scalding big (ad)ta
TRANSCRIPT

SCALDING BIG (AD)TA
Boris Trofimoff @ Sigma Software
@b0ris_1

REAL-TIME
BIDDINGor the story about the first second…
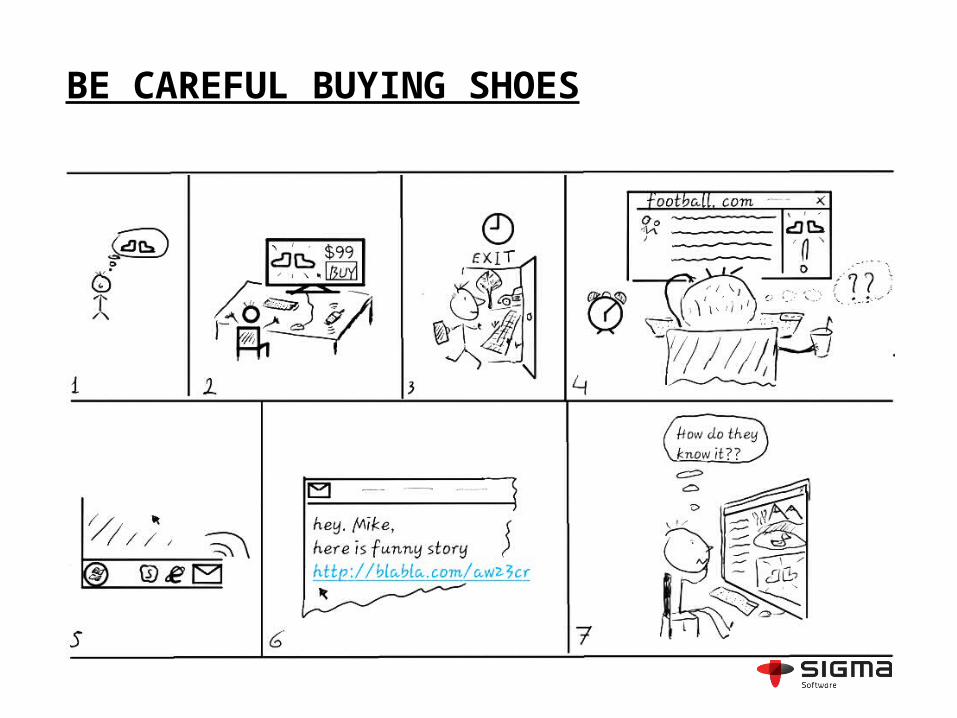
BE CAREFUL BUYING SHOES

THE FIRST SECOND ON A SCALE
User on Site
Request to bid
Accept bid
Deliver Ad
80 msto predict viewability
and make decision

REAL-TIME BIDDING IN DETAILS
STORY ACTORS:
User
Publisher(foxnews.com)
Ad Server(Google’s Doubleclick)
SSP(Ad Exchange)
DSP(decides what ad to show)
Advertiser(Nike)
COLLECTIVE

