physical design: types of indexes & files university of manitoba asper school of business 3500...
TRANSCRIPT

Physical Design:Types of Indexes
& Files
University of ManitobaAsper School of Business
3500 DBMSBob Travica
Based on G. Post, DBMS: Designing & Building Business Applications
Updated 2015

DDBB
SSYYSSTTEEMMSS
2 of 29
Physical Data Storage
Topics of interest:
File types for storing data
Index types - Data structures for retrieving data (Index to
sequential file, Linked List, B+-Tree, Hash Table)
Additional Physical Design Methods (file partitioning, clustering)

DDBB
SSYYSSTTEEMMSS
3 of 29
Terminology
Data entry or data element (a special short record containing usually the key attribute, address to the rest of data, and sometimes other addresses)
Pointer = address of data, designation of data location
DBMS task = any of CRUD operations

DDBB
SSYYSSTTEEMMSS
4 of 29
DBMS Tasks(CRUD)
Store (write, create) data Insert a row.
Retrieve (read) data Read entire table (scan all rows). Read arbitrary/random row.
Modify (update) data
(Change “Crag” into “Craig”)
Delete data.
(2 steps: mark + ”pack”)
LastName FirstName PhoneAdams Kimberly (406) 987-9338
Allbright Searoba (619) 281-2485Anderson Charlotte (701) 384-5623Baez Bessie (606) 661-2765Baez Lou Ann (502) 029-3909Bailey Gayle (360) 649-9754Bell Luther (717) 244-3484Carter Phillip (219) 263-2040Carver Bernice (804) 020-5842Crag Melinda (502) 691-7565x Duvall Pierre (502) 595-1052
Adkins Inga (706) 977-4337

DDBB
SSYYSSTTEEMMSS
5 of 29
File Types & Access Methods (Indexes)
Indexed Sequential Access Method (ISAM) &
Sequential File
Linked List index
B+-Tree index
Hash index
DDBB
SSYYSSTTEEMMSS
6 of 29
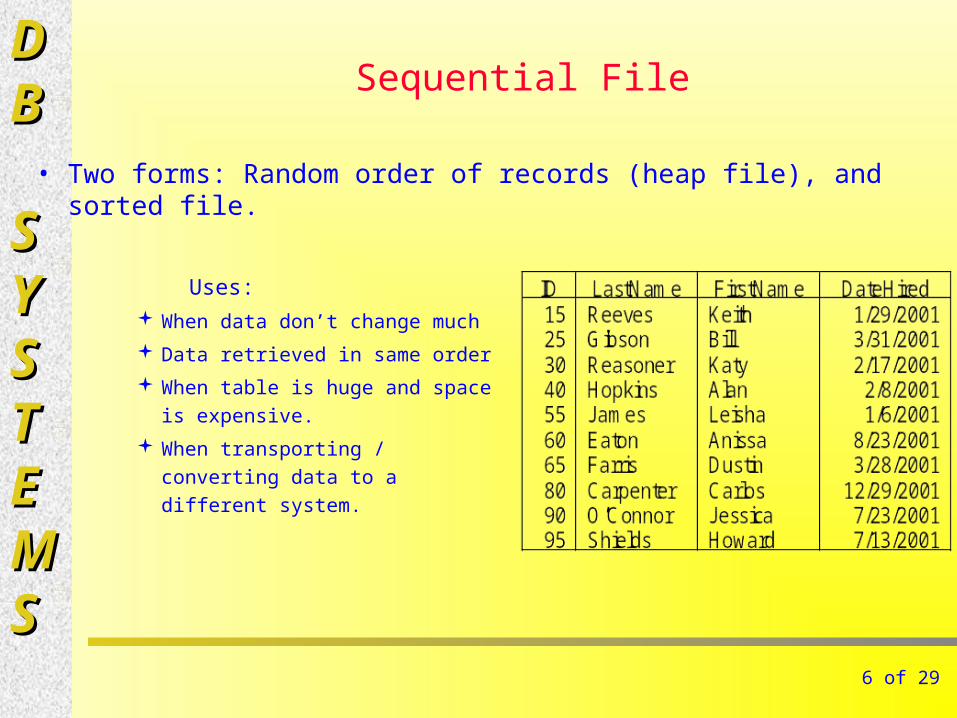
Sequential File
Uses: When data don’t change much
Data retrieved in same order
When table is huge and space
is expensive.
When transporting / converting
data to a different system.
• Two forms: Random order of records (heap file), and sorted file.

