parallel programming and timing analysis on embedded multicores eugene yip the university of...
TRANSCRIPT

1
Parallel Programmingand Timing Analysis
on Embedded Multicores
Eugene YipThe University of Auckland
Supervisors: Advisor:Dr. Partha Roop Dr. Alain GiraultDr. Morteza Biglari-Abhari (INRIA)(UoA)

2
Outline
• Introduction• ForeC Language• Timing Analysis• Results• Conclusions

3
Outline
• Introduction• ForeC Language• Timing Analysis• Results• Conclusions

4
Introduction
• Safety-critical systems:
– Perform specific real-time tasks.– Comply with strict safety standards
[IEC 61508, DO 178]– Time-predictability useful in real-time designs.
[Paolieri et al 2011] Towards Functional-Safe Timing-Dependable Real-Time Architectures.
Embedded Systems
Safety-critical concerns
Timing/Functionality requirements

5
Introduction
• Safety-critical systems:– Shift from single-core to multicore processors.– Cheaper, better power vs. execution performance.
Coren
Core0
System bus
Resource Resource
Shared
Shared Shared[Blake et al 2009] A Survey of Multicore Processors.[Cullmann et al 2010] Predictability Considerations in the Design of Multi-Core Embedded Systems.

6
Introduction
• Parallel programming:– From super computers to mainstream computers.– Frameworks designed for systems without
resource constraints or safety-concerns.• Optimised for average-case performance (FLOPS), not
time-predictability.
– Threaded programming model.• Pthreads, OpenMP, Intel Cilk Plus, ParC, ...• Non-deterministic thread interleaving makes
understanding and debugging hard.
[Lee 2006] The Problem with Threads.

7
Introduction
• Parallel programming:– Programmer responsible for shared resources.– Concurrency errors:• Deadlock, Race condition, Atomic violation, Order
violation.
[McDowell et al 1989] Debugging Concurrent Programs.[Lu et al 2008] Learning from Mistakes: A Comprehensive Study on Real World Concurrency Bug Characteristics.

8
Introduction
• Synchronous languages:– Deterministic concurrency (formal semantics).– Execution model similar to digital circuits.• Threads execute in lock-step to a global clock.• Threads communicate via instantaneous signals.
– Concurrency is logical. Typically compiled away.
[Benveniste et al 2003] The Synchronous Languages 12 Years Later.
Global ticks
Inputs
Outputs1 2 3 4

9
Introduction
• Synchronous languages:
Physical time1s 2s 3s 4s
Time for a tick
Must validate:max(Reaction time) < min(Time for each tick)
Reaction time
Specified by the system’s timing requirements
[Benveniste et al 2003] The Synchronous Languages 12 Years Later.

10
Introduction
• Synchronous languages– Esterel, Lustre, Signal– Synchronous extensions to C:• PRET-C• Reactive Shared Variables• Synchronous C• Esterel C Language
[Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.[Boussinot 1993] Reactive Shared Variables Based Systems.[Hanxleden et al 2009] SyncCharts in C - A Proposal for Light-Weight, Deterministic Concurrency.[Lavagno et al 1999] ECL: A Specification Environment for System-Level Design.
Retain the essence of C and add deterministic concurrency and thread communication.

11
Introduction
• Synchronous languages– Esterel, Lustre, Signal– Synchronous extensions to C:• PRET-C• Reactive Shared Variables• Synchronous C• Esterel C Language
[Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.[Boussinot 1993] Reactive Shared Variables Based Systems.[Hanxleden et al 2009] SyncCharts in C - A Proposal for Light-Weight, Deterministic Concurrency.[Lavagno et al 1999] ECL: A Specification Environment for System-Level Design.
Concurrent threads scheduled sequentially in a cooperatively manner. This ensures thread-safe access to shared variables.
Semantics designed to facilitate static analysis.

12
Introduction
• Synchronous languages– Esterel, Lustre, Signal– Synchronous extensions to C:• PRET-C• Reactive Shared Variables• Synchronous C• Esterel C Language
[Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.[Boussinot 1993] Reactive Shared Variables Based Systems.[Hanxleden et al 2009] SyncCharts in C - A Proposal for Light-Weight, Deterministic Concurrency.[Lavagno et al 1999] ECL: A Specification Environment for System-Level Design.
Read phase followed by write phase for shared variables.
Multiple writes to the same shared variable are combined using an associative and commutative “combine function”.

13
Introduction
• Synchronous languages– Esterel, Lustre, Signal– Synchronous extensions to C:• PRET-C• Reactive Shared Variables• Synchronous C• Esterel C Language
[Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.[Boussinot 1993] Reactive Shared Variables Based Systems.[Hanxleden et al 2009] SyncCharts in C - A Proposal for Light-Weight, Deterministic Concurrency.[Lavagno et al 1999] ECL: A Specification Environment for System-Level Design.
More expressive than PRET-C, but static timing analysis hasn’t been formulated yet.

14
Introduction
• Synchronous languages– Esterel, Lustre, Signal– Synchronous extensions to C:• PRET-C• Reactive Shared Variables• Synchronous C• Esterel C Language
[Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.[Boussinot 1993] Reactive Shared Variables Based Systems.[Hanxleden et al 2009] SyncCharts in C - A Proposal for Light-Weight, Deterministic Concurrency.[Lavagno et al 1999] ECL: A Specification Environment for System-Level Design.
Sequential execution semantics. Unsuitable for parallel execution.

