agilekdd: an agile process model to knowledge … · agilekdd: an agile process model to knowledge...
TRANSCRIPT

AGILEKDD: AN AGILE PROCESS MODEL TO KNOWLEDGE DISCOVERY IN DATABASES AND BUSINESS INTELLIGENCE SYSTEMATIZATION
Givanildo Santana do Nascimento (Petrobras, Sergipe, Brasil) - [email protected]éia Aparecida de Oliveira (Universidade Federal de Sergipe, Sergipe, Brasil) [email protected]
In the context of knowledge-based economies and Knowledge Society, the global competition is increasingly based on the capacity of transforming data into information, information into knowledge and knowledge into value. Data, information and knowledge constitute fundamental intangible assets for all organizations working in this social and economical model. In this context, the mission of Software Engineering is to produce systems able to process large volumes of data, transform them into relevant knowledge and deliver them to customers, so they can make right decisions at the right time. The development of this kind of systems must have the guidance of a process capable of conduct the transformation of customers business requirements into explicit knowledge and software products, observing harder time, budget and quality constraints. The Knowledge Discovery in Databases and Business Intelligence systematization effort has resulted in several process models. However, companies still face failures in determining the process model used in their Knowledge Discovery in Databases and Business Intelligence projects. The availableprocesses still do not consider Software Engineering fundamental capabilities as projects, requirements and changes managements disciplines. Several existing processes are unsuitable to the ever-changing business environments or lack of scientific experimentation in real cases, in order to confirm their qualities and identify their shortcomings. The process proposed in this work, the AgileKDD, aims to integrate the best practices of the main Knowledge Discovery in Databases processes with an agile software process. The AgileKDD applicability was verified by a real case study, in which common problems such as requirements changes and poor data quality strongly influenced the project results. The case study pointed out some process improvement needs, which were considered in AgileKDD refinement. The resulting refined process can be applied as an adaptive and flexible framework to develop software systems capable of discover knowledge from data and information. The process supports the early and continuous delivery of value to the costumer by means of an iterative and incremental lifecycle, immediate response to changes, as well as the adaptability and flexibility intrinsic to agile processes.
Keywords: Software Process, Knowledge Discovery in Databases, Business Intelligence, Agile Software Development.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3120

I. INTRODUÇÃOA Organização para a Cooperação Econômica e Desenvolvimento definiu as
economias, baseadas em conhecimento, como “economias que são diretamente baseadas na produção, distribuição e uso de conhecimento e informação” (OECD, 1996). No contexto das economias baseadas em conhecimento e, de forma mais ampla, na Sociedade doConhecimento, a competição global é cada vez mais baseada na capacidade de transformar dados em informações, informações em conhecimento e conhecimento em valor. O conhecimento equipara-se aos fatores tradicionais de produção – terra, capital, matéria-prima, energia e mão-de-obra – no processo de criação de riqueza. Desta forma, dados, informação e conhecimento constituem-se ativos intangíveis fundamentais para todas as organizações que atuam neste modelo sócio-econômico. Os processos produtivos tradicionais estão evoluindo para modelos de produção intensivos em informação e conhecimento e esta é uma das principais preocupações dos gestores no século XXI (BRASIL, 2010).
As empresas estão organizadas como grandes coleções de processos que consomem e produzem quantidades crescentes de dados e informações (GONÇALVES, 2000). Os dados têm a capacidade de acumular conhecimento sobre os processos de negócio e este conhecimento, por sua vez, pode ser utilizado na análise e melhoria dos processos. De acordo com Pressman (2006), ao longo da história, a computação nas organizações evoluiu dos Centros de Processamento de Dados (CPD) para as Gerências de Tecnologia da Informação e a grande maioria do software desenvolvido durante esse período teve como finalidade processar dados e produzir informações. A Engenharia de Software, como sustenta Pressman, tem o desafio de construir software que processe dados e informações e produza conhecimento.
A Descoberta de Conhecimento em Bases de Dados (DCBD), ou Knowledge Discovery in Databases (KDD), é o processo de busca e extração de conhecimento em bases de dados (BOENTE, OLIVEIRA e ROSA, 2007). Os Sistemas de Descoberta de Conhecimento em Banco de Dados (Sistemas de DCBD) apoiam a Gestão do Conhecimento possibilitando a extração e a disseminação de conhecimento organizacionaloculto em grandes volumes de dados provenientes dos processos de negócio (DIAS, 2001).
O Business Intelligence (BI) integra uma categoria de aplicações e tecnologias voltadas para a transformação de dados em informações e conhecimento (GOLFARELLI, RIZZI e CELLA, 2004). Fayyad et al. (1996) definiram DCBD como o processo não trivial de identificação de padrões válidos e potencialmente úteis, perceptíveis a partir dos dados. A Mineração de Dados (MD) é uma das principais técnicas utilizada tanto no BI quanto na DCBD, chegando a ser confundida com a própria DCBD (MARISCAL, MARBÁN e FERNÁNDEZ, 2010).
Os Sistemas de DCBD são desenvolvidos a partir de tecnologias como BI e DCBD, formando um arcabouço essencial para as organizações que competem no contexto sócio-econômico do conhecimento. Esses sistemas são vitais para organizações que desejam desenvolver, integrar, gerenciar e compartilhar informações e conhecimento como ativos indispensáveis para o alcance dos objetivos organizacionais. Por exemplo, os investimentos feitos pela Continental Airlines em BI tiveram um Retorno sobreInvestimento, ou Return on Investment (ROI), equivalente a 1000%, atribuídos ao aumento nas vendas e à redução de custos (ALNOUKARI et al., 2012; WATSON et al., 2006; WIXOM et al., 2008).
Com o objetivo de sistematizar as atividades relacionadas à implementação de Sistemas de DCBD, alguns modelos de processos e metodologias foram propostos. Os dois modelos mais utilizados, citados na literatura e suportados por ferramentas, são o KDD
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3121

Process (FAYYAD et al., 1996) e o CRoss Industry Standard Process for Data Mining(CRISP-DM) (CHAPMAN et al., 2000). Diversos outros processos foram propostos com o mesmo objetivo, entretanto o KDD Process e o CRISP-DM continuaram sendo os principais modelos e os outros processos são considerados variações deles (ALNOUKARIe SHEIKH, 2012; MARISCAL, MARBÁN e FERNÁNDEZ, 2010; ALNOUKARI et al., 2012). O KDD Process, o CRISP-DM e as suas variações são centrados nas técnicas deMD e não contemplam ciclos de vida, fases, disciplinas, papeis, produtos de trabalho e outros elementos tipicamente presentes na Engenharia de Sistemas de Software (KURGANe MUSILEK, 2006). Entretanto, tais elementos são indispensáveis no desenvolvimento de Sistemas de DCBD.
Por isso, Dias (2001) propôs um modelo para formalização do processo de desenvolvimento de Sistemas de DCBD. Nesse modelo, os dados são armazenados em um Data Warehouse (DW)1 antes de serem submetidos aos algoritmos de mineração de dados.A partir do modelo de processo proposto por Dias (2001), Valentin (2006) descreveu uma arquitetura de referência para Sistemas de DCBD. Sobre esta arquitetura de referência, foi definido o Unified Process for Knowledge Discovery in Database (UPKDD) (HERDEN,2007; HERDEN et al., 2011), um processo de software baseado no Processo Unificado(PU)2 para aplicações analíticas centradas em objetivos de descoberta de conhecimento. O UPKDD oferece uma sequência ordenada e disciplinada de atividades para especificação, projeto, implementação e evolução de Sistemas de DCBD.
1.1 Problemática e Hipótese
Apesar da prioridade dada pelas organizações à DCBD nos últimos anos, dos processos, metodologias e ferramentas criados, muitos projetos de DCBD não atingiram os seus objetivos ou foram cancelados (MARISCAL, MARBÁN e FERNÁNDEZ, 2010). O agravamento da crise financeira internacional provocou cortes significativos nos orçamentos de Tecnologia da Informação (TI) das organizações a partir de 2009, privilegiando iniciativas mais produtivas e econômicas, em detrimento das que possuemmaior risco e maior prazo para ROI. Por esses motivos, o BI deixou de ocupar o primeiro lugar na lista das dez maiores prioridades em TI em 2010 e 2011, caindo para o quinto lugar na lista (GARTNER GROUP, 2005, 2006, 2007, 2008, 2009, 2010, 2011). Outro estudo revelou que mais de cinquenta por cento dos projetos de BI tiveram baixa aceitação ou falharam devido à baixa qualidade dos dados e à falta de envolvimento dos clientes (GARTNER GROUP, 2005).
Assim como o desenvolvimento de sistemas de processamento operacional, o desenvolvimento de sistemas de processamento analítico, aqui denominados Sistemas de DCBD, deve ser guiado por processos de software. No entanto, as organizações ainda falham na determinação do modelo de processos utilizado para o desenvolvimento de Sistemas de DCBD (ALNOUKARI, 2011). À medida que os requisitos de negócio tornam-se mais dinâmicos e incertos, os processos de software tradicionais tornam-se menos adequados ao desenvolvimento deste tipo de sistemas. Larson (2012) afirma que os processos tradicionais de desenvolvimento de software não são efetivos no
1 O Data Warehouse é uma coleção de dados orientada por assuntos, integrada, não-volátil e variante em relação ao tempo, que tem por objetivo apoiar os processos de tomada de decisão (INMON, 1997).
2 O Processo Unificado determina um conjunto de atividades necessárias para transformar requisitos em sistemas de software, de forma iterativa e incremental (JACOBSON, BOOCH e RUMBAUGH, 1999).
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3122

desenvolvimento de Sistemas de DCBD porque são incompatíveis com a dinâmica e a evolução constante dos ambientes de negócios corporativos. O processo adotado para a implementação da maioria dos projetos de DCBD é o CRISP-DM, sendo este o padrão de facto. Contudo a adoção do CRISP-DM vem caindo devido à ausência de atividades relacionadas ao gerenciamento de projetos, requisitos e mudanças e à Engenharia de Software de forma geral (MARBÁN et al., 2008).
Portanto, o desenvolvimento de Sistemas de DCBD necessita de um processo de software que garanta o envolvimento do cliente em todas as etapas e a qualidade mínima dos dados operacionais, antecipe o retorno do investimento, contenha disciplinas para gerenciamento de projetos, requisitos e mudanças. O processo precisa ser suficientemente simples para ser compreendido e seguido por seus praticantes, sem aumentar a complexidade natural dos projetos de DCBD. Essas características esperadas de um processo para desenvolvimento de Sistemas de DCBD vão ao encontro dos valores presentes no Manifesto para o Desenvolvimento Ágil de Software (BECK et al., 2001).Estes valores estão presentes nos processos ágeis de software, os quais são caracterizados por flexibilidade, adaptabilidade, comunicação face a face e fluxo contínuo de conhecimento entre as equipes de projetos (ALZOABI, 2012; LARSON, 2012).
A hipótese deste trabalho é: um processo ágil de software pode aumentar o fator de sucesso dos projetos de desenvolvimento de Sistemas de DCBD em cenários nos quais há mudanças nos requisitos e baixa qualidade dos dados operacionais.
1.2 Contribuições Esperadas
Com o desenvolvimento deste trabalho, podem-se apontar as seguintes contribuições:• Avaliação dos processos de DCBD existentes;• Adequação dos processos de DCBD a um processo ágil de Engenharia de
Software;• Definição de um processo ágil de software para a Engenharia de Sistemas de
DCBD;• Melhoria do fator de sucesso dos projetos de Sistemas de DCBD, minimizando os
riscos de fracasso causados por mudança nos requisitos durante os projetos e baixa qualidade dos dados operacionais; e,
• Melhoria da satisfação dos clientes dos projetos de Sistemas de DCBD por meio da entrega antecipada e contínua de produtos de software, antecipando, por conseguinte, o retorno do investimento.
1.3 Organização do artigo
Este artigo está organizado da seguinte forma: a seção um, que corresponde a esta introdução, trata da contextualização, problemática, hipótese, objetivos, contribuições esperadas e organização deste artigo. A seção dois apresenta o enquadramento metodológico desta pesquisa. A seção três aborda os processos para descoberta de conhecimento em bancos de dados existentes. A seção quatro descreve o processo AgileKDD, suas fases, atividades e papeis. O estudo de caso que confirmou a aplicabilidade do AgileKDD é apresentado na seção cinco. A seção seis explica o refinamento do processo AgileKDD a partir dos pontos de melhoria identificados no estudo de caso. Finalmente, a seção sete apresenta as conclusões, as considerações finais, as principais contribuições, limitações deste trabalho e as oportunidades de trabalhos futuros.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3123

