mdmsc nastran user meeting - msc softwarepages.mscsoftware.com/rs/.../nastranusermeeting-msc... ·...
TRANSCRIPT

MSC Confidential
MD/MSC Nastran User Meeting MD/MSC Nastran User Meeting 09:00 - 10:30 Diskussionsgruppe PERFORMANCE
18. Mai 2011Gerald Himmler

2
MD/MSC Nastran
Agenda
� Memory
�Speeding things up
� Static� Real eigenvalues
MD/MSC Nastran User Meeting 2011
� Real eigenvalues� ACMS� Frequency response � SMP / DMP� Domainsolver� Other solvers and techniques

Memory
• MD Nastran memory layout
User Open Core
MD/MSC Nastran User Meeting 20113
Executive System Work Area
Master(RAM) Area
Scratch(MEM) Area
Buffer Pool Area
Memory resident file
and executive tables
Memory specified by the mem= keyword
Temporary database buffering
Permanent database buffering

Memory
• How memory is allocated in MD Nastran• The f04 file gives a summary of the memory allocated• This job was run with mem=4000 mb in the 32 bit executable
** MASTER DIRECTORIES ARE LOADED IN MEMORY.
USER OPENCORE (HICORE) = 1037375360 WORDS
EXECUTIVE SYSTEM WORK AREA = 1169591 WORDS
MASTER(RAM) = 200000 WORDS
MD/MSC Nastran User Meeting 20114
MASTER(RAM) = 200000 WORDS
SCRATCH(MEM) AREA = 6553700 WORDS ( 100 BUFFERS)
BUFFER POOL AREA (GINO/EXEC) = 3277350 WORDS ( 50 BUFFERS)
TOTAL MD NASTRAN MEMORY LIMIT = 1048576000 WORDS
Remark: Buffsize (Nastran system(1)) was set to 65537

Memory
• What is a good value for mem=• Two modules are sensitive to memory and they are executed in most
types of calculation• DCMP – matrix factorization• READ – real eigenvalue extraction
• Both these modules report their memory usage in the f04 file
At the end of the f04 file, look for this message:*** TOTAL MEMORY AND DISK USAGE STATISTICS ***
MD/MSC Nastran User Meeting 20115
+---------- SPARSE SOLUTION MODULES -----------+HIWATER SUB_DMAP DMAP (WORDS) DAY_TIME NAME MODULE 2884693 14:09:30 SEKRRS 73 DCMP
This is the maximum memory used and by which moduleCompare this with the memory available for the modules
** MASTER DIRECTORIES ARE LOADED IN MEMORY.USER OPENCORE (HICORE) = 13969712 WORDS
If this number is close to or greater than this number, the job would probably benefit from additional memory

Memory
• What is a good value for mem= (DCMP module)• Look for User Information Message 4157 in the f04 file• This will look something like this:
8:05:48 2:54 77621.0 0.0 170.3 0.0 SEKRRS 83 DCMP BEGN
*** USER INFORMATION MESSAGE 4157 (DFMSYM)PARAMETERS FOR PARALLEL SPARSE DECOMPOSITION OF DATA BLOCK KLL ( TYPE=RDP ) FOLLOW
MATRIX SIZE = 4287361 ROWS NUMBER OF NONZEROES = 122689156 TERMSNUMBER OF ZERO COLUMNS = 0 NUMBER OF ZERO DIAGONAL TERMS = 0
SYSTEM (107) = 32772 REQUESTED PROC. = 4 CPUSCPU TIME ESTIMATE = 8627 SEC I/O TIME ESTIMATE = 24 SEC
MD/MSC Nastran User Meeting 20116
CPU TIME ESTIMATE = 8627 SEC I/O TIME ESTIMATE = 24 SECMINIMUM MEMORY REQUIREMENT = 122150 K WORDS MEMORY AVAILABLE = 1037364 K WORDSMEMORY REQR'D TO AVOID SPILL = 188241 K WORDS MEMORY USED BY BEND = 122151 K WORDSEST. INTEGER WORDS IN FACTOR = 685274 K WORDS EST. NONZERO TERMS = 1273023 K TERMS
ESTIMATED MAXIMUM FRONT SIZE = 7056 TERMS RANK OF UPDATE = 248:06:08 3:14 82366.0 4745.0 190.1 19.9 SPDC BGN TE=86278:09:50 6:56 97452.0 15086.0 1918.3 1728.1 SPDC END
*** USER INFORMATION MESSAGE 6439 (DFMSA)ACTUAL MEMORY AND DISK SPACE REQUIREMENTS FOR SPARSE SYM. DECOMPOSITION
SPARSE DECOMP MEMORY USED = 188241 K WORDS MAXIMUM FRONT SIZE = 7056 TERMSINTEGER WORDS IN FACTOR = 46130 K WORDS NONZERO TERMS IN FACTOR = 1273023 K TERMS
SPARSE DECOMP SUGGESTED MEMORY = 120393 K WORDS• Memory available• Memory Reqr’d to Avoid Spill• Sparse Decomp Suggested Memory
Three numbers are of interest
= USER OPENCORE(HICORE)

