on compression of machine-derived context sets … · the relationship of subset size (design...
TRANSCRIPT

On Compression of Machine-derived Context Sets for
Fusion of Multi-modal Sensor Data
Nurali ViraniDepartment of Mechanical Engineering
The Pennsylvania State University
Co-authors: Shashi Phoha and Asok RayThe Pennsylvania State University
1st International Conference on InfoSymbiotics / DDDASSession - 10: Image and Video Computing Methods
This work has been supported by U.S. Air Force Office of Scientific Research (AFOSR) under Grant No. FA9550-12-1-0270 (Dynamic Data-driven Application Systems)

What is context and where does it enter the DDDAS framework?
2
Contextaffecting
data
Context affectingdecision,
but not data
Context affectingdecision,
but not data
Schematic of a DDDAS framework for situation awareness

Context is the set of all factors which affect the data
Before Rain
After Rain
* J. McKenna and M. McKenna, “Effects of local meteorological variability on surface and subsurface seismic-acoustic signals,” in
25th Army Science Conference, 2006.
Seismic signal amplitude for a hammer blow*
GeophoneOr Seismic
Calm
Windy
Acoustic Sunny
Foggy
Camera
Drysoil
Moistsoil
3

Definition: A finite non-empty set ℒ(𝑋) is called context set, if for all 𝑙 ∈ ℒ(𝑋), the
following holds:
Context can be learned from heterogeneous sensor data using density
estimation
𝐿 𝑋
𝑌1 𝑌2 𝑌𝑁…With nonparametric density estimation (Virani et al, 2015)*, conditional independence is guaranteed
for the modality-independent contexts
*N. Virani, J.-W. Lee, S. Phoha, and A. Ray. "Learning context-aware measurement models." In 2015 American Control Conference (ACC), pp. 4491-4496. IEEE, 2015. 4
In the presence of contextual effects assuming conditional independence given
state might be incorrect
𝑋
𝑌1 𝑌2 𝑌𝑁…

Machine-derived context is an output of the mixture-modeling technique
5
Joint conditional density as a mixture model :
where context set
The outputs of context learning includes:
• Machine-derived context set
• Contextual observation density
• Context priors
N. Virani, S. Sarkar, J.-W. Lee, S. Phoha, and A. Ray, “Algorithms for Context Learning and Information Representation for Multi-Sensor Teams,” in Context-Enhanced Information Fusion, edited by L. Snidaro et al., Springer, 2016
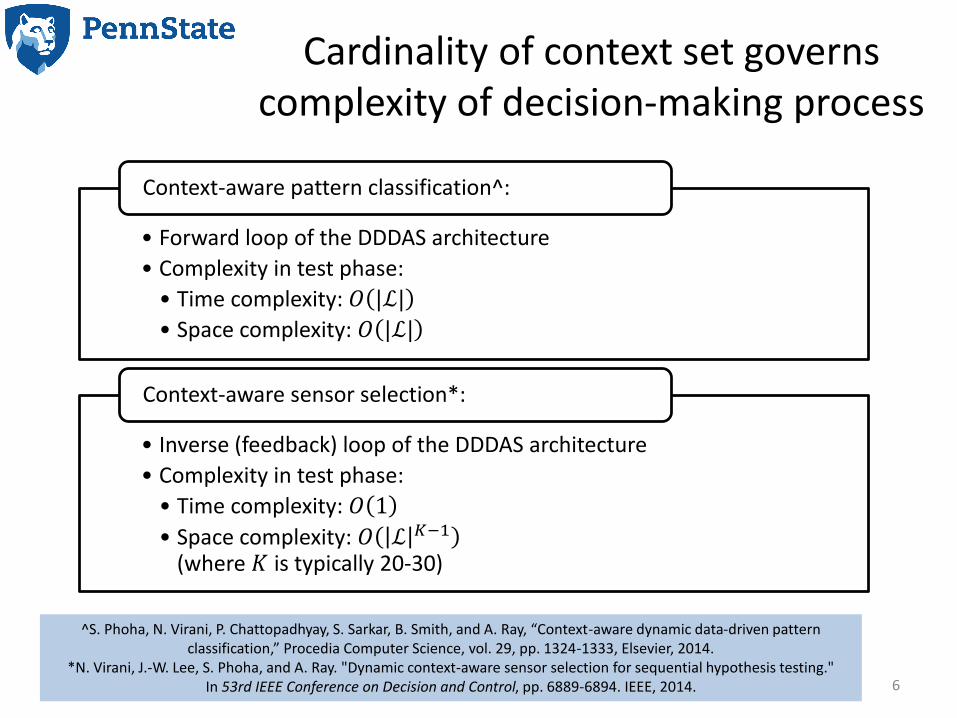
Cardinality of context set governs complexity of decision-making process
• Forward loop of the DDDAS architecture
• Complexity in test phase:
• Time complexity: 𝑂 |ℒ|
• Space complexity: 𝑂 |ℒ|
Context-aware pattern classification^:
• Inverse (feedback) loop of the DDDAS architecture
• Complexity in test phase:
• Time complexity: 𝑂 1
• Space complexity: 𝑂 ℒ 𝐾−1
(where 𝐾 is typically 20-30)
Context-aware sensor selection*:
^S. Phoha, N. Virani, P. Chattopadhyay, S. Sarkar, B. Smith, and A. Ray, “Context-aware dynamic data-driven pattern classification,” Procedia Computer Science, vol. 29, pp. 1324-1333, Elsevier, 2014.
*N. Virani, J.-W. Lee, S. Phoha, and A. Ray. "Dynamic context-aware sensor selection for sequential hypothesis testing." In 53rd IEEE Conference on Decision and Control, pp. 6889-6894. IEEE, 2014. 6