II. METODOLOGIAA Figura 1 apresenta o enquadramento metodológico desta pesquisa. Sob o ponto de
vista da sua natureza, esta pesquisa é aplicada, pois objetiva gerar conhecimentos para aplicação prática, dirigidos à solução de problemas específicos. Quanto à forma de abordagem do problema, esta pesquisa é qualitativa3, pois é baseada na interpretação dos resultados e na atribuição de significados descritivos (MIGUEL, 2007). Na pesquisa qualitativa, diferentemente da quantitativa, o pesquisador busca compreender os fenômenos observando-os, interpretando-os e descrevendo-os (MELLO et al., 2012).
Com relação aos seus objetivos, esta pesquisa é exploratória, pois visa proporcionar maior familiaridade com o problema com vistas a torná-lo explícito ou a construir hipóteses (GIL, 1996). Ela envolve levantamento bibliográfico e análise de exemplos que estimulam a compreensão. Este tipo de pesquisa assume, em geral, as formas de revisõesbibliográficas e estudos de caso (SILVA, 2005). Sob a ótica dos procedimentos técnicos, esta pesquisa utilizará Estudo de Caso4 para a validação de hipóteses. Para Severino (2007), esta modalidade de pesquisa científica se concentra no estudo de um caso particular, considerado representativo de um conjunto de casos análogos. Portanto, esta pesquisa é Aplicada, Qualitativa, Exploratória, com Estudo de Caso.
O estudo de caso é um estudo de natureza empírica que investiga um determinado fenômeno dentro de um contexto real. Trata-se de uma análise aprofundada de um ou mais objetos (casos), para que permita o seu amplo e detalhado conhecimento (GIL, 1996; MIGUEL, 2007). Seu objetivo é aprofundar o conhecimento acerca de um problema não suficientemente definido, visando estimular a compreensão, sugerir hipóteses e questões ou desenvolver a teoria. Os estudos de casos podem ser classificados segundo a quantidade de casos como caso único ou casos múltiplos. A principal tendência das pesquisas realizadas com estudo de caso é que estes tentem esclarecer o motivo pelo qual foram tomadas uma decisão ou um conjunto de decisões, como foram implementadas e como os resultadosforam alcançados (YIN, 2001).
3 Em pesquisas qualitativas os pesquisadores analisam os resultados indutivamente, sem utilizarem obrigatoriamente de métodos estatísticos, como acontece nas pesquisas quantitativas (MIGUEL, 2007).
4 Pesquisas com estudos de casos podem ser caracterizadas como exploratórias, pois provêem ao pesquisador e sua audiência um maior conhecimento sobre o tema, relacionando um caso real às teorias do assunto (MIGUEL, 2007).
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3124

Figura 1 – Enquadramento metodológico desta pesquisa.
A Figura 2 ilustra o método de condução de estudos de casos definido por Miguel (2007) e adotado neste trabalho. Primeiramente, foi definida uma estrutura conceitual-teórica acerca do tema estudado. Em seguida, planejou-se a execução do caso ou dos casos que serão trabalhados. Na sequência, o caso foi executado e os dados resultantes da execução do caso foram coletados e analisados. Finalmente, esta dissertação foi redigidapara descrever a execução e as conclusões do trabalho.
Este trabalho foi executado de acordo com o seguinte roteiro:(i) Definição da estrutura conceitual-teórica: revisão da literatura relacionada aos
processos de BI e DCBD, associando-os aos processos da Engenharia de Software. Ao final desta fase, foi elaborado o processo AgileKDD, visando à solução dos problemas encontrados nos processos estudados.
(ii) Planejamento do caso: foi selecionado um caso real de uma necessidade de Sistema de DCBD em uma empresa integrada de energia, para ser desenvolvido de acordo com o processo AgileKDD.
(iii) Condução do piloto: o Sistema de DCBD foi desenvolvido visando à confirmação da aplicabilidade do processo AgileKDD.
(iv) Coleta de dados: durante a condução do piloto, os dados relativos ao desenvolvimento do produto com base no processo AgileKDD foram coletados.
(v) Análise dos dados: os dados coletados foram analisados e, com base nesta análise, o processo AgileKDD foi refinado.
(vi) Geração do relatório: a presente dissertação foi escrita com a finalidade de descrever todas as etapas da pesquisa.
EnquadramentoMetodológico
Natureza dapesquisa
Abordagem doproblema
Natureza doobjetivo
Procedimentostécnicos
Aplicada
Básica
Qualitativa
Quantitativa
Quali-quantitativa
Exploratória
Descritiva
Explanatória
Estudo de caso
Pesquisa-ação
Pesquisa bibliográfica
Pesquisa documental
Pesquisa participante
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3125

Figura 2 – Método de condução de estudos de casos. Fonte: Miguel (2007).
III. PROCESSOS PARA DESCOBERTA DE CONHECIMENTO EM BANCOSDE DADOS
O esforço de sistematização da DCBD resultou em uma variedade de processos, cuja evolução, desde a definição do KDD Process em 1993, a definição do CRISP-DM em 2000 e do ASD-BI em 2012, está ilustrada na Figura 3. Entre todos os processos apresentados nesta figura, o KDD Process e o CRISP-DM destacam-se como os mais adotados, mais citados na literatura e suportados por ferramentas de DCBD. Esses dois processos são considerados os padrões de facto na área da DCBD (KURGAN e MUSILEK, 2006; MARISCAL, MARBÁN e FERNÁNDEZ, 2010; ALNOUKARI e SHEIKH, 2012; ALNOUKARI et al., 2012).
Outro processo que merece destaque por associar as atividades da DCBD às práticas da Engenharia de Software é o Unified Process for Knowledge Discovery in Database, o qual é baseado no Processo Unificado. O KDD Process, o CRISP-DM e o UPKDD serão apresentados individualmente e, ao final do capítulo, serão comparados com o objetivo de destacar as lacunas deixadas por eles.
3.1 KDD Process
O KDD Process foi proposto por Fayyad et al. (1996) como o resultado da primeira iniciativa de sistematização da DCBD, caracterizando-a como uma atividade multidisciplinar que envolve Bancos de Dados, Estatística, Reconhecimento de Padrões, Inteligência Computacional, entre outras disciplinas. O termo Process está relacionado à ideia de que a DCBD envolve um conjunto de passos que precisam ser executados para a descoberta de conhecimento útil a partir de um conjunto de dados.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3126

Figura 3 – Evolução dos processos de DCBD, do KDD Process ao ASD-BI.Fonte: Adaptado de Mariscal, Marbán e Fernández (2010).
O KDD Process é um processo iterativo e interativo, composto por nove passos que transformam dados operacionais em ações baseadas no conhecimento descoberto. O processo é interativo porque se não houver mecanismos de comunicação com o usuário, principalmente no domínio da aplicação, para a avaliação de padrões interessantes, a busca torna-se inválida e inadequada. É iterativo porque possibilita repetições entre quaisquer dos seus nove passos. A natureza iterativa proporciona maior interação do usuário ao processo de descoberta, visto que não é suficiente apenas seguir passos, mas sim interagir com o processo de descoberta várias vezes até que o conhecimento esperado pelo especialista seja encontrado. As iterações dos passos do processo indicam mais interação do usuário e a obtenção de conhecimento mais preciso, já que os refinamentos só podem ser realizados pelos usuários e não automaticamente pelas técnicas de mineração de dados (HERDEN, 2007).
O primeiro passo tem como objetivo entender o domínio de negócio do qual se deseja extrair conhecimento. No segundo passo um conjunto de dados no qual será aplicada a descoberta de conhecimento é selecionado. Em seguida é realizada a limpeza para remoção de ruídos e inconsistências dos dados, além do preenchimento de valoresimportantes ausentes nos dados originais. No quarto passo é feita a redução no número de variáveis consideradas pelo processo de DCBD e a busca por representações invariantes dos dados, nas quais a MD é infrutífera. Continuando o fluxo do processo, os objetivos do projeto de DCBD, definidos no primeiro passo, são relacionados a um método de MD, para que sejam selecionados os algoritmos de MD no passo seguinte (FAYYAD et al., 1996).
O sétimo passo é o da MD, no qual algoritmos procuram por relações de similaridade ou discordância entre dados, com o objetivo de encontrar padrões, irregularidades e regras.Os resultados da MD são interpretados por pessoas que possuem conhecimento tácito acerca do domínio de negócio. Caso sejam encontrados padrões inválidos, incoerentes ou os objetivos do projeto não sejam plenamente atingidos, volta-se a qualquer dos passos anteriores para que sejam realizados ajustes, até que sejam satisfeitas todas as expectativas do usuário. Finalmente, o conhecimento extraído dos dados é utilizado para subsidiar a tomada de decisões, podendo ser também representado, documentado e enviado ao seu
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3127

