ora9i dw ita poli2002 white - intranet...
TRANSCRIPT


Enrico ProserpioSales Consultant DirectorOracle Italia
Funzionalita’ di Oracle 9i2per il Data Warehousing

FY2002: Oracle?Oracle Corporation
• 9.7 Miliardi $ • Utile 2.3 Mld $• 145 filiali dirette• 42.000 dipendenti
?Oracle Italia• 460 Miliardi lire • 5 filiali (MI, RM, BO, PD, TO)• 800 dipendenti
http://www.oracle.com
http://www.oracle.com/it

2001 Relational Database Market Share
Informix3.3%
Others8.5%
Oracle 39.8%
IBM30.7%
Microsoft14.4%
Sybase3.3%
Source: Dataquest, May 2002
Oracle e’ il leader per il 4 anno consecutivo

2001 Database Market Share
IBM31.7%
Oracle 32.0%
Informix3.0%
Microsoft16.3% Others
14.4%
Sybase2.6%
Source: Dataquest, May 2002
IBM bought the #1 Position Through the Informix Acquisition
Overall Database also includes IBM IMS, VSAM, and Microsoft Access

2001 Unix RDBMS Market
Oracle 63.3%
IBM17.5%
Sybase4.6%
Informix7.2%
NCR3.9%
Others3.5%
Source: Dataquest, May 2002
Oracle: Still Unchallenged on Unix

2001 Windows RDBMS Market
Oracle 34.0%
Others3.7%
Microsoft39.9%
IBM20.0%
Informix0.8%
Sybase1.6%
Source: Dataquest, May 2002
Oracle and Microsoft are essentially tied on NT

Il DBMS piu’ usato per Data Warehouse
Giga Data Warehousing Survey Validates Expectations, Contains SuGiga Data Warehousing Survey Validates Expectations, Contains Surprises. rprises. by Lou Agosta, Giga Information Group by Lou Agosta, Giga Information Group –– 20022002

Oracle9iDBMost Popular on Linux
Other1.4%
Progress4.1%Informix
8.4%
IBM17.3%
Open Source
Ingres/Postgres
22.5%
Source: IDC, October 2001Source: IDC, October 2001
Oracle9i46.4%
Editor’s Choice AwardApril, 2002

Oracle: Il Database di riferimento per le “Packaged Applications”
OracleOracle76%76%
OtherOther24%24%
OracleOracle72%72%
OtherOther28%28%
OracleOracle81%81%
OtherOther19%19%
OracleOracle73%73%
OtherOther27%27%
SAPSAP PeopleSoftPeopleSoft
i2i2SiebelSiebel
Source: The Source: The FactPointFactPoint Group, April 2002Group, April 2002
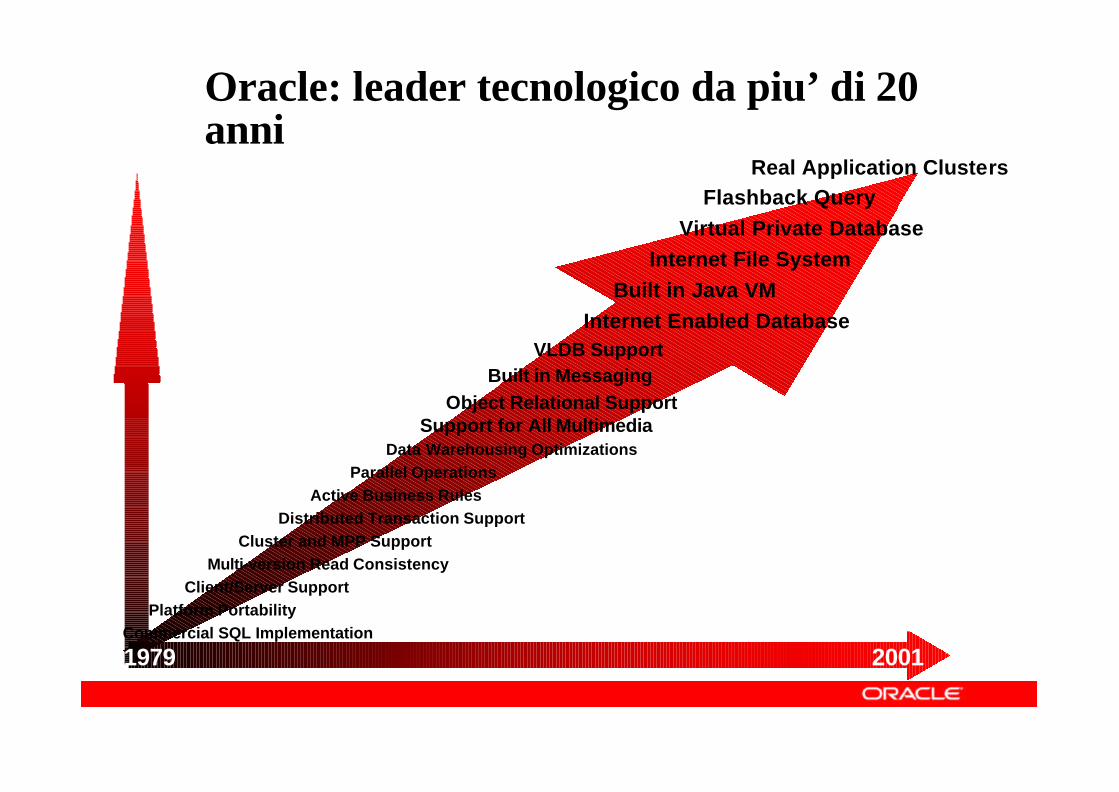
1979 2001
Oracle: leader tecnologico da piu’ di 20 anni
Real Application ClustersFlashback Query
Virtual Private DatabaseInternet File System
Built in Java VMInternet Enabled Database
VLDB SupportBuilt in Messaging
Object Relational SupportSupport for All Multimedia
Data Warehousing OptimizationsParallel Operations
Active Business RulesDistributed Transaction Support
Cluster and MPP SupportMulti-version Read Consistency
Client/Server SupportPlatform Portability
Commercial SQL Implementation

Oracle9iInfrastruttura Completa di e-Business Intelligence

Data Warehousing
ETL
OLAP
Data Mining
Metadata
Oracle9i DatabaseUnico Data Server per la e-Business Intelligence

Portal
BI Components
Query & Reporting
Real-time Personalization
Metadata
Hello! We have recommendations for you.
Oracle9i Application ServerPer tutte le applicazioni di e-Business Intelligence

Oracle9Oracle9iiDBDB Oracle9Oracle9iiASASData Warehousing
ETL
OLAP
Data Mining
Portal
BI Components
Query & Reporting
Real-Time Personalization
Metadata
Hello! We have recommendations for you.
Oracle9iInfrastruttura Completa di e-Business Intelligence

Oracle Warehouse: Architettura
MiningMining
AnalisiAnalisi
GESTIONE ACCESSO
Disegno ed Amministrazione
Metadati
Data MartData Mart
ReportingReporting
Integrazionedei Dati
SORGENTI
Dati Dati OperazionaliOperazionali
WarehouseWarehouse
Dati Dati WebWeb
Dati Dati EsterniEsterni
Distribuzionedelle
informazioni
QueryQuery

Oracle 8i Oracle Warehouse: Prodotti
CWM Metadata
WarehouseBuilder
WarehouseBuilder
ApplicationServer
ApplicationServerDatiDati
WebWeb
DatiDatiEsterniEsterni
Dati Dati OperazionaliOperazionali
Analytic ApplicationsSales Analyzer, Financial Analyzer,
ABM, Balanced Scorecard
Analytic ApplicationsSales Analyzer, Financial Analyzer,
ABM, Balanced Scorecard
Oracle8iOracle8i
ExpressExpress
DiscovererDiscoverer
ReportsReports
DarwinDarwinExpressExpress
PortalPortal

CWM Metadata
E-Business Intelligence SuiteE-Business Intelligence Suite
DatiDatiWebWeb
DatiDatiEsterniEsterni
Dati Dati OperazionaliOperazionali
WarehouseBuilder
WarehouseBuilder
Oracle 9iOracle Warehouse: Prodotti
BI BeansBI Beans
DiscovererDiscoverer
ReportsReports
PortalPortal
Oracle9i
ETL Infrastructureand
OLAP Services and
Data Mining
Oracle9i
ETL Infrastructureand
OLAP Services and
Data Mining

Oracle 9i Database Server:La Piattaforma per la Business Intelligence
Data Warehousing
ETL
OLAP
Data Mining
Oracle9Oracle9ii
?Performance, scalabilita’, VLDB, facilita’ di gestione
?ETL
?OLAP
?Data Mining

Oracle 9i Database Server:Data Warehousing
Data Warehousing
ETL
OLAP
Data Mining
Oracle9Oracle9ii
?Gestione di grandi volumi di dati?Elevate performance in interrogazione?Gestione di molti utenti concorrenti?Semplice amministrazione
Oracle9i introduce moltissime nuove DW features

Gestione di grandi volumi di dati

Gestione di grandi volumi di dati
? Partitizionamenti e parallelismi sono fondamentali per la gestione di un VLDB
? Il partizionamento dei dati consente operazioni ‘incrementali’per:
– Caricamenti– Indicizzazione– Backup e recovery
? Parallelismo per tutte le operazioni– DBA operations: loading, index-creation, table-creation, data-
modification, backup and recovery– End-user operations: Queries

Caricamenti efficenti:Operazioni “Rolling Window”
Tabelle partizionate per range con indici locali:
OCT2000OCT2000
SEP2000SEP2000
AUG2000AUG2000
NOV1999NOV1999
OCT1999OCT1999
1.carico ed indicizzo offline il nuovo mese
NOV2000NOV2000
NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000NOV2000
...

2. Aggiungo il nuovo mese alla tabella
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
NOV1999NOV1999
NOV1999NOV1999
OCT1999OCT1999
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
Caricamenti efficenti:Operazioni “Rolling Window”
Partitioned Tables with Local Indexes
OCT2000OCT2000
SEP2000SEP2000
NOV2000NOV2000
DEC1999DEC1999
NOV1999NOV1999
OCT1999OCT1999
NOV2000NOV2000
3. Rimuovo ed archivio il vecchio mese
OCT1999OCT1999OCT1999OCT1999
1. carico ed indicizzo offline il nuovo mese
...

Benefici del Partizionamento
?I nuovi dati vengono caricati con il minimo utilizzo di risorse e con il minor disturbo per l’utente (gli altri dati sono sempre disponibili)
?Schemi di partizionamento supportati – Range
– Hash
– List
– Composite
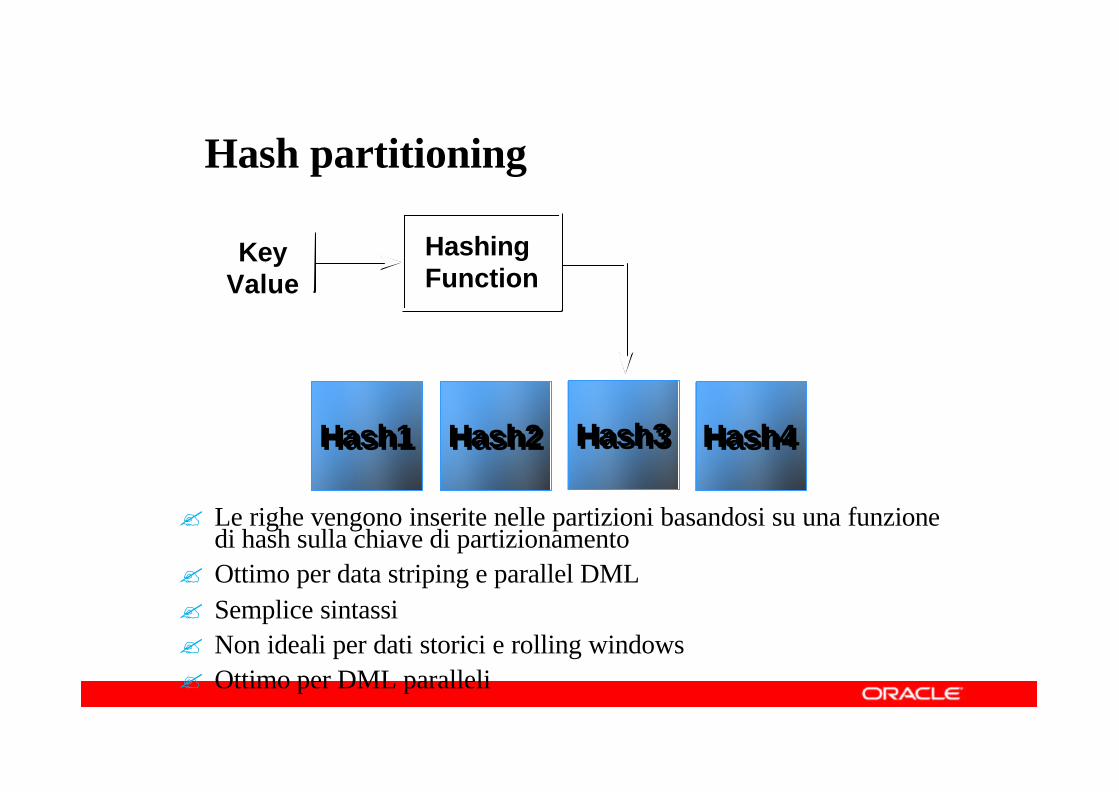
Hash partitioning
? Le righe vengono inserite nelle partizioni basandosi su una funzione di hash sulla chiave di partizionamento
? Ottimo per data striping e parallel DML? Semplice sintassi? Non ideali per dati storici e rolling windows? Ottimo per DML paralleli
Hash4Hash4Hash2Hash2Hash1Hash1 Hash3Hash3
HashingFunction
Key Value

