multiagent social learning in large repeated games jean oh
TRANSCRIPT

Multiagent social learning in large repeated games
Jean Oh

Selfish solutions can be suboptimal.
If short-sighted,
Motivation Approach Theoretical Empirical Conclusion
far
“Discovery of strategies that support mutually desirable outcomes”

3
A={ resource1, resource2… resourcem }
N={ } …
statet
agent1agent2 agentn
Strategy of agent iCost ci(si, s-i) ? Strategy profile
e1 e2
e4
e3
Multiagent resource selection problem
strategy
Individual objective: to find a path that minimizes cost

4
Congestion cost depends on:the number of agents that have chosen the same resource.
• Individual objective: to minimize congestion cost• “Selfish solutions” can be arbitrarily suboptimal [Roughgarden 2007].• Important subject in transportation science, computer networks, and
algorithmic game theory.
Congestion game!
“Selfish solution”: the cost of every path becomes more or less indifferent; thus no one wants to deviate from current path. (a.k.a. Nash equilibrium, Wardrop’s first principle)
social welfare:average cost of
all agents
5
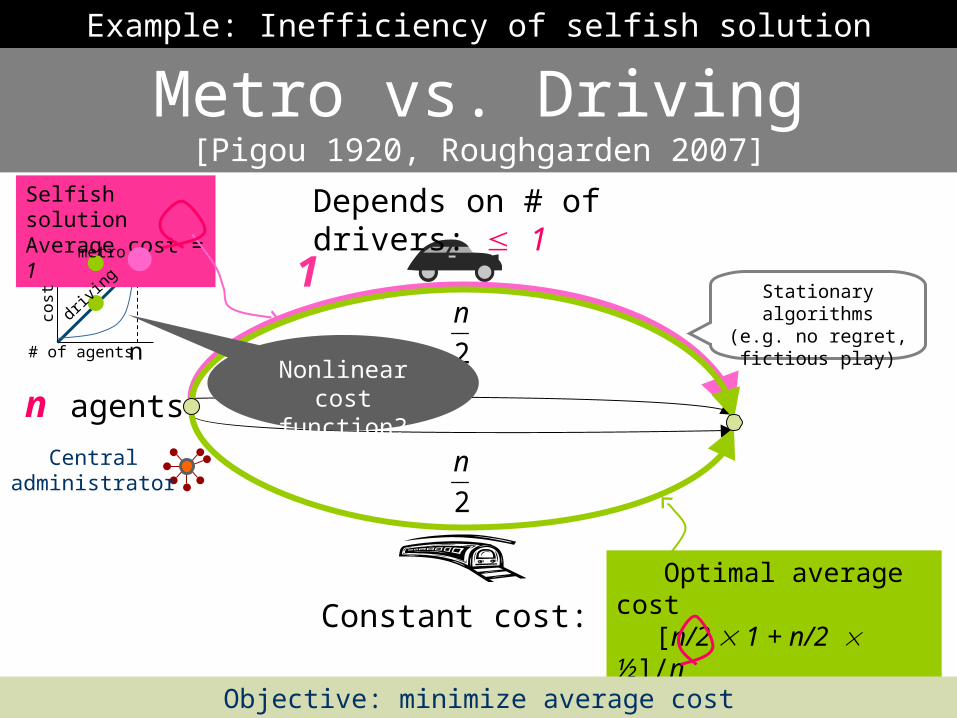
Constant cost: 1
n agents
Metro vs. Driving[Pigou 1920, Roughgarden 2007]
Example: Inefficiency of selfish solution
Depends on # of drivers: 1
Optimal average cost [n/2 1 + n/2 ½]/n = ¾
Objective: minimize average cost
Centraladministrator
Stationary algorithms(e.g. no regret, fictious play)
n
1 1
Selfish solution Average cost = 1
metro
drivi
ng
2
n
2
n
Nonlinear cost function?
# of agents
cost