THE FIRST SECOND IN DETAILS
Publisher
receives
request
Content
delivered
to user
Ad Server
sends signal to
Ad Exchange
All bidders should
send their decision
(participate? &
price) back
Ad Server
shows page that redirects to the DSP
winner server makes piggybacking
Publisher
sends
response
back
Site sends
request to
Ad Server
toshow ad
SSP (Ad Exchange)
receives ad request and
opens RTB Auction
Every bidder/DSP receives
info about user: ssp_cookie_id geo data site url
SSP chooses the
winning DSP
and sends this
info back to Ad
Server
User’s web page shows ad banner
with ad firing DSP’s 1x1
pixel (impression)
20 ms 100 150 170 200 210 280 300 350
~70% users have
this cookie aboard
thankfully to retargeting
>>1 independent companies take part in this auction
80 ms
400 1sec
Piggybacking – async JS redirect to all DSP
servers with ssp_cookie as a query param Chance for DSP to link ssp_cookie_id with own
dsp_cookie (retargeting again)
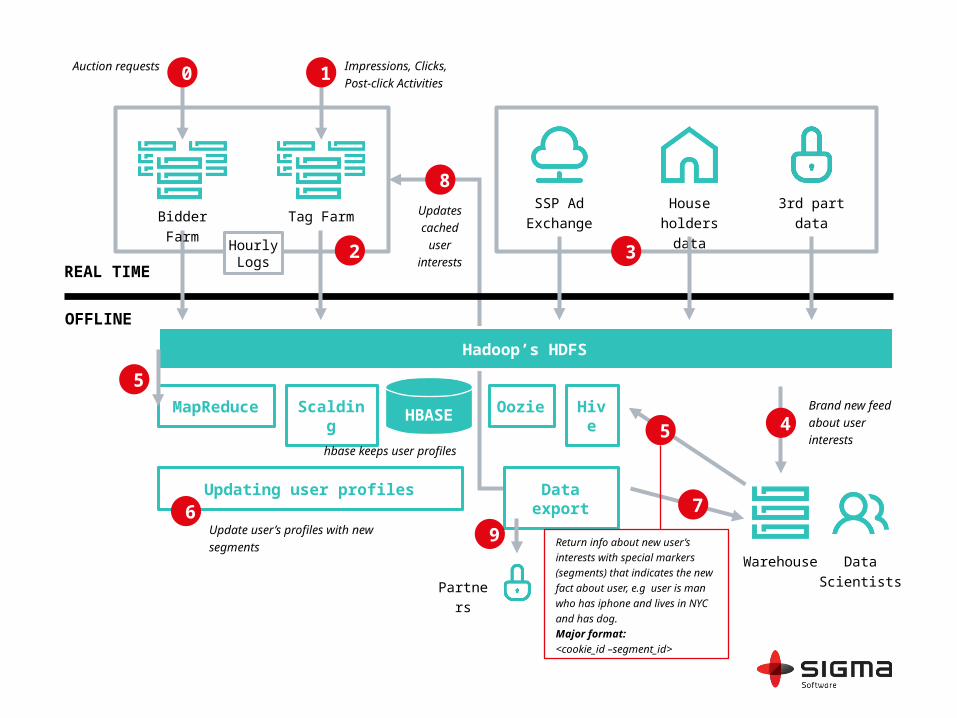
REAL TIME
OFFLINE
Hadoop’s HDFS
MapReduce ScaldingHBASE
Oozie Hive
Updating user profiles Data export
Update user’s profiles with new
segments
6
Partners
9
5
Warehouse Data
Scientists
Brand new
feed about
user interests5
7
Return info about new user’s
interests with special markers
(segments) that indicates the new
fact about user, e.g user is man
who has iphone and lives in NYC
and has dog.
Major format:
<cookie_id –segment_id>
hbase keeps user profiles
Bidder Farm
0Auction
requests
Tag Farm
1 Impressions, Clicks,
Post-click Activities
Hourly Logs
2
Updates
cached
user
interests
SSP Ad
Exchange
House holders
data
3rd part
data
3
8
4

QUICK FACTS ABOUT TECH STACK
REALTIME TEAM
LANGUAGES
Scala, Akka
Java
WEB SERVICES
RESTful interfaces
Pure Servlets
Spray
IN-MEMORY CACHES
Aerospike
Redis
HADOOP
HBASE to keep profile database
HDFS to store everything
OOZIE to build workflows + custom coordinator
implementation
Scalding
CLOUDERRA
CDH 5.4.1
EVENT-DRIVEN NEW GEN APPROACH
Spark + Kafka
OFFLINE TEAM

DATA SCIENCE?or why we need all this science

WHO ARE DATA SCIENTISTS?

WHO ARE DATA SCIENTISTS?