15
Introduction
• Synchronous languages– Esterel, Lustre, Signal– Synchronous extensions to C:• PRET-C• Reactive Shared Variables• Synchronous C• Esterel C Language
[Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.[Boussinot 1993] Reactive Shared Variables Based Systems.[Hanxleden et al 2009] SyncCharts in C - A Proposal for Light-Weight, Deterministic Concurrency.[Lavagno et al 1999] ECL: A Specification Environment for System-Level Design.
Compilation produces sequential programs. Unsuitable for parallel execution.

16
Outline
• Introduction• ForeC Language• Timing Analysis• Results• Conclusions

17
ForeC Language
“Foresee” ForeC • C-based, multi-threaded, synchronous
language. Inspired by PRET-C and Esterel.• Deterministic parallel execution on embedded
multicores.• Fork/join parallelism and shared memory
thread communication.• Program behaviour independent of chosen
thread scheduling.

18
ForeC Language
• Additional constructs to C:– pause: Synchronisation barrier. Pauses the
thread’s execution until all threads have paused.– par( st1, ..., stn ): Forks each statement to
execute as a parallel thread. Each statement is implicitly scoped.
– [weak] abort st when [immediate] exp: Preempts the statement st when exp evaluates to a non-zero value. exp is evaluated in each global tick before st is executed.

19
ForeC Language
• Additional variable type-qualifiers to C:– input and output: Declares a variable whose
value is updated or emitted to the environment at each global tick.

20
ForeC Language
• Additional variable type-qualifiers to C:– shared: Declares a shared variable that can be
accessed by multiple threads.

21
ForeC Language
• Additional variable type-qualifiers to C:– shared: Declares a shared variable that can be
accessed by multiple threads. 1. Threads make local copies of shared variables that they
may use at the start of their local ticks.2. Threads only modify their local copies during execution.3. If a par statement terminates:
• Modified copies from the child threads are combined (using a commutative & associative function) and assigned to the parent.
3. If the global tick ends:• The modified copies are combined and assigned to the actual
shared variables.
a
b

22
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Synchronisation
Fork-join
Shared variable
Commutative and associative combine function

23
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global
sum = 1

24
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global
sum = 1Global tick start

25
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global Local
f1 f2
sum = 1
sum1 = 1 sum2 = 1
Global tick start

26
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global Local
f1 f2
sum = 1
sum1 = 1sum1 = 2
sum2 = 1sum2 = 3
Global tick start

27
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global Local
f1 f2
sum = 1
sum1 = 1sum1 = 2
sum2 = 1sum2 = 3
Global tick start
Global tick end

28
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global Local
f1 f2
sum = 1
sum1 = 1sum1 = 2
sum2 = 1sum2 = 3
sum = 5
Global tick start
Global tick end

29
Execution Exampleshared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Global Local
f1 f2
sum = 1
sum1 = 1sum1 = 2
sum2 = 1sum2 = 3
sum = 5
sum1 = 5. . .
sum2 = 5. . .
Global tick start
Global tick end
Global tick start

30
Execution Example
Shared variables:– Threads modify local copies of shared variables.• Isolation of thread execution allows threads to truly
execute in parallel.• Thread interleaving does no affect the program’s
behaviour.
– Prevents most concurrency errors.• Deadlock, Race condition: No locks.• Atomic and order violation: Local copies.
– Copies for a shared variable can be split into groups and combined in parallel.

31
Execution Example
Shared variables:– Programmer has to define a suitable combine
function for each shared variable.• Must ensure the combine function is indeed
commutative & associative.
– Notion of “combine functions” is not entirely new:• Intel Cilk Plus, OpenMP, MPI, UPC, X10• Esterel, Reactive Shared Variables
[Intel Cilk Plus] http://software.intel.com/en-us/intel-cilk-plus [OpenMP] http://openmp.org[MPI] http://www.mcs.anl.gov/research/projects/mpi/ [Unified Parallel C] http://upc.lbl.gov/ [X10] http://x10-lang.org/[Berry et al 1992] The Esterel Synchronous Programming Language: Design, Semantics and Implementation.[Boussinot 1993] Reactive Shared Variables Based Systems.

32
[Intel Cilk Plus] http://software.intel.com/en-us/intel-cilk-plus [OpenMP] http://openmp.org[MPI] http://www.mcs.anl.gov/research/projects/mpi/ [Unified Parallel C] http://upc.lbl.gov/ [X10] http://x10-lang.org/[Berry et al 1992] The Esterel Synchronous Programming Language: Design, Semantics and Implementation.[Boussinot 1993] Reactive Shared Variables Based Systems.
Execution Example
Shared variables: – Programmer has to define a suitable combine
function for each shared variable.• Must ensure the combine function is indeed
commutative & associative.
– Notion of “combine functions” is not entirely new:• Intel Cilk Plus, OpenMP, MPI, UPC, X10• Esterel, Reactive Shared Variables
cilk::reducer_opcilk::holder_op
shared varreduction(operator: var)
MPI_ReduceMPI_Gather
shared varcollectives
Aggregates

