np-hardness and phylogeny reconstruction tandy warnow department of computer sciences university of...
TRANSCRIPT

NP-hardness and Phylogeny Reconstruction
Tandy Warnow
Department of Computer Sciences
University of Texas at Austin

PhylogenyFrom the Tree of the Life Website,
University of Arizona
Orangutan Gorilla Chimpanzee Human

DNA Sequence Evolution
AAGACTT
TGGACTTAAGGCCT
-3 mil yrs
-2 mil yrs
-1 mil yrs
today
AGGGCAT TAGCCCT AGCACTT
AAGGCCT TGGACTT
TAGCCCA TAGACTT AGCGCTTAGCACAAAGGGCAT
AGGGCAT TAGCCCT AGCACTT
AAGACTT
TGGACTTAAGGCCT
AGGGCAT TAGCCCT AGCACTT
AAGGCCT TGGACTT
AGCGCTTAGCACAATAGACTTTAGCCCAAGGGCAT

Evolution informs about everything in biology
• Big genome sequencing projects just produce data -- so what?
• Evolutionary history relates all organisms and genes, and helps us understand and predict – interactions between genes (genetic networks)– drug design– predicting functions of genes– influenza vaccine development– origins and spread of disease– origins and migrations of humans

Molecular Systematics
TAGCCCA TAGACTT TGCACAA TGCGCTTAGGGCAT
U V W X Y
U
V W
X
Y

Major methods for phylogeny reconstruction
• Biology: Polynomial time methods (good enough for small datasets), and local search heuristics for NP-hard optimization problems
• Linguistics: an exact algorithm for an NP-hard optimization problem

Outline for the rest of the talk
• NP-hard and polynomial time problems• Phylogeny reconstruction in biology: the NP-hard
maximum parsimony problem, and how we can solve it better
• Phylogeny reconstruction in linguistics: the NP-hard perfect phylogeny problem, and how we solve it exactly
• An open problem from whole genome phylogeny• Thoughts about computational biology, and the
role of mathematics in this field

Polynomial-time problems• Shortest path: Given edge-weighted graph G =
(V,E) and two vertices, v and w, find shortest path from v to w (O(n2) time)
• 2-colorability: Given graph G = (V,E), determine if we can assign two colors to the vertices of G so that no edge connects vertices of the same color (O(n+m) time)
• 3-clique: Given graph G = (V,E), determine if G contains a 3-clique (O(n3) time)
For all these, n=|V| and m=|E|.

NP-hard problems
Some problems seem “hard” to solve:• Hamilton path: Given graph G , determine if G has
a simple path going through every vertex• 3-colorability: Given graph G, determine if G can
be properly 3-colored• Max-clique: Given graph G, find a largest clique
in the graph

Technical definition of NP-hard
• NP is the class of decision problems for which “yes” instances can be “proven” in polynomial time. (Example: I can prove to you that a graph has a 3-coloring by presenting that 3-coloring to you. So 3-coloring is in NP.)
• Definition: A problem X is NP-hard if every problem in NP can be reduced to X in polynomial time (yes-instances mapped to yes-instances, and no-instances mapped to no-instances). So 2-coloring can be reduced to 3-coloring
• Definition: A problem X is in P if it is in NP and can be solved in polynomial time.

P vs. NP, continued
• The “big” question in theoretical computer science is:– Is it possible to solve an NP-hard
problem in polynomial time?
• If the answer is “yes”, then all NP-hard problems can be solved in polynomial time, so P=NP. This is generally not believed.

Coping with NP-hard problems
Since NP-hard problems may not be solvable in polynomial time, the options are:– Solve the problem exactly (but use lots of time
on some inputs)– Use heuristics which may not solve the problem
exactly (and which might be computationally expensive, anyway)

Example: Maximum Clique
• Exact solution: find largest k so that some subset of size k is a clique. Runs in O(nk) time.
• Heuristic: Pick a vertex at random, and greedily assemble a set which is a clique, and stop when you can’t add any more vertices. Repeat until tired (or bored, or running out of time, or …). How do we evaluate the running time, or accuracy?