DDBB
SSYYSSTTEEMMSS
7 of 29
Operations on Sequential Files
Read entire file sequentially: Easy and fast
Read next record: Fast
Random Read/Sequential (pattern matching): Slow Probability of any row lookup = 1/N
Delete, Insert, Modify: First find, then do… So, slow, costly
Row Prob. # ReadsA 1/N 1B 1/N 2C 1/N 3D 1/N 4E 1/N 5… 1/N i

DDBB
SSYYSSTTEEMMSS
8 of 29
Sequential Access to Sorted Sequential File
Sequential search
Find: Brown; 2 lookups,
Find: Jones; 10 lookups
Go one by one from top
Min lookups = 1, Max = 10
On the average = (N+1)/2 =
(10+1)/2= 11/2 = 5.5, i.e. 6
lookups
Record# Key
1. Adams 2. Brown
3. Cadiz4. Dorfmann5. Eaton6. Farris7. Goetz8. Hanson9. Inez
10. JonesSum (N) =10 entries
DDBB
SSYYSSTTEEMMSS
9 of 29
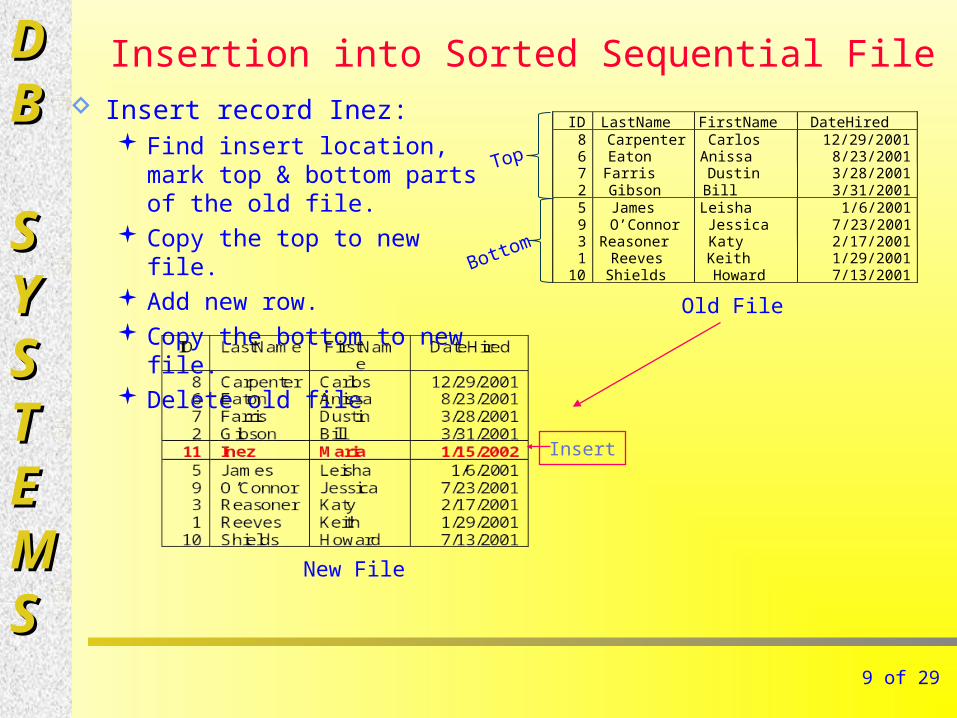
Insertion into Sorted Sequential File Insert record Inez:
Find insert location, mark top & bottom parts of the old file.
Copy the top to new file. Add new row. Copy the bottom to new file. Delete old file
ID LastName FirstName DateHired 8 6 7 2
Carpenter Eaton Farris Gibson
Carlos Anissa
Dustin Bill
12/29/2001 8/23/2001 3/28/2001 3/31/2001
5 9 3 1
10
James O’Connor
Reasoner Reeves Shields
Leisha Jessica Katy Keith Howard
1/6/2001 7 /23/2001 2/17/2001 1/29/2001 7/13/2001
Insert
Old File
New File
Top
Bottom

