podstawy obsługi spss - pracownik.kul.pl · podstawy obsługi spss • interfejs programu spss •...
TRANSCRIPT

Podstawy obsługi SPSS
• Interfejs programu SPSS• Deklarowanie zmiennych• Wprowadzanie danych• Zapisywanie i wczytywanie zbioru danych• Operacje na zmiennych• Podstawowe obliczenia statystyczne (rozkład
częstości, statystyki opisowe, tabele)

Interfejs programu SPSS
Czyli, jak TO wygląda
☺

Podgląd zmiennychTu deklarujemy zmienne, zmieniamy ich parametry, wartości jaki mogą one przyjmować itp.
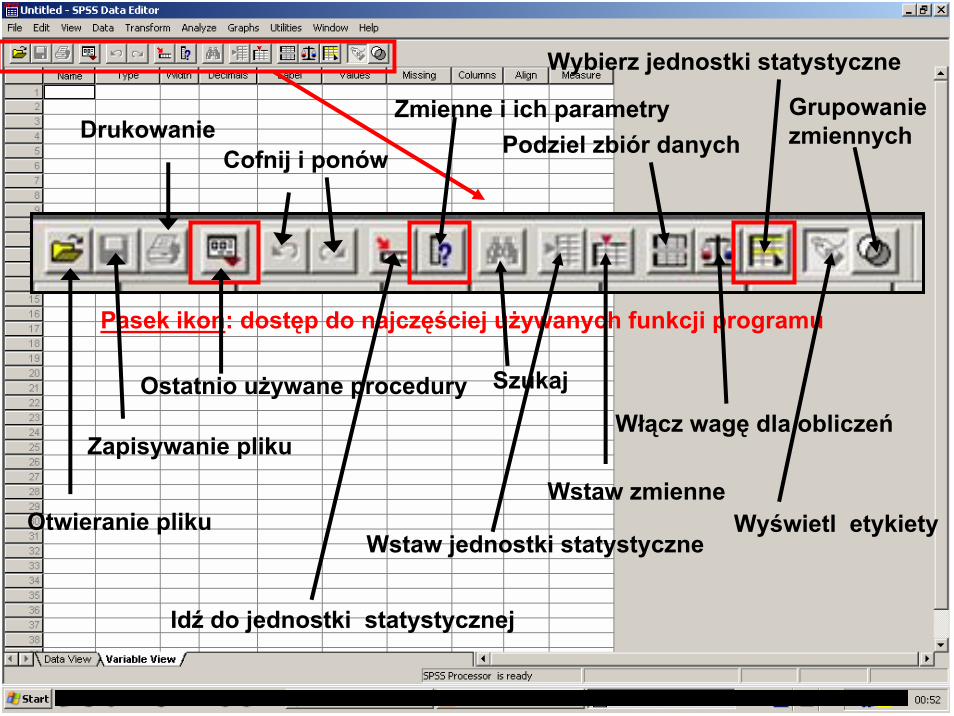
Pasek ikon: dostęp do najczęściej używanych funkcji programu
Otwieranie pliku
Zapisywanie pliku
Drukowanie
Ostatnio używane procedury
Cofnij i ponów
Idź do jednostki statystycznej
Zmienne i ich parametry
Szukaj
Wstaw jednostki statystyczne
Wstaw zmienne
Podziel zbiór danych
Wybierz jednostki statystyczne
Wyświetl etykiety
Włącz wagę dla obliczeń
Grupowanie zmiennych

Operacje na plikachOtwieranie, zapisywanie itp.
Operacje edycyjne Kopiuj, wklej itp
Wyświetlanie/ukrywanieelementów interfejsu
Operacje na zbiorze danych
Przekształcenia danych
Analizy statystyczne
Wykresy

Zakładka dane: przełącza do trybu edycji zbioru danych, dostęp do każdej jednostki statystycznej i wartości zmiennych
Zakładka zmienne: tryb edycji zmiennych, deklarowanie nowych zmiennych, edycja parametrów zmiennych w zbiorze

Deklarowanie zmiennych

Deklarowanie zmiennych
• Nazwa zmiennej• Typ zmiennej (numeryczna, czy tekstowa)• „Wielkość” zmiennej• Etykieta zmiennej (opis)• Zdeklarowane wartości zmiennej• Wartości oznaczone jako „brak danych”• Poziom pomiaru zmiennej

Nazwa zmiennej
• nazwa zmiennej powinna odzwierciedlaćfaktycznie reprezentowaną przez danązmienną cechę
• niektóre (starsze) wersje SPSS ograniczają długość nazwy zmiennej do 8 znaków, co wymusza stosowanie nazw skrótowych.

Typ zmiennej (numeryczna/tekstowa)
• Typ zmiennej określa czy wartości zmiennej są liczbami, czy ciągiem znaków.
• Na zmiennych, które przyjmują wartości będące ciągiem znaków nie możliwe jest wykonywanie większości obliczeństatystycznych.
• Często ciągi znaków wykorzystuje się dla pytań otwartych

„Wielkość” (szerokość) zmiennej
• Dla zmiennych przyjmujących wartości numeryczne (liczby) określa ilość cyfr i miejsc po przecinku
• Dla zmiennych przyjmujących wartości będące ciągami znaków (tekst) określa długość (liczbę znaków) ciągu znaków

Etykieta zmiennej
• Jest to skrótowy opis zmiennej.• dzięki temu możemy łatwiej zorientować
się do jakiej cechy dana zmienna sięodnosi.
• Etykiety zmiennych są wyświetlane przy wynikach obliczeń