33
[Intel Cilk Plus] http://software.intel.com/en-us/intel-cilk-plus [OpenMP] http://openmp.org[MPI] http://www.mcs.anl.gov/research/projects/mpi/ [Unified Parallel C] http://upc.lbl.gov/ [X10] http://x10-lang.org/[Berry et al 1992] The Esterel Synchronous Programming Language: Design, Semantics and Implementation.[Boussinot 1993] Reactive Shared Variables Based Systems.
Execution Example
Shared variables: – Programmer has to define a suitable combine
function for each shared variable.• Must ensure the combine function is indeed
commutative & associative.
– Notion of “combine functions” is not entirely new:• Intel Cilk Plus, OpenMP, MPI, UPC, X10• Esterel, Reactive Shared Variables
Valued signalsCombine operator
shared varCombine operator

34
Shared Variable Design Patterns
• Point-to-point• Broadcast• Software pipelining• Divide and conquer– Scatter/Gather– Map/Reduce

35
Overview of the Framework
Thread distribution
ForeCsource code
CCFG
Static scheduling
Compiled program
CCFG with assembly
Architecture model
ReachabilityComputed
WCRT
Compilation Timing AnalysisProgramming

36
Concurrent Control Flow Graph
shared int sum = 1 combine with plus;
int plus(int copy1, int copy2) { return (copy1 + copy2);}
void main(void) { par(f(1), f(2));}
void f(int i) { sum = sum + i; pause; ...}
Fork
Join
Computation
Condition
Pause
Abort
Graph End
Graph Start
f1 f2
main

37
Scheduling
• Light-Weight Static Scheduling:– Take advantage of multicore performance while
delivering time-predictability.– Generate code to execute directly on hardware
(bare metal/no OS).– Thread allocation and scheduling order on each
core decided at compile time by the programmer.• Develop a WCRT-aware scheduling heuristic.• Thread isolation allows for scheduling flexibility.
– Cooperative (non-preemptive) scheduling.

38
Scheduling
• Cores synchronise to fork/join threads and end each global tick.
• One core to perform housekeeping tasks at the end of the global tick:– Combining shared variables.– Emitting outputs.– Sampling inputs and trigger the next global tick.

39
Outline
• Introduction• ForeC Language• Timing Analysis• Results• Conclusions

40
Timing Analysis
Compute the program’s worst-case reaction time (WCRT).
Physical time1s 2s 3s 4s
Time for a tick
Must validate:max(Reaction time) < min(Time for each tick)
Reaction time
Specified by the system’s timing requirements
[Benveniste et al 2003] The Synchronous Languages 12 Years Later.

41
Timing Analysis
Existing approaches for synchronous programs:• Integer Linear Programming (ILP)• “Coarse-grained” Reachability (Max-Plus)• Model Checking
One existing approach for analysing the WCRT of synchronous programs on multicores:• [Ju et al 2010] Timing Analysis of Esterel Programs on General-Purpose
Multiprocessors.• Uses ILP, no tightness result, all experiments performed 4-core processor.

42
Timing Analysis
Existing approaches for synchronous programs.• Integer Linear Programming (ILP)– Execution time of the program described as a set
of integer equations.– Solving ILP is NP-complete.
[Ju et al 2010] Timing Analysis of Esterel Programs on General-Purpose Multiprocessors.

43
Timing Analysis
Existing approaches for synchronous programs.• “Coarse-grained” Reachability (Max-Plus)– Compute the WCRT of each thread.– Using the thread WCRTs, the WCRT of the program
is computed.– Assumes there is a global tick where all threads
execute their worst-case.
[M. Boldt et al 2008] Worst Case Reaction Time Analysis of Concurrent Reactive Programs.

44
Timing Analysis
Existing approaches for synchronous programs.• Model Checking– Computes the execution time along all possible
execution paths.– State-space explosion problem.– Binary search: Check the WCRT is less than “x”.– Trades-off analysis time for precision.– Counter example: Execution trace for the WCRT.
[P. S. Roop et al 2009] Tight WCRT Analysis of Synchronous C Programs.