DDBB
SSYYSSTTEEMMSS
10 of 29
Indexed Sequential Access Method (ISAM)
Common uses Uses an index like a table
with the columns key and pointer.
Multiple columns can be indexed, indexes built.
ID LastName FirstName DateHired1 Reeves Keith 1/29/20012 Gibson Bill 3/31/20013 Reasoner Cathy 2/17/20014 Hopkins Alan 2/8/ 20015 James Leisha 1/6/ 20016 Eaton Anissa 8/23/ 20017 Farris Dustin 3/28/ 20018 Carpenter Carlos 12/29/ 20019 O'Connor Jessica 7/23/ 200110 Shields Howard 7/13/ 2001
A11A22A32A42A47A58A63A67A78A83
Record address
ID Pointer1 A112 A223 A324 A425 A476 A587 A638 A679 A7810 A83
Index on ID
LastName PointerCarpenter A67Eaton A58Farris A63Gibson A22Hopkins A42James A47O'Connor A78Reasoner A32Reeves A11Shields A83
Index on LastName
Index is sorted, search performedon it, and the pointer used to fetch the record sought.
Records (Table), sorted or unsorted

DDBB
SSYYSSTTEEMMSS
11 of 29
Binary Search with ISAM
Task: Find Jones. Binary search
1) Split & test middle value Goetz vs. Jones.
Result: Jones comes after Goetz (Jones > Goetz), so look down + discard upper half
2) Split & test: Jones < Kalida, so look up
3) Split & test: Jones > Inez, so look down
4) Split & test: Jones = Jones, so match!
AdamsBrownCadizDorfmannEatonFarrisGoetzHansonInezJonesKalidaLomaxMirandaNorman
14 entries (=N)
2
1
3
4 Match! in
fourth
lookup
Index – Key Field

DDBB
SSYYSSTTEEMMSS
12 of 29
Binary Search (Cont.)
4 lookups in total: 1) 14/2=7 2) 7/2=3.5, round to 4;
3) 4:2=2
4) 2:2=1
Or: 2x2=4; 4x2=8; 8x2=16that is, appx. 24 . Number of lookups is the exponential to which 2 should be raised to get the number of items retrieved or bit over or
log214 ~ between 3 and 4.
DDBB
SSYYSSTTEEMMSS
13 of 29
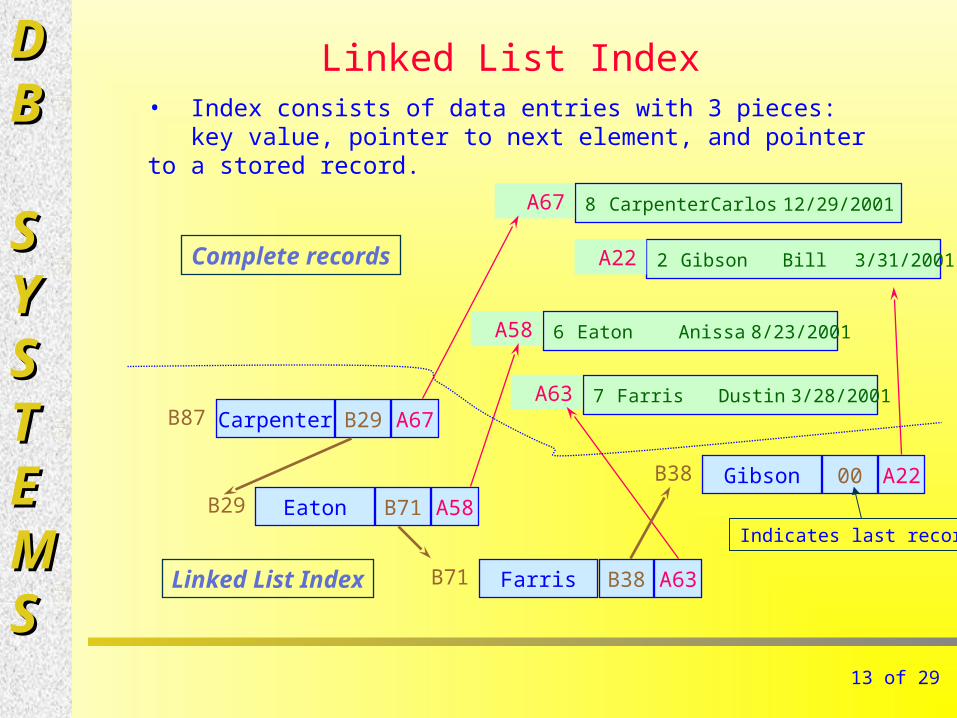
Linked List Index
CarpenterB87 B29 A67
GibsonB38 00 A22
EatonB29 B71 A58
FarrisB71 B38 A63
7 Farris Dustin 3/28/2001A63
8 Carpenter Carlos 12/29/2001A67
6 Eaton Anissa 8/23/2001A58
2 Gibson Bill 3/31/2001A22
• Index consists of data entries with 3 pieces: key value, pointer to next element, and pointer to a stored record.
Complete records
Linked List Index
Indicates last record