WHO ARE DATA SCIENTISTS?
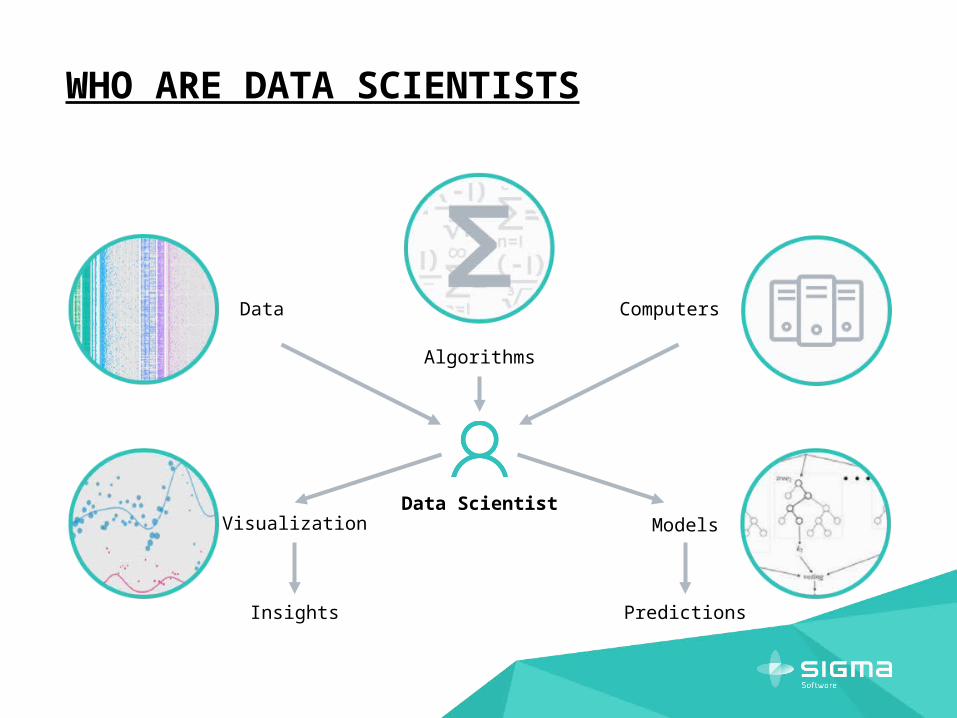
WHO ARE DATA SCIENTISTS
Data Scientist
Data
Visualization
Computers
Models
Algorithms
Insights Predictions
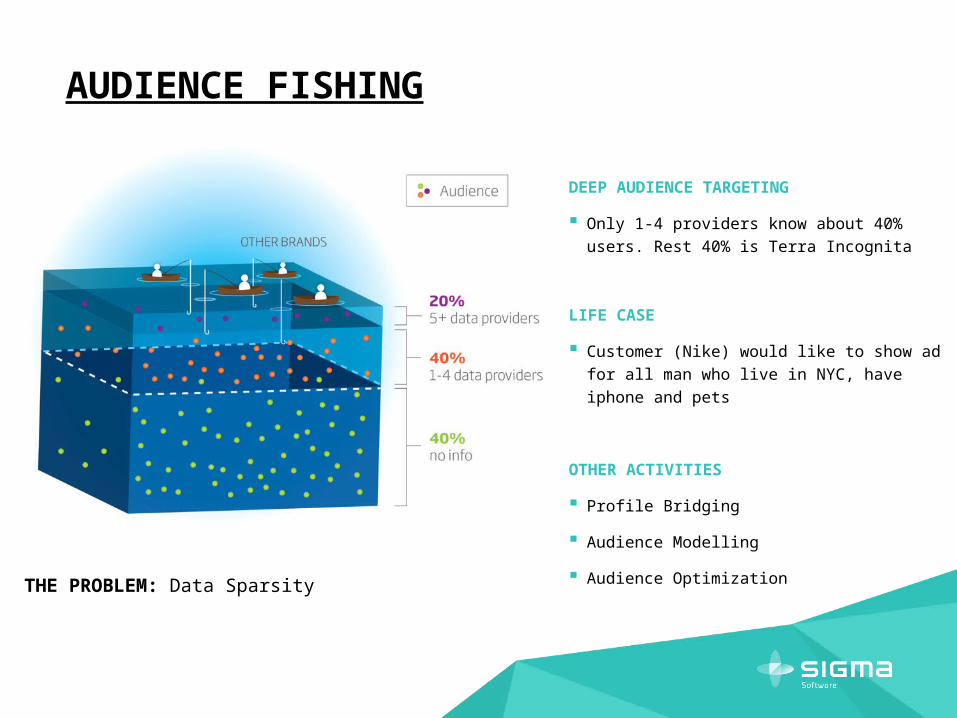
AUDIENCE FISHING
THE PROBLEM: Data Sparsity
DEEP AUDIENCE TARGETING
Only 1-4 providers know about 40% users. Rest
40% is Terra Incognita
LIFE CASE
Customer (Nike) would like to show ad for all man
who live in NYC, have iphone and pets
OTHER ACTIVITIES
Profile Bridging
Audience Modelling
Audience Optimization

DATA SOURCES
DATA USED FOR MODELING
PROPRIETARY DATA 3rd PARTY DATA
VISITATION HISTORY
Site / Page / Context
Time
IP DERIVED DATA
Location
Connection type
PERFORMANCE HISTORY
Actions
Engagements
USER AGENT DATA
Devices
OS & Browser
DEMOGRAPHICS
Age, Gender
Household
composition
POINT OF SALE
Purchase history
SEARCH
In-market for a
product
Find the meaningful signal
in noisy internet data
through high quality
models

