régression robuste - cedric.cnam.frcedric.cnam.fr/~saporta/regressionrobuste.pdf · • rousseeuw,...
TRANSCRIPT

1
Régression robuste
Gilbert Saporta Conservatoire National des Arts et Métiers http://cedric.cnam.fr/~saporta Décembre 2012

• En présence de contamination par une fraction d’observations ne suivant pas le modèle (données « aberrantes ») les moindres carrés sont peu robustes
• Les méthodes robustes ont pour but de trouver le modèle correspondant à la majorité des observations
2

3
1.Les moindres carrés
• Fonction de perte: • Minimisation de E(L) f optimal: f(x)= E(Y/x) • Hypothèse de régression linéaire:
E(Y/x)=β0+β1x en régression multiple: E(Y/x)=x’ β
( )2( ; ( )) ( )L y f x y f x= −

4
• Estimateur des moindres carrés ˆ
0 Equations normales
projecteur
W⊥ = ∀
-1
-1
y = Xb = Ayy - Xb (y - Xb)'Xu uX'y = X'Xb b = (X'X) X'y
A = X(X'X) X'
• b estimateur de variance minimale de β parmi les estimateurs linéaires sans biais • estimateur du maximum de vraisemblance si résidus gaussiens iid
2 1( ) (V σ −=b X'X)

5
• Démo
cours de Marc Bourdeau (Montréal) sur le modèle linéaire
http://www.agro-montpellier.fr/cnam-
lr/statnet/cours_autre.htm

6
• Sensibilité aux valeurs extrêmes
– Ne pas confondre observations aberrantes et observations influentes (au sens de l’écart au modèle)

• Différents types de points aberrants:
7 D’après E.Cantoni et C.Dehon

8
Résidus et influence des observations
• Résidu : vecteur • La « hat matrix » ou projecteur
• Les termes diagonaux hi
ˆy - y
ˆ' = =-1A X(X'X) X y Ay
1
1 1 1n
i ii
h h pn =
≤ ≤ = +∑

9
• Résidu: – espérance nulle,
• Résidu studentisé
• Résidu prédit (en enlevant i)
• Press: somme des carrés des résidus prédits • Influence d’une observation sur les estimations
des coefficients: la distance de Cook
– Devrait rester <1
2ˆ( ) (1 )i i iV y y hσ− = −ˆ
ˆ 1i i
i
y yhσ
−−
( )ˆˆ
1i i
i ii
y yy yh−
−− =
−
( ) ( ) ( )'
2( ) ( )2
1 ˆ ˆˆ( 1) 1 1
i i ii i i
i
hD y yp p hσ
− −−
− −= = −
+ + −
b b X'X b b

• Insuffisants pour détecter toutes les valeurs aberrantes: – effet de masque – estimations non robustes
• Nécessité d’utiliser des indicateurs robustes de tendance centrale et de dispersion pour calculer une variante robuste de la distance de Mahalanobis
10