Zadeklarowane wartości(etykiety kodów zmiennej)
• Gdy zmienna przyjmuje wartości numeryczne, można konkretnym kodom (liczbom) przypisaćetykiety (co dany kod oznacza)
• Np. zmienna „PLEC” zawierająca informację o płci respondenta przyjmuje wartości „1” dla kobiet i „2” dla mężczyzn. Dzięki etykietom kodów łatwo dowiemy się co oznaczają wartości zmiennej numerycznej

Braki Danych
• Czasem nie chcemy, aby jakieś wartości zmiennej były uwzględniane przy obliczeniach statystycznych. Możemy to uzyskać oznaczając te wartości jako „brak danych”

Poziom pomiaru zmiennej
• Poziom nominalny np. płeć, wyznanie, miejsce urodzenia, kolor oczu (różnice)
• Poziom porządkowynp. poziom wykształcenia, wielkość miejsca zamieszkania
(bardziej/mniej)
• Poziom interwałowy np. wyniki testów IQ (o ile bardziej)
• i ilorazowynp. wzrost w metrach, dochód miesięczny
(istnieje PUNKT ZEROWY, iloraz-stosunek ilościowy zmiennych)

Poziomu pomiaru
• Zmienne ilorazowe posiadają wszystkie cechy zmiennych interwałowych, porządkowych i nominalnych
• Zmienne interwałowe posiadają wszystkie cechy zmiennych porządkowych i nominalnych
• Zmienne porządkowe posiadają wszystkie cechy zmiennych nominalnych

Deklarowanie zmiennych
• Utworzymy zmienne opisujące następujące cechy: płeć, czy pali papierosy, jakiej marki papierosy pali, ile papierosów dziennie pali.
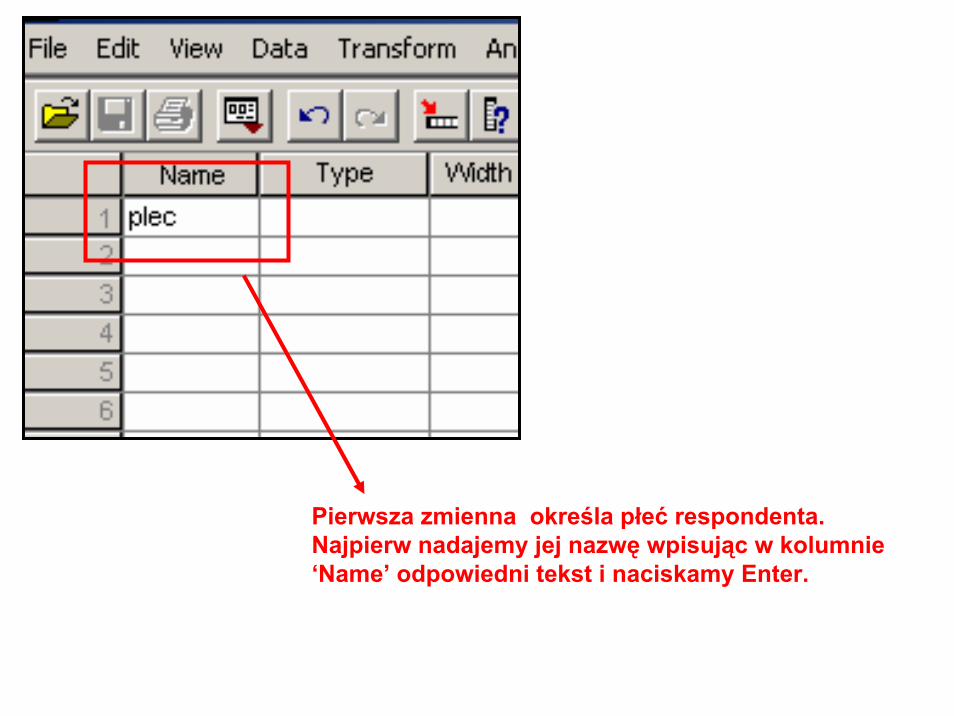
Pierwsza zmienna określa płeć respondenta. Najpierw nadajemy jej nazwę wpisując w kolumnie ‘Name’ odpowiedni tekst i naciskamy Enter.
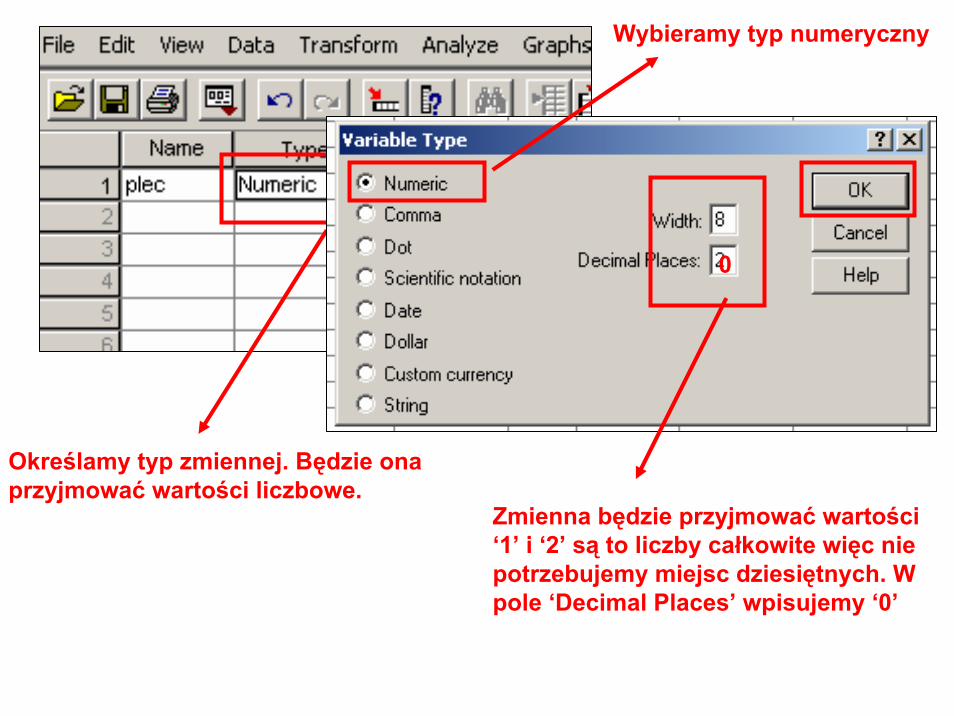
Określamy typ zmiennej. Będzie ona przyjmować wartości liczbowe.
Wybieramy typ numeryczny
Zmienna będzie przyjmować wartości ‘1’ i ‘2’ są to liczby całkowite więc nie potrzebujemy miejsc dziesiętnych. W pole ‘Decimal Places’ wpisujemy ‘0’
0