6
If a few agents take alternative route, everyone else is better off. Just a few altruistic agents to sacrifice, any volunteers?
Excellent! as long as it’s not me.
7
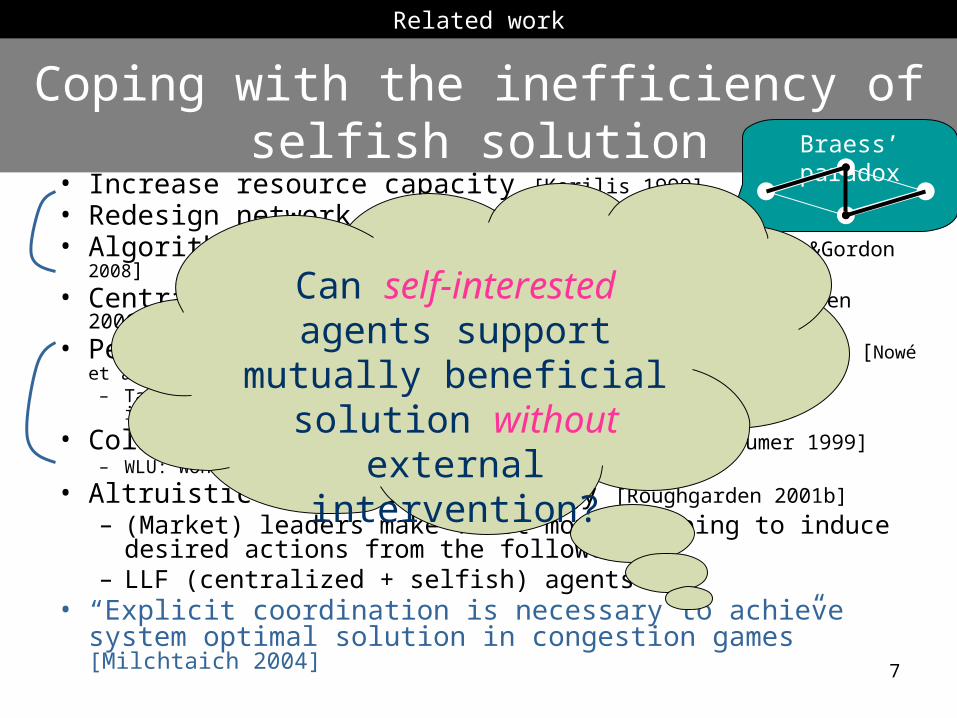
Coping with the inefficiency of selfish solution
• Increase resource capacity [Korilis 1999]
• Redesign network structure [Roughgarden 2001a]
• Algorithmic mechanism design [Ronen 2000,Calliese&Gordon 2008]
• Centralization [Shenker 1995, Chakrabarty 2005, Blumrosen 2006]
• Periodic policy under “homo-egualis” principle [Nowé et al. 2003]– Taking the worst-performing agent into consideration (to avoid inequality)
• Collective Intelligence (COIN) [Wolpert & Tumer 1999]– WLU: Wonderful Life Utility!
• Altruistic Stackelberg strategy [Roughgarden 2001b]
– (Market) leaders make first moves, hoping to induce desired actions from the followers
– LLF (centralized + selfish) agents• “Explicit coordination is necessary to achieve system
optimal solution in congestion games” [Milchtaich 2004]
Braess’ paradox
Related work
Can self-interested agents support mutually
beneficial solution without external
intervention?
8
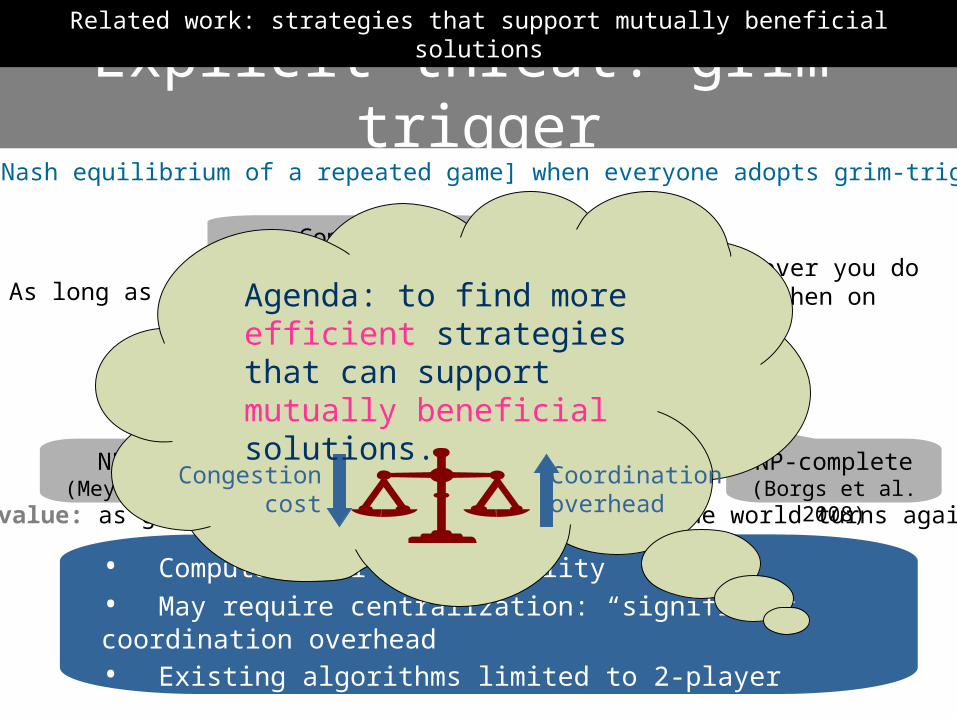
Explicit threat: grim-trigger
We’ll be mutually beneficial
I’ll punish you with minimax value
forever
As long as you stay If you deviateWhatever you do from then on
Minimax value: as good as [i] can get when the rest of the world turns against [i].
• Computational intractability• May require centralization: “significant coordination overhead”• Existing algorithms limited to 2-player games (Stimpson 2001, Littman & Stone 2003, Sen et al. 2003, Crandall 2005)
NP-complete(Borgs et al. 2008)
NP-hard(Meyers 2006)
Complete monitoring
Related work: strategies that support mutually beneficial solutions
Congestion cost
Coordinationoverhead
Agenda: to find more efficient strategies that can support mutually beneficial solutions.
[Nash equilibrium of a repeated game] when everyone adopts grim-trigger