45
Timing Analysis
Proposed “fine-grained” Reachability approach:• Only consider local ticks that can execute
together in the same global tick.• Timed execution trace for the WCRT.• To handle the state-space explosion:– Reduce the program’s CCFG before analysis.
Program binary
(annotated)
Find all global ticks
(Reachability)WCRT
Reconstruct the program’s
CCFG
46
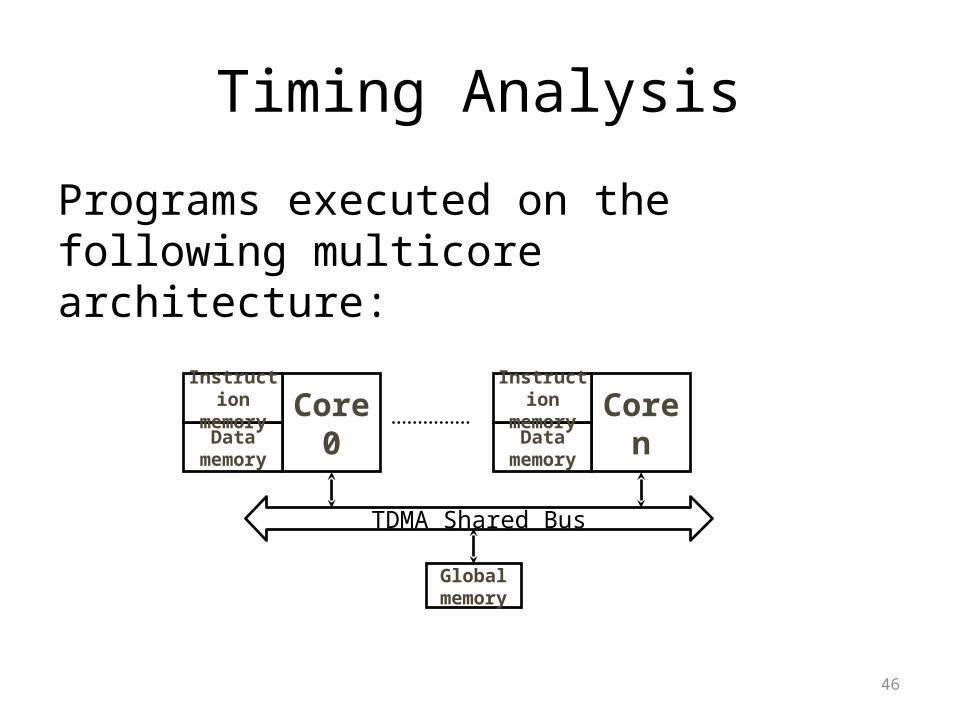
Timing Analysis
Programs executed on the following multicore architecture:
Core0
TDMA Shared Bus
Global memory
Datamemory
Instruction memory Core
nDatamemory
Instruction memory

47
Timing Analysis
Computing the execution time:1. Overlapping of thread execution time from
parallelism and inter-core synchronizations.2. Scheduling overheads.3. Variable delay in accessing the shared bus.

48
Timing Analysis
1. Overlapping of thread execution time from parallelism and inter-core synchronisations.• An integer counter to track each core’s execution time.• Synchronisation occurs when forking/joining, and ending
the global tick.• Advance the execution time of participating cores.
Core 1: Core 2:main f2
f1
Core 1 Core 2
mainf2f1
f1 f2
main

49
Timing Analysis
2. Scheduling overheads.– Synchronisation: Fork/join and global tick.
• Via global memory.
– Thread context-switching.• Copying of shared variables at the start the thread’s
local tick via global memory.
Synchronisation
Thread context-switch
Core 1 Core 2
mainf2f1
Global tick

50
Timing Analysis
2. Scheduling overheads.– Required scheduling routines statically known.– Analyse the scheduling control-flow.– Compute the execution time for each scheduling
overhead. Core 1 Core 2
main
f1
Core 1 Core 2
mainf2f1
f2

51
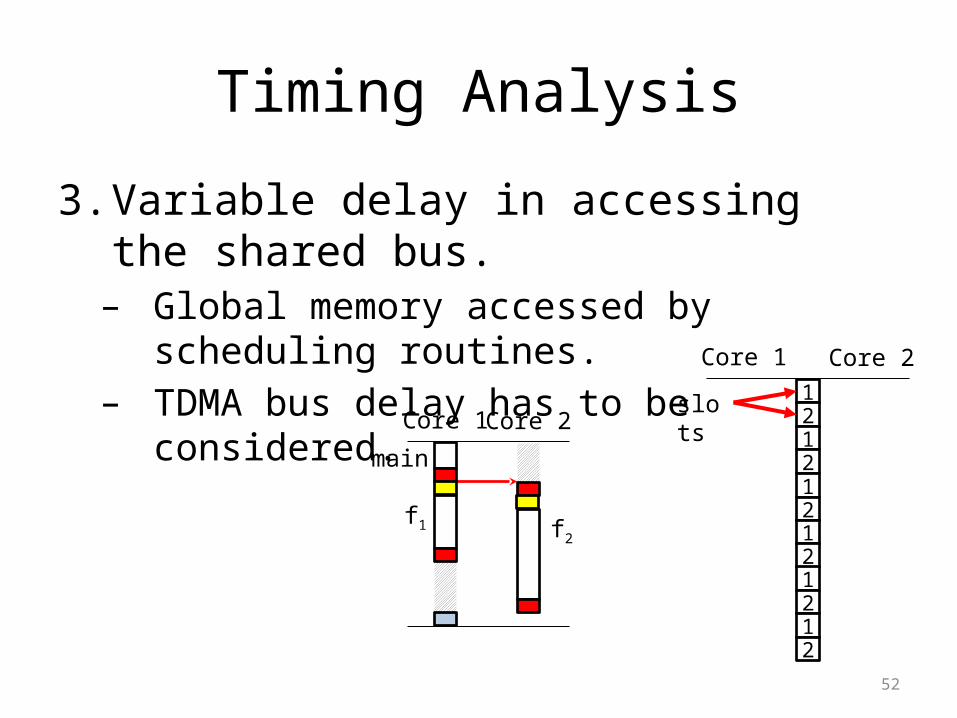
Timing Analysis
3. Variable delay in accessing the shared bus.– Global memory accessed by scheduling routines.– TDMA bus delay has to be considered.
Core 1 Core 2
main
f1 f2
52
Timing Analysis
3. Variable delay in accessing the shared bus.– Global memory accessed by scheduling routines.– TDMA bus delay has to be considered.
121212121212
Core 1 Core 2
slotsCore 1 Core 2
main
f1 f2

