multiprocessor real-time scheduling in industrial … fine...multiprocessor real-time scheduling in...
TRANSCRIPT

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor real-time schedulingin industrial embedded systems
Primiano Tucci
Tutor
Prof. Antonio Corradi
Co-Tutor
Prof. Eugenio Faldella

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Outline
•Background- Impact of multiprocessors in industrial real-time systems
•Real-time scheduling on Symmetric Multi Processors- Overview of multiprocessor scheduling approaches- The Global Earliest Deadline First algorithm (G-EDF)- Our contribute: a portable run-time infrastructure for conventional RTOSs
•Real-time scheduling on Asymmetric Multi Processors- Architectural limits to the application of unrestricted global policies- Our contribute: supporting the restricted migration model under AMP
•Concluding remarks
•Ongoing work- Offloading of scheduling functions using reconfigurable hardware platforms
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci
ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
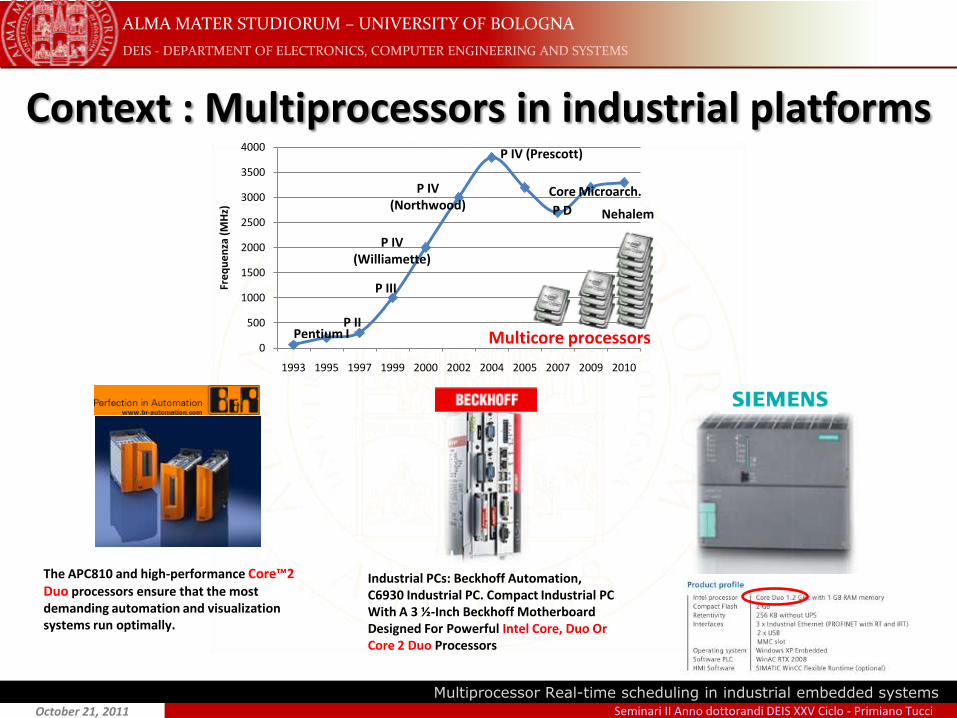
Context : Multiprocessors in industrial platforms
The APC810 and high-performance Core™2 Duo processors ensure that the most demanding automation and visualization systems run optimally.
Industrial PCs: Beckhoff Automation, C6930 Industrial PC. Compact Industrial PC With A 3 ½-Inch Beckhoff Motherboard Designed For Powerful Intel Core, Duo Or Core 2 Duo Processors
0
500
1000
1500
2000
2500
3000
3500
4000
1993 1995 1997 1999 2000 2002 2004 2005 2007 2009 2010
Fre
qu
en
za (
MH
z)
Pentium IP II
P III
P IV(Williamette)
P IV(Northwood)
P IV (Prescott)
P D
Core Microarch.
Nehalem
Multicore processors
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Multiprocessor computer architectures
Software methodology and
design patterns
Operating system
Real-Time Scheduling
•SMP (Symmetric Multi Processing)- A set of closely-coupled architecturally identical processors which operate as a single resource pool.- A unique real-time operating system (RTOS) yields a uniform memory view and is able to dynamically spawn, execute and migrate each task on any processor.- Require proper hardware mechanisms (e.g., cache coherency, MMU coord., interlocked mem. access)
•AMP (Asymmetric Multi Processing)- A set of loosely-coupled independent processors. Substantially a multi-uniprocessor architecture.- Distinct RTOS instances must be independently executed on each processor. - No direct support for task migrations.