DDBB
SSYYSSTTEEMMSS
14 of 29
Linked List: Insert Task
Task: Insert the Eccles row
Procedure: 1. Identify place of Eccles element in sorting order (Eccles is after Eaton and before Farris) – location is logical (pointer-related)
2. Store Eccles element at an available
location (B14)
3. Move pointer from Eaton element to
Eccles element – B71 (referencing Farris
element)
4. Insert pointer in Eaton to point to the
Eccles record – new location B14
FarrisB71 B38 A63
EatonB29 B71 A58
EcclesB14 B71 A97
B14RECORD
S4.
3.2.
1.
X

DDBB
SSYYSSTTEEMMSS
15 of 29
Tree (hierarhical) Indexes
Root = start point
Node (data entry)
Leaf (bottom node with no children)
Depth (n) = number of levels
Degree (m) = max. no. of children per node (2 or more)
Three = a hierarchical structure with a root element on top, branches,nodes, and leaves.
Pointer to keyswith higher/equalvalues
value< <=
Pointer to keys with lower values
Root

DDBB
SSYYSSTTEEMMSS
16 of 29
B+-Tree
Increased retrieval power and performs optimally on other tasks.
Typical index in modern DBMSes
Characteristics: Root, non-leaf nodes (some values of key attribute, used for
navigating through Tree), leaf-nodes (all key values, point to records)
Degree, m >= 3