público de interesse (FAYYAD et al., 1996). Uma possibilidade não prevista por Fayyad et al. (1996) é tradução do conhecimento descoberto para uma linguagem de representação do conhecimento, a fim de preservá-lo em bases de conhecimento.
A Figura 4 ilustra o KDD Process com foco nas transformações realizadas nos dados até atingirem o grau de conhecimento que conduz à ação. O processo foi resumido na figura aos cinco passos nos quais os dados são transformados em informações e conhecimento. O passo 1 foi suprimido; o passo 2 é exibido com o rótulo de Seleção; os passos 3 e 4 são resumidos como Transformação; os passos 5, 6 e 7 são apresentados como Data Mining; o passo 8 é apresentado sem adaptações; e, finalmente, o passo 9 é representado pelas ações tomadas com base no conhecimento descoberto.
Figura 4 – KDD Process resumido. Fonte: Fayyad et al. (1996).
O passo 7, Mineração de Dados, é o mais abordado pela literatura. Muitos trabalhosabordam as definições e otimizações dos algoritmos e ferramentas de mineração de dados. Entretanto, os outros passos são tão importantes quanto o sétimo para o sucesso de um projeto de DCBD (FAYYAD et al., 1996). O algoritmo mais eficiente para mineração de dados aplicado sobre um conjunto de dados mal selecionado não resultará em conhecimento útil. Da mesma maneira, a presença de ruídos em dados bem selecionados levará a distorções nos resultados da mineração de dados. Por fim, se não foreminterpretados, os padrões minerados não serão convertidos em conhecimento e ação.
3.2 Cross-Industry Standard Process for Data Mining – CRISP-DM
O Cross-Industry Standard Process for Data Mining (CRISP-DM) é um modelo de processos iterativo, genérico e padronizado para o uso de mineração de dados(CHAPMAN et al., 2000). O CRISP-DM organiza o processo de MD em seis fases, descrevendo um roteiro a ser seguido pelas organizações que desejam planejar e executar projetos de MD. As fases e o ciclo iterativo descrito pelo processo são ilustrados pela Figura 5.
A fase inicial do processo, Entendimento do Negócio, visa o entendimento dos objetivos do projeto e dos requisitos, sob o ponto de vista do negócio. Com base nesse entendimento, o problema de mineração de dados é definido e um plano preliminar do projeto é produzido. A fase Entendimento dos Dados inicia com uma coleta de dados e prossegue com atividades que visam descrever e explorar os dados, identificar problemas de qualidade e detectar subconjuntos interessantes para formar hipóteses da informação escondida. A terceira fase, Preparação de Dados, cobre todas as atividades de construção
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3128

de um conjunto de dados (dataset) de trabalho. As atividades desta fase incluem a seleção, a limpeza, o preenchimento, a integração e a formatação dos dados (CHAPMAN, 2000).As fases do CRISP-DM e as atividades prescritas para elas estão apresentadas na Figura 5.
Na fase Modelagem, técnicas de modelagem são selecionadas e aplicadas e seus parâmetros são ajustados para valores ótimos. Modelagem aqui significa encontrar um ou mais modelos que sejam compatíveis com os dados submetidos à MD. Ou seja, os modelos gerados correspondem aos padrões e às regras induzidos a partir dos dados. Geralmente, existem várias técnicas para o mesmo tipo de problema de mineração de dados, tais como indução de árvores de decisão, geração de redes neurais, regras de associação, entre outras. Algumas dessas técnicas têm requisitos específicos quanto à formatação dos dados, por isso pode ser necessário retornar à fase de preparação de dados. Nesta fase os conjuntos de dados de testes e treinamento são separados. O conjunto de testes tem a finalidade de assegurar a qualidade e a validade do modelo. A execução das técnicas de MD propriamente ditas ocorre na atividade Construir Modelo de Dados. A última atividade desta fase compreende a avaliação do modelo gerado (CHAPMAN, 2000).
Figura 5 – Fases e atividades do CRISP-DM. Fonte: Shearer (2000).
Na fase Avaliação, o modelo (ou os modelos) construído na fase anterior é avaliado e são revistos os passos executados na sua construção para se ter certeza de que o modelo representa os objetivos do negócio identificados na primeira fase. O propósito principal é determinar se existe algum objetivo de negócio importante que não foi alcançado. Após o modelo ser construído e avaliado, ele é publicado e interpretado na fase Utilização. Nesta fase, podem-se recomendar ações e decisões a serem tomadas com base nos resultadosmodelados ou pode-se repetir o fluxo com um novo conjunto de dados (DIAS, 2001).
O projeto CRISP-DM 2.0 é uma proposta de evolução do CRISP-DM pela inclusão do suporte a novos tipos de dados como texto e conteúdo Web, além de novas técnicas para o pré-processamento e a análise dos dados. O projeto também prevê a integração da DCBD com as técnicas de Gerenciamento de Processos de Negócio. O CRISP-DM 2.0 também modificará os conjuntos de fases, atividades e produtos de trabalho do processo atual (MARISCAL, MARBÁN e FERNÁNDEZ, 2010).
Entendimento do Negócio
Entendimento dos Dados
Preparação dos Dados
Modelagem UtilizaçãoAvaliação
Formatar Dados
Integrar Dados
Construir Dados
Limpar Dados
Selecionar Dados
Determinar Objetivos do
Negócio
Revisar Projeto
Produzir Relatório
Final
Planejar Monitoram. e Manutenção
Planejar Publicação
Determinar Próximos Passos
Revisar Processo
Avaliar Resultados
Avaliar Modelo
Construir Modelo
Gerar Projeto de Testes
Selecionar Técnicas de Modelagem
Avaliar Situação
Explorar Dados
Descrever Dados
Coleta Inicial de
Dados
Determinar Objetivos da
MD
Verificar Qualidade dos Dados
Produzir Plano de Projeto
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3129

3.3 Unified Process for Knowledge Discovery in Database – UPKDD
O Unified Process for Knowledge Discovery in Database (UPKDD) é definido como um processo de software para aplicações de tecnologias analíticas e centradas em objetivos de descoberta de conhecimento (HERDEN, 2007). O UPKDD tem como referências principais os seguintes processos, arquiteturas e práticas: (1) disciplinas de DCBD segundo o KDD Process; (2) definição e implementação da arquitetura de DW segundo a Data Mart Bus Architecture; (3) Práticas de ES segundo o PU; e (4) conjunto de Elementos-Chave – artefatos, papeis e atividades – das áreas de processo, arquitetura e implementação de soluções de sistemas de apoio à decisão. Os princípios, as fases, os workflows e também os elementos-chave do UPKDD, são similares aos estabelecidos no processo de softwarePU (HERDEN et al., 2011).
O UPKDD divide-se em duas fases: Concepção e Elaboração. As atividades do processo estão distribuídas nas disciplinas de Requisitos, Análise e Projeto. O processo não considera as disciplinas de Implementação e Teste, nem as fases de Construção e Transiçãodo PU, devido às incertezas e às dependências do ambiente de implantação do Sistema de DCBD, também porque o UPKDD nada acrescenta a essas fases e disciplinas em relação ao PU. O processo é modelado em linguagem UML, com os diagramas de pacotes, atividades, caso de uso e classes, para representar a visão geral e as disciplinas do processo(HERDEN et al., 2011).
Na fase de Concepção são definidos a visão do sistema, as listas de requisitos funcionais e não funcionais e os principais modelos de análise. Também é realizada a caracterização das ferramentas que serão utilizadas na implementação, juntamente com o modelo de projeto. Na fase Elaboração ocorre o detalhamento dos casos de usos, a definição da arquitetura do sistema, com foco na arquitetura do DW. Finalmente, o modelo dimensional do DW é elaborado.
A Figura 6 mostra uma visão geral do UPKDD em um diagrama de atividades. O fluxo inicia na disciplina de Requisitos, na qual as expectativas do cliente são mapeadas, a visão do projeto é definida e os dados operacionais disponíveis são examinados. Na disciplina de Análise, os casos de uso são detalhados e na disciplina Projeto, a arquitetura dimensional do sistema é definida e o modelo dimensional é elaborado.
Figura 6 – Diagrama de atividades do processo UPKDD. Fonte: Herden et al. (2011).
O UPKDD define os seguintes papeis para as pessoas envolvidas nos projetos:• Engenheiro de Conhecimento – responsável pela aquisição de conhecimento a
partir das informações de negócio do sistema.• Especialista de KDD – implementa aplicações analíticas de MD e OLAP em
resposta ao contexto de tomada de decisão.• Usuário final ou Tomador de decisão – visualiza as informações e o
conhecimento descoberto, assim como determina os requisitos do projeto.Sob o ponto de vista da arquitetura de software, o UPKDD utiliza uma arquitetura de
referência para Sistemas de DCBD definida por Valentin (2006). Essa arquitetura descreve o ciclo de vida dos dados desde as Fontes Operacionais, passando por uma Área de Estágio
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3130

até serem preservados definitivamente em um DW. O DW passa a ser a fonte de dados preferencial para as operações de OLAP e MD. Os padrões, regras e tendências identificados na análise dos dados, são mantidos em uma base de conhecimento, definida genericamente como Armazém de Resultados.
No UPKDD o DW é estruturado de acordo com a arquitetura Data Mart BusArchitecture, segundo Kimball e Ross (2002). Desta forma, o DW é composto por uma coleção de DM e não existe a figura do repositório central corporativo de dados (HERDEN, 2007; HERDEN et al., 2011).
3.4 Comparação dos processos
Os três processos descritos neste capítulo foram comparados quanto às suas fases, disciplinas, arquitetura e papeis. Também foram observadas as capacidades relativas à gestão de projeto, configuração e mudança. Outro fator analisado foi a capacidade de controlar o ciclo de vida dos dados desde as fontes operacionais, passando pelo DW e culminando numa base de conhecimento.
Quanto ao número de fases, o KDD Process é dividido em nove fases, o CRISP-DM em seis e o UPKDD em duas. O KDD Process e o CRISP-DM não especificam as disciplinas nas quais o esforço do projeto é distribuído. Já o UPKDD especifica as disciplinas Requisitos, Análise e Projeto. Este mesmo processo está alicerçado no PU e no KDD Process, utiliza a arquitetura de referência de Valentin (2006) e, como arquitetura de DW, a Data Mart Bus Architecture (KIMBALL e ROSS, 2002). No UPKDD o Armazém de resultados tem propósito semelhante ao de uma base de conhecimento. Quanto aos papeis, o UPKDD define o Engenheiro de conhecimento, o Especialista de KDD e o Usuário final ou tomador de decisão. Entre todas essas propriedades, somente as fases são especificadas no KDD Process e no CRISP-DM.
Tanto o KDD Process quanto o CRISP-DM utilizam a MD como principal forma de exploração analítica dos dados. O KDD Process, inclusive, recomenda que as técnicas de MD sejam aplicadas sobre um ambiente DW, visto que este tipo de ambiente apresenta condições de qualidade e acesso aos dados favoráveis para a MD. No UPKDD a principal forma de exploração dos dados é por ferramentas OLAP operando sobre os DM que compõem o DW.
As fases 1 (Entender o domínio da aplicação) e 2 (Selecionar um conjunto de dados alvo) do KDD Process são equivalentes às fases 1 (Entendimento do Negócio) e 2 (Entendimento dos Dados) do CRISP-DM. Já no UPKDD essa equivalência ocorre com a fase 1 (Concepção). As fases 3 (Limpeza e pré-processamento dos dados) e 4 (Redução e projeção de dados) do KDD Process são equivalentes à fase 3 (Preparação de Dados) do CRISP-DM e à 2 (Elaboração) do KDD Process.
Já as fases 5 (Relacionar os objetivos do projeto a um método de MD), 6 (Escolha do algoritmo de MD) e 7 (Mineração de dados) do KDD Process correspondem à fase 4 (Modelagem) do CRISP-DM. As fases 8 (Interpretação) e 9 (Utilização do conhecimento descoberto) do KDD Process possuem os mesmos propósitos das fases 5 (Avaliação) e 6 (Utilização) do CRISP-DM, respectivamente. Todas essas fases não possuem correspondência no UPKDD.
O controle do ciclo de vida dos dados é realizado parcialmente pelo UPKDD. Na arquitetura empregada neste processo, o repositório histórico dos dados continua sendo as bases operacionais, uma vez que não existe a figura do DW corporativo normalizado e de granularidade atômica. O processo também não especifica a estrutura do armazém de
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3131