Impact on software architecture?
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Run-time task model The run-time model of industrial control applications typically consists in a set of N periodic (sporadic) independent tasks, which must be executed respecting their temporal attributes:
•Period: interval between successive invocation (release) of two consequent jobs.•Deadline: latest permissible completion time from the release of the job.
Note: this is not the only task model when dealing with Real-Time applications.Other applications fields, still in the RT domain, might exhibit a completely different task model.E.g., DSPs (tasks pipelines) or data-parallel applications (SIMT).
Job1 1Task 1 Job1 2
Period
Deadline
Job1 3
JobN 1Task N
…
JobN 2 JobN 3
CPU time
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
A classification of multiprocessor scheduling policies
[1] J. M. Carpenter et al.: A categorization of real-time multiprocessor scheduling problems and algorithms. Handbook on Scheduling Algorithms Methods and Models (2004)[2] O. Zapata et al.: EDF and RM Multiprocessor Scheduling Algorithms: Survey and Performance Evaluation. (2005)
Depending on mapping of tasks to processors:•Partitioning approaches: each task is statically bound to a specific processor•Global approaches: tasks can be spawned and migrated among processors at run-time
Depending on priority handling:•Static priorities: tasks are scheduled according to a fixed priority, usually derived from its
temporal attributes (e.g., Rate Monotonic / Deadline Monotonic)•Dynamic priorities: tasks priorities may vary at run-time (e.g., Earliest Deadline First)
Depending on assumptions on the run-time worst cast execution time (WCET) :•WCET unaware: scheduling decisions are taken according to tasks static attributes only
(periods and deadlines). E.g., EDF, RM, DM.•WCET driven: scheduling decisions take into account also the WCET estimation.
E.g., Least-Laxity First (LLREF and derivates)
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
What’s wrong with WCET (Worst Case Execution Time) estimation
Modern computer architectures are amazingly fast… yet extremely unpredictable! Why?•Superscalar architecture: many instructions can be executed in parallel
•TLB Cache: effect of TLB misses and context switching (TLB flushing)
•Dynamic branch predictions + long pipelines: penalties for mispredicted branches
•Instruction and Data Caches: orders of magnitude between main memory vs. cache access time
Effect of data cache on memory accesses (RO, WO, RW)B&R Industrial PC APC810, Intel Core2 Duo T7400 (Cache: L1 64kB per core, L2: 4MB shared)
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Multiprocessor scheduling of RT tasks
Partitioning approaches
•The application is partitioned (off-line) into M disjoint task-setsFormerly a bin-packing problem
•Each task-set is independently executed on a processor employing conventional uniprocessor scheduling policies.
•Very easy to design and implement (both on SMP and AMP)
•Typically unable to achieve high CPU utilization factors.
TASKS
T4
SCHEDULER
T1, T2, T5
SCHEDULER
T3, T6
SCHEDULER
. . .
P1
P2
PMTask Period Computation CPU Usage
T1 4 Time Units 2 Time Units 0.5
T2 5 Time Units 3 Time Units 0.6
T3 10 Time Units 6 Time Units 0.6
Total computational demand 1.7
There is no feasible partition able to ensure schedulability of such system using M < 3 processors
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Multiprocessor scheduling of RT tasks
Global approaches•Tasks are dynamically spawned and migrated on available processors
•The M highest priority ready tasks are executed on the M processors
•Typically able to guarantee schedulability under higher utilization factors
•Their realization can be complex and yield to non-negligible overheads
•Require an underlying SMP architecture(unless we apply certain restrictions to the migration model)
GLOBAL QUEUE
SCHEDULER
…
P1
P2
PM
TASKS
Example of Global-RM (Rate Monotonic) scheduling on a dual-processor system
P1
P2
1 1 3 3 2 2 2
2 2 2 1 1 3 3 3 3
3 …
D3,1
D1,1
D2,1
D2,2
D1,2
Task Period Computation CPU Usage
T1 4 2 0.5
T2 5 3 0.6
T3 10 7 0.8
Total computational demand 1.9
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
The Global Earliest Deadline First (G-EDF) policy
D3,1D1,1
D2,1 D2,2D1,2
P1
P2
1 1 3 3 3 3 3 3
2 2 2 1 1 2 2 2
3…
Global-EDF (Earliest Deadline First)
Task Period Computation CPU Usage
T1 4 2 0.5
T2 5 3 0.6
T3 10 7 0.8
Total computational demand 1.9
•Tasks are assigned a dynamic priority, depending on their absolute deadline.