Every non-leaf node (except Root) has between m/2 and m children
Leaf-nodes (Leaves) are at the same level/depth & in
sequential order.
DDBB
SSYYSSTTEEMMSS
17 of 29
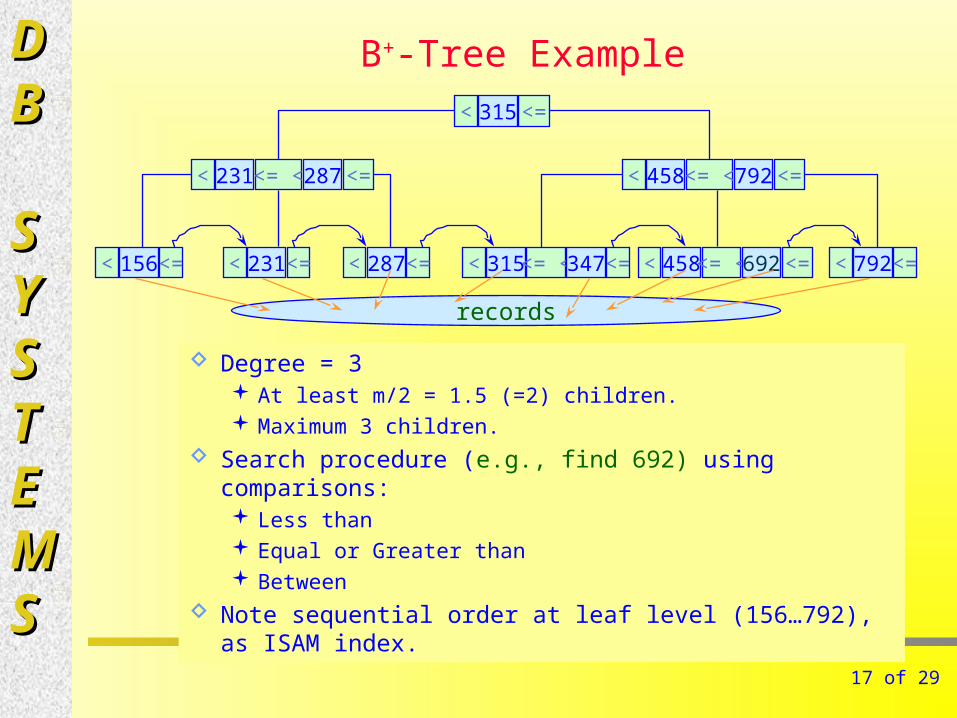
B+-Tree Example
Degree = 3 At least m/2 = 1.5 (=2) children. Maximum 3 children.
Search procedure (e.g., find 692) using comparisons: Less than Equal or Greater than Between
Note sequential order at leaf level (156…792), as ISAM index.
315< <=
231< <= < 287 <= 458< <= < 792 <=
315< <= <347<= 458< <= <692 <=156< <= 231< <= 792< <=287< <=
records
DDBB
SSYYSSTTEEMMSS
18 of 29
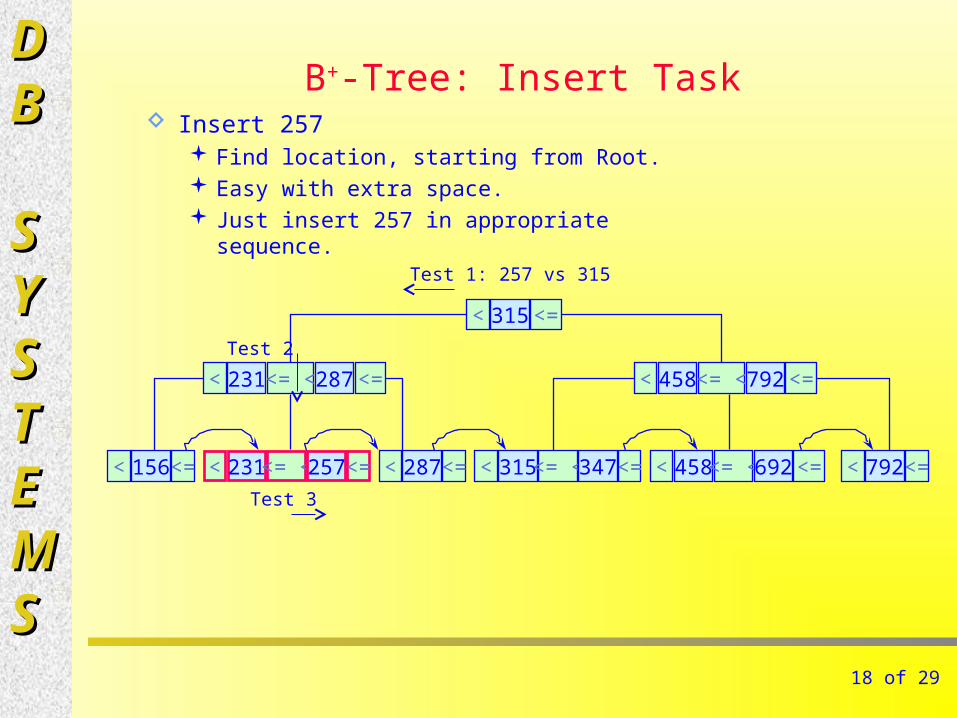
B+-Tree: Insert Task Insert 257
Find location, starting from Root. Easy with extra space. Just insert 257 in appropriate sequence.
315< <=
231< <= < 287 <= 458< <= < 792 <=
315< <= <347<= 458< <= <692 <=156< <= 792< <=287< <=231< <= <257<=
Test 1: 257 vs 315
Test 2
Test 3

DDBB
SSYYSSTTEEMMSS
19 of 29
B+-Tree Strengths
Designed to give good performance for any
type of data and usage.
Lookup speed is based on degree/depth.
Random and sequential retrieval fast.
Insert, delete, modify fast.
Many changes are easy.
Occasionally large sections must be reorganized to
balance the tree.