resultados para que ele possa ser considerado uma base de conhecimento. Para isto, seria necessária a utilização de técnicas para representação e preservação do conhecimento.
No tocante às capacidades para gestão de projetos e gestão de configuração e mudança, nenhum dos três processos contempla. E, finalmente, esses processos não possuem ciclos de vida iterativos e incrementais, como é comum se observar em processos considerados ágeis.
Na comparação entre as fases dos processos de DCBD e de ES, também é possível estabelecer relações de correspondência, como mostra o Quadro 1. As fases do KDD Process, do CRISP-DM e do UPKDD apresentam similaridades às do Processo Unificado e do OpenUP (SANTOS, 2009; HRISTOV, 2011). No entanto, somente no processo ágil de software OpenUP existem disciplinas específicas para gestão de projetos, configuração e mudanças.
Quadro 1 – Comparação entre as fases dos processos de DCBD e os processos de software.
KDD Process
CRISP-DM UPKDD Processo Unificado
OpenUP
1 – Entender o domínio da aplicação.
1 – Entendimento do Negócio.
2 – Selecionar um conjunto de dados alvo.
2 – Entendimento dos Dados.
1 – Concepção. 1 – Concepção. 1 – Concepção.
3 – Limpeza e pré-processamento dos dados.
4 – Redução e projeção de dados.
3 – Preparação de Dados.2 – Elaboração. 2 – Elaboração. 2 – Elaboração.
5 – Relacionar os objetivos do projeto a um método de MD.
6 – Escolha do algoritmo de MD.
7 – Mineração de dados.
4 – Modelagem.Não possui. 3 – Construção. 3 – Construção.
8 – Interpretação.5 – Avaliação.
Fases
9 – Utilização do conhecimento descoberto. 6 – Utilização.
Não possui. 4 – Transição. 4 – Transição.
Faz Gestão de Projeto? Não. Não. Não. Sim. Sim.
Faz Gestão de Configuração e
Mudança? Não. Não. Não. Não. Sim.
É iterativo e incremental? Não. Não. Não. Não. Sim.
O último fator a ser mencionado na comparação diz respeito à utilização dos processos de DCBD em projetos acadêmicos e industriais. Segundo Kurgan e Musilek (2006), a maior parte das utilizações do KDD Process ocorreram em projetos acadêmicos, enquanto o CRISP-DM teve maior aceitação na indústria. Foi encontrada uma referênciasobre a utilização do UPKDD em um projeto comercial, porém com o propósito acadêmico de avaliar experimentalmente o processo por meio de um estudo de caso (HERDEN et al., 2011).
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3132

IV. AGILEKDD: UM PROCESSO ÁGIL PARA A ENGENHARIA DE SISTEMASDE DESCOBERTA DE CONHECIMENTO
O desenvolvimento de Sistemas de DCBD necessita da definição de processos que contemplem tanto os aspectos de Banco de Dados e Inteligência Computacional quanto as disciplinas da ES. Um processo dessa natureza, que também seja ágil e disciplinado, pode melhorar o fator de sucesso dos projetos de DCBD e, consequentemente, a promoção deste tipo de sistemas nas organizações. Desta forma, finalmente será possível dar o passo seguinte ao longo do espectro traçado por Pressman (2006) e desenvolver sistemas que processem dados e informações e produzam conhecimento.
4.1 Introdução ao processo AgileKDD
O AgileKDD é um processo ágil e disciplinado para o desenvolvimento de Sistemas de DCBD, alicerçado pelos processos OpenUP, KDD Process e CRISP-DM(NASCIMENTO e OLIVEIRA, 2012a, 2012b). O OpenUP fornece o suporte relativo à ES, agregando também os valores e os princípios presentes no Manifesto para o Desenvolvimento Ágil de Software, especialmente a colaboração e a comunicação contínua entre os atores do processo, sem abrir mão das disciplinas de gerenciamento. Já o KDD Process e o CRISP-DM contribuem com os elementos específicos da DCBD relativos ao pré-processamento e mineração dos dados e ao pós-processamento do conhecimento descoberto.
O esforço pessoal em um projeto AgileKDD está organizado em micro-incrementos. Cada micro-incremento representa uma unidade de trabalho que produz um passo do progresso do projeto. O processo aplica a colaboração intensiva à medida que o sistema é desenvolvido incrementalmente por uma equipe comprometida e auto-organizada. Estes micro-incrementos fornecem um ciclo de feedback extremamente curto que direciona decisões adaptativas durante cada iteração.
O AgileKDD divide o projeto em iterações planejadas e com intervalos de tempo definidos, medidos em semanas. As iterações direcionam a equipe na entrega incremental do valor aos stakeholders de uma forma previsível. O plano de iteração define o que deve ser entregue durante a iteração e o resultado é uma versão demonstrável ou entregável do produto de software. As equipes dos projetos se auto-organizam para definir como atingir os objetivos da iteração e entregar o resultado. Elas fazem isso definindo e distribuindo tarefas detalhadas de uma lista de itens de trabalho. O processo define um ciclo de vida de iteração que estrutura como os micro-incrementos são aplicados para entregar versões estáveis e coesas do sistema, desenvolvidas incrementalmente até que todos os objetivos da iteração sejam alcançados.
O ciclo de vida de projeto fornece aos stakeholders e à equipe visibilidade e pontos de decisão durante a execução do projeto. Este ciclo possibilita uma efetiva supervisão do projeto e pontos de controle para avaliação de resultados e revisão do planejamento. Um plano de projeto define o ciclo de vida e o resultado final é uma aplicação liberada.
4.2 Fases e atividades do AgileKDD
O AgileKDD estrutura o ciclo de vida do projeto em quatro fases: Concepção, Elaboração, Construção e Transição. A Figura 7 apresenta uma visão geral das fases e atividades do AgileKDD. Resumidamente, o processo recebe como insumos os requisitos do projeto, a documentação e os dados dos sistemas operacionais e produz incrementos de
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3133

software entregues sucessivamente ao cliente, até que todos os requisitos viáveis sejam contemplados.
4.2.1 Concepção
A fase de Concepção (I) é a primeira das quatro fases no ciclo de vida do AgileKDD. Esta fase é representada na Figura 7 pela letra I (Inception). Desta fase resulta um entendimento geral sobre a visão, o escopo, os objetivos, a seleção dos dados alvo, a viabilidade e o planejamento geral do projeto. Os projetos podem ter uma ou mais iterações nesta fase, cujo foco recai na identificação dos requisitos, na comunicação com o cliente e no planejamento do projeto. Esta fase recebe como entradas os requisitos do projeto, os modelos de processos de negócio, os Diagramas Entidade-Relacionamento (DER), os dicionários de dados e os casos de uso dos sistemas transacionais, além das fontes de dados operacionais, sobre as quais os processos de descoberta de conhecimento serão executados. A fase de Concepção tem como saídas o documento de visão, o glossário inicial do projeto, a avaliação de viabilidade e riscos, o plano de projeto e os protótipos.
Figura 7 – Fases e atividades do AgileKDD inicial.As atividades entender o domínio da aplicação (I1) e identificar a visão e os
objetivos do projeto de DCBD (I2) estão relacionadas à disciplina Gerência de Requisitos. A atividade entender o domínio da aplicação tem como objetivo principal analisar e desenvolver um conhecimento acerca do domínio de negócios no qual a aplicação está inserida. Esse conhecimento pode ser obtido em modelos de processos de negócio, na documentação dos sistemas transacionais, em entrevistas com os stakeholders e qualquer
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3134

outra técnica de elicitação de requisitos. Um dos produtos de trabalhos criados nesta atividade é o glossário inicial do projeto, um documento no qual os principais termos e conceitos envolvidos no sistema são definidos.
A atividade identificar a visão e os objetivos do projeto de DCBD (I2) tem como principal saída o documento de visão do projeto. A visão do projeto fornece uma descriçãode alto nível para os requisitos funcionais e as restrições de projeto do sistema. A essência do sistema é apresentada e serve como entrada para o processo de aprovação do projeto, comunicando o propósito e os objetivos gerais do sistema.
Na atividade selecionar um conjunto de dados alvo (I3), um conjunto de dados no qual será aplicada a descoberta de conhecimento é selecionado a partir das fontes de dados operacionais. Em geral, esses dados são obtidos nos bancos de dados operacionais dos sistemas OLTP, num subconjunto das tabelas mantidas por estes sistemas.
A atividade gerir projeto, configuração e mudanças (I4) tem o objetivo principal de criar os planos de projeto e de configuração (versionamento, rótulos, ramos, etc.), bem como fazer a gestão das mudanças que o projeto ou a iteração provocarão nos dados e nos softwares existentes. Além de criar estes planos, o gerente de projeto avalia a viabilidade e os riscos do projeto com a equipe e atualiza Avaliação inicial de risco. A lista de riscos ajudará a equipe na priorização do que deve ser feito em cada iteração. Os riscos elevados são direcionados para as iterações iniciais.
4.2.2 Elaboração
A fase de Elaboração (E) tem foco na análise e no projeto (design) do sistema, na comunicação com o cliente e na definição da arquitetura. Os insumos desta fase são as entradas e saídas da fase de Concepção. As saídas da fase de Elaboração compreendem a descrição da arquitetura do software, os modelos de DW e DM, os mapeamentos de origem dos dados e os dados pré-processados.
As atividades limpeza e pré-processamento dos dados (E1) e redução e projeção de dados (E2) preparam os dados operacionais para o processamento analítico e a mineração de dados. O processo de preparação consiste na remoção de inconsistências, preenchimento de dados ausentes, agregação, redução da granularidade, entre outras tarefas inerentes ao pré-processamento dos dados.
A atividade definir arquitetura (E3) especifica como os componentes e módulos do sistema serão integrados. Os sistemas desenvolvidos segundo o processo AgileKDD têm o DW estruturado de acordo com a Hub and Spoke Architecture (INMON, 1997; INMON, STRAUSS e NEUSHLOSS, 2008). O processamento analítico e a mineração dos dados serão realizados por aplicações conectadas aos DM. A forma de carregamento e a frequência de atualização dos dados das fontes de dados operacionais (que podem estar dispersas geograficamente) para o DW são especificadas no escopo da atividade definir arquitetura. Também é definido se o DW será centralizado ou se haverá instâncias distribuídas dele. A arquitetura especifica também a forma de acesso aos dados pelas ferramentas de exploração (OLAP e MD), bem como os mecanismos de autenticação e autorização para acesso ao sistema pelo usuário final. A saída produzida por esta atividade é a descrição da arquitetura do software.
A atividade verificar qualidade dos dados (E4) tem como objetivo confirmar que os dados operacionais disponíveis têm a consistência e a integridade necessárias para o desenvolvimento do projeto. Esta é uma atividade crítica e essencial, uma vez que problemas na qualidade dos dados podem inviabilizar projetos de BI e DCBD.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3135