•In every moment the policy schedules the first M (num of CPUs) ready tasks with the closest deadline.
•Typically ensure schedulability under high utilization factors (for Hard RT systems), and bounded tardiness (for Soft RT systems).
But… how to concretely realize it?
OS IntegrationData structures
and operations
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Support for global scheduling in conventional RTOSs
Conventional RTOSs offer very limited support as regards RT scheduling strategies (though exhibiting some low level primitives for realizing ourselves). For instance the Linux-RT, VxWorks, Micro-C/OS-II, QNX, FreeRTOS, ECos and Windows CE RTOSs even lack the notion of a periodic task.
The support is almost always limited to the notion of straight process whose execution is carried out according to a numeric priority (e.g., POSIX 1003.1b).
How to deal with this?Kernel level interventions:
•UNC’s LITMUSRT [1] Testbed for Empirically Comparing Real-Time Multiprocessor Schedulers
•SSUP’s SCHED_DEADLINE [2] Patch for the Linux kernel scheduler
Dedicated Kernels:•ERIKA RTOS [2] Open Source RTOS for single- and multi-core applications (SSUP’s SpinOff)
Portable approach (our proposal):Exploit the low level primitives (e.g. the POSIX) exposed by the RTOS realizing a portable implementation of arbitrary scheduling policies (a meta-scheduler approach [4] ) without kernel-level interventions
[1] J. M. Calandrino et al.: LITMUS^RT : A Testbed for Empirically Comparing Real-Time Multiprocessor Schedulers. Real-Time Systems Symposium, 2006. RTSS '06[2] D. Faggioli, et al.: An EDF scheduling class for the Linux kernel. In Proceedings of the Eleventh Real-Time Linux Workshop, Dresden, Germany, September 2009[3] Evidence Srl, “ERIKA Enterprise RTOS”, http://www.evidence.eu.com.[4] Ravindran et al.: A formally verified application-level framework for real-time scheduling on POSIX real-time operating systems," IEEE TSE v. 30 n.9, 613- 629 Sept. 2004.
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Priority –driven RTOS scheduler
Core
1Core
M…
Multiprocessor/multicore platform
Real-time application
…Task 1 Task 2 Task N
Our Proposal : A portable infrastructure supportingglobal scheduling on conventional priority-driven RTOSs
Metascheduler
Primitives typically offered by conventional RTOSs
• taskCreate(…)
• taskPrioritySet(task, priority)
• taskCpuAffinitySet(task, cpus)
• taskSuspend(task)
• taskResume(task)
The roles of the meta-scheduler
• Realize the periodic tasks abstraction
• Realize the scheduling policy, e.g., handling in the case
of G-EDF, priority and affinity changes.
• Monitor the respect of deadlines and enforce corrective
actions in case of deadline misses or job overruns
Problems
•How to handle the mapping and interaction between
application tasks and OS processes?
•How to concretely implement the scheduling policy?
Which data structures employ?
•How to account performance/overheads?
