"mass surveillance" through distant reading
TRANSCRIPT

“MASS SURVEILLANCE” THROUGH DISTANT READING
Shalin Hai-Jew• Aesthesia• March 2, 2017• Marianna Kistler Beach
Museum of Art• Kansas State University

OVERVIEW
Distant reading refers to the uses of computers to “read” texts by counting words, identifying themes and subthemes (through topic modeling), extracting sentiment, applying psychological analysis to the author(s), and otherwise finding latent or hidden insights. This work is based on research on “mass surveillance” based on five text sets: academic, mainstream journalism, microblogging, Wikipedia articles, and leaked government data. The purpose was to capture some insights about the collective social discussions occurring around this issue in an indirect way. This presentation uses a variety of data visualizations (article network graphs, word trees, dendrograms, treemaps, cluster diagrams, line graphs, bar charts, pie charts, and others) to show how machines read and the types of summary data they enable (at computational speeds, at machine scale, and in a reproducible way). Also, some computational linguistic analysis tools enable the creation of custom dictionaries for unique types of applied research. The tools used in this presentation include NVivo 11 Plus and LIWC2015.
2

SOME COMMON TYPES OF “DISTANT READING” AND APPLICATIONS
Linguistic analysis
Topic modeling Theme and subtheme extraction
Sentiment analysis • Positive and negative
Text networks Word relationships
Authorship analysis (based on latent features) Stylometry “fingerprinting”
Author gender identification
Psychological analysis
Cultural analysis, culturomics
History-based applications
Literary analysis Dialogue analysis
Geographical referencing and patterning
Character analysis
Predictive analytics Classification
Trend
3

STUDIED PHENOMENA IN THE COMPUTATIONAL LINGUISTIC ANALYSIS RESEARCH LITERATURE
Political science, leader speech analysis (for profiling)
State-of-a-field research
Authorship identification
Plagiarism detection
Suicidality
Movie popularity, song popularity
Language studies
Law enforcement
Fraud detection
Threat detection, and others
4

WHY DISTANT READING?
Textual interpretation At computational speeds
At computational scale
Reproducible, repeatable
Measures various analytical constructs in quantized ways
Surfacing latent (hidden) ideas and data patterns not seeable otherwise (such as by human “close reading”)
Results comparable against large textual datasets of particular types of text (such as comparing a Tweetstream against other social media texts or even microblogging texts)
Complementary to and augmentary of human “close reading”
5

COMMON ANALYTICAL TRAJECTORIES
Curation of text sets (corpora) -> distant reading data summaries -> zoomed-in analysis (of concepts, names, dates, locations, symbols, and numbers, etc.) -> human close reading
General-to-specific trajectory
Baseline text set statistics based on curated text collections and text corpora
Comparisons across text sets
Relative data
6

“MASS SURVEILLANCE” AS A SEEDING TOPIC
7

WHY “MASS SURVEILLANCE”?
A timely construct
A point-of-global discussion
A mixed group of competing stakeholders re: the issue
Wide public availability of five (somewhat) disparate text sets:
Academic
Mainstream journalism
Microblogging
Wikipedia articles
Leaked government data
8