Na atividade modelar DW e DM (E5), o DW é modelado de acordo com amodelagem relacional normalizada. Já os DM, agrupados por assuntos ou processos de negócio, são modelados de acordo com o paradigma dimensional. A modelagem do DW é composta pelos diagramas Entidade-Relacionamento, pelos dicionários de dados, bem como pelos mapeamentos de origem dos dados. Primeiramente são criados modelos conceituais, representando as entidades, os fatos, as dimensões e os relacionamentos, numa perspectiva de alto nível. Os modelos conceituais são facilmente compreendidos e validados por todos os participantes do projeto. Após a validação, os modelos conceituais são transformados em modelos físicos, voltados para as tecnologias de implementação de banco de dados. A partir do projeto físico do DW, é elaborado um mapeamento dos dados disponíveis nas fontes de dados operacionais para o DW.
4.2.3 ConstruçãoA fase de Construção (C) traduz o modelo de projeto em produtos integrados de
software implementados de acordo com arquitetura definida na fase de Elaboração. Desta fase resultam principalmente os incrementos de software validados e preparados para serem entregues aos clientes e usuários.
A atividade ETL (C1) produz as rotinas responsáveis por extrair, transformar e carregar os dados das fontes de dados operacionais para o DW. Os processos ETL são programados para executarem periodicamente, mantendo o DW sincronizado com as fontes de dados operacionais. As tarefas de transformação dos processos ETL também realizam remoção de inconsistências, preenchimento de dados ausentes, agregação, redução da granularidade, entre outras tarefas inerentes ao pré-processamento dos dados.
A atividade denominada mineração de dados (C2) consiste na aplicação de algoritmos para extrair modelos ou padrões dos dados. Nesta atividade, os métodos de MD capazes de fazer o reconhecimento de padrões (árvores de decisão, máquinas de vetores de suporte, métodos estatísticos, redes neurais, algoritmos genéticos, entre outros) são aplicados sobre os dados carregados no DW. Para isso, são utilizadas ferramentas que disponibilizam os diversos algoritmos já implementados, testados e otimizados, para uso em uma série de aplicações.
A criação de consultas OLAP (C3) consiste no mapeamento do DW em uma ferramenta OLAP, criando uma representação lógico-conceitual compreensível pelos usuários. A partir desse mapeamento, são criados relatórios, gráficos e dashboardspredefinidos e personalizáveis. Também é oferecida ao usuário uma interface para a construção de consultas personalizadas (ad-hoc) a partir dos mapeamentos do DW.
A atividade integração de dados e aplicações (C4) trata da pesquisa pelos conceitos criados no DW em Data Marts já existentes. Esta atividade analisa também os impactos causados pelas mudanças que podem ser necessárias para modificação dos conceitos existentes. Os possíveis impactos incluem mudanças em aplicações que já acessam os conceitos que serão modificados.
O objetivo da atividade verificação e validação (C5) é assegurar que o softwarecumpra as suas especificações e atenda às necessidades dos usuários e clientes. A verificação confere se o software está sendo desenvolvido de acordo com a sua especificação, respondendo à seguinte pergunta: “Estamos construindo certo o produto?”. Já a validação busca assegurar que o software atenda às necessidades dos usuários:“Estamos construindo o produto certo?”. As técnicas de verificação e validação incluem a inspeção de software e os testes de software. Nesta atividade do AgileKDD, os resultados da mineração de dados e das consultas OLAP são confrontados com as fontes de dados operacionais. Assim, verifica-se não apenas os métodos de exploração do DW como
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3136

também os processos ETL que carregam os dados das fontes operacionais para o DW. A validação inclui também a homologação do software pelo cliente.
4.2.4 TransiçãoA fase de Transição (T) tem o objetivo de entregar o software para o cliente explorar,
interpretar e utilizar as informações e o conhecimento. Esta fase também contribui para a melhoria contínua do processo, por meio de uma retrospectiva que reflete sobre a adequação do processo ao projeto implementado.
A atividade GCM e publicação (T1) tem o propósito de rotular os artefatos do projeto, implantar os objetos de banco de dados, os processos ETL e o software executável nos ambientes de desenvolvimento, homologação e produção. A publicação consiste da execução de scripts, da configuração e agendamento dos processos ETL e da instalação do software necessário para a entrega do software ao usuário. Trata-se de uma atividade de infraestrutura, realizada juntamente com a gerência de configuração do software. Cada versão publicada dos artefatos deve ser rotulada, a fim de identificar a versão do softwareque está sendo entregue para homologação ou produção.
A interpretação (T2) é uma atividade relacionada essencialmente aos resultados damineração de dados. O conhecimento descoberto é submetido à análise das pessoas detentoras do conhecimento tácito, capazes de discernir acerca da validade das regras e dos padrões reconhecidos a partir dos dados. Após a interpretação, o conhecimento refinado e validado é utilizado (T3) pela organização no suporte à tomada de decisão e na melhoria dos seus processos de negócio.
A retrospectiva (T4) é uma atividade relacionada à melhoria contínua do processo e à sua melhor adequação ao projeto. Ao final de cada iteração, uma retrospectiva é realizada para que a equipe identifique as atividades e atitudes que contribuíram para o alcance dos objetivos e as que devem ser aperfeiçoadas ou ignoradas para a melhor adequação do processo ao projeto.
4.3 Papeis das pessoas no AgileKDD
O AgileKDD define os seguintes papeis para as pessoas envolvidas nos projetos:• Gerente de Projeto – conduz o planejamento do projeto, coordena as interações
com os clientes e mantêm o time focado em alcançar os objetivos do projeto.• Arquiteto – responsável por definir a arquitetura de software, incluindo a tomada
das principais decisões técnicas que orientam todo o design e a implementação do projeto.
• Analista de Requisitos – representa os interesses do cliente e do usuário final colhendo informações dos clientes para entender o problema a ser resolvido, capturando os requisitos e definindo suas prioridades.
• Administrador de dados – responsável pelo entendimento e avaliação da qualidade das bases de dados OLTP, pela modelagem e documentação do Data Warehouse e dos Data Marts.
• Testador – é responsável pelas principais atividades de verificação e validação. Estas atividades incluem identificar, definir, implementar e conduzir os testes necessários, bem como registrar e analisar os resultados dos testes.
• Desenvolvedor – responsável por desenvolver as rotinas ETL, executar os algoritmos de mineração de dados, criar as consultas OLAP e implementar a integração de dados e soluções.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3137

• Cliente – representa grupos de interessados cujas necessidades devem ser satisfeitas pelo projeto.
4.4 Disciplinas do AgileKDD
As disciplinas do processo AgileKDD são as mesmas do OpenUP: Requisitos, Arquitetura, Desenvolvimento, Teste, Gestão de Projeto e Gestão de Configuração e Mudança, como apresenta o Quadro 2.
Durante um ciclo completo de projeto, a maior parte do esforço da disciplina de Requisitos é concentrada na fase de Concepção. A Arquitetura é a principal disciplina durante a fase de Elaboração. Nesta mesma fase, o Desenvolvimento é intensificado a partir da definição da arquitetura do sistema e continua como principal disciplina da fase de Construção. Os testes ocorrem principalmente na tarefa Verificação e Validação da fase de Construção. A disciplina de Gestão de Projeto está concentrada predominantemente na fase de Concepção. A Gestão de Configuração e Mudança tem maior destaque na fase de Transição. Cada disciplina pode ser relacionada a um conjunto de produtos de trabalho criados durante as fases do processo.
Quadro 2 – Produtos de trabalho em cada disciplina do AgileKDD.Disciplina Propósito Produtos de Trabalho
Requisitos Elicitar, analisar, especificar, validar e gerenciar os requisitos para o sistema a ser desenvolvido.
Documento de visão.Glossário inicial do projeto.Protótipos.
Arquitetura Definir uma arquitetura para os componentes do sistema.
Descrição da arquitetura do software.Modelos de DW e DM.
Desenvolvimento Projetar e implementar uma solução técnica que seja aderente à arquitetura e atenda aos requisitos.
Componentes de software.Incremento integrado de software.
Teste Validar a maturidade do sistema através do projeto, implementação, execução e avaliação dos testes.
Plano e procedimento de teste.Registro de teste.
Gestão de Projeto Instruir, ajudar e suportar a equipe, ajudando-a a lidar com os riscos e obstáculos encontrados quando da construção de software.
Plano de projeto.Avaliação de viabilidade e riscos.
Gestão de Configuração e Mudança
Controlar as mudanças nos artefatos, assegurando uma evolução sincronizada do conjunto de Produtos de Trabalho que compõem um sistema de software.
Lista de itens de trabalho.
Uma vez definido o processo, faz-se necessário verificar a sua aplicabilidade em projetos de Sistemas de DCBD reais e confirmar se os resultados esperados pela aplicação do processo são alcançados. Esta verificação foi realizada por meio de um estudo de caso no qual o processo foi aplicado e os seus efeitos sobre a execução do projeto foram registrados sob o ponto de vista da Engenharia de Software. O estudo de caso indicou melhorias que posteriormente foram aplicadas ao processo visando à sua melhor adequação a projetos de Sistemas de DCBD gerenciados de acordo com os valores e princípios do Manifesto para o Desenvolvimento Ágil de Software.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3138

V. ESTUDO DE CASOApós a definição do processo AgileKDD, foi necessário validar a sua aplicabilidade
no desenvolvimento de Sistemas de DCBD. Para tanto, foi selecionado um projeto de Sistema de DCBD da área de Petróleo e Gás, executado em quatro iterações, como mostra a Figura 8. Estas iterações tiveram a finalidade de construir e entregar o produto de formasadaptativa, iterativa e incremental, verificando a aplicabilidade do processo AgileKDD a um projeto de Sistema de DCBD.
A primeira iteração do projeto foi destinada exclusivamente à fase de Concepção (I). A segunda iteração teve como objetivo atender aos requisitos funcionais de mineração de dados. A terceira iteração teve como objetivo calcular e apresentar os indicadores de gestão da atividade atendida pelo estudo de caso. A quarta iteração contemplou os requisitos funcionais de processamento analítico (OLAP).
Figura 8 – Iterações realizadas na implementação do estudo de caso.O estudo de caso escolhido permitiu avaliar a aplicabilidade do processo em um
projeto real, influenciado por restrições de prazo, escopo e qualidade comuns em projetos comerciais. As seguintes características do estudo de caso permitiram que ele confirmasse a aplicabilidade do AgileKDD:
(i) Abrangência. O estudo de caso contemplou tanto requisitos de MD como de OLAP, além dos indicadores de gestão. As atividades definidas no processo AgileKDD foram suficientemente abrangentes para suportarem a implementação de todos os requisitos.
(ii) Houve mudanças nos requisitos. A execução do estudo de caso foi influenciada por mudanças nos requisitos de negócio do cliente. O AgileKDD proporcionou a resposta rápida às mudanças dos requisitos, demonstrando a adaptabilidade esperada em um processo ágil.
(iii) Houve problemas de qualidade de dados. O alcance dos objetivos do projeto também foi influenciado por problemas de qualidade nos dados operacionais submetidos à DCBD. Esses problemas, ocorridos na execução do estudo de caso, permitiram identificar pontos de melhoria no processo.
(iv) Equipe multidisciplinar. O estudo de caso foi implementado por uma equipe multidisciplinar e distribuída geograficamente. Nesses cenários, a comunicação é um fator crítico para o sucesso do projeto de software. O
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3139