Określamy etykietę zmiennej wpisując w kolumnie ‘Label’ odpowiedni tekst
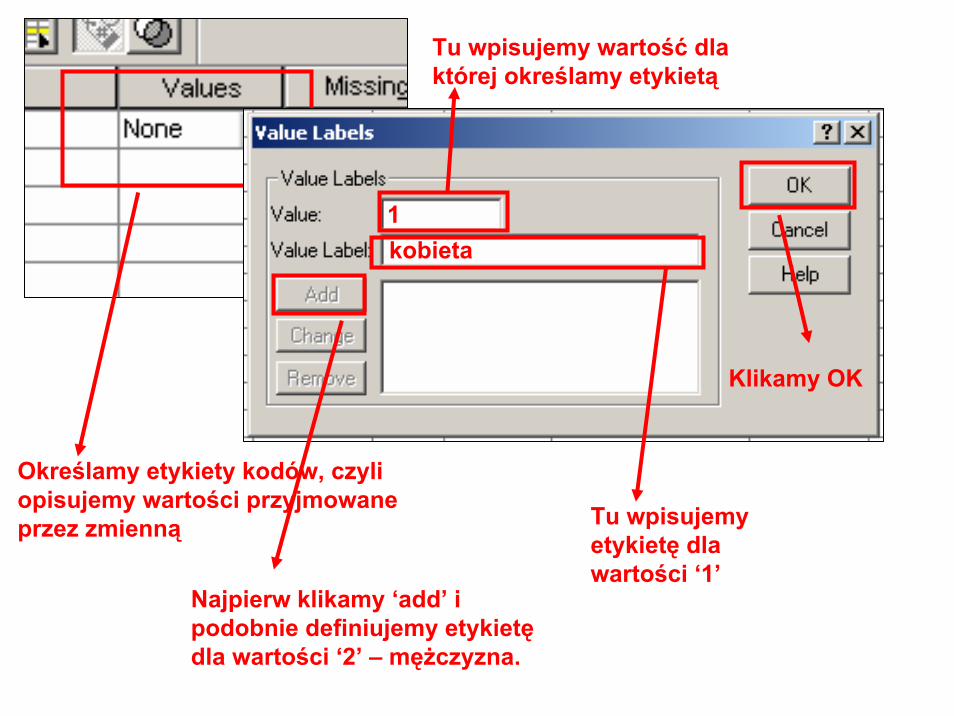
Określamy etykiety kodów, czyli opisujemy wartości przyjmowane przez zmienną
Tu wpisujemy wartość dla której określamy etykietą
1
Tu wpisujemy etykietę dla wartości ‘1’
kobieta
Najpierw klikamy ‘add’ i podobnie definiujemy etykietędla wartości ‘2’ – mężczyzna.
Klikamy OK

Pozostaje określić jeszcze poziom pomiaru. Zmienna ‘plec’ ma charakter nominalny

Deklarowanie zmiennych• Zmienna ‘pali’
– etykieta: czy pali papierosy– Wartości: ‘1’ – tak; ‘2’ – nie;
• Zmienna ‘marka’– Etykieta: jakiej marki papierosy pali– Wartości: ‘1’ – Extra mocne; ‘2’ – Fajrant; ‘3’-Wiarus;
‘4’-Stołeczne; ‘5’-różne; ‘6’-odmowa odpowiedzi; ‘7’-nie dotyczy– Brak danych: 6; 7;
• Zmienna ‘ilepali’– Etykieta: ile papierosów dziennie pali– Brak danych: 0

Wprowadzanie danych

Data View
• Jest to tryb pracy, w którym mamy bezpośredni dostęp zbioru danych
• Możemy wprowadzać dane i je edytować