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci
ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
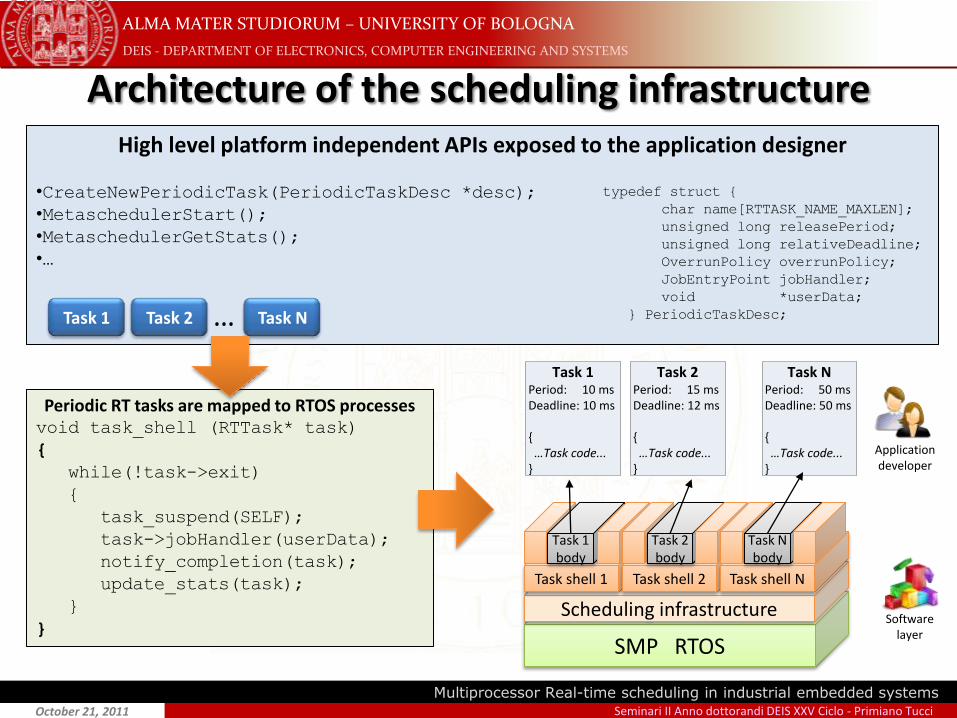
Architecture of the scheduling infrastructureHigh level platform independent APIs exposed to the application designer
•CreateNewPeriodicTask(PeriodicTaskDesc *desc);
•MetaschedulerStart();
•MetaschedulerGetStats();
•…
typedef struct {
char name[RTTASK_NAME_MAXLEN];
unsigned long releasePeriod;
unsigned long relativeDeadline;
OverrunPolicy overrunPolicy;
JobEntryPoint jobHandler;
void *userData;
} PeriodicTaskDesc;Task 1 Task 2 Task N…
Periodic RT tasks are mapped to RTOS processesvoid task_shell (RTTask* task)
{
while(!task->exit)
{
task_suspend(SELF);
task->jobHandler(userData);
notify_completion(task);
update_stats(task);
}
}SMP RTOS
Scheduling infrastructure
Task shell 1
Task 1 body
Task shell 2 Task shell N
Task 2 body
Task N body
Softwarelayer
Applicationdeveloper
Task 1Period: 10 msDeadline: 10 ms
{ …Task code...}
Task 2Period: 15 msDeadline: 12 ms
{ …Task code...}
Task NPeriod: 50 msDeadline: 50 ms
{ …Task code...}
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Run-time operation of the scheduling infrastructure
...
T1,j
Task resume
TN,k
T1,j+1
Metascheduler
Task 1
Task N
Self-suspend Self-suspend
Periodic metascheduler activity(raised by system timer interrupt)
Completionnotification
Time-driven actions (raised by the system timer):•Periodic tasks released according to their period.•They are correspondingly enqueued into the ready task queue (sorted by absolute deadlines)•The new set of M highest priority task is identified and scheduled on the M processors
Event-driven actions (raised upon completion of a task instance):•The task is removed from the ready queue•A suitable (previously pre-empted) task with the closest deadline is scheduled on the current processor
Self-suspend
Task resume
TN,k Pre-empted
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
A few considerations on G-EDF data structures
A1 [1]
B2 [3]
C3 [6]
D0 [6]
Δ
1 [1]
19 [20]
Merge
CPU #1CPU #2CPU #3
A1 [1]
B1 [3]
C3 [6]
D0 [6]
Δ
0 [1]
14 [20]
CPU #1CPU #3CPU #2
Ready queue (current)
Global-EDF must ensure that the M tasks with the closest deadlines must be running.However, while doing so, we should also avoid task unnecessary migrations.