Memory
• What is a good value for mem= (DCMP module)• The following model reported:
• Memory Reqr’d to Avoid Spill = 2652 Mb• Sparse Decomp Suggested Memory = 1560 Mb
• This model was run with 3 mem= settings, 800Mb, 1.6Gb and 3.2Gb
MD/MSC Nastran User Meeting 20117
3.2Gb
0
10
20
30
40
50
60
Ela
psed
Tim
e
0.8Gb 1.6Gb 3.2Gb

Memory
• What is a good value for mem= (READ module)• When using real eigenvalue extraction, use between 2 and 3 times
the memory reported for the “Sparse Decomp Suggested Memory” value, because mass matrix is not taken into account
MD/MSC Nastran User Meeting 20118
• Remarks• Values smaller than those indicated will still work, but will
progressively degrade the performance
• Always make sure your mem= setting does not exceed the installed amount of RAM or swapping will occur at the O/S level

Memory
• Using large memory• Allocating more memory than is required is not necessarily a good idea• This is because it robs precious memory from the I/O buffer cache
• However, if we have very large amounts of memory available, we can write the data that would normally be written to the scratch file on disk into
MD/MSC Nastran User Meeting 20119
write the data that would normally be written to the scratch file on disk into a special memory file
• This is most effective if the amount of additional memory available is as large as the MAXIMUM size of the scratch file (or thereabouts)
• The special memory file is always created by MD Nastran, but by default it is small
• It is enlarged using the smem= keyword• e.g. nastran jobname mem=6Gb smem=5Gb
• This will use 6Gb of RAM, but allocate only 1Gb to open core and 5Gb to the special memory file

Memory
• Using large memory• The following graph shows 3 configurations
1. Insufficient memory allocated, out-of-core solve with spill2. In core solve (Sparse decomp suggested memory)3. In core solve (Sparse decomp suggested memory) with 5Gb smem
file
100
MD/MSC Nastran User Meeting 201110
0
20
40
60
80
100
Ela
psed
Tim
e
mem=36Mb mem=1Gb mem=6Gb smem=5Gb

Speeding things up
• Statics • May be solved using either sparse or iterative methods
• Sparse is generally quicker for shell or beam type models• Iterative performs very well for solid element dominant models• For a mixtures of elements it is difficult to pick a clear winner• Iterative methods generally require more memory• Sparse is the default
MD/MSC Nastran User Meeting 201111
• Sparse is the default• For MSC iterative solver, use iter=yes keyword or SMETHOD = MATRIX• For CASI iterative solver, use SMETHOD=ELEMENT in case control
(not available in SOL 106)

12
Speeding things upExample (SOL 101) Run
Dell Precision M4500 Intel I7 quad core Windows 7
8GB memory
465 Gb disk
Hardware
FE-Model 17,2418
20
MD/MSC Nastran User Meeting 2011
FE-Model 17,24
14,21 14,17
11,11
2,04
0
2
4
6
8
10
12
14
16
18
mem=1 Gb mem=7 Gb / smem=6 Gb
mem=1 Gb / smp=2
mem=7 Gb / smem=6 Gb /
smp=2
casi mem=1 Gb
Ela
psed
tim
e [m
in]