W kolumnach znajdują sięzadeklarowane zmienne. Nazwa każdej zmiennej znajduje się w nagłówku kolumny
Wiersze reprezentują kolejne jednostki statystyczne (np. respondentów). Numer kolejnej jednostki statystycznej znajduje się w nagłówku wiersza
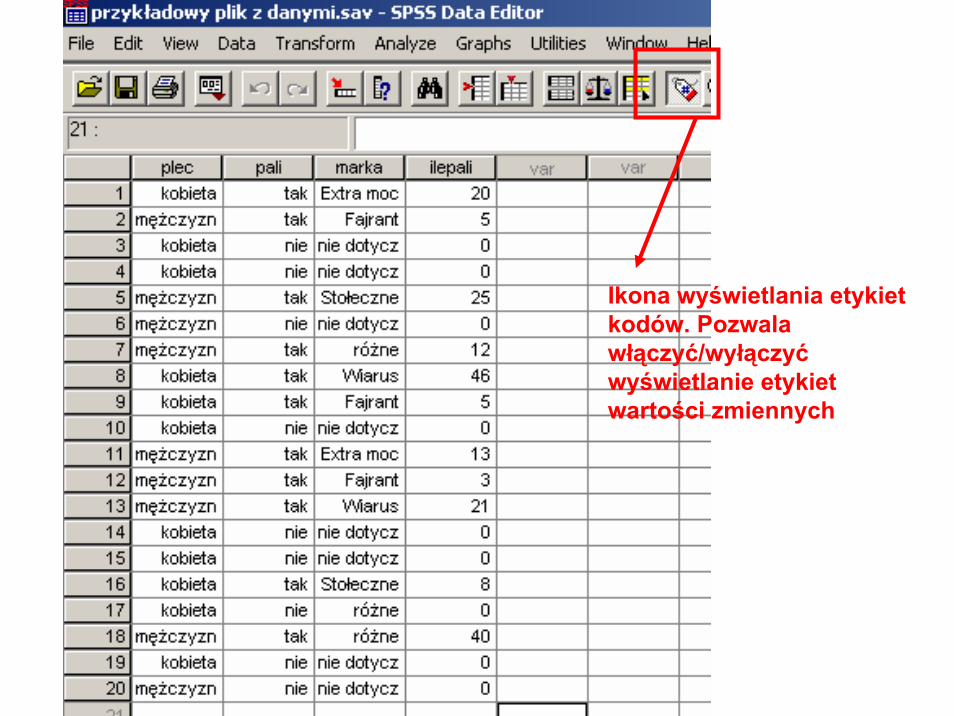
Ikona wyświetlania etykiet kodów. Pozwala włączyć/wyłączyćwyświetlanie etykiet wartości zmiennych
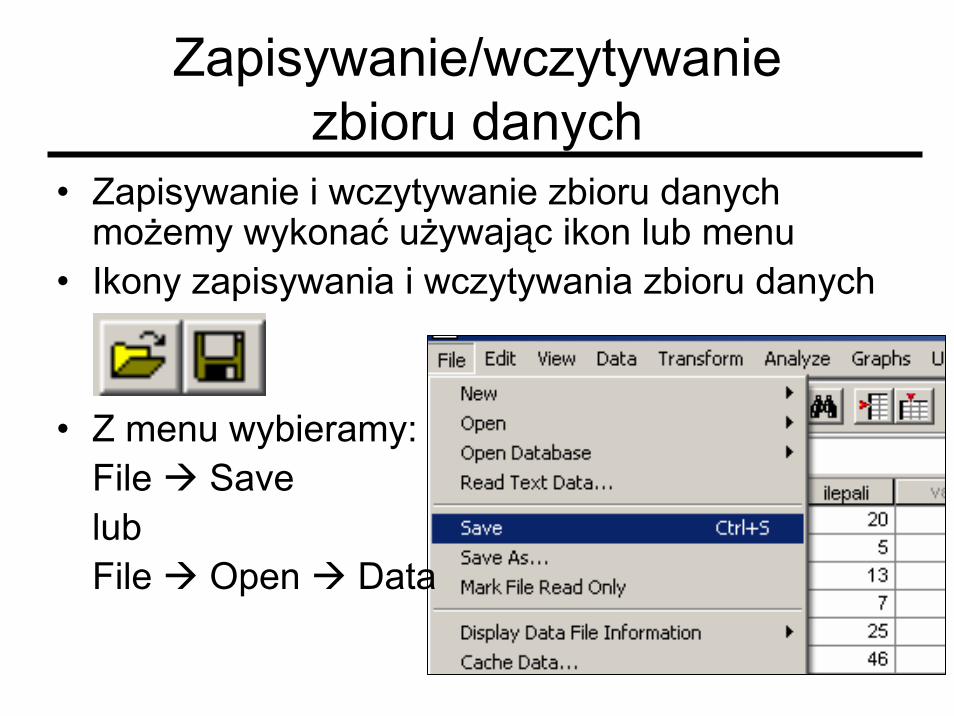
Zapisywanie/wczytywaniezbioru danych
• Zapisywanie i wczytywanie zbioru danych możemy wykonać używając ikon lub menu
• Ikony zapisywania i wczytywania zbioru danych
• Z menu wybieramy: File Savelub File Open Data

Operacje na zmiennych•Wybór jednostek statystycznych
Pozwala wybrać do dalszych analiz tylko takie jednostki statystyczne, które spełniają określone warunki (np. kobiety z wyższym wykształceniem, mieszkające w miastach powyżej 500tys. Mieszkańców)
•RekodowanieUmożliwia przekodowanie lub pogrupowanie wartości zmiennej w zbiorze. Np. wartości zmiennej określające liczbę lat respondenta możemy pogrupować w kategorie wiekowe.
•Obliczanie wartości zmiennejCzęsto podczas prowadzenia analiz musimy obliczyć wartośćnowej zmiennej bazując na danych istniejących w zbiorze danych. Np. wyznaczyć ilość lat respondenta znając rok urodzenia.

