os spring’04 file systems: design and implementation operating systems spring 2004
Post on 20-Dec-2015
218 views
TRANSCRIPT

OS Spring’04
File Systems:Design and Implementation
Operating SystemsSpring 2004

OS Spring’04
What is it all about? File system is a service which
supports an abstract representation of the secondary storage
Supported by OS
Why is a file system needed?What is so special about the secondary storage (as opposed to the main memory)?

OS Spring’04
Memory Hierarchy
Typical capacity
Main memory
SecondaryStorage: Disks
Off-line Storage:Tapes, CDs, etc

OS Spring’04
Main memory vs. Secondary storage
Small (MB/GB) ExpensiveFast (10-6/10-7 sec) VolatileDirectly accessible
by CPU Interface: (virtual)
memory address
Large (GB/TB)Cheap Slow (10-2/10-3 sec)Persistent Cannot be directly
accessed by CPUData should be first brought into the main memory

OS Spring’04
Some numbers… 1GB=230 ~109 Bytes 1TB=240 ~1012 (terabyte) 1PB=250 ~1015 (petabyte) 1EB=260 ~1018 (exabyte)
232 ~ 4 x 109: Genome base pairs 264 ~ 16 x 1018: Brain electrons 2256 ~ 65,536 x 1072: Particles in
Universe

OS Spring’04
Secondary storage structure A number of disks directly attached
to the computer Network attached disks accessible
through a fast networkStorage Area Network (SAN)
Simple disks Smart disks

OS Spring’04
Internal disk structure

OS Spring’04
Data Access Sector size is the minimum
read/write unit of data (usually 1KB)Access: (#surface, #track, #sector)
Smart disk drives hide out the internal disk layout
Access: (#sector)
Moving arm assembly (Seek) is expensive
Sequential access is x100 times faster than the random access

OS Spring’04
Overview File system services
What user applications see
File system implementationWhat the data on disk looks like, bit by bitThe runtime support of FS operations
The FS service and its implementation are deeply intertwined
Performance is the paramount issue for the file system implementation

OS Spring’04
File System services File system is a layer between the
secondary storage and the application
Presents the secondary storage as a collection of persistent objects with unique names, called files
Provides mechanisms for mapping the data between the secondary storage and the main memory

OS Spring’04
What is a file (קובץ) File is a named persistent collection of
data Unstructured, sequential (UNIX)
Data is accessed by specifying the offset Collection of records (database
systems)Supports associative access give me all records with “Name=Yossi”
Attributes: owner, permissions, modification time, size, etc…

OS Spring’04
File system interface File data access
READ: Bring a specified chunk of data from file into the process virtual address spaceWRITE: Write a specified chunk of data from the process virtual address space to the file
CREATE, DELETE, SEEK, TRUNCATE open, close, set_attributes Many semantical issues:
Automatic size-extensionHolesPersistence of open filesMore …

OS Spring’04
Accessing File Data: File Control Block
A control structure, File Control Block (FCB), is associated with each file in the file system
Each FCB has a unique identifier (FCB ID)UNIX: i-node, identified by i-node number
FCB structure: File attributesA data structure for accessing the file’s data

OS Spring’04
Accessing File Data Given the file name Get to the file’s FCB using the file
system catalog Use the FCB to get to the desired
offset within the file data

OS Spring’04
Accessing File Data: Catalog The catalog maps a file name to the FCB
Checks permissions This can be done for each file data access
Inefficient: Do this once when the file is first referenced
file_handle=open(file_name): search the catalog and bring FCB into the memoryUNIX: in-memory FCB: in-core i-node
close(file_handle): release FCB from memory

OS Spring’04
The Catalog Organization FCBs are stored in predefined
locations on the diskUNIX: i-node list
Hierarchical structure:Some FCBs are just a list of pointers to other FCBs Directories UNIX: directory is a file whose data is an
array of (file_name, i-node#) pairs
Recursive mapping

OS Spring’04
Directories Provide name to file mapping May provide additional attributes per
file Different from regular files
Support operations like create, delete, listPrevent duplicate namesMay be organized as a hash table for efficient searching
Mostly common structure: hierarchySupports hierarchical pathnames

OS Spring’04
Searching the UNIX catalog /a/b/c => i-node of /a/b/c Get the root i-node:
The i-node number of ‘/’ is pre-defined (2) Use the root i-node to get to the ‘/’ data Search (a, i-node#) in the root’s data Get the a’s i-node Get to the a’s data and search for (b, i-
node#) Get the b’s i-node Etc… Permissions are checked all along the way
Each dir in the path must be (at least) executable

OS Spring’04
Extending the directory hierarchy
Multiple volumesUnix: Mount/un-mount volume on directoryTransparent pathname traversal: in-core mount table, in-core i-node of mount point and or mounted root.
Remote volumesDistributed file systems: Sun NFS, AFS/Coda, etc.