List Partitioning?Utile per il partizionamento in domini discreti
?Geografia
?Categorie di prodotto?Data source, etc.
? Benefici: contollo piu’ preciso sulla distribuzione dei dati tra le partizioni
CREATE TABLE sales_by_region(...)
PARTITION BY LIST (state)( PARTITION q1_northwest VALUES (’OR’, ’WA’),
PARTITION q1_southwest VALUES (’AZ’, ’UT’, ’NM’),PARTITION q1_northeast VALUES (’NY’, ’VM’, ’NJ’),PARTITION q1_southeast VALUES (’FL’, ’GA’));

1200 GMT2000 GMT0400 GMT
List PartitioningStessi benefici delle rolling window: il dato e’partizionato in base ai business requirements
EuropeRegionEuropeRegion
AmericasRegion
AmericasRegion
AsiaRegionAsia
Region
Online Queries
Maintenance

OCT1998OCT1998
SEP1998SEP1998
NOV1998NOV1998
DEC1997DEC1997
NOV1997NOV1997
RANGE (sales_date)RANGE (sales_date)
Composite Partitioning
Range partition per i processi di business
...
Hash partition oppure List partition
HA
SH
(sa
les_
id)
HA
SH
(sa
les_
id)
...Sub-3Sub-3 Sub-3Sub-3Sub-3Sub-3 Sub-3Sub-3 Sub-3Sub-3
Sub-2Sub-2 Sub-2Sub-2Sub-2Sub-2 Sub-2Sub-2 Sub-2Sub-2...
OCT1998Sub-1
OCT1998Sub-1
SEP1998Sub-1
SEP1998Sub-1
NOV1998
Sub-1
NOV1998
Sub-1
DEC1997Sub-1
DEC1997Sub-1
NOV1997Sub-1
NOV1997Sub-1

Parallel data movement
? Bulk loading in un data warehouse:– Parallel load– Parallel index– Parallel analyze
? Costruzione e mantenimento di aggregati– Parallel create-table-as-select– Parallel insert
? Bulk changes e manutenzione– Parallel delete,update– Parallel partition operations: split, merge

Parallel INSERT, UPDATE, e DELETE
? Quando si devono gestire database di grandi dimensioni, le operazioni devono essere fatte in parallelo per ottenere i tempi di risposta che l’ utente vuole
? Le istruzioni di DML parallele consentono di effettuare le bulk operation in modo efficente, il che semplifica i processi di caricamento dati
CCPPUU
CCPPUU
CCPPUU
CCPPUU
CCPPUU
CCPPUU
CCPPUU
CCPPUU
Query--Index--LoadInsert--Update--Delete
Query--Index--LoadInsert--Update--Delete

Table Compression:Come funziona
<rowid> ‘650-506-7000’ ‘650-123-4567’<rowid> ‘650-506-7000’ ‘650-506-7001’<rowid> ‘650-506-7000’ ‘650-456-7890’<rowid> ‘650-506-7000’ ‘650-098-7654’<rowid> ‘650-506-7000’ ‘650-123-4567’<rowid> ‘650-506-7001’ ‘650-123-4567’<rowid> ‘650-506-7001’ ‘650-123-4567’…
<symbol table: <A>= ‘650-506-7000’, <B>=‘650-506-7001’, <C>=‘650-123-4567’>
<rowid> <A> ‘650-123-4567’<rowid> <A> <B><rowid> <A> ‘650-456-7890’<rowid> <A> ‘650-098-7654’<rowid> <A> <C><rowid> <B> <C><rowid> <B> <C>…
?Le righe duplicate vengono memorizzate in una symbol table per ogni blocco
Uncompressed Compressed

Table Compression: Compression Ratios
?Small CPG data warehouse (40GB)
?Compression can reduce total DW size to 1/3 its original size
3.7:12260183663Aggregate table #2
4.5:1214834973691Aggregate table #1
5.4:11138061937Fact Table (one partition)
Ratio# Blocks Compressed
# Blocks Uncompressed
Table

Elevate performance in interrogazione

Elevate performance in interrogazione
?Il miglior approccio per qualsiasi query– Integrato– Completo
Materialized ViewsMaterialized ViewsSummary managementSummary management
Access & Join MethodsAccess & Join MethodsFunctional indexesFunctional indexes
Analytic functionsAnalytic functionsCube e RollupCube e Rollup
PartitioningPartitioningParallel OperationsParallel Operations
QueryOptimizer

ApplicationApplication
SQLSQLSQL
Elevate performance in interrogazione:Partizionamento
PartitionThree
PartitionThreePartition
OnePartition
OnePartition
TwoPartition
Two
TableTable
Partizionamento e Performance? Scalabilita’ indipendente dal volume di dati
interessato– Ottimizzazione intelligente delle query con
eliminazione delle partizioni non interessate
? Trasparenti per utenti e applicazioni
? Il partizionamento degli indici consente la loro scansione parallela
? Striping dei dati su dischi diversi? Le partizioni hanno stessi attributi logici ma diversi
attributi fisici

Elevate performance in interrogazione:Partizionamento
Trova tutti i clienti maschi che hanno fatto un ordine in aprileTrova tutti i clienti maschi che Trova tutti i clienti maschi che hanno fatto un ordine in aprilehanno fatto un ordine in aprile
jan_orders feb_orders
order table
mar_orders apr_orders
Partition skipping? Oracle accede solo alle partizioni
interessate? Parallelismo non e’ limitato
dal partizionamento

Il Partitizionamento in un Data Warehouse...
?Le operazioni di interrogazione (comprese quelle in parallelo) traggono beneficio dal partizionamento, ma non dipendono dal partizionamento
Lo schema di Partizionamento deve Lo schema di Partizionamento deve essere disegnato per semplificare essere disegnato per semplificare la gestione del sistema, non per il la gestione del sistema, non per il parallelismo delle queryparallelismo delle query

SQLSQLSQL
querycoordinator
queryserver
queryserver
queryserver
queryserver
queryserver
queryserver
querycoordinator
resultsresultsresults
• Il Query coordinator alloca i query servers, e divide la query in subtasks distinti
• Ogni “set” di query servers effettua compiti diversi (e.g. scanning, sorting, joining)
• I risultati vengono passati da un set di query servers al successivo
Elevate performance in interrogazione:Esecuzione in Parallelo delle Query

select sum(revenue), storefrom line_itemsgroup by store cost
Coordinates servers,returns results
Data on Disk
scan line_items,in parallel
Query Servers
scanscan
sort by store,sum revenues
scanscan
scanscan
sort Asort A--KK
sort Lsort L--S S
sort Tsort T--ZZ
dispatch work;dispatch work;assemble assemble
resultsresults
Scanners Sorters
Coordinator
Elevate performance in interrogazione:Esecuzione in Parallelo delle Query

Ogni tabella e’ dinamicamente divisa in gruppi di blocchi basandosi su:
• grado di parallelismo• # di blocchi nella tabella
Part 1 of 4Oracle Parallel Query Dynamic Partitioning

Scanner 1
Scanner 2
Scanner 3
Oracle Parallel Query Dynamic Partitioning
I gruppi di blocchi vengono assegnatiai query processor per la scansione
Part 2 of 4
Ogni tabella e’ dinamicamente divisa in gruppi di blocchi basandosi su:
• grado di parallelismo• # di blocchi nella tabella
(Parallel Degree = 3)

Scanner 1
Scanner 2
Scanner 3
Next AvailableScanner
Next AvailableScanner
Oracle Parallel Query Dynamic Partitioning
Un insieme addizionale di blocchi vieneassegnato ad ogni query processor man mano che completa il lavoro assegnatogli
I gruppi di blocchi vengono assegnatiai query processor per la scansione
Part 3 of 4
Ogni tabella e’ dinamicamente divisa in gruppi di blocchi basandosi su:
• grado di parallelismo• # di blocchi nella tabella
(Parallel Degree = 3)
Non tutti i blocchi vengono inizialmenteassegnati ai gruppi da scandire

Scanner 2
Scanner 3
Oracle Parallel Query Dynamic Partitioning
L’obiettivo e’ di manterere occupati tuttii query processor finche l’intero job e’stato completato e di fare in modo chetutti finiscano quasi contemporaneamente
I gruppi di blocchi vengono assegnatiai query processor per la scansione
Ogni tabella e’ dinamicamente divisa in gruppi di blocchi basandosi su:
• grado di parallelismo• # di blocchi nella tabella
Scanner 1
(Parallel Degree = 3)
Un insieme addizionale di blocchi vieneassegnato ad ogni query processor man mano che completa il lavoro assegnatogli
Non tutti i blocchi vengono inizialmenteassegnati ai gruppi da scandire
Part 4 of 4

Elevate performance in interrogazione : Tecniche avanzate di indicizzazione e join
Indici ? Indici B-tree
i ‘tipici’ indici relazionali
? Indici Bitmap (7.3)
? Bitmap join index (9i)?Altri:
– Functional index (8i)– Indici Cluster e Hash Cluster – Index-Organized Tables
Join• Nested-loop join
i ‘classici’ join
• Sort-merge join
• Hash join (7.3)

Elevate performance in interrogazione :Hash Joins? Un algoritmo di join estremamente indicato per l’ esecuzione
parallela
? Usa uno schema di in-memory hashing costruito a run-time– evita l’ ordinamento (SMJ)
– nessun bisogno di un indice (NLJ)
? L’ottimizzatore sceglie l’ hash join nei casi piu’ appropriati basandosi su:
Dimensione tabelle Memoria disponibile Indici disponibili
? Supera in performance gli altri tipi di join
? Disponibile solo se si usa il cost-based optimizer

Hash Join: Come funziona ?
? Caso semplice– Tabelle A, B con A << B
– Memory disponibile: M (hash_area_size)
– M > A
? Passi1. Carica A in memoria
2. Costruisce la hash table su A per un efficente in-memory lookup
3. Scandisce B da disco. Per ogni riga in B, trova le righe corrispondenti in A usando la funzione di hash
4. Finisce quando termina la scansione
Table B
Sca
n
Memory
Table A

?Colonne con cardinalita’ medio-bassa– Dove il numero di valori distinti e’ piccolo rispetto al
numero di righe nella tabella
?Operazioni ‘Set-based’– Operazioni di tipo bitmap: AND, OR, MERGE,
MINUS, COUNT
?Adatti specialmente per query grandi e complesse e per operazioni logiche?Da 3 a 20 volte piu’ piccoli degli indici b-tree?Tempo di creazione ridotto
Elevate performance in interrogazione: Bitmap Index (static)

<Blue, <rowid>, 1000100100010010100><Green, <rowid>, 0001010000100100000><Red, <rowid>, 0100000011000001001>
<Yellow, <rowid>, 0010001000001000010>
Struttura di un bitmap indexStruttura di un bitmap index
Una Una ‘‘bitmapbitmap’’ distinta viene creata per distinta viene creata per ciascun valore della colonna color, con un ciascun valore della colonna color, con un bit per ciascuna rigabit per ciascuna riga
Viene inoltre creata una semplice struttura Viene inoltre creata una semplice struttura bb--tree per trovare ciascun bitmaptree per trovare ciascun bitmap
CREATE BITMAP INDEX PROD_COLOR ON PROD(COLOR)CREATE BITMAP INDEX PROD_COLOR ON PROD(COLOR)
Elevate performance in interrogazione: Bitmap Index