53
Timing Analysis
3. Variable delay in accessing the shared bus.– Global memory accessed by scheduling routines.– TDMA bus delay has to be considered.
121212121212
Core 1 Core 2
main
f1f2
Core 1 Core 2
main
f1 f2

54
Timing Analysis
CCFG optimisations:– merge: Reduces the number of CFG nodes that
need to be traversed.– merge-b: Reduces the number of alternate paths
in the CFG. (Reduces the number of global ticks)– Precision of the analysis is unaffected because we
are not performing value analysis to prune infeasible paths.

55
Timing Analysis
CCFG optimisations:– merge: Reduces the number of CFG nodes that
need to be traversed.– merge-b: Reduces the number of alternate paths
in the CFG. (Reduces the number of global ticks)
cost = 1
cost = 4
cost = 3
cost = 1
cost= 1 + 3= 4
cost= 1 + 4 + 1= 6
cost = 6
merge merge-b

56
Outline
• Introduction• ForeC Language• Timing Analysis• Results• Conclusions

57
Results
For the proposed reachability-based timing analysis, we demonstrate:– the precision of the computed WCRT.– the efficiency of the analysis, in terms of analysis
time.

58
Results
Timing analysis tool:
Program binary
(annotated)
Fine-grained Reachability(Proposed)
Coarse-grained
Reachability(Max-Plus)
Taking into account the 3 factors
WCRTProgram CCFG (optimisations)

59
Results
Multicore simulator (Xilinx MicroBlaze):– Based on http://www.jwhitham.org/c/smmu.html
and extended to be cycle-accurate and support multiple cores and a TDMA bus.
Core0
TDMA Shared Bus
Global memory
Datamemory
Instruction memory Core
nDatamemory
Instruction memory16KB
16KB
32KB5 cycles
1 cycle
5 cycles/core(Bus schedule round = 5 * no. cores)

60
Results
• Mix of control/data computations, thread structure and computation load.
* [Pop et al 2011] A Stream-Computing Extension to OpenMP.# [Nemer et al 2006] A Free Real-Time Benchmark.
*
*
#
Benchmark programs.

61
Results
• Each benchmark program was distributed over varying number of cores.– Up to the maximum number of parallel threads.
• Observed the WCRT:– Test vectors to elicit different execution paths.
• Computed the WCRT:– Proposed– Max-Plus

62
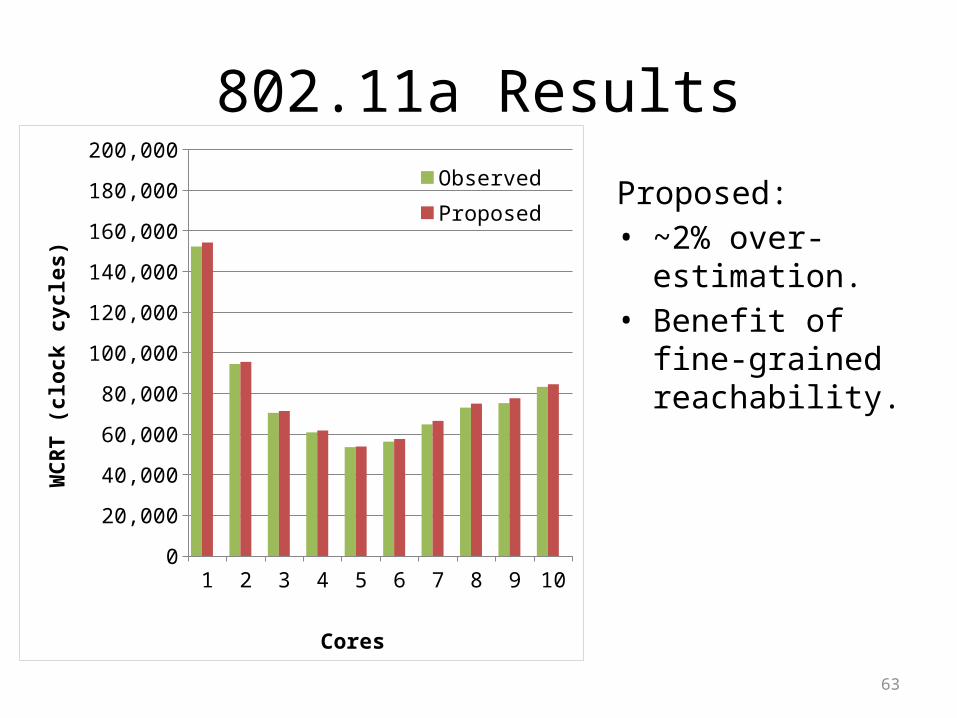
802.11a Results
Observed:• WCRT decreases
until 5 cores.• Global memory
increasingly expensive.
• Scheduling overheads.
1 2 3 4 5 6 7 8 9 100
20,000
40,000
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
Observed
Proposed
MaxPlus
Cores
WC
RT
(cl
ock
cyc
les)
63
802.11a Results
1 2 3 4 5 6 7 8 9 100
20,000
40,000
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
Observed
Proposed
MaxPlus
Cores
WC
RT
(cl
ock
cyc
les)
Proposed:• ~2% over-
estimation.• Benefit of fine-
grained reachability.