New task to be released
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
A scoreboarding technique for G-EDF CPU mapping
A1 [1]
B1 [3]
C3 [6]
D0 [6]
Δ
0 [1]
14 [20]
CPU #1CPU #3CPU #2
Old confirmed within boundary• confirmed[x] := true• if waiting[x] -> append the task to the overload queue
New within boundary•If running*x+ = Ǿ -> running[x] := task; confirmed[x] := true•Else if not(confirmed[X]) and waiting*x+ = Ǿ -> waiting[x] := task•Else -> append to the overload queue
Old shifted off boundary•If waiting*x+ != Ǿ -> assign task to CPU x and confirm it•Else if overload queue is not empty:
•pop(oq),assign and confirm
A1 [1]
B2 [3]
C3 [6]
D0 [6]
CPU #1CPU #2CPU #3
Merge
CPU Running Confirmed Waiting
1 A
2 B
3 C
CPU Mapping Scoreboard
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci
ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
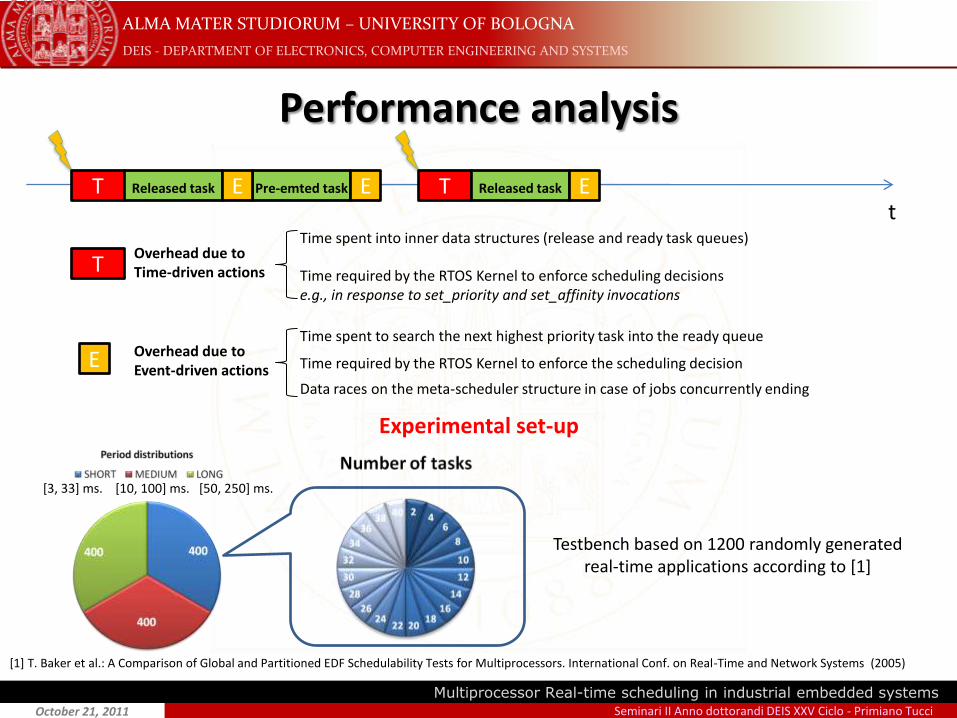
Performance analysis
tT Released task Pre-emted task E T Released task EE
TOverhead due toTime-driven actions
Time spent into inner data structures (release and ready task queues)
Time required by the RTOS Kernel to enforce scheduling decisionse.g., in response to set_priority and set_affinity invocations
E Overhead due toEvent-driven actions Time required by the RTOS Kernel to enforce the scheduling decision
Time spent to search the next highest priority task into the ready queue
Experimental set-up
[3, 33] ms. [10, 100] ms. [50, 250] ms.
Testbench based on 1200 randomly generated real-time applications according to [1]
Data races on the meta-scheduler structure in case of jobs concurrently ending
[1] T. Baker et al.: A Comparison of Global and Partitioned EDF Schedulability Tests for Multiprocessors. International Conf. on Real-Time and Network Systems (2005)
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Preliminary results in the VxWorks RTOS (1)
0
1
2
3
4
5
6
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40
Ove
rhe
ad [
us]
Number of tasks
Time-driven actions overheadShort
Medium
Long
Time driven overhead, worst case scenario:•Timer @ 1000 Hz (1 ms. Time granularity)•40 Short tasks
5 us. every 1 ms.: ≈ 0.5% CPU time
Context-switch overhead (same core)
Du
rati
on
[u
s]
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
Context switch overhead, worst case scenario:0,6 us x 2≈ 0.12% CPU time
Two context switches happening upon each invocation of the metascheduler (enter and exit) in the worst case.
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Preliminary results in the VxWorks RTOS (2)
00,20,40,60,8
11,21,41,61,8
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40
Ove
rhe
ad [
us]
Number of tasks
Event-driven actions overheadShort
Medium
Long
Event driven overhead•Difficult identify the worst case scenario•Considering a task completing on every tick
Worst case scenario: 1,6 us. every 1 ms.: ≈ 0.16% CPU time
Du
rati
on
[u
s]
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
Context-switch overhead (migration)
Context switch overhead (involving migration between cores), worst case scenario:
0,8 us x 2≈ 0.16% CPU time
A migration might be required to resume a task that was pre-empted on another core
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Concluding remarks
•The portable approach for the implementation of global scheduling policy seems a viable strategy
•The overhead introduced is reasonable (< 2% CPU @ 1ms), yet grows linearly with the number of tasks
•Further investigations are needed (mostly in progress)
•In our experiments task jobs are simple busy wait, involving no memory access
•In real-word cases the overheads of the scheduler infrastructure are likely to increase due the cache pollution and TLB invalidation.