Elevate performance in interrogazione: Bitmap Index
? Un bitmap per ciascun valore, un bit per ciascuna riga
? Combinazione efficente di bitmap usando operatori logici (AND, OR ecc)
? Elevato guadagno in performance per questo tipo di query
income: {A, B, C}
A: <1 0 0 1 1 0 0 1 0 0 0 0 >B: <0 1 1 0 0 0 1 0 0 1 1 0 >C: <0 0 0 0 0 1 0 0 1 0 0 1 >
sex: {M, F}
M: < 1 0 0 0 1 1 0 0 1 0 0 1>F: < 0 1 1 1 0 0 1 1 0 1 1 0>
Select name, addressfrom customerswhere income in (‘A’, ‘B’)and sex = ‘M’;
income = A or B: <1 1 1 1 1 0 1 1 0 1 1 0>
(income = A or B) and sex = M
<1 0 0 0 1 0 0 0 0 0 0 0>

Show all clients who live in California or Oregon AND whose client_id is between 2000 and 2200
BITMAP BITMAP ““OROR”” OPERATOROPERATOR
RANGE SCAN: BITMAPRANGE SCAN: BITMAPSTATE = STATE = ‘‘CaliforniaCalifornia’’
RANGE SCAN: BRANGE SCAN: B--TREETREECLIENT_ID BETWEEN ...CLIENT_ID BETWEEN ...
RANGE SCAN: BITMAPRANGE SCAN: BITMAPSTATE = STATE = ‘‘OregonOregon’’
BITMAP BITMAP ““ANDAND””OPERATOROPERATOR
Convert: BConvert: B--TREE TO BITMAPTREE TO BITMAP
TABLE ACCESSTABLE ACCESS
Elevate performance in interrogazione:Dynamic Bitmap Indexes

Join Indexes
Sales Products
CREATE TABLE Sales_Products AS SELECT s.*, p.* FROM sales s, products p WHERE s.product_id = p.product_id
CREATE TABLE Sales_Products AS SELECT s.*, p.* FROM sales s, products p WHERE s.product_id = p.product_id
SELECT prod_code FROM sales s, products p WHERE s.product_id = p.product_id AND p.product_group = ’HOUSEHOLD’
SELECT prod_code FROM sales s, products p WHERE s.product_id = p.product_id AND p.product_group = ’HOUSEHOLD’
SELECT prod_code FROM Sales_ProductsWHERE product_group = ’HOUSEHOLD’
SELECT prod_code FROM Sales_ProductsWHERE product_group = ’HOUSEHOLD’
Sales_Products

CREATE BITMAP INDEX cust_sales_bji ON Sales(Customer.state) FROM Sales, CustomerWHERE Sales.cust_id = Customer.cust_id;
Bitmap join indexes
Sales Customer
Index key is Customer.State
Sales(Customer.state)
Indexed table is Sales<Italia, <rowid>, 1000100100010010100>
<UK, <rowid>, 0001010000100100000><Francia, <rowid>, 0100000011000001001><Belgio, <rowid>, 0010001000001000010>

SELECT SUM (Sales.amount_sold) FROM Sales S, Customer CWHERE Sales.cust_id = Customer.cust_idAND Customer.state = ‘Italia’;
Bitmap join indexes
Sales Customer
<Italia, <rowid>, 1000100100010010100> <UK, <rowid>, 0001010000100100000>
<Francia, <rowid>, 0100000011000001001><Belgio, <rowid>, 0010001000001000010>
Per risolvere la query vengono usati solo l’indice e la Sales table. Nessun join con la tabella Customer

Functional Indexes
? L’accesso ad indice sostituisce un full table scan
?Accesso veloce a dati basati su una espressione, una built-in function o una user-defined function
select * from EMP where
SAL + COMM > 1600;
select * from EMP where
ENAME = ‘ADAMS’;
select * from EMP where
SAL + COMM > 1600;
select * from EMP where
ENAME = ‘ADAMS’;
create index on EMP ( );
create index on EMP ( );
create index on EMP ( );create index on EMP ( );
create index on EMP ( );create index on EMP ( );
--------------EMP Table --------------DEPT
Jones 1000 200 10Adams 1500 20 20Smith 2500 400 30
. . . .
--------------EMP Table --------------DEPT
Jones 1000 200 10Adams 1500 20 20Smith 2500 400 30
. . . .
++
UPPER()UPPER()
COMMCOMM
UPPER (ENAME)UPPER (ENAME)
SALSALENAMEENAME
SAL + COMMSAL + COMM

Elevate performance in interrogazione :Star Query
? Star Schema: diverse piccole tabelle “dimensionali” connesse ad una grandissima tabella dei “fatti”
? Le query devono mettere in join le tabelle dimensionali con la tabella dei fatti
PN ProductName ShipWgt
LJ3 Laserjet III 22LJ4 Laserjet 4 20LJ3P Laserjet 3P 18IJ500 Deskjet 500 12
PN C_Code Week Discount SaleLJ3 Btn 9503 90 3400LJ4 Dvn 9549 85 1420LJ3P Tpa 9516 50 1120IJ500 Dvn 9550 37 789LJ2 Btn 9507 100 1400IJ550 Dvr 9518 55 950
C_Code CityBtn BostonDvn DenverTpa TampaChg Chicago
Week WeekName AbbrevDate9503 Week ending 1/5/95 Jan059549 Week ending 1/12/95 Jan129516 Week ending 1/19/95 Jan199550 Week ending 1/26/95 Jan25
Sales TableProduct Table Market Table
Period Table
Fact Table

Star Query TransformationUso innovativo dei bitmap indexesStar Schema Complessi
diverse dimension tabledimension table non vincolategrandi dimension tablesnowflake schema
Ottimizzato per fact tables sparseEseguito in parallelo
Elevate performance in interrogazione:Star Query

Elevate performance in interrogazione :Star Query in Oracle 8
SELECT store.district, time.quarter, SUM(sales.dollar_sales)
FROM sales, store, time, productWHERE sales.store_key = store.store_key
AND store.district = ‘WEST’AND sales.time_key = time.time_keyAND time.quarter IN (‘3Q96’, ‘4Q96’)AND sales.product_key = product.product_keyAND product.dept = ‘GROCERY’
GROUP BY store.district, time.quarter;
TimeTime
SalesSales
StoreStore
ProductProduct
Example Query:

Elevate performance in interrogazione :Star Query in Oracle 8
SELECT SELECT ……FROM salesFROM salesWHEREWHERE store_key IN (SELECT store_key FROM storestore_key IN (SELECT store_key FROM store
WHERE district = WHERE district = ‘‘WESTWEST’’))AND AND time_key IN (SELECT time_key FROM timetime_key IN (SELECT time_key FROM time
WHERE quarter IN (WHERE quarter IN (‘‘3Q963Q96’’, , ‘‘4Q964Q96’’))))AND AND product_key INproduct_key IN (SELECT product_key FROM product (SELECT product_key FROM product
WHERE dept = WHERE dept = ‘‘GROCERYGROCERY’’));;
? L’ottimizzatore riconosce che questo e’ un potenziale candidato per lo star-query algorithm di Oracle8
? Implementa quindi una query transformation e sceglie le tecnichedi index/join piu’ opportune
Query Transformation:

STORE_KEY
1
2
3
4
5
6
7
SALES_DISTRICT
‘NORTH’
‘WEST’
‘SOUTHWEST’
‘SOUTH’
‘WEST’
‘NORTH’
‘WEST’
STORE_NAME
‘STORE #1’
‘STORE #2’
‘STORE #3’
‘STORE #4’
‘STORE #5’
‘STORE #6’
‘STORE #7’
store_key in (select store_key from store store_key in (select store_key from store where store.district = where store.district = ‘‘WESTWEST’’))
store_key in (2, 5, 7)store_key in (2, 5, 7)
Elevate performance in interrogazione :Star Query in Oracle 8
Each dimension:

Elevate performance in interrogazione :Star Query in Oracle 8
SELECT SELECT ……FROM salesFROM salesWHEREWHERE store_key IN (2, 5, 7, ...)store_key IN (2, 5, 7, ...)AND AND time_key IN (time_key IN (‘‘0101--JULJUL--9696’’ …… ‘‘3131--DECDEC--9696’’))AND AND product_key INproduct_key IN (46, 52, 81, 92, (46, 52, 81, 92, ……));;
?Questa e’ una query ideale per i bitmap index? La chiave per delle buone performance in una star-query e’ un
accesso efficente alla fact table?Vengono estratte solo le righe pertinenti della fact-table?Quindi viene fatto il join di queste righe con le dimension table
rilevanti
Query Transformation:

Summary Management tramite Materialized Views
• Incremento delle performance– riscrittura automatica delle query per accedere
alle sommarizzazioni gia’ create • Il sistema fornisce suggerimenti sulla creazione,
manutenzione e cancellazione delle materialized view • Permette aggiornamenti automatici e veloci delle
sommarizzazioni
SalesRegional sales
Product quantities
Quarterly sales

Summary Management tramite Materialized Views
Region
Time
City
SalesState
Product
Data pre-summarizedand automatically maintainedby the database
Sales byCity
Sales byBrand
Sales byMonth
Queries are re-written automaticallyto use any available summaries

Materialized Views? Una Materialized view e’ una
istanziazione di uno statement SQL -e’ una vista con una struttura dati
? L’ ottimizzatore riscrive le query fatte sulla tabella base perche’ vadano invece ad interrogare la vista
? Le riscritture sono trasparenti per le applicazioni
? Le riscritture non richiedono alcun privilegio particolare
? Le materialized views possono essere sia partizionate che indicizzate indipendetemente dalla tabella base
CREATE MATERIALIZED VIEW sf_sales AS SELECT * FROM sales WHERE city_name = ’SAN FRANCISCO’
CREATE MATERIALIZED VIEW sf_sales AS SELECT * FROM sales WHERE city_name = ’SAN FRANCISCO’
SF_Sales
SELECT prod_code FROM sales WHERE city_name = ’SAN FRANCISCO’
SELECT prod_code FROM sales WHERE city_name = ’SAN FRANCISCO’
SELECT prod_code FROM sf_salesSELECT prod_code FROM sf_sales
Sales
CREATECREATE

Materialized Views -Esempio di Summary Management
Region
Time
City Sales
State
Sales byBrand, City and Month
Product
CREATECREATE

CREATE MATERIALIZED VIEW sales_sumryTABLESPACE sum_data STORAGE(INITIAL 10M) PARALLEL(4) BUILD IMMEDIATE REFRESH FAST ENABLEQUERY REWRITE
ASSELECT p.brand, c.city_name, t.month, SUM(s.amt) AS tot_sales
FROM sales s, city c, time t, product pWHERE s.city_name = c.city_name
AND s.state_code = c.state_codeAND s.sdate = t.sdateAND s.prod_code = p.prod_code
GROUP BY p.brand,c.city_name,t.month;
CREATE MATERIALIZED VIEW sales_sumryTABLESPACE sum_data STORAGE(INITIAL 10M) PARALLEL(4) BUILD IMMEDIATE REFRESH FAST ENABLEQUERY REWRITE
ASSELECT p.brand, c.city_name, t.month, SUM(s.amt) AS tot_sales
FROM sales s, city c, time t, product pWHERE s.city_name = c.city_name
AND s.state_code = c.state_codeAND s.sdate = t.sdateAND s.prod_code = p.prod_code
GROUP BY p.brand,c.city_name,t.month;
Come creare una Summary

Esempi di Query rewrite -Exact Match
? Caso semplice - le colonne del join corrispondono a quelle dell’ aggregazione
? La Query puo’ contenere delle clausole di filtro come HAVING.
? Non richiede alcuna dimension
SELECT brand, city_name, month, tot_salesFROM sales_sumryWHERE tot_sales > 5000000;
SELECT brand, city_name, month, tot_salesFROM sales_sumryWHERE tot_sales > 5000000;
SELECT p.brand, c.city_name, t.month, SUM(s.amt)FROM sales s, city c, time t, product pWHERE s.city_name = c.city_name
AND s.state_code = c.state_codeAND s.sdate = t.sdateAND s.prod_code = p.prod_code
GROUP BY p.brand, c.city_name, t.monthHAVING SUM(s.amt) > 5000000;
SELECT p.brand, c.city_name, t.month, SUM(s.amt)FROM sales s, city c, time t, product pWHERE s.city_name = c.city_name
AND s.state_code = c.state_codeAND s.sdate = t.sdateAND s.prod_code = p.prod_code
GROUP BY p.brand, c.city_name, t.monthHAVING SUM(s.amt) > 5000000;