OS Spring’04
NFS Collection of remote file service
protocols VFS: Virtual file system layer
Client: system call -> VFS -> local FS/NFS clientServer: system call/remote invocation -> VFS -> local FS
Compatible with most local FS implementations

OS Spring’04
VFS model Unix-like file system services: files,
directories, links, .. Fhandle provides working-file
capability, as well as file attributes Remote mount provides a seamless
name space Lookup(path) instead of open
Lookup does not cross mount points (version 3)

OS Spring’04
RPC communication Support for heterogeneous clients Stateless server No client caching, write-thru policy No authenticated sessions No persistence
fhandle must be unique
File locking handled separately by a lock manager
No server-failure recovery needed

OS Spring’04
NFS: Advanced issues File sharing by multiple clients Caching Locking and fault tolerance Security and access control

OS Spring’04
Sharing Unix single machine: writes take
immediate effectFile persistence on open
NFS version 3:Write thru in principleSession semantics in practice
File lockingRead/write lock, per file range of bytesWait queue with no callbacks
Share reservationSupported to facilitate NFS on Windows clients

OS Spring’04
Fault Tolerance RPC
Retransmit on timeoutsSuppress duplicates via duplicate-cacheReturn cached-response on duplicate request
File lockingVersion 4 issues leases with expiration and renewalIntroduce problems of clock synchronization, and renewal reliability

OS Spring’04
Allocating disk blocks to file data
Assume unstructured filesArray of bytes
Efficient offset -> disk block mapping Efficient disk access for both
sequential and random patternsMinimizing number of long seeks
Efficient space utilizationMinimizing external/internal fragmentation

OS Spring’04
Static Contiguous Allocation Allocate each file a fixed number of blocks
at the creation time#blocks is pre-defined or supplied as an argument
Efficient offset lookupOnly the block # of the offset 0 is needed
Efficient disk access Inefficient space utilization
Internal, external fragmentation
No support for dynamic extension

OS Spring’04
Static Contiguous Allocation
Catalog

OS Spring’04
Extent-based allocation File gets blocks in contiguous
chunks called extentsMultiple contiguous allocations
For large files, B-tree is used for efficient offset lookup

OS Spring’04
Extent-based allocation
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
16 17 18 19
foo.c bar.c
core.666
foo.c (0,3) (7,2) (16,2)bar.c (3,1) (12,4)
core.666 (8,3) (18,1)
Catalog

OS Spring’04
Extent-based allocation Efficient offset lookup and disk access Support for dynamic growth/shrink Dynamic memory allocation
techniques are used (e.g., first-fit) External/internal fragmentation may
be a problemDepending on the implementation, requirements, etc…

OS Spring’04
Single-block allocation Extent-based allocation with a
fixed extent size of one disk block
File blocks are scattered anywhere on the diskInefficient sequential access
UNIX block allocation Linked allocation
MS-DOS File Allocation Table (FAT)

OS Spring’04
Block Allocation in UNIX 10 direct pointers 1 single indirect pointer: points to a
block of N pointers to data blocks 1 double indirect pointer: points to a
block of N pointers each of which points to a block of N pointers to data blocks
1 triple indirect pointer… Overall addresses 10+N+N2+N3 disk
blocks

OS Spring’04
Block Allocation in UNIX
Direct 1Direct 2
...
Direct 10Indirect
Double indirectTriple indirect
1
2
...
10
11
...
N
N+1
2N
...
...
Ind 1
Dbl 1
Ind 1
Ind N
...
Trpl
Dbl 2
Dbl N
Ind N+1
...
Ind N+1

OS Spring’04
Block Allocation in UNIX Optimized for small files
Outdated empirical studies indicate that 98% of all files are under 80 KB
Poor performance for random access of large files (redirections)
No external fragmentation Wasted space in pointer blocks for large
sparse files Modern UNIX implementations use the
extent-based allocation