General comments for NP-hard optimization problems
• Getting exact solutions may not be possible for some problems on some inputs, without spending a great deal of time.
• You may not know when you have an optimal solution, if you use a heuristic.
• Sometimes exact solutions may not be necessary, and approximate solutions may suffice. (But this may not be true for biology.)

Major methods for phylogeny reconstruction
• Biology: Polynomial time methods (good enough for small datasets), and local search heuristics for NP-hard optimization problems
• Linguistics: an exact algorithm for an NP-hard optimization problem

Polynomial time methods • Quartet-based methods:
– Construct trees on all 4-leaf subsets– Combine quartet trees into tree on full dataset
• Distance-based methods:– Estimate pairwise distance matrix dij
– Find tree T and edge-weights w(e) so that dTij
approximates dij
• For both methods, if there are no errors (in quartet trees or pairwise distances) then the correct tree can be obtained in polynomial time. Otherwise, optimization problems are NP-hard.
• Polytime heuristics along these lines are popular.

Phylogeny reconstruction
• In biology, the most popular approaches for reconstructing phylogenetic trees are heuristics for Maximum Parsimony (NP-hard) or Maximum Likelihood (conjectured to be NP-hard)
• In historical linguistics, a new approach based upon exactly solving the NP-hard Perfect Phylogeny problem has been useful.
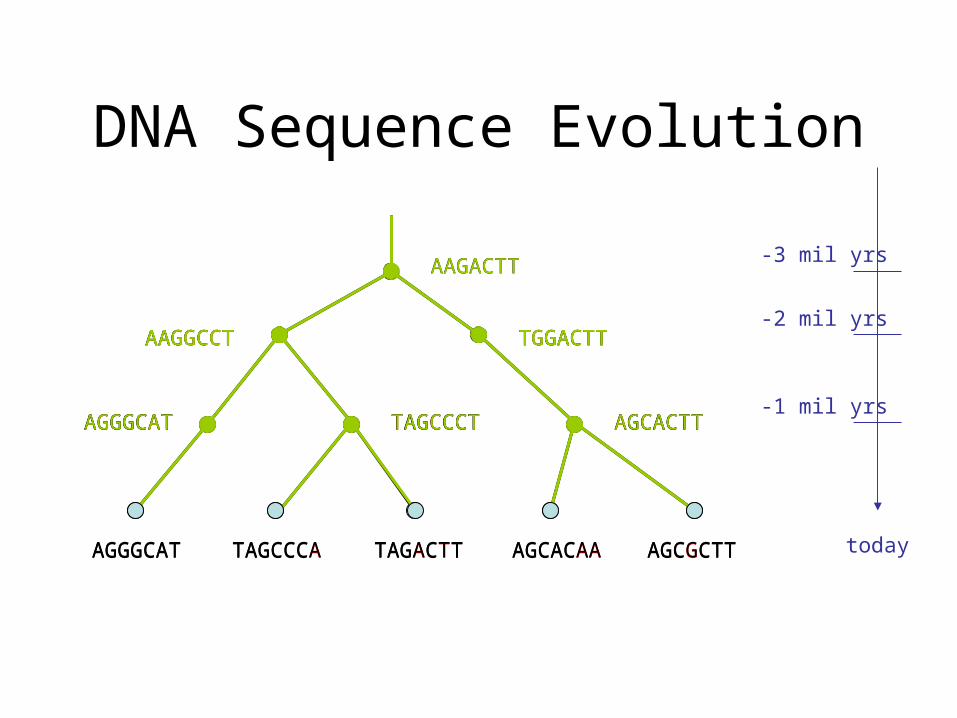
DNA Sequence Evolution
AAGACTT
TGGACTTAAGGCCT
-3 mil yrs
-2 mil yrs
-1 mil yrs
today
AGGGCAT TAGCCCT AGCACTT
AAGGCCT TGGACTT
TAGCCCA TAGACTT AGCGCTTAGCACAAAGGGCAT
AGGGCAT TAGCCCT AGCACTT
AAGACTT
TGGACTTAAGGCCT
AGGGCAT TAGCCCT AGCACTT
AAGGCCT TGGACTT
AGCGCTTAGCACAATAGACTTTAGCCCAAGGGCAT