Dimensions e Hierarchies
Year
Quarter
Month
Salesdate
Month name
WeekSeason
ALL
Level
Attribute
Hierarchy
SALES_DATE WEEK MONTHMONTH_NAME QUARTER YEAR SEASON---------- ---- --------------- ------- ---- ------1/1/88 1 1 January 1 1988 Winter1/2/88 1 1 January 1 1988 Winter1/3/88 1 1 January 1 1988 Winter1/4/88 1 1 January 1 1988 Winter1/5/88 1 1 January 1 1988 Winter1/6/88 1 1 January 1 1988 Winter1/7/88 1 1 January 1 1988 Winter1/8/88 2 1 January 1 1988 Winter1/9/88 2 1 January 1 1988 Winter….2/1/88 5 2 February 1 1988 Spring2/2/88 5 2 February 1 1988 Spring2/3/88 5 2 February 1 1988 Spring…
SALES_DATE WEEK MONTHMONTH_NAME QUARTER YEAR SEASON---------- ---- --------------- ------- ---- ------1/1/88 1 1 January 1 1988 Winter1/2/88 1 1 January 1 1988 Winter1/3/88 1 1 January 1 1988 Winter1/4/88 1 1 January 1 1988 Winter1/5/88 1 1 January 1 1988 Winter1/6/88 1 1 January 1 1988 Winter1/7/88 1 1 January 1 1988 Winter1/8/88 2 1 January 1 1988 Winter1/9/88 2 1 January 1 1988 Winter….2/1/88 5 2 February 1 1988 Spring2/2/88 5 2 February 1 1988 Spring2/3/88 5 2 February 1 1988 Spring…
TIME Table TIME Dimension
3 hierarchies

Come dichiarare Dimensions and Hierarchies
? Le Dimension possono essere dichiarate come oggetti del data dictionary
? Le Dimension possono basarsi su colonne di tabelle diverse
? Le Dimension sono opzionali ma sono raccomandate perche’:? Consentono ulteriori query rewrites
per le sommarizzazioni
? Aiutano a documentare le gerarchie
? Possono essere usate dai tool OLAP
CREATE DIMENSION time_dimLEVEL sdate IS time.sdateLEVEL month IS time.monthLEVEL qtr IS time.quarterLEVEL yr IS time.year
HIERARCHY calendar_rollup (sdate CHILD OFmonth CHILD OFqtr CHILD OF yr )
ATTRIBUTE month DETERMINES month_name;
CREATE DIMENSION time_dimLEVEL sdate IS time.sdateLEVEL month IS time.monthLEVEL qtr IS time.quarterLEVEL yr IS time.year
HIERARCHY calendar_rollup (sdate CHILD OFmonth CHILD OFqtr CHILD OF yr )
ATTRIBUTE month DETERMINES month_name;

Esempi di Query rewrite -Aggregate Roll-up
? La Query richiede una aggregazione ad un livello maggiore di quello della summary ? YEAR invece di
MONTH
? La Time dimension e’usata per determinare se e’ possibile fare il roll-up da MONTH a YEAR
SELECT v.year, s.brand, s.city_name, SUM(s.tot_sales) FROM sales_sumry s,
(SELECT distinct t.month, t.yearFROM time t) v
WHERE s.month = v.month GROUP BY v.year, s.brand, s.city_name;
SELECT v.year, s.brand, s.city_name, SUM(s.tot_sales) FROM sales_sumry s,
(SELECT distinct t.month, t.yearFROM time t) v
WHERE s.month = v.month GROUP BY v.year, s.brand, s.city_name;
SELECT t.year, p.brand , c.city_name, SUM(s.amt) FROM sales s, city c, time t, product pWHERE s.sdate = t.sdate AND s.city_name = c.city_name AND s.state_code = c.state_codeAND s.prod_code = p.prod_code GROUP BY t.year, p.brand, c.city_name;
SELECT t.year, p.brand , c.city_name, SUM(s.amt) FROM sales s, city c, time t, product pWHERE s.sdate = t.sdate AND s.city_name = c.city_name AND s.state_code = c.state_codeAND s.prod_code = p.prod_code GROUP BY t.year, p.brand, c.city_name;

Datadictionary
Summary Advisory
Summary usage
Summary advisor
Summary recommendations
Space requirements
OptionalOptionalworkloadworkload
Oracle Trace

Summary Advisor Wizard

Gestione di un numero elevato di utenti concorrenti

Windows 95/98/CEPalmOS, Epoc
Scalabilità
Unix: SUN Solaris, HP-UX, IBM AIX, Compaq Tru64,,...
MVS
MassiveParallelClusterSMP
SingoloProcessore
Laptop& PDA Mainframe
Windows NT- Windows 2000Linux OpenVMS

Oracle9i Real Application ClustersScalabilita’ lineare
Shared Cache ArchitectureShared Cache Architectureusing Cache Fusionusing Cache Fusion
• Full Cache Fusion Implementation– funziona con contention di tipo read/read, read/write, write/write
• Qualsiasi applicazione puo’ scalare in un cluster – Le applicazioni non devono essere “cluster aware”
• Scalabilita’ lineare--piu’ nodi, piu’ throughput

Oracle Parallel Query su Cluster e MPP
Server 1Server 1 Server 2Server 2 Server NServer N
• • •
SistemaSistemaoperativooperativo
ClusterWareClusterWare
ApplicationApplication
Server 3Server 3
Query
SistemaSistemaoperativooperativo
ClusterWareClusterWare
SistemaSistemaoperativooperativo
ClusterWareClusterWare
SistemaSistemaoperativooperativo
ClusterWareClusterWare
Oracle RDBMSOracle RDBMS
Real Application Real Application ClusterCluster
Oracle RDBMSOracle RDBMS
Real Application Real Application ClusterCluster
Oracle RDBMSOracle RDBMS
Real Application Real Application ClusterCluster
SubquerySubquery SubquerySubquery SubquerySubquery

Oracle9i Database - Alta affidabilita’
System System FailuresFailures
Data FailuresData Failures& Disasters& Disasters
Human Human ErrorsErrors
Real Application ClustersReal Application ClustersContinuous Availability for all ApplicationsContinuous Availability for all Applications
Data GuardData GuardGuaranteed Zero Data LossGuaranteed Zero Data Loss
Flashback QueryFlashback QueryEnable Users to Correct their MistakesEnable Users to Correct their Mistakes
SystemSystemMaintenanceMaintenance
Database Database MaintenanceMaintenance
Dynamic ReconfigurationDynamic ReconfigurationCapacity on Demand without InterruptionCapacity on Demand without Interruption
Online RedefinitionOnline RedefinitionAdapt to Change OnlineAdapt to Change Online
UnplannedUnplannedDowntimeDowntime
PlannedPlannedDowntimeDowntime

Gestione di un numero elevato di utenti concorrenti
?Requisiti:– Garantire sempre e comunque un utilizzo ottimale
delle risorse?Fornire la quantita’ di risorse appropriata per
qualsiasi job o query in base alla priorita’ ed al carico di sistema
– Prevenire le ‘runaway’ queries proattivamente– Prevenire i system overloading proattivamente
?La gestione di numeri elevati di utenti deve essere semplice ed automatica

Fornire le risorse appropriate a ogni Query
?CPU– I processi Business-critical ricevono piu’ CPU?Il Database Resource Manager permette ai DBA di
assegnare quantita’ di CPU a gruppi di utenti
?Memoria– Oracle9i alloca dinamicamente a runtime la memoria ai
processi basandosi su quella disponibile e sui requirement di ciascuna query
?Parallelismo – Il grado di parallelismo e’ determinato dinamicamente in base
alle risorse disponibili e ai requirement di ciascuna query

Database Resource Manager
? Il Database Resource Manager in 8i/9i gestisce:
– utilizzo della CPU
– numero massimo di sessioni attive
– limita il grado di parallelismo
?Obiettivi:
– permettere il massimo throughput, evitando contemporaneamente over-loading o thrashing
– fornire un meccanismo di priorita’: gruppi di utenti diversi hanno diversi livelli di accesso alle risorse del database

Gestione proattiva dei DW Workloads
?Predictive Query Governing and Dynamic Re-prioritization:
– Le query che si stima dureranno piu’ di un limite specificato dal DBA verranno abortite o ‘de-prioritizzate’
?Automatic Queuing: – Si puo’ mettere un limite sul numero di sessioni
attive per ogni gruppo di utenti; ulteriori query sottomesse al sistema oltre tale limite verranno accodate
?Il tutto con il Database Resource Manager

Example Scenario
? Power Users– Up to 70% of the CPU resources– Any degree of parallelism– Any query which is expected to take over one hour will be migrated to
background
? Report Users– Up to 20% of the CPU resources– No parallelism– Limit of 40 concurrent queries– Any query which is expected to take over 20 minutes will be aborted
? Background Jobs– Up to 10% of the CPU resources– Any degree of parallelism– Limit of 5 concurrent queries

Self-Tuning Parallel Query
?Setup semplificato per la parallel query
?Un algoritmo che adatta il grado di parallelismo della query a seconda del carico di lavoro concorrente sul sistema
?Load-balancing per Real Application Cluster
Gestione semplificataGestione semplificataMigliori performance complessive sia per Migliori performance complessive sia per ambienti single che multiambienti single che multi--useruser
PARALLEL_AUTOMATIC_TUNING = truePARALLEL_AUTOMATIC_TUNING = true PARALLEL_ADAPTIVE_MULTI_USER PARALLEL_PROCESSES_PER_CPU
PARALLEL_ADAPTIVE_MULTI_USER PARALLEL_PROCESSES_PER_CPU

Amministrazione semplificata

Amministrazione semplificata:Oracle Enterprise Manager Console
• Unico punto di gestione
• 100% Java
• Pannelli customizzabili
• eventi
• job

Architettura a tre livelli
ServerServer®®
AgentAgent
Web ServerWeb Server
(browser-based)
ConsoleConsole
Oracle Management
Server
Oracle Management
Server
RepositoryRepository
ServerServer®®
AgentAgent
ConsoleConsole
Oracle Management
Server
Oracle Management
Server
ServerServer
®®
ConsoleConsole
AgentAgent

Enterprise ManagerReporting Framework
?Disponibilita’ di report predefiniti: current status, setup/configuration info, etc.
? Possono essere editati e pubblicati su Web

Oracle Enterprise Manager: Management Packs
? Diagnostics Pack - Monitoraggio e diagnosi di sistema? Traccia le prestazioni del sistema? Fornisce operativita’ a minor costo, incrementa la produttivita del DBA,
massimizza la continuita di servizio
? Tuning Pack - Ottimizza le prestazioni ? Elimina i colli di bottiglia nel sistema - migliora l’impiego delle risorse
? Change Management Pack - Valutazione e pianificazione delle modifiche del sistema? Riduce i costi, aumenta la produttivita del DBA, consente risposte
rapide a nuovi requisiti

Correlazione delle performance del server e del Database• CPU• Memoria• I/O • Consumo di Risorse
Drilldown to• Details• Advice• Database Sessions
Performance Overview Chart

Graphical SQL Explain Plan

Oracle Change Management Pack
? Funzionalita’:– Track dei cambiamenti nello schema nel
tempo
– Implementa cambiamenti di schema complessi
– Propaga i cambiamenti
– Compara e sincronizza gli schema
– Impact Analysis e generazione degli scripts SQL
?Wizards semplici
?Utile per imparare– Imparo dai piani di implementazione