OS Spring’04
Linked Allocation Each file is a linked list of disk blocks Offset lookup:
Efficient for sequential accessInefficient for random access
Access to large files may be inefficient as the blocks are scattered
Solution: block clustering
No fragmentation, wasted space for pointers in each block

OS Spring’04
Linked AllocationCatalog

OS Spring’04
File Allocation Table (FAT) A section at the beginning of the disk
is set aside to contain the tableIndexed by the block numbers on diskAn entry for each disk block (or for a cluster thereof)
FAT Entries corresponding to blocks belonging to the same file are chained
The last file block, unused blocks and bad blocks have special markings

OS Spring’04
FATCatalog entry

OS Spring’04
FAT Pros and Cons Improved random access
just search a small table instead of the whole disk
Inefficient sequential accessSeek back to the table and forth to the block for each file block!
Block allocation is easyjust find the first 0 marked block

OS Spring’04
Free space management Disk bitmap: represent the disk
block allocation as an array of bitsBit for each disk block: 1 - non-allocated block, 0 - allocated block Simple and efficient in finding free blocksWastes space on disk
Linked list of free blocks (UNIX)Efficient for finding a single free block

OS Spring’04
File I/O CPU cannot access the file data directly Must be first brought to the main memory Problem:
Scenario 1: user process reads a block, meanwhile the process gets swapped out of memoryScenario 2: user process reads/writes 1 byte in blockScenario 3: user process continuously reads/writes a fileScenario 4: two processes access the same block
Solution: Read/Write mapping using buffer cache Memory mapped files

OS Spring’04
Read/Write Mapping File data is made available to
applications via a pre-allocated main memory region
Buffer cache The file systems transfers data
between the buffer cache and disk in granularity of disk blocks
The data is explicitly copied from/to buffer cache to/from the application address space
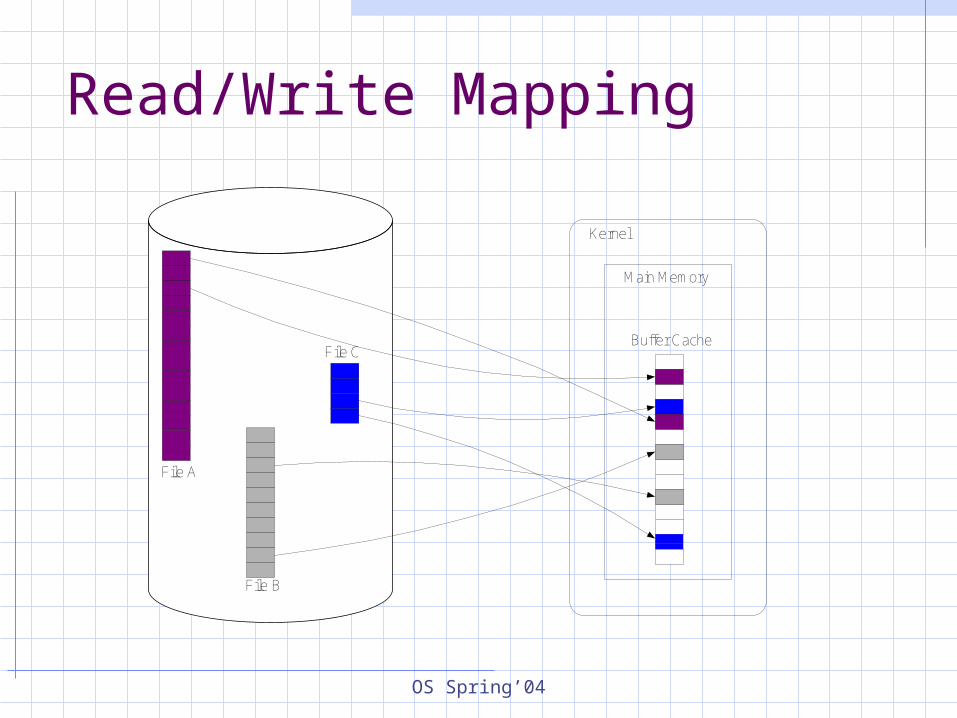
OS Spring’04
Read/Write Mapping
Buffer Cache
Main Memory
File A
File B
File C
Kernel

OS Spring’04
Reading data (Disk block=1K)
User
Buffer Cache
File C
Kernel
Buf
ptr
UNSIGNED CHAR BUF[8192];
UNSIGNED CHAR *PTR=BUF+126;
FD = OPEN(“C”,…);
SEEK(FD,1324); // 1324=1024+300
READ(FD,PTR,1848); // 724+1024+100=1848
1324
3172