9

10
pie chart

11
line chart
12
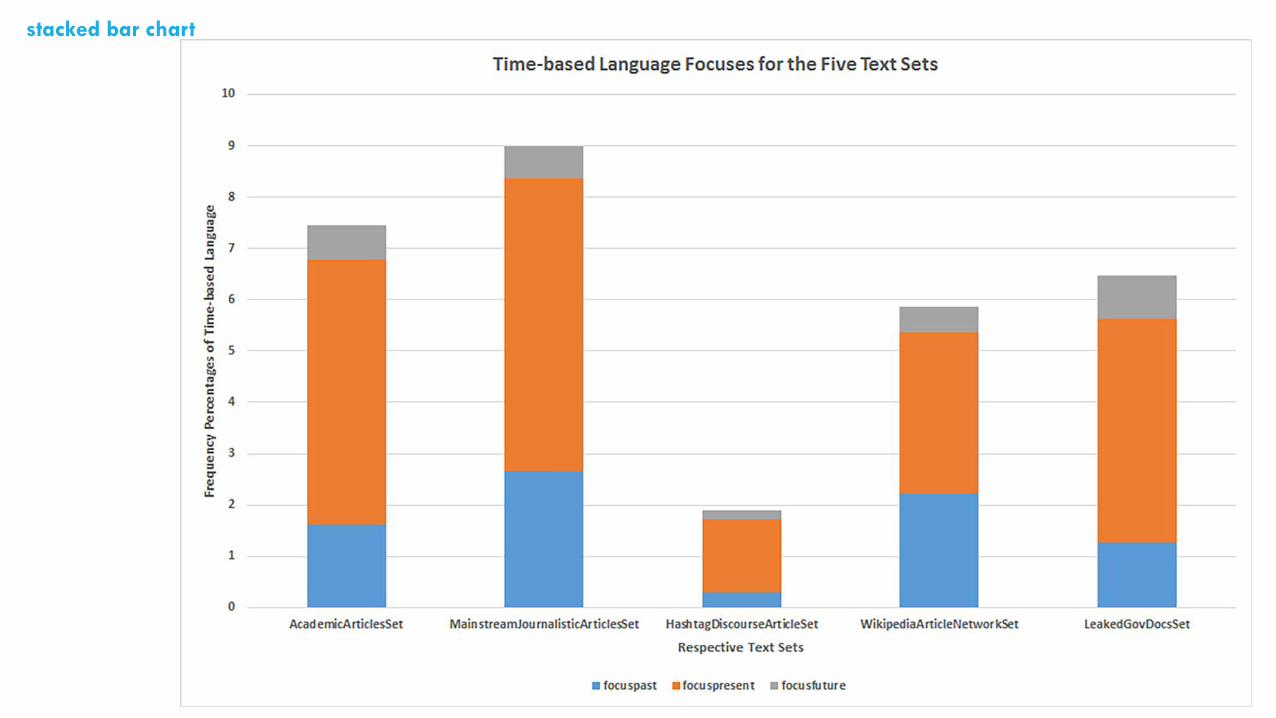
stacked bar chart

13
line graph

14
bar chart

15
stacked bar chart

16
bar chart

17
line graph

18
stacked bar chart

19
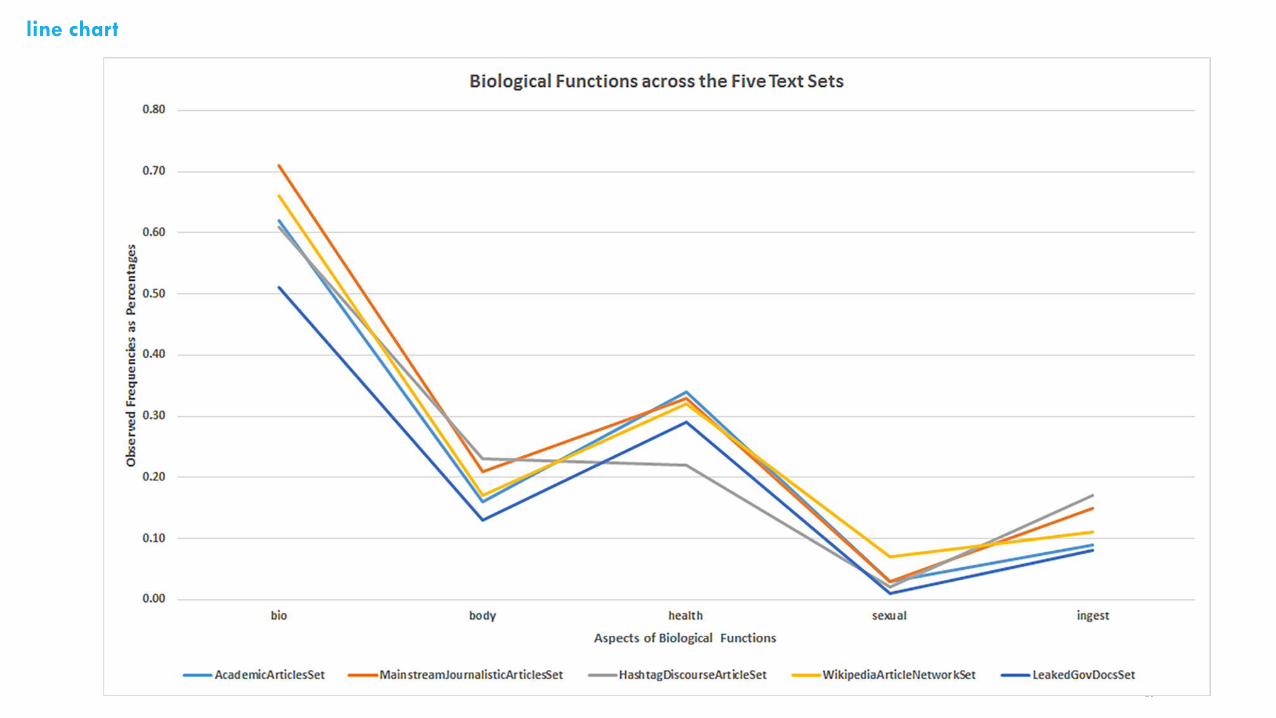
line chart
20
line chart

21
line chart

22
line chart

23
combined bar and line chart

24
bar chart

25
bar chart

26
bar chart

27
bar chart

28
bar chart

29
spider (radar) chart
(LIWC2015 and
Excel)

30
Gunning Fog Index Coleman Liau Index Flesch Kincaid
Grade Level
ARI (Automated
Readability Index)
SMOG Readability
Formula
Flesch
Reading
Ease ( /100)
Set 1: Academic article text
set (partial)
13.20 11.71 10.71 9.29 12.80 43.26
Set 2: Mainstream
journalistic text set
14.28 13.88 12.12 12.40 13.75 39.25
Set 3: Twitter
microblogging hashtag
discourse text set
28.88 32.36 24.40 29.73 21.75 -38.46 (on a
100 point
scale)
Set 4: Wikipedia article
network text set (partial)
11.09 12.25 9.46 8.31 11.07 44.39
Set 5: Leaked U.S.
government text set (partial)
14.65 12.45 12.29 10.89 13.97 36.44
data table