64
802.11a Results
Max-Plus:• Loss of execution
context: Uses only the thread WCRTs.
• Assumes one global tick where all threads execute their worst-case.
• Max execution time of the scheduling routines.1 2 3 4 5 6 7 8 9 10
0
20,000
40,000
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
Observed
Proposed
MaxPlus
Cores
WC
RT
(cl
ock
cyc
les)

65
802.11a Results
Both approaches:• Estimation of
synchronisation cost is conservative. Assumed that the receive only starts after the last sender.
1 2 3 4 5 6 7 8 9 100
20,000
40,000
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
Observed
Proposed
MaxPlus
Cores
WC
RT
(cl
ock
cyc
les)

66
802.11a Results
1 2 3 4 5 6 7 8 9 100
500
1,000
1,500
2,000
2,500
Cores
An
alys
is T
ime
(sec
ond
s)
Max-Plus takes less than 2 seconds.Proposed

67
802.11a Results
1 2 3 4 5 6 7 8 9 100
500
1,000
1,500
2,000
2,500
Cores
An
alys
is T
ime
(sec
ond
s)
Proposed (merge)
ProposedMax-Plus takes less than 2 seconds.
merge:• Reduction of ~9.34x

68
802.11a Results
1 2 3 4 5 6 7 8 9 100
500
1,000
1,500
2,000
2,500
Cores
An
alys
is T
ime
(sec
ond
s)
Proposed (merge)
Proposed (merge-b)
ProposedMax-Plus takes less than 2 seconds.
merge:• Reduction of ~9.34xmerge-b:• Reduction of ~342x• Less than 7 sec.

69
Results
Reduction in states reduction in analysis time
Number of global ticks explored.

70
Results
Proposed:• ~1 to 8% over-estimation.• Loss in precision mainly from over-estimating the synchronisation
costs.
1 2 3 40
5,000
10,000
15,000
20,000
25,000
30,000
35,000
40,000
45,000
FmRadio
Cores
1 2 3 4 5 6 70
1,000
2,000
3,000
4,000
5,000
6,000
7,000
Fly by Wire
Cores
1 2 3 4 5 6 7 80
20,000
40,000
60,000
80,000
100,000
120,000
140,000
Life
Cores1 2 3 4 5 6 7 8
0
5,000
10,000
15,000
20,000
25,000
30,000
35,000
Matrix
Observed
Proposed
MaxPlus
Cores

71
Results
Max-Plus:• Over-estimation very dependent on program structure.• FmRadio and Life very imprecise. Loops iterating over par
statement(s) multiple times. Over-estimations accumulate.• Matrix quite precise. Executes in one global tick. Thus, thread
WCRT assumption is valid.
1 2 3 40
5,000
10,000
15,000
20,000
25,000
30,000
35,000
40,000
45,000
FmRadio
Cores
1 2 3 4 5 6 70
1,000
2,000
3,000
4,000
5,000
6,000
7,000
Fly by Wire
Cores
1 2 3 4 5 6 7 80
20,000
40,000
60,000
80,000
100,000
120,000
140,000
Life
Cores1 2 3 4 5 6 7 8
0
5,000
10,000
15,000
20,000
25,000
30,000
35,000
Matrix
Observed
Reachability
MaxPlus
Cores

72
Results
• Our tool generates a timed execution trace for the computed WCRT:– For each core: Thread start/end time, context-
switching, fork/join, ...– Can be used to tune the thread distribution.• Was used to manually find good thread distributions for
each benchmark program.

Outline
• Introduction• ForeC Language• Timing Analysis• Results• Conclusions

Conclusions
• ForeC language for deterministic parallel programming of embedded multicores.
• Based on the synchronous framework, but amenable to parallel execution.
• Can achieve WCRT speedup while providing time-predictability.
• Very precise and fast timing analysis for parallel programs using reachability.

Future work
• Complete the formal semantics of ForeC.
Thread distribution
ForeCsource code
CCFG
Static scheduling
Compiled program
CCFG with assembly
Architecture model
ReachabilityComputed
WCRT
Compilation Timing AnalysisProgrammingAutomatic WCRT-aware scheduling.
Cache hierarchy.
Prune additional infeasible paths using value analysis.

76
Questions?

77
Design Patterns
• Point-to-point• Broadcast• Software pipelining• Divide and conquer– Scatter/Gather– Map/Reduce

78
Point-to-pointshared int sum = 0 combine with plus;
void main(void) { par( f(), g() );}
void f(void) { while (1) { sum = comp1(); pause; }}
void g(void) { while (1) { comp2(sum); pause; }}
New value of sum is received in the next global tick.
Combine operation is not required.