OS Spring’04
Writing data (Disk block=1K)
User
Buffer Cache
File C
Kernel
Buf
ptr
UNSIGNED CHAR BUF[8192];
UNSIGNED CHAR *PTR=BUF+126;
FD = OPEN(“C”,…);
SEEK(FD,1324); // 1324=1024+300
WRITE(FD,PTR,1848); // 724+1024+100=1848
1324
3172 Unallocated
region

OS Spring’04
Buffer Cache management All disk I/O goes through the buffer
cacheBoth user data and control data (e.g., i-node) are cached
LRU replacement Dirty (modified) marker to indicate
whether write-back is needed

OS Spring’04
Advantages Strict separation of concerns
Hiding disk access peculiarities from the user Block size, memory alignment, memory
allocation in multiples of the block size, etc…
Disk blocks are cachedAggregation for small transfers (locality)Block re-use across processesTransient data might be never written to disk

OS Spring’04
Disadvantages Extra copying
Disk->buffer cache->user space Vulnerability to failures
Does not care about the user data blocksThe control data blocks (metadata) is the real problem E.g., i-nodes, pointer blocks can be in cache
when a failure occurs As a result the file system internal state
might be corrupted

OS Spring’04
Memory mapped files A file (or a portion thereof) is
mapped into a contiguous region of the process virtual memory
UNIX: mmap system call
Mapping operation is very efficient:just marking
The access to file is governed by the virtual memory subsystem

OS Spring’04
Mmapped files: Pros and Cons Advantages:
reduce copyingno need for a pre-allocated buffer cache in the main memory
Disadvantages: less or no control over the actual disk writing: the file data becomes volatileA mapped area must fit the virtual address space

OS Spring’04
Reliability and Recovery File system data consists of
Control data (metadata), user data
Failures can cause data loss and corruption
Cached dataPower failure during the sector write may corrupt physically the data stored in the sector

OS Spring’04
Metadata vs. User data Lost or corruption of the metadata
might lead to a massive user data loss
File systems must care about the metadataFile systems usually do not care much about the user data Operation semantics? Users must care about their data themselves
(e.g., backups)

OS Spring’04
Reliability and caching Caching affects the WRITE semantics
The write operation returnsIs it guaranteed that the requested data is indeed written on disk?What if some data blocks in cache are the metadata blocks?
Solutionswrite-through: writes bypass cachewrite-back: dirty blocks are written asynchronously

OS Spring’04
User data reliability in UNIX Based on write-back policy
User data is written back to disk periodicallyPOSIX compatible semanticsCommands like sync and fsync are used for forced write of the dirty blocks

OS Spring’04
Metadata reliability Based on write-through policy
updates are written to disk immediately
Some data is not written in-placeCan go back to the last consistent version
Some data is replicated UNIX superblock
File system goes through consistency check/repair cycle at the boot time
fsck, ScanDisk

OS Spring’04
Metadata reliability using logging
Write-through negatively affects performance
Think about random access
Solution: maintain a sequential log of metadata updates: Journal
IBM’s Journal File System (JFS)

OS Spring’04
Journal File System (JFS) Operations logged (journaled):
create,link,mkdir,truncate,allocating write, …Each operation may involve several metadata updates (transaction)
Once operation is logged it returnswrite ahead logging
The disk writes are performed asynchronously
aggregation possible

OS Spring’04
JFS: Journal maintenance A cursor (pointer) is maintained The cursor is advanced once the
updated blocks associated with the transaction are written to disk (hardened)
hardened transaction records can be deleted from the journal
Upon recovery: Re-do all the operations starting from the last cursor position

OS Spring’04
JFS: Pros and Cons Advantages:
Asynchronous metadata writeFast recovery: depends on the Journal size and not on the file-system size
Disadvantagesextra writespace wasted by journal (insignificant)

OS Spring’04
Log Structured File System Ousterhout & Douglis (1992) Caching is enough for good read
performance Writes is the real performance
bottleneckwriting-back cached user blocks may require many random disk accesseswrite-through for reliability denies optimizations logging solves the problem for metadata

OS Spring’04
Log Structured File System The idea: everything is log Each write - both data and control -
is appended to the sequential log The problem: how to locate files and
data efficiently for random access by Reads
The solution: use a floating file map

OS Spring’04
Log structured file systemsupermap
supermap
supermap
Before
After block change
After block addition