31
Final Full Set Academic Themes and Subthemes Treemap
treemap diagram

32
Final Full Set Mainstream Journalist Themes and Subthemes Treemap
treemap diagram

33
Final Full Set #surveillance Microblogging Themes and Subthemes Treemap
treemap diagram

34
line graph

35
Manually Coded #surveillance Hashtag Network on Twitter
treemap diagram

36
Final Full Set of Mass-surveillance Article Network from Wikipedia Themes and Subthemes Treemap
treemap diagram

37
Final Full Set Leaked Government Documents Themes and Subthemes Treemap
treemap diagram

38
from the
academic article
dataset
(interactive) 3d cluster diagram

39
from the
academic article
dataset
(interactive) treemap diagram

40
from the
academic article
dataset
(interactive) word cloud

41
from the
journalism
dataset
(interactive) word tree

42
from the
journalism
dataset
(interactive) horizontal dendrogram

43
from the
journalism
dataset
(interactive) 2d cluster diagram

44
from the
microblogging
dataset
(interactive)
treemap diagram

45
from the
microblogging
dataset
(interactive) 3d bar chart

46
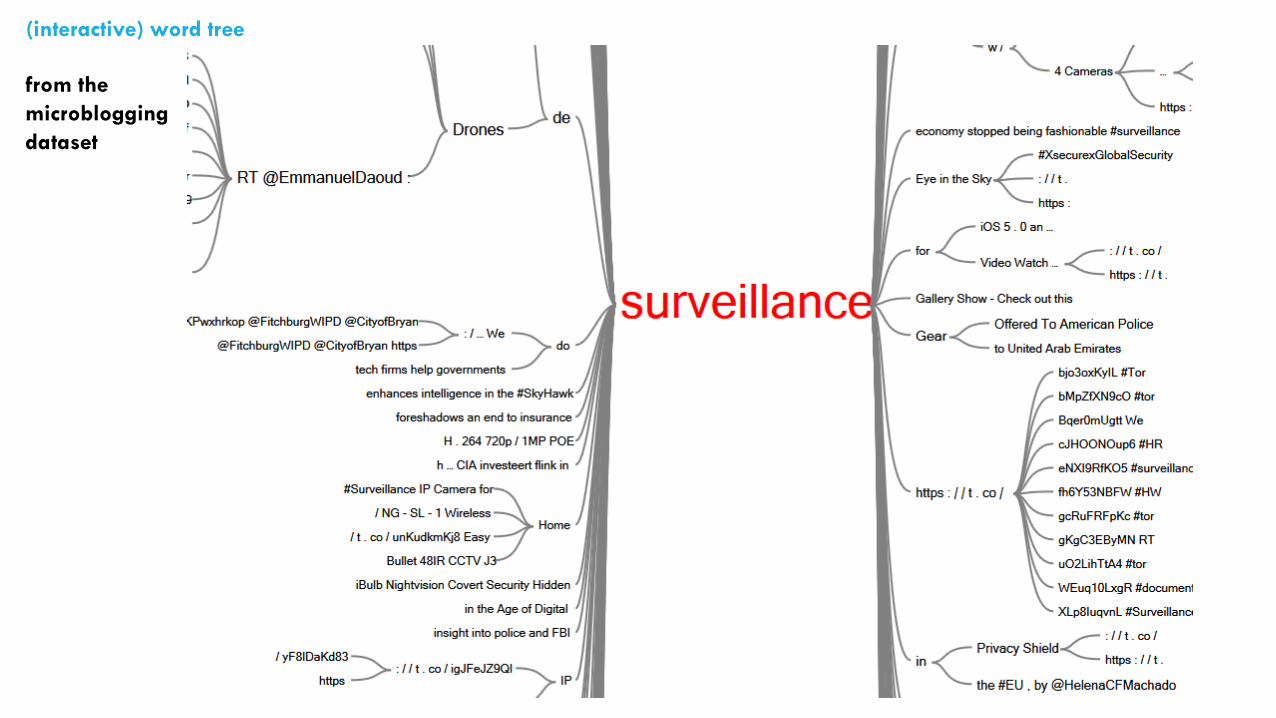
from the
microblogging
dataset
(interactive) word cloud

47
from the
microblogging
dataset
(interactive) 2d cluster chart
48
from the
microblogging
dataset
(interactive) word tree

49
article-article network
from Wikipedia
(NodeXL or
“Network Overview,
Discovery and
Exploration for Excel”)
article network graph