Maximum Parsimony
• Given a set S of strings of the same length over a fixed alphabet, find a tree T leaf-labelled by S and with all internal nodes labelled by strings of the same length over the same alphabet which minimizes the sum of the edge lengths.
• Motivation: seeks to minimize the total number of point mutations needed to explain the data
• NP-hard
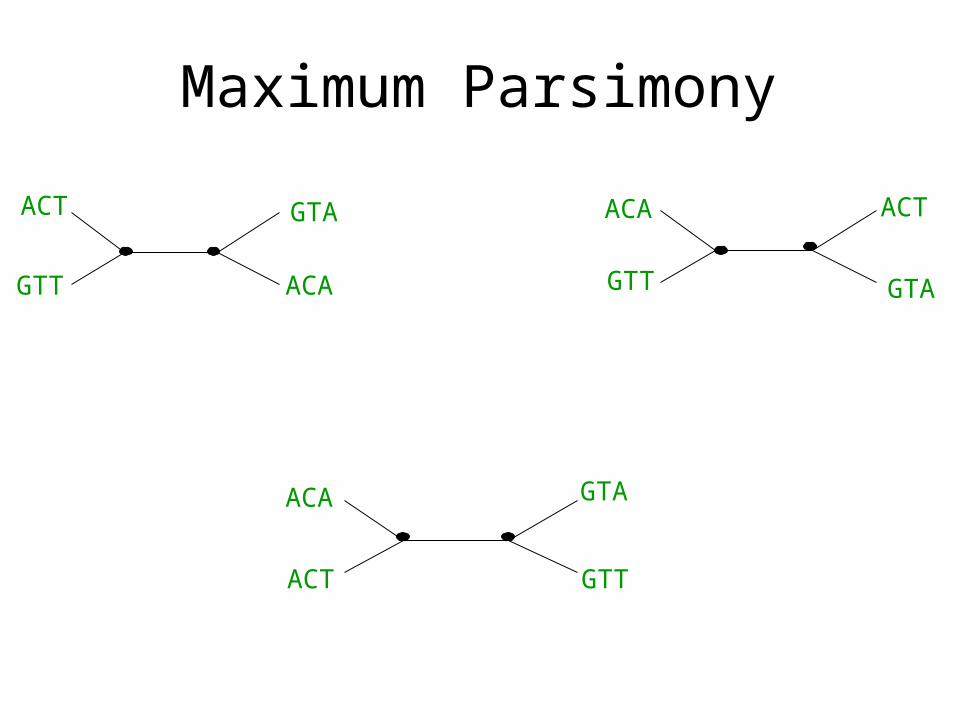
Maximum Parsimony
ACT
GTT ACA
GTA ACA ACT
GTAGTT
ACT
ACA
GTT
GTA

Maximum Parsimony
ACT
GTT
GTT GTA
ACA
GTA
12
2
MP score = 5
ACA ACT
GTAGTT
ACA ACT
3 1 3
MP score = 7
ACT
ACA
GTT
GTAACA GTA
1 2 1
MP score = 4
Optimal MP tree

Maximum Parsimony: computational complexity
ACT
ACA
GTT
GTAACA GTA
1 2 1
MP score = 4
Finding the optimal MP tree is NP-hard
Optimal labeling can becomputed in linear time O(nk)

Solving MP (maximum parsimony) and ML (maximum likelihood)
Phylogenetic trees
MP score
Global optimum
Local optimum
• Why are MP and ML hard? The search space is huge -- there are (2n-5)!! trees, it is easy to get stuck in local optima, and there can be many optimal trees.
• Why try to solve MP or ML? Our experimental studies show that polynomial time algorithms don’t do as well as MP or ML when trees are big and have high rates of evolution.
• Why solve MP and ML well? Because trees can change in biologically significant ways with small changes in objective criterion.