QUICK FACTS ABOUT TECH STACK
YARN-BASED
IMPALA & HIVE
Scalable local
warehouse
SPARK
Streaming via Kafka
CLASSIC
IBM Netezza
Local warehouse
PYTHON
R LANGUAGE
predictions
modelling
GGPLOT2
Visualizations
Insights

DATA
CHALLENGES

BIG DATA AT SCALE
USERS
>1B active user profiles
MODELS
1000s of models built weekly
PREDICTIONS
100s of billions predictions daily
MODELING AT SCALEVOLUME
Petabytes of data used
VARIETY
Profiles, formats, screens
VELOCITY
100k+ requests per second
20 billions events per day
VERACITY
Robust measurements

INFRASTRUCTURE
Expensive infrastructure (Cluster size >>100s machines)
We use private own cloud
We use Cloudera paltform (CDH 5.4.1)
Efficient software and hardware deployment strategy
LESSONS LEARNED
Do not delegate cluster maintenance to developers
relying on devops engineers and Cloudera
Any thing should be monitored and measured in real time
Think like Google. Our data disposes a lot of space. We track and log everything
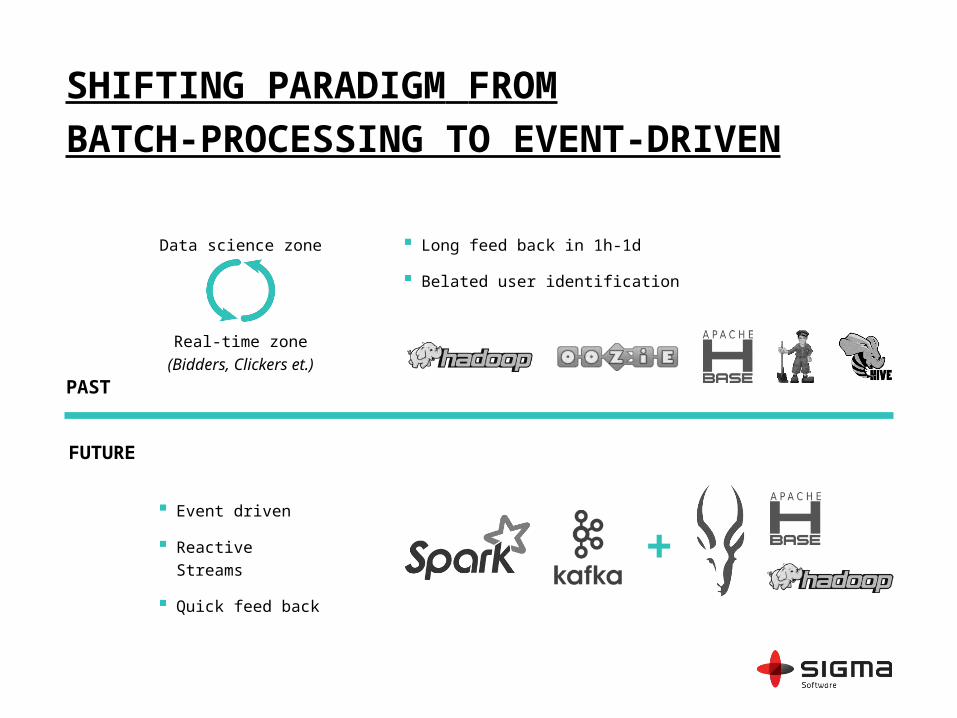
SHIFTING PARADIGM FROM
BATCH-PROCESSING TO EVENT-DRIVEN
PAST
FUTURE
Event driven
Reactive Streams
Quick feed back
Long feed back in 1h-1d
Belated user identification
+
Data science zone
Real-time zone
(Bidders, Clickers et.)