DDBB
SSYYSSTTEEMMSS
20 of 29
Direct Access / Hashed
Convert key value directly to location address (relative or absolute). Prime modulus algorithm:
Choose prime number greater than expected database size.
Divide key with prime no. and use remainder as address of storage location:
528 : 101 = 5 + 23
Very fast random retrieval (use: POS to retrieve price on product no.).
Slower sequential access. Collision/overflow space for
duplicates (disadvantage of hashing):Reorganize if out of space.
Example Prime = 101 Key = 528 Modulus = 23
416303
528
Overflow/collisions
0 1 201
3
2
3
Location
Store in
DDBB
SSYYSSTTEEMMSS
21 of 29
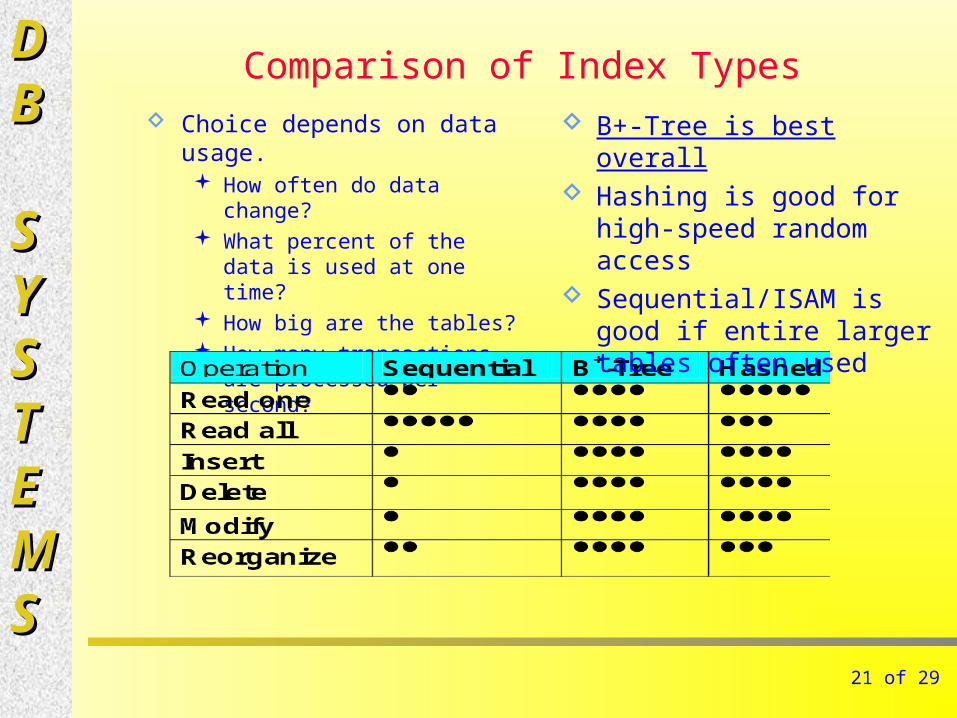
Comparison of Index Types Choice depends on data usage.
How often do data change? What percent of the data is
used at one time? How big are the tables? How many transactions are
processed per second?
B+-Tree is best overall Hashing is good for high-
speed random access Sequential/ISAM is good if
entire larger tables often used

DDBB
SSYYSSTTEEMMSS
22 of 29
Storing Data Columns
Different methods of storing data within each row.Fixed (Positional)Simple, common
Fixed with overflow(Memo/highly variable text;
VARCHAR data type)
A101: -Extra Large
A321: an-Premium
A532: r-Cat
Overflow text

DDBB
SSYYSSTTEEMMSS
23 of 29
Data Clustering
Grouping related data together to improve retrieval.
Data should be close to each other on one disk.
Preferably within the same disk page or cylinder.
Minimize disk reads and seeks.
Example: cluster each invoice with the matching
order.