13
Casi Iterative Solver Example (SOL 101) Run
IBM p5-585 2.3GHz POWER5+
512GB memory
6TB scratch filesystem striped across 30 physical d isks
Hardware
FE-Model
MD/MSC Nastran User Meeting 2011
Grids 151 892 898CHEXA elements 94 931 679
Dofs 452 751 3721 Loadcase
FE-Model
Memory 275 Gb
Real 21 h
Scratch 1500 Gb
Output2 99.9 Gb

Speeding things up
• Real eigenvalues• Real eigenvalue analysis should use Lanczos for all problems
except very small ones• METHOD entry selects an EIGRL entry• Use MAXSET=15 on the EIGRL entry or cell 263• Use 2 to 3 times more memory than the Sparse Decomp Suggested
Memory value
MD/MSC Nastran User Meeting 201114
• Use MASSBUF system cell (requires more memory)

Speeding things up
• Real eigenvalues, MDACMS DOMAINSOLVER ACMS (PARTOPT=DOF)
• For large models (1Mdof+) and number of modes > 200, use an automatic sub-structuring technique
• MDACMS with ILP-64 bit version gives huge performance advantage over one-shot Lanczos
10
MD/MSC Nastran User Meeting 201115
• 2.6 Mdof, modes up to 300 Hz
0
2
4
6
8
10
Ela
psed
Tim
e
Lanczos MDACMS Serial MD R2

Speeding things up
• Frequency response• If forced to use a direct method (e.g. frequency dependent elements),
consider the Krylov solver if many excitation frequencies are required• An alternative to the direct and iterative methods added at version 2004 –
use PARAM,FASTFR,YES to invoke this method• In MD R2, the choice among FRRD1 direct, FRRD1 iterative and FASTFR
methods is automatic. The parameters used to make this choice are a complicated mix of modes, excitation frequencies, applied loads and
MD/MSC Nastran User Meeting 201116
complicated mix of modes, excitation frequencies, applied loads and some other heuristic data – see the MD R2 release guide for more information

Speeding things up
• Message after the eigenvalue extraction in f06 indicates which method is used:
^^^
^^^ SYSTEM INFORMATION MESSAGE 9157 (GMAM)
^^^ FASTFR OPTION REQUESTED, BUT THE MODEL DID NOT MEET THE FOLLOWING CRITERIA:
^^^ THE H-SIZE OF THE PROBLEM IS SMALL. H-SIZE = 52
MD/MSC Nastran User Meeting 201117
^^^ THE H-SIZE OF THE PROBLEM IS SMALL. H-SIZE = 52
^^^ USER INFORMATION: STANDARD FREQUENCY RESPONSE METHOD WILL BE USED
^^^

Speeding things up
• Parallel processing• Two types of parallel
Shared Memory Parallel Distributed Memory Parallel
Interconnection Network
SMP DMP
Memory I/O
MD/MSC Nastran User Meeting 201118
Processors
Bus

Speeding things up
• SMP• It is only possible to parallelize some of the steps in MD Nastran• Most operations are intrinsically serial• Parallel phases are available for matrix factorization (DCMP), real
eigenvalues (READ), Forward-Backward Substitution (FBS), and Matrix multiplication (MPYAD)
• For this reason, the gains in parallel processing are not linear, but asymptotic. 4 CPUs will give you a ~2 times speedup
MD/MSC Nastran User Meeting 201119
asymptotic. 4 CPUs will give you a ~2 times speedup
0
0,2
0,4
0,6
0,8
1
Ela
psed
Tim
e
1 2 4 6 8 16

Speeding things up
• SMP• There is an overhead associated with parallel processing due to
the use of proprietary libraries from hardware vendors• If you run a job with parallel=1 (use the parallel libraries on 1 CPU),
the job will take longer to run!• Generally speaking, MSC routines are faster – it’s our job after all
MD/MSC Nastran User Meeting 201120
• SMP requires you to define only the number of CPU’s you want to use
• This can be done as a keyword or as a system cell• e.g. nastran jobname parallel=4 (or smp=4)• e.g. NASTRAN SYSTEM(107)=4• If you define 1 CPU, Nastran will use parallel libraries on 1 CPU