11 D’après E.Cantoni et C.Dehon

12
2.Régression en norme L1 (LAD)
• Fonction de perte:
• Minimisation de E(L) f optimal: f(x)= Med(Y/x) • En régression linéaire simple sur
échantillon
( ; ( )) ( )L y f x y f x= −
1min
n
i ii
y a bx=
− −∑
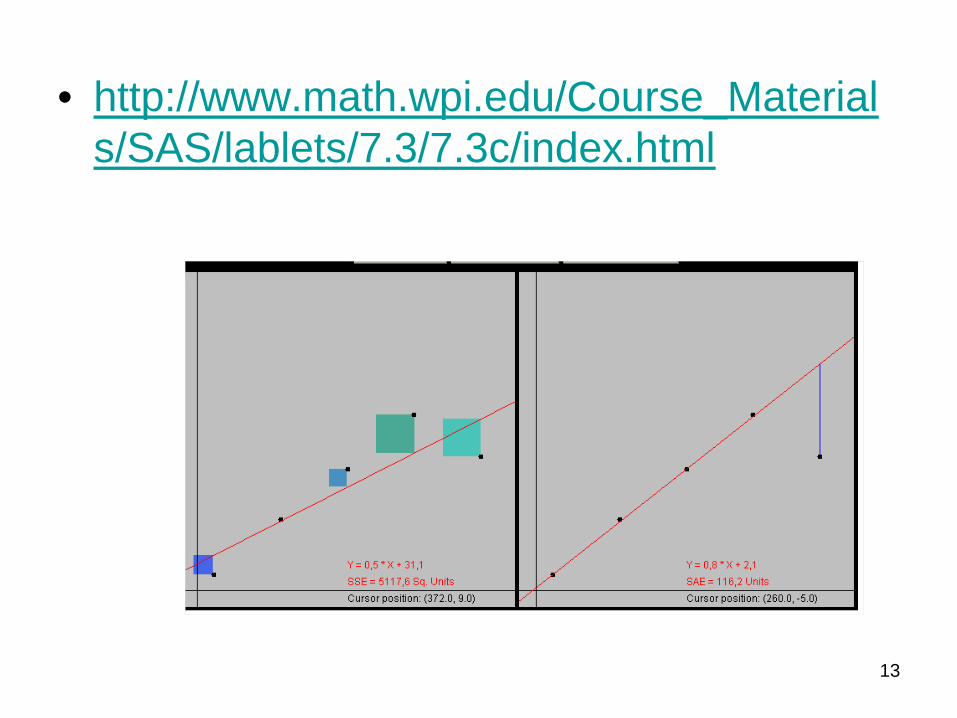
13
• http://www.math.wpi.edu/Course_Materials/SAS/lablets/7.3/7.3c/index.html

14
• 50 ans plus ancien que les moindres carrés: Boscovitch 1757
• Résolution plus difficile (surtout en régression multiple) – Pas de solution analytique – Nécessité d’un algorithme
• Propriété: – La droite de régression L1 passe par deux des
points

15
• Algorithme LAD simple (Birkes & Dodge, 1993) – Prendre un point (x1,y1), trouver la meilleure droite passant par
ce point. Elle passe par au moins un autre point noté (x2,y2) – Trouver la meilleure droite passant par (x2,y2) . Elle passe par
(x3,y3) – Continuer jusqu’ à ce que (xk,yk) = (xk-1,yk-1)
• Possibilité de non-unicité ou de dégénérescence
• Régression LAD multiple – Programmation linéaire – p+1 résidus sont nuls

16
• Erreurs standard asymptotiques
avec f densité de ε
( )( ) 1
21ˆ( ) '
4 (0)V
f−β X X

17
3.M-régression
• Issue des M-estimateurs de Huber • Exemple: fonction de perte quadratique
jusqu’à c, linéaire au delà

18
• Pour c grand, on retrouve les mco, pour c=0 la régression L1
• Si σ= 1, c=1.5 donne une estimation d’efficacité asymptotique 95% dans le cas gaussien

19
• ρ fonction convexe paire
– M-estimateur: maximum de vraisemblance avec erreurs de densité proportionnelle à exp(- ρ(u))
• En dérivant: • Notation usuelle ψ = ρ’ • Moindres carrés pondérés
( )1
minn
i ii
yρ=
−∑ x β
( )1
ˆ' ' 0n
i i ii
yρ=
− =∑ x β x
( ) ( )1
ˆ'ˆ ' 0 avec ˆ
n i ii i i i i
i i i
yw y w
y
ρ
=
−− = =
−∑
x βx β x
x β

20
Propriétés
• Si σ est inconnu on minimise avec a>0 • La matrice de covariance des estimateurs
est asymptotiquement proportionnelle à celle des moindres carrés
1
ni i
i
y aρ σσ=
− + ∑ x β

21

22
Weight Function Option Default a, b, c
andrews WF=ANDREWS<(C=c)>
bisquare WF=BISQUARE<(C=c)>
cauchy WF=CAUCHY<(C=c)>
fair WF=FAIR<(C=c)>
hampel WF=HAMPEL<( <A=a> <B=b> <C=c>)>
huber WF=HUBER<(C=c)>
logistic WF=LOGISTIC<(C=c)>
median WF=MEDIAN<(C=c)>
talworth WF=TALWORTH<(C=c)>
welsch WF=WELSCH<(C=c)>
4.Fonction de poids Proc ROBUSTREG de SAS

23

24
5.Régression LTS (Least Trimmed Squares) de Rousseuw
• Basée sur le sous ensemble de h individus (parmi n) où les mco donnent la plus petite somme des carrés des résidus. h est choisi entre n/2 et n . La valeur h=(3n+p+1)/4 est recommandée.