50
from the
crowd-sourced
encyclopedia
dataset
(interactive) word cloud

51
from the
crowd-sourced
encyclopedia
dataset
(interactive) treemap diagram

52
from the
crowd-sourced
encyclopedia
dataset
(interactive) 3d bar chart
53
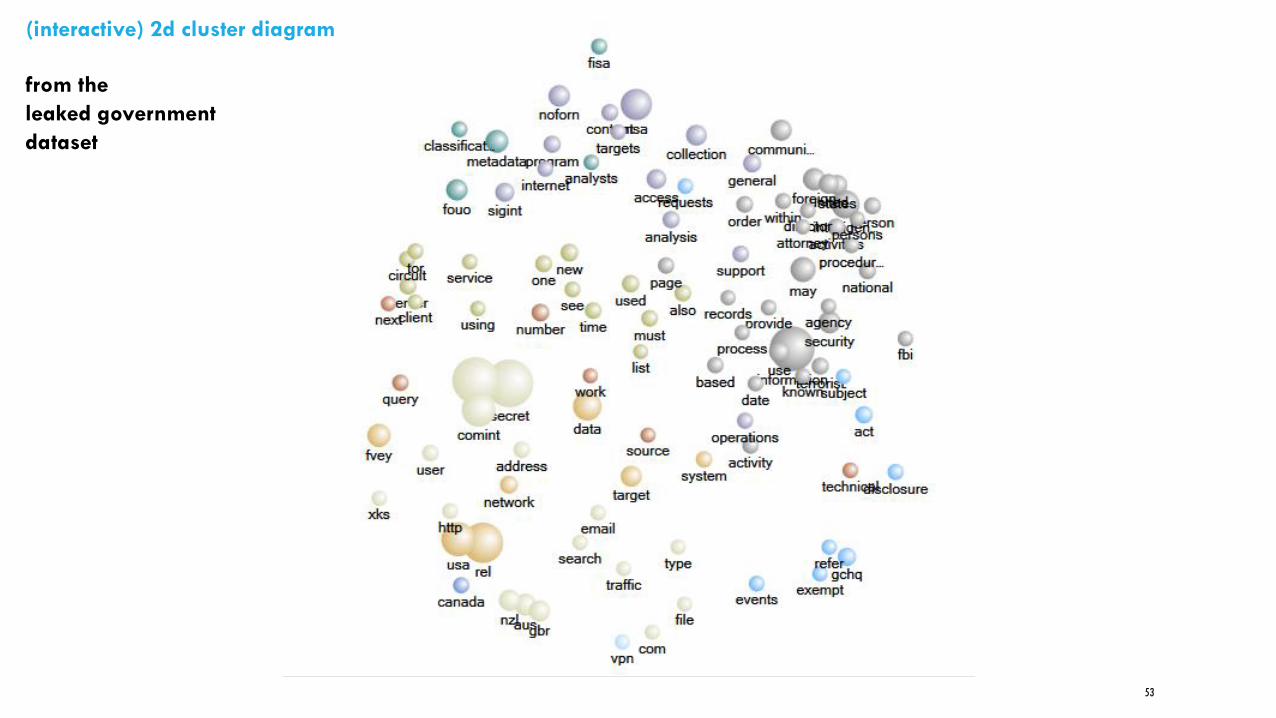
from the
leaked government
dataset
(interactive) 2d cluster diagram

54
from the
leaked government
dataset
(interactive) word tree

55
from the
leaked government
dataset
(interactive) word cloud

56
from the
leaked government
dataset
(long tail analysis)
data table

57
from the
leaked government
dataset (coding nodes)
(interactive) 3d cluster diagram

58
from the
leaked government
dataset
(interactive) 3d word tree

59
sunburst diagram

60
(interactive) intensity matrix

61
0
1
2
3
4
5
6
7
8
A : content B : dissemination C : front door D : hidden service E : information F : jflftflvjffdissemination
G : node H : onion I : r dissemination
Num
ber
of
Mentions
Auto-extracted Top-Level Themes from a Government Document
An Article Histogram of a Leaked Government Documentarticle
histogram
w/ main
theme
extractions

62
0 0.5 1 1.5 2 2.5 3 3.5
A : event
B : facebook
C : msn
D : notification
E : sources
F : target
Counts of Mentions of Top-Level Themes
Auto
-extr
act
ed T
op
-Level
Them
es
A Theme Histogram from a Government Document
article
histogram
w/ main
theme
extractions

ABOUT THE SEEDING TOPIC: “MASS SURVEILLANCE”?
63

CONTRIBUTIONS TO THE “MASS SURVEILLANCE” TOPIC
Academic writing: legal, philosophical, technological, and practical implications
Mainstream journalistic articles: domestic and foreign government engagement with the issue (executive, legislative, judicial, and others)
Microblogging messages: global surveillance challenges, changing technologies (drones)
Wikipedia (open-source and crowdsourced encyclopedia): summary details, highlighted events, personages, URLs, and timely observations
Government documents: bureaucratese, technical capabilities
64