IMPRESImplicit Reciprocal Strategy
Learning
Motivation Approach Theoretical Empirical Conclusion

10
Assumptions
The other agents are _______________.1. opponents
2. sources of uncertainty
3. sources of knowledge
The agents are _________ in their ability.1. symmetric
2. asymmetric
“sources of knowledge”
“asymmetric”
may be
IMPRES

“Learn to act more rationallyby using strategy given by others”
“Learn to act more rationallyby giving strategy to others”stop
Go
Intuition: social learning
IMPRES
Independent: non-zero probability of collision

12
Agent i
Agent k
congestion cost
path
Agent j
Inner-layer
Overview: 2-layered decision making
Meta-layer
Agent iAgent j Agent k
Environment
IMPRES
-solitary-subscriber-strategist
1. whose strategy?
2. which path?
3. Learn strategies using cost
“Take route 2”
- Meta-layer- Inner-layer

13
Meta-learning: which strategy?
LOOP:• p selectPath(a); take path p; find out congestion cost c• Update Q value of action a using cost c: Q(a) (1-)Q(a) + (MaxCost - c)• new action randomPick(strategist lookup table L); A A {}• Update meta-strategy s
• a select action according to meta-strategy s; if a = -strategist, L L {i}
Aa
TaQ
TaQ
as
Aa
,)'(
exp
)(exp
)(
'
IMPRES
A = {-strategist, -solitary }Q 0 0s 0.5 0.5
how to select action from A
Current meta-action a
-subscriber0
Environment
path
coststrategy Agent i
how to select path from P = {p1,…}
strategy …
Strategist lookuptable L
More probability mass to low cost actions