Can we develop techniques to reduce the cardinality of context sets?
7

Compression of context set: Graph-theoretic Clustering
ℒ(𝑥)
𝑙2 𝑙1
𝑙3
𝑙4
𝑙5𝑙7
𝑙6𝒄𝟏
𝒄𝟐
Partition the machine-derived context set by choosing a desired level of acceptable error (𝜀)
ℒ 𝑥 = 𝑙1, 𝑙2, 𝑙3, 𝑙4, 𝑙5, 𝑙6, 𝑙7𝒞𝜀 𝑥 = 𝑐1, 𝑐2𝑐1 = 𝑙1, 𝑙2, 𝑙3, 𝑙4𝑐2 = 𝑙5, 𝑙6, 𝑙7
8
ℒ 𝑥 = 6 𝒞 𝑥 = 2

Algorithm for cardinality reduction by clustering
• Construct a complete graph with V = ℒ 𝑥
• Assign weights to each edge: 𝑤𝑖𝑗 = 𝑤𝑗𝑖𝑤𝑖𝑗 = w 𝑙𝑖 , 𝑙𝑗 = 𝑑(𝑃(𝑌|𝑥, 𝑙𝑖), 𝑃(𝑌 |𝑥, 𝑙𝑗))
Graph Construction
• Remove edges with 𝑤𝑖𝑗 ≥ εThreshold
• Find all Maximal Cliques using underlying graphMaximal Clique
Enumeration
• Compute all set-difference and intersectionsMinterms
𝑙1
𝑙2 𝑙3
𝑙4
𝑙5
ℒ 𝑥 = 𝑙1, 𝑙2, 𝑙3, 𝑙4, 𝑙5
w12
w13
w14
w15
w23
w24
w25
w34
w35
w45
ℳ 𝑥 = 𝑙1, 𝑙2, 𝑙5 , 𝑙2, 𝑙4 , 𝑙3
𝒞 𝑥 = 𝑙1, 𝑙5 , 𝑙2 , 𝑙4 , 𝑙3
9
Given ℒ 𝑥 and 𝑃 𝑌 𝑥, 𝑙 , ∀ 𝑙 ∈ ℒ 𝑥 , ∀ 𝑥 ∈ 𝒳 :

Approximate context-aware measurement models
10
Cluster membership:
Context priors:
Context-aware measurement models:
Approximation: Replace the mixture model with a single component
Theorem 1: (Bound of error in density estimation and choosing 𝒍∗)

Can we find an alternative approach which does not have similar limitations?
Graph-theoretic clustering-based compression:
Pros: Approximation error is directly the design parameter Based on well-established concepts from graph theory Ensures representation from all regions of information space
Cons: The relationship of error threshold 𝜀 (design parameter) and cardinality
of context set 𝒞(𝑋) is not known a priori Computationally expensive if ℒ 𝑋 is large (exponential in worst case)
11

Compression of a finite set: Subset selection
Select only a k-subset of the machine-derived context set.
𝑙2
𝑙3 𝑙5
𝒞1 𝑥 = 𝑙5𝒞2 𝑥 = 𝑙2, 𝑙5
𝒞3 𝑥 = 𝑙2, 𝑙3, 𝑙5…
𝒞7 𝑥 = ℒ 𝑥
𝒞3 𝑥
ℒ(𝑥)
𝑙2 𝑙1
𝑙3
𝑙4
𝑙5𝑙7
𝑙6
Machine-derived context set k-subset context set
12
ℒ 𝑥 = 6 𝒞 𝑥 = 2

Error in density estimation due to subset selection
Original Compressed
Supremum Norm:
Theorem 2: (Bound of error in density estimation)
13

Optimal 𝑘-subset and Optimal 𝑘
14
Choose first 𝑘 machine-defined contexts as optimal 𝑘-subset.
To choose optimal 𝑘, we can perform multi-objective optimization to minimize error as well as model complexity, where model complexity can
be in terms of time or space complexity in test phase.