Oracle9i Recovery Manager
RecoveryRecoveryManagerManager
TapeTape
Media Management Layer
DiskDisk DiskDisk DiskDisk DiskDisk
TapeTape TapeTape TapeTape
EnterpriseEnterpriseManagerManager
ThirdThirdParty Party ToolsTools
? Mantiene un catalogo di informazioni di backup e recovery
? Gestisce il processo di backup, restore e recovery
? Opera on-line e usa il parallelismo per un processing veloce
? Integrato cone Enterprise Manager & 3rd Party Tools
? Supporta tra l’altro:– Backup incrementale– Corrupt block detection / Block
level media recovery– Restartable backup/restore, trial
recovery
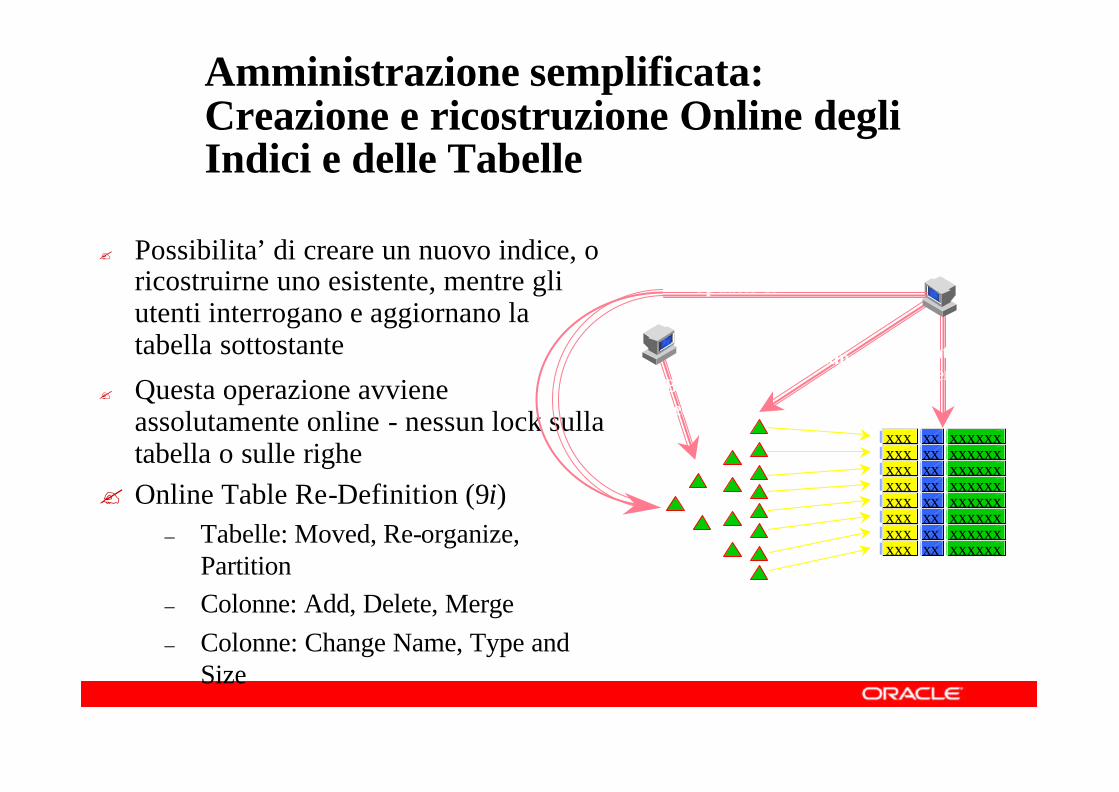
Amministrazione semplificata: Creazione e ricostruzione Online degli Indici e delle Tabelle
? Possibilita’ di creare un nuovo indice, o ricostruirne uno esistente, mentre gli utenti interrogano e aggiornano la tabella sottostante
? Questa operazione avviene assolutamente online - nessun lock sulla tabella o sulle righe
? Online Table Re-Definition (9i)– Tabelle: Moved, Re-organize,
Partition– Colonne: Add, Delete, Merge– Colonne: Change Name, Type and
Size
Index BuildStarted
UpdateTracking Updates &
Queries
xxx xxxxxxxxxxx xxxxxxxxxxx xxxxxxxxxxx xxxxxxxxxxx xxxxxxxxxxx xxxxxxxxxxx xxxxxxxxxxx xxxxxxxx
Index BuildCompleted
Updates &Queries
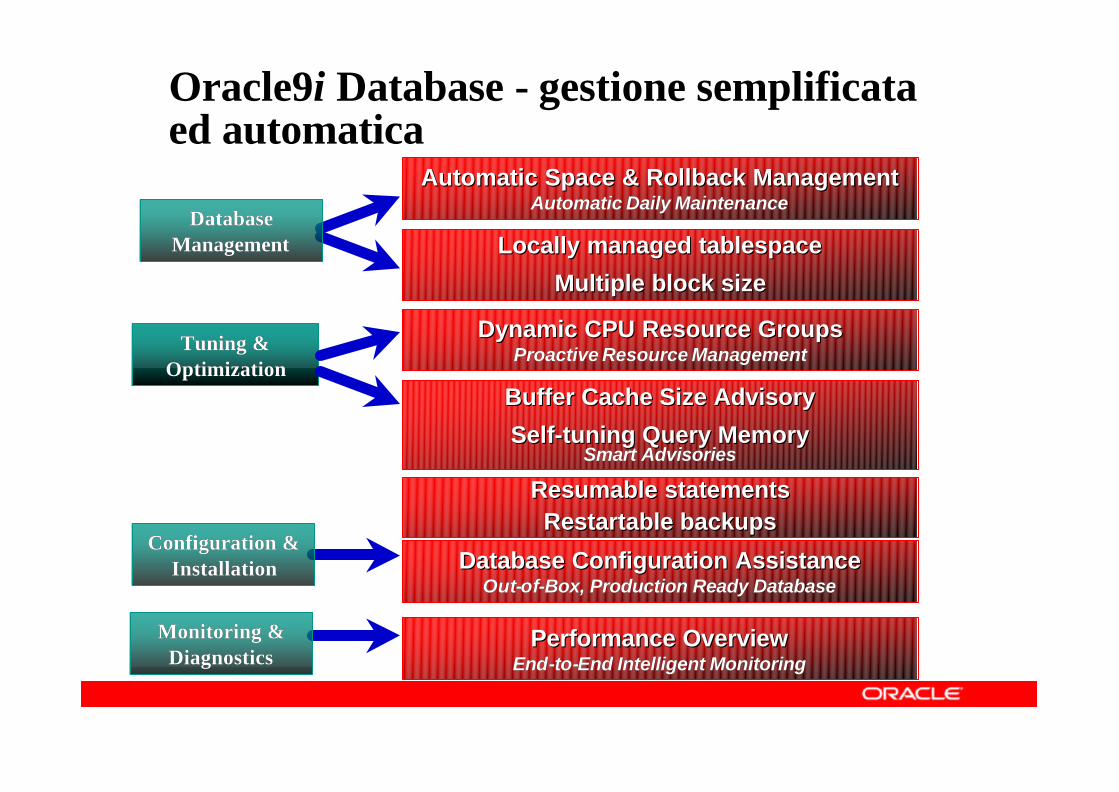
Oracle9i Database - gestione semplificata ed automatica
Automatic Space & Rollback ManagementAutomatic Space & Rollback ManagementAutomatic Daily MaintenanceAutomatic Daily Maintenance
Locally managed tablespaceLocally managed tablespace
Multiple block sizeMultiple block size
Tuning & Tuning & OptimizationOptimization
Dynamic CPU Resource GroupsDynamic CPU Resource GroupsProactive Resource ManagementProactive Resource Management
Buffer Cache Size Advisory Buffer Cache Size Advisory
SelfSelf--tuning Query Memory tuning Query Memory Smart AdvisoriesSmart Advisories
Database Configuration AssistanceDatabase Configuration AssistanceOutOut--ofof--Box, Production Ready DatabaseBox, Production Ready Database
Performance OverviewPerformance OverviewEndEnd--toto--End Intelligent MonitoringEnd Intelligent Monitoring
Database Database ManagementManagement
Resumable statementsResumable statementsRestartable backups Restartable backups
Configuration & Configuration & InstallationInstallation
Monitoring & Monitoring & DiagnosticsDiagnostics

SecurityPolicy
Virtual Private Database
? Possibilita’ di associare security policies (implementate da funzioni) a tabelle o viste
? La security policy limita il range di dati a cui l’utente puo’ accedere tramite predicate re-write (indipendentemente da come accedo al dato)
? Le policy eliminano il costo di usare diverse view per costruire una row level security
Dick
SELECT * FROM ORDERS;SELECT * FROM ORDERS;
OrdersTable
Harry
SELECT * FROM ORDERS;SELECT * FROM ORDERS;

Virtual Private Database
SELECT * FROM ORDERS;
SELECT * FROM ORDERS;
Sales Rep
Cliente
Il venditore vede solo gli ordini relativi ai suoi clienti
Il cliente vede solo i suoi ordini
ORDERS
SELECT * FROM orders WHERE cust_no = (SELECT cust_num FROM customers WHERE cust_name = USERENV(‘user’))
SELECT * FROM orders

Oracle 9i Database Server:ETL
Data Warehousing
ETL
OLAP
Data Mining
Oracle9Oracle9ii
Transformation EngineIntegrato in Oracle9iScalabile (parallel)Estendibile (Java, PL/SQL)
Efficente (no data staging)
Warehouse BuilderUn framework estensibile per disegnare e caricare un DW
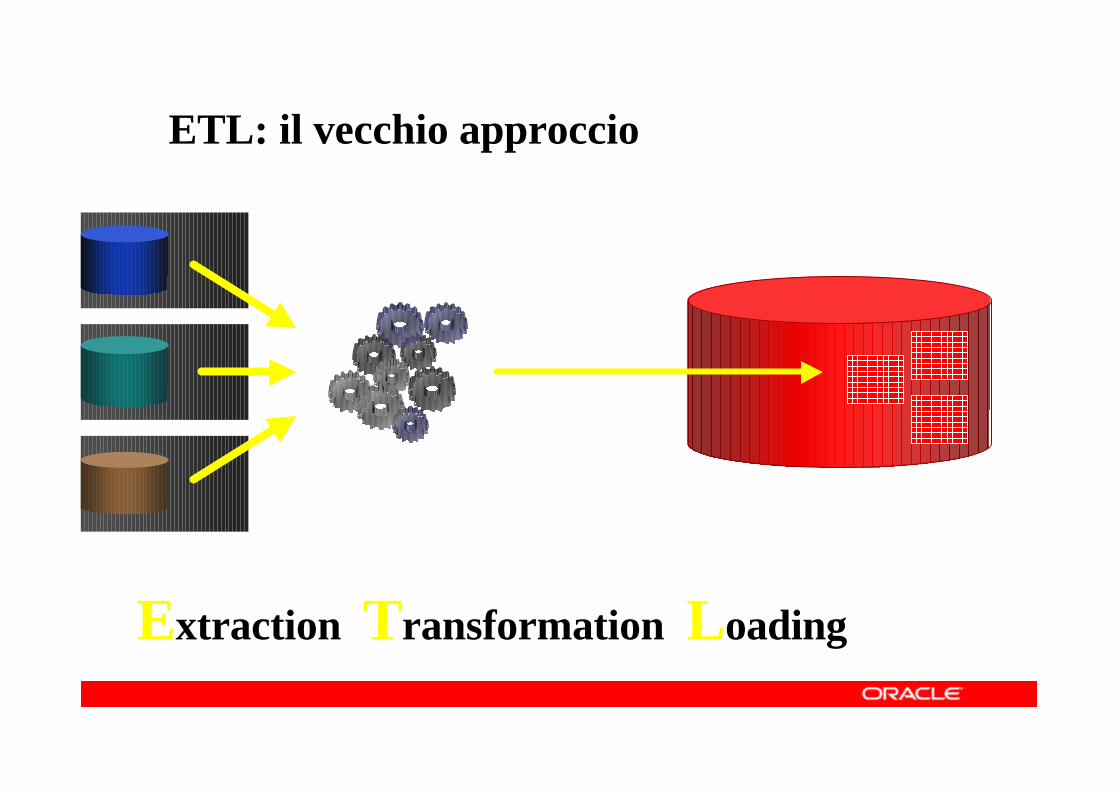
ETL: il vecchio approccio
Extraction Transformation Loading
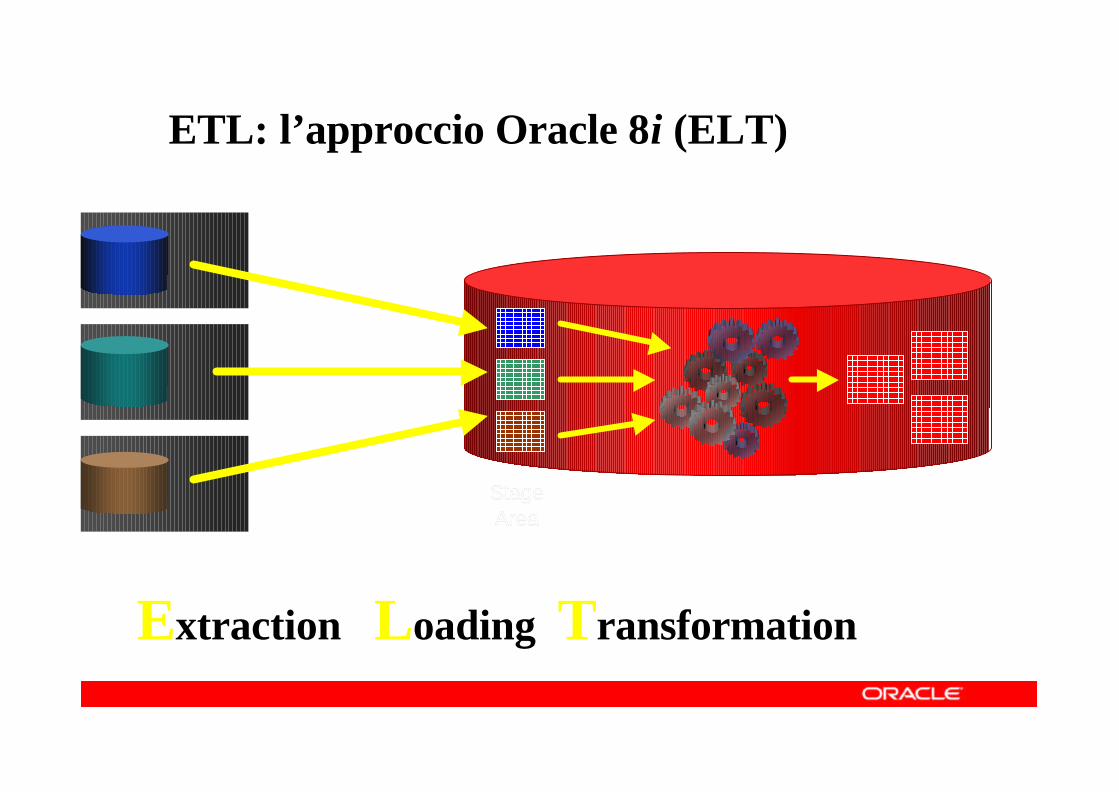
ETL: l’approccio Oracle 8i (ELT)
Extraction Loading Transformation
StageStageAreaArea

