use-the-index-luke.com/sql/table-of-contents● https://news.ycombinator.com/item?id=702713● http://www.postgresql.org/docs/9.3/static/indexes-types.
html