Wybór jednostek statystycznych

Lista zmiennych w zbiorze
Wybierz wszystkie jednostki
Wybierz te jednostki stat.,które spełniają określony warunek
Wybierz losową próbkę jednostek

Lista zmiennych w zbiorze
Pole gdzie zapisujemy warunek, który spełniać mają wybrane jednostki
Kalkulator, pozwala na wprowadzanie operatorów logicznych i arytmetycznych do warunku
V44<=5 | (v47=5 & v48=3)

Podstawowe operatory logiczne i arytmetyczne:+ dodawanie- odejmowanie/ dzielenie* mnożenie** potęgowanie~ negacja (nie jest tak, że)= równość~= nie równa się< mniejsze niż> większe niż<= mniejsze lub równe niż>= większe lub równe niż& koniunkcja logiczna ‘i’| alternatywa ‘lub’( )

Rekodowanie

Lista zmiennych w plikuZmienne poddane przekształceniu
Tu określamy nazwę i etykietędla zmiennej wynikowejTym przyciskiem dodajemy
zmienne do przekształcenia
Szczegółowe określenie parametrów przekształcenia

Przekształcenie:Wartości zmiennej ‘marka’ zostaną przekodowaneW wartości zmiennej ‘gr_marka’
Nazwa i etykieta nowej zmiennej

Wartości źródłoweWartości wynikowe

Konkretna wartość zmiennejźródłowej
Systemowe i zadeklarowanebraki danych
Zakres wartości od - do
Zakres wartości od najmniejszej do
Zakres wartości od – do wartości największej
Wszystkie pozostałe wartości

Nowa wartość zmiennej wynikowej
Systemowy brak danych zmiennej wynikowej
Przepisuje wartość zmiennej źródłowejdo zmiennej wynikowej
Dodaje przekształcenie do listy
Zmienia utworzoneprzekształcenie
Zmienia utworzone przekształcenie

Obliczanie wartości zmiennej

Lista zmiennych w pliku
Zmienna wynikowa
Wyrażenie algebraiczneJego wynik zostanie przypisanyzmiennej wynikowej

Podstawowe obliczenia statystyczne
• Rozkład częstości zmiennej• Miary tendencji centralnej• Miary dyspersji rozkładu• Kurtoza i skośność• Statystyki opisowe• Tabele Krzyżowe• Korelacje

Rozkład częstości zmiennej• Częstości są najprostszą i najczęściej wykonywaną
procedurą w programie SPSS.• Dzięki tej procedurze możemy sprawdzić jak wygląda
procentowy rozkład wartości zmiennej (odpowiedzi). Np. jaki odsetek osób pali papierosy?
• Analyze Descriptive Statistics Frequencies…


Lista zmiennych w pliku, które możemy wybrać do analizy
Lista zmiennych wybranych do analizy
Tym przyciskiem dodajemy zmienne do analizy
Dodatkowe statystyki
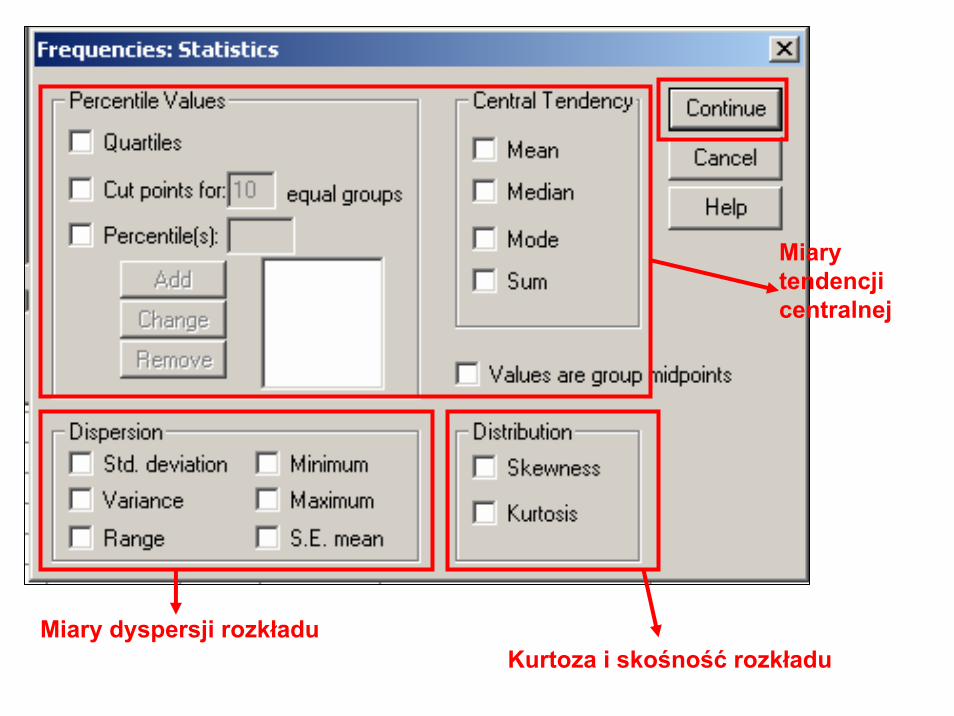
Miary tendencji centralnej
Miary dyspersji rozkładuKurtoza i skośność rozkładu

Otuput: tu wyświetlane są wyniki wszystkich procedur statystycznych
Outline: jest to spis wyników wykonanych procedur
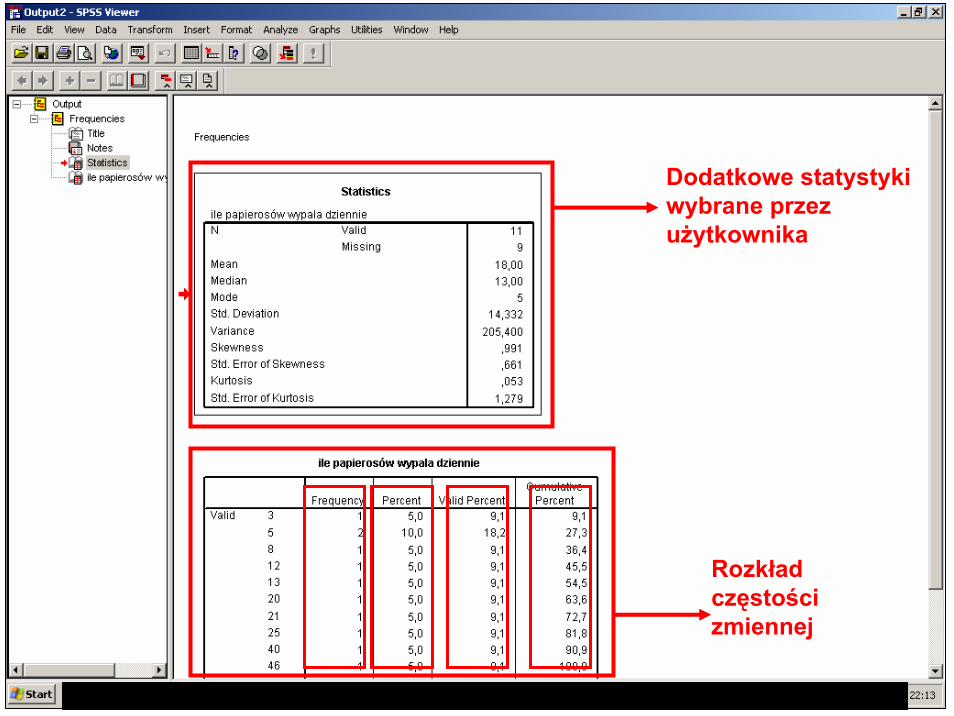
Dodatkowe statystyki wybrane przez użytkownika
Rozkład częstości zmiennej