ABOUT THE RELATED TEXT SETS…FROM DISTANT READING
Different genres of writing, based on a particular topic, manifest differently on different textual dimensions. Some textual features seem to co-vary and may be because these are features of prose writing, or
other factors.
Analysis of different features of the text sets may be helpful in identifying source types that may be most useful for certain types of research or questions.
Social media “netspeak” has not yet fully been captured in the two commercial tools used for this analysis.
Average word counts per unit differed: academic (7,624 – 8,073 words per unit), mainstream journalistic articles (1,460 – 1488 words per unit), microblogging hashtag discourse (44 – 61 per user account), Wikipedia articles (6,710 – 7,216 words per article), and leaked government documents (1,711 – 1,800 words). Variance in word counts were based on the uses of differing software programs to do the counts…and
natural ambiguity in word identification.
65

ABOUT THE RELATED TEXT SETS…FROM DISTANT READING (CONT.)
Computational analysis of the five text sets showed a spike in terms of human drives across all sets…in terms of “power.” Because this applied across all five text sets, it may be that “power” is a driving issue of concern regarding “mass surveillance.”
Sentiment was most present in the following (in descending order): Wikipedia articles, academic articles, leaked government documents, mainstream journalism, and hashtag discourse, according to analysis in NVivo 11 Plus but a different order was found using LIWC2015 (in descending order): mainstream journalism, Wikipedia articles, academic articles, leaked government documents, and hashtag discourse.
The only rank position of agreement was having hashtag discourse in last place with the least sentiment, which can partially be explained by the brevity of Tweets and the expression of emotion in emoticons and punctuation marks.
66

ABOUT THE RELATED TEXT SETS…BASED IN PART ON SELECTED CLOSE READING
All five text sets—academic, mainstream journalistic, microblogging messages, Wikipedia articles, and the government documents—were informed by the source government documents.
The journalistic articles, with a rights narrative of deep intrusions into privacy, seem to have captured the readership’s attention, while academic and government documents were not consumed as broadly.
Journalistic articles ranked high in sociality measures—and that may indicate why people see it as connecting with their lives.
Twitter was used to advertise writings from academia and mainstream journalism.
Some academic publications cited mainstream journalistic pieces, but fewer journalistic pieces cited academic works.
67

ABOUT THE RELATED TEXT SETS…BASED IN PART ON SELECTED CLOSE READING (CONT.)
Academia did not have a lot of pieces on this issue in the subscription databases and other sources that were checked.
It may be that more time has to pass for researchers to study the issues.
The technological complexity of the government documents required technology and legal and policy experts to interpret.
These documents were generally handled in a non-consumptive way for computational linguistic analysis. Non-consumptiveness refers to the extraction of statistical features of a text set without direct access to the underlying texts. For this analysis, the focus was on computational reading of the related documents, not a human interpretation of the text set or the related capabilities.
68

ABOUT USING COMPUTATIONAL LINGUISTIC ANALYSIS TO “READ” UP ON AN ISSUE
Selected text sets should be as comprehensive as possible in order to represent the topic. The text sets should be cleaned, so irrelevant elements may be eliminated. There should be clear documentation about how data was collected and processed and handled. How the text sets are handled affect the results.
The bundling of particular text sets will affect results as well.
Because social media only attracts some to participate, there can be some large gaps in informational coverage. Social media platform APIs are often rate- and data-limited, so it’s important to review the terms of
access to such data.
Using multiple software tools to conduct analysis makes sense because there are differences between tool designs which will affect what is observed or not. The “validity” and “reliability” of software tools vary…
69

ABOUT USING COMPUTATIONAL LINGUISTIC ANALYSIS TO “READ” UP ON AN ISSUE (CONT.)
How the researcher asks questions and wields the technology will affect what is seeable and seen. There is not an “objective” reading machine… Subjectivity and judgment play a role.
External validation may be an important piece of research using computational reading.
The data visualizations here are mostly interactive, and it is possible to link to original underlying data. All the data visualizations are informed by underlying data, and these should be accessed for deeper understandings.
These interactive features and underlying data should be engaged to fully benefit from the computational analyses. (Data visualizations are not used independent of the underlying data.)
“Non-consumptive” text analysis can sometimes be helpful even without the benefit of close reading and examination of the underlying text corpora used for the computational analysis.
70