14
Inner-learning: which path?• f: number of subscribers (to this strategy)
when f = 0, no inner-learning : joint strategy for f agents
1. path p; take path p; observe # of agents on edges of p
2. Predict traffic on each edge generated by others3. Select best joint strategy for f agents (exploration
with small probability) symmetric network congestion games
4. Shuffle joint strategy correlated strategy: probability distribution over all possible
joint actions
IMPRES
e1 e2
e4
e3
f = 2 f = 0
drive metro
drive 0 0.5
metro 0.5 0(drive, metro)

15
Motivation Approach Theoretical Empirical Conclusion
IMPRES
• Mechanics of the algorithm– Meta-layer: which strategy?– Inner-layer: which path?
• Structure of learned strategy– IMPRES vs. Grim-trigger– Main theoretical results
• Empirical results

16
Non-stationary strategy:strategy that depends on past plays
-subscriberstrategy
-solitarystrategy
exploitexplore
Cost(C) Cost(I)
Cost(C) ≥ Cost(I)
Cost(C) Cost(I)
Cost(I) Cost(C)
An IMPRES strategy
Correlated Strategy (C)
IndependentStrategy (I)
Motivation Approach Theoretical Empirical Conclusion
IMPRES: any correlated strategy that is better than independent strategy can
be supported.
Grim-trigger: any correlated strategy that is better than minimax can be supported.

17
Mutually beneficialstrategy
Independentstrategy
Cost(C) Cost(I)
Cost(C) ≥ Cost(I)
Cost(C) Cost(I)
Cost(I) Cost(C)
An IMPRES strategy
Grim-trigger vs. IMPRES
Mutually beneficialstrategy
Minimaxstrategy
Other playersobey Whatever
A grim-trigger strategy
Observe a deviator
Perfect monitoring Imperfect monitoring Intractable Tractable
Coordination overhead (centralization) Efficient coordination Deterministic Stochastic
Strategies that can support mutually beneficial outcome
Independentstrategy
Minimaxstrategy
exploitexplore

18
Mutually beneficialstrategy
Rational agents can support mutually beneficial outcome with
explicit threat.
General belief
Motivation Approach Theoretical Empirical Conclusion
Minimaxstrategy
Explicit threat
independentstrategy
Implicit threat
“Rationally bounded IMPRES”
“without”
Main result

Empirical evaluation
Motivation Approach Theoretical Empirical Conclusion
Selfish solutionsCongestion cost: arbitrarily suboptimal Coordination overhead: none
Con
gest
ion
cost
Mutually beneficial solutions Congestion cost: optimalCoordination overhead: significant
Coordination overhead
IMPRES
Quantifying “mutually beneficial” and “efficient”
(1-to-n centralization)

20
Evaluation criteria
1. Individual rationality: minimax-safety2. Average congestion cost of all agents
(social welfare); for problem p3. Coordination overhead (size of
subgroups) relative to a 1-to-n centrally administrated system.
4. Agent demographic (based on meta-strategy), e.g. percentage of solitaries, strategists, and subscribers.
Cost (solutionp)
Cost (optimump)
overhead (solutionp)
overhead (maxp)

21
• Number of agents n = 100; (n = 2 ~ 1000)• All agents use IMPRES (self-play)• Number of iterations = 20,000 ~ 50,000• Averaged over 10-30 trials • Learning parameters:
Experimental setup
Parameter Value Description
Learning step size; use bigger step size for actions tried less often.
T T0=10; T 0.95T Temperature in update eq.
k 10 Max number of actions in meta-layer
)10
1,01.0max(
iatrials