LET’S SCALDING
SOMETHING

SCALDING IN A NUTSHELL
hdfs
map
project
groupBy hdfs
CONCISE DSL OVER SCALA
Developed on top of Java-based Cascading
framework
CAN BE CONSIDERED AS A FLOW PIPE
CONFIGURABLE SOURCE AND SINK
Multiple sources and sinks
DATA TRANSFORM OPERATIONS:
Map / flatMap
Pivot / unpivot
Project
groupBy / reduce / foldLeft

JUST ONE EXAMPLE (JAVA WAY)public class WordCount { public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
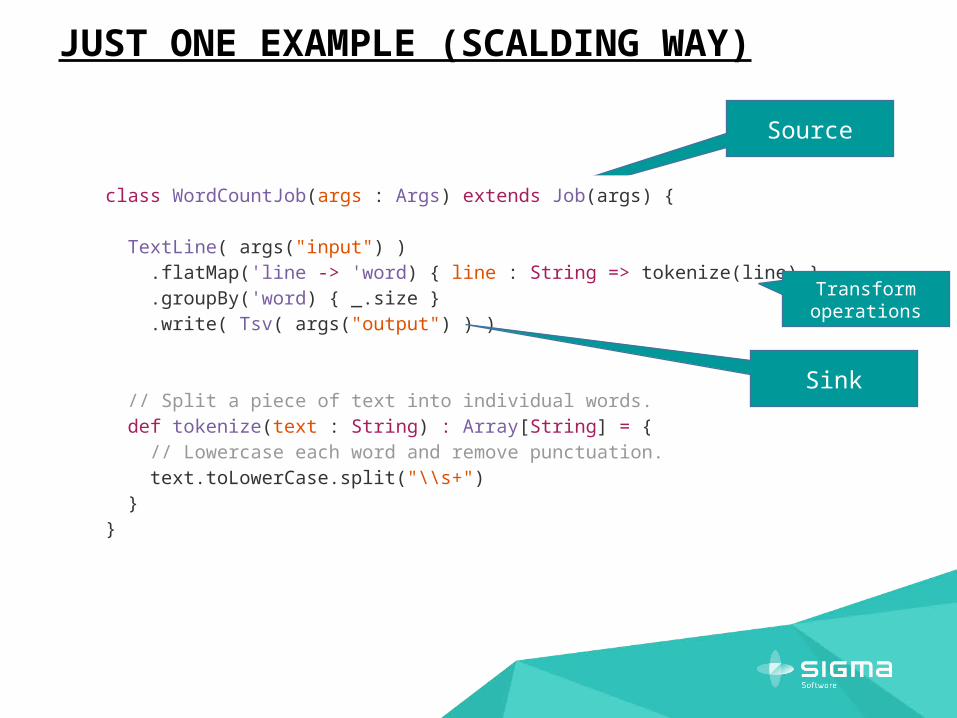
Source
JUST ONE EXAMPLE (SCALDING WAY)
class WordCountJob(args : Args) extends Job(args) { TextLine( args("input") ) .flatMap('line -> 'word) { line : String => tokenize(line) } .groupBy('word) { _.size } .write( Tsv( args("output") ) ) // Split a piece of text into individual words. def tokenize(text : String) : Array[String] = { // Lowercase each word and remove punctuation. text.toLowerCase.split("\\s+") }}
Sink
Transform operations

USE CASE 1 - SPLIT
val common = Tsv("./file").map(...) val branch1 = common.map(..).write(Tsv("output")) val branch2 = common.groupby(..).write(Tsv("output"))
MOTIVATION
Reuse calculated streams
Performance
MOTIVATION

USE CASE 3 - EXOTIC SOURCES / SINKS
HBASEHBaseSource
https://github.com/ParallelAI/SpyGlass
SCAN_ALL
GET_LIST
SCAN_RANGE
HBaseRawSource
https://github.com/btrofimov/SpyGlass
Advanced filtering via base64Scan
Support of CDH 5.4.1
Feature to remove particular columns from rows
val scan = new Scan()
scan.setCaching(caching)
val activity_filters = new FilterList(MUST_PASS_ONE, {
val scvf = new
SingleColumnValueFilter(toBytes("family"),
toBytes("column"), GREATER_OR_EQUAL,
toBytes(value))
scvf.setFilterIfMissing(true)
scvf.setLatestVersionOnly(true)
val scvf2 = ...
List(scvf, scvf2)
})
scan.setFilter(activity_filters)
new HBaseRawSource(tableName, quorum, families, base64Scan = convertScanToBase64(scan)).read. ...
val hbs3 = new HBaseSource( tableName, quorum, 'key, List("data"), List('data), sourceMode = SourceMode.SCAN_ALL) .read