Speeding things up
• DMP• Each processor has its own memory and I/O• The MD Nastran job is divided into pieces for matrix assembly,
solution and data recovery• Each processor works on one piece• DMP may be used alongside SMP• Requires additional software (MPI) to communicate among the
MD/MSC Nastran User Meeting 201121
• Requires additional software (MPI) to communicate among the pieces – Linux uses LAM/MPI (Local Area Multi-computer)
• MPI (Message Passing Interface) is not standardized, therefore the computers used for DMP must be homogeneous
• DMP yields close to linear scaling – some overhead is associated with necessary bookkeeping and message passing

Speeding things up
• DMP• DMP may be run on a single computer (with multiple processors)
or a set of computers connected by a network infrastructure• Each individual computer is called a host• Each host may have multiple processors that may be used in the
DMP process or in an SMP process• The choice of how many hosts and CPUs in each host will depend
MD/MSC Nastran User Meeting 201122
• The choice of how many hosts and CPUs in each host will depend on available hosts and the hardware specification of the hosts
• If DMP is run on a single computer, each of the DMPprocesses will put the same load on the machine as if it were
running the same number of individual, separate jobs – therefore, the hardware must be capable of supporting multiple job streams simultaneously

Speeding things up
• DMP• Consider the following networked computer setup
MD/MSC Nastran User Meeting 201123
• Let’s run a DMP job using 2 of the machines, but 4 CPUs
• The job is run with keywords dmp=4, hosts=host1:host2• In this situation, host1 and host2 would both be running the equivalent
of 2 MD Nastran jobs – are they up to the job?
host1 host2 host3 host4

Speeding things up
• DMP
MD/MSC Nastran User Meeting 201124
• Now let’s run the job using 4 machines and 4 CPUs• The job is run with keywords dmp=4,
hosts=host1:host2:host3:host4• All 4 machines will each run one piece using only 1 CPU each – we’ll
get the answer much quicker this way
host1 host2 host3 host4
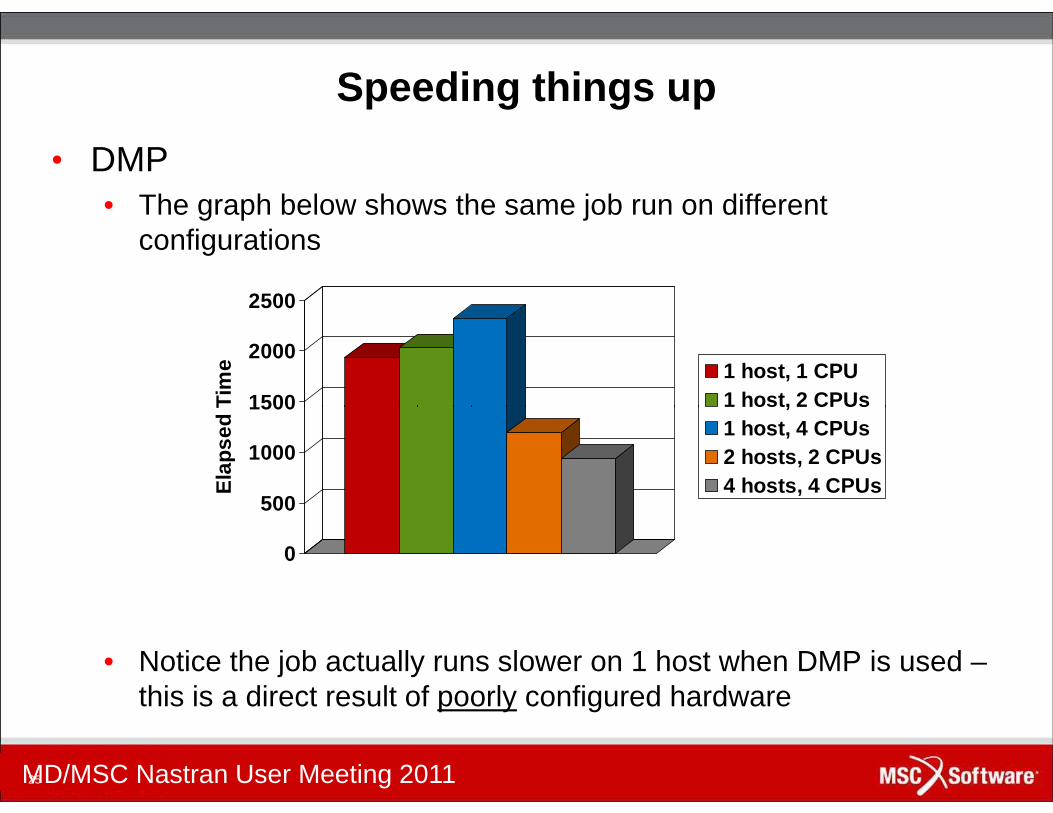
Speeding things up
• DMP• The graph below shows the same job run on different
configurations
1500
2000
2500
Ela
psed
Tim
e 1 host, 1 CPU1 host, 2 CPUs
MD/MSC Nastran User Meeting 201125
• Notice the job actually runs slower on 1 host when DMP is used –this is a direct result of poorly configured hardware
0
500
1000
1500
Ela
psed
Tim
e
1 host, 2 CPUs1 host, 4 CPUs2 hosts, 2 CPUs4 hosts, 4 CPUs