22
metro
driving
Metro vs. Driving (n=100)
metro
driving
Agent demographic
The lower, the better
Free riders:always driving
# of agents
cost
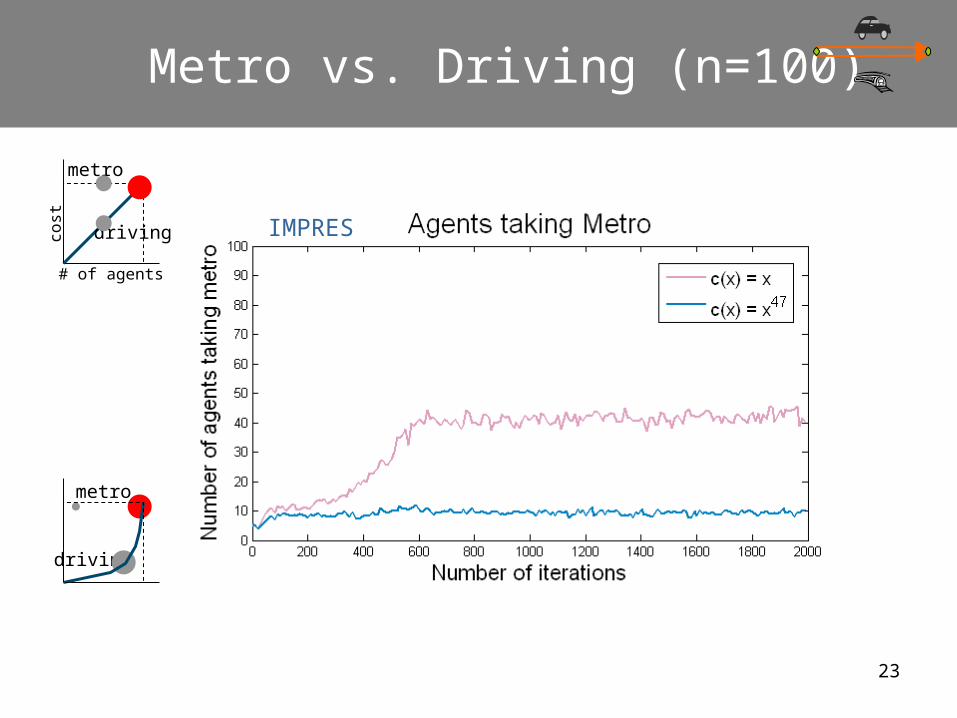
23
Metro vs. Driving (n=100)
IMPRES
metro
driving
metro
driving
# of agents
cost
24
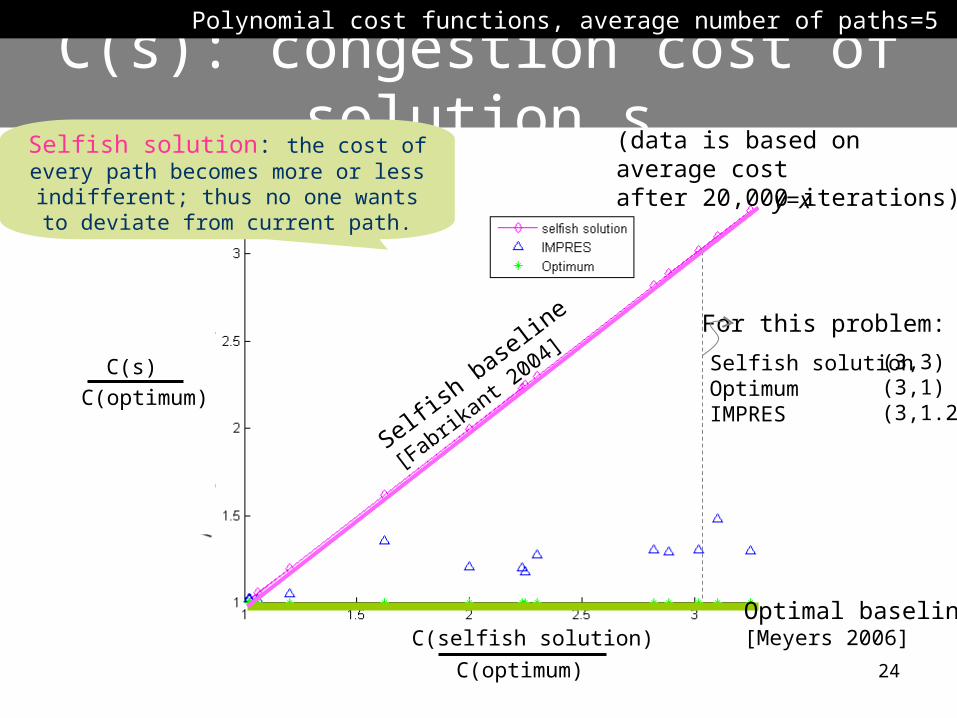
C(s): congestion cost of solution s
C(s)
C(optimum)
Selfish solution Optimum IMPRES
(3,3)(3,1)(3,1.2)
For this problem:
Polynomial cost functions, average number of paths=5
Optimal baseline[Meyers 2006]
Selfish base
line
[Fabrikant 2
004]
Selfish solution: the cost of every path becomes more or less
indifferent; thus no one wants to deviate from current path.
y=x
(data is based on average cost after 20,000 iterations)