Miary tendencji centralnej• Średnia suma wartości zmiennej wszystkich
jednostek badanej zbiorowości podzielona przez liczbętych jednostek
• Dominanta (modalna) wartość zmiennej, która w danym rozkładzie występuje najczęściej
• Kwantyle wartości cechy badanej zbiorowości, które dzielą ją na określone części pod względem liczby jednostek. – Kwartyle – pierwszy kwartyl 25% do 75%,
drugi kwartyl 50% do 50% (mediana), trzeci kwartyl75% do 25%
– Decyle dzielą zbiorowość na 10 części– Percentyle dzielą zbiorowość na 100 cześci

Miary dyspersji rozkładu• Odchylenie standardowe o ile wszystkie jednostki danej
zbiorowości różnią się średnio ze względu na wartość zmiennej od średniej arytmetycznej tej zmiennej.
• Wariancja średnia arytmetyczna z kwadratów odchyleńposzczególnych wartości od średniej arytmetycznej całej zbiorowości. Im zbiorowość jest bardziej zróżnicowana tym większa jest wartośćwariancji
NXx
s i2)(∑ −
=
NXx
s i∑ −=
22 )(

Kurtoza i skośność• Współczynnik asymetrii rozkładu przyjmuje wartość
‘0’ dla rozkładu symetrycznego, wartość > 0 dla asymetrii prawostronnej, wartość < 0 dla asymetrii lewostronnej.
• Kurtoza miara koncentracji rozkładu zmiennej w porównaniu do rozkładu normalnego. Wartość >0 koncentracja większa od rozkładu normalnego,wartość <0 koncentracja mniejsza od rozkładu normalnego

Kurtoza i skośność
Skośność
Kurtoza
Rozkład symetryczny Asymetria prawostronna Asymetria lewostronna
Rozkład normalny Rozkład platykurtyczny Rozkład leptokurtyczny

Statystyki opisowe
• Statystyki opisowe (średnia, odchylenie std., wariancja, kurtoza, współczynnik skośności rozkładu itp.,) możemy obliczyćniezależnie od rozkładu częstości miennej.
• Analyze Descriptive Statistics Descriptive…


Tu wybieramy statystyki
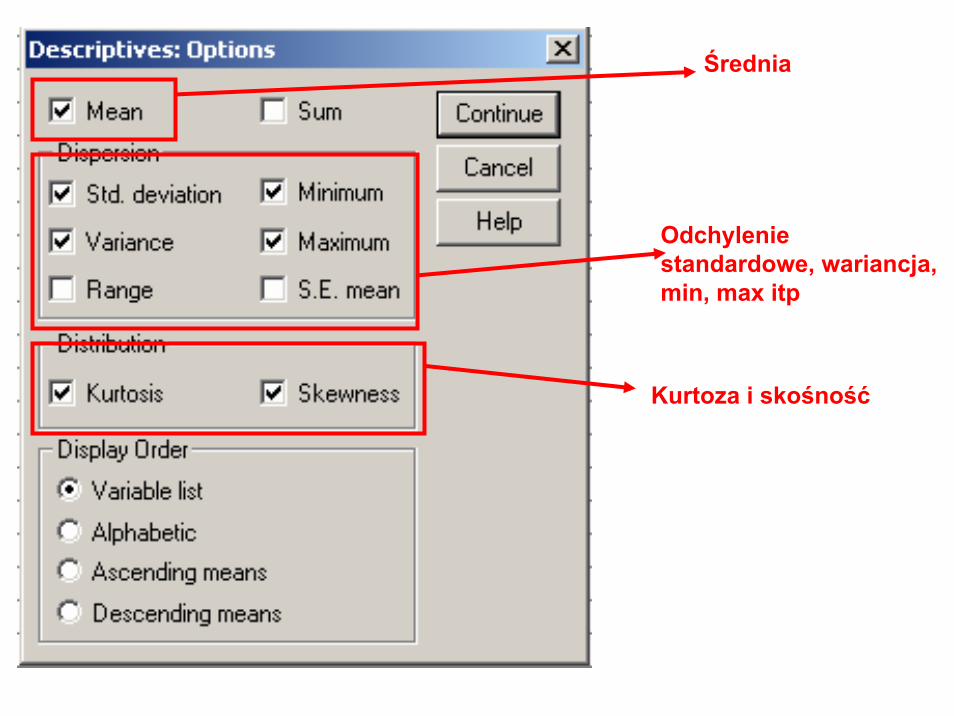
Średnia
Odchylenie standardowe, wariancja, min, max itp
Kurtoza i skośność