Speeding things up
ButIntel(R) Xeon(R) CPU X5670 @ 2.93GHz
96GB of memory
MD/MSC Nastran User Meeting 2011
2-Hex Cores
6 * 146GB SAS disk drives (Raid 0)
OS: Suse Linux 11.1

27
111,06
116,17
111,36
118,07
111,21
116,02115,28
110
115
120
Speeding things up
Number of same jobs on this hardware
Ela
psed
tim
e [m
in]
~ 7 % minus per job
~ 13 % minus per job
MD/MSC Nastran User Meeting 2011
104,5
95
100
105
1 3 4
Ela
psed
tim
e [m
in]
Number of Jobs

Speeding things up SOL 111 (ACMS)
Modes = 3596Frequency steps = 49930 Loadcases
Lanczos only run (with smp=4) = 2652 min
MD/MSC Nastran User Meeting 2011
smp = Shared Memory Parallel
dmp = Distributed Parallel

Speeding things up
• DMP• DMP not only requires definition of which computers and how
many CPUs will run the job, but also how the job will be split up• For example, a modal frequency response analysis (SOL 111)
• We want to use DMP for both the calculation of modes and the excitation at each frequency
• The modes can be calculated using an eigenvalue range (where each
MD/MSC Nastran User Meeting 201129
processor solves the entire model but only for a smaller range of eigenvalues) or using a sub-structuring method (where each processor solves a part of the structure) or both of these
• The applied loads at each frequency may also be divided into discrete frequency intervals and one processor solves each band of frequencies
• The “division” method is defined on an entry in the input file called DOMAINSOLVER

Speeding things up
• DMP• DOMAINSOLVER defaults are set to use sub-structuring for the modes
and frequency range division for frequency response
• If both frequency range division AND sub-structuring for the modes is required, the NCLUST or CLUSTSZ keywords are needed to define the frequency divisions
MD/MSC Nastran User Meeting 201130
• DMP is available for• Linear statics (SOL 101)• Normal Modes (SOL 103)• Direct Frequency Response (SOL 108)• Modal Frequency Response (SOL 111)• Modal Transient Response (SOL 112)• Design Optimization (SOL 200)• Implizit Nonlinear (SOL 400)

Speeding things up
• DOMAINSOLVER for statics
• DOMAINSOLVER STAT (PARTOPT=GRID)• Geometric partitioner• dmp= [hosts=]
• DOMAINSOLVER STAT (PARTOPT=DOF)
MD/MSC Nastran User Meeting 201131
• DOMAINSOLVER STAT (PARTOPT=DOF)• Matrix partitioner• dmp= [hosts=]

Speeding things up
• DOMAINSOLVER for normal modes• Two main methods are available
• ACMS – Automatic Component Mode Synthesis• MODES – Frequency range subdivision
• DOMAINSOLVER ACMS• 2 sub-methods available – GRID, DOF
MD/MSC Nastran User Meeting 201132
• 2 sub-methods available – GRID, DOF
• DOMAINSOLVER ACMS (PARTOPT=GRID)• Geometric partitioner to create superelements• [dmp=] [hosts=]
• DOMAINSOLVER ACMS (PARTOPT=DOF)• Matrix partitioner• [dmp=] [hosts=]
ACMS (obsolescent)
MDACMS