C(selfish solution)
C(optimum)
25
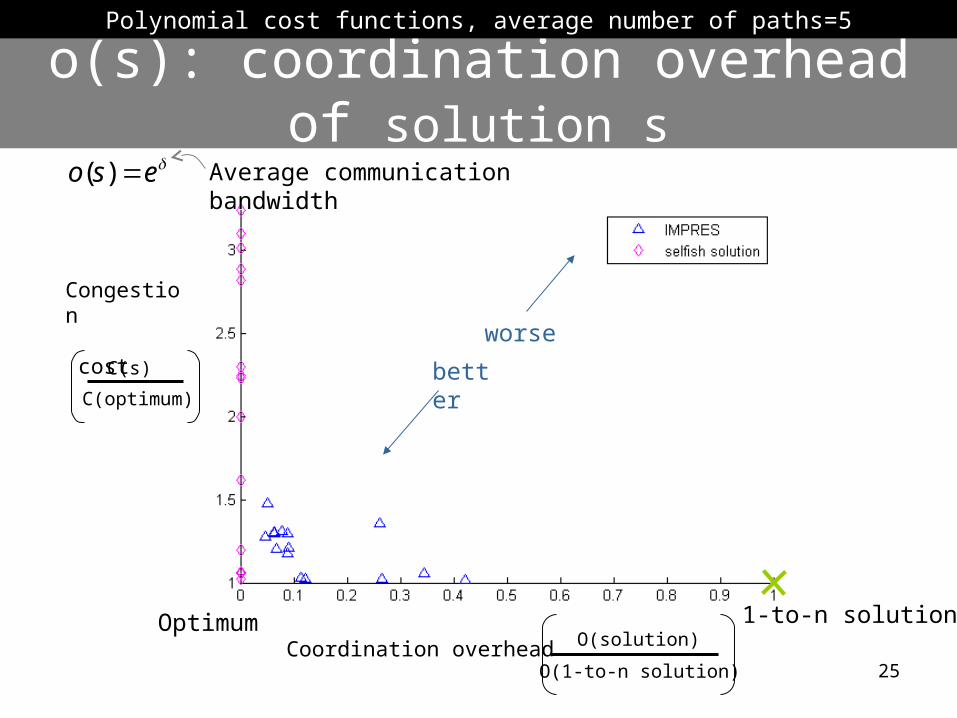
o(s): coordination overhead of solution s
C(s)
C(optimum)
O(solution)
O(1-to-n solution)
Polynomial cost functions, average number of paths=5
1-to-n solution
eso )( Average communication bandwidth
Congestion cost
Optimum
better
worse
Coordination overhead
26
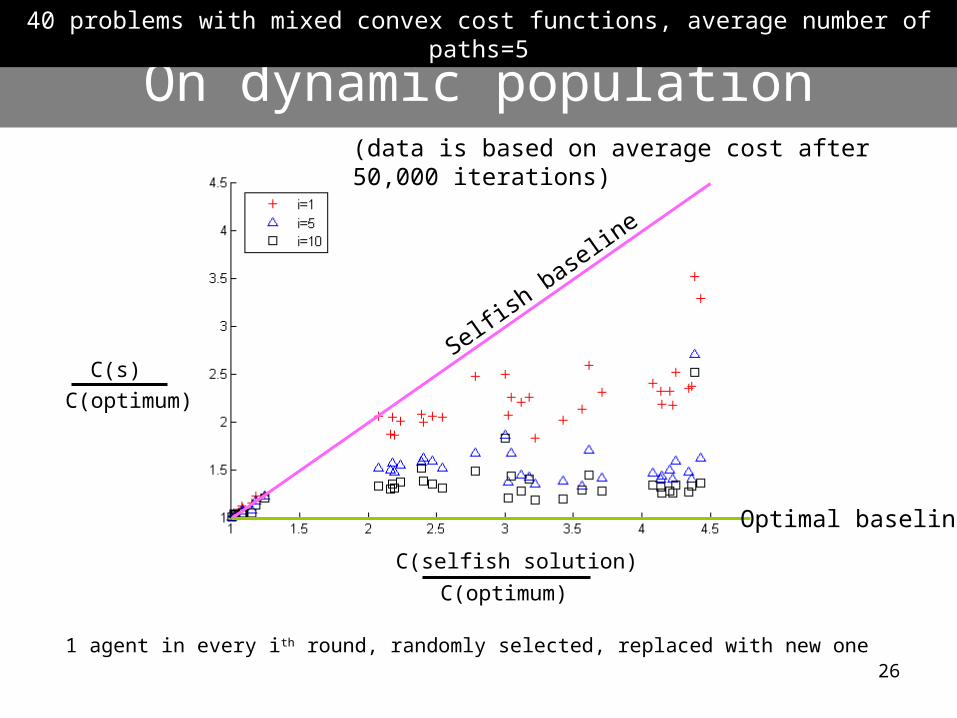
On dynamic population
1 agent in every ith round, randomly selected, replaced with new one
40 problems with mixed convex cost functions, average number of paths=5
Optimal baseline
(data is based on average cost after 50,000 iterations)
Selfish base
line
C(s)
C(optimum)
C(selfish solution)
C(optimum)