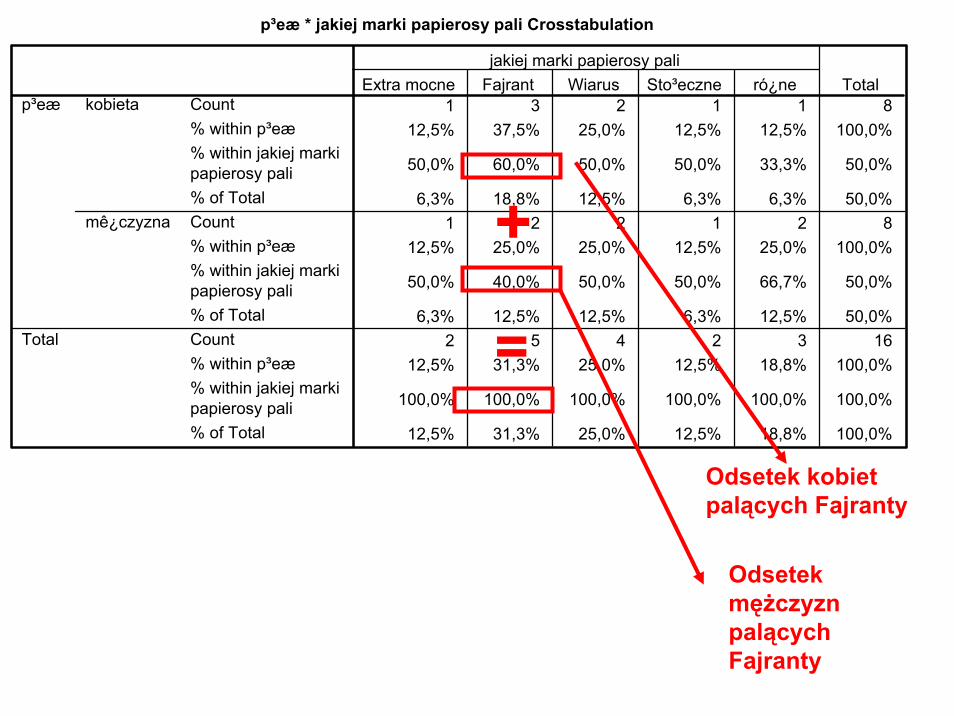
Tabele krzyżowe
• Tabele krzyżowe to tabele zawierające rozkład częstości wielu zmiennych. Dzięki nim możemy np. określić jaki odsetek osób palących pali papierosy marki ‘Stołeczne’
• Analyze Descriptive Statistics Crosstabs…


Lista zmiennych w zbiorze danych
Zmienne w wierszach
Zmienne w kolumnach
`zawartość komórek tabeli krzyżowej
Zmienne warstwując

Procenty w wierszach, procenty w kolumnach, procenty w całym zbiorze

p³eæ * jakiej marki papierosy pali Crosstabulation
1 3 2 1 1 812,5% 37,5% 25,0% 12,5% 12,5% 100,0%
50,0% 60,0% 50,0% 50,0% 33,3% 50,0%
6,3% 18,8% 12,5% 6,3% 6,3% 50,0%1 2 2 1 2 8
12,5% 25,0% 25,0% 12,5% 25,0% 100,0%
50,0% 40,0% 50,0% 50,0% 66,7% 50,0%
6,3% 12,5% 12,5% 6,3% 12,5% 50,0%2 5 4 2 3 16
12,5% 31,3% 25,0% 12,5% 18,8% 100,0%
100,0% 100,0% 100,0% 100,0% 100,0% 100,0%
12,5% 31,3% 25,0% 12,5% 18,8% 100,0%
Count% within p³eæ% within jakiej markipapierosy pali% of TotalCount% within p³eæ% within jakiej markipapierosy pali% of TotalCount% within p³eæ% within jakiej markipapierosy pali% of Total
kobieta
mê¿czyzna
p³eæ
Total
Extra mocne Fajrant Wiarus Sto³eczne ró¿nejakiej marki papierosy pali
Total
Odsetek kobiet palących określone marki papierosów
p³eæ * jakiej marki papierosy pali Crosstabulation
1 3 2 1 1 812,5% 37,5% 25,0% 12,5% 12,5% 100,0%
50,0% 60,0% 50,0% 50,0% 33,3% 50,0%
6,3% 18,8% 12,5% 6,3% 6,3% 50,0%1 2 2 1 2 8
12,5% 25,0% 25,0% 12,5% 25,0% 100,0%
50,0% 40,0% 50,0% 50,0% 66,7% 50,0%
6,3% 12,5% 12,5% 6,3% 12,5% 50,0%2 5 4 2 3 16
12,5% 31,3% 25,0% 12,5% 18,8% 100,0%
100,0% 100,0% 100,0% 100,0% 100,0% 100,0%
12,5% 31,3% 25,0% 12,5% 18,8% 100,0%
Count% within p³eæ% within jakiej markipapierosy pali% of TotalCount% within p³eæ% within jakiej markipapierosy pali% of TotalCount% within p³eæ% within jakiej markipapierosy pali% of Total
kobieta
mê¿czyzna
p³eæ
Total
Extra mocne Fajrant Wiarus Sto³eczne ró¿nejakiej marki papierosy pali
Total
Odsetek kobiet palących Fajranty
+
=
Odsetek mężczyzn palących Fajranty

Korelacje• Współczynnik korelacji liniowej Pearsona.
Mierzy siłę związku prostoliniowego między dwiema zmiennymi. Związkiem prostoliniowym nazywamy taką zależność, w której jednostkowym przyrostom jednej zmiennej towarzyszy, średnio, stały przyrost drugiej zmiennej.
• Współczynnik korelacji kolejnościowejSpearmana. Służy do opisu korelacji zmiennych, gdy mają one charakter jakościowy i istnieje możliwość uporządkowania obserwacji empirycznych w określonej kolejności.