Speeding things up• DOMAINSOLVER ACMS
• Both DOMAINSOLVER ACMS sub-methods can be used with the NUMDOM keyword
• DOMAINSOLVER ACMS (PARTOPT=DOF, NUMDOM=16)
• NUMDOM specifies the number of domains created during the partitioning phase
MD/MSC Nastran User Meeting 201133
• If NUMDOM is not specified, the default number of domains created depends on the size of the problem
• PARTOPT=GRID – number of GRID points• PARTOPT=DOF – number of degrees of freedom• See the DOMAINSOLVER entry in the QRG for more information
• Note: DOMAINSOLVER ACMS is the only option that does NOT require dmp

Speeding things up
• DOMAINSOLVER MODES• Three sub-methods available – FREQ, GRID, DOF
• DOMAINSOLVER MODES (PARTOPT=FREQ)• Frequency range divided into segments• dmp= [hosts=]• Number of segments = number specified on dmp= keyword
MD/MSC Nastran User Meeting 201134
• Number of segments = number specified on dmp= keyword• By default, segment sizes are equal• EIGRL entry may be used to re-define segments sizes
• DOMAINSOLVER MODES (PARTOPT=GRID)• Geometric partitioner• dmp= [hosts=]• Number of paritions = number specified on dmp= keyword

Speeding things up
• DOMAINSOLVER MODES• DOMAINSOLVER MODES (PARTOPT=DOF)
• Matrix partitioner• dmp= [hosts=]• Number of partitions = number specified on dmp= keyword
MD/MSC Nastran User Meeting 201135

Speeding things up
• MLDMP – Multi-level DMP (Hierarchical Method)• This hierarchical method allows relatively low specification hardware to
return answers rapidly• In the graph below, note the difference between CPU and elapsed time
for the left most data – the machine has a poor I/O system (nearly 3.5:1 Elapsed:CPU ratio) – distributing the job over many (poor I/O) machines allows each machine to solve a smaller problem commensurate with its capabilities
MD/MSC Nastran User Meeting 201136
0
5000
10000
15000
20000
25000
30000
35000
40000
Ela
psed
Tim
e
1 2 3 4 6 12 24
• Elapsed Time• CPU

Speeding things up
• DOMAINSOLVER MODES (Hierarchical Method)• Two sub-methods available – FREQ/GRID, DOF
• DOMAINSOLVER MODES (PARTOPT=FREQ NCLUST=n)• DOMAINSOLVER MODES (PARTOPT=GRID NCLUST=n)
• Frequency range is divided into NCLUST segments• Model geometry is partitioned into dmp/NCLUST domains
same
MD/MSC Nastran User Meeting 201137
• Model geometry is partitioned into dmp/NCLUST domains• n defined on the CLUST keyword should be such that dmp/NCLUST
yields a power of 2.• dmp= [hosts=]
• DOMAINSOLVER MODES (PARTOPT=DOF NCLUST=n)• Frequency range is divided into NCLUST segments• Model is partitioned into dmp/NCLUST matrix domains• n defined on the CLUST keyword should be such that dmp/NCLUST
yields a power of 2.

Speeding things up
• DOMAINSOLVER MODES (NCLUST or CLUSTSZ)• DOMAINSOLVER MODES (PARTOPT=FREQ CLUSTSZ=n)• DOMAINSOLVER MODES (PARTOPT=GRID CLUSTSZ=n)• DOMAINSOLVER MODES (PARTOPT=DOF CLUSTSZ=n)
• CLUSTSZ keyword allows the number of matrix or geometric domains to be defined instead of the number of frequency segments.
• If PARTOPT=DOF, the model is partitioned into CLUSTSZ matrix domains
MD/MSC Nastran User Meeting 201138
domains• If PARTOPT=GRID or FREQ (or if PARTOPT is not specified), the
model is partitioned into CLUSTSZ domains using geometric (GRID) partitioning
• In either case, the frequency range is divided into dmp/CLUSTSZ frequency segments