Graph-theoretic clustering-based compression:
Pros: Approximation error is directly the design parameter Based on well-established concepts from graph theory Ensures representation from all regions of information space
Cons: The relationship of error threshold 𝜀 (design parameter) and cardinality of context set
𝒞(𝑋) is not known a priori Computationally expensive if ℒ 𝑋 is large (exponential in worst case)
Subset selection-based compression:
Pros: The relationship of subset size 𝑘 (design parameter) and cardinality of context set
𝒞(𝑋) is known a priori Computationally inexpensive (same complexity as the sorting algorithm)
Cons: Does not ensure representation from all regions of information space
15

Experimental setup and data collection
Total runsWalking: 110Running: 118
16

Test procedure
• Cross-validation: 60% training 40% testing, repeat 10 times.
• Symbolic time-series analysis for feature extraction:
– Discrete Markov model Σ = 6, 𝐷 = 2, 𝑄 = 7
– Stationary distribution of Markov chain is used as a feature (ℝ2000 → ℝ7)
– PCA is used to reduce ℝ6 → ℝ2
• Learning context set using 2 seismic sensors:
– Gaussian kernel with parameter 0.01
– Cardinality of context set:
• Maximum likelihood classifier is used:
• Base case result: 99.78%
17

Results on cardinality reduction by clustering
18
Cardinality Accuracy
Accuracy same as base case, but,

Results on cardinality reduction by subset selection
19
Accuracy same as base case, but,
Cardinality Accuracy
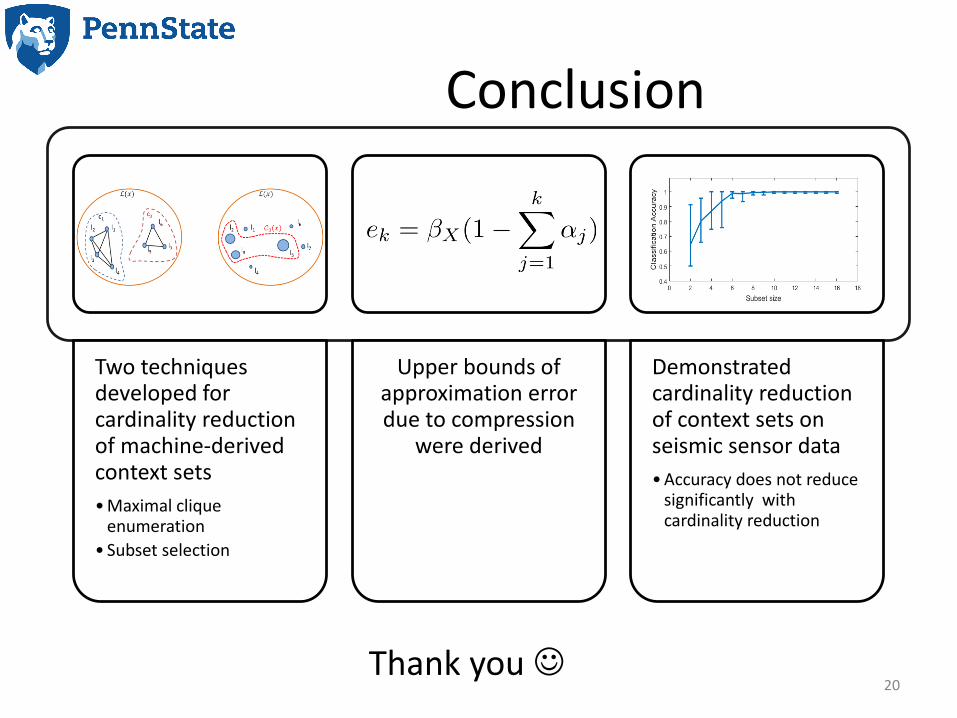
Conclusion
Two techniques developed for cardinality reduction of machine-derived context sets
• Maximal clique enumeration
• Subset selection
Upper bounds of approximation error due to compression
were derived
Demonstrated cardinality reduction of context sets on seismic sensor data
• Accuracy does not reduce significantly with cardinality reduction
20Thank you