AgileKDD foi capaz de promover a comunicação entre os membros da equipe, bem como a participação do cliente em todas as fases do projeto.
(v) Necessidade de entrega frequente de software funcional. As restrições de prazo do projeto demandavam a entrega de resultados do projeto em intervalos curtos de tempo. Esta necessidade confirmou a adequação de um processo ágil a projetos de Sistemas de DCBD nos quais o cliente necessita que o conhecimento descoberto suporte a tomada de decisões com rapidez.
Portanto, a aplicabilidade do AgileKDD foi confirmada por meio do estudo de caso desenvolvido. Observou-se que processo AgileKDD foi capaz de guiar o desenvolvimento do produto, desde o início da iteração de concepção até a fase de transição da última iteração realizada. Não obstante, verifica-se que alguns ajustes no processo são necessários para aumentar a sua adequação a projetos de Sistemas de DCBD. As observações e necessidades de ajustes identificados na realização das quatro iterações contribuíram para a revisão do processo, que será descrita no próximo capítulo.
Durante a execução do estudo de caso, algumas considerações gerais e pontos de melhoria existentes no AgileKDD foram coletados com o propósito de refinamento do processo. As considerações gerais e os principais pontos de melhoria identificados foram:
(i) A atividade Gerir projeto, configuração e mudanças (I4) concentrou as principais atividades de gestão do processo. Dada a importância dessas atividades e a completa distinção entre elas, percebe-se a necessidade de separá-las em atividades independentes.
(ii) A atividade Verificar qualidade dos dados (E4) deve migrar da fase Elaboração(E) para a fase Concepção (C) do processo, uma vez que o resultado dela influencia as avaliações de viabilidade e riscos e o planejamento do projeto.
(iii) As atividades Limpeza e pré-processamento dos dados (E1), Redução e projeção de dados (E2), previstas na fase de Elaboração (E) do AgileKDD, foram executadas como parte dos processos ETL (C1). Por se tratarem de atividades de relacionadas à preparação e transformação dos dados, observa-se que E1 e E2 podem ser consideradas tarefas internas à atividade C1.
(iv) As atividades Criar consultas OLAP (C3) e Integração de dados e aplicações(C4) não precisaram ser executadas na segunda iteração, focada na mineração de dados. Analogamente, as iterações focadas em OLAP e indicadores de gestão não necessitaram da atividade Mineração de dados (C2). Portanto, nem todas as atividades do processo são requeridas para todos os projetos. Devem-se admitir atividades opcionais, executadas somente quando a iteração necessitar das suas saídas.
(v) A arquitetura de DW Data Mart Bus Architecture é mais compatível com os valores ágeis do que a Hub and Spoke Architecture, uma vez que ela proporciona a antecipação da entrega de resultados ao cliente. A arquitetura de DW não deve ser determinada pelo processo, mas deve ser selecionada de acordo com as necessidades e prioridades de cada projeto.
(vi) O processo não deve direcionar como o produto será desenvolvido, mas deve limitar-se a especificar o que deve ser feito, quais fases e atividades devem ser realizadas, para que o produto seja criado e entregue ao cliente.
(vii) Toda a documentação escrita necessária para o desenvolvimento do estudo de caso foi composta pelo documento de visão e pelos modelos de dados das fontes operacionais e do DW. Não houve a necessidade de Casos de Uso, diagramas ou qualquer outra documentação adicional. Boa parte do
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3140

conhecimento necessário para a execução do projeto foi trocada pessoalmente entre os participantes do projeto, inclusive o cliente.
(viii) A verificação dos resultados da mineração de dados contra as fontes de dados operacionais foi fundamental para a aceitação do conhecimento descoberto por parte do cliente. A comprovação das regras utilizando os dados operacionais não deu margem a questionamentos quanto à correção dos métodos e ferramentas de MD utilizados.
(ix) A estabilidade dos requisitos ao longo do desenvolvimento da segunda iteração contribuiu para o alcance dos objetivos dentro das expectativas de prazo do cliente. No entanto, as mudanças nos requisitos durante o desenvolvimento da terceira iteração exerceram um impacto significativo no projeto. A identificação precoce das mudanças e a resposta imediata a elas foram fundamentais para que o produto desenvolvido atendesse às necessidades do cliente.
(x) Todos os envolvidos na execução do projeto devem compartilhar dos valores e princípios ágeis presentes no processo. O fato de a equipe de infraestrutura exigir toda a documentação exigida em projetos desenvolvidos de acordo com os processos tradicionais provocou um esforço adicional desnecessário e o atraso na entrega do produto ao cliente.
(xi) A documentação do conhecimento descoberto em uma apresentação eletrônica foi suficiente para suportar a comunicação com os usuários do conhecimento. Nenhuma outra forma de representação e armazenamento de conhecimento foisolicitada pelo cliente. Em seguida, a apresentação foi armazenada em uma base não estruturada de documentos. Entretanto, sob o ponto de vista da Gestão do Conhecimento, recomenda-se o armazenamento dos resultados em uma base de conhecimentos de forma estruturada.
Com base nas considerações sobre a aplicação do AgileKDD no estudo de caso, foi realizado o refinamento do processo.
VI. REFINAMENTO DO PROCESSO AGILEKDD APÓS O ESTUDO DE CASOO processo AgileKDD teve a sua aplicabilidade testada por meio de um estudo de
caso. No entanto, alguns aspectos do processo proposto não apresentaram resultados satisfatórios, o que levou à necessidade de melhorias e refinamento no processo. O refinamento do AgileKDD resultou nas seguintes mudanças na distribuição das atividades do processo:
(i) A atividade Gerir projeto, configuração e mudanças (I4) foi desmembrada nas atividades Gerir projeto e Gerir configuração e mudanças, permanecendo na fase Concepção (I).
(ii) A atividade Verificar qualidade dos dados (E4) migrou da fase Elaboração(E) para a fase Concepção (C) do processo, passando a contribuir para asavaliações de viabilidade e riscos, bem como para o planejamento do projeto.
(iii) As atividades Limpeza e pré-processamento dos dados (E1), Redução e projeção de dados (E2) foram transformadas em tarefas da atividade ETL(C1).
A nova representação gráfica do AgileKDD após o seu refinamento é apresentada na Figura 9. Uma mudança importante a ser ressaltada é a da representação quadrangular para uma representação circular. Esta mudança teve o objetivo principal de explicitar a orientação iterativa e incremental do processo. A representação circular também remete à
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3141
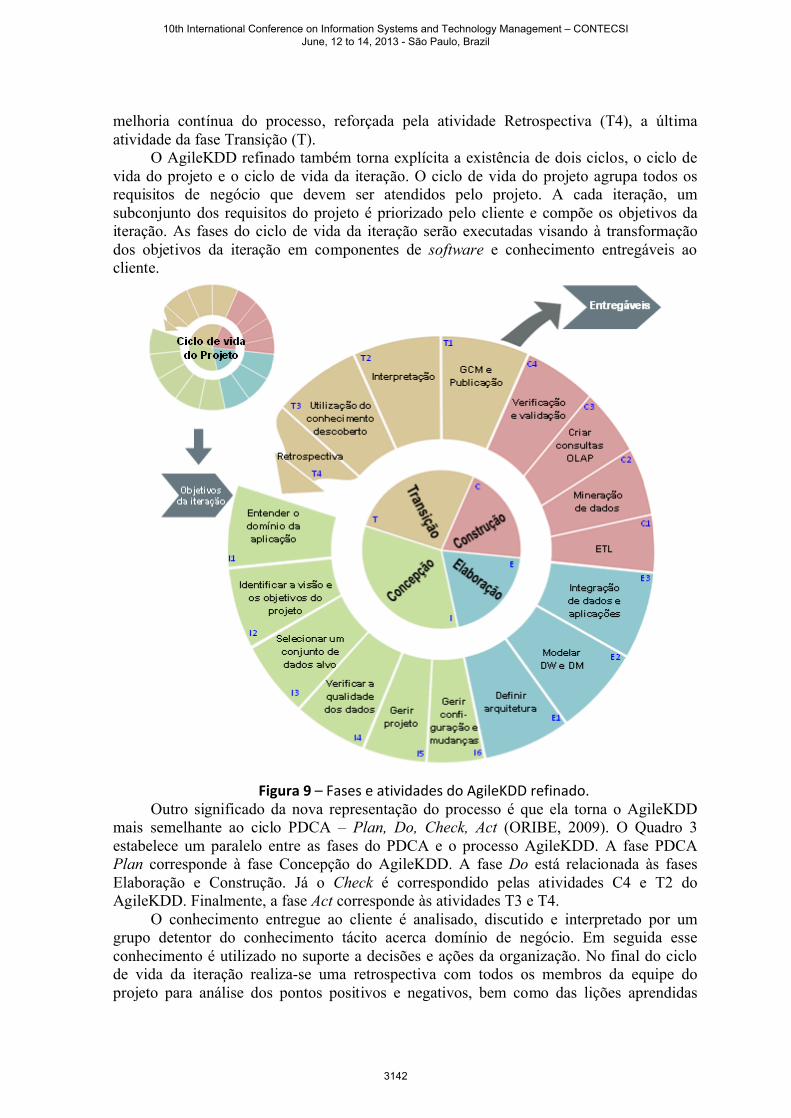
melhoria contínua do processo, reforçada pela atividade Retrospectiva (T4), a última atividade da fase Transição (T).
O AgileKDD refinado também torna explícita a existência de dois ciclos, o ciclo de vida do projeto e o ciclo de vida da iteração. O ciclo de vida do projeto agrupa todos os requisitos de negócio que devem ser atendidos pelo projeto. A cada iteração, um subconjunto dos requisitos do projeto é priorizado pelo cliente e compõe os objetivos da iteração. As fases do ciclo de vida da iteração serão executadas visando à transformação dos objetivos da iteração em componentes de software e conhecimento entregáveis ao cliente.
Figura 9 – Fases e atividades do AgileKDD refinado.Outro significado da nova representação do processo é que ela torna o AgileKDD
mais semelhante ao ciclo PDCA – Plan, Do, Check, Act (ORIBE, 2009). O Quadro 3estabelece um paralelo entre as fases do PDCA e o processo AgileKDD. A fase PDCA Plan corresponde à fase Concepção do AgileKDD. A fase Do está relacionada às fases Elaboração e Construção. Já o Check é correspondido pelas atividades C4 e T2 do AgileKDD. Finalmente, a fase Act corresponde às atividades T3 e T4.
O conhecimento entregue ao cliente é analisado, discutido e interpretado por um grupo detentor do conhecimento tácito acerca domínio de negócio. Em seguida esse conhecimento é utilizado no suporte a decisões e ações da organização. No final do ciclo de vida da iteração realiza-se uma retrospectiva com todos os membros da equipe do projeto para análise dos pontos positivos e negativos, bem como das lições aprendidas
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3142