25
Complément: notion de « point de rupture» d’un estimateur • Fraction des données qui peuvent être arbitrairement
changées sans changer arbitrairement la valeur de l’estimateur.
• Deux cas : n fini, n infini (pt de rupture asymptotique) – Ne peut être > 0.5 – Asymptotiquement:
• Nul pour la moyenne (si une valeur deveint infinie, la moyenne aussi)
• 0.5 pour la médiane – n fini
• 1/n pour la moyenne, (n-1)/2n pour la médiane, (n-h)/ h pour la régression LTS

26
Bibliographie • Birkes, D., Dodge, Y. (1993) Alternative methods of regression,
Wiley • Rousseeuw, P.J. and Leroy, A.M. (1987), Robust Regression and
Outlier Detection, New York: John Wiley & Sons, Inc.

27
Régression non-paramétrique
Gilbert Saporta Conservatoire National des Arts et Métiers http://cedric.cnam.fr/~saporta Décembre 2012

28
• Estimation de l’espérance conditionnelle E(Y/x0)= f(x0) , ou fonction de régression.
• Approche similaire à l’estimation de densité par la méthode du noyau
• Premières tentatives inspirées des moyennes mobiles: – les k plus proches voisins: moyenne de y pour
les k-ppv de x0
– moyenne des y sur une fenêtre de largeur fixe centrée sur x0
Inconvénient majeur: discontinuité

29

30
Méthode de la fenêtre mobile
• Moyenne des yi dans un voisinage autour de x0: [x0-h/2; x0+h/2]
[ ]
[ ]
0 0
0 0
/2; /21
0
/2; /21
1 ( )ˆ ( )
1 ( )
n
i ix h x hi
n
ix h x hi
y xf x
x
− +=
− +=
=∑
∑

31
Utilisation d’un noyau continu: l’estimateur
de Nadaraya-Watson Noyaux classiques:
– Epanechnikov
– Tricube
0
10
0
1
ˆ ( / )
ni
ii
ni
i
x xK yhE Y X x
x xKh
=
=
− = =
−
∑
∑
23( ) (1- ) si 1, 0 sinon4
K u u u= ≤
( )33( ) 1 si 1, 0 sinonK u u u= − ≤

32

33
• http://www.cs.uic.edu/~wilkinson/Applets/smoothers.html

34

35
• Biais et variance pour des xi fixés
( )( )
( )
0
01
0 0
1
2
2 10 2
2
1
( ) ( )ˆ ( ) ( )
ˆ ( )i
i
ii
n
i ii
n
ii
n
i
n
i
x xw Kh
w f x f xE f x f x
w
wV f x
wσ
=
=
=
=
− =
−− =
=
∑
∑
∑
∑

36
Si les xi sont nombreux et équidistants sur [a;b]
Valable si la fenêtre est incluse dans [a;b]
( ) ( )0 0 0 0
22
0
ˆ ( ) ( ) ( ) ( ) ( )
"( ) ( )2
E f x f x K u f x uh f x du
h g x u K u du
− + −∫
∫

37
• Problèmes d’estimation aux bornes

38
• Régression linéaire locale – Résout le problème de l’asymetrie du noyau
tronqué aux bornes. Enlève le biais à l’ordre 1 – On résout en chaque point x0 le problème de
moindres carrés pondérés:
– Nota: formules globales (pour tout x), mais chacune utilisée seulement en x0
[ ]0 0
200 0( ), ( ) 1
min ( ) ( )n
ii ix x i
x xK y x x xhα β
α β=
− − −
∑