79
Broadcastshared int sum = 0 combine with plus;
void main(void) { par( f(), g(), g() );}
void f(void) { while (1) { sum = comp1(); pause; }}
void g(void) { while (1) { comp2(sum); pause; }}
Multiple receivers.
Combine operation is not required.
New value of sum is received in the next global tick.

80
Software Pipeliningshared int s1 = 0, s2 = 0 combine with plus;
void main(void) { par( stage1(), stage2(), stage3() );}
void stage1(void) { while (1) { s1 = comp1(); pause; }}void stage2(void) { pause; while (1) { s2 = comp2(s1); pause; }}
Outputs from each stage are buffered.
Use the delayed behaviour of shared variables to buffer each stage.
void stage3(void) { pause; pause; while (1) { comp3(s2); pause; }}

81
Fork/Joininput int[1024] image;int edges = 0;
void main(void) { analyse(0, 1023);}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Count the number of edges in an image.
Sequential 1

82
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Parallel 1

83
Fork/Joininput int[1024] image;int edges = 0;
void main(void) { analyse(0, 1023);}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Keep a running total of the number of edges in an image.
For the parallel version, it is not as easy as this.
Sequential 2

84
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
edges = (1+2) + (1+2) = 6
Parallel 2

85
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Global Local
analyse(0,511)
analyse(512,1023)
edges = 0
edges = 0edges = 1
edges = 0edges = 2
edges = (1+2) + (1+2) = 6
Parallel 2

86
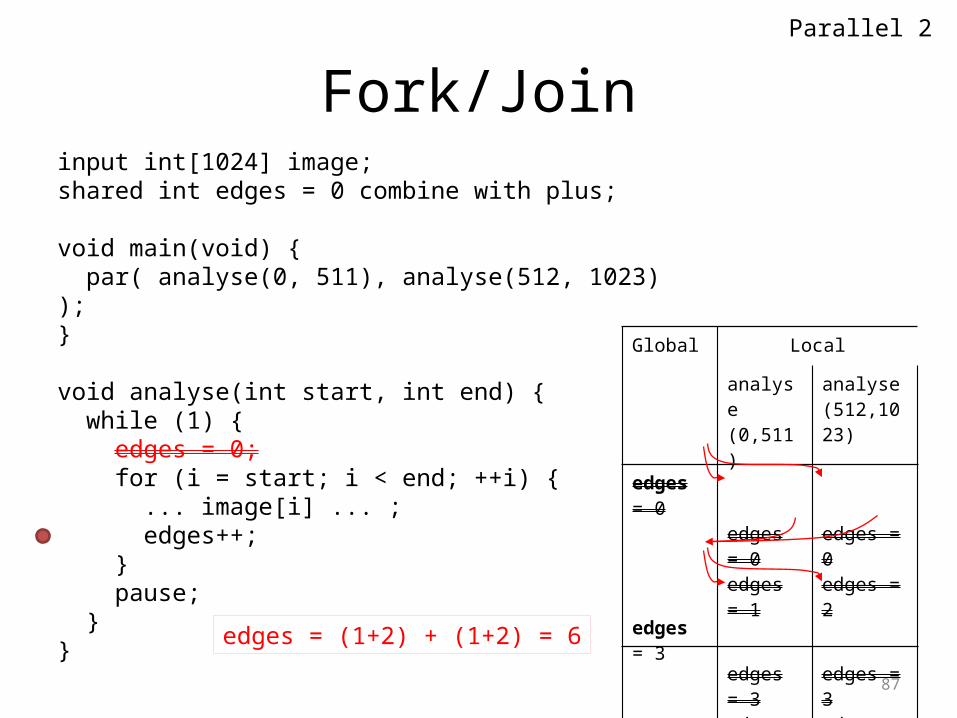
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Global Local
analyse(0,511)
analyse(512,1023)
edges = 0
edges = 3
edges = 0edges = 1
edges = 0edges = 2
edges = (1+2) + (1+2) = 6
Parallel 2
87
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Global Local
analyse(0,511)
analyse(512,1023)
edges = 0
edges = 3
edges = 0edges = 1
edges = 0edges = 2
edges = 3edges = 4
edges = 3edges = 5
edges = (1+2) + (1+2) = 6
Parallel 2

88
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Global Local
analyse(0,511)
analyse(512,1023)
edges = 0
edges = 3
edges = 0edges = 1
edges = 0edges = 2
edges = 9
edges = 3edges = 4
edges = 3edges = 5
edges = (1+2) + (1+2) = 6
Parallel 2

89
Fork/Joininput int[1024] image;shared int edges = 0 combine with plus;
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges++; } pause; }}
Global Local
analyse(0,511)
analyse(512,1023)
edges = 0
edges = 3
edges = 0edges = 1
edges = 0edges = 2
edges = 9
edges = 3edges = 4
edges = 3edges = 5
edges = (1+2) + (1+2) = 6
We should track the running total separately from the number of new edges.
Parallel 2

90
Fork/Joininput int[1024] image;typedef struct { int total; int new } Edges;shared Edges edges = { .total = 0, .new = 0 } combine with accum;
Edges accum(Edges copy1, Edges copy2) { copy1.total = copy1.total + copy1.new + copy2.new; copy1.new = 0; return copy1;}
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges.new = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges.new++; } pause; }}
edges = (1+2) + (1+2) = 6
Parallel 3