•Our test-bench hardware is made of just a 2-way SMP system.Further investigations should be taken to analyze the scalability of the approach.
•The approach should be compared to native kernel implementations under the same HW/SW scenario
•Analysis on other operating systems (Linux-RT, QNX)
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Ongoing work : HW offloading of scheduling functions
•We realized an hardware implementation of the G-EDF scheduler (currently based on Altera NIOS-II soft-cores) to test viability of HW scheduling approach.
•Release, Priority and deadline monitoring of tasks are entirely performed in hardware
•Scheduling overhead is almost completely avoided
•Interrupts are delivered to the proper cores whereas a context-switch is required
•RT Tasks just need to notify (a simple I/O operation) their completion to the HW scheduler
•Hardware accelerators are becoming a viable approach considering current trends of microprocessors which involve programmable hardware (FPGAs)
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Ongoing work : HW offloading of scheduling functions
•The work has been presented to (and won! ) the Altera InnovateItaly design contest 2010
A similar work is currently being undertaken for Intel x86 CPU, employing a PCI-Express FPGA for the HW scheduler
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Architecture of the hardware scheduler
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Ongoing work : why a HW scheduler
•Other architectural-related factors weak determinism of RT embedded systems
•One example: Interference of DMA
...
Task 1Low priority
Task 2High priority
Suppose T1 launches a DMA program just before being preempted
T2 is granted CPU according to the scheduling policy, but its memory accessed are heavily slowed down
Task ready
Task running
•How can we deal with this?
1. Account DMA interference in scheduling analysis [1]
2. Hardware interventions: Coordination between the HW scheduler and DMA
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Publications & Awards
Date Title Conference
Oct 2009
A model-driven approach to automated diagnosis of industrial distributed I/O systems based on fieldbus technologies (E. Faldella, P. Tucci)
ICAT 2009 - Information, Communication and Automation Technologies
Sep2010
Logic Device Agents: Smart and Highly Reusable Components in Industrial Automation Systems (E. Faldella, A. Tilli, P. Tucci)
ETFA 2010 - Emerging Technologies and Factory Automation
May 2011
Network evasion via DNS covert channels (P. Tucci, E. Faldella) ICTSM2011 - 2011 International Conference on Telecommunication Systems, Modeling and Analysis
Oct2011
A Portable Infrastructure Supporting Global Scheduling of Embedded Real-Time Applications on Asymmetric MPSoCs (E. Faldella, P. Tucci)
ICA3PP 2011 - 11th International Conference on Algorithms and Architectures for Parallel Processing, M2A2 Workshop
Date Contest Score
2011 B&R European Industrial Ethernet Award 2010/11. Winner in the category “Relevance for the industry”“Powerlink over PowerLine: the next generation of home automation runs in real-time over mains”
2010 Altera InnovateItaly 2010. First place (Ex-aequo)“Hard real-time meets embedded multicore SoPCs”
2009 B&R European Industrial Ethernet Award 2008/09. Top 10“A Model-Driven Approach to Automated Diagnosis of Complex Distributed I/O Systems based on Ethernet Powerlink Fieldbus Technology”
Publications
Design contest awards
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Collected credits
Current:• Seminar “Calcolatori a insieme di istruzioni riconfigurabile “ (Ing. Campi , Ing. Mucci), Aprile 2010: 6 credits• Summer School UPMARC 2010: Summer School on Multicore Computing (Sweden) 21-24 Giugno 2010, 19 credits.
Planned:• Sistemi Mobili M: 90 credits• Abroad stay (2012): 60 credits
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Thank you
Questions?
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011 Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci

ALMA MATER STUDIORUM – UNIVERSITY OF BOLOGNA
DEIS - DEPARTMENT OF ELECTRONICS, COMPUTER ENGINEERING AND SYSTEMS
Multiprocessor Real-time scheduling in industrial embedded systems
October 21, 2011
Appendix : (Sufficient) bounds for RT scheduling policies
RMPO uniprocessor (or partitioned)
EDF uniprocessor (or partitioned)
Global RMPO
General case Tasks with armonic periods
Global EDF
Seminari II Anno dottorandi DEIS XXV Ciclo - Primiano Tucci