27
Summary of experiments
• Symmetric network congestion games– Well-known examples– Linear, polynomial, exponential, & discrete cost functions– Scalability
• number of alternative paths (|S| = 2 ~ 15)• Population size (n = 2 ~ 1000)
– Robustness under dynamic population assumption
• 2-player matrix games• Inefficiency of solution based on 121 problems:
– Selfish solutions: 120% higher than optimum– IMPRES solutions: 30% higher than optimum
25% coord. overhead of 1-to-n model
Motivation Approach Theoretical Empirical Conclusion
limitation

28
Contributions
• Discovery of social norm (strategies) that can support mutually beneficial solutions
• Investigated “social learning” in multiagent context• Proposed IMPRES: 2-layered learning algorithm
– significant extension to classical reinforcement learning models
– the first algorithm that learns non-stationary strategies for more than 2 players under imperfect monitoring
• Demonstrated IMPRES agents self-organize:– Every agent is individually rational (minimax-safety)– Social welfare is improved by approx. 4 times from selfish
solutions– Efficient coordination (overhead within 25% of 1-to-n model)
Motivation Approach Theoretical Empirical Conclusion

29
Future work
• Short-term goals: more asymmetry– Strategists – give more incentive– Individual threshold (sightseers vs. commuters)– Tradeoffs between multiple criteria (weight)– Free rider problem
• Long-term goals:– Establish the notion of social learning in artificial
agent learning context• Learning by copying actions of others• Learning by observing consequences of other agents
Motivation Approach Theoretical Empirical Conclusion

30
Conclusion
Rationally bounded agents adopting social learning can support mutually beneficial outcomes without the explicit notion of threat.

31
Thank you.