91
Fork/Joininput int[1024] image;typedef struct { int total; int new } Edges;shared Edges edges = { .total = 0, .new = 0 } combine with accum;
Edges accum(Edges copy1, Edges copy2) { copy1.total = copy1.total + copy1.new + copy2.new; copy1.new = 0; return copy1;}
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges.new = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges.new++; } pause; }}
edges = (1+2) + (1+2) = 6
Global Local
analyse(0,511)
analyse(512,1023)
edges = { .total=0, .new=0}
edges = { .total=0, .new=0}edges = { .total=0, .new=1}
edges = { .total=0, .new=0}edges = { .total=0, .new=2}
Parallel 3

92
Fork/Joininput int[1024] image;typedef struct { int total; int new } Edges;shared Edges edges = { .total = 0, .new = 0 } combine with accum;
Edges accum(Edges copy1, Edges copy2) { copy1.total = copy1.total + copy1.new + copy2.new; copy1.new = 0; return copy1;}
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges.new = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges.new++; } pause; }}
edges = (1+2) + (1+2) = 6
Global Local
analyse(0,511)
analyse(512,1023)
edges = { .total=0, .new=0}
edges = { .total=3, .new=0}
edges = { .total=0, .new=0}edges = { .total=0, .new=1}
edges = { .total=0, .new=0}edges = { .total=0, .new=2}
Parallel 3

93
Fork/Joininput int[1024] image;typedef struct { int total; int new } Edges;shared Edges edges = { .total = 0, .new = 0 } combine with accum;
Edges accum(Edges copy1, Edges copy2) { copy1.total = copy1.total + copy1.new + copy2.new; copy1.new = 0; return copy1;}
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges.new = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges.new++; } pause; }} edges = (1+2) + (1+2) = 6
Global Local
analyse(0,511)
analyse(512,1023)
edges = { .total=0, .new=0}
edges = { .total=3, .new=0}
edges = { .total=0, .new=0}edges = { .total=0, .new=1}
edges = { .total=0, .new=0}edges = { .total=0, .new=2}
edges = { .total=3, .new=0}edges = { .total=3, .new=1}
edges = { .total=3, .new=0}edges = { .total=3, .new=2}
Parallel 3

94
Fork/Joininput int[1024] image;typedef struct { int total; int new } Edges;shared Edges edges = { .total = 0, .new = 0 } combine with accum;
Edges accum(Edges copy1, Edges copy2) { copy1.total = copy1.total + copy1.new + copy2.new; copy1.new = 0; return copy1;}
void main(void) { par( analyse(0, 511), analyse(512, 1023) );}
void analyse(int start, int end) { while (1) { edges.new = 0; for (i = start; i < end; ++i) { ... image[i] ... ; edges.new++; } pause; }} edges = (1+2) + (1+2) = 6
Global Local
analyse(0,511)
analyse(512,1023)
edges = { .total=0, .new=0}
edges = { .total=3, .new=0}
edges = { .total=0, .new=0}edges = { .total=0, .new=1}
edges = { .total=0, .new=0}edges = { .total=0, .new=2}
edges = { .total=6, .new=0}
edges = { .total=3, .new=0}edges = { .total=3, .new=1}
edges = { .total=3, .new=0}edges = { .total=3, .new=2}
Parallel 3

Introduction
• Existing parallel programming solutions.– Shared memory model.• OpenMP, Pthreads• Intel Cilk Plus, Thread Building Blocks• Unified Parallel C, ParC, X10
– Message passing model.• MPI, SHIM
– Provides ways to manage shared resources but not prevent concurrency errors.
[OpenMP] http://openmp.org [Pthreads] https://computing.llnl.gov/tutorials/pthreads/ [X10] http://x10-lang.org/[Intel Cilk Plus] http://software.intel.com/en-us/intel-cilk-plus [Intel Thread Building Blocks] http://threadingbuildingblocks.org/[Unified Parallel C] http://upc.lbl.gov/ [Ben-Asher et al] ParC – An Extension of C for Shared Memory Parallel Processing.[MPI] http://www.mcs.anl.gov/research/projects/mpi/ [SHIM] SHIM: A Language for Hardware/Software Integration.

Introduction
• Deterministic runtime support.– Pthreads• dOS, Grace, Kendo, CoreDet, Dthreads.
– OpenMP• Deterministic OMP
– Concept of logical time.– Each logical time step broken into an execution
and communication phase.
[Bergan et al 2010] Deterministic Process Groups in dOS.[Olszewski et al 2009] Kendo: Efficient Deterministic Multithreading in Software. [Bergan et al 2010] CoreDet: A Compiler and Runtime System for Deterministic Multithreaded Execution.[Liu et al 2011] Dthreads: Efficient Deterministic Multithreading.[Aviram 2012] Deterministic OpenMP.

ForeC Language
• Behaviour of shared variables is similar to:– Intel Cilk+ (Reducers)– Unified Parallel C (Collectives)– DOMP (Workspace consistency)– Grace (Copy-on-write)– Dthreads (Copy-on-write)