DDBB
SSYYSSTTEEMMSS
24 of 29
Data Clustering
Keeping data on the same drive Keeping data close together
Same cylinder Same I/O page Consecutive sectors
Order# 1123 Customer# 8876 OrderDate
Order# 1123 Item# 240 Quantity 2
Order# 1123 Item# 987 Quantity 1
Order# 1123 Item# 078 Quantity 3
Order# 1124
Order
OrderItem
Order# 1124 ItemOrder# 1124 Item

DDBB
SSYYSSTTEEMMSS
25 of 29
Data Partitioning
Split table: Horizontally or Vertically
Infrequent access to some rows Large tables Move less used rows to
slower / cheaper storage
High speed hard disk
Low cost optical disk
Customer# Name Address Phone2234 Inouye 9978 Kahlea Dr. 555-555-22225532 Jones 887 Elm St. 666-777-33330087 Hardaway 112 West 2000 888-222-11110109 Pippen 873 Lake Shore 333-111-2235
Activecustomers
Horizontal Partition
Current Customers
Customers w/ no purchase in last 3 years

DDBB
SSYYSSTTEEMMSS
26 of 29
Data Partitioning
Some columns less used and large (long) Store often used data on hi speed disk. Store less used data on optical disk. DBMS retrieves both automatically as
needed.
High speed hard disk
Low cost optical disk
Item# Name QOH Description TechnicalSpecifications875 Bolt 268 1/4” x 10 Hardened, meets standards ...937 Injector 104 Fuel injector Designed 1995, specs . . .
Vertical Partition
DDBB
SSYYSSTTEEMMSS
27 of 27
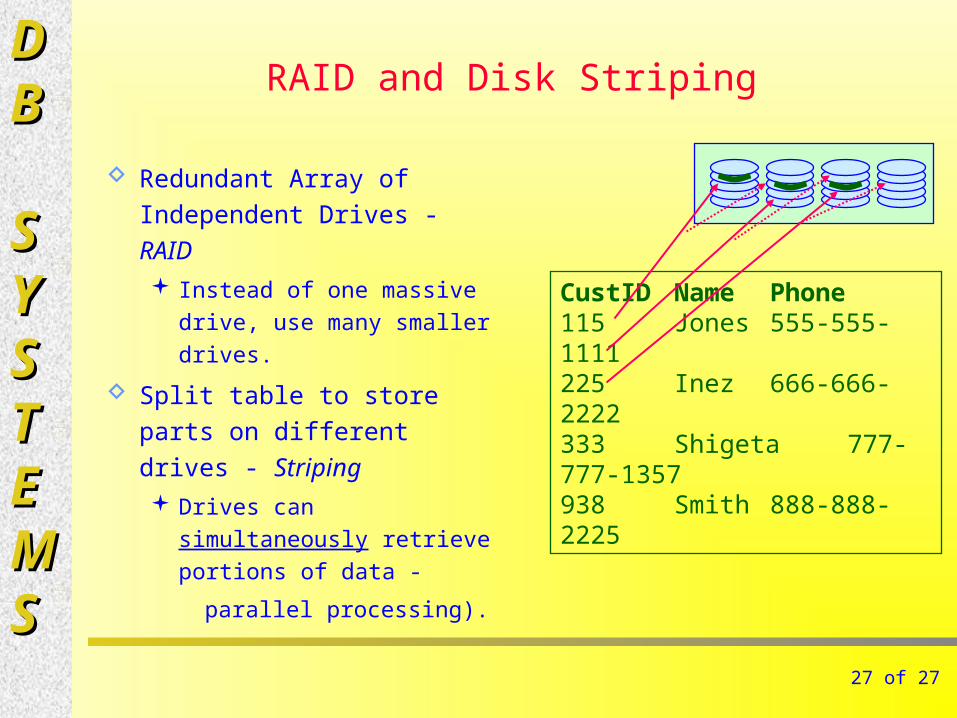
RAID and Disk Striping
Redundant Array of
Independent Drives - RAID Instead of one massive drive,
use many smaller drives.
Split table to store parts on
different drives - Striping Drives can simultaneously
retrieve portions of data -
parallel processing).
CustID Name Phone115 Jones 555-555-1111225 Inez 666-666-2222333 Shigeta 777-777-1357938 Smith 888-888-2225