Speeding things up
• DOMAINSOLVER for frequency response• Three methods of frequency response, SOL 108 & SOL 111
• DOMAINSOLVER FREQ• Direct frequency response (SOL 108)
• DOMAINSOLVER MODES or ACMS
MD/MSC Nastran User Meeting 201139
• DOMAINSOLVER MODES or ACMS• Modal frequency response (SOL 111)• Two sub-methods
• Matrix domain• Frequency band
• The modal extraction phase follows the same behaviour as for normal modes (SOL 103)

Speeding things up
• DOMAINSOLVER MODES (for frequency response)
• DOMAINSOLVER MODES (PARTOPT=FREQ)• Frequency segmentation logic is used to solve both the calculation of
the normal modes and the frequency response• After the normal modes are calculated, the frequency range is divided
into segments
MD/MSC Nastran User Meeting 201140
• DOMAINSOLVER MODES (PARTOPT=DOF)• The matrix based partitioning logic is used to solve the normal modes • After the normal modes are calculated, the frequency range is divided
into segments

41
Speeding things up
• DOMAINSOLVER FREQ Multilevel DMP for SOL 108, up to 64 CPUs
MD/MSC Nastran User Meeting 2011
Multilevel DMP on 1,500,000 dof BIW modelFreq range up to 400HZ

Speeding things up
• Note• If NCLUST or CLUSTSZ are used, the number of processors is
equal to the value specified on the dmp= keyword
• The number of frequency segments for both normal modes and the frequency response phase will be equal to either the number specified on NCLUST, or the quotient dmp/CLUSTSZ
MD/MSC Nastran User Meeting 201142
specified on NCLUST, or the quotient dmp/CLUSTSZ
• This means fewer processors are used for the frequency response calculation. If the frequency response calculation is the dominant factor in the modal frequency response calculation, consider using a method other than the hierarchic method for the calculation of the normal modes

Speeding things up
• DMP comments• DMP will only function with SOLs 101, 103, 108, 111, 112, 200, 400• MDACMS has a limit of DMP=8• DMP and SMP may be used together
MD/MSC Nastran User Meeting 201143

Speeding things up• True 64 bit version for handling large models, and extended memory use (mode=i8 in Nastran submit)
MD/MSC Nastran User Meeting 20115/19/2011

1466
1000
1200
1400
1600
Ela
psed
tim
e [m
in]
MD 2010.1
SOL 111 (ACMS)
Modes = 7200 Frequency steps = 700Material damping ge129 Loadcases
MD/MSC Nastran User Meeting 2011
460
261
120
0
200
400
600
800
seriell dmp=4/smp=2
Ela
psed
tim
e [m
in]
MD 2010.1MD 2010.2
smp = Shared Memory Parallel
dmp = Distributed Parallel
MD 2010.1MD 2011.1

46
Speeding things up
• UMFPACK Solver for unsymmetric Matrices (Acoustics)
• NASTRAN USPARSE = 16 or NASTRAN SYSTEM(209) = 16
• IBM Power4 1.45GHz 4CPUs; 32GB RAM
• MEM=5GB, SMEM=2GB,
Powertrain Acoustics
MD/MSC Nastran User Meeting 2011
• MEM=5GB, SMEM=2GB, MIO=2GB
• Structural Modes by ACMS

47
Speeding things up
• CASI Solver extended to contact problems• SMETHOD=ELEMENT case control
MD/MSC Nastran User Meeting 2011

48
Speeding things up
• Iterative solver for Nonlinear Transient• SMETHOD=ELEMENT (or SMETHOD=MATRIX)
• Iterative base solver for NON-Symmetric problems• Heat transfer with advection or radiation• Follower force stiffness• Friction force stiffness
MD/MSC Nastran User Meeting 2011
• Damping matrices• Transfer functions

49
Speeding things up Automatic External SE Optimization
MD/MSC Nastran User Meeting 2011
Remark: not available for Topology optimization yet
assign aeso='OUTDIR:aeso1_2.dat
Doptprm,autose,1,dratio,0.9

• DMP comments• DMP will only function with SOLs 101, 103, 108, 111, 112, 200, 400• MDACMS has a limit of DMP=8• DMP and SMP may be used together
Speeding things up
MD/MSC Nastran User Meeting 201150

Thank you
MD/MSC Nastran User Meeting 2011
Thank you