39
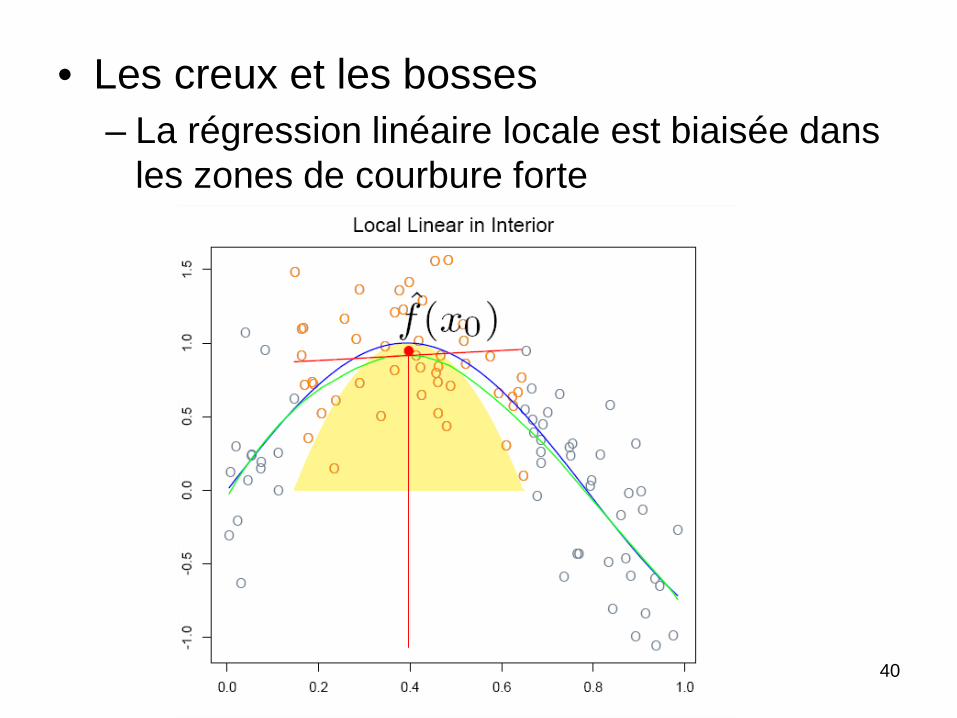
40
• Les creux et les bosses – La régression linéaire locale est biaisée dans
les zones de courbure forte

41
• Régression polynomiale locale
0 0
2
00 0( ), ( ) 1 1
min ( ) ( )i
n dji
i jx x i j
x xK y x x xhα β
α β= =
− − −
∑ ∑

42
• Estimation linéaire et noyau équivalent – moindres carrés pondérés X matrice à n lignes et d+1 colonnes des xj
( ) 1'0 0 0 0
01
ˆ ( ) ( ) ( )
( ) = n
i ii
f x x x
l x y
−
=
=
∑
x X'W X X'W y
00 ,( ) matrice diagonale de terme in n K
x xxh−
W

43

44
• Choix de h – validation croisée
• Méthode proche: LOESS ou LOWESS • Extension possible à la régression
logistique

45
SAS INSIGHT

46

47

48

49
Avantages et inconvénients
• Utile si la forme de la régression est totalement inconnue
• Méthode adaptative qui s’ajuste automatiquement mais • Pas de formule explicite, prévision délicate en
dehors du domaine (extrapolation) • Généralisation difficile en régression multiple
« curse of dimensionality »

50
Bibliographie • Cleveland, W.S.; Devlin, S.J. (1988). Locally-Weighted Regression:
An Approach to Regression Analysis by Local Fitting . Journal of the American Statistical Association 83 (403): 596–610.
• Droesbeke, J.J., Saporta G. (éditeurs) (2011) Approches non paramétriques en régression, Editions Technip
• Hastie, T., Tibshirani,R., Friedman, J.( 2009): The Elements of Statistical Learning , 2nd edition, chapitre 6, Springer, http://www-stat.stanford.edu/~hastie/Papers/ESLII.pdf
• Lejeune, M. (1985), Estimation non paramétrique par noyaux : régression polynomiale mobile, Revue de Statistique Appliquée, 33, 43-68.