durante a execução do projeto. A partir dessa retrospectiva, são identificadas oportunidades de melhoria contínua e de adaptação do processo ao projeto.
Outras mudanças realizadas no processo não têm reflexos na estrutura de fases e atividades, mas no modo de aplicação do AgileKDD. A arquitetura de DW não é maisdeterminada pelo processo, devendo ser selecionada de acordo com as necessidades e prioridades de cada projeto. As atividades previstas no processo devem ser realizadas de acordo com as necessidades de cada iteração ou projeto, não sendo obrigatória a execução todas as atividades em uma determinada iteração ou em um projeto.
VII. CONCLUSÃOA construção de sistemas de software capazes de extrair conhecimento de dados e de
informações constitui um dos desafios mais significativos com que se depara a comunidade de Engenharia de Software (PRESSMAN, 2006). O desenvolvimento desse tipo de sistemas deve ser guiado por processos específicos, capazes de conduzir a transformação dos requisitos de negócio do cliente em produtos de software, observando restrições cada vez mais rígidas de prazo, custo e qualidade.
Quadro 3 – Relação entre o ciclo PDCA e o AgileKDD.Fases do PDCA Fases e atividades do AgileKDD Propósitos
Plan Concepção (I) Identificar a visão e os objetivos do projeto.Planejar o projeto.
Do Elaboração (E) e Construção (C)
Definir a arquitetura do software.Modelar e carregar as estruturas informacionais.Desenvolver os componentes de software.
Check Verificação e validação (C4) eInterpretação (T2)
Testes e homologação dos componentes de software.Validação e interpretação do conhecimento descoberto.
Act Utilização do conhecimento descoberto(T3) e Retrospectiva (T4)
Decisões e ações suportadas pelo conhecimento descoberto.Melhoria contínua do processo.
O esforço de sistematização da Descoberta de Conhecimento em Bancos de Dados e do Business Intelligence resultou em uma variedade de processos, sendo o KDD Process e o CRISP-DM os mais aceitos pelas comunidades acadêmica e industrial. O processo adotado para a implementação da maioria dos projetos de DCBD é o CRISP-DM, sendo este o padrão de facto na implementação da DCBD (MARISCAL, MARBÁN e FERNÁNDEZ, 2010; ALNOUKARI et al., 2012; ALNOUKARI e SHEIKH, 2012). No entanto, a adoção do CRISP-DM vem caindo devido à ausência de atividades relacionadas ao gerenciamento de projetos, requisitos e mudanças e à Engenharia de Software de forma geral (MARBÁN et al., 2008).
Dias (2001), Kurgan e Musilek (2006), Herden (2007) e Herden et al. (2011) observaram que os processos de DCBD e BI existentes não contemplavam ciclos de vida, fases, disciplinas, papéis, produtos de trabalho e outros elementos fundamentais para a Engenharia de Sistemas de Software. Buscando solucionar esse problema, Herden (2007) definiu o processo UPKDD, baseado no Processo Unificado. O UPKDD fornece elementos de Engenharia de Software sólidos para o desenvolvimento de Sistemas de DCBD, em uma perspectiva tradicional, orientada a planejamento e com muitos artefatos documentais.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3143

Todavia, de acordo com Alnoukari, Alzoabi e Hanna (2008), Alnoukari (2011), Larson (2012), Alnoukari (2012) e Alnoukari e Sheikh (2012), processos tradicionais de software não são efetivos no desenvolvimento de Sistemas de DCBD porque são incompatíveis com a dinâmica e as evoluções constantes dos ambientes de negócios corporativos atuais. Esses autores foram os primeiros a relacionarem o desenvolvimento de Sistemas de DCBD às metodologias ágeis de desenvolvimento de software. Estas metodologias são caracterizadas por flexibilidade, adaptabilidade, iteratividade, comunicação face a face e fluxo contínuo de conhecimento entre as pessoas que atuam nosprojetos (ALZOABI, 2012; LARSON, 2012). A junção da metodologia ágil Adaptive Software Development com o processo CRISP-DM resultou na definição dos processosASD-DM5 (ALNOUKARI, ALZOABI e HANNA, 2008) e ASD-BI (ALNOUKARI, 2012).
Não obstante as contribuições trazidas pelo ASD-DM e pelo ASD-BI para o maior sucesso dos projetos de DCBD, estes processos são fundamentados em uma metodologia ágil carente de comprovação científica. A metodologia ASD estrutura os projetos nas fases Especulação (Speculation), Colaboração (Collaboration) e Aprendizado (Learning). Estas fases pouco se assemelham às fases que estruturam os processos de software maduros, a saber: Concepção (Inception), Elaboração (Elaboration), Construção (Construction) e Transição (Transition), as quais tiveram origem no Processo Unificado. O ASD-DM e o ASD-BI também carecem de atividades e disciplinas relacionadas ao gerenciamento de projetos, requisitos e mudanças, as quais são imprescindíveis em um processo de software.Finalmente, falta a esses processos uma maior experimentação científica em casos reais,capazes de confirmar as suas qualidades e identificar as suas deficiências.
O processo proposto neste trabalho, o AgileKDD, busca integrar as melhores práticas do KDD Process e do CRISP-DM com o OpenUP, um processo de software ágil efundamentado no Processo Unificado. A aplicabilidade do AgileKDD foi verificada em um projeto de Sistema de DCBD real, executado em quatro iterações, nas quais problemas como mudanças nos requisitos e baixa qualidade dos dados operacionais exerceram uma influência significativa no alcance dos objetivos. O estudo de caso apontou necessidades de melhoria do processo, as quais foram consideradas no refinamento do AgileKDD.
Portanto, a resposta para a pergunta que motivou este trabalho é: sim, um processo ágil tem a capacidade de guiar projetos de Sistemas de DCBD na direção do alcance dos seus objetivos em cenários de mudanças nos requisitos e baixa qualidade dos dados operacionais.
O AgileKDD passa a integrar a relação de processos definidos com o propósito de sistematizar a DCBD. A Figura 10 posiciona o AgileKDD na linha evolutiva dos processos de DCBD e destaca os processos ágeis como uma nova categoria composta pelo ASD-DM, ASD-BI e, a partir deste trabalho, pelo AgileKDD.
Finalmente, conclui-se que o AgileKDD pode ser empregado no desenvolvimento de Sistemas de DCBD como um arcabouço adaptável e flexível, do qual são utilizadas apenas as atividades necessárias para cada iteração ou projeto. O processo favorece a entrega antecipada e contínua de valor ao cliente por meio de um ciclo de vida iterativo e
5 Apesar de os autores classificarem o ASD-DM como uma metodologia, ele seria mais bem classificado como um processo, uma vez que define uma sequência ordenada de fases e atividades para o desenvolvimento de projetos de DCBD. Uma metodologia pressupõe um conjunto de práticas e procedimentos técnicos que determinam como um produto pode ser desenvolvido, o que não é encontrado no ASD-DM. Por isso, neste documento, o ASD-DM será classificado como um processo.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3144

incremental, da resposta imediata a mudanças, da adaptabilidade e da flexibilidade inerentes aos processos ágeis.
7.1 Limitações e trabalhos futurosUma limitação deste trabalho refere-se à aplicação do AgileKDD em apenas um
caso. A validação efetiva do processo demanda sua aplicação em mais casos, não apenas na área de petróleo como também em outras áreas como a jurídica, a bancária, a varejista, entre outras. Portanto, trabalhos futuros podem contribuir para a avaliação experimental e a melhoria contínua do AgileKDD em casos reais e representativos.
Figura 10 – Evolução dos processos de DCBD, do KDD Process ao AgileKDD.Fonte: Adaptado de Mariscal, Marbán e Fernández (2010).
Pode-se também trabalhar na criação de ferramentas que facilitem a utilização do processo em projetos de DCBD. Um tipo possível de ferramenta conduziria as equipes de projetos na execução das fases e atividades do processo, orientando-os quanto à necessidade de realizar ou não cada atividade, de acordo com os requisitos de negócio do cliente. Outro tipo de ferramenta poderia integrar o processo a ferramentas de MD e OLAP, de modo a permitir a integração entre todos os artefatos produzidos durante os projetos de DCBD. Desta forma, será possível a rastreabilidade entre os requisitos, os modelos, os códigos-fontes e quaisquer outros produtos de trabalho dos projetos. Esta rastreabilidade auxiliará nas análises de impactos causados por mudanças nos requisitos, bem como na manutenção dos Sistemas de DCBD.
Outra limitação deste trabalho refere-se ao armazenamento dos resultados da DCBD em bases de conhecimentos, não contemplado no AgileKDD. Esse armazenamento é fundamental para uma efetiva Gestão do Conhecimento e deve estar presente em um processo de DCBD. Entretanto, verifica-se que os processos ágeis de DCBD existentes, inclusive o AgileKDD, ainda não são capazes de atender a esta necessidade. Portanto, umpossível trabalho futuro incluiria no AgileKDD atividades específicas para a definição da arquitetura da base de conhecimento, bem como para o armazenamento dos resultados (árvores de decisão, regras de associação, padrões, anormalidades, etc.) obtidos pelos Sistemas de DCBD.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3145