ETL: l’approccio Oracle 9i (ETwL)
Extraction Transform While Loading

ETL: l’approccio Oracle 9i (ETwL)
ETL EngineETL EngineOracle SQL / PLSQLOracle SQL / PLSQL
OracleOracle-- SQL*Net 8/9SQL*Net 8/9
Flat FileFlat File-- SQL*LoaderSQL*Loader-- External TablesExternal Tables
NonNon--OracleOracle-- Generic connectivityGeneric connectivity-- GatewaysGateways
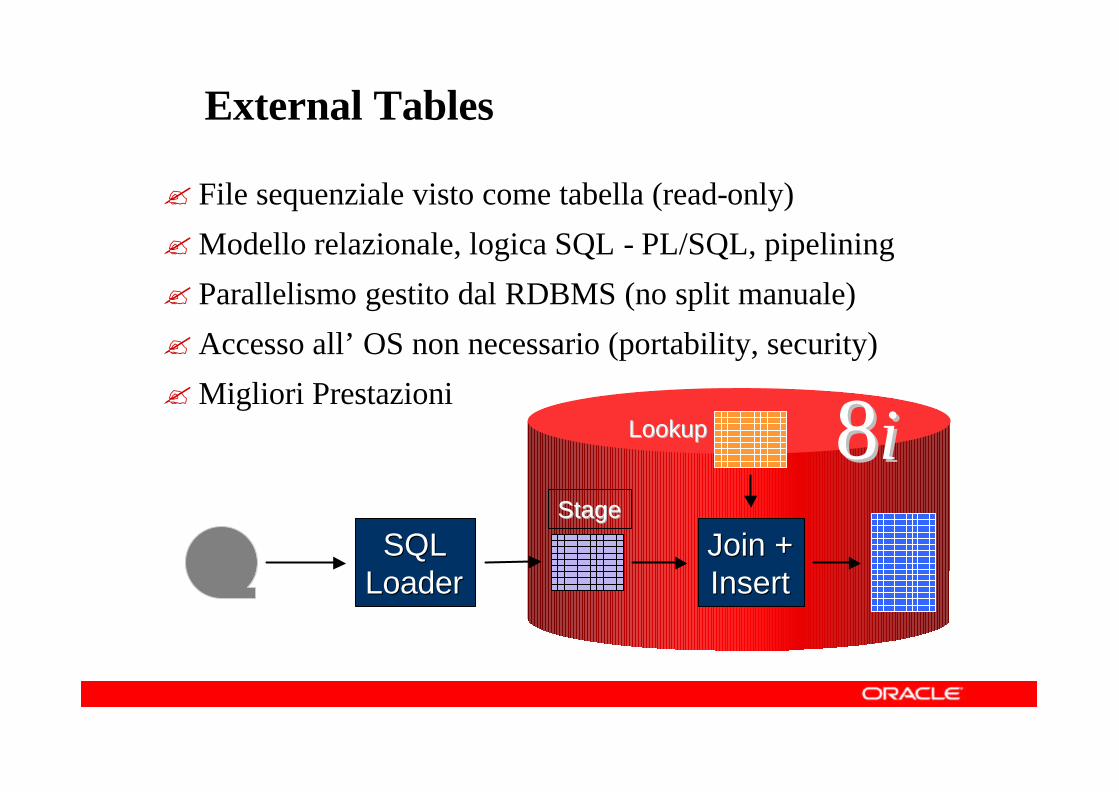
LookupLookup 88ii
External Tables
? File sequenziale visto come tabella (read-only)
?Modello relazionale, logica SQL - PL/SQL, pipelining
? Parallelismo gestito dal RDBMS (no split manuale)
?Accesso all’ OS non necessario (portability, security)
?Migliori Prestazioni
SQLSQLLoaderLoader
Join +Join +InsertInsert
StageStage

External Tables
? File sequenziale visto come tabella (read-only)
?Modello relazionale, logica SQL - PL/SQL, pipelining
? Parallelismo gestito dal RDBMS (no split manuale)
?Accesso all’ OS non necessario (portability, security)
?Migliori Prestazioni
Join +Join +InsertInsert
External TableExternal Table
LookupLookup 99ii

Table Functions
? Funzione PL/SQL che ha in Input– Set di righe, es.: il risultato di una SELECT
? In Output:– Set di righe, es.: input di una INSERT– Anche in Pipelining
? Riusabilita’ e Flessibilità per le trasformazioni procedurali
? Parallelismo, Streaming, Migliori Prestazioni
TableTableFunctionFunction

Upsert
?UPDATE e INSERT condizionale in un’unica istruzione? Scansione unica, elaborazione set-based, parallelismo?Migliori Prestazioni, Maggiore Leggibilita’?Nuova keyword SQL MERGE (prop. ANSI SQL Standard)
PRODUCTSID NAME LIST_PRICE MIN_PRICE-- ------- ---------- ---------10 Sweater 22.00 17.0020 Skirt 25.50 17.0030 Trousers 50.00 41.00
ID NAME LIST_PRICE MIN_PRICEID NAME LIST_PRICE MIN_PRICE---- -------------- -------------------- ------------------10 Sweater 22.00 10 Sweater 22.00 15.0015.0020 20 Skirt Skirt 25.50 17.0025.50 17.0030 30 TrousersTrousers 55.00 46.0055.00 46.0099 99 Shoes Shoes 70.99 70.9970.99 70.99
PRODUCTS_DELTAPRODUCTS_DELTA
ID NAME LIST_PRICE MIN_PRICE-- ------- ---------- ---------10 Sweater 22.00 15.0020 Skirt 25.50 17.5030 Trousers 55.00 46.0099 Shoes 70.99 70.99
MergeMerge

Multi-Table Insert?Una singola istruzione INSERT per inserire in piu’ tabelle
? Scansione unica, elaborazione set-based, parallelismo
? Incapsula logiche complesse (condizionale, semi-procedurale)
?Maggiore Scalabilita’, Migliori Prestazioni
? Sviluppo piu’ semplice, maggiore leggibilita’
CUSTOMERS_NEWCUSTOMERS_NEWID NAME CREDITID NAME CREDIT---- -------------- --------------------10 Joseph 3000.0010 Joseph 3000.0020 George 5000.0020 George 5000.0030 Nancy 3000.0030 Nancy 3000.0099 99 Ryan 4500Ryan 4500.00.00
CUSTOMERS
ID NAME CREDIT-- ------- ----------10 Joseph 3000.0020 George 5000.0030 Nancy 3000.0099 Ryan 4500.00
SPECIAL_CUST
ID CREDIT-- ----------20 5000.0099 4500.00
MultiMulti--TableTableInsertInsert

Tutto Insieme
Staging TableStaging Table Staging TableStaging Table
Step 1 Step 1 Caricamento su Caricamento su Tabelle di StagingTabelle di Staging
Step 2 Step 2 Controllo e Controllo e TrasformazioneTrasformazione
Step 3 Step 3 Inserimento / Inserimento / AggiornamentoAggiornamento
TransformTransform UpsertUpsertLoadLoad
Oracle8Oracle8ii
Oracle 9Oracle 9ii: Caricamento : Caricamento ParalleloParallelo e in e in PipelinePipeline

Oracle 9i Database Server:OLAP
Data Warehousing
ETL
OLAP
Data Mining
Oracle9Oracle9ii
OLAP ServicesAnalysis-ready Oracle database
Supporto a query multidimensionali complesse
Altamente scalabile
Piattaforma di sviluppo per applicazioni analitiche Internet-ready
Business Intelligence Beans e JdeveloperJava OLAP API

3966975953E
10643805974D
14327654107F
59232687I
EDCBAGen
3966975953E10643805974D14327654107F59232687IEDCBA
3966975953E
10643805974D
14327654107F
59232687I
EDCBAFeb
Prodotti
Pae
se3966975953E
10643805974D
14327654107F
59232687I
EDCBAMar
3966975953E
10643805974D
14327654107F
59232687I
EDCBAApr
Mesi
OLAP e Modello MultidimensionaleSemplice e Potente
Dimensioni
Misure
Prodotti
Pae
se
Vendite

VenditeVendite
TempoTempo
ProdottoProdotto CanaleCanale
ClienteCliente

ConsegnaConsegna (Quantita’, Ricavi, Costi, (Quantita’, Ricavi, Costi, MargineMargine))
TempoTempo
ProdottoProdotto CanaleCanale
ClienteCliente
Misure

ConsegnaConsegna (Quantita’, Ricavi, Costi, (Quantita’, Ricavi, Costi, MargineMargine))
TempoTempoClienteCliente
CanaleCanale
TotaleTotale
TipoTipo
FamigliaFamiglia
ProdottoProdotto
Elementi Dimensionali
Livelli
Dimensione Prodotto

ConsegnaConsegna (Quantita’, Ricavi, Costi, (Quantita’, Ricavi, Costi, MargineMargine))
TotaleTotale
GiornoGiorno
MeseMese
Anno Anno SolareSolare
SettimanaSettimana
Anno Anno FiscaleFiscale
TrimestreTrimestre
MeseMese
Anno Anno CommercialeCommerciale
StagioneStagione
CampagnaCampagna
ZonaZona
AgenteAgente
TotaleTotale
TipoTipo
FamigliaFamiglia
ProdottoProdotto
TotaleTotale
RivenditoreRivenditore
OrdineOrdine
TotaleTotale
NazioneNazione
RegioneRegione
ProvinciaProvincia
Localita’Localita’
ShipShip--toto
SettoreSettore
AziendaAzienda
GruppoGruppo

Dal Modello Logico al Modello Fisico
Modello LogicoModello LogicoMultidimensionaleMultidimensionale
Modello Fisico RelazionaleModello Fisico Relazionale
CuboCubo
Modello FisicoModello FisicoMultidimensionaleMultidimensionale
Star SchemaStar Schema SnowflakeSnowflake

SISINO (query)NO (query)Analisi
Indipendenti dai Indipendenti dai volumivolumi
Dipendenti dai Dipendenti dai volumivolumi
Tempi di Risposta
Eccellente Eccellente (matriciale)(matriciale)
Buona (lineare)Buona (lineare)Potenza di Calcolo
GeometricaGeometricaLineareLineareCrescita Occupazione Disco
““DepartmentDepartment””““EnterpriseEnterprise””Utenti
Moderati Moderati (<10GB) (<10GB) (Express: >200 GB)(Express: >200 GB)
Enormi (TB)Enormi (TB)Volumi
MDDBMSMDDBMSMultidimensionaleMultidimensionale
RDBMSRDBMSRelazionaleRelazionale
Un problema Un problema “antico”“antico”