MP/ML heuristics
Time
MP scoreof best trees
Performance of hill-climbing heuristic
Fake study

Speeding up MP/ML heuristics
Time
MP scoreof best trees
Performance of hill-climbing heuristic
Desired Performance
Fake study

Iterative-DCM3 vs Ratchet
01
2
3
45
6
7
8
Average time (in hours) to
reach within 1 step of optimal
(averaged over 10 runs)
Dataset #1(taxa=500)
Dataset #2(taxa=567)
Dataset #3(taxa=854)
Iterative-DCM3 Ratchet

Iterative-DCM3 vs Ratchet
02468
101214161820
Average time (in hours) to
reach optimal (averaged over
10 runs)
Dataset #1(taxa=500)
Dataset #2(taxa=567)
Dataset #3(taxa=854)
Iterative-DCM3 Ratchet

Comments
• Developing heuristics with good performance takes mathematical insights, but may not involve proofs. Even so, it’s really important.
• Extracting information from the set of optimal (and near-optimal) solutions is a major open problem.
• Other types of data (gene orders, morphology) present novel challenges.
• Reticulate evolution detection and reconstruction is a major open problem.

Ringe-Warnow Phylogenetic Tree of Indo-European

Phylogenies of Languages
• Languages evolve over time, just as biological species do (geographic and other separations induce changes that over time make different dialects incomprehensible -- and new languages appear)
• The result can be modelled as a rooted tree• The interesting thing is that many characteristics
of languages evolve without back mutation or parallel evolution -- so a “perfect phylogeny” is possible!

Historical Linguistic Data
• A character is a function that maps a set of languages, L, to a set of states.
• Three kinds of characters:– Phonological (sound changes)– Lexical (meanings based on a wordlist)– Morphological (grammatical features)

“Homoplasy-Free” Evolution (perfect phylogenies)
YES NO

The Perfect Phylogeny Problem
• Given a set S of taxa (species, languages, etc.) determine if a perfect phylogeny T exists for S.
• The problem of determining whether a perfect phylogeny exists is NP-hard (McMorris et al. 1994, Steel 1991).

Triangulated Graphs
• A graph is triangulated if it has no simple cycles of size four or more.
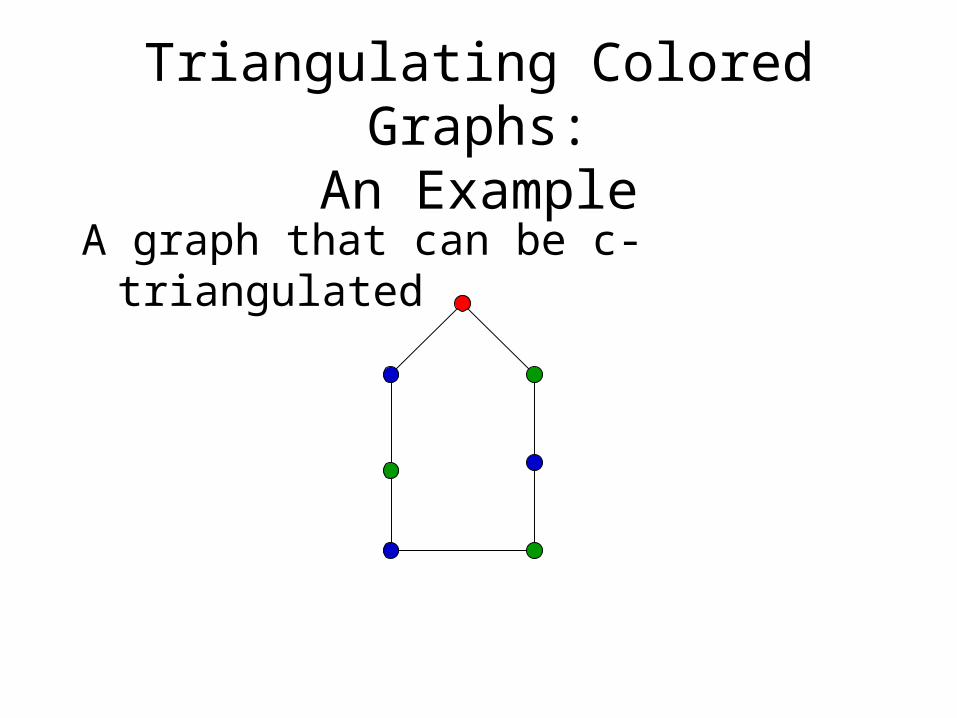
Triangulating Colored Graphs:An Example
A graph that can be c-triangulated