ABOUT USING COMPUTATIONAL LINGUISTIC ANALYSIS TO “READ” UP ON AN ISSUE (CONT.)
Close reading always a part of the work, even though distant reading is brought to bear. Both enhance the other, and there are many rich processing sequences to read.
What a human reader “sees” vs. what a computer does differs.
71

SOME POSSIBLE EFFECTS OF THE RESEARCH
Different genres of texts may reach different parts of a population. Those who limit themselves to particular genres will only capture some aspects of information about a topic.
Those engaged in strategic communications would benefit from gaining a sense of which communications modes to engage in order to reach their target audience.
It helps to know what issues are trending at any particular time…and the collective emotions which are being expressed.
It helps to strategically target limited human close reading attention based on observations from distant reading.
72

WHY “MASS SURVEILLANCE” AND “DISTANT READING”?
There is an elision of mass surveillance and distant reading…in this slideshow…in part because technological enablements enable “mass surveillance” and dataveillance (data + surveillance, in a portmanteau term).
Practically speaking, human close reading would be wholly insufficient to interact with mass data. There are not enough human years to plough through the masses of structured and unstructured data being created today.
For complex data, human close reading requires close and slow attention (200 wpm / words per minute).
Human close reading is not known for great objective accuracy. Rather, human reading is informed by a trained and subjective lens. Human reading is known for a unique perspective and voice.
73

WHY “MASS SURVEILLANCE” AND “DISTANT READING”? (CONT.)
Together, “distant” and “close” reading expand human power to read, interpret, and learn. Sometimes, these complementary efforts help solve very human challenges.
Computational distant reading does not “displace” people or what they can bring to research and analysis. Oftentimes, the findings from each diverge, resulting in different insights attained in different ways.
74

NVIVO 11 PLUS
75

ABOUT NVIVO 11 PLUS
Enables the building of unstructured, semi-structured, and structured data (using SQL as the understructure on Windows)
Enables analysis of any data represented by UTF-8 (Unicode character set) but requires a main base language
Enables exact matches, stemmed words, synonyms, specializations, and generalizations
Enables the application of special characters and Boolean terms
Enables the building of an exportable code dictionary
Enables topic modeling, sentiment analysis, and “coding by existing pattern”
Enables “distant reading” and interactive data visualizations including word trees, dendrograms, treemaps, cluster diagrams, and others
76

LIWC2015
77

ABOUT LIWC2015 PLUS
Has a built-in linguistic analysis dictionary which has been built up over decades of refinement and empirical research
Summarizes datasets on four scores: Analytic, Clout, Authentic, and Tone
Includes psychological and socio-psychological elements
Includes sentiment and emotional analysis features
Includes gender reference counts
Includes human drives counts
Includes generic linguistic analysis counts (including for function words)
78

ABOUT LIWC2015 PLUS (CONT.)
Is back-stopped by decades of solid research
Is a very well and smartly documented tool
Is set up as a processor and a dictionary
Enables the building of custom dictionaries to run against textual datasets to surface more unique insights
79

ABOUT LIWC2015 PLUS (CONT.)
Requires some in-depth reading of the related documentation
The Development and Psychometric Properties of LIWC2015
Linguistic Inquiry and Word Count: LIWC2015
Requires reading of years of research for the smoothest research applications
Requires experience in Excel since data dump out into .xl or .xlsx
There is no proprietary file to save an analysis using LIWC2015
80

CONTACT AND CONCLUSION
Dr. Shalin Hai-Jew
Instructional Designer
Kansas State University
785-532-5262
“Distant reading” is a term originated by Franco Moretti (founder of the Stanford Literary Lab) in 2011.
This slideshow is based on a research-based chapter forthcoming in 2017.
81