Oracle Relational Database
?High performance cell access– Parallel query
– Bitmap join indexes
– Grouping sets & partition pruning
– Automatic memory tuning
– OLAP Calculations
?Summary Management

Estensioni SQL per l’Aggregazione
?Estensioni alla clausola GROUP BY?ROLLUP subtotali a livello delle colonne indicate (n+1)?CUBE tutte le combinazioni di subtotali (2n)? Funzioni GROUPING per interpretare correttamente i
risultati (GROUP_ID, GROUPING_ID)?Espressione GROUPING SET
per limitare le combinazioni di una CUBE
TotaleTotale
AA BB CC
11 22 33 44 55 66
II IIII IIIIII IVIV VV
TotaleTotale
aa bb cc dd ee ff

Operatori Cube e Rollup —Una estensione di GROUP BY
REGION QTR SALES
East Q1 20East Q2 40West Q1 60West Q2 80
REGION QTR SALES
East Q1 20East Q2 40West Q1 60West Q2 80
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY REGION, QTR
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY REGION, QTR
il risultato della GROUP BY
il risultato della GROUP BY
QTRREGION Q1 Q2
East 20 40West 60 80
QTRREGION Q1 Q2
East 20 40West 60 80
e’ equivalente ad una cross-tab
e’ equivalente ad una cross-tab

Operatori Cube e Rollup —Una estensione di GROUP BY
REGION QTR SALES
East Q1 20West Q1 40East Q2 60West Q2 80
REGION QTR SALES
East Q1 20West Q1 40East Q2 60West Q2 80
QTRREGION Q1 Q2
East 20 40West 60 80
QTRREGION Q1 Q2
East 20 40West 60 80
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY REGION, QTR
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY REGION, QTR
QTRREGION Q1 Q2 TOTAL
East 20 40 60West 60 80 140
QTRREGION Q1 Q2 TOTAL
East 20 40 60West 60 80 140
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY
ROLLUP (REGION, QTR)ROLLUP (REGION, QTR)
ROLLUP sommarizza su una dimensione
ROLLUP sommarizza su una dimensione

QTRREGION Q1 Q2
East 20 40West 60 80
QTRREGION Q1 Q2
East 20 40West 60 80
Operatori Cube e Rollup —Una estensione di GROUP BY
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY REGION, QTR
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY REGION, QTR
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY
CUBE (REGION, QTR)CUBE (REGION, QTR)
QTRREGION Q1 Q2 TOTAL
East 20 40 60West 60 80 140
TOTAL 80 120 200
QTRREGION Q1 Q2 TOTAL
East 20 40 60West 60 80 140
TOTAL 80 120 200
CUBE sommarizzasu tutte le dimensioni
CUBE sommarizzasu tutte le dimensioni

select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY
select REGION, QTR, SUM(SALES)from sales_detail
GROUP BY
CUBE (REGION, QTR)CUBE (REGION, QTR)
QTRREGION Q1 Q2 TOTAL
East 20 40 60West 60 80 140
TOTAL 80 120 200
QTRREGION Q1 Q2 TOTAL
East 20 40 60West 60 80 140
TOTAL 80 120 200
Operatori Cube e Rollup —Una estensione di GROUP BY
? CUBE e ROLLUP calcolano piu’ aggregati su una combinazione di dimensioni
? Eseguiti in un unico step; nessun sort inutile
Result: efficient Result: efficient datadata--intensive intensive computationcomputation

SELECT Time, Region, Department, sum(Profit) AS ProfitSELECT Time, Region, Department, sum(Profit) AS ProfitFROM salesFROM salesGROUP BY GROUP BY ROLLUP(Time, Region, Department)ROLLUP(Time, Region, Department)
TIMETIME REGIONREGION DEPARTMENTDEPARTMENT PROFITPROFIT---------- -------------- -------------------------- ----------------19961996 CentralCentral VideoRentalVideoRental 75,00075,00019961996 CentralCentral VideoSalesVideoSales 74,00074,00019961996 CentralCentral 149,000149,00019961996 EastEast VideoRentalVideoRental 89,00089,00019961996 EastEast VideoSalesVideoSales 115,000115,00019961996 EastEast 204,000204,00019961996 WestWest VideoRentalVideoRental 87,00087,00019961996 WestWest VideoSalesVideoSales 86,00086,00019961996 WestWest 173,000173,00019961996 526,000526,00019971997 CentralCentral VideoRentalVideoRental 82,00082,00019971997 CentralCentral VideoSalesVideoSales 85,00085,00019971997 CentralCentral 167,000167,00019971997 EastEast VideoRentalVideoRental 101,000101,00019971997 EastEast VideoSalesVideoSales 137,000137,00019971997 EastEast 238,000238,00019971997 WestWest VideoRentalVideoRental 96,00096,00019971997 WestWest VideoSalesVideoSales 97,00097,00019971997 WestWest 193,000193,00019971997 598,000598,000
1,124,0001,124,000
TIME:TIME:1996199619971997
Region:Region:CentralCentralEastEastWestWest
Department:Department:VideoRentalVideoRentalVideoSalesVideoSales

Analytic Functions
? Estensioni dell’SQL per l’Analisi (SQL ? OLAP)
? Standard ANSI (o proposte all’ANSI)
?Maggiore Produttività nello Sviluppo– Complesso codice PL/SQL ? singola query SQL
– Analisi complesse, minimo codice, senza tabelle temporanee– Accesso da qualsiasi tool di front-end
? Prestazioni incrementate– Elaborazione server-side
– Parallelismo e Caching nativo – In molti casi fino a 10 volte più veloci.
0
20
40
60
80
100
Q1 Q2 Q3 Q4
R3R2
R1

Analysis Ready RDBMSCapacita’ analitiche in Oracle database
?Oracle8i, Release 2– Rank, percentile – Window (moving average, cumulative sum)– LAG/LEAD – Ratio-to-Report– Statistical functions (linear regression, correlation)
?Oracle9i– Inverse Percentile – Hypothetical Rank and Distribution functions– Histogram Function– First/Last Values

Analytic SQL : Tipologie di funzioni 1
?Ranking– Classifiche, percentili, (n-tili) di valori in un result set
– «Quali sono i nostri dieci migliori clienti?»
– «In che fascia e’ questo prodotto?»
?Windowing– Aggregati cumulativi e mobili.
– Si applicano a: SUM, AVG, MIN, MAX, FIRST_VALUE, LAST_VALUE ed alle funzioni statistiche
– «Qual e’ il venduto medio degli ultimi tre mesi (mobili)?»

Funzioni AnaliticheEsempio di Rank e Dense_Rank
SELECT sales_person, region, amount, RANK() OVER (PARTITION BY region ORDER BY amount DESC)AS rank,DENSE_RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS d_rank
FROM Sales_table;
SELECT sales_person, region, amount, RANK() OVER (PARTITION BY region ORDER BY amount DESC)AS rank,DENSE_RANK() OVER (PARTITION BY region ORDER BY amount DESC) AS d_rank
FROM Sales_table;
Sales_PersonSales_Person RegionRegion AmountAmount RankRank
DavisDavis EastEast 100100 11
BakerBaker East East 89 89 22
SmithSmith EastEast 89 89 22
FitzpatrickFitzpatrick EastEast 75 75 44
JonesJones WestWest 98 98 11
PetersonPeterson WestWest 85 85 22
LeeLee West West 7777 33
D_RankD_Rank
11
22
22
33
11
22
33
Q: Quale e’ il ranking dei nostri venditori in base alle revenue all’ interno di ciascuna sales region ?

Funzioni AnaliticheEsempio di aggregati mobili
SELECT Account, TransDate, TransAmt,SUM(TransAmt) OVER (PARTITION BY Account ORDER BY TransDate
ROWS UNBOUNDED PRECEDING) AS BalanceFROM Ledger ORDER BY Account, TransDate;
SELECT Account, TransDate, TransAmt,SUM(TransAmt) OVER (PARTITION BY Account ORDER BY TransDate
ROWS UNBOUNDED PRECEDING) AS BalanceFROM Ledger ORDER BY Account, TransDate;
AccountAccount TransDateTransDate TransAmtTransAmt BalanceBalance
7382973829 1717--JANJAN--0000 113.45113.45 113.45113.45
7382973829 1818--JANJAN--00 00 --52.0152.01 61.4461.44
7382973829 1919--JANJAN--00 00 36.2536.25 97.6997.69
8293082930 2020--JANJAN--00 00 10.5610.56 10.5610.56
8293082930 2121--JANJAN--00 00 32.5532.55 43.1143.11
8293082930 2222--JANJAN--00 00 --5.025.02 38.0938.09
Q: Quale e’ la somma cumulativa dei vari depositi nel tempo ?

Analytic SQL : Tipologie di funzioni 2
?Reporting– Calcolano le incidenze (share).– Si applicano a: SUM, AVG, MIN, MAX, RATIO_TO_REPORT
ed alle funzioni statistiche– «Che percentuale ha questo prodotto rispetto al totale?»
?LAG / LEAD– Restituiscono il valore di una riga che si trova un certo
numero di righe prima o dopo la riga corrente– «Come stiamo andando rispetto allo stesso mese
dell’anno scorso?»

ProductProduct SalesSales Sales_RatioSales_Ratio
shoesshoes 100100 0.190.19
jacketsjackets 9090 0.170.17
shirtsshirts 8080 0.150.15
sweaterssweaters 7575 0.140.14
shirtsshirts 7575 0.140.14
tiesties 1010 0.020.02
pantspants 4545 0.090.09
sockssocks 4545 0.090.09
Funzioni Analitiche Esempio di Ratio-to-report
SELECT Product, SUM(Amount) AS Sales,RATIO_TO_REPORT(SUM(Amount)) OVER () AS Sales_Ratio
FROM Sales GROUP BY Product
SELECT Product, SUM(Amount) AS Sales,RATIO_TO_REPORT(SUM(Amount)) OVER () AS Sales_Ratio
FROM Sales GROUP BY Product
Q: A quanto ammontano le mie revenue di vendita per ciascun prodotto, e quanto pesa ciascun prodotto sulle vendite totali ?

Funzioni Analitiche Esempio di funzioni Lag/Lead
SELECT TransDate, Price,LAG(Price,1) OVER (ORDER BY TransDate) AS PrevClose,
Price - NVL(LAG(Price,1) OVER (ORDER BY TransDate),0) AS DailyChangeFROM Sales ORDER BY TransDate;
SELECT TransDate, Price,LAG(Price,1) OVER (ORDER BY TransDate) AS PrevClose,
Price - NVL(LAG(Price,1) OVER (ORDER BY TransDate),0) AS DailyChangeFROM Sales ORDER BY TransDate;
TransDateTransDate PricePrice PrevClosePrevClose DailyChangeDailyChange
1010--JANJAN--20002000 125.00125.00 NULLNULL 125.00125.00
1111--JANJAN--2000 2000 150.00150.00 125.00125.00 25.0025.00
1212--JANJAN--2000 2000 175.00175.00 150.00150.00 25.0025.00
1313--JANJAN--2000 2000 100.00100.00 175.00175.00 --75.0075.00
1414--JANJAN--2000 2000 50.0050.00 100.00100.00 --50.0050.00
Q: Qual e’ il prezzo giornaliero del prodotto e la differenza rispetto a quello del giorno precedente ?

Analytic SQL : Tipologie di funzioni 3
?FIRST / LAST– Primo o ultimo valore di un set ordinato
– «Qual e’ l’importo medio del primo ordine dei nostri nuovi clienti?»
?Linear Regression
?Inverse Percentile
?Hypothetical Rank and Distribution

select * select * fromfrom(select (select productproduct_id, _id, sumsum(sales_(sales_amtamt) as ) as productproduct_sales, _sales, RANK() RANK() overover((orderorder by by sumsum(sales_(sales_amtamt) ) descdesc)) as as productproduct__rank rank fromfrom sales sales where customerwhere customer_id in _id in
(select (select customercustomer_id _id from from (select (select customercustomer_id, _id,
100 * 100 * CUME_DIST() CUME_DIST() overover((orderorder by by sumsum(sales_(sales_amtamt) ) ascasc))as as custcust__percentile percentile fromfrom sales group by sales group by customercustomer_id) _id) wherewhere custcust__percentilepercentile > 85) > 85) group by group by productproduct_id) _id)
where productwhere product__rankrank <= 5 <= 5 orderorder by by productproduct__rankrank; ;
PRODUCT_ID PRODUCT_SALES PRODUCT_RANK -------------- -------------- ---------------SO-1278 3569871 1 SE-9087 2998109 2 SI-7652 2587397 3 SD-0386 2001298 4 CO-8925 1098763 5
I 5 prodotti più acquistati dal top 15% dei miei clienti?