REFERÊNCIASALNOUKARI, M.; ALZOABI, Z.; HANNA, S. Applying adaptive software development (ASD) agile modeling on predictive data mining applications: ASD-DM Methodology. In IEEE Proceedings of International Symposium on Information Technology, 2008, p. 1083-1087.
ALNOUKARI, M. Business Intelligence and Agile Methodologies for Knowledge-Based Organizations: Cross-Disciplinary Applications. In: CEPIS UPGRADE: The European Journal for the Informatics Professional. v. 12, n. 3, p. 56-59, Jul. 2011. Disponível em: <http://www.cepis.org/upgrade/media/III_2011_alnoukari1.pdf>. Acesso em: 20 jan. 2012.ALNOUKARI, M. ASD-BI: A Knowledge Discovery Process Modeling Based on Adaptive Software Development Agile Methodology. In: SHEIKH, A. E.; ALNOUKARI, M. Business Intelligence and Agile Methodologies for Knowledge-Based Organizations: Cross-Disciplinary Applications. IGI Global, 2012. p. 183-207. doi:10.4018/978-1-61350-050-7.ch009.
ALNOUKARI, M. et al. Business Intelligence: Body of Knowledge. In: SHEIKH, A. E.;ALNOUKARI, M. Business Intelligence and Agile Methodologies for Knowledge-Based Organizations: Cross-Disciplinary Applications. IGI Global, 2012. p. 1-13.doi:10.4018/978-1-61350-050-7.ch001.
ALNOUKARI, M.; SHEIKH, A. E. Knowledge Discovery Process Models: From Traditional to Agile Modeling. In: SHEIKH, A. E.; ALNOUKARI, M. Business Intelligence and Agile Methodologies for Knowledge-Based Organizations: Cross-Disciplinary Applications. IGI Global, 2012. p. 72-100. doi:10.4018/978-1-61350-050-7.ch004.ALZOABI, Z. Agile Software: Body of Knowledge. In: SHEIKH, A. E.; ALNOUKARI, M. Business Intelligence and Agile Methodologies for Knowledge-Based Organizations: Cross-Disciplinary Applications. IGI Global, 2012. p. 14-34. doi:10.4018/978-1-61350-050-7.ch002.BECK, K. et al. Manifesto para o desenvolvimento ágil de software. 2001. Disponível em http://manifestoagil.com.br/. Acesso em 01 out. 2011.BOENTE, A. N. P.; OLIVEIRA, F. S. G.; ROSA, J. L. A.. Utilização de Ferramenta de KDD para Integração de Aprendizagem e Tecnologia em Busca da Gestão Estratégica do Conhecimento na Empresa. Anais do Simpósio de Excelência em Gestão e Tecnologia, v. 1, p. 123-132, 2007.BRASIL. Universidade Federal do Rio de Janeiro. Centro de Referência em Inteligência Empresarial. Gestão do Conhecimento. Disponível em:http://portal.crie.coppe.ufrj.br/portal/main.asp?ViewID={B796852D-22A7-4515-997F-537BD8378B1C}&u=u. Acesso em: 02 dez. 2010.CARVALHO, A. C. et al. Grandes Desafios da Pesquisa em Computação no Brasil –2006 – 2016. São Paulo. Sociedade Brasileira de Computação. 2006.CHAPMAN, P.; CLINTON, J.; LERBER, R.; KHABAZA, T.; REINARTZ, T.; SHEARER, C.; WIRTH, R. CRoss Industry Standard Process for Data Mining (CRISP-DM 1.0): step-by-step data mining guide. 2000. Disponível em: <http://www.crisp-dm.org/>. Acessado em 05 Maio 2011.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3146

DIAS, M. M. Um modelo de formalização do processo de desenvolvimento de sistemas de descoberta de conhecimento em banco de dados. Tese de Doutorado. Universidade Federal de Santa Catarina. Florianópolis. 2001.
FAYYAD, U.; PIATETSKY-SHAPIRO, G.; SMYTH, P.; UTHURUSAMY, R. Advances in Knowledge Discovery and Data Mining. 1996. AAAIPress, The Mit Press.
GARTNER GROUP. Gartner says more than 50 percent of data warehouse projects will have limited acceptance or will be failures through 2007. 2005. Disponível em http://www.gartner.com/press_releases/asset_121817_11.html. Acesso em 01 out. 2011.______. Gartner Survey of 1,400 CIOs Shows Transformation of IT Organisation is Accelerating. 2006. Disponível em http://www.gartner.com/press_releases/asset_143678_11.html. Acesso em 01 out. 2011.
______. Gartner EXP Survey of More than 1,400 CIOs Shows CIOs Must Create Leverage to Remain Relevant to the Business. 2007. Disponível emhttp://www.gartner.com/it/page.jsp?id=501189. Acesso em 01 out. 2011.______. Gartner EXP Worldwide Survey of 1,500 CIOs Shows 85 Percent of CIOs Expect "Significant Change" Over Next Three Years. 2008. Disponível emhttp://www.gartner.com/it/page.jsp?id=587309. Acesso em 01 out. 2011.
______. Gartner EXP Worldwide Survey of More than 1,500 CIOs Shows IT Spending to Be Flat in 2009. 2009. Disponível em http://www.gartner.com/it/page.jsp?id=855612.Acesso em 01 out. 2011.______. Gartner EXP Worldwide Survey of Nearly 1,600 CIOs Shows IT Budgets in 2010 to be at 2005 Levels. 2010. Disponível emhttp://www.gartner.com/it/page.jsp?id=1283413. Acesso em 01 out. 2011.
______. Gartner Executive Programs Worldwide Survey of More Than 2,000 CIOs Identifies Cloud Computing as Top Technology Priority for CIOs in 2011. 2011.Disponível em http://www.gartner.com/it/page.jsp?id=1526414. Acesso em 01 out. 2011.GIL, A. C. Como elaborar projetos de pesquisa. São Paulo: Atlas, 1996.
GOLFARELLI, M.; RIZZI, S.; CELLA, I. Beyond data warehousing: what's next in business intelligence?. In Proceedings of the 7th ACM international workshop on Data warehousing and OLAP. Washington, EUA. 2004.GONÇALVES, J. E. L. As Empresas São Grandes Coleções de Processos. RAE – Revista de Administração de Empresas. , v. 40, n.1, p. 6-19, 2000.HERDEN, A.. UPKDD: um processo para desenvolvimento de sistemas de descoberta de conhecimento em banco de dados. Dissertação (Mestrado em Ciência da Computação) - Universidade Estadual de Maringá. 2007.
HERDEN, A. et al. UPKDD: Processo de Software para Aplicações de Tecnologias Analíticas e Centradas em Objetivos de Descoberta de Conhecimento. In: Simpósio Brasileiro de Qualidade de Software, 10, 2011, Curitiba. Anais do X Simpósio Brasileiro de Qualidade de Software (SBQS), 2011. v. 1. p. 327-341.
HRISTOV, H. T. Introduction to OpenUP. 2011. Disponível emhttp://epf.eclipse.org/wikis/openup/index.htm. Acesso em 08 out. 2011.
INMON, W. Como Construir o Data Warehouse. Rio de Janeiro. Campos. 1997.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3147

INMON, W.; STRAUSS, D.; NEUSHLOSS, G. DW 2.0: the architecture for the next generation of data warehousing. Amsterdam. 2008.JACOBSON, I.; BOOCH, G.; RUMBAUGH, J. The unified software development process. 2.ed. Addison-Wesley, 1999. 463p.KIMBALL, R. Data Warehouse toolkit. São Paulo. Makron Books, 1998.
KIMBALL, R.; ROSS, M. Data warehouse toolkit: o guia completo para modelagemdimensional. Rio de Janeiro: Campus, 2002. 494p.
KURGAN, L.; MUSILEK, P. A survey of Knowledge Discovery and Data Mining process models. The Knowledge Engineering Review, 21 , p. 1-24. 2006.
LARSON, D. Agile Methodologies for Business Intelligence. In: SHEIKH, A. E.;ALNOUKARI, M. Business Intelligence and Agile Methodologies for Knowledge-Based Organizations: Cross-Disciplinary Applications. IGI Global, 2012. p. 101-119.MARBÁN, Ó.; SEGOVIA, J.; MENASALVAS, E.; FERNÁNDEZ, C. Towards data mining engineering: a software engineering approach. 2008. Information Systems Journal.
MARISCAL, G.; MARBÁN, Ó.; FERNÁNDEZ, C. A survey of data mining and knowledge discovery process models and methodologies. The Knowledge Engineering Review, ed. 25, p. 137-166. 2010.MELLO, C. H. P. et al . Pesquisa-ação na engenharia de produção: proposta de estruturação para sua condução. Produção, São Paulo, v. 22, n. 1, 2012 . Disponível em: <http://www.scielo.br/scielo.php?script=sci_arttext&pid=S0103-65132012000100001&lng=pt&nrm=iso>. Acesso em: 12 jul. 2012.http://dx.doi.org/10.1590/S0103-65132011005000056.
MIGUEL, P. A. C. Estudo de caso na engenharia de produção: estruturação e recomendações para sua condução. Produção, São Paulo, v. 17, n. 1, Abr. 2007.Disponível em: <http://www.scielo.br/scielo.php?script=sci_arttext&pid=S0103-65132007000100015&lng=en&nrm=iso>. Acessado em 09 Jul. 2012.http://dx.doi.org/10.1590/S0103-65132007000100015.NASCIMENTO, G. S.; OLIVEIRA, A. A. AgileKDD: An Agile Business Intelligence Process Model. In: ICSEA 2012 - The Seventh International Conference on Software Engineering Advances, 2012a, Lisboa.
______. An Agile Knowledge Discovery in Databases Software Process. In: Xiang et al. (Eds.): IDCS 2012 and ICDKE 2012, LNCS – Springer Lecture Notes in Computer Science, vol. 7646, p. 343-351. Springer, Heidelberg, 2012b.OECD. Organisation for Economic Cooperation and Development. The Knowledge-Based Economy. Paris, 1996. Disponível em <http://www.oecd.org/dataoecd/51/8/1913021.pdf>. Acesso em 01 mai. 2012.
ORIBE, C. Y. Os 70 Anos do Ciclo PDCA. Revista Banas Qualidade. n. 209. p.20-25. 2009.
PRESSMAN, R. S. Engenharia de Software. 6 ed. São Paulo. McGraw-Hill. 2006.SANTOS, S. S. OpenUP: Um processo ágil Disponível em:http://www.ibm.com/developerworks/br/rational/local/open_up/index.html. 2009. Acesso em 08 out 2011.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3148

SEVERINO, A. J. Metodologia do trabalho científico. 23 ed. rev. e atualizada. São Paulo: Cortez, 2007.SHEARER, C. The CRISP-DM model: the new blueprint for data mining. Journal for data warehousing, Vol. 5, No. 4, 13-22, ISSN 1548-3924. 2000.SILVA, E. L.; MENEZES, E. M. Metodologia da pesquisa e elaboração de dissertação. 4. ed. Florianópolis: UFSC, 2005. 138 p. Disponível em: <http://www.portaldeconhecimentos.org.br/index.php/por/content/view/full/10232>. Acesso em: 12 dez. 2010.VALENTIN, L. G. Uma arquitetura de software para sistemas de descoberta de conhecimento em banco de dados. Dissertação (Mestrado em Ciência da Computação) –Universidade Estadual de Maringá. 2006.
YIN, R. K. Estudo de Caso – Planejamento e Método. 2. ed. São Paulo: Bookman, 2001.WATSON, H. J.; WIXOM, B. H.; HOFFER, J. A.; LEHMAN, R. A. REYNOLDS, A. M.Real-Time Business Intelligence: Best Practices at Continental Airlines. Information Systems Management, Bristol, v. 23, n. 1, p. 7-18, Dez. 2006. Disponível em: <http://dx.doi.org/10.1201/1078.10580530/45769.23.1.20061201/91768.2>. Acesso em: 10 jul. 2012.
WIXOM, B. H.; WATSON, H. J.; REYNOLDS, A. M.; HOFFER, J. A. Continental Airlines Continues to Soar with Business Intelligence. Information Systems Management, Bristol, v. 25, n. 2, p. 102-112, Mar. 2008. Disponível em: <http://dl.acm.org/citation.cfm?id=1451615>. Acesso em: 10 jul. 2012.
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil
3149