USE CASE 4 - JOIN
Joining two streams by key
Different performance strategies:
joinWithLarger
joinWithSmaller
joinWithTiny
Inner, Left, Right, strategies
MOTIVATION
val pipe1 = Tsv("file1").readval pipe2 = Tsv("file2").read // small fileval pipe3 = Tsv("file3").read // huge file val joinedPipe = pipe1.joinWithTiny('id1 -> 'id2, pipe2) val joinedPipe2 = pipe1.joinWithLarge('id1 -> 'id2, pipe3)

USE CASE 5 – DISTRIBUTED CACHING
AND COUNTERS
//somewhere outside Job definitionval fl = DistributedCacheFile("/user/boris/zooKeeper.json") // next value can be passed through any Scalding's jobs via Args object for instanceval fileName = fl.path... class Job(val args:Args) { // once we receive fl.path we can read it like a ordinary file val fileName = args.get("fileName") lazy val data = readJSONFromFile(fileName) ... TSV(args.get("input")).read.map('line -> 'word ) { line => ... /* using data json object*/ ... }}
// counter exampleStat("jdbc.call.counter","myapp").incBy(1)

USE CASE 5
PROFILE BRIDGING
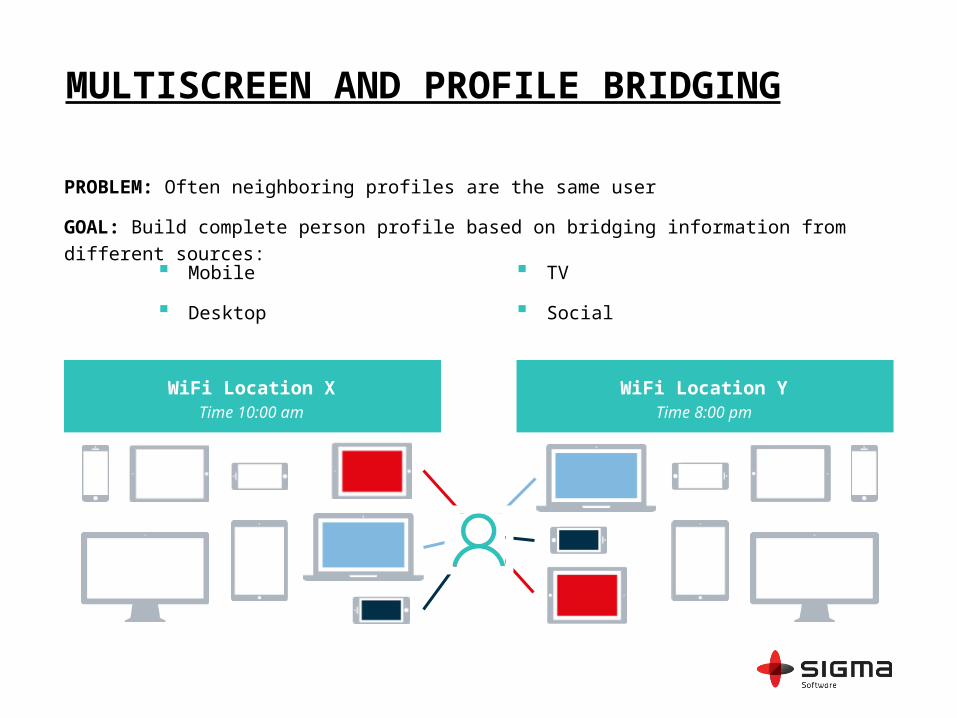
MULTISCREEN AND PROFILE BRIDGING
PROBLEM: Often neighboring profiles are the same user
GOAL: Build complete person profile based on bridging information from different sources:
Mobile
Desktop
TV
Social
WiFi Location XTime 10:00 am
WiFi Location YTime 8:00 pm
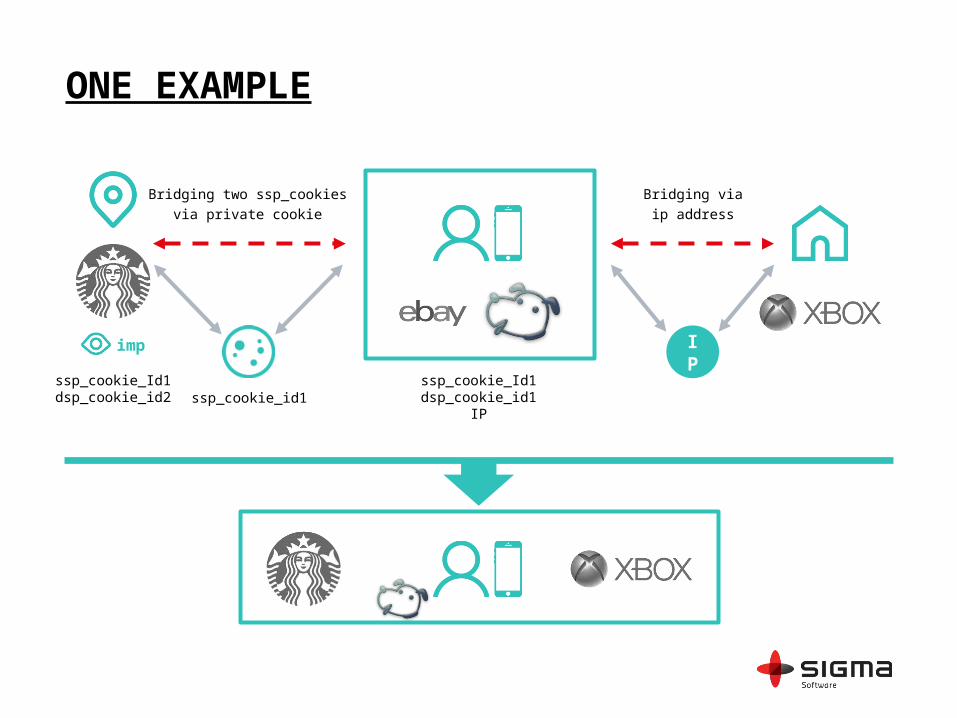
ONE EXAMPLE
ssp_cookie_Id1dsp_cookie_id1
IP
Bridging via
ip address
IP
Bridging two ssp_cookies
via private cookie
imp
ssp_cookie_Id1dsp_cookie_id2 ssp_cookie_id1