Amministrazione integrata via Oracle Enterprise Manager

La piattaforma OLAP
Oracle9iOracle9iScaleable data storeIntegrated metadata
Summary managementSQL analytic functions
Oracle9i OLAP ServicesOracle9i OLAP ServicesJava OLAP API
Predictive analysis functions
Oracle Business Intelligence Oracle Business Intelligence BeansBeans
Rapid application developmentAnalysis ready
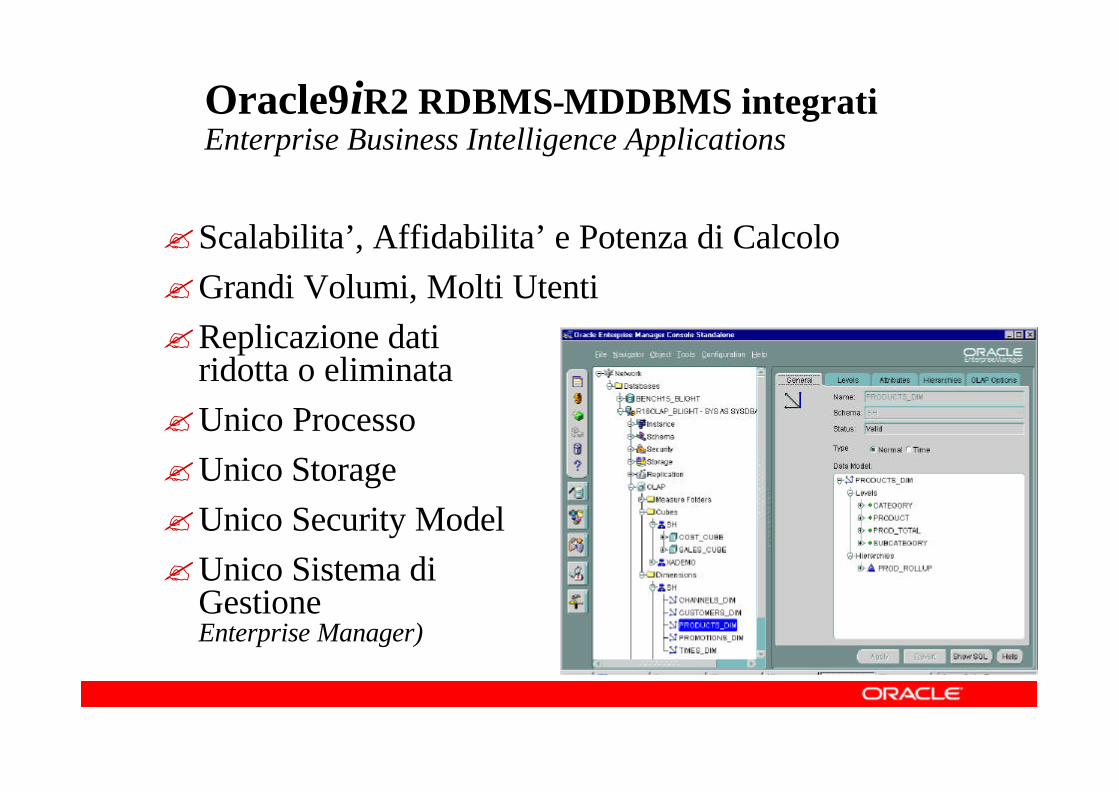
?Scalabilita’, Affidabilita’ e Potenza di Calcolo?Grandi Volumi, Molti Utenti?Replicazione dati
ridotta o eliminata?Unico Processo?Unico Storage ?Unico Security Model?Unico Sistema di
Gestione (Oracle Enterprise Manager)
Oracle9iR2 RDBMS-MDDBMS integratiEnterprise Business Intelligence Applications

Oracle9iR2 RDBMS-MDDBMS integrati
Oracle Call InterfaceOracle Call Interface
Relational TechnologyRelational Technology
SQL EngineSQL Engine
Object TechnologyObject Technology
Storage
Relational Objects
Table FunctionsTable Functions
OLAP TechnologyOLAP Technology
OLAP APIOLAP API
Multidimensional Multidimensional EngineEngine
Multidimensional Objects
Oracle DatabaseOracle Database
JDBCJDBC

Oracle OLAP: Componenti?Motore di Calcolo
– Selezioni e Calcoli Multidimensionali
?Analytic Workspace– Spazio di Lavoro Individuale (Sessione)– Database Multidimensionale (Cubo, LOB)
? PL/SQL Table Function– MDB -> (ADT + Table Function) -> Relational View
?OLAP Catalog– Caratteristiche Oggetti Multidimensionali (Locazione Fisica,
Informazioni per Selezione, Elaborazione e Presentazione)
?OLAP DML (OLAP Data Manipulation Language)
?OLAP API (OLAP Application Programming Interface)

Oracle OLAP DMLOn Line Analytical Processing Data Manipulation Language
? Comandi e Funzioni per Analisi Complesse
? Programmi e Stored Procedures
? Aggregazioni
? Allocazioni? Operazioni Finanziarie
? Previsioni e Regressioni
? Calcolo di Modelli ? Serie Temporali
? Funzioni Statistiche
? Calcoli Numerici
? Selezione Dati
? Scambio Dati
? Lettura e Scrittura Files
?Manipolazione TestoFORECAST FORECAST
LENGTH 12 LENGTH 12 METHOD EXPONENTIALMETHOD EXPONENTIALFCNAME fcst.salesFCNAME fcst.salesTIME month salesTIME month sales

Table FunctionTable Function
MultidimensionalMultidimensionalEngineEngine
Abstract Data TypeAbstract Data Type
OLAPI ApplicationOLAPI Application
OLAP SQL GeneratorOLAP SQL Generator
OLAP API
RelationalView
SQL
RelationalObjects
MultidimensionalObjects
Storage
Generic SQL Generic SQL ApplicationApplication
Select * fromview
OCI or JDBC
‘‘OLAP awareOLAP aware’’ SQL SQL ApplicationApplication
Select * fromtable function
OCI or JDBC
‘‘DirectDirect’’ OLAP OLAP applicationapplication
OCI or JDBC

Business Intelligence Beans?Accesso alle Funzioni Analitiche di Oracle 9i
– Analytic SQL– OLAP Option
? Componenti Integrati in Oracle9i JDeveloper
? Sviluppo RAPIDO di Applicazioni di Interrogazione e Analisi
? Tre Categorie– Presentation (Table, Crosstab,
e Graph)– OLAP (QueryBuilder,
CalcBuilder, DimensionList)– Catalog per Condivisione e
Collaborazione

BI Beans Architecture
TableTable Cross TabCross Tab GraphGraph
Query Query BuilderBuilder
Calculation Calculation BuilderBuilder
Oracle9Oracle9iiOracle9Oracle9ii OLAP ServicesOLAP Services
QueryQuery
Metadata ManagerMetadata Manager
PersistencePersistence
Beans RepositoryBeans Repository
ConnectionConnection
PresentationPresentation
OLAPOLAP
CatalogCatalog

Deployment: Java o Servlet
Oracle9Oracle9ii DatabaseDatabase
Oracle9i OLAP
Client Oracle9iAS
Servlet Engine
BI Beans Servlet /JSP Application
Web Browser
Java OLAP API
BI Beans Java App
BI Beans Catalog

Query Builder

Calculation Builder

Java Crosstab

Java Graph
HTML Crosstab

HTML Graph

Platform for Business Intelligence:Data Mining
Data Warehousing
ETL
OLAP
Data Mining
Oracle9Oracle9ii
Data Mining Funzionalita’ integrate e scalabili di data-mining

Data Mining
Oracle9iOracle9i
Data mining algorithmsData mining algorithmsAlgoritmi eseguiti nel RDBMS
Oracle9i, Release 1:Transactional Naïve Bayes Predictive Assocation rules
Oracle9i, Release 2:Decision TreesClassic Naïve Bayes
Data MiningData Mining
UI-based environment supports business processes (Release 2):
Customer ChurnCustomer ProfilingResponse ModelingProfitability Modeling

Enhanced Analytic Platform– Data Mining
?New Data Mining algorithms in the RDBMS– Decision Trees (e.g., customer profiling through rules)
– Clustering (e.g., segmentation for marketing campaigns)
?Additional Capabilities in the database– Model Seeker (automatically selects best model)
– Attribute importance (automatically selects key predictors)– Automatic Binning (standard data prep technique)
? PMML compliant scoring engine in the database

Traditional Analytic Servers
Data Data WarehouseWarehouse
EngineEngine
DataIntegrationEngine
OLAPEngine
MiningEngine

Oracle9i Analytic Platform
Data Warehousing
ETL
OLAP
Data Mining
Oracle9Oracle9ii

Oracle DB e il Data WarehousingInnovazione continua
Oracle 8.0– Partitioned Tables and Indexes– Partition Pruning– Parallel Index Scans– Parallel Insert, Update, Delete– Parallel Bitmap Star Query– Parallel ANALYZE– Parallel Constraint Enabling– Server-Managed Backup/Recovery– Incremental Backup/Recovery
Oracle 7.1– Parallel Query: Scan, Sort, Join...– Parallel Load– Parallel Create Index– Efficient Multi-Block Reads, Writes
Oracle 7.2– Star Query Support– Direct Database Reads, Writes– Parallel Create Tables As Select– Faster Star Query Execution
Oracle 7.3– Hash Join– Bitmap Indexes– Parallel-Aware Optimizer– Partition Views– Instance Affinity: Function Shipping– Parallel Union All– Scalable GROUP BY, small # of groups– Asynchronous Read-Ahead– Histograms– Anti-Join
Oracle 8i– Summary Management– Summary Navigation– Hash, composite data partitioning – Resource Management– Data Movement infrastructure– Transportable TABLESPACE– Direct Load API
Oracle 8i2RankingMoving aggragatesPeriod over period comparisonRatio to report

Oracle9i e il Data Warehousing Ancora piu’ avanti....
? Automatic Memory Tuning ? ETL Infrastructure
– Change data capture– External tables– Table functions– Upserts– Multi-table INSERTs– Resumable statements– Transportable tablespace
enhancements? List Partitioning? Internal enhancements for:
– parallel query– aggregation– cost-based optimization
? Bitmap Join Indexes ? Analytic SQL fns
– Grouping sets– FIRST/LAST aggregates– Inverse distribution– Hypothetical rank
? Proactive query governing Enhancements to MVs
– Broader refresh and rewrite capabilities
– More sophisticated summary advisor
? Full Outer Joins? WITH-clause

Ulteriori informazioni….
http://www.oracle.comhttp://www.oracle.com/ithttp://www.oracle.com/ebusinessnetwork/http://www.oracle.com/iseminars/http://www.oracle.com/oramaghttp://www.oracle.com/events
Oracle Technology Networkhttp://otn.oracle.com

Ulteriori informazioni….Oracle 9i on line manuals
http://otn.oracle.com/docs/products/oracle9i/content.htmlhttp://otn.oracle.com/docs/products/oracle9i/doc_library/release2/index.htm
Oracle 9ihttp://otn.oracle.com/products/oracle9i/content.html
Oracle9i by Examplehttp://otn.oracle.com/products/oracle9i/htdocs/9iober2/index.html
Oracle Portalhttp://portalcenter.oracle.com
http://portalstudio.oracle.com http://portalcatalog.oracle.comhttp://my.oracle.com http://portal.oracle.com

Maggiori Informazioni…
?Oracle9i Data Warehousing Guide (Release 2)– ETL:
?Cap. 10 Overview of ETL
?Cap. 11 Loading and Transformation– Aggregations
?Cap. 18: SQL for Aggregation in Data Warehouses
– Analysis?Cap. 19: SQL for Analysis in Data Warehouses

Maggiori Informazioni…
?Oracle9i OLAP – User’s Guide (Release 2)
– Developer’s Guide to the OLAP API
– Developer’s Guide to the OLAP DML
?Oracle 9i Enterprise Manager Concepts Guide (rel.2)