Triangulating Colored Graphs:An Example
A graph that can be c-triangulated

Triangulating Colored Graphs:An Example
A graph that cannot be c-triangulated

Triangulating Colored Graphs (TCG)
Triangulating Colored Graphs: given a vertex-colored graph G, determine if G can be c-triangulated.

The PP and TCG Problems
• Buneman’s Theorem: A perfect phylogeny exists for a set S if and only if the associated character state intersection graph can be c-triangulated.
• The PP and TCG problems are polynomially equivalent and NP-hard.

Solving the PP Problem Using Buneman’s Theorem
“Yes” Instance of PP:
c1 c2 c3
s1 3 2 1
s2 1 2 2
s3 1 1 3
s4 2 1 1

Solving the PP Problem Using Buneman’s Theorem
“Yes” Instance of PP:
c1 c2 c3
s1 3 2 1
s2 1 2 2
s3 1 1 3
s4 2 1 1

Some special cases are easy
• Binary character perfect phylogeny solvable in linear time
• r-state characters solvable in polynomial time for each r (combinatorial algorithm)
• Two character perfect phylogeny solvable in polynomial time (produces 2-colored graph)
• k-character perfect phylogeny solvable in polynomial time for each k (produces k-colored graphs -- connections to Robertson-Seymour graph minor theory)

The Indo-European (IE) Dataset
• 24 languages• 22 phonological characters, 15 morphological characters,
and 333 lexical characters• Total number of working characters is 390 (multiple
character coding, and parallel development)• A phylogenetic tree T on the IE dataset (Ringe, Taylor and
Warnow)• T is compatible with all but 22 characters: 16 (18)
monomorphic and 6 polymorphic• Resolves most of the significant controversies in Indo-European
evolution; shows however that Germanic is a problem (not treelike)

Phylogenetic Tree of the IE Dataset

An open problem to take home…
computing the “transposition” distance between two genomes
(important in whole genome phylogeny reconstruction)

Genomes As Signed Permutations
1 –5 3 4 -2 -6or
6 2 -4 –3 5 –1etc.

Genomes Evolve by Rearrangements
• Inverted Transposition
1 2 3 9 -8 –7 –6 –5 –4 10
1 2 3 4 5 6 7 8 9 10
• Inversion (Reversal)
1 2 3 –8 –7 –6 –5 -4 9 10
• Transposition
1 2 3 9 4 5 6 7 8 10

An open problem to play with
• Given two permutations on 1,2,…n, compute the minimum “transposition” distance (unknown computational complexity)
• (The corresponding problem for inversion distances involves very beautiful graph theory and algorithms.)

Summary
• NP-hard optimization problems abound in phylogeny reconstruction, and in computational biology in general, and need very accurate solutions
• Many real problems have beautiful and natural combinatorial and graph-theoretic formulations

Acknowledgements
• NSF and the David and Lucile Packard Foundation (funding)
• Collaborators Bernard Moret (UNM CS), Donald Ringe (Penn Linguistics)
• Students: Usman Roshan and Luay Nakhleh

Phylolab, U. TexasPlease visit us athttp://www.cs.utexas.edu/users/phylo/