PROFILE BRIDGING THROUGH MATH
LENSES
General task definition:
Build graph
Vertexes – user’s interests
Edges – bridging rules [cookies, IP,…]
Task – Identify connected components
We do bridging on daily basis

SCALDING CONNECTED COMPONENTS
/**
* The class represents just one iteration of searching connected component algorithm.
* Somewhere outside the Job code we have to run this job iteratively until N [~20] and should check number inside "count" file.
* If it is zero then we can stop running other iterations
*/
class ConnectedComponentsOneIterationJob(args : Args) extends Job(args) {
val vertexes = Tsv( args("vertexes"),('id,'gid)).read // by default gid is equal to id
val edges = Tsv( args("edges"), ('id_a,'id_b) ).read
val groups = vertexes.joinWithSmaller('id -> 'id_b, vertexes.joinWithSmaller('id -> 'id_a, edges).discard('id ).rename('gid ->'gid_a))
.discard('id )
.rename('gid ->'gid_b)
.filter('gid_a, 'gid_b) {gid : (String, String) => gid._1 != gid._2 }
.project ('gid_a, 'gid_b)
.mapTo(('gid_a, 'gid_b) -> ('gid_a, 'gid_b)) {gid : (String, String) => max(gid._1, gid._2) -> min(gid._1, gid._2) }
// if count=0 then we can stop running next iterations
groups.groupAll { _.size }.write(Tsv("count"))
val new_groups = groups.groupBy('gid_a) {_.min('gid_b)}.rename(('gid_a,'gid_b)->('source, 'target))
val new_vertexes = vertexes.joinWithSmaller('id -> 'source, new_groups, joiner = new LeftJoin )
.mapTo( ('id,'gid,'source,'target)->('id, 'gid)) { param:(String, String, String, String) =>
val (id, gid, source,target) = param
if (target != null) ( id , min( gid, target ) ) else ( id, gid )
}
new_vertexes.write( Tsv( args("new_vertexes") ) )
}

OTHER SWEET THINGS
Typed Pipes
Elegant and fast Matrix operations
Simple migration on Spark/Kafka
More sources: e.g. retrieve data from hive’s hcatalog, jdbc, …
Simple Integration Testing

USEFUL RESOURCES
http://www.adopsinsider.com/ad-serving/how-does-ad-serving-work/
http://www.adopsinsider.com/ad-serving/diagramming-the-ssp-dsp-and-rtb-redirect-path/
https://github.com/twitter/scalding
https://github.com/ParallelAI/SpyGlass
https://github.com/btrofimov/SpyGlass
https://github.com/branky/cascading.hive

THANK YOU!