Korelacje
• Współczynniki korelacji przyjmują wartości od -1 do +1
• -1 maksymalna korelacja ujemna (im więcej jednej cechy tym mniej drugiej)
• +1 maksymalna korelacja pozytywna(im więcej jednej cechy tym więcej drugiej)
• 0 brak związku korelacyjnego między zmiennymi

Korelacje
1 ,926**
,000
300 300
,926** 1
,000
300 300
Korelacja Pearsona
Istotność (dwustronna)
N
Korelacja Pearsona
Istotność (dwustronna)
N
China
Russia
China Russia
Korelacja jest istotna na poziomie 0.01**.

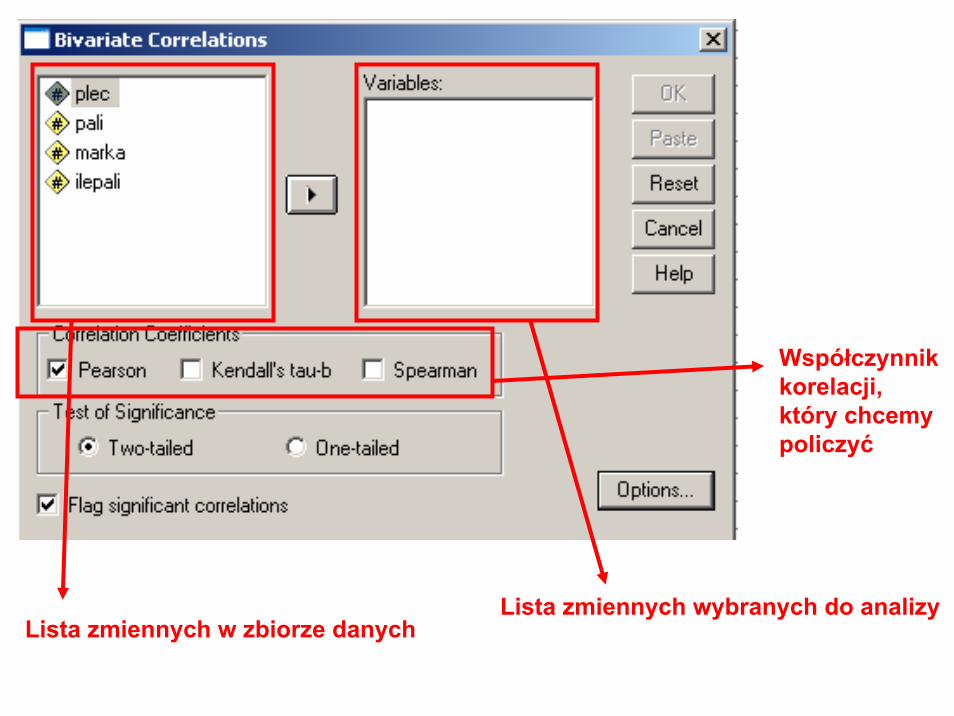
Lista zmiennych w zbiorze danychLista zmiennych wybranych do analizy
Współczynnik korelacji, który chcemy policzyć

Poziom istotności
• Poziom istotności to prawdopodobieństwo odrzucenia testowanej hipotezy, gdy jest ona prawdziwa (błąd I rodzaju).
• W przypadku korelacji w teście istotności sprawdzamy hipotezę, że istnieje związek między zmiennymi.
• Przyjmuje się, że korelacja jest istotna statystycznie, przy poziomie istotności co najwyżej 0,05

95% przedział ufności
Prosta regresji
Yi =β0 + β1X1i+ β2X2i+ ….. +βpXpi

Współczynnikia
2,825 ,124 22,779 ,000
,637 ,015 ,926 42,325 ,000
(Stała)
Russia
Model1
BBłąd
standardowy
Współczynnikiniestandaryzowane
Beta
Współczynnikistandaryzowane
t Istotność
Zmienna zależna: Chinaa.
Model - Podsumowanieb
,926a ,857 ,857 ,25481Model1
R R-kwadratSkorygowane
R-kwadrat
Błądstandardowyoszacowania
Predyktory: (Stała), Russiaa.
Zmienna zależna: Chinab. Often the independent variables aremeasures in different units. Thestandardized coefficients or betas are anattempt to make the regressioncoefficients more comparable.

Wykorzystanie programu SPSS w analizie danych CBOS

CBOS marzec 2005
• Jaki odsetek respondentów deklaruje udział w wyborach prezydenckich?
• Na kogo głosowałoby najwięcej badanych osób?
• Jaki odsetek respondentów deklaruje udział w wyborach parlamentarnych?
• Na którą partię głosowałoby najwięcej badanych osób?

• Jakie jest średnie zaufanie do osób publicznych?
• Jaki jest stosunek respondentów do Partii Demokratycznej?
• Jaki jest rozkład cech społeczno-demograficznych przebadanej populacji? (płeć, wiek, poziom wykształcenia, miesięczne dochody netto na 1 osobę w gospodarstwie domowym).
CBOS marzec 2005

• Jaki jest rozkład poziomu wykształcenia w populacji przebadanych kobiet i populacji przebadanych mężczyzn?
• Jakie są cechy społ.-demog. osób zamierzających głosować na poszczególnych kandydatów do fotela prezydenckiego?
• Czy istnieje związek między zainteresowaniem polityką, rokiem urodzenia, poziomem wykształcenia i wielkością miejsca zamieszkania?
CBOS marzec 2005